



Body-Pose-Guided Action Recognition with Convolutional Long Short-Term Memory (LSTM) in Aerial Videos

 ,
,  and
and 
Abstract
:1. Introduction
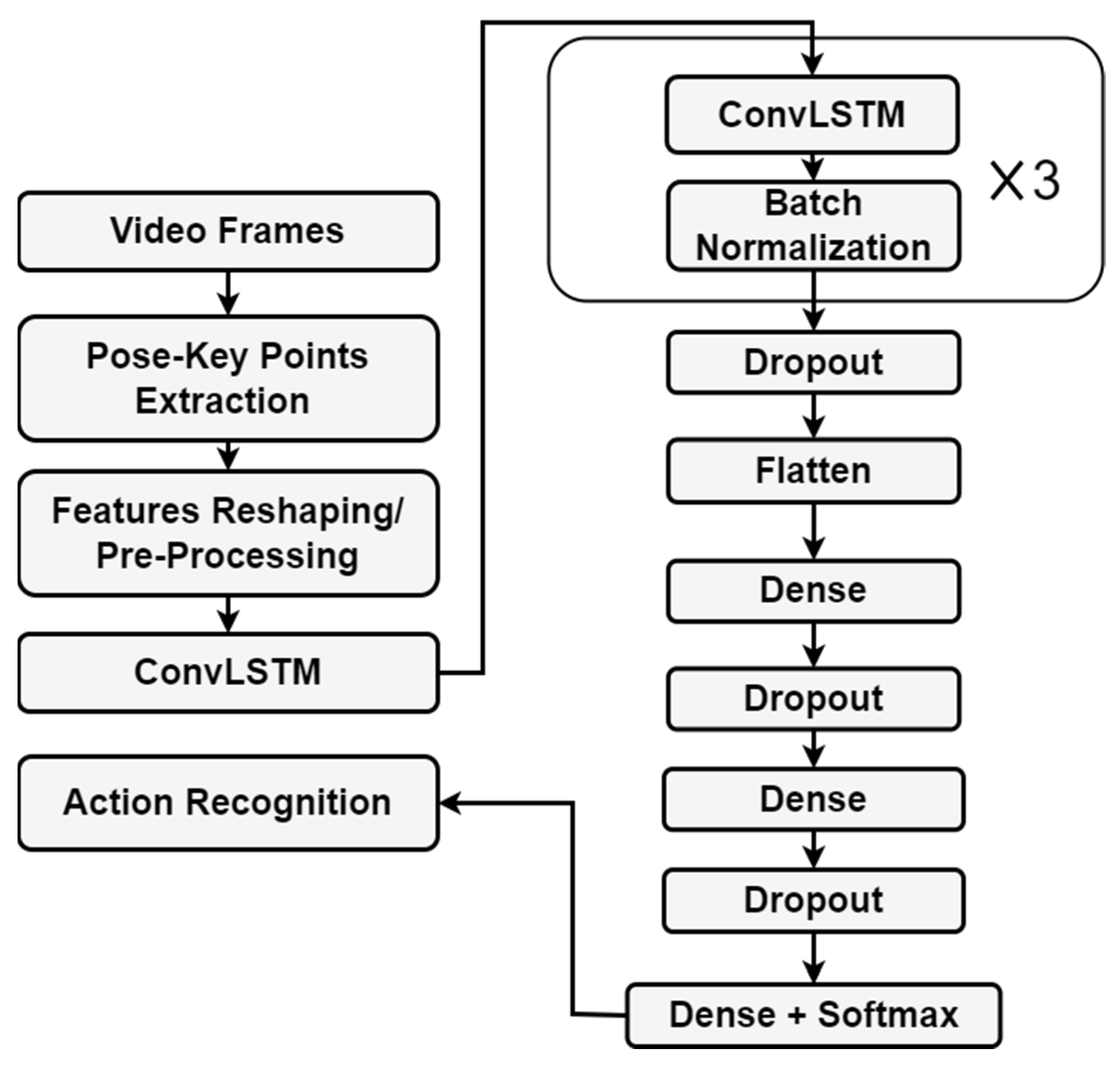
2. Proposed Action Recognition Method
2.1. Pose Extraction
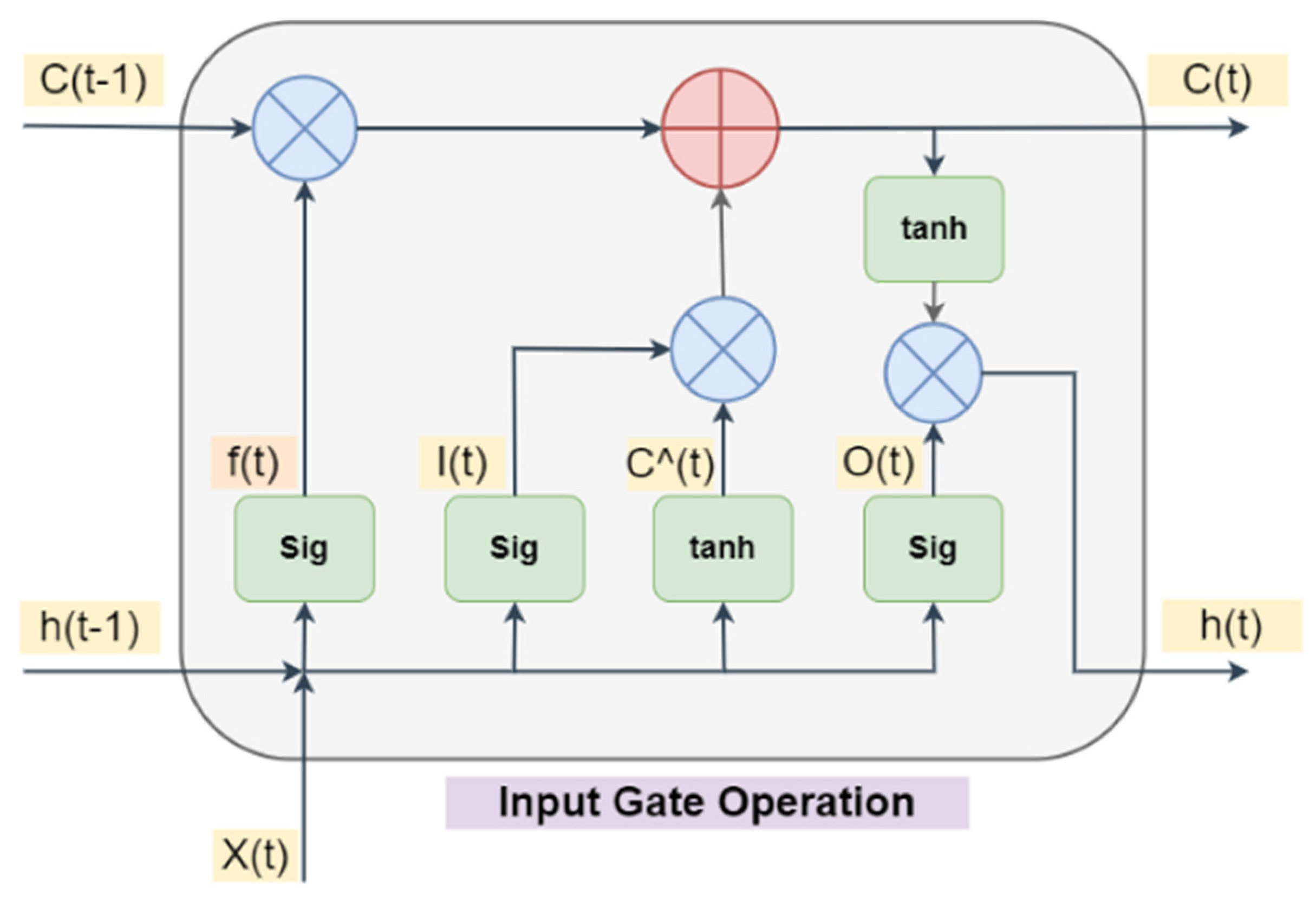
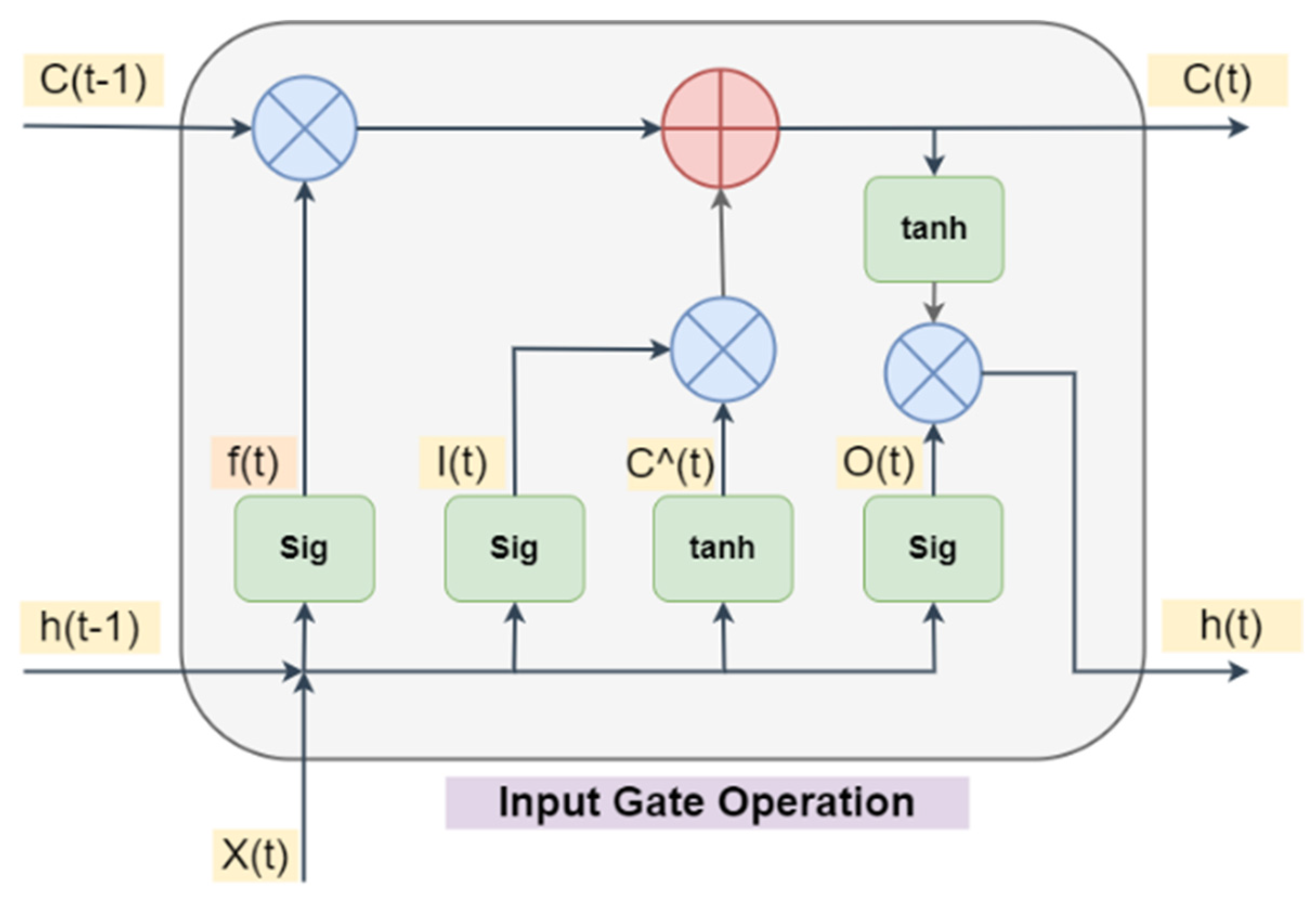
2.2. Custimized Convolutional LSTM Model
3. Experimental Results and Analysis
3.1. Dataset
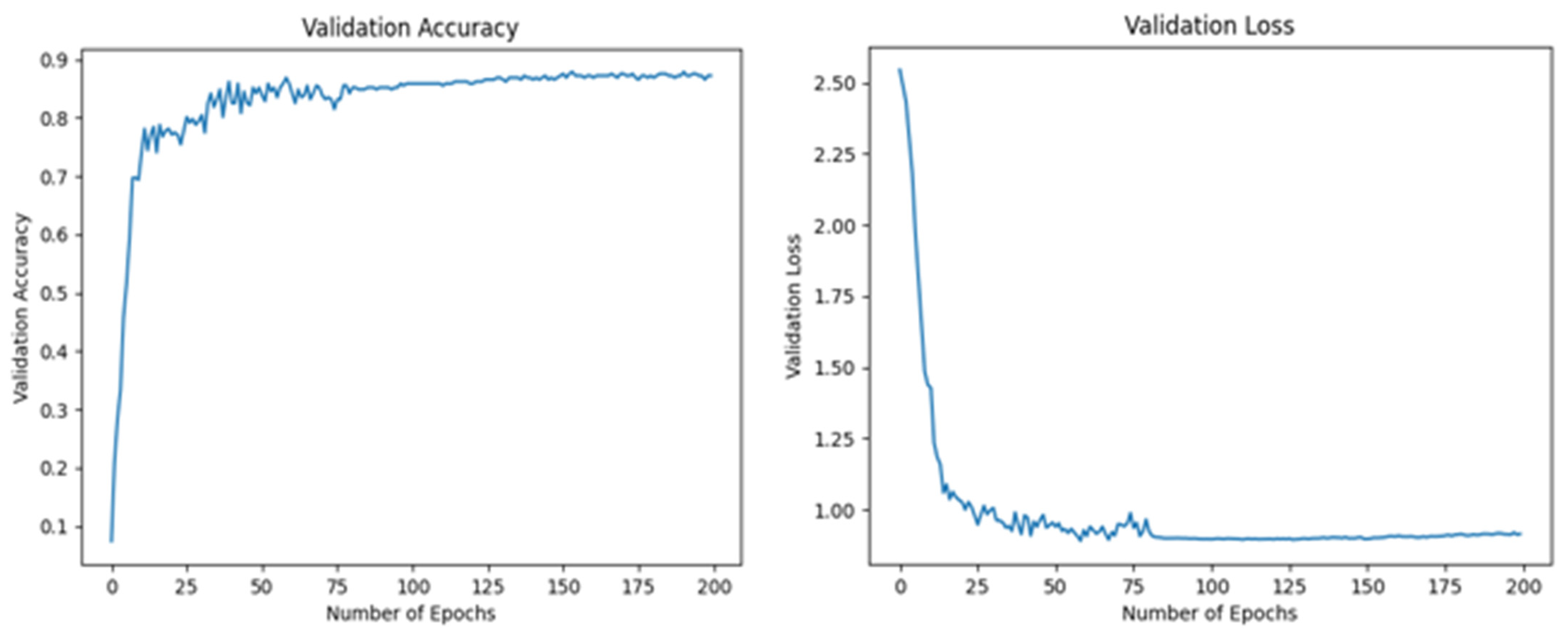
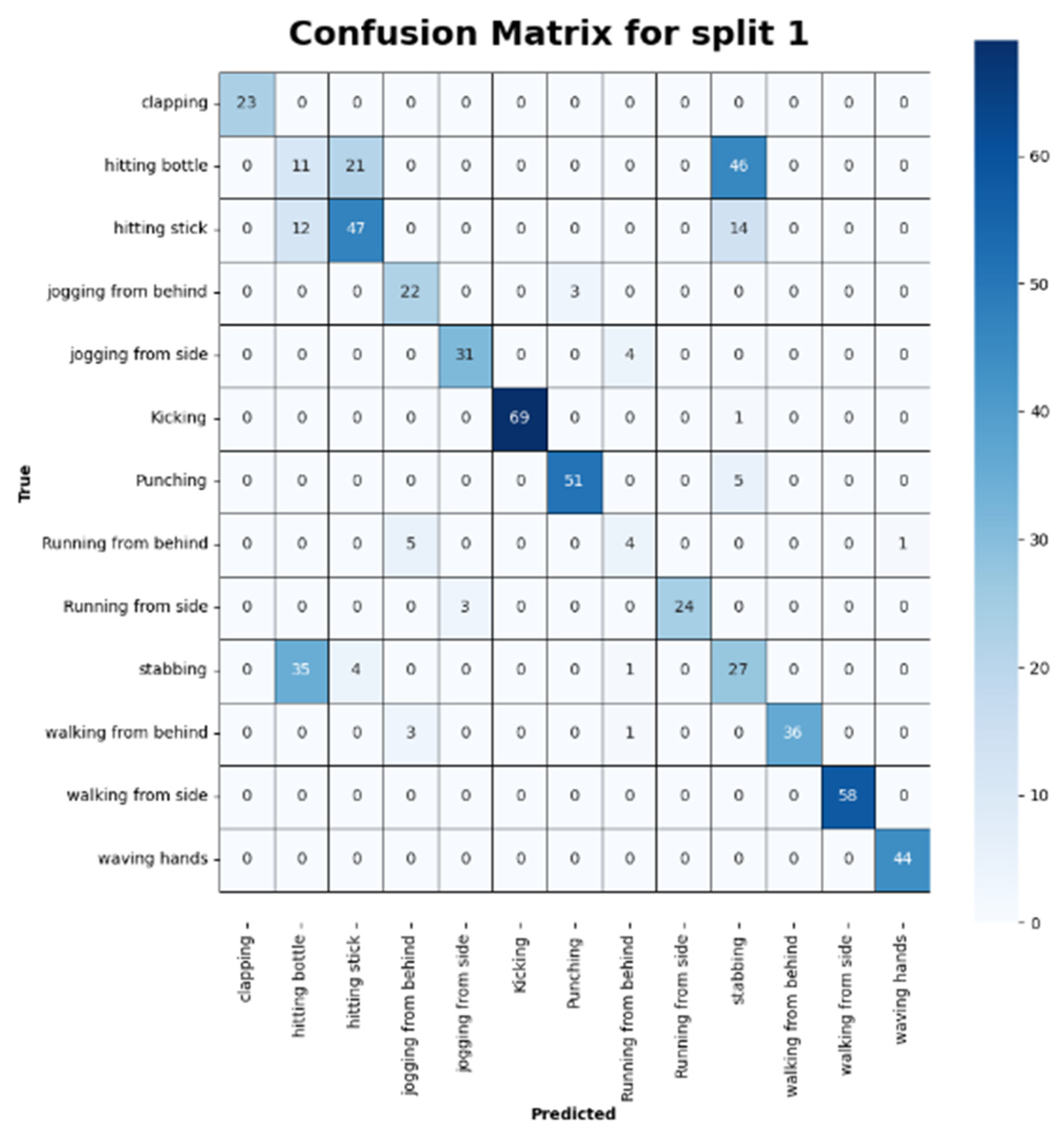
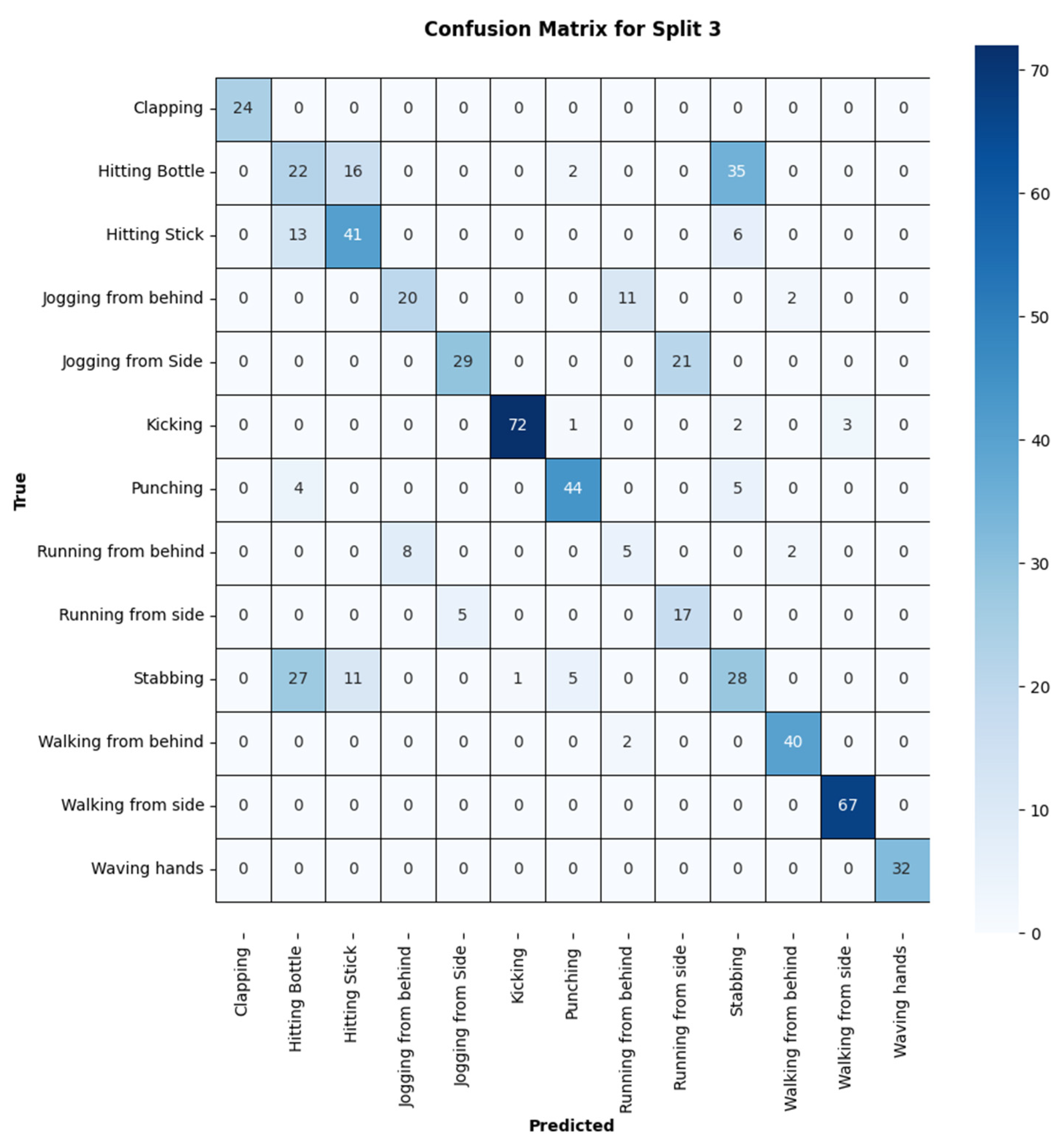
3.2. Evaluation of Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
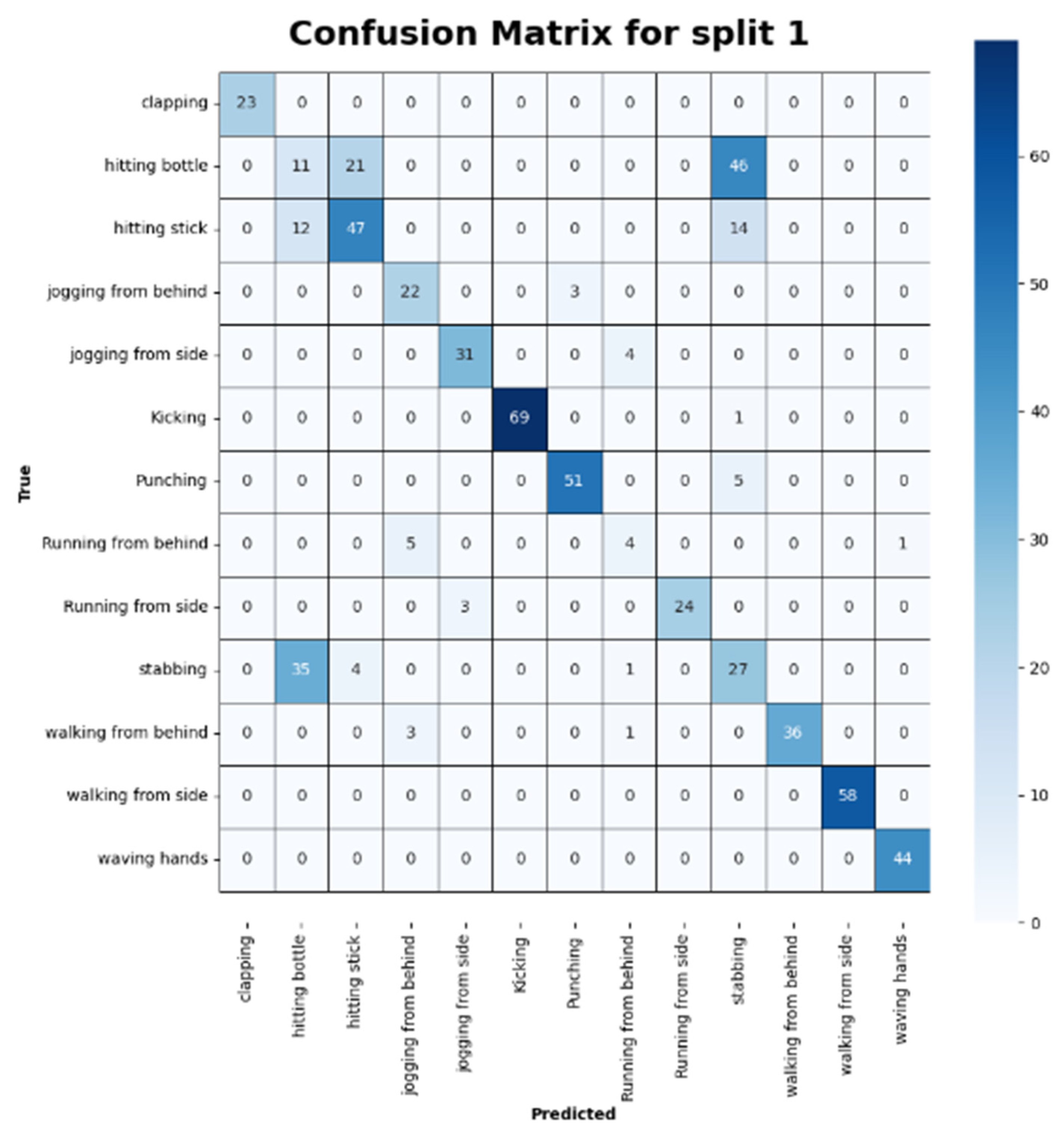
{kind=link}
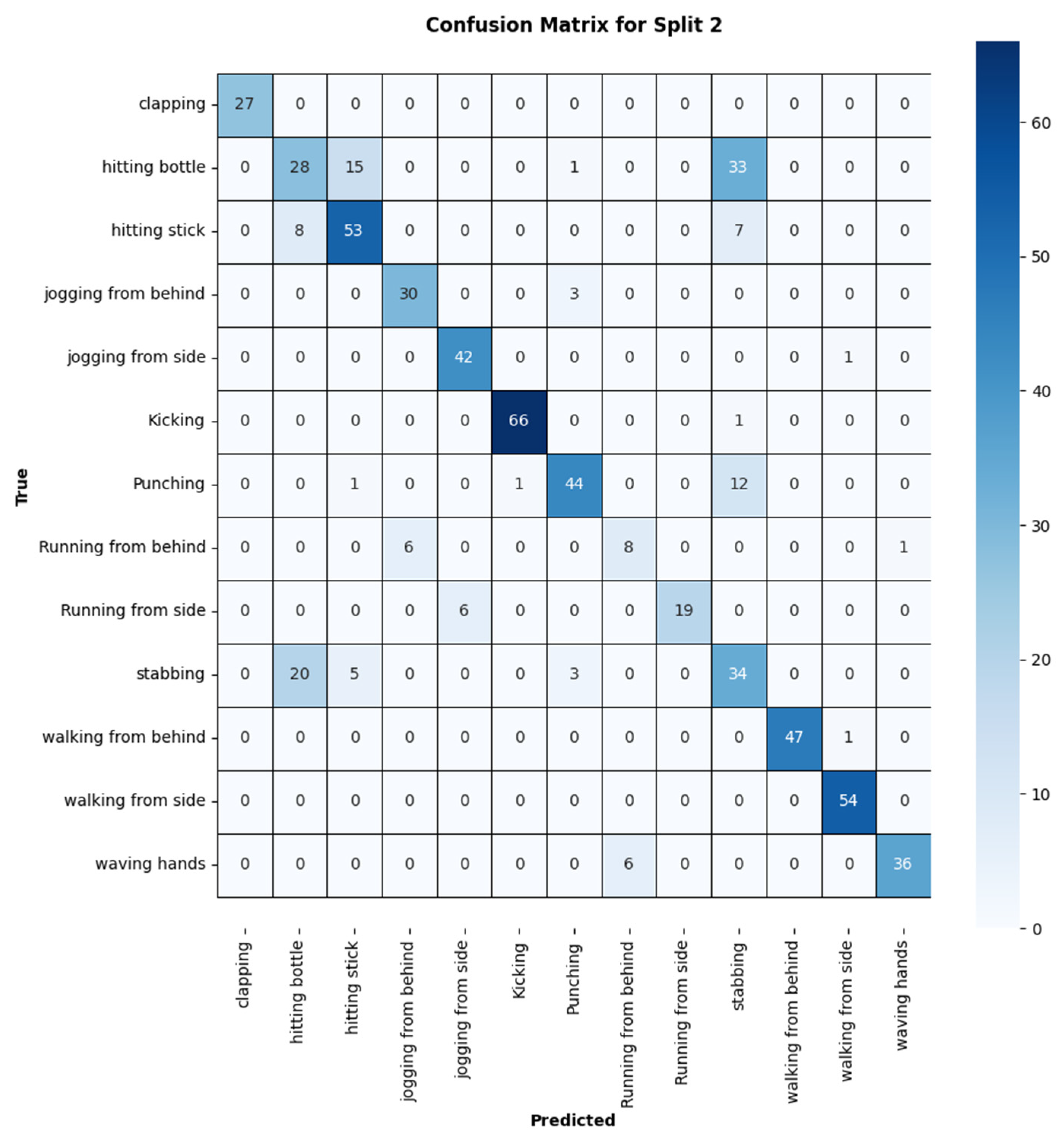
{kind=link}
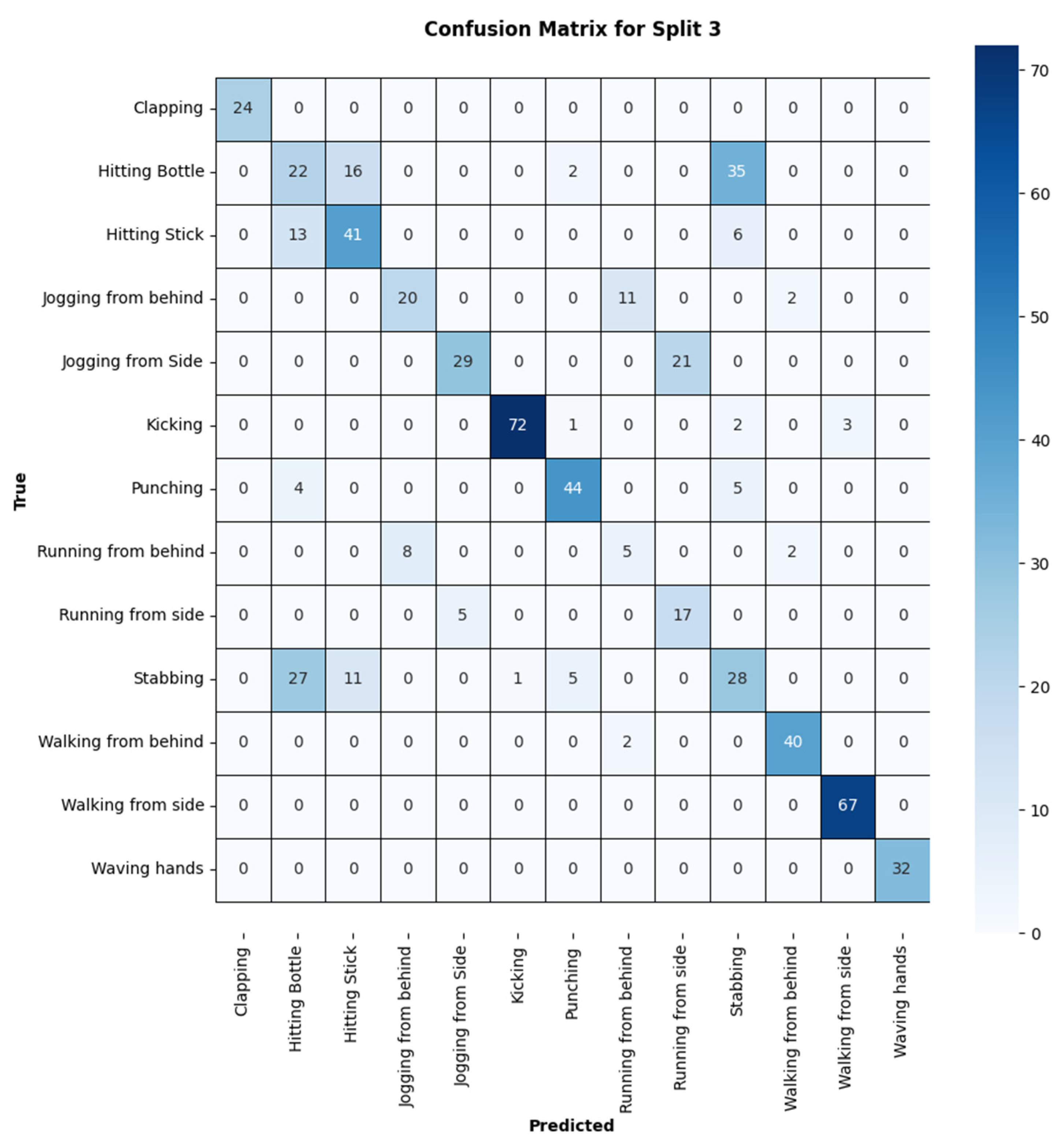
{kind=link}
| Action | Precision | Recall | F1-Score |
|---|---|---|---|
| Clap | 1.00 | 1.00 | 1.00 |
| Hit_botl | 0.19 | 0.14 | 0.16 |
| Hit_stick | 0.65 | 0.64 | 0.65 |
| Jogging | 0.73 | 0.88 | 0.80 |
| Jog_side | 0.91 | 0.89 | 0.90 |
| Kick | 0.99 | 1.00 | 0.99 |
| Punch | 0.91 | 0.99 | 0.95 |
| Run_fb | 0.50 | 0.40 | 0.44 |
| Run_side | 0.86 | 0.89 | 0.87 |
| Stab | 0.29 | 0.40 | 0.34 |
| Walk_fb | 1.00 | 0.90 | 0.95 |
| Walk_side | 1.00 | 1.00 | 1.00 |
| Wave_hands | 0.98 | 1.00 | 0.99 |
| Average | 0.77 | 0.78 | 0.77 |
| Action | Precision | Recall | F1-Score |
|---|---|---|---|
| Clap | 1.00 | 1.00 | 1.00 |
| Hit_botl | 0.50 | 0.36 | 0.42 |
| Hit_stick | 0.72 | 0.78 | 0.75 |
| Jog_fb | 0.83 | 0.91 | 0.87 |
| Jog_side | 0.86 | 0.98 | 0.91 |
| Kick | 0.99 | 0.92 | 1.00 |
| Punch | 0.76 | 0.99 | 0.83 |
| Run_fb | 0.73 | 0.53 | 0.62 |
| Run_side | 1.00 | 0.76 | 0.86 |
| Stab | 0.40 | 0.55 | 0.46 |
| Walk_fb | 1.00 | 1.00 | 1.00 |
| Walk_side | 0.98 | 0.98 | 0.98 |
| Wave_hands | 0.97 | 1.00 | 0.99 |
| Average | 0.83 | 0.83 | 0.82 |
| Action | Precision | Recall | F1-Score |
|---|---|---|---|
| Clap | 1.00 | 0.89 | 0.94 |
| Hit_botl | 0.33 | 0.29 | 0.31 |
| Hit_stick | 0.59 | 0.68 | 0.64 |
| Jog_fb | 0.67 | 0.61 | 0.63 |
| Jog_side | 0.85 | 0.58 | 0.69 |
| Kick | 0.99 | 0.85 | 0.92 |
| Punch | 0.83 | 0.95 | 0.84 |
| Run_fb | 0.28 | 0.33 | 0.30 |
| Run_side | 0.45 | 0.77 | 0.57 |
| Stab | 0.37 | 0.39 | 0.38 |
| Walk_fb | 0.91 | 0.95 | 0.93 |
| Walk_side | 0.96 | 1.00 | 0.98 |
| Wave_hands | 1.00 | 1.00 | 1.00 |
| Average | 0.71 | 0.71 | 0.70 |
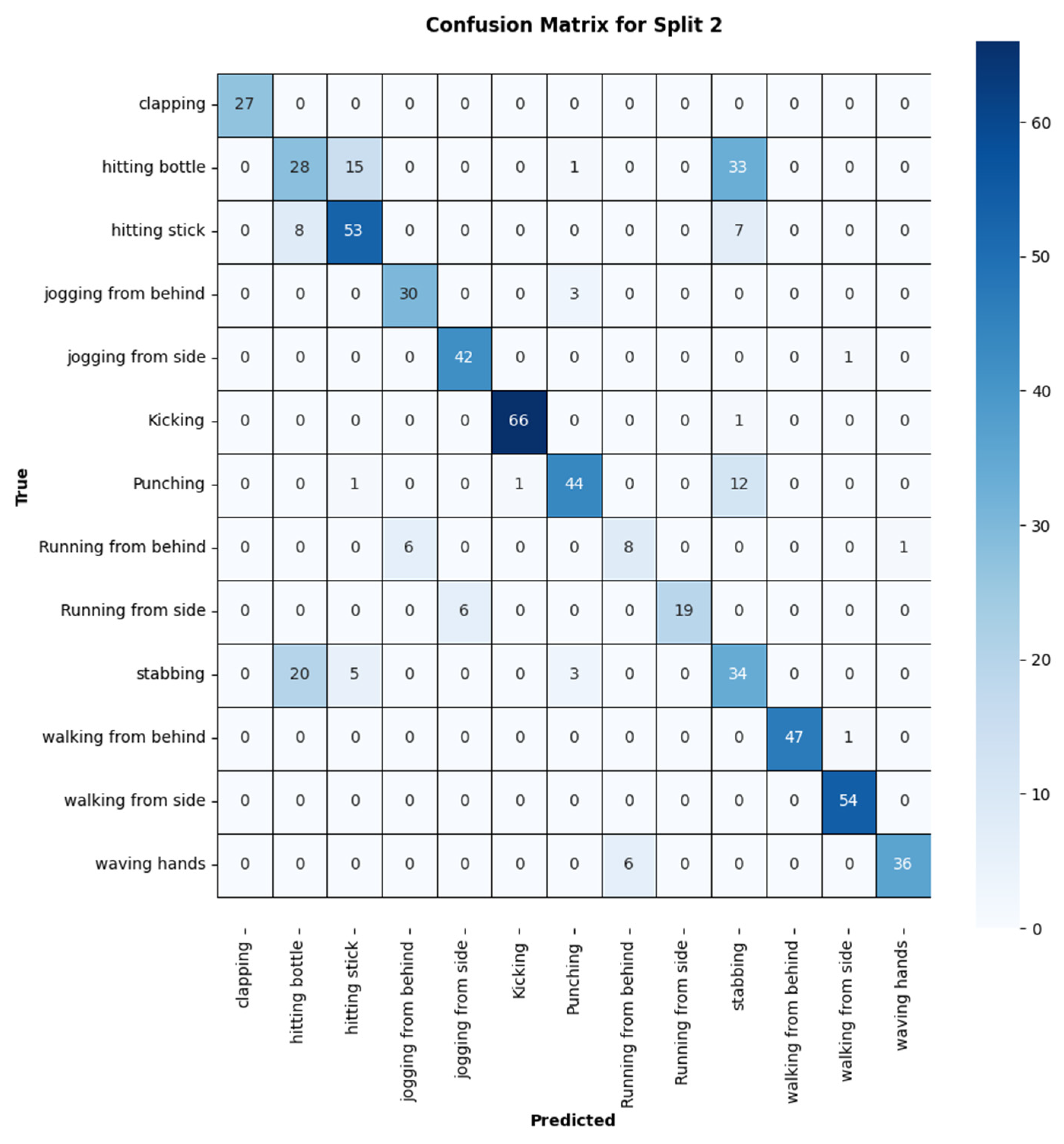
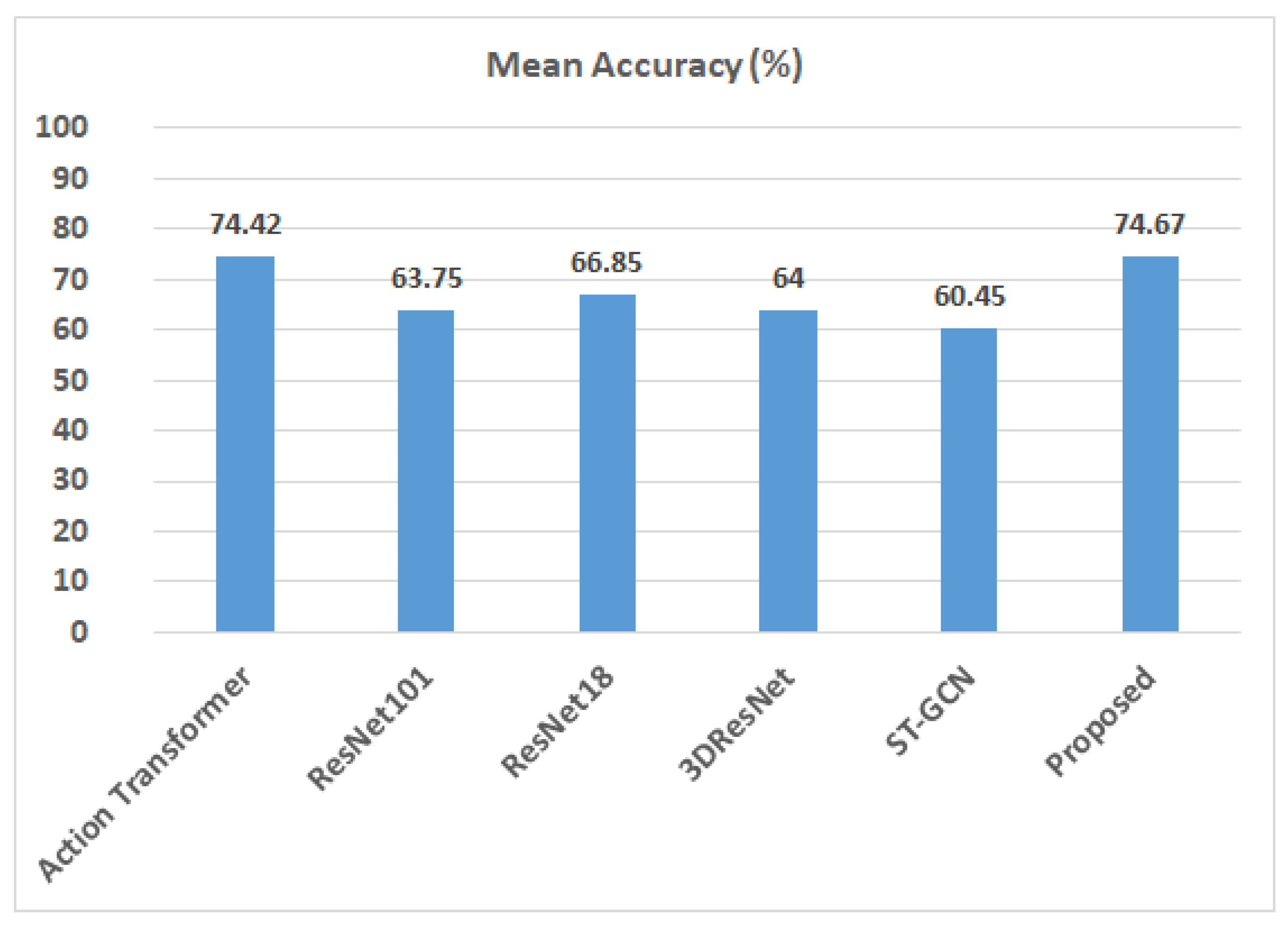
3.3. Performance Comparison with Related Approaches
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, R.; Tripathi, R.; Marchang, N.; Srivastava, G.; Gadekallu, T.R.; Xiong, N.N. A secured distributed detection system based on IPFS and blockchain for industrial image and video data security. J. Parallel Distrib. Comput. 2021, 152, 128–143. [Google Scholar] [CrossRef]
- Shorfuzzaman, M.; Hossain, M.S.; Alhamid, M.F. Towards the sustainable development of smart cities through mass video surveillance: A response to the COVID-19 pandemic. Sustain. Cities Soc. 2021, 64, 102582. [Google Scholar] [CrossRef] [PubMed]
- Kashef, M.; Visvizi, A.; Troisi, O. Smart city as a smart service system: Human-computer interaction and smart city surveillance systems. Comput. Hum. Behav. 2021, 124, 106923. [Google Scholar] [CrossRef]
- Özyer, T.; Ak, D.S.; Alhajj, R. Human action recognition approaches with video datasets—A survey. Knowl.-Based Syst. 2021, 222, 106995. [Google Scholar] [CrossRef]
- Sultani, W.; Shah, M. Human Action Recognition in Drone Videos Using a Few Aerial Training Examples. arXiv 2021, arXiv:1910.10027. Available online: http://arxiv.org/abs/1910.10027 (accessed on 15 June 2023).
- Wang, X.; Xian, R.; Guan, T.; de Melo, C.M.; Nogar, S.M.; Bera, A.; Manocha, D. AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning. arXiv 2023, arXiv:2303.01589. Available online: http://arxiv.org/abs/2303.01589 (accessed on 15 June 2023).
- Hejazi, S.M.; Abhayaratne, C. Handcrafted localized phase features for human action recognition. Image Vis. Comput. 2022, 123, 104465. [Google Scholar] [CrossRef]
- El-Ghaish, H.; Hussein, M.; Shoukry, A.; Onai, R. Human Action Recognition Based on Integrating Body Pose, Part Shape, and Motion; IEEE Access: Piscataway, NJ, USA, 2018; pp. 49040–49055. [Google Scholar] [CrossRef]
- Arunnehru, J.; Chamundeeswari, G.; Bharathi, S.P. Human Action Recognition using 3D Convolutional Neural Networks with 3D Motion Cuboids in Surveillance Videos. Procedia Comput. Sci. 2018, 133, 471–477. [Google Scholar] [CrossRef]
- Sánchez-Caballero, A.; de López-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Casillas-Pérez, D.; Sarker, M.I. 3DFCNN: Real-time action recognition using 3D deep neural networks with raw depth information. Multimed Tools Appl. 2022, 81, 24119–24143. [Google Scholar] [CrossRef]
- Sánchez-Caballero, A.; Fuentes-Jiménez, D.; Losada-Gutiérrez, C. Real-time human action recognition using raw depth video-based recurrent neural networks. Multimed Tools Appl. 2023, 82, 16213–16235. [Google Scholar] [CrossRef]
- Muhammad, K.; Mustaqeem; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; de Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated CNN features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, S.; Huang, Z.; Wang, Y.; Jiang, H. Two-stream transformer network for sensor-based human activity recognition. Neurocomputing 2022, 512, 253–268. [Google Scholar] [CrossRef]
- Zhao, Y.; Man, K.L.; Smith, J.; Siddique, K.; Guan, S.-U. Improved two-stream model for human action recognition. EURASIP J. Image Video Process. 2020, 2020, 24. [Google Scholar] [CrossRef]
- Ahmad, T.; Jin, L.; Zhang, X.; Lai, S.; Tang, G.; Lin, L. Graph Convolutional Neural Network for Human Action Recognition: A Comprehensive Survey. IEEE Trans. Artif. Intell. 2021, 2, 128–145. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, Y.; Zhao, W.; Tang, J. A comparative review of graph convolutional networks for human skeleton-based action recognition. Artif. Intell. Rev. 2022, 55, 4275–4305. [Google Scholar] [CrossRef]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 14043–14053. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, S.; Qing, Z.; Shao, Y.; Zuo, Z.; Gao, C.; Sang, N. OadTR: Online Action Detection with Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 7545–7555. [Google Scholar] [CrossRef]
- Barekatain, M.; Martí, M.; Shih, H.-F.; Murray, S.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2153–2160. [Google Scholar] [CrossRef]
- Liu, C.; Szirányi, T. Real-Time Human Detection and Gesture Recognition for On-Board UAV Rescue. Sensors 2021, 21, 2180. [Google Scholar] [CrossRef]
- Mliki, H.; Bouhlel, F.; Hammami, M. Human activity recognition from UAV-captured video sequences. Pattern Recognit. 2020, 100, 107140. [Google Scholar] [CrossRef]
- Perera, A.G.; Law, Y.W.; Chahl, J. Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition. Drones 2019, 3, 82. [Google Scholar] [CrossRef]
- Malik, N.U.R.; Abu-Bakar, S.A.R.; Sheikh, U.U.; Channa, A.; Popescu, N. Cascading Pose Features with CNN-LSTM for Multiview Human Action Recognition. Signals 2023, 4, 40–55. [Google Scholar] [CrossRef]
- Yang, S.-H.; Baek, D.-G.; Thapa, K. Semi-Supervised Adversarial Learning Using LSTM for Human Activity Recognition. Sensors 2022, 22, 4755. [Google Scholar] [CrossRef]
- Kumar, A.; Rawat, Y.S. End-to-End Semi-Supervised Learning for Video Action Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 14680–14690. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Lai, J. Human action recognition using two-stream attention based LSTM networks. Appl. Soft Comput. 2020, 86, 105820. [Google Scholar] [CrossRef]
- Mathew, S.; Subramanian, A.; Pooja, S. Human Activity Recognition Using Deep Learning Approaches: Single Frame CNN and Convolutional LSTM. arXiv 2023, arXiv:2304.14499. [Google Scholar]
- Zhang, J.; Bai, F.; Zhao, J.; Song, Z. Multi-views Action Recognition on 3D ResNet-LSTM Framework. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 289–293. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. Available online: http://arxiv.org/abs/2305.09972 (accessed on 16 June 2023).
- Arif, S.; Wang, J.; Ul Hassan, T.; Fei, Z. 3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition. Future Internet 2019, 11, 42. [Google Scholar] [CrossRef]
- Mateus, B.C.; Mendes, M.; Farinha, J.T.; Cardoso, A.M. Anticipating Future Behavior of an Industrial Press Using LSTM Networks. Appl. Sci. 2021, 11, 6101. [Google Scholar] [CrossRef]
- Khan, L.; Amjad, A.; Afaq, K.M.; Chang, H.-T. Deep Sentiment Analysis Using CNN-LSTM Architecture of English and Roman Urdu Text Shared in Social Media. Appl. Sci. 2022, 12, 2694. [Google Scholar] [CrossRef]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. Available online: http://arxiv.org/abs/1512.03385 (accessed on 19 November 2022).
- Chen, S.; Xu, K.; Jiang, X.; Sun, T. Pyramid Spatial-Temporal Graph Transformer for Skeleton-Based Action Recognition. Appl. Sci. 2022, 12, 9229. [Google Scholar] [CrossRef]



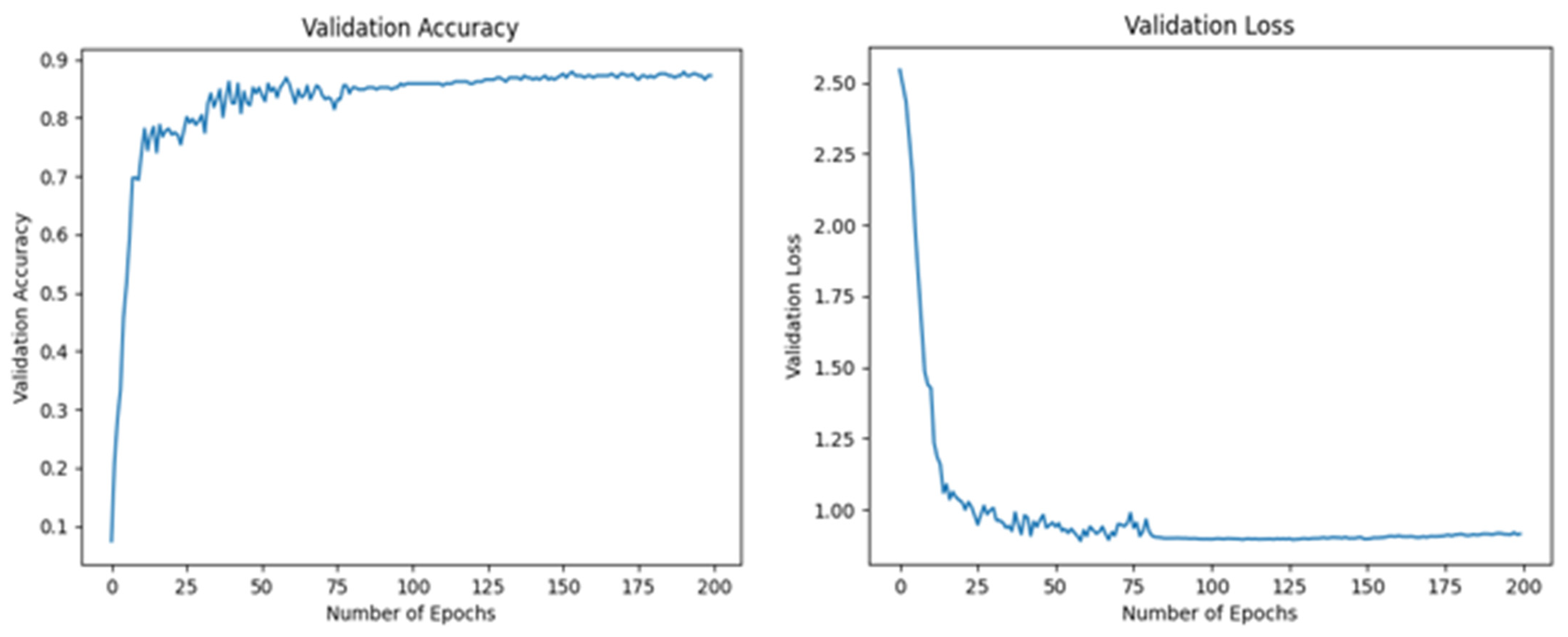

| Dataset | Epochs | Validation Loss | Validation Accuracy |
|---|---|---|---|
| Split 1 | 200 | 2.75–0.25 | 0.05–0.88 |
| Split 2 | 200 | 2.55–1.00 | 0.13–0.83 |
| Split 3 | 200 | 2.58–1.00 | 0.12–0.82 |
| Method | Accuracy (Split 1) | Accuracy (Split 2) | Accuracy (Split 3) | Mean Accuracy |
|---|---|---|---|---|
| HLPF | 63.89% | 68.09% | 61.11% | 64.36% |
| P-CNN | 72.22% | 81.94% | 73.61% | 75.92% |
| Pose+ LSTM | 74.00% | 80.00% | 70.00% | 74.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, S.M.; Akbar, H.; Nawaz, T.; Elahi, H.; Khan, U.S. Body-Pose-Guided Action Recognition with Convolutional Long Short-Term Memory (LSTM) in Aerial Videos. Appl. Sci. 2023, 13, 9384. https://doi.org/10.3390/app13169384
Saeed SM, Akbar H, Nawaz T, Elahi H, Khan US. Body-Pose-Guided Action Recognition with Convolutional Long Short-Term Memory (LSTM) in Aerial Videos. Applied Sciences. 2023; 13(16):9384. https://doi.org/10.3390/app13169384
Chicago/Turabian StyleSaeed, Sohaib Mustafa, Hassan Akbar, Tahir Nawaz, Hassan Elahi, and Umar Shahbaz Khan. 2023. "Body-Pose-Guided Action Recognition with Convolutional Long Short-Term Memory (LSTM) in Aerial Videos" Applied Sciences 13, no. 16: 9384. https://doi.org/10.3390/app13169384
APA StyleSaeed, S. M., Akbar, H., Nawaz, T., Elahi, H., & Khan, U. S. (2023). Body-Pose-Guided Action Recognition with Convolutional Long Short-Term Memory (LSTM) in Aerial Videos. Applied Sciences, 13(16), 9384. https://doi.org/10.3390/app13169384