

Early Prediction of Students’ Performance Using a Deep Neural Network Based on Online Learning Activity Sequence

Abstract
1. Introduction
- (1)
- We propose a representation of an online learning activity sequence that can be used as the input for a deep neural network to predict students’ academic performance.
- (2)
- We design an unsupervised autoencoder based on a deep neural network. This can extract latent features from the sequence of students’ online learning activities, which can then be used for visual analysis and further improve the accuracy of our predictions.
- (3)
- We designed an end-to-end prediction model of student’s performance based on the online learning activity sequence. This model is composed of an autoencoder and a classifier based on a deep neural network. Aiming to address the imbalance in the training dataset, we use an algorithm based on K-Means and SMOTE to resample the training dataset, which improves the accuracy of the prediction model for non-major classes.
2. Problem Definition and Related Work
2.1. Problem Definition
2.2. Related Work
3. Method
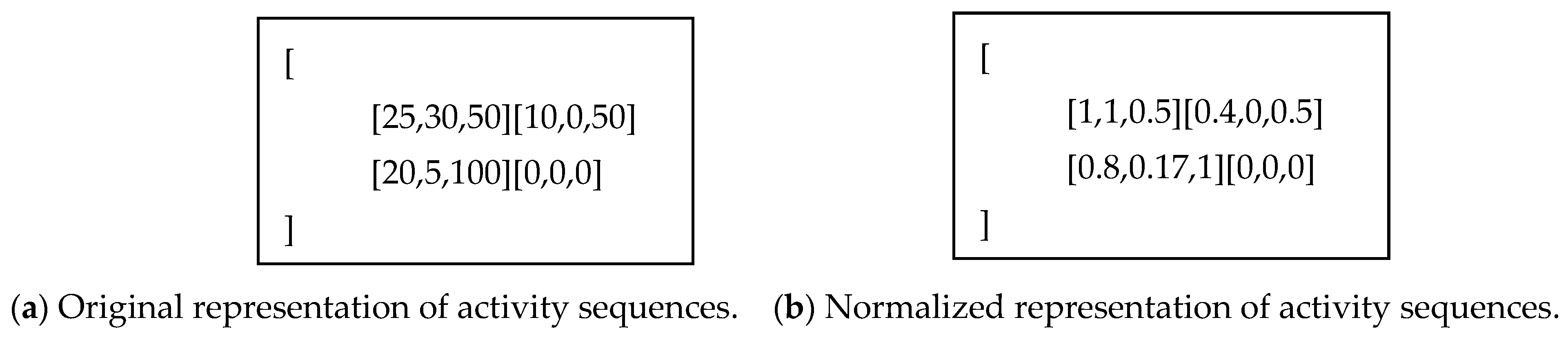
3.1. Representation of an Online Learning Activity Sequence
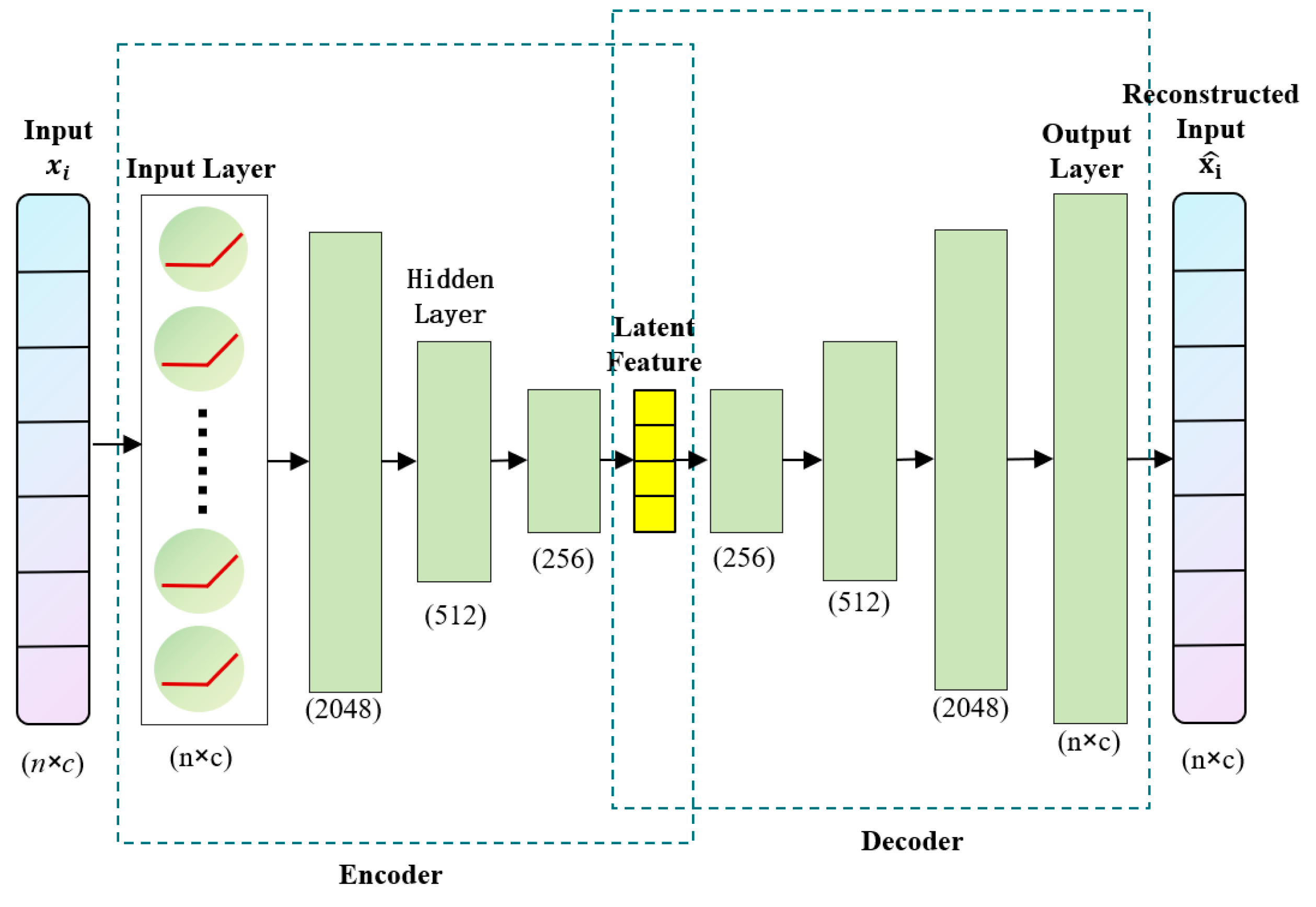
3.2. Autoencoder of Learning Activity Sequence
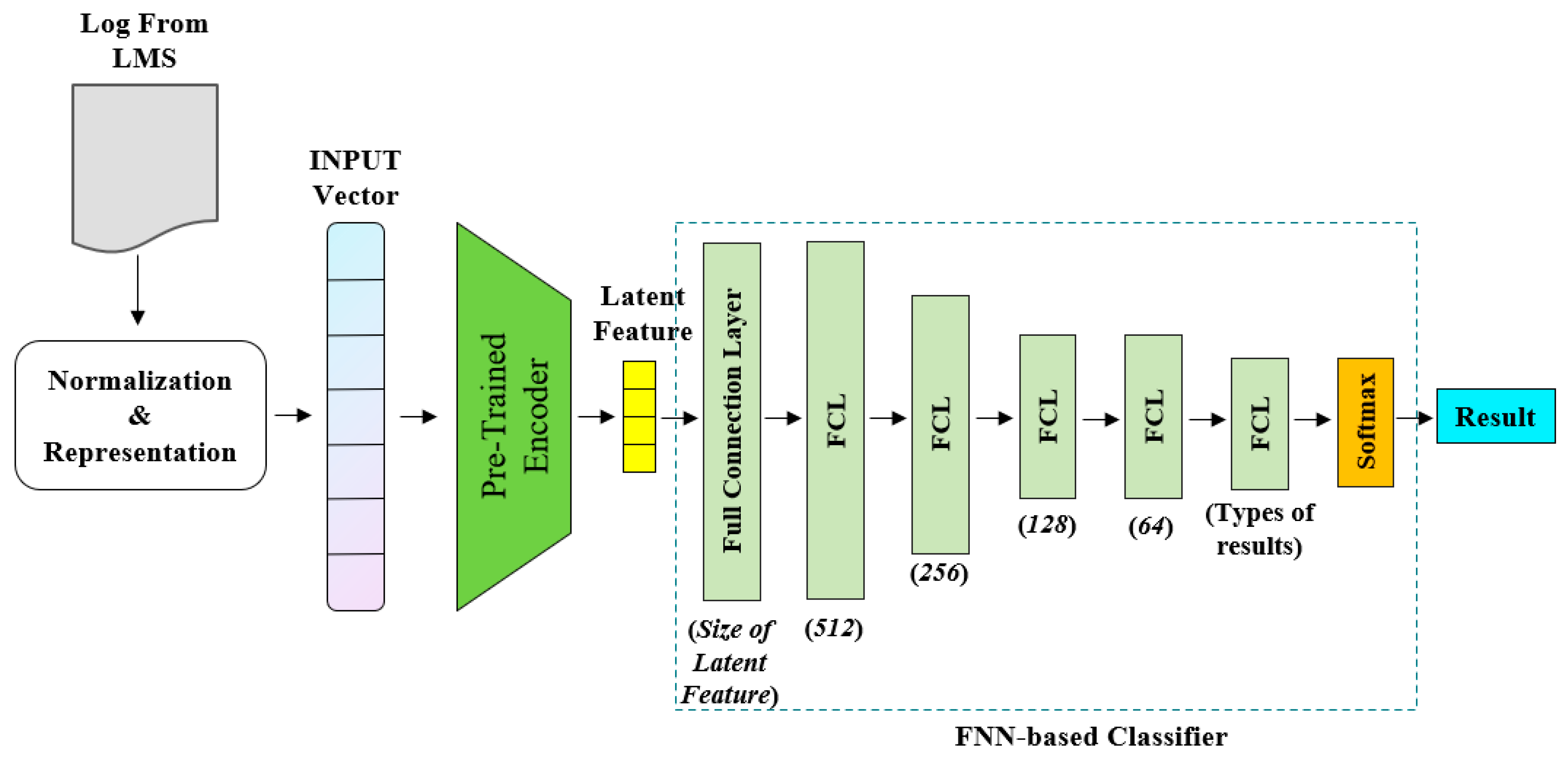
3.3. End-to-End Prediction Model of Students’ Performance
4. Experimental Results and Discussion
4.1. Setting of Experiments
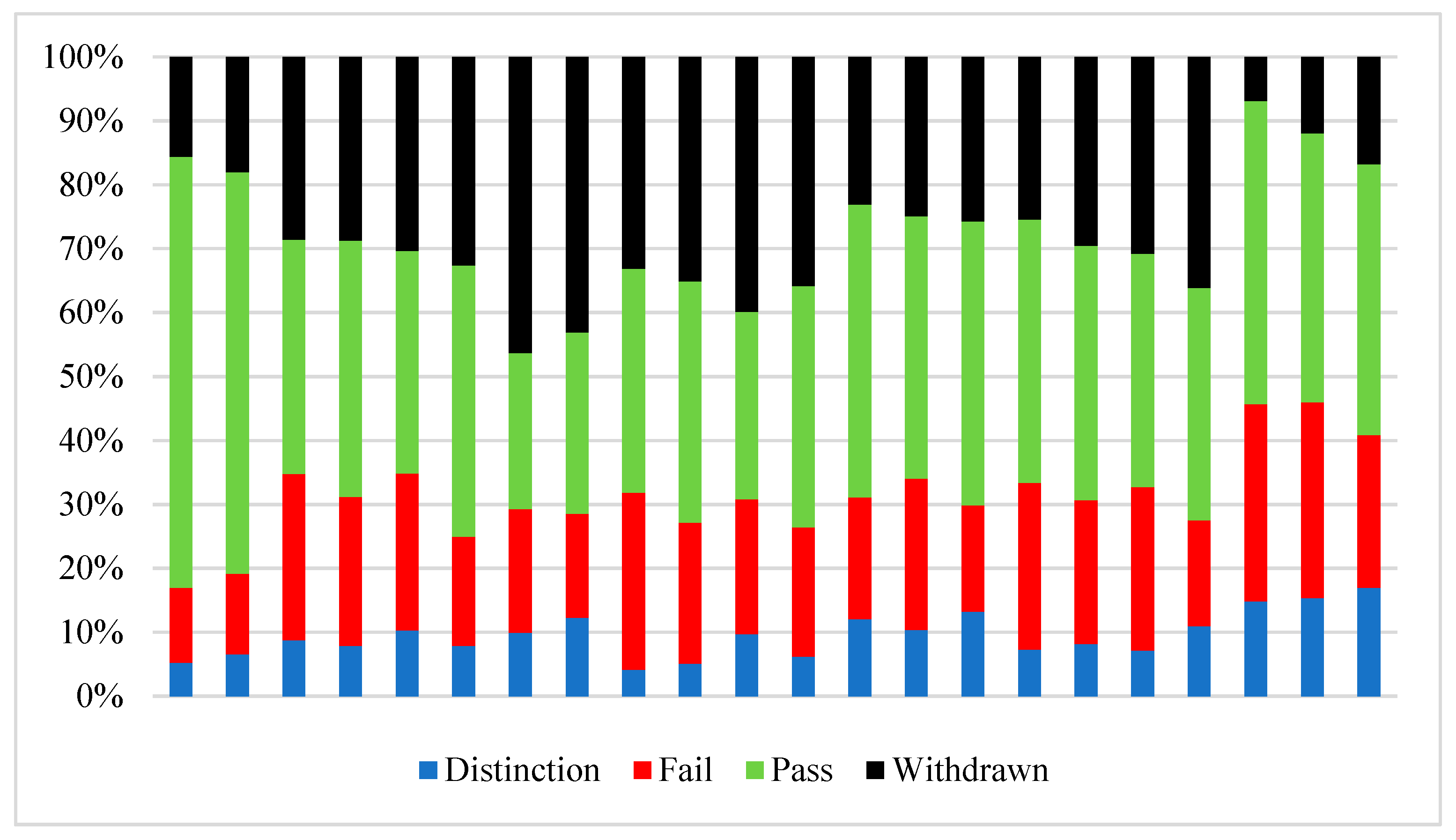
4.1.1. Dataset
4.1.2. Experimental Environment and Parameters of Training
4.1.3. Metrics
4.2. Results and Discussion
4.2.1. Evaluation of Representation
4.2.2. Evaluation of Autoencoder
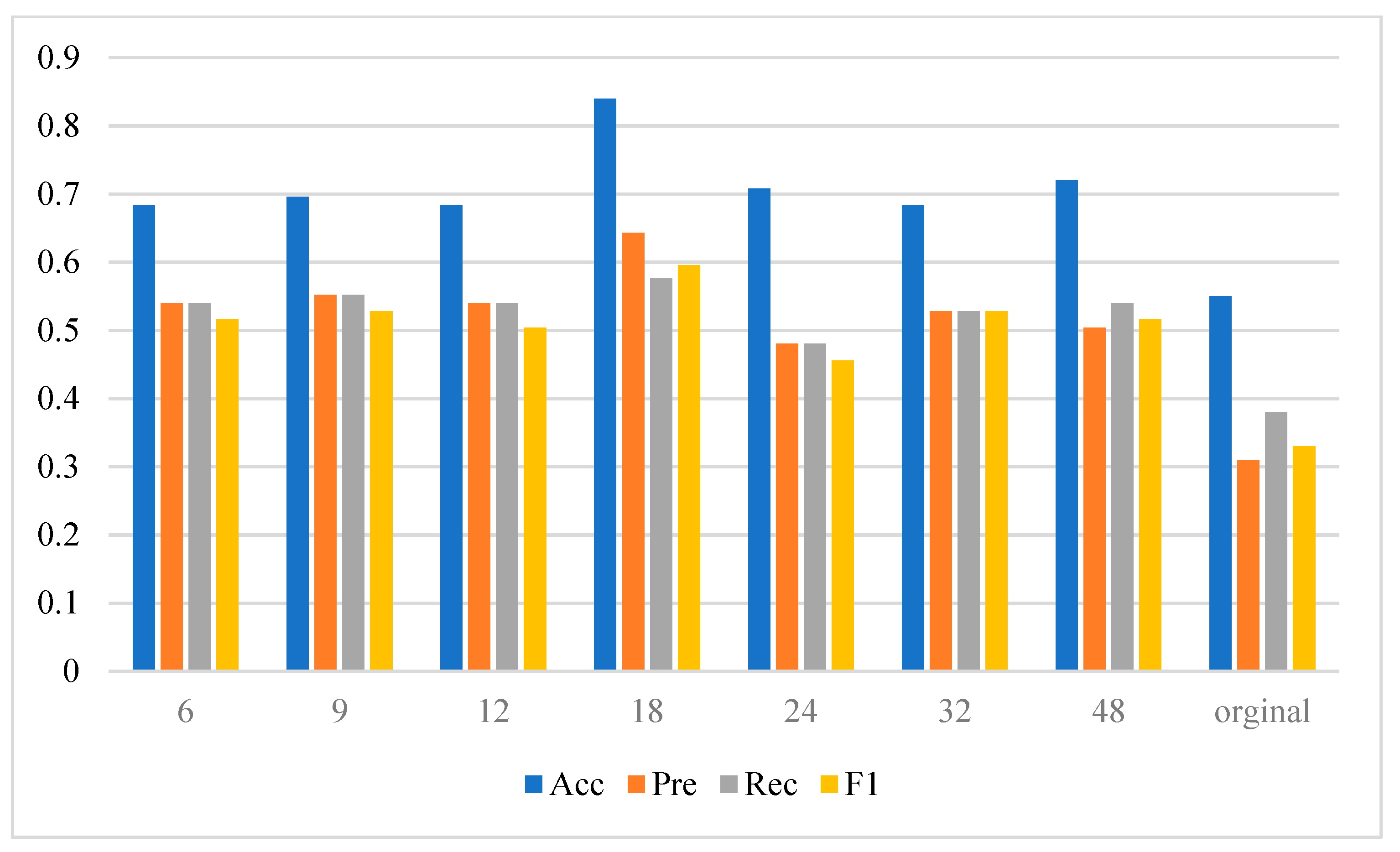
4.2.3. Evaluation of End-to-End Prediction Model
5. Key Findings and Future Research
5.1. Key Findings
- (1)
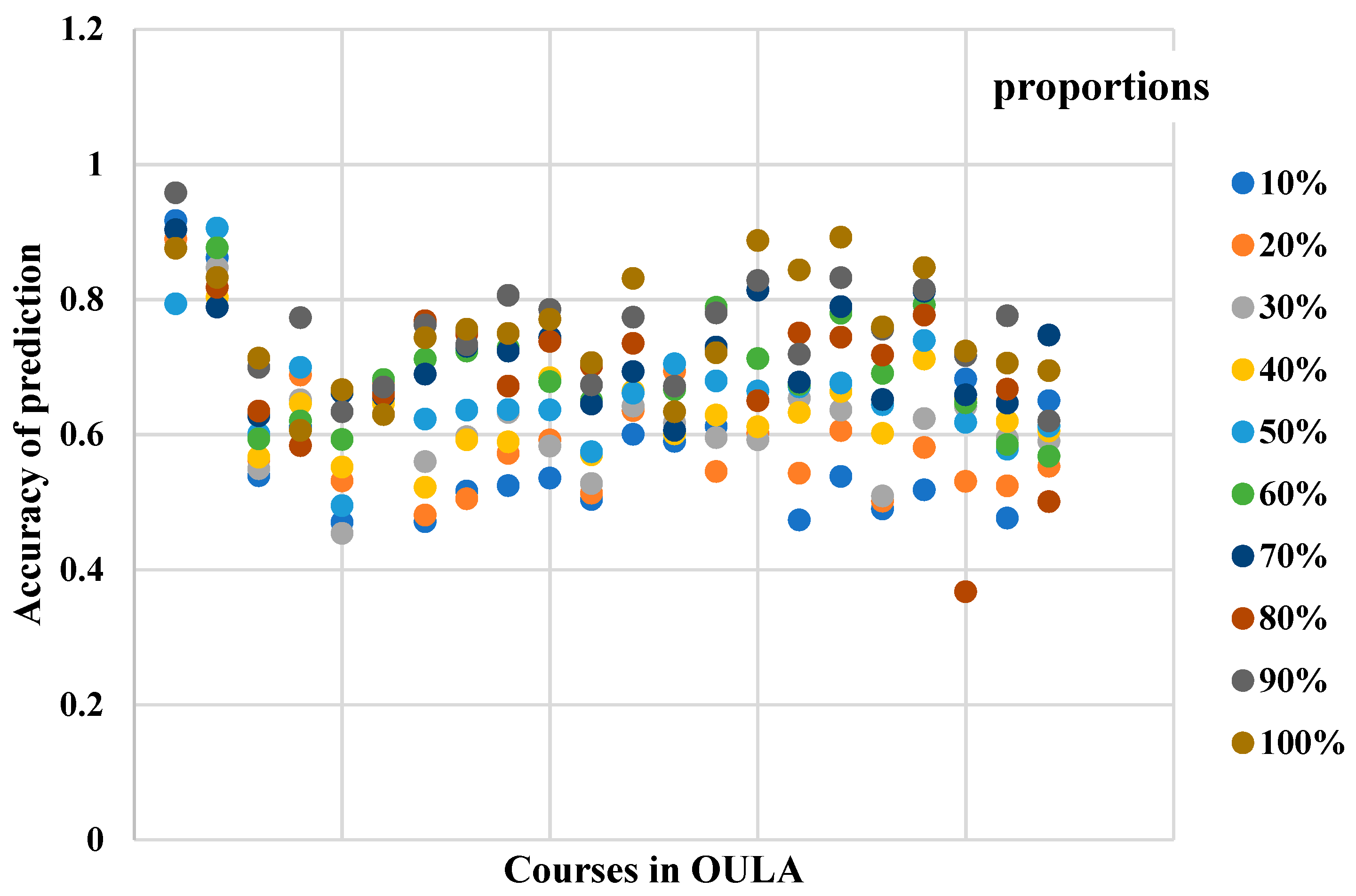
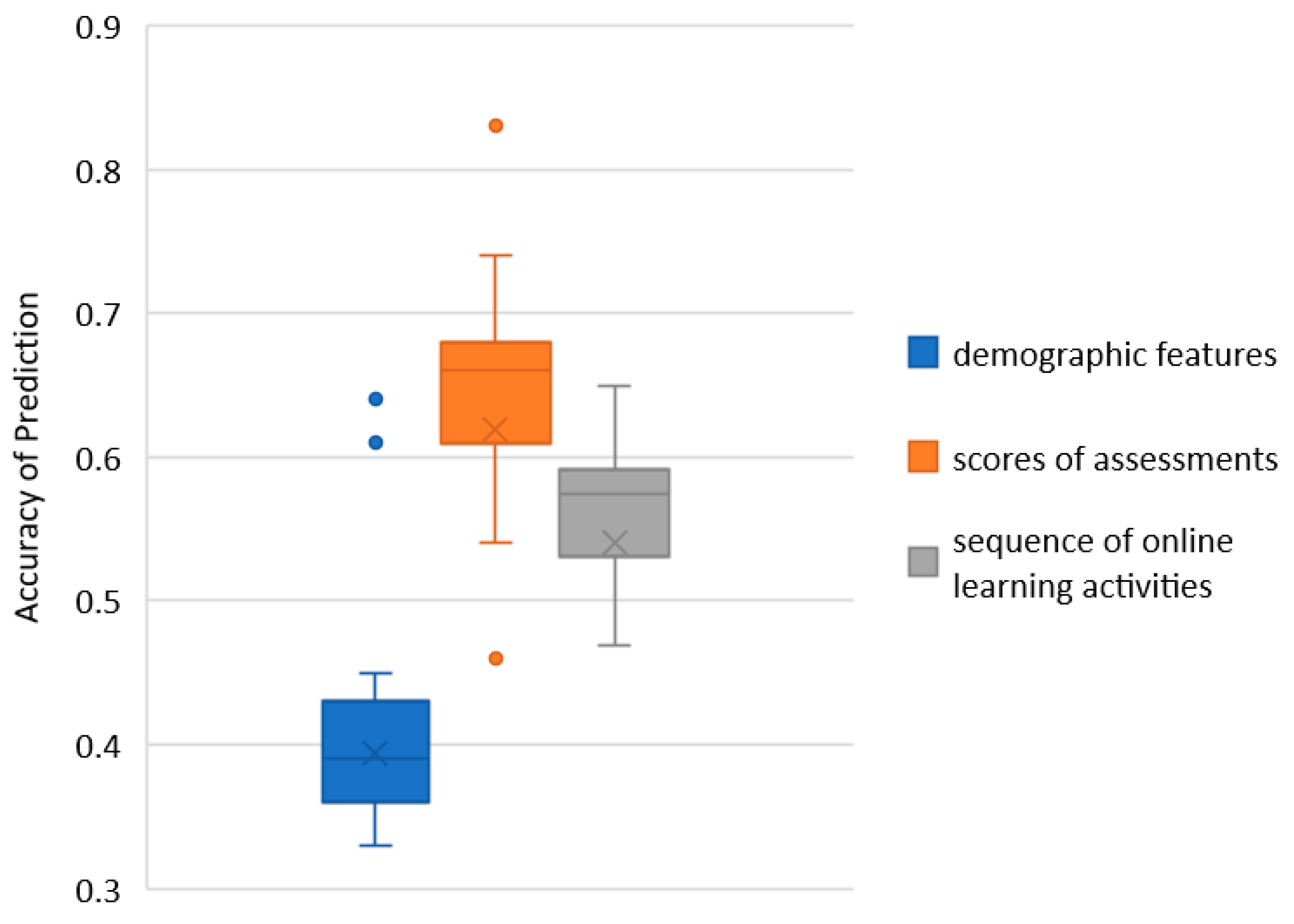
- Students’ online learning activity sequences can be used to effectively predict students’ learning performance. Compared with students’ demographic features and assessment scores, a small part of the online learning activity sequences can be used to predict students’ performance at the beginning, rather than waiting for all learning activities to be completed. The prediction result based on online learning activity sequence has better stability, and the prediction accuracy is proportional to the length of the online learning activity sequence.
- (2)
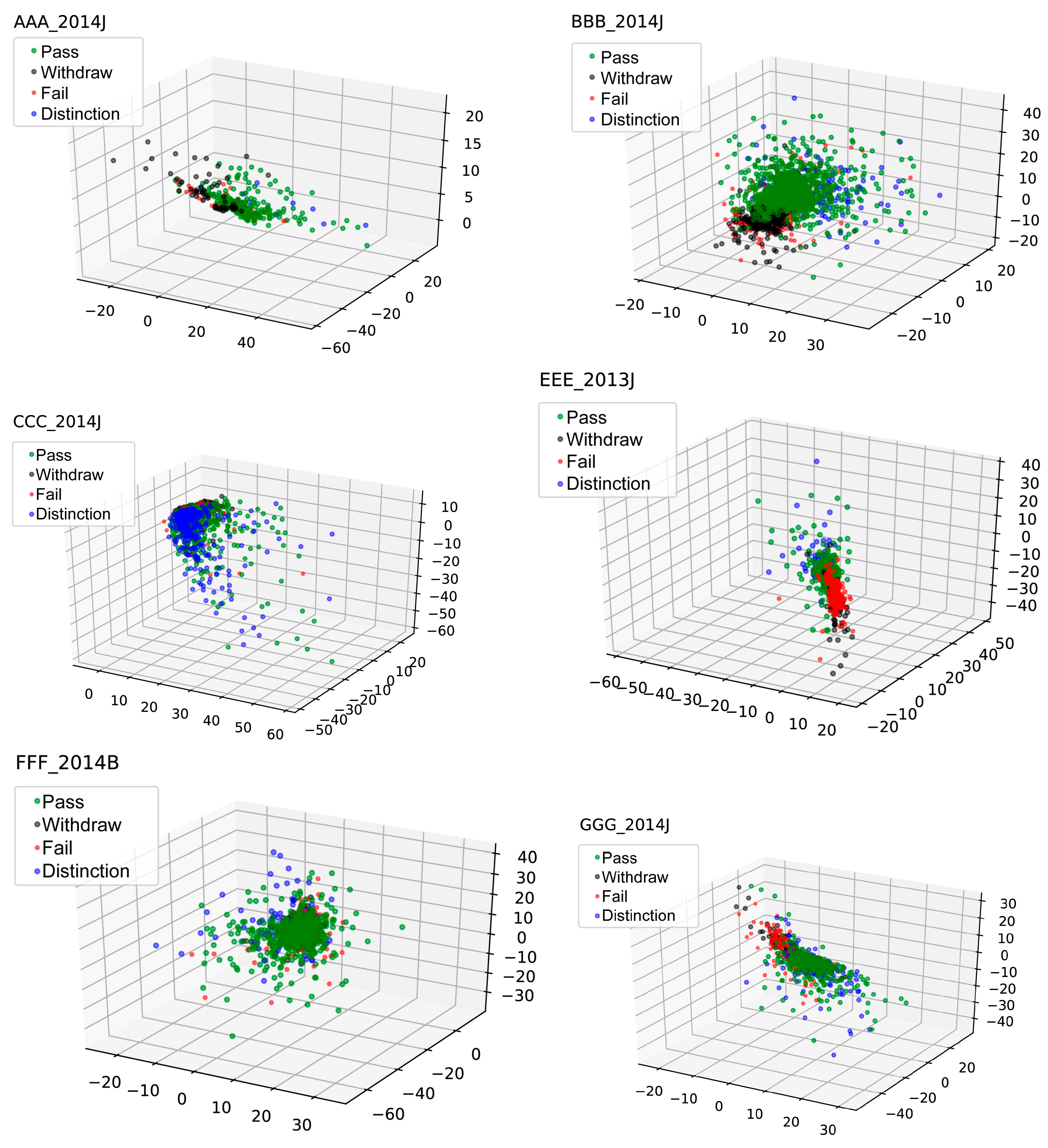
- The autoencoder based on a deep neural network can extract latent features with lower dimensions from the original high-dimensional online learning activity sequences, which contains the essential information of learners’ online learning behavior, so that students with the same performance have a closer distance in the new feature space. Using latent features can further improve the accuracy of performance prediction.
- (3)
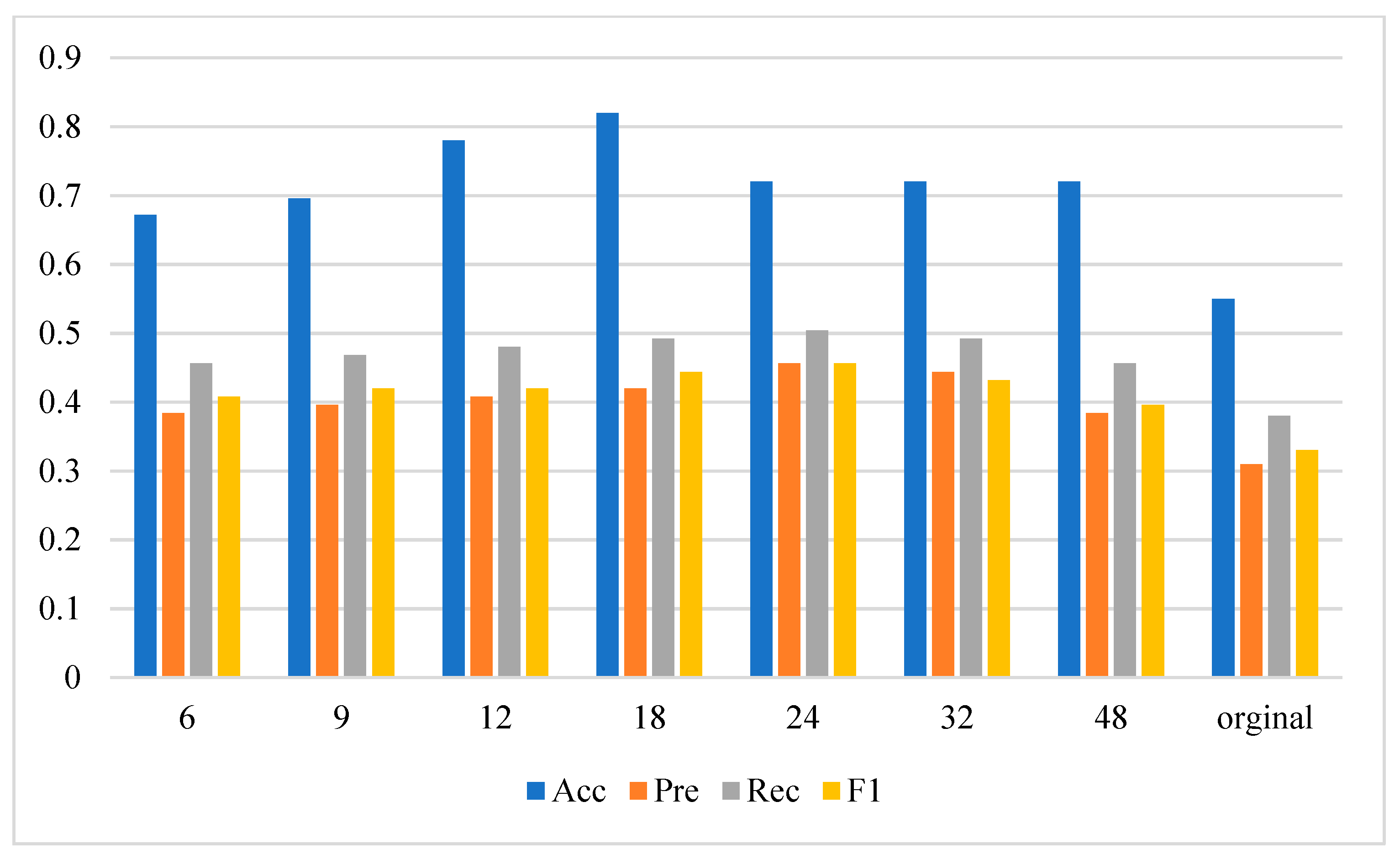
- The classifier based on a deep feedforward neural network can be used to predict students’ performance. Although there is no clear standard for the selection of hyperparameters of this network, the experimental results show that the network with more than five hidden layers and a single hidden layer containing up to 512 artificial neurons can achieve a prediction accuracy of more than 70%. The parameters used to train the autoencoder and classifier based on a deep neural network need to be selected through experiments according to the hardware, volume and properties of the training datasets.
- (4)
- The training dataset containing students’ performance is often imbalanced, which leads to bias in the prediction model for non-major grades. Distance-based and oversampling methods such as KMeansSMOTE can generate a new, balanced training dataset and improve the performance of the prediction model.
5.2. Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Romero, C.; Ventura, S. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. In Educational Data Mining and Learning Analytics: An Updated Survey; John Wiley & Sons: Hoboken, NJ, USA, 2020; Volume 10, p. e1355. [Google Scholar]
- Xiao, W.; Ji, P.; Hu, J.J.E.R. A survey on educational data mining methods used for predicting students’ performance. Eng. Rep. 2022, 4, e12482. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Hernández-Blanco, A.; Herrera-Flores, B.; Tomás, D.; Navarro-Colorado, B. A systematic review of deep learning approaches to educational data mining. Complexity 2019, 2019, 1306039. [Google Scholar] [CrossRef]
- Luo, Y.; Han, X.; Zhang, C. Prediction of learning outcomes with a machine learning algorithm based on online learning behavior data in blended courses. Asia Pac. Educ. Rev. 2022, 1–19. [Google Scholar] [CrossRef]
- Lee, C.-A.; Tzeng, J.W.; Huang, N.F.; Su, Y.S. Prediction of student performance in Massive Open Online Courses using deep learning system based on learning behaviors. Educ. Technol. Soc. 2021, 24, 130–146. [Google Scholar]
- Xie, S.-t.; Chen, Q.; Liu, K.-H.; Kong, Q.-Z.; Cao, X.-J. Learning Behavior Analysis Using Clustering and Evolutionary Error Correcting Output Code Algorithms in Small Private Online Courses. Sci. Program. 2021, 2021, 9977977. [Google Scholar]
- Delgado, S.; Morán, F.; San José, J.C.; Burgos, D. Analysis of Students’ Behavior Through User Clustering in Online Learning Settings, Based on Self Organizing Maps Neural Networks. IEEE Access 2021, 9, 132592–132608. [Google Scholar] [CrossRef]
- Yang, Y.; Hooshyar, D.; Pedaste, M.; Wang, M.; Huang, Y.-M.; Lim, H. Prediction of students’ procrastination behaviour through their submission behavioural pattern in online learning. J. Ambient. Intell. Humaniz. Comput. 2020, 1–18. [Google Scholar] [CrossRef]
- Li, L.-Y.; Tsai, C.-C. Accessing online learning material: Quantitative behavior patterns and their effects on motivation and learning performance. Comput. Educ. 2017, 114, 286–297. [Google Scholar]
- Yang, J.; Huang, G.; Ma, J.; Howard, S.K.; Ciao, M.; Gao, J. Fuzzy Contrastive Learning for Online Behavior Analysis. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, Luxembourg, 11–14 July 2021. [Google Scholar]
- Altuwairqi, K.; Jarraya, S.K.; Allinjawi, A.; Hammami, M. Student Behavior Analysis to Measure Engagement Levels in Online Learning Environments. Signal Image Video Process. 2021, 15, 1387–1395. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Z.; Liu, H.; Cao, T.; Liu, S. Data-driven online learning engagement detection via facial expression and mouse behavior recognition technology. J. Educ. Comput. Res. 2020, 58, 63–86. [Google Scholar] [CrossRef]
- Jia, J.; Zhang, J. The Analysis of Online Learning Behavior of the Students with Poor Academic Performance in Mathematics and Individual Help Strategies. In Proceedings of the International Conference on Blended Learning, Kralove, Czech Republic, 2–4 July 2019; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kavitha, S.; Mohanavalli, S.; Bharathi, B. Predicting Learning Behaviour of Online Course Learners’ using Hybrid Deep Learning Model. In Proceedings of the 2018 IEEE 6th International Conference on MOOCs, Innovation and Technology in Education (MITE), Hyderabad, India, 29–30 November 2018. [Google Scholar]
- Wu, S.-Y.; Hou, H.-T. How cognitive styles affect the learning behaviors of online problem-solving based discussion activity: A lag sequential analysis. J. Educ. Comput. Res. 2015, 52, 277–298. [Google Scholar] [CrossRef]
- Šarić, I.; Grubišić, A.; Šerić, L.; Robinson, T.J. Data-Driven Student Clusters Based on Online Learning Behavior in a Flipped Classroom with an Intelligent Tutoring System. In Proceedings of the International Conference on Intelligent Tutoring Systems, Kingston, Jamaica, 3–7 June 2019; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Wu, B.; Xiao, J. Mining Online Learner Profile through Learning Behavior Analysis. In Proceedings of the 10th International Conference on Education Technology and Computers, Tokyo, Japan, 26–28 October 2018. [Google Scholar]
- Van den Beemt, A.; Buijs, J.; Van der Aalst, W. Analysing structured learning behaviour in massive open online courses (MOOCs): An approach based on process mining and clustering. Int. Rev. Res. Open Distrib. Learn. 2018, 19, 37–60. [Google Scholar]
- Kizilcec, R.F.; Pérez-Sanagustín, M.; Maldonado, J.J. Self-regulated learning strategies predict learner behavior and goal attainment in Massive Open Online Courses. Comput. Educ. 2017, 104, 18–33. [Google Scholar] [CrossRef]
- Wang, G.-H.; Zhang, J.; Fu, G.-S. Predicting Student Behaviors and Performance in Online Learning Using Decision Tree. In Proceedings of the 2018 Seventh International Conference of Educational Innovation through Technology (EITT), Auckland, New Zealand, 12–14 December 2018. [Google Scholar]
- Zhang, W.; Huang, X.; Wang, S.; Shu, J.; Liu, H.; Chen, H. Student Performance Prediction Via Online Learning Behavior Analytics. In Proceedings of the 2017 International Symposium on Educational Technology (ISET), Hong Kong, China, 27–29 June 2017. [Google Scholar]
- Chen, W.; Brinton, C.G.; Cao, D.; Chiang, M. Behavior in Social Learning Networks: Early Detection for Online Short-Courses. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Li, H.; Wei, H.; Wang, Y.; Song, Y.; Qu, H. Peer-Inspired Student Performance Prediction in Interactive Online Question Pools with Graph Neural Network. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Thomas, J.J.; Ali, A.M. Dispositional Learning Analytics Structure Integrated with Recurrent Neural Networks in Predicting Students Performance. In International Conference on Intelligent Computing & Optimization; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Zhang, Y.; An, R.; Liu, S.; Cui, J.; Shang, X. Predicting and understanding student learning performance using multi-source sparse attention convolutional neural networks. IEEE Trans. Big Data 2021, 9, 118–132. [Google Scholar] [CrossRef]
- Aydoğdu, Ş. Predicting student final performance using artificial neural networks in online learning environments. Educ. Inf. Technol. 2020, 25, 1913–1927. [Google Scholar] [CrossRef]
- Waheed, H.; Hassan, S.-U.; Aljohani, N.R.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. Comput. Hum. Behav. 2020, 104, 106189. [Google Scholar] [CrossRef]
- Zheng, Y.; Shao, Z.; Deng, M.; Gao, Z.; Fu, Q. MOOC dropout prediction using a fusion deep model based on behaviour features. Comput. Electr. Eng. 2022, 104, 108409. [Google Scholar] [CrossRef]
- Fu, Q.; Gao, Z.; Zhou, J.; Zheng, Y. CLSA: A novel deep learning model for MOOC dropout prediction. Comput. Electr. Eng. 2021, 94, 107315. [Google Scholar] [CrossRef]
- Yin, S.; Lei, L.; Wang, H.; Chen, W. Power of attention in MOOC dropout prediction. IEEE Access 2020, 8, 202993–203002. [Google Scholar] [CrossRef]
- Xiao, W.; Hu, J.J.E.R. A state-of-the-art survey of predicting students’ performance using artificial neural networks. Eng. Rep. 2023, e12652. [Google Scholar] [CrossRef]
- Sethy, A.; Ramabhadran, B. Bag-of-Word Normalized n-Gram Models. In Proceedings of the Ninth Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- Yang, Z.; Xu, B.; Luo, W.; Chen, F. Autoencoder-based representation learning and its application in intelligent fault diagnosis: A review. Measurement 2022, 189, 110460. [Google Scholar] [CrossRef]
- Donoho, D.L. High-dimensional data analysis: The curses and blessings of dimensionality. AMS Math Chall. Lect. 2000, 1, 32. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Zhang, X.; Chen, X.; Yao, L.; Ge, C.; Dong, M. Deep Neural Network Hyperparameter Optimization with Orthogonal Array Tuning. In Proceedings of the International Conference on Neural Information Processing, Vancouver, Canada, 8–14 December 2019; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Overview of Supervised Learning; Springer: Berlin/Heidelberg, Germany, 2009; pp. 9–41. [Google Scholar]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-supervised representation learning: Introduction, advances, and challenges. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef]
- Last, F.; Douzas, G.; Bacao, F. Oversampling for imbalanced learning based on k-means and smote. arXiv 2017, arXiv:1711.00837. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B 1999, 29, 433–439. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Data Sources | Features | Machine Learning Model | Evaluation |
|---|---|---|---|---|
| [5] | Blended courses | 21 features of learning behavior | RF | Accuracy: 0.49 |
| [6] | MOOC | 16 features of watching videos 8 features of answering questions | FNN | MAE: 6.8 |
| [7] | SPOC | Not specifically indicated | ECOC | Accuracy: 0.8 |
| [21] | MOOC | 8 features of learning behavior | DT | Accuracy: 0.7 |
| [22] | Blended courses | 19 features of learning behavior | LR | Accuracy: 0.95 |
| [23] | Online short course | 3 features of content 10 features of learning behavior | SVM | Accuracy: 0.89 AUC: 0.8 |
| [24] | Online question library | 4 features of students 6 features of questions 12 features of mouse movement | GNN | Accuracy: 0.66 |
| [25] | LMS | 5 features of students 4 features of assign and exam | BiLSTM | Accuracy: 0.8 |
| [26] | LMS | Sequence of student grade records | CNN with attention | Accuracy: 0.85 |
| [27] | LMS | 8 features of learning behavior | FNN | Accuracy: 0.8 |
| [28] | OULA | 54 features of learning behavior | FNN with SVD | Accuracy: 0.86 |
| Student | Date | Activity | Duration (Minute) |
|---|---|---|---|
| S1 | 1 January 2022 | A1 | 25 |
| S1 | 1 January 2022 | A2 | 30 |
| S1 | 1 January 2022 | A3 | 50 |
| S1 | 2 January 2022 | A1 | 10 |
| S1 | 2 January 2022 | A3 | 50 |
| S2 | 1 January 2022 | A1 | 20 |
| S2 | 1 January 2022 | A2 | 5 |
| S2 | 1 January 2022 | A3 | 100 |
| Parameter | Value | Description |
|---|---|---|
| countEpoch | 500 | Epoch for training autoencoder and prediction model |
| batch_size | 200 | Size of each batch of training data |
| optimizer | Adam | Adaptive Moment Estimation, which is the most popular optimizer at present |
| learning_rate | 0.001 | Rate of updating artificial neuron parameters |
| test_percent | 0.25 | Proportion of dataset split for each course: 75% for training and 25% for evaluation |
| Course | Demographic Features | Score of Assessment | Sequence of Online Learning Activities | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | |
| AAA_2013J | 0.64 | 0.16 | 0.25 | 0.20 | 0.83 | 0.41 | 0.47 | 0.43 | 0.804 | 0.204 | 0.3 | 0.24 |
| AAA_2014J | 0.61 | 0.15 | 0.25 | 0.19 | 0.74 | 0.42 | 0.41 | 0.40 | 0.768 | 0.192 | 0.3 | 0.24 |
| BBB_2013B | 0.35 | 0.25 | 0.28 | 0.26 | 0.61 | 0.42 | 0.45 | 0.42 | 0.66 | 0.444 | 0.516 | 0.456 |
| BBB_2013J | 0.37 | 0.28 | 0.28 | 0.26 | 0.67 | 0.41 | 0.42 | 0.40 | 0.564 | 0.144 | 0.3 | 0.192 |
| BBB_2014B | 0.37 | 0.32 | 0.30 | 0.29 | 0.61 | 0.42 | 0.45 | 0.42 | 0.612 | 0.492 | 0.492 | 0.456 |
| BBB_2014J | 0.44 | 0.32 | 0.31 | 0.30 | 0.69 | 0.45 | 0.47 | 0.43 | 0.576 | 0.144 | 0.3 | 0.192 |
| CCC_2014B | 0.45 | 0.14 | 0.25 | 0.17 | 0.61 | 0.38 | 0.47 | 0.38 | 0.684 | 0.42 | 0.528 | 0.432 |
| CCC_2014J | 0.39 | 0.30 | 0.28 | 0.27 | 0.61 | 0.35 | 0.46 | 0.38 | 0.696 | 0.564 | 0.552 | 0.528 |
| DDD_2013B | 0.36 | 0.27 | 0.28 | 0.27 | 0.63 | 0.43 | 0.45 | 0.44 | 0.696 | 0.468 | 0.504 | 0.492 |
| DDD_2013J | 0.42 | 0.32 | 0.31 | 0.30 | 0.67 | 0.44 | 0.49 | 0.44 | 0.708 | 0.48 | 0.516 | 0.492 |
| DDD_2014B | 0.36 | 0.27 | 0.27 | 0.25 | 0.60 | 0.40 | 0.47 | 0.40 | 0.648 | 0.468 | 0.528 | 0.492 |
| DDD_2014J | 0.43 | 0.28 | 0.30 | 0.28 | 0.69 | 0.48 | 0.51 | 0.48 | 0.768 | 0.516 | 0.552 | 0.528 |
| EEE_2013J | 0.45 | 0.14 | 0.25 | 0.18 | 0.68 | 0.37 | 0.46 | 0.39 | 0.588 | 0.144 | 0.3 | 0.192 |
| EEE_2014B | 0.33 | 0.23 | 0.26 | 0.24 | 0.54 | 0.35 | 0.38 | 0.31 | 0.66 | 0.6 | 0.588 | 0.588 |
| EEE_2014J | 0.40 | 0.21 | 0.26 | 0.21 | 0.46 | 0.31 | 0.36 | 0.27 | 0.54 | 0.132 | 0.3 | 0.192 |
| FFF_2013B | 0.39 | 0.27 | 0.28 | 0.26 | 0.66 | 0.44 | 0.47 | 0.45 | 0.78 | 0.54 | 0.576 | 0.552 |
| FFF_2013J | 0.39 | 0.28 | 0.28 | 0.27 | 0.67 | 0.45 | 0.48 | 0.45 | 0.732 | 0.504 | 0.564 | 0.516 |
| FFF_2014B | 0.35 | 0.25 | 0.27 | 0.25 | 0.65 | 0.45 | 0.48 | 0.45 | 0.516 | 0.132 | 0.3 | 0.18 |
| FFF_2014J | 0.40 | 0.31 | 0.30 | 0.29 | 0.60 | 0.39 | 0.47 | 0.41 | 0.78 | 0.528 | 0.588 | 0.552 |
| GGG_2013J | 0.42 | 0.19 | 0.24 | 0.21 | 0.70 | 0.37 | 0.42 | 0.39 | 0.576 | 0.144 | 0.3 | 0.192 |
| GGG_2014B | 0.37 | 0.22 | 0.26 | 0.23 | 0.67 | 0.37 | 0.42 | 0.38 | 0.564 | 0.348 | 0.432 | 0.384 |
| GGG_2014J | 0.36 | 0.24 | 0.26 | 0.23 | 0.66 | 0.39 | 0.41 | 0.37 | 0.636 | 0.576 | 0.564 | 0.564 |
| Average | 0.41 | 0.25 | 0.27 | 0.25 | 0.65 | 0.4 | 0.45 | 0.4 | 0.55 | 0.31 | 0.38 | 0.33 |
| Model | Acc | Pre | Rec | F1 |
|---|---|---|---|---|
| Naïve Bayes | 0.47 | 0.14 | 0.26 | 0.17 |
| SVM | 0.58 | 0.41 | 0.39 | 0.35 |
| Logistic Regression | 0.53 | 0.29 | 0.32 | 0.25 |
| Random Forest | 0.66 | 0.56 | 0.48 | 0.46 |
| KNN | 0.38 | 0.34 | 0.32 | 0.27 |
| Our Model | 0.84 | 0.64 | 0.57 | 0.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, X.; Juan, H. Early Prediction of Students’ Performance Using a Deep Neural Network Based on Online Learning Activity Sequence. Appl. Sci. 2023, 13, 8933. https://doi.org/10.3390/app13158933
Wen X, Juan H. Early Prediction of Students’ Performance Using a Deep Neural Network Based on Online Learning Activity Sequence. Applied Sciences. 2023; 13(15):8933. https://doi.org/10.3390/app13158933
Chicago/Turabian StyleWen, Xiao, and Hu Juan. 2023. "Early Prediction of Students’ Performance Using a Deep Neural Network Based on Online Learning Activity Sequence" Applied Sciences 13, no. 15: 8933. https://doi.org/10.3390/app13158933
APA StyleWen, X., & Juan, H. (2023). Early Prediction of Students’ Performance Using a Deep Neural Network Based on Online Learning Activity Sequence. Applied Sciences, 13(15), 8933. https://doi.org/10.3390/app13158933