
DroidDetectMW: A Hybrid Intelligent Model for Android Malware Detection


Abstract
:1. Introduction
- DroidDetectMW is proposed as a functional and systematic model for detecting and identifying Android malware and its family and category based on a combination of Dynamic and Static attributes.
- Methods are proposed for selecting features, either statically or dynamically, to use.
- A hybrid fuzzy-metaheuristics-optimization approach is proposed for selecting the optimal dynamic feature subset.
- An enhanced version of the HHO algorithm is proposed to optimize the parameters of ANN for malware detection.
- A Comparison is applied between the results of the proposed Deep learning method with those of more traditional machine learning classifiers in determining how well DroidDetectMW works.
- Evaluate the performance of DroidDetectMW in comparison to seven traditional machine learning methods: the Decision Tree (DT), the support vector machine (SVM), the K-Nearest Neighbor, the Multilayer Perceptron (MLP), the Sequential Minimal Optimization (SMO), Random Forest (RF) and the Naive Bayesian (NB).
- Compared to traditional machine learning algorithms and state-of-the-art studies, DroidDetectMW significantly improves detection performance and achieves good accuracy on both Static and Dynamic attributes.
2. Related Work
3. Preliminary
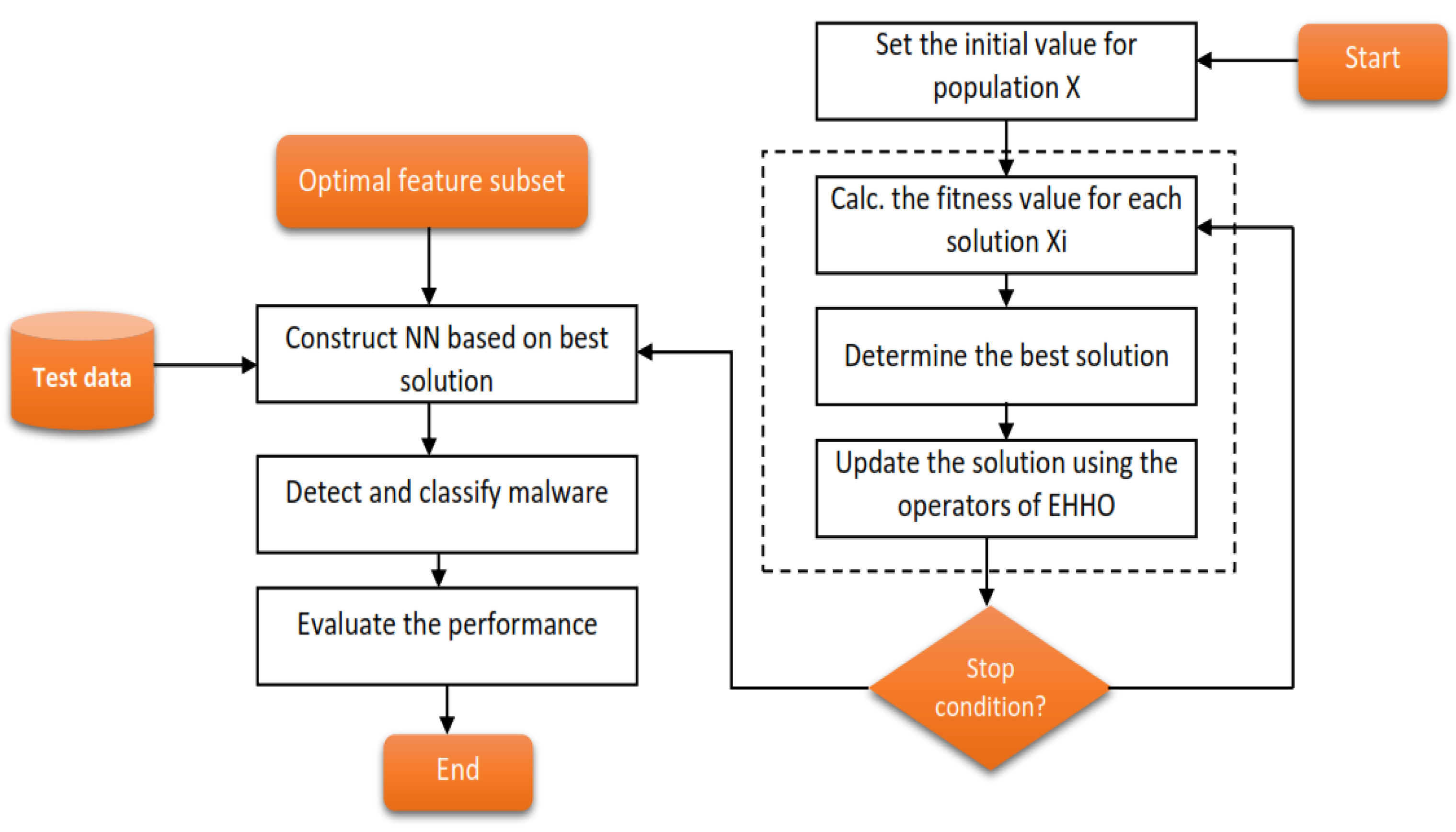
3.1. Harris Hawks Optimization (HHO)
3.2. Dataset and Malware Categories
- Adware: To generate as much revenue as possible from unsolicited banner ads, the ad-ware will display these ads automatically [47].
- Ransomware: One goal of malicious software is to prevent apps from accessing system resources. To extort money from users, it can encrypt their files and demand payment before allowing them to access their files or recover their devices [48].
- Scareware: This malware software uses scare tactics to convince users to buy bogus security updates [49].
- SMS malware: A malicious malware that makes sms calls and sends text messages with-out the user’s permission. The malware operator can use the compromised handsets as a high-end SMS distribution channel [50].
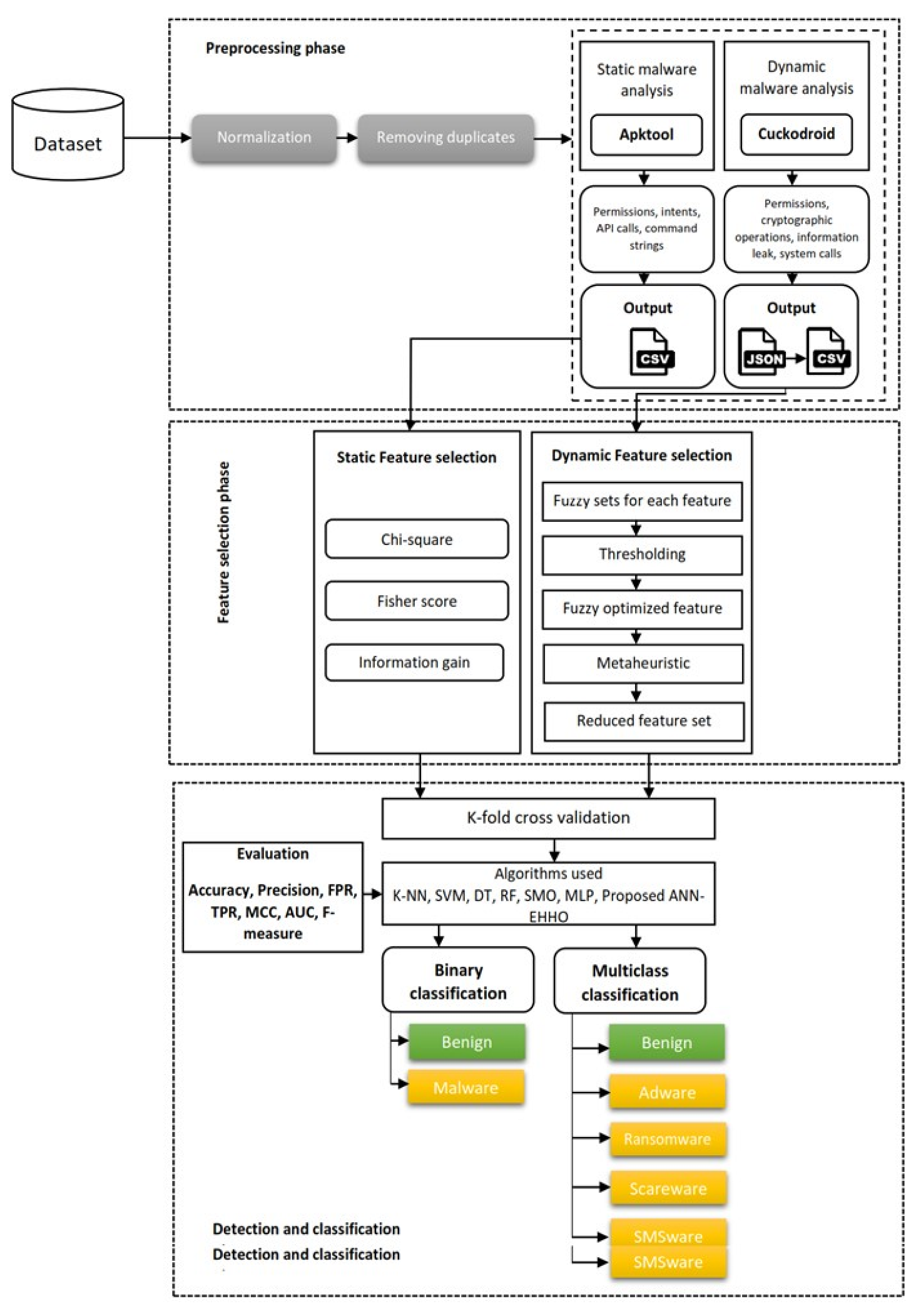
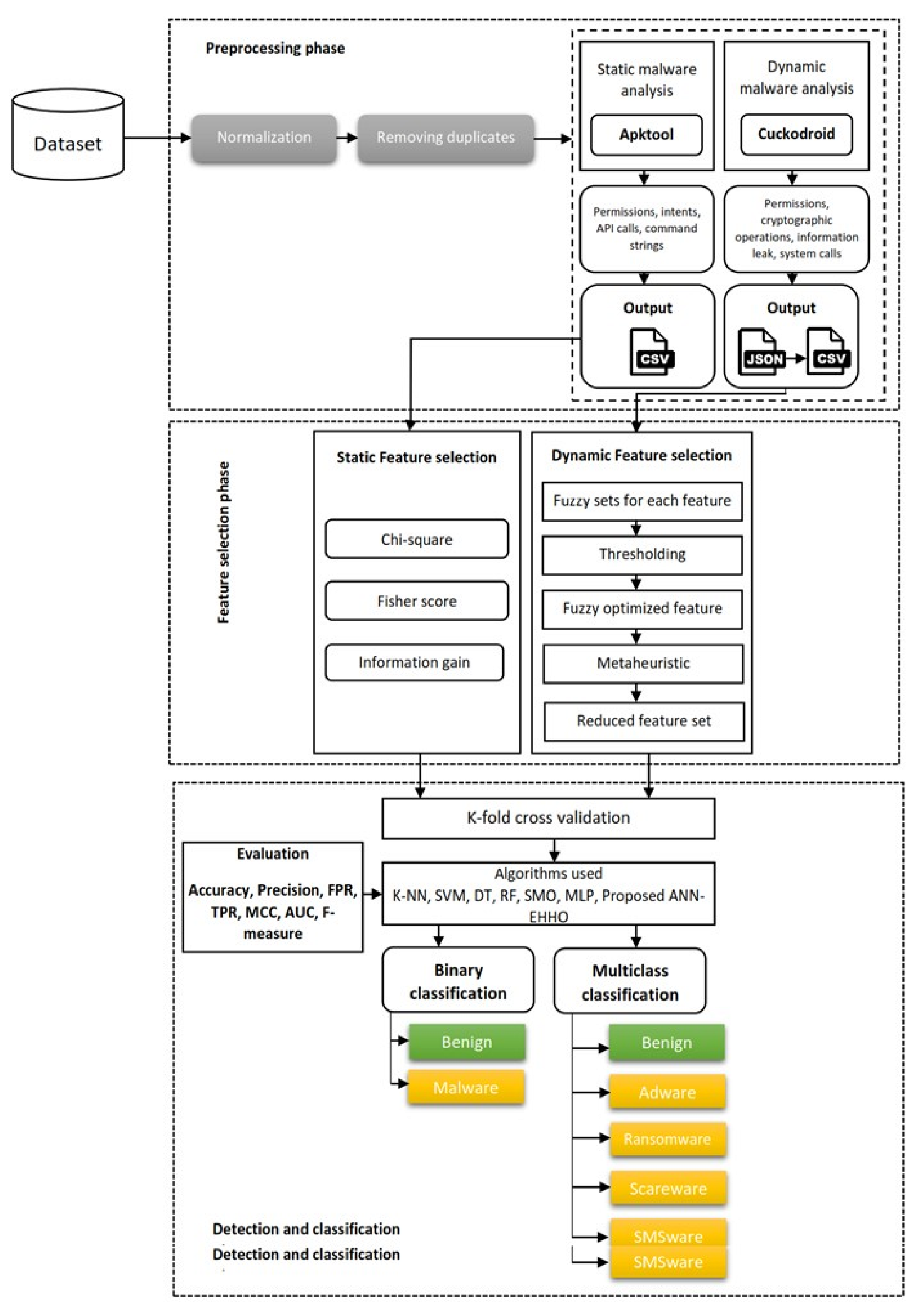
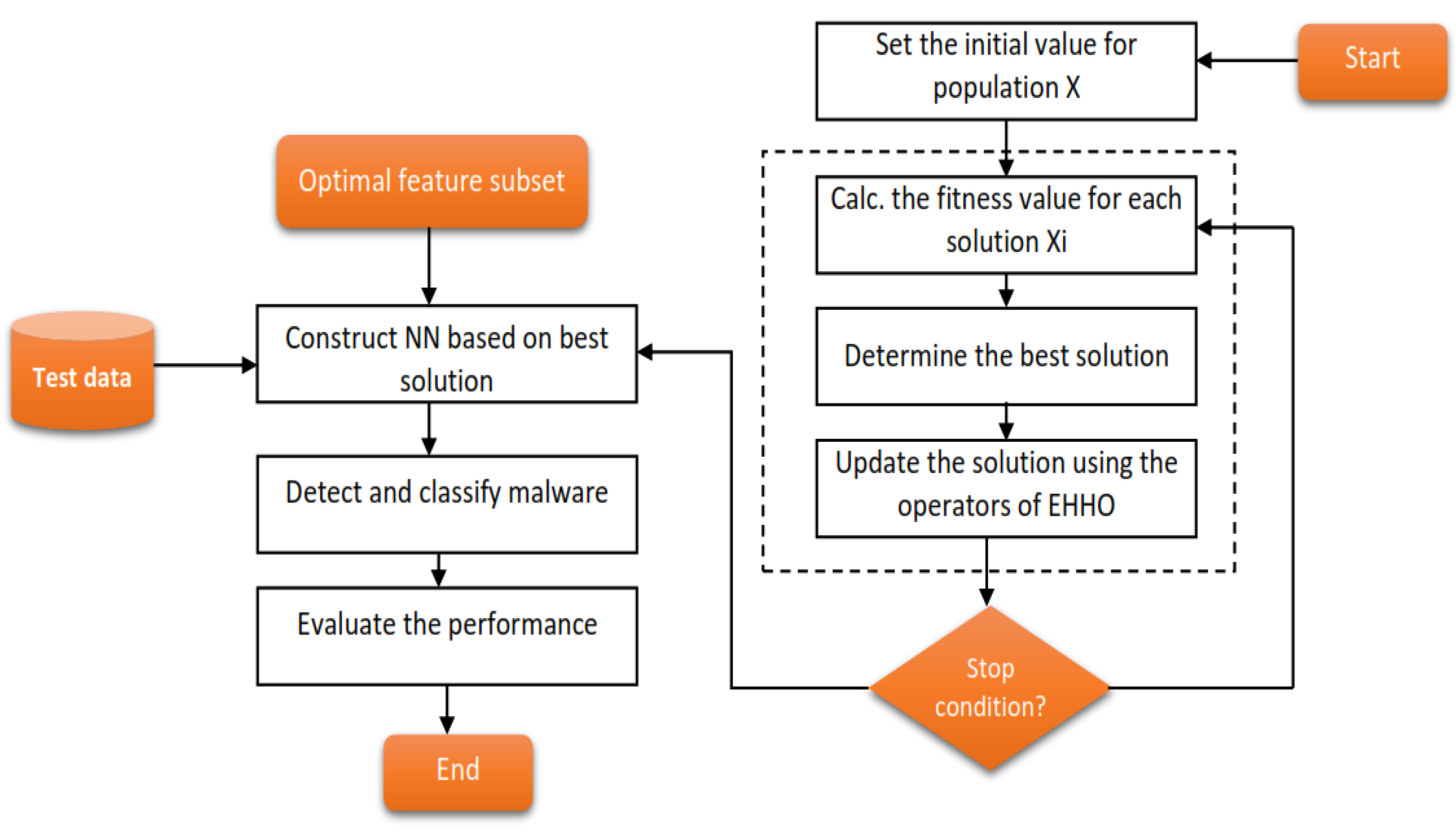
4. Proposed Framework
4.1. Data Pre-Processing
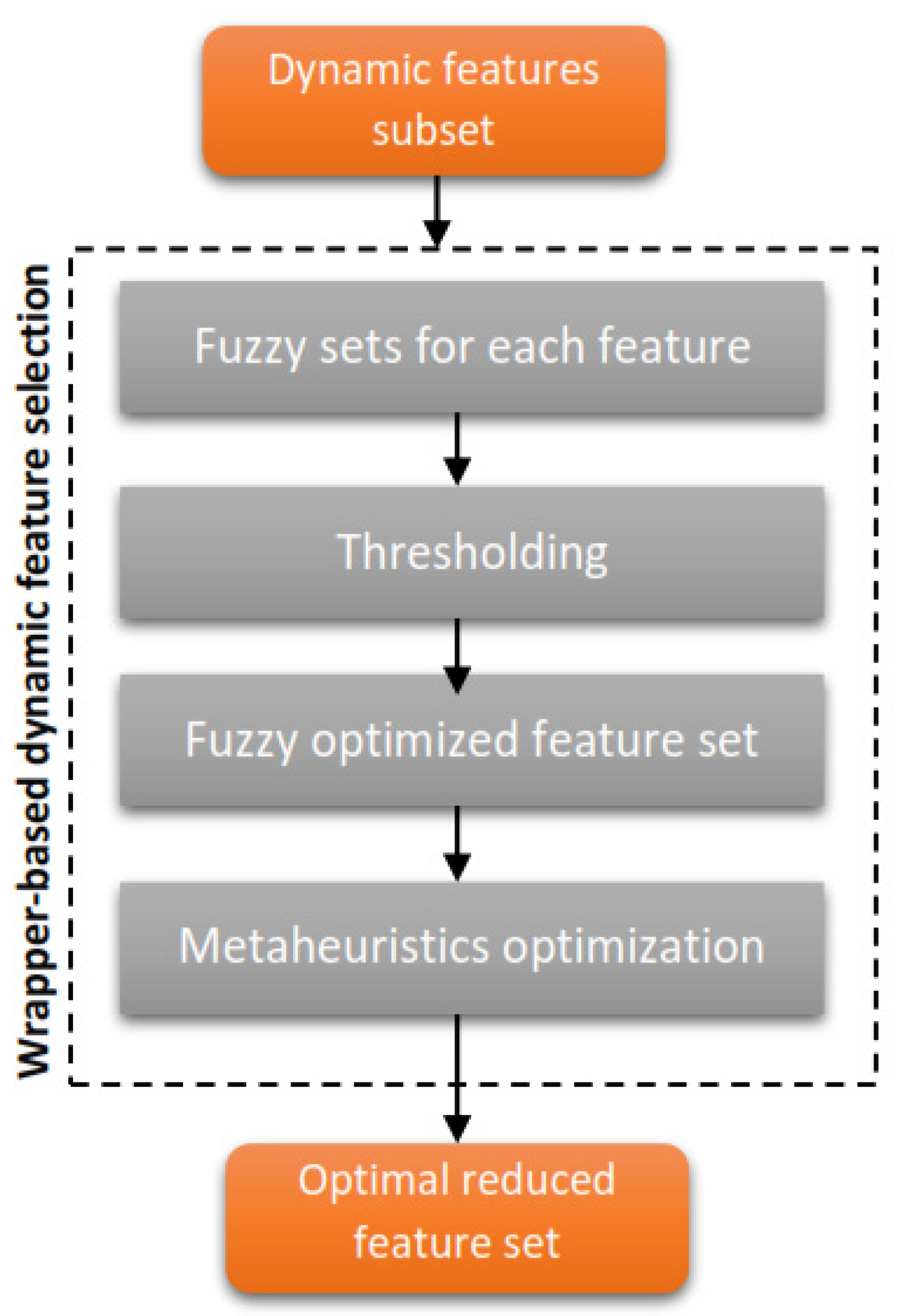
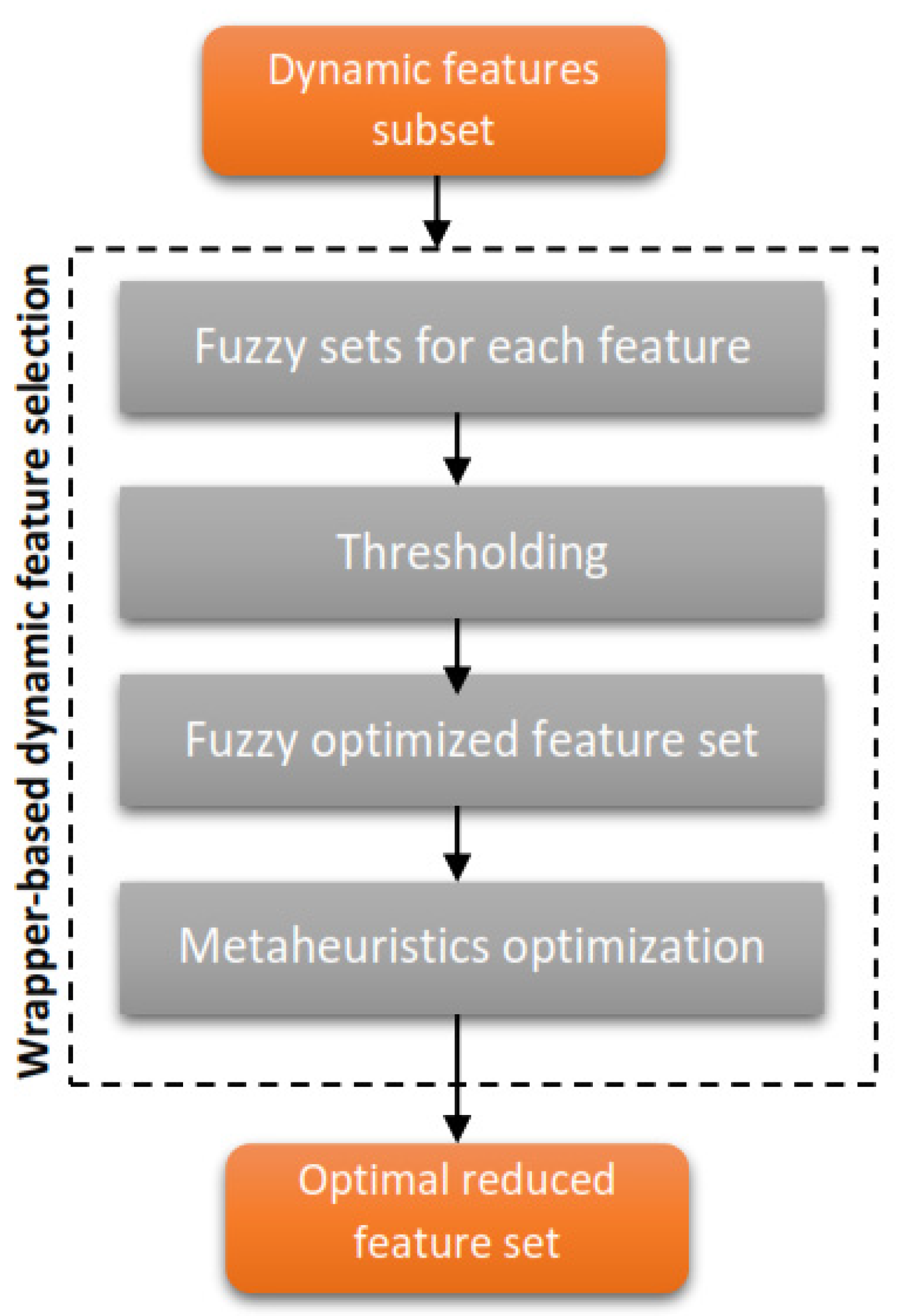
4.2. Feature Selection
| Algorithm 1: static-feature-select |
| Input: Training dataset D with static features S Output: optimal subset of features Snew 1. def static-feature-select(D,S): 2. Calculate feature importance using chi-square, fisher and information gain from S 3. S1 = remove features with score 0 and NaN from chi-s 4. S2 = remove features with score 0 and NaN from fisher 5. S3 = remove features with score 0 and NaN using MIG 6. A = avg-perf-model(S1,S2,S3) 7. M = best-subset(S1,S2,S3) 8. S = best-subset(S1,S2,S3) 9. return Snew 10. End def |
4.3. Detection and Family Classification
- K-Nearest Neighbors (K-NN) is a simple supervised learning technique. This concept shares terminology with the lazy learner [58]. This technique does not care about the underlying data structure when a new instance appears. Instead, it uses distance measurements (e.g., Euclidean distance, Manhattan distance) to determine which training samples are most similar to the incoming instance. Majority voting notions ultimately determine this new instance’s class.
- Sequential Minimal Optimization (SMO) takes a set of points as its input. The method generates a hyperplane that separates points within the same class by analyzing the gaps between them. Kernel functions fill in the blanks in SMO by revealing data about the distance between two spots.
- SVM is a technique [59] that uses a hyperplane to partition the information. In a nutshell, it’s a dividing line from which to choose. Distances between the nearest data points are called support vectors, and the hyperplane is calculated randomly after the hyperplane is drawn. It searches for the optimal hyperplane that maximizes the profit.
- Random Forest (RF): A considerable number of independent decision trees are used in RF to form a unified whole [60]. Each decision tree generates an output classification for the input data, then compiled by RF and represented graphically based on a majority vote.
- A Decision Tree (DT) is organized in the form of a tree, where each node (whether internal, leaf, terminal) represents a test on an attribute, and each branch (whether internal, leaf, or terminal) carries a class name and the results of the test. The C4.5 algorithm has been utilized in this work to categorize Android malware [61].
- Bayes’ theorem provides the theoretical foundation for the NB idea. The program predicts the probabilities of class membership or the likelihood that a set of tuples belongs to a specific class. Multi-class and binary classification problems [57] both benefit from their application.
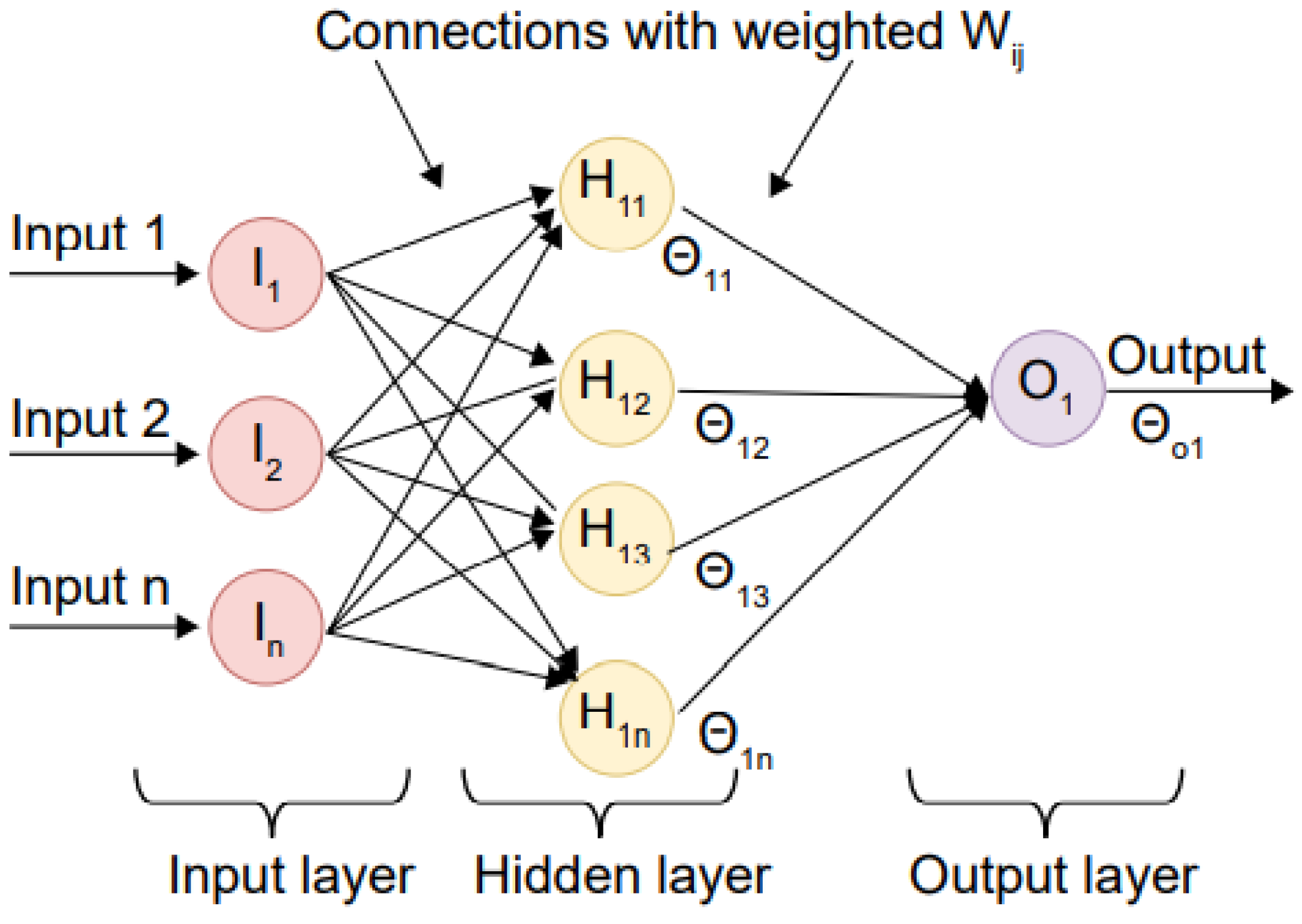
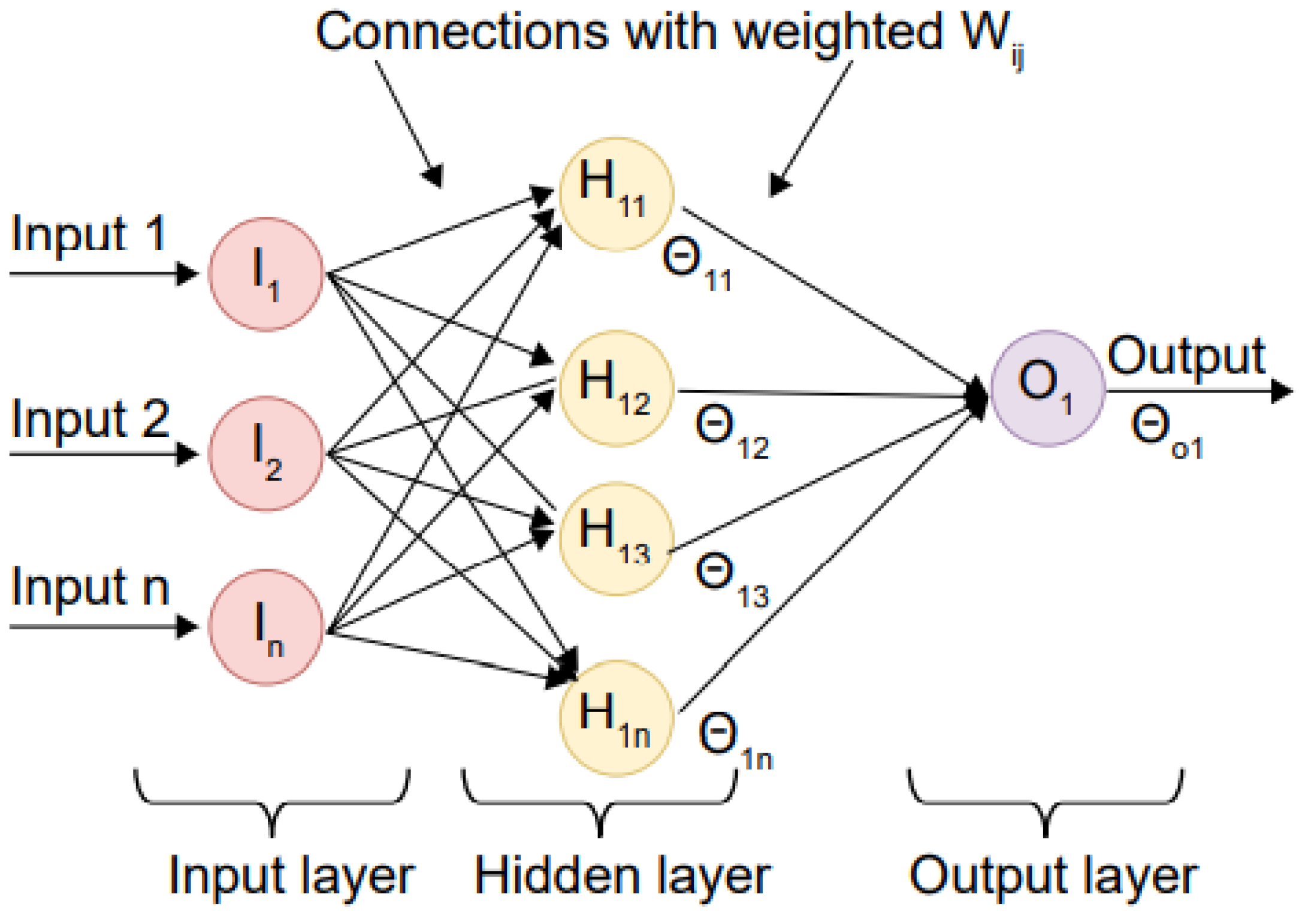
- Multilayer Perceptron (MLP): There are the hidden and output layers and the input layer. It can produce results in several different measurement systems. The hidden layer’s output units are fed into the subsequent layer as input applied deep learning approaches like ANNs classifiers to various classification challenges. The authors use MLP to identify and categorize Android malware when classifying and predicting gait data. The MLP is executed using a hidden layer of h = 3 and sigmoid activation function for the binary classification and h = 5 and softmax activation function for the multi-class classification. Learning is assumed to occur at a rate of 0.35. For a high-level overview of how backpropagation works in a neural network, see Figure 4.
5. Experiments
5.1. Evaluation Measures and Experimental Setup
- TPR—Recall: It is calculated by dividing the number of confirmed positive results by the total number of positive results. As illustrated in Equation, it can be estimated by Equation (14):
- FPR: This metric represents the proportion of false positive cases relative to the total number of true negative cases. The calculation is described by the following Equation (15):
- Precision is calculated by dividing the number of correct predictions by the total number of correct predictions. It can be calculated by Equation (16):
- F-measure: It indicates the harmonic mean of precision and recall. Equation (17) is used to deter-mine this is:
- Accuracy: It is calculated by dividing the number of cases by the sum of the instances that are both true negatives and true positives. Equation (18) used to determine this is:
- MCC: It is a standard for evaluating the efficacy of binary classifiers. Its numerical value ranges from +1 to −1. Here, a value of +1 indicates an exact prediction, while a value of −1 indicates an opposite forecast. Equation (19) used to determine this is:
- AUC curve: The F-measure is a crucial indicator of a classification model’s efficacy. It is a quantitative indicator of how easily things can be separated.
5.2. Malware Binary Detection Based on Static Features
5.3. Malware Category Detection Based on Static Features
5.4. Malware Family Classification and Detection Based on Static Features Selection
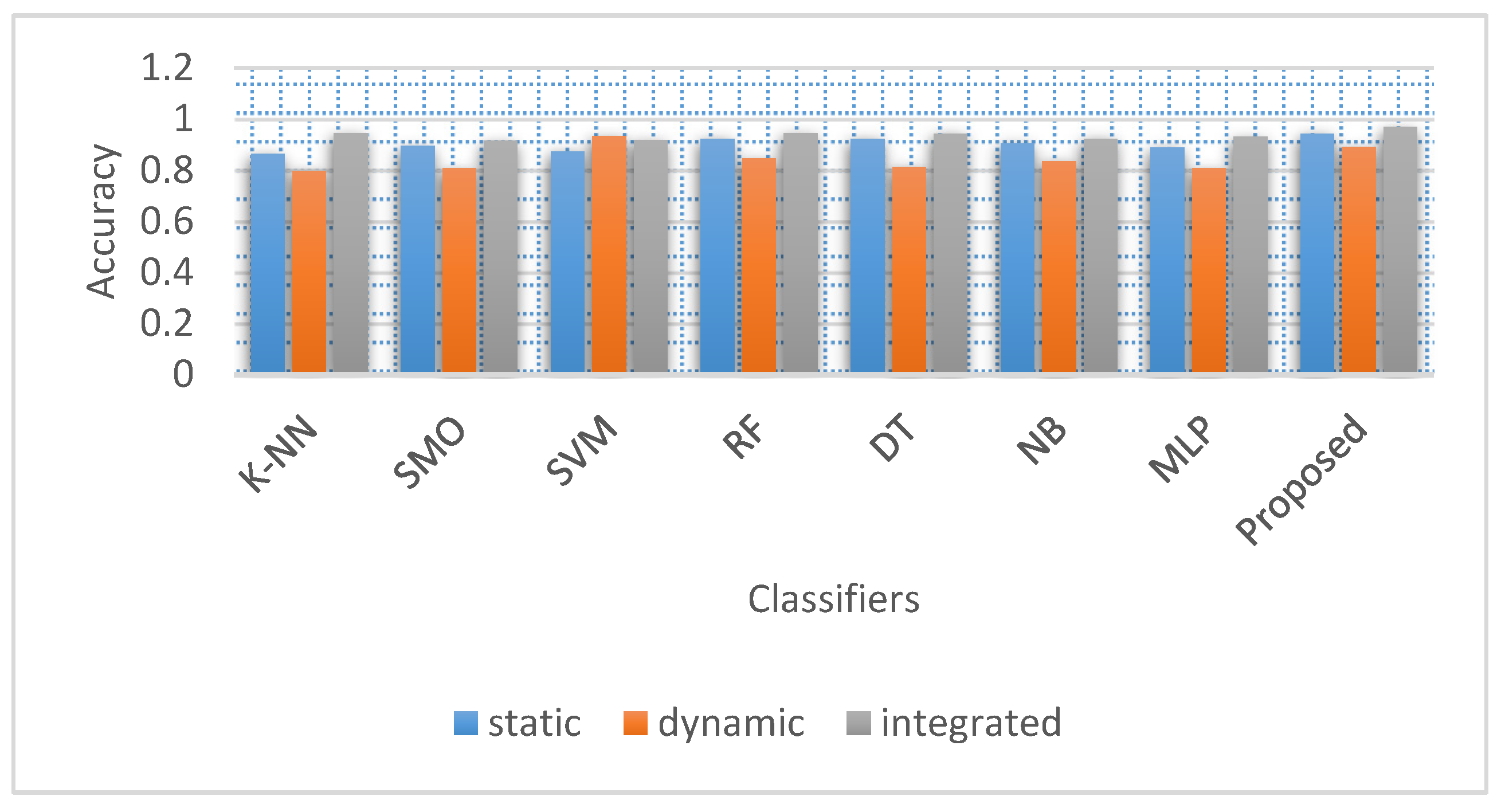
5.5. Malware Binary Detection Based on Dynamic Features Selection
5.6. Malware Category Detection Based on Dynamic Features Selection
5.7. Malware Family Classification and Detection Based on Dynamic Feature Selection
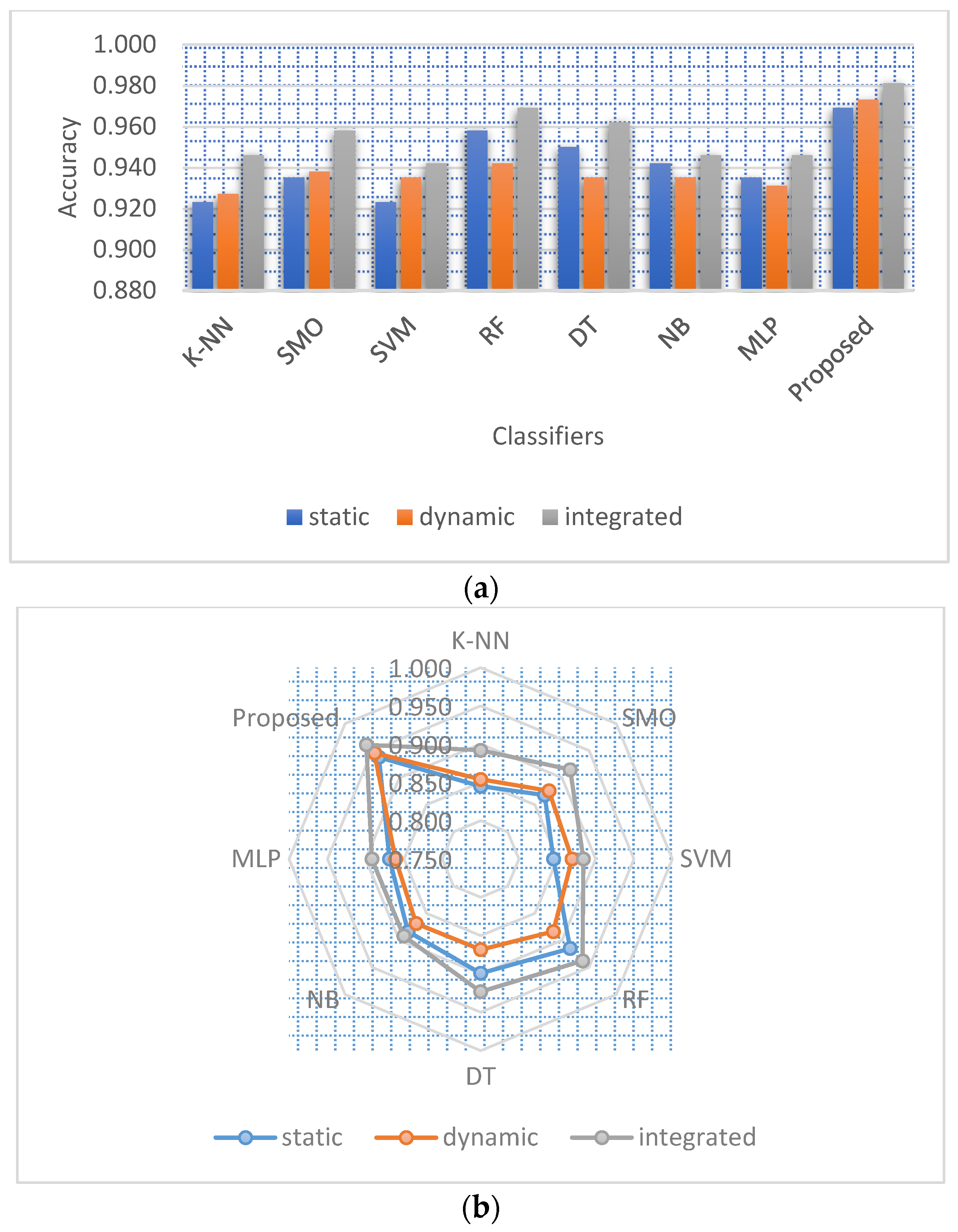
5.8. Classification Results Based on Hybrid Features
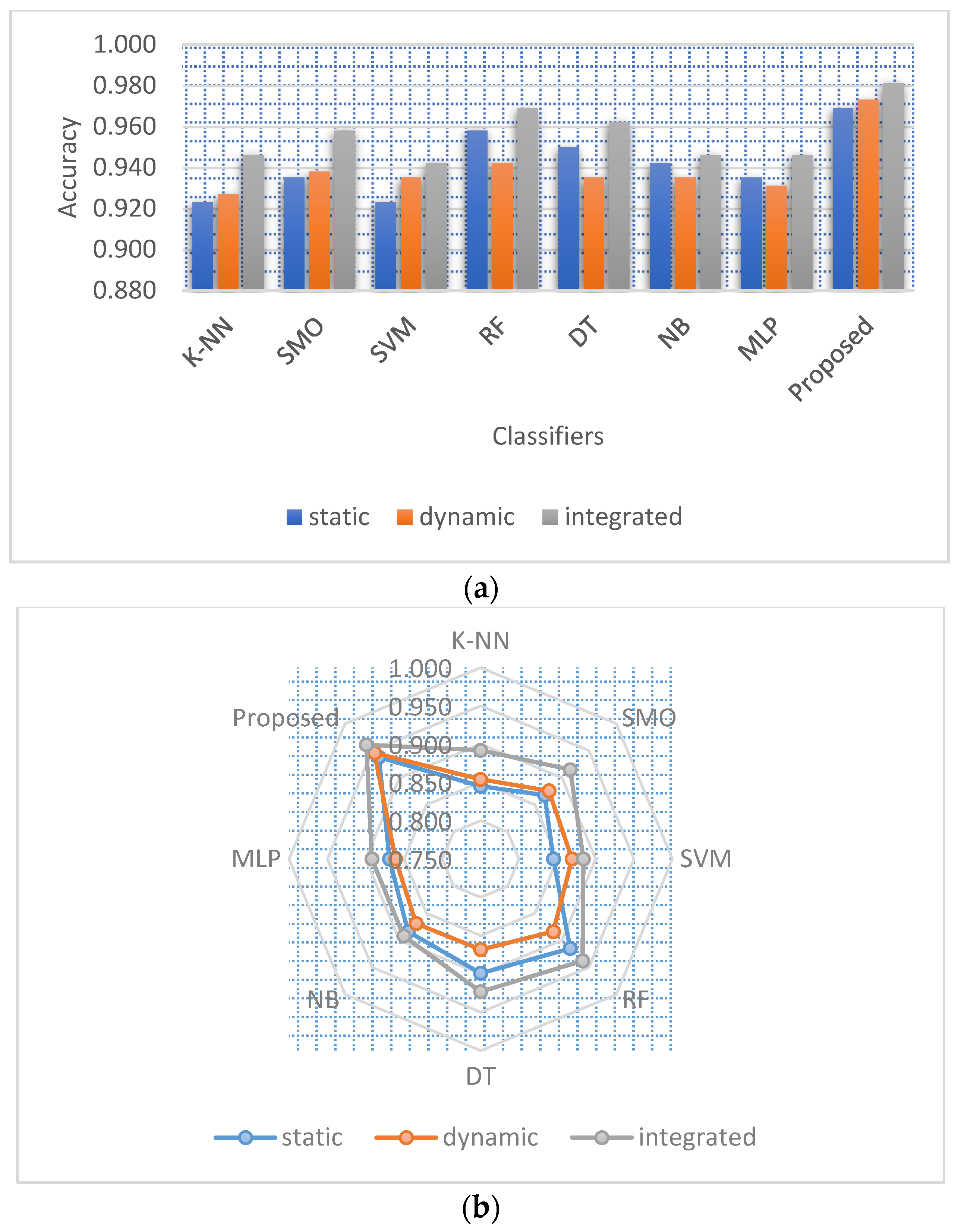
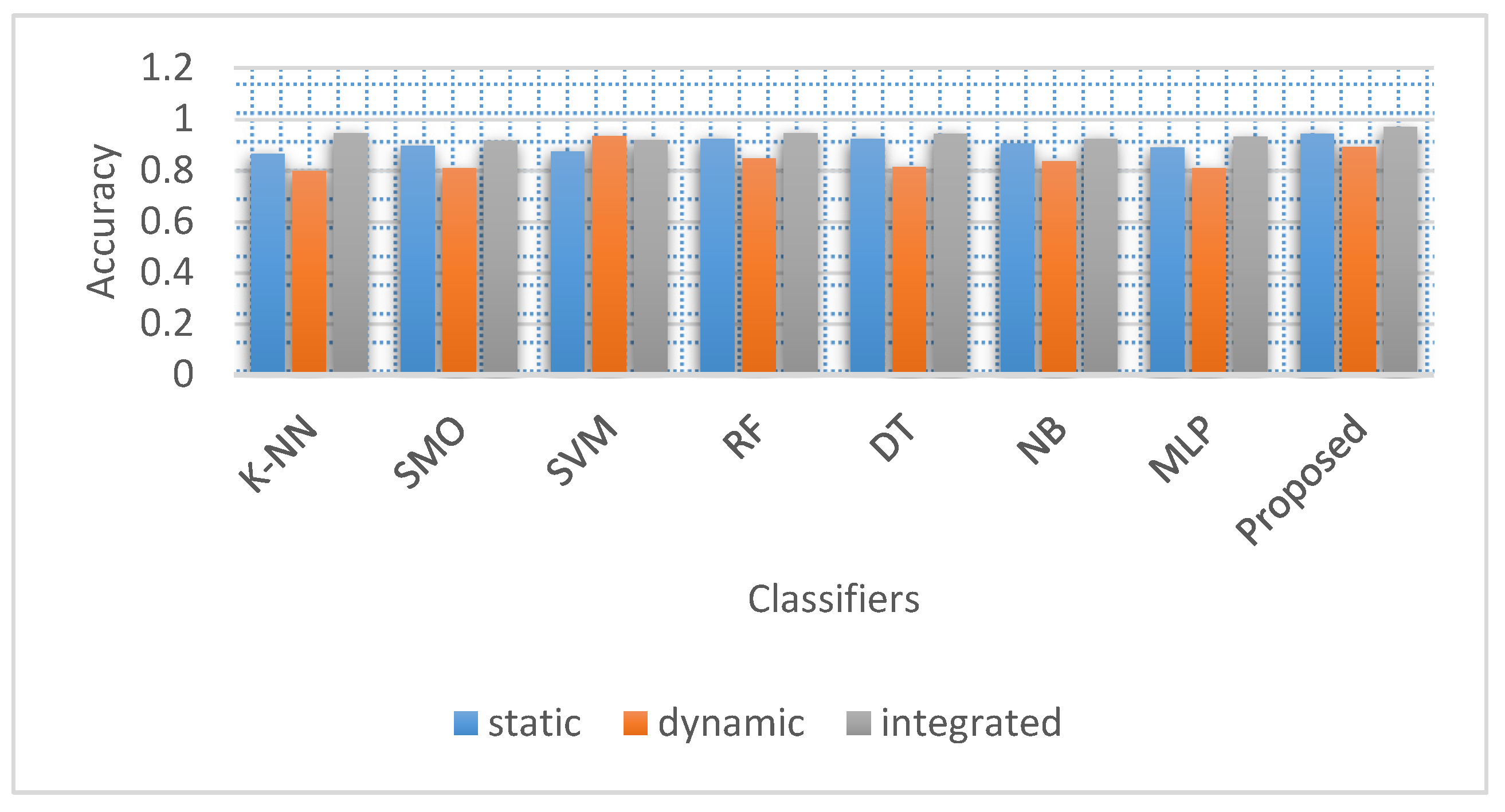
5.9. Comparative Analysis
5.10. Feature Selection Effect on Static and Dynamic Features
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smartphone Users Worldwide 2016–2023. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 27 December 2022).
- Mosa, A.S.M.; Yoo, I.; Sheets, L. A Systematic Review of Healthcare Applications for Smartphones. BMC Med. Inform. Decis. Mak. 2012, 12, 67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Number of Apps Available in Leading App Stores as of 4th Quarter 2020. 2021. Available online: https://www.statista.com/statistics/276623/number-of-apps-available-in-leading-app-stores/#:%7e:text=As (accessed on 27 December 2022).
- Alzaylaee, M.K.; Yerima, S.Y.; Sezer, S. DL-Droid: Deep learning based android malware detection using real devices. Comput. Secur. 2020, 89, 101663. [Google Scholar] [CrossRef]
- Dhalaria, M.; Gandotra, E. Android malware detection techniques: A literature review. Recent Pat. Eng. 2021, 15, 225–245. [Google Scholar] [CrossRef]
- Taher, F.; Abdel-Salam, M.; Elhoseny, M.; El-Hasnony, I.M. Reliable Machine Learning Model for IIoT Botnet Detection. IEEE Access 2023, 11, 49319–49336. [Google Scholar] [CrossRef]
- Agrawal, P.; Trivedi, B. Machine Learning Classifiers for Android Malware Detection. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 311–322. [Google Scholar]
- Rajagopal, A. Incident of the Week: Malware Infects 25m Android Phones. 2019. Available online: https://www.cshub.com/malware/articles/incident-of-the-week-malware-infects-25m-android-phones (accessed on 27 December 2022).
- BBC. One Billion Android Devices at Risk of Hacking. 2021. Available online: https://www.bbc.com/news/technology-51751950 (accessed on 27 December 2022).
- Goodin, D. Google Play Has Been Spreading Advanced Android Malware for Years. 2021. Available online: https://arstechnica.com/information-technology/2020/04/sophisticated-android-backdoors-have-been-populating-google-play-for-years/ (accessed on 27 December 2022).
- Vaas, L. Android Malware Flytrap Hijacks Facebook Accounts. 2022. Available online: https://threatpost.com/android-malware-flytrap-facebook/168463/ (accessed on 27 December 2022).
- Wang, C.; Xu, Q.; Lin, X.; Liu, S. Research on data mining of permissions mode for Android malware detection. Clust. Comput. 2019, 22, 13337–13350. [Google Scholar] [CrossRef]
- Ko, J.-S.; Jo, J.-S.; Kim, D.-H.; Choi, S.-K.; Kwak, J. Real Time Android Ransomware Detection by Analyzed Android Applications. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Ideses, I.; Neuberger, A. Adware Detection and Privacy Control in Mobile Devices. In Proceedings of the 2014 IEEE 28th Convention of Electrical & Electronics Engineers in Israel (IEEEI), Eilat, Israel, 3–5 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–5. [Google Scholar]
- Faghihi, F.; Abadi, M.; Tajoddin, A. Smsbothunter: A novel anomaly detection technique to detect sms botnets. In Proceedings of the 2018 15th International ISC (Iranian Society of Cryptology) Conference on Information Security and Cryptology (ISCISC), Tehran, Iran, 28–29 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-On Guide to Dissecting Malicious Software; No Starch Press: San Francisco, CA, USA, 2012. [Google Scholar]
- Iwendi, C.; Jalil, Z.; Javed, A.R.; Reddy, T.; Kaluri, R.; Srivastava, G.; Jo, O. Keysplitwatermark: Zero watermarking algorithm for software protection against cyber-attacks. IEEE Access 2020, 8, 72650–72660. [Google Scholar] [CrossRef]
- Manikandan, R.; Keerthana, S.; Priya, S.S.; Madhumitha, R.; Aditya, A.G.S.; Priya, D. Android-based System for Intelligent Traffic Signal Control and Emergency Call Functionality. J. Cogn. Hum.-Comput. Interact. 2023, 5, 31–44. [Google Scholar] [CrossRef]
- Pustokhin, D.A.; Pustokhina, I.V. FLC-NET: Federated Lightweight Network for Early Discovery of Malware in Resource-constrained IoT. J. Int. J. Wirel. Ad Hoc Commun. 2023, 6, 43–55. [Google Scholar] [CrossRef]
- Taheri, L.; Kadir, A.F.A.; Lashkari, A.H. Extensible Android Malware Detection and Family Classification Using Network-Flows and API-Calls. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Tchakounté, F.; Wandala, A.D.; Tiguiane, Y. Detection of android malware based on sequence alignment of permissions. Int. J. Comput. 2019, 35, 26–36. [Google Scholar]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef] [Green Version]
- CuckooDroid. Available online: https://cuckoo-droid.readthedocs.io/en/latest/installation/ (accessed on 27 December 2022).
- Gandotra, E.; Bansal, D.; Sofat, S. Malware intelligence: Beyond malware analysis. Int. J. Adv. Intell. Paradig. 2019, 13, 80–100. [Google Scholar] [CrossRef]
- Abid, R.; Rizwan, M.; Veselý, P.; Basharat, A.; Tariq, U.; Javed, A.R. Social Networking Security during COVID-19: A Systematic Literature Review. Wirel. Commun. Mob. Comput. 2022, 2022, 2975033. [Google Scholar] [CrossRef]
- Lakovic, V. Crisis management of android botnet detection using adaptive neuro-fuzzy inference system. Ann. Data Sci. 2020, 7, 347–355. [Google Scholar] [CrossRef]
- Saridou, B.; Rose, J.R.; Shiaeles, S.; Papadopoulos, B. SAGMAD—A Signature Agnostic Malware Detection System Based on Binary Visualisation and Fuzzy Sets. Electronics 2022, 11, 1044. [Google Scholar] [CrossRef]
- Gupta, D.; Ahlawat, A.K.; Sharma, A.; Rodrigues, J.J. Feature selection and evaluation for software usability model using modified moth-flame optimization. Computing 2020, 102, 1503–1520. [Google Scholar] [CrossRef]
- Sahu, P.C.; Bhoi, S.K.; Jena, N.K.; Sahu, B.K.; Prusty, R.C. A robust Multi Verse Optimized fuzzy aided tilt Controller for AGC of hybrid Power System. In Proceedings of the 2021 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON), Bhubaneswar, India, 8–9 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M. Quasi-oppositional differential evolution. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 2229–2236. [Google Scholar]
- Strumberger, I.; Bacanin, N.; Tuba, M.; Tuba, E. Resource scheduling in cloud computing based on a hybridized whale optimization algorithm. Appl. Sci. 2019, 9, 4893. [Google Scholar] [CrossRef] [Green Version]
- Strumberger, I.; Minovic, M.; Tuba, M.; Bacanin, N. Performance of elephant herding optimization and tree growth algorithm adapted for node localization in wireless sensor networks. Sensors 2019, 19, 2515. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-An, W.; Ye, H. Significant permission identification for machine-learning-based android malware detection. IEEE Trans. Ind. Inform. 2018, 14, 3216–3225. [Google Scholar] [CrossRef]
- Wang, W.; Wang, X.; Feng, D.; Liu, J.; Han, Z.; Zhang, X. Exploring permission-induced risk in android applications for malicious application detection. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1869–1882. [Google Scholar] [CrossRef] [Green Version]
- Yerima, S.Y.; Sezer, S. Droidfusion: A novel multilevel classifier fusion approach for android malware detection. IEEE Trans. Cybern. 2018, 49, 453–466. [Google Scholar] [CrossRef]
- Das, S.; Liu, Y.; Zhang, W.; Chandramohan, M. Semantics-based online malware detection: Towards efficient real-time protection against malware. IEEE Trans. Inf. Forensics Secur. 2015, 11, 289–302. [Google Scholar] [CrossRef]
- Bläsing, T.; Batyuk, L.; Schmidt, A.-D.; Camtepe, S.A.; Albayrak, S. An android application sandbox system for suspicious software detection. In Proceedings of the 2010 5th International Conference on Malicious and Unwanted Software, Nancy, France, 19–20 October 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 55–62. [Google Scholar]
- Zhu, H.-J.; Wang, L.-M.; Zhong, S.; Li, Y.; Sheng, V.S. A hybrid deep network framework for Android malware detection. IEEE Trans. Knowl. Data Eng. 2021, 34, 5558–5570. [Google Scholar] [CrossRef]
- Zhang, J. Deepmal: A CNN-LSTM model for malware detection based on dynamic semantic behaviours. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 313–316. [Google Scholar]
- Kotian, P.; Sonkusare, R. Detection of Malware in Cloud Environment using Deep Neural Network. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Kadir AF, A.; Taheri, L.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark android malware datasets and classification. In Proceedings of the International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Virustotal: Virustotal Free Antivirus Scanners. Available online: https://support.virustotal.com/hc/en-us/categories/360000160117-About-us (accessed on 27 December 2022).
- Ahvanooey, M.T.; Li, Q.; Rabbani, M.; Rajput, A.R. A survey on smartphones security: Software vulnerabilities, malware, and attacks. arXiv 2020, arXiv:2001.09406. [Google Scholar]
- Liao, Q. Ransomware: A growing threat to SMEs. In Proceedings of the Conference Southwest Decision Science Institutes: Southwest Decision Science Institutes, Houston, TX, USA, 4–8 March 2008; pp. 1–7. [Google Scholar]
- Abuthawabeh, M.K.A.; Mahmoud, K.W. Android malware detection and categorization based on conversation-level network traffic features. In Proceedings of the 2019 International Arab Conference on Information Technology (ACIT), Al Ain, United Arab Emirates, 3–5 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 42–47. [Google Scholar]
- Hamandi, K.; Chehab, A.; Elhajj, I.H.; Kayssi, A. Android SMS malware: Vulnerability and mitigation. In Proceedings of the 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1004–1009. [Google Scholar]
- Chizi, B.; Maimon, O. Dimension reduction and feature selection. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 83–100. [Google Scholar]
- Pedregosa, F. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Sapre, S.; Mini, S. Emulous mechanism based multi-objective moth–flame optimization algorithm. J. Parallel Distrib. Comput. 2021, 150, 15–33. [Google Scholar] [CrossRef]
- Sanki, P.; Mazumder, S.; Basu, M.; Pal, P.S.; Das, D. Moth flame optimization based fuzzy-PID controller for power–frequency balance of an islanded microgrid. J. Inst. Eng. Ser. B 2021, 102, 997–1006. [Google Scholar] [CrossRef]
- Liu, X.; Du, X.; Lei, Q.; Liu, K. Multifamily classification of Android malware with a fuzzy strategy to resist polymorphic familial variants. IEEE Access 2020, 8, 156900–156914. [Google Scholar] [CrossRef]
- Aljarah, I.; Faris, H.; Heidari, A.A.; Mafarja, M.M.; Al-Zoubi, A.M.; Castillo, P.A.; Merelo, J.J. A robust multi-objective feature selection model based on local neighborhood multi-verse optimization. IEEE Access 2021, 9, 100009–100028. [Google Scholar] [CrossRef]
- Darrell, T.; Indyk, P.; Shakhnarovich, G. Nearest-Neighbor Methods in Learning and Vision: Theory and Practice; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Keerthi, S.S.; Gilbert, E.G. Convergence of a generalized SMO algorithm for SVM classifier design. Mach. Learn. 2002, 46, 351–360. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Ewees, A.A.; Abd Elaziz, M.; Houssein, E.H. Improved grasshopper optimization algorithm using opposition-based learning. Expert Syst. Appl. 2018, 112, 156–172. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Program for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993; pp. 1–299. Available online: https://books.google.ae/books?id=b3ujBQAAQBAJ&printsec=frontcover&hl=ar&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false (accessed on 27 December 2022).
- Domingos, P.; Pazzani, M. On the optimality of the simple Bayesian classifier under zero-one loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Semwal, V.B.; Mondal, K.; Nandi, G.C. Robust and accurate feature selection for humanoid push recovery and classification: Deep learning approach. Neural Comput. Appl. 2017, 28, 565–574. [Google Scholar] [CrossRef]
- Vasan, D.; Alazab, M.; Wassan, S.; Naeem, H.; Safaei, B.; Zheng, Q. IMCFN: Image-based malware classification using fine-tuned convolutional neural network architecture. Comput. Netw. 2020, 171, 107138. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Malware Family Types | Malware Category | # of Samples |
|---|---|---|
| Ewind | Adware | 154 |
| Kemoge | Adware | 153 |
| Dowgin | Adware | 176 |
| Zsone | SMSmalware | 105 |
| Jisut | Ransomware | 117 |
| Svpeng | Ransomware | 116 |
| AndroidDefender | scareware | 133 |
| FakeAV | scareware | 103 |
| Penetho | scareware | 142 |
| Biige | SMSmalware | 174 |
| SMSsniffer | SMSmalware | 181 |
| Youmi | Adware | 164 |
| Ginmaster | Adware | 192 |
| Dataset | Number of Samples | #of Malware Samples | # of Benign Samples |
|---|---|---|---|
| Drebin | 1400 | 450 | 950 |
| CICAndMal2017 | 1240 | 450 | 790 |
| APKMirror | 1200 | 410 | 790 |
| VirusShare | 1050 | 600 | 450 |
| Total | 4890 | 1910 | 2980 |
| Setting | Parameter |
|---|---|
| PU | Intel(R) Core(TM)i7-2.40 GHz |
| Operating System | Windows 10 Home Single |
| GPU | NVIDIA 1060 |
| RAM | 32 GB |
| Python Version | 3.8 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Average |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.923 | 0.935 | 0.923 | 0.958 | 0.950 | 0.942 | 0.935 | 0.938 |
| Precision (%) | 0.917 | 0.925 | 0.908 | 0.942 | 0.933 | 0.917 | 0.933 | 0.925 |
| F-measure (%) | 0.917 | 0.929 | 0.916 | 0.954 | 0.945 | 0.936 | 0.929 | 0.932 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Average |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.904 | 0.915 | 0.902 | 0.912 | 0.941 | 0.922 | 0.942 | 0.918 |
| Precision (%) | 0.925 | 0.925 | 0.901 | 0.909 | 0.933 | 0.910 | 0.930 | 0.919 |
| F-measure (%) | 0.904 | 0.912 | 0.901 | 0.904 | 0.940 | 0.916 | 0.933 | 0.915 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Average |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.931 | 0.933 | 0.916 | 0.934 | 0.948 | 0.944 | 0.931 | 0.933 |
| Precision (%) | 0.922 | 0.927 | 0.910 | 0.931 | 0.916 | 0.915 | 0.927 | 0.921 |
| F-measure (%) | 0.925 | 0.921 | 0.911 | 0.928 | 0.944 | 0.940 | 0.928 | 0.928 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.923 | 0.935 | 0.923 | 0.958 | 0.950 | 0.942 | 0.935 | 0.969 |
| FPR (%) | 0.071 | 0.064 | 0.077 | 0.049 | 0.056 | 0.069 | 0.058 | 0.029 |
| TPR (%) | 0.917 | 0.933 | 0.924 | 0.966 | 0.957 | 0.957 | 0.926 | 0.967 |
| Precision (%) | 0.917 | 0.925 | 0.908 | 0.942 | 0.933 | 0.917 | 0.933 | 0.967 |
| F-measure (%) | 0.917 | 0.929 | 0.916 | 0.954 | 0.945 | 0.936 | 0.929 | 0.967 |
| MCC (%) | 0.845 | 0.868 | 0.845 | 0.915 | 0.899 | 0.884 | 0.869 | 0.938 |
| AUC (%) | 0.923 | 0.931 | 0.915 | 0.946 | 0.939 | 0.924 | 0.938 | 0.969 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.865 | 0.896 | 0.873 | 0.923 | 0.923 | 0.904 | 0.888 | 0.942 |
| FPR (%) | 0.138 | 0.105 | 0.126 | 0.083 | 0.071 | 0.092 | 0.117 | 0.069 |
| TPR (%) | 0.87 | 0.897 | 0.872 | 0.931 | 0.917 | 0.899 | 0.896 | 0.957 |
| Precision (%) | 0.833 | 0.875 | 0.85 | 0.9 | 0.917 | 0.892 | 0.858 | 0.917 |
| F-measure (%) | 0.851 | 0.886 | 0.861 | 0.915 | 0.917 | 0.895 | 0.877 | 0.936 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.848 | 0.885 | 0.862 | 0.908 | 0.923 | 0.900 | 0.871 | 0.924 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.858 | 0.854 | 0.850 | 0.869 | 0.862 | 0.835 | 0.846 | 0.915 |
| FPR (%) | 0.129 | 0.155 | 0.142 | 0.132 | 0.134 | 0.170 | 0.158 | 0.090 |
| TPR (%) | 0.843 | 0.866 | 0.840 | 0.871 | 0.856 | 0.841 | 0.851 | 0.922 |
| Precision (%) | 0.850 | 0.808 | 0.833 | 0.842 | 0.842 | 0.792 | 0.808 | 0.892 |
| F-measure (%) | 0.846 | 0.836 | 0.837 | 0.856 | 0.849 | 0.815 | 0.829 | 0.907 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.860 | 0.826 | 0.846 | 0.855 | 0.854 | 0.811 | 0.825 | 0.901 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.927 | 0.938 | 0.935 | 0.942 | 0.935 | 0.935 | 0.931 | 0.973 |
| FPR (%) | 0.094 | 0.069 | 0.082 | 0.050 | 0.064 | 0.051 | 0.076 | 0.028 |
| TPR (%) | 0.955 | 0.948 | 0.956 | 0.934 | 0.933 | 0.919 | 0.940 | 0.975 |
| Precision (%) | 0.883 | 0.917 | 0.900 | 0.942 | 0.925 | 0.942 | 0.908 | 0.967 |
| F-measure (%) | 0.918 | 0.932 | 0.927 | 0.938 | 0.929 | 0.930 | 0.924 | 0.971 |
| MCC (%) | 0.854 | 0.876 | 0.869 | 0.884 | 0.868 | 0.869 | 0.861 | 0.946 |
| AUC (%) | 0.895 | 0.924 | 0.909 | 0.946 | 0.931 | 0.945 | 0.916 | 0.969 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.796 | 0.808 | 0.935 | 0.846 | 0.812 | 0.835 | 0.808 | 0.892 |
| FPR (%) | 0.204 | 0.179 | 0.082 | 0.143 | 0.173 | 0.183 | 0.188 | 0.106 |
| TPR (%) | 0.796 | 0.792 | 0.956 | 0.833 | 0.793 | 0.860 | 0.802 | 0.890 |
| Precision (%) | 0.750 | 0.792 | 0.900 | 0.833 | 0.800 | 0.767 | 0.775 | 0.875 |
| F-measure (%) | 0.773 | 0.792 | 0.927 | 0.833 | 0.797 | 0.811 | 0.788 | 0.882 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.773 | 0.807 | 0.909 | 0.845 | 0.814 | 0.792 | 0.794 | 0.885 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.788 | 0.804 | 0.812 | 0.812 | 0.804 | 0.800 | 0.808 | 0.827 |
| FPR (%) | 0.229 | 0.209 | 0.210 | 0.206 | 0.213 | 0.222 | 0.204 | 0.194 |
| TPR (%) | 0.816 | 0.822 | 0.845 | 0.838 | 0.829 | 0.833 | 0.824 | 0.857 |
| Precision (%) | 0.700 | 0.733 | 0.725 | 0.733 | 0.725 | 0.708 | 0.742 | 0.750 |
| F-measure (%) | 0.753 | 0.775 | 0.780 | 0.782 | 0.773 | 0.766 | 0.781 | 0.800 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.735 | 0.762 | 0.757 | 0.763 | 0.756 | 0.743 | 0.769 | 0.778 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.946 | 0.958 | 0.942 | 0.969 | 0.962 | 0.946 | 0.946 | 0.981 |
| FPR (%) | 0.068 | 0.049 | 0.063 | 0.035 | 0.042 | 0.056 | 0.056 | 0.021 |
| TPR (%) | 0.965 | 0.966 | 0.949 | 0.975 | 0.966 | 0.949 | 0.949 | 0.983 |
| Precision (%) | 0.917 | 0.942 | 0.925 | 0.958 | 0.950 | 0.933 | 0.933 | 0.975 |
| F-measure (%) | 0.940 | 0.954 | 0.937 | 0.966 | 0.958 | 0.941 | 0.941 | 0.979 |
| MCC (%) | 0.892 | 0.915 | 0.884 | 0.938 | 0.923 | 0.892 | 0.892 | 0.961 |
| AUC (%) | 0.924 | 0.946 | 0.931 | 0.962 | 0.954 | 0.938 | 0.938 | 0.977 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.946 | 0.915 | 0.919 | 0.946 | 0.942 | 0.923 | 0.931 | 0.969 |
| FPR (%) | 0.068 | 0.096 | 0.101 | 0.063 | 0.063 | 0.095 | 0.082 | 0.042 |
| TPR (%) | 0.965 | 0.930 | 0.946 | 0.957 | 0.949 | 0.946 | 0.947 | 0.983 |
| Precision (%) | 0.917 | 0.883 | 0.875 | 0.925 | 0.925 | 0.883 | 0.900 | 0.950 |
| F-measure (%) | 0.940 | 0.906 | 0.909 | 0.941 | 0.937 | 0.914 | 0.923 | 0.966 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.924 | 0.894 | 0.887 | 0.931 | 0.931 | 0.894 | 0.909 | 0.954 |
| Algorithm | K-NN | SMO | SVM | RF | DT | NB | MLP | Proposed |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 0.866 | 0.765 | 0.779 | 0.846 | 0.842 | 0.823 | 0.831 | 0.889 |
| FPR (%) | 0.092 | 0.086 | 0.131 | 0.103 | 0.093 | 0.097 | 0.115 | 0.072 |
| TPR (%) | 0.875 | 0.790 | 0.746 | 0.727 | 0.743 | 0.752 | 0.726 | 0.903 |
| Precision (%) | 0.897 | 0.893 | 0.885 | 0.865 | 0.855 | 0.863 | 0.850 | 0.860 |
| F-measure (%) | 0.850 | 0.756 | 0.759 | 0.822 | 0.827 | 0.802 | 0.812 | 0.862 |
| MCC (%) | - | - | - | - | - | - | - | - |
| AUC (%) | 0.824 | 0.744 | 0.732 | 0.812 | 0.813 | 0.792 | 0.801 | 0.852 |
| Related Work | Precision | Recall |
|---|---|---|
| Abuthawabeh et al. [49] | ||
| Taheri et al. [21] | ||
| Abuthawabeh et al. [49] | (DT) | |
| Lashkari et al. [45] | ||
| Jiang et al. [48] | 93.8 (DT) | 94.36 (DT) |
| DroidDetectMW |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taher, F.; AlFandi, O.; Al-kfairy, M.; Al Hamadi, H.; Alrabaee, S. DroidDetectMW: A Hybrid Intelligent Model for Android Malware Detection. Appl. Sci. 2023, 13, 7720. https://doi.org/10.3390/app13137720
Taher F, AlFandi O, Al-kfairy M, Al Hamadi H, Alrabaee S. DroidDetectMW: A Hybrid Intelligent Model for Android Malware Detection. Applied Sciences. 2023; 13(13):7720. https://doi.org/10.3390/app13137720
Chicago/Turabian StyleTaher, Fatma, Omar AlFandi, Mousa Al-kfairy, Hussam Al Hamadi, and Saed Alrabaee. 2023. "DroidDetectMW: A Hybrid Intelligent Model for Android Malware Detection" Applied Sciences 13, no. 13: 7720. https://doi.org/10.3390/app13137720
APA StyleTaher, F., AlFandi, O., Al-kfairy, M., Al Hamadi, H., & Alrabaee, S. (2023). DroidDetectMW: A Hybrid Intelligent Model for Android Malware Detection. Applied Sciences, 13(13), 7720. https://doi.org/10.3390/app13137720