1. Introduction
Community noise (also called environmental, urban, or residential noise) is one of the main problems that cause a negative impact on health. Since the 1990s, the World Health Organization (WHO) has developed different guidelines to serve as a basis for the standards in the management of environmental noise. In the European Union, since the publication of the Environmental Noise Directive 2002/49/EC (END) [
1], the European Member States have developed their own legislation to reduce the noise levels to which their populations are exposed. Although considerable efforts have been made to reduce noise levels, the latest report published by the European Environmental Agency [
2] indicates that this has not been accomplished. This concern to control and manage noise pollution in general, has resulted in the advent of smart cities, which have boosted the deployment of monitoring systems.
Monitoring systems are effective tools for the evaluation and management of acoustic pollution, which complement noise strategic maps, the main tool currently in use. Noise maps have certain limitations for noise-source assessment: only a few noise sources are taken into account and they use averaged data over long periods for calculating the acoustic emission of the sources. The use of monitoring systems would overcome those limitations and contribute to obtain a more realistic approximation of noise levels, especially in cities. The data provided using real-time monitoring systems allow other types of analysis, such as the characterization of behavioural patterns and detection of high-level short-duration noise events that can cause annoyance and negative health effects.
However, current monitoring systems have the downside of not identifying the sound sources that generate the noises, making it difficult to take corrective actions. This problem arosed in one of the earliest research projects on the use of sensors in a continuous monitoring system for evaluating noise pollution, conducted in Palma de Mallorca [
3]. This project’s objective was to assess how sound pressure levels (SPL) and particulate matter (PM10) particles produced by port activity were related to one another. They were unable to establish a clear connection between the noise levels recorded and the noise sources responsible for them. Sound-classification techniques can be used to solve this issue, making it possible to identify the noise source responsible for a specific sound event.
New approaches to age-old problems in the analysis and processing of sound signals, like speech recognition and sound categorization, have been made possible by the application of machine learning techniques. Machine learning is a set of techniques that allow computer programs to automatically improve doing a task through experience. These systems are able to extract and identify complex patterns in the data (in our case sound) that could not be processed using traditional processing and handcrafted features. More specifically, the term Machine Listening or Machine Audition [
4], encompasses the study of techniques and systems that allow computers to automatically identify sounds as humans do. There are many uses for machine listening, but two of the most important ones are the sound event detection [
5], which identifies the beginning and end of a sound event in a recording, and audio classification which aims to categorize or label a recording. There are many application fields for audio classification, including the categorization of environmental sounds (both urban and nature) [
6], bioacoustics signal classification and detection [
7,
8] and the classification of urban sound events in noise monitoring systems [
9,
10,
11], our research topic.
A lot of the research in this area has been promoted by the Detection and Classification of Acoustic Scenes and Events (DCASE) community, which has been organising challenges and workshops for the last years. The aim of the DCASE community is the support development of computational scene and event analysis methods by providing public datasets [
12,
13], and giving researches the opportunity to continuously compare different approaches on the same datasets, using consistent performance measures. The challenges “Urban Sound Tagging with Spatiotemporal context”, organized in 2020, and “Acoustic Scene Classification”, organized in 2021 [
14], had important contributions in the sound-classification area.
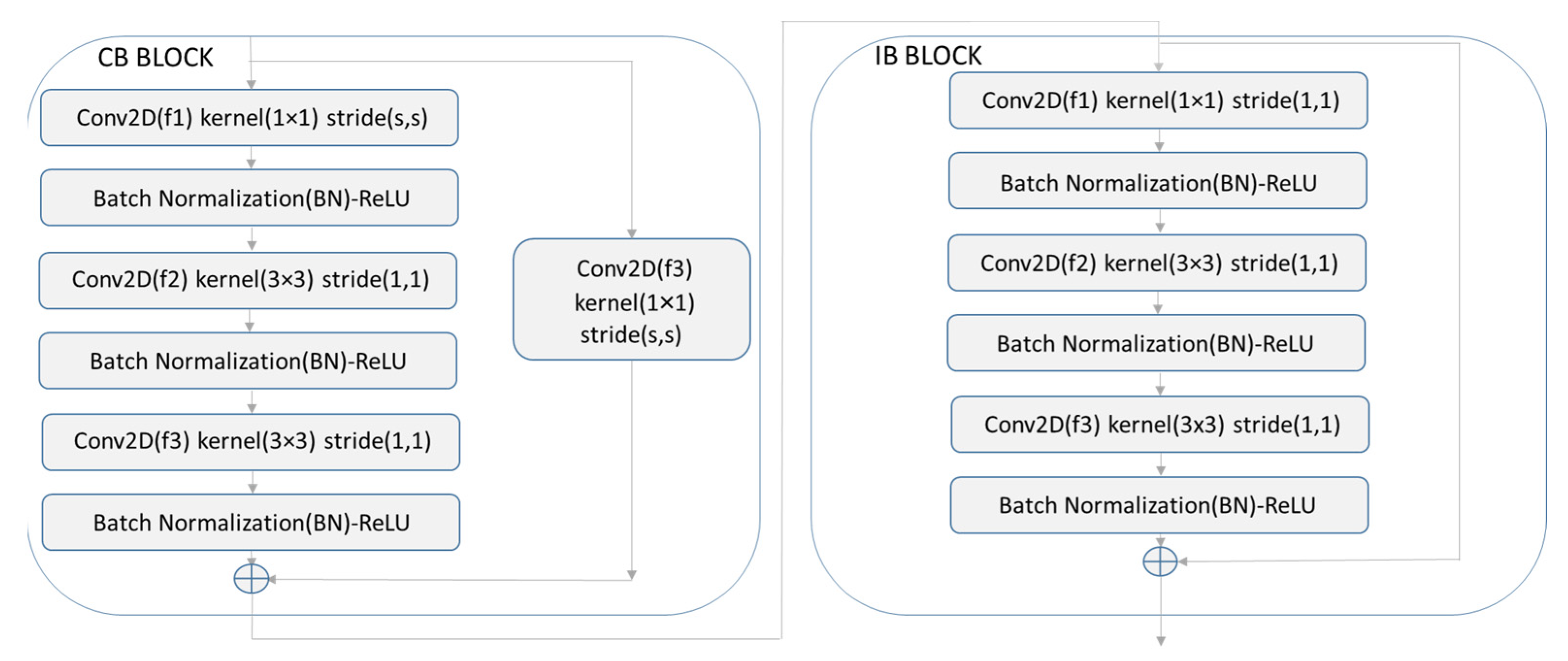
For these classification tasks, the majority of researchers use deep neural network (DNN) architectures that perform rather well as they have the ability to extract discriminative feature representations. The most popular architectures are based in Convolutional Neural Networks (CNN) [
6,
15,
16]. Some other researches, motivated by the fact that the CNNs do not learn long-term dependencies, propose solutions based on CNNs combined with Recurrent Neural Networks (RNN) [
17,
18,
19]. However, the RNNs suffer from the vanishing gradient problem. To overcome this problem the ResNets [
20,
21,
22] were introduced, as they use residual blocks that enable training a large number of layers. More recently, transformer architectures purely based on attention mechanisms [
23,
24,
25] and hybrid architectures combining transformers with RNNs [
26] and ResNets [
27], have been proposed. Most of the systems apply data augmentation and transfer learning techniques. Some other systems propose the fusion of different classifiers [
28,
29,
30,
31] and features [
32,
33].
Good outcomes depend on the network architecture selected, which is influenced by the problem to be solved, the quantity and quality of the data available and other factors. Despite the widespread use of DNNs, researchers are still facing some challenges as the lack of annotated data for certain tasks, especially for real-world applications. The ESC dataset [
34], UrbanSound8k [
35], AudioSet [
36], and the more recently released SONYC-UST [
13] and SONYC-USTv2 [
37] datasets are the most popular and openly accessible datasets that are frequently utilized in the development and evaluation of urban sound classification systems. The ESC dataset consists of three parts. Two of them, ESC-10 and ESC-50, comprise a labelled set of 10 and 50 classes of different environmental sounds while the third part, ESC-US, is a set of non-labelled data. All clips were extracted from the public field recordings available in the Freesound project [
38]. UrbanSound8k contains labelled recordings for 10 classes of urban sounds, also extracted from the Freesound project. In turn, AudioSet corpus consists of labelled sounds from different sources (domestic, environmental, nature, music, ...) drawn from YouTube.
The majority of the aforementioned datasets have the drawback of not having been recorded for monitoring urban noise. SONYC project [
9], addresses this problem, deploying a number of noise monitoring sensors for collecting data. The aim of collecting the data was to develop a classification system for a specific task, namely to confirm that the complaints made by residents about violations of the noise code of New York City were true. SONYC-UST and SONYC-USTv2 are multi-label datasets for urban sound tagging that comprise a fine labelled set of 23 classes that are grouped into 8 coarse classes with more general descriptors. The main difference between them is that the latter includes spatio-temporal context information about the recording event. More recently, the so called SINGA-PURA database has been published [
39] following the structure of SONYC-UST V2 taxonomy and expanding some classes in more detail.
In any case, more datasets with samples from real application scenarios are still needed in this area. In this line, we present a novel audio database, the so called NoisenseDB, with real urban sound events intended to be used in sound-classification tasks. The recording of this database was performed by deploying a continuous monitoring system developed by the company NOISMART in real urban locations.
Another problem that researchers have to face is how to label the great amount of acquired material generated by a sensor recording continuously. Manual identification of sound sources in large audio files takes up a significant amount of research time. Some projects have used crowdsourcing [
40], where volunteers tagged the audio files using internet platforms like Zooniverse. Since this method of labelling often produces low-quality results, other approaches, such as Active Learning [
41] or Semi Supervised Learning [
42] are very interesting. These methods are grounded on the idea that by means of actively choosing the most accurately predicted data, algorithms can increase their performance while utilizing less training data. Pseudo-labelling [
43], also called self-training [
44] is one of the techniques that has garnered the greatest interest in recent years. This method, involves training a classifier on labelled data, predicting the labels for the unlabelled data and retraining the model adding confident predicted data to the training data.
In this paper, besides presenting the new NoisenseDB, we propose several state-of-the art urban sound events classification systems. We also analyse the feasibility of a semi-supervised training approach to cope with the labelling of the large amounts of data produced by such continuous monitoring systems.
This paper is organized as follows:
Section 2 describes the data-acquisition device and recording locations;
Section 3 explains the creation of the NoisenseDB database, its taxonomy and structure;
Section 4 introduces the tested sound event classification systems;
Section 5 shows the experimental results using these systems with NoisenseDB. Finally, some conclusions are presented in
Section 6.
3. NoisenseDB
3.1. Sound Event Extraction
Obviously, not all the recorded data (more than 1200 h) contained meaningful and identifiable sound events, and thus, we had to establish an efficient way to extract these interesting sound events for the creation of the database. The criteria was to use the SPL measures to determine where these sound events were, assuming that sounds with higher SPL will be easier to identify and also easier for an automatic classification system to learn.
From the total of the recorded hours, we extracted a set of variable-length audio clips corresponding to the sound events that registered a peak level equal or greater than 71 dB(A) and kept above 60 dB(A) during at least 3 consecutive seconds.
The segmentation of the audio clips with sound events in the original recordings was done taking 3 s before the SPL threshold was surpassed. This criterion was applied because for some events the onset of the noise gives important information about its source. The downside is that this additional period can introduce noise into the system since other unlabelled sound events may appear.
The resulting audio clips have variable length depending of the sound event and make a total of 692 sound clips. A single trained person labelled all the audio clips, assigning one single label to the entire audio clip. This is known as monophonic labelling, and implies the assumption that each audio clip included just one type of sound. Thus, sometimes we will use event as synonym for audio clip in the following sections. Actually, sometimes two different audio events occur within the same clip. This happened in the 20% of the clips, especially when mixing “Music” and “Voice” categories. In these cases, the clip is labelled with the most prominent of both events. The criterion is to use first the length of each event and, if their length is similar, their intensity.
Exceptionally, in the case of very scarce sound events (dog barking and impact sounds), the annotation criteria has been to prioritise these events for labelling, even though other possible sounds in the clip can even last longer. Thus if any of these events appear in the clip the whole clip is assigned to that event.
3.2. NoisenseDB Taxonomy
In order to define our taxonomy, we analysed the semantic classification of sounds carried out by J. Salomon et al. [
35]. They created an extensive taxonomy, with more than 50 sound events, distributed in different levels with four higher-level categories. The SONYC project defined a simpler taxonomy with just two levels [
13]. Both these taxonomies have more types of events than our recorded data, so we defined a simpler taxonomy.
NoisenseDB taxonomy can be seen in
Table 1. It consists of nine different (fine) categories gathered in four higher-level (coarse) categories, grouping those sound events with similar origin. This taxonomy was used for labelling the NoisenseDB.
3.3. Database Structure
NoisenseDB is divided into two datasets, using the peak SPL of the event as criterion. The main one is called supervised dataset (SD) and it is designed for supervised learning. It is composed of the audio clips of sound events with highest SPLs, namely greater than or equal to 72 dB(A). Its 432 audio clips are distributed in 5 folds that can be used as training, validation and evaluation partitions in cross validation experiments. The audio clips, and consequently the sound events, are never divided into different folds. The audio clips have been distributed in folds trying to keep a balance in the total duration of the audio samples for each class. For the class “Machinery” this approach was not possible due to the small number of events and their different duration, and in this case, the distribution was done keeping the number of events balanced in each fold independently of their duration.
The second dataset, the so-called unsupervised dataset (UD), is intended to be used as evaluation set for unsupervised learning. It included 260 audio clips of sound events with the highest SPL values equal or greater than 71 dB(A) and less than 72 dB(A).
The distribution of sound events per class is shown in
Table 2 along with some statistics related to their length. The minimum possible length is 6 s corresponding to 3 s over the SPL threshold limit plus the previous 3 s. The maximum length is also bounded to 3 + 120 s.
Table 2 shows that the classes are heavily unbalanced both in the SD and UD sets. In the SD part, five categories have less than 20 events, while the others have more than 40. The length of the events is also very different. The categories of “Impact” and “Dog” are really scarce both in terms of number of events and length of the samples. In the UD part the imbalance is still worse but in this case the less represented ones are “Storm” and “Music”. We have not taken any measure to reduce the original imbalance of the database, because the aim of this work was to obtain a database representing the real-world difficulties of the urban sound events classification task. Thus, the database contains all the sound events that have been registered during the two months of the monitoring period.
5. Classification Experiments
We used the different parts of the NoisenseDB for two different objectives. First, we used the SD to obtain baseline results for the three DNN classifiers presented in
Section 4. Second, we also used the UD of the NoisenseDB to evaluate the feasibility of a semi-supervised learning strategy using convolutional classification systems.
5.1. Evaluation Metrics
Although accuracy is one of the most frequently used metrics to assess the performance of a classification system, it is not suitable if the test database is unbalanced. In those cases, the use of another metric such as recall is recommended. We have used the macro-average recall [
53] as main assessment metric. For calculating the macro-average recall, first, the recall is computed for each class (1), and then we average all the recall values of the n (number of classes) to get the macro-average recall (2).
For each of the evaluated architectures, we presented the baseline results in two different ways. The first one calculated the macro average recall at the fragment level, while the second one calculated the metric for the entire sound clip, which was composed of several fragments. For calculating the metrics for the entire audio clip, we used a modified majority voting method.
Normally, in the majority voting method, the predicted output class for the whole audio clip would be the class that has a greater number of predictions for the fragments of that audio. Taking into account the criteria that we used during the labelling phase, especially for “Dog” and “Impact” categories, we made some modifications on the majority voting method. This modification consisted on assigning “Dog” or “Impact” category to the whole audio clip if just one frame is classified as ”Dog” or “Impact”.
5.2. Classification of the Supervised Dataset
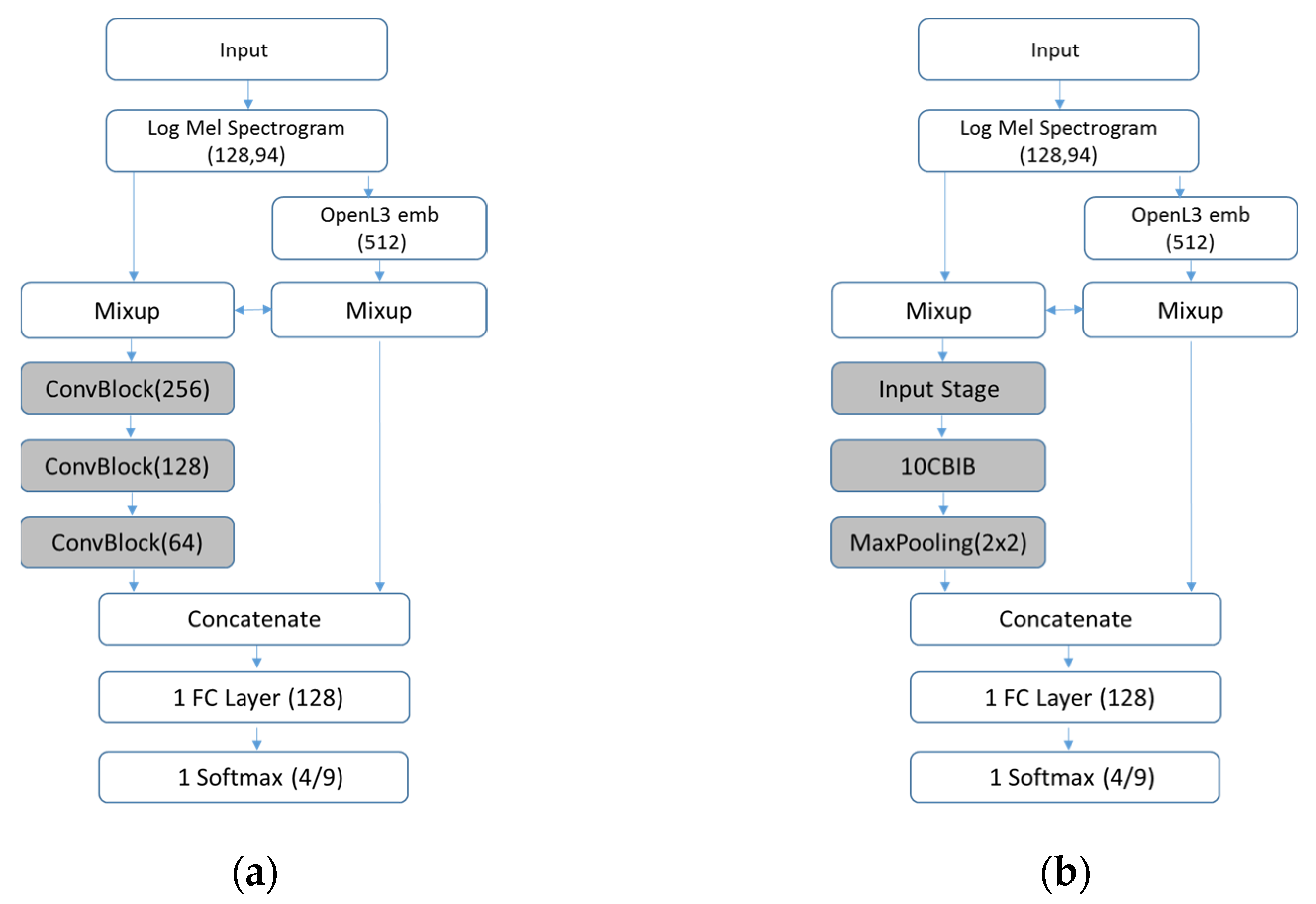
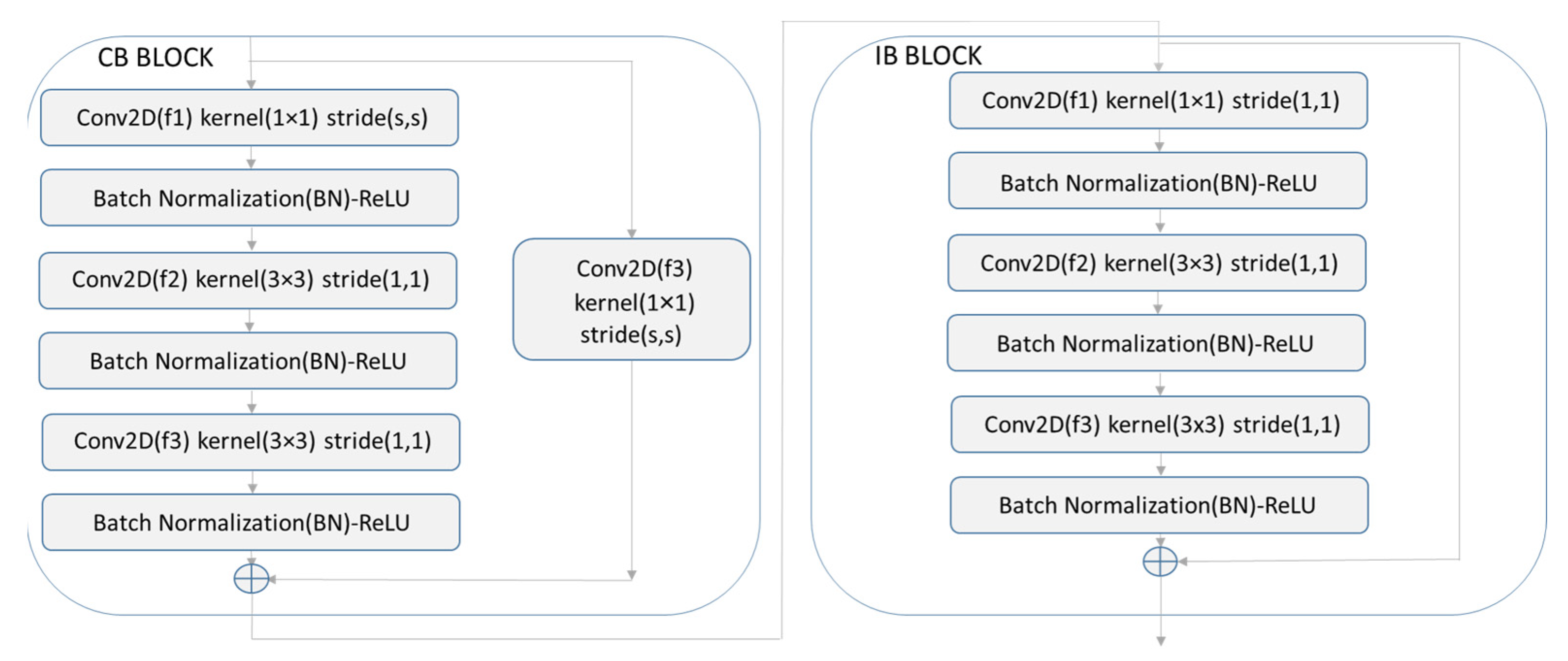
For the SD classification, we used five-fold cross validation using the distribution of the database shown in
Table 2. For each iteration, we used one fold for validation and the remaining folds for training (approx. 80–20%). The convolutional classification systems (ConvBlock and ResNet) were trained using an Adam optimizer with a learning rate of 1 × 10
−4. L2 regularization with a factor of 1 × 10
−5 was also used. We also applied a learning rate reduction of 0.5 if the validation loss metric did not improve after 4 epochs. The values of the aforementioned parameters were chosen from previous experiments carried out with different databases. The AST model was trained using the Adam optimizer for 25 epochs with an initial learning rate of 1 × 10
−5 and decreasing it with a factor of 0.85 every epoch after the 5th one. These are the recommended parameters of the original architecture.
5.2.1. Baseline Results for Coarse Classification
We computed the metrics to evaluate the performance for the four-category taxonomy. We have calculated the results both at fragment level and for the entire audio clip. We applied majority voting without modification as “Dog” and “Impact” labels are not present in the four-category taxonomy.
Table 3 shows the mean and standard deviation of the cross-validation iterations of the recall values (per class and macro-averaged) for each system at fragment level.
Although the differences between the models are not statistically significant (confidence intervals for p > 0.95: ConvBlock 4.9, ResNet 4.9, AST 2.1), ResNet achieves the best overall result.
The results for all the most represented categories are very good for the three systems, but the performance decays for the mechanical sounds category due to the scarcity of training material for this category and the different kind of sounds that are included in it.
Table 4 shows the metrics for the entire audio classification. In this task, the overall performance of the systems is worse compared to the fragment classification scores. This is due to several factors: first, the number of audio clips is smaller than the number of frames and this produces greater variability in the results for each iteration. Second, in the classes where frame classification accuracy is worse (e.g., in short, punctual events) the frames correctly classified can be easily outnumbered by frames wrongly classified in other classes. This is the case for “Mechanical” and to a lesser extent for “Nature”. It would be worth evaluating other methods apart from majority voting to see if this performance can be improved. Conversely the classes that have higher accuracy at fragment level are boosted because the majority voting filters out the sporadic fragment-level classification errors.
The results were similar for both ConvBlock and AST in most of the categories, but for ResNet, the performance reduced more due to the fall in the most difficult classes (“Nature” and “Mechanical”). Nevertheless, regarding the macro recall, the difference between the models was not statistically significant (confidence intervals for p > 0.95: ConvBlock 4.3, ResNet 4.3, AST 4.7).
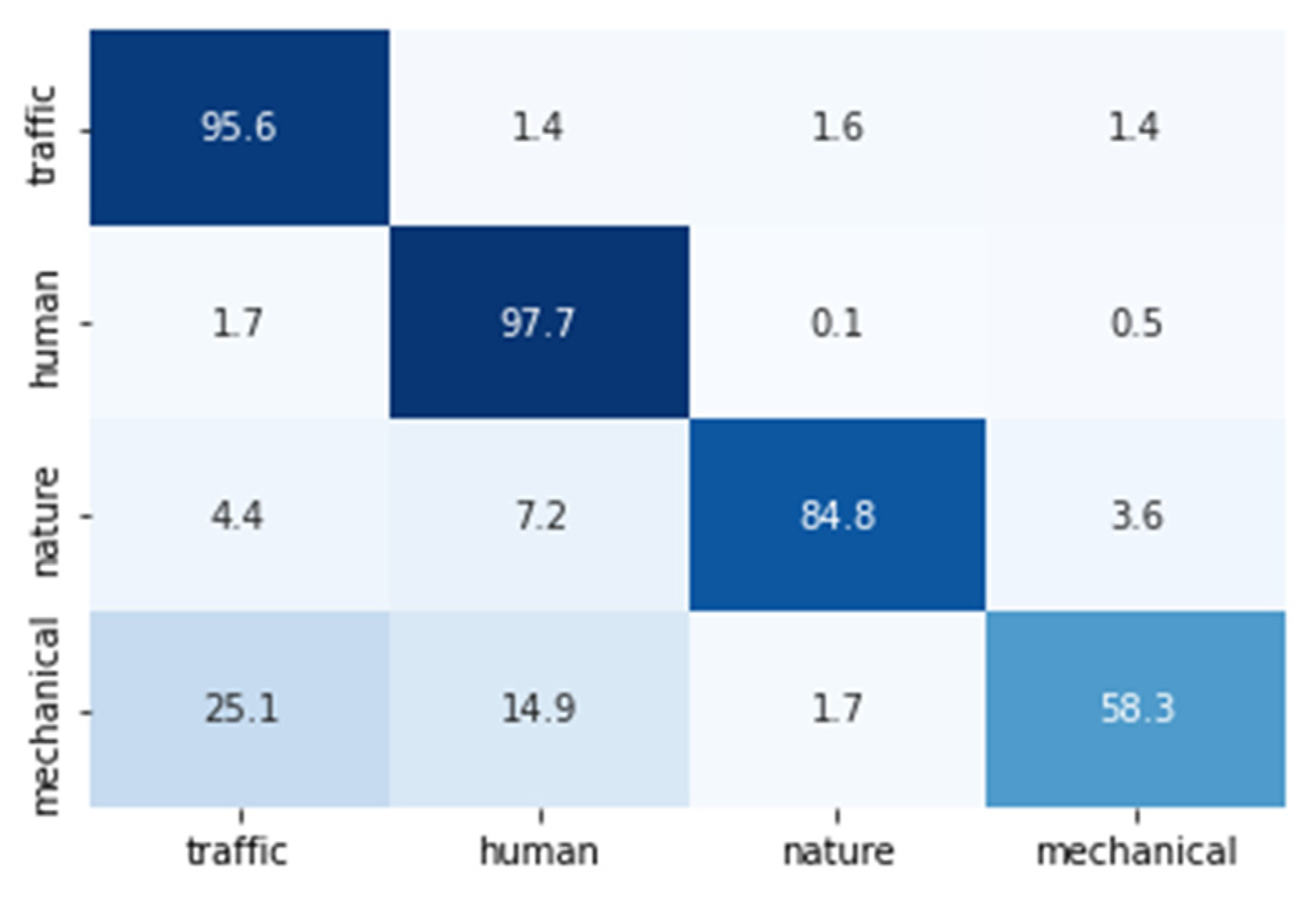
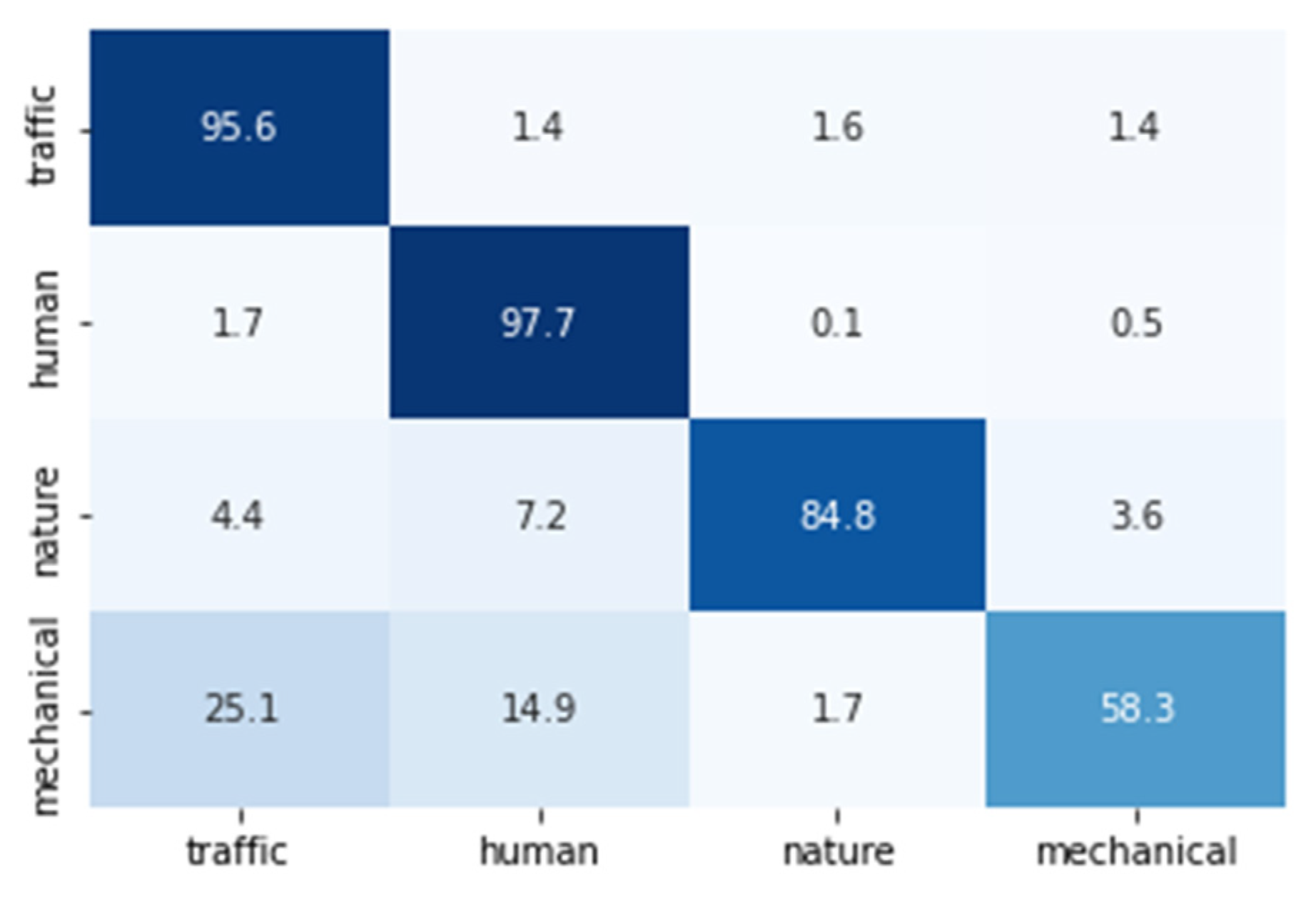
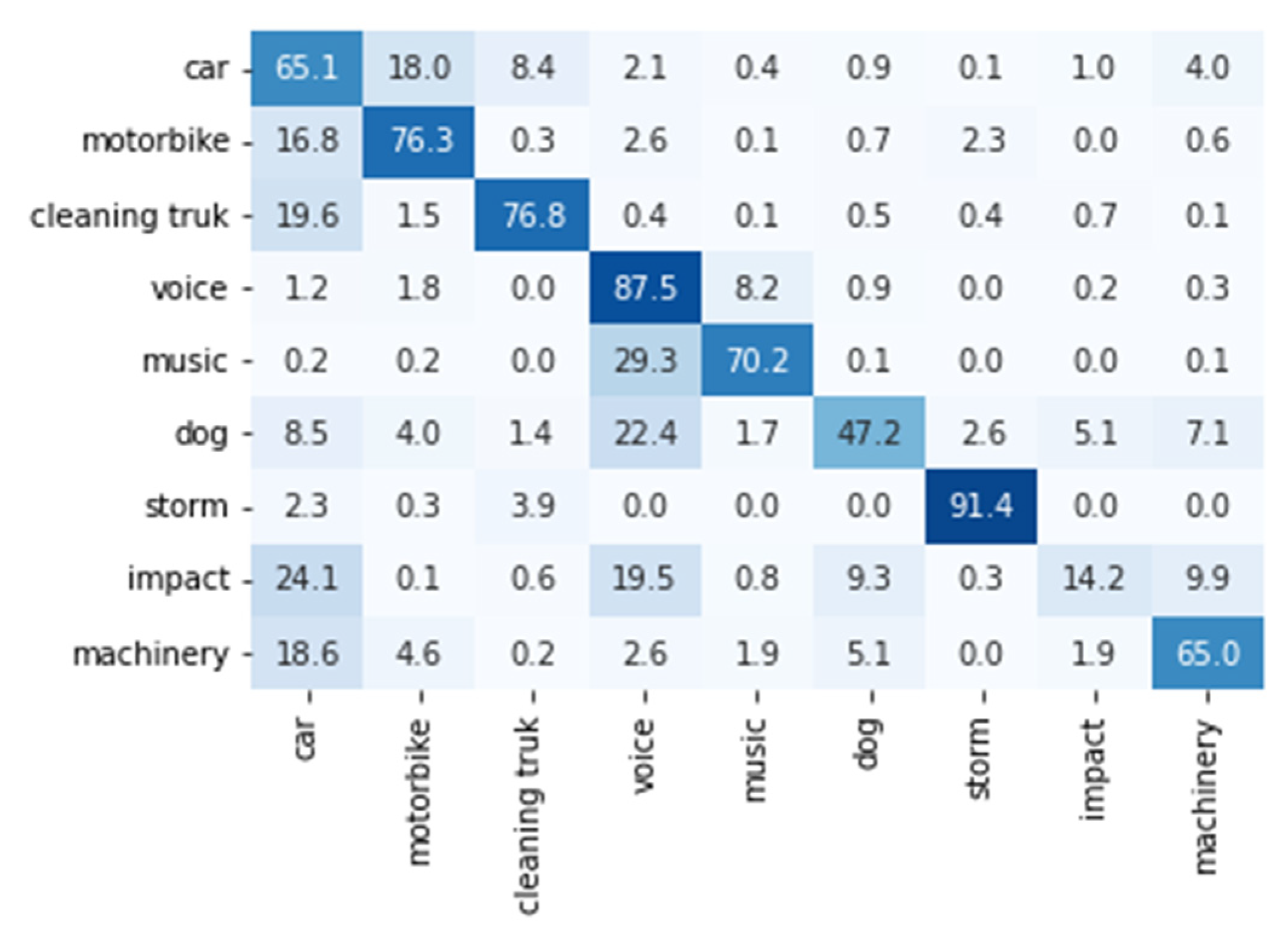
Figure 5 shows the confusion matrix of the ResNet architecture for which we achieved the best results at the fragment level. The rows represent the true labels while the columns represent the predicted ones. The global confusion matrix was calculated considering the classifications obtained in all the iterations by each class and divided by the total number of elements in that class. Darker colors represent the highest scores.
The results were good for all the categories except for the “Mechanical” one, for which 25.1% and 14.9% of the fragments were erroneously classified as “Traffic” and “Human”, respectively. The differences between the values of the diagonal of the confusion matrix (
Figure 5) and the values of
Table 3, corresponding to the ResNet, were due to the fact that the former was calculated by adding all the classification results for the frames of every iteration, whereas the latter was calculated averaging the recalls of each iteration.
5.2.2. Baseline Results for Fine Label Classification
We also trained the classifiers with the nine-category taxonomy, making decisions both at fragment level and for the entire audio clip. In this last case, we used the modified majority voting for “Dog” and “Impact” categories.
Table 5 shows the mean and standard deviation for all the iterations of the recall values (per class and macro-averaged) at the fragment level. Once again, the difference between the models was not statistically significant (confidence intervals for
p > 0.95, ConvBlock 3.9, ResNet 4.4, AST 3.2) but the best macro-average recall was obtained for the AST system.
In general, the performance was good for most of the classes. The main exceptions were the “Dog” and especially the “Impact” classes, which had a very bad recall. This is due to the scarcity of samples of this class and to the different kind of events (beats, firecrackers, etc.) grouped under this label. The AST architecture performed better in these categories, probably because it benefited from the transfer learning to compensate the lack of training material. It is worth noting that if we exclude the “Impact” category from the calculus of the global recalls, the results are very similar for all the systems: ConvBlock 71.9, ResNet 71.1 and AST 72.5.
Table 6 shows the metrics for the entire audio clip classification. The performance in this case improves slightly for the ConvBlock compared to the fragment-by-fragment classification, but decays for the others. The effects explained in the four-category case for the entire audio clip classification, namely the small number of events of some classes and the dispersion of results depending of the accuracy level of the class, apply also here. It is worth mentioning the effect of the modified majority voting in the “Dog” and “Impact” categories which boosts their accuracy in some cases.
Overall, ConvBlock was the best performing system, although the difference between the models was not statistically significant (confidence intervals for p > 0.95, ConvBlock 4.4, ResNet 6.3, AST 3.1).
Finally, in
Figure 6, we present the overall confusion matrix at fragment level for the best system, i.e., the AST architecture. The rows of the matrix represent the true labels while the columns show the predictions. Darker colors represent the highest scores. It can be said that the system classifies well the “Storm”, “Voice”, “Cleaning-truck” and “Motorbike” categories. On the contrary, the “Impact” category presents the worst classification rate with 14.2% of correct answers. Among the categories belonging to the traffic group (car, motorbike and cleaning truck), it is observed that the fragments that have not been correctly classified are confused with the other categories of the same group. “Voice” and “Music” categories are also mixed to some extent. This is probably due to the fact that many of the occurrences of music are sung songs.
5.3. Semi-Supervised Strategy for Automatic Labelling
As we have mentioned before, one of the issues of obtaining datasets to train urban-sound-event classifying systems is the initial labelling of the sound events that are registered by the monitoring devices. In this work, for the supervised part (SD) of the database, we used the 72 dB(A) threshold to obtain a manageable set of clips that could be labelled manually. However, we wanted to tackle the problem of automating the labelling for larger datasets. With this objective, a new set of events, with SPLs between 71 and 72 dB(A)s, was extracted from the recordings and manually labelled. This dataset was used to experiment with unsupervised training and, thus, was called the unsupervised dataset (UD). We presented a novel semi-supervised strategy to train a classifier for automatic labelling. Such a strategy can be applied to create the final classifier directly, but also as a way of obtaining an initial labelling that can be refined by human labellers afterwards. In order to evaluate the proposed strategy, we carried out an experiment using the convolutional architectures.
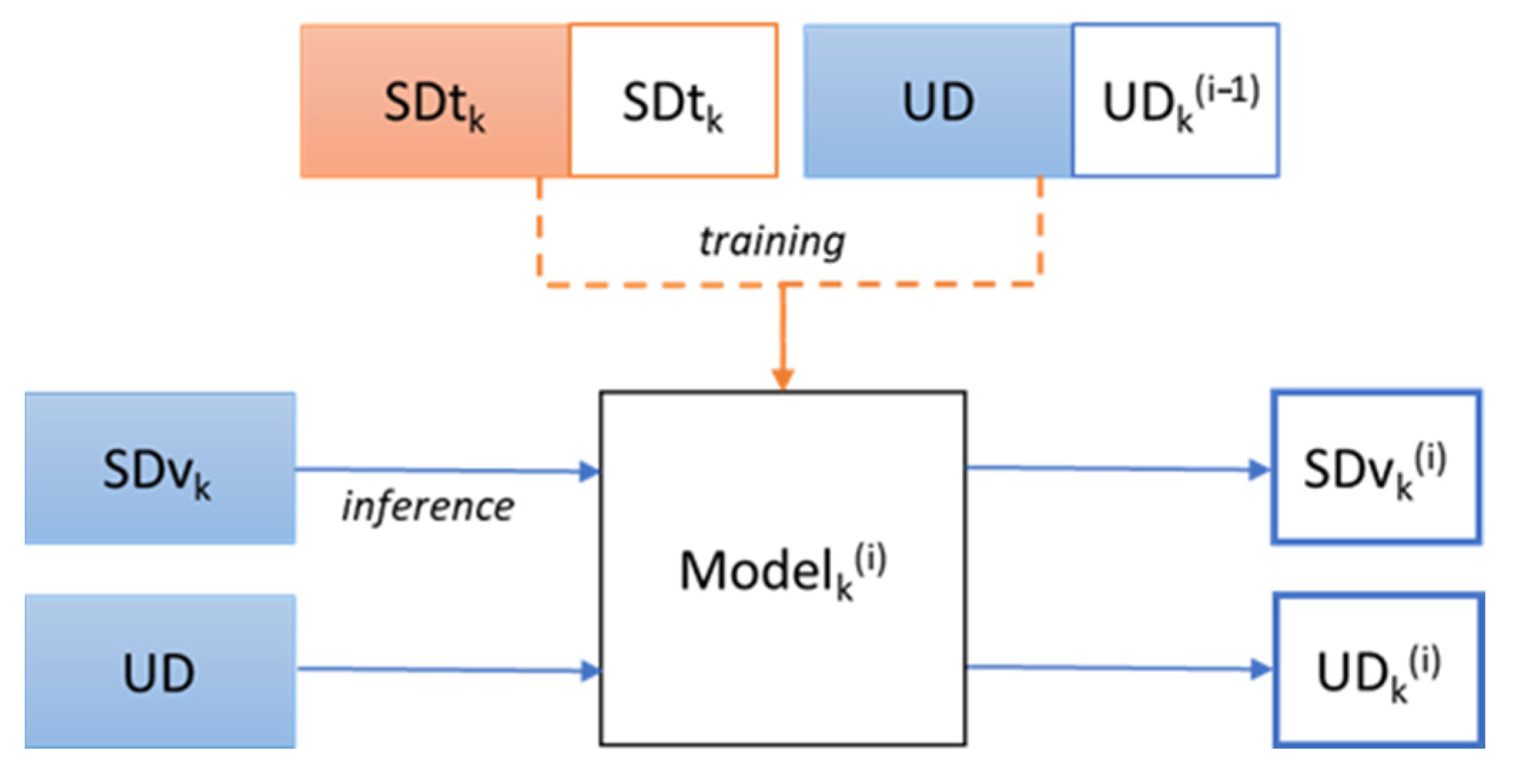
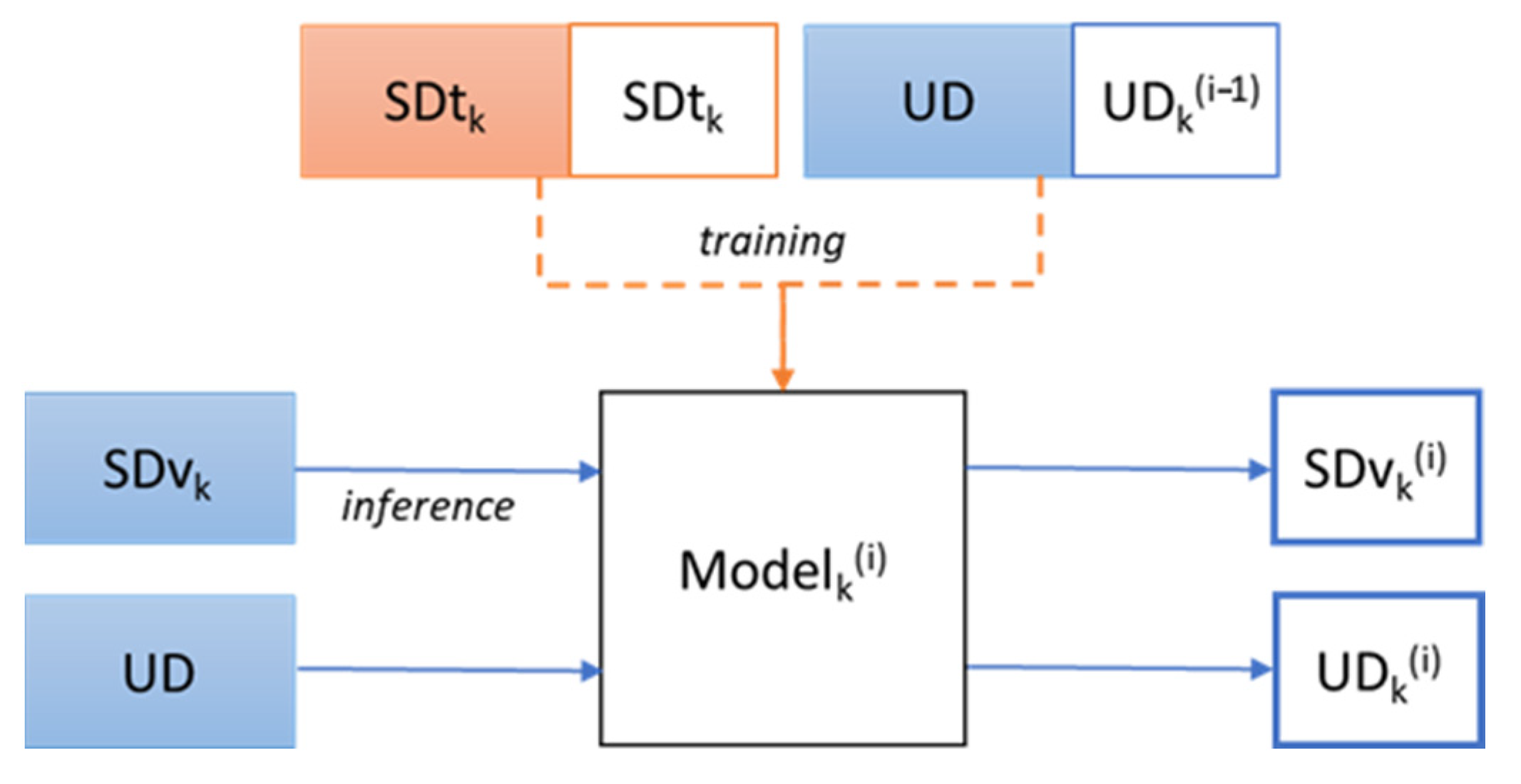
The proposed semi-supervised training method consists of several training and labelling iterations using labelled data (SD part) and unlabelled one (UD part). In the process the unlabelled data is automatically labelled and the accuracy of this labelling is refined iteratively. We have applied cross-validation for the evaluation of the method and thus the semi-supervised training iterative process that we describe bellow have been repeated 5 times using different folds of the SD part as train and validation data. The process is depicted in
Figure 7.
For a particular cross-validation iteration (k), we reserve one of the folds of the SD part of the dataset for validation SDvk and the rest 4 folders are the labelled part for training (SDtk). On the first iteration of the semi-supervised labelling process (iter0 or i = 0), we train the system using the labelled part, SDtk. UDk(−1) is not used in this initial training because it has no labels, i.e., UDk(−1) is empty. Once the training is finished, we obtain the labels for two different groups of data. The first group is the unlabelled part (getting the predicted labels UDk(0)), and the second one is the reserved validation fold of SDvk data, getting the corresponding SDvk(0) labels. In the second iteration (i = 1), the model is trained again but in this case the UD dataset with the new labels automatically predicted in the previous iteration UDk(0), is added to the initial training set (the SDtk part). The resulting model, Modelk(1) is used to relabel the UD getting UDk(1) and the validation SDvk, getting a new set of labels, SDvk(1). We repeat the process for four more iterations and analyse the recall of the labelling obtained in each iteration for the UD part, for the SDvk part and the combination of both (SDvk&UD) in order to see the overall effect in the classification performance. The idea is to check if the system is able to improve using its own predictions of the unsupervised data in a self-convergence iteration sequence. As we have mentioned before, in the following experiments this process has been performed 5 times using 4 different folds to compose the training dataset SDtk and the remaining fold as validation dataset SDvk. The UD part is used entirely in every cross-validation iteration, without dividing it in folds. We have decided to do so because its labelling ground truth information is never used in the training process, and because the amount of samples of this part was not very big. Note that although the UD audios are the same for each of the k folds of the cross-validation, the labels predicted are different because the training material for the Modelk has been different, that is why it is denoted by the subscript k in UDk(i).
5.3.1. Results for Four-Class Taxonomy
Table 7 shows how the macro-average recall evolves with each iteration of the method for each dataset. This value is actually the mean recall averaged for the k = 5 cross-validation iterations.
The results show an improvement in both data sets and in both classifiers. If we look to the ConvBlock results, the UD part improved by 2.8 points and the SDv&UD part by 2 points. It has to be noticed that this improvement did not impair the classification of the SD part, which indeed improved by 0.4. If we take a look at the ResNet results, the UD part was the one that improved most, by 1.7 points, followed by the SDv&UD part, which only improved 0.6 points. In this case, this improvement was achieved at the expense of a slight reduction (0.5 points) in the SDv part.
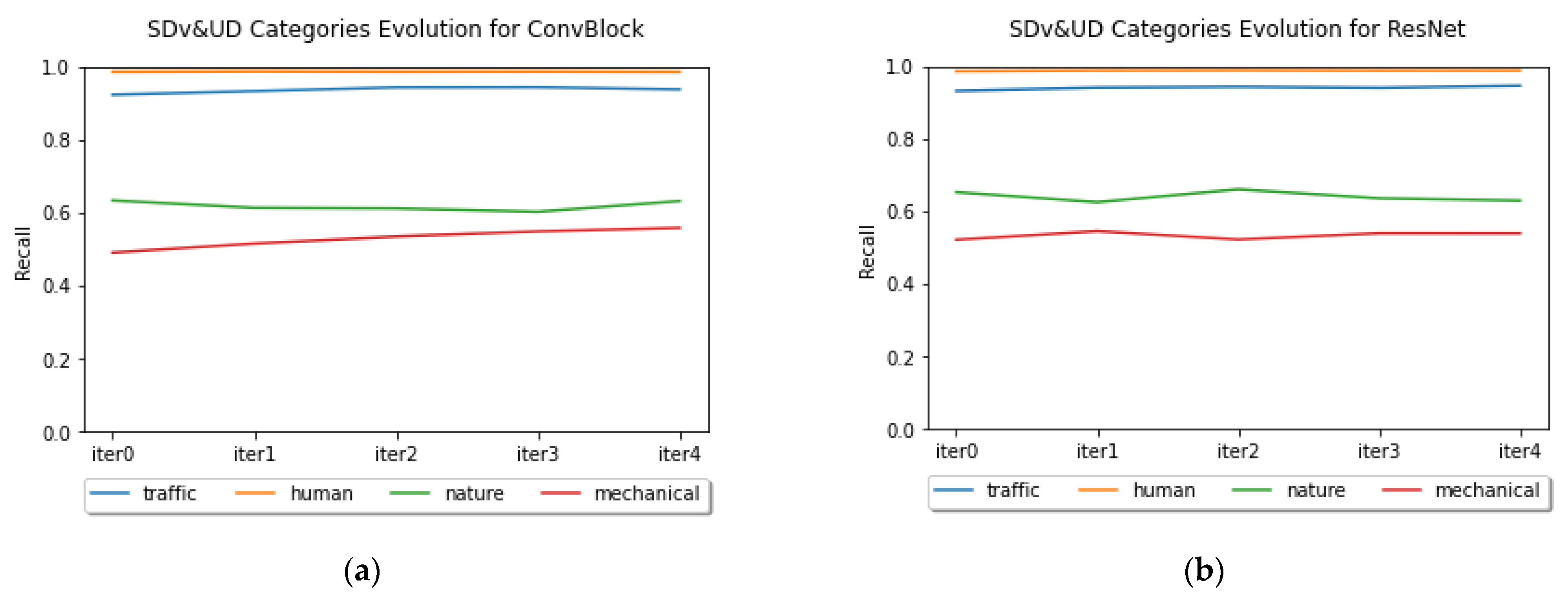
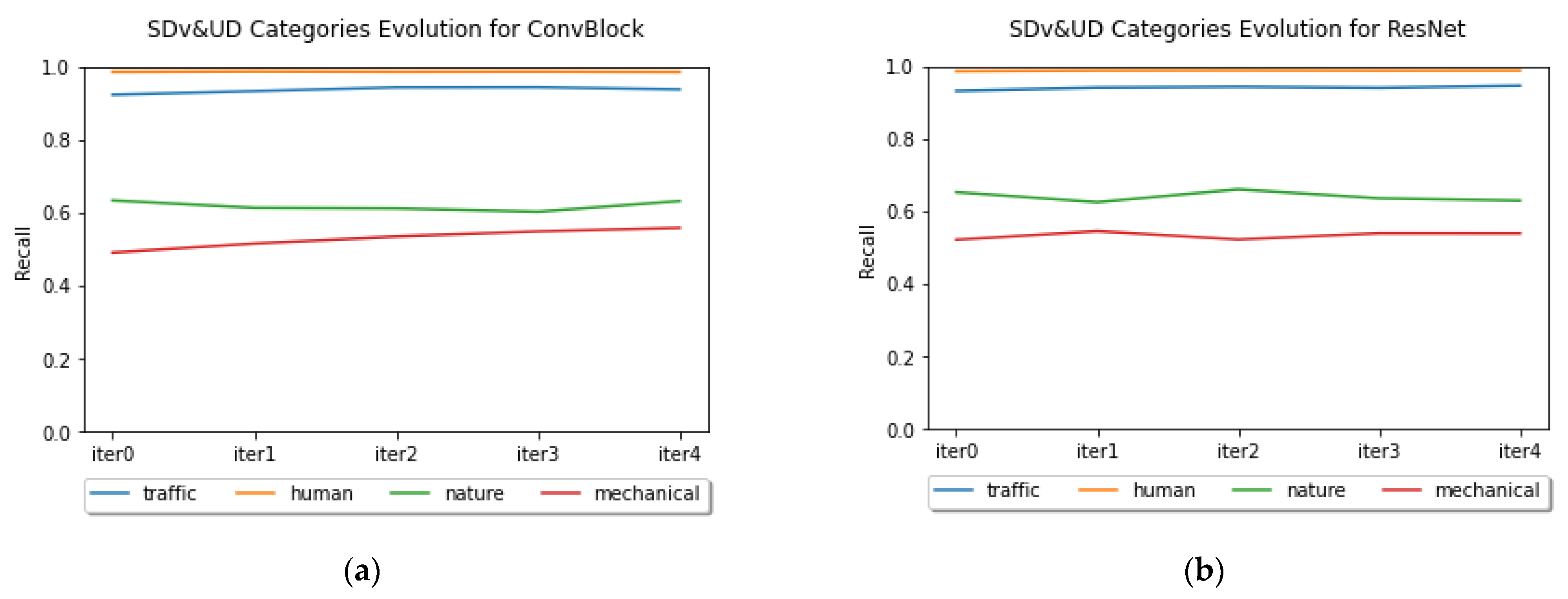
In
Figure 8, we can see the evolution of the recall values of the four categories through the different iterations, considering the whole datasets (SDv&UD). The best performing classes had slight improvements during the process while the worse ones behaved irregularly.
5.3.2. Results for Nine-Class Taxonomy
Table 8 shows the recall results of each of the iterations for each of the datasets. We calculated the metrics as described in
Section 5.3.1.
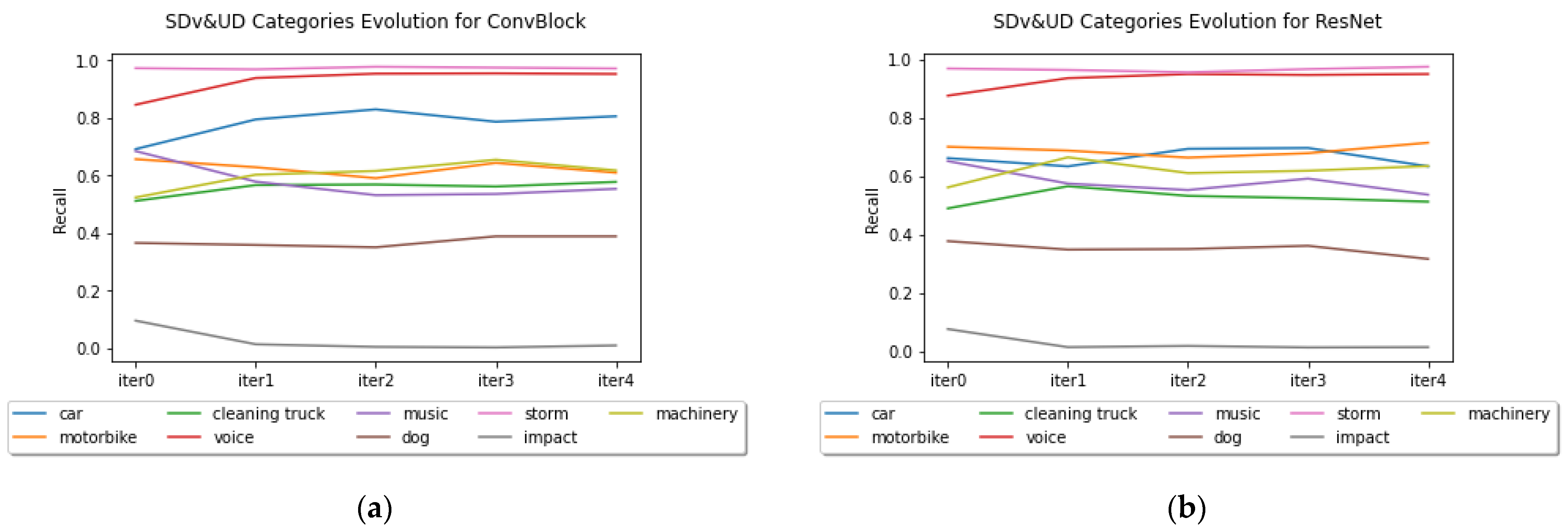
For the ConvBlock system, an improvement was observed up to iter4 for the UD part and up to iter 3 for the SDv&UD part. In the case of the ResNet, an improvement was observed up to iter3 for the UD part and up to iter2 for the SDv&UD part.
The improvement rate is different for both system. For the ConvBlock system, the UD part improves 6.2 points and the SDv&UD improves 1.8 points. While, for the ResNet the UD part improves 4.1 and the SDv&UD part improves nearly 1 point. The SDv part only improves in the first iteration and then loses recall. The improvement in the UD part compensates the loss of accuracy of the SDv part on the SDv&UD result.
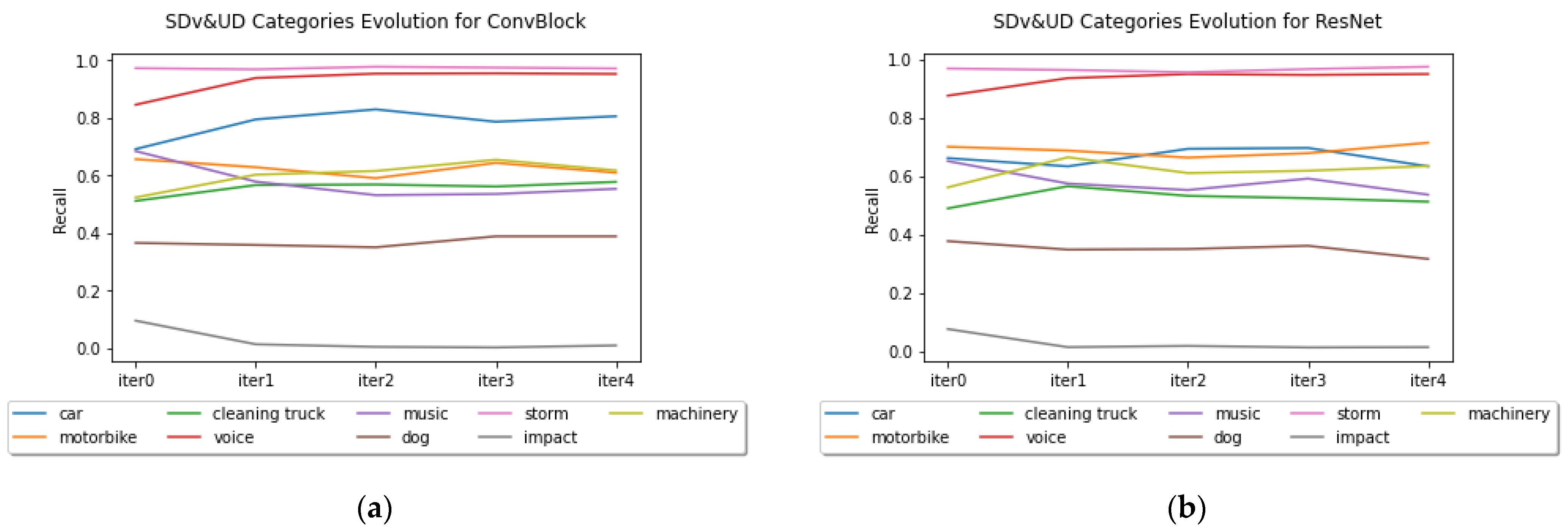
Figure 9 shows the evolution of the recall results for the different categories during the different iterations for both architectures. We present the results for the SDv&UD dataset. In both cases it can be seen that the good performing classes tend to improve with the through the iteration whereas the worse performing class “Impact” degrades. The classes with intermediate recalls vary in an unpredictable way.
6. Conclusions
In this paper, we described a new sound-classification database, NoisenseDB. The database was recorded in an urban environment and high-SPL events were extracted and labelled by a single supervisor following a two-level taxonomy. The database is publicly available for research upon request.
The database was used to evaluate and obtain baseline results for three different types of neural network-based architectures, two of them developed expressly for this work, and the third a state-of-the-art system (AST). Data-augmentation and transfer learning techniques were applied in these systems. We tested the three architectures for the defined taxonomy, both for the coarse and fine categories.
The results of the evaluation using the coarse level of the taxonomy (4 categories) gave an overall performance around 82% for fragment level classification and 70% for entire sound clip classification, with the two original neural architectures proposed by the authors performing at the same level as the AST. For the fine level of the taxonomy, the results are around 64% for all the systems.
The classifiers tended to confuse the categories belonging to the traffic group (“Car”, “Motorbike” and “Cleaning truck”) and also “Voice” and “Music”. The databases were very unbalanced and the categories with few samples (“Impact”, “Dog”) were very hard to classify.
Trying to tackle the problem of the human labelling of the large amounts of audio produced by a continuous monitoring system, we explored the possibility of a semi-supervised procedure. This experiment has shown that the initial labelling of part of the database can be used to effectively label other audio segments, and that this automated labelled part can be used to retrain the system for two or more iterations so as the automated labelling is refined. Including this new material in the training iterations does not impair the performance of the system. Actually, it can slightly improve the overall performance of the system in the first iterations.
The proposed semi-supervised labelling procedure can be used to obtain new automatically labelled data that can be used for the refinement of the models in continuous training applications. These preliminary experiments will be enhanced with more data to better understand the behaviour of the procedure.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}