
Federated Deep Reinforcement Learning for Energy-Efficient Edge Computing Offloading and Resource Allocation in Industrial Internet


Abstract
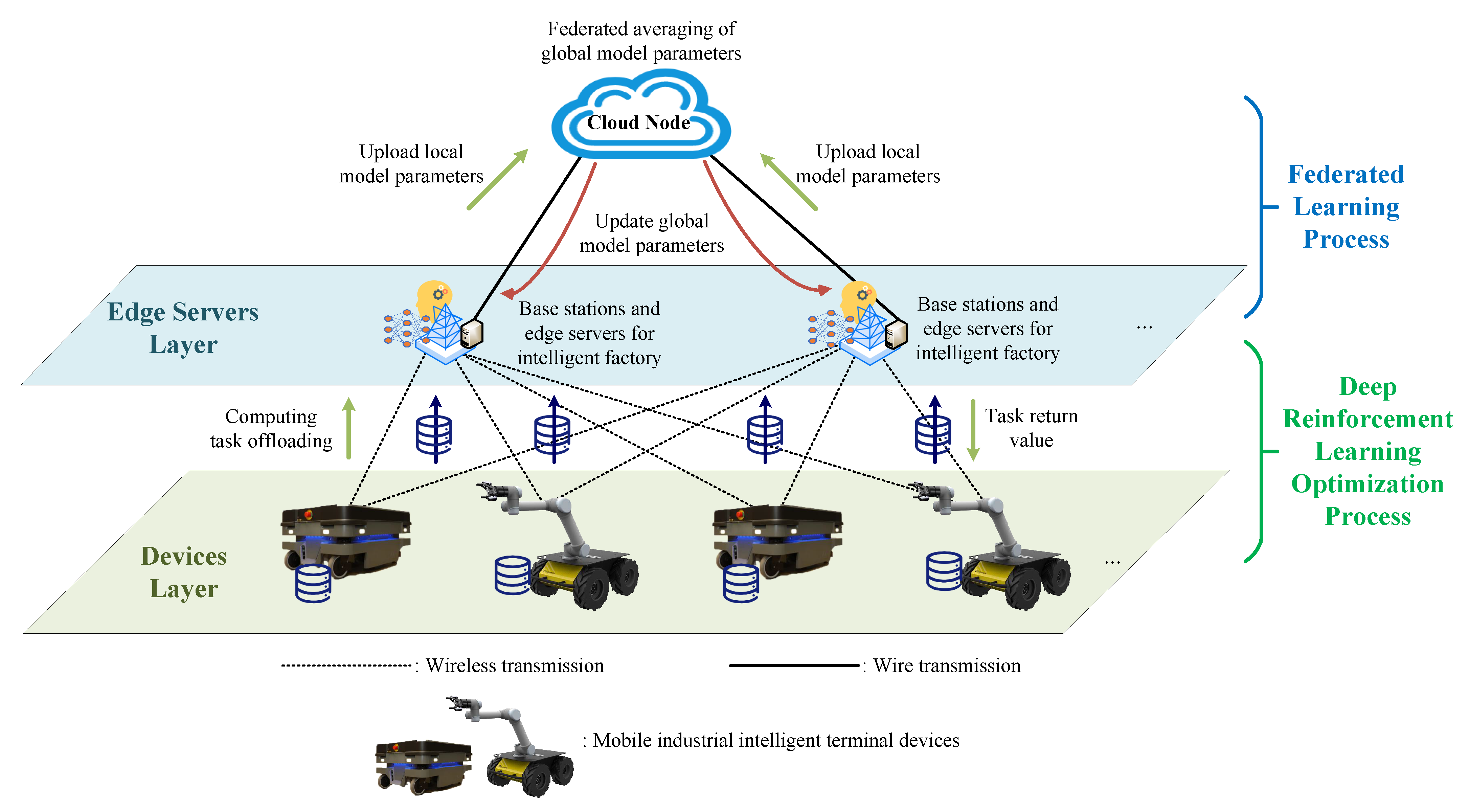
1. Introduction
- This article examines the resource allocation and computing offloading of multiedge-terminal collaboration within the MEC for an Industrial Internet intelligent factory. In this situation, work from terminal devices can be delegated to a single edge server or a group of edge servers simultaneously. Tasks are also capable of being computed locally on terminal devices. Task offloading has the potential to be either full offloading or partial offloading to the edge servers.
- Our focus is on enhancing the energy efficiency of conventional algorithms, and we are exploring ways to lower the system’s entire usage of energy. Specifically, we are investigating how multiedge device collaboration can be leveraged to optimize computing offload and resource allocation. We transform the resource allocation and computing offloading combined optimization issue into a Markov decision process (MDP) problem. To minimize energy consumption, we want to optimize the MEC system. We plan to accomplish this by optimizing various system variables, including the task offloading ratio, subcarrier quantity, transmission power, and computing frequency, while satisfying the constraint of task completion delay.
- A novel computing offloading and resource allocation algorithm due to DDPG and FL is introduced in this work. DDPG is an effective DRL algorithm with two deep neural networks. FL is a decentralized machine learning technique that makes devices to learn from each other without sharing their local data. We integrate a federated learning approach into the policy network and value network of the conventional DDPG algorithm. Following gradient updates, we upload the neural network parameters from multiple DDPG algorithms to a cloud node for federated averaging. Subsequently, these parameters are distributed back to the neural networks of each DDPG algorithm to facilitate the updating of their respective neural network parameters. Combining the DDPG algorithm with FL enables the multiuser system in the Industrial Internet networks to achieve a better strategy for computing offloading and resource allocation with lower overall usage of energy while maintaining computing efficiency.
2. Related Work
2.1. Transmission Efficiency
2.2. Algorithms
3. System Model
3.1. Communication Model
3.2. Computation Model
3.3. Delay Model
3.4. Energy Consumption Model
3.5. Problem Formulation
4. Industrial Federated Deep Deterministic Policy Gradient
- State Space: The state space is denoted by a total of M mobile smart Industrial Internet of Things sensors/terminal devices and N small base stations equipped with edge servers. The system state of the terminal device i in the current epoch t can be defined aswhere is the maximum delay threshold for completing the task, is the location information of the mobile terminal device, are the location information of the mobile edge servers, specifically represented by , is the remaining data size of the task chain at the current epoch t, and denotes the magnitude of task data that must be computed in the current epoch t.
- Action Space: In our scenario, the agent selects actions based on the environment observed by the MEC system and its current state. The actions include task offloading ratio, number of subcarriers, subcarrier transmission power, and computing frequency of the CPU in mobile smart terminal devices. The action of the terminal device i in the current epoch t can be expressed aswhere is a vector of offloading ratios for offloading to edge servers, which can be specifically represented as , corresponding to different edge servers. is the vector of subcarrier numbers selected by the terminal device for offloading data, which can be specifically represented as , corresponding to different edge servers. is the vector of transmission powers used for offloading to the edge server, which can be specifically represented as , corresponding to different edge servers. The computational frequency of the device CPU is continuously adjusted. is the computing frequencies vector of the CPU, which can be specifically represented as , corresponding to different cores of the CPU. The algorithm optimizes the four aforementioned actions together to reduce the entire cost of the system.
- Reward Function: The actions selected by an agent are influenced by rewards. The agent chooses an action based on state and then receives an immediate reward . The algorithm’s performance greatly depends on selecting the suitable reward function. The primary aim of the optimization objective in Equation (13) is to decrease the entire energy used by terminal devices, while the reward function’s objective is to maximize the reward. As a result, energy consumption should be inversely associated with the reward function. The reward function is given bywhere the reward parameter C is a constant greater than zero. Its purpose is to enhance the effect of the reward and to highlight the quality of the current action more clearly. The DDPG algorithm can be used to find the action that maximizes the value function q and achieve lower energy consumption for individual terminal devices.
| Algorithm 1 IF-DDPG |
|
5. Results and Analysis
5.1. Simulation Settings
- DQN-based edge computing offloading and resource allocation algorithm: A comparison between the DQN based on discrete action space and IF-DDPG [51].
- AC-based edge computing offloading and resource allocation algorithm: A comparison between AC based on continuous action space and IF-DDPG [52].
- Dueling DQN-based edge computing offloading and resource allocation algorithm (DDQN): DDQN, in contrast to DQN, stores the experience sample data from the agent’s interactions with the environment in an experience pool. A tiny batch of data from the experience pool is chosen at random for training [13].
- DDPG-based edge computing offloading and resource allocation algorithm: A comparison between the traditional DDPG without incorporating FL and IF-DDPG. The above comparison algorithms are similar to IF-DDPG, which are all DRL algorithms.
5.2. Simulation Results
5.2.1. Parameter Analysis
5.2.2. Algorithm Performance Comparison
5.2.3. Effects of Edge Servers, Terminal Devices, and Number of CPU Cores
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Convergence Proof of Gradient Update
References
- Boyes, H.; Hallaq, B.; Cunningham, J.; Watson, T. The Industrial Internet of Things (IIoT) An Analysis Framework. Comput. Ind. 2018, 101, 1–12. [Google Scholar] [CrossRef]
- Liu, W.; Nair, G.; Li, Y.; Nesic, D.; Vucetic, B.; Poor, H.V. On the Latency, Rate, and Reliability Tradeoff in Wireless Networked Control Systems for IIoT. IEEE Internet Things J. 2021, 8, 723–733. [Google Scholar] [CrossRef]
- Bozorgchenani, A.; Mashhadi, F.; Tarchi, D.; Salinas Monroy, S.A. Multi-Objective Computation Sharing in Energy and Delay Constrained Mobile Edge Computing Environments. IEEE Trans. Mob. Comput. 2021, 20, 2992–3005. [Google Scholar] [CrossRef]
- Qiu, T.; Chi, J.; Zhou, X.; Ning, Z.; Atiquzzaman, M.; Wu, D.O. Edge Computing in Industrial Internet of Things: Architecture, Advances and Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 2462–2488. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Yang, L.; Dai, Z.; Li, K. An Offloading Strategy Based on Cloud and Edge Computing for Industrial Internet. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1666–1673. [Google Scholar] [CrossRef]
- Jiang, C.; Fan, T.; Gao, H.; Shi, W.; Liu, L.; Cérin, C.; Wan, J. Energy Aware Edge Computing: A Survey. Comput. Commun. 2020, 151, 556–580. [Google Scholar] [CrossRef]
- Kuang, Z.; Li, L.; Gao, J.; Zhao, L.; Liu, A. Partial Offloading Scheduling and Power Allocation for Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 6774–6785. [Google Scholar] [CrossRef]
- Misra, S.; Mukherjee, A.; Roy, A.; Saurabh, N.; Rahulamathavan, Y.; Rajarajan, M. Blockchain at the Edge: Performance of Resource-Constrained IoT Network. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 174–183. [Google Scholar] [CrossRef]
- Sun, L.; Wang, J.; Lin, B. Task Allocation Strategy for MEC-Enabled IIoTs via Bayesian Network Based Evolutionary Computation. IEEE Trans. Ind. Inform. 2021, 17, 3441–3449. [Google Scholar] [CrossRef]
- Xu, H.; Li, Q.; Gao, H.; Xu, X.; Han, Z. Residual Energy Maximization-Based Resource Allocation in Wireless-Powered Edge Computing Industrial IoT. IEEE Internet Things J. 2021, 8, 17678–17690. [Google Scholar] [CrossRef]
- Chu, J.; Pan, C.; Wang, Y.; Yun, X.; Li, X. Edge Computing Resource Allocation Algorithm for NB-IoT Based on Deep Reinforcement Learning. IEICE Trans. Commun. 2022, 106, 439–447. [Google Scholar] [CrossRef]
- Li, Z.; He, Y.; Yu, H.; Kang, J.; Li, X.; Xu, Z.; Niyato, D. Data Heterogeneity-Robust Federated Learning via Group Client Selection in Industrial IoT. IEEE Internet Things J. 2022, 9, 17844–17857. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed Machine Learning for on-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar] [CrossRef]
- Shu, C.; Zhao, Z.; Han, Y.; Min, G. Dependency-Aware and Latency-Optimal Computation Offloading for Multi-User Edge Computing Networks. In Proceedings of the 16th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Boston, MA, USA, 10–13 June 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Zhang, X.; Chen, X.; Zhou, P. Joint Task Offloading and Payment Determination for Mobile Edge Computing: A Stable Matching Based Approach. IEEE Trans. Veh. Technol. 2020, 69, 12148–12161. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation Offloading and Resource Allocation For Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Kai, C.; Zhou, H.; Yi, Y.; Huang, W. Collaborative Cloud-Edge-End Task Offloading in Mobile-Edge Computing Networks with Limited Communication Capability. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 624–634. [Google Scholar] [CrossRef]
- Wang, T.; Lu, Y.; Wang, J.; Dai, H.-N.; Zheng, X.; Jia, W. EIHDP: Edge-Intelligent Hierarchical Dynamic Pricing Based on Cloud-Edge-Client Collaboration for IoT Systems. IEEE Trans. Comput. 2021, 70, 1285–1298. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Khurshid, W.; Liu, L.; Arif, S.Z.; Khan, I.A.; Khalid, O.; Nawaz, R. Adaptive Multi-Cost Routing Protocol to Enhance Lifetime for Wireless Body Area Network. Comput. Mater. Contin. 2022, 72, 1089–1103. [Google Scholar] [CrossRef]
- You, C.; Huang, K.; Chae, H.; Kim, B.-H. Energy-Efficient Resource Allocation for Mobile-Edge Computation Offloading. IEEE Trans. Wirel. Commun. 2017, 16, 1397–1411. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.; Zhao, L.; Liu, A. Energy-Efficient Joint Task Offloading and Resource Allocation in OFDMA-Based Collaborative Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 1960–1972. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Zhang, Y.; Wu, Y.; Chen, X.; Zhao, L. Deep Reinforcement Learning-Based Dynamic Resource Management for Mobile Edge Computing in Industrial Internet of Things. IEEE Trans. Ind. Inform. 2021, 17, 4925–4934. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, X.; Xu, T.; Wan, X.; Ji, W.; Zhang, Y. Reinforcement Learning-Based Mobile Offloading for Edge Computing Against Jamming and Interference. IEEE Trans. Commun. 2020, 68, 6114–6126. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X. Decentralized Computation Offloading for Multi-User Mobile Edge Computing: A Deep Reinforcement Learning Approach. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 188. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation with General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Li, M.; Gao, J.; Zhao, L.; Shen, X. Adaptive Computing Scheduling for Edge-Assisted Autonomous Driving. IEEE Trans. Veh. Technol. 2021, 70, 5318–5331. [Google Scholar] [CrossRef]
- Yan, L.; Chen, H.; Tu, Y.; Zhou, X. A Task Offloading Algorithm with Cloud Edge Jointly Load Balance Optimization Based on Deep Reinforcement Learning for Unmanned Surface Vehicles. IEEE Access. 2022, 10, 16566–16576. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep Reinforcement Learning for Dynamic Computation Offloading and Resource Allocation in Cache-Assisted Mobile Edge Computing Systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- AlQerm, I.; Pan, J. Enhanced Online Q-Learning Scheme for Resource Allocation with Maximum Utility and Fairness in Edge-IoT Networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 3074–3086. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. arXiv 2015, arXiv:1509.02971. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Aguera y Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtarik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Nazir, M.; Yousafzai, A.; Khan, M.A.; Shaikh, A.A.; Algarni, A.D.; Elmannai, H. Modified Artificial Bee Colony Based Feature Optimized Federated Learning for Heart Disease Diagnosis in Healthcare. Appl. Sci. 2022, 12, 12080. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Nazir, M.; Khan, M.A.; Qureshi, S.; Al-Rasheed, A. Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction. Appl. Sci. 2023, 13, 1911. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Zhou, Z.; Gong, X.; Wu, D. When Deep Reinforcement Learning Meets Federated Learning: Intelligent Multitimescale Resource Management for Multiaccess Edge Computing in 5G Ultradense Network. IEEE Internet Things J. 2021, 8, 2238–2251. [Google Scholar] [CrossRef]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing Federated Learning on Non-IID Data with Reinforcement Learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar] [CrossRef]
- Khodadadian, S.; Sharma, P.; Joshi, G.; Maguluri, S.T. Federated Reinforcement Learning: Linear Speedup Under Markovian Sampling. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 10997–11057. Available online: https://proceedings.mlr.press/v162/khodadadian22a/khodadadian22a.pdf (accessed on 24 February 2023).
- Tianqing, Z.; Zhou, W.; Ye, D.; Cheng, Z.; Li, J. Resource Allocation in IoT Edge Computing via Concurrent Federated Reinforcement Learning. IEEE Internet Things J. 2022, 9, 1414–1426. [Google Scholar] [CrossRef]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Zhu, Z.; Wan, S.; Fan, P.; Letaief, K.B. Federated Multiagent Actor–Critic Learning for Age Sensitive Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 1053–1067. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Elbamby, M.S.; Perfecto, C.; Liu, C.-F.; Park, J.; Samarakoon, S.; Chen, X.; Bennis, M. Wireless Edge Computing with Latency and Reliability Guarantees. Proc. IEEE 2019, 107, 1717–1737. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Huang, P.-Q.; Wang, Y.; Wang, K.; Liu, Z.-Z. A Bilevel Optimization Approach for Joint Offloading Decision and Resource Allocation in Cooperative Mobile Edge Computing. IEEE Trans. Cybern. 2020, 50, 4228–4241. [Google Scholar] [CrossRef]
- White Paper on Edge Computing Network of Industrial Internet in the 5G Era. Available online: http://www.ecconsortium.org/Uploads/file/20201209/1607521755435690.pdf (accessed on 24 February 2023).
- Wang, J.; Zhao, L.; Liu, J.; Kato, N. Smart Resource Allocation for Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1529–1541. [Google Scholar] [CrossRef]
- Liu, K.-H.; Hsu, Y.-H.; Lin, W.-N.; Liao, W. Fine-Grained Offloading for Multi-Access Edge Computing with Actor-Critic Federated Learning. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Area | 100 × 100 m | I | 2 Mbits |
| B | 1 MHz | [60–80] Kbits | |
| dB | 0.1 GHz | ||
| dBm | 0.2 GHz | ||
| 1 | s | 1000 cycles/bit | |
| 10 | |||
| 1 w | 0.001 | ||
| 10 w | 0.01 | ||
| 100 ms | C | 100 |
| Schemes | Learning Rate | Learning Rate |
|---|---|---|
| 1 | 0.01 | 0.02 |
| 2 | 0.001 | 0.002 |
| 3 | 0.0001 | 0.0002 |
| 4 | 0.00001 | 0.00002 |
| 5 | 0.000001 | 0.000002 |
| Energy (J) | Running Time (s) | |
|---|---|---|
| IF-DDPG | 0.219 | 283 |
| Exhaustion | 0.178 | 398,049 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhang, J.; Pan, C. Federated Deep Reinforcement Learning for Energy-Efficient Edge Computing Offloading and Resource Allocation in Industrial Internet. Appl. Sci. 2023, 13, 6708. https://doi.org/10.3390/app13116708
Li X, Zhang J, Pan C. Federated Deep Reinforcement Learning for Energy-Efficient Edge Computing Offloading and Resource Allocation in Industrial Internet. Applied Sciences. 2023; 13(11):6708. https://doi.org/10.3390/app13116708
Chicago/Turabian StyleLi, Xuehua, Jiuchuan Zhang, and Chunyu Pan. 2023. "Federated Deep Reinforcement Learning for Energy-Efficient Edge Computing Offloading and Resource Allocation in Industrial Internet" Applied Sciences 13, no. 11: 6708. https://doi.org/10.3390/app13116708
APA StyleLi, X., Zhang, J., & Pan, C. (2023). Federated Deep Reinforcement Learning for Energy-Efficient Edge Computing Offloading and Resource Allocation in Industrial Internet. Applied Sciences, 13(11), 6708. https://doi.org/10.3390/app13116708