
Forecasting Fine-Grained Air Quality for Locations without Monitoring Stations Based on a Hybrid Predictor with Spatial-Temporal Attention Based Network

 , ,
, ,
Abstract
:1. Introduction
- To the best of our knowledge, we are the first to combine the air quality forecasting of monitoring stations, and predict the air quality of sites without monitoring stations, forecast the long-term fine-grained air quality without monitoring stations and realize the goal of long-term prediction for locations without monitoring stations.
- This study proposes a hybrid predictor with two complementary data flows that can perform well in long-term prediction for the locations without monitoring stations.
- The experimental results show that the proposed model outperforms the baseline methods. In addition, the ablation study confirms the effectiveness of the proposed structure.
2. Related Work
- Air Quality Forecasting: Previous studies have proposed many data-driven approaches for air quality modeling. For example, the work [7] introduced autoregressive integrated moving average (ARIMA), which is a famous and widely adopted data-driven model for air pollution forecast at monitoring stations. In [8], the authors proposed a traditional physical-based numerical model that used historical air pollution data [9] to formulate the urban pollution process and pollutant dispersion. Moreover, studies [3,4,17] used the combination of spatial and temporal features to model air quality forecasting. Recently, big data and neural network techniques have improved the traditional methods and achieved state-of-the-art performance in urban air quality forecasting [10,11]. Graph convolution neural network (GCN) has become particularly popular in many works. The GCN-based air quality prediction takes monitoring stations as nodes of the graph and uses static features to calculate the node embedding to forecast the predicted values [13].
- Fine-Grained Estimation: Several studies have proposed to use basic interpolation methods such as spatial averaging, nearest neighbor, inversed distance weighting (IDW), and kriging to solve the fine-grained estimation of air quality for locations without monitoring stations [18,19]. In addition, the work [5] proposed an affinity graph framework to infer real-time air quality of a location without a monitoring station, and recommend the best locations for new monitoring stations. As air quality forecasting, several studies have investigated interpolation methods using the combination of spatial and temporal features [3,6,20]. In addition, a neural network with an attention mechanism [12] has become popular for estimating the air quality of a region without monitoring stations.
- Joint Air Quality Forecasting and Fine-Grained Estimation: Few studies have attempted to achieve both air quality forecasting and fine-grained estimation. The work [15] used the combination of GCN and LSTM networks to learn the spatial–temporal correlation and then predict these two targets. The work in [16] proposed a hybrid model to perform feature selection, air quality forecasting, and fine-grained estimation jointly in one single model. Moreover, the studies in [14,21] show that using air quality forecasting and fine-grained estimating as multi-task learning can improve the generalization performance by leveraging the commonalities and differences between these two tasks.
3. Preliminaries
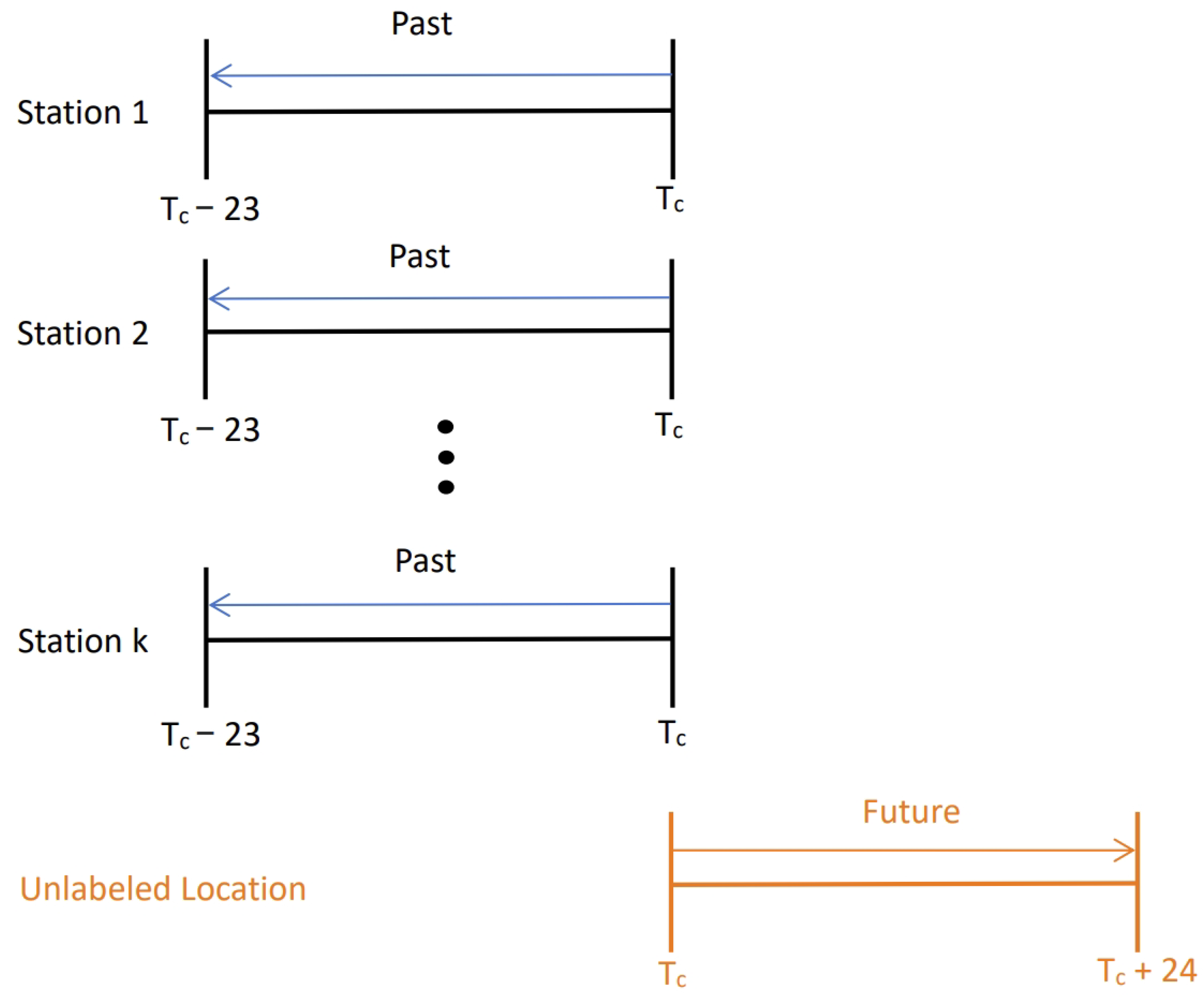
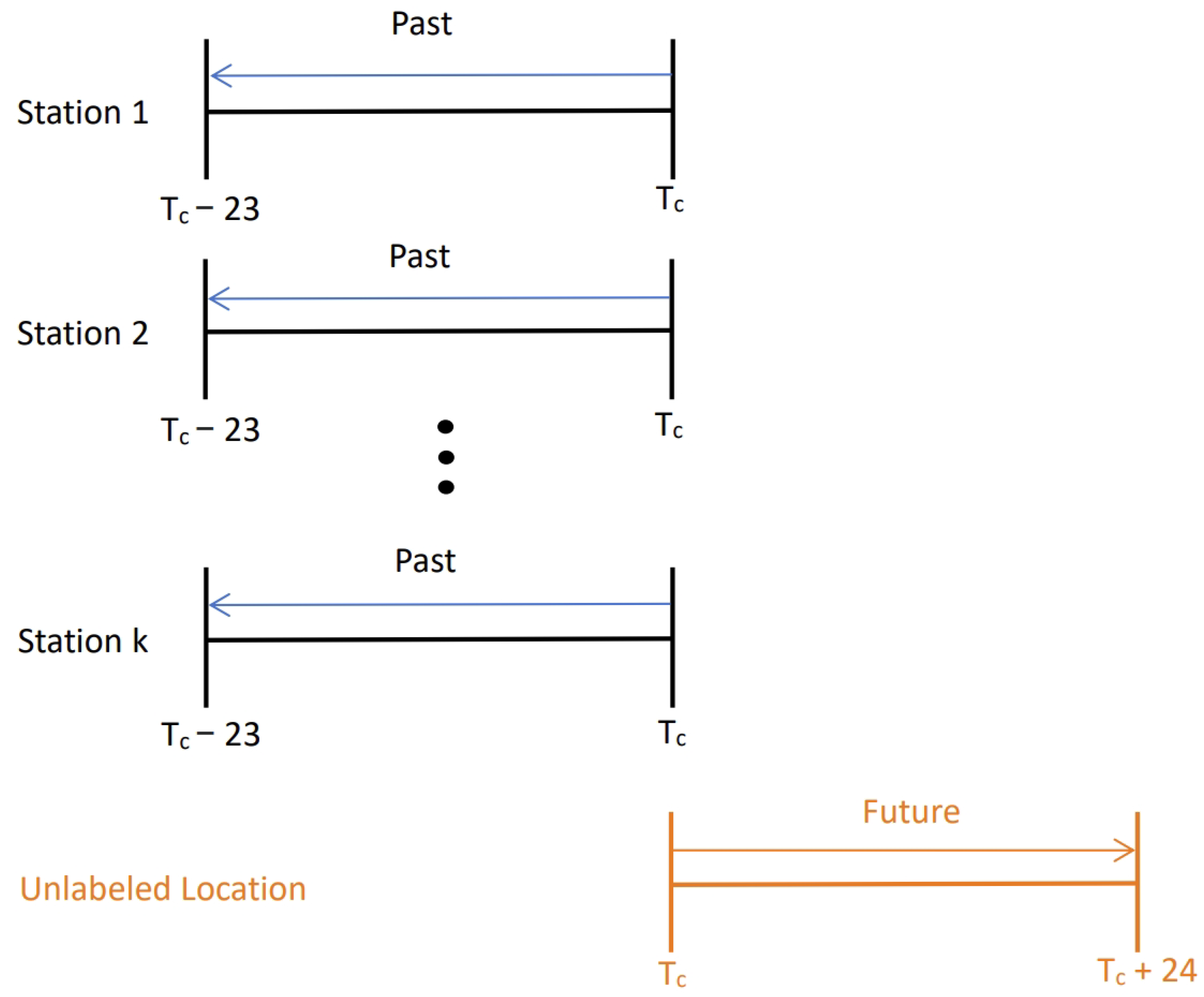
3.1. Problem Statement
3.2. Definition of Input Features
- Grid: We use longitude and latitude to divide the target area into disjoint square grids as the basic unit. Notably, we adjust the size of the grid to ensure that each grid contains only one air quality monitoring station. A grid region with no monitoring station is denoted as unlabeled grids , and a grid region with a monitoring station is denoted as labeled grids .
- AQI: In this study, we use the dataset collected by [22]. We choose PM2.5 values observed by air-quality monitoring stations every hour as the predictive features because PM2.5 is the main pollutant that influences the air quality level and also the most widely used indicators of an air quality report.
- Meteorological Data: The meteorological data are critical factors to air quality level. The grid-level meteorological data in [22] includes temperature, pressure, humidity, wind direction, and wind speed.
- POIs: The amounts of POIs represent activities and the density of people in a region, which might have a huge influence on the air quality. In this study, we collect POIs data from Gaode Map and select 14 types of POIs.
- Road Network: It is known that air quality is strongly affected by traffic condition. The type and accumulated length of a road might be strongly correlated to the real-time traffic condition. In this study, the road network data are collected using OpenStreetMap and four features are identified for each grid: (1) total length of highway, (2) total length of primary road, (3) total length of secondary road, and (4) total length of the pedestrian walk.
- Land Use: The air quality of a region is highly affected by its surrounding land. For example, “Industrial Area” could be the source of air pollution; “Residential” is the place that attracts people and traffic, which worsens the air quality. Conversely, the region with a larger area of open “Green” or “Water” land might improve the air quality. In this study, we use OpenStreetMap to collect four types of land use data including (1) total area of green land, (2) total area of industrial area, (3) total area of residential area and (4) total area of waters for each grid.
4. Methodology
4.1. Data Preprocessing and Symbols
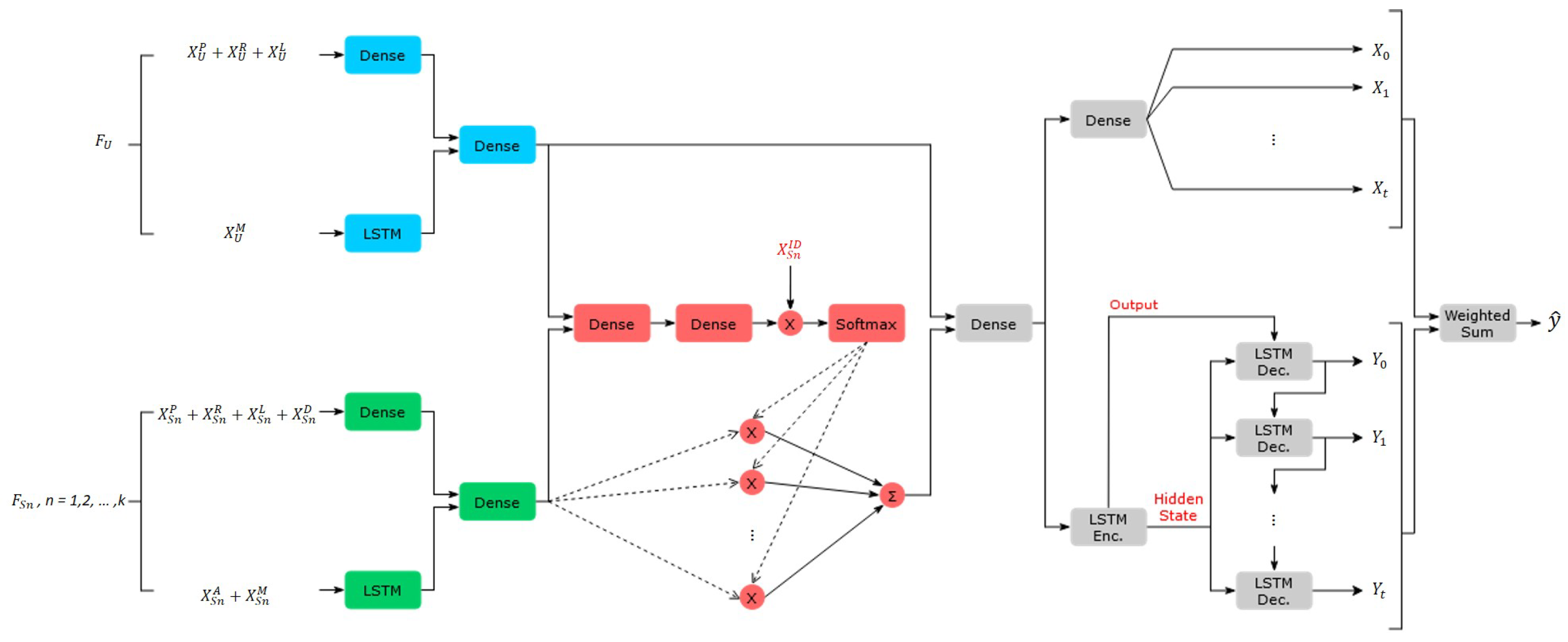
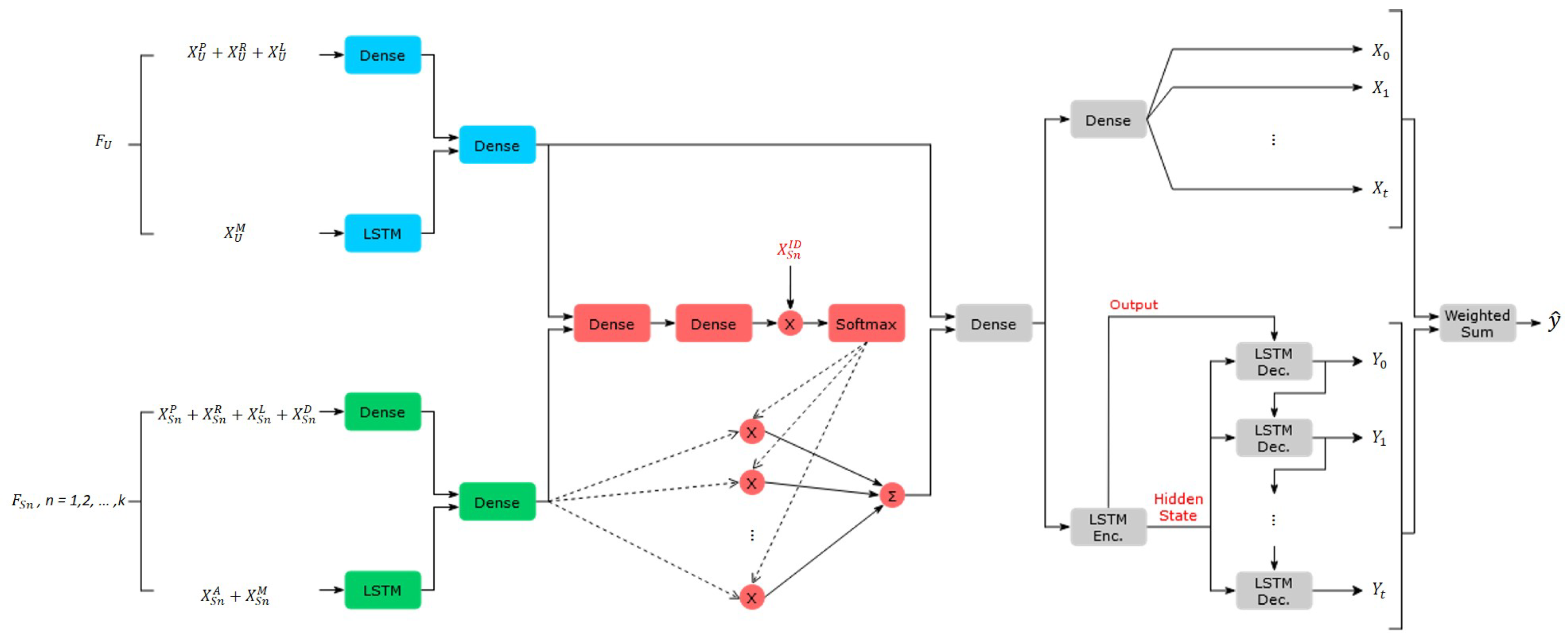
4.2. Feature Extractor
4.3. Inversed Distance Attention
4.4. Hybrid Predictor
5. Experiments
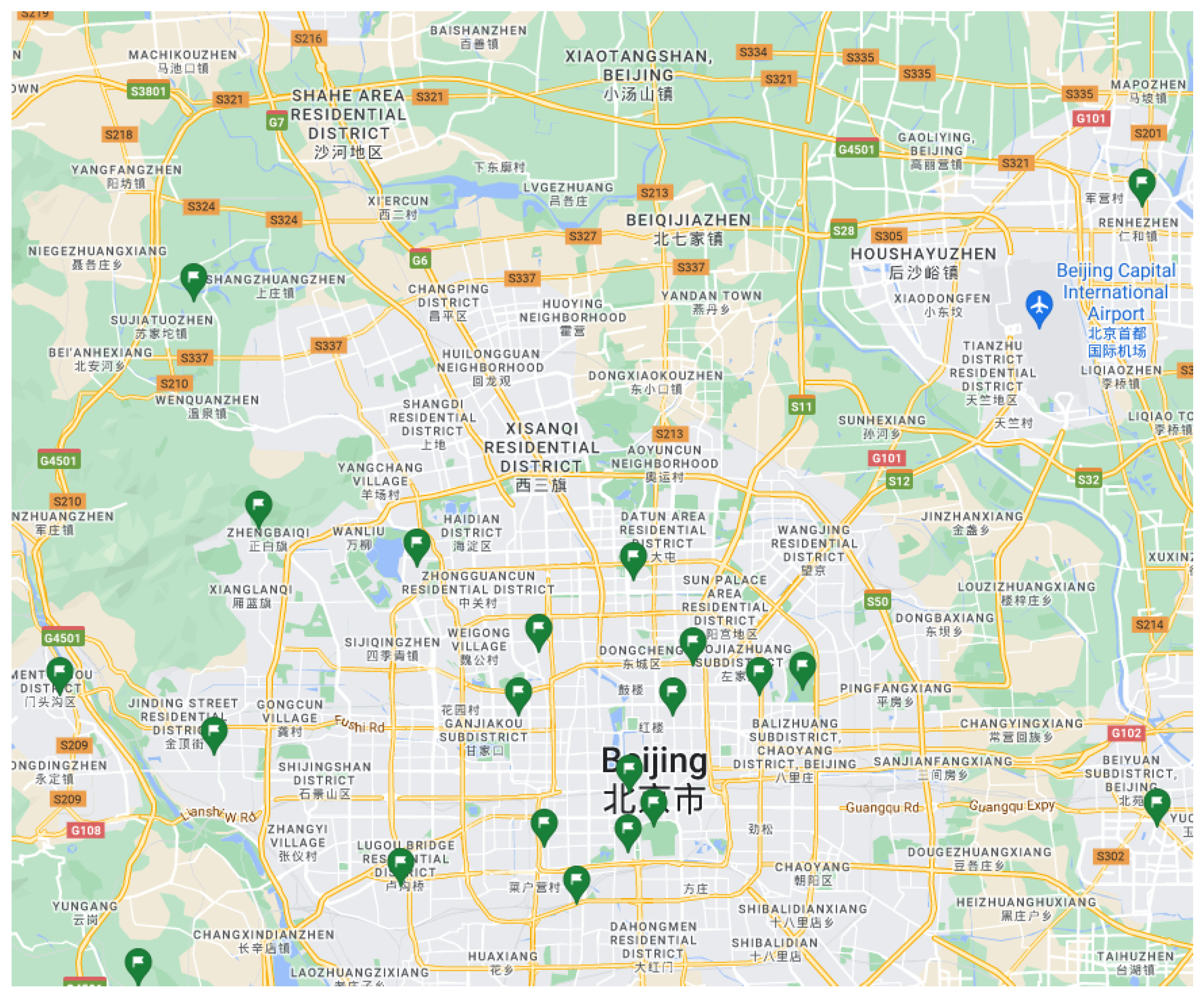
5.1. Dataset
5.2. Experimental Settings and Evaluation Metrics
5.3. Experimental Results
5.3.1. Comparison with Baseline Models
- K-nearest neighbor (K-NN) regression: The idea of the K-NN regressor is to predict the value by using the nearest monitoring stations as references. In this study, we set the nearest neighbors to three (i.e., k = 3). That is, the predicted value was calculated by using the average scores of the three nearest stations.
- Weighted KNN regression: The weighted K-NN predicts the target values by using the inverse-distance-weighted [26] average scores of the nearest stations. That is, a closer station will have a greater influence on the predicted value of the target station. In this study, we used k = 3 as the setting of the K-NN regressor.
- Gradient Boosting Decision Tree (GBDT) regression: GBDT is a state-of-art tree-based model that captures complex cross features [27].
- Linear Regression: A linear model that assumes a linear relationship between the input variables and the output variable.
- Multilayer Perceptron (MLP): For the MLP model, we concatenate all features on all timestamps as input. The MLP model has two layers.
- LSTM: For the LSTM model, we concatenated all static features with every time step of time-series data as input features. The LSTM model contains two LSTM layers and one dense output layer.
- LSTM-IDW: The LSTM-IDW model is a combination of the LSTM model and the IDW method. We use LSTM to make an AQI prediction of the labeled grids using their historical data first, and then use IDW interpolation to infer the future predictive values of unlabeled grids based on the prediction values of LSTM.
5.3.2. Ablation Study of Inversed Distance Attention
- Model without Attention mechanism: We disabled all the attention structures in our model and used summation to aggregate the embedding vectors of all labeled grids.
- Model without Inversed Distance Attention: In Figure 1b, we only disregard the inversed distance feature to calculate the attention weight, while the process and parameter settings are the same as our proposed method.
- Model with Inversed Distance Attention: This is our proposed model with inversed distance attention structure. We compare our prediction result with the two above models to show the advantage of the proposed inversed distance attention layer.
5.3.3. Ablation Study of Hybrid Predictor
5.3.4. Affection of Number of Labeled Grids
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xing, Y.F.; Xu, Y.H.; Shi, M.H.; Lian, Y.X. The impact of PM2.5 on the human respiratory system. J. Thorac. Dis. 2016, 8, E69. [Google Scholar] [PubMed]
- Menut, L.; Bessagnet, B.; Siour, G.; Mailler, S.; Pennel, R.; Cholakian, A. Impact of lockdown measures to combat Covid-19 on air quality over western Europe. Sci. Total Environ. 2020, 741, 140426. [Google Scholar] [CrossRef] [PubMed]
- Qin, S.; Liu, F.; Wang, C.; Song, Y.; Qu, J. Spatial-temporal analysis and projection of extreme particulate matter (PM10 and PM2.5) levels using association rules: A case study of the Jing-Jin-Ji region, China. Atmos. Environ. 2015, 120, 339–350. [Google Scholar] [CrossRef]
- Zheng, Y.; Yi, X.; Li, M.; Li, R.; Shan, Z.; Chang, E.; Li, T. Forecasting fine-grained air quality based on big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 2267–2276. [Google Scholar]
- Hsieh, H.P.; Lin, S.D.; Zheng, Y. Inferring air quality for station location recommendation based on urban big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 437–446. [Google Scholar]
- Le, V.D.; Bui, T.C.; Cha, S.K. Spatiotemporal deep learning model for citywide air pollution interpolation and prediction. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; IEEE: Piscataway, NJ, USA; pp. 55–62. [Google Scholar]
- Kumar, K.; Yadav, A.; Singh, M.; Hassan, H.; Jain, V. Forecasting daily maximum surface ozone concentrations in Brunei Darussalam—An ARIMA modeling approach. J. Air Waste Manag. Assoc. 2004, 54, 809–814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lateb, M.; Meroney, R.N.; Yataghene, M.; Fellouah, H.; Saleh, F.; Boufadel, M. On the use of numerical modelling for near-field pollutant dispersion in urban environments—A review. Environ. Pollut. 2016, 208, 271–283. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approaches for outdoor air quality modelling: A systematic review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef] [Green Version]
- Xayasouk, T.; Lee, H.; Lee, G. Air pollution prediction using long short-term memory (LSTM) and deep autoencoder (DAE) models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444. [Google Scholar]
- Cheng, W.; Shen, Y.; Zhu, Y.; Huang, L. A neural attention model for urban air quality inference: Learning the weights of monitoring stations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lin, Y.; Mago, N.; Gao, Y.; Li, Y.; Chiang, Y.Y.; Shahabi, C.; Ambite, J.L. Exploiting spatiotemporal patterns for accurate air quality forecasting using deep learning. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 359–368. [Google Scholar]
- Chen, L.; Ding, Y.; Lyu, D.; Liu, X.; Long, H. Deep multi-task learning based urban air quality index modelling. Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. 2019, 3, 1–17. [Google Scholar] [CrossRef]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Qi, Z.; Wang, T.; Song, G.; Hu, W.; Li, X.; Zhang, Z. Deep air learning: Interpolation, prediction, and feature analysis of fine-grained air quality. IEEE Trans. Knowl. Data Eng. 2018, 30, 2285–2297. [Google Scholar] [CrossRef] [Green Version]
- Soh, P.W.; Chang, J.W.; Huang, J.W. Adaptive deep learning-based air quality prediction model using the most relevant spatial-temporal relations. IEEE Access 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Li, L.; Zhang, X.; Holt, J.B.; Tian, J.; Piltner, R. Spatiotemporal interpolation methods for air pollution exposure. In Proceedings of the Ninth Symposium of Abstraction, Reformulation, and Approximation, Catalonia, Spain, 17–18 July 2011. [Google Scholar]
- Wong, D.W.; Yuan, L.; Perlin, S.A. Comparison of spatial interpolation methods for the estimation of air quality data. J. Exp. Sci. Environ. Epidemiol. 2004, 14, 404–415. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Chiang, Y.Y.; Pan, F.; Stripelis, D.; Ambite, J.L.; Eckel, S.P.; Habre, R. Mining public datasets for modeling intra-city PM2.5 concentrations at a fine spatial resolution. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Zhao, X.; Xu, T.; Fu, Y.; Chen, E.; Guo, H. Incorporating spatio-temporal smoothness for air quality inference. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: Piscataway, NJ, USA; pp. 1177–1182. [Google Scholar]
- Wang, H. Air Pollution and Meteorological Data in Beijing 2016–2017. 2019. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/RGWV8X (accessed on 10 November 2021).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; pp. 5998–6008. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar]
- Appice, A.; Ciampi, A.; Fumarola, F.; Malerba, D. Missing sensor data interpolation. In Data Mining Techniques in Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2014; pp. 49–71. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Metrics | |||||
|---|---|---|---|---|---|---|
| k-NN Nearest Average | MAE RMSE | 23.19 40.87 | 32.01 52.82 | 45.21 71.41 | 53.25 81.46 | 58.05 85.92 |
| IDW Interpolation | MAE RMSE | 22.80 40.24 | 31.77 52.44 | 45.08 71.25 | 53.43 81.33 | 57.94 85.78 |
| GBDT Regression | MAE RMSE | 21.41 37.33 | 25.70 41.32 | 29.90 45.90 | 32.54 49.83 | 34.04 51.10 |
| Linear Regression | MAE RMSE | 24.93 39.15 | 29.00 43.68 | 35.14 51.42 | 39.09 57.14 | 40.30 58.38 |
| MLP | MAE RMSE | 24.95 43.28 | 26.64 45.22 | 31.54 52.23 | 33.74 56.89 | 36.02 59.91 |
| LSTM | MAE RMSE | 52.66 88.60 | 53.73 91.33 | 57.30 97.18 | 60.90 102.53 | 62.53 103.55 |
| LSTM-IDW | MAE RMSE | 22.80 40.24 | 31.87 52.61 | 42.43 68.72 | 51.29 77.48 | 57.85 81.22 |
| Our Model | MAE RMSE | 19.35 33.78 | 19.41 32.08 | 19.72 33.14 | 20.41 35.88 | 22.25 39.95 |
| Methods | Metrics | |||||
|---|---|---|---|---|---|---|
| Without Attention | MAE RMSE | 21.53 36.74 | 20.88 35.40 | 22.00 37.35 | 22.12 39.94 | 24.91 45.75 |
| Without IDA | MAE RMSE | 20.42 33.28 | 19.67 31.84 | 20.68 33.26 | 21.21 36.12 | 23.14 40.65 |
| With IDA | MAE RMSE | 19.35 33.78 | 19.41 32.08 | 19.72 33.14 | 20.41 35.88 | 22.25 39.95 |
| No. of Data | |||||
|---|---|---|---|---|---|
| Data 1 | 18.53 | 18.50 | 20.79 | 19.82 | 21.85 |
| Data 2 | 22.11 | 20.14 | 19.23 | 19.09 | 20.30 |
| Data 3 | 24.41 | 22.54 | 23.63 | 23.40 | 29.16 |
| Data 4 | 17.88 | 18.31 | 18.90 | 20.48 | 23.59 |
| Data 5 | 18.68 | 21.77 | 26.85 | 22.76 | 24.47 |
| Data 6 | 23.28 | 19.83 | 22.08 | 23.17 | 25.53 |
| Data 7 | 23.80 | 23.19 | 25.07 | 23.80 | 24.80 |
| Data 8 | 22.13 | 19.76 | 19.97 | 23.97 | 23.45 |
| Data 9 | 19.81 | 17.73 | 18.78 | 20.05 | 21.54 |
| Data 10 | 18.02 | 17.61 | 18.79 | 19.39 | 22.16 |
| AVERAGE | 20.86 | 19.94 | 21.41 | 21.59 | 23.68 |
| No. of Data | |||||
|---|---|---|---|---|---|
| Data 1 | 25.41 | 25.59 | 28.45 | 31.00 | 33.14 |
| Data 2 | 31.70 | 27.86 | 25.01 | 26.77 | 32.33 |
| Data 3 | 28.73 | 29.01 | 31.15 | 34.45 | 43.32 |
| Data 4 | 27.00 | 28.76 | 30.65 | 34.68 | 37.84 |
| Data 5 | 25.52 | 27.91 | 33.87 | 33.67 | 34.52 |
| Data 6 | 28.28 | 27.64 | 31.20 | 33.95 | 37.78 |
| Data 7 | 30.75 | 30.88 | 30.54 | 29.28 | 29.05 |
| Data 8 | 33.25 | 31.23 | 34.69 | 39.48 | 42.04 |
| Data 9 | 28.00 | 26.77 | 27.81 | 28.80 | 32.11 |
| Data 10 | 22.77 | 22.97 | 25.32 | 25.77 | 29.80 |
| AVERAGE | 28.14 | 27.86 | 29.87 | 31.78 | 35.19 |
| No. of Data | ||||||
|---|---|---|---|---|---|---|
| Data 1 | 16.88 | 17.31 | 18.39 | 19.66 | 20.61 | |
| Data 2 | 20.46 | 17.90 | 17.46 | 18.80 | 19.83 | |
| Data 3 | 23.12 | 20.86 | 22.39 | 23.74 | 28.83 | |
| Data 4 | 17.50 | 19.16 | 19.37 | 21.29 | 23.29 | |
| Data 5 | 18.60 | 21.90 | 26.15 | 22.00 | 25.08 | |
| Data 6 | 20.28 | 18.33 | 20.41 | 21.31 | 23.84 | |
| Data 7 | 21.40 | 22.67 | 24.79 | 23.46 | 24.08 | |
| Data 8 | 23.41 | 20.61 | 19.24 | 22.27 | 23.29 | |
| Data 9 | 20.17 | 17.76 | 18.72 | 19.71 | 20.22 | |
| Data 10 | 15.42 | 15.93 | 17.16 | 17.41 | 18.78 | |
| AVERAGE | MAE RMSE | 19.72 33.90 | 19.24 32.76 | 20.41 34.76 | 20.97 37.46 | 22.78 41.71 |
| No. of Data | ||||||
|---|---|---|---|---|---|---|
| Data 1 | 16.92 | 17.49 | 18.78 | 19.36 | 20.18 | |
| Data 2 | 19.98 | 18.24 | 18.38 | 18.83 | 19.93 | |
| Data 3 | 21.02 | 20.17 | 20.31 | 21.11 | 22.26 | |
| Data 4 | 19.86 | 22.63 | 23.77 | 24.89 | 30.67 | |
| Data 5 | 16.18 | 18.15 | 18.33 | 17.83 | 19.18 | |
| Data 6 | 20.92 | 20.83 | 19.16 | 20.93 | 23.08 | |
| Data 7 | 21.96 | 22.36 | 23.81 | 22.97 | 25.89 | |
| Data 8 | 22.34 | 20.78 | 20.34 | 23.52 | 23.80 | |
| Data 9 | 19.16 | 17.49 | 17.54 | 17.92 | 19.34 | |
| Data 10 | 15.21 | 15.98 | 16.76 | 16.75 | 18.17 | |
| AVERAGE | MAE RMSE | 19.35 33.78 | 19.41 32.08 | 19.72 33.14 | 20.41 35.88 | 22.25 39.95 |
| Number of Labeled Grids (k) | Metrics | |||||
|---|---|---|---|---|---|---|
| k = 10 | MAE RMSE | 20.89 36.71 | 23.22 40.73 | 27.94 47.36 | 27.76 47.34 | 32.22 56.61 |
| k = 15 | MAE RMSE | 19.98 35.86 | 22.62 39.74 | 27.46 45.67 | 26.63 44.94 | 30.43 52.54 |
| k = 20 | MAE RMSE | 19.43 35.01 | 21.83 39.05 | 25.72 43.63 | 25.33 42.59 | 28.8 50.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, H.-P.; Wu, S.; Ko, C.-C.; Shei, C.; Yao, Z.-T.; Chen, Y.-W. Forecasting Fine-Grained Air Quality for Locations without Monitoring Stations Based on a Hybrid Predictor with Spatial-Temporal Attention Based Network. Appl. Sci. 2022, 12, 4268. https://doi.org/10.3390/app12094268
Hsieh H-P, Wu S, Ko C-C, Shei C, Yao Z-T, Chen Y-W. Forecasting Fine-Grained Air Quality for Locations without Monitoring Stations Based on a Hybrid Predictor with Spatial-Temporal Attention Based Network. Applied Sciences. 2022; 12(9):4268. https://doi.org/10.3390/app12094268
Chicago/Turabian StyleHsieh, Hsun-Ping, Su Wu, Ching-Chung Ko, Chris Shei, Zheng-Ting Yao, and Yu-Wen Chen. 2022. "Forecasting Fine-Grained Air Quality for Locations without Monitoring Stations Based on a Hybrid Predictor with Spatial-Temporal Attention Based Network" Applied Sciences 12, no. 9: 4268. https://doi.org/10.3390/app12094268
APA StyleHsieh, H.-P., Wu, S., Ko, C.-C., Shei, C., Yao, Z.-T., & Chen, Y.-W. (2022). Forecasting Fine-Grained Air Quality for Locations without Monitoring Stations Based on a Hybrid Predictor with Spatial-Temporal Attention Based Network. Applied Sciences, 12(9), 4268. https://doi.org/10.3390/app12094268