
Medical Application of Big Data: Between Systematic Review and Randomized Controlled Trials


Abstract
Featured Application
Abstract
1. Introduction
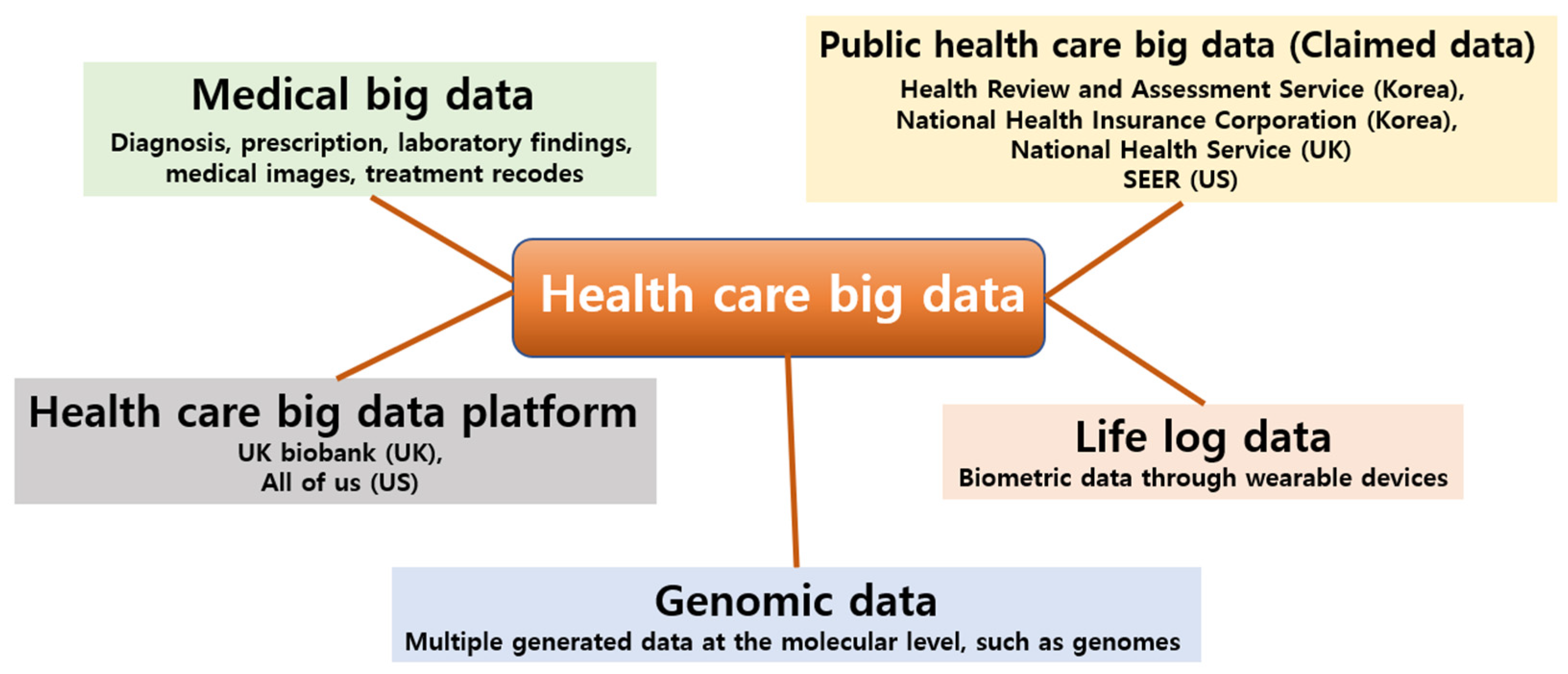
2. Definition and Types of Big Data in Medical Health Area
3. Current Application Status of Big Data in Medical Health Area
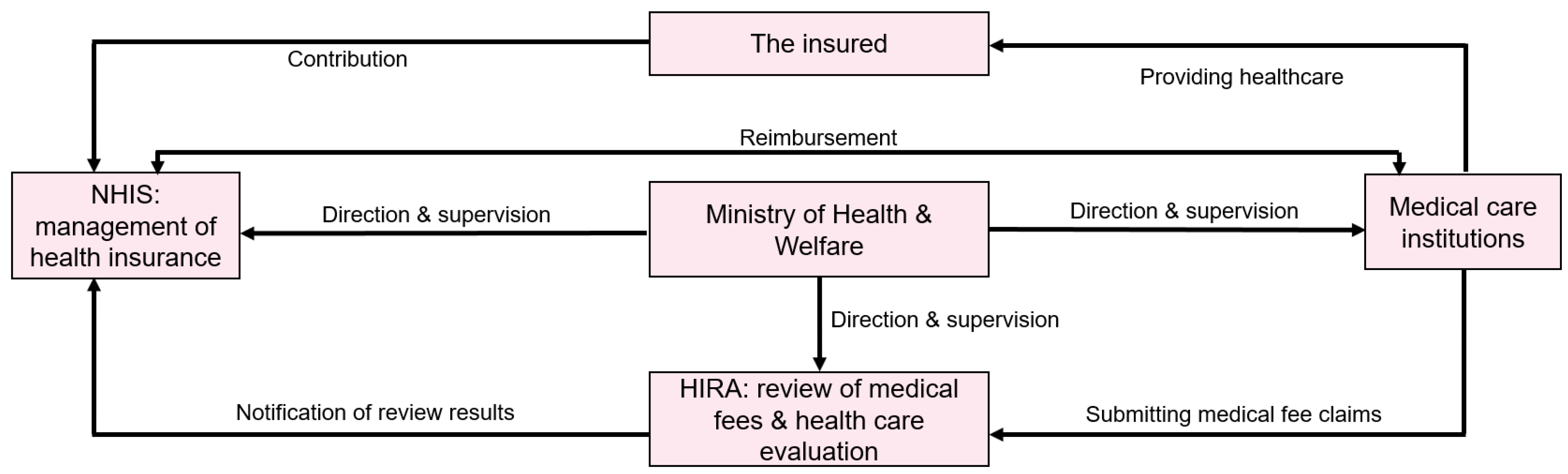
4. Korean National Health Claimed Data for Medical Research
5. Advantages and Disadvantages of Big Data Research Using Industrial Data
6. Big Data Research Design
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hariton, E.; Locascio, J.J. Randomised controlled trials—The gold standard for effectiveness research: Study design: Randomised controlled trials. Bjog 2018, 125, 1716. [Google Scholar] [CrossRef]
- Armstrong, R.; Hall, B.J.; Doyle, J.; Waters, E. Cochrane Update. ‘Scoping the scope’ of a cochrane review. J. Public Health 2011, 33, 147–150. [Google Scholar] [CrossRef]
- Higgins, J.P.T.; Green, S. Cochrane Handbook for Systematic Reviews of Interventions. Version 5.1.0. The Cochrane Collaboration; 2011. Available online: https://handbook-5-1.cochrane.org/ (accessed on 1 August 2023).
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety; Scientific Research Publishing: Wuhan, China, 2001. [Google Scholar]
- Davenport, T.H. Big Data at Work: Dispelling the Myths, Uncovering the Opportunities; Harvard Business School Publishing: Boston, MA, USA, 2014. [Google Scholar]
- Senthilkumar, S.A.; Rai, B.K.; Meshram, A.; Gunasekaran, A.; Chandrakumarmangalam, S. Big Data in Healthcare Management: A Review of Literature. Am. J. Theor. Appl. Bus. 2018, 4, 57–69. [Google Scholar]
- Dinov, I.D. Methodological challenges and analytic opportunities for modeling and interpreting Big Healthcare Data. Gigascience 2016, 5, 12. [Google Scholar] [CrossRef] [PubMed]
- Bellazzi, R.; Zupan, B. Predictive data mining in clinical medicine: Current issues and guidelines. Int. J. Med. Inform. 2008, 77, 81–97. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, S.; Tanaka, S.; Kawakami, K. Methodological issues in observational studies and non-randomized controlled trials in oncology in the era of big data. Jpn. J. Clin. Oncol. 2015, 45, 323–327. [Google Scholar] [CrossRef]
- Scruggs, S.B.; Watson, K.; Su, A.I.; Hermjakob, H.; Yates, J.R., 3rd; Lindsey, M.L.; Ping, P. Harnessing the heart of big data. Circ. Res. 2015, 116, 1115–1119. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Krishnan, E. Big data and clinicians: A review on the state of the science. JMIR Med. Inform. 2014, 2, e1. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.H.; Yoon, H.J. Medical big data: Promise and challenges. Kidney Res. Clin. Pract. 2017, 36, 3–11. [Google Scholar] [CrossRef]
- Khoury, M.J.; Ioannidis, J.P. Medicine. Big data meets public health. Science 2014, 346, 1054–1055. [Google Scholar] [CrossRef]
- Rumsfeld, J.S.; Joynt, K.E.; Maddox, T.M. Big data analytics to improve cardiovascular care: Promise and challenges. Nat. Rev. Cardiol. 2016, 13, 350–359. [Google Scholar] [CrossRef]
- United Nations. Non-Communicable Diseases Deemed Development Challenge of ‘Epidemic Proportions’ in Political Declaration Adopted During Landmark General Assembly Summit. 2011. Available online: https://press.un.org/en/2011/ga11138.doc.htm (accessed on 1 August 2023).
- Linsk, J.A. American medical culture and the health care crisis. Am. J. Med. Qual. 1993, 8, 174–180. [Google Scholar] [CrossRef]
- Kim, E.Y. Korea’s Healthcare Spending Grows Fastest among OECD. Korea Biomedical Review; 2021. Available online: https://www.koreabiomed.com/news/articleView.html?idxno=10890 (accessed on 1 August 2023).
- World Health Organization. World Health Statistics. 2023. Available online: https://data.who.int/ (accessed on 1 August 2023).
- Atchinson, B.K.; Fox, D.M. The politics of the Health Insurance Portability and Accountability Act. Health Aff. 1997, 16, 146–150. [Google Scholar] [CrossRef] [PubMed]
- Korea Health Information Service. Healthcare Big Data Platform. Korean. Public Health Big Data Platform. 2023. Available online: https://hcdl.mohw.go.kr/ (accessed on 1 August 2023).
- Korea Disease Control and Prevention Agency. Korea Health Statistics 2019: Korea National Health and Nutrition Examination Survey (KNHANES VII-3). 2020. Available online: https://knhanes.kdca.go.kr/knhanes/sub04/sub04_04_01.do (accessed on 1 August 2023).
- Korean Law Information Center. Criteria for Special Exceptions to Copayment Calculations. Korean. Korean Law Information Center. 2023. Available online: https://www.law.go.kr (accessed on 1 August 2023).
- Kim, H.; Lee, C.H.; Kim, S.H.; Kim, Y.D. Epidemiology of complex regional pain syndrome in Korea: An electronic population health data study. PLoS ONE 2018, 13, e0198147. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, S.; Kim, J.H. A Korean nationwide investigation of the national trend of complex regional pain syndrome vis-à-vis age-structural transformations. Korean J. Pain 2021, 34, 322–331. [Google Scholar] [CrossRef] [PubMed]
- Bzdok, D. Classical Statistics and Statistical Learning in Imaging Neuroscience. Front. Neurosci. 2017, 11, 543. [Google Scholar] [CrossRef]
- Bzdok, D.; Altman, N.; Krzywinski, M. Statistics versus machine learning. Nat. Methods 2018, 15, 233–234. [Google Scholar] [CrossRef]
- Sinha, A.; Hripcsak, G.; Markatou, M. Large datasets in biomedicine: A discussion of salient analytic issues. J. Am. Med. Inform. Assoc. 2009, 16, 759–767. [Google Scholar] [CrossRef] [PubMed]
- Li, L. Dimension reduction for high-dimensional data. Methods Mol. Biol. 2010, 620, 417–434. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Park, J.J.; Kim, K.; Choi, J.Y.; Shim, S.R.; Kim, J.H. Long-term mortality of living kidney donors: A systematic review and meta-analysis. Int. Urol. Nephrol. 2021, 53, 1563–1581. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.Y.; Kim, J.H.; Kim, J.M.; Kim, H.J.; Ahn, H.S.; Joh, J.W. Outcomes of living liver donors are worse than those of matched healthy controls. J. Hepatol. 2022, 76, 628–638. [Google Scholar] [CrossRef] [PubMed]
- DerSimonian, R.; Laird, N. Meta-analysis in clinical trials. Control Clin. Trials 1986, 7, 177–188. [Google Scholar] [CrossRef]
- Shim, S.R.; Kim, S.J. Intervention meta-analysis: Application and practice using R software. Epidemiol. Health 2019, 41, e2019008. [Google Scholar] [CrossRef] [PubMed]
- Sterne, J.A.C.; Savović, J.; Page, M.J.; Elbers, R.G.; Blencowe, N.S.; Boutron, I.; Cates, C.J.; Cheng, H.Y.; Corbett, M.S.; Eldridge, S.M.; et al. RoB 2: A revised tool for assessing risk of bias in randomised trials. BMJ 2019, 366, l4898. [Google Scholar] [CrossRef]
- Stang, A. Critical evaluation of the Newcastle-Ottawa scale for the assessment of the quality of nonrandomized studies in meta-analyses. Eur. J. Epidemiol. 2010, 25, 603–605. [Google Scholar] [CrossRef] [PubMed]
- Sterne, J.A.; Hernán, M.A.; Reeves, B.C.; Savović, J.; Berkman, N.D.; Viswanathan, M.; Henry, D.; Altman, D.G.; Ansari, M.T.; Boutron, I.; et al. ROBINS-I: A tool for assessing risk of bias in non-randomised studies of interventions. BMJ 2016, 355, i4919. [Google Scholar] [CrossRef] [PubMed]
- Shim, S.; Yoon, B.H.; Shin, I.S.; Bae, J.M. Network meta-analysis: Application and practice using Stata. Epidemiol. Health 2017, 39, e2017047. [Google Scholar] [CrossRef]
- White, I.R. Network meta-analysis. Stata J. 2015, 15, 951–985. [Google Scholar] [CrossRef]
- Harbord, R.M.; Deeks, J.J.; Egger, M.; Whiting, P.; Sterne, J.A. A unification of models for meta-analysis of diagnostic accuracy studies. Biostatistics 2007, 8, 239–251. [Google Scholar] [CrossRef]
- Orsini, N.; Greenland, S. A procedure to tabulate and plot results after flexible modeling of a quantitative covariate. Stat. J. 2011, 11, 1–29. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Stroup, D.F.; Berlin, J.A.; Morton, S.C.; Olkin, I.; Williamson, G.D.; Rennie, D.; Moher, D.; Becker, B.J.; Sipe, T.A.; Thacker, S.B. Meta-analysis of observational studies in epidemiology: A proposal for reporting. Meta-analysis Of Observational Studies in Epidemiology (MOOSE) group. JAMA 2000, 283, 2008–2012. [Google Scholar] [CrossRef] [PubMed]
- U.S. Food and Drug Administration. Meta-Analyses of Randomized Controlled Clinical Trials to Evaluate the Safety of Human Drugs or Biological Products Guidance for Industry. 2023. Available online: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/meta-analyses-randomized-controlled-clinical-trials-evaluate-safety-human-drugs-or-biological (accessed on 1 August 2023).
- U.S. Food and Drug Administration. Enhancing Regulatory Science—Methodologies for Meta-Analysis. 2023. Available online: https://www.fda.gov/industry/prescription-drug-user-fee-amendments/enhancing-regulatory-science-methodologies-meta-analysis (accessed on 1 August 2023).
- Murad, M.H.; Asi, N.; Alsawas, M.; Alahdab, F. New evidence pyramid. Evid. Based Med. 2016, 21, 125–127. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Disease Code | Specific Code |
|---|---|---|
| Chronic renal failure | ||
| End stage renal disease with dialysis | V001, V003 | |
| Blood clotting disorders (e.g., hemophilia) | ||
| Acquired clotting factor deficiency | D68.4 | V284 |
| Organ transplantation | ||
| Liver, kidney, lung, heart, pancreas, | V013, V014, V015, V005, | |
| small bowel transplantation | V277, V278 | |
| Psychiatric disease | ||
| Schizophrenia (81 cases) | F20.0 | V161 |
| Specific Infection | V103, V124, V131, V140, | |
| V142, V162, V170, V201, | ||
| Specific encephalitis (118 cases) | A81.1 | V223, V237, V279, V280, V282, V283, V285, V286, V287, V288, V289, V290 |
| Dementia Early onset Alzheimer’s dementia (14 cases) | F00.0 | V800 |
| Dementia Late onset Alzheimer’s dementia (12 cases) | F00.1 | V810 |
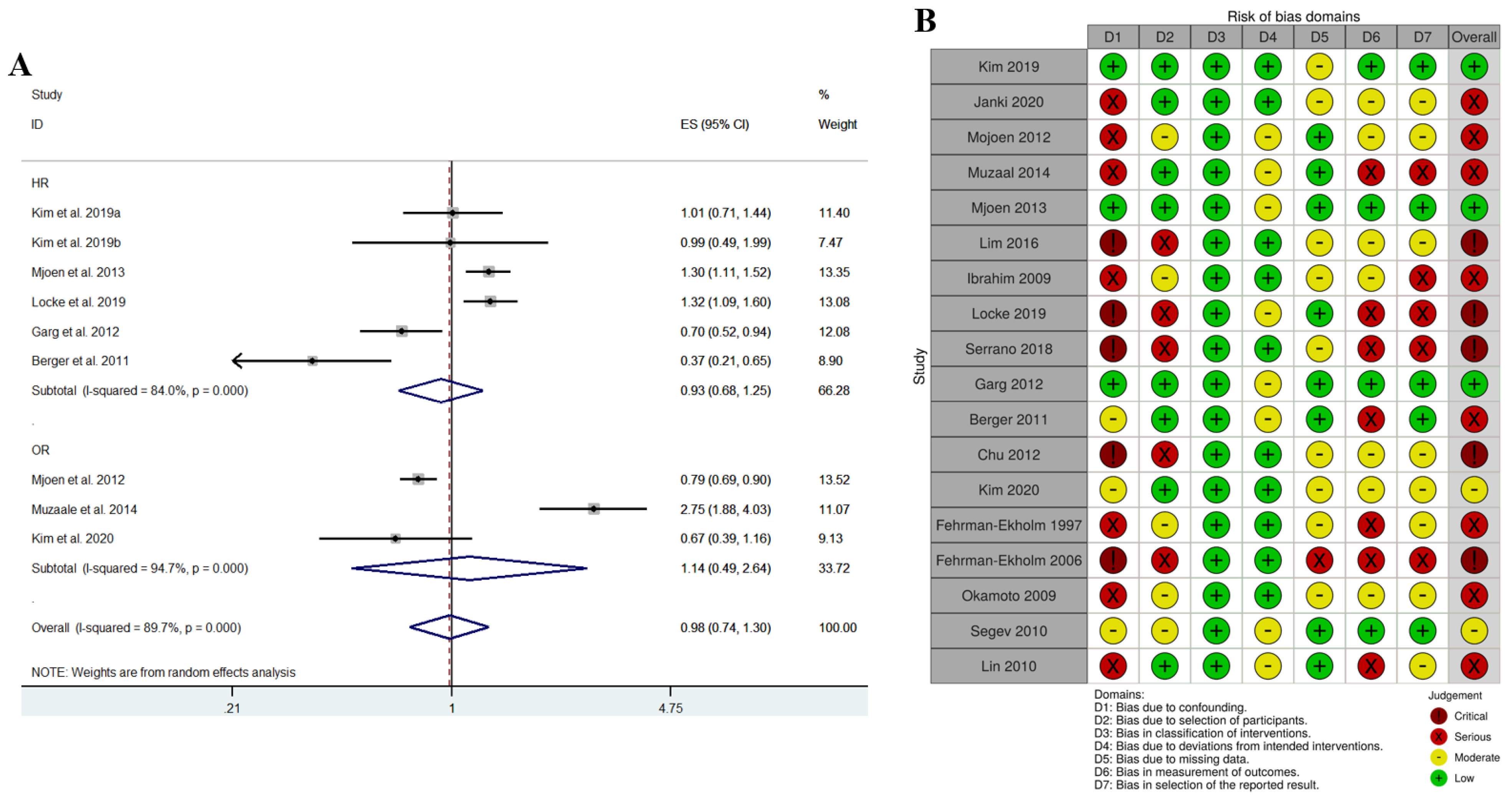
| Bias Domain | Bias Due to Confounding | Bias Due to Selection of Participants | Bias in Classification of Intervention | Bias Due to Deviations from Intended Intervention | Bias Due to Missing Data | Bias Due to Measurement of Outcomes | Bias in Selection of the Reported Results |
|---|---|---|---|---|---|---|---|
| Evaluation standard for each bias domain | (1) Low: Matched control, adjusted HR (2) Moderate: (i) Matched control, unadjusted HR (ii) Unmatched control, adjusted HR (3) Serious: Unmatched control, no HR Critical: No control | (1) Low: Healthy control (2) Moderate: Non-healthy control (3) Serious: No control (or No description of control group) | (1) Low: Because all studies are on donor nephrectomy | (1) Low: Single center (2) Moderate: Multicenter, claimed data | (1) Low: Claimed data (2) Moderate: Not claimed data, description of the follow up method (3) Serious: Not claimed data, no description of the follow up method | (1) Low: HR is calculated, median follow up period is presented (2) Moderate: No HR, median follow up period and survival rate are presented (3) Serious: HR, median follow up period and survival rate are not presented | (1) Low: HR, survival rate and cause of death are presented (2) Moderate: HR isn’t presented (3) Serious: HR and survival rate are not presented |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shim, S.R.; Lee, J.-H.; Kim, J.H. Medical Application of Big Data: Between Systematic Review and Randomized Controlled Trials. Appl. Sci. 2023, 13, 9260. https://doi.org/10.3390/app13169260
Shim SR, Lee J-H, Kim JH. Medical Application of Big Data: Between Systematic Review and Randomized Controlled Trials. Applied Sciences. 2023; 13(16):9260. https://doi.org/10.3390/app13169260
Chicago/Turabian StyleShim, Sung Ryul, Joon-Ho Lee, and Jae Heon Kim. 2023. "Medical Application of Big Data: Between Systematic Review and Randomized Controlled Trials" Applied Sciences 13, no. 16: 9260. https://doi.org/10.3390/app13169260
APA StyleShim, S. R., Lee, J.-H., & Kim, J. H. (2023). Medical Application of Big Data: Between Systematic Review and Randomized Controlled Trials. Applied Sciences, 13(16), 9260. https://doi.org/10.3390/app13169260