1. Introduction
Image captioning is a classical task that aims at automatically describing an image using natural language. This research is at the intersection of two popular research fields, i.e., Computer Vision and Natural Language Processing. This task is simple for humans. However, it is a considerable challenge for computers, which not only requires understanding the content of the image but also generates sentences with human language habits. Image captioning has wide applications in image retrieval, image indexing, human–computer interaction, assisting visually impaired people, automatic video security monitoring, and journalism. Because of its importance, it is becoming a research hotspot.
Typically, image captioning models are based on the encoder-decoder structure. Most models are trained on parallel data of image-sentence pairs. Some models [
1,
2,
3,
4] even outperform humans on the MSCOCO dataset in some metrics. Those models perform well when describing the objects that often appear in the training set, but fail to describe novel objects (rarely seen or never-seen). The most straightforward way to overcome this limitation is to collect more data [
5,
6]. Such methods are effective, but the data collection process is highly expensive and time-consumption. In order to reduce consumption while still maintaining a competitive performance, most inexpensive approaches rely on the object detection model [
7,
8,
9]. Modern object detection models can recognize a wide range of objects through incredibly large training sets [
10] or zero-shot methods [
11]. Those captioning models improve the noun-region matching ability by describing the nouns corresponding to the attended regions. Those models are good for describing rarely seen objects but are useless for never-seen objects. In particular, the number of never-seen objects is unknown while the dimension of the word embedding layer and final fully-connected layer in the captioning model is fixed. It is impossible to understand the meaning of the never-seen word and describe it.
Even though the current novel captioning model can generate sentences containing selected tags through constrained beam search (CBS) [
12], when the selected tag is semantically unclear novel words, it is harmful to the probability of subsequent words and affects the final sentence selection. The harm is especially severe when the selected tag is incorrect. However, the current novel object captioning model does not address this issue.
To overcome those issues, we propose an external knowledge-based novel image captioning method that purposefully uses external knowledge to extend the word embedding casually, and makes the captioning model understand the meaning of the extended words. Specifically, the main contribution of our work is two blocks, i.e., the Semi-Fixed Word Embedding and Candidate Sentences Selection. The Semi-Fixed Word Embedding is a new embedding layer that can be extended to the never-seen word through external knowledge while assisting the captioning model in understanding the meaning of the extended never-seen word. The Candidate Sentences Selection block assists the captioning model in the selection of the candidate sentences to avoid the influence of the novel words in CBS.
The study’s contributions are as follows:
- (1)
We propose a novel prior-based word embedding block that incorporates semantic information to enable the model to understand various words, including never-seen words. It is beneficial for the captioning model to understand the meaning of the novel words and generate more accurate subsequent words.
- (2)
We propose a new block to evaluate candidate sentences through the semantic similarity between generated sentences and the given image which is obtained by external knowledge so as to reduce the influence of never-seen words.
- (3)
Proposed blocks can be attached to a detection-based captioning model to enable them to describe the rarely seen and never-seen objects.
- (4)
We performed a comprehensive evaluation of the captioning datasets MSCOCO and Nocaps, demonstrating that the proposed blocks outperform several state-of-the-art methods in most metrics and have the ability to describe never-seen objects without additional data.
2. Related Work
In this section, we will introduce related work from two aspects: image captioning and novel object captioning.
2.1. Image Captioning
The structure of image captioning is mainly divided into three approaches. (1) The first is the template-based method [
13,
14], which fills the sentences with object detection results. Farhadi et al. [
13] detect all candidate scenes, objects, and objects’ attributes, then use the CRF algorithm to predict the correct three-element filling in the template as the captioning. The template-based methods require a manually designed syntactic template but have higher accuracy than the retrieval-based models. (2) The second is retrieval-based methods [
15,
16], which retrieve similar images from the whole database and selectively combine the sentences of similar images to create image captioning. The quality of the caption depends on the similarity evaluation method and the quality of the database. The retrieval-based methods can generate sufficiently fluent sentences, but they heavily rely on the sentences in the database. Hence, it is difficult to generate a new corpus to describe new images. (3) The second is encoder-decoder-based methods, in which the encoder structure first converts the image into some vectors to represent the content of the image, and then, the decoder structure generates sentences word by word based on the vector. Early encoder-decoder methods [
14,
17] encode images with soft attention to focus on different regions to generate a feature vector, and then decode the feature vector to sentences. Long et al. [
18] incorporate spatial and channel-wise attention into CNN to encourage the model to focus on meaningful regions. Considering that the whole image contains a large amount of redundant information, to reduce redundant information, Anderson et al. [
19] propose a bottom-up attention mechanism to provide region information, which comes from the detection network (Faster R-CNN [
20]). The detection model trained on the large dataset not only removes redundant areas irrelevant to the description but also extracts better visual features. However, the region features a lack of relationship information. Some researchers [
21,
22,
23] adopt the scene graph [
24] to express objects and the semantic relationship between objects. Scene graphs bring richer information, but richer information contains more redundancy information, and the scene graph must be processed by graph convolution. These reasons limit the development of the methods based on the scene graph.
In particular, with the success of transformers [
25] in the field of NLP, many state-of-the-art models [
26,
27,
28] adopt the transformer structure to design the encoder or decoder. Huang et al. [
26] incorporate the attention block into the encoder and decoder to measure the relevance between the attention result and the query. Cornia et al. [
27] extend self-attention with additional “slots” to encode prior information. Sharma et al. [
29] design an LRN that discovers the relationship between the object and the image regions. Apart from this, BERT, a pre-trained model composed of deep bidirectional transformers, achieved outstanding results. Many models [
30,
31,
32] exploit BERT-like structures pre-trained on a large corpus to achieve state-of-the-art performance.
Although many researchers have improved the accuracy of generated sentences through the attention-based model or transformer-based model, since the captioning model needs to be trained on the dataset, the number of images and the types of objects in the training set are limited. Hence, it is difficult to describe objects that are rarely seen or never seen in the training set.
2.2. Novel Object Captioning
The novel object captioning task is an extension of the image captioning task for describing objects that are rarely seen or never seen in the training set. Some works have been proposed to address this challenge through visual and semantic alignment. LSTM_C [
33] exploited a copying mechanism to copy the selected words into the sentences. However, LSTM_C is difficult to determine which detected objects need to be described, the ANOC [
34] utilizes human attention from visual information to identify novel objects that need to be described. CRN [
35] selects more accurate words from the detection result by the visual matching module, and ensures that the novel words fit in the right position through a semantic matching module. NOC-NER [
36] designs a retrieved vocabulary to find the novel objects that might be described. Oscar [
31] and VinVL [
30] pre-train large-scale models and then fine-tune the model to adopt downstream tasks. Those methods are effective for rarely seen objects in the dataset, but not for never-seen objects.
Hence, some researchers focus on the zero-shot novel object captioning task, which does not require additional training sentences for never-seen objects. NBT [
37], DNOC [
8], and ZSC [
9] use a special token to represent all the novel objects, which enables them to replace the novel object label with the special token. The common issue for those models is how to select a proper word to replace the novel object label. SNOC [
38] uses words of most similar objects as proxy visual words to solve the out-of-vocabulary issue, and retrieves proper nouns through the designed switchable LSTM to replace the similar objects. Similar to the special token-based model, the issue of which words should be replaced is central. SMALLCAP [
39] generates a caption conditioned on the image and related captions retrieved from a datastore. This method can effectively avoid the problem of replacing special tokens, but the accuracy of the generated statements is low. Compared with those zero-shot novel captioning methods, rather than based on the special token, our designed blocks allow the captioning model to understand the meaning of rarely-seen and never-seen objects. Meanwhile, the designed blocks can be attached to the most popular captioning models, enabling them to describe novel objects without additional training data.
3. Preliminary
Constrained Beam Search
The constrained beam search (CBS) [
12] is a commonly used method to generate sentences containing selected tag words at inference time. This method enables existing deep captioning models to describe novel objects.
The example of the constrained beam search is shown in
Figure 1, in which the selected tag is “dolphin” and the
. To generate a sentence containing the selected tag “dolphin”, the candidate sentences are distinguished into two cases: 1. Not containing “dolphin” 2. Containing “dolphin”.
First, generate the words “a” and “dolphin” based on the start symbol for two cases. After obtaining case 1 “a” and case 2 “dolphin”, generate subsequent words for case 1 and case 2. The generated sentence “a swimming” belongs to case 1, and the sentences “a dolphin”, “dolphin swimming”, and “dolphin dolphin” belong to case 2. Keep beam size sentences for each case according to probability. The retained sentences are “a swimming” and “a dolphin”, respectively. Continuing the above operation, the CBS will eventually output candidate sentences, where 2 is the number of the case. In CSB, the final output is the sentence with the selected tag and the highest score.
Traditional captioning models with CBS can generate a sentence containing the selected tags, but novel tags with unclear semantic content are harmful to the probability of candidate sentences and will affect the selection of the final sentence. Particularly when tags are incorrect, the harm is more severe.
4. Proposed Model
Novel object captioning is a subtask of image captioning. The captioning model contains a training phase and an inference phase. In the training phase, the model is trained by the Masked Language Model (MLM) [
1,
2,
3] or Language Model (LM) [
4,
19]. The MLM is to predict the middle words on both sides. LM is the autoregressive approach to predicting word by word. In the inference phase, either MLM or LM, the sentences are generated through the autoregressive approach, as shown in
Figure 2.
The earlier encoder-decoder structure and the current transformer structure predict the next word based on the previous word vectors and the image features as follows,
where
is the word generated by the
at time step
t.
E is word embedding.
I denotes the input image.
All captioning models exploit the word embedding layer E to encode the word into a word vector and predict the word probability through the final fully-connected layer.
Even if CBS enables the captioning model to describe the selected words in the vocabulary, current novel image captioning models still have three shortcomings: firstly, the final fully-connected layer cannot predict the probability of never-seen words that are out of the dimension vocabulary; secondly, the word embedding cannot encode the never-seen words; thirdly, even if the captioning model is able to encode never-seen words, inappropriate word embedding leads the model to generate incorrect subsequent words and corresponding probabilities.
4.1. Motivation
This manuscript is inspired by the experiments of CLIP [
40]. The structure of CLIP is shown in
Figure 3. The CLIP jointly trains an image encoder and a text decoder to predict the correct image-text pair. The image encoder can be ResNet [
41] or VIT [
42]. The text encoder is a transformer-based model [
43]. The CLIP evaluates the similarity between the image feature and the text feature through the cosine function.
Table 1 shows the visual similarity of each image and word. When images and words have higher matching scores, they have similar visual concepts. This means that CLIP features express the visual concepts of words and images. Meanwhile, the CLIP text decoder can encode any word. Considering the characteristics of CLIP, we construct two blocks to assist the traditional captioning model in solving the three shortcomings. In the following, we describe the proposed Semi-Fixed Word Embedding and candidate sentence selection methods in detail.
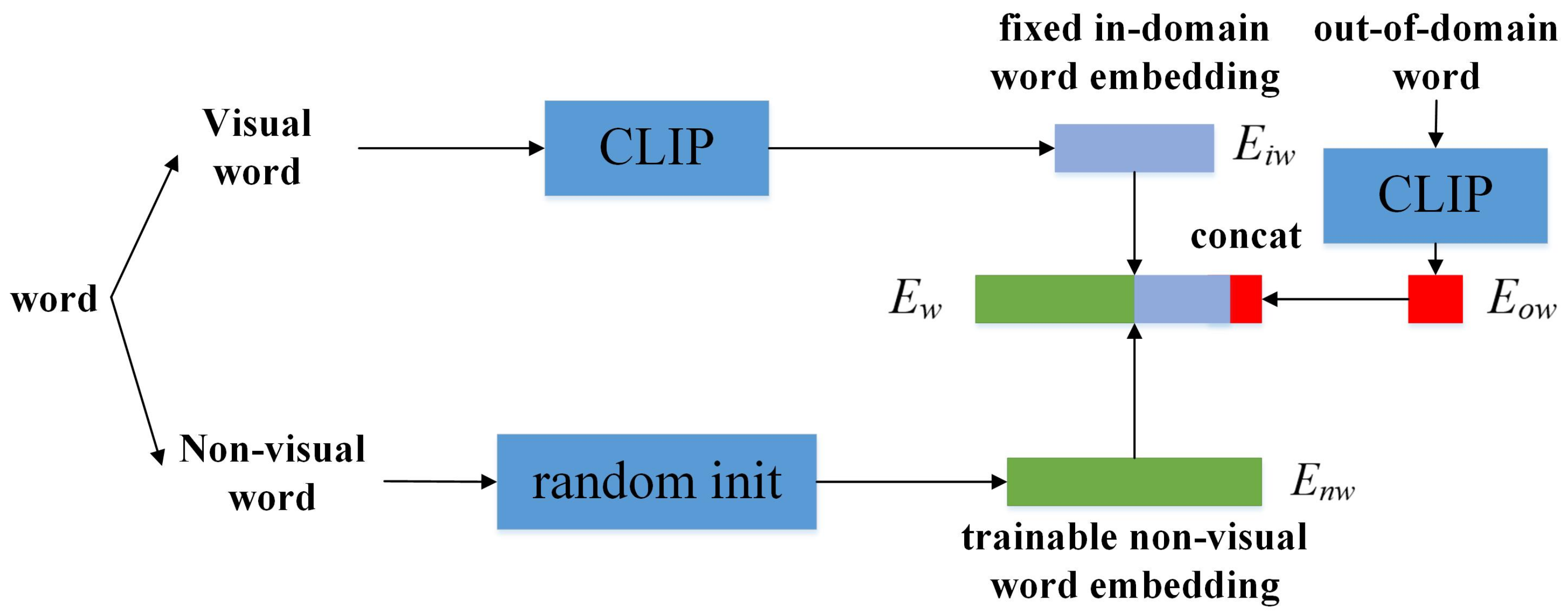
4.2. Semi-Fixed Word Embedding
In the current novel image captioning task, some models initialize word embedding via glove [
44]. The experiments in Nocaps [
45] use glove for initial word embedding and demonstrate that glove is useful for rarely seen and never-seen words (out-of-domain), but harmful for common words (in-domain). For in-domain, the model with glove outperforms the model without glove by 0.4 in Spice but underperforms by 0.7 in CIDEr. According to the definitions of SPICE and CIDEr, CIDEr takes into account non-visual words, while SPICE only considers the relationship between visual words. This shows that glove works well for visual words, but slightly worse for non-visual words.
Considering the CLIP predicts the correct image-text pair from the visual content. The non-visual words do not have visual information, while the novel object captioning task aims to describe the novel object. The word for the novel object must be a visual word. Therefore, we decide to fix the embedding of visual words through the CLIP feature and learn the embedding of non-visual words from the training set.
Figure 4 shows the structure of our proposed Semi-Fixed Word Embedding. It mainly consists of three parts. The first part is a trainable non-visual word embedding
. The second part is fixed in-domain visual word embedding
, which enables the captioning model to understand the meaning of CLIP noun features. The third part is the never-seen visual word feature
used in the inference phase, which allows the embedding layer to be extensible and can be used to understand the meaning of the novel words specified by the CBS.
In the training phase and inference phase, word features can be calculated by Equation (
2) and Equation (
3), respectively.
where
is the one-hot encoding of the input word
at time step
t.
The traditional captioning model calculates the probabilities of candidate words through the fully-connected layer and softmax layer as follows,
where
is the hidden semantic feature. The size of the fully-connected layer is unchangeable in the inference stage.
The traditional CBS predicts
through Equation (
4) for each case based on
. When the selected word is not included in the vocabulary, the probability and loss for the selected word are uncomputable. Hence, this manuscript calculates the loss for each word as follows:
where
can be a selected tag or generated word.
is a fixed loss. This modification enables CBS to generate words beyond the dimension of the final fully-connected layer.
4.3. Candidate Sentences Selection
The selected tag in the CBS is obtained by the detection method but does not always need to be described. The CBS contains multiple cases, each case contains various selected tags and generates beam size candidate sentences. Traditional CBS only outputs sentences that contain all the selected tags with the highest loss. However, the never-seen word with a fixed loss is harmful for sentence selection, and the sentences containing all selected tags may not always be optimal.
In order to reduce the impact of never-seen words and the selected tags for the captioning process. This manuscript designs a novel candidate sentence selection to replace the original selection method. The candidate sentence selection evaluates the semantic similarity between the given image and candidate sentences using external knowledge through Equation (
2).
where
is the CLIP feature of the given image
i,
is the CLIP feature of all candidate sentences,
n is the number of candidate sentences. The final output is the similarity of each sentence with the image
i.
In this way, this manuscript avoids the condition that output sentences must contain all selected tags, further improving the accuracy of the generated sentences.
5. Experiments
5.1. Dataset
All of the experiments were conducted on the Open Images V4 [
10], Microsoft COCO (MSCOCO) 2015 Captions datasets [
46], and Nocaps [
45] datasets. The Open Images is the object detection training set, which has 1.7M images annotated with bounding boxes for 600 object classes. The detected objects may be the selected tag in CBS. MS COCO dataset contains 123,287 images labeled with 5 captions for each. We follow the Karpathy split [
47], where 113,287 images are used for training, 5000 for validation, and 5000 for testing. MSCOCO is used to train the captioning model. Nocaps consist of 15,100 images, each annotated with 11 human-generated captions, of which 4500 are for validation and 10,600 for testing. The images in Nocaps to validate the model can be further divided into three subsets, namely in-domain, near-domain, and out-of-domain, where the in-domain images contain only objects described in the MS COCO, the near-domain images contain some objects described in the MS COCO, the out-of-domain images are very distinct from the MS COCO images, i.e., the out-of-domain contain novel objects that are rarely-seen or never-seen in the MS COCO. All of the corresponding results were obtained from the Nocaps dataset. The selected tags in CBS are obtained by performing a filter on the detected objects.
5.2. Evaluation Metrics
To evaluate the performance of proposed blocks and generated sentences, we employ a set of commonly used captioning metrics: BLEU, METEOR, ROUGE-L, CIDEr-D, and SPICE.
BLEU [
48]: This metric is usually used in machine translation. It measures the co-occurrences of
n-grams (
n = 1, 2, 3, 4) in generated sentences and ground truth sentences. The metrics are calculated by counting the mean of the
n-grams precision scores as follows,
where
and
are the precision and weight for
n-grams, respectively.
is a brevity penalty as Equation (
8) is used to penalize sentences that are shorter than ground truth sentences.
where
and
are the lengths of the generated and ground truth sentences, respectively.
METEOR [
49]: These metrics evaluate an alignment between the generated and ground truth sentences. First, METEOR calculates the F-Score (
) based on the uni-gram precision
and recalls
as follows:
The METEOR is calculated as follows:
where
is the number of contiguous order matches of the generated and ground truth sentence.
is the number of matched uni-grams.
ROUGE-L [
50]: This metric calculates the recall to measure the longest common sequence (LCS) between the generated and ground truth sentences. The ROUGE-L is based on the precision
and recall
score of LCS as follows:
where
and
are the length of ground truth sentence
and generated sentences
.
is the longest common subsequence of
and
.
CIDEr-D [
51]: This metric gives different weights based on the frequency of
n-grams. That is, CIDEr-D gives higher weights to rarely seen
n-grams. It calculates a term frequency-inverse document frequency (TF-IDF) weight to
n-grams.
for
n-grams as follows,
where
is the number of ground truth sentences,
is the
ground truth sentence,
is the generated sentence.
is the TF-IDF weighting for n-gram. The CIDEr is calculated as follows,
where
and
.
SPICE [
52]: This metric uses the rule-based method to parse the sentence into a dependency tree and map the tree into a scene graph. Finally, it calculates the F-score of the objects, attributes, and relations. The SPICE focuses on evaluating the objects, attributes, and relations in generated sentences.
5.3. Implementation Details
Our structure was developed in PyTorch. For a fair comparison, this manuscript utilizes UPDN [
19], X-LAN [
4], and Oscar [
31] as the basis of our network structure for comparison experiments, respectively. Note that Oscar is a transformer-based model trained on a larger dataset. The parameter settings of the UPDN, X-LAN, and Oscar are the same as the original model, except for the word embedding and the subsequent feature dimensions. The training strategy of each model is the same as the original. To better extract semantic features for each image, we use Faster R-CNN [
20] fine-tuned on the Visual Genome dataset [
53] to detect object regions and extract regional features through CLIP. When the selected word was never seen in the MS COCO, we set the loss of the word
to −20. The experiments were conducted on an NVIDIA GTX 1080 Ti.
5.4. Ablative Analysis
We conducted ablative studies to explore the impact of our proposed blocks, including (1) the effectiveness of proposed blocks on various captioning models and (2) the effectiveness of the proposed embedding method for never-seen words. All of the results were obtained using XE-loss, self-critic, and trained under the same training strategy and dataset.
5.4.1. The Effectiveness of Proposed Blocks on Various Captioning Models
We tried to explore the effectiveness of Candidate Sentences Selection, Semi-Fixed Word Embedding on various captioning models, i.e., UpDown [
19] and XLAN [
4], and insert each block into these approaches. The experiment was performed on the Nocaps dataset [
45], where the images in “In-domain” only contain frequently seen objects, the image in “Near-domain” contain frequently seen, rarely seen and never-seen objects, the images in “Out-Of-domain” only contain rarely seen or never seen objects. To illustrate the impact of Semi-Fixed Word Embedding more clearly, we also compare it with the commonly used glove initialization.
From the results shown in
Table 2, we can see the efficacy of each block. Comparing the results of rows 1, 2, and 3 with other rows shows that CBS reduces the score of in-domain, but significantly improves the scores of out-of-domain, indicating that CBS is necessary for the novel object captioning task.
The comparison of rows 4/5, 6/8, and 7/9 shows the effectiveness of Candidate Sentences Selection. The improvement of CIDEr and SPICE on in-domain/near-domain/out-of-domain is 4.93/4.49/5.28 and 0.64/0.34/0.69 for rows 4 and 5, 4.86/5.76/8.23 and 0.27/0.5/0.54 for rows 6 and 8, 3.23/5.04/7.12 and 0.71/0.44/0.51 for rows 7 and 9, respectively. It is clear that Candidate Sentences Selection can effectively solve the problem of semantic mismatch, and therefore, the accuracy of generated sentences is significantly improved.
The effectiveness of Semi-Fixed Word Embedding is shown by the comparison of rows 6/7. The improvement of CIDEr and SPICE on in-domain/near-domain/out-of-domain is 0.79/1.2/0.81 and −0.01/0.25/0.34 for rows 6 and 7. The Semi-Fixed Word Embedding outperforms the glove in the near-domain and out-of-domain, showing that the Semi-Fixed Word Embedding assists the captioning model in understanding the meaning of the novel words. In particular, the SPICE metrics reflect the semantic matching of the described object and relationship. The most significant improvement on the out-of-domain shows that Semi-Fixed Word Embedding works better for novel words.
Rows 8/9 show the result of using Semi-Fixed Word Embedding or glove on the basis of Candidate Sentences Selection, respectively. The metrics of SPICE are improved in all domains, which means that the semantic matching can be improved by Semi-Fixed Word Embedding.
When replacing the captioning model with the XLAN [
4], the same results can be observed, indicating the effectiveness and robustness of the proposed blocks.
5.4.2. The Effectiveness of Proposed Embedding Block for Never-Seen Objects
Consider that out-of-domain images contain rarely seen and never-seen objects, while the Semi-Fixed Word Embedding focuses on never-seen objects. To further demonstrate the effectiveness of the proposed block,
Table 3 shows the scores of sentences generated by various embedding methods for the never-seen selected tags. In this table, we only analyze the results for different sentences, ignoring the same generated sentences, in which the Common and Never denote the words included or not included in the training set. The our, glove, replace, and random denote the different ways to obtain word embedding.
From the result, we can see that the improvement of the CIDEr/SPICE in rows 1 and 2, rows 9 and 10, rows 3 and 4, and rows 11 and 12 is −0.12/0.08, 6.62/1.53, 10.18/5.39, and 10.97/6.58. Compared with random embedding, Semi-Fixed Word Embedding significantly improves the accuracy of generated sentences. Compared with manual replacement, Semi-Fixed Word Embedding performs well on XLAN and slightly worse on UPDN; meanwhile, Semi-Fixed Word Embedding does not need manual replacement.
By observing the corresponding results of glove, it is better than random embedding, but worse than manual replacement and Semi-Fixed Word Embedding in UPDN and XLAN, indicating that glove is difficult to reflect the visual semantic of the noun. It is also demonstrated that the proposed block is beneficial for the captioning model to understand the meaning of the noun.
5.5. Quantitative Analysis
In this subsection, we will present the experiment results to demonstrate that the proposed blocks can enhance the performance of the novel image captioning tasks. First, we chose several of the most representative state-of-the-art methods, which include both regular and transformer-based methods. The comparison methods are briefly described as follows: (1) OVE [
7] (2020), in which a low-cost method is proposed to expand word embeddings from a few images of the novel objects; (2) ANOC [
34] (2021), which combines object detector and human attention to guide the model to describe novel objects; (3) NOC-REK [
36] (2022) retrieves vocabulary from external knowledge and generates captions; (4) VIVO [
54] (2021), (5) VinVL [
30] (2021), and (6) Oscar [
31] (2020), which are the large-scale vision-language transformer model and fine-tune the pre-trained model to adopt downstream tasks; (7) ClipCap [
55] (2021) produces a prefix by applying a mapping network over the CLIP visual embedding; (8) SMALLCAP [
39] (2023) generates sentences conditioned on the input image and related captions retrieved from a datastore; (9) UpDown [
19] (2018) proposes the standard two-layer LSTM structure, in which the attention LSTM encodes the previous words to decide the current attended region features, and the language LSTM generates the next word based on the attended region features and the previous words; (10) XLAN [
4] (2020), which proposes an X-Linear attention to model the 2nd order interactions with both spatial and channel-wise bilinear attention. In those models, UpDown and XLAN are the regular image captioning models without any models designed for the novel objects. Other models contain particular modules for the novel objects.
For a fair comparison, we re-implemented some methods and attached the proposed blocks to those models. The model with “*” indicates our re-implementations. “+our” indicates attaching the proposed blocks. From
Table 4, it can be seen that the model with our proposed block presented a higher performance in the Nocaps dataset than the base model, especially on the out-of-domain, which contains many novel objects. Compared with other novel image captioning models that pay more attention to rarely seen objects but ignore the never-seen object, the model with our blocks has remarkable results. In particular, observing the results of UPDown*, XLAN*, OVE, UpDown+our, and XLAN+our. The models of UpDown* and XLAN* are lower than OVE in out-of-domain at CIDEr/SPICE metrics by 4.1/0.2 and 3.2/−0.1, respectively. However, the UpDown+our and XLAN+our outperform the OVE in CIDEr/SPICE metrics by 2.5/0.4 and 3.2/1.2. This shows that the proposed blocks enable the regular captioning model to better describe the novel objects. Compared with VIVO, VinVL, ClipCap, SMALLCAP, and Oscar, the Oscar+our achieves the best performance, and improves the SPICE metrics in in-domain and near-domain by 0.3, and 0.2, and both metrics in out-of-domain by 5.1 and 0.4, respectively. The improvement in SPICE and CIDEr indicates that the proposed blocks enable the captioning model to generate more semantically accurate sentences. The improvement of all metrics in the out-of-domain further demonstrates the effectiveness of the proposed blocks for novel objects.
5.6. Qualitative Analysis
Table 5 shows a few examples of image, caption, and the loss for each word generated by the base models (random) and the model with Semi-Fixed Word Embedding (fixEmbed). We generated the sentences with the same setting, base model, training data, and training strategy. From these examples, we found that although some images can also generate the same sentence through random initialization of the word embedding for novel words, the random initialization increases the loss of words after the novel word. For example, our proposed block benefits the model more confidently by generating “in a field” in the first example, “in a living room” in the second example, “sitting on top of a table” in the third example, “with a bunch of fish” in the fourth example. The fact that the captioning model with Semi-Fixed Word Embedding is able to say subsequent words more accurately means that the proposed block enables the captioning model to better understand the meanings of the never-seen words.
Table 6 shows a few examples with images and captions generated by the traditional selection way (base) and our proposed Candidate Sentences Selection (CSS). We generate the captions using the same model and only modify the way to select candidate sentences. Observing the examples, we found that this “base” method is difficult to accurately reflect the image content, while our block can result in better captions. More specifically, our proposed block is superior in the following two aspects: (1) The proposed CSS could assist the captioning model in choosing selected tags. For example, our proposed blocks help the model only describe the ”jaguar“ in the first example. (2) The proposed CSS could assist the captioning model in generating sentences that better match the content of the image. For example, there is “canary” not ”canary bird“ sitting on top of a chair in the second example, there is “a swimming pool and palm trees and a umbrella” not “a group of chairs and palm trees on a umbrella.” in the third example, which incorrectly describes the relationships between the palm trees and umbrella. In the fourth example, the base model chooses “a invertebrates of fish on top of a fish.”, but CSS chooses “a bunch of fish on top of a invertebrates”. It is clear that although the model does not understand the meaning of “invertebrates”, the CSS is able to select sentences that better match the meaning of the image.
6. Conclusions
This manuscript is oriented to the novel object captioning task. In view of the current model’s failure to describe the rarely seen and never-seen object, through the experiment and the analysis of the captioning model, we found that there are three reasons why the current models fail to describe never-seen words. Firstly, in the inference stage, the dimension of the word embedding layer is fixed; hence, it cannot encode new words. Secondly, the captioning model cannot understand the meaning of the never-seen words. Thirdly, the novel words affect the total loss of generated sentences and interfere with the way to select optimal sentences.
In this paper, we believe that the traditional captioning model can describe novel objects when the above problems are solved. Hence, we propose a Semi-Fixed Word Embedding block and Candidate Sentences Selection block to assist the captioning model in describing novel objects. For the first issue, the Semi-Fixed Word Embedding is an extensible embedding layer to encode arbitrary visual words. For the second issue, the Semi-Fixed Word Embedding incorporating external knowledge helps the captioning model understand the meaning of the never-seen words. For the third issue, the Candidate Sentences Selection block chooses candidate sentences by semantic matching rather than total loss, avoiding the influence of never-seen words. This method is simple to implement and can be plug-and-play, with only a few changes to various models. In the following experiment, the effectiveness of the proposed blocks for novel objects was proven. In future work, we intend to investigate the problem of declining metrics for in-domain.
Author Contributions
S.D. and H.Z. conceived and designed the whole experiment. S.D. designed and performed the experiment, and wrote the original draft. H.Z. contributed to the review of this paper. J.S. and D.W. participated in the design of the experiments and in the verification of the experimental results. G.L. participated in the review and revision of the paper and provided funding support. H.Z. contributed to the review of this paper and provided funding support. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the NSFC No. 61771386, and by the Key Research and Development Program of Shaanxi No. 2020SF-359, and by the Research and development of manufacturing information system platform supporting product lifecycle management No. 2018GY-030, Doctoral Research Fund of Xi’an University of Technology, China under Grant Program no. 103-451119003, the Xi’an Science and Technology Foundation under Grant No. 2019217814GXRC014CG015-GXYD14.11., Natural Science Foundation of Shaanxi Province, Under Grant No. 2023-JC-YB-550, and by the Natural Science Foundation of Shaanxi Province No. 2021JQ-487.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are included within the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Mei, T. X-linear attention networks for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10971–10980. [Google Scholar]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Venugopalan, S.; Anne Hendricks, L.; Rohrbach, M.; Mooney, R.; Darrell, T.; Saenko, K. Captioning images with diverse objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5753–5761. [Google Scholar]
- Tanaka, M.; Harada, T. Captioning images with novel objects via online vocabulary expansion. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2021. [Google Scholar]
- Wu, Y.; Zhu, L.; Jiang, L.; Yang, Y. Decoupled novel object captioner. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1029–1037. [Google Scholar]
- Demirel, B.; Cinbiş, R.G.; İkizler Cinbiş, N. Image Captioning with Unseen Objects. arXiv 2019, arXiv:1908.00047. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Bansal, A.; Sikka, K.; Sharma, G.; Chellappa, R.; Divakaran, A. Zero-shot object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Guided Open Vocabulary Image Captioning with Constrained Beam Search. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the Computer Vision—ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuznetsova, P.; Ordonez, V.; Berg, A.; Berg, T.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jeju Island, Korea, 8–14 July 2012; pp. 359–368. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2text: Describing images using 1 million captioned photographs. Adv. Neural Inf. Process. Syst. 2011, 24. Available online: https://proceedings.neurips.cc/paper_files/paper/2011/hash/5dd9db5e033da9c6fb5ba83c7a7ebea9-Abstract.html (accessed on 7 June 2023).
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper_files/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 7 June 2023). [CrossRef] [PubMed] [Green Version]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10685–10694. [Google Scholar]
- Guo, L.; Liu, J.; Tang, J.; Li, J.; Luo, W.; Lu, H. Aligning linguistic words and visual semantic units for image captioning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 765–773. [Google Scholar]
- Ma, S.; Wan, W.; Yu, Z.; Zhao, Y. EDET: Entity Descriptor Encoder of Transformer for Multi-Modal Knowledge Graph in Scene Parsing. Appl. Sci. 2023, 13, 7115. [Google Scholar] [CrossRef]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5831–5840. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 7 June 2023).
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10578–10587. [Google Scholar]
- Xian, T.; Li, Z.; Zhang, C.; Ma, H. Dual global enhanced transformer for image captioning. Neural Netw. 2022, 148, 129–141. [Google Scholar] [CrossRef] [PubMed]
- Sharma, H.; Srivastava, S. Multilevel attention and relation network based image captioning model. Multimed. Tools Appl. 2023, 82, 10981–11003. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5579–5588. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–137. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021, arXiv:2108.10904. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Incorporating copying mechanism in image captioning for learning novel objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6580–6588. [Google Scholar]
- Chen, X.; Jiang, M.; Zhao, Q. Leveraging human attention in novel object captioning. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021. [Google Scholar]
- Feng, Q.; Wu, Y.; Fan, H.; Yan, C.; Xu, M.; Yang, Y. Cascaded revision network for novel object captioning. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3413–3421. [Google Scholar] [CrossRef] [Green Version]
- Vo, D.M.; Chen, H.; Sugimoto, A.; Nakayama, H. Noc-rek: Novel object captioning with retrieved vocabulary from external knowledge. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17979–17987. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Neural baby talk. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7219–7228. [Google Scholar]
- Wu, Y.; Jiang, L.; Yang, Y. Switchable novel object captioner. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1162–1173. [Google Scholar] [CrossRef] [PubMed]
- Ramos, R.; Martins, B.; Elliott, D.; Kementchedjhieva, Y. Smallcap: Lightweight image captioning prompted with retrieval augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Convention Center, Convention Center, Vancouver, Canada, 18–22 June 2023; pp. 2840–2849. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Agrawal, H.; Desai, K.; Wang, Y.; Chen, X.; Jain, R.; Johnson, M.; Batra, D.; Parikh, D.; Lee, S.; Anderson, P. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8948–8957. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 228–231. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Yin, X.; Lin, K.; Wang, L.; Zhang, L.; Gao, J.; Liu, Z. Vivo: Surpassing human performance in novel object captioning with visual vocabulary pre-training. In Proceedings of the AAAI Conference on Artificial Intelligenc (AAAI), Virtual, 2–9 February 2021. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}