
An Open-Domain Event Extraction Method Incorporating Semantic and Dependent Syntactic Information

Abstract
:1. Introduction
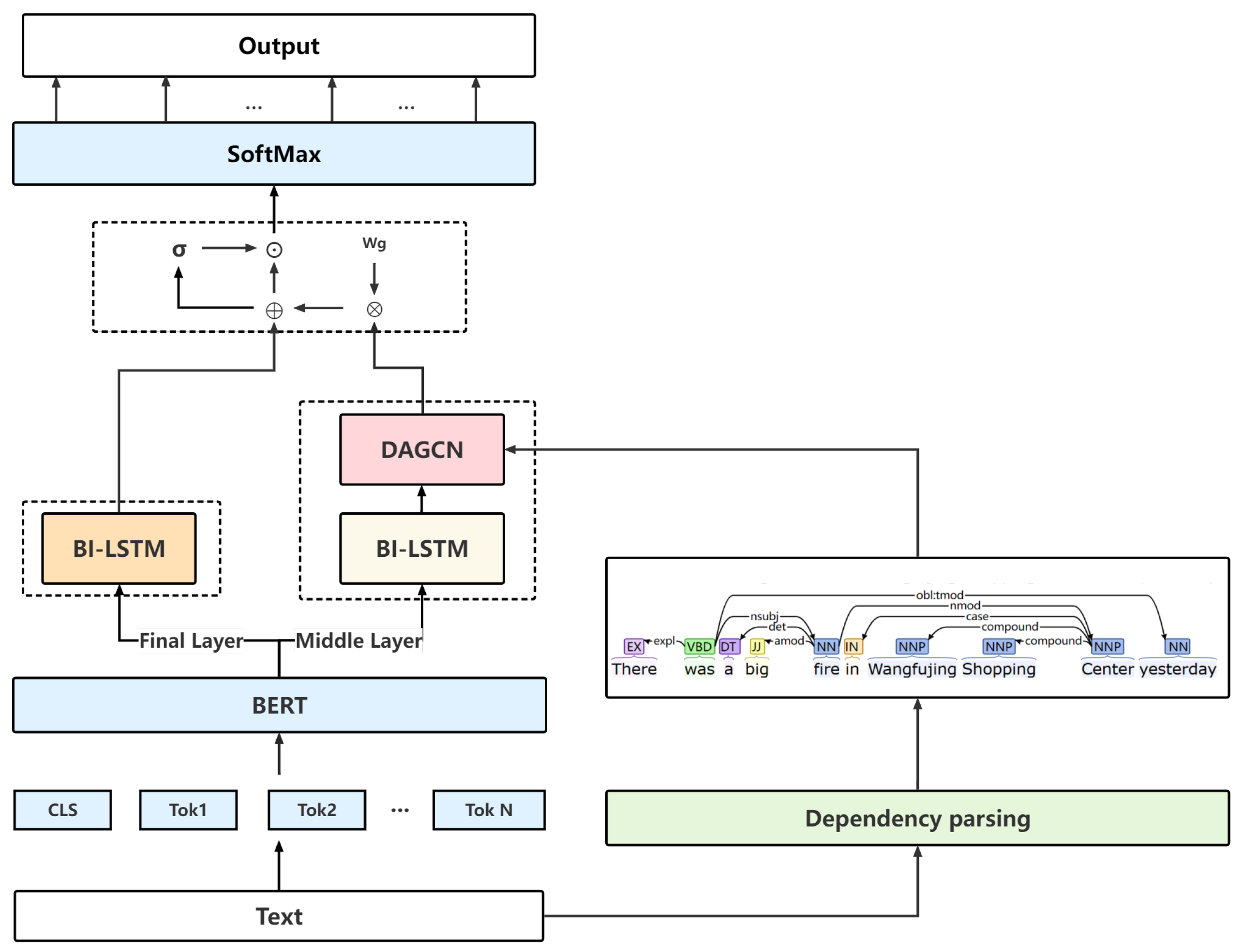
- Semantic information is introduced based on BERT. We selected BERT end-layer features to obtain rich semantic features through Bi-LSTM and conducted experiments on the dataset to verify the validity of the semantic information;
- Dependency syntactic information is further integrated. We analyzed the dependency syntactic information based on BERT middle layer features using the Stanford CoreNLP tool, further increasing the attention of nodes to the information in the graph through a DAGCN;
- Semantic information and semantically enhanced dependency syntactic information are dynamically fused. We introduced a gating mechanism to reasonably control the information flow, extract rich and accurate feature representations, and again verify the feasibility of combining semantics and dependent syntax.
2. Related Work
3. Our Approach
3.1. Embedding Layer
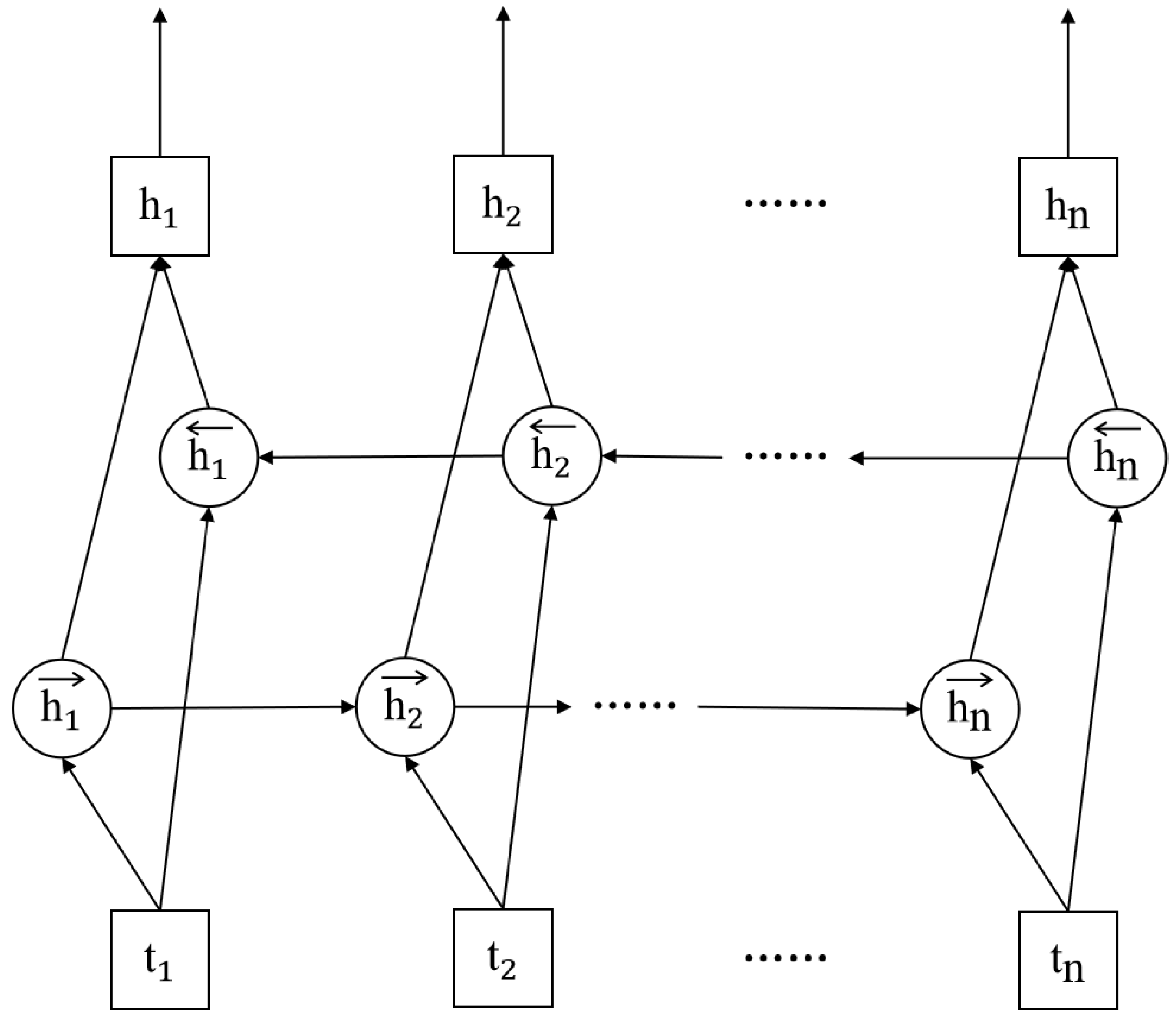
3.2. Semantic Enhancement Presentation Layer Based on the Final Layer Features
3.3. Semantic Enhancement Dependency Syntax Representation Layer Based on Middle Layer Features
3.4. Semantic Representation and Enhancement Depend on the Syntactic Representation Fusion Layer
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.3. Experimental Results and Analysis
4.3.1. Comparison Experiments
4.3.2. Ablation Experiments
- (1)
- Influence of different factors on model performance.
- (2)
- The impact of intermediate layer selection on model performance.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Nguyen, T.; Grishman, R. Graph convolutional networks with argument-aware pooling for event detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Voluem 32. [Google Scholar]
- Bai, Y. Research on Key Technologies of Text-Based Event Extraction; University of Electronic Science and Technology: Chengdu, China, 2022. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; Song, Y.; Yang, R.; Ranjan, R.; Yu, P.S.; He, L. Streaming social event detection and evolution discovery in heterogeneous information networks. ACM Trans. Knowl. Discov. Data 2021, 15, 1–33. [Google Scholar] [CrossRef]
- De Vroe, S.B.; Guillou, L.; Stanojević, M.; McKenna, N.; Steedman, M. Modality and negation in event extraction. arXiv 2021, arXiv:2109.09393. [Google Scholar]
- Wang, R.; Zhou, D.; He, Y. Open event extraction from online text using a generative adversarial network. arXiv 2019, arXiv:1908.09246. [Google Scholar]
- Arnulphy, B.; Tannier, X.; Vilnat, A. Automatically generated noun lexicons for event extraction. In Proceedings of the Computational Linguistics and Intelligent Text Processing: 13th International Conference, CICLing 2012, New Delhi, India, 11–17 March 2012; Proceedings, Part II 13. Springer: Berlin/Heidelberg, Germany, 2012; pp. 219–231. [Google Scholar]
- Zhou, D.; Chen, L.Y.; He, Y. A simple bayesian modelling approach to event extraction from twitter. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 700–705. [Google Scholar]
- Liu, X.; Huang, H.; Zhang, Y. Open domain event extraction using neural latent variable models. arXiv 2019, arXiv:1906.06947. [Google Scholar]
- Chau, M.T.; Esteves, D.; Lehmann, J. A Neural-based model to Predict the Future Natural Gas Market Price through Open-domain Event Extraction. In Proceedings of the CLEOPATRA@ESWC, Heraklion, Crete, Greece, 3 June 2020; pp. 17–31. [Google Scholar]
- Yu, J.; Bohnet, B.; Poesio, M. Named entity recognition as dependency parsing. arXiv 2020, arXiv:2005.07150. [Google Scholar]
- Kilicoglu, H.; Bergler, S. Syntactic dependency based heuristics for biological event extraction. In Proceedings of the BioNLP 2009 Workshop Companion Volume for Shared Task, Boulder, CO, USA, 5 June 2009; pp. 119–127. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Voluem 32. [Google Scholar]
- Li, J.; Yu, C.; Hong, J.W. An Event Detection Method Using Gating Mechanism to Fuse Dependency and Semantic Information; Soochow University: Suzhou, China, 2020; Volume 34, pp. 51–60. [Google Scholar]
- Yu, Y. Study on Event Extraction based on Dependency Syntax and Role Knowledge; Huazhong Normal University: Wuhan, China, 2022. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag | Description | Explanation | Case |
|---|---|---|---|
| expl | expletive | The main verb of the clause | “There is a ghost in the room” expl (is, There) |
| tmod | temporal modifier | Time modification | “Last night, I swam in the pool” tmod (swam, night) |
| nsubj | nominal subject | Nominal subject | “Clinton defeated Dole” nsubj (defeated, Clinton) |
| det | determiner | Determiner | “The man is here” det (man, the) |
| amod | adjectival modifier | A descriptive modifier that modifies a noun phrase | “Sam eats red meat” amod (meat, red) |
| acomp | adjectival complement | A form complement used in verbs | “She looks very beautiful”. acomp (looks, beautiful) |
| advcl | adverbial clause modifier | An adverbial clause that modifies a verb | “The accident happened was falling” advcl (happened, falling) |
| dobj | direct object | Direct object | “She gave me a raise” dobi (gave, raise) |
| nsubjp ass | passive nominal subject | Passive noun subject | “Dole was defeated by Clinton”nsubjpass (defeated, Dole) |
| Method | Scheme Matching (%) | ||
|---|---|---|---|
| Bi-LSTM | 60.5 | 41.6 | 49.3 |
| DBRNN [14] | 52.1 | 47.7 | 49.8 |
| GCN-ED [2] | 53.1 | 49.8 | 51.4 |
| DAGCN [3] | 53.5 | 50.4 | 51.9 |
| Yuanfang Yu et al. [16] | 52.6 | 49.7 | 51.1 |
| GFDS [15] | 52.5 | 51.9 | 52.2 |
| Our Model | 53.5 | 52.3 | 52.9 |
| Method | Scheme Matching (%) | ||
|---|---|---|---|
| − Bi-LSTM Final Layer | 52.9 | 51.7 | 52.3 |
| −Bi-LSTM Middle Layer | 53.4 | 52.0 | 52.7 |
| −DAGCN | 53.0 | 51.2 | 52.1 |
| −Gating Mechanism | 53.1 | 51.7 | 52.4 |
| Spacing Number | Corresponding Layer | P | R | |
|---|---|---|---|---|
| 5 | 1, 6, 11 | 51.6 | 50.0 | 50.8 |
| 4 | 1, 5, 9, 11 | 52.5 | 51.7 | 52.1 |
| 3 | 1, 4, 7, 10 | 53.6 | 52.2 | 52.9 |
| 3 | 2, 5, 8, 11 | 52.5 | 52.3 | 52.4 |
| 3 | 3, 6, 9, 12 | 51.8 | 51.4 | 51.6 |
| 2 | 2, 4, 6, 8 | 50.9 | 51.5 | 51.2 |
| 2 | 5, 7, 9, 11 | 51.2 | 50.6 | 50.9 |
| 1 | 13 | 51.5 | 49.2 | 50.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Zhang, Q.; Duan, J.; Wang, H. An Open-Domain Event Extraction Method Incorporating Semantic and Dependent Syntactic Information. Appl. Sci. 2023, 13, 7942. https://doi.org/10.3390/app13137942
He L, Zhang Q, Duan J, Wang H. An Open-Domain Event Extraction Method Incorporating Semantic and Dependent Syntactic Information. Applied Sciences. 2023; 13(13):7942. https://doi.org/10.3390/app13137942
Chicago/Turabian StyleHe, Li, Qian Zhang, Jianyong Duan, and Hao Wang. 2023. "An Open-Domain Event Extraction Method Incorporating Semantic and Dependent Syntactic Information" Applied Sciences 13, no. 13: 7942. https://doi.org/10.3390/app13137942
APA StyleHe, L., Zhang, Q., Duan, J., & Wang, H. (2023). An Open-Domain Event Extraction Method Incorporating Semantic and Dependent Syntactic Information. Applied Sciences, 13(13), 7942. https://doi.org/10.3390/app13137942