Abstract
Image matting methods based on deep learning have made tremendous success. However, the success of previous image matting methods typically relies on a massive amount of pixel-level labeled data, which are time-consuming and costly to obtain. This paper first proposes a semi-supervised deep learning matting algorithm based on semantic consistency of trimaps (Tri-SSL), which uses trimaps to provide weakly supervised signals for the unlabeled data, to reduce the labeling cost. Tri-SSL is a single-stage semi-supervised algorithm that consists of a supervised branch and a weakly supervised branch that share the same network in one iteration during training. The supervised branch is consistent with standard supervised matting methods. In the weakly supervised branch, trimaps of different granularities are used as weakly supervised signals for unlabeled images, and the two trimaps are naturally perturbed samples. Orientation consistency constraints are imposed on the prediction results of trimaps of different granuliarty and the intermediate features of the network. Experimental results show that Tri-SSL improves model performance by effectively utilizing unlabeled data.
1. Introduction
Image matting refers to precisely estimating the foreground opacity mattes from a given image. It is a necessary task in the computer vision field and has a broad set of applications in image or video editing. Mathematically, the observed image is modeled as a convex combination of the foreground and background as follows:
where denotes the opacity of the foreground at pixel i, and and are the foreground (FG) and background (BG) colors. Different from segmentation tasks which aim to identify the semantic scope of the object, image matting seeks to extract the smooth boundary and accurate opacity of the foreground object. As shown in Figure 1, semantic segmentation is a hard segmentation that identifies the category of each pixel, while image matting is a soft segmentation that predicts the proportion of each pixel that belongs to the foreground. It is a continuous prediction, representing the ratio as alpha matte.

Figure 1.
Semantic segmentation and nature image matting.
The matting problem is highly ill-posed. When multiple foreground objects appear in a given image, the algorithm cannot determine the target object by itself, so previous work introduced a user-designed trimap to mark the target foreground region. Trimap indicates the rough area of the target foreground object and divides an image into three parts: known FG, known BG, and unknown transition region, with three colors: white, black, and gray. The gray region (unknown transition region) is the target region needed to be estimated in the matting problem. Therefore, the matting task is simplified as assigning alpha values on the range [0, 1] for each pixel in the unknown transition region.
In recent years, deep learning-based image matting methods have achieved remarkable success. However, these methods often require a massive amount of pixel-level labeled data, which are both time-consuming and expensive to obtain. The lack of large-scale matting datasets is a major obstacle that hinders the further development of image matting. In contrast, the trimap—an auxiliary input for image matting—has a lower annotation cost and is easier to obtain. Furthermore, many image editing software programs require users to manually annotate auxiliary recognition maps, similar to the trimap, in their matting functions. To reduce data annotation costs, we introduce semi-supervised learning methods to image matting to explore feasible ways of using unlabeled data with trimap.
In the Alphamatting dataset [1], each experimental image has three trimaps of different labeling granularities. Figure 2 shows that the use of a fine trimap generally results in a better alpha matte than a coarse trimap. This is because a fine trimap provides more precise location information for the foreground objects, making it easier for the matting algorithm to capture their details and boundaries.

Figure 2.
Trimap with different granularity. Fine trimap and coarse trimap have strong semantic consistency correlations, and the fine trimap helps to generate a better alpha matte. The result with coarse trimap has an incorrectly transparent prediction.
It is worth noting that the trimaps of varying labeling granularities have strong semantic consistency correlations, as they reflect the position and outline of the same foreground object. This characteristic fits well with the consistency regularization in semi-supervised learning. Consistency regularization enforces the current optimized model to yield stable and consistent predictions under various perturbations. These perturbations can take several forms, such as different data argumentations, dropouts, or networks with different initializations [2,3]. Trimaps of different granularities can be regarded as naturally perturbed samples of the image matting task. Although trimaps are coarse-grained and inaccurate weakly supervised signals that cannot directly offer pixel-level supervision for matting, the inherent semantic consistency among trimaps of different granularities can help to learn more robust semantic representations.
Based on the motivation above, we propose a semi-supervised deep matting method based on the semantic consistency of trimaps (Tri-SSL). Specifically, Tri-SSL is a single-stage semi-supervised algorithm that includes a supervised branch and a weakly supervised branch in each training iteration. The supervised branch is consistent with ordinary supervised matting methods. In the weakly supervised branch, an unlabeled image has two trimaps of different labeling granularities. The trimap provides weakly supervised signals for unlabeled images, and the two trimaps are concatenated with the image as input. We apply the directional consistency constraints on the alpha predictions of different-granularity trimaps and the intermediate features, enabling the network to learn more information from unlabeled data. Tri-SSL leverages the consistency among the trimaps to improve the robustness of the learned semantic representations, resulting in high-quality alpha mattes with limited labeled data.
In general, the main contributions of our work are as follows:
- We propose the first semi-supervised learning framework for deep image matting (Tri-SSL). Tri-SSL utilizes the inherent semantic correlations of different-granularity trimaps to conduct consistency regularization;
- We apply directional consistency constraints to learn better semantic representations from the unlabeled samples using only trimaps;
- The experimental results demonstrate that our method can effectively utilize the unlabeled data to improve model performance.
2. Related Works
In this section, we briefly review the traditional and deep learning-based matting methods and semi-supervised learning methods in computer vision.
2.1. Traditional Matting Methods
Traditional matting methods usually rely on low-level features such as color, texture, and brightness to separate foreground objects. Depending on the specific separation strategy, these traditional methods can be divided into two categories: sampling-based methods and propagation-based methods.
Sampling-based methods sample pixels in the known region and select the best foreground and background color pairs to estimate the alpha value of each pixel in the unknown region. There are various ways to sample pixel pairs and select appropriate color pairs. For example, Bayesian matting [4] uses the Gaussian Mixture Model (GMM) to learn the local color distribution and iteratively estimate alpha, foreground, and background using maximum likelihood criteria. Robust matting [5] samples a set of foreground–background pairs for each unknown pixel based on color similarity. Global matting [6] selects all pixels on the boundary of the known foreground and background regions to construct candidate pairs and finds the best color pairs.
Propagation-based methods establish connections between adjacent pixels, then use different optimization strategies to propagate alpha values from the known region to the unknown region. Non-local propagation-based methods establish connections between non-adjacent pixels. Closed-form matting [7] is a classic propagation-based method, which derives a cost function based on the local smoothness assumption and estimates the global optimal alpha value by solving a sparse linear equation system. Poisson matting [8] assumes the local smoothness of the input image, then utilizes the gradient field and Dirichlet boundary conditions to solve the Poisson equation and estimates the alpha value.
2.2. Deep Matting Methods
Due to deep learning networks’ solid high-level semantic comprehension ability and excellent performance, deep learning methods have become increasingly popular in image matting tasks.
In 2016, Cho et al. [9] proposed DCNN, which utilizes a convolutional neural network to optimize the matting result of closed-form matting [7] and KNN matting [10] with the assistance of the original trimap. Shen et al. [11] used a convolutional neural network to generate a trimap, then estimated alpha values by closed-form matting [7]. These works only used deep learning as optimization tools; no large-scale matting datasets were available for training. In 2017, Xu et al. [12] proposed Deep Image Matting (DIM), an end-to-end convolutional neural network matting method. It consists of two stages: a matting encoder–decoder network and a small refinement network. Specifically, the image and trimap are fed into the matting encoder–decoder; the refinement network then uses the original image as auxiliary information to optimize the output from the previous stage, generating a refined alpha matte. They first released a large-scale matting dataset, which became essential to developing deep matting methods.
Beginning with DIM, more and more deep learning methods were proposed and achieved good results. Sebastian et al. [13] proposed AlphaGAN, which applies generative adversarial networks (GAN) to image matting, and it contains two key components: a generator and a discriminator. The generator generates alpha mattes of given images, and the discriminator evaluates the quality of the alpha mattes generated by the generator and helps the generator to produce better results. Qiao et al. [14] utilized channel attention and spatial attention mechanism to fuse low-level and high-level features and make networks focus on valuable channels and spatial regions. Liu et al. [15] explored the semantic correlation between the trimap and image using a three-branch encoder. Park et al. [16] and Hu et al. [17] combined the latest Transformer [18] with image matting and achieved good results. In recent years, there were also some works focused on trimap-free matting [14], portrait matting [19], and background-based matting [20]. There has been no semi-supervised deep matting method yet.
2.3. Semi-Supervised Learning
Semi-supervised learning (SSL) utilizes unlabeled data to improve feature representation given limited labeled data. Two main branches of methods have been proposed in recent years, namely, consistency regularization and pseudo-labeling.
Consistency regularization is based on the cluster assumption, which states that the predicted result should not change significantly with minor perturbations because data points with different labels are separated in low-density regions. Given an unlabeled data point x and its perturbation , SSL aims to minimize the distance between the two outputs. Popular distance measures are mean square error (MSE), Kullback–Leibler divergence (KL), and Jensen–Shannon divergence (JS). Consistency regularization enforces the current optimized model to yield stable and consistent predictions under various perturbations on the same unlabeled data. VAT [21] applies adversarial perturbations to the output. The model [2] applies different data augmentations and dropouts to form perturbed samples and aligns them. Dual struent [3] uses two networks with different initializations to generate perturbed outputs for the same input and aligns the different network outputs. MixMatch [22] and ReMixMatch [23] use data interpolation to generate perturbations.
Pseudo-labeling can be roughly divided in two ways: self-training and multi-view training.
Self-training [24] is a packaging algorithm repeatedly using supervised methods in the training process of each round. It uses the labeled data to train the model in the first round. The trained model predicts pseudo-labels for the unlabeled samples, and the high-confidence unlabeled samples are added to the training set for the re-training. There is no limit to the total training round. The advantage of self-training is that it is simple, but its learning performance depends on the supervised method used internally, and the model can hardly correct its errors, which may lead to error accumulation. The performance of this method is closely related to error labeling correction strategies and high-confidence unlabeled sample screening strategies.
Multi-view training has more than one model in the training process; the unlabeled data and their pseudo-label generated by one model are used for another model in the next training round. Co-training [25] has two models and trained on different datasets. In each iteration, if either model considers its prediction result of sample X trustworthy, with confidence higher than the threshold , then that model will generate a pseudo-label for sample X and add the training sample X to the training set of the other model. Tri-training [26] is similar to Co-training, except that, in Tri-training, the newly acquired unlabeled training instances of one model are jointly determined by two other models. Tri-training first bootstraps the labeled sample set for repeatable sampling to obtain three labeled training sets and then trains a classifier from each labeled training set. In the cooperative training process, the new unlabeled samples with pseudo-labels obtained by each model are jointly provided by the other two classifiers. Specifically, suppose two classifiers predict the same unlabeled sample and have the same output. In that case, the sample is considered to have higher confidence and is added to the labeled training set of the third classifier after generating the pseudo-label.
In addition to classification tasks, semi-supervised learning is widely used in semantic segmentation. In the semi-supervised semantic segmentation, CCT [27] enforces similar predictions under multiple perturbed embeddings. Lai proposed a method [28] that enforces similar predictions under two different contextual crops. CPS [29] enforces consistency between dual differently initialized models. Similar to FixMatch [30], PseudoSeg [31] adapts the weak-to-strong consistency to the segmentation scenario and further applies a calibration module to refine the pseudo-masks. ST++ [32] proposes an advanced self-training framework that performs selective re-training via prioritizing reliable unlabeled images based on holistic prediction-level stability.
3. Methodology
In this section, we introduce our semi-supervised learning framework for nature image matting. The overall architecture of the Tri-SSL is shown in Figure 3. Tri-SSL is a single-stage semi-supervised matting network, consisting of a supervised branch and a weakly supervised branch which share the same network in one iteration during training, as shown in Figure 3. In the supervised branch, the labeled images pass through the network as standard supervised matting methods. In the weakly supervised branch, two trimaps with different granularity are generated for an unlabeled image, and they are concatenated with the original image separately as input to pass through the network. Then, we apply consistency loss on the alpha predictions of two trimap inputs and their intermediate features to help the network learn semantic information from unlabeled images.
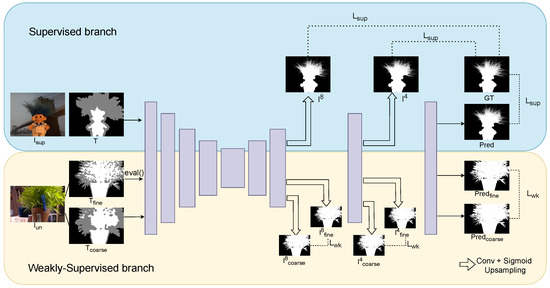
Figure 3.
The overall structure of Tri-SSL.
3.1. Supervised Branch
In the supervised training branch, labeled data pass through the network as in standard supervised matting methods. Specifically, the is concatenated with the corresponding trimap T as a four-channel input, then the input is fed into the baseline model for feature extraction and alpha prediction. The predicted alpha matte is supervised by ground-truth labels with the supervised loss .
The last two stages of the decoder produce side outputs: a 3 × 3 convolution layer, a sigmoid function, and an upsampling to the input image size. and represent the side outputs of the decoder with downsampling strides 4 and 8. The supervised loss is applied to both side outputs and . The loss of side output helps to strengthen the supervision constraints for the intermediate stages of the network, which improves the matting performance of the network.
3.2. Weakly Supervised Branch
In the weakly supervised training branch, each unlabeled image is provided with two trimaps of different granularity, denoted as and . Two training samples are generated by concatenating the original image and the two trimaps separately and then feeding them into the network. Additionally, side outputs are also produced in the last two stages of the decoder, where downsampling strides are 4 and 8. The side outputs obtained from are denoted as and , while those obtained from are denoted as and .
Notably, there is no labeled alpha matte as ground truth to supervise the predictions in the weakly supervised branch. Previous experiments have shown that the trimap with a finer granularity produces better alpha predictions than the trimap with a coarser granularity. Moreover, the trimaps of different labeling granularities have inherent strong semantic consistency correlations. Therefore, we use the prediction results of the sample as the supervised ground truth for the sample, and lead the network to learn in the direction from to .
To achieve directional learning from to , the weakly supervised branch is trained by the following steps:
- During the forward propagation of , the network is converted to evaluation mode using the eval() function, not keeping track of gradients, retaining the intermediate features and final prediction results for consistency constraints;
- During the forward propagation of , the network is switched back to regular training mode. Loss is then calculated on the intermediate features and prediction results between and .
Specifically, the weakly supervised loss includes the loss between alpha predictions and , the loss between and , and the loss between and . The trimaps with different granularity can be regarded as different perturbed samples of the unlabeled image with inherent semantic correlations. The consistency constraints between different perturbed samples help the network learn the distribution information of the unlabeled data and strengthen the semantic feature representation ability.
3.3. Baseline
The baseline model of Tri-SSL can be any deep matting model with an encoder–decoder structure. This work mainly adopts the Matteformer [16] and ELGT [17] as the baseline, which are the SOTA performance models in natural image matting. Matteformer is a transformer-based method that introduces the trimap-based prior tokens, which fully utilize the global prior information of the trimap and help local window-based self-attention to capture global prior features. ELGT is also a transformer-based method that designs the window-level global self-attention mechanism, which allows window-based self-attention to fuse local and global context information.
3.4. Loss for Supervised Branch
Tri-SSL has a weakly supervised branch and a supervised branch. For the supervised branch, we adopt the regression loss, composition loss [12], and Laplacian loss [33], and denote them as , , and , respectively. is defined as the absolute difference between the predicted and the ground-truth alpha matte:
where U indicates the region marked as unknown in Trimap, and and indicate the predicted and ground-truth alpha values at pixel i.
The composition loss is defined as the absolute difference between the real RGB image and the newly composited RGB image composed of the real foreground, real background, and predicted alpha matte:
where C indicates the RGB color value of the real image at pixel i, and represents the RGB color value of pixel i in the newly composited image using the predicted alpha matte.
The Laplacian loss measures the difference between the Laplacian pyramid representations of the predicted and ground-truth alpha matte, capturing local and global differences:
where represents the k-th level of the Laplacian pyramid of the alpha matte. The overall loss formulates as follows:
In addition to the final predicted alpha matte , the loss function is also performed for the side outputs and . In the supervised branch, the weights of , , and are 0.4, 0.2, and 0.2, respectively. The final form of the supervised loss function is as follows:
3.5. Loss for Weakly Supervised Branch
The weakly supervised loss also uses regression loss, composition loss, and Laplacian loss. Furthermore, the loss function is also performed for the side outputs and . Since the weakly supervised loss generates more errors than the supervised loss, the overall weight of the weakly supervised loss is adjusted to 1/4 of the weight of the supervised loss.
The weakly supervised training branch relies on the semantic consistency between the samples with trimaps of different granularity. Therefore, it is necessary to shrink the gap between the semantic representations of the two samples. As such, a higher weight is assigned for the side outputs and in the deeper layer that contains stronger semantic information, and a lower weight is assigned to to prevent the network from learning too many detail errors. Within the weakly supervised loss, the weights of the predicted result and the side outputs and are set to 0.05, 0.1, and 0.15, respectively. The final form of the weakly supervised loss function is as follows:
The final loss formulates as
4. Experiments
In this section, we first introduce the datasets used in the experiments and the relative experimental settings. Following the semi-supervised semantic segmentation experiment, we designed a dataset partition experiment, selecting some data as labeled data and others as unlabeled data. Additionally, we designed a dataset combination experiment, which combined the Adobe training set with the Distinctions-646 training set, leveraging the former as supervised learning data and the latter as semi-supervised learning data to enhance model performance. Ablation studies were also conducted to evaluate the effectiveness of the method design. Finally, we evaluated the best model on real-world images.
4.1. Datasets
We use three common public datasets to evaluate our method.
The first dataset was Adobe Composition-1k [12]. The training set includes 431 foreground objects with the corresponding ground-truth alpha mattes. Each foreground image is composited with 100 background images from the Microsoft COCO dataset [34] to generate 43,100 training samples. The test set (Composition-1k) consists of 50 foreground images with the corresponding alpha mattes, and each one is composited with 20 background images from the PASCAL VOC2012 dataset [35] to generate 1000 test samples. The composition algorithm of the training set and test set is provided by [12].
The second dataset was Distinctions-646 [14]. To improve the versatility and robustness of the matting network during training, the researchers constructed the Distinctions-646 dataset from 646 distinct foreground images. The 646 foreground images were divided into 596 and 50 for training and testing separately, and then they produced 59,600 training images and 1000 test images, using the composition rules in [12].
The third dataset was AIM-500 [36]. It is a test set that contains 500 diverse natural real-world images covering all types (especially salient transparent/meticulous foregrounds or non-salient foregrounds), along with manually labeled alpha mattes; it can help to evaluate the generalization ability of image matting methods.
All experiments were trained on the Composition-1k training set and tested on all three test sets.
4.2. Metrics
We evaluated the alpha mattes with the following four well-known quantitative metrics: the Sum of Absolute Differences (SAD), Mean Square Error (MSE), the Gradient error (Grad), and Connectivity error (Conn), proposed by [1].
Regarding the four quantitative metrics listed, SAD and MSE measure pixel-wise errors by comparing the difference between predicted and ground-truth alpha mattes. Specifically, SAD represents absolute differences of all pixels between the predicted alpha matte and the ground-truth alpha matte, and SAD in the unknown region can be formulated as
where and represent the predicted alpha and corresponding ground-truth values at pixel i, respectively. The unknown region, denoted by U, is the focus region of matting defined in the trimap. Furthermore, MSE in the unknown region is defined as
which is the mean square error between the predicted and ground-truth alpha matte.
SAD and MSE do not necessarily reflect visual quality as perceived by a human. In order to evaluate alpha more comprehensively, Rhemann et al. [1] proposed two metrics (Grad and Conn) to evaluate visual quality. Grad is defined as
where and refer to the normalized gradients of the predicted alpha matte and ground-truth at pixel i, while the parameter q is a user-defined hyperparameter. Additionally, Conn is defined as
where represents a source region that is identified as the largest connected area where the predicted alpha value and the ground-truth are fully opaque. denotes the degree of connectivity for a given pixel i with alpha value to the source region , while the parameter p corresponds to a user-defined hyperparameter.
4.3. Implementation Details
During the training stage, whether in the supervised branch or weakly supervised branch, the input images were first resized into . Then, they were augmented following the rules in [12], which include random foreground composition, image cropping, rotation, resizing, clipping, horizontal flipping, and vertical flipping.
Generally, supervised matting algorithms generate the required trimaps by performing an erosion function on the ground-truth alpha mattes. Therefore, the trimaps required for the weakly supervised branch were also generated in the same way to simulate the trimap annotation process. During the training stage, different-granularity trimaps were generated by controlling the kernel coefficients of the erosion function. Specifically, for the fine trimap, the kernel coefficients ranged from 2 to 30 pixels, while, for the coarse trimap, the kernel coefficients of the corrosion function ranged from 32 to 60 pixels.
We used Adam optimizer for loss optimization, and the arguments were and . For the learning rate, we initialized it to , then adjusted the learning rate with cosine weight decay. We set a warm-up strategy in the first 10,000 iterations to help the model converge faster and achieve stability.
We used two NVIDIA GeForce RTX 3090 GPUs to train our model. In dataset partitioning experiments, a training batch consisted of 12 annotated and 12 unlabeled images. To ensure stable training, we only enabled the supervised branch in the early stage. After several training epochs, we enabled the weakly supervised branch. The specific parameters used in the experiments are detailed in Section 4.4.
4.4. Dataset Partitioning
Tri-SSL is the first semi-supervised learning framework in deep learning image matting, having no comparable precedent. Therefore, when designing our experiments, we referred to experimental methods used in semi-supervised semantic segmentation [28,32,37]. Typically, these works divide the dataset internally and select some data as labeled data and others as unlabeled data for the experiment. We followed a similar approach in our experiments and partitioned the dataset into labeled and unlabeled subsets to evaluate the effectiveness of Tri-SSL.
In this work, we used the Adobe dataset [12] for model training, with partition ratios of 1/8, 1/16, and 1/32. The selected portions were used as labeled data, while the rest were used as unlabeled data. The experiments were conducted using Matteformer [16].
For each partition ratio, two experiments were conducted: supervised training using only labeled data (SupOnly) and semi-supervised training using both labeled and unlabeled data (Tri-SSL). The experiment with a ratio of 1/32 was trained for a total of 100,000 iterations, while the other ratios of 1/16 and 1/8 were trained for 200,000 iterations. The Tri-SSL experiment only enabled the supervised branch in the early stage to ensure stable training. For the partition ratios of 1/32, 1/16, and 1/8, the weakly supervised branch was enabled after 40,000, 60,000, and 80,000 iterations, respectively.
All partitioning experiments were evaluated on the Composition-1k, Distinction-646, and AIM-500 test sets, and the results are presented in Table 1. To verify the performance improvement of Tri-SSL, we compared it with SupOnly, which only employs the supervised branch (blue branch in Figure 3). According to the results, Tri-SSL outperforms SupOnly in all four metrics across experiments with various partition ratios for each test set. In the 1/16 partition experiment on the Composition-1k test set, Tri-SSL achieved a 29% improvement in MSE, reducing it from 13.8 to 9.8. In the 1/32 partition experiment on the Distinction-646 test set, Tri-SSL demonstrated a 17% improvement in MSE. These experimental results show that Tri-SSL can effectively leverage data without accurate alpha matte annotation.

Table 1.
The quantitative results of dataset partitioning experiments based on the Matteformer on various test sets. The ↓ indicates that the lower the value, the better. The indicates supervised training using only labeled data.
Figure 4 shows the qualitative comparison of the 1/16 partition experiment on the Composition-1k test set. It can be seen that Tri-SSL, which additionally learned from the unlabeled data, performs better in predicting high-quality alpha mattes compared to SupOnly. This means that it is feasible for the Tri-SSL framework to use unlabeled data without alpha mask ground truth, successfully reducing the cost of data labeling.

Figure 4.
The qualitative results of the 1/16 dataset partition ratio on Composition-1k. The green box zooms in on the detail.
Furthermore, Tri-SSL demonstrates superior semantic recognition ability. For instance, consider the image of a woman’s head in the last row of Figure 4. The provided trimap for this image is quite distinctive, with only two colors, and the entire foreground object is labeled as an unknown region (gray) without any definite foreground region (white). When generating an alpha matte for this image, SupOnly failed to recognize the face and hair as a whole, which identified the face as part of the background. In contrast, the prediction produced by Tri-SSL more accurately recognized the overall semantic information.
4.5. Dataset Combination
To further validate the performance of Tri-SSL, we conducted dataset combination experiments. The experiments consisted of two steps: (1) in the first step, we performed supervised training on the Adobe dataset; (2) in the second step, we performed semi-supervised training with Distinction-646 dataset as unlabeled data. This helped to improve overall performance.
The experiment utilized Matteformer [16] and ELGT [17] as baseline models to demonstrate Tri-SSL’s ability to improve the performance of different matting methods. In the first step, both base models were trained using their original training parameters. Matteformer underwent 200,000 iterations (approximately 93 epochs) with a batch size of 20 and an initial learning rate of . ELGT was trained for 200,000 iterations (approximately 112 epochs), with a batch size of 24 and an initial learning rate of .
The trained model was loaded in the second step, and the Distinction-646 dataset was employed as weakly annotated data. The weakly supervised branch was added to optimize the model and training for another 100,000 iterations. At this point, the batch size for Matteformer was adjusted to 12, with 12 labeled and 12 unlabeled images per iteration and a learning rate of . Meanwhile, ELGT’s batch size was adjusted to 10, with 10 labeled and 10 unlabeled images per iteration and a learning rate of . The batch size was halved because the semi-supervised branch doubled the number of image samples in a single iteration.
To control the influence of other factors and prove the effectiveness of Tri-SSL, the following control experiment was conducted in the second step: we loaded the model trained in the first step, but did not add the weakly supervised branch to the model. The model was trained for an additional 100,000 iterations to ensure consistency of the training iterations with the Tri-SSL experiments. The experimental results based on Matteformer and ELGT are presented in Table 2 and Table 3, respectively.
Table 2.
The results of dataset combination experiments based on the Matteformer on various test sets. The ↓ indicates that the lower the value, the better.
Table 3.
The results of dataset combination experiments based on the ELGT on various test sets. The ↓ indicates that the lower the value, the better.
In Table 2 and Table 3, the model refers to the target experiment, where the first-stage trained model was loaded and semi-supervised fine-tuning with unlabeled data (from the Distinction-646 dataset) was conducted. The model refers to the control experiment where the first-stage trained model was loaded, and supervised training of the same number of iterations was conducted.
As shown in Table 2, after semi-supervised fine-tuning, the mean square error (MSE) of Matteformer decreased from 8.63 to 7.56, and the sum of absolute differences (SAD) value reduced from 25.04 to 22.11 on the Distinction-646 dataset. On the AIM-500 dataset, the MSE value improved from 32.5 to 29.6. In Table 3, the is seen to outperform on the Adobe test set, decreasing the MSE value from 3.79 to 3.58. The control experiment slightly improved over , with the MSE value of 3.70 inferior to the 3.58 of . The results demonstrate the ability of the proposed semi-supervised training method to learn from weakly annotated data and improve model performance.
After introducing Distinction-646 data as weakly annotated data for additional training, the Tri-SSL model based on the ELGT achieved state-of-the-art performance. We compared Tri-SSL quantitatively with three traditional and nine deep learning methods on the Composition-1k test set. The comparison results are shown in Table 4, demonstrating that Tri-SSL based on ELGT achieved the best results in all four metrics. Moreover, the qualitative comparison results in Figure 5 show that the alpha mattes generated by Tri-SSL are smoother and clearer.
Table 4.
The quantitative comparison of Tri-SSL and supervised methods on Composition-1k. The ↓ indicates that the lower the value, the better.

Figure 5.
Visual comparison of Tri-SSL and supervised methods on Composition-1k. The green box zooms in on the detail. (a) Image. (b) GCA [38]. (c) Image. (d) GCA [38]. (e) Trimap. (f) Matteformer [16]. (g) Trimap. (h) Matteformer [16]. (i) DIM [12]. (j) Tri-SSL. (k) DIM [12]. (l) Tri-SSL. (m) IndexNet [39]. (n) GT. (o) IndexNet [39]. (p) GT.
4.6. Ablation Study
We conducted granularity ablation and loss ablation to demonstrate the effectiveness of the Tri-SSL method design. All ablation experiments were conducted based on the dataset combination experiment with ELGT.
The first ablation experiment evaluated whether the differently perturbed samples used in the weakly supervised branch had sufficient gap for the network to learn valid information. The differently perturbed samples were formed by different-granularity trimaps. For the fine trimap, the kernel coefficients of the erosion function ranged from 2 to 30 pixels, while, for the coarse trimap, the kernel coefficients ranged from 32 to 60 pixels. In the granularity ablation experiment, we shrank the gap between the different perturbed samples and set the kernel coefficients’ range from 2 to 30 pixels for both trimaps. The results are shown in Table 5. The granularity ablation experiment was inferior to the for all four metrics on Composition-1k. Moreover, the performance of declined on the AIM-500 test set.
Table 5.
The results of ablation experiments based on the ELGT on various test sets. The ↓ indicates that the lower the value, the better.
The second ablation experiment evaluated the loss function design of the weakly supervised branch. The overall weight of the weakly supervised loss was adjusted to 1/4 of the weight of the supervised loss, and higher weight was assigned for the side outputs and in the deeper layer. In the loss ablation experiment, we adjusted the proportion of loss weights in the weakly supervised branch to be consistent with the supervised branch, and kept the overall weight 1/4 of the supervised loss weight. The weakly supervised loss function in the ablation experiment was formed as
The results are shown in Table 5. The loss ablation experiment was inferior to the for all four metrics on Composition-1k and had a similar relative performance on the other two test sets.
4.7. Results on Real-World Images
We also evaluated Tri-SSL on the real-world natural image test set AIM-500 [36] to measure its generalization performance on real-world images. Figure 6 shows some prediction results on real-world images, including different types of images such as plants, animal fur, flames, semi-transparent ice cubes, and spider webs. Tri-SSL generated high-quality alpha masks for these images, demonstrating good generalization ability and robustness.

Figure 6.
The results of Tri-SSL working on real-world images.
5. Discussion
We designed two experiments to evaluate the proposed semi-supervised framework Tri-SSL: the dataset partitioning and combination experiments. Additionally, we evaluated the best result of Tri-SSL on real-world images. The dataset partitioning experiment demonstrated that Tri-SSL was able to train a good-performance model with few labeled data. In the dataset combination experiment, Tri-SSL improved the current best-performing matting model and achieved new state-of-the-art performance through semi-supervised learning with an additional unlabeled Distinction-646 dataset. The evaluation of the real-world images also demonstrated the good generalization ability and robustness of Tri-SSL. Tri-SSL is the first attempt to introduce semi-supervised learning into deep image matting. Tri-SSL uses the inherent semantic consistency correlation of different granularity trimaps to impose consistency regularization, which reduces the labeling cost of deep model training.
6. Conclusions
The data labeling cost of matting tasks is high, and current deep matting methods are all trained using datasets which are enlarged by combining one foreground with several background images to meet the training requirements of the deep learning models. To reduce the labeling cost, this paper first proposes a semi-supervised matting algorithm Tri-SSL based on the semantic consistency of trimaps. In the matting task, a finely labeled trimap can produce a better alpha matte than a coarse trimap, and the different-granularity trimaps have inherent semantic consistency correlation. Based on this rule, this paper uses trimaps as weak supervision signals for the unlabeled images. Two trimaps with different granularity are made for the unlabeled data, passing through the network to obtain the alpha prediction separately. The directional consistency constraints are imposed on the prediction results of different-granularity trimaps and the intermediate features of the network. Experimental results show that Tri-SSL can effectively use the weak supervision information of trimaps to improve the model’s performance, achieving new state-of-the-art performance.
Author Contributions
Conceptualization, J.L. and Y.K.; methodology, Y.K. and J.L.; software, Y.K.; validation, Y.K.; formal analysis, Y.K.; investigation, Y.K.; resources, X.L.; data curation, Y.K.; writing—original draft preparation, Y.K.; writing—review and editing, Y.K., L.H., J.L. and X.L.; visualization, Y.K.; supervision, X.L.; project administration, X.L.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
The Science and Technology Innovation Plan of Shanghai Science and Technology Commission, under Grant 21511100600.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rhemann, C.; Rother, C.; Wang, J.; Gelautz, M.; Kohli, P.; Rott, P. A perceptually motivated online benchmark for image matting. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1826–1833. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Ke, Z.; Wang, D.; Yan, Q.; Ren, J.; Lau, R.W. Dual student: Breaking the limits of the teacher in semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6728–6736. [Google Scholar]
- Chuang, Y.Y.; Curless, B.; Salesin, D.H.; Szeliski, R. A bayesian approach to digital matting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 2, p. II. [Google Scholar]
- Wang, J.; Cohen, M.F. Optimized color sampling for robust matting. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- He, K.; Rhemann, C.; Rother, C.; Tang, X.; Sun, J. A global sampling method for alpha matting. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2049–2056. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 228–242. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Jia, J.; Tang, C.K.; Shum, H.Y. Poisson matting. In Proceedings of the ACM SIGGRAPH 2004, Los Angeles, CA, USA, 8–12 August 2004; pp. 315–321. [Google Scholar]
- Cho, D.; Tai, Y.W.; Kweon, I. Natural image matting using deep convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 626–643. [Google Scholar]
- Chen, Q.; Li, D.; Tang, C.K. KNN matting. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2175–2188. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Tao, X.; Gao, H.; Zhou, C.; Jia, J. Deep automatic portrait matting. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 92–107. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2970–2979. [Google Scholar]
- Lutz, S.; Amplianitis, K.; Smolic, A. AlphaGAN: Generative adversarial networks for natural image matting. In Proceedings of the British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, 3–6 September 2018; BMVA Press: Durham, UK, 2018; p. 259. [Google Scholar]
- Qiao, Y.; Liu, Y.; Yang, X.; Zhou, D.; Xu, M.; Zhang, Q.; Wei, X. Attention-guided hierarchical structure aggregation for image matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13676–13685. [Google Scholar]
- Liu, Y.; Xie, J.; Shi, X.; Qiao, Y.; Huang, Y.; Tang, Y.; Yang, X. Tripartite Information Mining and Integration for Image Matting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7555–7564. [Google Scholar]
- Park, G.; Son, S.; Yoo, J.; Kim, S.; Kwak, N. Matteformer: Transformer-based image matting via prior-tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11696–11706. [Google Scholar]
- Hu, L.; Kong, Y.; Li, J.; Li, X. Effective Local-Global Transformer for Natural Image Matting. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhang, Z.; Wang, Y.; Yang, J. Deep quantised portrait matting. IET Comput. Vis. 2020, 14, 339–349. [Google Scholar] [CrossRef]
- Sengupta, S.; Jayaram, V.; Curless, B.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Background matting: The world is your green screen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2291–2300. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. Workshop Challenges Represent. Learn. ICML 2013, 3, 896. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-supervised semantic segmentation with cross-consistency training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12674–12684. [Google Scholar]
- Lai, X.; Tian, Z.; Jiang, L.; Liu, S.; Zhao, H.; Wang, L.; Jia, J. Semi-supervised semantic segmentation with directional context-aware consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1205–1214. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-supervised semantic segmentation with cross pseudo supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. Pseudoseg: Designing pseudo labels for semantic segmentation. arXiv 2020, arXiv:2010.09713. [Google Scholar]
- Yang, L.; Zhuo, W.; Qi, L.; Shi, Y.; Gao, Y. St++: Make self-training work better for semi-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4268–4277. [Google Scholar]
- Hou, Q.; Liu, F. Context-aware image matting for simultaneous foreground and alpha estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4130–4139. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.; Tao, D. Deep Automatic Natural Image Matting. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–27 August 2021; pp. 800–806. [Google Scholar] [CrossRef]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-supervised semantic segmentation with high-and low-level consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1369–1379. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Lu, H. Natural image matting via guided contextual attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11450–11457. [Google Scholar]
- Lu, H.; Dai, Y.; Shen, C.; Xu, S. Indices matter: Learning to index for deep image matting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3266–3275. [Google Scholar]
- Aksoy, Y.; Ozan Aydin, T.; Pollefeys, M. Designing effective inter-pixel information flow for natural image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 29–37. [Google Scholar]
- Cai, H.; Xue, F.; Xu, L.; Guo, L. TransMatting: Enhancing Transparent Objects Matting with Transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXIX. Springer: Cham, Switzerland, 2022; pp. 253–269. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).