
Robust Facial Expression Recognition Using an Evolutionary Algorithm with a Deep Learning Model

 , ,
, ,  , and
, and 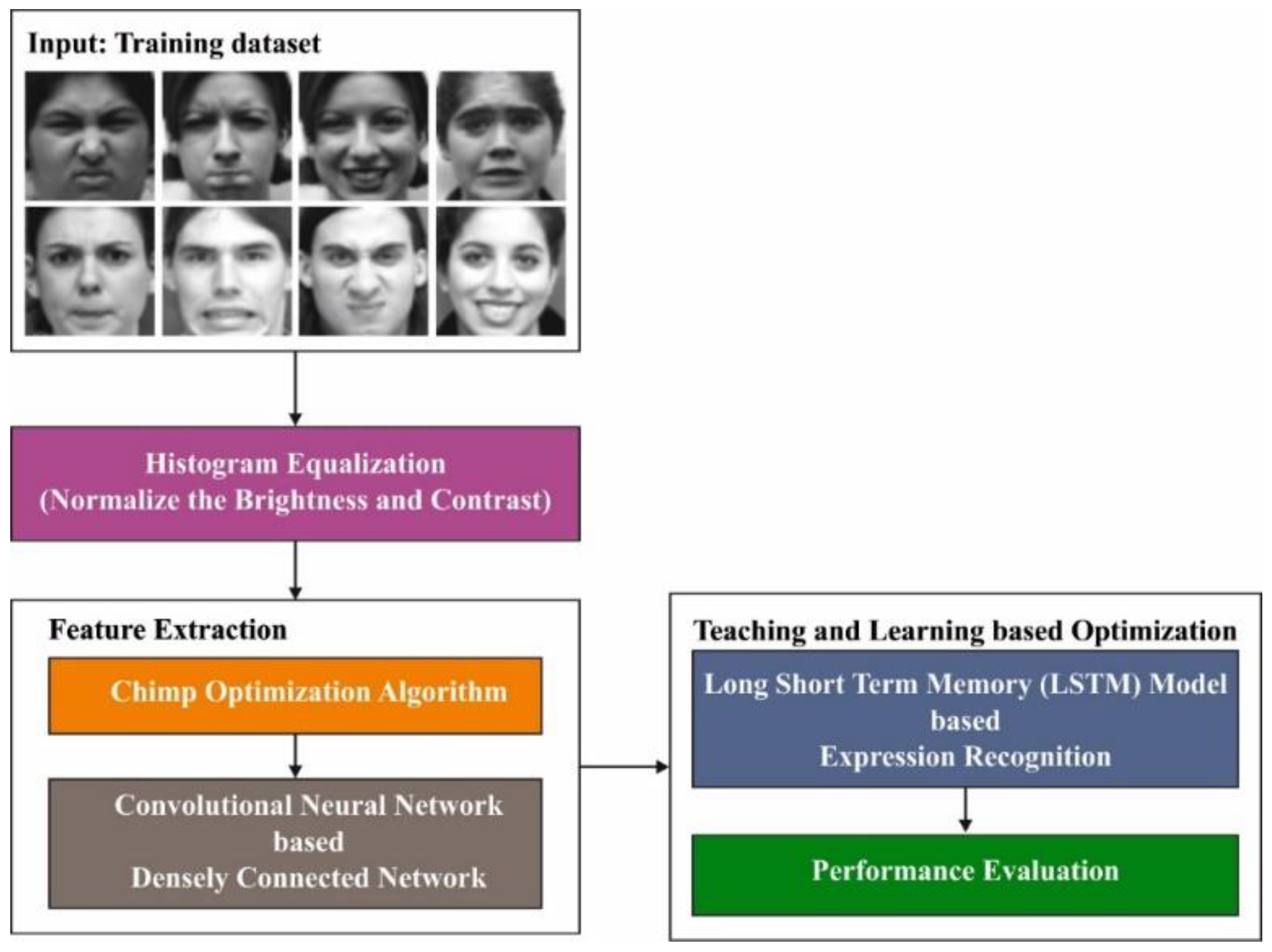{kind=link}
{kind=link}
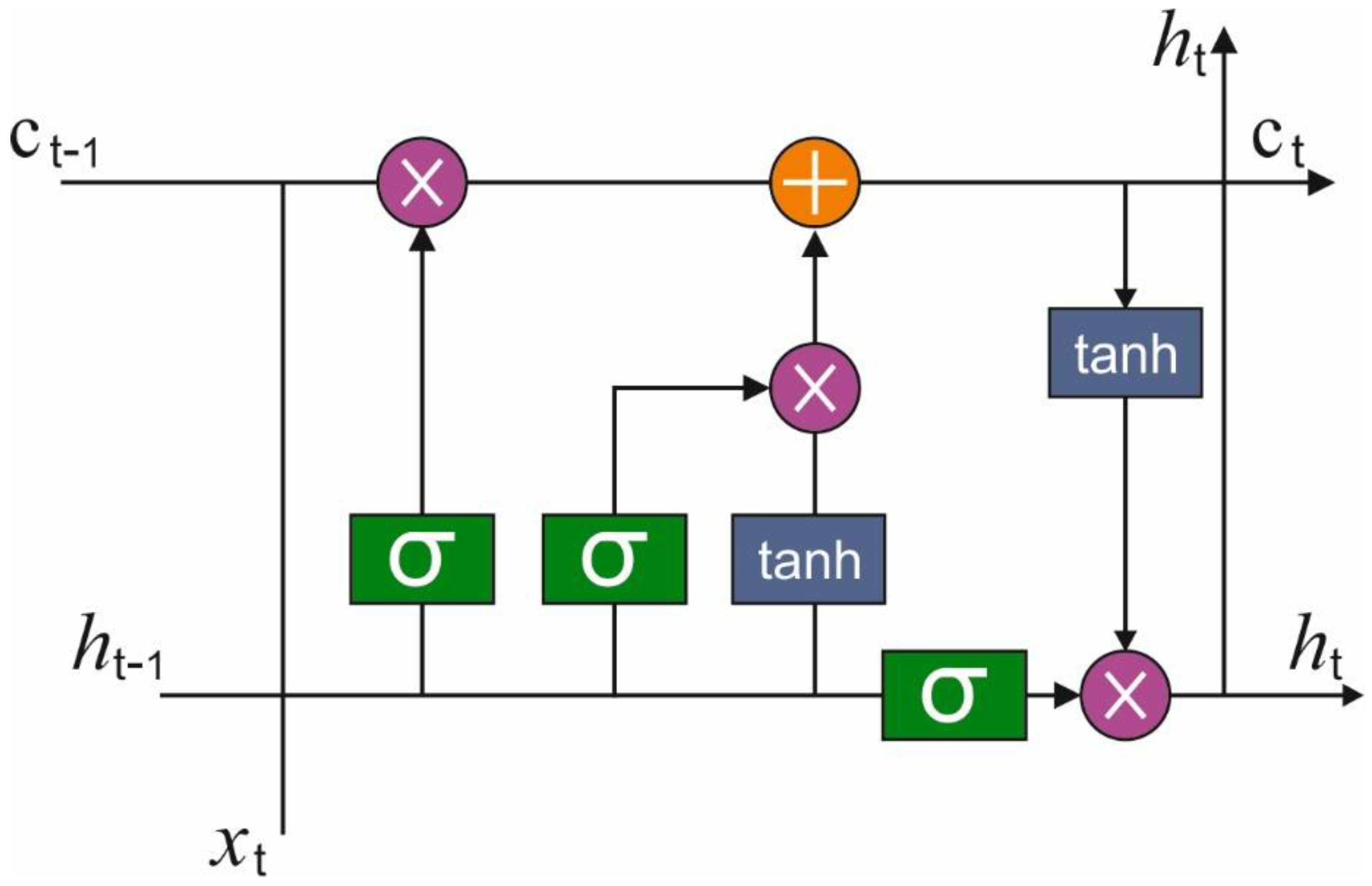
{kind=link}
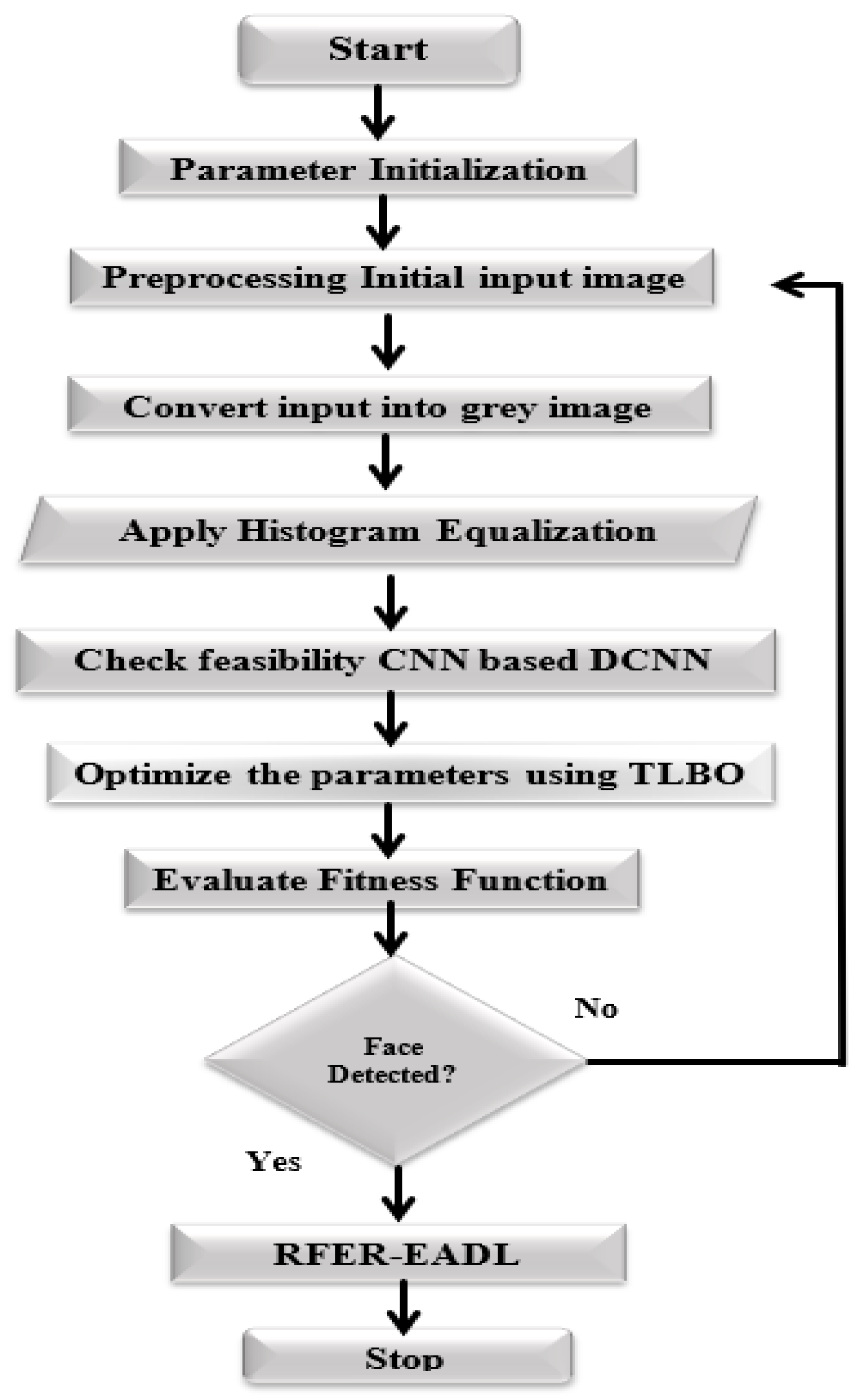
{kind=link}
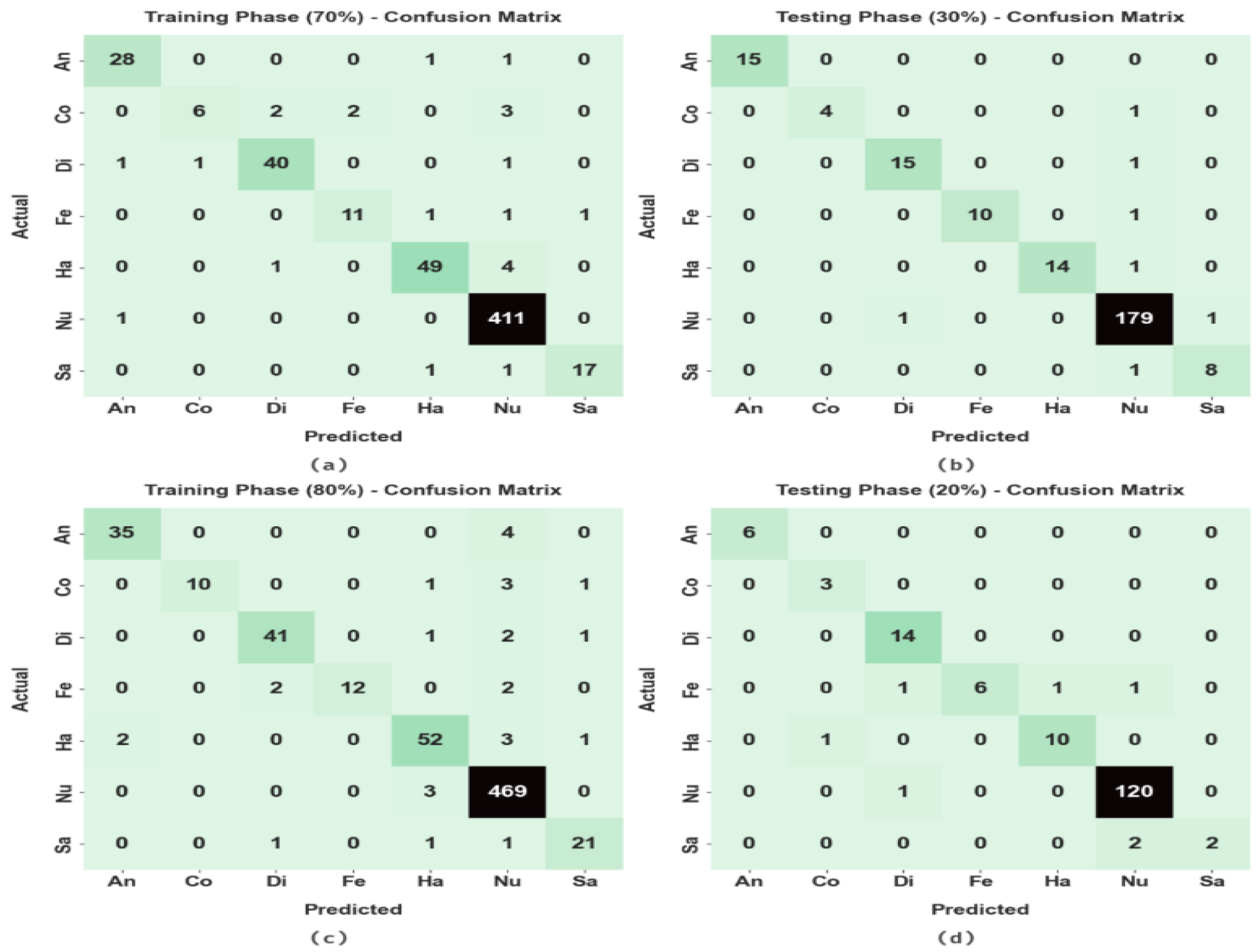{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
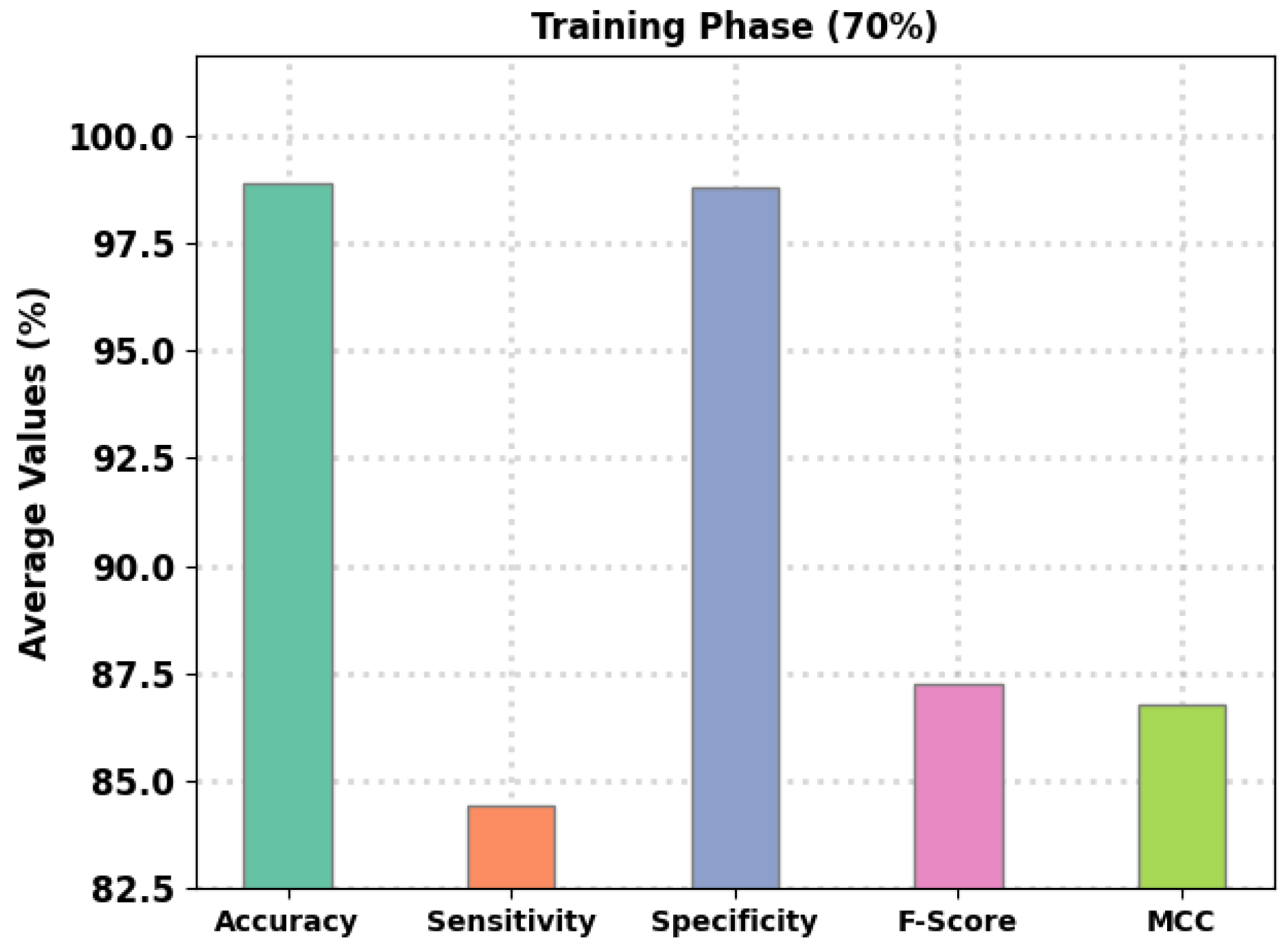
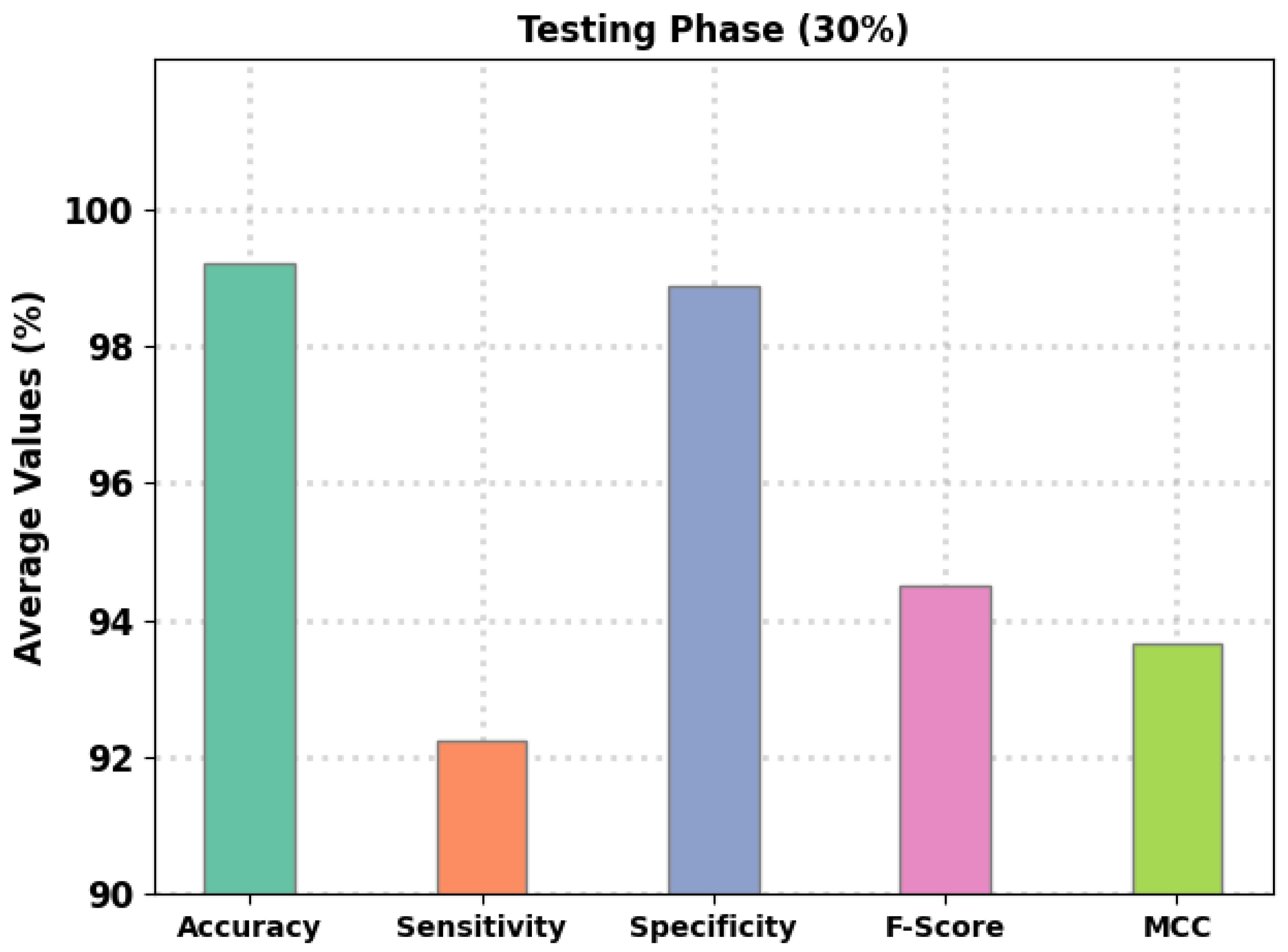
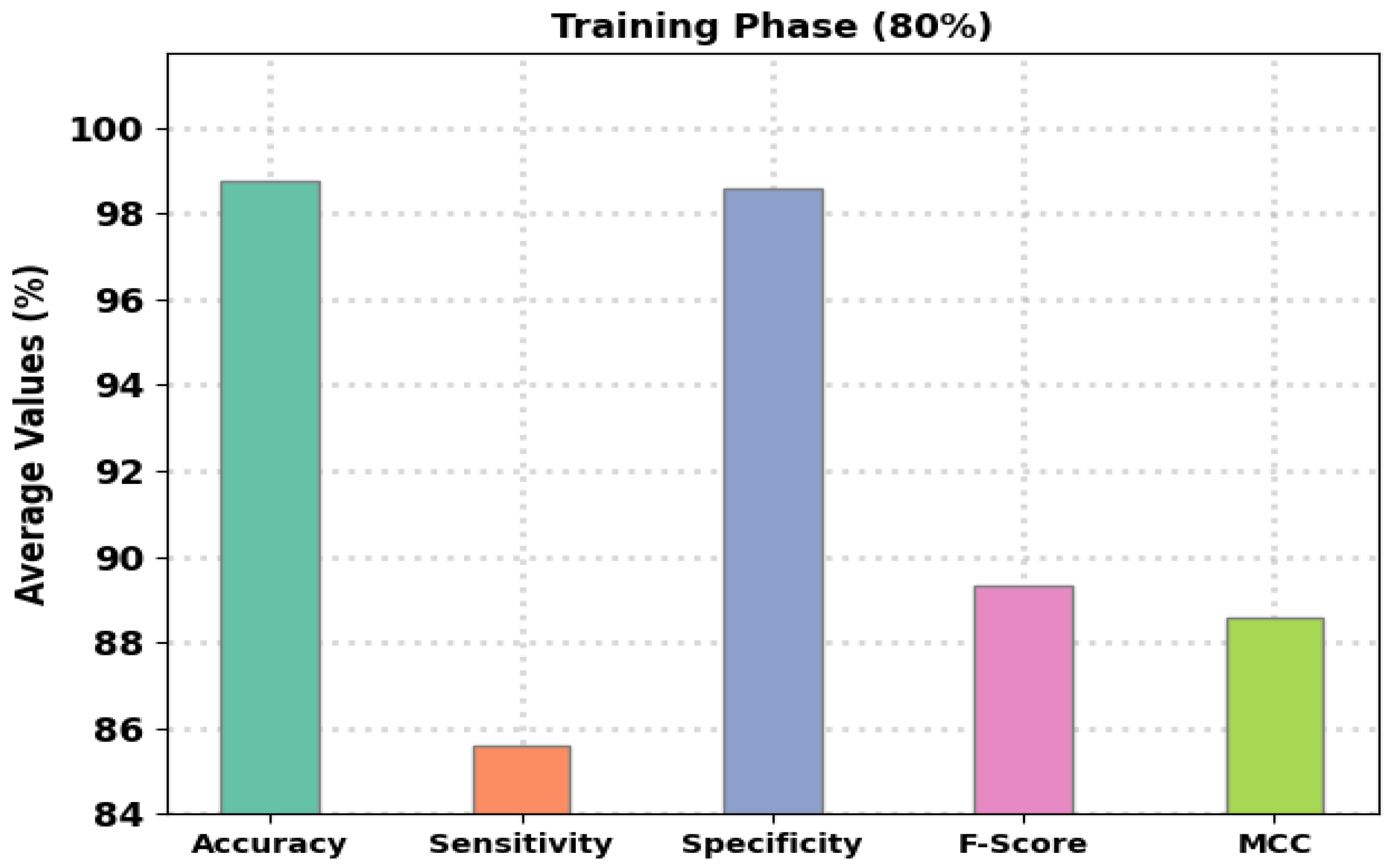
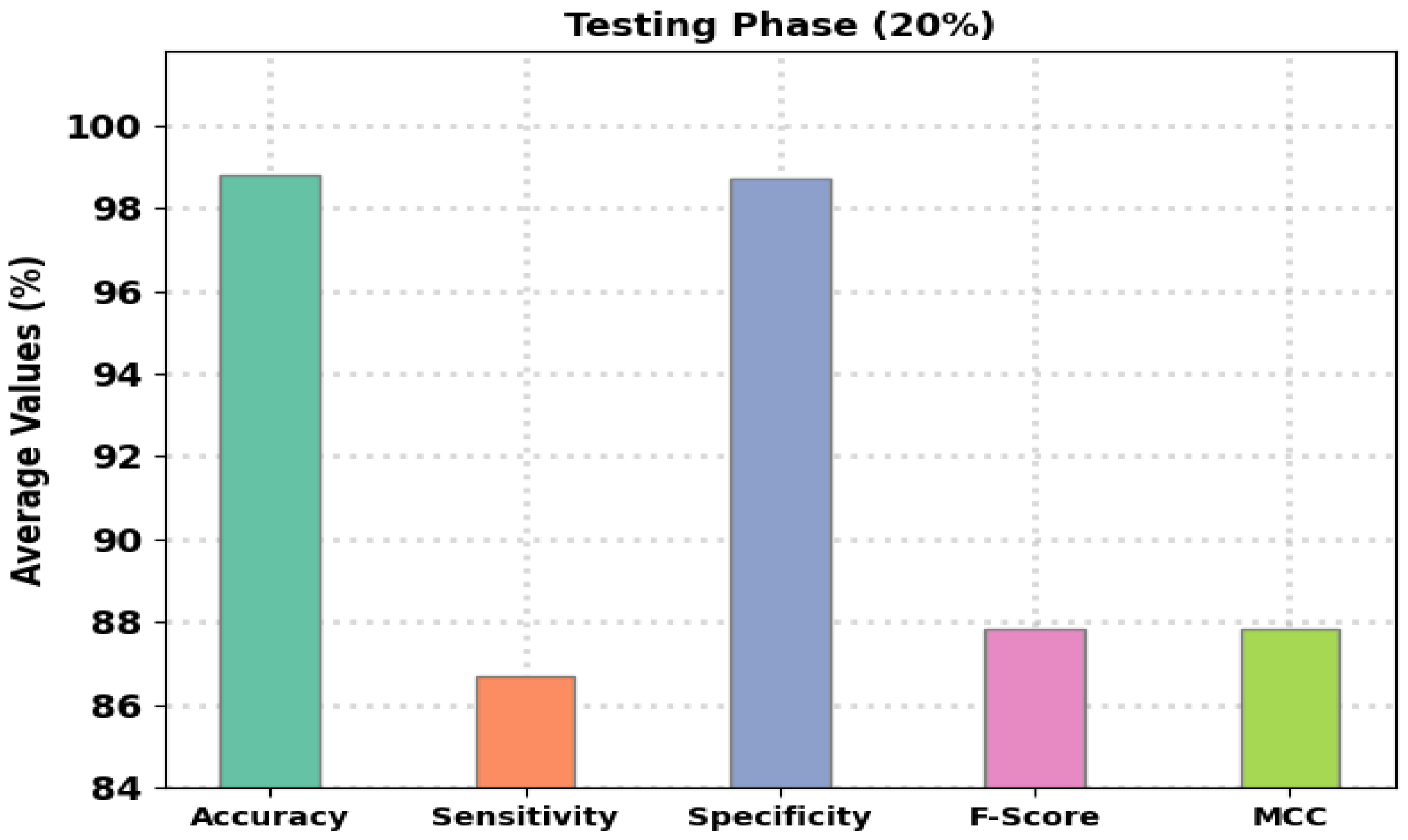
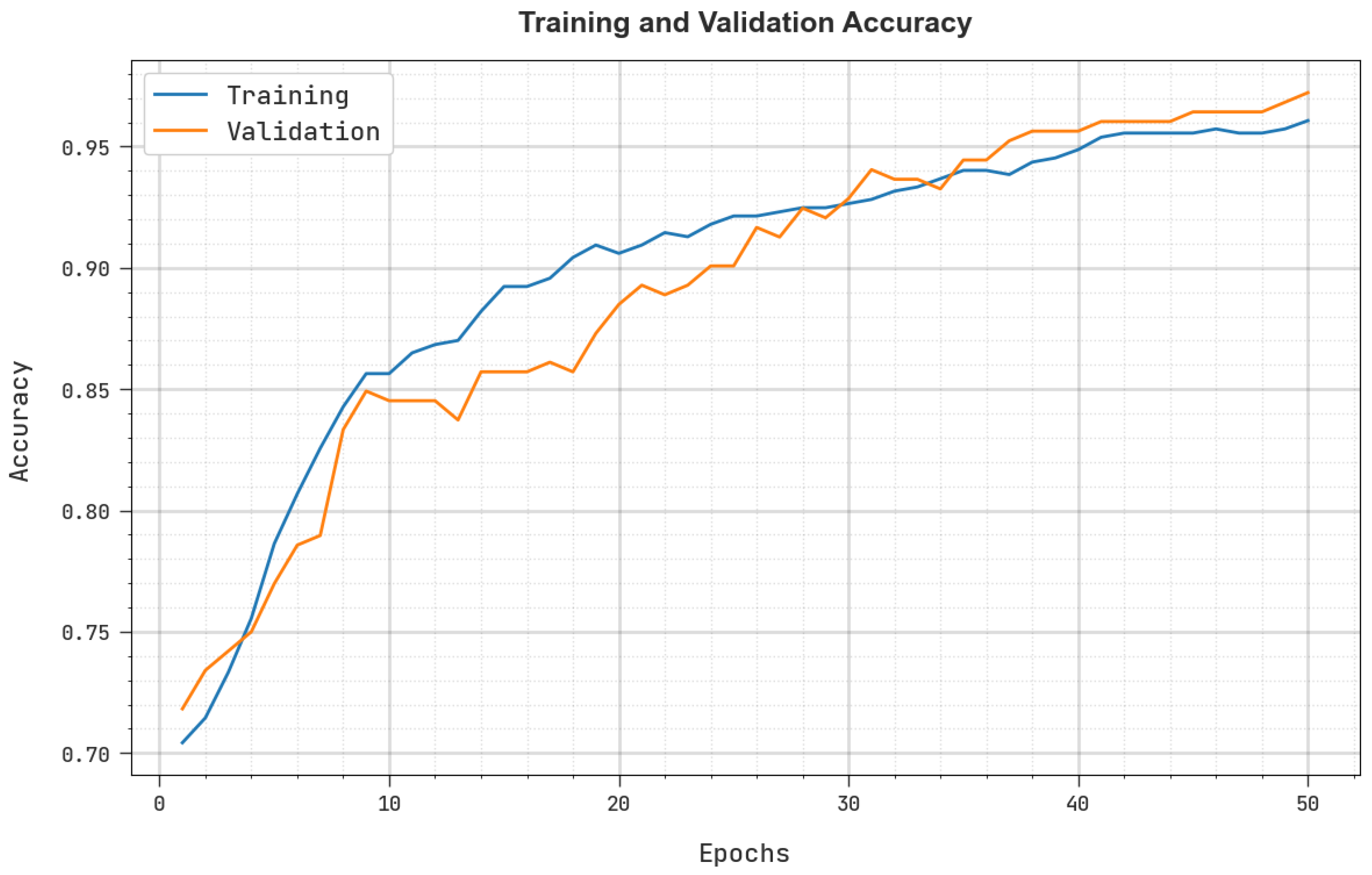
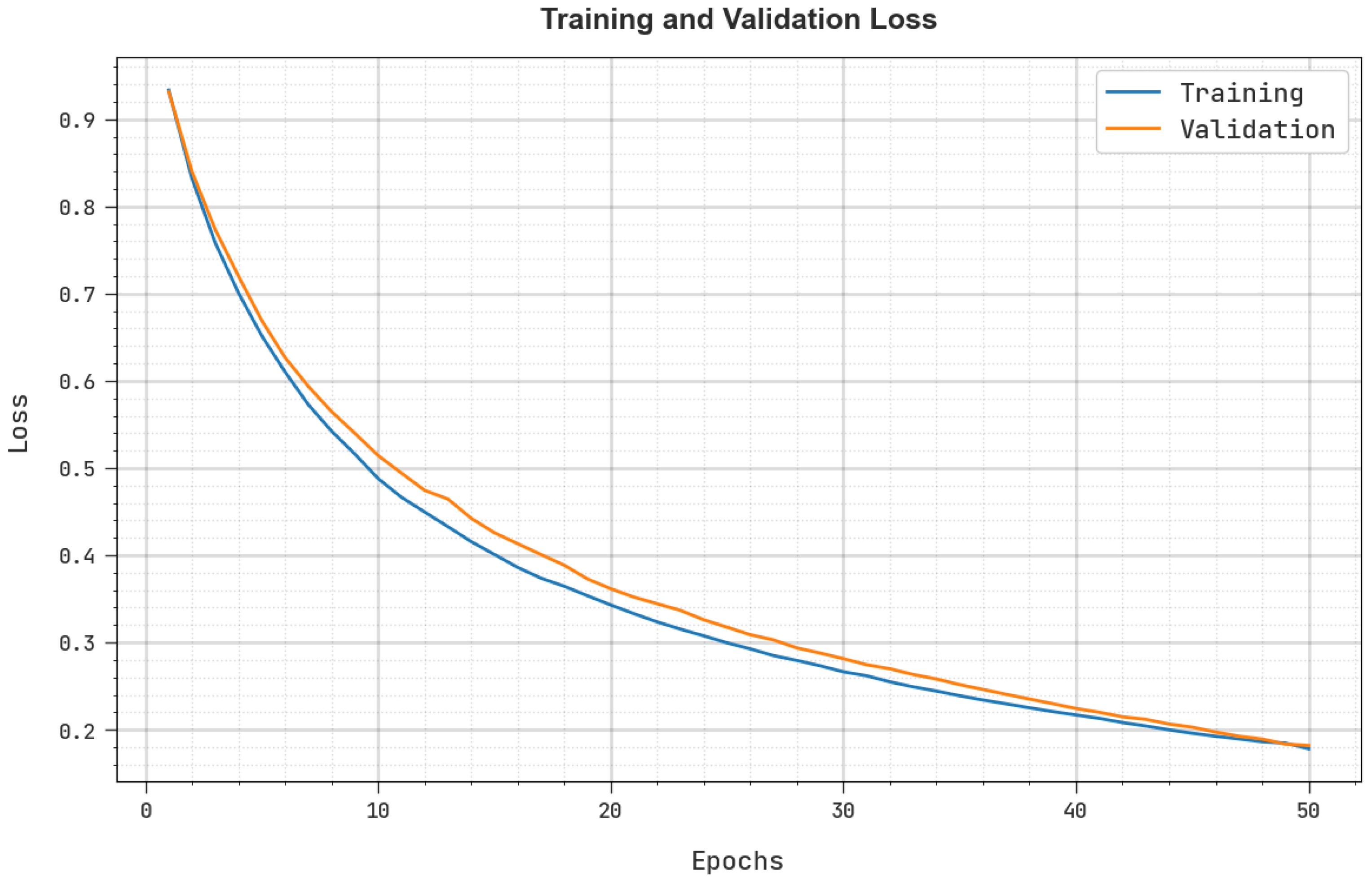
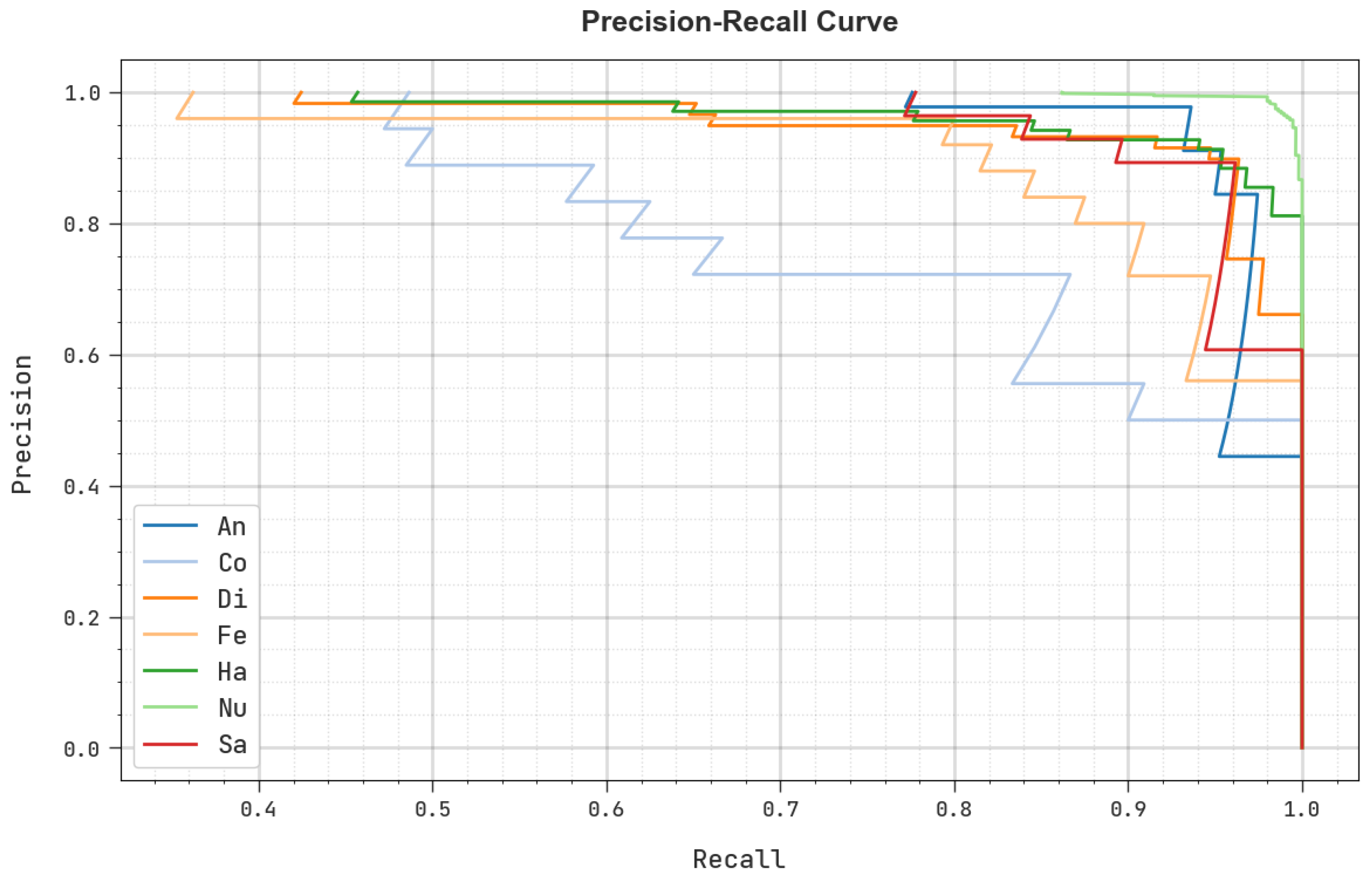
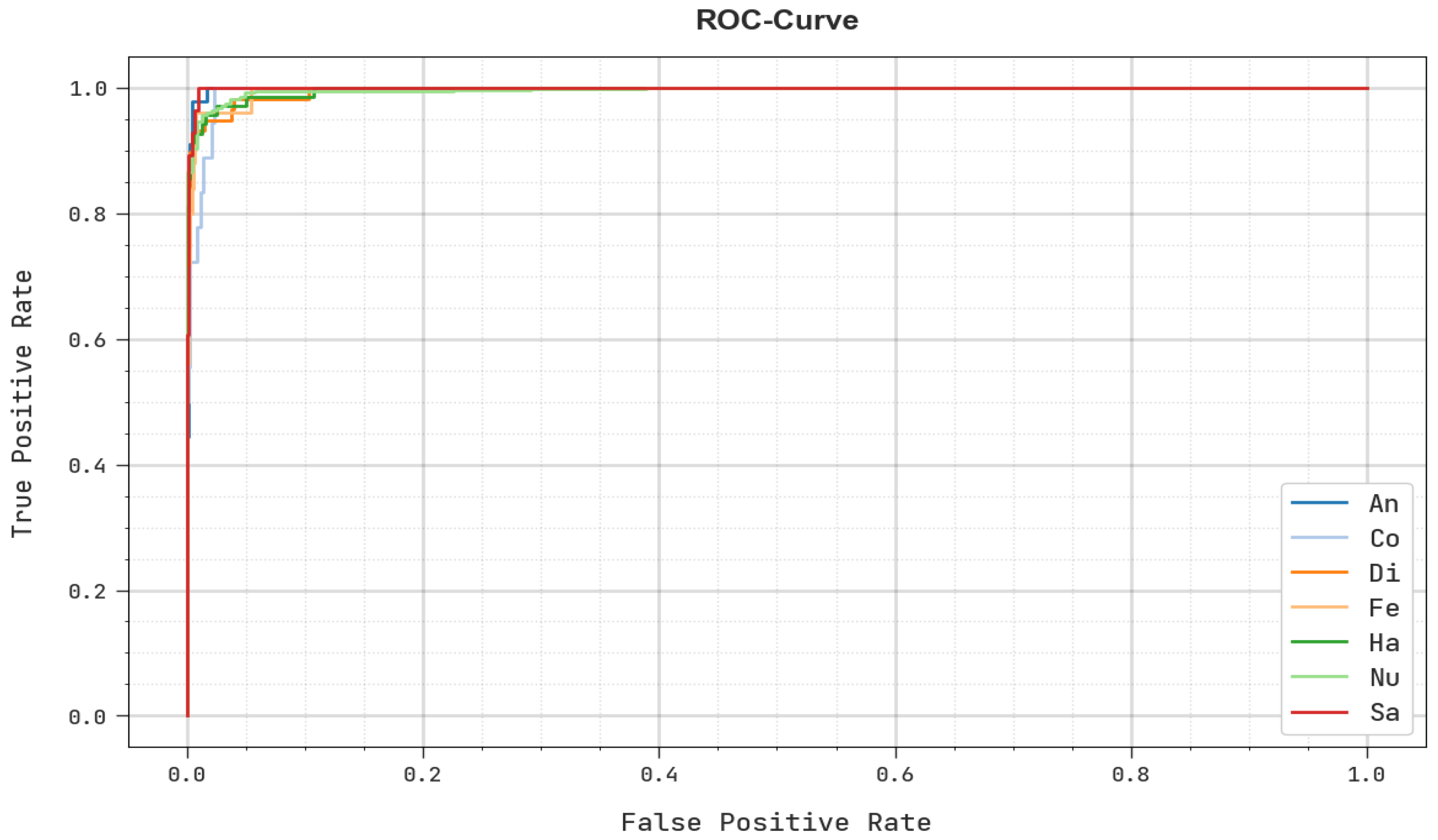
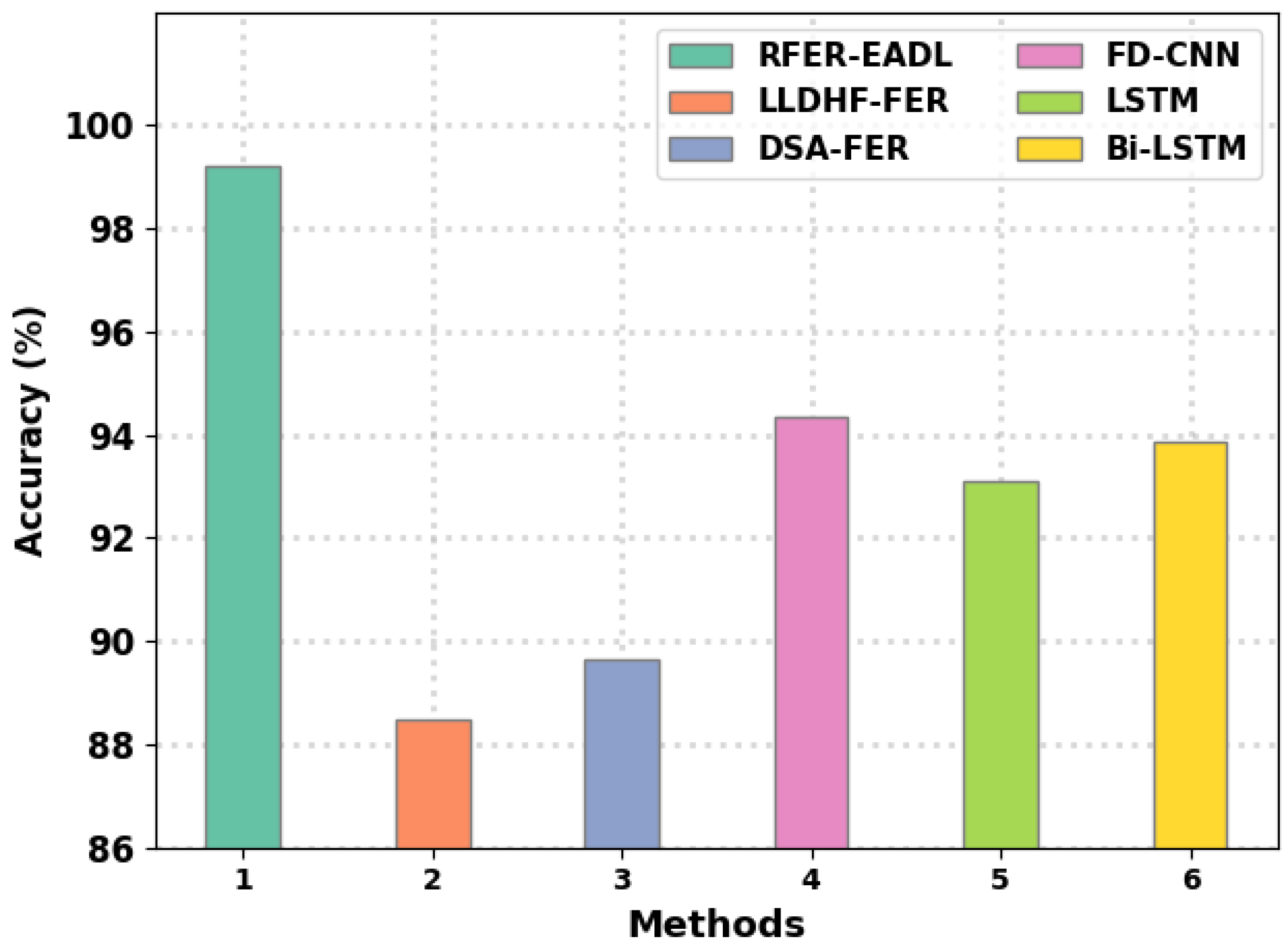
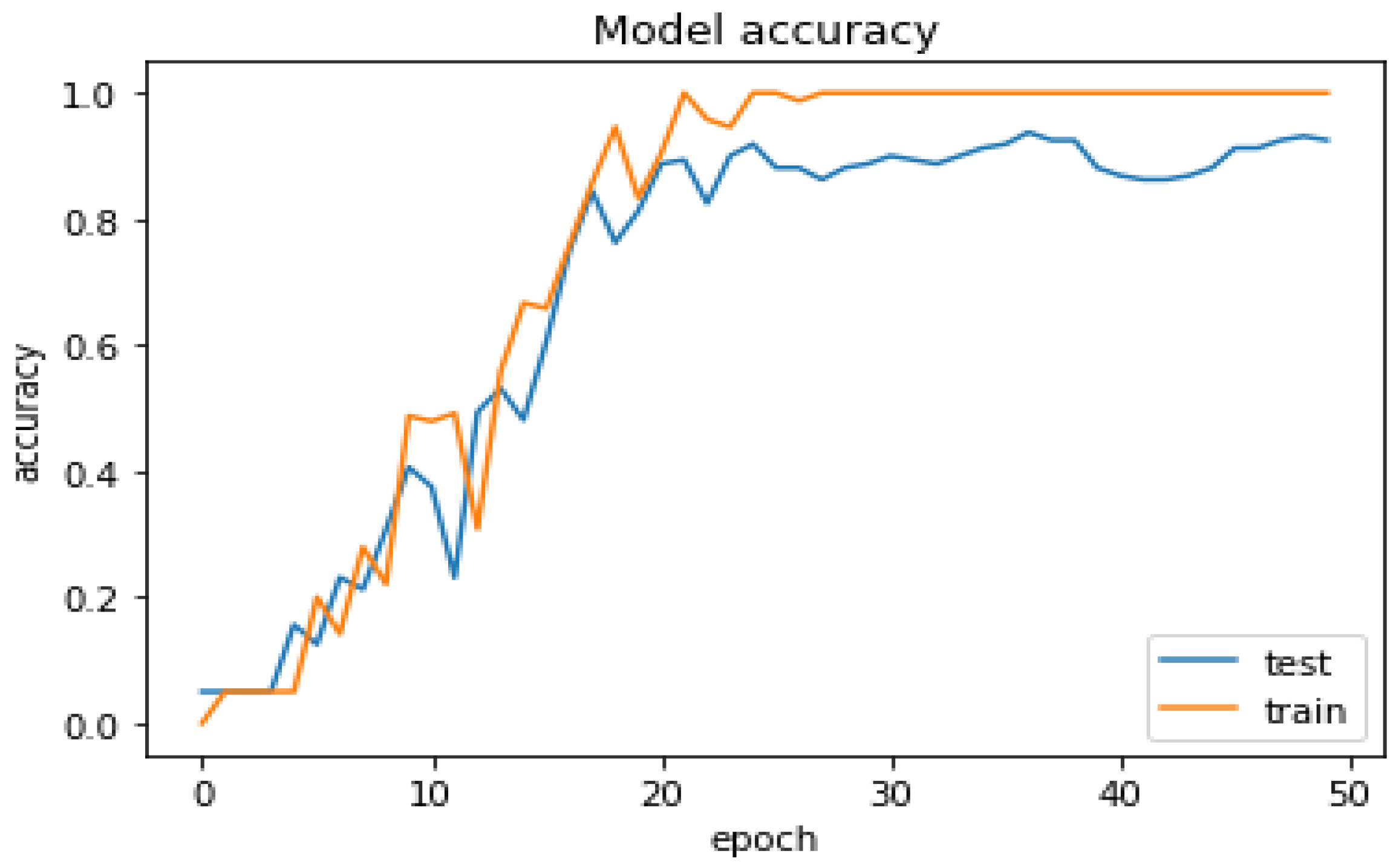
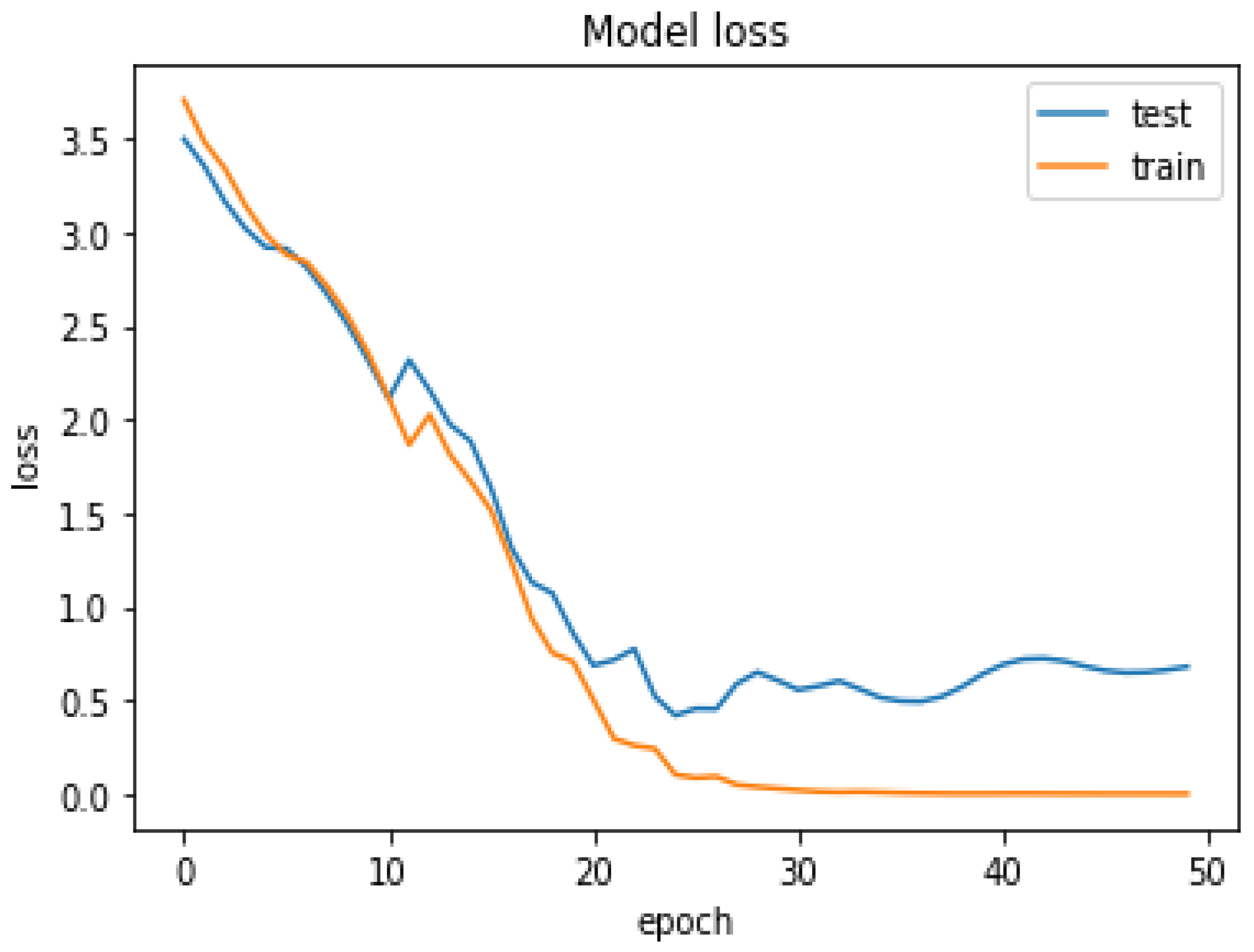
Abstract
Share and Cite
Arul Vinayakam Rajasimman, M.; Manoharan, R.K.; Subramani, N.; Aridoss, M.; Galety, M.G. Robust Facial Expression Recognition Using an Evolutionary Algorithm with a Deep Learning Model. Appl. Sci. 2023, 13, 468. https://doi.org/10.3390/app13010468
Arul Vinayakam Rajasimman M, Manoharan RK, Subramani N, Aridoss M, Galety MG. Robust Facial Expression Recognition Using an Evolutionary Algorithm with a Deep Learning Model. Applied Sciences. 2023; 13(1):468. https://doi.org/10.3390/app13010468
Chicago/Turabian StyleArul Vinayakam Rajasimman, Mayuri, Ranjith Kumar Manoharan, Neelakandan Subramani, Manimaran Aridoss, and Mohammad Gouse Galety. 2023. "Robust Facial Expression Recognition Using an Evolutionary Algorithm with a Deep Learning Model" Applied Sciences 13, no. 1: 468. https://doi.org/10.3390/app13010468
APA StyleArul Vinayakam Rajasimman, M., Manoharan, R. K., Subramani, N., Aridoss, M., & Galety, M. G. (2023). Robust Facial Expression Recognition Using an Evolutionary Algorithm with a Deep Learning Model. Applied Sciences, 13(1), 468. https://doi.org/10.3390/app13010468