
A Research on Manipulator-Path Tracking Based on Deep Reinforcement Learning
Abstract
:1. Introduction
2. Method
2.1. Deep Q Network
2.2. Soft Actor-Critic
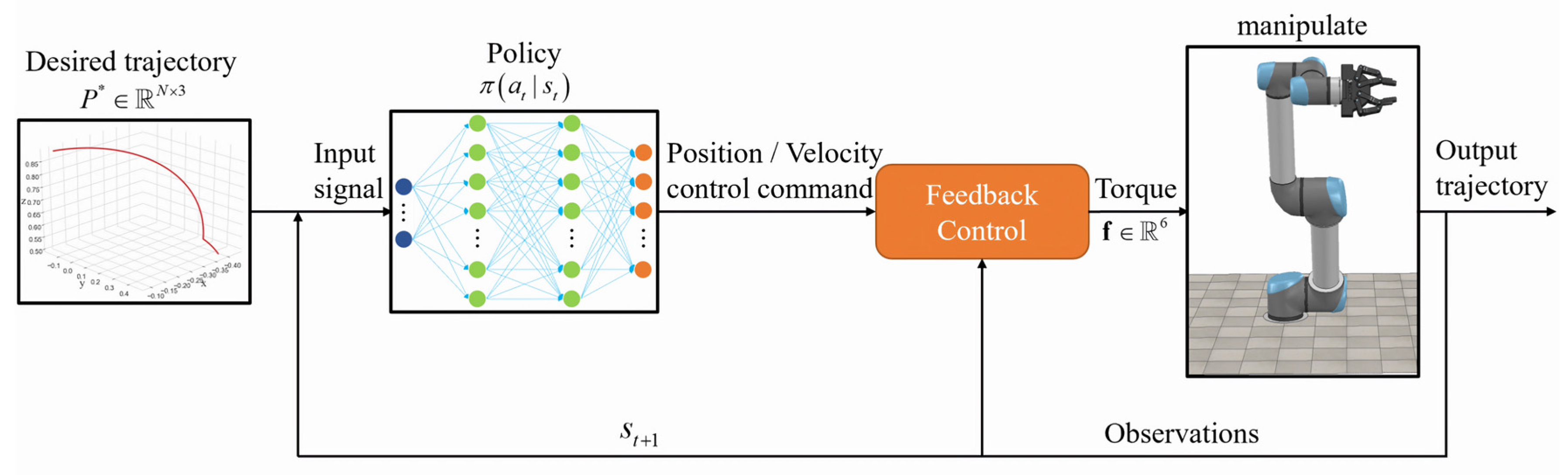
2.3. Deep-Reinforcement-Learning Algorithm Combined with Manipulator
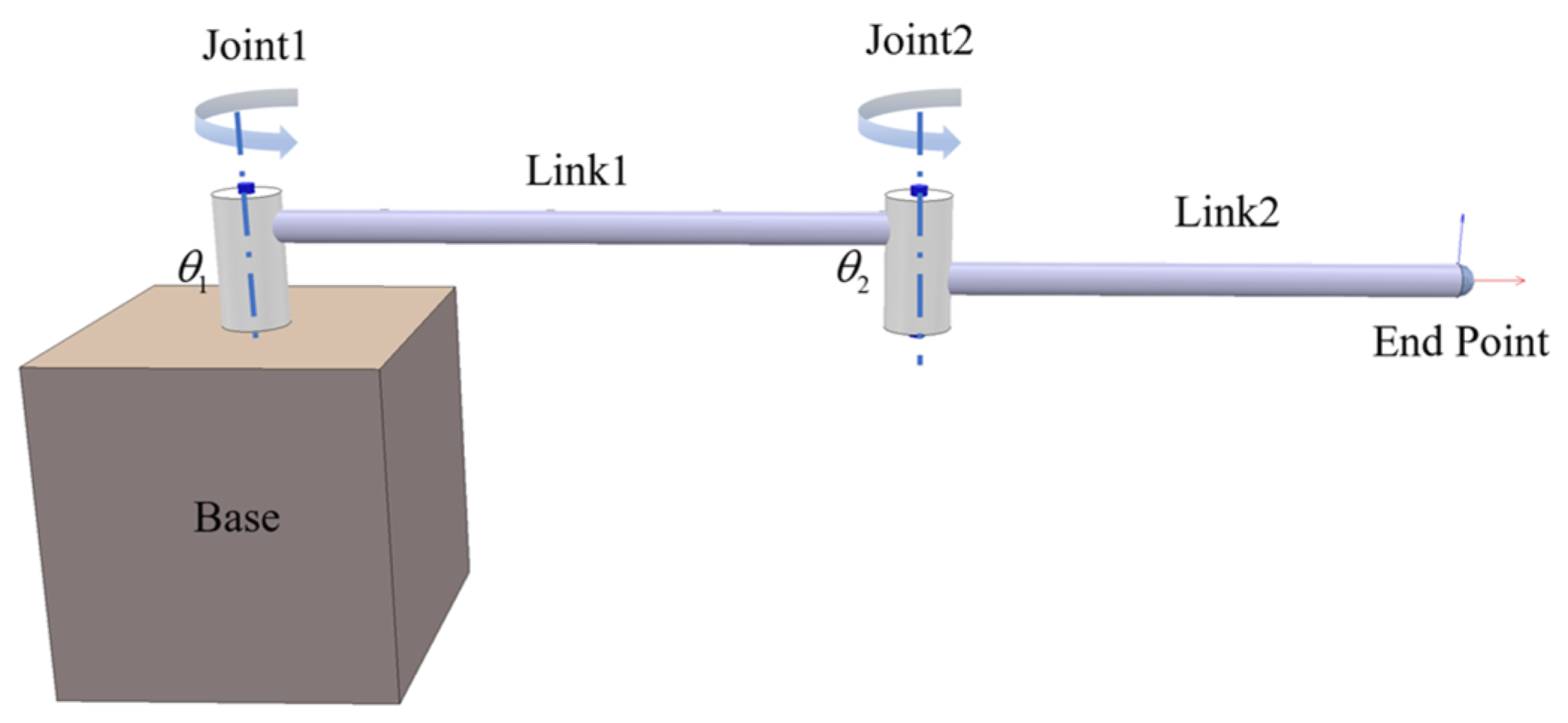
2.3.1. Application of Two-Link Manipulator
2.3.2. Application of Multi-Degree-of-Freedom Manipulator
- The upper control method of the manipulator adopts two control methods, position control and velocity control. The position control is the control of the joint angle, and the input action is the increment of the joint angle. The range of the increment at each moment is set as [−0.05, 0.05] rad. The velocity control is the control of joint angular velocity. The input action is the increment of joint angular velocity. The increment range of each moment was set to [−0.8, 0.8] rad/s in the experiment. In addition, the underlying control of the manipulator adopts the traditional PID torque-control algorithm.
- Addition of noise to the observations. This paper set up two groups of control experiments, one of which added random noise to the observations; the noise was adopted from the standard normal distribution N(0,1), and the size was 0.005 × N(0,1).
- The setting of the time-interval distance . The target path points given by the manipulator at every n time are the target path points at the N* time, where N = 1, 2, 3…, and are used to study the effect of different interval points on the tracking results. In the experiments, the interval distances were set as 1, 5, and 10, respectively.
- Terminal reward. A control experiment was set up in which, during the training process, when the distance between the endpoint of the robotic arm and the target point was within 0.05 m (the termination condition is met), an additional +5 reward was given to study its impact on the tracking results.
2.3.3. Application of Redundant Manipulator
3. Simulation Results
3.1. Simulation Results of Planar Two-Link Manipulator
3.2. Simulation Results of Multi-Degree-of-Freedom Manipulator
3.3. Simulation Results of Redundant Manipulator
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arteaga-Peréz, M.A.; Pliego-Jiménez, J.; Romero, J.G. Experimental Results on the Robust and Adaptive Control of Robot Manipulators Without Velocity Measurements. IEEE Trans. Control Syst. Technol. 2020, 28, 2770–2773. [Google Scholar] [CrossRef]
- Liu, A.; Zhao, H.; Song, T.; Liu, Z.; Wang, H.; Sun, D. Adaptive control of manipulator based on neural network. Neural Comput. Appl. 2021, 33, 4077–4085. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, Y.; He, X. Cooperative output feedback control of a mobile dual flexible manipulator. J. Frankl. Inst. 2021, 358, 6941–6961. [Google Scholar] [CrossRef]
- Gao, J.; He, W.; Qiao, H. Observer-based event and self-triggered adaptive output feedback control of robotic manipulators. Int. J. Robust Nonlinear Control 2022, 32, 8842–8873. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhao, S.; Li, H.; Lu, R.; Wu, C. Adaptive neural network tracking control for robotic manipulators with dead zone. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 3611–3620. [Google Scholar] [CrossRef]
- Zhu, W.H.; Lamarche, T.; Dupuis, E.; Liu, G. Networked embedded control of modular robot manipulators using VDC. IFAC Proc. Vol. 2014, 47, 8481–8486. [Google Scholar] [CrossRef]
- Jung, S. Improvement of Tracking Control of a Sliding Mode Controller for Robot Manipulators by a Neural Network. Int. J. Control Autom. Syst. 2018, 16, 937–943. [Google Scholar] [CrossRef]
- Cao, S.; Jin, Y.; Trautmann, T.; Liu, K. Design and Experiments of Autonomous Path Tracking Based on Dead Reckoning. Appl. Sci. 2023, 13, 317. [Google Scholar] [CrossRef]
- Leica, P.; Camacho, O.; Lozada, S.; Guamán, R.; Chávez, D.; Andaluz, V.H. Comparison of Control Schemes for Path Tracking of Mobile Manipulators. Int. J. Model. Identif. Control 2017, 28, 86–96. [Google Scholar] [CrossRef]
- Cai, Z.X. Robotics; Tsinghua University Press: Beijing, China, 2000. [Google Scholar]
- Fareh, R.; Khadraoui, S.; Abdallah, M.Y.; Baziyad, M.; Bettayeb, M. Active Disturbance Rejection Control for Robotic Systems: A Review. Mechatronics 2021, 80, 102671. [Google Scholar] [CrossRef]
- Purwar, S.; Kar, I.N.; Jha, A.N. Adaptive output feedback tracking control of robot manipulators using position measurements only. Expert Syst. Appl. 2008, 34, 2789–2798. [Google Scholar] [CrossRef]
- Jasour, A.M.; Farrokhi, M. Fuzzy Improved Adaptive Neuro-NMPC for Online Path Tracking and Obstacle Avoidance of Redundant Robotic Manipulators. Int. J. Autom. Control 2010, 4, 177–200. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.B.; Su, W.C.; Tsai, C.C.; Nguyen, T. Intelligent Tracking Control of a Dual-Arm Wheeled Mobile Manipulator with Dynamic Uncertainties. Int. J. Robust Nonlinear Control 2013, 23, 839–857. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, S.; Guo, J.-X.; Gao, X.-S. Time-Optimal Path Tracking for Robots under Dynamics Constraints Based on Convex Optimization. Robotica 2016, 34, 2116–2139. [Google Scholar] [CrossRef]
- Annusewicz-Mistal, A.; Pietrala, D.S.; Laski, P.A.; Zwierzchowski, J.; Borkowski, K.; Bracha, G.; Borycki, K.; Kostecki, S.; Wlodarczyk, D. Autonomous Manipulator of a Mobile Robot Based on a Vision System. Appl. Sci. 2023, 13, 439. [Google Scholar] [CrossRef]
- Tappe, S.; Pohlmann, J.; Kotlarski, J.; Ortmaier, T. Towards a follow-the-leader control for a binary actuated hyper-redundant manipulator. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3195–3201. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Martín-Guerrero, J.D.; Lamata, L. Reinforcement Learning and Physics. Appl. Sci. 2021, 11, 8589. [Google Scholar] [CrossRef]
- Guo, X. Research on the Control Strategy of Manipulator Based on DQN. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2018. [Google Scholar]
- Hu, Y.; Si, B. A Reinforcement Learning Neural Network for Robotic Manipulator Control. Neural Comput. 2018, 30, 1983–2004. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.C.; Huang, C.Y. DDPG-Based Adaptive Robust Tracking Control for Aerial Manipulators With Decoupling Approach. IEEE Trans Cybern 2022, 52, 8258–8271. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Fujimoto, S.; Meger, D.; Precup, D. Off-policy deep reinforcement learning without exploration. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 2052–2062. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-Based Algorithms for Optimal Motion Planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Li, D.; Ye, C.; Ding, H. An Analytical C3 Continuous Tool Path Corner Smoothing Algorithm for 6R Robot Manipulator. Robot. Comput.-Integr. Manuf. 2020, 64, 101947. [Google Scholar] [CrossRef]
- Kim, M.; Han, D.-K.; Park, J.-H.; Kim, J.-S. Motion Planning of Robot Manipulators for a Smoother Path Using a Twin Delayed Deep Deterministic Policy Gradient with Hindsight Experience Replay. Appl. Sci. 2020, 10, 575. [Google Scholar] [CrossRef] [Green Version]
- Carvajal, C.P.; Andaluz, V.H.; Roberti, F.; Carelli, R. Path-Following Control for Aerial Manipulators Robots with Priority on Energy Saving. Control Eng. Pract. 2023, 131, 105401. [Google Scholar] [CrossRef]
- Li, B.; Wu, Y. Path Planning for UAV Ground Target Tracking via Deep Reinforcement Learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Position Control | w/o Observation-Noise | Observation-Noise | |||||
|---|---|---|---|---|---|---|---|
| Interval | Interval | ||||||
| 1 | 5 | 10 | 1 | 5 | 10 | ||
| Average error between tracks (m) | w/o terminal reward | 0.0374 | 0.0330 | 0.0592 | 0.0394 | 0.0427 | 0.0784 |
| terminal reward | 0.0335 | 0.0796 | 0.0502 | 0.0335 | 0.0475 | 0.0596 | |
| Distance between end points (m) | w/o terminal reward | 0.0401 | 0.0633 | 0.0420 | 0.0443 | 0.0485 | 0.0292 |
| terminal reward | 0.0316 | 0.0223 | 0.0231 | 0.0111 | 0.0148 | 0.0139 | |
| Velocity Control | w/o Observation-Noise | Observation-Noise | |||||
|---|---|---|---|---|---|---|---|
| Interval | Interval | ||||||
| 1 | 5 | 10 | 1 | 5 | 10 | ||
| Average error between tracks(m) | w/o terminal reward | 0.0343 | 0.0359 | 0.0646 | 0.0348 | 0.0318 | 0.0811 |
| terminal reward | 0.0283 | 0.0569 | 0.0616 | 0.0350 | 0.0645 | 0.0605 | |
| Distance between end points (m) | w/o terminal reward | 0.0233 | 0.0224 | 0.0521 | 0.0456 | 0.0365 | 0.0671 |
| terminal reward | 0.0083 | 0.0030 | 0.0337 | 0.0275 | 0.0192 | 0.0197 | |
| Position Control | 0.5 kg | 1 kg | 2 kg | 3 kg | 5 kg | ||
|---|---|---|---|---|---|---|---|
| Average error between tracks (m) | w/o observation noise | w/o terminal reward | 0.03742 | 0.03743 | 0.03744 | 0.03745 | 0.03746 |
| terminal reward | 0.03354 | 0.03354 | 0.03359 | 0.03355 | 0.03355 | ||
| observation noise | w/o terminal reward | 0.03943 | 0.03943 | 0.03943 | 0.03942 | 0.03941 | |
| terminal reward | 0.03346 | 0.03346 | 0.03346 | 0.03346 | 0.03345 | ||
| Distance between end points (m) | w/o observation noise | w/o terminal reward | 0.04047 | 0.04047 | 0.04048 | 0.04049 | 0.04050 |
| terminal reward | 0.03165 | 0.03166 | 0.03157 | 0.03159 | 0.03161 | ||
| observation noise | w/o terminal reward | 0.04430 | 0.04441 | 0.04438 | 0.04430 | 0.04436 | |
| terminal reward | 0.01110 | 0.01109 | 0.01109 | 0.01108 | 0.01105 | ||
| Velocity Control | 0.5 kg | 1 kg | 2 kg | 3 kg | 5 kg | ||
|---|---|---|---|---|---|---|---|
| Average error between tracks (m) | w/o observation noise | w/o terminal reward | 0.03426 | 0.03427 | 0.03425 | 0.03426 | 0.03425 |
| terminal reward | 0.02826 | 0.02825 | 0.02866 | 0.02873 | 0.02882 | ||
| observation noise | w/o terminal reward | 0.03478 | 0.03479 | 0.03483 | 0.03486 | 0.03497 | |
| terminal reward | 0.03503 | 0.03503 | 0.03503 | 0.03502 | 0.03501 | ||
| Distance between end points (m) | w/o observation noise | w/o terminal reward | 0.02326 | 0.02444 | 0.02436 | 0.02430 | 0.02422 |
| terminal reward | 0.00831 | 0.01201 | 0.01395 | 0.01463 | 0.01513 | ||
| observation noise | w/o terminal reward | 0.04560 | 0.04562 | 0.04565 | 0.04569 | 0.04578 | |
| terminal reward | 0.02748 | 0.02746 | 0.02743 | 0.02741 | 0.02733 | ||
| Velocity Control | w/o Terminal Reward | Terminal Reward | Jacobian Matrix | ||||
|---|---|---|---|---|---|---|---|
| Interval | Interval | ||||||
| 1 | 5 | 10 | 1 | 5 | 10 | ||
| Smoothness | 0.5751 | 0.3351 | 0.5925 | 0.0816 | 0.5561 | 0.4442 | 0.7159 |
| Energy Consumption | 0.5 kg | 1 kg | 2 kg | 3 kg | 5 kg | |
|---|---|---|---|---|---|---|
| Position Control | w/o terminal reward | 4.44438 | 4.71427 | 5.27507 | 5.79426 | 6.92146 |
| terminal reward | 5.01889 | 5.34258 | 5.95310 | 6.55227 | 7.76305 | |
| Velocity Control | w/o terminal reward | 4.97465 | 5.38062 | 6.23886 | 6.95099 | 8.33596 |
| terminal reward | 6.03735 | 6.37981 | 7.05696 | 7.75185 | 9.15828 | |
| Traditional | Jacobian matrix | 8.95234 | 9.81593 | 10.8907 | 10.9133 | 13.3241 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Zhang, J.; Kan, J. A Research on Manipulator-Path Tracking Based on Deep Reinforcement Learning. Appl. Sci. 2023, 13, 7867. https://doi.org/10.3390/app13137867
Zhang P, Zhang J, Kan J. A Research on Manipulator-Path Tracking Based on Deep Reinforcement Learning. Applied Sciences. 2023; 13(13):7867. https://doi.org/10.3390/app13137867
Chicago/Turabian StyleZhang, Pengyu, Jie Zhang, and Jiangming Kan. 2023. "A Research on Manipulator-Path Tracking Based on Deep Reinforcement Learning" Applied Sciences 13, no. 13: 7867. https://doi.org/10.3390/app13137867
APA StyleZhang, P., Zhang, J., & Kan, J. (2023). A Research on Manipulator-Path Tracking Based on Deep Reinforcement Learning. Applied Sciences, 13(13), 7867. https://doi.org/10.3390/app13137867