
Temporal Variations Dataset for Indoor Environmental Parameters in Northern Saudi Arabia




Abstract
1. Introduction
- Environmental dataset: This manuscript presents significant contributions to the domain of environmental data collection, particularly in the realm of indoor environments in Saudi Arabia. The dataset is publicly available at PLOMS Press [11].
- Addressing a Research Gap: The paper aims to fill a gap in the existing research and data collection efforts in Saudi Arabia, which have predominantly concentrated on outdoor settings. This manuscript introduces one of the nation’s initial datasets of indoor environments.
- Regional Specificity: The dataset holds significant value for research endeavors that concentrate on the northern region of Saudi Arabia, owing to its distinct environmental features.
- Use of Arduino IDE: The data was acquired through the use of the Arduino Integrated Development Environment (IDE), an open-source electronics platform that integrates both hardware and software. The implementation of this platform signifies a novel method for collecting indoor environmental data.
- Wide Range of Variables: The dataset comprises measurements from various sensors that capture data on light, temperature, humidity, pressure, and altitude. The diverse range of data points can offer a comprehensive overview of the indoor environment.
- Real-time Data Collection: Real-time data collection was conducted by generating a dataset from sensor readings taken over one month. The collected data provides a rich temporal perspective for analysis.
- Practical Application: This dataset holds significant value for researchers investigating indoor environments, their effects on health and well-being, and the advancement of smart home technologies. It is suitable for training, testing, and validating machine learning algorithms within these domains.
2. Related Work
3. Methodology
- Temperature and Humidity Sensors: DHT11 and DHT22 are two common sensors used to monitor temperature and humidity in the environment. To provide precise measurements, these sensors make use of digital signals.
- Light Sensors: For measuring the light level in the surrounding area, photodiodes and photoresistors may be used, such as the LDR (Light Dependent Resistor).
- Select the sensors necessary for the project and attach them to the Arduino board in line with the wiring diagrams provided by the sensors.
- Create an Arduino sketch and upload it to read data from the sensors. To simplify this process, utilize the built-in features or libraries unique to each sensor.
- Collecting the sensor data regularly may transfer it to a computer or other storage device for long-term preservation, or you can temporarily store it in the Arduino’s memory.
- Analyze and delete the information gathered. In this stage, outliers may be eliminated, noise may be filtered, or raw sensor results may be converted into useful units (for example, translating ADC values to temperature in Celsius).
- To make analysis and visualization easier, arrange the cleaned data into an organized format, such as a CSV file or a relational database. Then, we can utilize this information for various things, including developing machine learning models, keeping an eye on trends, or generating predictions.
Data Acquisition
- Sensor Selection and Integration:
- 2.
- Arduino Programming:
- 3.
- Data Collection:
- 4.
- Data Transmission:
- Serial Communication: We utilized Arduino’s built-in serial communication capabilities to send data directly to a computer via USB. This method allowed real-time monitoring and data collection using a serial monitor or a custom software interface. We imported the library and used a serial monitor, which begins at 9600, which is the speed. The sensor reads the temperature in Celsius, and we set a delay of 5 min before accessing the sensor to integrate these sensors.
- Wireless Communication: In cases where a wired connection was not feasible, we employed wireless communication modules such as Bluetooth, Wi-Fi, or LoRa to transmit data to a nearby computer or a cloud-based storage solution.
- 5.
- Data Storage and Organization:
4. Dataset Description
- Central Tendency: By evaluating the mean, median, and mode of the dataset, we can determine the central tendency of the temperature readings. This provides insight into the typical or “average” temperature observed within the monitored environment.
- Dispersion: Analyzing the data’s range, variance, and standard deviation allows us to understand the degree of dispersion in the temperature readings. A higher dispersion indicates a greater variation in the collected data, whereas a lower dispersion suggests more consistent temperature values.
- Skewness and Kurtosis: Assessing the skewness and kurtosis of the distribution provides information on the data’s asymmetry and tail behavior, respectively. A positively skewed distribution indicates that the data is more concentrated toward the lower end of the temperature range, while a negatively skewed distribution suggests a higher concentration toward the upper end. Kurtosis measures the “tailedness” of the distribution, with high kurtosis indicating heavy tails and more extreme values, while low kurtosis signifies light tails and fewer extreme values.
- Outliers: By identifying any potential outliers in the dataset, we can assess the presence of unusual or unexpected temperature readings. Outliers can be detected using various methods, such as the IQR or Z-score methods. It is essential to investigate the source of any identified outliers to determine if they represent genuine fluctuations or errors in the data collection process.
4.1. Measures of Central Tendency
- Mean: The arithmetic average of the data;
- Median: The middle value that separates the data into two halves;
- Mode: The value that appears most frequently in the data.
4.2. Measures of Dispersion
- Range: The difference between the maximum and minimum values;
- Variance: The average of the squared differences from the mean;
- Standard Deviation: The square root of the variance, representing the dispersion or spread of the data;
- Interquartile Range (IQR): The range between the first quartile (25th percentile) and the third quartile (75th percentile).
4.3. Measures of Shape
4.4. Measures of Association
4.5. Summary Statistics
- Count: The number of data points in the dataset;
- Minimum and Maximum: The smallest and largest values in the dataset;
- Percentiles: The values below which a given percentage of the data falls. Common percentiles are the 25th, 50th (median), and 75th percentiles.
4.6. Distribution
5. Proposed Applications
- Smart Homes: The datasets may be used in developing and enhancing smart home applications, especially in locations with comparable environmental features to Saudi Arabia. Controlling the home environment for comfort, energy efficiency, or special health requirements falls under this category.
- Remote Patient Monitoring Systems: This dataset may be used to enhance these systems, which are used to monitor patients at home. For example, healthcare practitioners might utilize this data to evaluate how changes in a patient’s home environment may affect their health.
- Aged Care Technologies: This dataset may help technologies that let the elderly live independently at home. Sensors that monitor environmental conditions might give useful information about possible hazards or health problems.
- Environmental Health Research: Researchers may use this data to investigate the influence of various environmental factors on health outcomes. This might result in creating treatments or recommendations for protecting people’s health in certain surroundings.
- Models for Disease Prediction: These models might utilize environmental data and personal health data to predict the probability of specific diseases or health problems.
- Personalized Health Recommendations: This data may be used by mobile apps that deliver individualized health recommendations to account for the environmental context. For example, depending on the current situation at hand, an app may recommend certain activities or precautions.
- Climate Control Systems: Maintaining a certain range of environmental conditions in hospitals or healthcare facilities may be critical for patient comfort and health. This dataset may be used to train machine learning models that improve the performance of these systems.
- Emergency Alert Systems: These systems may advise users or healthcare practitioners to take appropriate action in the event of severe environmental conditions (e.g., high temperature).
- Indoor Farming and Agriculture: Indoor farming and agriculture may also benefit from these statistics since they can give insights into improving plant growth conditions. Although this application does not directly relate to healthcare, it is nonetheless essential due to the need for environmental monitoring.
- Air Quality Monitoring Systems: Although the dataset does not directly assess air quality, it may be used with other data sources to construct or enhance such systems. Machine learning algorithms, for example, might estimate air quality based on temperature, humidity, and pressure data.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manley, K.; Nyelele, C.; Egoh, B.N. A review of machine learning and big data applications in addressing ecosystem service research gaps. Ecosyst. Serv. 2022, 57, 101478. [Google Scholar] [CrossRef]
- Salam, A.A.; Elsegaey, I.; Khraif, R.; Al-Mutairi, A. Population distribution and household conditions in Saudi Arabia: Reflections from the 2010 Census. SpringerPlus 2014, 3, 530. [Google Scholar] [CrossRef] [PubMed]
- Nabhan, G.P.; Richter, B.D.; Riordan, E.C.; Tornbom, C. Toward Water-Resilient Agriculture in Arizona: Future Scenarios Addressing Water Scarcity; Lincoln Institute of Land Policy: Cambridge, MA, USA, 2023. [Google Scholar]
- Yusuf, N.; Lytras, M.D. Competitive Sustainability of Saudi Companies through Digitalization and the Circular Carbon Economy Model: A Bold Contribution to the Vision 2030 Agenda in Saudi Arabia. Sustainability 2023, 15, 2616. [Google Scholar] [CrossRef]
- Nassar, H.; Biltagy, M.; Safwat, A.M. The role of waste-to-energy in waste management in Egypt: A techno-economic analysis. Rev. Econ. Political Sci. 2023. [Google Scholar] [CrossRef]
- Dubais, F.A.; Urbanization Key Driver towards Smarter Cities. Saudigazette. 2015. Available online: http://www.saudigazette.com.sa/article/120798 (accessed on 10 April 2023).
- Khashoggi, A.; Mohammed, M.F. Smart Mobility in Smart City: A Critical Review of the Emergence of the Concept. Focus on Saudi Arabia. In Research and Innovation Forum 2022: Rupture, Resilience and Recovery in the Post-Covid World; Springer International Publishing: Cham, Switzerland, 2023; pp. 233–241. [Google Scholar]
- Khahro, S.H.; Kumar, D.; Siddiqui, F.H.; Ali, T.H.; Raza, M.S.; Khoso, A.R. Optimizing Energy Use, Cost and Carbon Emission through Building Information Modelling and a Sustainability Approach: A Case-Study of a Hospital Building. Sustainability 2021, 13, 3675. [Google Scholar] [CrossRef]
- Mohdher, L. Design Guidelines to Improve the Air Quality in Hot Climate Open Spaces-Jeddah City as a Case Study. Ph.D. Thesis, Effat University, Jeddah, Saudi Arabia, 2023. [Google Scholar]
- Rajoria, N.; Jhamaria, C.; Sharma, S.; Singh, N.; Ameriya, T.; Gupta, A. Sources and Effects of Indoor Air Pollutants: A Review. Ann. For. Res 2023, 66, 1035–1047. [Google Scholar]
- Rajaa Al-Shammari, T.S.; Ramadan, R.A.; Northern Saudi Arabia Indoor Environmental Dataset|PLOMS PRESS. Northern Saudi Arabia Indoor Environmental Dataset|PLOMS PRESS. 2023. Available online: https://plomscience.com/press/index.php/Press/catalog/book/2 (accessed on 10 April 2023).
- Borghi, J.; Van Gulick, A. Promoting Open Science Through Research Data Management. Harv. Data Sci. Rev. 2022, 4. [Google Scholar] [CrossRef]
- Hřebíček, J.; Hejč, M. Quality of Data, Information and Indicators in Environmental Systems. In Proceedings of the 4th WSEAS International Conference on Mathematical Biology And Ecology (MABE’08), Acapulco, Mexico, 25–27 January 2008; WSEAS: Athens, Greece, 2008; pp. 35–40. [Google Scholar]
- Choi, J.-H.; Loftness, V.; Aziz, A. Post-Occupancy Evaluation of 20 Office Buildings as Basis for Future IEQ Standards and Guidelines; Elsevier Ltd.: Amsterdam, The Netherlands, 2012; pp. 167–175. [Google Scholar]
- Bachmann, N.; Tripathi, S.; Brunner, M.; Jodlbauer, H. The Contribution of Data-Driven Technologies in Achieving the Sustainable Development Goals. Sustainability 2022, 14, 2497. [Google Scholar] [CrossRef]
- Diebold, G. Citizen Science and Crowdsourced Data Can Improve Environmental Data in the United States. Center for Data Innovation. 2022. Available online: https://datainnovation.org/2022/06/citizen-science-and-crowdsourced-data-can-improve-environmental-data-in-the-united-states/ (accessed on 10 April 2023).
- Cao, B.; Ouyang, Q.; Zhu, Y.; Huang, L.; Hu, H.; Deng, G. Development of a multivariate regression model for overall satisfaction in public buildings based on field studies in Beijing and Shanghai. Build. Environ. 2012, 47, 394–399. [Google Scholar] [CrossRef]
- Andargie, M.; Azar, E. An applied framework to evaluate the impact of indoor office environmental factors on occupants’ comfort and working conditions. Sustain. Cities Soc. 2019, 46, 101447. [Google Scholar] [CrossRef]
- Sharmin, T.; Gül, M.; Li, X.; Ganev, V.; Nikolaidis, I.; Al-Hussein, M. Monitoring building energy consumption, thermal performance, and indoor air quality in a cold climate region. Sustain. Cities Soc. 2014, 13, 57–68. [Google Scholar] [CrossRef]
- Jurado, S.R.; Bankoff, A.D.; Sanchez, A. Indoor air quality in Brazilian universities. Int. J. Environ. Res. Public Health 2014, 11, 7081–7093. [Google Scholar] [CrossRef]
- Pei, Z.; Lin, B.; Liu, Y.; Zhu, Y. Comparative study on the indoor environment quality of green office buildings in China with a long-term field measurement and investigation. Build. Environ. 2015, 84, 80–88. [Google Scholar] [CrossRef]
- Zuhaib, S.; Manton, R.; Griffin, C.; Hajdukiewicz, M.; Keane, M.M.; Goggins, J. An Indoor Environmental Quality (IEQ) assessment of a partially-retrofitted university building. Build. Environ. 2018, 139, 69–85. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J.; Ren, J. Impact of various ventilation modes on IAQ and energy consumption in Chinese dwellings: First long-term monitoring study in Tianjin, China. Build. Environ. 2018, 143, 99–106. [Google Scholar] [CrossRef]
- Sant’anna, D.; Dos Santos, P.; Vianna, N.; Romero, M. Indoor environmental quality perception and users’ satisfaction of conventional and green buildings in Brazil. Sustain. Cities Soc. 2018, 43, 95–110. [Google Scholar] [CrossRef]
- Tardioli, G.; Kerrigan, R.; Oates, M.; James, O.D.; Finn, D. Data driven approaches for prediction of building energy consumption at urban level. Energy Procedia 2015, 78, 3378–3383. [Google Scholar] [CrossRef]
- A Lou, H.; Ou, D. A comparative field study of indoor environmental quality in two types of open-plan offices: Open-plan administrative offices and open-plan research offices. Build. Environ. 2019, 148, 394–404. [Google Scholar] [CrossRef]
- Geng, Y.; Lin, B.; Yu, J.; Zhou, H.; Ji, W.; Chen, H.; Zhang, Z.; Zhu, Y. Indoor environmental quality of green office buildings in China: Large-scale and long-term measurement. Build. Environ. 2019, 150, 266–280. [Google Scholar] [CrossRef]
- Ma, F.; Zhan, C.; Xu, X. Investigation and Evaluation of Winter Indoor Air Quality of Primary Schools in Severe Cold Weather Areas of China. Energies 2019, 12, 1602. [Google Scholar] [CrossRef]
- Huang, K.; Sun, W.; Feng, G.; Wang, J.; Song, J. Indoor air quality analysis of 8 mechanically ventilated residential buildings in northeast China based on long-term monitoring. Sustain. Cities Soc. 2020, 54, 101947. [Google Scholar] [CrossRef]
- Zhu, Y.-D.; Li, X.; Fan, L.; Li, L.; Wang, J.; Yang, W.-J.; Wang, L.; Yao, X.-Y.; Wang, X.-L. Indoor air quality in the primary school of China—Results from CIEHS 2018 study. Environ. Pollut. 2021, 291, 118094. [Google Scholar] [CrossRef]
- Kim, J.; Kim, S.; Bae, S.; Kim, M.; Cho, Y.; Lee, K.-I. Indoor environment monitoring system tested in a living lab. Build. Environ. 2022, 214, 108879. [Google Scholar] [CrossRef]
- Botero-Valencia, J.; Castano-Londono, L.; Marquez-Viloria, D. Indoor Temperature and Relative Humidity Dataset of Controlled and Uncontrolled Environments. Data 2022, 7, 81. [Google Scholar] [CrossRef]
- Najjar, G.A.; Akkad, K.; Almahdaly, A.H. Classification of Lighting Design Aspects in Relation to Employees’ Productivity in Saudi Arabia. Sustainability 2023, 15, 3614. [Google Scholar] [CrossRef]
- Giddings, B.; Almehrej, M.; Cresciani, M. The Dilemma of Saudi Arabian Homes in Riyadh. Space Cult. 2023, 26, 4–22. [Google Scholar] [CrossRef]
- Frank, A. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2010; Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 10 April 2023).
- Asuncion, A.; Newman, D.J. UCI Machine Learning Repository. 2007. Available online: http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 10 April 2023).
- Nazaroff, W.W.; Singer, B.C. Inhalation of hazardous air pollutants from environmental tobacco smoke in US residences. J. Expo. Sci. Environ. Epidemiol. 2004, 14, S71–S77. [Google Scholar] [CrossRef]
- Crawley, D.B.; Lawrie, L.K.; Pedersen, C.O.; Winkelmann, F.C.; Witte, M.J.; Strand, R.K.; Liesen, R.J.; Buhl, W.F.; Huang, Y.J. Robert H. Henninger; et al. EnergyPlus: New, capable, and linked. J. Archit. Plan. Res. 2004, 21, 292–302. [Google Scholar]
- Crawley, D.B.; Lawrie, L.K.; Winkelmann, F.C.; Buhl, W.; Huang, Y.; Pedersen, C.O.; Strand, R.K.; Liesen, R.J.; Fisher, D.E.; Witte, M.J.; et al. EnergyPlus: Creating a new-generation building energy simulation program. Energy Build. 2001, 33, 319–331. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra-Llanas, X.; Reyes-Ortiz, J. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 2013 International Symposium on Wearable Computers (ISWC), Zurich, Switzerland, 8–12 September 2013. [Google Scholar]
- Brown, Z.; Ting, K.C.; Srivastava, M.B. DEBS: A dataset for building energy analysis. In Proceedings of the 4th ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Buildings, Toronto, ON, Canada, 6 November 2012; pp. 25–30. [Google Scholar]
- Geng, Y.; Lin, B.; Zhu, Y. Comparative study on indoor environmental quality of green office buildings with different levels of energy use intensity. Build. Environ. 2020, 168, 106482. [Google Scholar] [CrossRef]
- de Dear, R.; Brager, G. Developing an adaptive model of thermal comfort and preference. ASHRAE Trans. 1998, 104, 145–167. [Google Scholar]
- Allen, J.G.; MacNaughton, P.; Satish, U.; Santanam, S.; Vallarino, J.; Spengler, J.D. Associations of Cognitive Function Scores with Carbon Dioxide, Ventilation, and Volatile Organic Compound Exposures in Office Workers: A Controlled Exposure Study of Green and Conventional Office Environments. Environ. Health Perspect. 2016, 124, 805–812. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.-L.; Fan, X.-M.; Jin, X.-B.; Su, T.-L.; Bai, Y.-T.; Ma, H.-J.; Zuo, M. BMAE-Net: A Data-Driven Weather Prediction Network for Smart Agriculture. Agronomy 2023, 13, 625. [Google Scholar] [CrossRef]
- Wang, G.G.; Tsai, H.P. Using Long Short-Term Memory Model for Cloud Forest Vegetation Growth Status Prediction—A Case Study in Shei-Pa National Park. ISPRS-Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2022, XLIII-B3-2022, 1033–1038. [Google Scholar] [CrossRef]
- Jiang, W.; Yan, Z.; Feng, D.-H.; Hu, Z. Wind speed forecasting using autoregressive moving average/generalized autoregressive conditional heteroscedasticity model. Eur. Trans. Electr. Power 2011, 22, 662–673. [Google Scholar] [CrossRef]
- Xiao, Z.; Ye, S.-J.; Zhong, B.; Sun, C.-X. BP neural network with rough set for short term load forecasting. Expert Syst. Appl. 2009, 36, 273–279. [Google Scholar] [CrossRef]
- Li, H.; Gao, W.; Xie, J.; Yen, G.G. Multiobjective bilevel programming model for multilayer perceptron neural networks. Inf. Sci. 2023, 642, 119031. [Google Scholar] [CrossRef]
- Roy, A.; Chakraborty, S. Support vector machine in structural reliability analysis: A review. Reliab. Eng. Syst. Saf. 2023, 233, 109126. [Google Scholar] [CrossRef]
- Glennie, R.; Adam, T.; Leos-Barajas, V.; Michelot, T.; Photopoulou, T.; McClintock, B.T. Hidden Markov models: Pitfalls and opportunities in ecology. Methods Ecol. Evol. 2023, 14, 43–56. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, H.; Deng, H.; Liu, D.; Shen, W.; Chan, S.H.; Zhang, Q. Concept-Level Explanation for the Generalization of a DNN. arXiv 2023, arXiv:2302.13091. [Google Scholar]
- Khaldi, R.; El Afia, A.; Chiheb, R.; Tabik, S. What is the best RNN-cell structure to forecast each time series behavior? Expert Syst. Appl. 2023, 215, 119140. [Google Scholar] [CrossRef]
- Seabe, P.L.; Moutsinga, C.R.B.; Pindza, E. Forecasting Cryptocurrency Prices Using LSTM, GRU, and Bi-Directional LSTM: A Deep Learning Approach. Fractal Fract. 2023, 7, 203. [Google Scholar] [CrossRef]
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 10 April 2023).
- Li, B.; Qi, P.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From Principles to Practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Singh, R.; Gill, S.S. Edge AI: A survey. Internet Things Cyber-Phys. Syst. 2023, 3, 71–92. [Google Scholar] [CrossRef]
- General Data Protection Regulation (GDPR)—Official Legal Text. General Data Protection Regulation (GDPR). Available online: https://gdpr-info.eu/ (accessed on 10 April 2023).
- Privacy and Data Protection in the Kingdom of Saudi Arabia. Privacy and Data Protection in the Kingdom of Saudi Arabia. Available online: https://www.my.gov.sa/wps/portal/snp/content/dataprotection/?lang=en#:~:text=Anyone%20who%20discloses%20sensitive%20data,data%20owner%20or%20to%20achieve (accessed on 10 April 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Study | Year | Parameters Measured | City of Measurement |
|---|---|---|---|
| [14] | 2012 | Thermal, air quality, lighting/visual, and acoustic measurements | USA |
| [17] | 2012 | Air temperature, mean radiant temperature, relative humidity, air velocity, CO2, illumination intensity, sound pressure levels | China |
| [18] | 2012 | PM10, PM2.5, PM1 and CO concentrations | India |
| [19] | 2014 | CO2 concentration, relative humidity | Canada |
| [20] | 2014 | Carbon dioxide (CO2), temperature, relative humidity (RH), wind speed, viable mold, and airborne dust levels. | Brazil |
| [21] | 2015 | Thermal environment, indoor air quality, visual and acoustic environment | China |
| [22] | 2018 | Air temperature, relative humidity, mean radiant temperature, air velocity, illumination, CO2, and noise level PMV—PPD | Ireland |
| [23] | 2018 | Air freshness, air cleanliness, humidity, natural lighting, acoustic environment | China |
| [24] | 2018 | Thermal comfort, lighting, acoustics, ergonomics, cleaning, air quality | Brazil |
| [25] | 2018 | CO2, PM2.5, energy consumption | China |
| [18] | 2019 | Sound level, air velocity, radiant temperature, air temperature, illuminance, relative humidity | Canada |
| [26] | 2019 | Layout, air quality, thermal comfort, lighting, and acoustic environment | China |
| [27] | 2019 | Air temperature, relative humidity, CO2, PM2.5, illuminance | China |
| [28] | 2019 | Carbon dioxide (CO2) | China |
| [29] | 2020 | Temperature and concentrations of formaldehyde, VOC, CO2, and PM2.5 | China |
| [30] | 2021 | Temperature, relative humidity, PM2.5, PM10, CO2, CO, formaldehyde concentrations | Beijing, China |
| [31] | 2022 | Temperature, humidity, PM1.0, PM2.5, PM10, and CO2 | Republic of Korea |
| [32] | 2022 | Timestamp, indoor temperature, and relative humidity | USA |
| Our Dataset (NorthSaudi) | 2023 | Temperature, humidity, pressure, altitude, light, and timestamps | Northern Saudi Arabia |
| Dataset Name | Parameters Measured | Short Description | Reference |
|---|---|---|---|
| UCI Air Quality | CO, NOx, NMHC, Benzene, NO2, O3 | A dataset collected from an air quality monitoring station in Italy includes outdoor and indoor air quality data. | [35,36] |
| Berkeley Indoor Air Quality Dataset | CO2, temperature, humidity, PM2.5, TVOC | A dataset collected from multiple San Francisco Bay-area indoor environments includes homes, schools, and offices. | [37] |
| Office Building Energy Dataset | Temperature, humidity, CO2, occupancy, lighting | A dataset collected from an office building in the US includes data from multiple floors and rooms. | [38,39] |
| UCI Human Activity Recognition | Accelerometer data | A dataset collected from wearable accelerometers includes data on human activity recognition in indoor environments. | [40] |
| DEBS | Temperature, humidity, CO2 | A dataset collected from a New Hampshire, USA, residential building includes data from multiple rooms and floors. | [41] |
| NA | Thermal comfort, air quality, and visual environment | A dataset collected from 20 green office buildings in China. | [42] |
| UC Berkeley Thermal Comfort Database | Temperature, humidity, air speed | A dataset collected from experiments on human thermal comfort in different indoor environments includes data on occupant comfort in different temperature and humidity conditions. | [43] |
| NA | CO2, temperature, humidity, TVOC | A dataset collected from multiple indoor environments in the US includes data from homes, schools, and offices. | [44] |
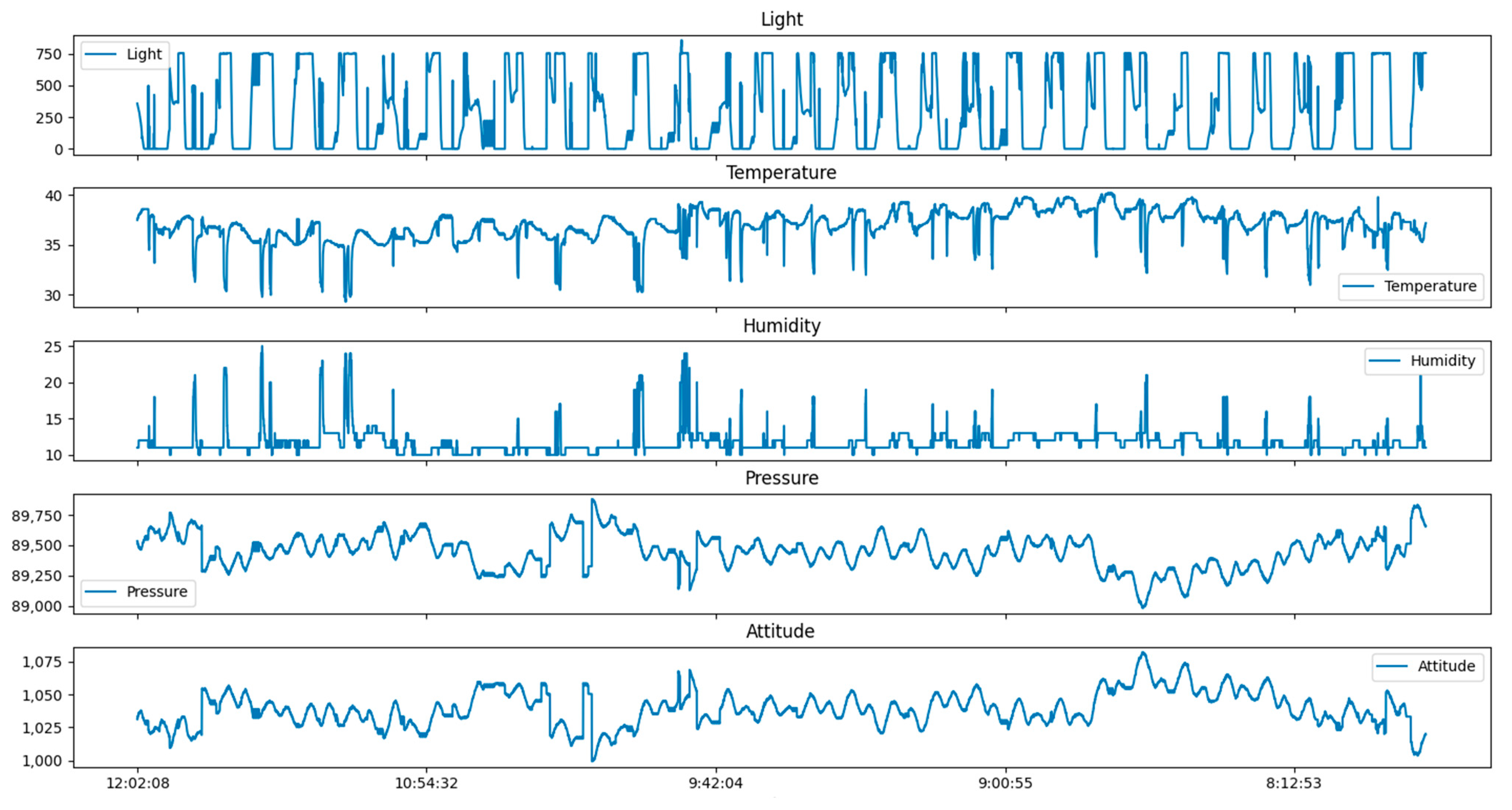
| Time (HH:MM:SS) | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| 12:02:08 | 357 | 37.5 | 11 | 89,535 | 1031.2 |
| 12:07:09 | 352 | 37.6 | 11 | 89,536 | 1031.1 |
| 12:12:10 | 349 | 37.6 | 11 | 89,532 | 1031.47 |
| 12:33:54 | 339 | 37.7 | 11 | 89,510 | 1033.5 |
| 12:38:55 | 336 | 37.7 | 11 | 89,512 | 1033.31 |
| 12:43:56 | 330 | 37.7 | 11 | 89,507 | 1033.77 |
| 12:48:57 | 325 | 37.7 | 11 | 89,501 | 1034.33 |
| 12:53:58 | 322 | 37.9 | 11 | 89,502 | 1034.23 |
| 12:58:59 | 315 | 37.9 | 11 | 89,499 | 1034.51 |
| 13:04:01 | 312 | 37.9 | 11 | 89,492 | 1035.15 |
| 13:09:02 | 304 | 38 | 12 | 89,495 | 1034.88 |
| 13:14:03 | 300 | 38 | 12 | 89,487 | 1035.61 |
| 13:19:04 | 293 | 38 | 12 | 89,477 | 1036.53 |
| Measure | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| mean | 265.865881 | 36.96486 | 11.775421 | 89,448.598429 | 1039.161420 |
| Median | 102.00 | 37.10 | 11.00 | 89,455.00 | 1038.56 |
| Mode | 0.0 | 36.6 | 11.0 | 89,326.0 | 1050.45 |
| Measure | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| std | 305.715927 | 1.64157 | 1.827553 | 140.646670 | 12.951571 |
| min | 0.000000 | 29.30000 | 10.000000 | 88,982.000000 | 999.590000 |
| max | 856.000000 | 40.20000 | 25.000000 | 89,882.000000 | 1082.210000 |
| Range | 856.00 | 10.90 | 15.00 | 900.00 | 82.62 |
| Variance | 93,462.227717 | 2.694752 | 3.339950 | 19,781.485821 | 167.743187 |
| IQR | 565.00 | 1.90 | 1.00 | 186.75 | 17.22 |
| Measure | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| Skewness | 0.641172 | −1.223877 | 3.668192 | −0.141923 | 0.144958 |
| Kurtosis | −1.270747 | 2.977807 | 16.744838 | 0.190931 | 0.190579 |
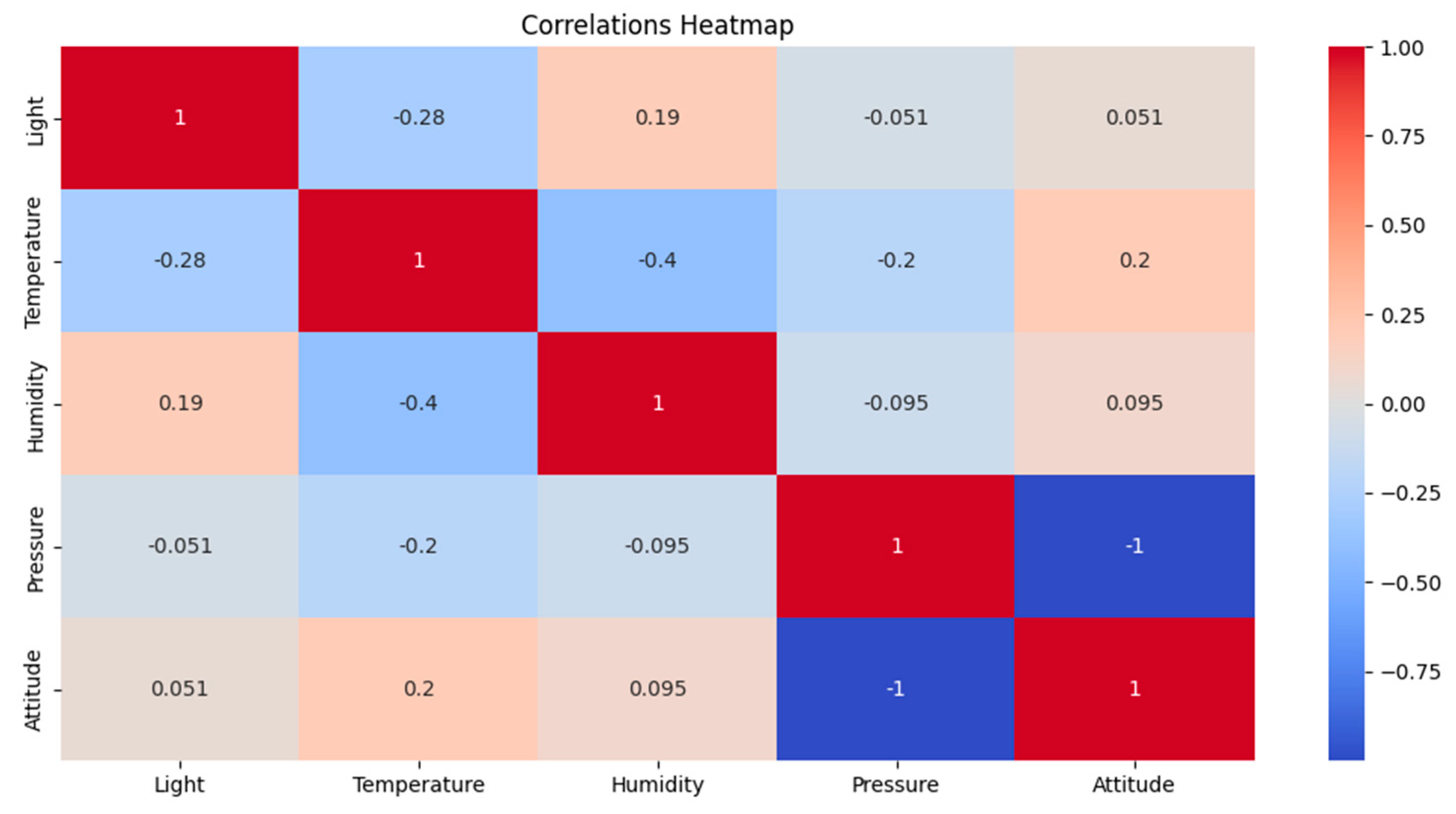
| Correlation | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| Light | 1.000000 | −0.282322 | 0.187878 | −0.051294 | 0.051339 |
| Temperature | −0.282322 | 1.000000 | −0.395346 | −0.195911 | 0.195760 |
| Humidity | 0.187878 | −0.395346 | 1.000000 | −0.094870 | 0.094785 |
| Pressure | −0.051294 | −0.195911 | −0.094870 | 1.000000 | −0.999907 |
| Attitude | 0.051339 | 0.195760 | 0.094785 | −0.999907 | 1.000000 |
| Measure | Light (Lumen (lm)) | Temperature (°C) | Humidity (%) | Pressure (Pascal (Pa)) | Attitude |
|---|---|---|---|---|---|
| Covariance | 93,462.227717 | 2.694752 | 3.339950 | 19,781.485821 | 167.743187 |
| Measure | Light | Temperature | Humidity | Pressure | Attitude |
|---|---|---|---|---|---|
| count | 8910.000000 | 8910.00000 | 8910.000000 | 8910.000000 | 8910.000000 |
| min | 0.000000 | 29.30000 | 10.000000 | 88,982.000000 | 999.590000 |
| max | 856.000000 | 40.20000 | 25.000000 | 89,882.000000 | 1082.210000 |
| 25% | 0.000000 | 36.20000 | 11.000000 | 89,355.250000 | 1030.550000 |
| 50% | 102.000000 | 37.10000 | 11.000000 | 89,455.000000 | 1038.560000 |
| 75% | 565.000000 | 38.10000 | 12.000000 | 89,542.000000 | 1047.770000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshammari, T.; Ramadan, R.A.; Ahmad, A. Temporal Variations Dataset for Indoor Environmental Parameters in Northern Saudi Arabia. Appl. Sci. 2023, 13, 7326. https://doi.org/10.3390/app13127326
Alshammari T, Ramadan RA, Ahmad A. Temporal Variations Dataset for Indoor Environmental Parameters in Northern Saudi Arabia. Applied Sciences. 2023; 13(12):7326. https://doi.org/10.3390/app13127326
Chicago/Turabian StyleAlshammari, Talal, Rabie A. Ramadan, and Aakash Ahmad. 2023. "Temporal Variations Dataset for Indoor Environmental Parameters in Northern Saudi Arabia" Applied Sciences 13, no. 12: 7326. https://doi.org/10.3390/app13127326
APA StyleAlshammari, T., Ramadan, R. A., & Ahmad, A. (2023). Temporal Variations Dataset for Indoor Environmental Parameters in Northern Saudi Arabia. Applied Sciences, 13(12), 7326. https://doi.org/10.3390/app13127326