1. Introduction
In the context of power construction, safety accidents resulting from unsafe behaviors among staff are common occurrences. In complex construction site scenarios, hidden safety hazards may arise when workers neglect to wear safety equipment, which poses a serious threat to their safety and lives [
1]. Compliance with safety regulations, including the proper usage of safety helmets, safety belts, work clothes, and safety gloves, is of paramount importance in safeguarding the well-being of individuals engaged in construction work. Despite the existence of safety regulations, enforcement among workers often falls short, which poses challenges in ensuring safety at construction sites. Consequently, power grid enterprises face difficulties in monitoring and verifying workers’ compliance with these regulations. Identifying and warning workers about non-compliance is crucial to maintaining safety on construction sites.
In recent years, video surveillance cameras have been widely adopted in substation construction safety management systems [
2]. However, traditional detection methods that rely on manual labor exhibit several drawbacks, such as high rates of missed detection, low efficiency, labor-intensiveness, and low reliability [
3]. These drawbacks are largely attributed to the complex backgrounds and terrains of Yunnan province, where substation construction takes place. To address the challenges of slow transmission speed and lack of timely warning for violations, real-time detection of compliance wearing is necessary to prevent accidents. Deep learning-based object detection algorithms have been increasingly applied in recent years to replace manual monitoring of on-site safety regulations. These algorithms offer a more reliable and efficient way to ensure the safe operation of the power grid [
4]. Furthermore, recent advances in drone and camera phone technology have made it possible to capture video sequences with moving cameras for detecting and tracking of moving objects [
5]. These object detection algorithms rely on cloud platforms with substantial computing power or high-performance GPU computer clusters to achieve superior detection rates. However, GPU chips have limitations in terms of server power consumption, size, and portability, making them unsuitable for front-end scenarios. Therefore, low-cost edge devices offer a viable solution by simplifying hardware complexity and providing efficient and effective power construction safety detection in real-world settings.
At a construction site that requires significant power, video acquisition equipment is connected to the substation’s intelligent management system via a high-speed 4G or 5G network. This advanced technology allows the substation’s remote safety construction management and control system center to capture live video feeds and closely monitor every aspect of the construction process. However, environmental constraints such as incomplete 4G or 5G signal coverage and signal delays in certain field construction environments must be taken into consideration. For instance, Yunnan Province exhibits a complex topography, with mountains and plateaus comprising over 90% of its landscape. As a result, signal delays can easily trigger electric shock hazards and high-altitude accidents. Furthermore, traditional safety measures primarily focus on post-incident actions rather than proactive prevention. Therefore, real-time violation detection is crucial in reducing casualties. In addition, given the special environmental requirements, the model developed in this study is deployed based on edge devices. Edge devices provide the necessary localized processing for time-sensitive operations and can provide local versions of cloud services to maintain system functionality in the event of a cloud server disconnection.
Object detection is a crucial task in computer vision, and numerous methods and algorithms have been proposed to address this issue. However, most of these methods are designed for detecting and analyzing a single wearable object, which limits their effectiveness in the multi-specification wearable application environment of power systems. To improve the detection accuracy of targets in power systems and to more effectively locate illegal wearing, advanced target detection algorithms are often combined with traditional or binary classification algorithms. However, these models tend to be relatively complex and struggle to achieve a balance between speed and accuracy. Additionally, there has been a lack of emphasis on the development of real-time detectors for low-cost edge hardware, such as the Jetson Xavier NX. To address these limitations, it is urgent to propose an advanced multi-wearable object recognition and defect location method that can effectively solve the aforementioned problems. In this paper, we investigate an improved intelligent detection method based on Edge-YOLO for detecting instances of illegal wearing among on-site power construction workers. Our proposed approach embeds lightweight models into the edge devices, achieving a balance between precision and real-time network architecture.
Our main contributions are summarized as follows: (1) Our proposed Edge-YOLO model enhances object detection accuracy by integrating the SE [
6] module, which adds a channel attention mechanism to the bottleneck structure of the backbone network for improved feature extraction. This module prioritizes informative features and suppresses less relevant ones, enabling it to perform well on edge devices for automatically detecting complete compliance with wearing requirements for power construction site workers; (2) We present a novel embedded real-time detection system, leveraging Jetson Xavier NX and Edge-YOLO, for the purpose of identifying and alarming instances of illegal wearing behavior among power construction workers. To achieve a lightweight implementation of the embedded model, we adopt a strategy of designing suitable detection heads that take into consideration the size and distribution of the targets. This approach aims to reduce the model’s parameter count while simultaneously improving detection speed, all while minimizing potential accuracy reduction; (3) A data augmentation method has been proposed to increase the number and diversity of the dataset. We collect original images from real power construction sites or networks and enhance the resulting dataset to be used for training our models.
The remainder of this paper is organized as follows:
Section 2 introduces the related work. In
Section 3, we present our improved detection methods for various objects.
Section 4 provides detailed explanations of our data augmentation methods.
Section 5 outlines the experiments we conducted to evaluate our method. Finally, in
Section 6, we present our conclusions.
2. Related Work
Wearing compliance on power construction sites is an important measure to ensure the safety of power grid construction. Previously, substation supervision mainly relied on manual monitoring. However, with the development of surveillance technology, human supervision is gradually being replaced by video surveillance. Nevertheless, video monitoring tasks still require manual observation of the camera system, leading to challenges in achieving real-time and accurate feedback due to the extensive time required for monitoring multiple surveillance cameras. In recent years, intelligent video analysis has emerged as a promising approach to replace traditional methods to support electric power enterprises in behavior recognition and prediction, employee safety, perimeter intrusion detection, and vandalism deterrence. To leverage the benefits of video monitoring systems for the aforementioned purposes, a computer vision-based automatic solution is necessary to enable real-time detection of the substantial volume of unstructured image data collected.
Traditional object detection algorithms, such as ViolaJones detector (VJ.Det) [
7], histogram of oriented gradient (HOG.Det) [
8], and the deformable part-based mode [
9], adopt window sliding and manual feature extraction methods. However, these methods have limitations in adapting to multiscale features and tend to exhibit low detection efficiency and accuracy. In recent years, deep learning-based object detection methods have been proposed and continuously applied, taking advantage of the ongoing development of deep learning. Therefore, many object detection algorithms based on deep learning have been introduced, including AlexNet [
10] and residual learning [
11]. Based on their approaches, current object detection methods using deep learning can be categorized into two-stage and one-stage object detection. The former includes faster R-CNN [
12], FPN [
13], Certernet [
14], etc. While achieving high accuracy, the previously mentioned two-stage object detectors often exhibit low efficiency, making real-time detection challenging. In contrast, one-stage target detectors, such as the YOLO (You Only Look Once) series [
15], RetinaNet [
16], EfficientNet [
17], etc., strike a balance between real-time detection and accuracy. Additionally, lightweight models are designed for mobile devices and other computing resource-constrained environments, such as drones and edge devices [
18,
19]. Among these models, SSDLite [
20] is a typical architecture used in lightweight object detection. The MobileNet series [
21] gradually improve the performance of the constructed model with depthwise separable convolutions, while Xception [
22] is designed to enhance network performance without increasing network complexity.
Moreover, several breakthroughs have been achieved in the field of object detection, particularly with the YOLO family of detectors. Many researchers have succeeded in reducing the size of YOLO models, enabling real-time detection. YOLO-LITE [
23] offers a more efficient model for mobile devices, while YOLObile [
24] introduces block-punched pruning and mobile acceleration using a collaborative scheme between mobile GPUs and CPUs. However, research on real-time object detection for safety construction monitoring is still in its early stages. YOLOv5s is an improvement of the YOLO series for lightweight networks, which provides a trade-off between detection speed and precision [
25]. Yan et al. [
26] proposed a system that combines remote substation construction management and artificial intelligence object detection techniques during construction in real-time based on YOLOv5s. Several researchers have conducted studies on related variants of YOLOv5 to improve the model’s performance. For example, Liao et al. [
27] built the device components using a simple online and real-time tracking and counting algorithm on pruned YOLOv5. Liu et al. [
28] improved YOLOv5n by optimizing the configuration of the target detector head and the network structure, solving the problems of low efficiency and redundant parameters in feature extraction in the model. Additionally, Xu et al. [
29] proposed a target detection algorithm based on the YOLOv5 algorithm to address the issues of low accuracy and strong interference in existing safety helmet wearing detection algorithms and successfully improves the detection accuracy of safety helmets. The algorithm effectively demonstrated that by adding the SE (squeeze-and-excitation) block module to the YOLOv5 model, it is not only possible to obtain the weights of image channels but also to accurately separate the foreground and background of the image. By contrast, we aim to further improve YOLOv5s models [
30] for real-time detection on low-cost edge devices in the study for real-time safety monitoring of electric power enterprises. We deployed the model to low-cost edge devices, ultimately achieving accurate and fast detection of compliance wearing in power grid construction. The study focuses on the automatic detection of complete compliance wearing for power construction site workers, including safety helmets, safety belts, work clothes, and safety gloves, rather than just detection a single item.
3. Materials and Methods
3.1. Jetson Xavier NX
The Jetson Xavier NX is an edge device that can serve as either an end device or an edge server capable of performing computing tasks on the device itself [
31]. It is designed for high-performance AI systems such as drones, portable medical devices, small commercial robots, automated optical detection, and other IoT-embedded systems. It is designed to deliver powerful deep learning computations while maintaining portability. In addition, the Jetson Xavier NX has a WIFI module on the back for connecting to the host system via a wireless network. This device offers several advantages, including high computational efficiency, rapid response time, low energy consumption, and cost-effectiveness, among others. In this study, the YOLOv5s-based lightweight model proposed is embedded into the Jetson Xavier NX to provide efficient and effective solutions for power construction safety detection.
Table 1 shows the parameters of the Jetson Xavier NX.
3.2. The Edge-YOLO Architecture
The objective of this study is to detect compliance violations in the safety gear of power construction workers, including safety helmets, safety belts, work clothes, and safety gloves. Given that the system is intended to be deployed on edge devices, the real-time performance of the detection model is critical. Additionally, due to the unique nature of power construction safety detection, the system must operate continuously once activated. Thus, the accuracy and stability of the model become indispensable. In this paper, we present an innovative deep learning network architecture, Edge-YOLO, which is an improved version of YOLOv5s. Our proposed model is specifically designed for real-time monitoring of power construction sites and is capable of detecting non-compliant worker behavior related to safety regulations.
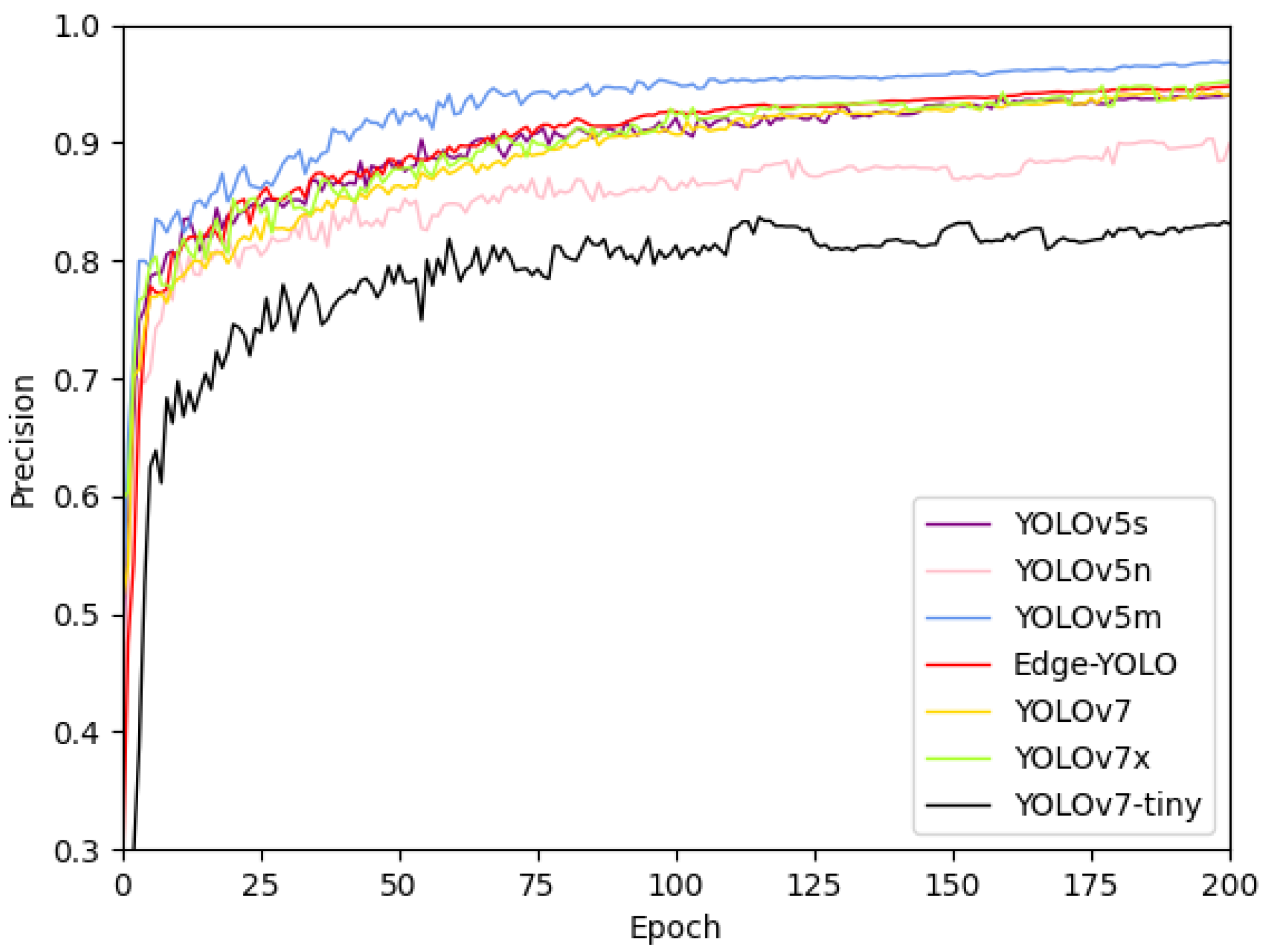
The YOLOv5 algorithm is a popular object detection model optimized for GPU computing. It is the fifth iteration of the original YOLO algorithm and includes several variations based on the width and depth of the network. The latest version, YOLOv5 7.0 [
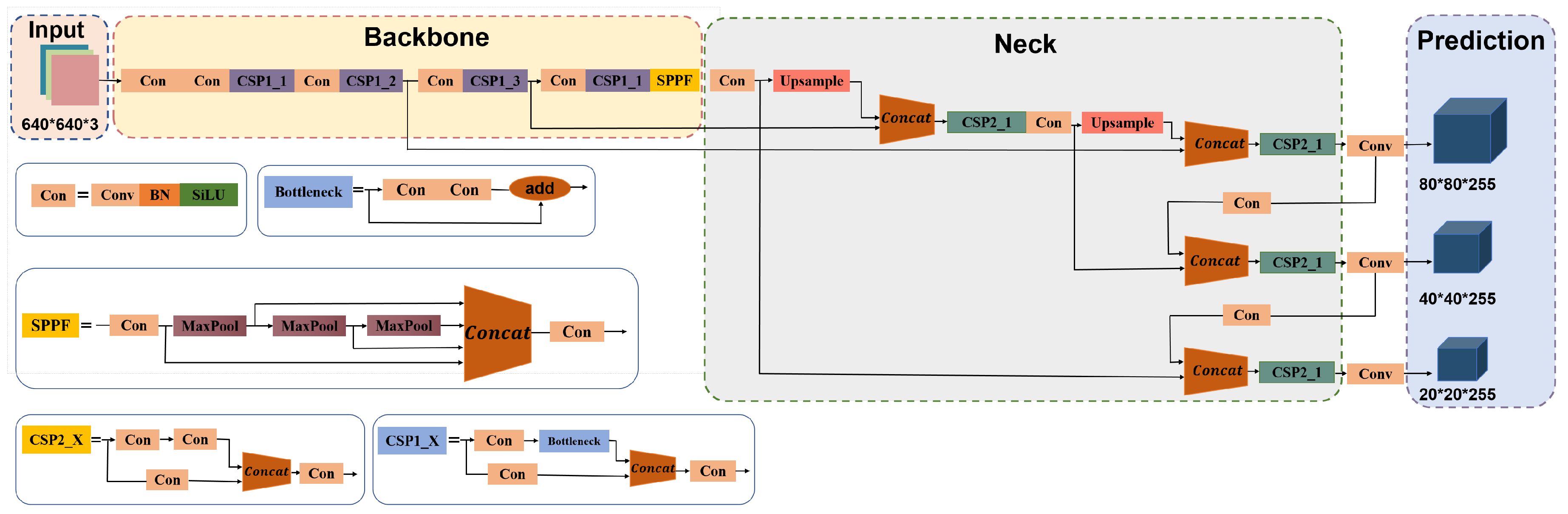
32], includes YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. Among these variations, the YOLOv5s model has been specifically designed to streamline the network and achieve high speed on edge devices, such as the Jetson Xavier NX, with a frame rate of up to 30 FPS. Additionally, the YOLOv5s model offers several advantages, including high detection accuracy, stability, and ease of deployment. Notably, it outperforms YOLOv5n, YOLOv7-tiny, and YOLOv8n in terms of both accuracy and stability. Therefore, a model based on YOLOv5s is well-suited for deployment on the Jetson Xavier NX and is an ideal choice for an intelligent power construction compliance wearing detection system. The YOLOv5s model consists of three primary components: backbone, neck, and prediction (as illustrated in
Figure 1). The entire working process of the YOLOv5s network can be described in detail as follows.
- (1)
Backbone: The backbone network comprises a Con structure, Batch Normalization (BN), and SiLu operations. It includes CSP1_X blocks and a SPPF (Spatial Pyramid Pooling-Fast) module. CSP1_X blocks concatenate different convolutions to extract valuable features from the input image. The network applies a Convolution module with a size of 3 and a step size of 2 to extract image features, producing an output image of size 160 × 160 × 128. Three groups of CSP1 and Conv layers further enhance feature extraction, resulting in a feature map of size 20 × 20 × 1024. A bottleneck structure improves detection accuracy. An SPPF module is incorporated to enhance the accuracy of the 20 × 20 feature map, capturing features at multiple scales and improving object detection accuracy.
- (2)
Neck: The Neck module, comprising CSP1_X and CSP2_X, plays a critical role in balancing network speed and accuracy. CSP2_X reduces model parameters while improving precision. Additionally, the Neck also includes an upsampling process that upsampled feature maps of size 80 × 80 × 512 using two sets of CSP2_X, Conv, Upsample, and Concat connections of size 1 and step 1. As a result, the network produces feature maps of 80 × 80 × 512, 40 × 40 × 512, and 20 × 20 × 512 after subsampling the initial 80 × 80 × 512 feature map.
- (3)
Prediction: The prediction module of YOLOv5s adopts a multi-scale feature map approach for comprehensive object detection. Convolutional (Conv) operations generate three feature maps of different scales: 80 × 80 × 255, 40 × 40 × 255, and 20 × 20 × 255. These feature maps enable the model to detect both small and large targets within a single image. By utilizing Conv operations and generating candidate boxes on these feature maps, the model accurately detects the presence and location of objects within the image.
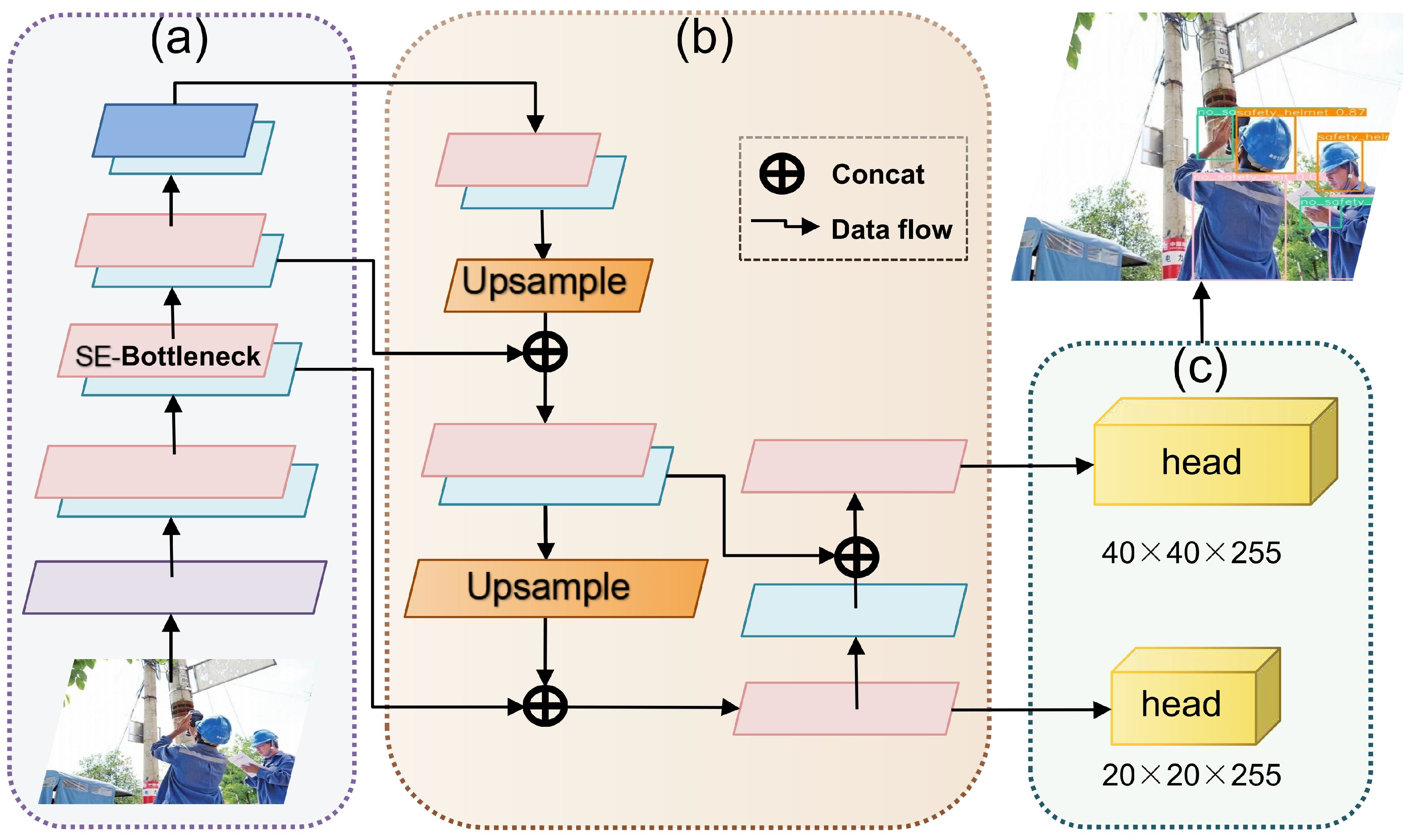
To further improve accuracy and meet real-time requirements for edge device optimization, this paper proposes an improved model named Edge-YOLO based on the YOLOv5s framework.
Figure 2 illustrates the overall architecture of Edge-YOLO. In the backbone structure, we have added the SE module into the bottleneck structure of YOLOv5s to improve detection accuracy. In the head structure, we have designed appropriate detection heads to reduce the model’s parameter size. Specifically, we designed the largest header to significantly increase detection speed without a noticeable decline in accuracy, meeting the speed requirements of edge equipment.
To ensure high accuracy while meeting the resource constraints of edge devices, we investigated the impact of reducing the detection head of YOLOv5s. We found that the detection accuracy decreased as the size of the head was reduced. To mitigate this decline, we introduced the Squeeze-and-Excitation (SE) module to refine the features. By incorporating the SE module, we were able to improve the detection accuracy while still maintaining a small model size that is well-suited for deployment on edge devices.
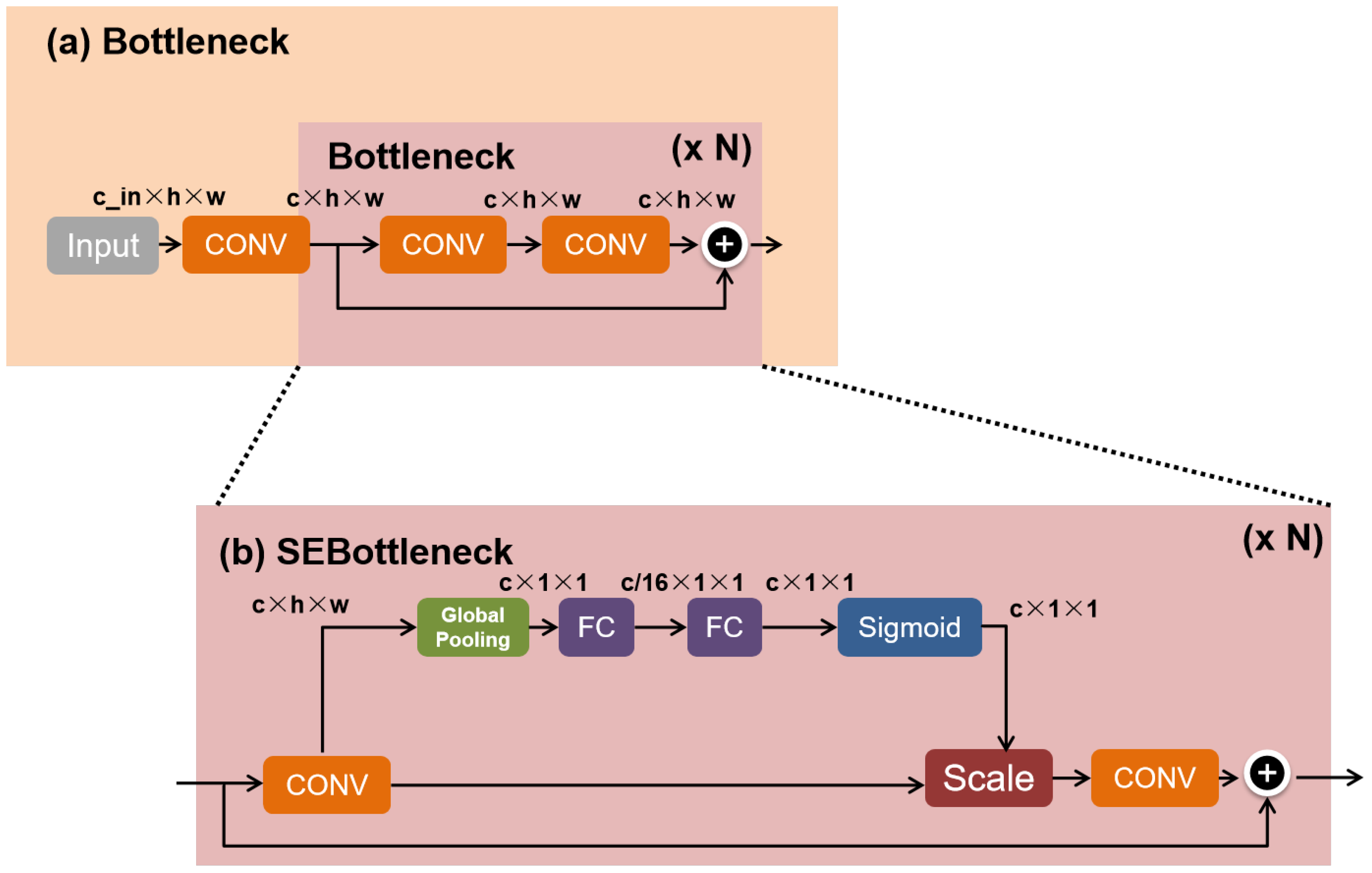
Figure 3 illustrates the integration of the Squeeze-and-Excitation (SE) module, which serves as a channel attention mechanism. The SE module is added to the original residual block as an additional pathway. It computes the initial channel weights via the global pooling layer and subsequently refines them for each channel using two fully connected layers and a sigmoid activation function. Finally, the original channel is multiplied by the weights for each channel, leading to improved detection accuracy during the learning and training process through the gradient descent method in the network. The formula for the squeezing operation is shown below:
where
is the squeeze operation,
u denotes the input space, and
, and
c represents each channel. Furthermore, the excitation formula is given as follows:
where
presents the excitation operation,
,
,
r denotes a hyperparameter with a default value of 16, indicating the dimension reduction coefficient of the first fully connected layer. Additionally, the formula of scale is shown as follows:
where
shows the scale operation. The SE module plays a crucial role in learning the weight coefficients to effectively distinguish features in the model. The embedding of the SE module can significantly enhance the detection accuracy of the model.
3.3. Optimizing Model Deployment and Application on Jetson Xavier NX
In a conventional detection system, the process of capturing images or videos through a camera and transmitting the video signal to a server over the network can be time-consuming. Subsequently, the detection of illegal wearing by power construction workers relies on a detection model deployed on the server, with the detection results and alarm signals transmitted back to the client. However, this process introduces network delays and alarm delays, thereby compromising the reliability of standard wearing detection. To address these limitations, we have deployed the trained Edge-YOLO model on the powerful Jetson Xavier NX-embedded device. This embedded device has been strategically deployed in various substations. Leveraging the computational capabilities of Jetson Xavier NX, the need for server deployment and network transmission has been eliminated. Consequently, real-time detection and early warning of illegal wearing by power construction workers have become achievable. This deployment paradigm significantly improves the reliability and efficiency of standard wearing detection for power construction workers, offering a more practical solution for real-time monitoring and timely intervention in substations.
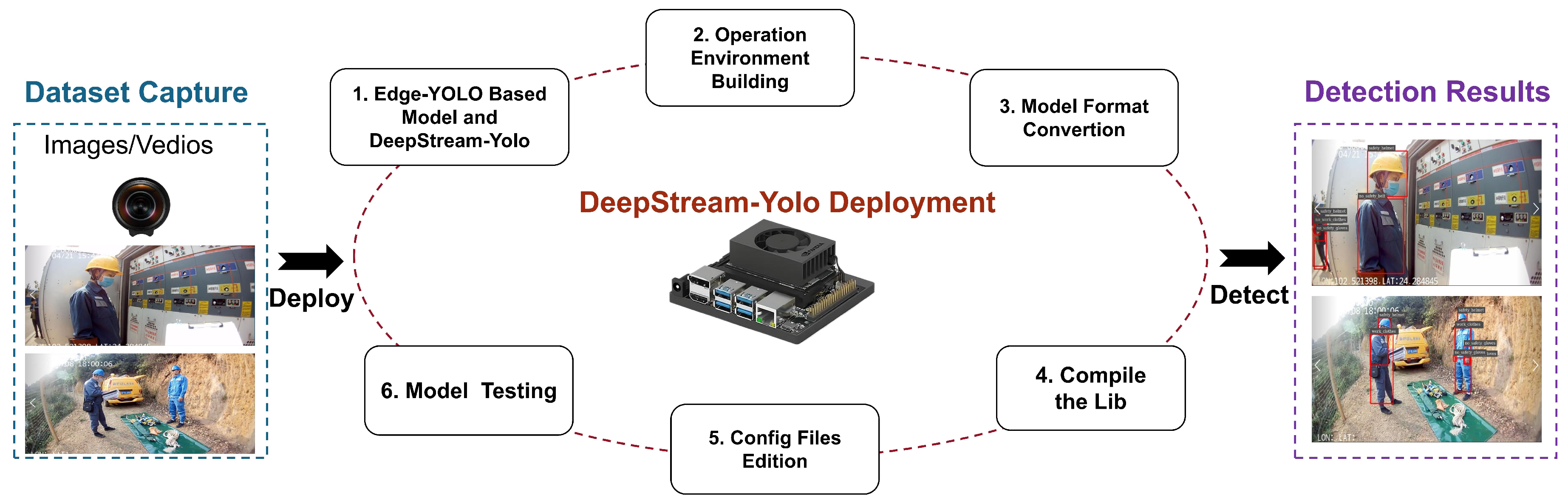
The deployment of the Jetson Xavier NX algorithm involved its seamless integration with the NVIDIA DeepStream SDK. To accomplish this, we followed a series of systematic steps as outlined below, the detection system flowchart is shown in
Figure 4.
(1) Preparation of test dataset and operating environment setup: We meticulously prepared the required test dataset for evaluation purposes. In addition, based on DeepStream YOLO and the Edge-YOLO model, we established the necessary operating environment.
(2) Trained model import and file conversion: We imported a trained “pt” model into the system for deployment on Jetson Xavier NX. Through the conversion process, we obtained the configuration (cfg) and weight (wts) files required for further proceedings.
(3) Compilation of libraries and configuration file editing: We compiled the necessary libraries to ensure compatibility with the deployed algorithm. As per specific requirements, we meticulously edited the configuration files, fine-tuning them for optimal performance.
(4) Model testing and comparative analysis: We rigorously conducted tests on the deployed model to assess its performance in real-world scenarios. Through comparative analyses, we evaluated the detection results, comparing them against established benchmarks.
Upon successful deployment of the trained YOLOv5.pt model to the Jetson Xavier NX, the current embedded device can be utilized as a comprehensive intelligent detection system for identifying illegal wearing practices among power construction workers. This system can be deployed in various substations without the need for a host, enabling real-time detection of safety helmet, safety belt, work clothes, and safety gloves without relying on a network connection. The proposed method for detecting illegal wearing among power construction workers comprises the following three stages:
(1) Data Acquisition Phase: The Jetson Xavier NX-embedded device is deployed in substations to capture real-time video streams or images using a monocular camera connected to the device.
(2) Image Pre-processing Phase: Video streams and images are processed by the Jetson Xavier NX using the YOLOv5s training model. Leveraging the powerful computing capabilities of the Jetson Xavier NX, this stage ensures accurate and real-time standardized wearing detection for power construction workers without the need for host support.
(3) Detection Result Display and Non-standard Dress Warning: A high-definition display and voice warning device can be connected to the Jetson Xavier NX via the USB terminal or wireless network. This setup allows for real-time monitoring of electric workers’ illegal wearing practices through video or voice alerts.
4. Data Augmentation
The dataset utilized in the experiment consists of four components: safety helmet, safety belt, work clothes, and safety gloves. These components encompass both positive and negative samples. During the data collection process, the diversity of sample data was taken into account. However, due to the high number of data classes, obtaining a sufficient amount of data can be challenging, particularly for the standard wearing of Yunnan Power Grid Corporation’s work clothes and safety gloves.
During the training process of our neural network model, a small dataset can lead to overfitting, which weakens the model’s ability to generalize. Overfitting occurs when the model performs well on the training set but performs poorly on the test set. To avoid this issue, appropriate data augmentation methods can be used to increase the variety of images in the dataset and achieve a more reasonable data distribution. This approach can help prevent overfitting and enhance the model’s generalization performance.
To account for the effects of equipment at the power construction site and environmental factors during filming, this paper employs four primary techniques for data augmentation: (1) merging object segmentation with the background; (2) affine transformations; (3) definition transformations [
26]; (4) brightness and contrast transformations. Each operation simulates a range of real-life surveillance video scenarios encountered during on-site power construction, including changes in viewing angles, variations in distance, fluctuations in backgrounds, differences in image clarity, and adjustments in illumination.
4.1. Merging Object Segmentation with Background
The training dataset can be divided into two categories based on their role during training: foreground information and background information. The foreground information includes the detection targets such as safety helmets, safety belts, work clothes, and safety gloves, while the background information refers to other image information. Due to the lack of real-world power construction scenes, the available dataset are limited. To meet the volume requirements of the training dataset and enhance the performance of the trained model, we utilized a method of fusing foreign objects and background to augment the construction dataset. Specifically, we collected background images taken in realistic power construction sites without any workers present, and then performed segmentation on images from various scenarios to extract the workers under construction. These segmented workers were subsequently fused into the power construction environment [
26].
Figure 5 presents an example of using the existing dataset to generate a new dataset through segmentation and fusion.
4.2. Affine Transformation
Affine transformations were applied to modify the size, orientation, and position of safety helmets, safety belts, work clothes, and safety gloves in the original images and fused images, simulating the conditions of power construction sites. Geometric transformations such as rotation, scaling, translation, and zooming were used to augment the dataset, generating additional image samples. The robustness of detection models can be improved by utilizing generated images for training. For instance, a power construction scene captured by a video camera can be simulated from different angles, resulting in a diverse set of training data. By incorporating these generated images into the training process, the detection model can learn to recognize and adapt to a wider range of scenarios, ultimately leading to improved robustness.
4.3. Definition Transformation
We utilize Gaussian noise as a data augmentation technique to simulate sensor noise resulting from poor lighting and/or high temperature during data acquisition. The primary objective is to introduce noise to elements within the image of the source dataset, resulting in an image with added noise. To accomplish this, we utilize a Gaussian kernel function to perform a convolution on the image, transforming it into a blurred image. The integration of artificially generated images during the training phase can lead to a considerable enhancement in both accuracy and stability of detection models.
4.4. Brightness and Contrast Transformation
In the field of deep learning research, brightness and contrast transformations are commonly categorized into linear and nonlinear transformations. These transformations are applied to generate diverse dataset that can simulate real-world changes in illumination resulting from different weather conditions. This approach aims to enhance the robustness of detection models when dealing with varying illumination conditions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}