1. Introduction
Text classification is one of the most fundamental tasks in natural language processing and is the basis for recommendation tasks, question-and-answer systems, sentiment analysis, and many other tasks. The text classification referred to in this paper is to multiclassify texts according to topics into multiple categories, such as financial, sports, military, social, etc. As the amount of text data increases geometrically, the study of text classification tasks, which are the basis of many applications, has become more and more important. As Chinese and English belong to different language families, the minimum units of text composition are different (English takes letters as the minimum units, and Chinese takes Chinese characters as the minimum units); in addition, Chinese needs to be processed by word separation, while each word in English is separated by spaces. This directly affects the transferability of English methods. In recent years, domain long text classification has received a lot of attention from researchers and has made great progress, but most of the existing studies focus on the data dimension, which means extracting deep semantic representations of Chinese text by deep learning models to obtain contextual information, making it difficult to solve the problem of multiple meanings of words in different contexts and leading to problems such as ambiguous semantic understanding and inadequate feature representation.
In terms of text vectorization representation, BERT can obtain dynamic word vectors to better represent semantic information, but since the research content of this paper is long text classification, the text length is long and much larger than the maximum input sequence length of BERT. If truncated text is used to make it meet the input sequence length requirement of BERT, a large amount of information in the text will be lost and the accuracy of classification will be reduced. On the one hand, it will consume a lot of hardware resources; on the other hand, it will consume a lot of computational time because the computational complexity grows with the square of the input text length if the length of the positional embedding is increased and retrained from scratch.
In terms of classification model construction, the long text classification task causes many text classification models to fail to perform optimally due to the long text. For text classification algorithms using only convolutional neural networks, the convolutional kernel field of view is controlled by the size of the convolutional kernel, so only local features can be extracted, and longer field of view features cannot be focused on; for text classification algorithms using only recurrent neural networks, the memorability of the internal memory network gradually decreases as the input text length becomes longer for long texts. Although the combination of convolutional and recurrent neural networks can solve the respective drawbacks of the above two models, however, all the above text classification models ignore the unique structured features of long texts themselves. In addition, long texts can extract more features compared to short texts, but they also have more redundant words, which are irrelevant words that have no positive impact on the classification structure and tend to affect the classification accuracy.
To address the above issues, a domain long text classification model based on a knowledge graph is proposed for the above problems. At the data dimension, dynamic word vectors are trained using BERT to enrich semantic information, and GCN is used to obtain long-distance text semantic dependencies. At the knowledge dimension, prior knowledge is introduced through the knowledge graph to solve the problem of multiple meanings of words in different contexts. The main idea of the model is, firstly, the data text is encoded using BERT to obtain the initialization vector containing rich semantic information, and each word’s corresponding vector is used as the node of GCN. Secondly, using the trained entity–relationship extraction model, we extract the entity information and the relationship information between entities in the document, use them together with the syntactic dependency information as the edges of the graph neural network, and compute and backpropagate the document representation of BERT together with the document vector of GCN. To further enhance the learning ability of the model for semantic dependencies between words, the graph structure mask is used to learn edge relations and edge types. Finally, a softmax function is connected to obtain the classification probability to finally achieve domain-length text classification. The method further improves the accuracy of long text classification by fusing knowledge features and data features.
Overall, our contributions to this paper are listed as follows:
There is a problem of lack of domain knowledge in existing Chinese long text classification techniques, and we consider that knowledge graphs can solve this problem well. The entity–entity–relationship in the knowledge graph fully reflects the text features and semantic relationships, which can be used as the edge of the graph neural network together with the dependency information in the dependency syntax tree, and the introduction of knowledge can better improve the model performance;
The problem of word ambiguity generated by static word vectors can be solved by using BERT to encode text to learn dynamic word vectors. BERT and GCN jointly calculate the loss function, which can solve the problem of lack of word sense information in graph convolutional neural networks. However, the BERT and GCN models have too many parameters and are prone to the problem of overfitting or difficult convergence. We splice the vectors of the last four layers of BERT to prevent the model from using only the output of the last layer of BERT, which generates the problem of over-computation of parameters;
In order to improve the learning ability of the model for semantic dependencies between words and make the model more adaptable to the fusion of the knowledge graph and GCN, we propose graph structure masking, i.e., randomly masking the edge connection between two tokens, and then let the model predict whether there is a connection relationship between two tokens and the type of connection.
2. Related Work
The research on domain long text classification techniques revolves around improving the accuracy, efficiency, and generality of classification. Traditional text classification models such as naive Bayes (NB) and SVM usually require dividing the classification process into two parts, feature engineering design and classifier design, which are expensive to construct. With the development of deep learning techniques, domain long text classification tasks have been gradually combined with deep learning models [
1,
2,
3].
Xu et al. [
4] proposed using TextCNN for domain text classification, which improved the detection efficiency while ensuring accuracy. Li et al. [
5] used a BiLSTM network model with an attention mechanism to extract global key features and multi-window CNN to extract local semantic features of text for an agricultural domain text classification task, which effectively improved the text classification effect in the agricultural domain. The pre-trained language model, BERT, which is based on an attention mechanism, has achieved better performance on many NLP tasks. Ding et al. [
6] applied BERT to domain text classification tasks with an F1 value of up to 97.31%.
Yan et al. [
7] proposed an R-Transformer_BiLSTM model for the problems of the difficult extraction of sequence information and the apparent lack of semantic information when text sequences grow, using the R-Transformer model combined with lexical embedding to obtain the global and local information of text sequences, BiLSTM and CRF to obtain the entity information of the text, the self-attention mechanism to obtain the keywords of entity information, and then bidirectional attention and label embedding to further generate text representation and label representation to improve the classification performance. Li et al. [
8] conducted a study on long texts in the medical field and proposed a two-channel text classification model that combines medical terms with BiGRU and an attention mechanism to obtain the local features and global features of the text. Yang et al. [
9] found that long texts have the problem of unbalanced distribution, so they proposed a feature-enhanced long text classification method, which mainly extracts shallow information with the initial module, then extracts deep information with BiGRU and the capsule network, and later uses K-MaxPooling to reduce the dimension of the shallow and deep features to obtain the overall enhanced features. Huang et al. [
10] combined an improved self-attention mechanism with the Skip-GRU network (SA-SGRU) to achieve skipping content that is not important for text classification while reading the text and capturing only valid global information.
Although the attention mechanism has a stronger ability to model semantic dependencies compared to the gating mechanism of LSTM, the attention-based model is weaker in capturing semantic dependencies over long distances and is poor in handling long texts. Graph neural networks [
11] establish inter-node connections based on word co-occurrence relations, etc., so that they have no long-distance limitation and, thus, can handle long text at the document level. Wu et al. [
12] modeled documents as graphs to construct DAGNNs, using graphs to model each document so that it can capture discontinuous semantics and long-distance semantics. In recent years, a large number of studies have exploited this feature to explore the application of graph convolutional neural networks to text classification tasks to express semantic relationships in a text [
13,
14,
15,
16,
17,
18,
19]. The vector initialization of these model graph nodes is often based on the degree of the node, and the edge information is encoded one-hot, missing the semantic information of the word or words themselves. In addition, a word in GNN corresponds to only one vector representation in the vector space word, which is a static word vector; however, a word often has multiple meanings. Therefore, Lin et al. [
20] proposed BertGCN, which uses BERT to encode the input text. BERT is massively pre-trained to give words a semantic information-rich vector initially and learn dynamic word vectors to solve the problem of multiple meanings of words. The edges are connected between words and documents. The weights of edges are determined by TF-IDF and PPMI. However, PPMI only measures the co-occurrence relationship between words and lacks sufficient semantic information. To address the above problems, Tian et al. [
21] proposed A-GAN to use syntactic dependency information relations as edges between tokens while adding syntactic dependency types to GCN, and considering the weight relations between individual tokens in the attention matrix to further enrich the edge information of graph neural networks.
The above Chinese long text classification methods extract semantic information mainly based on text features; ignoring domain knowledge leads to weak deep text relevance and limits the text classification performance. A knowledge graph is a kind of knowledge system that represents knowledge in a structured way and is mainly used to describe various entities and concepts that exist in the real world and the relationships among them. Many studies combine knowledge graphs with pre-trained models or deep neural networks to achieve text classification [
22,
23,
24,
25,
26]. Zhao et al. [
27] solved the problem of small data samples by injecting sentiment domain knowledge into a linguistic representation model to exploit the additional information in sentiment knowledge graphs and obtain the embedding vectors of entities in sentiment knowledge graphs and words in a text in a consistent vector space. Tang et al. [
28] proposed a two-level filtering model for long text classification in science combined with a knowledge graph to reduce the interference of topic-irrelevant information and improve the classification performance of the model. Zhong et al. [
29] proposed a knowledge graph augmentation network (KGAN) that learns contextual and syntactic representations in parallel to fully extract semantic features, and then integrates the knowledge graph into the embedding space, based on which aspect-specific knowledge representations are further obtained through an attention mechanism that captures sentiment feature representations from several different perspectives. Liu et al. [
30] targeted the specificity of Chinese text, obtained the vector representation of the sentiment knowledge triad through the TransE model, deeply fused it with the feature vectors obtained from the BiGRU and attention mechanism models, and proposed a method for sentiment analysis of Chinese text with multi-granularity semantic features driven by knowledge and data synergy.
Numerous experiments have proven that introducing knowledge graphs into natural language processing enables models to extract additional prior knowledge from knowledge graphs, and also solves the problem of small data sample size by knowledge introduction, which is very effective for improving model performance.
In general, there are three problems in the existing research related to long Chinese text classification techniques, as follows: (1) Long text length—due to long text lengths and the extensive and scattered key information, long sequence processing tends to ignore rich semantic information in the text hierarchy. (2) Lack of expert domain knowledge—the pre-trained model requires certain a priori knowledge, and relying on text similarity alone can cause the problem of inaccurate classification. (3) Classification accuracy is not high—because the text of the dataset exists in various domains with different lengths and features, the robustness of the existing model still needs to be improved, resulting in biased classification results. Improvement methods should be proposed mainly around these problems.
3. Domain Chinese Long Text Classification Model
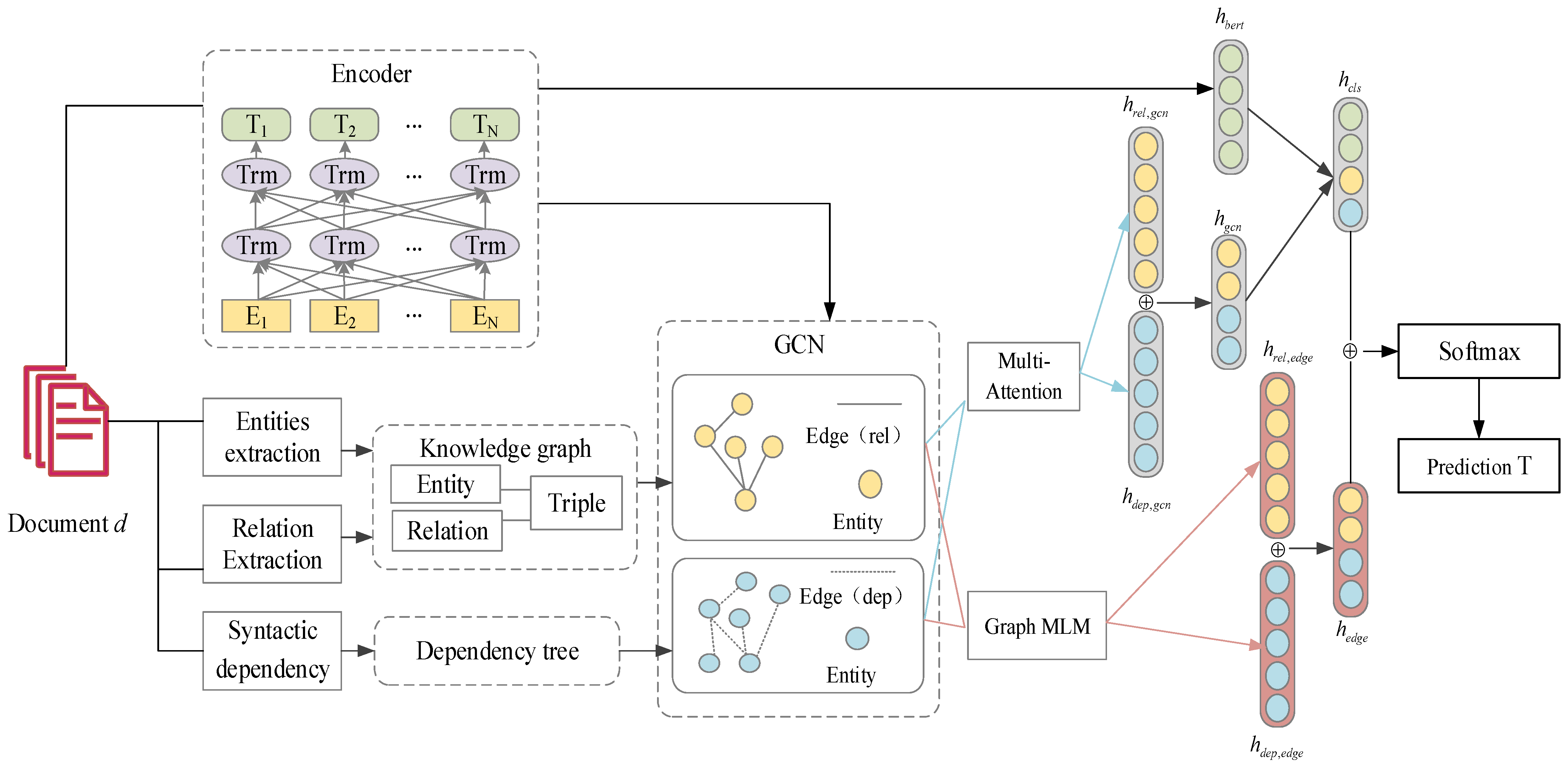
In this section, we present the proposed knowledge-graph- and BERT-based graph convolutional neural network model (KGBGCN). The general framework is shown in
Figure 1. It is shown how the model constructs a relational graph and its relation types based on the entity and relation types of the input sentences and the dependent syntactic tree, models the contextual information by the attention graph convolutional neural network model, further allows the model to understand the semantic dependencies by the graph structure mask, and, finally, achieves classification by backpropagation together with the BERT model.
Specifically, for each input text, an entity–relationship extraction model is first used to extract its entities and inter-entity–relationships to construct a knowledge graph. Entities are used as nodes, entity relations are used as connecting edges between nodes, and the GCN transfer matrix is constructed with the existence of edges and edge types. Similarly, a dependency syntax tool is used to automatically process the text and generate a dependency syntax tree, and then, a graph is constructed on the dependency relationship tree.
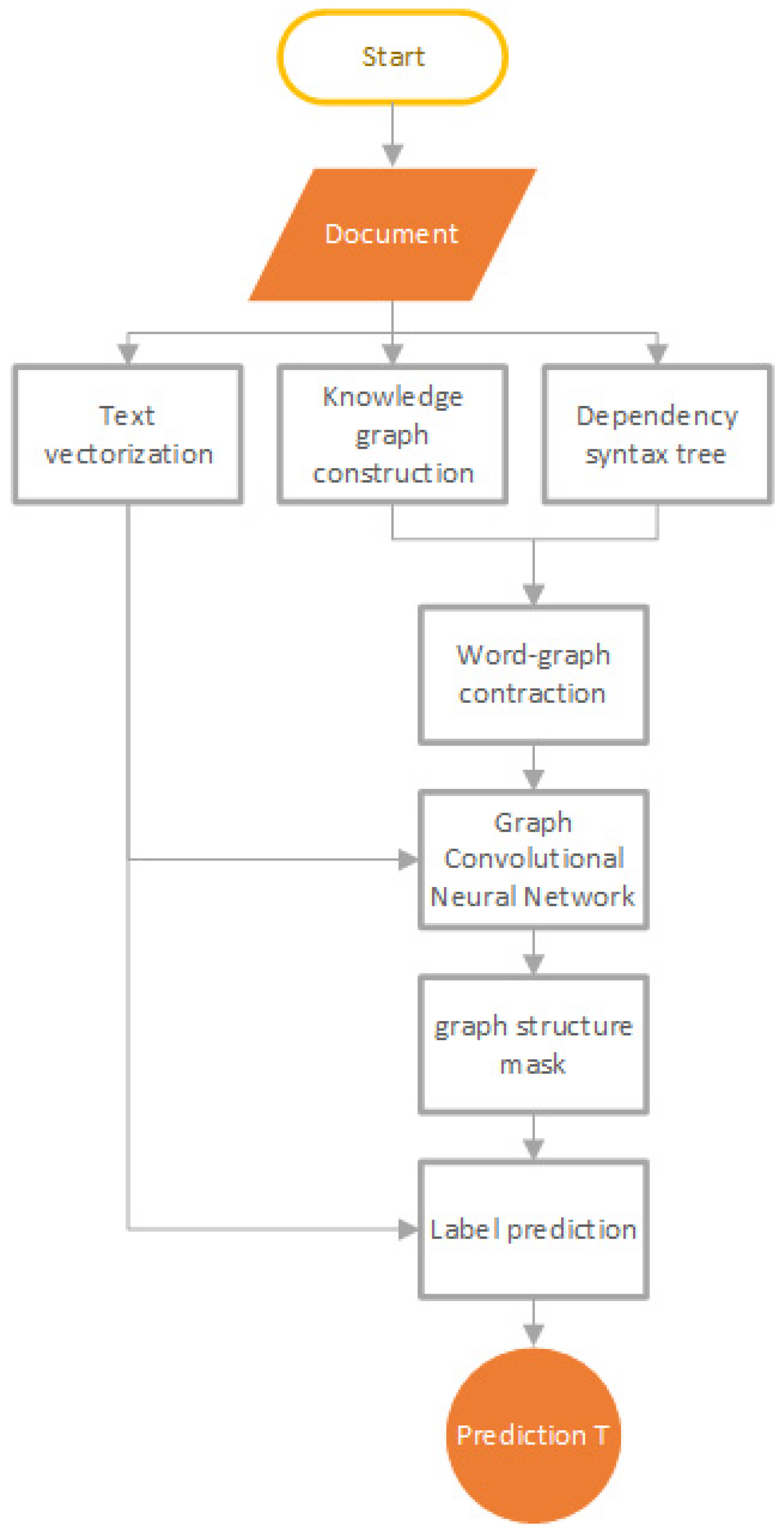
Then, the representation of the text sequence is extracted using BERT as an encoder, and the entity–relationship graph and the dependency graph, which are characterized by the text sequence, are fed into two GCN modules. In the GCN modules, for each word in the sequence, its entity–relationship or dependency type with the related context word is encoded as a contextual feature. Meanwhile, using the attention mechanism to assign different weights to different marked entity relations and dependency relations between any two words, the weights are calculated based on the connection and its relation type, and the attention matrix is constructed by calculating the dot product between words. In addition, to improve the learning ability of the model for semantic dependencies between words, the graph structure mask model is used to randomly mask the edge connection between two tokens, and then, the model is allowed to predict whether there is a connection relationship between two tokens and the type of connection. The two GCN modules and the graph structure mask training are used to obtain entity–relationship representations and dependency representations, respectively, and the two vectors are stitched together to obtain the GCN output. Finally, the fusion output of BERT, GCN, and the graph structure mask is used to predict the category labels of documents. The flow of the method is shown in
Figure 2.
3.1. Entity–Relationship Extraction
Pre-trained language models (e.g., BERT, word2vec, and GloVe) all lack domain-specific knowledge, which usually leads to unsatisfactory performance of text feature representation [
31]. To solve these two problems, a knowledge graph is constructed based on unclassified documents, using their entity–entity relationships as graph neural network nodes and edges for better text classification. Referring to the top–down construction method of the domain knowledge graph, ontology and pattern information are extracted from high-quality data based on classified data sources, and entity and inter-entity relationships are extracted to form domain prior knowledge in the form of the knowledge graph.
A knowledge graph is a set of nodes and edges that form a triad. The nodes are the entities existing in the sentences, and the edges are the inter-entity relationships. First, the keywords of the articles are extracted by the TextRank algorithm, while the articles are clustered by the K-Means clustering algorithm. By manually observing the keywords and clustering results, a preliminary domain key entity type can be obtained, after which the entity types are modified and their entity relationships are defined by using statistical methods combined with manual generalization, refinement by drawing on high-quality generic mapping, and expert guidance. A trained entity–relationship extraction model is used to extract triples based on the defined entity and relationship types.
3.2. BERT-Based Text Vectorization Coding
As an important component of modern NLP tasks, pre-trained word embedding (e.g., word2vec and GloVe) can substantially improve the performance of NLP tasks compared to embedding learned from scratch. For each word in a vocabulary, these context-free models produce only a single representation of the word embedding, even though the meaning of these words may vary across scenarios. In contrast, contextual models, such as OpenAI GPT, ELMo, and BERT [
32], can generate different representations for the same word in different contexts based on the context (i.e., surrounding words in a sentence). These contextual models usually contain more hidden layers and improve model performance by training on a large amount of unlabeled data and fine-tuning with only a small amount of labeled data when applied to domain-specific tasks. BERT was proposed as an alternative to Word2Vec, and its accuracy was substantially refreshed in 11 directions in the NLP domain, such as text classification, question answering, and language. BERT is massively pre-trained to give words an initialized vector rich in semantic information. The word vector is trained using BERT and used as a node for GCN to avoid the problem of having only one vector representation of a word, thus learning a dynamic word vector.
The longest text data can reach several thousand words, while the maximum length of BERT input is limited to 512, which also includes CLS markers. Therefore, special processing is required for BERT representation of long texts. General processing can directly truncate the long text and take only the beginning or the end part, which may lead to the omission of key information. Using the sliding window approach, different parts of a long text are intercepted by sliding window, and then all the sentence representations are summed and averaged as the final BERT vector.
In addition to making the BERT output as GCN nodes, referring to the predictive interpolation practice of BertGCN, the text treats the document representation of BERT as a separate output, calculates the loss together with the final output of GCN, and backpropagates. Due to the large number of parameters of GCN, the model is prone to overfitting or difficult to converge after fusion with BERT; to solve this problem, the vectors of the last four layers of BERT are spliced to prevent the model from using only the last layer of BERT output with too many parameters calculated. Then, we can obtain the output of the vectors of BERT layers, and this expression is shown in Equation (1):
where ; represents the splicing;
,
,
, and
denote the vectors obtained from the last four layers of BERT encoding;
W is the trainable weight matrix; and
b is the bias term.
3.3. Entity Relations and Dependencies-Based Graph Convolutional Neural Network
In the classical GCN, the connection relationship between words is not distinguished, and if there is a connection between two nodes, then that element in the adjacency matrix is 1; otherwise, it is 0. Therefore, the GCN model cannot distinguish the importance of different connections, nor can it reflect the difference between entity relationships and dependency relationships among nodes. To fully learn and utilize the knowledge graph information in
Section 3.1, we use two GCN modules—one for entity–relationship information and the other for dependency information—drawing on the idea of the A-GCN model proposed by Tian et al. [
26]. We also improve the original simple connection matrix of GCN by using an attention mechanism and adding node and edge-type features.
Specifically, set the initial feature matrix of nodes,
, where
is the number of text nodes and
is the number of extracted entities, and use BERT to obtain the node embedding. For an utterance of length n, a connection matrix,
, is constructed, and when there is a syntactic dependency or entity relationship between words
xi and
xj, then
, and vice versa, when no relationship exists, then
. If there exists any word
xi, then the output of the lth level of GCN is represented as
, the expression of which is shown in Equation (2):
where
,
is the output of word
xj at GCN layer
l − 1,
is the trainable matrix,
is the bias of GCN at layer
l, and
is the activation function
ReLU.On this basis, two graphs are constructed based on syntactic dependency types and entity–relationship types.
Denote the matrix of entity–relationship types by
, where
ri,j is the entity–relationship type with
xi and
xj, and map each type,
ri,j, to its embedding,
. Calculate the weight of the connection between nodes
I and
j at layer
l in GCN based on the attention mechanism as
, the expression of which is shown in Equation (3):
where
and
are the intermediate vectors of
xi and
xj, respectively, the expressions of which are shown in Equations (4) and (5):
where
and
are the outputs of nodes
i and
j at the
l−1st layer of GCN, respectively, with
denoting the splicing. The expression of the final entity–relationship GCN output vector,
, is shown in Equation (6):
is the vector with the added edge-type information, the expression of which is shown in Equation (7):
where
maps the dependency-type embedding,
, to the same dimension as
, and
is the output of word
xj at GCN layer
l − 1.
To obtain the syntactic dependencies, the text is experimented with Stanza, an open-source NLP tool from Stanford University, to process it and obtain the syntactic dependency tree. The dependency-type matrix is denoted by
, where
ti,j are the dependency types associated with the directed dependency connections between
xi and
xj, and each type,
ti,j, is mapped to its embedding,
. The weights of the connections between nodes
i and
j at layer
l in GCN are calculated based on the attention mechanism as
, the expression of which is shown in Equation (8):
where
and
are the intermediate vectors of
xi and
xj, respectively, the expressions of which are shown in Equations (9) and (10):
where
and
are the outputs of nodes
i and
j at the
l−1st layer of GCN, respectively, with
denoting the splicing. The final dependency graph neural network output vector is
, the expression of which is shown in Equation (11):
is the vector with added edge-type information, the expression of which is shown in Equation (12):
where
maps the dependency-type embedding,
, to the same dimension as
. Finally, the two modules generate vector representations stitched together to obtain the GCN vector output,
, the expression of which is shown in Equation (13):
3.4. Graph Structure Mask
The masked language model (MLM) is one of the training tasks of the BERT model, which differs from the general language model in that instead of predicting all texts as autoregressive LM, it predicts certain words in a sentence by randomly masking them and using the context of the masked word to predict that word—the model is called autoencoder language model (Autoencoder LM). The BERT model trained by MLM can learn and establish better connections between words and text to achieve different dynamic word vector outputs in different contextual environments, which is also one of the reasons to improve the performance of the BERT model.
Based on the MLM idea, the graph structure mask model is proposed to further improve the learning ability of the model for semantic dependencies between words. The model structure is shown in
Figure 3.
Similar to the masked language model, the graph structure mask model randomly masks the edge connection between two tokens, allowing the model to predict whether there is a connection relationship between two tokens and the type of connection and, finally, obtaining the entity–relationship and dependency edge type representation outputs, respectively, the expressions of which are shown in Equations (14) and (15):
where
and
are the training output vectors of the graph structure mask, and
and
denote the connected edges between nodes
i and
j.
The two parts of the mask training results are stitched together to obtain
, the expression of which is shown in Equation (16):
3.5. Loss Function and Label Prediction
Cross-entropy loss function (CELF) is a common loss function in deep learning with powerful generalization ability and good convex optimality, which can help the model training converge so that the prediction result of the model is close to the actual labeled value. Using cross-entropy loss as the loss function, the BERT layer prediction probability distribution,
, and the loss function,
, can be represented as follows:
where
is the true label of a sample belonging to category
i and
M is the total number of labels.
The convolutional neural network layer prediction probability distribution,
, and loss function,
, can be represented as follows:
The linear interpolation of BERT and GCN is calculated as follows:
where
controls the tradeoff between the two objectives. When
, only the BERT model is used, while
when using only the GCN module. When
, it is possible to balance the predictions of both models and to better optimize the modeland to better optimize the model.
The graph structure mask layer prediction probability distribution,
, and loss function,
, can be represented as follows:
where
can adjust the graph structure mask module weights to further optimize the model performance.
4. Experimental Results and Analysis
4.1. Datasets
To prove the validity of the model, three publicly available long text classification datasets were selected for validation: IFLYTEK, THUCNEWS, and the Chinese corpus of Fudan University.
The IFLYTEK’s long text classification dataset has more than 17,000 pieces of long text annotated data about APP application descriptions. Among them, there are 12,133 items in the training set, 2599 items in the test set, and 2600 items in the validation set. The model performance is evaluated using the test set data. The text categories contain various application topics related to daily life, with a total of 119 categories. Each piece of data has three attributes, which are category ID, category name, and text content.
THUCNews is a sub-dataset of the THUCTC dataset, which is generated by filtering and filtering historical data from Sina News from 2005 to 2011, containing 740,000 news documents. The data are divided into 14 candidate categories: finance, lottery, real estate, stocks, home, education, technology, society, fashion, current affairs, sports, horoscope, games, and entertainment. The volume of data is large, and 90,000 pieces of data are randomly selected for testing.
The Chinese corpus of Fudan University contains 20 categories of documents such as art, education, history, etc. The total number of documents is 16,000.
The data distribution of this experiment is shown in
Table 1.
4.2. Parameter and Experimental Settings
The parameters of the model selected after the experimental text are set as shown in the table. Among them, epoch indicates the number of times the experimental data set is cyclically traversed during training; using early stopping, set a counter, and when the model effect is worse than the last, the counter value increases by 1. When the counter reaches the threshold value, then automatically stop the training and set a threshold value of 8; this method can avoid model overfitting or underfitting, in training, and the model basically stops at 4–6 epochs. batch_size is the number of samples in each input model during training, lr denotes the learning rate of the model, hidden_dim denotes the number of neurons in the hidden layer of the model, and dropout denotes the discard rate of model neurons during the training phase, which is used to avoid overfitting and improve the generalization ability of the model. The parameter settings are shown in
Table 2.
The experimental method in this paper is a simple training–test–validate approach. A dataset of parameters within the model is trained on the training set, and the model adjusts itself to obtain better classification results based on the training set. The validation set is used to adjust the parameters, and the performance of several sets of models on the validation set is used to determine which set of parameters has the best performance, while early stopping is used to monitor the model during the training process to prevent overfitting. The test set is used to evaluate the generalization ability of the model and to test the accuracy and F1 values.
4.3. Performance Metrics
The experiment is a multi-categorization task, and the ACC (accuracy) and F1 index are chosen as the evaluation metrics in this experiment.
where TP represents the number of positive classes actually predicted with a positive result, TN represents the number of positive classes actually predicted with a negative result, FP represents the number of negative classes actually predicted with a positive result, and FN represents the number of negative classes actually predicted with a negative result. PRE is the precision rate and REC is the recall rate.
4.4. Baseline
To prove the superiority of KGBGCN, a series of typical methods that also utilize graph convolutional neural networks or knowledge incorporation are selected for comparison experiments:
- (1)
KNN: one of the simplest methods in data mining classification techniques.
- (2)
NB: a statistical probability classification method, one of the classical and simple classification algorithms.
- (3)
Linear SVM: in the field of machine learning, it is a supervised learning model, usually used for pattern recognition, classification, and regression analysis.
- (4)
Random forest: the number of features is chosen randomly, the training data are chosen randomly, and the prediction label with the most occurrences for the same prediction data is taken as the final prediction label.
- (5)
LSTM: it is a kind of temporal recurrent neural network, which is specially designed to solve the long-term dependency problem of the general RNN.
- (6)
BiLSTM: bidirectional long- and short-term memory network, which is based on an improvement in LSTM.
- (7)
TextCNN: the first model that applies a convolutional neural network to text classification, keeping the original network structure and simplifying the convolutional layer, with a simple network structure and, therefore, a small number of parameters, low computation, and fast training.
- (8)
BERT: This model is a large-scale pre-trained model proposed by Google in 2018, and the model framework is based on Transformer, which implements a multilayer bidirectional Transformer encoder. Once released, the model achieved SOTA results in several NLP tasks. Although the main task of this model is not text classification, due to its excellent text representation capability, the Chinese BERT pre-training model is used as an encoder, and the results are fed into the softmax function and fully connected layers to achieve the text classification task.
- (9)
TextGCN: the first model that applies GCN to text classification, models the entire corpus as a heterogeneous graph, and learns word and document embeddings together through graph neural networks without using pre-trained word embeddings or external knowledge, and also learns predicted words and document embeddings automatically.
- (10)
BertGCN [
20]: This model combines the pre-trained model, BERT, with the graph network GCN for text classification. The same heterogeneous graph is constructed as TextGCN, but the document nodes in this model graph are initialized with the pre-trained BERT; after that, the BERT and GCN are jointly trained to fully integrate the ability of both to process data and extract features, and the training process uses techniques such as prediction interpolation, memory storage, and small learning rate; finally, the GCN is used for text classification.
4.5. Experimental Result and Analysis
The experimental results are shown in
Table 3. Among them, the labels of IFLYTEK’s long text dataset are not publicly available, and the results are obtained from the Chinese Language Understanding Evaluation Benchmark (CLUE) assessment, which only provides the accuracy value.
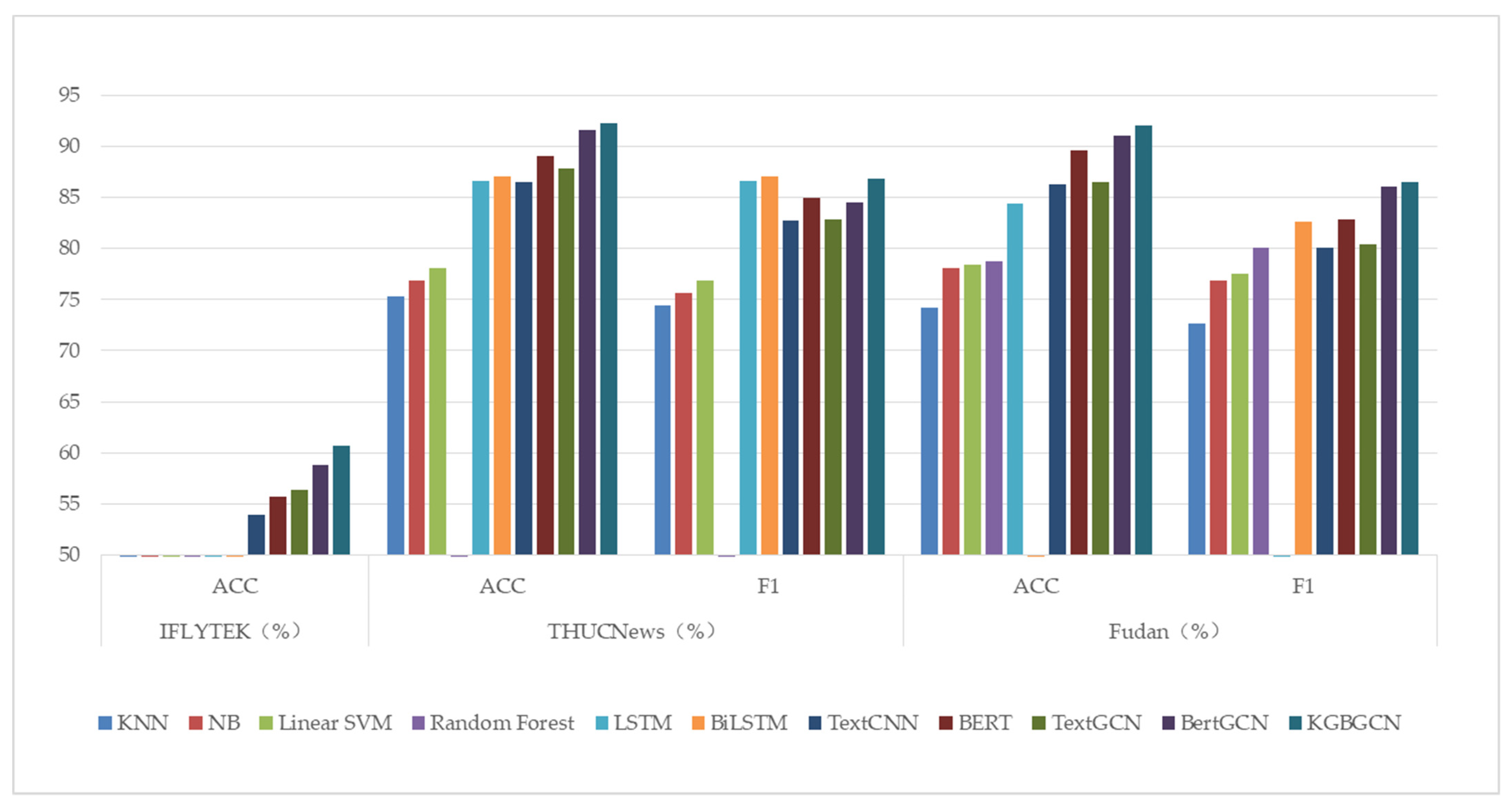
From the experimental results, we can see that the method we proposed, namely, the KGBGCN model, has the best ACC and F1 values on all three datasets, which proves the effectiveness of KGBGCN.
A comparison of the results of the experiments is shown in
Figure 4.
According to the experimental results, it can be observed that the classification effect of machine learning methods is generally lower than that of deep learning, which may be due to its smaller number of features and the larger data size of the dataset we tested, so the classification effect is relatively lower. We can observe that the KNN model has the worst effect. Its core idea is that for the point to be judged, it finds a few data points closest to it and decides the type of the point to be judged according to their types. It is characterized by completely following the data, and there is no mathematical model to speak of. The core idea of Bayesian is to calculate the type of the point to be judged according to the conditional probability, which is a relatively easy-to-understand model and is still used by spam filters, but the results of dealing with high-dimensional data are not satisfactory. The core idea of the SVM model is to find the interface between different categories so that the samples of the two categories fall on both sides of the face and as far as possible from the interface. The earliest SVM was flat and very limited. SVM has excellent performance on many data sets. SVM is relatively resistant to attack due to its nature of trying to maintain the distance between samples. However, SVM is still essentially “shallow learning”, as it can only classify linearly without a kernel function, and with a kernel function, it is essentially mapping a linearly indistinguishable problem to a distinguishable one, which is still linear in nature. The test results of random forest on the Fudan Chinese dataset are better than the above machine learning methods, which shows that the random forest method has some advantages in the multi-classification problem. Compared with machine learning methods, deep learning models are more complex, resulting in a larger system of models and algorithms and, thus, greater progress in functionality.
Both LSTM and BiLSTM work better than TextCNN on the THUCNews dataset. BiLSTM is better at classification because it uses a bidirectional LSTM, which can capture both above and below semantic features. These two models solve the sequence learning problem, but both models recursively apply the same set of weights to the sequence data to produce a vector representation, which can learn the text dependencies but cannot achieve parallel computation, and the same weight treatment cannot highlight the expressiveness of the key data. Compared with the method proposed in this paper, it lacks the focus on the key information brought by the attention mechanism and the features of the dependency and entity relationships, and they are less capable of handling long-distance text compared with GCN, so the classification effect is not as good as the model proposed in this paper. TextGCN uses the GCN to model the graph, which can capture high-order neighborhood information, establish the boundary between two word nodes using word co-occurrence information, establish the boundary between word nodes and document nodes using word frequency, and then transform the text classification problem into a node classification problem, so the effect is significantly improved compared with the TextCNN model. Combining BERT with GCN, the BERT model is trained with large-scale numbers to obtain dynamic word vectors with rich semantic features, which gives better performance and improved accuracy.
Static word vectors are prone to word ambiguity problems, KGBGCN uses BERT to encode text to learn word dynamic word vectors, and BERT and GCN jointly calculate the loss function. To solve the problem of too many parameters of BERT and GCN models, which are prone to overfitting or difficult to converge, the vectors of the last four layers of BERT are stitched together. To solve the problem of lack of domain knowledge, entity–entity relationships, together with syntactic dependency information, are proposed as edges of the GCN to improve model performance with knowledge introduction, and dependency types and relationship types are added directly to each GCN layer to capture richer text features with graph structure. Applying the attention mechanism to each relational connection in the GCN layers allows the GCN in KGBGCN to encode dependency and entity relations more densely, so that they can be better utilized to guide text classification. To improve the learning ability of the model for semantic dependencies between words, graph structure masking is proposed, which randomly masks the edge connections between two tokens and then allows the model to predict whether there is a connection relationship between two tokens and the type of connection. KGBGCN adds entity relations and dependency relations in GCN, and the GCN puts domain knowledge in the form of graph structures with pre-trained models The integration is a key factor to achieve the improvement of model performance. Among the three publicly available Chinese datasets, the IFLYTEK dataset has the smallest sample length, and the THUCNews dataset and the Fudan dataset are longer. In
Table 3, we can observe that KGBGCN has a better classification effect for the latter two datasets, which means that KGBGCN has a better classification effect for longer texts, which can verify the effectiveness of our proposed model for classifying long Chinese texts.
4.6. Ablation Study
To demonstrate the effectiveness of the two parts of the proposed knowledge graph fusion and graph structure masking, ablation experiments are set up:
- (1)
Exp1: completely remove the word vectors generated by BERT pre-training and use GCN nodes as the initial vectors.
- (2)
Exp2: CGN is processed without using entity and dependency relations, and only the connection matrix is constructed with the presence or absence of edges between nodes.
- (3)
Exp3: remove the knowledge graph part on model KGBGCN, and use only syntactic dependencies for graph construction and classification probability prediction.
- (4)
Exp4: the graph structure mask is removed from the model KGBGCN, and the output of the graph convolution network and attention mechanism is directly used as the final representation for classification probability prediction.
The results of the ablation experiments are shown in
Table 4.
As shown in
Table 4, subtracting both the graph structure mask and the knowledge graph has an impact on the model, but subtracting the knowledge graph part has a greater impact on the model performance. This result proves that constructing graphs with entities as nodes and entity relationships as edges is effective, and long texts may produce more document connections transmitted through intermediate word nodes, which facilitates message transmission through graphs, resulting in better performance when BERT is combined with GCN. The graph structure mask, on the other hand, allows the model to learn entity–relationship types autonomously through training, which improves the semantic dependency between model words and achieves improved accuracy and F1 values. A comparison of the accuracy of the ablation experiments is shown in
Figure 5.
4.7. The Effect of α and λ
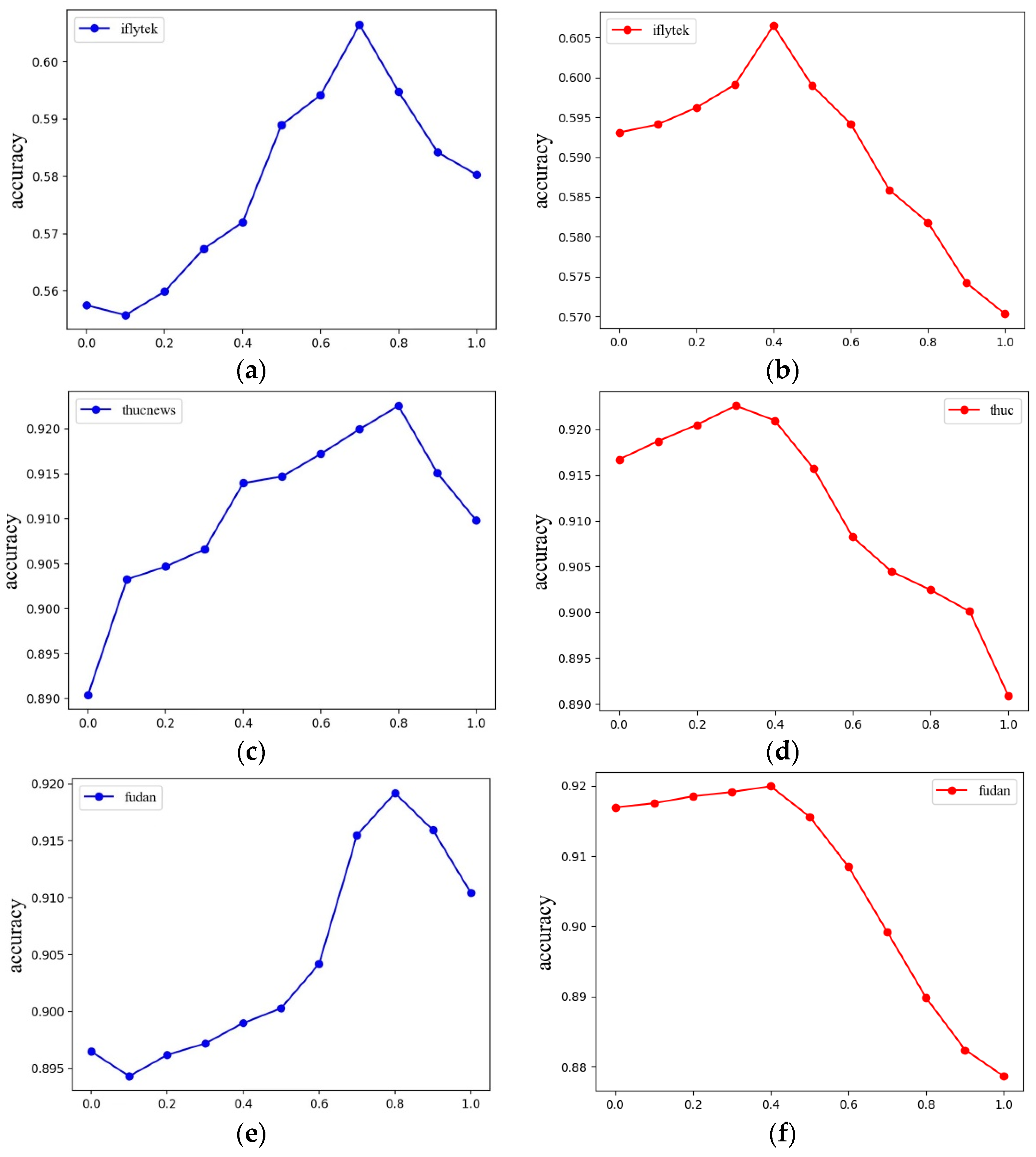
To verify the effects of and on the experimental results, experiments are conducted for and taking values 0 to 1, respectively, and the results are shown in
Figure 6.
As shown in the figure, the predictive interpolation model performs best at 0.7 on the IFLYTEK’s long text dataset and achieves the highest accuracy at 0.8 on both THUCNews and Fudan University Chinese corpus datasets, which is consistent with the experimental verification of the best model performance in the literature. The experimental results further verify the effectiveness of the graph structure mask, which is 0.3 for the THUCNews dataset and 0.4 for the IFLYTEK’s long text and Fudan University Chinese corpus datasets, i.e., the best value is between 0.3 and 0.4. This is because when the weight of the graph structure mask is too small, the dependency and entity–relationship types cannot be fully learned and trained by the model, instead, redundant information is added and the model does not perform optimally. The large weight of the graph structure mask reduces the contribution of the graph neural network and attention mechanism to the performance improvement of the model, and also makes the node information too complex, leading to the problem of gradient explosion and gradient disappearance of the model.
5. Conclusions and Future Work
Domain long text classification is one of the important tasks in NLP. Domain texts have strong domain specialization and are generic models that are difficult to migrate and use directly. For long texts, it is difficult to capture their features accurately due to their long length and redundant words. Existing classification methods have problems such as ambiguous semantic understanding and inadequate feature representation. In this paper, we propose a Chinese domain long text classification model that integrates a knowledge graph and GCN to address the existing problems. The model obtains dynamic word vectors by encoding document context information through BERT, and uses an attentional graph convolutional model combining syntactic dependencies and entity relations to mine deep-level feature information of the text so as to enrich the relationships of words within the text and realize improvements in model performance and classification accuracy in the case of longer texts. The graph structure mask further learns and trains the edge relationship types in the graph structure to obtain the relationship-type features. The embedding of the knowledge graph allows the model to acquire prior knowledge of the domain text classification work and perform better in combination with the pre-trained model. The F1 values reach 60.65%, 86.83%, and 86.52% on three different datasets, which are improved compared with other models, verifying the feasibility and effectiveness of the method and providing some technical reference for the domain long text classification task.
In future research, we will continue to improve the KGBGCN model to extend it to other languages or general domains. In addition, we will try to introduce an artificial intelligence content model similar to ChatGPT to improve the quality of entity and entity–relationship extraction, further enhance text features, and improve the overall classification performance.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}