
Network Intrusion Detection Model Based on CNN and GRU


Abstract
:1. Introduction
- (1)
- To address the problem of feature redundancy, this paper proposes a feature selection algorithm (RFP algorithm). First, a random forest algorithm is introduced to calculate the importance of features, and then Pearson correlation analysis is used to select features;
- (2)
- To address the problem of sample imbalance, this paper proposes a hybrid sampling algorithm (ADRDB algorithm) by combining the Adaptive Synthetic Sampling (ADASYN) [26] and Repeated Edited nearest neighbors (RENN) [27] sampling methods for sampling, while using Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [28] to reject noise, and finally achieving a balanced dataset;
- (3)
- In this paper, CNN is introduced to extract spatial features from the network data traffic and use its weight sharing feature to improve the speed; GRU network is introduced to extract temporal features and learn the dependency between features, so as to avoid overfitting problems; the attention mechanism is introduced to assign different weights to the features, thus reducing the overhead and improving the model performance.
2. Related Work
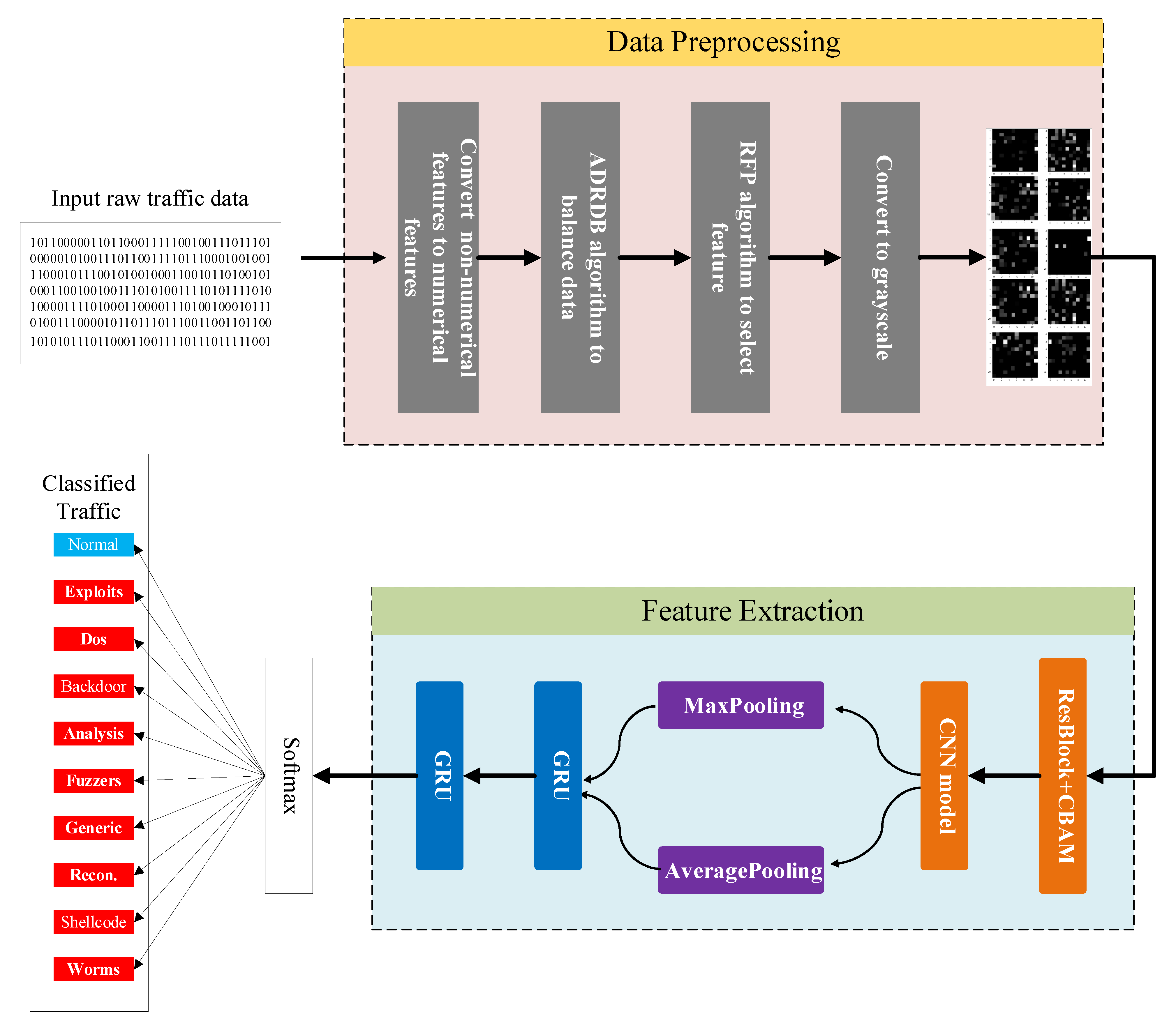
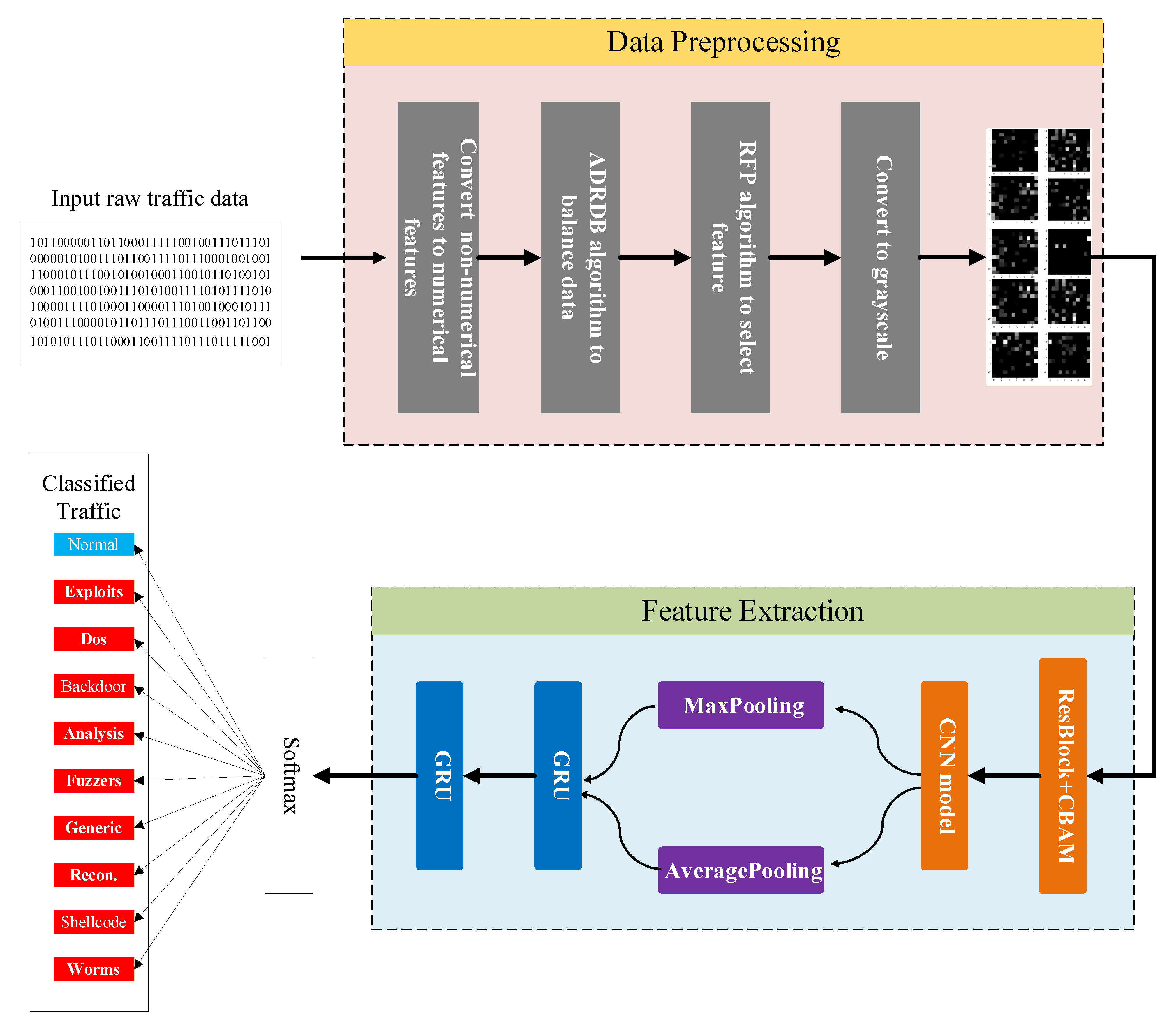
3. Network Intrusion Detection Model Based on CNN and GRU
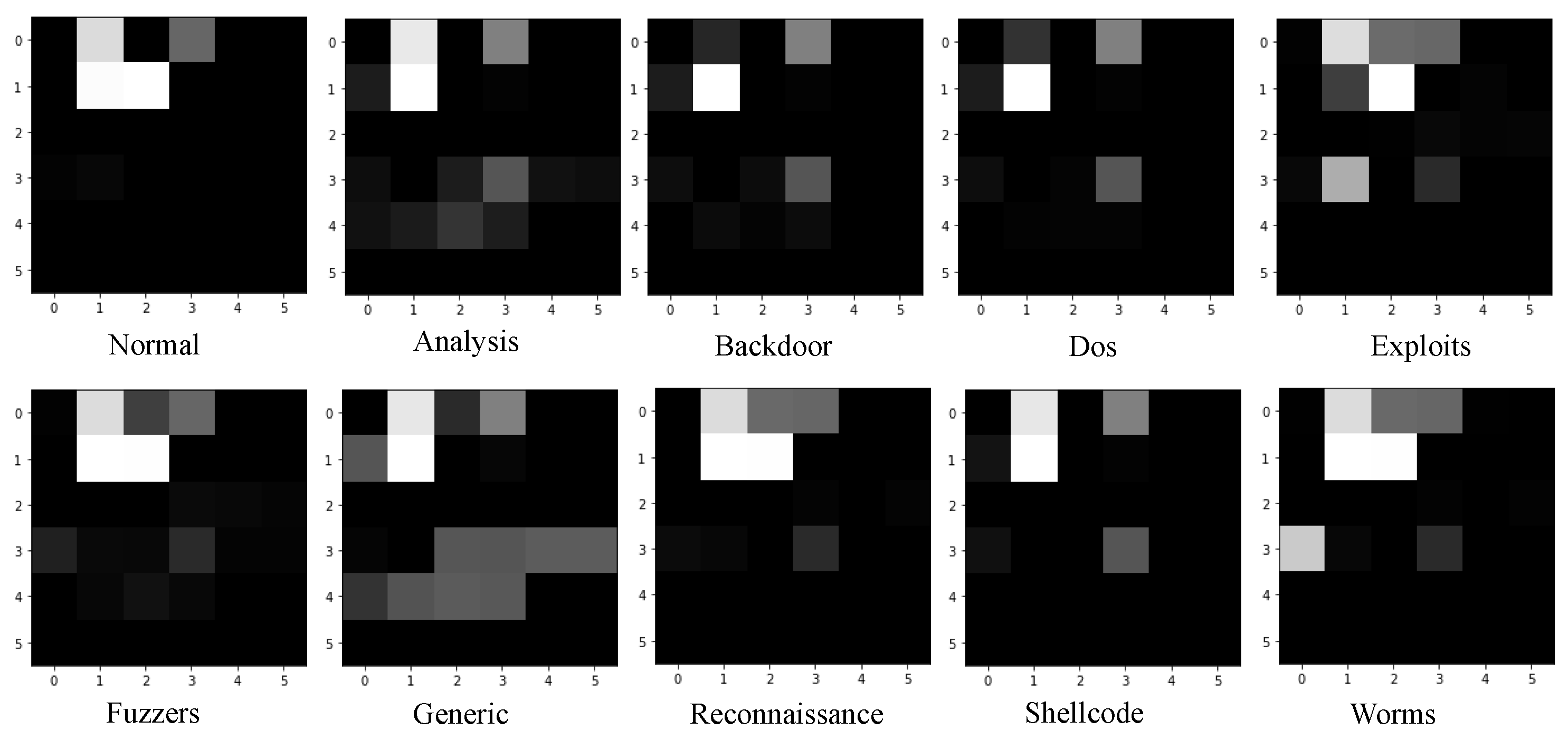
3.1. Data Pre-Processing
3.1.1. Non-Numerical Feature Transformation and Normalization
3.1.2. Hybrid Sampling Method Combining ADASYN and RENN
- (1)
- Calculate the degree of imbalance of the dataset d.
- (2)
- If (where is a pre-determined value for the maximum allowed degree of imbalance ratio), the following operations are performed: firstly, calculate the number of G samples that are needed to be generated for the minority class; secondly, for each sample in N find its nearest neighbors and calculate the ratio , where denotes the number of samples belonging to the majority class among the k nearest neighbors of and |X| all represent the number of samples; afterwards, normalize to ; finally, calculate the number of samples that need to be synthesized for each minority class sample.
- (3)
- For each sample in N, generate samples in steps to obtain a new minority sample set.
- (4)
- For each sample in P, select nearest neighbor from newN.
- (5)
- Calculate the number of minority samples in the nearest neighbors of each majority sample and eliminate the sample if the number of samples is greater than e. (e = 1)
- (6)
- Repeat steps (4) and (5) to generate a new majority class sample set.
- (7)
- Remove the noise in newP and newN to get the final newN and newP.
| Algorithm 1: Hybrid sampling method combining ADASYN and RENN (ADRDB) |
| Input: Minority class sample set, P. Majority class sample set, N. |
| Output: The balanced minority class sample set, newP. The balanced majority class sample set, newN. |
| Process: |
| (1) |
| (2) If |
| do |
| end for |
| (3) |
| do |
| end for |
| (4) |
| (5) |
| (6) |
| (7) for each do |
| end for |
| (8) Repeat (6), (7) |
| (9) |
| (10) DBSCAN Algorithm to remove noise |
| (11) |
3.1.3. Feature Selection Algorithm
- (1)
- For each base learner, select the corresponding out-of-bag data (some of the remaining samples that are not selected) and calculate its error, denoted as error_a;
- (2)
- Randomly add disturbances to the full sample of out-of-bag data and calculate its error, noted as error_b;
- (3)
- Assuming that the forest contains M trees, the value of Importance of a feature is as follows:
- ((4)
- A new dataset is constructed by filtering out the features with a high level of importance.
| Algorithm 2: Feature selection algorithm (RFP) |
| Input: Original data set, D |
| Output: Processed dataset, NewD |
Procedure:
|
3.2. Model Structure
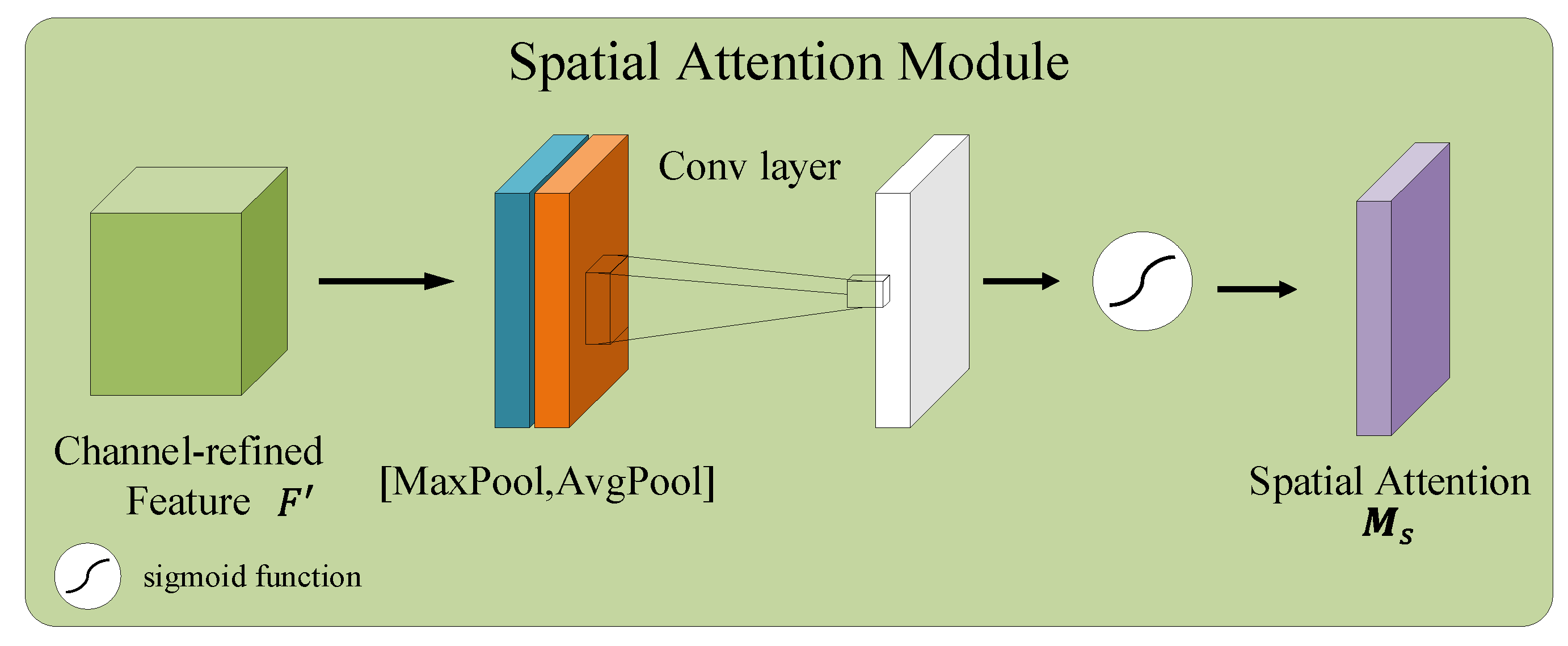
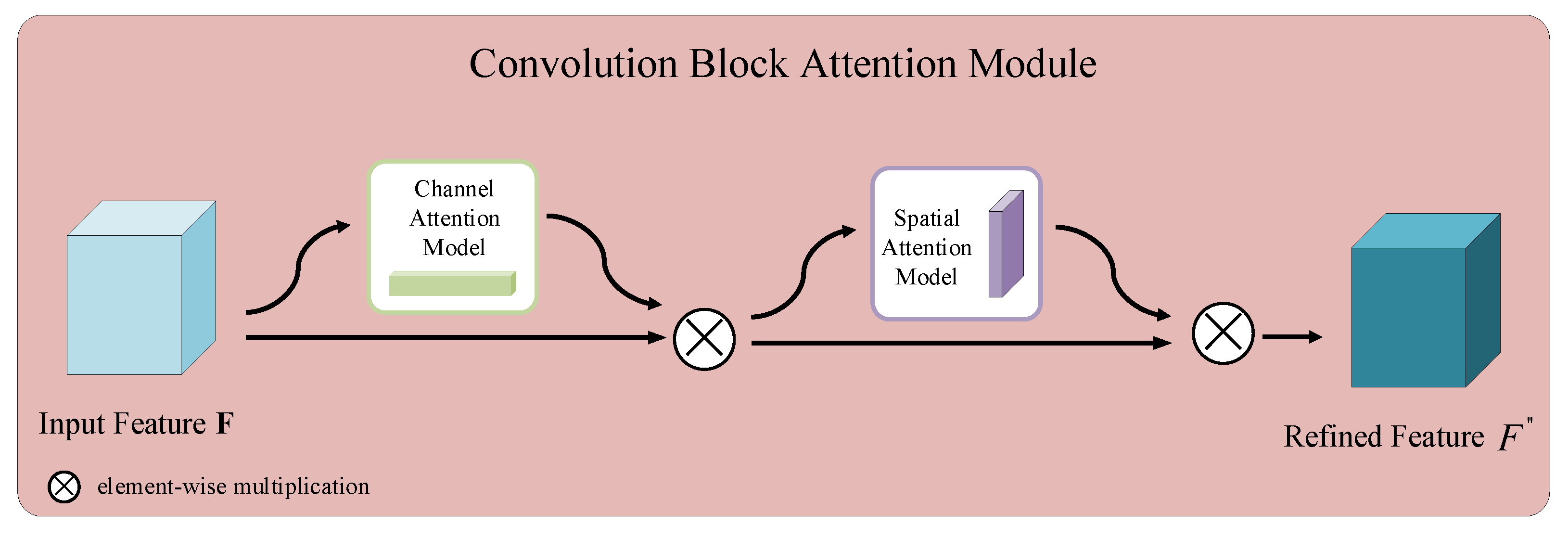
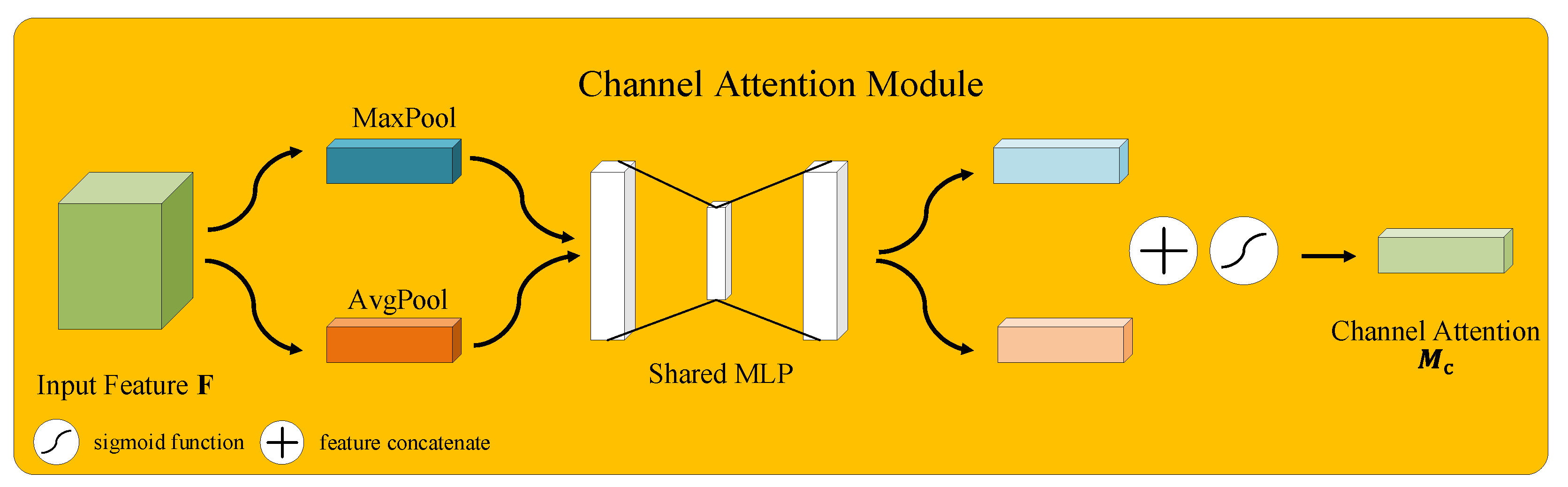
3.2.1. Convolutional Block Attention Module
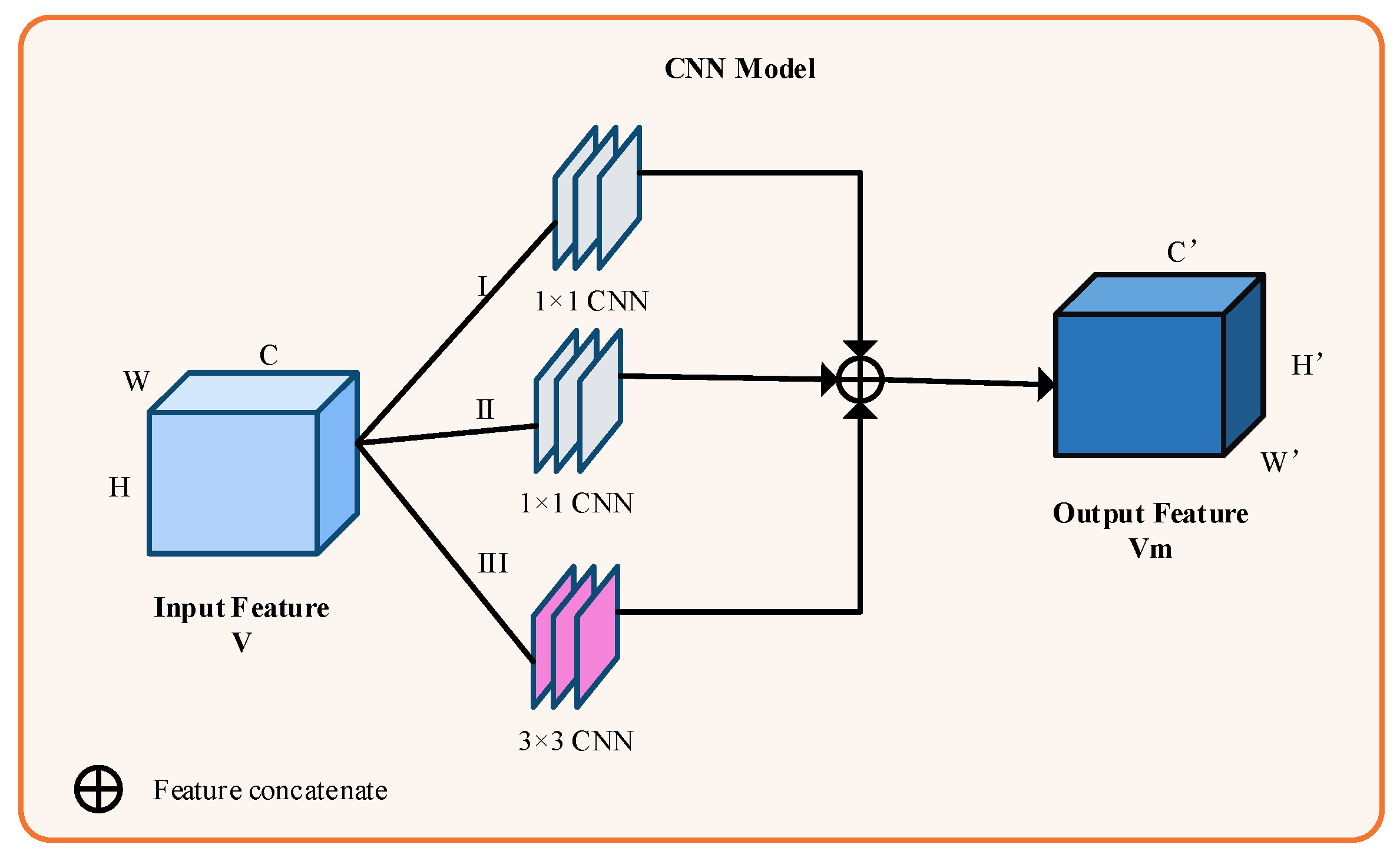
3.2.2. Convolutional Neural Networks
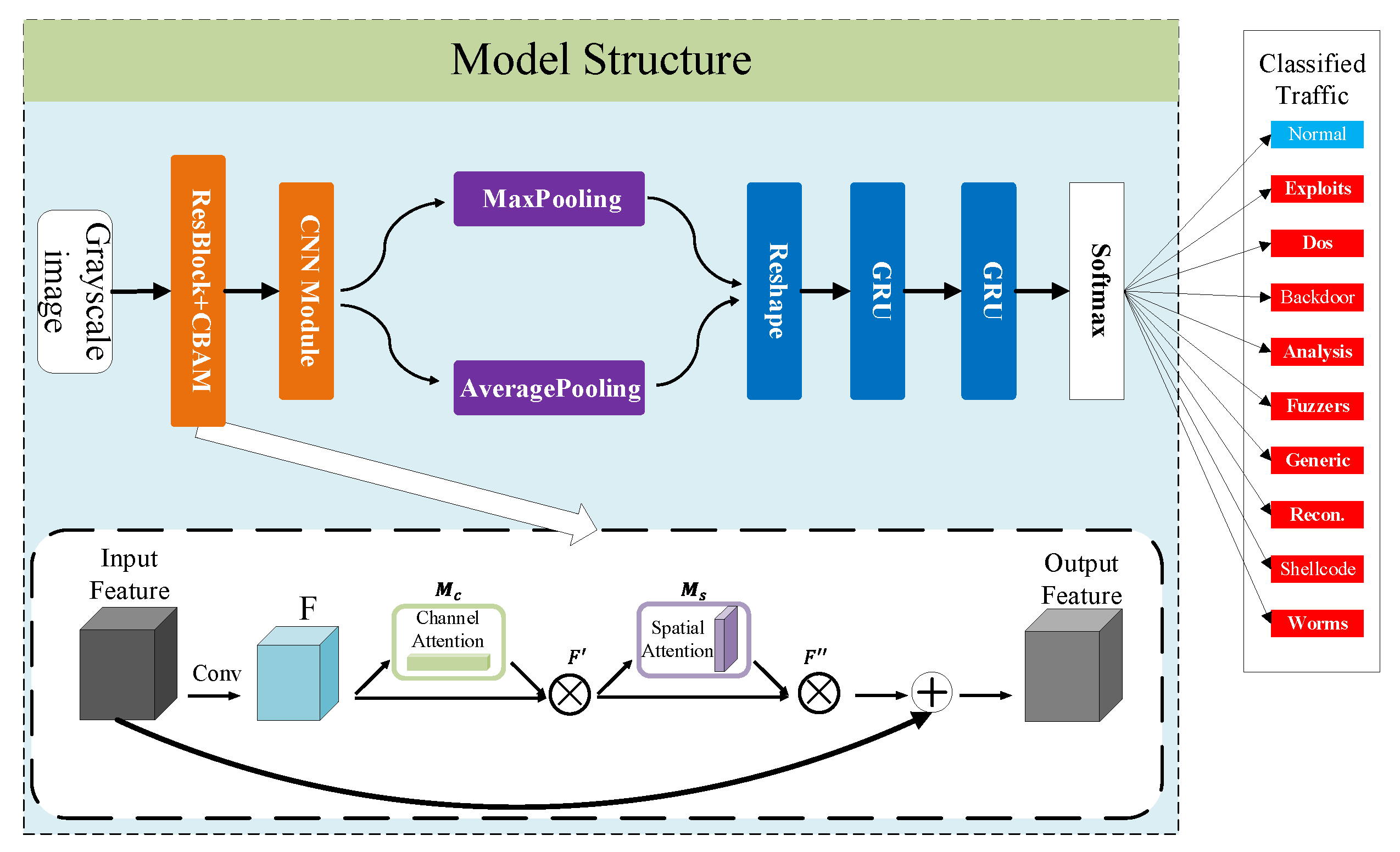
3.2.3. Model Structure
- (1)
- The grayscale map obtained after pre-processing is input to the CBAM module based on residual, and the features are given different weights to obtain the output F.
- (2)
- The new feature map F is input into the CNN module for feature extraction, after which the spatial information is aggregated using Maxpooling and Averagepooling to obtain the new feature map .
- (3)
- Pass to the GRU unit to extract the dependencies between features and obtain the output .
- (4)
- Pass to the fully connected layer, which uses Softmax as the activation function to achieve the classification of intrusion detection behavior.
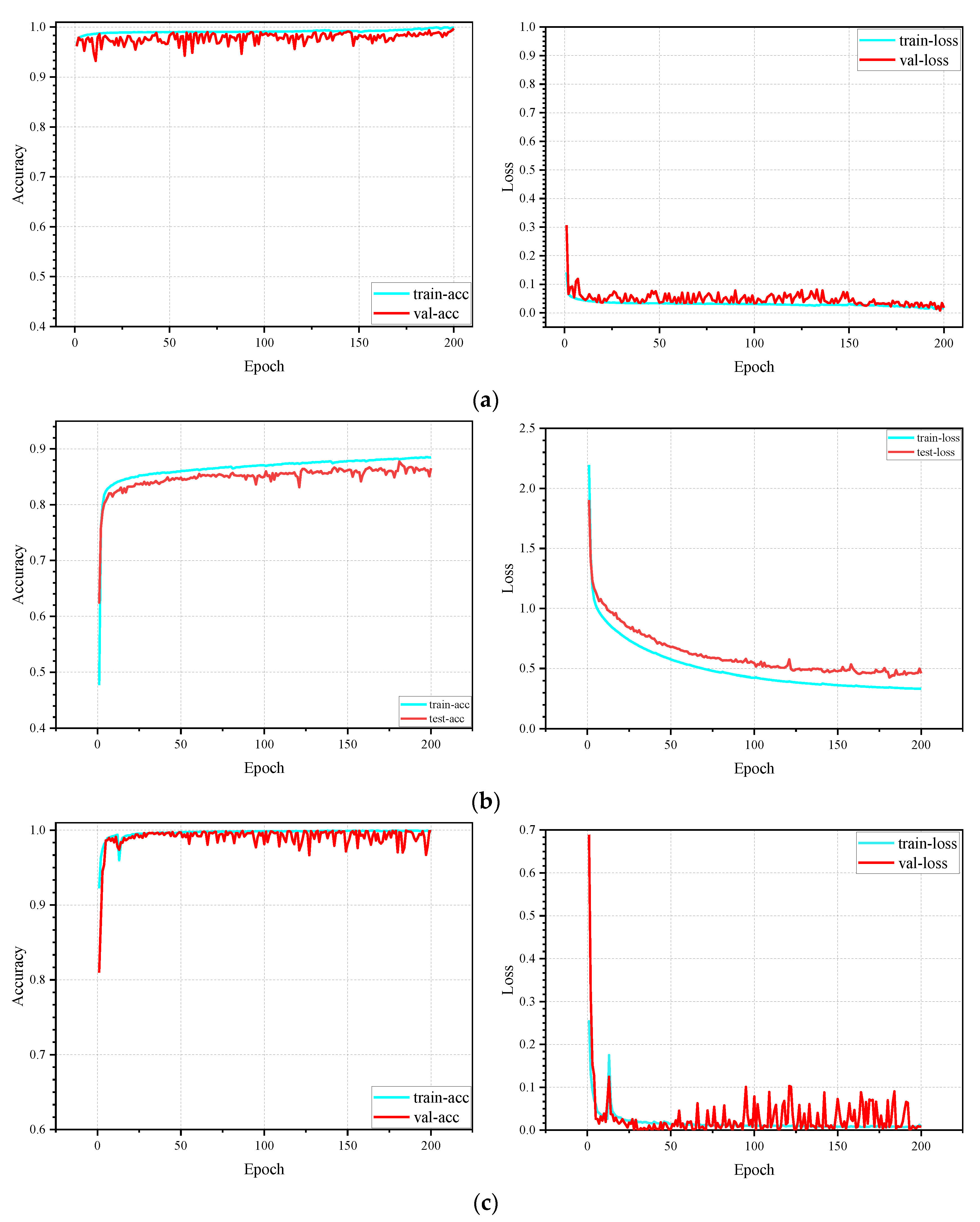
4. Experimental Simulations
4.1. Experimental Setup
- Experiment 1: Feature selection analysis experiment
- Experiment 2: Comparison of different feature selection methods
- Experiment 3: Comparison of different sampling methods
- Experiment 4: Comparison of single model and hybrid model
- Experiment 5: Comparison of different pooling methods
- Experiment 6: Performance comparison experiment
4.2. Dataset and Evaluation Criteria
4.3. Experimental Results and Analysis
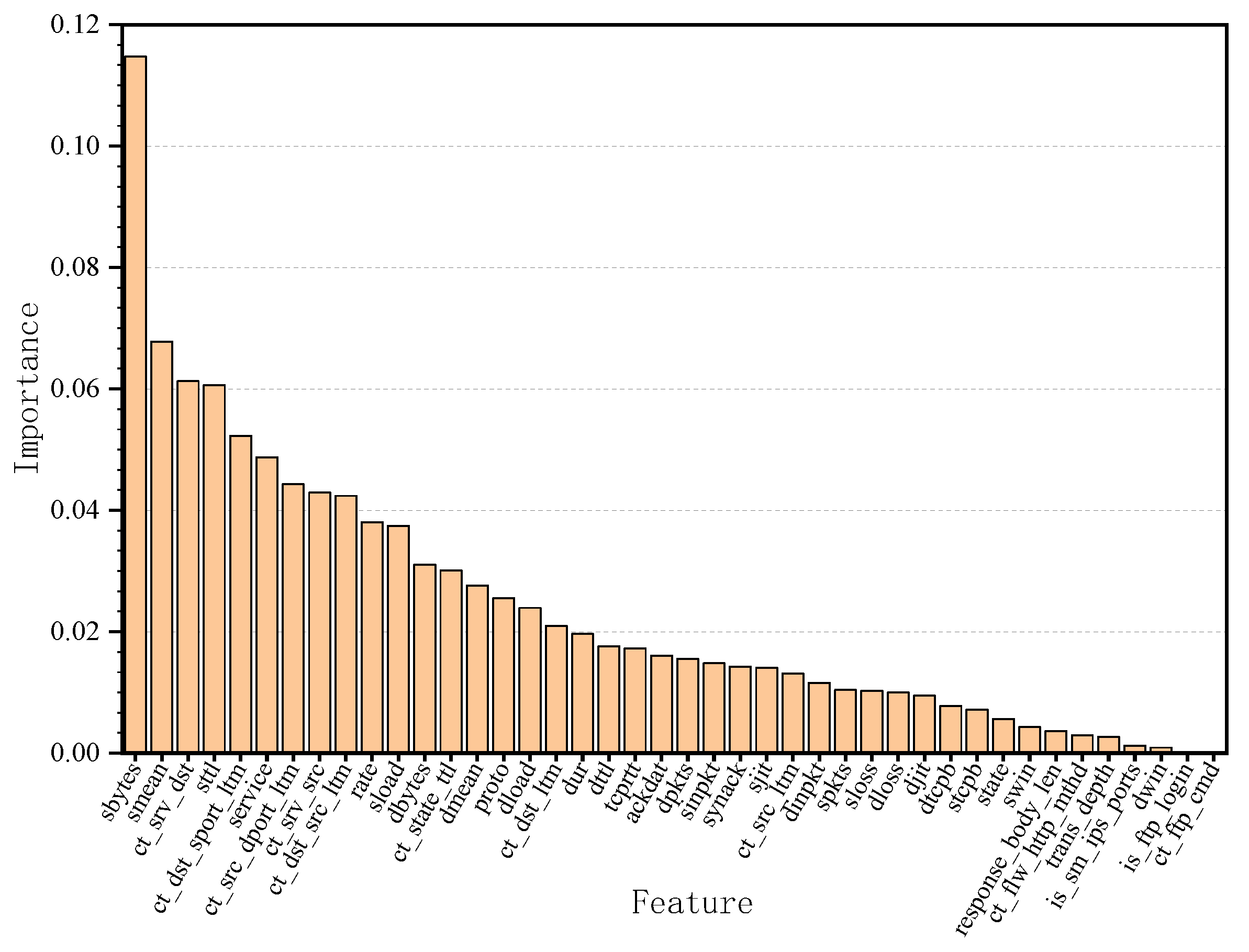
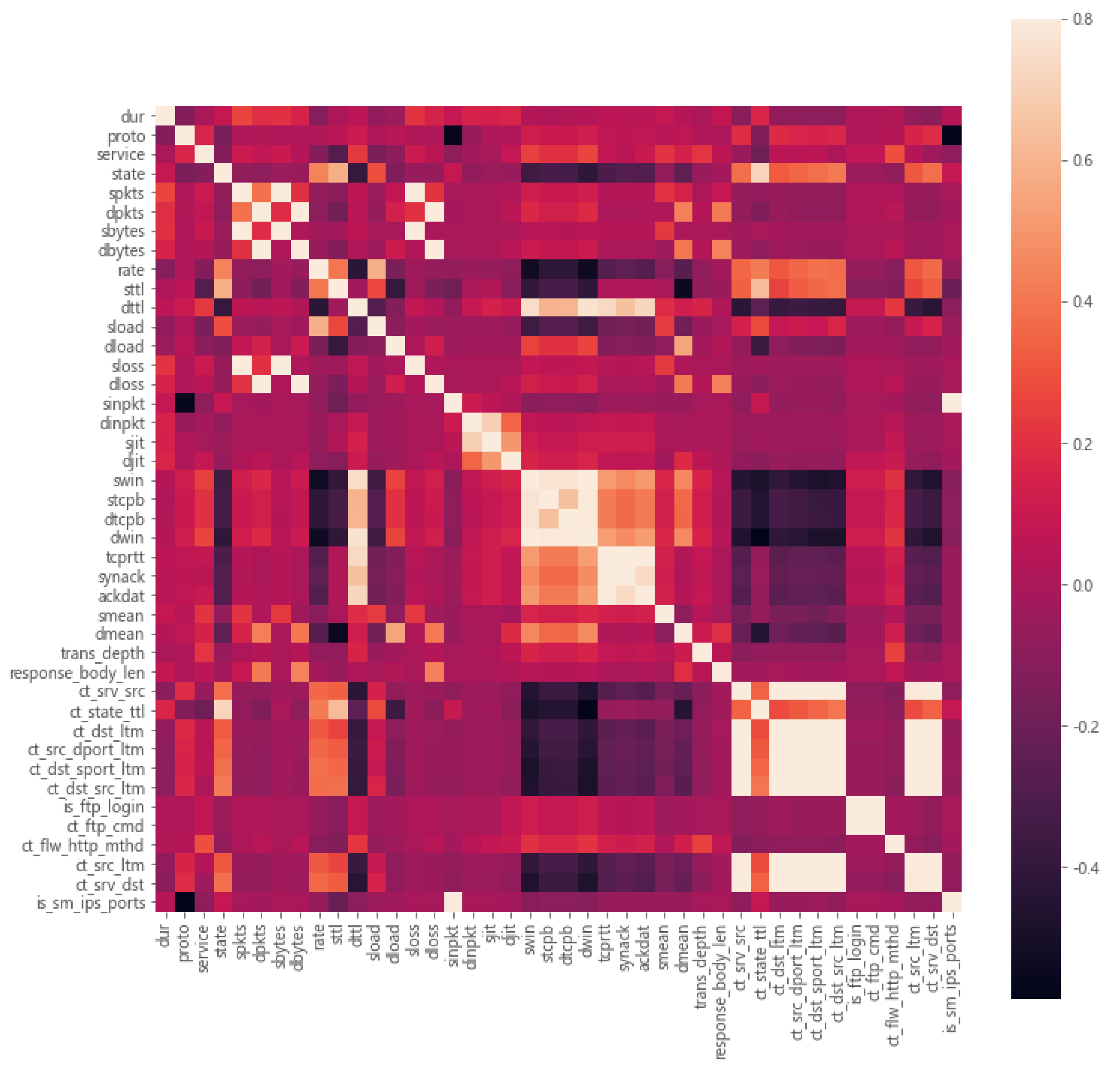
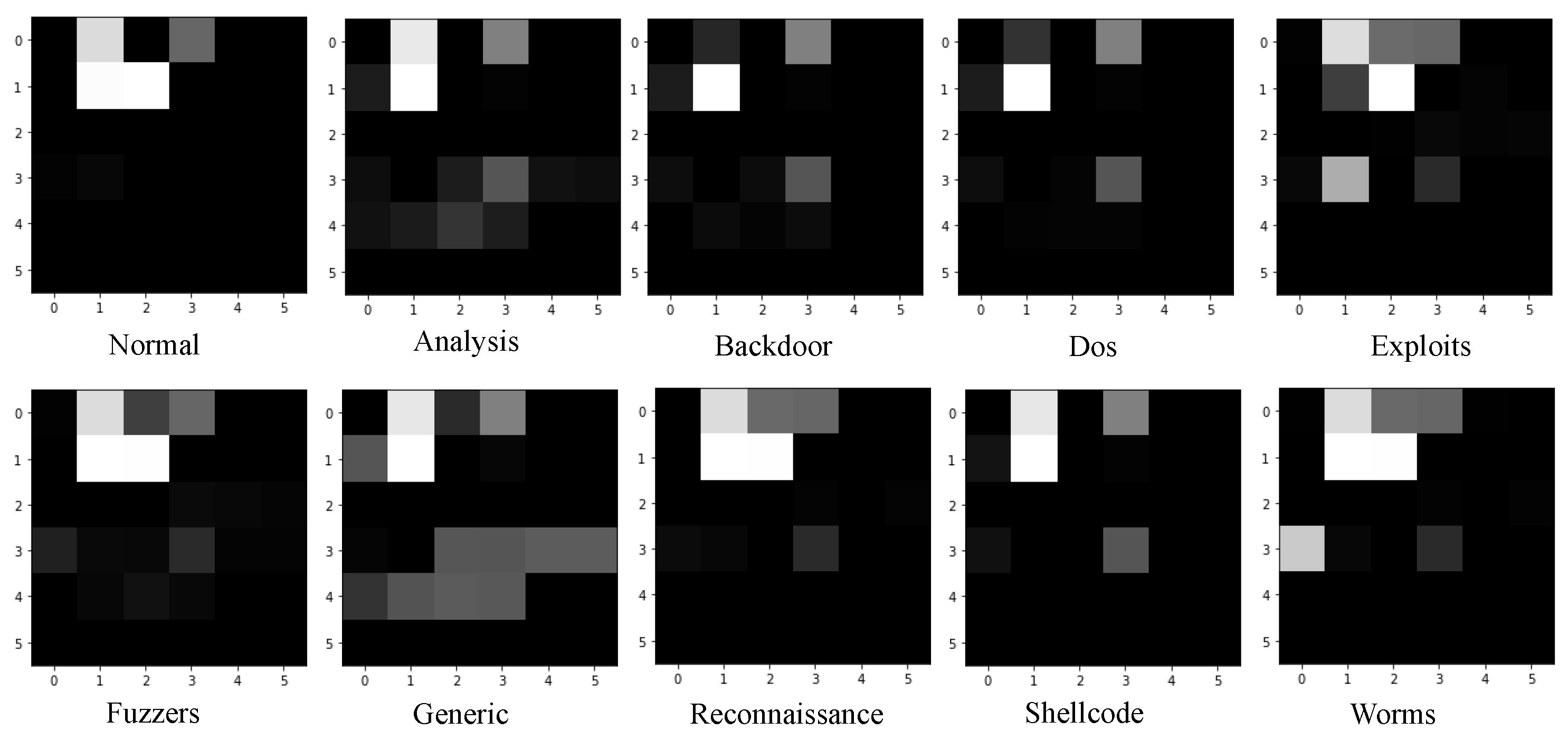
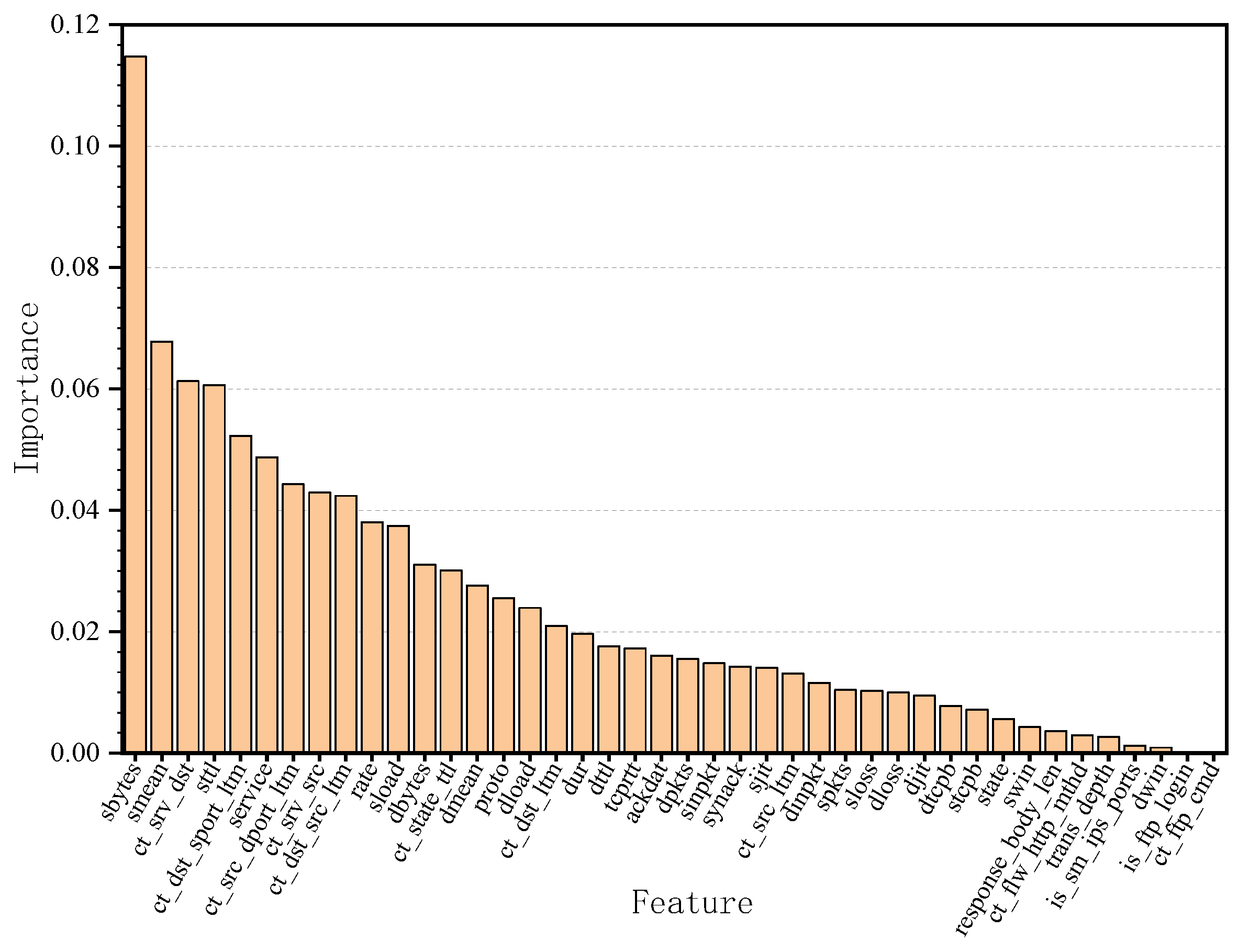
4.3.1. Experiment on Feature Selection Analysis
4.3.2. Comparison Experiments of Different Feature Selection Methods
4.3.3. Experiment Comparing Single Model with Hybrid Model
4.3.4. Comparison Experiments of Different Sampling Methods
4.3.5. Comparison Experiments with Different Pooling Methods
4.3.6. Comparison Experiments of Run-Time Performance
4.3.7. Performance Analysis and Comparison Experiments
4.3.8. Statistical Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, L.; Quan, Y. Dynamic Enabling Cyberspace Defense; People’s Posts and Telecommunications Press: Beijing, China, 2018. [Google Scholar]
- Yu, N. A Novel Selection Method of Network Intrusion Optimal Route Detection Based on Naive Bayesian. Int. J. Appl. Decis. Sci. 2018, 11, 1–17. [Google Scholar] [CrossRef]
- Ren, X.K.; Jiao, W.B.; Zhou, D. Intrusion Detection Model of Weighted Navie Bayes Based on Particle Swarm Optimization Algorithm. Comput. Eng. Appl. 2016, 52, 122–126. [Google Scholar]
- Koc, L.; Mazzuchi, T.A.; Sarkani, S. A network intrusion detection system based on a Hidden Naïve Bayes multiclass classifier. Expert Syst. Appl. 2012, 39, 13492–13500. [Google Scholar] [CrossRef]
- Teng, L.; Teng, S.; Tang, F.; Zhu, H.; Zhang, W.; Liu, D.; Liang, L. A Collaborative and Adaptive Intrusion Detection Based on SVMs and Decision Trees. In Proceedings of the IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 898–905. [Google Scholar] [CrossRef]
- Chen, S.X.; Peng, M.L.; Xiong, H.L.; Yu, X. SVM Intrusion Detection Model Based on Compressed Sampling. J. Electr. Comput. Eng. 2016, 2016, 6. [Google Scholar] [CrossRef] [Green Version]
- Reddy, R.R.; Ramadevi, Y.; Sunitha, K.V.N. Effective discriminant function for intrusion detection using SVM. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 1148–1153. [Google Scholar]
- Tao, Z.; Sun, Z. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Wang, H.W.; Gu, J.; Wang, S.S. An Effective Intrusion Detection Framework Based on SVM with Feature Augmentation. Knowl.-Based Syst. 2017, 136, 130–139. [Google Scholar] [CrossRef]
- Sahu, S.K.; Katiyar, A.; Kumari, K.M.; Kumar, G.; Mohapatra, D.P. An SVM-Based Ensemble Approach for Intrusion Detection. Int. J. Inf. Technol. Web Eng. 2019, 14, 66–84. [Google Scholar] [CrossRef]
- Sahu, S.; Mehtre, B.M. Network intrusion detection system using J48 Decision Tree. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 2023–2026. [Google Scholar] [CrossRef]
- Jiang, F.; Chun, C.P.; Zeng, H.F. Relative Decision Entropy Based Decision Tree Algorithm and Its Application in Intrusion Detection. Comput. Sci. 2012, 39, 223–226. [Google Scholar]
- Ahmim, A.; Maglaras, L.A.; Ferrag, M.A.; Derdour, M.; Janicke, H. A Novel Hierarchical Intrusion Detection System Based on Decision Tree and Rules-Based Models. In Proceedings of the 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini Island, Greece, 29–31 May 2019; pp. 228–233. [Google Scholar] [CrossRef] [Green Version]
- Yun, W. A Multinomial Logistic Regression Modeling Approach for Anomaly Intrusion Detection. Comput. Secur. 2005, 24, 662–674. [Google Scholar] [CrossRef]
- Kamarudin, M.H.; Maple, C.; Watson, T.; Sofian, H. Packet Header Intrusion Detection with Binary Logistic Regression Approach in Detecting R2L and U2R Attacks. In Proceedings of the Fourth International Conference on Cyber Security, Cyber Warfare, and Digital Forensic (CyberSec), Jakarta, Indonesia, 29–31 October 2015; pp. 101–106. [Google Scholar] [CrossRef] [Green Version]
- Ioannou, C.; Vassiliou, V. An Intrusion Detection System for Constrained WSN and IoT Nodes Based on Binary Logistic Regression. In Proceedings of the 21st ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Montreal, QC, Canada, 28 October–2 November 2018; pp. 259–263. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Yuqing, Z.; Ying, D.; Caiyun, L.; Kenan, L.; Hongyu, S. Situation, trends and prospects of deep learning applied to cyberspace security. J. Comput. Res. Dev. 2018, 55, 1117–1142. [Google Scholar]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies, New York, NY, USA, 3–5 December 2015; ACM Press: New York, NY, USA, 2016; pp. 21–26. [Google Scholar]
- Wei, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning Hierarchical Spatial-Temporal Features Using Deep Neural Networks to Improve Intrusion Detection. IEEE Access 2018, 6, 1792–1806. [Google Scholar] [CrossRef]
- Zexuan, M.; Jin, L.; Yanli, L.; Chen, C. A network intrusion detection method incorporating WaveNet and BiGRU. Syst. Eng. Electron. Technol. 2021, 11, 1–12. [Google Scholar]
- Liu, J.; Sun, X.; Jin, J. Intrusion detection model based on principal component analysis and cyclic neural network. Chin. J. Inf. Technol. 2020, 34, 105–112. [Google Scholar]
- Zhou, P.; Zhou, Z.; Wang, L.; Zhao, W. Network intrusion detection method based on autoencoder and RESNET. Comput. Appl. Res. 2020, 37, 224–226. [Google Scholar]
- Yan, B.H.; Han, G.D. Combinatorial Intrusion Detection Model Based on Deep Recurrent Neural Network and Improved SMOTE Algorithm. Chin. J. Netw. Inf. Secur. 2018, 4, 48–59. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Han, M.; Li, X.; Zhang, N.; Cheng, H. Review of Classification Methods on Unbalanced Data Sets. IEEE Access 2021, 9, 64606–64628. [Google Scholar] [CrossRef]
- Deng, Y.W.; Pu, H.T.; Hua, X.B.; Sun, B. Research on lane line detection based on RC-DBSCAN. J. Hunan Univ. 2021, 48, 85–92. [Google Scholar]
- Tama, B.A.; Comuzzi, M.; Rhee, K.H. TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system. IEEE Access 2019, 7, 94497–94507. [Google Scholar] [CrossRef]
- Bu, S.J.; Cho, S.B. A convolutional neural-based learning classifier system for detecting database intrusion via insider attack. Inf. Sci. 2020, 512, 123–136. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Kim, Y.; Kim, H. Network Intrusion Detection Based on Novel Feature Selection Model and Various Recurrent Neural Networks. Appl. Sci. 2019, 9, 1392. [Google Scholar] [CrossRef] [Green Version]
- Hassan, M.M.; Gumaei, A.; Alsanad, A.; Alrubaian, M.; Fortino, G. A hybrid deep learning model for efficient intrusion detection in big data environment. Inf. Sci. 2020, 513, 386–396. [Google Scholar] [CrossRef]
- Louk, M.H.L.; Tama, B.A. Exploring Ensemble-Based Class Imbalance Learners for Intrusion Detection in Industrial Control Networks. Big Data Cogn. Comput. 2021, 5, 72. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2021, 9, 7550–7563. [Google Scholar] [CrossRef]
- Yan, M.; Chen, Y.; Hu, X.; Cheng, D.; Chen, Y.; Du, J. Intrusion detection based on improved density peak clustering for imbalanced data on sensor-cloud systems. J. Syst. Archit. 2021, 118, 102212. [Google Scholar] [CrossRef]
- Alharbi, A.; Alosaimi, W.; Alyami, H.; Rauf, H.T.; Damaševičius, R. Botnet Attack Detection Using Local Global Best Bat Algorithm for Industrial Internet of Things. Electronics 2021, 10, 1341. [Google Scholar] [CrossRef]
- Toldinas, J.; Venčkauskas, A.; Damaševičius, R.; Grigaliūnas, Š.; Morkevičius, N.; Baranauskas, E. A Novel Approach for Network Intrusion Detection Using Multistage Deep Learning Image Recognition. Electronics 2021, 10, 1854. [Google Scholar] [CrossRef]
- Khan, M.A. HCRNNIDS: Hybrid Convolutional Recurrent Neural Network-Based Network Intrusion Detection System. Processes 2021, 9, 834. [Google Scholar] [CrossRef]
- Pu, G.; Wang, L.; Shen, J.; Dong, F. A hybrid unsupervised clustering-based anomaly detection method. Tsinghua Sci. Technol. 2021, 26, 146–153. [Google Scholar] [CrossRef]
- Nguyen, G.N.; Viet, N.H.L.; Elhoseny, M.; Shankar, K.; Gupta, B.B.; Abd El-Latif, A.A. Secure blockchain enabled Cyber-physical systems in healthcare using deep belief network with ResNet model. J. Parallel Distrib. Comput. 2021, 153, 150–160. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S.; Bhoi, A.K.; Ijaz, M.F.; Pramanik, M.; Kumar, Y.; Jhaveri, R.H. A Consolidated Decision Tree-Based Intrusion Detection System for Binary and Multiclass Imbalanced Datasets. Mathematics 2021, 9, 751. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Multi-Stage Optimized Machine Learning Framework for Network Intrusion Detection. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1803–1816. [Google Scholar] [CrossRef]
- Lv, Z.; Chen, D.; Lou, R.; Song, H. Industrial Security Solution for Virtual Reality. IEEE Internet Things J. 2021, 8, 6273–6281. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Shimizu, S.; Ma, J.; Jin, Q. Siamese Neural Network Based Few-Shot Learning for Anomaly Detection in Industrial Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2021, 17, 5790–5798. [Google Scholar] [CrossRef]
- Zhou, X.; Hu, Y.; Liang, W.; Ma, J.; Jin, Q. Variational LSTM Enhanced Anomaly Detection for Industrial Big Data. IEEE Trans. Ind. Inform. 2021, 17, 3469–3477. [Google Scholar] [CrossRef]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2017, 27, 659–678. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018. ECCV 2018. Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef] [Green Version]
- Lippmann, R.; Haines, J.W.; Fried, D.J.; Korba, J.; Das, K. Analysis and Results of the 1999 DARPA Off-Line Intrusion Detection Evaluation. In Recent Advances in Intrusion Detection. RAID 2000; Lecture Notes in Computer Science; Debar, H., Mé, L., Wu, S.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1907. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Li, J.L.; Liu, X.M.; Dong, C. Multi-dimensional feature fusion and stacking ensemble mechanism for network intrusion detection. Future Gener. Comput. Syst. 2021, 122, 130–143. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Rosay, A.; Riou, K.; Carlier, F.; Leroux, P. Multi-layer perceptron for network intrusion detection. Ann. Telecommun. 2021, 6, 1–24. [Google Scholar] [CrossRef]
- Damasevicius, R.; Venckauskas, A.; Grigaliunas, S.; Toldinas, J.; Morkevicius, N.; Aleliunas, T.; Smuikys, P. LITNET-2020: An Annotated Real-World Network Flow Dataset for Network Intrusion Detection. Electronics 2020, 9, 800. [Google Scholar] [CrossRef]
- Xiao, Y.; Xiao, X. An Intrusion Detection System Based on a Simplified Residual Network. Information 2019, 10, 356. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.; Xing, C.; Zhang, T.; Zhao, Z. An Intrusion Detection Model Based on Feature Reduction and Convolutional Neural Networks. IEEE Access 2019, 7, 42210–42219. [Google Scholar] [CrossRef]
- Xie, X.; Wang, B.; Wan, T.; Tang, W. Multivariate Abnormal Detection for Industrial Control Systems Using 1D CNN and GRU. IEEE Access 2020, 8, 88348–88359. [Google Scholar] [CrossRef]
- Sinha, J.; Manollas, M. Efficient deep CNN-BILSTM model for network intrusion detection. In Proceedings of the 3rd International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 26–28 June 2020; pp. 223–231. [Google Scholar] [CrossRef]
- Niu, Q.; Li, X. A High-performance Web Attack Detection Method based on CNN-GRU Model. In Proceedings of the IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 804–808. [Google Scholar] [CrossRef]
- Jiang, Y.; Jia, M.; Zhang, B.; Deng, L. Malicious Domain Name Detection Model Based on CNN-GRU-Attention. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1602–1607. [Google Scholar] [CrossRef]
- Hu, J.; Zheng, W. A deep learning model to effectively capture mutation information in multivariate time series prediction. Knowl.-Based Syst. 2020, 203, 106139. [Google Scholar] [CrossRef]
- Teng, F.; Guo, X.; Song, Y.; Wang, G. An Air Target Tactical Intention Recognition Model Based on Bidirectional GRU With Attention Mechanism. IEEE Access 2021, 9, 169122–169134. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Dataset | Methods | Evaluation Metrics | Accuracy |
|---|---|---|---|---|
| [36] | N-BaIoT | LGBA-NN | precision, recall F1-score, support | Gained 90% accuracy |
| [37] | UNSW_NB15 BOUN Ddos | ML.NET | precision, ROC confusion matrix | 99.8% of the generic attack 99.7% of the Ddos attack |
| [38] | CSE-CIC-IDS2018 | HRCNNIDS | precision, recall F1-score, DR, FAR | Gained 97.75% accuracy |
| [39] | NSL-KDD | SSC-OCSVM | recall, FAR, ROC confusion matrix | Obtained satisfactory results |
| [40] | NSL-KDD 2015 CIDDS-001 | Proposed DBN | precision, recall F1-score, accuracy | Obtained satisfactory results |
| [41] | NSL-KDD CICIDS2017 | SRRS + IIFS-MC(ALL) + CTC | DR, FPR, accuracy | 99.96% of NSL-KDD 99.95% of CICIDS2017 |
| [42] | CICIDS2017 UNSW-NB15 | NIDS-s | precision, recall FAR, accuracy | Gained 99% accuracy of two datasets |
| [43] | KDDCUP1999 | CSWC-SVM | precision, accuracy | Obtained satisfactory results |
| [44] | UNSW_NB15 | FSL-SCNN | precision, recall F1-score, FAR | Obtained satisfactory results |
| [45] | UNSW_NB15 | VLSTM | precision, recall F1-score, FAR, AUC | Gained 86% accuracy |
| Model Parameters | Parameter Settings |
|---|---|
| Batch size | 1024 |
| Loss function | SparseCategoricalCrossentropy |
| Optimizer | SGD |
| Optimizer learning rate | 0.001 |
| Epoch | 200 |
| Resblock + CBAM | 64 |
| GRU | 32/64/128 |
| Dropout | 0.5 |
| Dataset | Attack Behavior | Total | ||||
|---|---|---|---|---|---|---|
| Normal | Dos | Probe | R2L | U2R | ||
| KDDTrain+ | 67,343 | 45,927 | 11,656 | 995 | 52 | 125,973 |
| KDDTest+ | 9889 | 7460 | 2707 | 2421 | 67 | 22,544 |
| Total | 77,232 | 53,387 | 14,363 | 3416 | 119 | 148,517 |
| Dataset | Attack Behaviors | Total | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | Fuzzers | Analysis | Backdoors | DoS | Exploits | Generic | Recon. | Shellcode | Worms | ||
| Train | 56,000 | 18,174 | 2000 | 1746 | 12,264 | 33,393 | 40,000 | 10,491 | 1133 | 130 | 175,341 |
| Test | 37,000 | 6062 | 677 | 583 | 4089 | 11,132 | 18,871 | 3496 | 378 | 44 | 82,332 |
| Total | 93,000 | 24,246 | 2677 | 2329 | 16,353 | 44,525 | 58,871 | 13,987 | 1511 | 174 | 257,673 |
| Dataset | Attack Behaviors | Total | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BENIGN | Dos | PortScan | Patator | Ddos | Bot | Web Attack | Infiltration | Heartbleed | ||
| Train | 1,654,737 | 176,863 | 111,251 | 9685 | 89,619 | 2752 | 1526 | 25 | 7 | 2,046,465 |
| Test | 709,173 | 75,798 | 47,679 | 4150 | 38,408 | 1180 | 654 | 11 | 4 | 877,057 |
| Total | 2,363,910 | 252,661 | 158,930 | 13,835 | 128,027 | 3932 | 2180 | 36 | 11 | 2,923,522 |
| Classification | Predicted Positive Category | Predicted Negative Category |
|---|---|---|
| Actual Positive Category | TP | FN |
| Actual Negative Category | FP | TN |
| Features | Correlation Index | Features | Correlation Index | ||
|---|---|---|---|---|---|
| spkts | sbytes | 0.964 | tcprtt | synack | 0.943 |
| spkts | sloss | 0.972 | tcprtt | ackdat | 0.920 |
| dpkts | dbytes | 0.973 | ct_srv_src | ct_dst_src_ltm | 0.954 |
| dpkts | dloss | 0.980 | ct_srv_src | ct_srv_dst | 0.949 |
| sbytes | sloss | 0.996 | ct_dst_ltm | ct_src_dport_ltm | 0.962 |
| dbytes | dloss | 0.997 | ct_dst_ltm | ct_src_ltm | 0.902 |
| sinpkt | is_sm_ips_ports | 0.942 | ct_src_dport_ltm | ct_dst_sport_ltm | 0.908 |
| swin | dwin | 0.980 | ct_src_dport_ltm | ct_src_ltm | 0.909 |
| ct_dst_src_ltm | ct_srv_dst | 0.960 | is_ftp_login | ct_ftp_cmd | 0.999 |
| Dataset | Feature Selection Method | Evaluation Indicators (%) | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| NSL-KDD | RFP | 99.69 | 99.65 | 99.69 | 99.70 |
| PCA | 98.26 | 98.79 | 98.26 | 98.48 | |
| AE | 97.61 | 97.63 | 97.61 | 97.59 | |
| UNSW_NB15 | RFP | 86.25 | 86.92 | 86.25 | 86.59 |
| PCA | 79.37 | 79.70 | 79.37 | 76.92 | |
| AE | 81.01 | 80.43 | 81.01 | 80.05 | |
| CIC-IDS2017 | RFP | 99.65 | 99.63 | 99.65 | 99.64 |
| PCA | 89.64 | 93.02 | 89.64 | 90.60 | |
| AE | 98.66 | 98.70 | 98.66 | 98.67 | |
| Dataset | Feature Selection Method | Evaluation Indicators (%) | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| NSL-KDD | CNN | 98.22 | 98.23 | 98.22 | 98.18 |
| GRU | 98.67 | 98.95 | 98.67 | 98.78 | |
| CNN-GRU | 99.69 | 99.65 | 99.69 | 99.70 | |
| UNSW_NB15 | CNN | 84.51 | 84.08 | 84.51 | 84.29 |
| GRU | 83.69 | 83.81 | 83.68 | 83.74 | |
| CNN-GRU | 86.25 | 86.92 | 86.25 | 86.59 | |
| CIC-IDS2017 | CNN | 92.94 | 93.24 | 92.94 | 92.04 |
| GRU | 98.15 | 98.36 | 98.15 | 98.16 | |
| CNN-GRU | 99.65 | 99.63 | 99.65 | 99.64 | |
| Dataset | Feature Selection Method | Evaluation Indicators (%) | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| NSL-KDD | Random Oversampler | 92.79 | 95.12 | 92.79 | 93.74 |
| Random Undersampler | 84.83 | 93.26 | 84.93 | 87.04 | |
| SMOTE | 98.97 | 99.03 | 98.97 | 98.99 | |
| ADASYN | 98.35 | 98.83 | 98.35 | 98.57 | |
| ENN | 98.85 | 98.87 | 98.85 | 98.85 | |
| RENN | 98.02 | 98.06 | 98.02 | 98.03 | |
| ADASYN + RENN | 99.69 | 99.65 | 99.69 | 99.70 | |
| UNSW_NB15 | Random Oversampler | 81.90 | 82.27 | 81.90 | 79.33 |
| Random Undersampler | 73.09 | 79.69 | 73.09 | 72.33 | |
| SMOTE | 83.51 | 81.08 | 83.51 | 82.71 | |
| ADASYN | 83.04 | 80.69 | 83.04 | 84.23 | |
| ENN | 80.12 | 78.98 | 80.12 | 77.49 | |
| RENN | 81.40 | 81.93 | 81.40 | 81.66 | |
| ADASYN + RENN | 86.25 | 86.92 | 86.25 | 86.59 | |
| CIC-IDS2017 | Random Oversampler | 96.09 | 95.87 | 96.09 | 95.98 |
| Random Undersampler | 17.24 | 81.48 | 17.24 | 17.46 | |
| SMOTE | 92.13 | 92.13 | 92.13 | 92.03 | |
| ADASYN | 97.38 | 97.41 | 97.38 | 97.36 | |
| ENN | 95.20 | 95.51 | 95.20 | 94.74 | |
| RENN | 97.05 | 97.13 | 97.05 | 97.01 | |
| ADASYN + RENN | 99.65 | 99.63 | 99.65 | 99.64 | |
| Dataset | Pooling Method | Evaluation Indicators (%) | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| NSL-KDD | Averagepooling | 98.96 | 98.95 | 98.96 | 98.94 |
| Maxpooling | 98.42 | 98.38 | 98.42 | 98.39 | |
| Averagepooling + Maxpooling | 99.69 | 99.65 | 99.69 | 99.70 | |
| UNSW_NB15 | Averagepooling | 83.13 | 84.97 | 83.13 | 84.03 |
| Maxpooling | 83.25 | 84.96 | 83.25 | 84.10 | |
| Averagepooling + Maxpooling | 86.25 | 86.92 | 86.25 | 86.59 | |
| CIC-IDS2017 | Averagepooling | 98.55 | 98.64 | 98.55 | 96.37 |
| Maxpooling | 93.85 | 94.52 | 93.85 | 93.89 | |
| Averagepooling + Maxpooling | 99.65 | 99.63 | 99.65 | 99.64 | |
| Dataset (Train/Test) | Method | Evaluation Indicators | |||
|---|---|---|---|---|---|
| Train/s | Prediction/s | Total Time/s | Accuracy | ||
| NSL-KDD (125973/22544) | Before RFP | 739.6 | 9.51 | 749.11 | 98.71 |
| Before ADRDB | 617.2 | 9.53 | 626.73 | 98.59 | |
| CNN | 633.2 | 7.31 | 640.51 | 98.22 | |
| GRU | 272.4 | 4.89 | 277.29 | 98.67 | |
| Proposed Model | 648.4 | 8.75 | 657.15 | 99.69 | |
| UNSW_NB15 (175341/82332) | Before RFP | 1553.6 | 25.03 | 1578.6 | 85.69 |
| Before ADRDB | 1259 | 28.74 | 1287.7 | 85.56 | |
| CNN | 1118 | 18.11 | 1136.1 | 84.51 | |
| GRU | 785.6 | 5.63 | 791.23 | 83.69 | |
| Proposed Model | 1423.6 | 30.87 | 1454.47 | 86.25 | |
| CIC-IDS2017 (1654737/709173) | Before RFP | 23450.4 | 286.35 | 23736.75 | 98.73 |
| Before ADRDB | 21548.4 | 268.39 | 21816.79 | 98.82 | |
| CNN | 16500 | 185.75 | 16685.75 | 92.94 | |
| GRU | 4146.4 | 52.8 | 4199.2 | 98.15 | |
| Proposed Model | 21,200.2 | 275.67 | 21475.9 | 99.65 | |
| Dataset | Feature Selection Method | Evaluation Indicators (%) | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||
| NSL-KDD | Random Forest | 75.41 | 84.00 | 75.41 | 77.53 |
| K-means | 79.34 | 78.01 | 79.34 | 76.28 | |
| Decision Tree | 76.92 | 71.98 | 54.52 | 55.97 | |
| CNN-LSTM [21] | 98.64 | 98.61 | 98.64 | 98.56 | |
| S-ResNet [56] | 98.33 | 98.39 | 98.33 | 98.34 | |
| CNN [57] | 97.78 | 97.74 | 97.78 | 97.75 | |
| CNN-GRU [58] | 99.15 | 99.15 | 99.15 | 99.15 | |
| CNN-BiLSTM [59] | 99.22 | 99.18 | 99.14 | 99.15 | |
| CNN-GRU [60] | 98.97 | 99.11 | 98.97 | 99.04 | |
| CNN-GRU-attention [61] | 99.26 | 99.23 | 99.26 | 99.24 | |
| Proposed Model | 99.69 | 99.65 | 99.69 | 99.70 | |
| UNSW_NB15 | Random Forest | 75.41 | 84.00 | 75.41 | 77.53 |
| K-means | 70.93 | 82.42 | 70.91 | 76.23 | |
| Decision Tree | 73.37 | 80.94 | 73.36 | 76.30 | |
| CNN-LSTM [21] | 82.6 | 81.9 | 82.6 | 80.6 | |
| S-ResNet [56] | 83.8 | 85.0 | 83.8 | 84.4 | |
| CNN [57] | 82.9 | 82.6 | 82.9 | 82.7 | |
| CNN-GRU [58] | 84.3 | 83.7 | 84.3 | 84.0 | |
| CNN-BiLSTM [59] | 82.08 | 82.68 | 80.00 | 81.32 | |
| CNN-GRU [60] | 84.25 | 84.31 | 84.25 | 84.28 | |
| CNN-GRU-attention [61] | 84.36 | 83.78 | 84.36 | 84.07 | |
| Proposed Model | 86.25 | 86.92 | 86.25 | 86.59 | |
| CIC-IDS2017 | Random Forest | 98.21 | 98.58 | 93.40 | 95.92 |
| K-means | 95.03 | 96.40 | 95.21 | 95.80 | |
| Decision Tree | 96.60 | 97.62 | 96.66 | 97.14 | |
| CNN-LSTM [21] | 96.64 | 96.87 | 96.64 | 96.45 | |
| S-ResNet [56] | 95.94 | 96.10 | 95.94 | 95.41 | |
| CNN [57] | 89.14 | 84.18 | 89.14 | 85.56 | |
| CNN-GRU [58] | 99.42 | 99.34 | 99.42 | 99.38 | |
| CNN-BiLSTM [59] | 99.43 | 99.39 | 99.42 | 99.40 | |
| CNN-GRU [60] | 99.38 | 99.41 | 99.38 | 99.39 | |
| CNN-GRU-attention [61] | 99.45 | 99.39 | 99.45 | 99.42 | |
| Proposed Model | 99.65 | 99.63 | 99.65 | 99.64 | |
| Datasets | |||||
|---|---|---|---|---|---|
| NSL-KDD | 0.9969 | 0.9929 | 0.00348 | 5.268 | 0.99 |
| UNSW_NB15 | 0.8625 | 0.8438 | 0.01040 | 8.041 | 0.99 |
| CIC-IDS2017 | 0.9965 | 0.9949 | 0.00120 | 5.971 | 0.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, B.; Li, C.; Song, Y.; Qin, Y.; Chen, C. Network Intrusion Detection Model Based on CNN and GRU. Appl. Sci. 2022, 12, 4184. https://doi.org/10.3390/app12094184
Cao B, Li C, Song Y, Qin Y, Chen C. Network Intrusion Detection Model Based on CNN and GRU. Applied Sciences. 2022; 12(9):4184. https://doi.org/10.3390/app12094184
Chicago/Turabian StyleCao, Bo, Chenghai Li, Yafei Song, Yueyi Qin, and Chen Chen. 2022. "Network Intrusion Detection Model Based on CNN and GRU" Applied Sciences 12, no. 9: 4184. https://doi.org/10.3390/app12094184
APA StyleCao, B., Li, C., Song, Y., Qin, Y., & Chen, C. (2022). Network Intrusion Detection Model Based on CNN and GRU. Applied Sciences, 12(9), 4184. https://doi.org/10.3390/app12094184