
AU-Guided Unsupervised Domain-Adaptive Facial Expression Recognition



Abstract
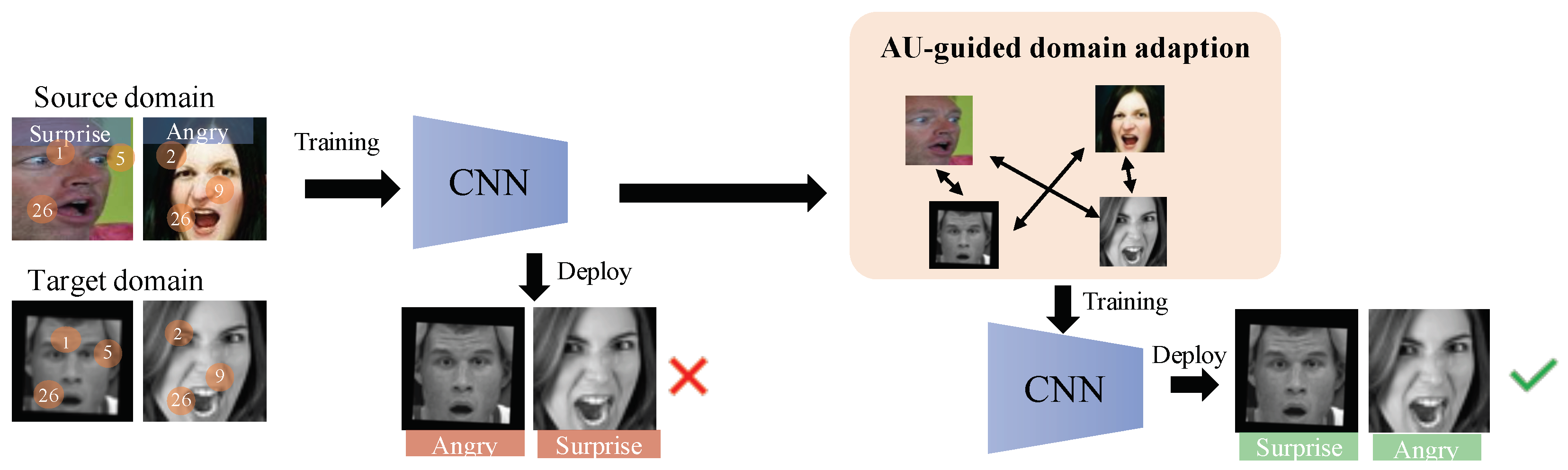
:1. Introduction
- We heuristically utilize the relationship between action units and facial expressions for cross-domain facial expression recognition, and propose an AU-guided unsupervised domain-adaptive FER (AdaFER) framework;
- We elaborately design an AU-guided annotation module to assign soft labels for a target domain and an AU-guided triplet training module to learn structure-reliable and compact facial expression features;
- We conduct extensive experiments on several popular benchmarks and significantly outperform the state-of-the-art methods.
2. Related Work
2.1. Facial Expression Recognition
2.2. Action Units Detection
2.3. Cross-Domain FER
3. Methodology
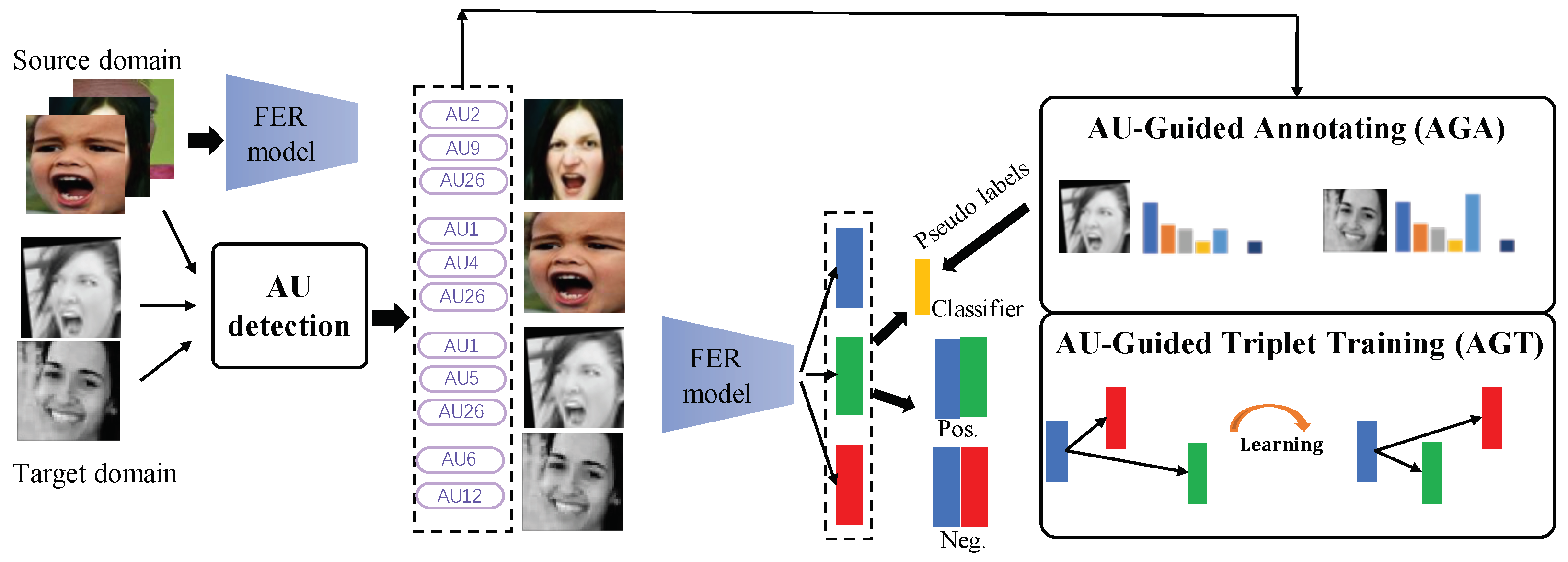
3.1. Overview of AdaFER
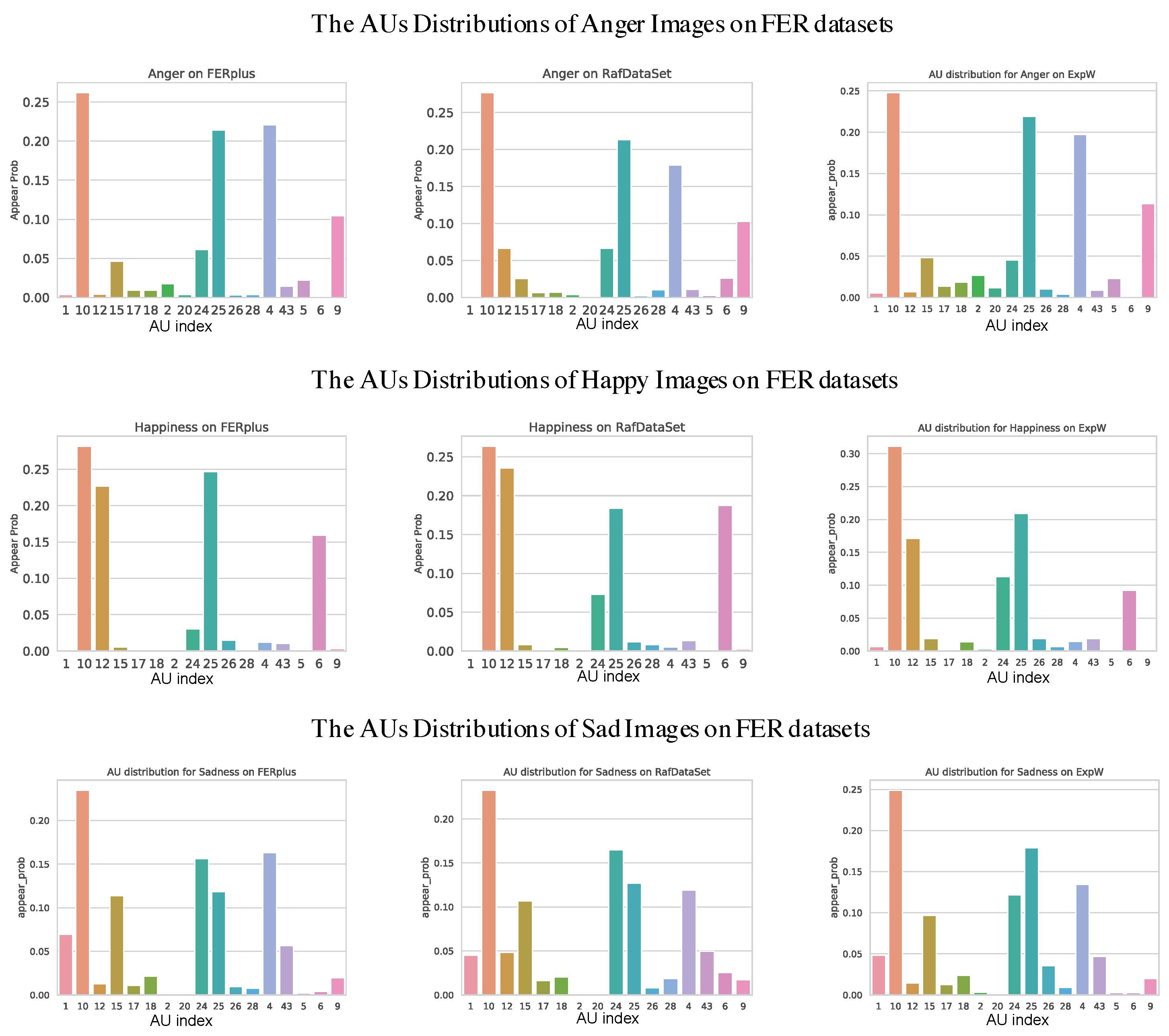
3.2. The AU Distributions of FER Datasets
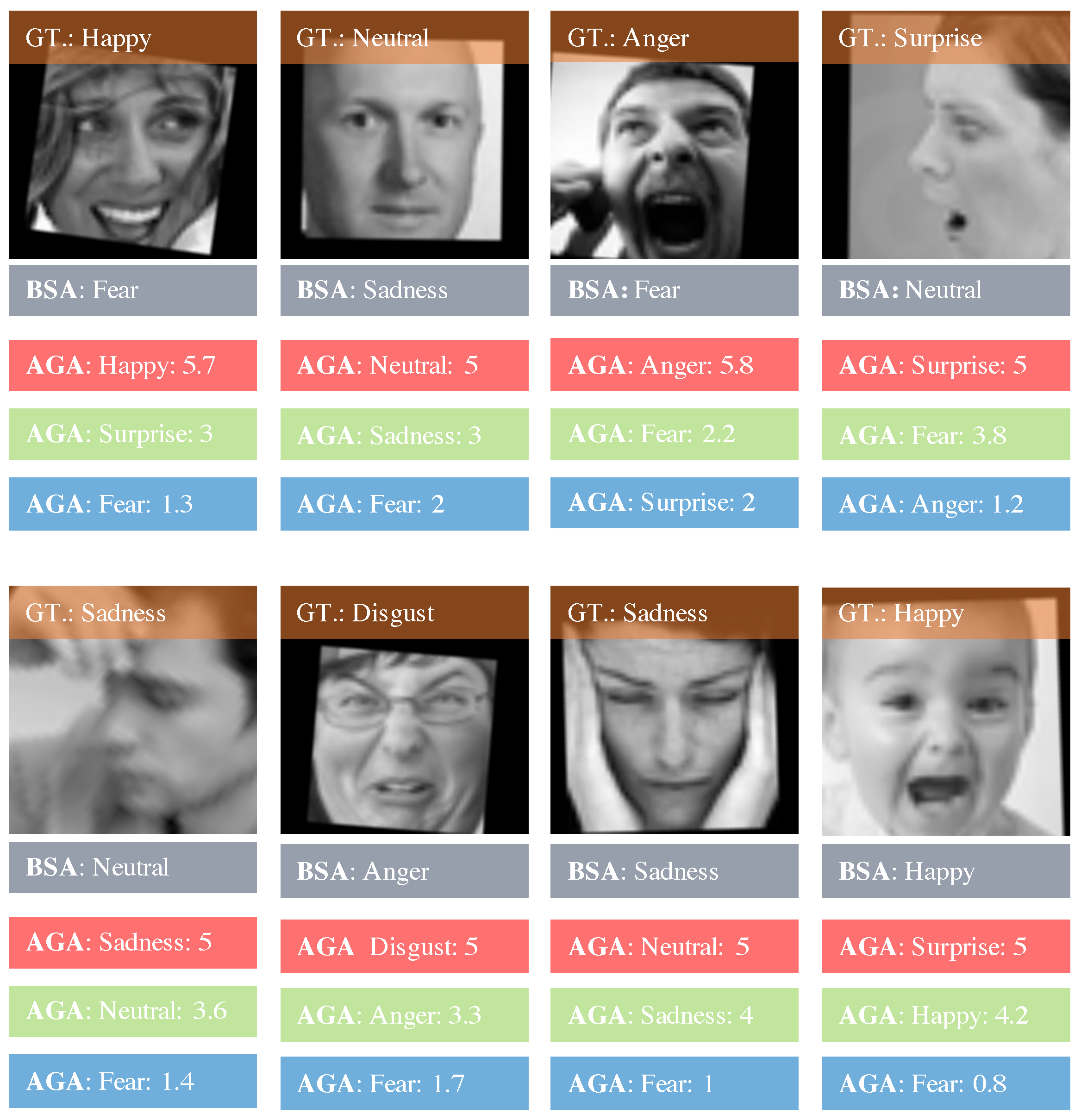
3.3. AU-Guided Annotating
3.4. AU-Guided Triplet Training
3.5. Implementation Details
4. Experiments
4.1. Datasets
4.2. AdaFER for Unsupervised CD-FER
- #1: We train the ResNet-18 (also pre-trained on MS-Celeb-1M) model on source data and directly test on target data;
- #2: We first extract AUs for both the source and the target data, and then use the AUs of each image in the target data to query the source data. Finally, we assign the most-frequent category of retrieval images to the target image;
- #3: We first use the trained model on the source data to predict hard pseudo-labels of the target data, then fine-tune the model on target data;
- #4: This method is identical to method #3, except that the predicted pseudo-labels are kept as vectors (i.e., soft labels);
- #5: We use both the images and the detected AUs as inputs to train a classification on the source set, and then fine-tune the model on pseudo-soft labelled target data.
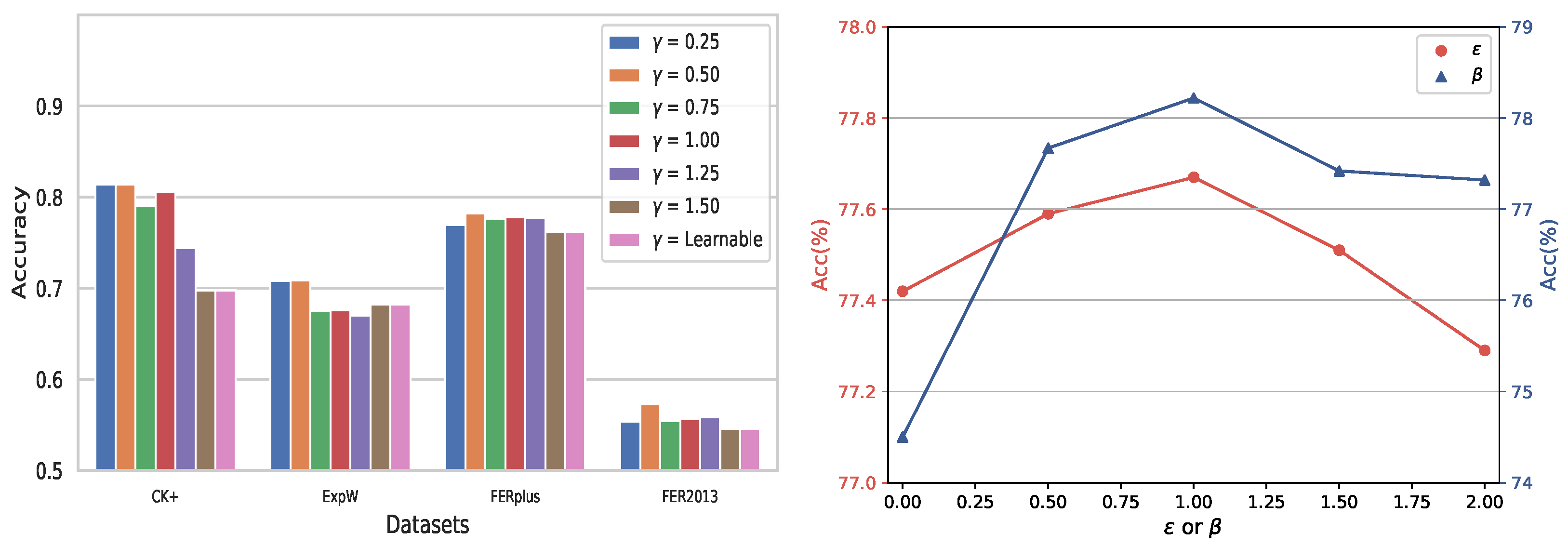
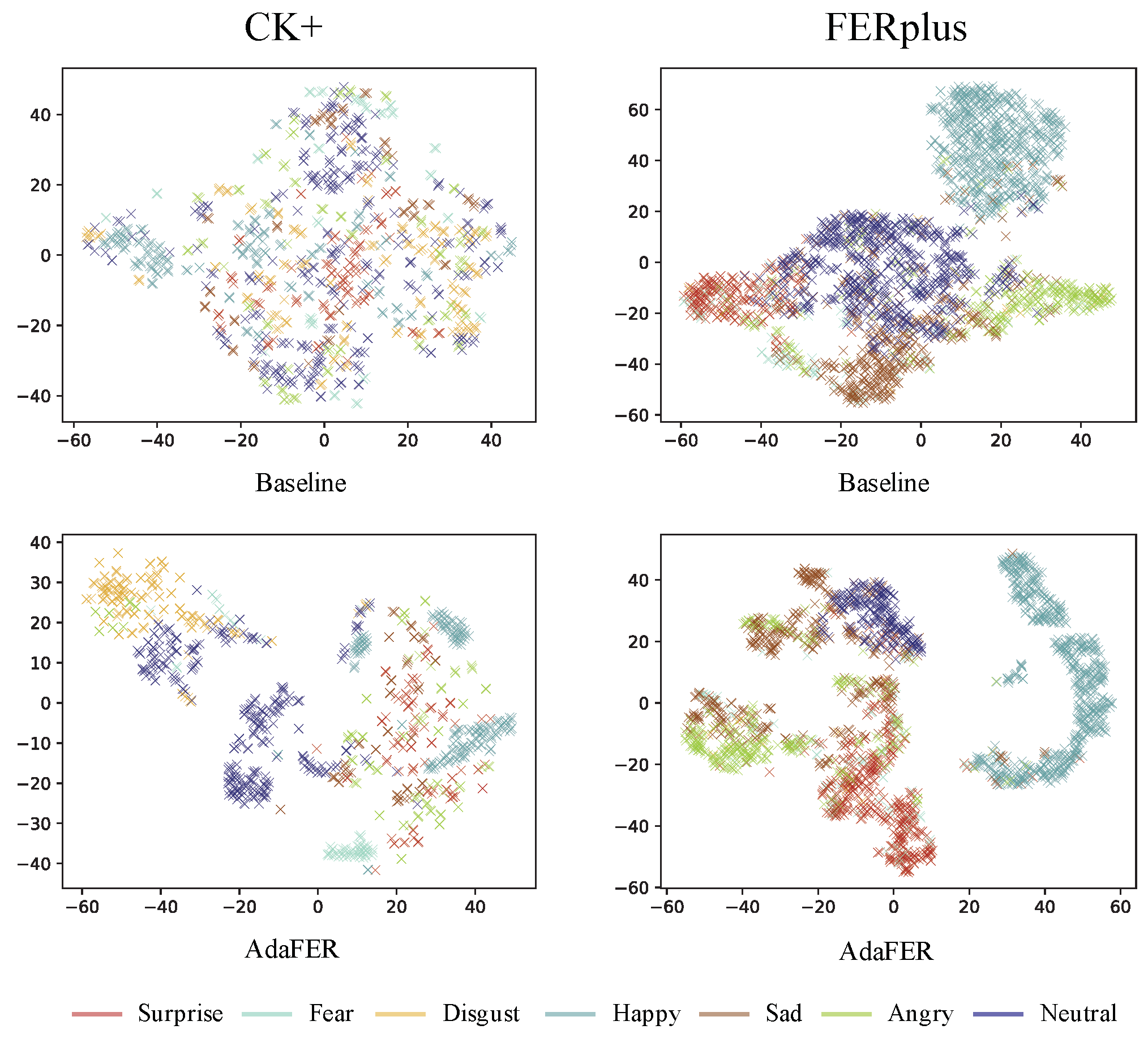
4.3. Ablation Studies
4.4. Comparison with State-of-the-Art Methods
5. Conslusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Giorgana, G.; Ploeger, P.G. Facial expression recognition for domestic service robots. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2011; pp. 353–364. [Google Scholar]
- Jiang, W.; Yin, Z.; Pang, Y.; Wu, F.; Kong, L.; Xu, K. Brain functional changes in facial expression recognition in patients with major depressive disorder before and after antidepressant treatment: A functional magnetic resonance imaging study. Neural Regen. Res. 2012, 7, 1151. [Google Scholar] [PubMed]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Workshop on EMOTION: Corpora for Research on Emotion and Affect, Paris, France, 17–23 May 2010; p. 65. [Google Scholar]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; PietikäInen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In Proceedings of the IEEE ICCV Workshops, Barcelona, Spain, 6–13 November 2011; pp. 2106–2112. [Google Scholar]
- Barsoum, E.; Zhang, C.; Canton Ferrer, C.; Zhang, Z. Training Deep Networks for Facial Expression Recognition with Crowd-Sourced Label Distribution. In Proceedings of the ACM ICMI, Tokyo, Japan, 12–16 November 2016. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. TAC 2017, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Fabian Benitez-Quiroz, C.; Srinivasan, R.; Martinez, A.M. Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Liu, Y.J. Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE TIP 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using cnn with attention mechanism. IEEE TIP 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 6897–6906. [Google Scholar]
- Yan, K.; Zheng, W.; Zhang, T.; Zong, Y.; Tang, C.; Lu, C.; Cui, Z. Cross-domain facial expression recognition based on transductive deep transfer learning. IEEE Access 2019, 7, 108906–108915. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, T.; Pu, T.; Wu, H.; Lin, L. Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition. In Proceedings of the 28th ACMMM, Seattle, WA, USA, 12–16 October 2020; pp. 1255–1264. [Google Scholar]
- Zong, Y.; Zheng, W.; Huang, X.; Shi, J.; Cui, Z.; Zhao, G. Domain regeneration for cross-database micro-expression recognition. IEEE Trans. Image Process. 2018, 27, 2484–2498. [Google Scholar] [CrossRef]
- Ji, S.; Wang, K.; Peng, X.; Yang, J.; Zeng, Z.; Qiao, Y. Multiple Transfer Learning and Multi-Label Balanced Training Strategies for Facial AU Detection in the Wild. In Proceedings of the IEEE CVPR Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 414–415. [Google Scholar]
- Niu, X.; Han, H.; Shan, S.; Chen, X. Multi-label co-regularization for semi-supervised facial action unit recognition. arXiv 2019, arXiv:1910.11012. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. Openface: A general-purpose face recognition library with mobile applications. CMU Sch. Comput. Sci. 2016, 6, 20. [Google Scholar]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [Green Version]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE CVPR, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Kahou, S.E.; Pal, C.; Bouthillier, X.; Froumenty, P.; Gülçehre, Ç.; Memisevic, R.; Vincent, P.; Courville, A.; Bengio, Y.; Ferrari, R.C.; et al. Combining modality specific deep neural networks for emotion recognition in video. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 543–550. [Google Scholar]
- Zhou, H.; Meng, D.; Zhang, Y.; Peng, X.; Du, J.; Wang, K.; Qiao, Y. Exploring emotion features and fusion strategies for audio-video emotion recognition. In Proceedings of the 2019 ICMI, Suzhou, China, 14–18 October 2019; pp. 562–566. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- McDuff, D.; Mahmoud, A.; Mavadati, M.; Amr, M.; Turcot, J.; Kaliouby, R.E. AFFDEX SDK: A Cross-Platform Real-Time Multi-Face Expression Recognition Toolkit. In Proceedings of the Association for Computing Machinery, CHI EA ’16, New York, NY, USA, 7–12 May 2016; pp. 3723–3726. [Google Scholar]
- Ekman, P.; Rosenberg, E.L. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, MI, USA, 1997. [Google Scholar]
- Feldman, R.S.; Jenkins, L.; Popoola, O. Detection of deception in adults and children via facial expressions. Child Dev. 1979, 50, 350–355. [Google Scholar] [CrossRef]
- Rubinow, D.R.; Post, R.M. Impaired recognition of affect in facial expression in depressed patients. Biol. Psychiatry 1992, 31, 947–953. [Google Scholar] [CrossRef]
- Niu, X.; Han, H.; Zeng, J.; Sun, X.; Shan, S.; Huang, Y.; Yang, S.; Chen, X. Automatic engagement prediction with GAP feature. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 599–603. [Google Scholar]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. Disfa: A spontaneous facial action intensity database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
- Girard, J.M.; Chu, W.S.; Jeni, L.A.; Cohn, J.F. Sayette group formation task (gft) spontaneous facial expression database. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 581–588. [Google Scholar]
- Walecki, R.; Pavlovic, V.; Schuller, B.; Pantic, M. Deep structured learning for facial action unit intensity estimation. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3405–3414. [Google Scholar]
- Peng, G.; Wang, S. Dual semi-supervised learning for facial action unit recognition. In Proceedings of the AAAI, Montreal, QC, Canada, 2–5 July 2019; Volume 33, pp. 8827–8834. [Google Scholar]
- Wu, S.; Wang, S.; Pan, B.; Ji, Q. Deep facial action unit recognition from partially labeled data. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 3951–3959. [Google Scholar]
- Chu, W.S.; De la Torre, F.; Cohn, J.F. Selective transfer machine for personalized facial expression analysis. IEEE TPAMI 2016, 39, 529–545. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Deng, W. A deeper look at facial expression dataset bias. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- Miao, Y.Q.; Araujo, R.; Kamel, M.S. Cross-domain facial expression recognition using supervised kernel mean matching. In Proceedings of the 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; Volume 2, pp. 326–332. [Google Scholar]
- Sangineto, E.; Zen, G.; Ricci, E.; Sebe, N. We are not all equal: Personalizing models for facial expression analysis with transductive parameter transfer. In Proceedings of the 22nd ACMMM, Orlando, FL, USA, 3–7 November 2014; pp. 357–366. [Google Scholar]
- Yan, H. Transfer subspace learning for cross-dataset facial expression recognition. Neurocomputing 2016, 208, 165–173. [Google Scholar] [CrossRef]
- Yan, K.; Zheng, W.; Cui, Z.; Zong, Y. Cross-database facial expression recognition via unsupervised domain adaptive dictionary learning. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 427–434. [Google Scholar]
- Zhu, R.; Sang, G.; Zhao, Q. Discriminative feature adaptation for cross-domain facial expression recognition. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–7. [Google Scholar]
- Zheng, W.; Zong, Y.; Zhou, X.; Xin, M. Cross-Domain Color Facial Expression Recognition Using Transductive Transfer Subspace Learning. IEEE Trans. Affect. Comput. 2016, 9, 21–37. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the 2015 ACM ICMI, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Valstar, M.F.; Pantic, M. Fully Automatic Recognition of the Temporal Phases of Facial Actions. IEEE Trans. Syst. Man, Cybern. Part B (Cybernetics) 2012, 42, 28–43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Wang, X.; Ni, Y. Unsupervised domain adaptation for facial expression recognition using generative adversarial networks. Comput. Intell. Neurosci. 2018, 2018, 7208794. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-stage dense face localisation in the wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. From facial expression recognition to interpersonal relation prediction. IJCV 2018, 126, 550–569. [Google Scholar] [CrossRef] [Green Version]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Zavarez, M.V.; Berriel, R.F.; Oliveira-Santos, T. Cross-database facial expression recognition based on fine-tuned deep convolutional network. In Proceedings of the 30th SIBGRAPI, Niterói, Brazil, 17–20 October 2017; pp. 405–412. [Google Scholar]
- Chen, T.; Xie, Y.; Pu, T.; Wu, H.; Lin, L. Cross-Domain Facial Expression Recognition:A Unified Evaluation Benchmark and Adversarial Graph Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Da Silva, F.A.M.; Pedrini, H. Effects of cultural characteristics on building an emotion classifier through facial expression analysis. J. Electron. Imaging 2015, 24, 023015. [Google Scholar] [CrossRef]
- Hasani, B.; Mahoor, M.H. Facial expression recognition using enhanced deep 3D convolutional neural networks. In Proceedings of the IEEE CVPR Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–40. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Spatio-temporal facial expression recognition using convolutional neural networks and conditional random fields. In Proceedings of the 12th IEEE FG 2017, Washington, DC, USA, 30 May–3 June 2017; pp. 790–795. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the IEEE WACV, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. Adv. Neural Inf. Process. Syst. 2018, 31, 1640–1650. [Google Scholar]
- Xu, R.; Li, G.; Yang, J.; Lin, L. Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation. In Proceedings of the IEEE ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 1426–1435. [Google Scholar]
- Lee, C.Y.; Batra, T.; Baig, M.H.; Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE CVPR, Long Beach, CA, USA, 15–20 June 2019; pp. 10285–10295. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CK+ | JAFFE | ExpW | FER2013 | FERPlus |
|---|---|---|---|---|---|
| #1 | 70.54 | 46.51 | 61.53 | 52.91 | 62.40 |
| #2 | 65.11 | 27.50 | 66.52 | 46.31 | 68.35 |
| #3 | 74.42 | 55.81 | 68.13 | 55.89 | 63.81 |
| #4 | 73.64 | 58.14 | 69.41 | 54.81 | 70.02 |
| #5 | 71.32 | 53.49 | 73.58 | 57.15 | 77.99 |
| AdaFER | 81.40 | 61.37 | 70.86 | 57.29 | 78.22 |
| Source | Target | CK+ | ExpW | FER2013 | FERPlus |
|---|---|---|---|---|---|
| √ | × | 80.62 | 69.90 | 54.36 | 77.61 |
| × | √ | 71.23 | 69.73 | 55.45 | 77.93 |
| √ | √ | 81.40 | 70.86 | 57.29 | 78.22 |
| AGA | AGT | CK+ | ExpW | FER2013 | FERPlus |
|---|---|---|---|---|---|
| × | × | 70.54 | 61.53 | 52.91 | 62.40 |
| √ | × | 80.62 | 68.45 | 55.20 | 77.42 |
| × | √ | 80.28 | 69.80 | 56.45 | 74.50 |
| √ | √ | 81.40 | 70.86 | 57.29 | 78.22 |
| Threshold | CK+ | ExpW | FER2013 | FERPlus |
|---|---|---|---|---|
| 0 | 68.99 | 65.24 | 52.21 | 66.68 |
| 0.25 | 72.03 | 68.23 | 56.23 | 74.23 |
| 0.5 | 81.40 | 70.86 | 57.29 | 78.22 |
| 0.75 | 80.96 | 69.12 | 55.80 | 77.72 |
| Methods | Source Dataset | Backbones | CK+ | JAFFE | FER2013 | ExpW | Mean |
|---|---|---|---|---|---|---|---|
| Da et al. [58] | BOSPHORUS | HOG and Gabor Filters | 57.60 | 36.2 | - | - | - |
| Hasani et al. [59] | MMI and FERA and DISFA | Inception-ResNet | 67.52 | - | - | - | - |
| Hasani et al. [60] | MMI and FERA | Inception-ResNet | 73.91 | - | - | - | - |
| Zavarez et al. [56] | Six Datasets | VGG-Net | 88.58 | 44.32 | - | - | - |
| Mollahosseini et al. [61] | Six Datasets | Inception | 64.20 | - | 34.00 | - | - |
| DETN [62] | RAF-DB | Manually Designed Net | 78.83 | 57.75 | 52.37 | - | - |
| ECAN [42] | RAF-DB 2.0 | VGG-Net | 86.49 | 61.94 | 58.21 | - | - |
| CADA [63] | RAF-DB | ResNet-18 | 73.64 | 55.40 | 54.71 | 63.74 | 61.87 |
| SAFN [64] | RAF-DB | ResNet-18 | 68.99 | 49.30 | 53.31 | 68.32 | 59.98 |
| SWD [65] | RAF-DB | ResNet-18 | 72.09 | 53.52 | 53.70 | 65.85 | 61.29 |
| LPL [11] | RAF-DB | ResNet-18 | 72.87 | 53.99 | 53.61 | 68.35 | 62.20 |
| DETN [62] | RAF-DB | ResNet-18 | 64.19 | 52.11 | 42.01 | 43.92 | 50.55 |
| ECAN [42] | RAF-DB | ResNet-18 | 66.51 | 52.11 | 50.76 | 48.73 | 54.52 |
| AGRA [17] | RAF-DB | ResNet-18 | 77.52 | 61.03 | 54.94 | 69.70 | 65.79 |
| AdaFER | RAF-DB | ResNet-18 | 81.40 | 61.37 | 57.29 | 70.86 | 67.73 |
| Baseline (#3) | FERPlus | ResNet-18 | 64.34 | 41.86 | - | 66.64 | 57.87 |
| AdaFER | FERPlus | ResNet-18 | 65.12 | 46.51 | - | 73.58 | 61.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Gu, Y.; Zhang, P. AU-Guided Unsupervised Domain-Adaptive Facial Expression Recognition. Appl. Sci. 2022, 12, 4366. https://doi.org/10.3390/app12094366
Peng X, Gu Y, Zhang P. AU-Guided Unsupervised Domain-Adaptive Facial Expression Recognition. Applied Sciences. 2022; 12(9):4366. https://doi.org/10.3390/app12094366
Chicago/Turabian StylePeng, Xiaojiang, Yuxin Gu, and Panpan Zhang. 2022. "AU-Guided Unsupervised Domain-Adaptive Facial Expression Recognition" Applied Sciences 12, no. 9: 4366. https://doi.org/10.3390/app12094366
APA StylePeng, X., Gu, Y., & Zhang, P. (2022). AU-Guided Unsupervised Domain-Adaptive Facial Expression Recognition. Applied Sciences, 12(9), 4366. https://doi.org/10.3390/app12094366