


eDA3-X: Distributed Attentional Actor Architecture for Interpretability of Coordinated Behaviors in Multi-Agent Systems

Abstract
1. Introduction
2. Related Work
3. Preliminaries
3.1. Dec-POMDP
3.2. Problem Setting
3.3. Multi-Head Attention
4. Proposed Method: eDA3-X
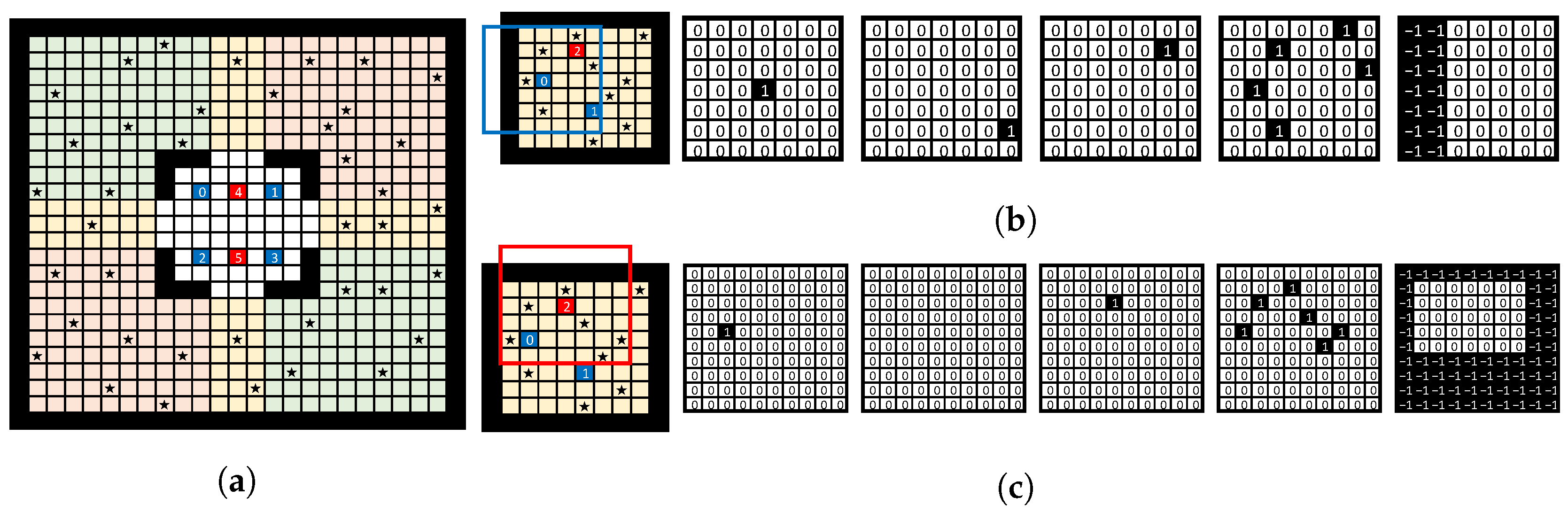
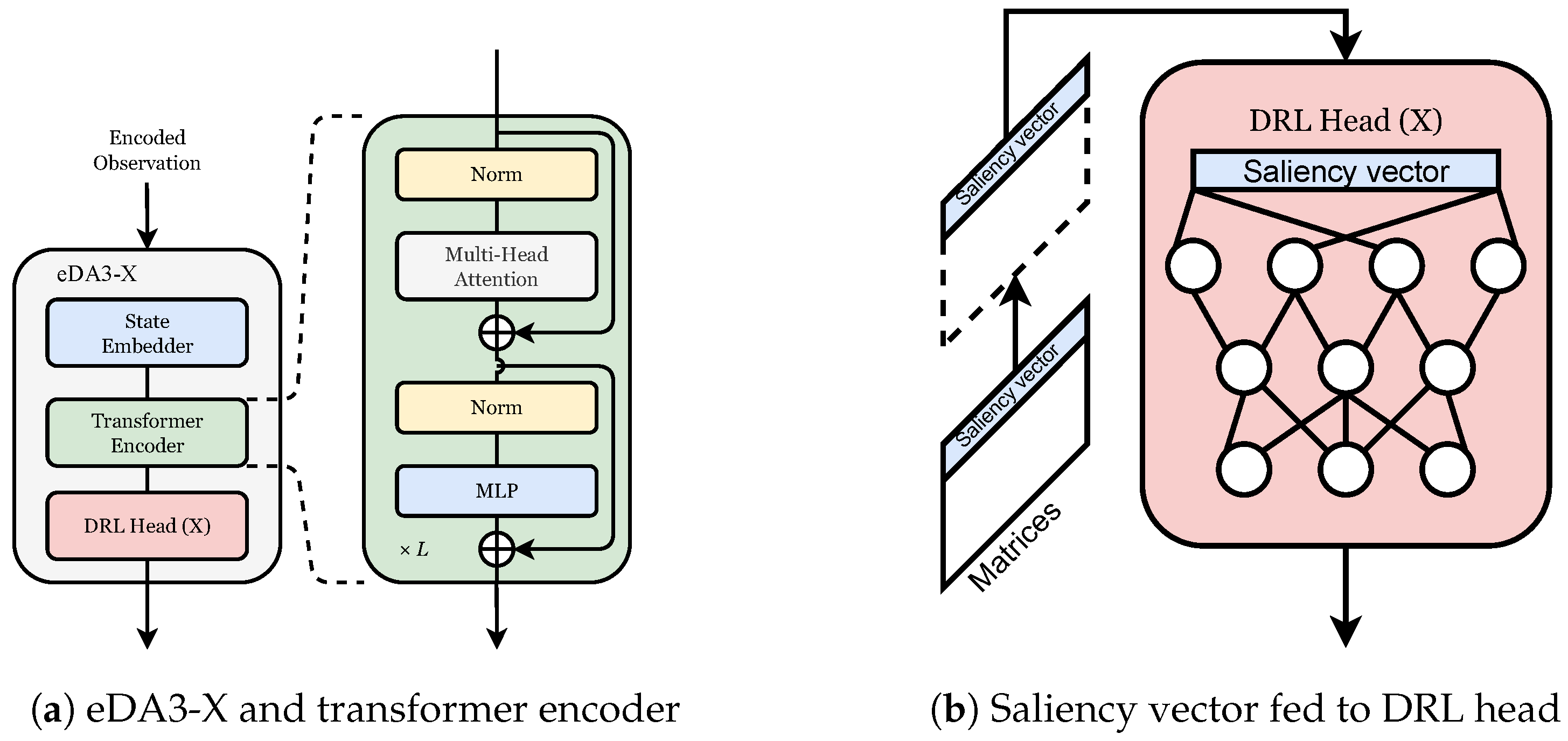
4.1. Neural Network Architecture
4.2. Standard, Positional, and Class Attentions
5. Experiments and Results
5.1. Experimental Setup
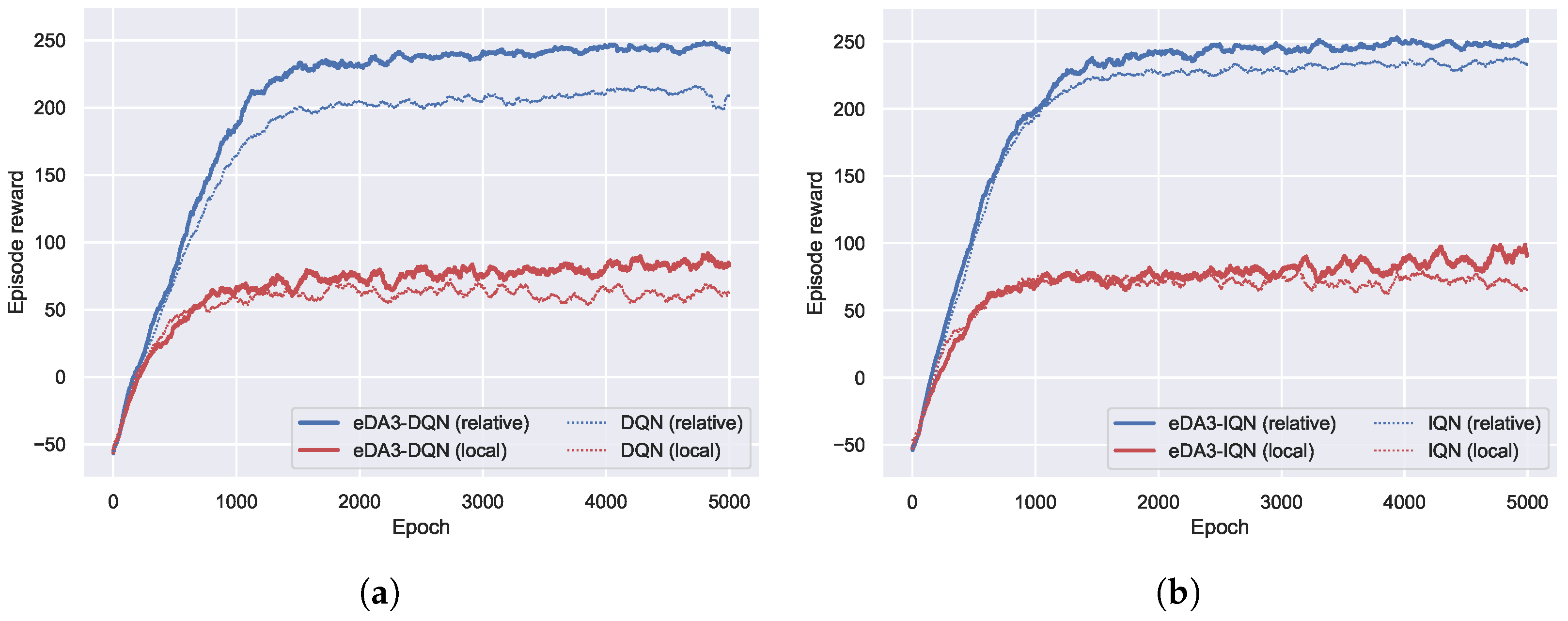
5.2. Quantitative Learning Performance
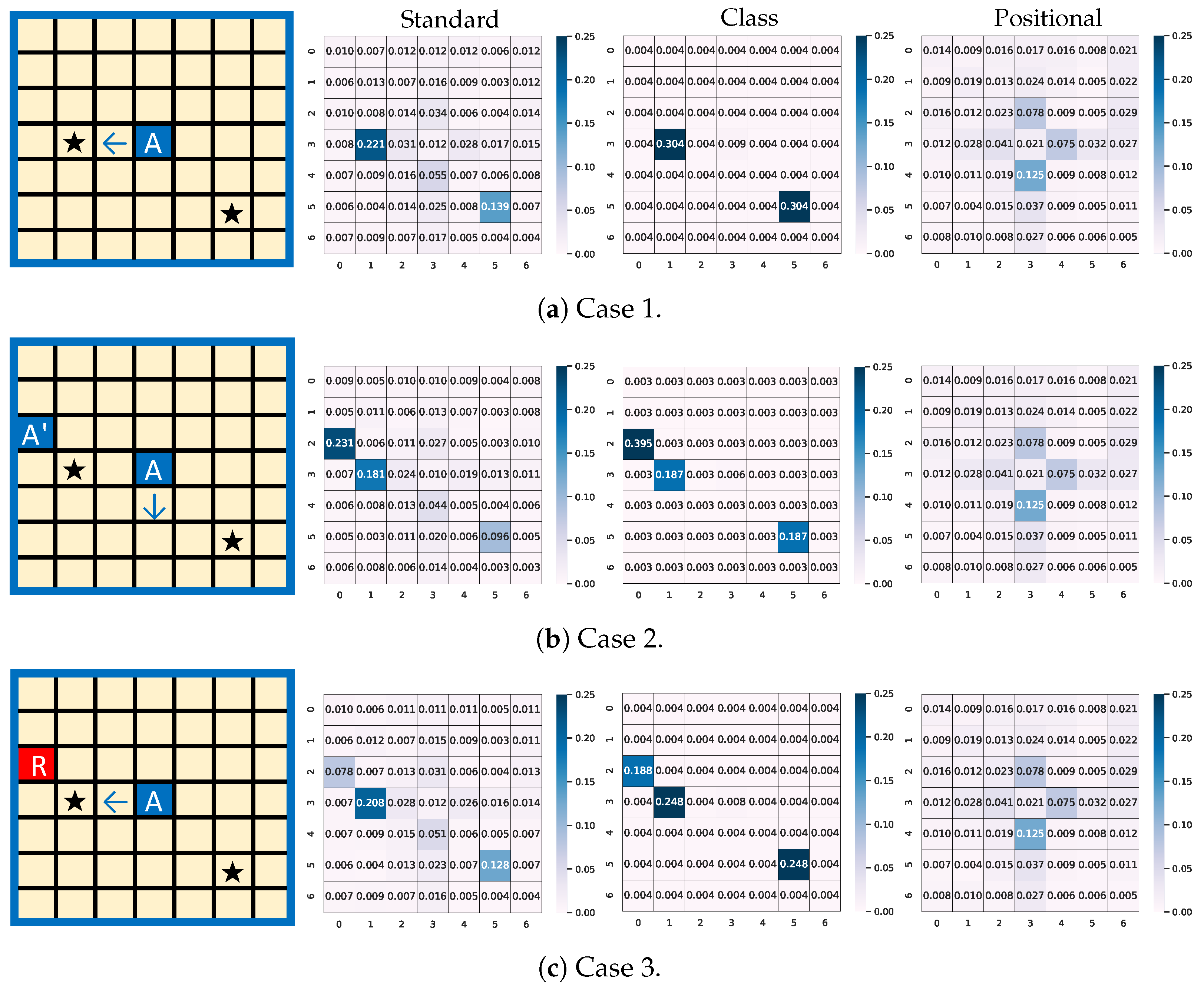
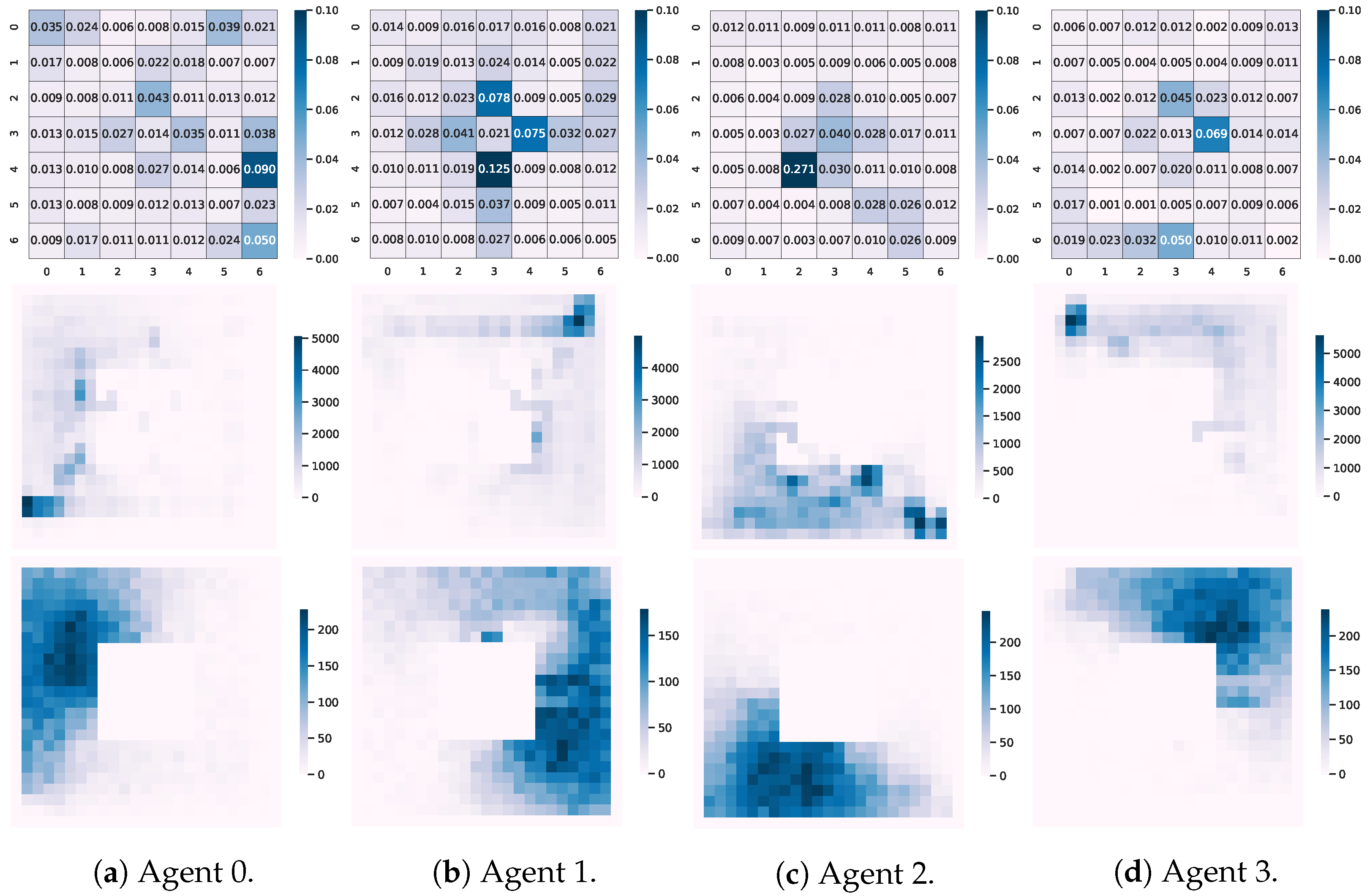
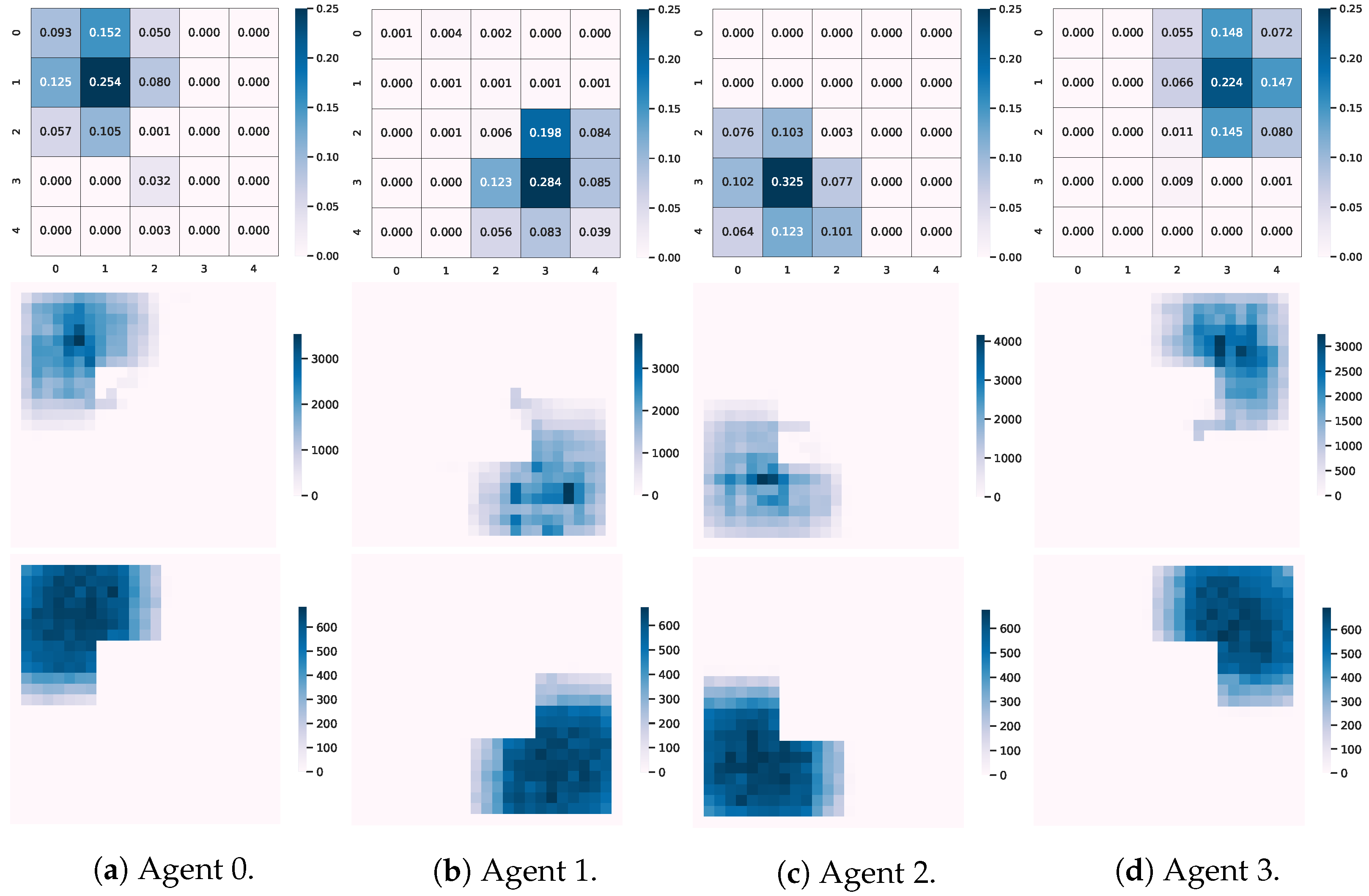
5.3. Attention Analysis from Coordination
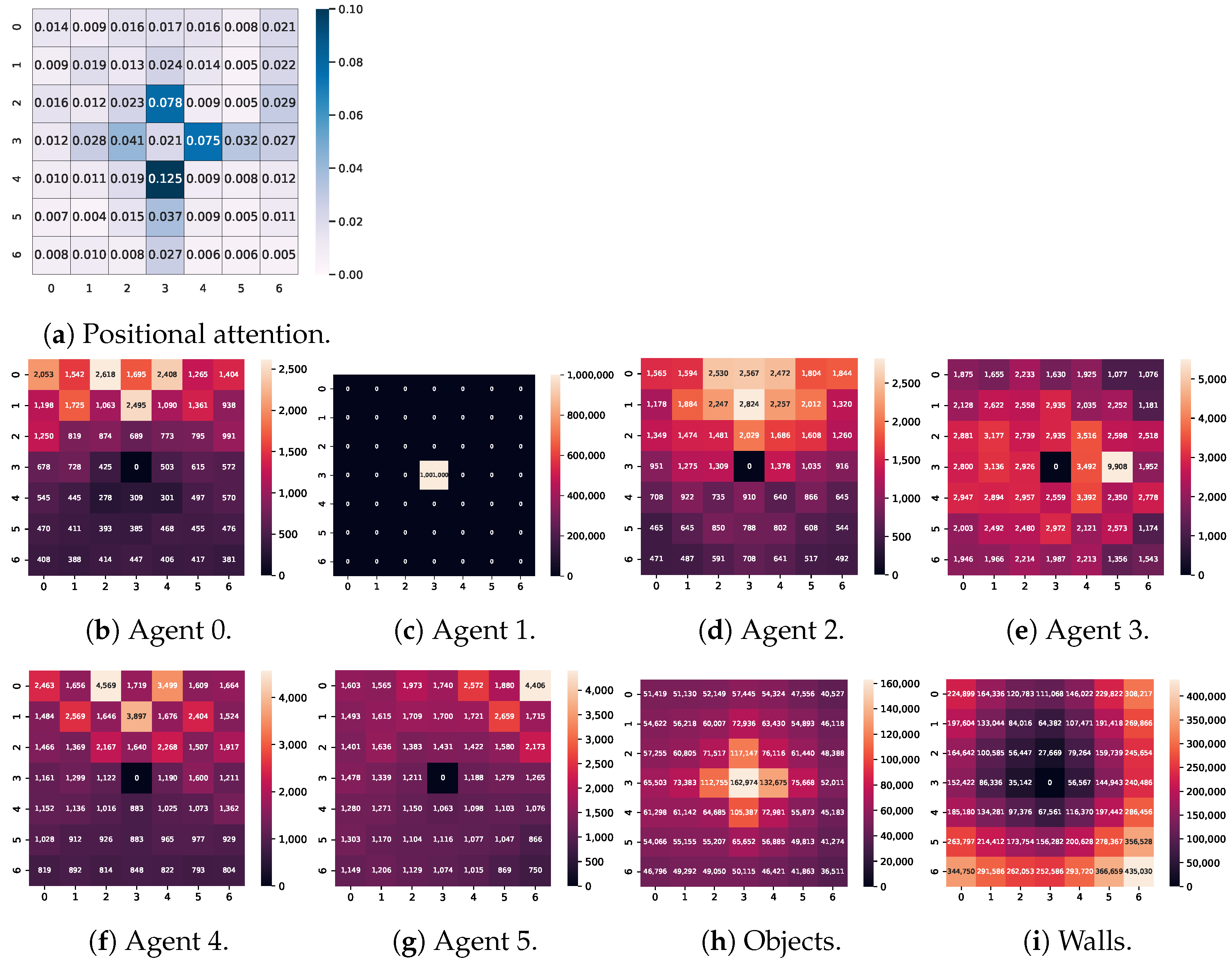
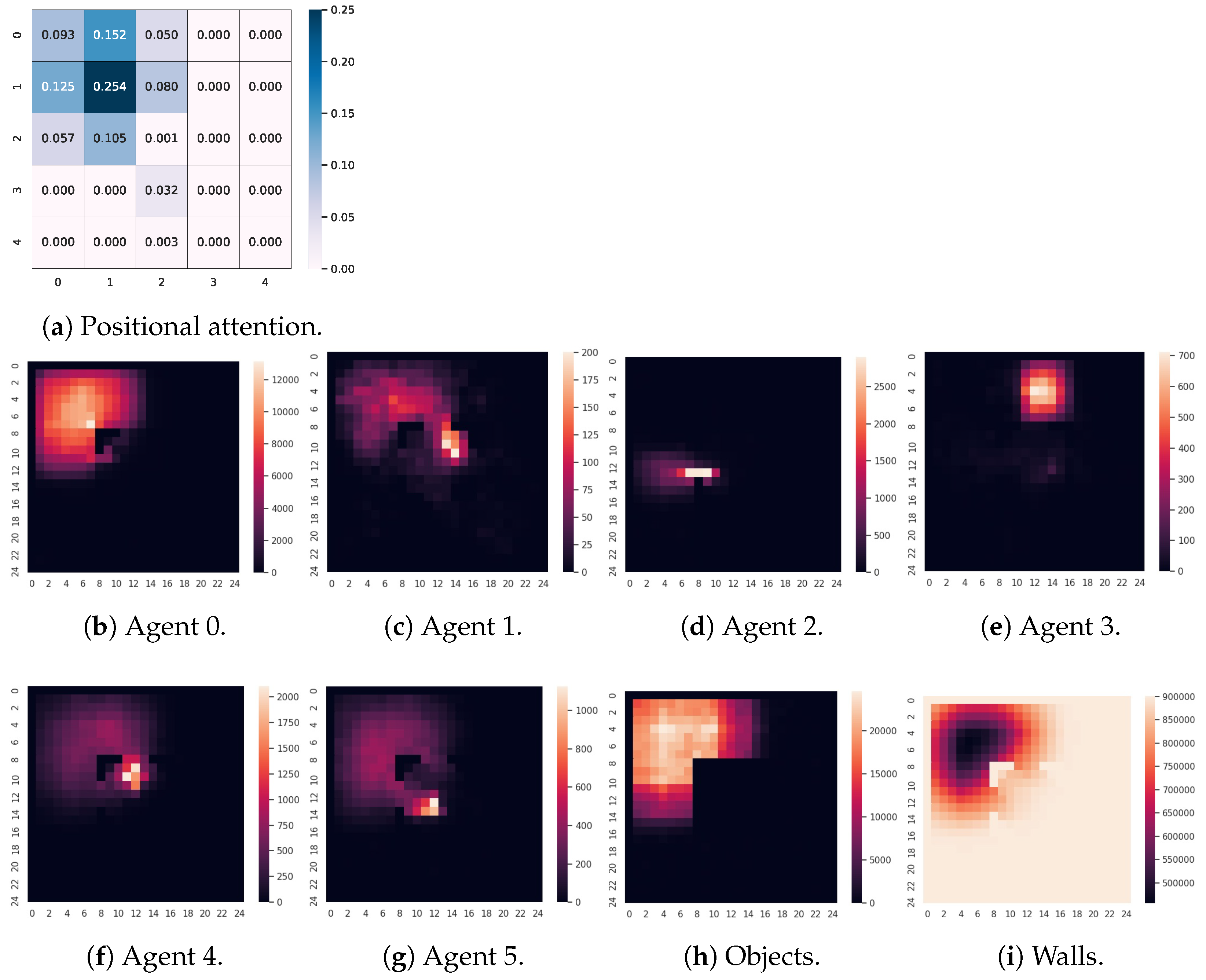
5.4. Positional Attention Analysis
5.5. Positional Attentions Analysis from Respective Channels
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. A Survey of Explainable Reinforcement Learning. arXiv 2022, arXiv:2202.08434. [Google Scholar] [CrossRef]
- Puiutta, E.; Veith, E.M.S.P. Explainable Reinforcement Learning: A Survey. In Proceedings of the Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 77–95. [Google Scholar]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Guo, W.; Wu, X.; Khan, U.; Xing, X. EDGE: Explaining Deep Reinforcement Learning Policies. Adv. Neural Inf. Process. Syst. 2021, 34, 12222–12236. [Google Scholar]
- Anderson, A.; Dodge, J.; Sadarangani, A.; Juozapaitis, Z.; Newman, E.; Irvine, J.; Chattopadhyay, S.; Fern, A.; Burnett, M. Explaining Reinforcement Learning to Mere Mortals: An Empirical Study. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, IJCAI’19, Macao, China, 10–16 August 2019; AAAI Press: Washington, DC, USA, 2019; pp. 1328–1334. [Google Scholar]
- Bica, I.; Jarrett, D.; Huyuk, A.; van der Schaar, M. Learning “What-if” Explanations for Sequential Decision-Making. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Juozapaitis, Z.; Koul, A.; Fern, A.; Erwig, M.; Doshi-Velez, F. Explainable Reinforcement Learning via Reward Decomposition. In Proceedings of the International Joint Conference on Artificial Intelligence. A Workshop on Explainable Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, ICML’17, Sydney, Australia, 6–11 August 2017; JMLR: Norfolk, MA, USA, 2017; pp. 3319–3328. [Google Scholar]
- Zahavy, T.; Ben-Zrihem, N.; Mannor, S. Graying the black box: Understanding DQNs. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Proceedings of Machine Learning Research. Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: Norfolk, MA, USA; Volume 48, pp. 1899–1908. [Google Scholar]
- Weitkamp, L.; van der Pol, E.; Akata, Z. Visual Rationalizations in Deep Reinforcement Learning for Atari Games. In Proceedings of the Artificial Intelligence, Hertogenbosch, The Netherlands, 8–9 November 2018; Atzmueller, M., Duivesteijn, W., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 151–165. [Google Scholar]
- Huber, T.; Schiller, D.; André, E. Enhancing Explainability of Deep Reinforcement Learning Through Selective Layer-Wise Relevance Propagation. In Proceedings of the KI 2019: Advances in Artificial Intelligence, Kassel, Germany, 23–26 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 188–202. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. Adv. Neural Inf. Process. Syst. 2021, 34, 15084–15097. [Google Scholar]
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Norfolk, MA, USA; Volume 97, pp. 2961–2970. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6382–6393. [Google Scholar]
- Motokawa, Y.; Sugawara, T. MAT-DQN: Toward Interpretable Multi-Agent Deep Reinforcement Learning for Coordinated Activities. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2021: 30th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2021; pp. 556–567. [Google Scholar] [CrossRef]
- Motokawa, Y.; Sugawara, T. Distributed Multi-Agent Deep Reinforcement Learning for Robust Coordination against Noise. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Hessel, M.; Modayil, J.; van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971, arXiv:1509.02971. [Google Scholar]
- Dabney, W.; Ostrovski, G.; Silver, D.; Munos, R. Implicit Quantile Networks for Distributional Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Proceedings of Machine Learning Research. Dy, J., Krause, A., Eds.; PMLR: Norfolk, MA, USA; Volume 80, pp. 1096–1105. [Google Scholar]
- Wang, W.; Shen, J.; Lu, X.; Hoi, S.C.H.; Ling, H. Paying Attention to Video Object Pattern Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2413–2428. [Google Scholar] [CrossRef] [PubMed]
- Iyer, R.R.; Li, Y.; Li, H.; Lewis, M.; Sundar, R.; Sycara, K.P. Transparency and Explanation in Deep Reinforcement Learning Neural Networks. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018. [Google Scholar]
- Goel, V.; Weng, J.; Poupart, P. Unsupervised Video Object Segmentation for Deep Reinforcement Learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, Red Hook, NY, USA, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 5688–5699. [Google Scholar]
- Shi, W.; Huang, G.; Song, S.; Wang, Z.; Lin, T.; Wu, C. Self-Supervised Discovering of Interpretable Features for Reinforcement Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2712–2724. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Fong, R.; Vedaldi, A. Interpretable Explanations of Black Boxes by Meaningful Perturbation; IEEE: New York, NY, USA, 2018; pp. 3449–3457. [Google Scholar]
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 3543–3556. [Google Scholar] [CrossRef]
- Serrano, S.; Smith, N.A. Is Attention Interpretable? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 2931–2951. [Google Scholar] [CrossRef]
- Wiegreffe, S.; Pinter, Y. Attention is not not Explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Annasamy, R.M.; Sycara, K. Towards Better Interpretability in Deep Q-Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’19/IAAI’19/EAAI’19, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]
- Tang, Y.; Nguyen, D.; Ha, D. Neuroevolution of Self-Interpretable Agents. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, GECCO’20, Cancún, Mexico, 8–12 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 414–424. [Google Scholar] [CrossRef]
- Sorokin, I.; Seleznev, A.; Pavlov, M.; Fedorov, A.; Ignateva, A. Deep Attention Recurrent Q-Network. arXiv 2015, arXiv:1512.01693. [Google Scholar] [CrossRef]
- Mott, A.; Zoran, D.; Chrzanowski, M.; Wierstra, D.; Jimenez Rezende, D. Towards Interpretable Reinforcement Learning Using Attention Augmented Agents. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Manchin, A.; Abbasnejad, E.; van den Hengel, A. Reinforcement Learning with Attention that Works: A Self-Supervised Approach. In Advances in Neural Information Processing Systems; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 223–230. [Google Scholar]
- Itaya, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H.; Sugiura, K. Visual Explanation using Attention Mechanism in Actor-Critic-based Deep Reinforcement Learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–10. [Google Scholar]
- Yang, Z.; Bai, S.; Zhang, L.; Torr, P.H.S. Learn to Interpret Atari Agents. arXiv 2018, arXiv:1812.11276. [Google Scholar] [CrossRef]
- Mousavi, S.; Schukat, M.; Howley, E.; Borji, A.; Mozayani, N. Learning to predict where to look in interactive environments using deep recurrent q-learning. arXiv 2016, arXiv:1612.05753. [Google Scholar] [CrossRef]
- Zhao, M.; Li, Q.; Srinivas, A.; Gilaberte, I.C.; Lee, K.; Abbeel, P. R-LAtte: Visual Control via Deep Reinforcement Learning with Attention Network. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Dasari, S.; Gupta, A.K. Transformers for One-Shot Visual Imitation. In Proceedings of the CoRL, Virtual Event, 16–18 November 2020. [Google Scholar]
- Abramson, J.; Ahuja, A.; Barr, I.; Brussee, A.; Carnevale, F.; Cassin, M.; Chhaparia, R.; Clark, S.; Damoc, B.; Dudzik, A.; et al. Imitating Interactive Intelligence. arXiv 2020, arXiv:2012.05672. [Google Scholar] [CrossRef]
- Upadhyay, U.; Shah, N.; Ravikanti, S.; Medhe, M. Transformer Based Reinforcement Learning For Games. arXiv 2019, arXiv:1912.03918. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, L.; Fang, M.; Wang, Y.; Zhang, C. Deep Reinforcement Learning with Transformers for Text Adventure Games. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 65–72. [Google Scholar] [CrossRef]
- Ritter, S.; Faulkner, R.; Sartran, L.; Santoro, A.; Botvinick, M.; Raposo, D. Rapid Task-Solving in Novel Environments. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Janner, M.; Li, Q.; Levine, S. Offline Reinforcement Learning as One Big Sequence Modeling Problem. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 1273–1286. [Google Scholar]
- Sak, H.; Senior, A.W.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the INTERSPEECH, Singapore, 14–18 September 2014; pp. 338–342. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Ciatto, G.; Calegari, R.; Omicini, A.; Calvaresi, D. Towards XMAS: eXplainability through Multi-Agent Systems. In Proceedings of the 1st Workshop on Artificial Intelligence and Internet of Things Co-Located with the 18th International Conference of the Italian Association for Artificial Intelligence (AI*IA 2019), Rende (CS), Italy, 22 November 2019; CEUR Workshop Proceedings. Savaglio, C., Fortino, G., Ciatto, G., Omicini, A., Eds.; CEUR-WS: London, UK, 2019; Volume 2502, pp. 40–53. [Google Scholar]
- Kraus, S.; Azaria, A.; Fiosina, J.; Greve, M.; Hazon, N.; Kolbe, L.M.; Lembcke, T.; Müller, J.P.; Schleibaum, S.; Vollrath, M. AI for Explaining Decisions in Multi-Agent Environments. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Washington, DC, USA, 2020; pp. 13534–13538. [Google Scholar]
- Calvaresi, D.; Mualla, Y.; Najjar, A.; Galland, S.; Schumacher, M. Explainable Multi-Agent Systems Through Blockchain Technology. In Proceedings of the Explainable, Transparent Autonomous Agents and Multi-Agent Systems: First International Workshop, EXTRAAMAS 2019, Montreal, QC, Canada, 13–14 May 2019; Revised Selected Papers. Springer: Berlin, Heidelberg, 2019; pp. 41–58. [Google Scholar] [CrossRef]
- Alzetta, F.; Giorgini, P.; Najjar, A.; Schumacher, M.I.; Calvaresi, D. In-Time Explainability in Multi-Agent Systems: Challenges, Opportunities, and Roadmap. Explain. Transparent Auton. Agents Multi-Agent Syst. 2020, 12175, 39–53. [Google Scholar]
- Choi, J.; Lee, B.J.; Zhang, B.T. Multi-focus Attention Network for Efficient Deep Reinforcement Learning. arXiv 2017, arXiv:1712.04603. [Google Scholar] [CrossRef]
- Jiang, J.; Lu, Z. Learning Attentional Communication for Multi-Agent Cooperation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, Red Hook, NY, USA, 2–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 7265–7275. [Google Scholar]
- Liu, Y.; Wang, W.; Hu, Y.; Hao, J.; Chen, X.; Gao, Y. Multi-Agent Game Abstraction via Graph Attention Neural Network. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Ryu, H.; Shin, H.; Park, J. Multi-Agent Actor-Critic with Hierarchical Graph Attention Network. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Niu, Y.; Paleja, R.; Gombolay, M. Multi-Agent Graph-Attention Communication and Teaming. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS’21, Virtual Event, 3–7 May 2021; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2021; pp. 964–973. [Google Scholar]
- Mao, H.; Zhang, Z.; Xiao, Z.; Gong, Z.; Ni, Y. Learning Multi-Agent Communication with Double Attentional Deep Reinforcement Learning. Auton. Agents Multi-Agent Syst. 2020, 34, 32. [Google Scholar] [CrossRef]
- Hoshen, Y. VAIN: Attentional Multi-Agent Predictive Modeling. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2698–2708. [Google Scholar]
- Parnika, P.; Diddigi, R.B.; Danda, S.K.R.; Bhatnagar, S. Attention Actor-Critic Algorithm for Multi-Agent Constrained Co-Operative Reinforcement Learning. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS’21, Virtual Event, 3–7 May 2021; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2021; pp. 1616–1618. [Google Scholar]
- Li, M.G.; Jiang, B.; Zhu, H.; Che, Z.; Liu, Y. Generative Attention Networks for Multi-Agent Behavioral Modeling. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Li, J.; Yang, F.; Tomizuka, M.; Choi, C. EvolveGraph: Multi-Agent Trajectory Prediction with Dynamic Relational Reasoning. In Proceedings of the Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020. [Google Scholar]
- Li, L.; Yao, J.; Wenliang, L.; He, T.; Xiao, T.; Yan, J.; Wipf, D.; Zhang, Z. GRIN: Generative Relation and Intention Network for Multi-agent Trajectory Prediction. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 27107–27118. [Google Scholar]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Tuyls, K.; Reichert, D.; Lillicrap, T.; Lockhart, E.; et al. Deep reinforcement learning with relational inductive biases. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, D.; Jaques, N.; Kew, C.; Wu, J.; Eck, D.; Schuurmans, D.; Faust, A. Joint Attention for Multi-Agent Coordination and Social Learning. arXiv 2021, arXiv:2104.07750. [Google Scholar] [CrossRef]
- Xueguang Lyu, Y.X. Contrasting Centralized and Decentralized Critics in Multi-Agent Reinforcement Learning. In Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, Honolulu, HI, USA, 14–18 May 2007. [Google Scholar]
- Lyu, X.; Xiao, Y.; Daley, B.; Amato, C. Contrasting Centralized and Decentralized Critics in Multi-Agent Reinforcement Learning. arXiv 2021, arXiv:2102.04402, arXiv:2102.04402. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Miyashita, Y.; Sugawara, T. Analysis of coordinated behavior structures with multi-agent deep reinforcement learning. Appl. Intell. 2021, 51, 1069–1085. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari With Deep Reinforcement Learning. In NIPS Deep Learning Workshop; NeurIPS: New Orleans, LA, USA, 2013. [Google Scholar]
- Hasselt, H.v.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI’16, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Washington, DC, USA, 2016; pp. 2094–2100. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—Volume 48, ICML’16, New York, NY, USA, 19–24 June 2016; JMLR: Norfolk, MA, USA, 2016; pp. 1995–2003. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation | Model | Episode Reward | Objects Collected | Agents Collision | Walls Collision |
|---|---|---|---|---|---|
| local | dqn | ||||
| iqn | |||||
| eda3-dqn | |||||
| eda3-iqn | |||||
| relative | dqn | ||||
| iqn | |||||
| eda3-dqn | |||||
| eda3-iqn |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Motokawa, Y.; Sugawara, T. eDA3-X: Distributed Attentional Actor Architecture for Interpretability of Coordinated Behaviors in Multi-Agent Systems. Appl. Sci. 2023, 13, 8454. https://doi.org/10.3390/app13148454
Motokawa Y, Sugawara T. eDA3-X: Distributed Attentional Actor Architecture for Interpretability of Coordinated Behaviors in Multi-Agent Systems. Applied Sciences. 2023; 13(14):8454. https://doi.org/10.3390/app13148454
Chicago/Turabian StyleMotokawa, Yoshinari, and Toshiharu Sugawara. 2023. "eDA3-X: Distributed Attentional Actor Architecture for Interpretability of Coordinated Behaviors in Multi-Agent Systems" Applied Sciences 13, no. 14: 8454. https://doi.org/10.3390/app13148454
APA StyleMotokawa, Y., & Sugawara, T. (2023). eDA3-X: Distributed Attentional Actor Architecture for Interpretability of Coordinated Behaviors in Multi-Agent Systems. Applied Sciences, 13(14), 8454. https://doi.org/10.3390/app13148454