
A Stave-Aware Optical Music Recognition on Monophonic Scores for Camera-Based Scenarios


Abstract
:1. Introduction
2. Related Work
3. Method Details
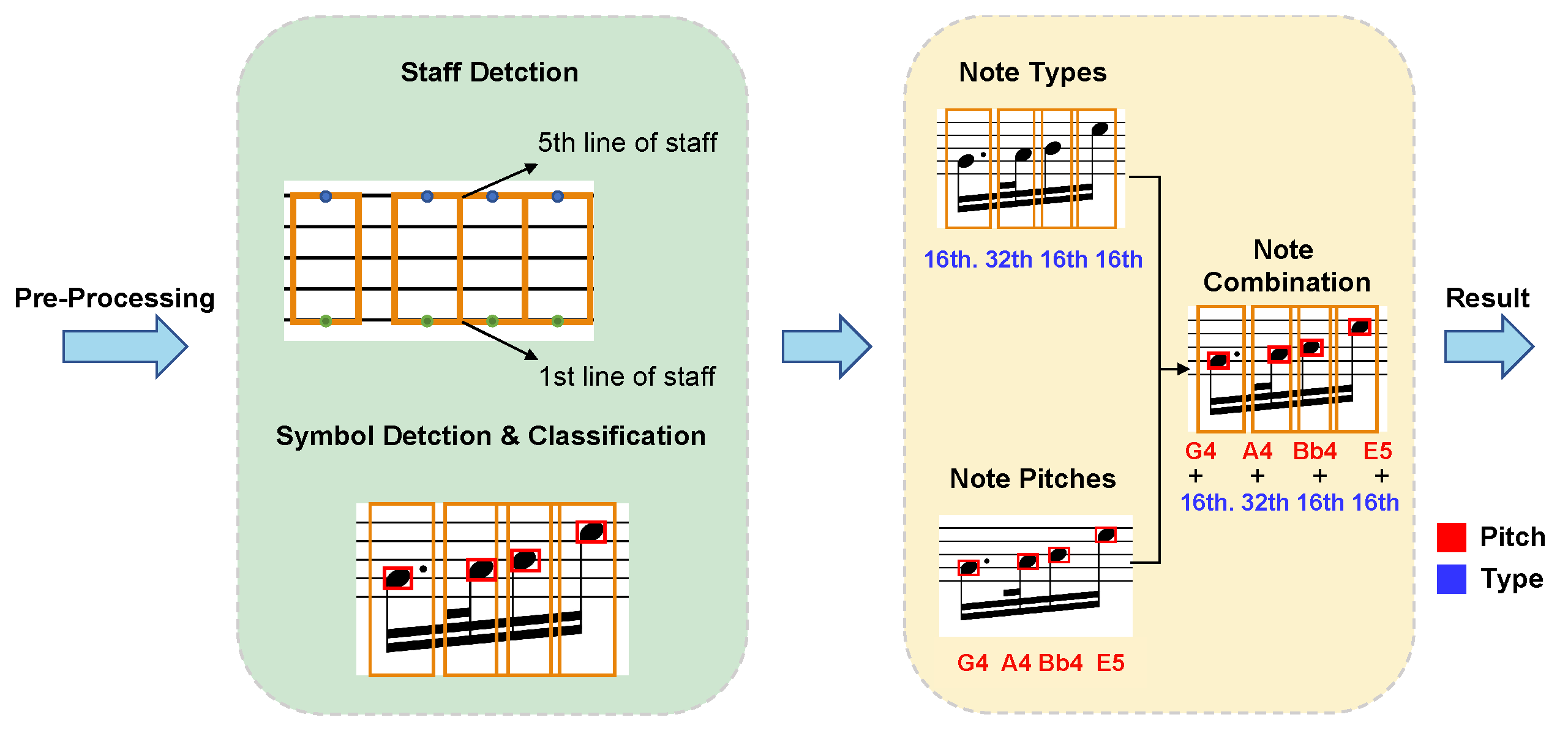
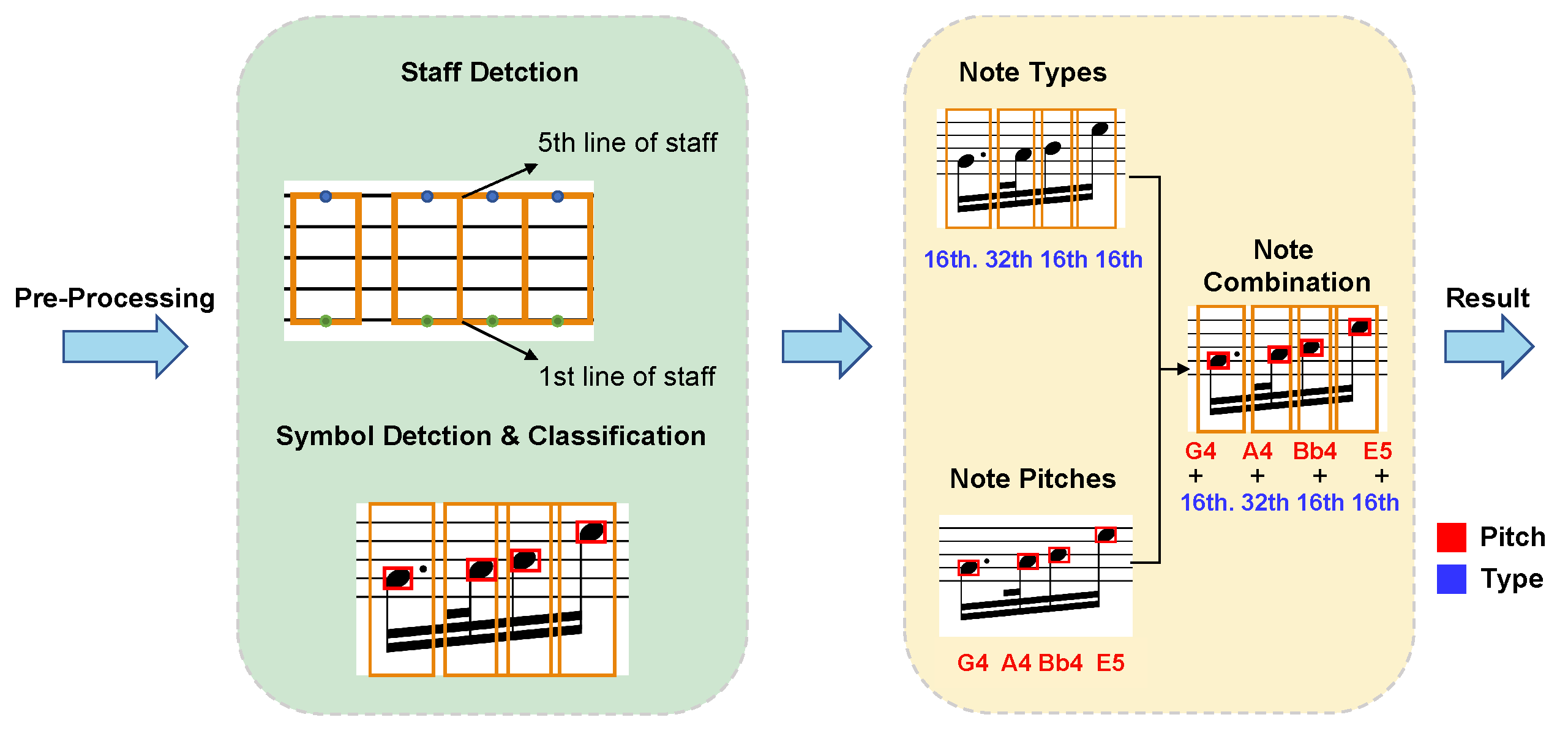
3.1. Overall Design
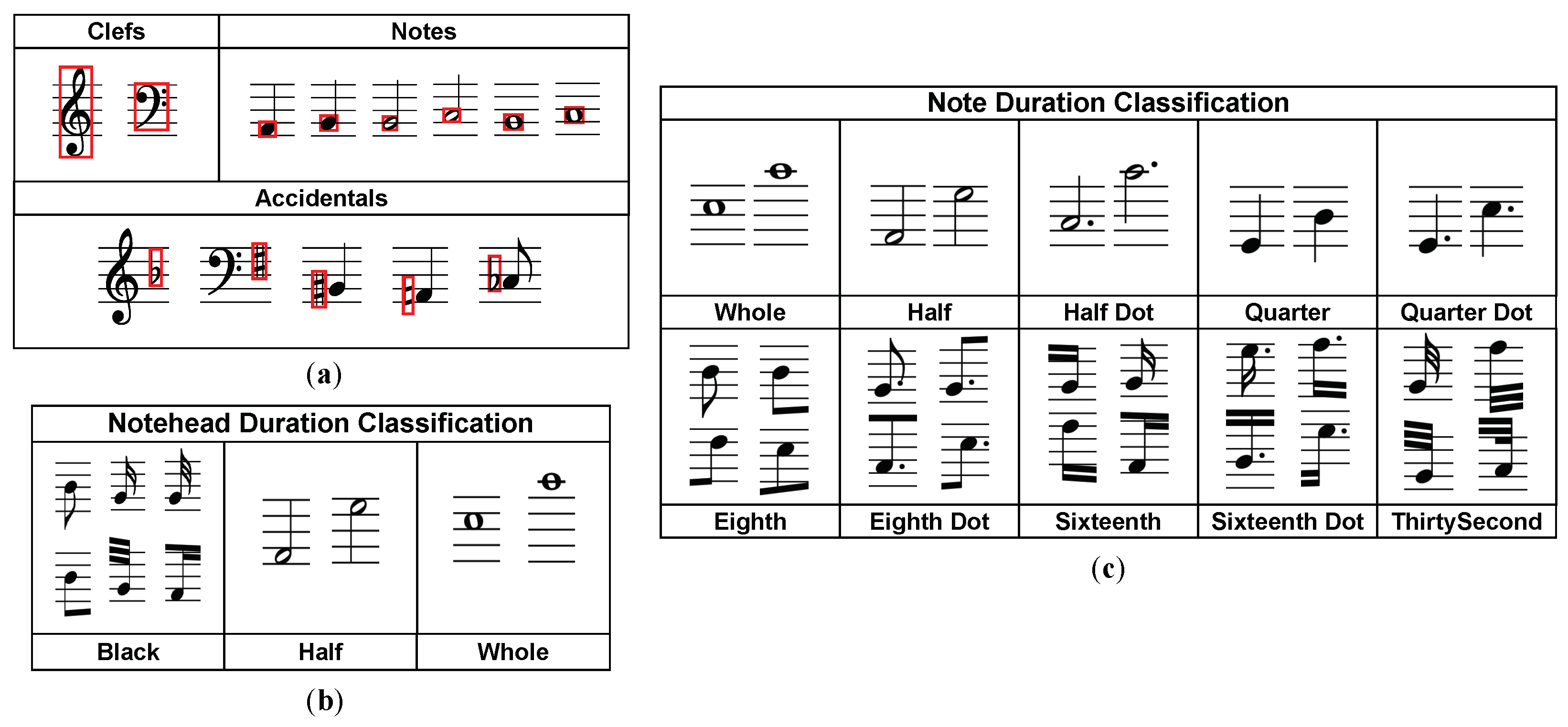
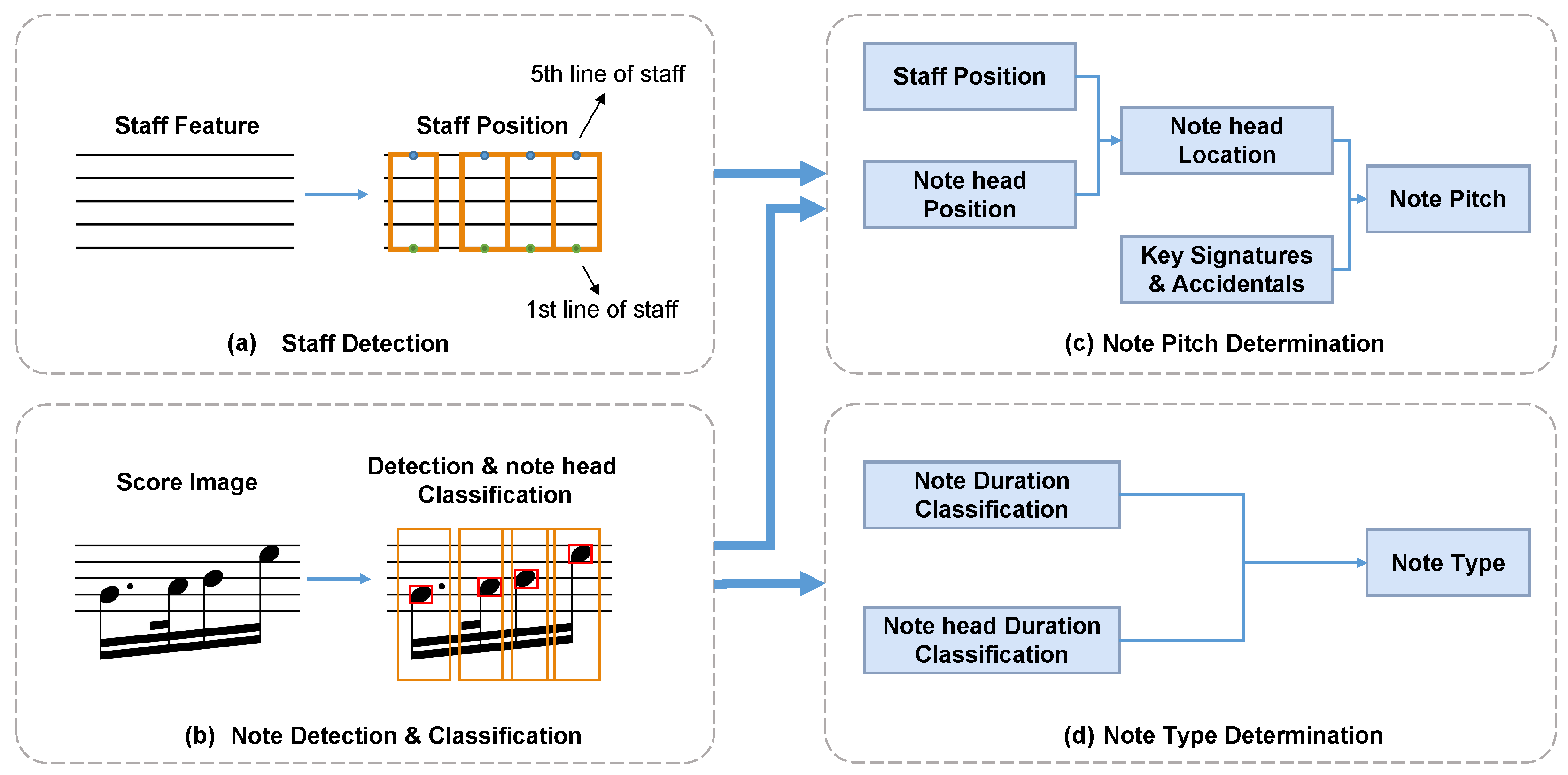
- Symbol detection. In this stage, we detect symbols, which affect the pitch of notes, in the music sheet such as note heads, clefs, key signatures, and accidentals. Simultaneously, the detection of staff lines and the segmentation of notes are also conducted. The result will be utilized for recognizing the pitch and type of the notes.
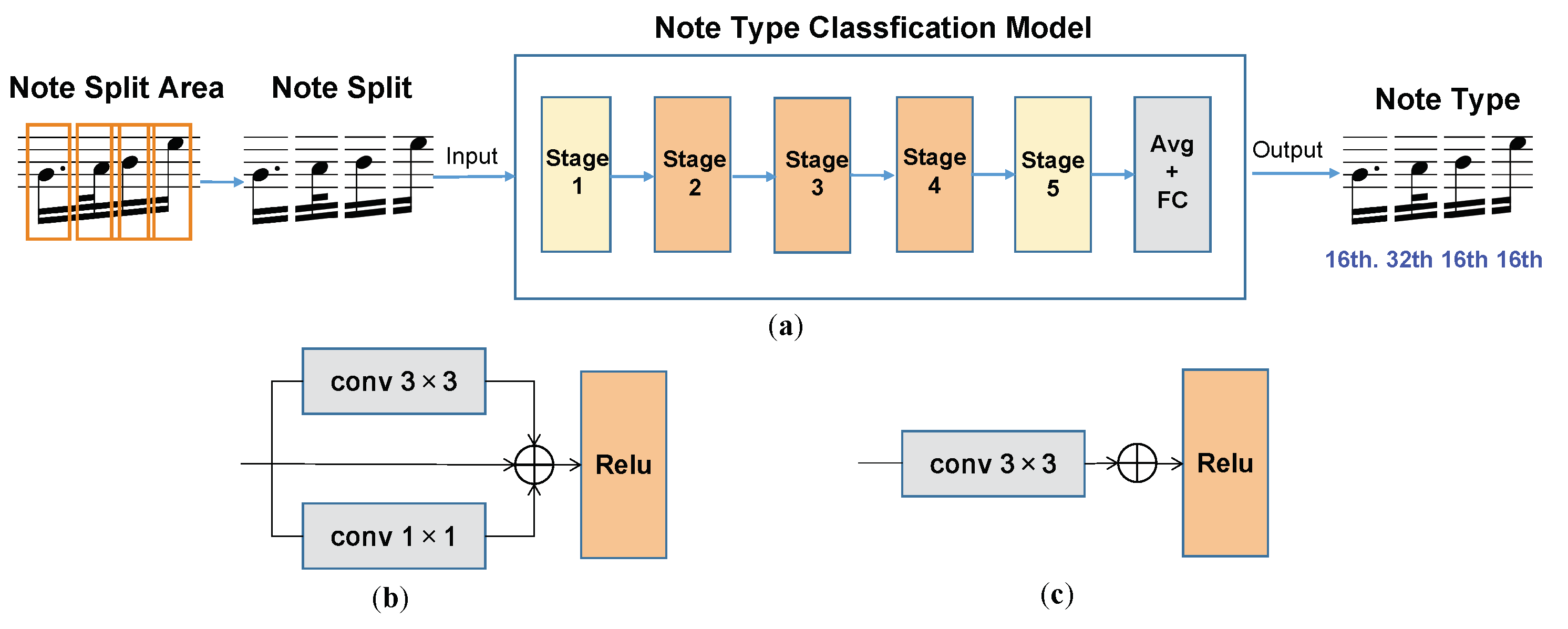
- Symbol assembly. This stage includes pitch assembly and duration assembly. In the pitch assembly, information about the type and position of accidentals, and the position of note heads and staff lines are fused. In duration assembly, we combine information about note head duration and note duration to obtain note type. Note head duration refers to the type of note heads through an object detection network, whereas note duration is determined by the stem type and whether it is dotted or not through a classification network.
3.2. Preprocessing
- Remove the background lighting. All input images are converted into grayscale because color is an unnecessary element for OMR. Then, Gaussian blur [40] is applied to obtain blurred images. Finally, subtract the original grayscale image from the blurred image. The purpose of this step is to mitigate the brightness and contrast differences between different regions in the musical score image caused by uneven light distribution.
- Resize the image. Firstly, we divide the image into a fixed number of columns, calculate the median gray scale value of each row within each column, and assign it as the value for that respective row. Next, convolve the modified image with a set of comb filters corresponding to different staff line spacing. We choose the spacing represented by the accumulated response of the most prominent comb filter as the distance between adjacent lines. Finally, we resize the image to ensure the lines’ distance is fixed. The purpose of this step is to keep a constant distance between adjacent staff lines of the musical score.
- Morphological filtering. We perform two rounds of morphological filtering on the image shown in Figure 2. The first round removes non-horizontal pixels, and the second round removes thin staff lines. Finally, subtracting the results of the two filtering steps provides the staff lines eliminated during the second round. The purpose of this step is to eliminate the musical notes from the image, preserving only the staff lines for stave detection.
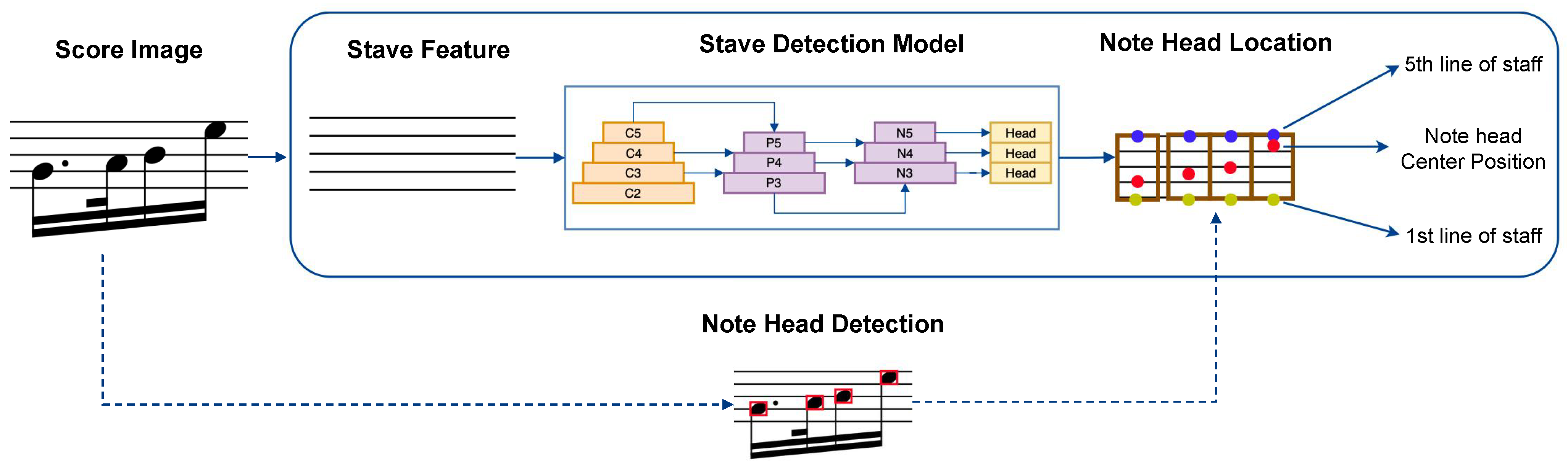
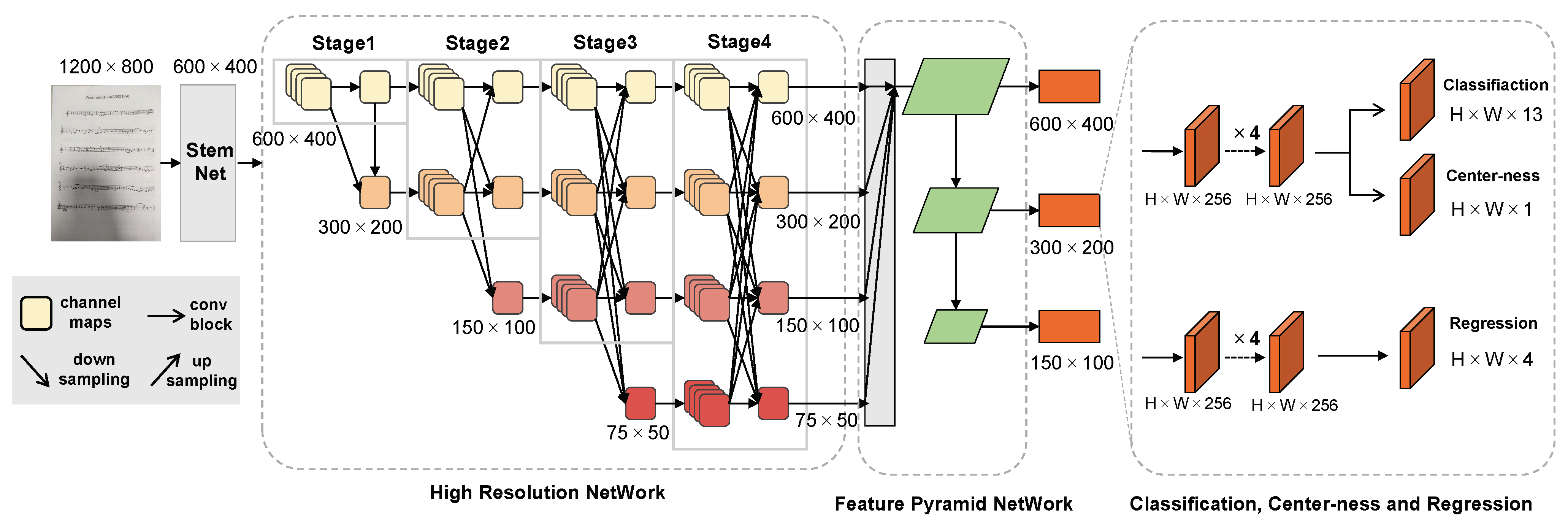
3.3. Stave Detection
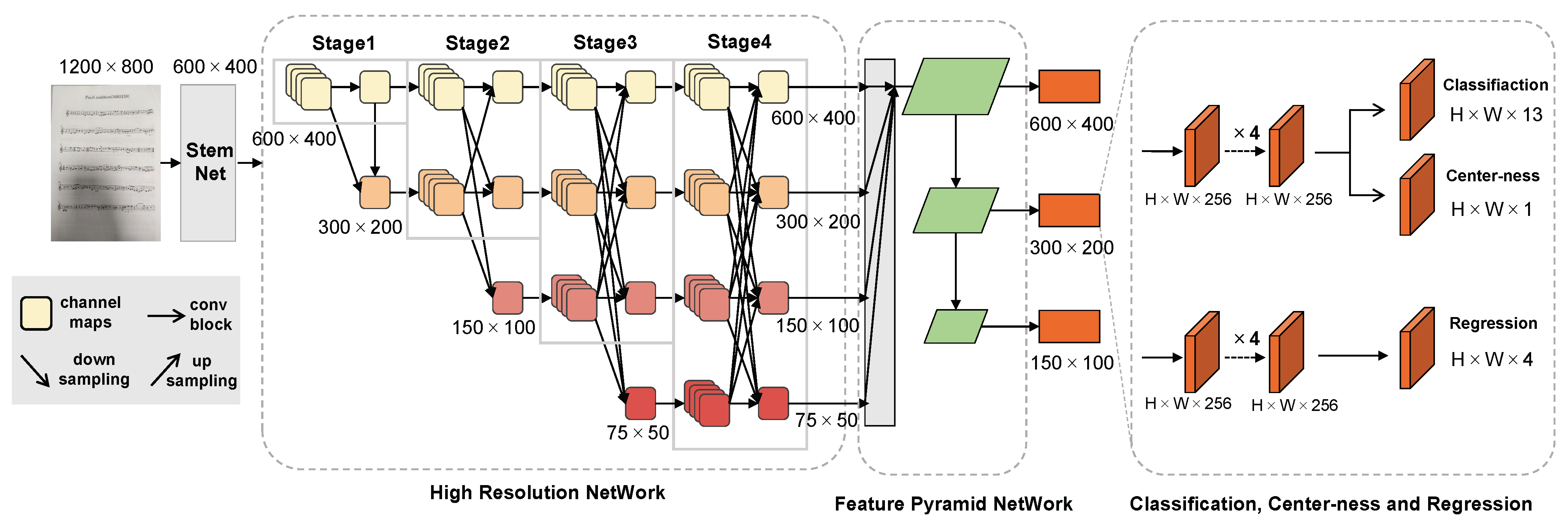
- Feature extraction. We choose the CSPDarknet [42] backbone to extract the features of the staff lines (sized ). The CSPDarknet adopts the structure of YOLOv5s but replaces the LeakyReLU activation function with SiLU.
- Feature fusion. The output of the backbone is an image with a size of , which is then fed into PANet [43] for feature fusion. Finally, the network will obtain three feature branches with sizes of , , and .
- Decoupling of prediction branch. On the fused feature map, different channel feature maps are first unified to 128 dimensions with a convolution. Then, two branches are used to perform decoupling on the detection head, and an IOU branch is added to the regression branch. Finally, the network merges the output of the three branches. Since the spectral-aware network used in this paper has a classification number of 1, the final network will output a two-dimensional vector of size 6 × 8400. Here, 8400 represents the number of predicted boxes, and 6 represents the regression and classification information for each predicted box.
3.4. Musical Symbol Detection
3.5. Notation Assembly
- Determining the note pitch. Note pitch is decided by the relative position of the note heads and the positions of accidental, clef, and staff lines.
- Determining the note type. Note type is judged by the classification of note head duration and note duration.
- Combining output note sequences. Identify the fused output sequence of notes by note pitch and note type.
4. Dataset and Experiment
4.1. Dataset
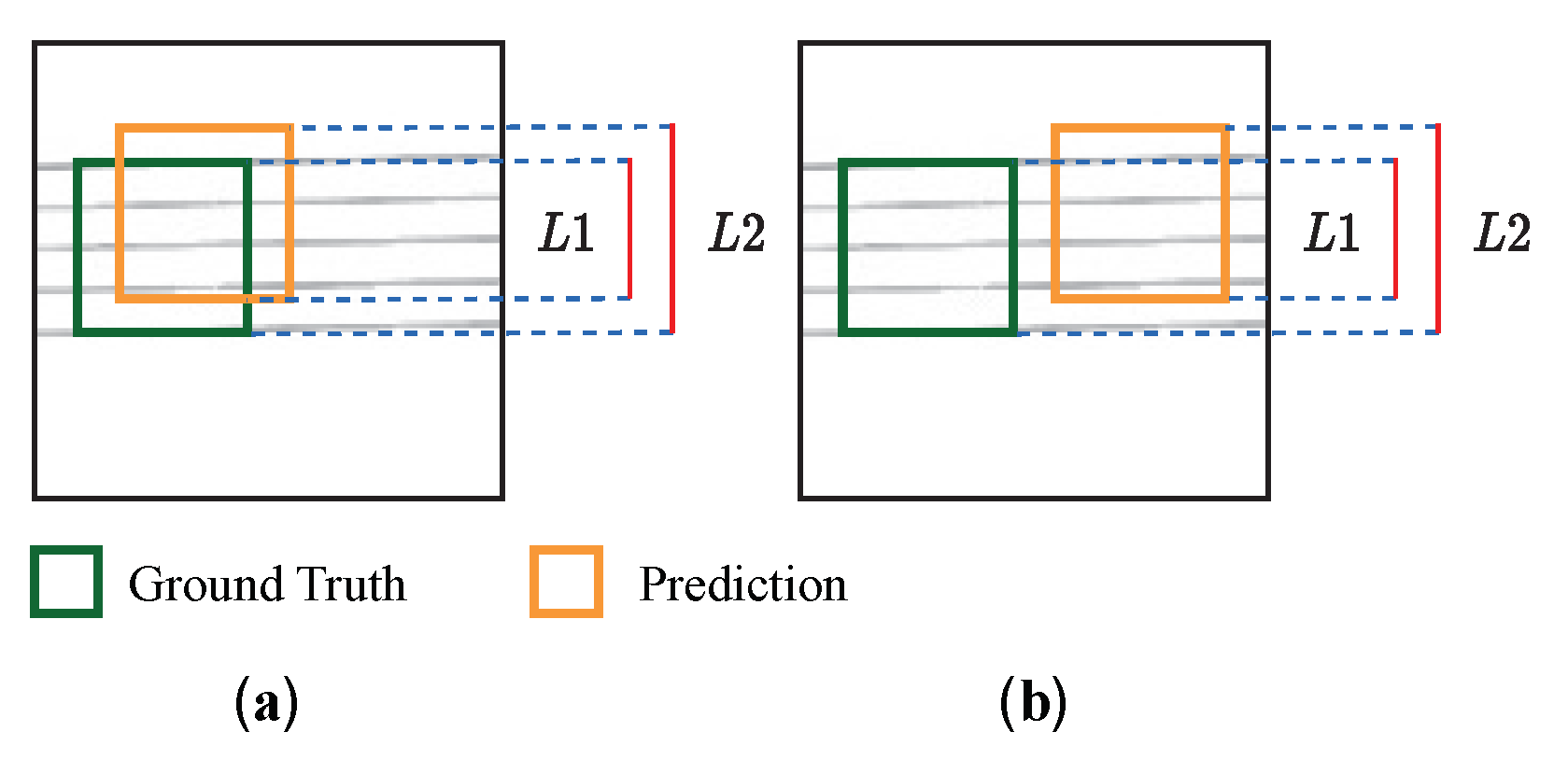
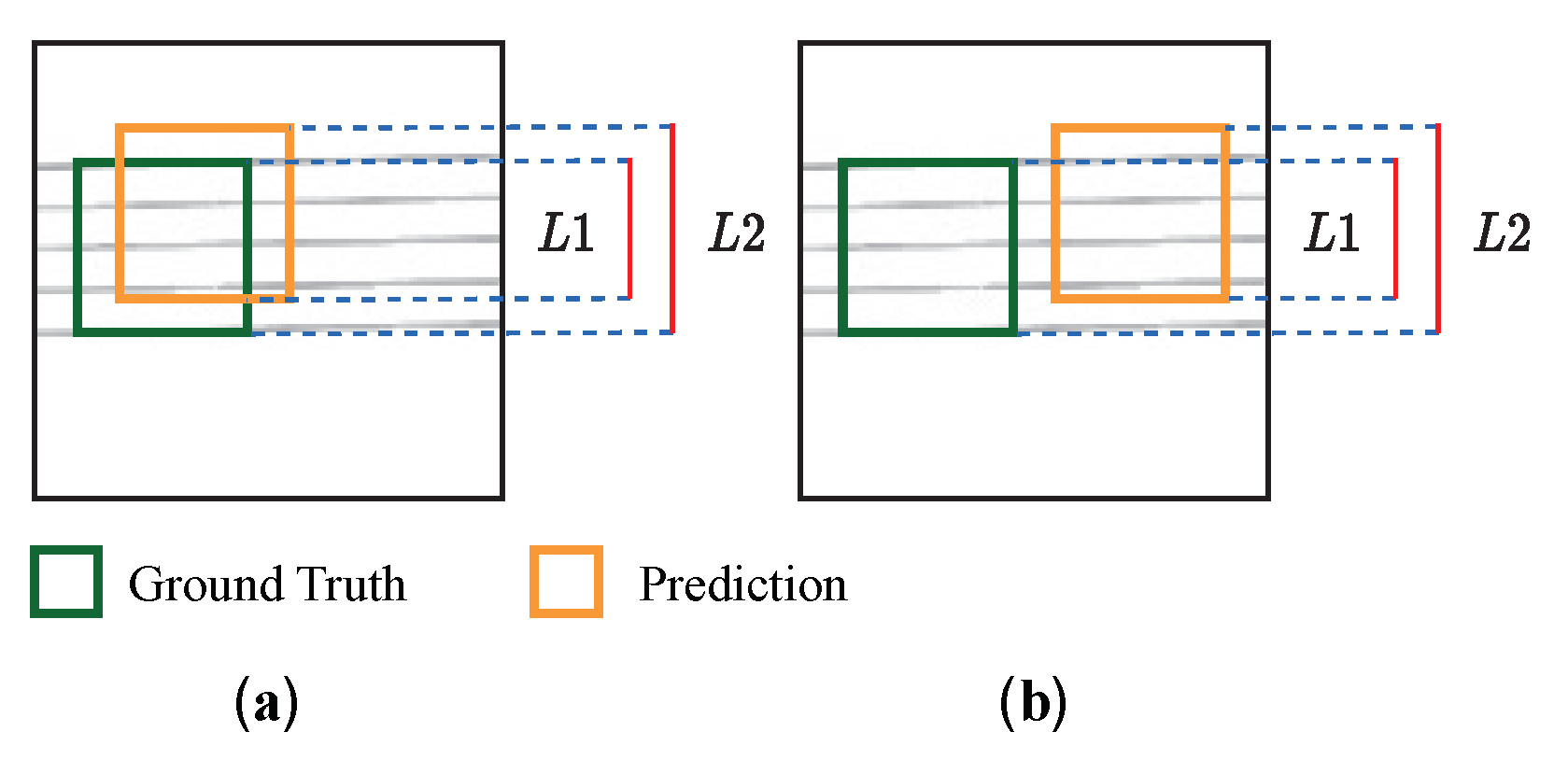
4.2. Evaluation Metric
- Pitch Accuracy: the proportion of notes whose pitch is correctly predicted to the total number of notes.
- Type Accuracy: the proportion of notes whose type is correctly predicted to the total number of notes.
- Note Accuracy: the proportion of notes whose pitch as well as type is correctly predicted to the total number of notes.
4.3. Implementation Details
4.4. Experiment
4.4.1. Factors Affecting Pitch Accuracy
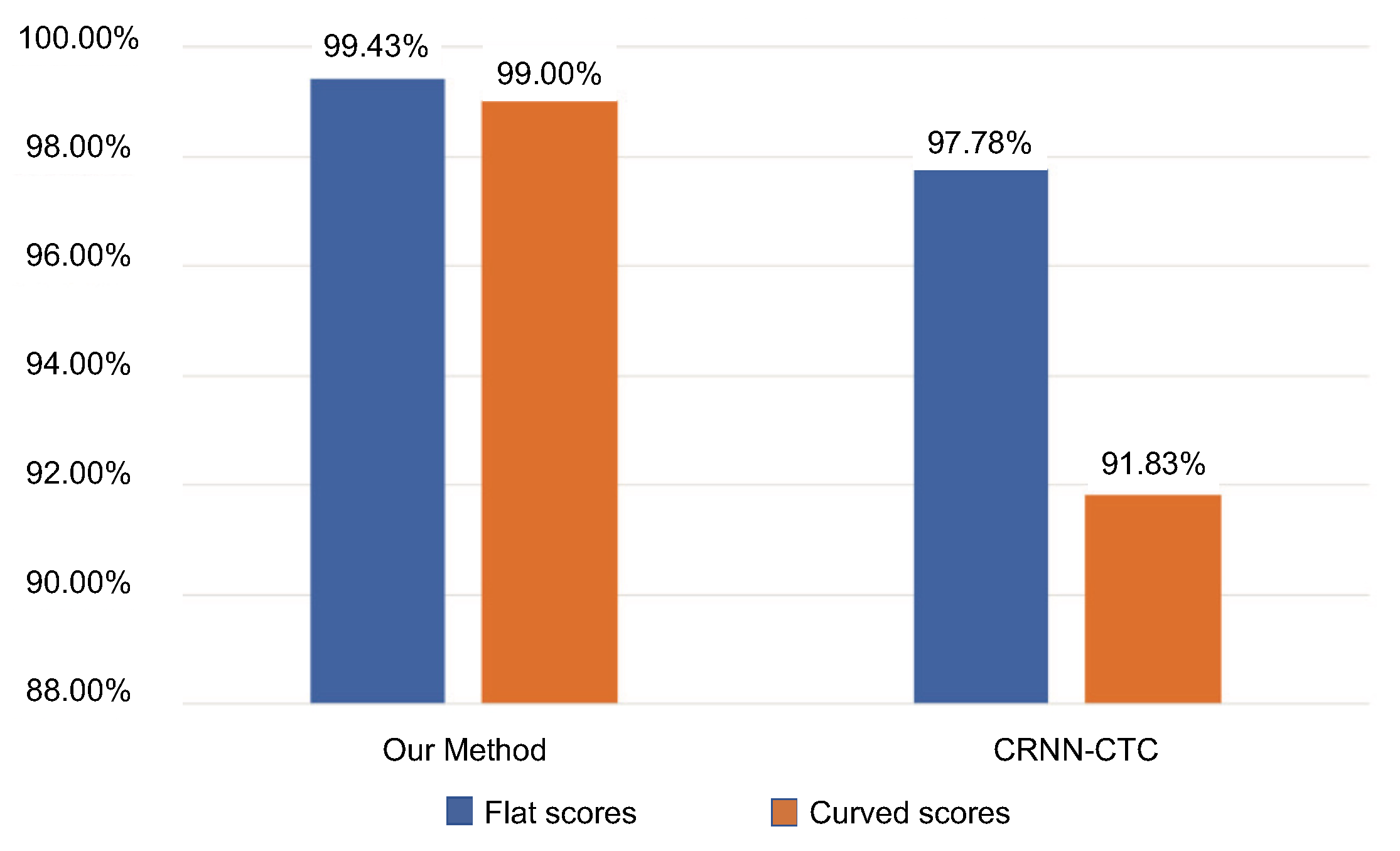
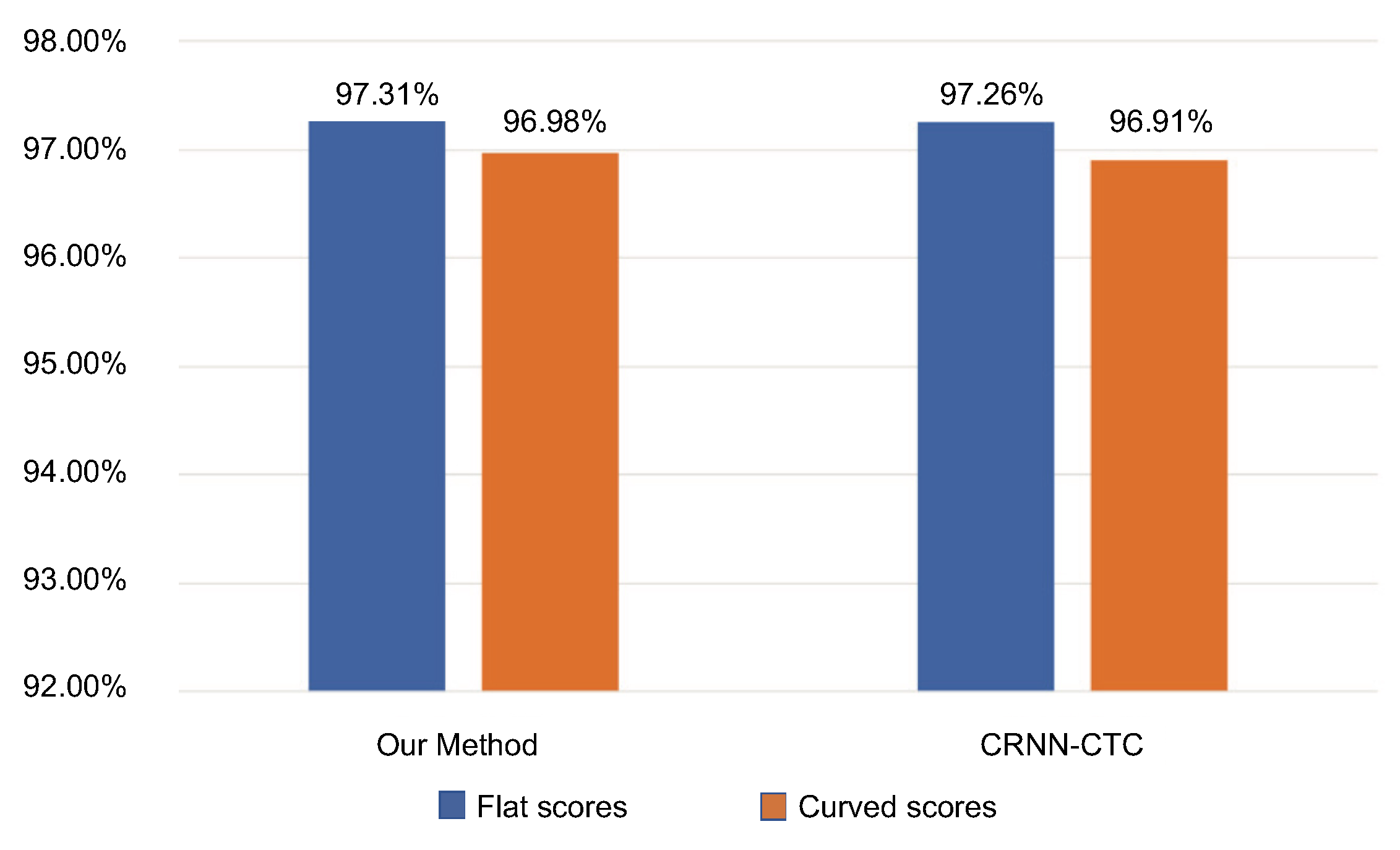
4.4.2. Robustness Comparison
4.4.3. Data Dependence Proof
5. Results and Discussion
5.1. Experimental Results
5.2. Distribution of Errors
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shatri, E.; Fazekas, G. Optical Music Recognition: State of the Art and Major Challenges. arXiv 2020, arXiv:2006.07885. [Google Scholar]
- Calvo-Zaragoza, J.; Valero-Mas, J.J.; Pertusa, A. End-to-end optical music recognition using neural networks. In Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR, Suzhou, China, 23–27 October 2017; pp. 23–27. [Google Scholar]
- Calvo-Zaragoza, J.; Rizo, D. End-to-end neural optical music recognition of monophonic scores. Appl. Sci. 2018, 8, 606. [Google Scholar] [CrossRef]
- Qiong, W.; Qiang, L.; Xin, G. Optical Music Recognition Method Combining Multi-Scale Residual Convolutional Neural Network and Bi-Directional Simple Recurrent Units. Laser Optoelectron. Prog. 2020, 57, 081006. [Google Scholar] [CrossRef]
- Li, Y.; Liu, H.; Jin, Q.; Cai, M.; Li, P. TrOMR: Transformer-Based Polyphonic Optical Music Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Ríos-Vila, A.; Rizo, D.; Iñesta, J.M.; Calvo-Zaragoza, J. End-to-end optical music recognition for pianoform sheet music. Int. J. Doc. Anal. Recognit. (IJDAR) 2023, 26, 347–362. [Google Scholar] [CrossRef]
- Hajič, J.; Pecina, P. The MUSCIMA++ dataset for handwritten optical music recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 39–46. [Google Scholar]
- Hajic, J.; Pecina, P. Detecting Noteheads in Handwritten Scores with ConvNets and Bounding Box Regression. arXiv 2017, arXiv:1708.01806. [Google Scholar]
- Calvo-Zaragoza, J.; Toselli, A.H.; Vidal, E. Handwritten music recognition for mensural notation with convolutional recurrent neural networks. Pattern Recognit. Lett. 2019, 128, 115–121. [Google Scholar] [CrossRef]
- Baró, A.; Badal, C.; Fornés, A. Handwritten historical music recognition by sequence-to-sequence with attention mechanism. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 7–10 September 2020; pp. 205–210. [Google Scholar]
- Calvo-Zaragoza, J.; Rizo, D. Camera-PrIMuS: Neural End-to-End Optical Music Recognition on Realistic Monophonic Scores. In Proceedings of the ISMIR, Paris, France, 23–27 September 2018; pp. 248–255. [Google Scholar]
- Liu, A.; Zhang, L.; Mei, Y.; Han, B.; Cai, Z.; Zhu, Z.; Xiao, J. Residual recurrent CRNN for end-to-end optical music recognition on monophonic scores. In Proceedings of the 2021 Workshop on Multi-Modal Pre-training for Multimedia Understanding, Taipei, Taiwan, 21 August 2021; pp. 23–27. [Google Scholar]
- Shishido, T.; Fati, F.; Tokushige, D.; Ono, Y.; Kumazawa, I. Production of MusicXML from Locally Inclined Sheetmusic Photo Image by Using Measure-based Multimodal Deep-learning-driven Assembly Method. Trans. Jpn. Soc. Artif. Intell. 2023, 38, A-MA3_1–A-MA3_12. [Google Scholar] [CrossRef]
- Alfaro-Contreras, M.; Valero-Mas, J.J. Exploiting the two-dimensional nature of agnostic music notation for neural optical music recognition. Appl. Sci. 2021, 11, 3621. [Google Scholar] [CrossRef]
- Alfaro-Contreras, M.; Ríos-Vila, A.; Valero-Mas, J.J.; Iñesta, J.M.; Calvo-Zaragoza, J. Decoupling music notation to improve end-to-end Optical Music Recognition. Pattern Recognit. Lett. 2022, 158, 157–163. [Google Scholar] [CrossRef]
- Rebelo, A.; Fujinaga, I.; Paszkiewicz, F.; Marcal, A.R.; Guedes, C.; Cardoso, J.S. Optical music recognition: State-of-the-art and open issues. Int. J. Multimed. Inf. Retr. 2012, 1, 173–190. [Google Scholar] [CrossRef]
- Pinto, T.; Rebelo, A.; Giraldi, G.; Cardoso, J.S. Music score binarization based on domain knowledge. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Las Palmas de Gran Canaria, Spain, 8–10 June 2011; Springer: Berlin/Heidelberg, Germany; pp. 700–708. [Google Scholar]
- Szwoch, M. Guido: A musical score recognition system. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 809–813. [Google Scholar]
- Chen, G.; Zhang, L.; Zhang, W.; Wang, Q. Detecting the staff-lines of musical score with hough transform and mathematical morphology. In Proceedings of the 2010 International Conference on Multimedia Technology, Ningbo, China, 29–31 October 2010; pp. 1–4. [Google Scholar]
- Miyao, H.; Nakano, Y. Note symbol extraction for printed piano scores using neural networks. IEICE Trans. Inf. Syst. 1996, 79, 548–554. [Google Scholar]
- Li, C.; Zhao, J.; Cai, J.; Wang, H.; Du, H. Optical Music Notes Recognition for Printed Music Score. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 285–288. [Google Scholar]
- Pacha, A.; Hajič, J.; Calvo-Zaragoza, J. A baseline for general music object detection with deep learning. Appl. Sci. 2018, 8, 1488. [Google Scholar] [CrossRef]
- Tuggener, L.; Elezi, I.; Schmidhuber, J.; Stadelmann, T. Deep Watershed Detector For Music Object Recognition. arXiv 2018, arXiv:1805.10548. [Google Scholar]
- Huang, Z.; Jia, X.; Guo, Y. State-of-the-art model for music object recognition with deep learning. Appl. Sci. 2019, 9, 2645. [Google Scholar] [CrossRef]
- Gao, C.; Tang, W.; Jin, L.; Jun, Y. Exploring Effective Methods to Improve the Performance of Tiny Object Detection. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Cham, Switzerland; pp. 331–336. [Google Scholar]
- Feng, Y.; Wang, X.; Xin, Y.; Zhang, B.; Liu, J.; Mao, M.; Xu, S.; Zhang, B.; Han, S. Effective feature enhancement and model ensemble strategies in tiny object detection. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Cham, Switzerland; pp. 324–330. [Google Scholar]
- Yu, X.; Han, Z.; Gong, Y.; Jan, N.; Zhao, J.; Ye, Q.; Chen, J.; Feng, Y.; Zhang, B.; Wang, X.; et al. The 1st tiny object detection challenge: Methods and results. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; Springer: Cham, Switzerland; pp. 315–323. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Huang, J.; Zhu, P.; Geng, M.; Ran, J.; Zhou, X.; Xing, C.; Wan, P.; Ji, X. Range scaling global u-net for perceptual image enhancement on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 230–242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Van Der Wel, E.; Ullrich, K. Optical Music Recognition with Convolutional Sequence-to-Sequence Models. In Proceedings of the 18th International Society for Music Information Retrieval Conference, ISMIR 2017, Suzhou, China, 23–27 October 2017; pp. 731–737. [Google Scholar]
- Ríos-Vila, A.; Calvo-Zaragoza, J.; Inesta, J.M. Exploring the two-dimensional nature of music notation for score recognition with end-to-end approaches. In Proceedings of the 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 7–10 September 2020; pp. 193–198. [Google Scholar]
- Edirisooriya, S.; Dong, H.W.; McAuley, J.; Berg-Kirkpatrick, T. An Empirical Evaluation of End-to-End Polyphonic Optical Music Recognition. arXiv 2021, arXiv:2108.01769. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef]
- Ríos-Vila, A.; Iñesta, J.M.; Calvo-Zaragoza, J. On the use of transformers for end-to-end optical music recognition. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Aveiro, Portugal, 4–6 May 2022; pp. 470–481. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tsai, T.J.; Yang, D.; Shan, M.; Tanprasert, T.; Jenrungrot, T. Using Cell Phone Pictures of Sheet Music To Retrieve MIDI Passages. IEEE Trans. Multimed. 2020, 22, 3115–3127. [Google Scholar] [CrossRef]
- Fisher, R.; Perkins, S.; Walker, A.; Wolfart, E. Hypermedia Image Processing Reference; John Wiley & Sons Ltd.: Chichester, UK, 1996; pp. 118–130. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Tuggener, L.; Satyawan, Y.P.; Pacha, A.; Schmidhuber, J.; Stadelmann, T. The DeepScoresV2 dataset and benchmark for music object detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9188–9195. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Note Pitch Accuracy on CPMS (%) |
|---|---|
| Comb filter-based method | 85.54 |
| Comb filter-based method + note head position | 91.23 |
| Stave detection model | 95.49 |
| Stave detection model + note head position | 99.23 |
| Method | Training Set | Accuracy on CPMS(%) | ||
|---|---|---|---|---|
| Pitch | Type | Note | ||
| CRNN-CTC | PrIMuS | 44.23 | 51.58 | 37.42 |
| Ours | 89.77 | 94.46 | 85.17 | |
| CRNN-CTC | PrIMuS + CPMS training set | 95.07 | 96.74 | 91.95 |
| Ours | 97.10 | 97.15 | 94.40 | |
| Method | Training Set | Accuracy on CPMS(%) | ||
|---|---|---|---|---|
| Pitch | Type | Note | ||
| Ours | PrIMuS | 89.77 | 94.46 | 85.17 |
| PrIMuS + CPMS training set | 97.10 | 97.15 | 94.40 | |
| DeepScoresV2 | 99.23 | 96.87 | 96.29 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wu, R.; Wu, Y.; Luo, L.; Xu, W. A Stave-Aware Optical Music Recognition on Monophonic Scores for Camera-Based Scenarios. Appl. Sci. 2023, 13, 9360. https://doi.org/10.3390/app13169360
Liu Y, Wu R, Wu Y, Luo L, Xu W. A Stave-Aware Optical Music Recognition on Monophonic Scores for Camera-Based Scenarios. Applied Sciences. 2023; 13(16):9360. https://doi.org/10.3390/app13169360
Chicago/Turabian StyleLiu, Yipeng, Ruimin Wu, Yifan Wu, Lijie Luo, and Wei Xu. 2023. "A Stave-Aware Optical Music Recognition on Monophonic Scores for Camera-Based Scenarios" Applied Sciences 13, no. 16: 9360. https://doi.org/10.3390/app13169360
APA StyleLiu, Y., Wu, R., Wu, Y., Luo, L., & Xu, W. (2023). A Stave-Aware Optical Music Recognition on Monophonic Scores for Camera-Based Scenarios. Applied Sciences, 13(16), 9360. https://doi.org/10.3390/app13169360