1. Introduction
The problem of localization and map-building for mobile robots, which is the basis for achieving autonomous navigation, has become a hot research topic. To solve the indoor and outdoor localization problems and achieve accurate autonomous navigation, the robot map-building process—a single sensor—cannot complete complex map-building. In simultaneous localization and map-building (SLAM), fusing multiple sensors for map-building has become a popular research topic [
1,
2]. Traditional SLAM algorithms usually rely on a single sensor, such as LiDAR or a camera. Still, using a single sensor has some limitations [
3]: vision sensors are susceptible to lighting conditions, while object reflections and occlusions limit LiDAR. To overcome these limitations, researchers have started to fuse multiple sensors to improve the accuracy and robustness of map-building [
4].
Standard sensors include LiDAR, cameras, inertial measurement units (IMU), GPS, and more. LiDAR provides accurate distance and depth information. IMU can give information about robot attitude and acceleration, and vision sensors can provide visual information about the environment [
5,
6,
7]. The choice of fused sensors depends on the specific application scenario and requirements [
8]. The map-building algorithm for fusing multiple sensors involves techniques for calibrating sensor data, data correlation, and state estimation. Wei Shen et al. [
9] proposed a USV LiDAR–slam-assisted fusion localization method that combines GNSS/INS localization with LiDAR–slam, which uses different sensor-fusion information and data-feedback correction to achieve the effect in different situations, and obtains data with more stability and observability. Xing Wei et al. [
10] proposed an improved Hector–SLAM algorithm by finding that the Hector–SLAM algorithm has the problem of map drift and overlap when constructing maps, which first eliminates invalid laser data and then uses Inertial Measurement Unit (IMU) for compensation, and the method effectively improves the accuracy of the maps and the efficiency of the robot. Zhang Shaojiang et al. [
11] proposed a map-matching method based on the combination of LiDAR, IMU, and an odometer for point-cloud data, which matches the point-cloud information collected by LiDAR with the known point-cloud data, introduces the point-to-point iterative closest-point algorithm (PP-ICP), and at the same time, the starting point of the autopilot car is set to be the initial coordinates of the point-cloud map data, and then establishes a predictive-state equation composed of the autopilot car’s gas-pedal control and steering wheel control of the self-driving car, then selects the predictive-state equations consisting of the throttle control and steering wheel control of the self-driving car. Finally, it utilizes the extended Kalman filter to fuse the information data from the three sensors, to update and correct the localization. Its robustness and localization accuracy meet engineering requirements, but on the other hand, it also increases the computational volume and difficulty of the algorithm. IMU-based fusion methods pose significant challenges in solving time synchronization and measurement delay problems. Researchers have been optimizing the Kalman filter update process to address this issue. Xia Xin et al. [
12] proposed an algorithm for estimating the sideslip angle of self-driving cars based on the synthesis of consensus and vehicle kinematics/dynamics. Based on the measurement of the velocity error between the Reduced-Delay Inertial Navigation System (R-INS) and the Global Navigation Satellite System (GNSS), the velocity-based Kalman filter is formalized to estimate the R-INS velocity error, attitude error, and gyro bias error. Xin Xia and Lu Xiong et al. [
13] fused the information from the Inertial Measurement Unit (IMU) and the Global Navigation Satellite System (GNSS) to align the heading of the GNSS and proposed a method for estimating the sideslip angle based on the vehicle kinematics model. Lu Xiong et al. [
14] offered an adaptive Kalman filter low-sampling-rate Global Navigation Satellite System (GNSS) speed and position measurement method based on Inertial Measurement Unit (IMU). Liu Wei et al. [
15] proposed a kinematic model-based VSA estimation method by fusing the information from Global Navigation Satellite System (GNSS) and Inertial Measurement Unit (IMU).
With the diversification and requirements of simultaneous localization and map-building application scenarios, academics have paid increasing attention to the development of SLAM algorithms [
16]. Researchers are committed to designing efficient versions of SLAM algorithms suitable for different hardware platforms to meet the performance requirements in different environments and application scenarios [
17], and graph-optimization algorithms are gradually being applied. Olson et al. [
18] proposed an optimization method based on stochastic gradient descent (SGD), where iteratively, the non-repeatedly randomly selecting constraints and calculating the corresponding gradient descent direction, in which the optimal solution of the objective function is found, can effectively correct the bitmap. Grisetti et al. [
19] extended Olson’s algorithm—a novel node parameterization is applied to the graph, which significantly improves the performance. The ability to handle arbitrary network topologies allows the binding of the complexity of the algorithm to the size of the mapping region rather than to the length of the trajectory. One of the most representative open-source SLAM algorithms for graph optimization is the Cartographer algorithm proposed by Google, which adjusts the bit pose of the submap on the path using loopback detection [
20], thus removing the accumulated error in the process of building the graph from the last loopback to the current moment while achieving a balance between computational effort and real-time performance. In the literature [
21], an adaptive multi-stage distance scheduler is used to optimize the processing speed of the Cartographer, and the local positional correction is achieved by controlling the scanning range of the LiDAR sensor and the search window of the point-cloud matcher through the scheduling algorithm. The algorithm effectively increases the processing speed of the Cartographer to a level similar to that of close-range LiDAR scanning while maintaining the accuracy of long-range scanning. Han Wang and Chen Wang et al. [
22] introduced point-cloud intensity information into SLAM systems and proposed a novel SLAM framework by adding intensity constraints in the front-end odometry and back-end optimization phases, which uses frame-to-map matching to compute the optimal bit position by minimizing the geometric residuals and intensity residuals, which provides higher accuracy compared to purely geometric SLAM methods. Still, LOAM-based algorithms must perform downsampling operations of the point-cloud data in the execution phase, which does not accurately represent the underlying local network structure.
In the autonomous driving technology field, the sensors’ localization algorithm, one of the most basic and essential aspects, has received increasingly extensive attention [
23]. With the continuous development of deep-learning technology, many scholars have now studied deep-learning-based SLAM schemes to obtain better accuracy and stronger robustness. Deep-learning-based SLAM technology has made many breakthroughs, especially in feature extraction, and matching has shown excellent performance [
24]. Li Zhichao et al. [
25] implemented geometric constraints in the odometry framework to decompose bit position estimation into two parts: the learning-based matching network part and the rigid transform estimation part based on singular value decomposition, and the experimental results show that the method has comparable performance with the traditional LiDAR odometry method. Liu Wei et al. [
26] proposed a new algorithm, YOLOv5-tassel, which employs four detection heads and BiFPN to enhance feature fusion for small fringe detection, and introduces the attention mechanism of SimAM to extract the part of interest in feature mapping.
This study addresses the problem of local SLAM localization and map-building in indoor and outdoor environments, based on Google’s open-source Cartographer algorithm for improvement. In this paper, an improved voxel filtering and IMU information preprocessing method is proposed, and IMU information is introduced using the idea of multi-sensor fusion. The technique can be applied to mapping and navigation, and the experimental results verify the superiority of the algorithm of fused IMU information in constructing high-precision environmental maps.
2. Research of SLAM Algorithm
The Cartographer algorithm is a real-time map-construction algorithm capable of generating maps with a resolution of 0.05 m [
27]. The algorithm is based on the principle of graph optimization, which graphically represents the process of robotic SLAM [
28]. The optimization process is a nonlinear least-squares approach to optimize the cumulative error in building the map [
29] to obtain a consistent map representation. The nodes in graph optimization represent the poses of the robot, while the edges represent the spatially constrained relationships between the nodes. Graph optimization is divided into two parts: front end and back end [
30], while the optimization approach used in this paper is mainly applied to the front end.
Figure 1 illustrates the infrastructure of the algorithm.
2.1. Submap
The usual scan-to-scan laser-matching accumulates errors. The Cartographer algorithm introduces the concept of submap, which turns the original scan-to-scan matching into scan-to-map matching, i.e., the laser matches with the submap first.
Several consecutive scans create a submap. When a submap is made, the raster probability is less than for no obstacle at that point, between and for unknown, and greater than for an obstacle at that point. Each frame of scans will generate a set of raster points called hits and a set of raster points called misses. Its submap is a raster map, and the submap can be considered a two-dimensional array whose value values under each index indicate the probability. To improve the performance and speed of operations, the Cartographer optimizes the probability representation.
As shown in
Figure 2, the grid points in each hit are given the initial value
, and the grid points in each miss are called
. If the grid point already has a
p-value, the value of the grid point is updated with the following.
The probability of a lattice probability
p is defined as
.
where clamp is the interval-limited function,
is the a priori lattice probability of the
x under consideration. Each time, the latest scan obtained needs to be inserted into the optimal position in the submap so that when the bit pose of the point bundle in the scan is transformed and falls into the submap, each point has the highest confidence sum.
2.2. Local Slam
The front-end stage starts with data extraction, in which two methods, voxel filtering and adaptive voxel filtering, are used to compress the LiDAR data to reduce resource consumption and facilitate subsequent data processing. Due to the large scale of each frame of point-cloud data acquired by LiDAR and influenced by several factors, it can impact the point-cloud processing results. To estimate the trajectory and the bit position of the robot [
31], an IMU and an odometer are used for extrapolation, and the estimated value of the bit position is used as the initial value. The LiDAR data are fused with the obtained positional estimates by a traceless Kalman filter [
32] to update the positional estimates and to correct the LiDAR data. Each LiDAR scan forms a submap, and each frame of the point cloud is compared with the previous submap, and the pixel probability values in the submap are updated [
33]. A motion filter is used to reject sensor frames of data at rest and continuously update the subgraph until a fully optimized subgraph is obtained when no new point clouds are inserted. The pseudo-code of the motion filter is as follows (Algorithm 1).
| Algorithm 1: Motion Filter. |
- 1:
Input: Odometry, IMU, LaserScan - 2:
Output: Filtered motion estimation - 3:
Initialization: - 4:
Initialize motion filter parameters - 5:
Initialize state variables: pose, velocity, covariance matrix - 6:
- 7:
Procedure MotionFilter: - 8:
loop - 9:
Receive Odometry, IMU, and LaserScan data - 10:
Predict motion using odometry information - 11:
Update state variables: pose, velocity - 12:
Update covariance matrix based on the motion model - 13:
Correct motion using IMU data - 14:
Calculate IMU-based motion estimate - 15:
Compare the estimated motion with the predicted motion - 16:
Update state variables and covariance matrix based on the correction - 17:
Fuse LaserScan data with motion estimate - 18:
Perform scan-matching to align the laser scan with the estimated map - 19:
Update state variables and covariance matrix based on the scan-matching result - 20:
Output the filtered motion estimation - 21:
end loop - 22:
- 23:
End Procedure
|
The process uses a scan matcher based on the Ceres library to compute the poses of the point cloud, transforming the pose-solving problem into a nonlinear least-squares problem [
34]:
where
are the coordinates of the submap in world coordinates;
is the locus of scan in world coordinates;
denotes the poses of the scan under the submap;
is the corresponding covariance matrix [
35].
Residuals
E and the error
e:
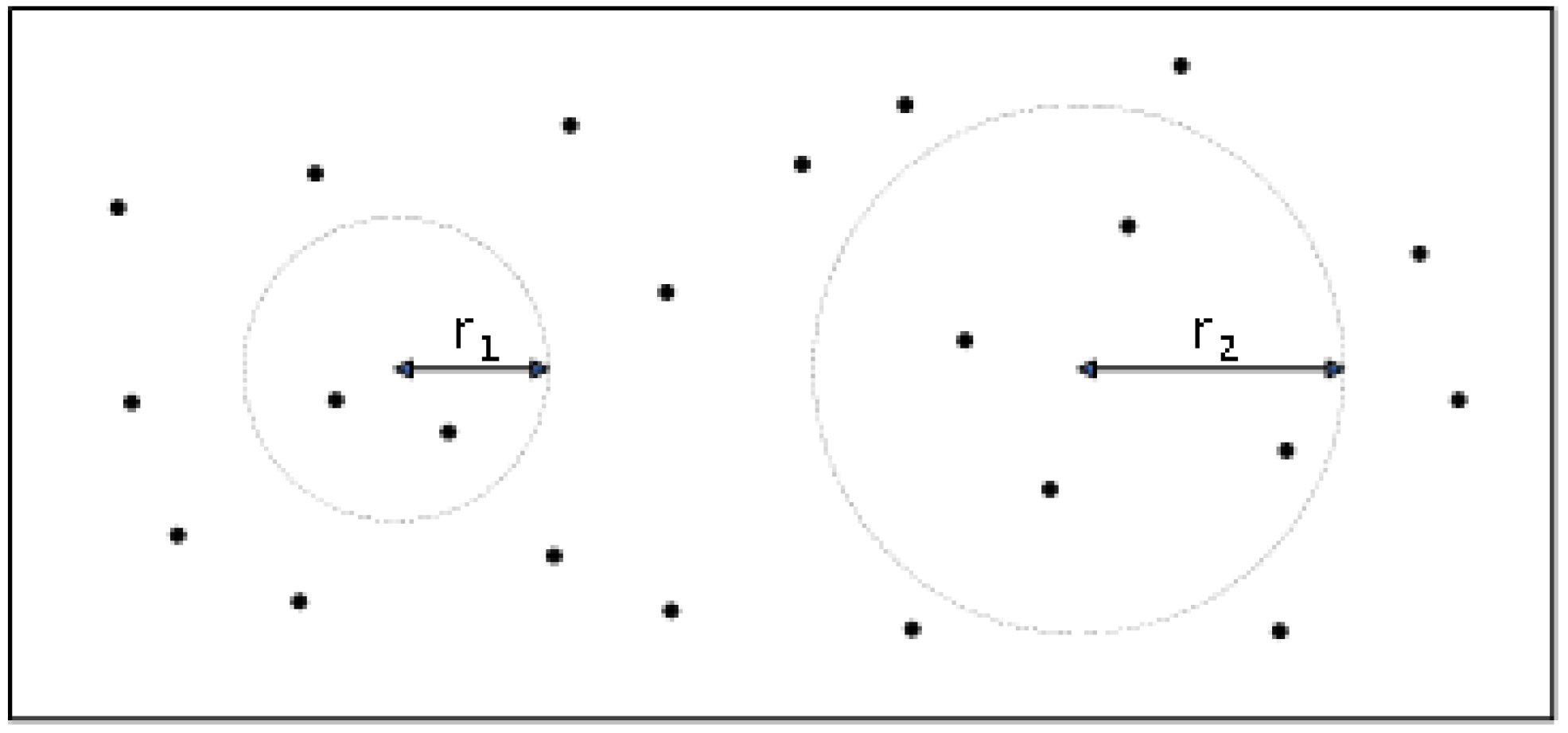
First, during the loopback detection process, the system performs loopback optimization, i.e., it detects whether there is a loopback or not and then optimizes accordingly. When the current scan data are close enough in the distance to a certain laserscan position in the already created submap, the loopback can be found through a scan-matching strategy. To reduce the computation and improve the efficiency of real-time loop detection, Cartographer applies the branch-and-bound optimization method to optimize the search [
36]. If a good-enough match is obtained, the loop-detection part is over by this point. The next step is to optimize the poses in all the submaps based on the current scan’s pose and one of the closest matches in the submap, even if the residual
E is minimized.
In Equations (4) and (5),
e is the error of optimizing the bit positions between the submap local and the submap global. Because there is a constraint on the bit positions of all the submaps, it is the optimization of the bit positions of all the submaps to minimize the error, as shown in Equation (
5).
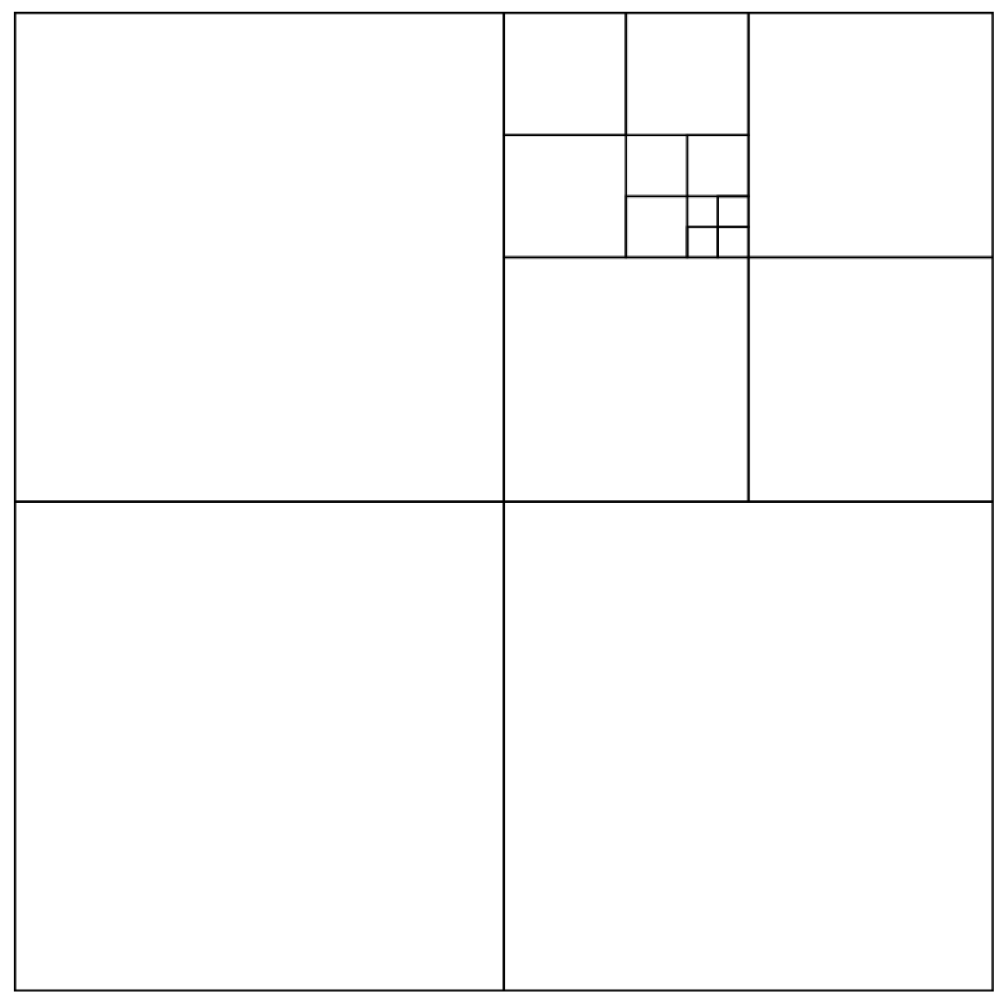
The subgraphs are inserted at the back end, the subgraphs are optimized using graph optimization, and the branch-delimitation method is used in the loopback detection process. The “branch-and-bound method” expands the feasible solution of a problem, like a branch of a tree, and then finds the best solution through each component. As shown in
Figure 3.
Branch-and-bound aims to find the optimal pose of the newly built submap.
where
first proximity to find the closest point and then expansion to the corresponding surrounding points;
W is the search space; and
is the center of the search space.
The branch-delimitation method performs cumulative error elimination [
37], and each submap is matched with the corresponding bit pose to obtain the global map, i.e., the complete environmental map.
3. Cartographer Algorithm Improvement
Based on Google’s open-source Cartographer algorithm, this study improves and optimizes its front-end part to enhance the SLAM system’s performance in environment modeling and robot self-localization. In the front-end optimization, the focus is on processing point-cloud data and introducing the secondary filtering method of radius filtering after the voxel filter.
First, by applying the voxel filter, we effectively reduce the volume of the point-cloud data while retaining the critical feature information. However, after the voxel filtering process, the point-cloud data still has some diffusivity. To solve this problem, this paper adopts the secondary filtering method of radius filtering. The filtering effect is further improved by setting the threshold radius to filter out the point clouds that do not satisfy the conditions.
In the implementation process, the PCL library converts the point-cloud data to the format for the filtering operation. After converting the point-cloud data to the data format in the PCL library, the data can be processed using the rich filtering methods provided. After filtering, the data are converted back to the point-cloud data type required by the Cartographer algorithm to ensure compatibility with the subsequent SLAM algorithm.
In addition, this paper also preprocesses the IMU data and uses a multi-sensor-fusion method to fuse the processed IMU data with the point-cloud data. By combining the techniques of filter improvement and IMU data preprocessing, the accuracy and stability of the SLAM system for environment modeling and robot self-localization are improved.
Through these improvements and optimizations, this study aims to advance the performance of SLAM algorithms in practical applications and provide more accurate and reliable solutions for research and development in areas such as map construction and robot localization.
Figure 4 shows the flow chart of the improved algorithm.
3.1. Improved Voxel Filtering for Point-Cloud Preprocessing
The purpose of point-cloud preprocessing is to simplify and reduce noise on point-cloud data to improve the operation efficiency of the algorithm and reduce the negative impact of noise in the subsequent scan-matching algorithm. Among them, radius filtering is a filtering method for filtering outliers. By setting thresholds for the filtering radius and the number of point clouds, the point clouds that do not meet the threshold conditions within the specified radius can be effectively filtered out. Using radius filtering, the speed of point-cloud preprocessing can be accelerated, and the algorithm’s efficiency can be improved. Such optimization measures help optimize the algorithm’s performance and make it more efficient and reliable in practical applications. The radius filtering is shown in
Figure 5.
The steps to use the filtering algorithm are as follows:
1. Import the point cloud.
2. Filter type selection: Select the suitable filter type for the point cloud, commonly radius filter, statistical filter, Gaussian filter, etc. Each filter has different characteristics and applicable scenarios. Analyzing and comparing the advantages and disadvantages of the three filters, the radius filter is selected in this paper.
3. Parameter setting: According to the characteristics of the point cloud and the effect of filtering needed, set the filter parameters. For example, for the radius filter, you need to determine the radius size of the filter and decide the range of the filter search. In this paper, the parameters of the radius filter are selected after several iterative tests, and the relatively optimal radius of 5 and the minimum number of neighboring points of 100 are chosen.
4. Apply the filter: Use the filter to perform filtering operations on the point cloud. The filter will be calculated within a certain radius around each point in the point cloud to smooth or remove noise.
5. Handle boundary points: The point cloud may have boundary points, and you must choose an appropriate handling method. One standard practice is to leave the boundary points untreated, i.e., keep them in their original state; another way treats the boundary points, especially according to the filter type. This paper uses the first approach.
6. Filtering result output: After the filtering operation, the filtered point-cloud data are obtained, and the point-cloud data can be saved or subsequently analyzed and processed.
The pseudo-code for radius filtering is as follows (Algorithm 2):
| Algorithm 2: Radius filtering. |
 |
A radius filter can effectively remove noise and outliers, making the cloud data smoother and more consistent. The choice of filtering radius is crucial to the filtering effect; too small a radius may not remove all the noise, while too large a radius may lead to data loss or blurring. Therefore, selecting the appropriate radius value according to the specific application scenario and the characteristics of the point-cloud data is necessary before applying radius filtering.
3.2. IMU Preprocessing
First, noise-removal processing of IMU data is required [
38]. Since environmental noise and interference may affect IMU data, noise removal of IMU data is necessary before the LiDAR map-building. Standard methods include mean filtering and Gaussian filtering.
Second, because of the time delay in IMU data, smoothing of the data is required to reduce the impact of the time delay on the bit-pose estimation. Commonly used methods include moving average filtering and exponential smoothing.
In the pose estimation of robots, the Kalman filter algorithm is usually used to estimate the poses based on IMU data [
39]. To improve the accuracy and stability of attitude estimation, preprocessing IMU data is necessary. The Kalman filtering algorithm [
40] is as follows:
In the above equation, the
is the Kalman gain;
is the a posteriori state estimate at the moment
, which is one of the filtering results, i.e., the updated result, also called the optimal estimate;
denotes the a priori state estimate at the moment k, and the predicted state at the moment k based on the optimal estimate at the moment
;
is the posterior estimate covariance at the moment
;
is the prior estimate covariance at the moment k [
41].
By noise removal and smoothing of IMU data, the quality and accuracy of the data can be improved to better utilize the IMU data to measure the robot’s positional information.
4. Laboratory Platform Construction
The software platform used in this paper is the PC and robot side, respectively, the PC side is the Ubuntu system, and the system version is Ubuntu 20.04, using the ROS system for operation. The version of ROS is noetic and packaged with Rviz and Gazebo (Rviz version 1.14.20; Gazebo version 11.11.0).
The LiDAR model is SLAMTEC S1, with a sampling speed of 9200 times/s, a scanning frequency of 10 Hz, a range resolution of 3 cm, and a measurement accuracy of 5 cm. The IMU model is WHEELTEC N100, a nine-axis attitude sensor for mobile robots. The sensor includes a three-axis gyroscope with a resolution of 0.02 degrees/s, a three-axis accelerometer with a solution of 0.5 mg, a three-axis magnetometer with a resolution of 1.5 Milligauss, and a thermometer. The baud rate of the serial port is 921,600 Bit/s. The robot side is the jetson nano main control board cart.
The distributed software architecture is shown in
Figure 6.
Based on the robotics platform test, experiments were conducted in the long corridor on the third floor of the college building and in the lobby of the academic establishment. The scenes selected were large and simple to ensure the local maps would not have duplicate areas. The specific locations are shown in
Figure 7.
The pictures above are of the corridor on the third floor and the lobby of the school building, respectively.
Laboratory Scenario Testing
A field run was performed on the robot, using the revo_lds.lua file that comes with the Cartographer algorithm to build the map and query the frame_id based on the LiDAR and the IMU hardware configuration.
The tf tree is shown in
Figure 8 when fusing the IMU data.
The actual path when building the map on the third floor of the laboratory building is shown in
Figure 9.
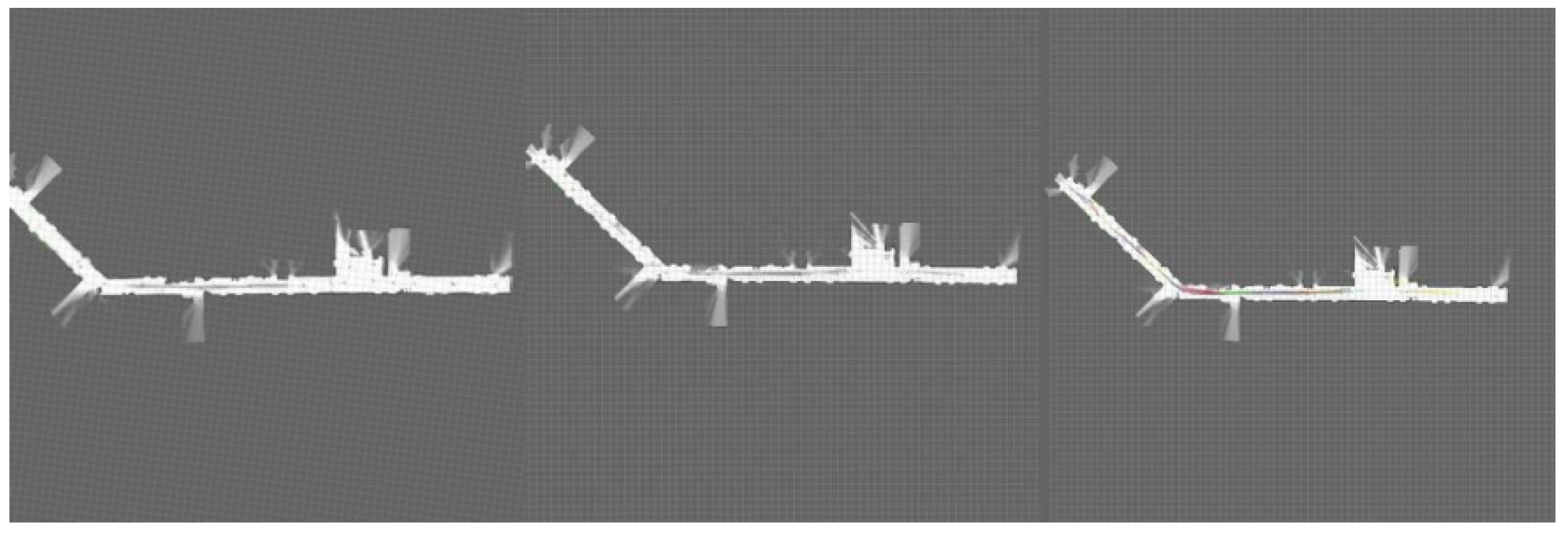
The following figure shows a scanned build of the robot in the third-floor corridor scene. After saving the map information, the 2D raster map is visualized on the PC side by rviz software.
Figure 10 shows the rendering effect of the laboratory corridor. The images from left to right show the rendering result of the original algorithm, the rendering mark of the original algorithm with IMU, and the rendering effect of the improved algorithm with IMU;
Figure 11 shows the architectural impact of the teaching building lobby and the images from left to right are shown as above. The figure shows that after the effect is applied, the scanned map is more accurate than the original map, and the effects increase in sequence.
6. Conclusions
In this paper, a new map-building algorithm is proposed for the inaccuracy of Cartographer algorithm position fusion, the existence of dense point-cloud data with high computational volume, and the low accuracy and efficiency of map construction. To reduce the diffusivity of the point-cloud data after voxel filter processing, this paper adopts the secondary filtering method of PCL library radius filtering. By setting the thresholds for the filter radius and the number of point clouds, the point clouds that do not satisfy the threshold conditions within the specified radius range are effectively filtered out, accelerating the speed of point-cloud preprocessing and improving the algorithm’s efficiency. At the same time, the multi-sensor-fusion method is adopted to fuse the IMU data information with the algorithm after preprocessing to enhance the effectiveness of the front-end map construction and the back-end loopback detection and ultimately to realize the construction of high-precision maps. By comparing and analyzing the experimental results of the original algorithm and the improved algorithm to construct the map, in the environment of the long corridor of the experimental building, the absolute error of measuring and analyzing the obstacles is reduced by 0.06 m, and the relative error is decreased by 1.63%; in the environment of the hall of the teaching building, the absolute error of measuring and analyzing the longest side of the map is reduced by 1.121 m. The relative error is decreased by 5.52%. In addition, during the experimental run, the CPU occupancy of the optimized algorithm is around 59.5%, while the CPU occupancy of the original algorithm averages 67% and sometimes spikes to 75%. This paper concludes that the fusion of inertial sensors based on the improved algorithm can improve the efficiency and accuracy of map-building. This paper concludes that the fusion of inertial sensors based on improved algorithms can improve the efficiency and accuracy of map-building.
In the future, in addition to the algorithms in this paper, there are sub-tasks such as loopback detection, position recovery, and sliding window optimization that plays an optimization role for map-building and localization in SLAM tasks—integrating these sub-tasks in the priority definition algorithm and network inference model to reach multi-task joint learning and realize the unity of multi-modal, multi-task, and real-time. Joint multi-task learning with correlation can also improve the performance of localization and map-building, which is one of the sub-directions worth studying.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}