
User Opinion Prediction for Arabic Hotel Reviews Using Lexicons and Artificial Intelligence Techniques


Abstract
1. Introduction
- It proposes an Arabic emojis and emoticons opinion lexicon (ArEmo lexicon) for Arabic opinion mining application tasks. It contains emoticons and emojis with additional descriptions. Each emotion score was calculated based on five levels of ratings using the HARD dataset instead of the three levels in other studies.
- It suggests an emoticon disambiguation algorithm by applying regular expression and recursion techniques to prepare a text for calculating the total weight of emoticons and replacing emoticons with their meanings to reflect their emotional contents.
- It proposes a user opinion classification approach for five-star ratings of online Arabic hotel reviews using supervised learning, which combines shallow and deep learning methods and employs Arabic resources to obtain valuable features, in addition to the fastText word embeddings.
2. Related Work
2.1. Arabic Dataset and Opinion Mining Methods
2.2. Arabic Text-Based Lexicons
2.3. Emojis and Emoticons Lexicons
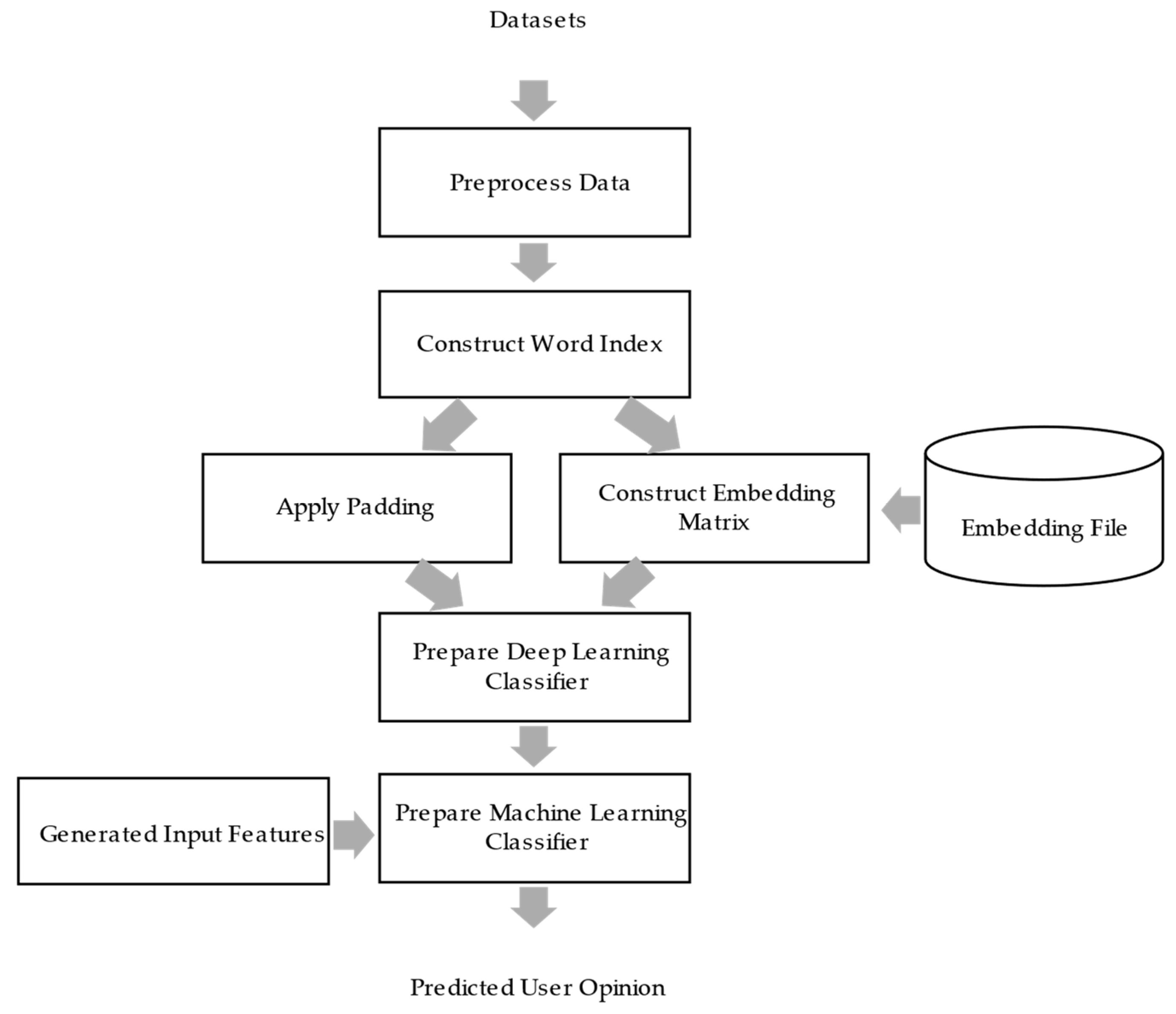
3. Proposed Work
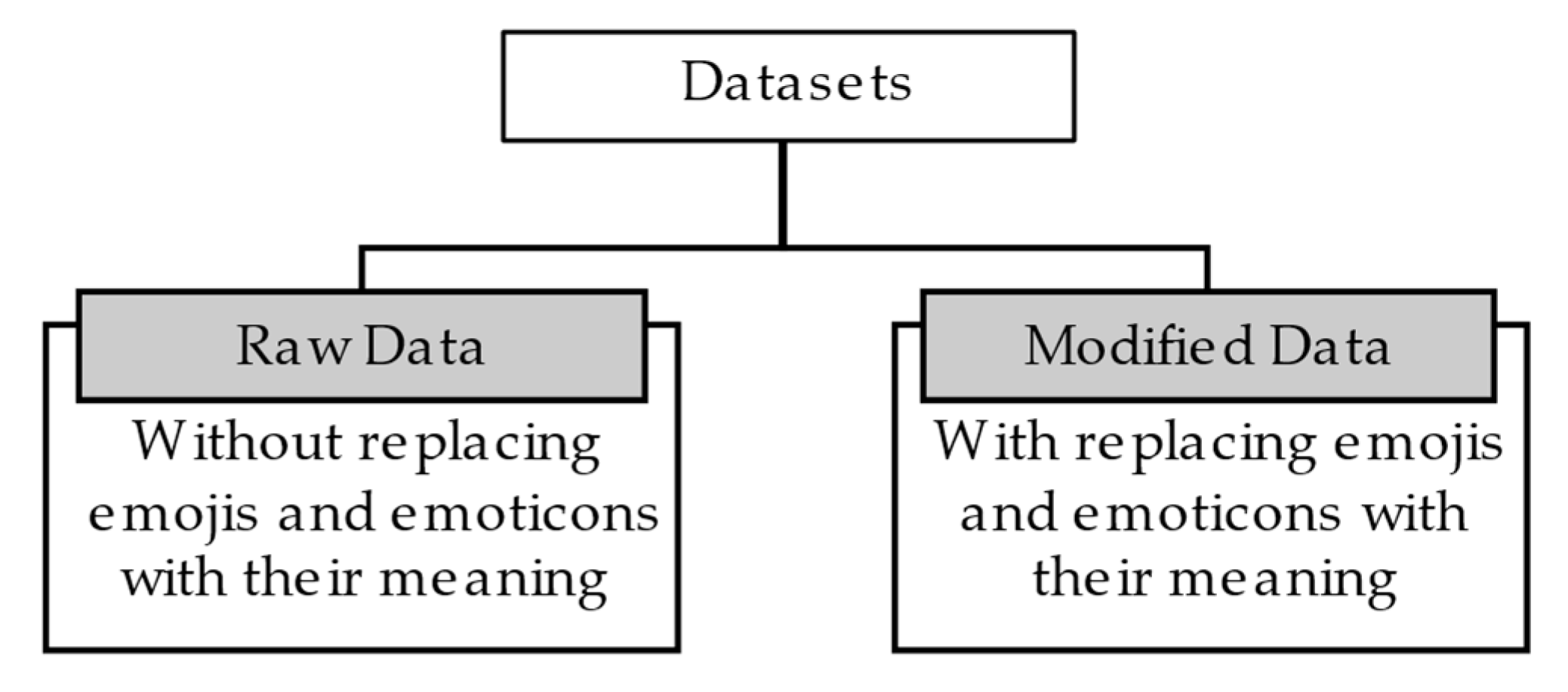
3.1. Dataset Preparation
| Algorithm 1: Emoji and Emoticon Replacer Algorithm |
| Input: a review without uniform resource locators and enclosed brackets that do not belong to emoticons and the ArEmo Lexicon. Output: an updated review after replacing its emojis and emoticons with their estimated equivalent meaning. START 1. def ReplaceEmojiEmoticonWithMeaning(Review, ArEmoLexicon): 2. { 3. ReviewWords = Review.split() 4. for each key, value in ArEmoLexicon do 5. for each word in ReviewWords do 6. if key in word then 7. UpdatedReview = Review.replace(key, f” {value} “) 8. UpdatedReview = re.sub(r” +”, “ “, UpdatedReview).strip() 9. return UpdatedReview 10. } END |
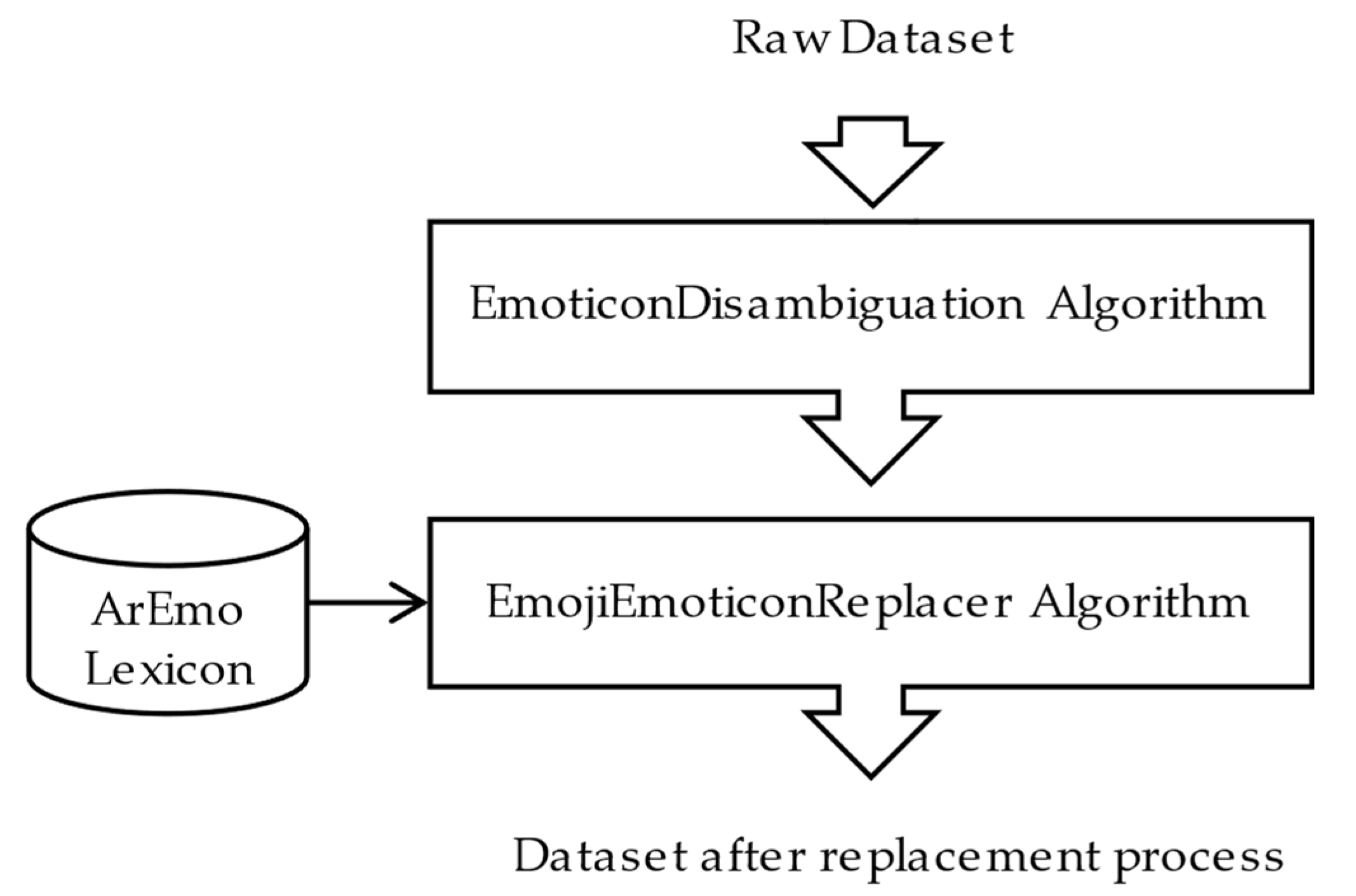
3.2. Emoticon Disambiguation
| Algorithm 2: Emoticon Disambiguation Algorithm |
| Input: a review Output: an updated review without uniform resource locators and enclosed brackets that do not belong to emoticons. START 1. URLRegEx=‘(?i)(http[17]?:\/\/\S+)’ 2. def DisambiguateEmoticon(Review): 3. { 4. UpdatedReview = re.sub(URLRegEx, ‘‘, Review) 5. UpdatedReview = RemoveEnclosedBrackets(UpdatedReview) 6. return UpdatedReview 7. } END |
| Algorithm 3: Enclosed Brackets Removal Algorithm |
| Input: a review. Output: an updated review after recursively removing all enclosed and nested brackets while preventing removal of the emoticons surrounded by two brackets. START 1. BracketsRegEx = ‘\[(?! [\_\-\ ‿\^\^\$\۾\*\ڼ\s])((.){0,}?)(?<![\_\-\ ‿\^\^\$\۾\*\ڼ\s])\]’ 2. ParanthesesRegEx = ‘ 3. SmallChevronsRegEx = ‘\<(?![\_\-\ ‿\^\^\$\۾\*\ڼ\s])((.){0,}?)(?<![\_\- \ ‿\^\^\$\۾\*\ڼ\s])\>’ 4. LargeChevronsRegEx = ‘\〈(?![\_\-\ ‿\^\^\$\۾\*\ڼ\s])((.){0,}?)(?<![\_\- \ ‿\^\^\$\۾\*\ڼ\s])\〉’ 5. BracesRegEx = ‘\{(?![\_\-\ ‿\^\^\$\۾\*\ڼ\s])((.){0,}?)(?<![\_\- \ ‿\^\^\$\۾\*\ڼ\s])\}’ 6. def RemoveEnclosedBrackets(Review): 7. { 8. if (Review.find(‘[’) != −1 and Review.find(‘]’) != −1) or (Review.find(‘(’) != −1 and Review.find(‘)’) != −1) or (Review.find(‘<’) != −1 and Review.find(‘>’) != −1) or (Review.find(‘〈’) != −1 and Review.find(‘〉’) != −1) or (Review.find(‘{’) != −1 and Review.find(‘}’) != −1) then 9. if (Review.find(‘[’) != −1 and Review.find(‘]’) != −1) then 10. Temp = Review 11. Review = re.sub(BracketsRegEx, r’\1’, Review) 12. if (Review.find(‘(’) != −1 and Review.find(‘)’) != −1) then 13. Temp = Review 14. Review = re.sub(ParanthesesRegEx, r’\1’, Review) 15. if (review.find(‘<’) != −1 and Review.find(‘>’) != −1) then 16. Temp = Review 17. Review = re.sub(SmallChevronsRegEx, r’\1’, Review) 18. if (Review.find(‘〈’) != −1 and Review.find(‘〉’) != −1) then 19. Temp = review 20. Review = re.sub(LargeChevronsRegEx, r’\1’, Review) 21. if (Review.find(‘{’) != −1 and Review.find(‘}’) != −1) then 22. Temp = Review 23. Review = re.sub(BracesRegEx, r’\1’, Review) 24. if len(Review) == len(Temp) then 25. return Review 26. else return RemoveEnclosedBrackets(Review) 27. else return Review 28. } 29. //end of RemoveEnclosedBrackets END |
3.3. Arabic Emoji and Emoticon Opinion Lexicon Creation
3.3.1. Emoji and Emoticon Collection
3.3.2. Emotion Score Method
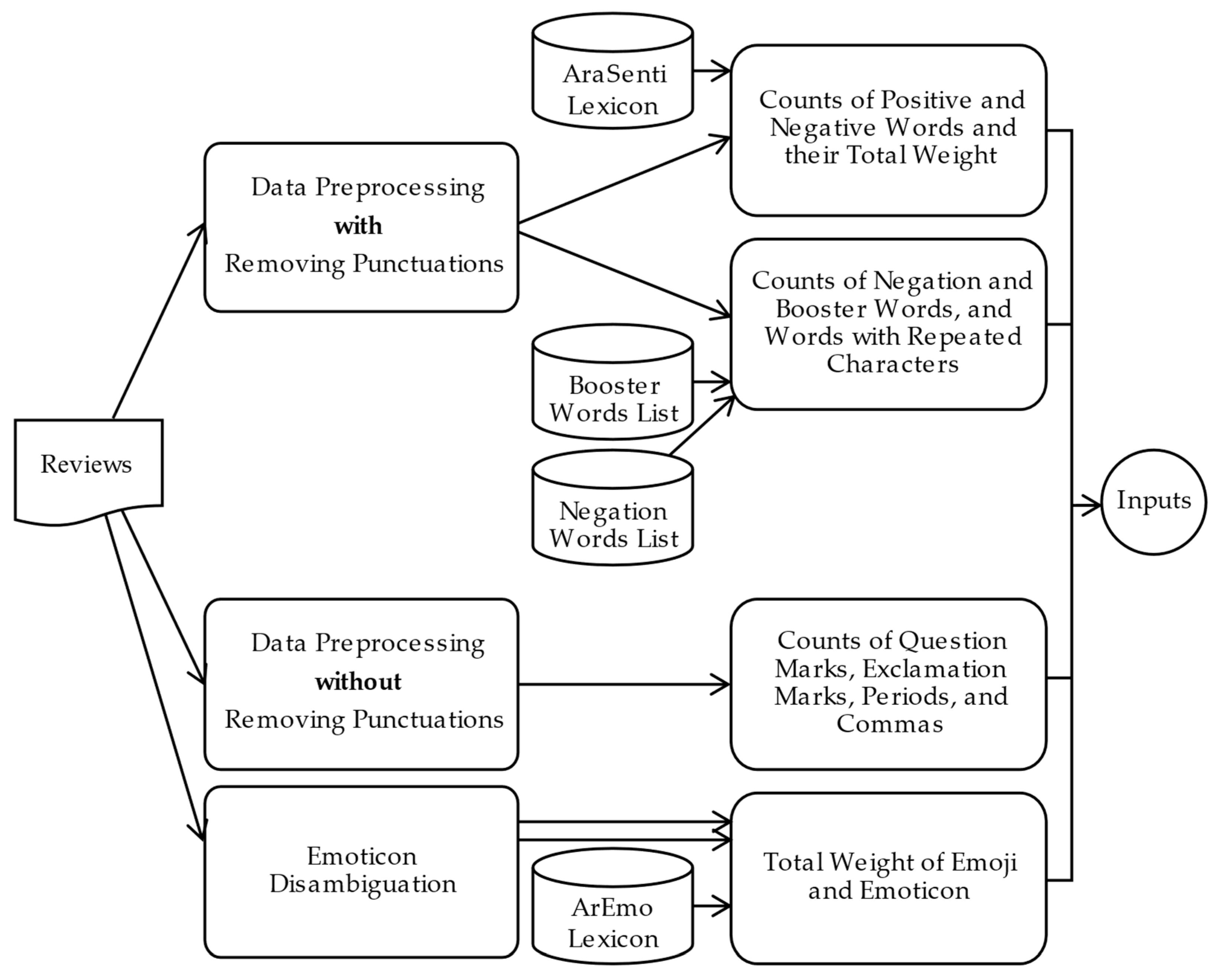
3.4. Feature Production
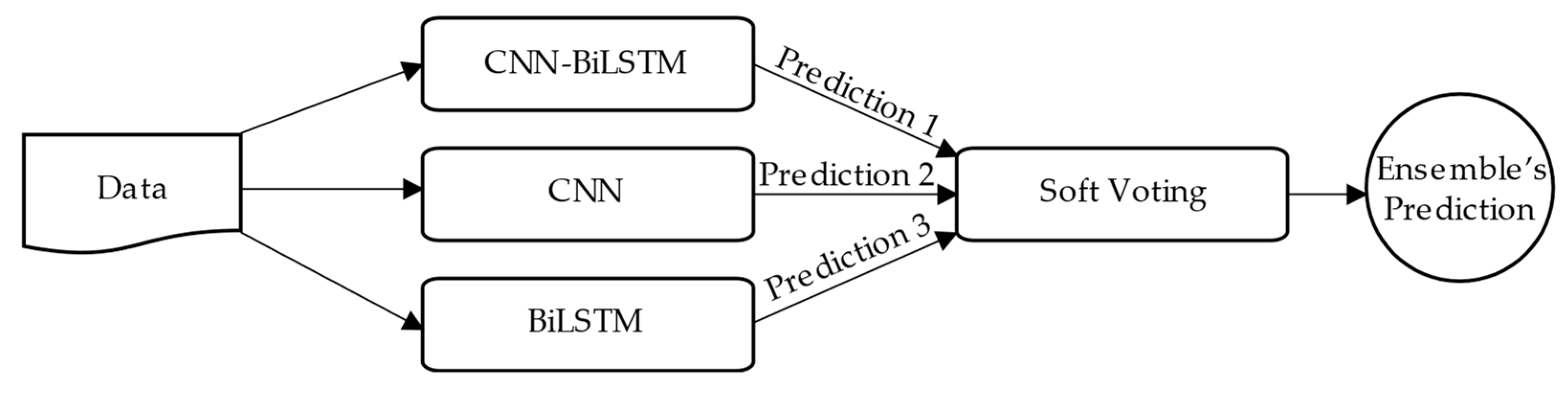
3.5. Modeling
4. Results and Discussion
 . The found studies related to those pictorial symbols in the literature did not cover these considerations. Therefore, this study recommends those considerations with the newly generated lexicons for emojis and emoticons in the future to be more comprehensive.
. The found studies related to those pictorial symbols in the literature did not cover these considerations. Therefore, this study recommends those considerations with the newly generated lexicons for emojis and emoticons in the future to be more comprehensive.5. Conclusions and Future Work
- Evaluate the use of context-based against context-free Arabic emoji and emoticon opinion lexicon using an Arabic dataset of emoji and emoticons.
- Improve non-Arabic emoji opinion lexicon for automated opinion mining by adding emoticons to it through suggested methods and algorithms.
- Work on more extensive extensible lists of emoji, emoticons, and negation words in both the standard Arabic language and dialectical Arabic. For instance, pictural symbols or negation words, combined with positive words, can be helpful to classify words while classifying text into negative when creating an Arabic corpus.
- Test the proposed approach using a dataset from a different domain while applying a robustness method and statistical significance analysis of the results.
- Apply an error detection and correction phase supporting the Arabic language as a preliminary step before applying the user opinion prediction approach to improve performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model 1 | Model 2 | Model 3 | |||
|---|---|---|---|---|---|
| Layer (Type) | Output Shape | Layer (Type) | Output Shape | Layer (Type) | Output Shape |
| embedding (Embedding) | (None, 615, 300) | embedding_1 (Embedding) | (None, 615, 300) | embedding_2 (Embedding) | (None, 615, 300) |
| conv1d (Conv1D) | (None, 613, 64) | conv1d_1 (Conv1D) | (None, 613, 64) | bidirectional_1 (Bidirectional) | (None, 615, 128) |
| max_pooling1d (MaxPooling1D) | (None, 306, 64) | max_pooling1d_1 (MaxPooling1D) | (None, 306, 64) | global_max_pooling1d_1 (GlobalMaxPooling1D) | (None, 128) |
| bidirectional (Bidirectional) | (None, 306, 128) | conv1d_2 (Conv1D) | (None, 304, 32) | dense_6 (Dense) | (None, 32) |
| global_max_pooling1d (GlobalMaxPooling1D) | (None, 128) | max_pooling1d_2 (MaxPooling1D) | (None, 152, 32) | dense_7 (Dense) | (None, 16) |
| dense (Dense) | (None, 16) | flatten (Flatten) | (None, 4864) | dense_8 (Dense) | (None, 8) |
| dense_1 (Dense) | (None, 8) | dense_3 (Dense) | (None, 16) | dense_9 (Dense) | (None, 5) |
| dense_2 (Dense) | (None, 5) | dense_4 (Dense) | (None, 8) | ||
| dense_5 (Dense) | (None, 5) | ||||
References
- Kuppusamy, S.; Thangavel, R. Deep Non-linear and Unbiased Deep Decisive Pooling Learning–Based Opinion Mining of Customer Review. Cogn. Comput. 2023, 15, 765–777. [Google Scholar] [CrossRef]
- Farah, H.A.; Kakisim, A.G. Enhancing Lexicon Based Sentiment Analysis Using n-gram Approach. In Smart Applications with Advanced Machine Learning and Human-Centred Problem Design; Springer International Publishing: Cham, Switzerland, 2023; pp. 213–221. [Google Scholar] [CrossRef]
- Chouikhi, H.; Alsuhaibani, M.; Jarray, F. BERT-Based Joint Model for Aspect Term Extraction and Aspect Polarity Detection in Arabic Text. Electronics 2023, 12, 515. [Google Scholar] [CrossRef]
- El Khadrawy, A.S.A.I.; Abbas, S.; Omar, Y.K.; Jawad, N.H.A. Extracting Semantic Relationship Between Fatiha Chapter (Sura) and the Holy Quran. In Proceedings of the 8th International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 20–22 November 2022. [Google Scholar]
- Saeed, R.M.K.; Rady, S.; Gharib, T.F. Optimizing sentiment classification for Arabic opinion texts. Cogn. Comput. 2021, 13, 164–178. [Google Scholar] [CrossRef]
- Alshahrani, A.; Dennehy, D.; Mäntymäki, M. An attention-based view of AI assimilation in public sector organizations: The case of Saudi Arabia. Gov. Inf. Q. 2022, 39, 101617. [Google Scholar] [CrossRef]
- Zarezadeh, Z.Z.; Rastegar, R.; Xiang, Z. Big data analytics and hotel guest experience: A critical analysis of the literature. Int. J. Contemp. Hosp. Manag. 2022, 34, 2320–2336. [Google Scholar] [CrossRef]
- Zubair, F.; Shamsudin, M.F. Impact of covid-19 on tourism and hospitality industry of Malaysia. J. Postgrad. Curr. Bus. Res. 2021, 6, 6. [Google Scholar]
- Darvishmotevali, M.; Altinay, L. Toward pro-environmental performance in the hospitality industry: Empirical evidence on the mediating and interaction analysis. J. Hosp. Mark. Manag. 2022, 31, 431–457. [Google Scholar] [CrossRef]
- Ray, A.; Bala, P.K.; Jain, R. Utilizing emotion scores for improving classifier performance for predicting customer’s intended ratings from social media posts. Benchmarking Int. J. 2021, 28, 438–464. [Google Scholar] [CrossRef]
- Mammola, S.; Malumbres-Olarte, J.; Arabesky, V.; Barrales-Alcalá, D.A.; Barrion-Dupo, A.L.; Benamú, M.A.; Bird, T.L.; Bogomolova, M.; Cardoso, P.; Chatzaki, M.; et al. An expert-curated global database of online newspaper articles on spiders and spider bites. Sci. Data 2022, 9, 109. [Google Scholar] [CrossRef]
- Antil, A.; Verma, H.V. Rahul Gandhi on Twitter: An analysis of brand building through Twitter by the leader of the main opposition party in India. Glob. Bus. Rev. 2021, 22, 1258–1275. [Google Scholar] [CrossRef]
- Djatmiko, F.; Ferdiana, R.; Faris, M. A review of sentiment analysis for non-English language. In Proceedings of the 2019 International Conference of Artificial Intelligence and Information Technology (ICAIIT), Yogyakarta, Indonesia, 13–15 March 2019; pp. 448–451. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Shahin, I.; Henno, S. Deep learning for Arabic subjective sentiment analysis: Challenges and research opportunities. Appl. Soft Comput. 2021, 98, 106836. [Google Scholar] [CrossRef]
- Abo, M.E.M.; Raj, R.G.; Qazi, A. A review on Arabic sentiment analysis: State-of-the-art, taxonomy and open research challenges. IEEE Access 2019, 7, 162008–162024. [Google Scholar] [CrossRef]
- Ghallab, A.; Mohsen, A.; Ali, Y. Arabic sentiment analysis: A systematic literature review. Appl. Comput. Intell. Soft Comput. 2020, 2020, 1–21. [Google Scholar] [CrossRef]
- Elnagar, A.; Khalifa, Y.S.; Einea, A. Hotel Arabic-reviews dataset construction for sentiment analysis applications. Intell. Nat. Lang. Process. Trends Appl. 2018, 740, 35–52. [Google Scholar] [CrossRef]
- Novak, P.K.; Smailović, J.; Sluban, B.; Mozetič, I. Sentiment of emojis. PLoS ONE 2015, 10, e0144296. [Google Scholar] [CrossRef]
- Nath, D.; Phani, S. Mood Analysis of Bengali Songs Using Deep Neural Networks. In Information and Communication Technology for Competitive Strategies (ICTCS 2020) Intelligent Strategies for ICT; Springer: Singapore, 2021; pp. 1103–1113. [Google Scholar] [CrossRef]
- Nassif, A.B.; Darya, A.M.; Elnagar, A. Empirical evaluation of shallow and deep learning classifiers for Arabic sentiment analysis. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2021, 21, 1–25. [Google Scholar] [CrossRef]
- Bashir, M.F.; Javed, A.R.; Arshad, M.U.; Gadekallu, T.R.; Shahzad, W.; Beg, M.O. Context aware emotion detection from low resource urdu language using deep neural network. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2022, 22, 1–30. [Google Scholar] [CrossRef]
- Fei, H.; Zhang, Y.; Ren, Y.; Ji, D. Latent emotion memory for multi-label emotion classification. Proc. AAAI Conf. Artif. Intell 2020, 34, 7692–7699. [Google Scholar] [CrossRef]
- Chakraborty, S.; Goyal, P.; Mukherjee, A. Aspect-based sentiment analysis of scientific reviews. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020, Virtual, 1–5 August 2020; pp. 207–216. [Google Scholar] [CrossRef]
- Fei, H.; Chua, T.-S.; Li, C.; Ji, D.; Zhang, M.; Ren, Y. On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training. ACM Trans. Inf. Syst. 2022, 41, 1–32. [Google Scholar] [CrossRef]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. In Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019), Hong Kong, China, 4 November 2019; pp. 34–41. [Google Scholar] [CrossRef]
- Fei, H.; Li, F.; Li, C.; Wu, S.; Li, J.; Ji, D. Inheriting the wisdom of predecessors: A multiplex cascade framework for unified aspect-based sentiment analysis. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 4096–4103. [Google Scholar]
- Shi, W.; Li, F.; Li, J.; Fei, H.; Ji, D. Effective Token Graph Modeling using a Novel Labeling Strategy for Structured Sentiment Analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 4232–4241. [Google Scholar] [CrossRef]
- Fei, H.; Shengqiong, W.; Jingye, L.; Bobo, L.; Fei, L.; Libo, Q.; Meishan, Z.; Min, Z.; Tat-Seng, C. LasUIE: Unifying information extraction with latent adaptive structure-aware generative language model. Adv. Neural Inf. Process. Syst. 2022, 35, 15460–15475. [Google Scholar]
- Wu, S.; Fei, H.; Ren, Y.; Ji, D.; Li, J. Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Rich Syntactic Knowledge. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), Virtual, 19–26 August 2021. [Google Scholar]
- Fei, H.; Shengqiong, W.; Yafeng, R.; Meishan, Z. Matching structure for dual learning. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 6373–6391. [Google Scholar]
- Wu, S.; Fei, H.; Li, F.; Zhang, M.; Liu, Y.; Teng, C.; Ji, D. Mastering the explicit opinion-role interaction: Syntax-aided neural transition system for unified opinion role labeling. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2022; Volume 36, no. 10, pp. 11513–11521. [Google Scholar] [CrossRef]
- Mo, X.; Tang, R.; Liu, H. A relation-aware heterogeneous graph convolutional network for relationship prediction. Inf. Sci. 2023, 623, 311–323. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; AlSalman, A. Arasenti: Large-scale twitter-specific Arabic sentiment lexicons. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 697–705. [Google Scholar] [CrossRef]
- Alowisheq, A.; Al-Twairesh, N.; Altuwaijri, M.; Almoammar, A.; Alsuwailem, A.; Albuhairi, T.; Alahaideb, W.; Alhumoud, S. MARSA: Multi-domain Arabic resources for sentiment analysis. IEEE Access 2021, 9, 142718–142728. [Google Scholar] [CrossRef]
- Alqmase, M.; Al-Muhtaseb, H.; Rabaan, H. Sports-fanaticism formalism for sentiment analysis in Arabic text. Soc. Netw. Anal. Min. 2021, 11, 52. [Google Scholar] [CrossRef]
- Alhuri, L.A.; Aljohani, H.R.; Almutairi, R.M.; Haron, F. Sentiment analysis of COVID-19 on Saudi trending hashtags using recurrent neural network. In Proceedings of the 2020 13th International Conference on Developments in eSystems Engineering (DeSE), Virtual, 14–17 December 2020; pp. 299–304. [Google Scholar] [CrossRef]
- Alqmase, M.; Al-Muhtaseb, H. Sport-fanaticism lexicons for sentiment analysis in Arabic social text. Soc. Netw. Anal. Min. 2022, 12, 56. [Google Scholar] [CrossRef]
- Hakami, S.A.A.; Robert, J.H.; Phillip, S. A Context-free Arabic Emoji Sentiment Lexicon (CF-Arab-ESL). In Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools with Shared Tasks on Qur’an QA and Fine-Grained Hate Speech Detection, Marseille, France, 20 June 2022; pp. 51–59. [Google Scholar]
- Hakami, S.A.A.; Robert, J.H.; Phillip, S. Arabic emoji sentiment lexicon (Arab-ESL): A comparison between Arabic and European emoji sentiment lexicons. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Virtual, 19 April 2021; pp. 60–71. [Google Scholar]
- Hakami, S. Arabic_Emoji_Sentiment_Lexicon_Version_1.0.csv. GitHub, February 24. 2021. Available online: https://github.com/ShathaHakami/Arabic-Emoji-Sentiment-Lexicon-Version-1.0 (accessed on 18 August 2022).
- UnicodePlus—Search for Unicode Characters. 2021. Available online: https://unicodeplus.com/ (accessed on 27 September 2022).
- Cyber Definitions. Available online: https://www.cyberdefinitions.com/ (accessed on 27 September 2022).
- Full Emoji List, v15.0. 2023. Available online: https://unicode.org/emoji/charts/full-emoji-list.html (accessed on 21 March 2023).
- Wikipedia, the Free Encyclopedia. 2023. Available online: https://ar.wikipedia.org/ (accessed on 21 March 2023).
- Internet Slang Words—Internet Dictionary—InternetSlang.com. 2023. Available online: https://www.internetslang.com/ (accessed on 27 September 2022).
- HiNative|A Question and Answer Community for Language Learners. 2023. Available online: https://hinative.com/en-US (accessed on 27 September 2022).
- PC.net—Your Personal Computing Resource. 2023. Available online: https://pc.net/ (accessed on 27 September 2022).
- Shaari, A.H. Accentuating illocutionary forces: Emoticons as speech act realization strategies in a multicultural online communication environment. 3L Southeast Asian J. Engl. Lang. Stud. 2020, 26, 135–155. [Google Scholar] [CrossRef]
- Trending—FastEmoji. n.d. Available online: https://www.fastemoji.com/ (accessed on 27 September 2022).
- Amaghlobeli, N. Linguistic features of typographic emoticons in SMS discourse. Theory Pract. Lang. Stud. 2012, 2, 348. [Google Scholar] [CrossRef]
- Kaddoura, S.; Itani, M.; Roast, C. Analyzing the effect of negation in sentiment polarity of facebook dialectal arabic text. Appl. Sci. 2021, 11, 4768. [Google Scholar] [CrossRef]
- Çoban, Ö.; Selma, A.Ö.; Ali, İ. Deep learning-based sentiment analysis of Facebook data: The case of Turkish users. Comput. J. 2021, 64, 473–499. [Google Scholar] [CrossRef]
- Mohammed, A.; Arunachalam, N. Imbalanced machine learning based techniques for breast cancer detection. In Proceedings of the 2021 International Conference on System, Computation, Automation and Networking (ICSCAN), Puducherry, India, 30–31 July 2021; pp. 1–4. [Google Scholar] [CrossRef]






| Preprocessing Step | Arabic Text |
|---|---|
| Original Arabic Text (Before Preprocessing) | مخيب للأمل. لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال. المويه انقطعت كذا مره + الكهرباء برضو انقطع تقريباً نص ساعة  الفطور سيء جداً الفطور سيء جداًTranslation: “Disappointing. Had it not been for the hotel’s location, the hotel would not have been worth anything. The water was cut off many times + the electricity also went out for about half an hour breakfast is very bad” |
| Emoji Removal | مخيب للأمل. لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال. المويه انقطعت كذا مره + الكهرباء برضو انقطع تقريباً نص ساعة الفطور سيء جداً Translation: “Disappointing. Had it not been for the hotel’s location, the hotel would not have been worth anything. The water was cut off many times + the electricity also went out for about half an hour breakfast is very bad” |
| Arabic Diacritics Removal | مخيب للأمل. لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال. المويه انقطعت كذا مره + الكهرباء برضو انقطع تقريبا نص ساعة الفطور سيء جدا Translation: “Disappointing. Had it not been for the hotel’s location, the hotel would not have been worth anything. The water was cut off many times + the electricity also went out for about half an hour breakfast is very bad” |
| URL Removal | مخيب للأمل. لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال. المويه انقطعت كذا مره + الكهرباء برضو انقطع تقريبا نص ساعة الفطور سيء جدا Translation: “Disappointing. Had it not been for the hotel’s location, the hotel would not have been worth anything. The water was cut off many times + the electricity also went out for about half an hour breakfast is very bad” |
| Special Characters Removal | مخيب للأمل. لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال. المويه انقطعت كذا مره الكهرباء برضو انقطع تقريبا نص ساعة الفطور سيء جدا Translation: “Disappointing. Had it not been for the hotel’s location, the hotel would not have been worth anything. The water was cut off many times the electricity also went out for about half an hour breakfast is very bad” |
| Punctuation Removal | مخيب للأمل لولا موقع الفندق ولا كان الفندق ما يسوى ولا ريال المويه انقطعت كذا مره الكهرباء برضو انقطع تقريبا نص ساعة الفطور سيء جدا Translation: “Disappointing Had it not been for the hotels location the hotel would not have been worth anything The water was cut off many times the electricity also went out for about half an hour breakfast is very bad” |
| Tokenization | [‘مخيب’, ‘للأمل’, ‘لولا’, ‘موقع’, ‘الفندق’, ‘ولا’, ‘كان’, ‘الفندق’, ‘ما’, ‘يسوى’, ‘ولا’, ‘ريال’, ‘المويه’, ‘انقطعت’, ‘كذا’, ‘مره’, ‘الكهرباء’, ‘برضو’, ‘انقطع’, ‘تقريبا’, ‘نص’, ‘ساعة’, ‘الفطور’, ‘سيء’, ‘جدا’] Translation: [‘Disappointing’, ‘Had’, ‘it’, ‘not’, ‘been’, ‘for’, ‘the’, ‘hotels’, ‘location’, ‘the’, ‘hotel’, ‘would’, ‘not’, ‘have’, ‘been’, ‘worth’, ‘anything’, ‘The’, ‘water’, ‘was’, ‘cut’, ‘off’, ‘many’, ‘times’, ‘the’, ‘electricity’, ‘also’, ‘went’, ‘out’, ‘for’, ‘about’, ‘half’, ‘an’, ‘hour’, ‘breakfast’, ‘is’, ‘very’, ‘bad’] |
| Arabic Review | Translated Review into English | Ambiguous Emoticon |
|---|---|---|
| “مميز ?”. - عندهم أفضل مركز صحي للمساج جربته بحياتي للآن .- أعجبني كذلك عبارتهم المميزة :( أشياء بسيطة تصنع الفارق )- يستحق التمييز ?. | “Special ?”. - They have the best health center for massages that I have tried in my life so far. - I also liked their distinctive phrase :( Simple things make a difference ) - Worth the distinction?. | :( or :( |
| استثنائي. ممتاز جدا ويستحق الزيارة مره اخرى. عدم توفر بعض الخدمات الاخرى حول الفندق مثل : ( المطاعم و المحلات ..) | Exceptional. Very excellent and worth visiting again. Unavailability of some other services around the hotel such as : ( restaurants, shops...) | ) : or : ( Note: there is a space between the bracket and colon. |
| “لا انصح فيه”. اعجبني تواجد الصراصير منظر غير لائق جدا ولا نصح فيه. النظافة معدومةصراصير الصورة هنا http://cdn.top4top.co/i_ba52fbf59d0.jpg | “I do not recommend it.” I liked the presence of cockroaches a very inappropriate view, and I don’t recommend it. Hygiene is lacking. Cockroaches photo here http://cdn.top4top.co/i_ba52fbf59d0.jpg | :/ |
| Emo | Type | Emoji Unicode | Classification | Short English Naming | Short Arabic Naming | Emotion Score | Total Count |
|---|---|---|---|---|---|---|---|
 | Emoji | \U0001f44d | - | thumbs up | إبهام مرفوع لأعلى | 0.797428 | 933 |
| ❤ | Emoji | \u2764 | - | red heart | قلب أحمر | 0.885193 | 466 |
| :) | Emoticon | - | Western | smiling face | وجه مبتسم | 0.646119 | 438 |
| :( | Emoticon | - | Western | sad face | وجه حزين | 0.259574 | 235 |
| Emoji | \U0001f44e | - | thumbs down | إبهام متجه لأسفل | −0.22886 | 201 |
 | Emoji | \u2b50 | - | star | نجمة | 0.763889 | 180 |
 | Emoji | \U0001f60d | - | smiling face with heart-eyes | وجه مبتسم بعيون قلب | 0.868571 | 175 |
 | Emoji | \U0001f44c | - | ok hand | يد حسنا | 0.849112 | 169 |
 | Emoji | \U0001f60a | - | smiling face with smiling eyes | وجه مبتسم بعيون مبتسمة | 0.732283 | 127 |
 | Emoji | \U0001f339 | - | rose | ورد | 0.756 | 125 |
| Emo | Type | Emoji Unicode | Classification | Short English Naming | Short Arabic Naming | Emotion Score | Total Count |
|---|---|---|---|---|---|---|---|
| Emoji | \U0001f44d | - | thumbs up | إبهام مرفوع لأعلى | 0.708861 | 79 |
| :) | Emoticon | - | Western | smiling face | وجه مبتسم | 0.416667 | 60 |
| Emoji | \U0001f44e | - | thumbs down | إبهام متجه لأسفل | −0.5 | 56 |
| ❤ | Emoji | \u2764 | - | red heart | قلب أحمر | 0.829268 | 41 |
| :( | Emoticon | - | Western | sad face | وجه حزين | −0.21622 | 37 |
| Emoji | \U0001f44c | - | ok hand | يد حسنا | 0.692308 | 26 |
 | Emoji | \U0001f602 | - | tearful laughing face | وجه يضحك بدموع | −0.11765 | 17 |
 | Emoji | \u274c | - | error | خطأ | −0.61765 | 17 |
| Emoji | \u2b50 | - | star | نجمة | 0.59375 | 16 |
 | Emoji | \U0001f621 | - | pouting face | وجه عابس | −0.40625 | 16 |
| Arabic Word | English Translation | Type of Arabic | Arabic Word | English Translation | Type of Arabic |
|---|---|---|---|---|---|
| جدا | Very | Standard | واجد | Very | Dialectal |
| جدن | Very | Dialectal | وايد | Very | Dialectal |
| قدا | Very | Dialectal | خالص | Very | Dialectal |
| قدن | Very | Dialectal | بزاف | A lot | Dialectal |
| مرة | Very | Dialectal | بالزاف | A lot | Dialectal |
| مره | Very | Dialectal | بقوة | Very | Dialectal |
| مرا | Very | Dialectal | بقوه | Very | Dialectal |
| كثير | A lot | Standard | مفرط | Excessive | Standard |
| كثيرا | A lot | Standard | بإفراط | Excessively | Standard |
| كتير | A lot | Dialectal | بافراط | Excessively | Dialectal |
| Arabic Word | English Translation | Type of Arabic | Arabic Word | English Translation | Type of Arabic |
|---|---|---|---|---|---|
| لا | No/Do not/Does not | Standard | لستم | You are not | Standard |
| لم | Did not | Standard | لسن | They are not | Standard |
| ما | No/Not | Standard | ليسوا | They are not | Standard |
| لن | Will not | Standard | مش | Not | Dialectal |
| لما | Not yet | Standard | مو | Not | Dialectal |
| إن | Not | Standard | مفي | There is no | Dialectal |
| لات | Not | Standard | مافي | There is no | Dialectal |
| غير | Not/Without | Standard | منو | Not | Dialectal |
| بدون | Without | Standard | مانو | Not | Dialectal |
| بلا | Without | Standard | ماكو | There is no | Dialectal |
| ArEmo Lexicon | Emoji Sentiment Ranking [18] | CF-Arab-ESL [38] | Arab-ESL [39] | ||||
|---|---|---|---|---|---|---|---|
| Emoji and Emoticon | Score | Emoji | Score | Emoji | Score | Emoji | Score |
| 0.709 | | 0.221 | | 0.839 | | 0.272 |
| :) | 0.417 | ❤ | 0.746 | | 0.946 |  | −0.934 |
| −0.5 | ♥ | 0.657 | ❤ | 0.911 | ❤ | 0.561 |
| ❤ | 0.829 | | 0.678 |  | −0.4 |  | −0.678 |
| :( | −0.216 | | −0.093 | | −0.446 | | 0.87 |
| 0.692 |  | 0.701 | ♥ | 0.946 | | 0.766 |
| −0.118 | | 0.644 | | 0.946 | | 0.227 |
| −0.618 | | 0.563 |  | 0.786 |  | 0.488 |
| 0.594 | | 0.632 |  | 0.839 |  | 0.534 |
| −0.406 |  | 0.52 | | 0.161 |  | 0.616 |
| Model | Accuracy | Precision | Recall | F1-Score | |||
|---|---|---|---|---|---|---|---|
| Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | ||
| EDLBWE | 76.15% | 75.90% | 75.90% | 76.15% | 76.15% | 75.74% | 75.74% |
| EDLB | 76.57% | 76.38% | 76.38% | 76.57% | 76.57% | 76.22% | 76.22% |
| EDLUWE | 77.59% | 76.81% | 77.45% | 72.05% | 77.59% | 74.02% | 77.41% |
| EDLU | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 1 | 76.18% | 60.37% | 67.36% | 2904 |
| 2 | 71.50% | 68.39% | 69.91% | 7579 |
| 3 | 77.33% | 72.49% | 74.83% | 16,221 |
| 4 | 74.70% | 75.87% | 75.28% | 26,452 |
| 5 | 82.27% | 86.67% | 84.41% | 28,756 |
| Accuracy | 77.75% | 81,912 | ||
| Macro Average | 76.40% | 72.75% | 74.36% | 81,912 |
| Weighted Average | 77.64% | 77.75% | 77.62% | 81,912 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN-BiLSTM | 74.83% | 74.75% | 74.83% | 74.47% |
| CNN | 73.03% | 72.72% | 73.03% | 72.55% |
| BiLSTM | 75.06% | 75.12% | 75.06% | 74.92% |
| EDLB | 76.57% | 76.38% | 76.57% | 76.22% |
| Model | Accuracy | Precision | Recall | F1-Score | |||
|---|---|---|---|---|---|---|---|
| Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | ||
| CNN-BiLSTM | 76.79% | 75.98% | 76.79% | 71.25% | 76.79% | 73.24% | 76.69% |
| CNN | 75.78% | 75.06% | 75.86% | 70.11% | 75.78% | 72.04% | 75.66% |
| BiLSTM | 77.26% | 75.12% | 77.13% | 72.97% | 77.26% | 73.91% | 77.13% |
| EDLU | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Applied Feature | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Num pos words | 76.57% | 76.38% | 76.57% | 76.22% |
| Num neg words | 76.57% | 76.38% | 76.57% | 76.22% |
| Weight pos words | 76.56% | 76.37% | 76.56% | 76.21% |
| Weight neg words | 76.56% | 76.37% | 76.56% | 76.21% |
| Num negation words | 76.57% | 76.38% | 76.57% | 76.22% |
| Num booster words | 76.57% | 76.38% | 76.57% | 76.22% |
| Num repeated characters | 76.57% | 76.38% | 76.57% | 76.22% |
| Num question marks | 76.56% | 76.37% | 76.56% | 76.21% |
| Num exclamation marks | 76.57% | 76.38% | 76.57% | 76.22% |
| Num periods | 76.57% | 76.38% | 76.57% | 76.22% |
| Num commas | 76.57% | 76.38% | 76.57% | 76.22% |
| Emo score | 76.58% | 76.39% | 76.58% | 76.23% |
| All features | 76.54% | 76.36% | 76.54% | 76.19% |
| Applied Feature | Accuracy | Precision | Recall | F1-Score | |||
|---|---|---|---|---|---|---|---|
| Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | Macro Avg | Weighted Avg | ||
| Num pos words | 77.74% | 76.39% | 77.63% | 72.75% | 77.74% | 74.35% | 77.62% |
| Num neg words | 77.74% | 76.40% | 77.63% | 72.75% | 77.74% | 74.36% | 77.62% |
| Weight pos words | 77.75% | 76.40% | 77.63% | 72.75% | 77.75% | 74.36% | 77.62% |
| Weight neg words | 77.75% | 76.42% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Num negation words | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Num booster words | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Num repeated characters | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Num question marks | 77.75% | 76.40% | 77.63% | 72.75% | 77.75% | 74.36% | 77.62% |
| Num exclamation marks | 77.74% | 76.39% | 77.63% | 72.73% | 77.74% | 74.34% | 77.61% |
| Num periods | 77.74% | 76.40% | 77.63% | 72.75% | 77.74% | 74.36% | 77.62% |
| Num commas | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| Emo score | 77.75% | 76.40% | 77.64% | 72.75% | 77.75% | 74.36% | 77.62% |
| All features | 76.33% | 76.40% | 77.61% | 72.65% | 77.72% | 74.26% | 77.59% |
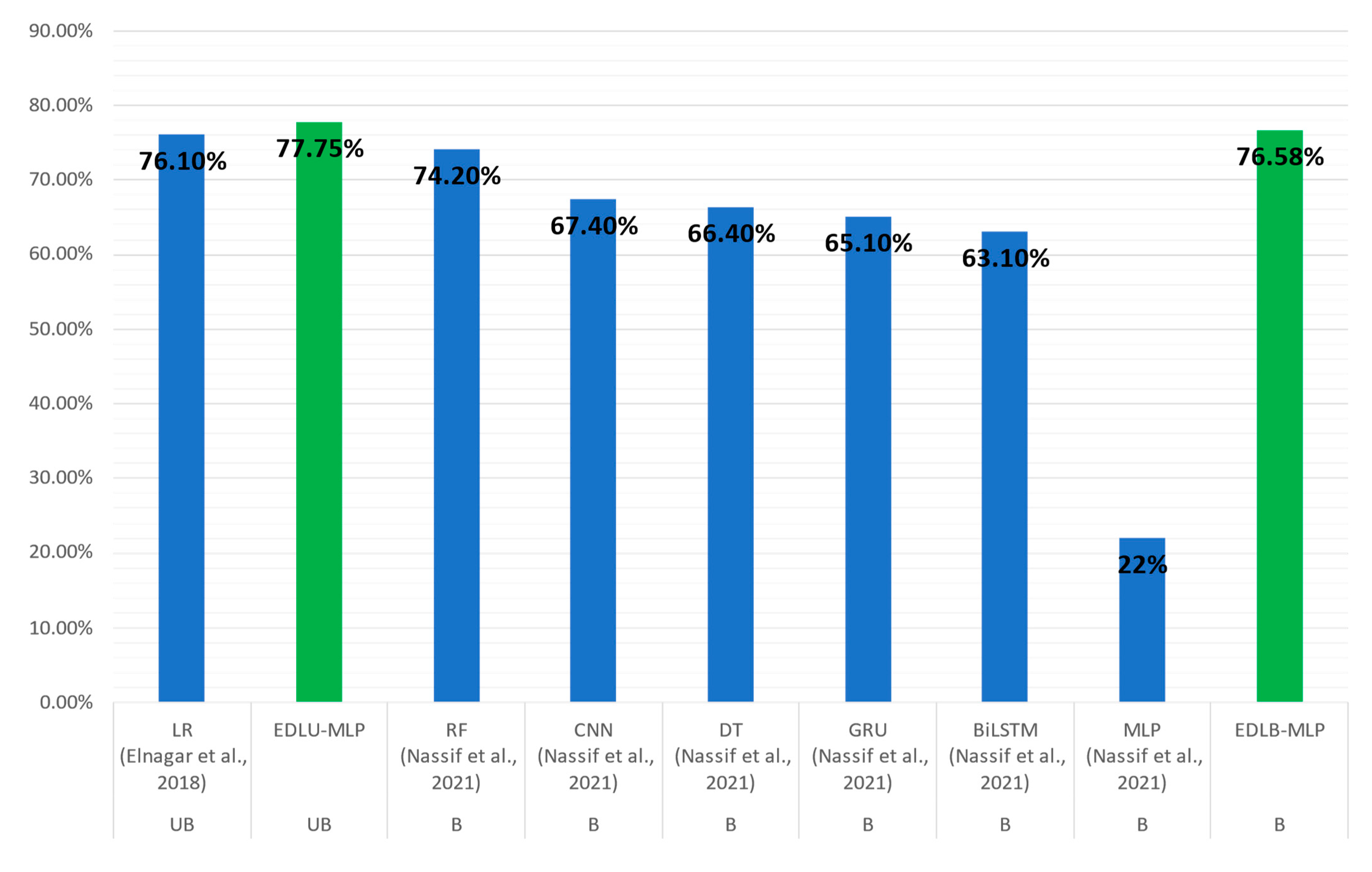
| Model | Type of Data | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Elnagar et al. [17] LR | Unbalanced | 76.1% | - | - | - |
| Nassif et al. [20] RF | Balanced | 74.2% | 74.0% | 74.0% | 74.0% |
| Nassif et al. [20] CNN | Balanced | 67.4% | 77.3% | 67.4% | 72.0% |
| Nassif et al. [20] DT | Balanced | 66.4% | 66.0% | 66.0% | 66.0% |
| Nassif et al. [20] GRU | Balanced | 65.1% | 75.4% | 65.3% | 69.8% |
| Nassif et al. [20] BiLSTM | Balanced | 63.1% | 72.5% | 63.2% | 67.4% |
| Nassif et al. [20] MLP | Balanced | 22% | 20% | 21% | 14% |
| EDLU-MLP | Unbalanced | 77.75% | 76.42% | 72.75% | 74.36% |
| EDLB-MLP | Balanced | 76.58% | 76.39% | 76.58% | 76.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Mutawa, R.F.; Al-Aama, A.Y. User Opinion Prediction for Arabic Hotel Reviews Using Lexicons and Artificial Intelligence Techniques. Appl. Sci. 2023, 13, 5985. https://doi.org/10.3390/app13105985
Al-Mutawa RF, Al-Aama AY. User Opinion Prediction for Arabic Hotel Reviews Using Lexicons and Artificial Intelligence Techniques. Applied Sciences. 2023; 13(10):5985. https://doi.org/10.3390/app13105985
Chicago/Turabian StyleAl-Mutawa, Rihab Fahd, and Arwa Yousef Al-Aama. 2023. "User Opinion Prediction for Arabic Hotel Reviews Using Lexicons and Artificial Intelligence Techniques" Applied Sciences 13, no. 10: 5985. https://doi.org/10.3390/app13105985
APA StyleAl-Mutawa, R. F., & Al-Aama, A. Y. (2023). User Opinion Prediction for Arabic Hotel Reviews Using Lexicons and Artificial Intelligence Techniques. Applied Sciences, 13(10), 5985. https://doi.org/10.3390/app13105985