1. Introduction
The cooperative control of multi-agent systems (MASs) has been widely investigated in many disciplines [
1,
2,
3]. The leader-following consensus problem of MASs is an important problem for cooperative control that needs to be explored and solved [
4,
5,
6,
7,
8]. In such MASs, the leader is a special agent whose movements are not affected by followers, and all the other followers are driven to follow the leader.
However, steady-state performance is mainly pursued in the leader-following consensus of MASs, while transient performance is less considered. To address this issue, the finite-time consensus protocol was developed [
9], such that consensus in finite-time by using a distributed, event-triggered method is achieved, and in [
10], an adaptive, dynamic sliding mode-based control protocol was proposed for heterogeneous MASs with uncertain dynamics and external disturbances to achieve finite-time consensus. Furthermore, so-called reset consensus protocols were proposed in [
11,
12], which provide faster convergence and less control effort than some conventional consensus controllers. In practice, it is usually expected that a large convergence rate and small overshoot can be guaranteed simultaneously, which is a trade-off. Sometimes, it is also desired that the controlled variable can be evolved within some certain boundary envelope. However, most of the literature, such as [
9,
10,
11,
12], cannot achieve this requirement. In order to achieve such expected performance requirements, the prescribed performance control (PPC) approach was firstly proposed in [
13], solving the robust adaptive control problem for single systems. It is worth mentioning that guaranteeing the prescribed performance means that the controlled variable converges to a given region, achieving a large convergence rate with a small overshoot. Due to the capability of allowing people to prescribe the above-mentioned performance in practice, the concepts of PPC are widely used and applied in many single systems, such as strict feedback systems, non-strict-feedback systems and multi-degree-of-freedom robot systems, which can be found in [
14,
15,
16,
17,
18,
19]. Moreover, PPC has also been applied in MASs. In [
20,
21], PPC is applied to linear MASs with guaranteed prescribed performance to address the average consensus on undirected graphs. Subsequently, scholars began to study leader-following consensus in MASs under directed graphs to ensure prescribed performance [
22,
23,
24,
25,
26]. Bechlioulis and Rovithakis designed a decentralized control law based on the Lyapunov theory to achieve leader-following consensus with guaranteed prescribed performance, for uncertain nonlinear MASs in [
22]. PPC-based controllers were designed based on a backstepping method to address the consensus tracking problem for nonlinear MASs in [
23,
24,
25,
26]. Considering the agents’ state may be unmeasured, observers were designed to estimate state variables in [
23,
25,
26]. However, applying the backstepping method may lead to the computational complexity explosion problem because of the repeated differentiation of virtual controllers at each step. In fact, we need a controller with lower complexity; in other words, we need the generation of control signals that only requires simple calculations.
When analyzing and dealing with consensus problems, in addition to ensuring that the control variable can be predefined with maximum allowable overshoot and minimum convergence rate, whether the consensus can be achieved in a finite-time is also an important issue. Because in some scenarios, such as military drone operations, it is necessary to ensure that the agents achieve formation consensus at the appointed time. Therefore, this topic has also attracted the attention and research of many scholars. The distributed finite-time consensus protocol was firstly proposed by Cortés [
27]. Subsequently, various finite-time controllers for MASs have been designed in the current works [
28,
29,
30]. However, in these studies, the convergence time depends on the initial states of agents, which means that if the initial states are not known a priori, and the convergence time for the consensus can not be estimated. To relax such a limitation, in [
31,
32], the fixed-time control was realized, and the upper bound of the settling time can be determined by some state-independent parameter by using the terminal sliding mode control technology. The cost is that the controller will be discontinuous, and in this case, it is difficult to be effectively applied in practical engineering. Therefore, it is necessary to find other control schemes, so that the controller is continuous, making it suitable for a wide range of practical engineering applications. In addition, most of the PPC methods in the literature usually use traditional exponential performance functions to quantitatively describe the transient and steady-state performance of the controlled systems, and sometimes it is difficult to guarantee that the controlled variable achieves the expected accuracy in fixed time.
Motivated by the above issues, we propose a PPC method to achieve leader-following consensus for the second-order MASs in this paper. The specified performance index is described as error constraints, and the constrained MAS is transformed into an unconstrained system by using the transformation error function. The controller of each agent only uses the position and velocity information of the neighbor agent and itself. The main contributions are given as follows.
The rest of this paper is arranged as follows. In
Section 2, the basic knowledge of graph theory, the core idea of PPC design, and the description of the problem studied in this paper are introduced. The main results are presented in
Section 3, which includes the proposed controller and the proof of leader-following appointed-time consensus with prescribed performance. Simulation examples are presented in
Section 4. Some conclusions are drawn in
Section 5.
Notations: Throughout this paper, denotes the i-dimensional Euclidean space; is the absolute value of a real number; is the Euclidean norm of a vector; and , respectively, denote the smallest eigenvalue of a matrix and the largest eigenvalue of a matrix; matrix means K is positive definite. An M-matrix can be expressed in the form , where with for , and , with being the spectral radius of matrix D.
2. Problem Formulation and Preliminaries
2.1. Graph Theory
The network among the N followers is represented by a directed graph , where is the set of nodes that represent the followers, with representing the ith follower, and is a directed edge set. is the adjacency matrix with , . In particular, if follower has access to follower information, then , which also means that edge exists, otherwise , and in adjacency matrix , for any i. For a directed graph, the Laplace matrix related to the adjacency matrix is defined as for ; Matrix with . In this paper, we only consider the case where there is only one leader. It is defined that when information flows from the leader to the follower , , otherwise, . To distinguish the leader node from the follower nodes, we use to denote the leader and denotes the follower nodes. Then, the whole topology can be described by with .
A directed path is an ordered sequence of edges. For example, the edge sequence of a directed path from node to node has the form . In a directed graph, if every node except the root node (the root node has no parent node and has a directed path to other nodes) has a parent node, we call such a directed graph a spanning tree. If there is a (directed) spanning tree that is a subset of a graph, the graph is said to have (or contain) a (directed) spanning tree.
2.2. Prescribed Performance Control
In this section, we will introduce the main idea for the PPC approach, which is used for linearizable MIMO nonlinear systems [
13].
First, the constraints are imposed on the controlled variable
, which are designed as upper and lower bound constraints. The mathematical expression of the prescribed performance specification can be formulated by the following inequality [
13]:
for all
, where
and
is the performance function satisfying that (i)
is a smooth function, (ii)
is positive and decreasing, and (iii)
, where
is a small positive constant.
Second, by means of spatial equivalent mapping, the nonlinear system under constraint (in the sense of (
1)) can be transformed to the unconstrained system of
. More specifically, define
where
,
is the transformed error, and
satisfies
- (i)
is strictly increasing and smooth
- (ii)
- (iii)
if
if
A diagrammatic sketch of
is represented in
Figure 1. The boundedness of
leads to
in the case of
and
in the case of
. Hence, the evolution of
with some constraint specification, namely, (
1) holds if
is bounded.
2.3. Problem Statement
We consider the MASs with
N followers and a leader over directed graphs. The double-integrator dynamics of follower
i are described as follows:
where
are the position, velocity, control input, and external disturbance of the
ith follower, respectively, for
. Let
and
be the stack vector of MASs. The leader’s dynamics is described as
where
is leader’s position and
is leader’s velocity. In order to simplify the subsequent controller design of each follower, the following assumptions are required.
Assumption 1. The graph contains a spanning tree with the root node being the leader, and there exists no self-loop for each vertex.
Assumption 2. is piecewise continuous and is bounded.
Assumption 3. For the external disturbance , there exists a positive constant such that .
We use
and
to represent the cumulative position difference and the cumulative velocity difference of the
ith follower agent, respectively, which are defined as follows:
Then, we define the position tracking error and the velocity tracking error for the ith follower as , .
Definition 1 ([
35]).
(Practical appointed-time consensus for leader-following networks): For the leader-follower networks described by MASs (3) and (4), the practical appointed-time consensus can be achieved if the following conditions hold:andwhere is the appointed setting time, is the maximum allowable steady-state error, and . Our goal is to design a distributed consensus control protocol for linear MASs expressed by (
3) and (
4) such that the following apply:
(1) The practical appointed-time consensus as defined by Definition 1 is achieved.
(2) The cumulative position difference
evolves within a prescribed region, which is quantified as
where
is the performance function.
(3) The control input and the velocity of the ith follower, i.e., , are bounded.
Before moving on, three lemmas are introduced as follows, which will be employed in the proof of the main results.
Lemma 1 ([
36]).
Let be a nonsingular M-matrix, then there exists a diagonal positive definite matrix such that is positive definite, where and . Lemma 2 (H
lder’s Inequality [
37]).
For and , the following inequality is satisfied:with and being real numbers and . Lemma 3 ([
38]).
Consider a class of differential equation such that , with β: and being a non-empty open set. If the conditions hold:- (i)
β is locally Lipschitz over χ;
- (ii)
β is continuous over t;
- (iii)
β is locally integrable over t, .
A unique maximal solution can be obtained that χ: [0,) of on the time domain with , and consequently, , . Furthermore, if and , there exists a time moment such that .
3. Main Results
Define
,
. The dynamic model of the cumulative difference in vector form is written as follows:
where
and
.
Let us define the normalized error
as
. Then, let
where
, with
being performance functions to be determined later.
Define the transformation error
Let
Differentiating
with respect to
t obtains
where
,
. In order to simplify the description of
and
,
and
S are used to denote
and
, respectively, in the following content.
Next, partly inspired by [
39], a novel smooth performance function is defined as
where
,
, and
.
With the given performance function (
12), Lemma 4 is introduced.
Lemma 4. The performance function (12) satisfies the following properties: - (1)
- (2)
- (3)
and for any where represents any small constant and is the setting time.
- (4)
is a smooth function.
Remark 1. In the present research results on PPC, a conventional performance function [13] is shown in (13). Compared with , our proposed performance function in (12) has the property that it guarantees appointed-time convergence, which does not hold for due to where , and . The distributed control protocol is given as follows:
with
,
being positive constants, and
,
have been defined in (
6) and (
10), respectively.
With control input (
14), system (
8) can be rewritten as follows:
The following theorem presents our main results.
Theorem 1. Under Assumptions 1 and 2, consider MASs (3) and (4) with a directed graph. With the control protocol given by (14), if the controller parameters are chosen such that , , and with , , , , , and let , then the control objectives mentioned in Section 2.3 can be achieved. Proof. It follows from Assumption 1 that
is a nonsingular M-matrix [
40]. According to Lemma 1, there exists a diagonally positive definite matrix
, with
and
. We propose the following Lyapunov function candidate:
with
and
. It can be verified that
which means that the Lyapunov function is positive definite. Differentiating (
16) with respect to
t obtains
Differentiating
versus time obtains
Since the performance functions
are selected such that
, then
is satisfied. Suppose there is a time instant
after which
escapes from
. It is deduced
Then, it is easy to find that there exists
and
, such that the following inequalities hold,
where
,
is a constant to be determined. Define
.
Define
with
and
.
is the subset of
, and
escapes from
only when
. In other words,
Owing to (
21) and the boundedness of
by its construction, it can be obtained that there exists a
, such that
, for all
. Then the following inequality is satisfied for all
.
where
,
,
. It is noted that in the above expression,
is obtained by using
, and
is obtained by using
.
Moreover, one yields
where
,
,
,
and
with
,
.
By choosing appropriate
and
, we can ensure that
W is positive definite. More specifically, by chosing
, it can be verified that
. To guarantee that
, one obtains the following inequality
where
. We further require that
, which is equivalent to
, and in this case,
.
Then it follows from (
22) that
if
. Owing to Assumption 2, we obtain that
is finite. It is concluded that
From (
24), it can be further obtained that
, and
for all
. Through (
10), (
19), and (
20), it is obtained that for
where
and
. It is noted that if
,
and
can be guaranteed by selecting
. Similarly, if
,
can be chosen such that
.
Define
. From (
25) we can obtain that at all
,
. Hence, assuming
, it follows from Lemma 3 that
implies the existence of
, such that
, which contradicts (
25). Therefore,
and then
can be extended to
. Thus we can obtain, for any time
. Moreover, owing to Lemma 4, it is easy to verify that
.
In addition, according to [
22], one has
where
,
, and
.
Therefore, it can be further obtained that
From (
28), we can verify that
and
are also bounded.
Moreover, the control input
remains bounded:
This completes the proof of the Theorem 1. □
Remark 2. It is noted that in [35], the control input information of its neighbor followers is needed to achieve appointed-time consensus for second-order MASs with guaranteed prescribed performance. As a contrast, our proposed controller of the ith follower does not need the control input information of its neighbors. In order to summarize the main results, we provide the following algorithm in
Table 1, and the consensus control block diagram is shown in
Figure 2.
4. Simulations
This section presents an example to validate the effectiveness of our proposed control protocol. Consider the MASs with one leader agent and seven following agents in this example, wherein the dynamics of the leader and the followers are represented by (
3) and (
4), respectively.
Figure 3 shows the information flow among all agents, with which Assumption 1 is satisfied. From
Figure 3, the Laplace matrix
L, the adjacency matrix
, and matrix
B are given as
. Let , , be the position and the velocity of each follower i, respectively. The initial values of the followers are set as , , , , , , , , , , , , , . The vector of disturbance for followers on x-dimension and y-dimension are both set as .
Let , be the position and the velocity of the leader. The values of the leader’s initial position and initial velocity are set as and , respectively.
The designed parameters in (
12) are selected as
,
,
. Finally, by using Theorem 1, the control parameters are selected as
,
. In order to prove that the controller proposed in this paper achieves the appointed-time leader–follower consensus for the MASs with the prescribed performance, the simulation results will be compared with the existing controller without PPC [
6], whose controller is given as follows:
where
and
, and Wei’s controller in [
35], whose controller is given as follows:
where
,
,
and
is the performance function designed in [
35]. The designed parameters in (
31) are selected as
,
,
,
,
,
and the
was defined in [
35].
Simulations are carried out based on the MATLAB R2020b platform. The simulation results are illustrated in
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10. In
Figure 4, we can see the comparison with respect to the transient performance of MASs using controller (
14) and controller (
30). It is worth noting that controller (
30) can only deal with the MASs without disturbance, and controller (
14) deals with the MASs whose disturbance is
d set above. We can see that the controller (
30) cannot guarantee the prescribed transient performance, i.e., overshoot and convergence speed, and it is also difficult to determine when the system can reach the tracking accuracy. Looking back at
Figure 4a, using controller (
14), seven followers’ cumulative position difference evolves within the performance function boundary, and the error converges to an arbitrarily small expected region within the appointed time, proving that the proposed controller can ensure that each follower satisfies the prescribed performance constraints. Define the average control effort as
. It should be noted that
Table 2 and
Figure 5 are obtained with the disturbance equaling 2
d rather than
d.
Table 2 shows the maximum amplitude of the control input and control effort of followers using both controller (
14) and controller (
31). We can see that the proposed controller (
14) reduces the maximum control input and control effort, while the appointed-time and tracking accuracy are the same as (
31).
Figure 5 shows the seven followers’ cumulative position difference trajectories using both controler (
14) and (
31). Although using controller (
31) can achieve faster convergence rate, the control input also increases accordingly. Furthermore, the controller (
31) of follower
i needs the control input
of its neighbor
j, which needs more information, and thus it is more difficult to implement in practice.
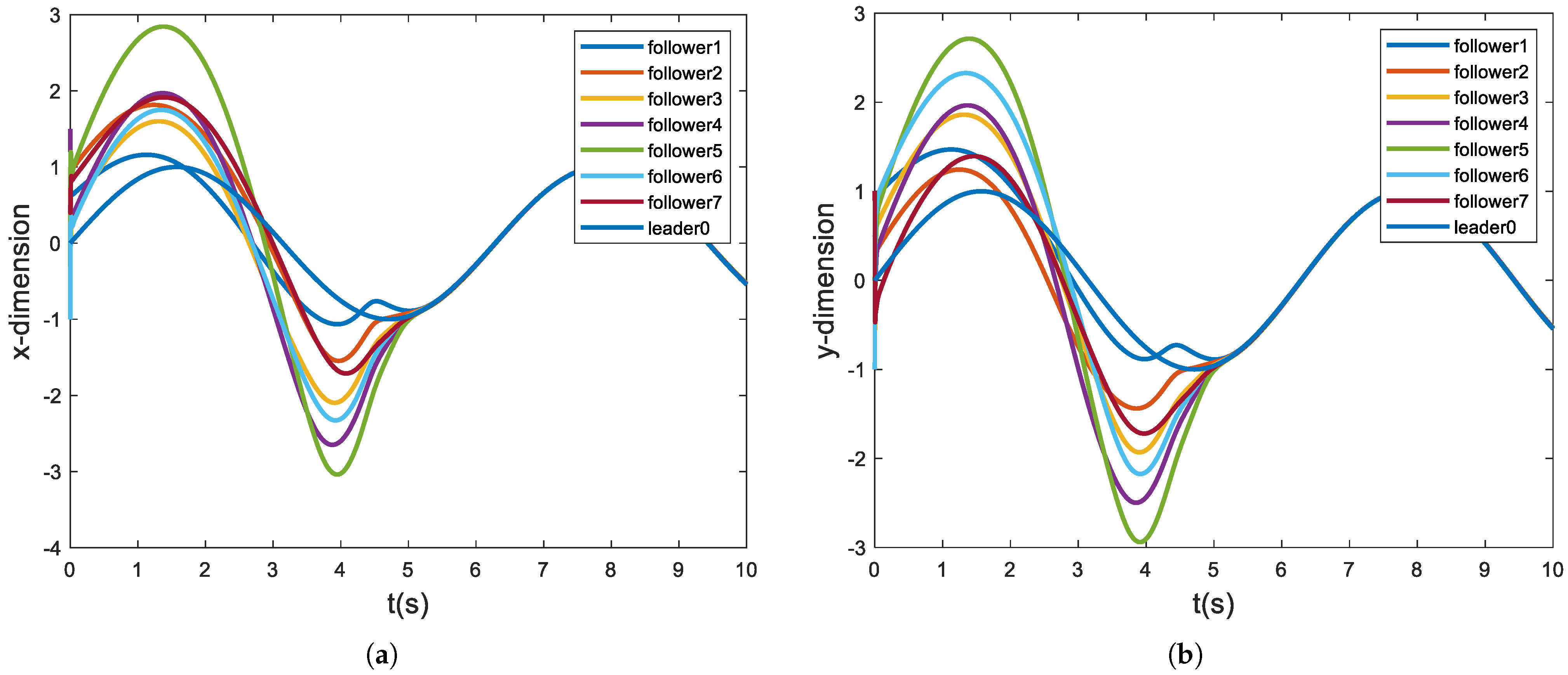
Figure 6 shows the seven followers’ cumulative velocity difference converges to a bounded region. The trajectories of the agents in the x-y dimension are pictured in
Figure 7, and it can be seen from the figure that all followers can follow the leader’s movements within 6 s. As demonstrated by
Figure 8, the velocity of each follower is bounded, and before the appointed time, the follower’s velocity converges to the leader’s velocity, which is also consistent with the convergence of the followers’ position, as shown in
Figure 7.
Figure 9 further shows that the position tracking error converges to an arbitrarily small expected region within the appointed time, which verifies that the system achieves the practically leader-following appointed-time consensus.
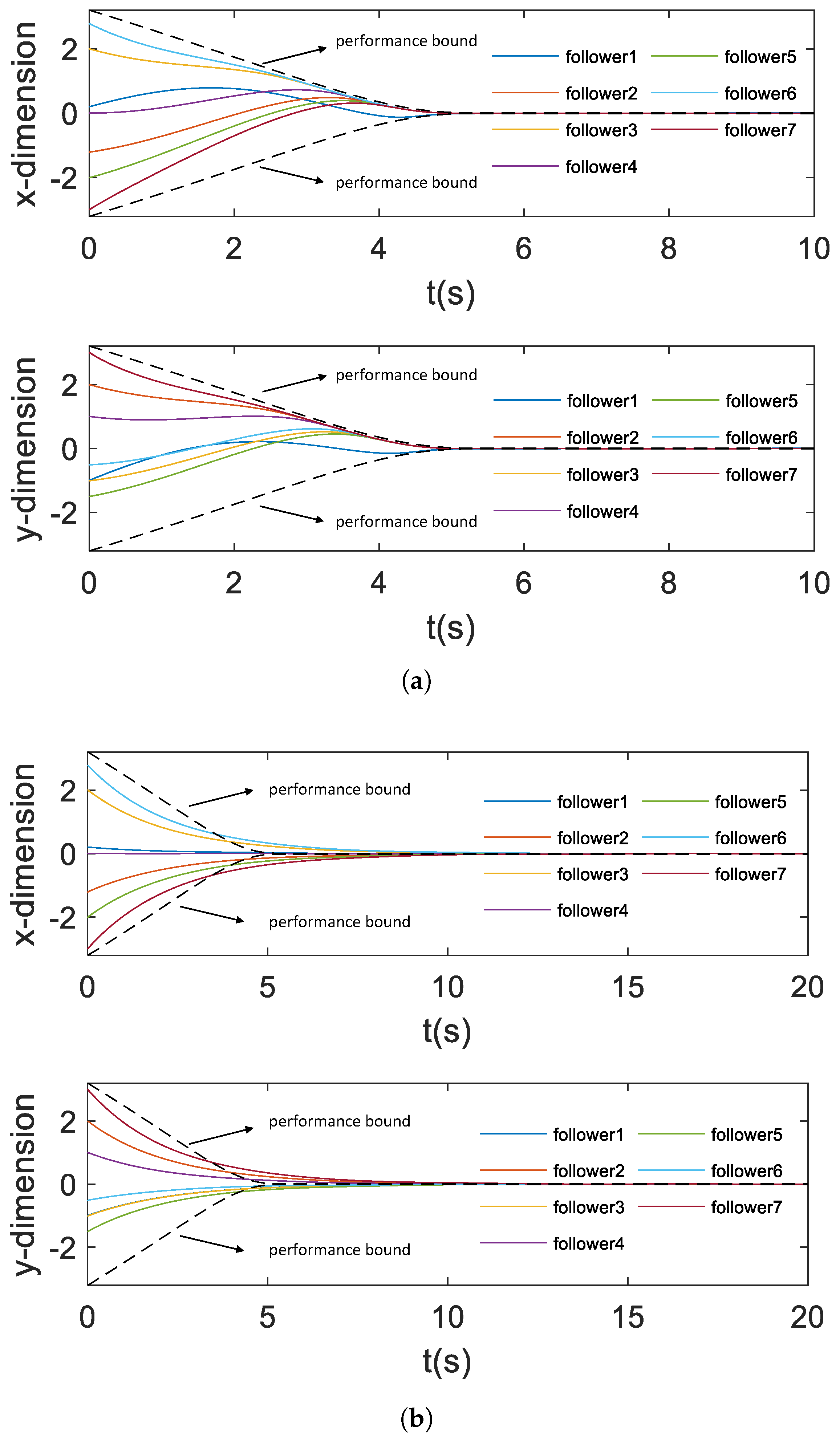
In order to analyze the sensitivities of the control parameters for the system performance, we choose different control parameters for the proposed control scheme. In both three cases, except for
and
, all other parameters remain the same. The maximum amplitude of the control input and the control effort under different parameters on x-dimension are shown in
Table 3.
Figure 10a,b show the cumulative position difference trajectories with controller parameters set to
,
and
,
, respectively.
Remark 3. As shown in Table 3, we further choose different and . In all the three cases, convergence can be achieved with the similar control effort. Furthermore, as and are increased, the oscillation is reduced at the cost of increasing the control input, as shown in Figure 4a and Figure 10. 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}