Abstract
Deep learning-based medical image analysis technology has been developed to the extent that it shows an accuracy surpassing the ability of a human radiologist in some tasks. However, data labeling on medical images requires human experts and a great deal of time and expense. Moreover, medical image data usually have an imbalanced distribution for each disease. In particular, in multilabel classification, learning with a small number of labeled data causes overfitting problems. The model easily overfits the limited number of labeled data, while it still underfits the large amount of unlabeled data. In this study, we propose a method that combines entropy-based Mixup and self-training to improve the performance of data-imbalanced chest X-ray classification. The proposed method is to apply the Mixup algorithm to limited labeled data to alleviate the data imbalance problem and perform self-training that effectively utilizes the unlabeled data while iterating this process by replacing the teacher model with the student model. Experimental results in an environment with a limited number of labeled data and a large number of unlabeled data showed that the classification performance was improved by combining entropy-based Mixup and self-training.
1. Introduction
Currently, research using machine learning technology in the field of medical image analysis is being actively studied [1,2,3,4,5]. Research on medical image analysis, particularly the development of deep learning-based systems for chest X-ray classification and diagnosis, has garnered increasing attention due to the growing importance of immediate and accurate diagnosis. These studies focus on leveraging deep learning technology to automate the annotation process, thereby facilitating efficient and accurate diagnosis [6]. However, since creating labeled data for medical image analysis requires experts and takes substantial time and money, obtaining medical image training data and dealing with imbalanced distribution of the training data are recognized as important problems. Especially in multilabel classification, learning with a small number of labeled data causes severe overfitting problems. The model easily overfits the limited number of labeled data, while it still underfits the large amount of unlabeled data.
To address the challenges of imbalanced data distribution and overfitting caused by a limited number of labeled data, this study proposes a method that combines entropy-based Mixup [7,8,9,10] and self-training [11,12,13,14,15]. The proposed approach involves generating new data samples by applying entropy-based Mixup to a small number of labeled data. In the Mixup process, data samples with high entropy and those with low entropy are selected for synthesis. By iteratively repeating this process, replacing the teacher model with the student model, and incorporating a self-training method that effectively utilizes a large volume of unlabeled data, optimal performance can be achieved.
Mixup is a popular data augmentation technique used in this study. It combines two existing samples through a linear combination, eliminating the need for additional data collection. The combination ratio is determined using a beta distribution. By generating these mixed samples, the model’s generalization performance is improved by increasing the training data. Mixup introduces variability and enhances model robustness, even with challenging or unsuitable data. It effectively addresses overfitting by utilizing the principle of vicinal risk minimization (VRM). In multilabel classification tasks, Mixup proves valuable as it enables the model to capture complex label relationships. The learning model presented in this paper can be seen as a kind of self-training, as it generates pseudo-labels from unlabeled data that are used to retrain themselves to improve performance. In particular, the noisy student model combines the advantages of semi-supervised learning and supervised data augmentation to achieve improved results. In this study, we utilized the process of the teacher–student model and the concept of iterative training.
The learning process in this study can be broadly divided into two main stages: training the teacher model using the entropy-based Mixup technique and self-training the student model with repetition. To provide a more detailed explanation, the process can be further divided into four steps. In the first step, we perform an entropy-based Mixup with a small number of labeled data to increase the number of samples and train the teacher model. In the second step, to extract meaningful samples from a large number of unlabeled data, the trained teacher model generates softmax prediction vectors of unlabeled data, classifies them by disease, and extracts the top-ranked data. In the third step, we use the extracted data samples to pretrain the student model and perform fine-tuning with the initial labeled data. In the final step, we select synthesized samples for data expansion, remove noisy synthesized samples that degrade performance, and repeat the process by using the student model as a teacher model. To confirm the validity of the proposed method, the classification performance of entropy-based data augmentation and self-training is verified using unbalanced chest X-ray data. In summary, we suggest a way to improve performance by repeating the process of sample creation, selection, and expansion through the proposed method.
The main contributions of this study are as follows:
- We propose an entropy-based Mixup method for data augmentation. The entropy is calculated and sorted to select two labeled data for synthesis, and data with high entropy and data with low entropy are selected for mixed synthesis. Two target selection methods to solve the imbalance in the number of samples are compared through experiments: random selection and entropy-based selection.
- We propose a self-training method for utilizing unlabeled data to overcome the low-resource problem. It improves performance by cycling through sample generation, selection, and expansion with sample synthesis. Through self-training, the overfitting problem that occurs during the training process can also be reduced.
- Mixup and self-training are combined to improve the performance of imbalanced multilabel chest X-ray classification. The proposed method applies the Mixup algorithm to a small number of labeled data to alleviate data imbalance and applies self-training with a large number of unlabeled data, replacing the teacher model with the student model repeatedly to perform sampling, which can effectively utilize unlabeled data.
2. Related Work
2.1. Data Augmentation
Data augmentation is a technique that increases the number of training data by synthesizing new data from existing data without additionally collecting new data samples. Geometric transformations [16] for image data include horizontal axis flipping, vertical axis flipping, translation, rotation, and cropping of some images. Modern data augmentation technologies such as Cutout [17], Cutmix [18], and PuzzleMix [19] have been developed, starting with Mixup, which uses linear interpolation in the training data space to generate new data. In particular, Co-Mixup [20] ensures diversity while having as many salient regions as possible for all input data. Oversampling techniques such as SMOTE [21], SWIM [22], and its variants generate synthetic minority class instances to solve the class imbalance problem. In this paper, an algorithm based on Mixup was applied to solve the data imbalance problem in image classification.
In recent research on data augmentation, the consistency regularization paradigm, which starts from the assumption that the prediction results of an unlabeled image should match the prediction results after the image is augmented, has been actively studied. Augmented learning models use dropouts to improve the performance of the model. The noisy student methodology combines semi-supervised learning and supervised data augmentation to achieve very good results. This methodology makes the model robust to small changes in the data—noise that would not significantly affect the label when viewed by a human.
There are also hybrid methods that combine previous studies on self-training and consistency regularization that have shown good results in performance evaluation. In particular, the FixMatch [23] method combines pseudo-labels [24] and consistency regularization, which simplifies the overall process compared to previous studies while showing high performance. For labeled images, it trains the supervised model with a loss function using the cross-entropy error, and, for unlabeled images, it applies weak augmentation and strong augmentation for self-training and optimization. The image generated by weak augmentation serves to generate pseudo-labels, and it optimizes the model by calculating the cross-entropy loss with the pseudo-label values and the output of strong augmentation. FixMatch’s weak augmentation method uses random horizontal flipping and random vertical and horizontal shifting, while the strong augmentation method uses cutout enhancement after applying augmentation methods such as RandAugment [25] and CTAugment [26].
2.2. Self-Training
Self-training [15] is a method of improving the performance of the classifier by starting to learn from a small number of samples, creating classifiers, predicting pseudo-labels of a large number of unlabeled data, and relearning with selected samples. The difference with knowledge distillation is that knowledge distillation is a way of learning a small student model from a large well-learned teacher model, whereas self-training uses a teacher/student model composed of equal model for continuous learning.
In particular, MixMatch [26,27] presents the label guessing process, which applies entropy minimization to labeled data and unlabeled data. UDA [28] describes a combination of consistency training and data augmentation. The teacher–student model can be viewed as a process of reusing pretrained weights and has been mixed with self-supervised learning and self-training. In this paper, our teacher–student model is similar to the noisy teacher–student and mean–teacher models [29].
The pseudo-label [24] follows the same method of using both labeled and unlabeled data to train the model. It uses the labeled data to predict the class of the unlabeled data with cross-entropy loss, assuming the maximal confidence prediction value to be the pseudo-label, i.e., the class of the unlabeled data. The overall loss function adds the loss for supervised learning and the loss for unlabeled data, and adjusts the balance between the two with a coefficient. The MixText model [30] applies the data augmentation approach in the field of natural language processing. The possibility of overfitting was greatly reduced because the sentences can be mixed regardless of labeled and unlabeled data, and infinite data augmentation is possible.
3. Proposed Learning Model
In this section, we describe our learning model in detail. The task is chest X-ray classification, which involves performing multilabel classification for 14 types of chest diseases. In this task, there are difficulties in handling imbalanced data distribution and multilabel classification using a small number of data. To alleviate these problems, we propose a combined method of entropy-based Mixup and self-training. We present the process of generating new data samples by applying the proposed method to a small amount of labeled data, and we also explain how to use unlabeled data effectively by applying self-training. The process of sample selection, sample synthesis, and oversampling through entropy-based Mixup is explained in Figure 1, Figure 2, Figure 3 and Figure 4, respectively. Furthermore, Equations (1)–(3) provide an explanation of the Mixup methodology and the calculation process for entropy.
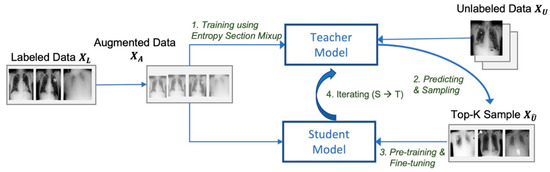
Figure 1.
Learning model that combines entropy-based Mixup and self-training.
Figure 1 shows the overall learning process proposed in this paper. The learning process can be described in four stages that go through the following steps:
- (1)
- Training the teacher model using data augmented by entropy-based Mixup;
- (2)
- Predicting labels of unlabeled data and top-K sampling of pseudo-label data;
- (3)
- Pretraining and fine-tuning the student model;
- (4)
- Replacing the teacher model with the student model, and going back to step 2.
3.1. Training the Teacher Model Using Entropy-Based Mixup
Step 1 is to train the teacher model with a small number of labeled data () and the augmented data (). In the experiment with the labeled data only (Section 4.2 Effects of Entropy-Based Mixup), the average AUROC of the teacher model was 0.6409, while the AUROC of the hernia class was the lowest at 0.5498. This is mainly due to the class imbalance, with only 27 image samples (0.15% of total training data) of the hernia class. To solve the problem, the number of samples is increased by data augmentation with the Mixup algorithm.
New samples are generated by performing weighted linear interpolation of images and labels of two randomly extracted data as follows.
where
In above equations, denote the two images and labels selected for Mixup, and is the ratio of mixing the two samples, sampled from the beta distribution. is the image and label created by synthesizing with Mixup.
For effective sample synthesis, we propose the entropy-based selection method, which can alleviate the overfitting problem and increase the number of samples. Given a classification model M, the entropy represents the uncertainty of the model’s predictions. We calculate the entropy on the basis of the probability distribution generated by the teacher classifier as follows:
where represents the prediction probability of class k. If the entropy is very low, no additional training samples are needed because they are close to the ground-truth class, and, if the entropy is high, additional training samples should be generated because they are far from the ground-truth class. Therefore, we select the sample with the highest entropy and the sample with the lowest entropy to perform Mixup. Figure 2 shows the entropy-based sample selection process. From labeled data, we compute the entropy of each data by the teacher model, sort them by the entropy, and then continuously select data samples of highest and lowest entropy for Mixup. Figure 3 shows the example result of Mixup. Through this process of data augmentation, the model can alleviate the problem of overfitting that can occur due to the imbalanced distribution of the training data.
There are two ways of oversampling: (a) equalizing the total number of samples for each class to the number of samples of largest class (Mixup to same size); (b) increasing the number of samples for every class by a certain percentage (Mixup to same ratio). Figure 4 shows the two different strategies of oversampling. Through experiments, we observed that the Mixup to same ratio produced a better performance; hence, we adopted it for other experiments.

Figure 2.
Sample selection for entropy-based Mixup. The best performance is achieved by selecting sample data with highest entropy and sample data with lowest entropy. The used samples are removed, and the remaining data are mixed in the same way.

Figure 3.
Sample synthesis for Mixup of high-entropy sample with low-entropy sample.

Figure 4.
Oversampling by Mixup: (a) oversampling equally to the largest class (Mixup to same size); (b) oversampling every class by same percentage (Mixup to same ratio).
3.2. Self-Training the Student Model and Repetition
Step 2 is to extract meaningful samples from a large number of unlabeled data (). For all unlabeled data, we first generate a softmax prediction vector, with the probability of each class, by using the teacher model; then, P highest values are selected. For example, if P = 5, we keep the top five elements and set the rest to 0. Next, the entire data labels are sorted in descending order by class, and K data located at the top are extracted. For example, if K = 1000, we get the top 1000 data with high probability values for each class. We collect samples while allowing overlap for each class and consider those classes as a pseudo-label of the data. The proper values of parameters P and K are determined experimentally, and we use those values in the experiments thereafter.
In Step 3, the student model is pretrained using the pseudo-labeled data samples () extracted in step 2, and it is fine-tuned with the original labeled data and augmented data () used in step 1. The student model uses the same model as the teacher model.
Finally, we repeat the training from step 2 and step 3. The student model replaces the teacher model, performs the prediction and sampling in step 2, trains on the newly collected unlabeled data, and proceeds with the rest of the process. Models initially trained with a small number of labeled data will make inaccurate predictions on unlabeled data due to the limitations of the training data; however, as the model iteratively trains, it becomes less sensitive to incorrect pseudo-labels as its generalization performance improves. As the prediction performance on unlabeled data improves, we can get better pseudo-labels and collect more high-quality training data.
4. Experiments
4.1. Datasets and Base Model
Experiments were conducted to verify the validity of the proposed method using the ChestX-ray14 dataset published by the National Institutes of Health (NIH) [31]. The dataset consists of 112,120 X-ray images of 30,805 patients with multiple labels for 14 diseases (atelectasis, cardiomegaly, consolidation, edema, pleural effusion, emphysema, fibrosis, hernia, infiltration, mass, nodule, pleural thickening, pneumonia, and pneumothorax). Among the data, 86,524 data were defined as training data, and the remaining data were used for validation and testing.
We used 5% of the training data for the first experiment regarding entropy-based Mixup, and then 15,000 training, 5000 validation, and 5000 test data for the second experiment regarding self-training. To establish an experimental environment considering the actual field, the ratio of data for each class in the training, validation, and test datasets were configured with the same ratio for each disease of the original data. Figure 5 shows the distribution of 15,000 training data by classes. The difference in data distribution for infiltration (2366, 13.02%) and hernia (27, 0.15%) was 87 times; compared with no finding (8747, 48.15%), the proportion of the hernia class was only 1/323. For reference, the ChestX-ray14 dataset contained 86,524 training data and 25,596 test data samples. Among them, there were 227 samples that belonged to the hernia class. All of the remaining 90,000 data were assumed to be unlabeled data.
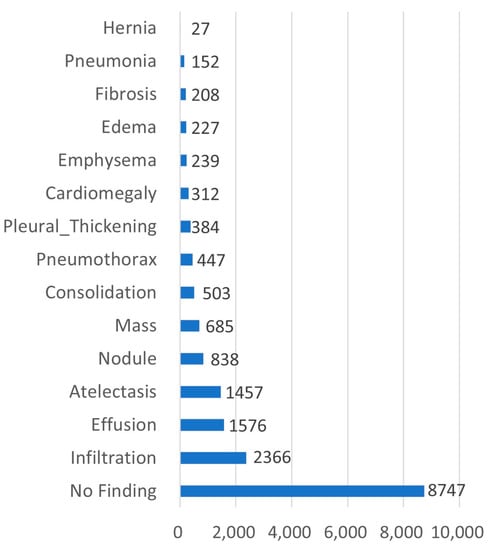
Figure 5.
Distribution of the ChestX-ray14 dataset.
ResNet-50 [32] was used for both the teacher model and the student model, and Adam and BCELoss were used as the optimization algorithms for multilabel problems. As a preprocessing step, 14 diseases were set in the same order as in the previous study, and a 14-dimensional vector was generated by indicating the disease found in the sample image as 1. In the case of no finding, it became a vector in which all elements were 0. Multiple binary classification was performed by setting 14 nodes in the last layer of the ResNet-50 model and applying a sigmoid function.
4.2. Effects of Entropy-Based Mixup
For effective sample synthesis, the concept of entropy was introduced, and the effectiveness of the entropy-based oversampling technique was tested through experiments. In this experiment, we assumed that a very small number of labeled data were available to see the effectiveness of the Mixup more clearly; thus, 5% of total labeled training data were used for training. The data augmentation was performed by (1) random Mixup to same size, (2) random Mixup to same ratio (200%), and (3) entropy-based Mixup to same ratio (200%).
The results in Table 1 show that, compared to the teacher model trained without data augmentation, the random Mixup improved the performance, and the entropy-based Mixup improved it further. The AUROC average of entropy-based Mixup was 2.7% higher than the unaugmented case, and 1.4% higher than the random Mixup (same ratio), which was the best case we could get with plain Mixup. Table 1 signifies that, while the conventional approach typically involved the random selection and synthesis of two samples during sample synthesis, the entropy-based sample selection method demonstrated exceptional performance. The experiment was conducted using only 5% of the training data in order to establish the criteria for sample selection in future learning models. In particular, in the case of the hernia class that had the fewest data, the AUROC improved 50.8% from 0.4424 to 0.6670, indicating that the data imbalance problem was greatly alleviated.

Table 1.
Effect of data augmentation by Mixup—AUROC.
4.3. Effect of Self-Training
The effectiveness of self-training was tested through the second experiment. We increased the training dataset to 15,000 in the second experiment, which was about 17% of the total (86,524). Table 2 shows the classification accuracy according to AUROC when the proposed model was applied step-by-step to the ChestX-ray14 dataset. Looking at the results, compared to the basic teacher model, the AUROC average was improved by 1.8% when Mixup was applied, and the AUROC average was further improved by 8.2% in the student model to which self-training was applied. This shows that the performance of multilabel classification can be improved by the proposed learning process using unlabeled data.
Table 2.
Comparison of AUROC for each stage of the proposed learning model (P = 10, K = 2000).
Table 3 shows the experimental results on self-training with different combinations of parameters. The parameter P indicates how many elements were used in the softmax prediction vector, and the parameter K indicates how many data were selected for each class according to the prediction probability for pseudo-labeling.
Table 3.
AUROC of student model for various P, K combinations.
As the parameter P value decreased, the accuracy tended to decrease, because the ChestX-ray14 dataset had multiple labels. As the parameter K value increased, it was generally advantageous because more data were used for training. In the ChestX-ray14 dataset, the proposed method showed the highest performance when p = 10 and K = 2000, and this combination was used for the student model training.
In order to confirm the effectiveness of repeated self-training, the performance was measured by repeating the second and third steps of the proposed method n times. The student model in step 3 was trained with the data collected in step 2; then, the student model replaced the teacher model, and step 2 was performed again to observe whether the performance of the learning model improved as the process were repeated. The results are shown in Table 4. As the cycle progressed, the AUROC average was continuously increased by 8.2%, 2.3%, and 2.6%, from 0.6522 to 0.7409. After the third iteration, the growth rate slowed down. The improvement in performance was due to the increased predictive performance for unlabeled data as the model circulated. As learning progressed, the error of the pseudo-label decreased, and the overall performance increased and converged to certain value. In future research, further investigations will be conducted on dynamically setting parameters P and K in the self-training process as it iterates, aiming to optimize the performance of the model.
Table 4.
Result of repeated self-training (P = 10, K = 2000).
5. Conclusions
In this study, we proposed a model that combines entropy-based Mixup and self-training to improve the performance of chest X-ray multilabel classification by alleviating the problem of data shortage and imbalance distribution.
The data augmentation by entropy-based Mixup efficiently increased the number of data samples to overcome the overfitting problem caused by severe imbalance in training dataset. The self-training process effectively utilized unlabeled data to improve the generalization performance of the model; by repeating the teacher–student cycles, the performance was further improved as it collected more high-quality training data.
The experimental results on the ChestX-ray14 dataset showed that the proposed entropy-based Mixup could increase the AUROC average by 1.8–2.7%, and the self-training further increased the AUROC average by 8.2%. It was also shown that, as the repeated self-training cycle progressed, the AUROC average increased continuously to the third iteration.
As a follow-up study, we plan to further develop the proposed method by applying label guessing and label smoothing [33] to the entropy-based Mixup algorithm for more effective utilization of unlabeled data. We also plan to develop a method for dynamically adjusting the parameters in self-training while iterating, as well as apply the RandAugment [11,25] technique to the self-training for data expansion.
Author Contributions
Writing—original draft, M.P.; Writing—review & editing, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (2021R1A2C2008414) and by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2023-2020-0-01789) supervised by the IITP (Institute for Information and Communications Technology Planning and Evaluation).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We utilized the publicly available CXR8 dataset for experimentation. The dataset can be accessed online at the following link: https://nihcc.app.box.com/v/ChestXray-NIHCC (accessed on 1 March 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Baltruschat, I.M.; Nickisch, H.; Grass, M.; Knopp, T.; Saalbach, A. Comparison of Deep Learning Approaches for Multi-Label Chest X-Ray Classification. Sci. Rep. 2019, 9, 6381. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Shen, D.; Wu, G.; Suk, H.I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep Learning Applications in Medical Image Analysis. IEEE Access 2018, 6, 9375–9389. [Google Scholar] [CrossRef]
- Zhang, Y.-D.; Zhang, Z.; Zhang, X.; Wang, S.-H. MIDCAN: A multiple input deep convolutional attention network for COVID-19 diagnosis based on chest CT and chest X-ray. Pattern Recognit. Lett. 2021, 150, 8–16. [Google Scholar] [CrossRef]
- Monshi, M.M.A.; Poon, J.; Chung, V. Deep learning in generating radiology reports: A survey. Artif. Intell. Med. 2020, 106, 101878. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Kabra, A.; Chopra, A.; Puri, N.; Badjatiya, P.; Verma, S.; Gupta, P.; Krishnamurthy, B. MixBoost: Synthetic Oversampling using Boosted Mixup for Handling Extreme Imbalance. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1082–1087. [Google Scholar]
- Thulasidasan, S.; Chennupati, G.; Bilmes, J.A.; Bhattacharya, T.; Michalak, S. On mixup training: Improved calibration and predictive uncertainty for deep neural networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold Mixup: Better Representations by Interpolating Hidden States. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6438–6447. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17. [Google Scholar]
- Xie, Q.; Luong, M.-T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Miyato, T.; Maeda, S.-i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Kim, J.-H.; Choo, W.; Song, H.O. Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 5275–5285. [Google Scholar]
- Kim, J.-H.; Choo, W.; Jeong, H.; Song, H.O. Co-mixup: Saliency guided joint mixup with supermodular diversity. arXiv 2021, arXiv:2102.03065. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bellinger, C.; Sharma, S.; Japkowicz, N.; Zaïane, O.R. Framework for extreme imbalance classification: SWIM—Sampling with the majority class. Knowl. Inf. Syst. 2019, 62, 841–866. [Google Scholar] [CrossRef]
- Sohn, K.; Berthelot, D.; Li, C.-L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv 2020, arXiv:2001.07685. [Google Scholar]
- Lee, D.-H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. Workshop Chall. Represent. Learn. ICML 2013, 3, 896. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. Mixmatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.-T.; Le, Q.V. Unsupervised data augmentation for consistency training. arXiv 2019, arXiv:1904.12848. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Chen, J.; Yang, Z.; Yang, D. Mixtext: Linguistically-informed interpolation of hidden space for semi-supervised text classification. arXiv 2020, arXiv:2004.12239. [Google Scholar]
- National Institutes of Health-Clinical Center CXR8. Available online: https://nihcc.app.box.com/v/ChestXray-NIHCC (accessed on 1 March 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).