
Generating Function Reallocation to Handle Contingencies in Human–Robot Teaming Missions: The Cases in Lunar Surface Transportation



Abstract
:1. Introduction
2. Methods
2.1. Formulation of the Problem
2.2. Overview of the Algorithm for Dynamic Human–Robot Function Allocation
2.3. Definition and Calculation of the Fitness
2.3.1. Task Fitness
2.3.2. Environment Fitness
2.3.3. Distance Fitness
2.4. Hierarchical Reinforcement Learning Algorithm
2.4.1. HRL Algorithm-Layer One
2.4.2. HRL Algorithm-Layer Two
3. Experiments
3.1. Experiment 1
3.2. Experiment 2
4. Results
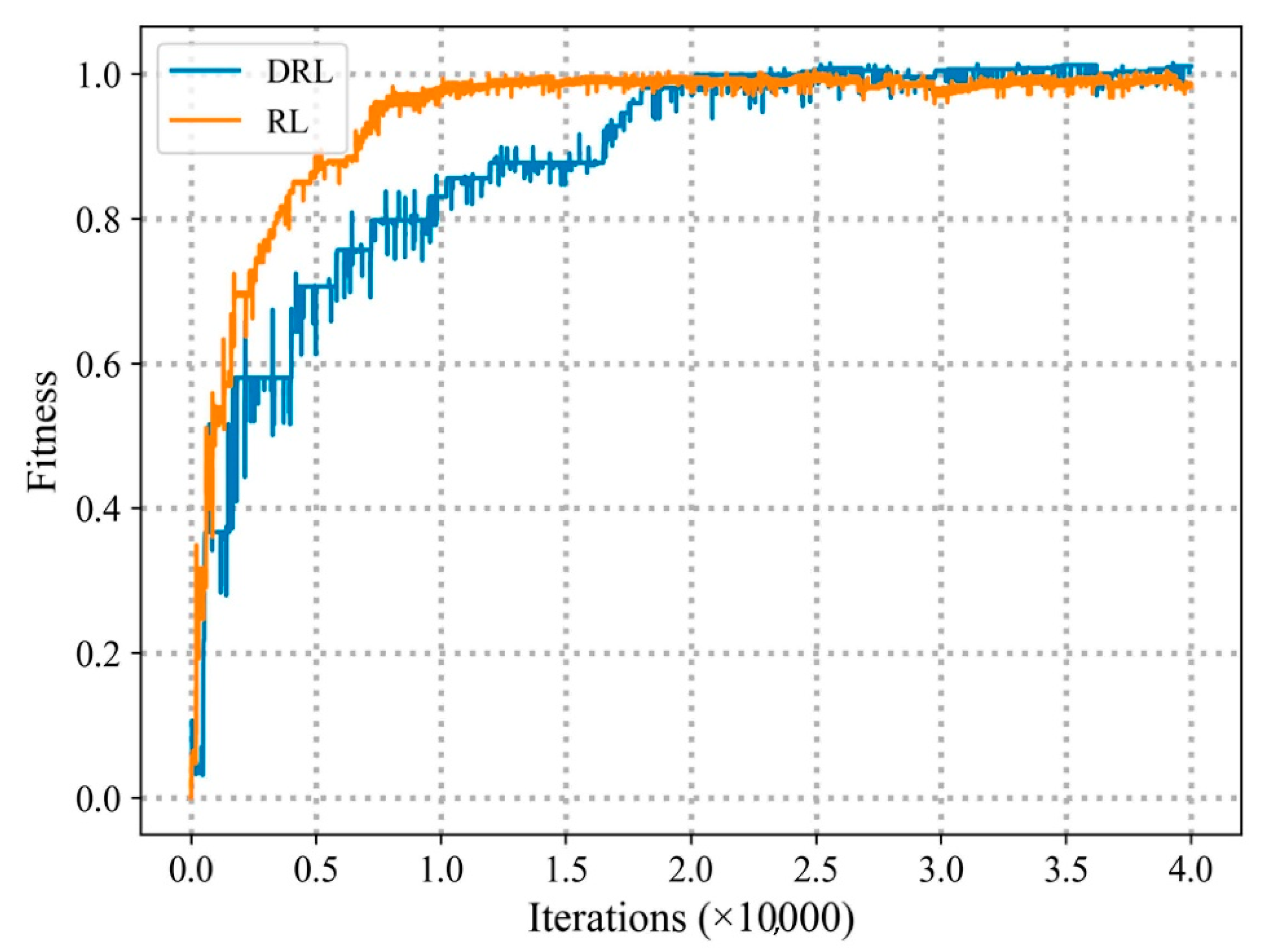
4.1. Comparison with Other Algorithms under Different Agent Numbers
4.2. Comparison with Other Algorithms under the Same Agent Number
5. Conclusion
- Compared to RL, DRL, and HDRL algorithms, the proposed method improves the task allocation efficiency by approximately 98.24%, 98.78%, and 71.79%, respectively, for the same number of agents;
- When the number of agents is varied, the proposed method improves the task allocation efficiency by about 90.49%, 94.89% and 88.26% compared to RL, DRL and HDRL algorithms, respectively. It can demonstrate the better robustness of the proposed approach when the number of agents varies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Timman, S.; Landgraf, M.; Haskamp, C.; Lizy-Destrez, S.; Dehais, F. Effect of time-delay on lunar sampling tele-operations: Evidences from cardiac, ocular and behavioral measures. Appl. Ergon. 2023, 197, 103910. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Yuhui, G.; Rui, Z.; XiaoFeng, C.; Jun, S.; Peng, L. Automatic Planning Method of Space-Ground Integrated Tele-Operation for Unmanned Lunar Exploration Rovers. In Advances in Guidance, Navigation and Control; Springer: Singapore, 2023; pp. 3644–3655. [Google Scholar] [CrossRef]
- Reviews [review of two books]. IEEE Ann. Hist. Comput. 2008, 30, 104–105. [CrossRef]
- Elfes, A.; Weisbin, C.R.; Hua, H.; Smith, J.H.; Mrozinski, J.; Shelton, K. The HURON Task Allocation and Scheduling System: Planning Human and Robot Activities for Lunar Mis-Sions. In Proceedings of the 2008 World Automation Congress, Waikoloa, HI, USA, 28 September–2 October 2008; pp. 1–8. [Google Scholar]
- Thomas, G.; Howard, A.M.; Williams, A.B.; Moore-Alston, A. Multi-Robot Task Allocation in Lunar Mission Construction Scenarios. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005. [Google Scholar] [CrossRef]
- Okubo, T.; Takahashi, M. Multi-Agent Action Graph Based Task Allocation and Path Planning Considering Changes in Environment. IEEE Access 2023, 11, 21160–21175. [Google Scholar] [CrossRef]
- Schleif, F.-M.; Biehl, M.; Vellido, A. Advances in machine learning and computational intelligence. Neurocomputing 2009, 72, 1377–1378. [Google Scholar] [CrossRef]
- Eijyne, T.; G, R.; G, P.S. Development of a task-oriented, auction-based task allocation framework for a heterogeneous multirobot system. Sadhana 2020, 45, 1–13. [Google Scholar] [CrossRef]
- Otte, M.; Kuhlman, M.J.; Sofge, D. Auctions for multi-robot task allocation in communication limited environments. Auton. Robot. 2019, 44, 547–584. [Google Scholar] [CrossRef]
- Zhu, Z.; Tang, B.; Yuan, J. Multirobot task allocation based on an improved particle swarm optimization approach. Int. J. Adv. Robot. Syst. 2017, 14, 172988141771031. [Google Scholar] [CrossRef] [Green Version]
- Lim, C.P.; Jain, L.C. Advances in Swarm Intelligence; Springer: Cham, Switzerland, 2009; pp. 1–7. [Google Scholar] [CrossRef]
- Farinelli, A.; Iocchi, L.; Nardi, D. Distributed on-line dynamic task assignment for multi-robot patrolling. Auton. Robot. 2016, 41, 1321–1345. [Google Scholar] [CrossRef]
- Nagarajan, T.; Thondiyath, A. Heuristic based Task Allocation Algorithm for Multiple Robots Using Agents. Procedia Eng. 2013, 64, 844–853. [Google Scholar] [CrossRef] [Green Version]
- Sundaram, E.; Gunasekaran, M.; Krishnan, R.; Padmanaban, S.; Chenniappan, S.; Ertas, A.H. Genetic algorithm based reference current control extraction based shunt active power filter. Int. Trans. Electr. Energy Syst. 2020, 31, e12623. [Google Scholar] [CrossRef]
- Chi, W.; Agrawal, J.; Chien, S.; Fosse, E.; Guduri, U. Optimizing Parameters for Uncertain Execution and Rescheduling Robustness. Int. Conf. Autom. Plan. Sched. 2021, 29, 501–509. [Google Scholar] [CrossRef]
- Hu, H.-C.; Smith, S.F. Learning Model Parameters for Decentralized Schedule-Driven Traffic Control. Proc. Thirtieth Int. Conf. Autom. Plan. Sched. 2020, 30, 531–539. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Chen, W.; Yu, J.; Chen, J. An Incidental Delivery Based Method for Resolving Multirobot Pairwised Transportation Problems. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1852–1866. [Google Scholar] [CrossRef]
- Lyu, X.-F.; Song, Y.-C.; He, C.-Z.; Lei, Q.; Guo, W.-F. Approach to Integrated Scheduling Problems Considering Optimal Number of Automated Guided Vehicles and Conflict-Free Routing in Flexible Manufacturing Systems. IEEE Access 2019, 7, 74909–74924. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, P.; Du, G.; Li, F. A distributed method for dynamic multi-robot task allocation problems with critical time constraints. Robot. Auton. Syst. 2019, 118, 31–46. [Google Scholar] [CrossRef]
- Zitouni, F.; Maamri, R.; Harous, S. FA–QABC–MRTA: A solution for solving the multi-robot task allocation problem. Intell. Serv. Robot. 2019, 12, 407–418. [Google Scholar] [CrossRef]
- Al-Hussaini, S.; Gregory, J.M.; Gupta, S.K. Generating Task Reallocation Suggestions to Handle Contingencies in Human-Supervised Multi-Robot Missions. IEEE Trans. Autom. Sci. Eng. 2023, 1. [Google Scholar] [CrossRef]
- Tai, R.; Wang, J.; Chen, W. A prioritized planning algorithm of trajectory coordination based on time windows for multiple AGVs with delay disturbance. Assem. Autom. 2019, 39, 753–768. [Google Scholar] [CrossRef]
- Nie, Z.; Chen, K.-C. Hypergraphical Real-Time Multirobot Task Allocation in a Smart Factory. IEEE Trans. Ind. Inform. 2021, 18, 6047–6056. [Google Scholar] [CrossRef]
- Wang, H.; Li, S.; Ji, H. Fitness-Based Hierarchical Reinforcement Learning for Multi-human-robot Task Allocation in Complex Terrain Conditions. Arab. J. Sci. Eng. 2022, 48, 7031–7041. [Google Scholar] [CrossRef]
- Plaat, A.; Kosters, W.; Preuss, M. High-accuracy model-based reinforcement learning, a survey. Artif. Intell. Rev. 2023, 1–33. [Google Scholar] [CrossRef]
- Alpdemir, M.N. A Hierarchical Reinforcement Learning Framework for UAV Path Planning in Tactical Environments. Turk. J. Sci. Technol. 2023, 18, 243–259. [Google Scholar] [CrossRef]
- Pateria, S.; Subagdja, B.; Tan, A.-H.; Quek, C. Hierarchical Reinforcement Learning: A Comprehensive Survey. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Astronaut in the Capsule | Astronaut Outside the Capsule | Small Exploration Robot | Large Recue Robot | Material Transport Robot | Lunar Rover | ||
|---|---|---|---|---|---|---|---|
| Ground Exploration | Terrain Detection | ||||||
| Path Planning | |||||||
| Obstacle Avoidance | |||||||
| Robot Rescue | Positioning Robot | ||||||
| Trouble Shooting | |||||||
| Moving Robot | |||||||
| Material Transportation | Lifting Material | ||||||
| Moving Material | |||||||
| Lowering Material | |||||||
| Lunar surface samples | Trajectory Planning | ||||||
| Cutting Operation |
| ID | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Environment Type | unknown terrain | powdery, no-coordinates, dark | powdery, no-coordinates, bright | powdery, coordinates, dark | powdery, coordinates, bright |
| ID | 6 | 7 | 8 | 9 | 10 |
| Environment Type | rocky, no-coordinates, dark | rocky, no-coordinates, bright | rocky, coordinates, dark | rocky, coordinates, bright | undulating, no-coordinates, dark |
| ID | 11 | 12 | 13 | ||
| Environment Type | undulating, no-coordinates, bright | undulating, coordinates, dark | undulating, coordinates, bright |
| Item | Type | Number |
|---|---|---|
| Astronaut | Astronauts in the Capsule | 4 |
| Astronauts outside the Capsule | 4 | |
| Robot | Small Exploration Robot | 4 |
| Large Rescue Robot | 4 | |
| Material transport Robot | 4 | |
| Lunar Rover | 4 | |
| Task | Ground Exploration | 1 |
| Robot Rescue | 1 | |
| Material transport | 1 | |
| Lunar surface samples | 1 |
| Item | Type | Number | ||||
|---|---|---|---|---|---|---|
| Astronaut | Astronauts in the Capsule | 3 | 4 | 5 | 6 | 7 |
| Astronauts outside the Capsule | 3 | 4 | 5 | 6 | 7 | |
| Robot | Small Exploration Robot | 3 | 4 | 5 | 6 | 7 |
| Large Rescue Robot | 3 | 4 | 5 | 6 | 7 | |
| Material transport Robot | 3 | 4 | 5 | 6 | 7 | |
| Lunar Rover | 3 | 4 | 5 | 6 | 7 | |
| Task | Ground Exploration | 1 | 1 | 1 | 1 | 1 |
| Robot Rescue | 1 | 1 | 1 | 1 | 1 | |
| Material transport | 1 | 1 | 1 | 1 | 1 | |
| Lunar surface samples | 1 | 1 | 1 | 1 | 1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Guo, W.; Wang, H.; Xue, S.; Wang, C. Generating Function Reallocation to Handle Contingencies in Human–Robot Teaming Missions: The Cases in Lunar Surface Transportation. Appl. Sci. 2023, 13, 7506. https://doi.org/10.3390/app13137506
Fu Y, Guo W, Wang H, Xue S, Wang C. Generating Function Reallocation to Handle Contingencies in Human–Robot Teaming Missions: The Cases in Lunar Surface Transportation. Applied Sciences. 2023; 13(13):7506. https://doi.org/10.3390/app13137506
Chicago/Turabian StyleFu, Yan, Wen Guo, Haipeng Wang, Shuqi Xue, and Chunhui Wang. 2023. "Generating Function Reallocation to Handle Contingencies in Human–Robot Teaming Missions: The Cases in Lunar Surface Transportation" Applied Sciences 13, no. 13: 7506. https://doi.org/10.3390/app13137506
APA StyleFu, Y., Guo, W., Wang, H., Xue, S., & Wang, C. (2023). Generating Function Reallocation to Handle Contingencies in Human–Robot Teaming Missions: The Cases in Lunar Surface Transportation. Applied Sciences, 13(13), 7506. https://doi.org/10.3390/app13137506