1. Introduction
Cross-lingual summarization (CLS) involves extracting the core content of a document in one language and expressing it in another language [
1]. This task requires addressing both redundant information and language differences, which usually involves multiple steps. However, decomposing cross-lingual text summarization into multiple tasks does not guarantee optimal results for each individual neural network. In addition, the distinct linguistic and syntactic structures of different languages need to be considered. Directly applying an end-to-end model across languages can result in the loss of important linguistic nuances and syntactic patterns, potentially leading to the omission of key information or the incorrect placement of sentences within the summary. Therefore, we must address two problems: how to integrate multiple tasks into an effective workflow [
2], and how to capture the connections between different languages to generate summaries with reasonable content.
To improve the quality of summaries, recent studies have focused on reducing variability between tasks [
3,
4]. Transformer-based neural networks [
5] have demonstrated the ability to share feature representations of languages between hidden layers in a language-independent way. Based on this idea, this paper abstracts the translation task into a cross-lingual summarization task with the same input sequence to output sequence length ratio, and integrates it with the monolingual summarization (MS) task in the same model. The overall objective of the model is simplified to “monolingual summarization task + cross-lingual summarization task”. The optimized cross-lingual pre-training model [
6] is used as the basis, and the corpus with monolingual and cross-lingual summaries is used as input to allow all information to be shared between tasks. Integrating sequences helps the model gain a comprehensive understanding of the core content in the source language and facilitates better alignment of information across different languages. Furthermore, given the presence of unique nuances and expressions in each language, direct translation is often insufficient to capture these subtleties. By incorporating both monolingual and cross-lingual summary sequences, the model can effectively capture and comprehend these language-specific nuances. This becomes particularly crucial in the context of cross-language summarization, as it enables the model to capture the essence of the source document in its original language and generate a summary in the target language with efficiency.
While end-to-end approaches are known for their improved generalization performance in handling noisy text inputs and reducing issues such as error accumulation [
7], those based on pre-trained models often lack flexibility and fail to fully exploit the benefits of pre-training. Consequently, they frequently encounter overfitting problems during downstream task training. To tackle these challenges, we propose novel reinforced regularization methods. By introducing randomness during training, the reinforced regularization method effectively provides regularization, while the inclusion of sparse softmax encourages sparsity, preventing the model from excessively relying on specific features or classes. This combination further enhances the model’s robustness.
Given that the model integrates both monolingual and multilingual summarization tasks, it is necessary to configure the corresponding generation methods to enhance the quality of the generated summaries. However, many previous summarization approaches, such as top-k [
8] or pointer networks [
9], primarily focus on providing raw output content without ensuring the coherence of the generated statements. Unfortunately, these methods are insufficient for capturing semantic relationships between languages in cross-language summarization tasks. To address this limitation, we have devised the ABO mechanism. This mechanism leverages flexible keyword tags to preserve important semantic information in the abstract and maintain continuity between words. Additionally, we have incorporated a filtering mechanism during the generation stage to effectively mitigate issues such as word duplication and the inclusion of near-synonyms.
The main work presented in this paper can be summarized as follows:
We provide a multitask training strategy that combines the monolingual summary task with the cross-lingual summary task. By using the model features and combining the inputs of both tasks, we achieve hard parameter sharing of the overall process, which eliminates task differences and reduces the semantic loss from segmentation tasks, thereby improving the performance of the cross-lingual summary model;
We optimize the model for multiple input and output features. To enhance the regularization ability of the fine-tuned model and reduce the risk of overfitting in downstream tasks, we improve the consistency of the model output by averaging the weights of the forward network with different dropout probabilities. Additionally, we incorporate a sparse set of softmax filtering predictors in the regularization process to improve the output accuracy. Furthermore, we streamline the pre-trained model parameters and customize the cross-lingual word list to reduce the training cost;
We design a targeted sequence generation and filtering mechanism based on the proposed model and method. We combine the monolingual summary sequences annotated with word tags to form consecutive fragments which effectively solve the problem of sequential alignment and loss of important information in different languages. Moreover, we use an external word list to ensure the occurrence of keywords in the source text in the summary, ensuring the generation of key information and alleviating the problem of multiple meanings of words and that of words out of vocabulary (OOV).
The chapters in this paper are organized as follows:
Section 2 provides an introduction to the related work on cross-lingual summarization and generation mechanisms.
Section 3 elaborates on the methods proposed in this paper, including the strengthened regularization method, the ABO mechanism, and the multitask fusion method.
Section 4 describes the experimental details and analysis of the results. The experiments cover ablation experiments with different sample magnitudes, model comparison experiments with full data sets, and single-language summary experiments. In
Section 5, the process of constructing a cross-lingual summarization data set in the professional field and the results of the model ablation experiment on this data set are presented. Finally,
Section 6 summarizes the main work presented in this paper and outlines future directions for research.
3. Methods
The model proposed in this paper is based on the standard seq2seq structure. It utilizes the baseline model to perform two different tasks consecutively, sharing all parameters within the model. In the fine-tuning process, a reinforced regularity approach is incorporated. The input sequence passes through a forward network twice, with different drop probabilities, which is approximated as passing through two distinct sub-networks. The prediction word distribution is then filtered by sparsifying the output, and the distribution results are obtained by calculating the
KL scatter [
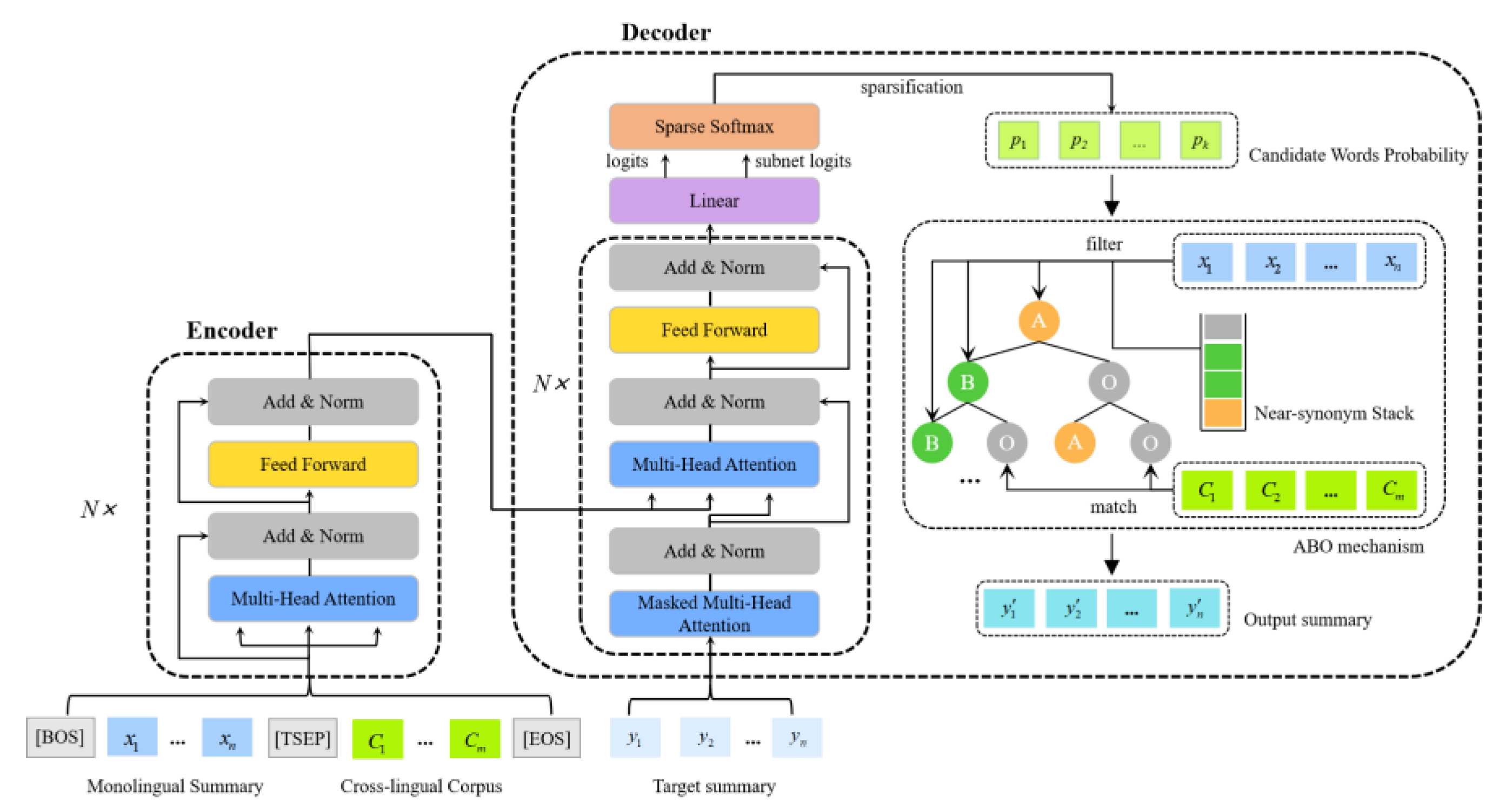
25]. Regularization is provided by reinforced regularization, which introduces randomness during training. On the other hand, sparse softmax promotes sparsity, preventing the model from overly relying on specific features or classes. These regularization techniques help the model generalize better and enhance its robustness to unseen examples. In the generation phase, the ABO mechanism is added, which combines the core semantic content of monolingual summaries and the cross-lingual summary sequences generated by screening the near-sense candidates. Important semantics are preserved through the use of selected tag words, while the correctness of linguistic sequences is maintained by leveraging potential connections between these tag words. The overall flow of the model is illustrated in
Figure 1.
In the figure, a linguistic corpus is provided, which corresponds to a monolingual summary sequence and a target summary sequence . Input sequence starts with and the final target output sequence is obtained after being processed by the encoder, ending with . The identifier represents the truncate separate character.
3.1. Reinforced Regularization Method
Fully trained large language models typically have a high number of model parameters, which can provide substantial prior knowledge, but the limited data resources available for downstream tasks can result in overfitting during model fine-tuning. Therefore, it is necessary to introduce an appropriate regularization strategy to reduce overfitting and improve the model’s generalization performance. The baseline model does not incorporate dropout regularization during the pre-training phase because it may inhibit the model’s fitting effect and reduce its learning ability. However, during the fine-tuning phase, the model may suffer from overfitting when facing a single downstream task, so adding a more effective regularization method can significantly improve the fine-tuning performance of the model. As a result, a reinforced regularization method is added during fine-tuning.
During training, performing forward calculations with different sampling processes for the same input
is equivalent to the same data sample going through two sub-networks and obtaining two different distributions,
and
. The final weighting of the cross-entropy of the two components is shown in the following equation:
To keep the output of the path network consistent across dropouts, the
KL scatter is calculated.
The final loss after two loss calculations is the weighted sum of the two losses, which is calculated as shown below:
In the equation above, represents the weight coefficient of the KL loss and is the only hyperparameter. By weighting the two losses with , the model space is further regularized, compensating for the inconsistency of dropout in training and testing, and improving the model’s generalization ability.
The above method performs data augmentation while maintaining the input semantics, which boosts the confidence level of the primary categories but increases the training cost by adding numerous non-target classes in the prediction stage. To address this issue, we sparsify the output to provide a positive gain for the regular method via the category-invariant property.
Typically, the softmax function is capable of mapping multiple neuron outputs to the
interval, thereby enabling the numerical assignment of approximate probabilities. The common exponential form of softmax [
26] is calculated as
In the above equation, represents the score of an output result, represents the corresponding probability, and denotes the total number of output results. The softmax function transforms the set of real-valued scores into a probability distribution.
The decoder part uses softmax for two main functions: (1) calculating the normalized attention weights, and (2) computing the prediction probability distributions. However, traditional softmax cannot assign a probability of 0 to any predictor, making it impossible to exclude low-probability predictors. To address this, sparse softmax is utilized instead, where the hyperparameter
is manually set to fix the category and complete the initial screening of low-probability words.
The output logits of the fully connected layer are denoted as . These logits are sorted from largest to smallest, and the set of subscripts of the first elements is denoted as . At this point, sparse softmax only retains the probability values of the first elements after sorting when calculating the probability. The values of the remaining elements after will be directly set to 0.
As shown in
Figure 2, same sequence is input into two forward networks, each with different dropout probabilities, resulting in distinct scores after computation. Before passing through the softmax function, the computed results from the two networks need to be sorted. Additionally, manual parameters are used to sparsify the distributions. When the hyperparameter
is set to 3, sparse softmax considers the top 3 logits after sorting as the target class and calculates their corresponding probabilities, while the probabilities of logits in non-target classes are set to 0 directly. Based on the results, the sparse output prevents the probability distribution from being wasted on unlikely outputs and significantly enhances the accuracy of the output. In tasks with low output ambiguity, the sparse output typically requires producing only one or a few fixed sets containing the correct answers.
Although the aforementioned approach involving reinforced regularity includes two forward calculations during training, it effectively alleviates the problem of long-tailed multicategorical distribution, improves the confidence level of the main categories, and significantly reduces the search space of the model. As a result, the pre-trained model’s robustness in downstream tasks is improved while maintaining computational efficiency.
3.2. ABO Mechanism
The most common problem faced by generative cross-lingual summary models is the semantic drift between different languages. This occurs when the generation of a summary in another language results in a representation that is contrary to the original due to issues such as sequence length or near-synonyms, even though a better representation has been obtained with the monolingual summary of that corpus. To tackle this issue, we filter out cross-lingual summaries that exhibit semantic errors by comparing them with the monolingual summaries generated by the same model.
Before generating cross-lingual summaries, the model tags the monolingual summary sequences. The token with the largest L2 paradigm among the candidate words is selected as the anchor word (
), and the neighboring words are gradually identified through pointers. Assuming that the set of candidate words is
,
tag word for
, then
is
When a word is identified during the traversal of the sequence that is not present in the original corpus, it is marked as an out-of-text word (), and all the words that have been traversed are marked as bound words (). O-labeled words refer to the words generated to summarize the semantics of paragraphs in monolingual summaries, and preserving them is crucial for maintaining semantic coherence in cross-lingual summarization. Additionally, multiple consecutive B-labeled words serve as the basis for forming a smooth abstract word order. During marking, a binary tree with fixed combination rules is maintained, with as the root node, and only and nodes allowed under nodes, and nodes under nodes, and and nodes under nodes.
During cross-lingual summary generation, the same approach is used to select the anchor word tagged as , but it is restricted to selecting a word that has the translated word tagged as in the monolingual summary or its near-synonym as the anchor word in the cross-lingual summary sequence. Otherwise, the candidate sequence is considered to be missing the core word and discarded. To prevent unmatched cases, we use a two-stage out-stack operation to determine whether core words are present in the sequence. The -tagged words in monolingual summaries are copied into the sequences of cross-lingual summaries through the translation word list. Using the properties of the -tagged words and the -tagged words, we ensure that the core words appear in the cross-lingual summary and maintain the basic semantic structure. For the -tagged words, we ensure the closeness of meaning and alignment of the word order through filtering. Specifically, we maintain a list of proximity words for -tags in monolingual summaries and traverse the cross-lingual summary candidate sequence, skipping if a word is found and discarding if it is not found by more than 2-g. The specific implementation is described in Algorithm 1.
| Algorithm 1 ABO mechanism |
| Algorithm implementation: |
| Input: monolingual summarization sequence , tag set , cross-lingual summarization candidate token set , synonym dictionary |
| Output: cross-lingual summarization output sequence |
- 1.
for do - 2.
if then - 3.
- 4.
to the set - 5.
else - 6.
- 7.
end if - 8.
for do - 9.
if or then - 10.
- 11.
else - 12.
Break - 13.
end if - 14.
end for - 15.
end for - 16.
for do - 17.
if or then - 18.
remove c from - 19.
else if then - 20.
- 21.
break - 22.
else - 23.
to the set - 24.
end if - 25.
end for - 26.
return
|
To generate a summary sequence, labeling the summary words in the source corpus is necessary. Therefore, predicting the label distribution during training is crucial. We calculate the loss function by computing the cross-entropy loss between the predicted label distribution and the ground truth label distribution for all samples. The cross-entropy loss quantifies the dissimilarity between the predicted and true label distributions. By minimizing this loss, the model’s predictions are improved and aligned with the actual labels, enhancing its performance. The calculation method is as follows:
In the above formula,
is the length of the input corpus sequence,
is the batch size,
is the tagged word, and
is the predicted tag word. To account for the sparsity of label predictions, we average the loss over the batch size (
). This ensures that the loss remains consistent and independent of the batch size, allowing for fair comparisons between different batch sizes. Combined with Equation (3), the loss is calculated as
In
Figure 3, the
appearing in the second and third levels of the binary tree is not a real node but a determination step during the construction of monolingual summary generation to check whether the next word exists in the original text. Besides the probability distribution output by the decoder, the “filter” in the figure also includes other conventional determination methods, such as basic grammar rules, conventional phrase combinations, and sequence length restrictions.
3.3. Multitask Fusion Approach
To fully leverage crucial information from the corpus using multiple tasks, a model with hard parameter sharing is used to embed the data representation of various tasks in the same semantic space [
27]. As a result, the decoder is shared by multiple tasks, and the target sequence is replaced by a combination of multitask sequences. The overall loss calculation becomes
In the above equation,
is the loss function of the monolingual summary task which includes the weighted sum with added
KL scatter, as mentioned above. The term
includes the joint probability of both the translation task and the cross-lingual summary task. Given a monolingual corpus
, the model generates the summary content
by performing the monolingual summary task. The target sequence consists of a probability distribution of
. The expression is as follows:
In Equation (9),
and
are the weights that adjust the multitask loss. However, since the overall model can converge slowly due to the larger loss value after weighting, the learning rate needs to be reduced. To address this, the weights are dynamically adjusted by calculating the state of each task, setting such weights in the following way:
In actual calculations, is fixed after one derivative to maintain numerical stability of the overall gradient.
4. Experiments
4.1. Datasets
In the cross-lingual summarization experiments, our main focus is on both Chinese–English and English–Chinese summary approaches. Therefore, in our experiments, we mainly use two datasets, En2ZhSum and Zh2EnSum [
19]. En2ZhSum is converted by the back-translation method using the general text summarization datasets CNN/DailyMail [
28] and MSMO [
29]. The dataset is divided into 364,687 training data pairs, 3000 evaluation data pairs, and 3000 test data pairs. Zh2EnSum is created by converting the summary part of the large open-domain Chinese dataset LCSTS [
30] into English by the same method. It contains 1,693,713 Chinese-to-English training samples, 3000 evaluation data pairs, and 3000 test data pairs.
For the ablation experiments, we first conducted experiments on the methods proposed in this paper, retaining the settings of minimum, medium, and maximum to reflect the differences among methods while controlling the number of samples. The specific sample size settings are listed in
Table 1.
4.2. Experimental Settings
In this paper, we combined the approach mentioned above with the Transformer structural pre-training model to construct an end-to-end model. Before the experiment, we first simplified the model’s input. After taking into account the statistics, we found that the parameters of the model input and output layers accounted for 65% of the total number of parameters. However, since our experiments only included Chinese and English, we removed most of the other language contents from the word list. Following the processing method of mBERT [
31], we streamlined the word list and added some commonly used Chinese words in a targeted manner. Finally, the overall word list included 11,000 English words, 30,000 Chinese words, and 100 special symbols, reducing the number of words to 20% of the original word list. We then processed the sentencepiece word splitter of the original model by replacing the first 40,000 words and removing other irrelevant content. After manual debugging, we set the hyperparameters
for the reinforcement regular and
for the Sparse softmax. Since the model uses Adafactor [
32], a larger initial learning rate was chosen, and we set the initial learning rate of the model to be
. We used different prefix task identifiers to distinguish the monolingual summarization task from the cross-lingual summarization task and trained the model by alternating the two tasks. This part of the automatic evaluation compares the performance differences of several models by the standard ROUGE [
33] method and shows the ROUGE-1, ROUGE-2 and ROUGE-L scores.
4.3. Ablation Study
This section of the experiments explores the performance improvement of the proposed methods on different scales of cross-linguistic summary datasets, En2ZhSum and Zh2EnSum, by controlling the joint models. The experimental models are divided into three parts: Base, which is the base model; Base + RR, which is the model with the addition of reinforced regularity; and Base + RR + ABO, which is the model with the addition of reinforced regularity and the ABO mechanism. Base + RR + ABO uses the original monolingual summary sentence in the dataset. The experimental results are compared in the table below.
The results in
Table 2 indicate that the model achieved a quantitative improvement with the addition of the reinforcement regularity for a small sample size. This is because during training, the same samples are forward computed twice, which is formally equivalent to augmenting the overall dataset, and repeated learning reduces the risk of overfitting the pre-trained model on a small number of samples. Additionally, the sparse output reduces the search range of the predicted words. When combined with the regularization method, it provides higher reliability for a small number of prediction categories under artificial constraints. Thus, the overall reinforced regularity approach improves the effectiveness of the pre-trained model on specific downstream tasks.
After the addition of the ABO mechanism to the model, the generated summaries showed more improvement in the ROUGE-2 and ROUGE-L scores. This is mainly because the ABO mechanism preserves the proximity of candidate words when selecting anchor words and bound words. As a result, the semantic span between anchor words and bound words is not suddenly increased after filtering by basic grammar rules. Additionally, the proximity of candidate words and phrases of bound words can be used as the basis for the calculation of the same subsequence in 2-g and above. Therefore, the summaries generated by the model incorporating the ABO mechanism usually have higher fluency.
4.4. Cross-Lingual Summary Comparison Experiments
This section performs cross-lingual summary comparison experiments using the full dataset of two cross-lingual datasets, En2ZhSum and Zh2EnSum, which are divided into automatic and manual evaluations.
4.4.1. Contrast Model
TLTran: Transformer-based Late Translation. The model is a pipeline approach with a monolingual summary model as the main body. The method first uses the source document as input and generates the same language summary, and then translates the generated summary into the target language summary by the translation model.
TETran [
12]: Transformer-based translation priority model. This method first translates the source document into the source document of the target language, and then extracts the target summary from the translated corpus through another trained single-language summary model of the Transformer structure.
TNCLS [
19]: Transformer-based Neural Cross-Lingual Summarization (TNCLS). The model accomplishes the cross-lingual summarization task by jointly training encoders and decoders for different languages and different input sequence lengths.
CLS + MS [
20]: Combining Cross-Lingual Summarization with Monolingual Summarization. A shared encoder is used to encode the input utterances, and the decoder for the Cross-Lingual Summarization task is connected to the Monolingual Summarization decoder at the same time to train both tasks in a unified manner.
CLS + MT: Combining Cross-Lingual Summarization (CLS) with a translation task (Machine Translation) [
17]. The decoder for the translation task part is trained by an additional translation corpus and alternatively trained using a shared encoder while adding the decoder for the Cross-Lingual Summarization task.
4.4.2. Experimental Results Analysis
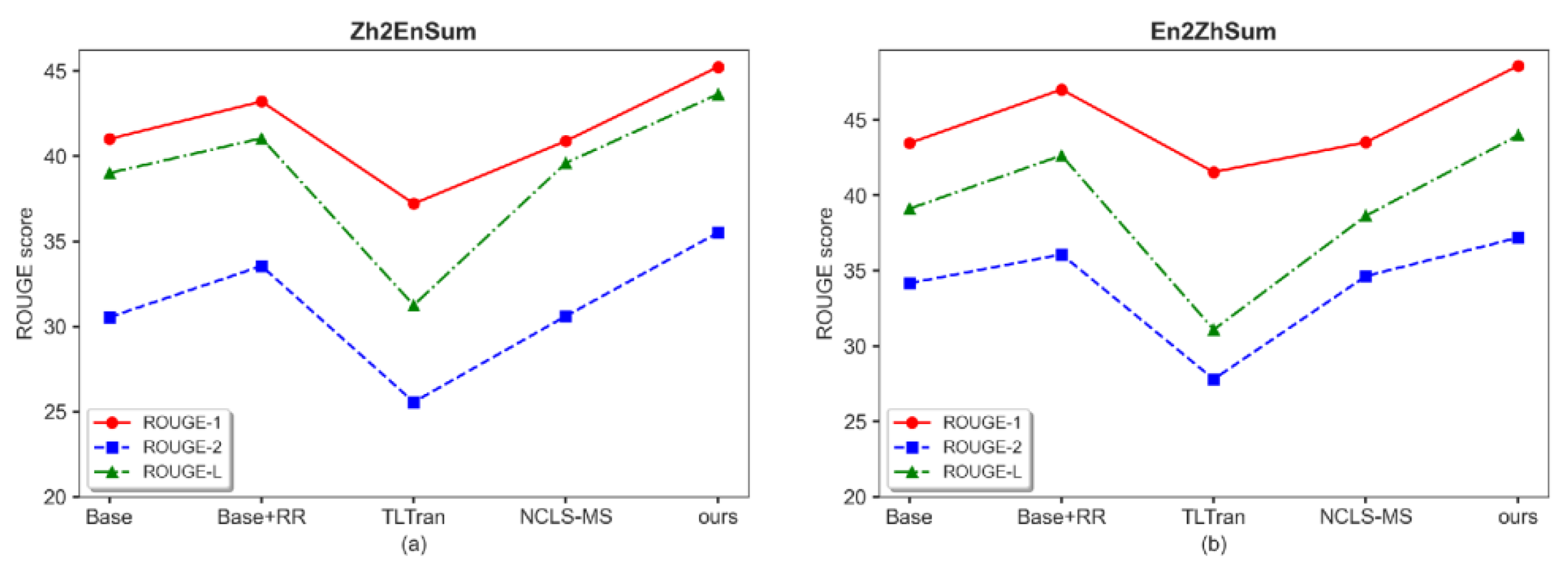
Table 3 shows that our model outperforms other cross-lingual summarization methods on both datasets. It is known that pipelined models usually cannot achieve the same results as end-to-end models since multitask integration often shares some of the parameters, which mitigates the loss of transformation between different tasks [
34]. Although models that integrate multiple tasks have significant advantages over pipelined models, CLS + MS and CLS + MT still share parameters in the encoder part, but can only pass single-task content in the attention part of the encoder. The single-language summary task during training allows the overall model to learn the content of the single-language summary part repeatedly, which helps the model learn the corpus more accurately. Additionally, the reinforced regularization method proposed in this paper can avoid training-time oscillations caused by random noise in the new input sequence before generating the cross-lingual digest. This stabilizes the training process of the model and fully utilizes the performance of the pre-trained model. The ABO mechanism proposed in this paper can also avoid this problem since the anchor words and bound words in ABO can easily form consecutive clauses that potentially affect the order of the generated summaries. This motivates the formal alignment of the generated summaries with the target summaries, avoiding the problem when the whole is divided by subwords, which can lead to the unbalanced number of generated words in both languages and information loss. The display of the generated results is shown in
Figure 4.
4.4.3. Human Evaluation
This section of the manual evaluation aims to compare the usefulness of the generated summaries. We randomly selected 20 samples from each of the En2ZhSum and Zh2EnSum test sets, and three evaluators rated the summaries on a scale of 1 (worst) to 5 (best) based on their informativeness (IF), conciseness (CC), and fluency (FL). The average score for each group was calculated based on the total sample size.
Table 4 shows that the model proposed in this paper outperforms other models in terms of completeness, indirection, and fluency. In terms of fluency, the ABO mechanism combines consecutive fragments, allowing the model to select words that match back and forth, resulting in a subjectively fluent sentence. Regarding conciseness, the model in this paper is similar to the CLS + MS and CLS + MT models, as both set the output with the same sequence length in the encoder part and use alternating tasks in the decoder part. However, our model uses a unified encoder and decoder to integrate multiple tasks, enabling the model to learn the corpus content more comprehensively. Additionally, compared to the multitask framework that uses multiple decoders, our model relies more on the transfer of hidden states between encoders and decoders, resulting in a more holistic content transfer, which provides a clear advantage in terms of completeness and fluency.
4.5. Monolingual Summary Comparison Experiments
To demonstrate that our model does not suffer from performance degradation in single-language summarization tasks due to partial repetition during parallel training on multiple tasks, we conducted separate experimental validations for text summarization tasks in Chinese and English. As the ABO mechanism does not incorporate the translation process with the near-synonym word list in single-language summarization, we searched for anchor words and bound words in the original text to ensure summary generation fidelity compared to the original text.
To showcase the practical effects of other optimization methods on pre-trained models, we conducted incremental and non-incremental experimental models in addition to the monolingual summary comparison experiments. The initial model parameter settings in the incremental experimental model were the same as those in the cross-lingual summarization experiments. The baseline models in both Base and Base + RR groups were not fine-tuned for the cross-lingual summarization task. The non-incremental experimental model retained the same part of the monolingual summarization model used by TLTran and TETran, and only the shared encoder and monolingual summarization decoder were kept in the CLS + MS model. The TNCLS and CLS + MT models do not contain a separate monolingual summarization part, so this experiment was not included. The experimental results are shown in the figure below.
Figure 5 illustrates that the model with enhanced regularization has significantly improved the single-language summarization task compared to the baseline model. For the baseline that does not use dropout in the pre-training stage, enhanced regularization can better ensure the consistency between the model and downstream tasks. In incremental experiments, our model has significantly improved the longest subsequence calculation index compared to Base and Base + RR due to the continuous fragments generated by the combination of ABO labels. Compared with simple beam search and other methods, it can better establish the connection between n-grams. In non-incremental experiments, TLTran is a Transformer monolingual summary model trained from scratch. Due to data and training condition limitations, its effect lags far behind other fine-tuned pre-training models. NCLS + MS, as a combination of mBert and Transformer decoder, cannot share the overall parameters, which results in insufficient interaction of the model in the training of cross-lingual summarization and monolanguage summarization tasks. However, our model fully learns the information of the two language summaries and maintains the sharing of the parameter space in the interactive training, ensuring a positive impact of both tasks on the model.
5. Application
We created a cross-lingual summarization dataset that includes English and Chinese using proprietary domain data. The data set is sourced from a combination of internal maintenance manuals from an automobile company, instructional materials, and the text component of FETA Car-Manuals [
35]. The 357 PDF documents were subjected to OCR recognition, and the text component was extracted. Each document in the dataset contains a varying number of text paragraphs with different topics, resulting in a total of 4472 text paragraphs that were manually separated. As only some text paragraphs contain headings, the process of summarization required the selection of sentences based on the three most frequently occurring keywords in texts without headings or with headings that were too short. After counting the word frequency, the corresponding sentences were manually screened and the selected sentences were combined and spliced to create a summary of the corresponding paragraph. The length of the combined abstract was kept at approximately 15% of the length of the original text. The following
Figure 6 is the length statistics of the processed summary dataset.
In the cross-lingual summary section, we utilized a translation tool to batch translate the text. Furthermore, we also extracted the professional vocabulary from this dataset.
Table 5 below presents the final statistics of the document.
We intend to conduct experiments on this dataset to validate the effectiveness of the proposed method in improving the model’s performance on professional datasets. However, due to the limited number of datasets and the vast professional vocabulary, initializing the training model for comparison experiments poses a significant challenge. Thus, we only used the fine-tuned baseline model and the proposed method for ablation experiments in this test section. The experimental settings employed here are consistent with those in
Section 4.2. To maximize the utilization of the limited dataset and mitigate the risk of model overfitting, we employ a fivefold cross-validation during the training process. The evaluation methodology remains the same, utilizing ROUGE-1, ROUGE-2, and ROUGE-L scores. The experimental results are shown in the following table.
Based on
Table 6 above, it is evident that the proposed method enhances the performance of the model on specialized domain datasets. Even with a limited number of datasets, the proposed method effectively maintains the model’s ability to generate high-quality summaries. Notably, the utilization of the ABO mechanism enables the model to generate cohesive and fluent summaries efficiently, without requiring extensive training data.
6. Conclusions
Owing to the phenomenon of information misalignment resulting from disparities in language and syntactic structures, the process of generating cross-language summaries often encounters notable challenges such as substantial semantic loss and errors in semantic expression. To address these issues, this paper presents a cross-language summarization model founded on the ABO mechanism. Primarily, a novel multitasking approach for cross-language summarization is introduced, which simplifies the diverse subtasks involved in this process by integrating monolingual summarization and cross-language summarization. This strategy facilitates the sharing of parameters within the unified model, thereby enhancing alignment across different languages. Additionally, a reinforced regularization method for model characteristics is proposed. This method elevates the performance of the model in cross-language text summarization tasks by enhancing regularization through the amalgamation of sub-networks with varying dropout probabilities, which introduces a controlled level of randomness. Furthermore, it employs sparsification of output categories to prioritize the inclusion of valid information. In the stage of summary generation, an innovative ABO mechanism is devised and incorporated to strengthen the correlation between summaries in different languages. This mechanism encompasses a predictive labeling and filtering mechanism to mitigate semantic loss and discrepancies in word order within the summaries generated by the model. The effectiveness of the proposed approach is empirically evaluated through experiments conducted on publicly available datasets, namely Zh2EnSum and En2ZhSum. Moreover, a proprietary domain-specific cross-language summary dataset, CarManualSum, is constructed to provide further insights into the performance of the method. Nonetheless, there are certain limitations associated with the proposed approach. Although the enhanced regularity approach and the ABO mechanism contribute to improvements in cross-language summarization, they currently lack the flexibility required to adapt to the majority of pre-trained models. Moreover, variations in results between the public dataset and the specialized domain dataset are observed. Consequently, future research will concentrate on exploring the effectiveness of the proposed method across different models and downstream tasks. Furthermore, efforts will be made to broaden the research scope by constructing corpora encompassing a wider range of languages, thereby enhancing the efficacy of the model for cross-language summarization within diverse language scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}