
X-Transformer: A Machine Translation Model Enhanced by the Self-Attention Mechanism


Abstract
:1. Introduction
- ●
- The X-Transformer modifies the structure of the Transformer by reducing the number of model parameters in both the encoder and decoder.
- ●
- The basic building block of the encoder in the X-Transformer is refined. We believe that applying the self-attention mechanism in the feed forward layer of the encoder is helpful for the model to understand natural languages, as will be shown in the experimental results.
- ●
- Two different language pairs are applied to train the Transformer and X-Transformer at the same time. The experiment results reveal that the proposed X-Transformer has an outstanding performance.
- ●
- The visual heat map is used to aid the comprehension ability of the trained models. The results again demonstrate the superiority of the X-Transformer. The refined encoder structure of the X-Transformer elevates the comprehension ability to a token-to-token level.
2. Review of the Literature
2.1. Machine Translation
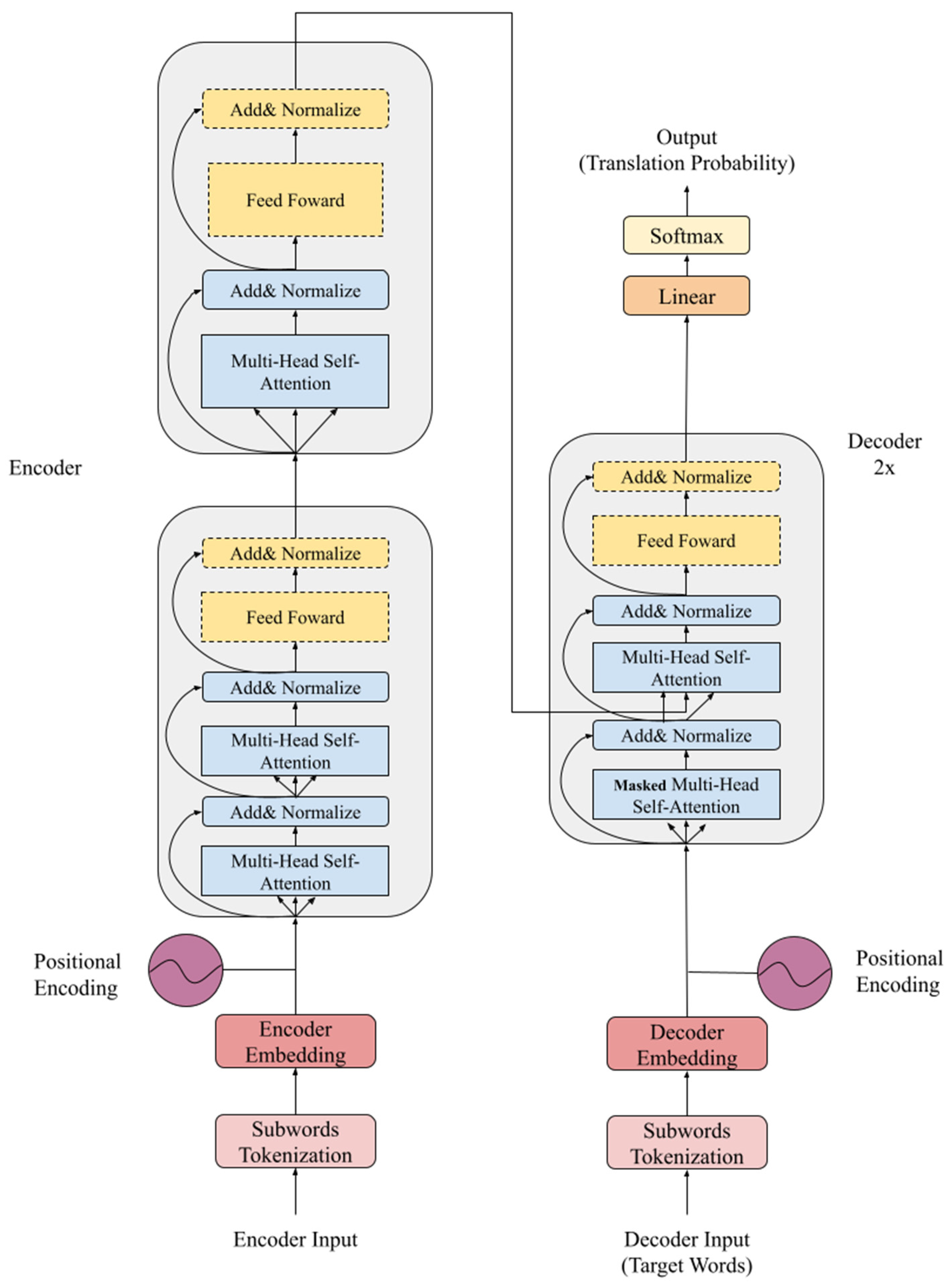
2.2. Transformer
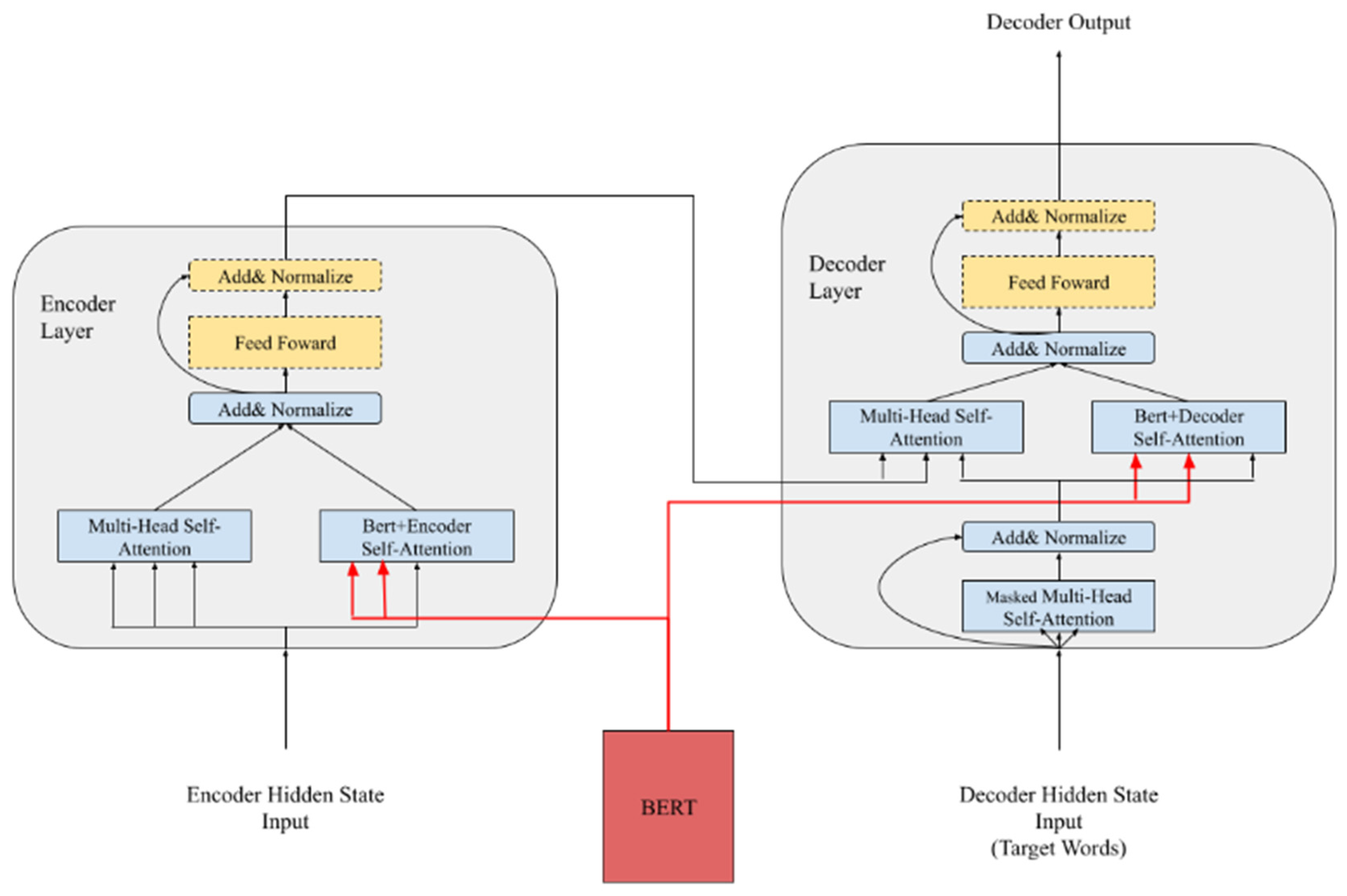
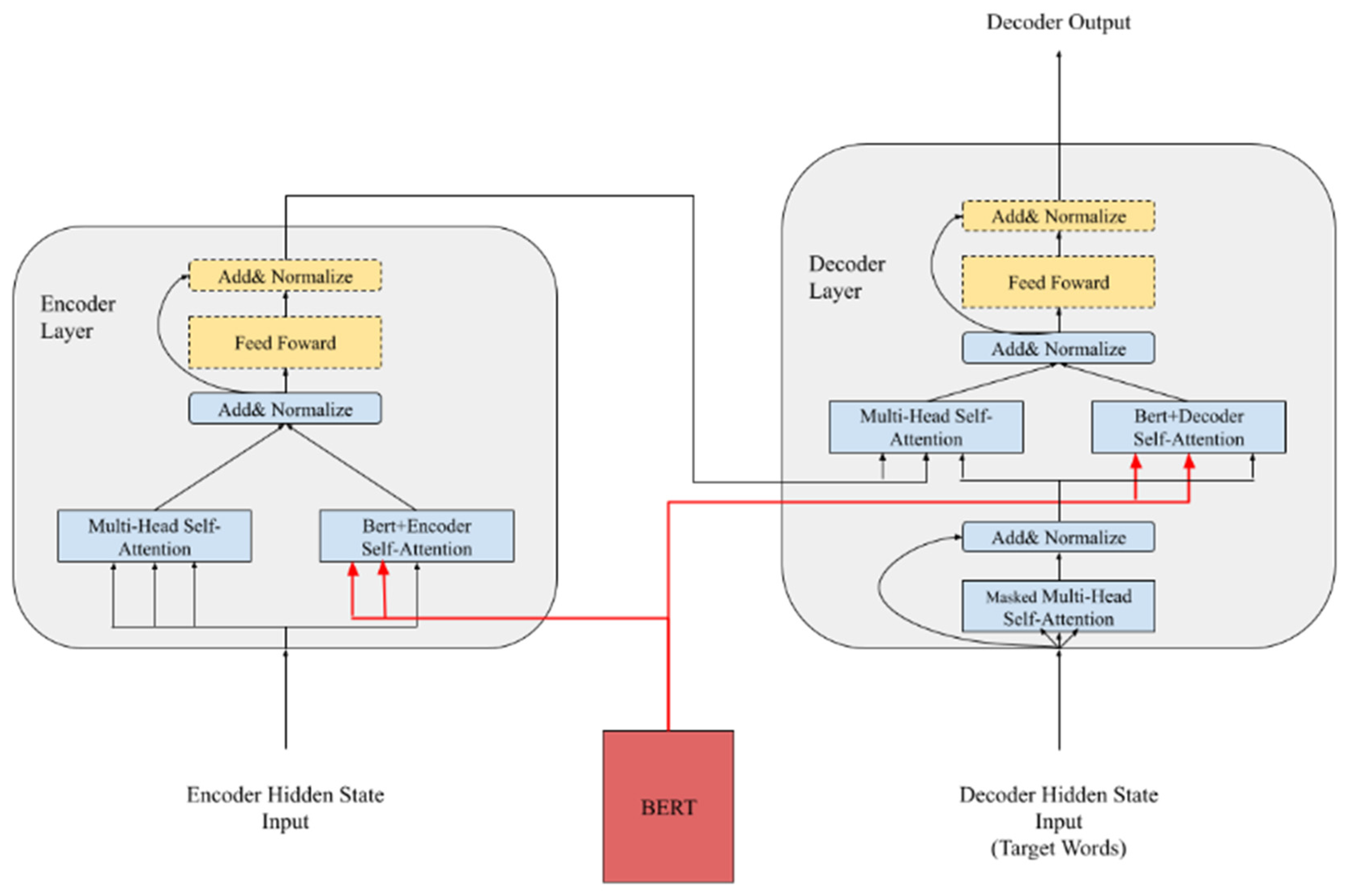
2.3. Combination with the Pre-Trained Model
2.4. Model Parameter Compression
3. The Proposed Model
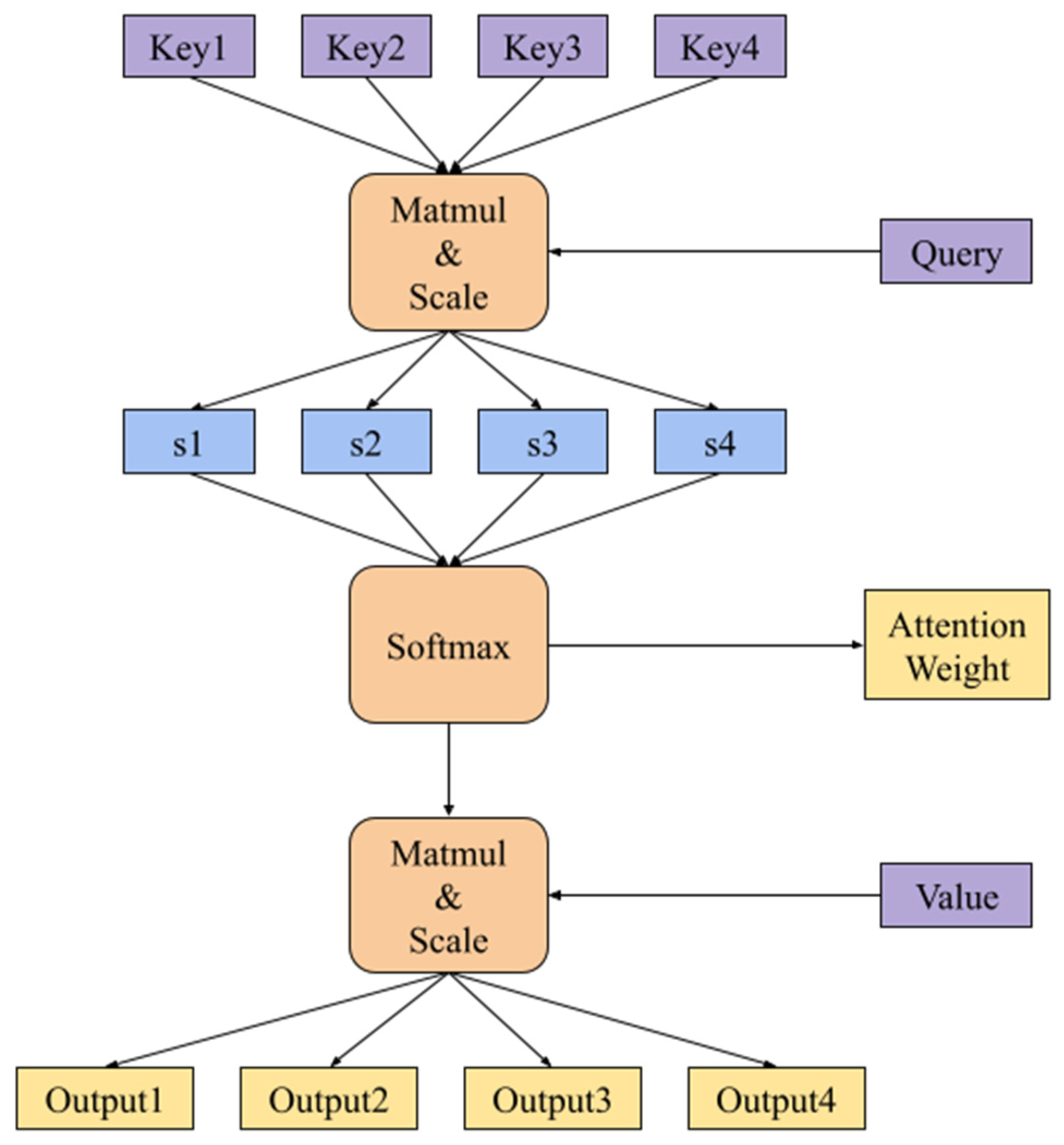
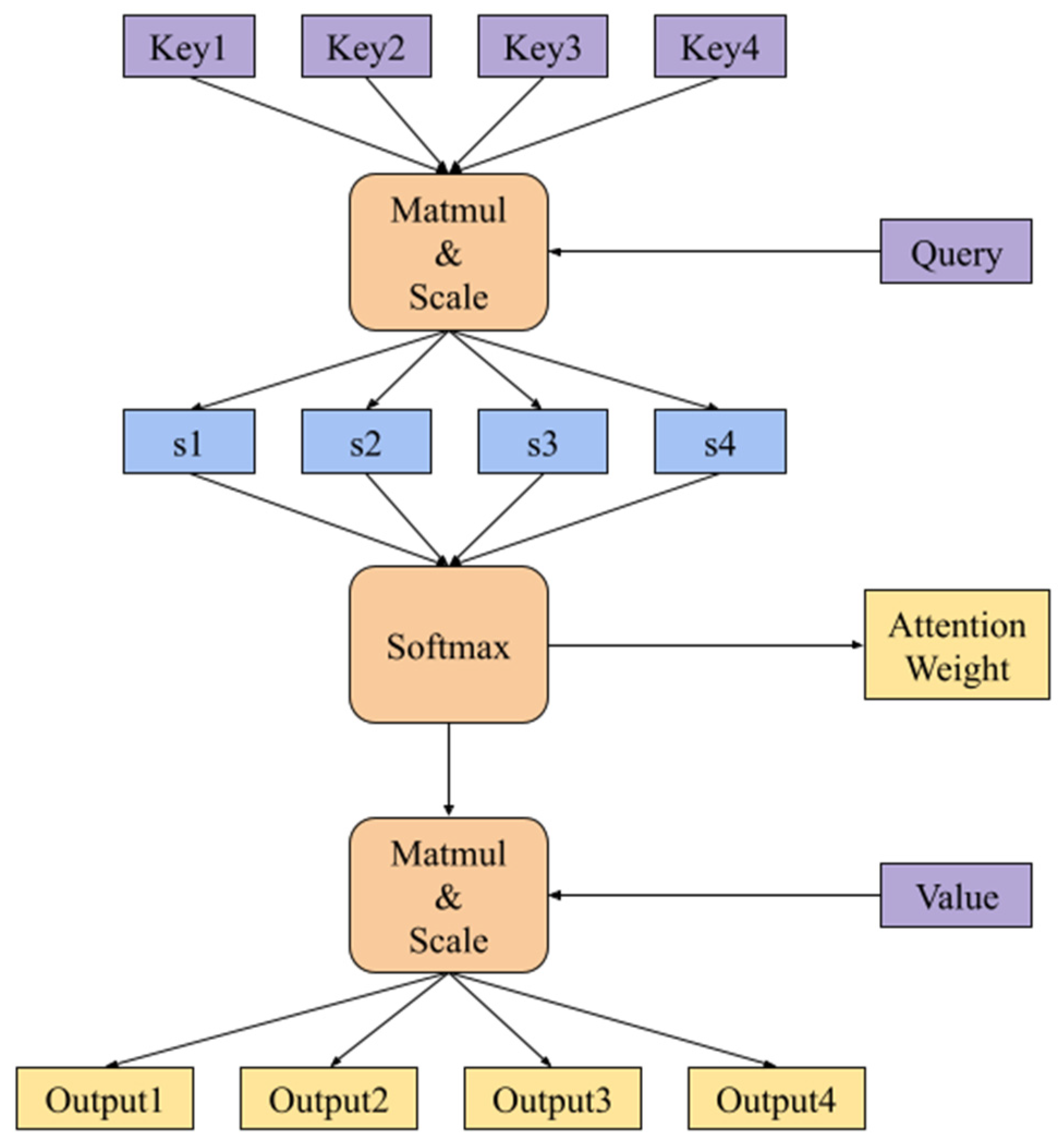
3.1. Multi-Head Self-Attention Mechanism
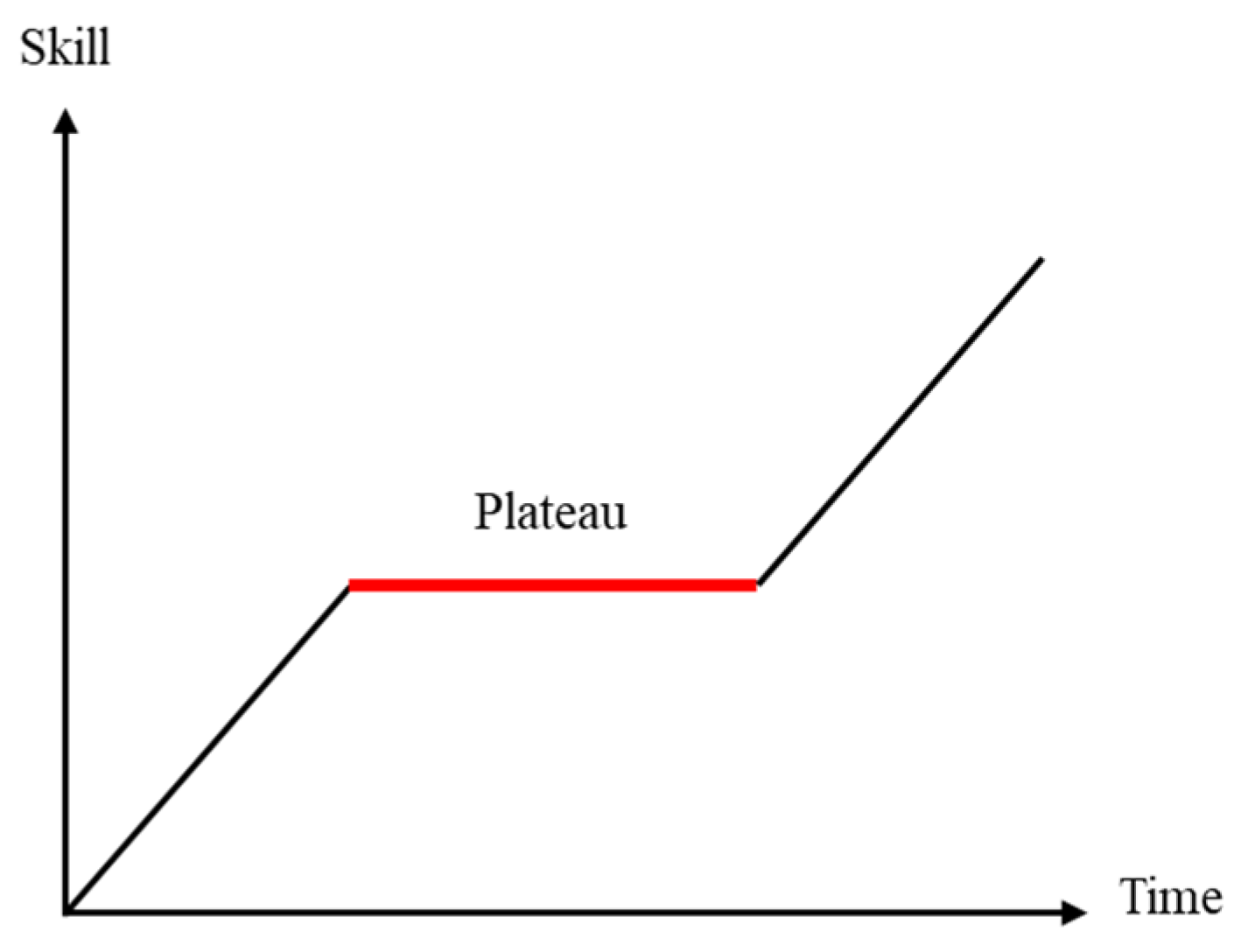
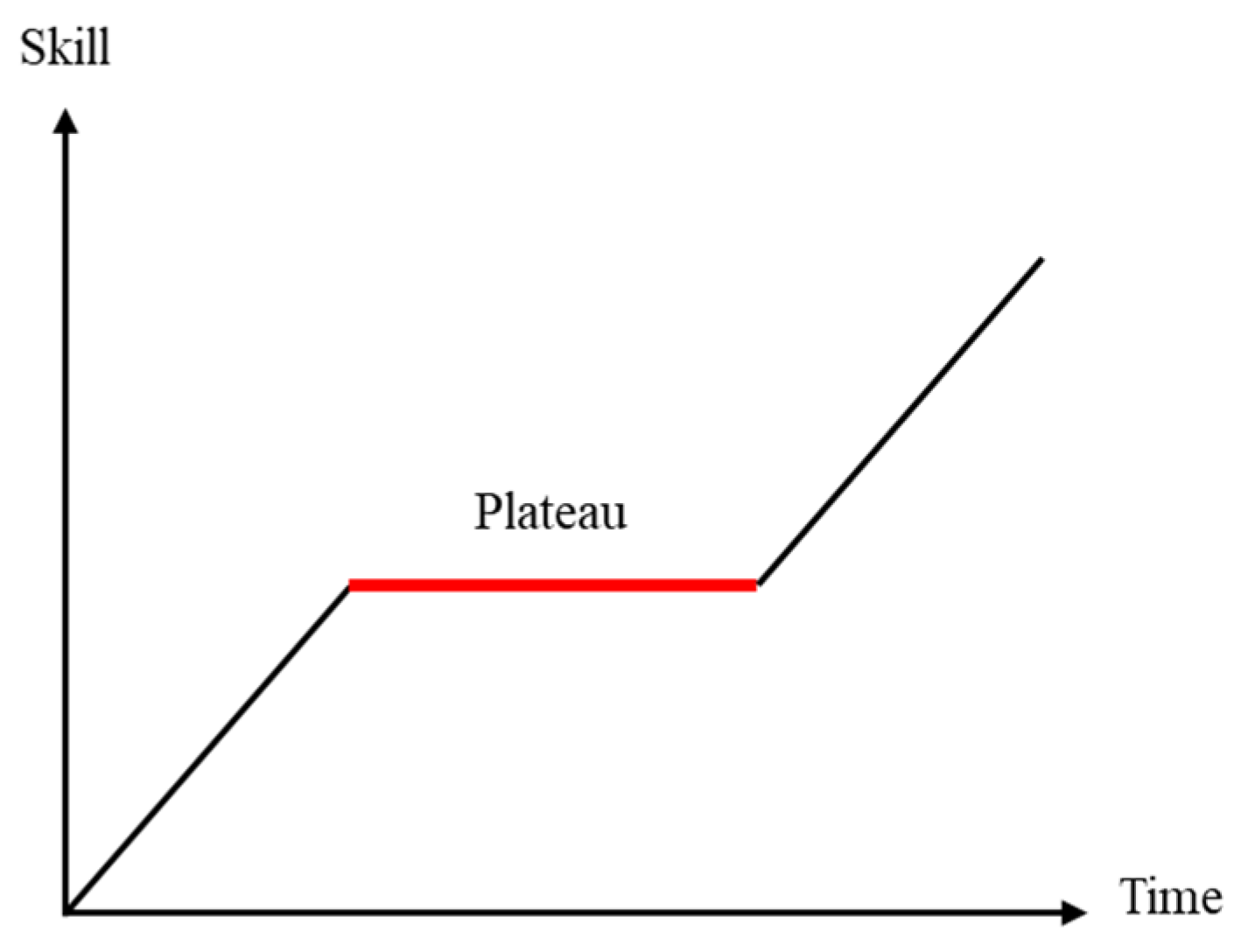
3.2. The Lazy Layer Question
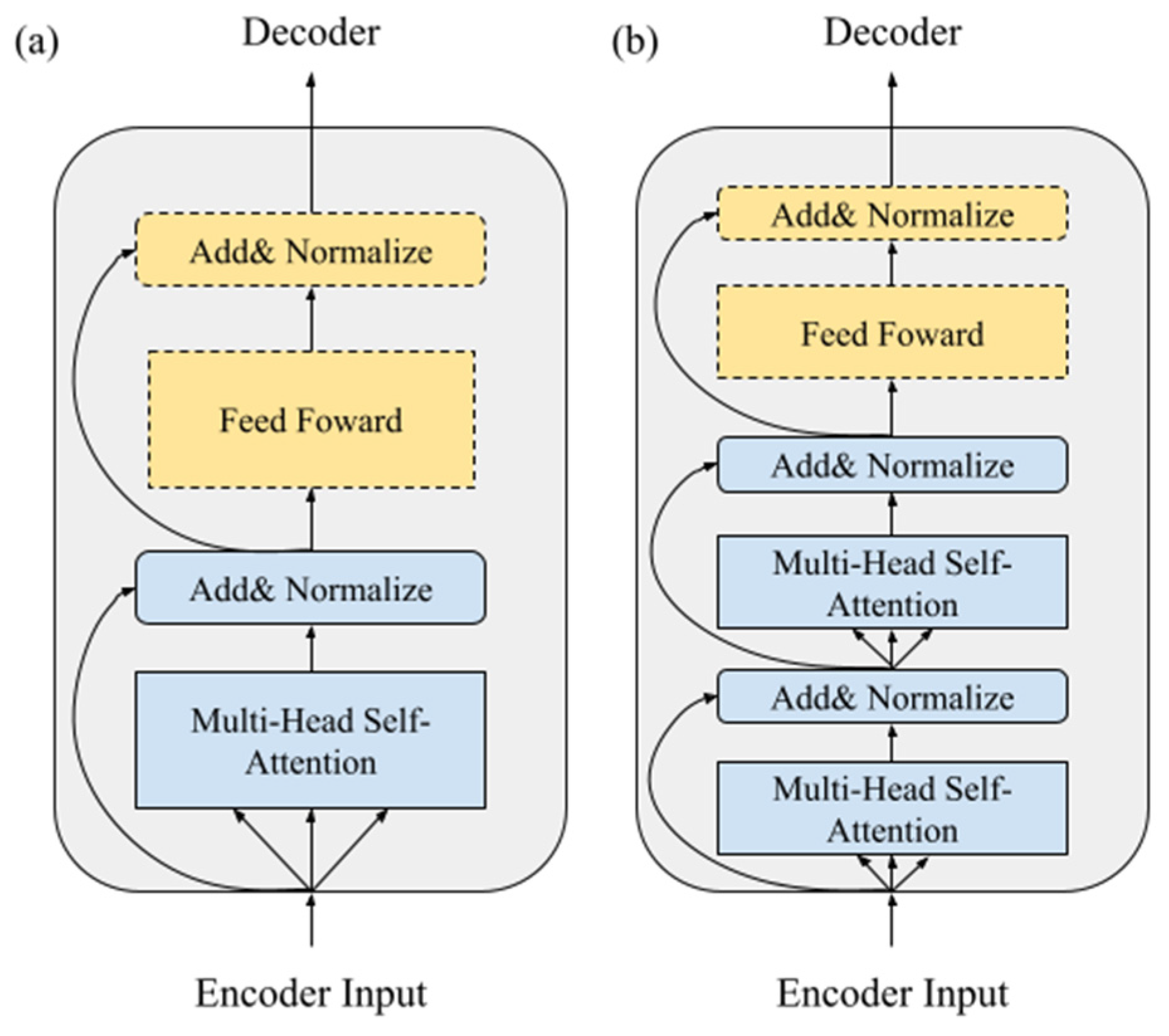
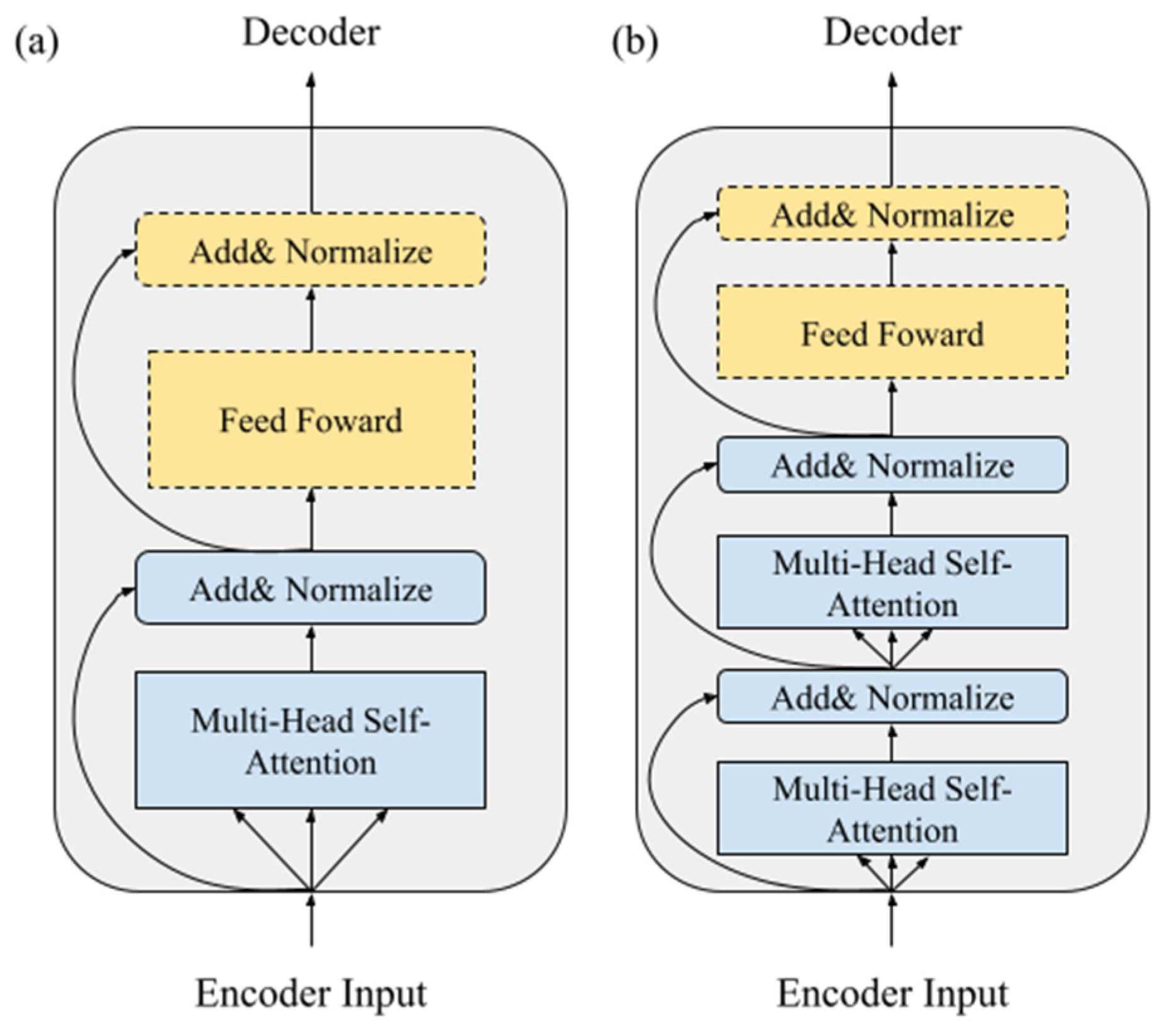
3.3. The Modified Encoder of the X-Transformer
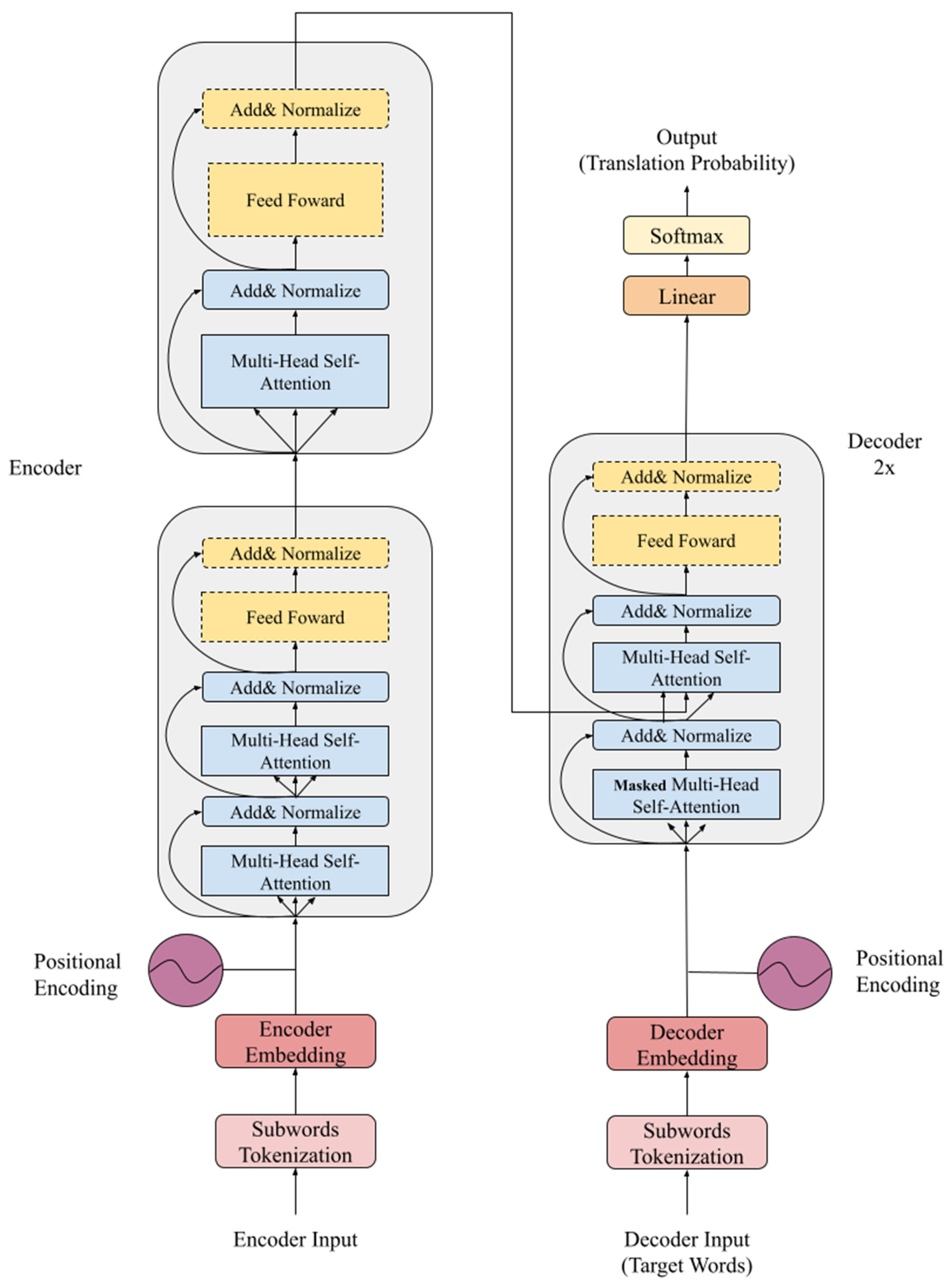
3.4. X-Transformer
- ●
- Sub-word tokenization: Sub-words can reduce the sparse words (such as terminology) of the model, improve the relevance of each vocabulary through sub-words, and reduce the dictionary size.
- ●
- Modifies the basic building block of the encoder: It can rearrange the self-attention mechanism and feed forward layer and modify the ratio number to improve the accuracy of the attention given to the input sequence.
- ●
- Reduces the number of encoder and decoder layers: It can reduce an excessive self-attention mechanism in both the encoder and decoder to ease the learning plateau in the model and also increase inference speed. In addition, reducing the decoder layers also increases the influence of the encoder output and helps to obtain a better output.
4. Experimental Results and Discussion
- ●
- First, the comparison of the performance between the X-Transformer and related models. In addition to comparing our model with the baseline Transformer, we also compared it with the results of adding the pre-trained model BERT, so that readers have a clearer understanding the performance of the X-Transformer.
- ●
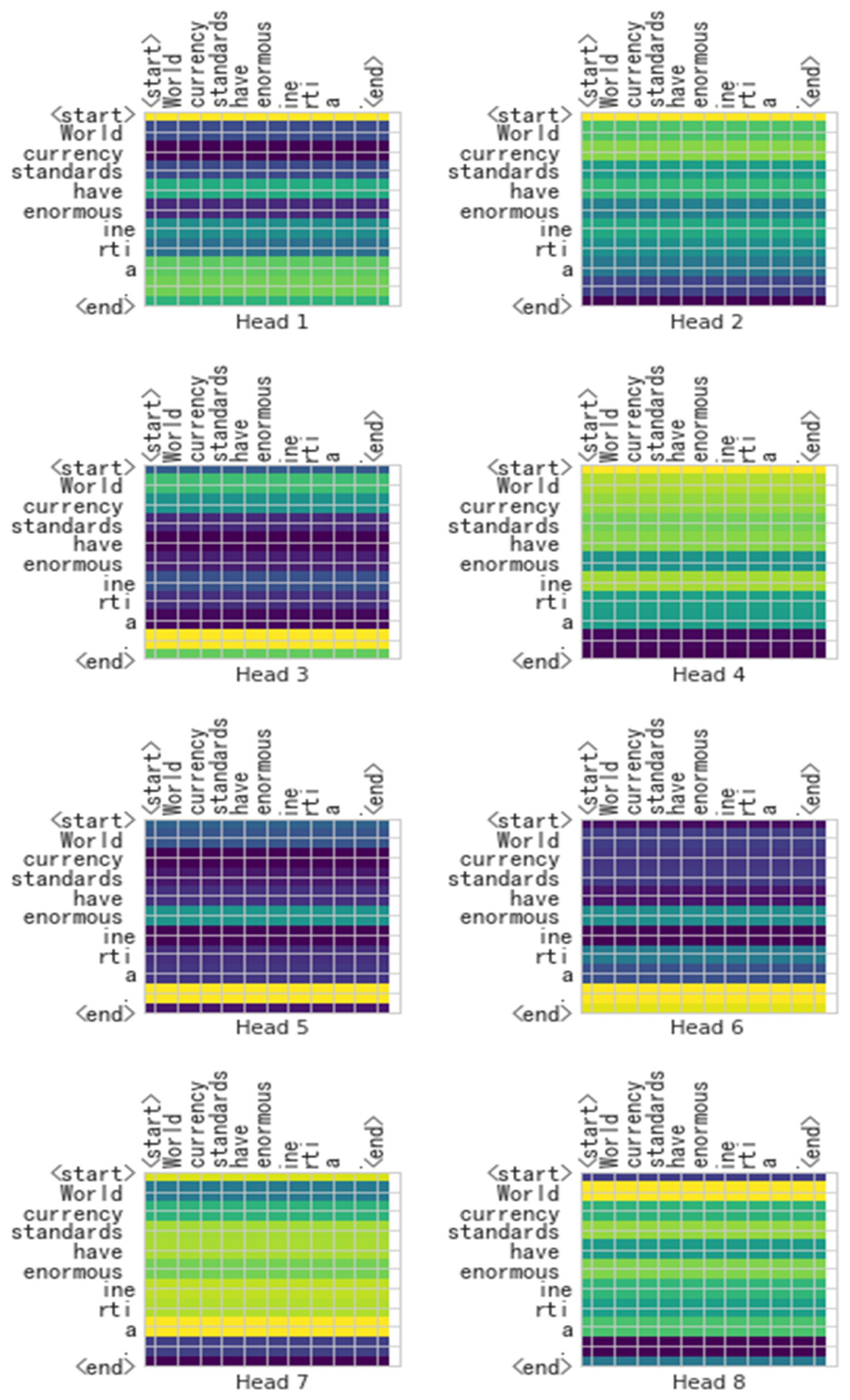
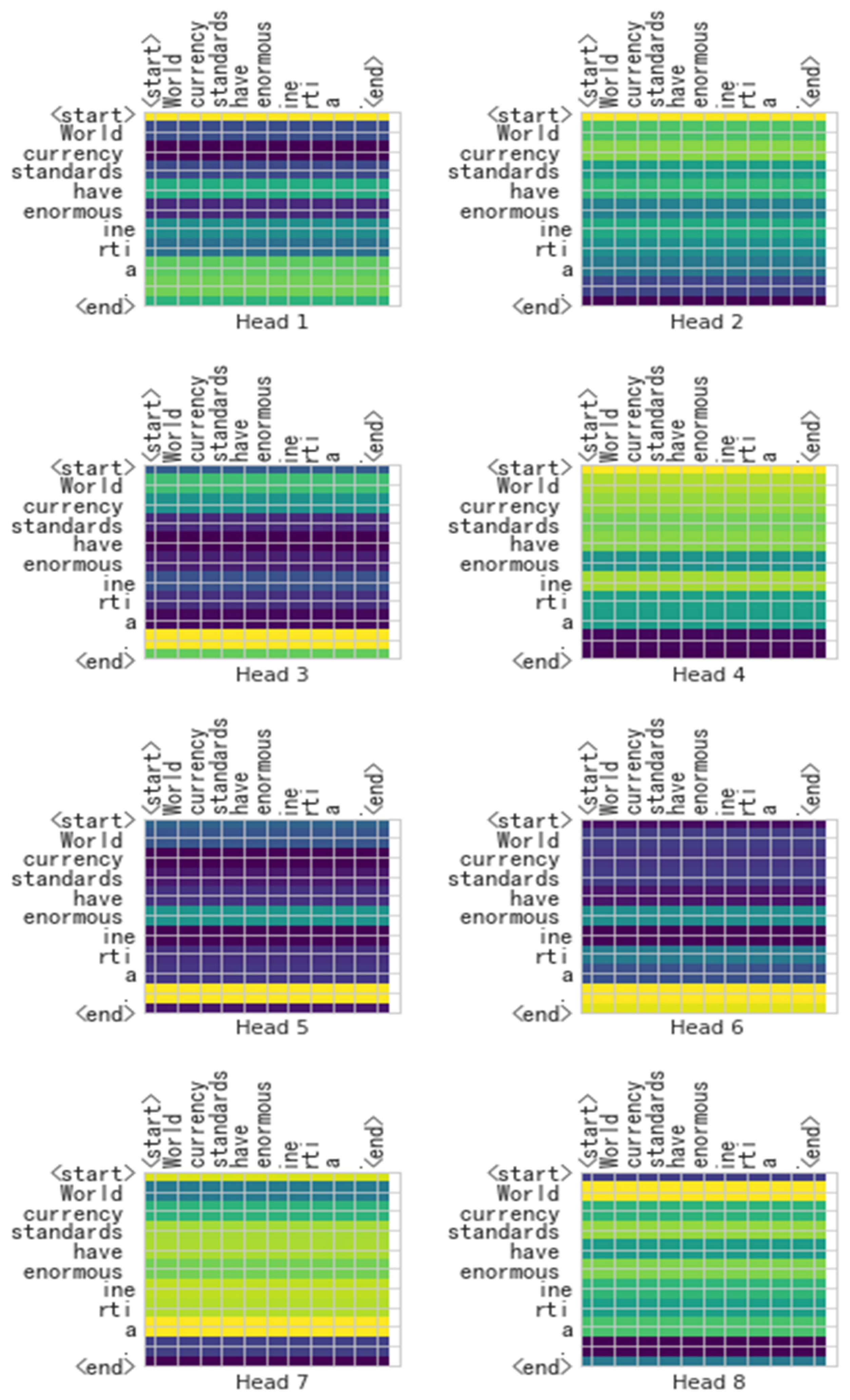
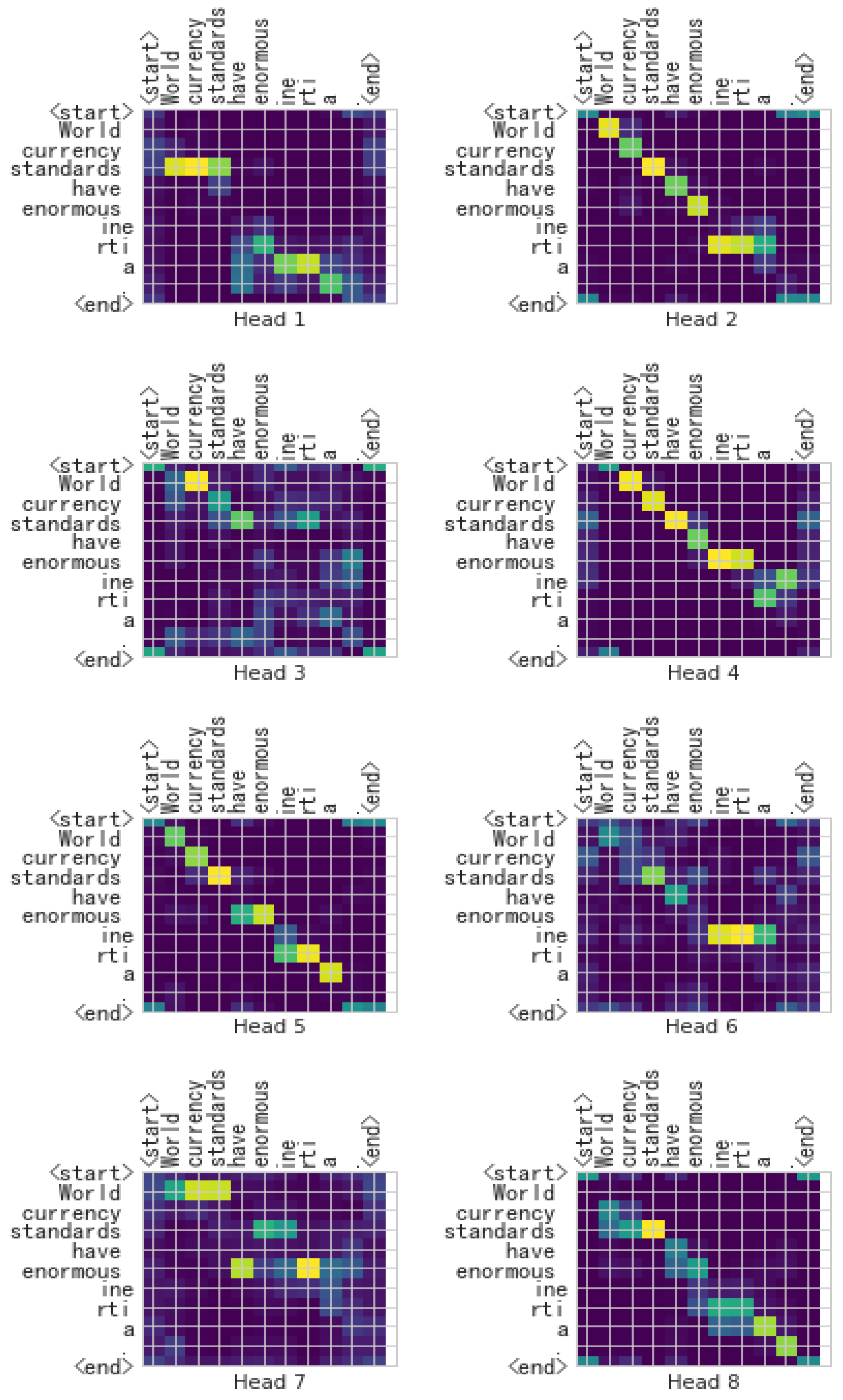
- Second, the learning situation of the self-attention mechanism in the encoder is presented, which is displayed by a visual heat map. Through the visualized heat maps of the Transformer and X-Transformer, we can understand whether the mechanism pays attention to the correct tokens and the attention relationship between tokens. These also reveal the comprehension of the models.
4.1. The Hyperparameter
4.2. The Result of Newstest 2014 EN-DE and EN-FR
4.3. The Visualization Heat Map
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References and Note
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 2017 Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Bojar, O.; Buck, C.; Federmann, C.; Haddow, B.; Koehn, P.; Leveling, J.; Monz, C.; Pecina, P.; Post, M.; Saint-Amand, H.; et al. Findings of the 2014 Workshop on Statistical Machine Translation. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 30 May 2014; pp. 12–58. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 2017 International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Luong, M.-T.; Sutskever, I.; Le, Q.V.; Vinyals, O.; Zaremba, W. Addressing the Rare Word Problem in Neural Machine Translation. arXiv 2014, arXiv:1410.8206. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. arXiv 2016, arXiv:1603.06393. [Google Scholar]
- Gulcehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the Unknown Words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On Using Very Large Target Vocabulary for Neural Machine Translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2014; Volume 1, pp. 1–10. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Ott, M.; Edunov, S.; Grangier, D.; Auli, M. Scaling Neural Machine Translation. arXiv 2018, arXiv:1806.00187. [Google Scholar]
- Xu, H.; van Genabith, J.; Liu, Q.; Xiong, D. Probing Word Translations in the Transformer and Trading Decoder for Encoder Layers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021; pp. 74–85. [Google Scholar]
- Press, N.; Smith, A.; Levy, O. Improving Transformer Models by Reordering their Sublayers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 9 December 2019; pp. 2996–3005. [Google Scholar]
- Shi, X.; Huang, H.-Y.; Wang, W.; Jian, P.; Tang, Y.-K. Improving Neural Machine Translation by Achieving Knowledge Transfer with Sentence Alignment Learning. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 11 September 2019; pp. 260–270. [Google Scholar]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.Y. Incorporating Bert into Neural Machine Translation. In Proceedings of the 2019 Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2020. [Google Scholar]
- Clinchant, S.; Jung, K.W.; Nikoulina, V. On the use of BERT for Neural Machine Translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 108–117. [Google Scholar]
- Kim, Y.; Rush, A.M. Sequence-Level Knowledge Distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 21 September 2016; pp. 1317–1327. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for Bert Model Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4323–4332. [Google Scholar]
- Mirzaei, M.; Zoghi, M. Understanding the Language Learning Plateau: A Grounded-Theory Study. Teach. Engl. Lang. 2017, 11, 195–222. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 19–27. [Google Scholar]
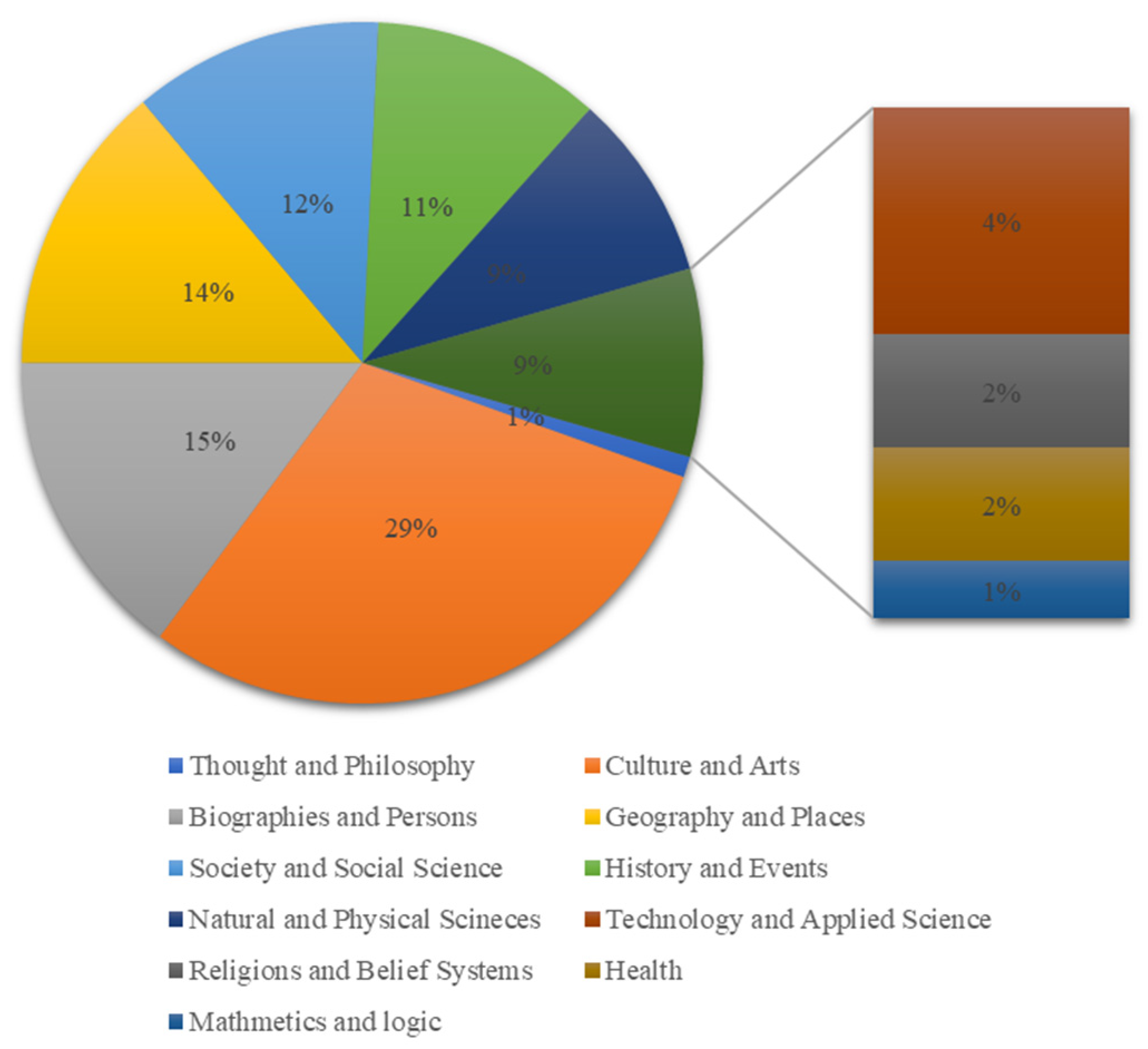
- Häggström, M. Wikipedia content by subject.png. Wikimedia.org. Wikimedia Commons. Web. 2010.
- Kingma, P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder Layers | Decoder Layers | BLEU | Training Time (under the Same Env.) |
|---|---|---|---|
| 6 | 6 | 29.33 | 1× |
| 6 | 4 | 29.26 | 0.82× |
| 6 | 2 | 30.99 | 0.68× |
| 8 | 6 | 29.26 | 1.19× |
| 8 | 4 | 29.82 | 1.01× |
| Modified Encoder | BLEU |
|---|---|
| sf-sf-sf-sf-sf-sf (Baseline) | 29.33 |
| s-sf-s-sf-s-sf | 32.14 |
| s-sf-sf (X-Transformer) | 46.63 |
| s-sf-sf-sf | 46.72 |
| s-sf-s-sf | 46.62 |
| Parameters | |
|---|---|
| Batch size | 128 |
| Token Length | 80 |
| Token Per Batch | 10,240 |
| Embedding Dimension | 512 |
| dff | 2048 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.-I.; Chen, W.-L. X-Transformer: A Machine Translation Model Enhanced by the Self-Attention Mechanism. Appl. Sci. 2022, 12, 4502. https://doi.org/10.3390/app12094502
Liu H-I, Chen W-L. X-Transformer: A Machine Translation Model Enhanced by the Self-Attention Mechanism. Applied Sciences. 2022; 12(9):4502. https://doi.org/10.3390/app12094502
Chicago/Turabian StyleLiu, Huey-Ing, and Wei-Lin Chen. 2022. "X-Transformer: A Machine Translation Model Enhanced by the Self-Attention Mechanism" Applied Sciences 12, no. 9: 4502. https://doi.org/10.3390/app12094502
APA StyleLiu, H.-I., & Chen, W.-L. (2022). X-Transformer: A Machine Translation Model Enhanced by the Self-Attention Mechanism. Applied Sciences, 12(9), 4502. https://doi.org/10.3390/app12094502