
An Easy Partition Approach for Joint Entity and Relation Extraction

Abstract
:1. Introduction
- We propose a simple but effective joint coding relation extraction approach, namely, easy partition approach for relation extraction (EPRE). Particularly, EPRE models the features between NER and RC tasks to ensure the independence and interaction of specific tasks.
- We consider different gate modules to fuse task features to increase the elasticity of the model.
- Our method is superior in speed, and yields the state-of-the-art results of the NER task and RC task on some benchmark datasets.
2. Related Work
3. Method
3.1. Triple Extraction Task
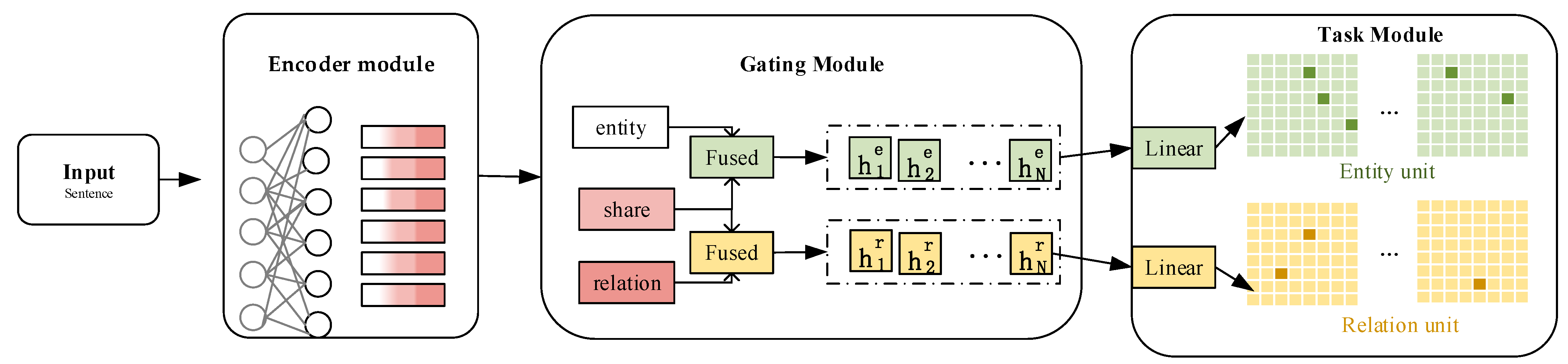
3.2. EPRE Architecture
3.2.1. Encoder Module
3.2.2. Fused Module
3.2.3. Task Module
3.3. Training and Inference
4. Experiments
4.1. Setup
- ADE [33] is a dataset for adverse drug events (ADE) extraction, which contains 4272 sentences collected from the medical literature, and each sentence is labeled with three entities, namely, drug, disease, and adverse event. The difficulty of the ADE dataset is the diversity and ambiguity of adverse events, and the complexity and implication of cause–effect relationships.
- SCIERC [34] is a dataset for information extraction in the scientific domain, which contains 2687 sentences collected from computer science papers. The difficulties of the SCIERC dataset are the fine granularity of entities and relations, and the presence of a large number of abbreviations, symbols, and formulas in the text.
- WebNLG [35] is a dataset for knowledge graph to natural language generation, which contains a collection of 23,767 triads extracted from the DBpedia knowledge graph. The difficulty of the WebNLG dataset is the size and diversity of the triad collection, and the fluency and diversity of the natural language descriptions.
4.1.1. Evaluation Metrics
4.1.2. Implementation Details
4.2. Comparison with Previous Work
4.2.1. Main Results
4.2.2. Computation Efficiency
4.2.3. Detailed Results
4.3. Ablation Studies
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ekbal, A.; Bandyopadhyay, S. Bengali Named Entity Recognition Using Classifier Combination. In Proceedings of the 2009 Seventh International Conference on Advances in Pattern Recognition, Washington, DC, USA, 4–6 February 2009; pp. 259–262. [Google Scholar] [CrossRef]
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring Various Knowledge in Relation Extraction. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 427–434. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language 163 Technologies, Online, 6–11 June 2021; pp. 50–61. [Google Scholar] [CrossRef]
- Patil, N.; Patil, A.; Pawar, B. Named Entity Recognition using Conditional Random Fields. Procedia Computer Science. In Proceedings of the International Conference on Computational Intelligence and Data Science, Las Vegas, NV, USA, 16–18 December 2020; Volume 167, pp. 1181–1188. [Google Scholar] [CrossRef]
- Yang, L.; Fu, Y.; Dai, Y. BIBC: A Chinese Named Entity Recognition Model for Diabetes Research. Appl. Sci. 2021, 11, 9653. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Ma, Z.; Gao, L.; Xu, Y. An ERNIE-Based Joint Model for Chinese Named Entity Recognition. Appl. Sci. 2020, 10, 5711. [Google Scholar] [CrossRef]
- Peng, T.; Han, R.; Cui, H.; Yue, L.; Han, J.; Liu, L. Distantly Supervised Relation Extraction using Global Hierarchy Embeddings and Local Probability Constraints. Knowl. -Based Syst. 2022, 235, 107637. [Google Scholar] [CrossRef]
- Li, Q.; Li, L.; Wang, W.; Li, Q.; Zhong, J. A comprehensive exploration of semantic relation extraction via pre-trained CNNs. Knowl. -Based Syst. 2020, 194, 105488. [Google Scholar] [CrossRef]
- Zheng, S.; Xu, J.; Zhou, P.; Bao, H.; Qi, Z.; Xu, B. A neural network framework for relation extraction: Learning entity semantic 179 and relation pattern. Knowl. -Based Syst. 2016, 114, 12–23. [Google Scholar] [CrossRef]
- Wan, Q.; Wei, L.; Chen, X.; Liu, J. A region-based hypergraph network for joint entity-relation extraction. Knowl. -Based Syst. 2021, 228, 107298. [Google Scholar] [CrossRef]
- Tang, R.; Chen, Y.; Qin, Y.; Huang, R.; Dong, B.; Zheng, Q. Boundary assembling method for joint entity and relation extraction. Knowl. -Based Syst. 2022, 250, 109129. [Google Scholar] [CrossRef]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint 185 entity and relation extraction. Knowl. -Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1572–1582. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A Unified Label Space for Entity Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 220–231. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, C.; Fu, J.; Zhang, Q.; Wei, Z. A Partition Filter Network for Joint Entity and Relation Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 185–197. [Google Scholar] [CrossRef]
- Zhao, L.; Gao, W.; Fang, J. High-Performance Englishndash;Chinese Machine Translation Based on GPU-Enabled Deep Neural 198 Networks with Domain Corpus. Appl. Sci. 2021, 11, 10915. [Google Scholar] [CrossRef]
- Tanoli, I.K.; Amin, I.; Junejo, F.; Yusoff, N. Systematic Machine Translation of Social Network Data Privacy Policies. Appl. Sci. 2022, 12, 10499. [Google Scholar] [CrossRef]
- AlBadani, B.; Shi, R.; Dong, J.; Al-Sabri, R.; Moctard, O.B. Transformer-Based Graph Convolutional Network for Sentiment Analysis. Appl. Sci. 2022, 12, 1316. [Google Scholar] [CrossRef]
- Li, F.; Lin, Z.; Zhang, M.; Ji, D. A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4814–4828. [Google Scholar] [CrossRef]
- Wang, B.; Lu, W. Combining Spans into Entities: A Neural Two-Stage Approach for Recognizing Discontiguous Entities. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6216–6224. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar] [CrossRef] [Green Version]
- Ye, D.; Lin, Y.; Li, P.; Sun, M. Packed Levitated Marker for Entity and Relation Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 4904–4917. [Google Scholar] [CrossRef]
- Wang, H.; Qin, K.; Lu, G.; Luo, G.; Liu, G. Direction-sensitive relation extraction using Bi-SDP attention model. Knowl. -Based Syst. 2020, 198, 105928. [Google Scholar] [CrossRef]
- Zheng, H.; Wen, R.; Chen, X.; Yang, Y.; Zhang, Y.; Zhang, Z.; Zhang, N.; Qin, B.; Ming, X.; Zheng, Y. PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–9 August 2021; pp. 6225–6235. [Google Scholar] [CrossRef]
- Ren, F.; Zhang, L.; Yin, S.; Zhao, X.; Liu, S.; Li, B.; Liu, Y. A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2646–2656. [Google Scholar] [CrossRef]
- Xue, F.; Sun, A.; Zhang, H.; Chng, E.S. GDPNet: Refining Latent Multi-View Graph for Relation Extraction. arXiv 2020, arXiv:2012.06780. [Google Scholar] [CrossRef]
- Liang, Z.; Du, J. Sequence to sequence learning for joint extraction of entities and relations. Neurocomputing 2022, 501, 480–488. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Under-standing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Alt, C.; Gabryszak, A.; Hennig, L. Probing Linguistic Features of Sentence-Level Representations in Neural Relation Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1534–1545. [Google Scholar] [CrossRef]
- Conneau, A.; Kruszewski, G.; Lample, G.; Barrault, L.; Baroni, M. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2126–2136. [Google Scholar] [CrossRef] [Green Version]
- Gurulingappa, H.; Rajput, A.M.; Roberts, A.; Fluck, J.; Hofmann-Apitius, M.; Toldo, L. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. Inform. 2012, 243, 885–892. [Google Scholar] [CrossRef] [PubMed]
- Riedel, S.; Yao, L.; McCallum, A. Modeling Relations and Their Mentions without Labeled Text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating Training Corpora for NLG Micro-Planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 179–188. [Google Scholar] [CrossRef] [Green Version]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar] [CrossRef]
- Eberts, M.; Ulges, A. Span-based Joint Entity and Relation Extraction with Transformer Pre-training. arXiv 2019, arXiv:1909.07755. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Type | Meaning of Methods | Related Paper |
|---|---|---|
| Span-based method | In NER tasks, it refers to the process of identifying entity spans in text and classifying them. In RE tasks, it is the process of classifying entity span pairs. | [19,20] |
| Tag-based method | In NER, it refers to assigning a label to tokens in text, often using “BIO” and “BIOS” to label token positions, and combining token positions and entity types as labels for entities, such as B-location. In RE tasks, a combination of token position, relation type, and entity position is often used as labels, such as B-CEO-1. | [21,23] |
| Table filling method | Usually using T × N × the matrix of N represents the sentence sequence, T represents the entity type or relation type, and N represents the sentence length. In NER, take the diagonal of the matrix as the starting position of the entity, find the corresponding ending position of the entity in the upper triangle of the matrix, and mark it as 1. Determine the entity in the sentence according to the matrix. In RE, find the position corresponding to the token pair of the head or tail of the entity pair in the matrix, mark it as 1, and determine the entity pairs with relation based on the matrix. | [15,24,25] |
| Graph-based method | The main idea of this method is to represent entities and relationships as nodes and edges in the graph, and then use graph algorithms to process them. | [26,27] |
| Dataset | Entity Type | Relation Type | Sentence | ||
|---|---|---|---|---|---|
| Train | Test | Dev | |||
| SCIERC | 6 | 7 | 1861 | 275 | 551 |
| WebNLG | None | 170 | 5019 | 500 | 703 |
| ADE | 2 | 1 | 3845 | - | 427 |
| Method | WebNLG | ADE | SCIERC | |||
|---|---|---|---|---|---|---|
| NER | RE | NER | RE | NER | RE | |
| CasRel [36] | 95.5 | 91.8 | - | - | - | - |
| TPLinker [13] | - | 91.9 | - | - | - | - |
| PURE [3] | - | - | - | - | 66.6 | 35.6 |
| SpERT [37] | - | - | 89.3 | 79.2 | ||
| PFN [15] | 98.0★ | 93.5★ | 89.7★ | 80.3★ | 68.4★ | 37.5★ |
| EPRE | 97.5 | 92.9 | 90.0 | 81.9 | 67.6 | 38.3 |
| Model | Computing Time |
|---|---|
| CasRel [36] | 76.8 |
| TPLinker [13] | 25.6 |
| PFN [15] | 23.8 |
| EPRE | 10.2 |
| Ablation | Settings | Entity | Triple | ||||
|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | ||
| Gate Module | No gate | 89.10 | 90.30 | 89.34 | 81.30 | 81.30 | 81.30 |
| Add Gate | 87.71 | 91.29 | 89.40 | 80.61 | 82.99 | 81.80 | |
| Cat Gate | 88.71 | 91.39 | 90.00 | 80.90 | 82.99 | 81.90 | |
| Partition Proportion | 1:1:1 | 88.71 | 91.39 | 90.00 | 80.90 | 82.99 | 81.90 |
| 2:1:2 | 87.81 | 90.70 | 89.20 | 78.52 | 81.90 | 80.21 | |
| 1:2:1 | 88.11 | 90.40 | 89.30 | 81.70 | 81.80 | 81.70 | |
| Partition Granularity | One Part | 88.40 | 90.00 | 89.26 | 81.70 | 80.41 | 81.20 |
| Two Part | 87.51 | 90.50 | 89.00 | 80.90 | 82.70 | 81.12 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, J.; Deng, X.; Han, P. An Easy Partition Approach for Joint Entity and Relation Extraction. Appl. Sci. 2023, 13, 7585. https://doi.org/10.3390/app13137585
Hou J, Deng X, Han P. An Easy Partition Approach for Joint Entity and Relation Extraction. Applied Sciences. 2023; 13(13):7585. https://doi.org/10.3390/app13137585
Chicago/Turabian StyleHou, Jing, Xiaomeng Deng, and Pengwu Han. 2023. "An Easy Partition Approach for Joint Entity and Relation Extraction" Applied Sciences 13, no. 13: 7585. https://doi.org/10.3390/app13137585
APA StyleHou, J., Deng, X., & Han, P. (2023). An Easy Partition Approach for Joint Entity and Relation Extraction. Applied Sciences, 13(13), 7585. https://doi.org/10.3390/app13137585