
Viability of ABO Blood Typing with ATR-FTIR Spectroscopy

 , , and
, , and
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
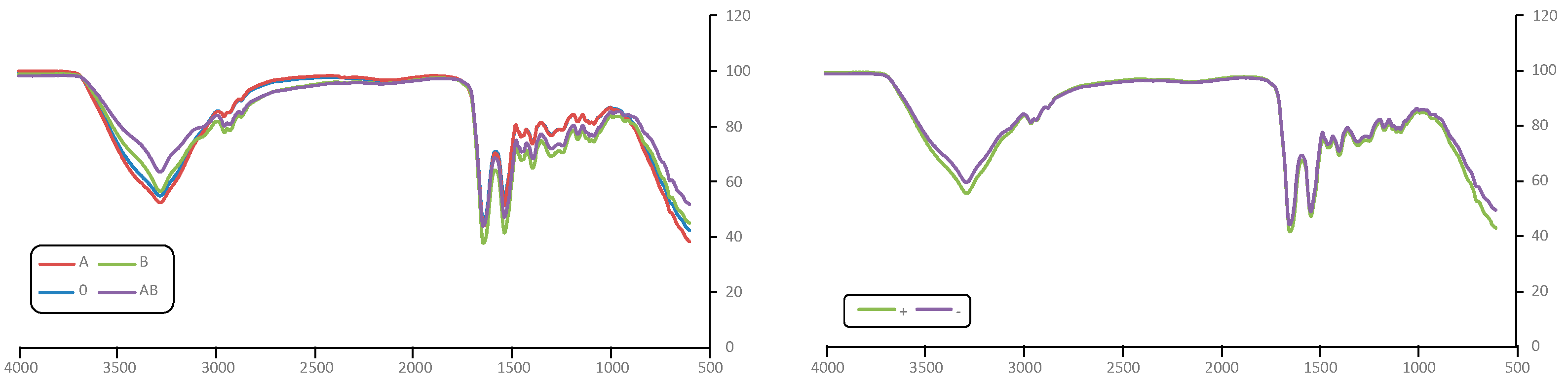
3. Results and Discussion
3.1. Probabilities of Random Classification
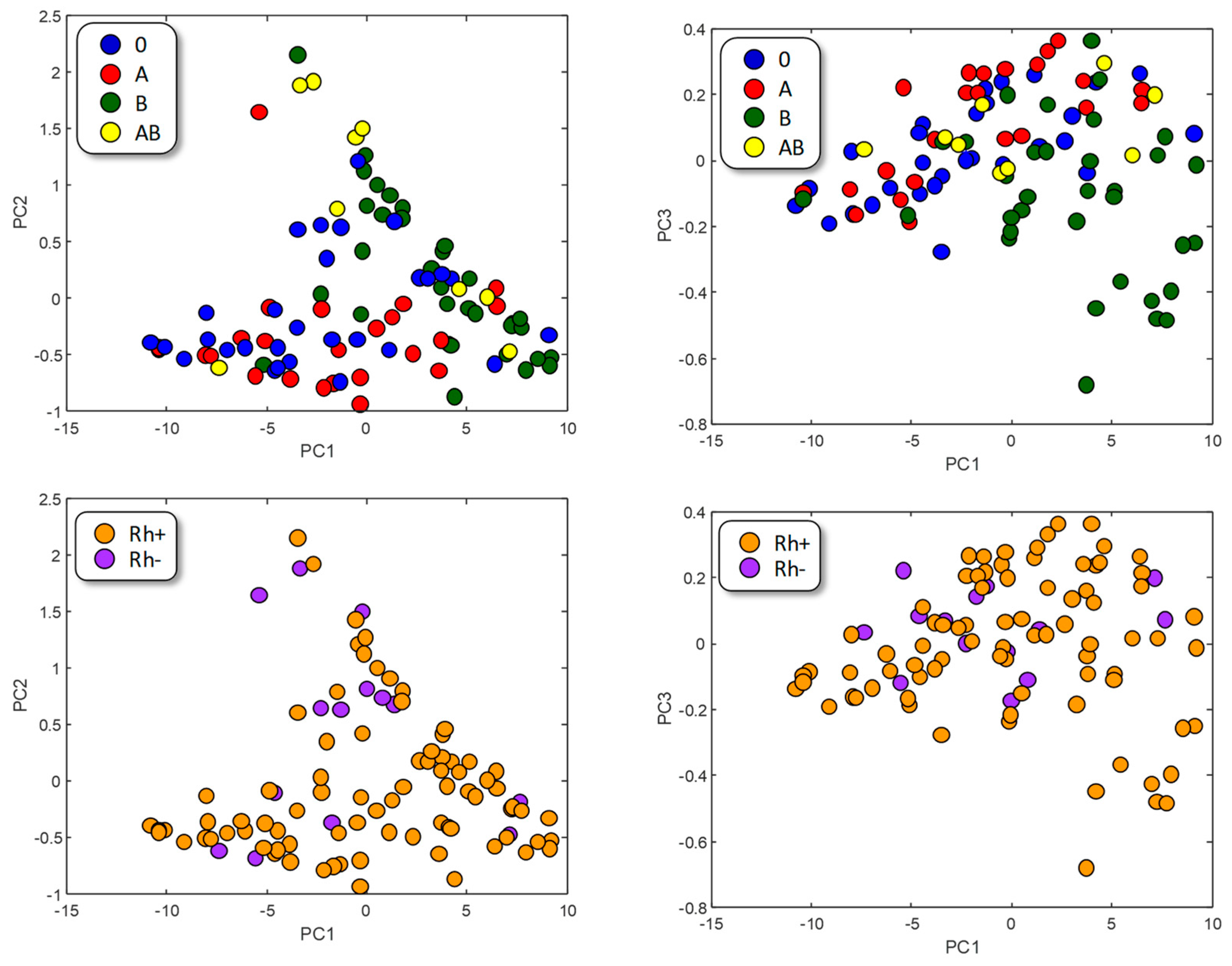
3.2. Principal Component Analysis (PCA)
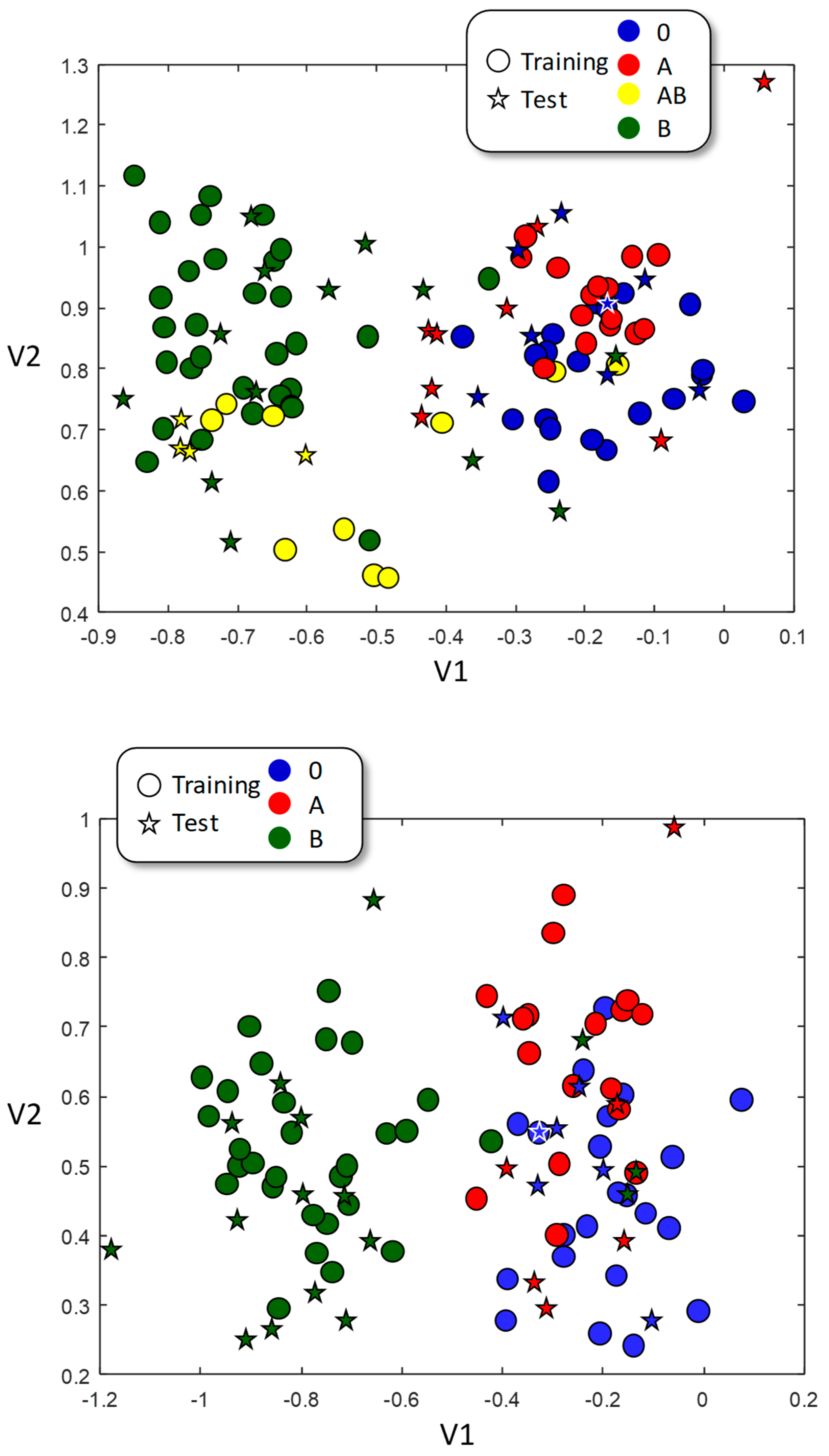
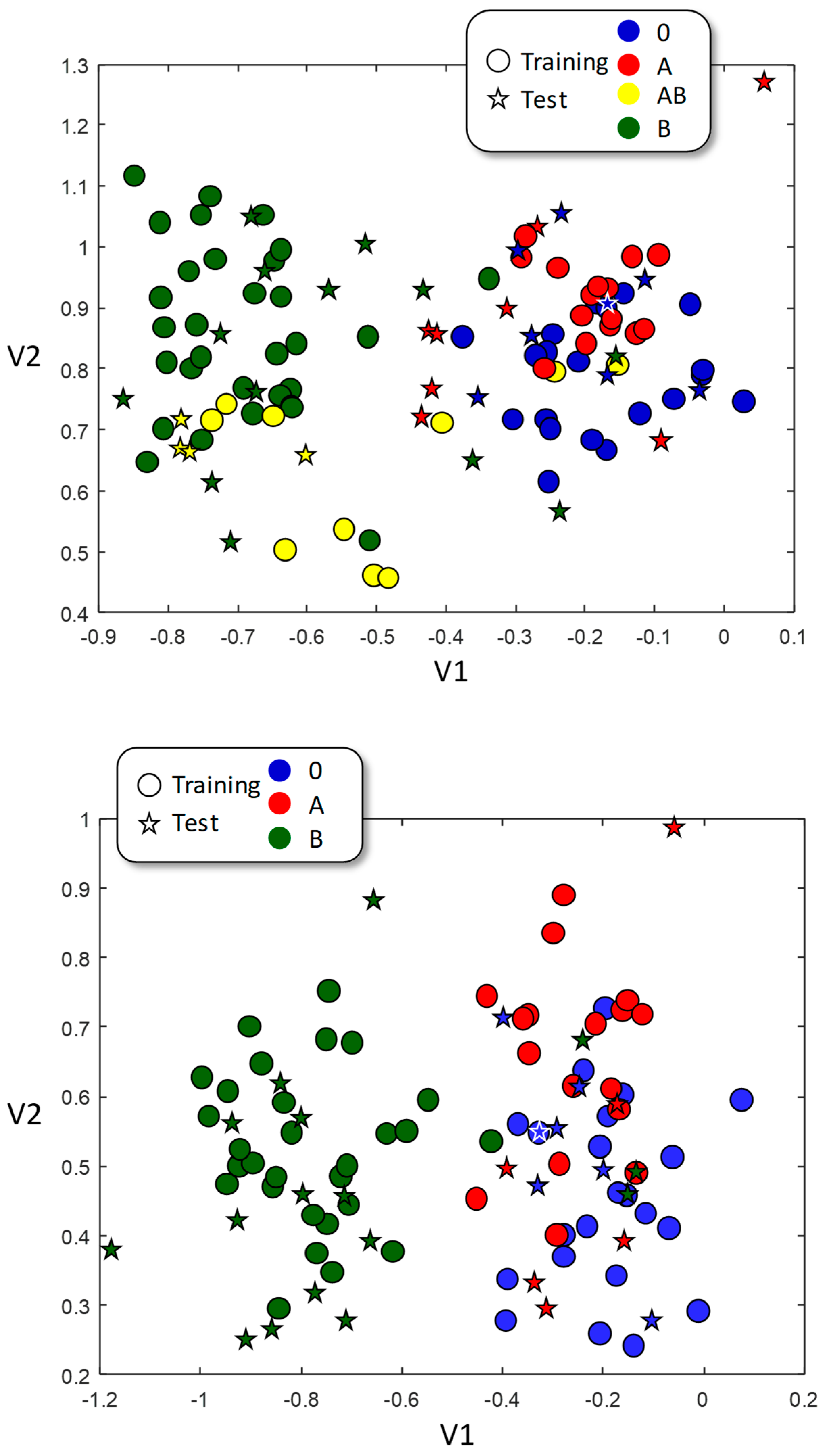
3.3. Linear Discriminant Analysis (LDA)
3.4. Naïve Bayesian Classifier
3.5. Principal Components Cobined with Naïve Bayesian Classifier
3.6. Single-Antigen Identification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, S.; Srinivasan, A.; Nikolajeff, F. Role of Infrared Spectroscopy and Imaging in Cancer Diagnosis. Curr. Med. Chem. 2018, 25, 1055–1072. [Google Scholar] [CrossRef] [PubMed]
- Petrov, M.S.; Gordetzov, A.S.; Amelyanov, N.V. Usefulness of infrared spectroscopy in diagnosis of acute pancreatitis. ANZ J. Surg. 2007, 77, 347–351. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.M.; Guang, P.W.; Li, L.; Song, H.; Huang, F.R.; Li, Y.P.; Wang, L.H.; Hu, J.H. Early rapid diagnostis of Alzheimer’s disease based on fusion of near- and mid-infrared spectral features combined with PLS-DA. Optik 2021, 241, 166485. [Google Scholar] [CrossRef]
- Dogan, A.; Lasch, P.; Neuschl, C.; Millrose, M.K.; Alberts, R.; Schughart, K.; Naumann, D.; Brockmann, G.A. ATR-FTIR spectroscopy reveals genomic loci regulating the tissue response in high fat diet fed BXD recombinant inbred mouse strains. BMC Genomics 2013, 14, 386. [Google Scholar] [CrossRef] [PubMed]
- Glassford, S.E.; Byrne, B.; Kazarian, S.G. Recent applications of ATR FTIR spectroscopy and imaging to proteins. Biochim. Biophys. Acta Proteins Proteom. 2013, 1834, 2849–2858. [Google Scholar] [CrossRef] [PubMed]
- Graca, A.; Magalhaes, S.; Nunes, A. Biological predictors of aging and potential of FTIR to study age-related diseases and aging metabolomics fingerprint. Curr. Metabolomics 2017, 5, 119–137. [Google Scholar] [CrossRef]
- Muñoz, M.; Uyar, A.; Correia, E.; Díez, C.; Fernández-González, A.; Caamaño, J.N.; Trigal, B.; Carrocera, S.; Seli, E.; Gómez, E. Non-invasive assesment of embrionic sex in cattle by metabolomic fingerprint of in vitro culture medium. Metabolomics 2014, 10, 443–451. [Google Scholar] [CrossRef]
- Muñoz, M.; Uyar, A.; Correia, E.; Díez, C.; Fernández-González, A.; Caamaño, J.N.; Martínez-Bello, D.; Trigal, B.; Humblot, P.; Ponsart, C.; et al. Prediction of pregnancy viability in bovine in vitro-produced embryos and recipient plasma with Fourier Transform infrared spectroscopy. J. Dairy Sci. 2014, 97, 5497–5507. [Google Scholar] [CrossRef] [PubMed]
- Weber, A.; Hoplight, B.; Ogilvie, R.; Muro, C.; Khandasammy, S.R.; Pérez-Almodóvar, L.; Sears, S.; Lednev, I.K. Innovative vibrational spectroscopy research for forensic application. Anal. Chem. 2023, 95, 167–205. [Google Scholar] [CrossRef] [PubMed]
- Cebi, N.; Bekiroglu, H.; Erarslan, A.; Rodríguez-Saona, L. Rapid Sensing: Hand-Held and Portable FTIR Applications for On-Site Food Quality Control from Farm to Fork. Molecules 2023, 28, 3727. [Google Scholar] [CrossRef] [PubMed]
- Murru, C.; Chimeno-Trinchet, C.; Díaz-García, M.E.; Badía-Laíño, R.; Fernández-González, A. Artificial Neural Network and Attenuated Total Reflectance-Fourier Transform Infrared Spectroscopy to identify the chemical variables related to ripeness and variety classification of grapes for protected designation of origin wine production. Comput. Electron. Agric. 2019, 164, 104922. [Google Scholar] [CrossRef]
- Daniels, G.L.; Fletcher, A.; Garratty, G.; Henry, S.; Jørgensen, J.; Judd, W.J.; Levene, C.; Lomas-Francis, C.; Moulds, J.J.; Moulds, J.M.; et al. International Society of Blood Transfusion. Vox Sang. 2004, 87, 304–316. [Google Scholar] [CrossRef] [PubMed]
- Hosoi, E. Biological and clinical aspects of ABO blood group system. J. Med. Investig. 2008, 55, 174–182. [Google Scholar] [CrossRef] [PubMed]
- Daniels, G.; Reid, M.E. Blood groups: The past 50 years. Transfusion 2010, 50, 281–289. [Google Scholar] [CrossRef] [PubMed]
- Tipos de Sangre|Todo Sobre la Donación de Sangre|Cruz Roja—Donación de Sangre. Available online: https//www.donarsangre.org/todo-sobre-la-sangre/tipos-de-sangre/ (accessed on 27 September 2022).
- Socrates, G. Biological Molecules—Macromolecules. In Infrared and Raman Characteristic Group Frequencies, Tables and Charts, 3rd ed.; John Wiley and Sons Inc.: Chichester, UK, 2001; pp. 328–340. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| 0+ | A+ | B+ | AB+ | 0- | A- | B- | AB- | |
|---|---|---|---|---|---|---|---|---|
| Spanish population | 35% | 36% | 8% | 2.5% | 9% | 7% | 2% | 0.5% |
| Number of samples | 24 (24%) | 21 (21%) | 36 (36%) | 5 (5%) | 5 (5%) | 2 (2%) | 3 (3%) | 4 (4%) |
| Region/cm−1 | Region/cm−1 | Region/cm−1 |
|---|---|---|
| 910–945 | 1213–1257 | 2829–2887 |
| 980–999 | 1257–1348 | 2887–2941 |
| 1059–1092 | 1348–1425 | 2941–2995 |
| 1092–1113 | 1425–1477 | 2995–3107 |
| 1113–1140 | 1477–1583 | 3107–3224 |
| 1140–1186 | 1583–1716 | 3224–3383 |
| Ratio of | T+ | T- | F+ | F- |
|---|---|---|---|---|
| Mathematical expression | 1-T+-F+-F- | |||
| Considering four classes: A, B, AB, and 0 | ||||
| With p(i) = f(i) = Table 1 Natural frequencies | 9.7% | 59.7% | 15.3% | 15.3% |
| With p(i) = f(i) = Table 1 Sampling frequencies | 7.4% | 57.4% | 17.6% | 17.6% |
| Considering three classes: A, B, and 0 | ||||
| With p(i) = f(i) = Table 1 Natural frequencies | 13.8% | 47.0% | 19.6% | 19.6% |
| With p(i) = f(i) = Table 1 Sampling frequencies | 11.7% | 44.9% | 21.7% | 21.7% |
| LDA Classification | Random Classification | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assigned Class | Assigned Class | ||||||||||
| Real class | A | B | AB | 0 | Real class | A | B | AB | 0 | ||
| A | 6% | <1% | 2% | 7% | A | 5% | 9% | 3% | 6% | ||
| B | 6% | 26% | 9% | 4% | B | 9% | 15% | 5% | 10% | ||
| AB | 2% | 6% | 6% | 0% | AB | 3% | 5% | 2% | 3% | ||
| 0 | 15% | 0% | 3% | 10% | 0 | 6% | 10% | 3% | 7% | ||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 6.1% | ↑ 62.1% | ↓ 22.2% | ↑ 9.6% | |||||||
| B-type success rate | ↘ 25.8% | ↗ 50.0% | ↑ 6.1% | ↓ 18.2% | |||||||
| AB-type success rate | ↓ 6.1% | ↑ 73.2% | ↗ 13.6% | ↑ 7.1% | |||||||
| 0-type success rate | ↓ 9.6% | ↑ 62.1% | ↗ 10.6% | ↘ 17.7% | |||||||
| Average success rate | ↓ 11.9% | ↑ 61.9% | ↗ 13.1% | ↗ 13.1% | |||||||
| LDA classification | Random classification | ||||||||||
| Assigned class | Assigned class | ||||||||||
| Real class | A | B | 0 | Real class | A | B | 0 | ||||
| A | 10% | 2% | 13% | A | 6% | 11% | 7% | ||||
| B | 3% | 37% | 4% | B | 11% | 23% | 14% | ||||
| 0 | 15% | 1% | 16% | 0 | 7% | 14% | 9% | ||||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 9.8% | ↑ 58.0% | ↓ 17.8% | ↓ 14.4% | |||||||
| B-type success rate | ↗ 36.8% | ↑ 53.4% | ↑ 2.9% | ↗ 6.9% | |||||||
| 0-type success rate | ↓ 16.1% | ↑ 51.1% | ↓ 16.7% | ↓ 16.1% | |||||||
| Average success rate | ↓ 20.9% | ↑ 54.2% | ↘ 12.5% | ↘ 12.5% | |||||||
| NBC Classification | Random Classification | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assigned Class | Assigned Class | ||||||||||
| Real class | A | B | AB | 0 | Real class | A | B | AB | 0 | ||
| A | 9% | 5% | 1% | 2% | A | 5% | 8% | 3% | 6% | ||
| B | 8% | 29% | 4% | 1% | B | 8% | 15% | 5% | 10% | ||
| AB | 4% | 8% | 6% | 2% | AB | 3% | 5% | 2% | 3% | ||
| 0 | 11% | 8% | 3% | 3% | 0 | 6% | 10% | 3% | 7% | ||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 8.6% | ↑ 62.1% | ↓ 22.2% | ↑ 7.1% | |||||||
| B-type success rate | ↘ 29.3% | ↗ 38.4% | ↓ 19.7% | ↗ 12.6% | |||||||
| AB-type success rate | ↓ 6.1% | ↑ 73.7% | ↑ 7.6% | ↗ 12.6% | |||||||
| 0-type success rate | ↓ 2.5% | ↑ 72.2% | ↑ 4.0% | ↓ 21.2% | |||||||
| NBC Success rate | ↓ 11.6% | ↑ 61.6% | ↘ 13.4% | ↘ 13.4% | |||||||
| NBC classification | Random classification | ||||||||||
| Assigned class | Assigned class | ||||||||||
| Real class | A | B | 0 | Real class | A | B | 0 | ||||
| A | 10% | 7% | 6% | A | 6% | 11% | 7% | ||||
| B | 10% | 30% | 3% | B | 11% | 23% | 13% | ||||
| 0 | 16% | 11% | 7% | 0 | 7% | 13% | 8% | ||||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 9.8% | ↑ 50.6% | ↓ 25.9% | ↗ 13.8% | |||||||
| B-type success rate | ↘ 29.9% | ↗ 39.1% | ↘ 18.4% | ↑ 12.6% | |||||||
| 0-type success rate | ↓ 6.9% | ↑ 56.9% | ↑ 9.2% | ↓ 27.0% | |||||||
| Average Success rate | ↓ 15.5% | ↑ 48.9% | ↗ 17.8% | ↗ 17.8% | |||||||
| NBC Classification | Random Classification | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assigned Class | Assigned Class | ||||||||||
| Real class | A | B | AB | 0 | Real class | A | B | AB | 0 | ||
| A | 4% | 7% | 1% | 9% | A | 5% | 8% | 3% | 6% | ||
| B | 5% | 32% | 4% | 5% | B | 8% | 15% | 5% | 10% | ||
| AB | 0% | 7% | 6% | 0% | AB | 3% | 5% | 2% | 3% | ||
| 0 | 11% | 8% | 0% | 5% | 0 | 6% | 10% | 3% | 7% | ||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 3.5% | ↑ 67.7% | ↗ 13.1% | ↘ 15.7% | |||||||
| B-type success rate | ↘ 31.8% | ↘ 31.3% | ↓ 23.7% | ↗ 13.1% | |||||||
| AB-type success rate | ↓ 5.6% | ↑ 83.8% | ↑ 4.0% | ↑ 6.6% | |||||||
| 0-type success rate | ↓ 5.1% | ↗ 63.1% | ↗ 13.1% | ↘ 18.7% | |||||||
| NBC Success rate | ↓ 11.5% | ↗ 61.5% | ↗ 13.5% | ↗ 13.5% | |||||||
| T+ | T- | F+ | F- | |
|---|---|---|---|---|
| Identifying A with LDA | ↓ 9.6% * | ↑ 50.0% * | ↗ 19.2% | ↗ 21.2% |
| Identifying B with LDA | ↑ 46.5% | ↑ 42.4% | ↓ 35.4% | ↑ 7.6% |
| Identifying A with NBC | ↘ 21.2% | ↗ 35.3% * | ↓ 31.3% * | ↑ 12.1% |
| Identifying B with NBC | ↑ 44.4% | ↘ 26.8% | ↗ 16.2% | ↑ 12.6% |
| IMAC Number | LDA—A | LDA—B | NBC—A | NBC—B | Blood Type |
|---|---|---|---|---|---|
| 0 | - | - | - | - | O |
| 1 | - | - | - | + | O |
| 2 | - | - | + | - | O |
| 3 | - | - | + | + | A |
| 4 | - | + | - | - | B |
| 5 | - | + | - | + | B |
| 6 | - | + | + | - | B |
| 7 | - | + | + | + | B |
| 8 | + | - | - | - | O/A |
| 9 | + | - | - | + | A |
| 10 | + | - | + | - | A |
| 11 | + | - | + | + | A |
| 12 | + | + | - | - | B |
| 13 | + | + | - | + | AB |
| 14 | + | + | + | - | AB |
| 15 | + | + | + | + | AB |
| NBC Classification | Random Classification | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assigned Class | Assigned Class | ||||||||||
| Real class | A | B | AB | 0 | Real class | A | B | AB | 0 | ||
| A | 7% | 3% | 0% | 10% | A | 5% | 8% | 2% | 4% | ||
| B | 3% | 31% | 7% | 4% | B | 8% | 21% | 5% | 10% | ||
| AB | 1% | 8% | 4% | 1% | AB | 2% | 5% | 2% | 3% | ||
| 0 | 12% | 2% | 0% | 10% | 0 | 4% | 10% | 3% | 6% | ||
| T+ | T- | F+ | F- | ||||||||
| A-type success rate | ↓ 7.1% | ↑ 66.2% | ↓ 14.7% | ↘ 12.1% | |||||||
| B-type success rate | ↘ 31.3% | ↗ 42.9% | ↘ 12.1% | ↓ 13.6% | |||||||
| AB-type success rate | ↓ 3.5% | ↑ 80.8% | ↑ 7.1% | ↑ 8.6% | |||||||
| 0-type success rate | ↓ 10.1% | ↑ 62.1% | ↓ 14.1% | ↓ 13.6% | |||||||
| IMAC Success rate | ↓ 13.0% | ↑ 63.0% | ↘ 12.0% | ↘ 12.0% | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-González, A.; Obaya, Á.J.; Chimeno-Trinchet, C.; Fontanil, T.; Badía-Laíño, R. Viability of ABO Blood Typing with ATR-FTIR Spectroscopy. Appl. Sci. 2023, 13, 9650. https://doi.org/10.3390/app13179650
Fernández-González A, Obaya ÁJ, Chimeno-Trinchet C, Fontanil T, Badía-Laíño R. Viability of ABO Blood Typing with ATR-FTIR Spectroscopy. Applied Sciences. 2023; 13(17):9650. https://doi.org/10.3390/app13179650
Chicago/Turabian StyleFernández-González, Alfonso, Álvaro J. Obaya, Christian Chimeno-Trinchet, Tania Fontanil, and Rosana Badía-Laíño. 2023. "Viability of ABO Blood Typing with ATR-FTIR Spectroscopy" Applied Sciences 13, no. 17: 9650. https://doi.org/10.3390/app13179650
APA StyleFernández-González, A., Obaya, Á. J., Chimeno-Trinchet, C., Fontanil, T., & Badía-Laíño, R. (2023). Viability of ABO Blood Typing with ATR-FTIR Spectroscopy. Applied Sciences, 13(17), 9650. https://doi.org/10.3390/app13179650