
Machine-Learning Approach to Determine Surface Quality on a Reactor Pressure Vessel (RPV) Steel

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
1.1. Addressing Small Data Sets for Analysis Using Machine Learning
1.2. Data Imputation and Augmentation for Low Data Sets
1.2.1. Exploratory Data Analysis
1.2.2. Regression Models
1.2.3. Decision Trees, Random Forest, and Extra Trees Regression
2. Surface Quality and Barkhausen Noise Sensor Experiment Setup
| Experimental Setup |
| Dimensions samples 10 × 10 × 55 mm3 Material 22NiMoCr37 Orientation L-T Engraving one side Measuring device Accretech Handysurf Tokyo Seimistsu E-35B Cut-off value 0.8 mm Evaluation length 4 mm Measuring range automatic |
Barkhausen Noise
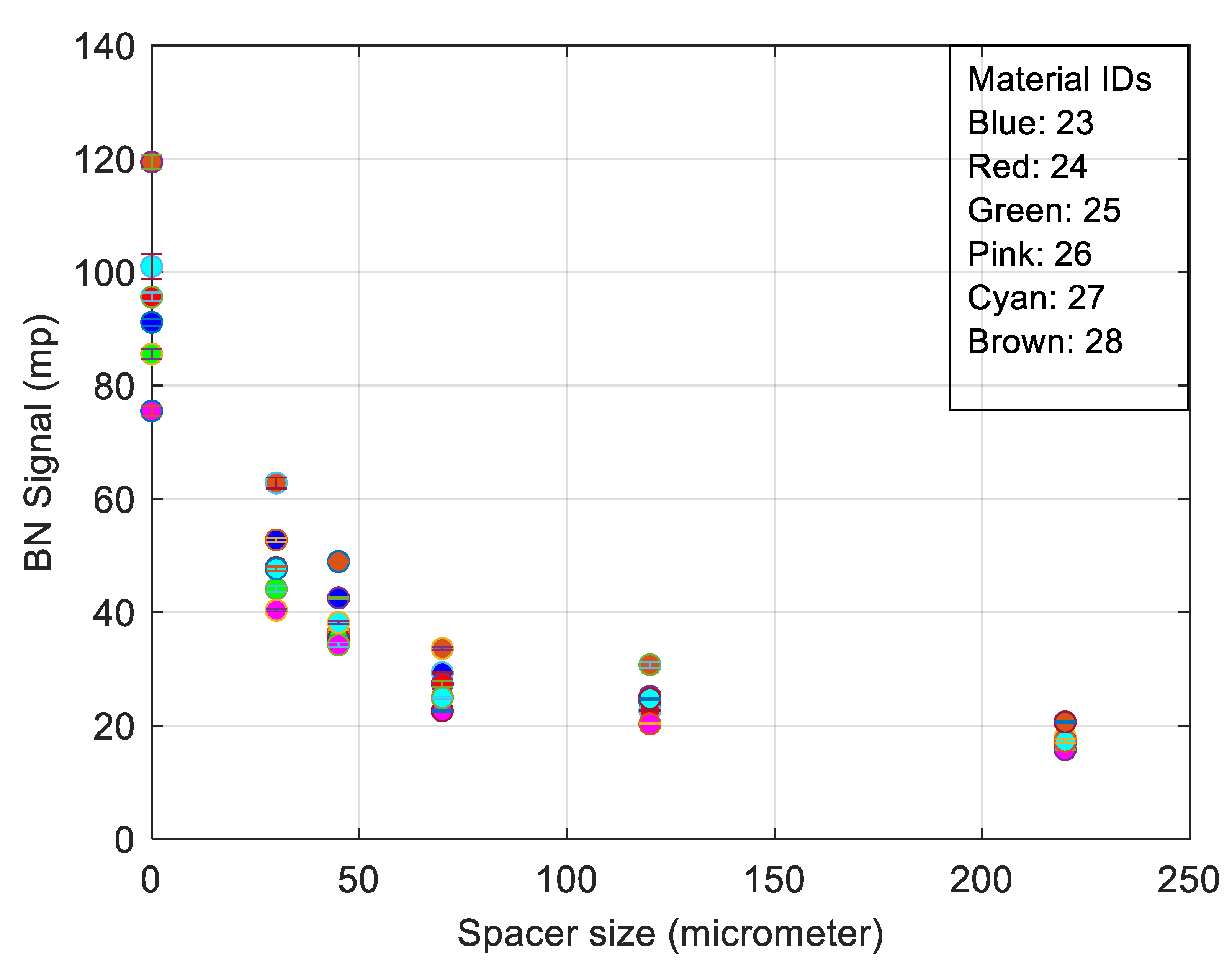
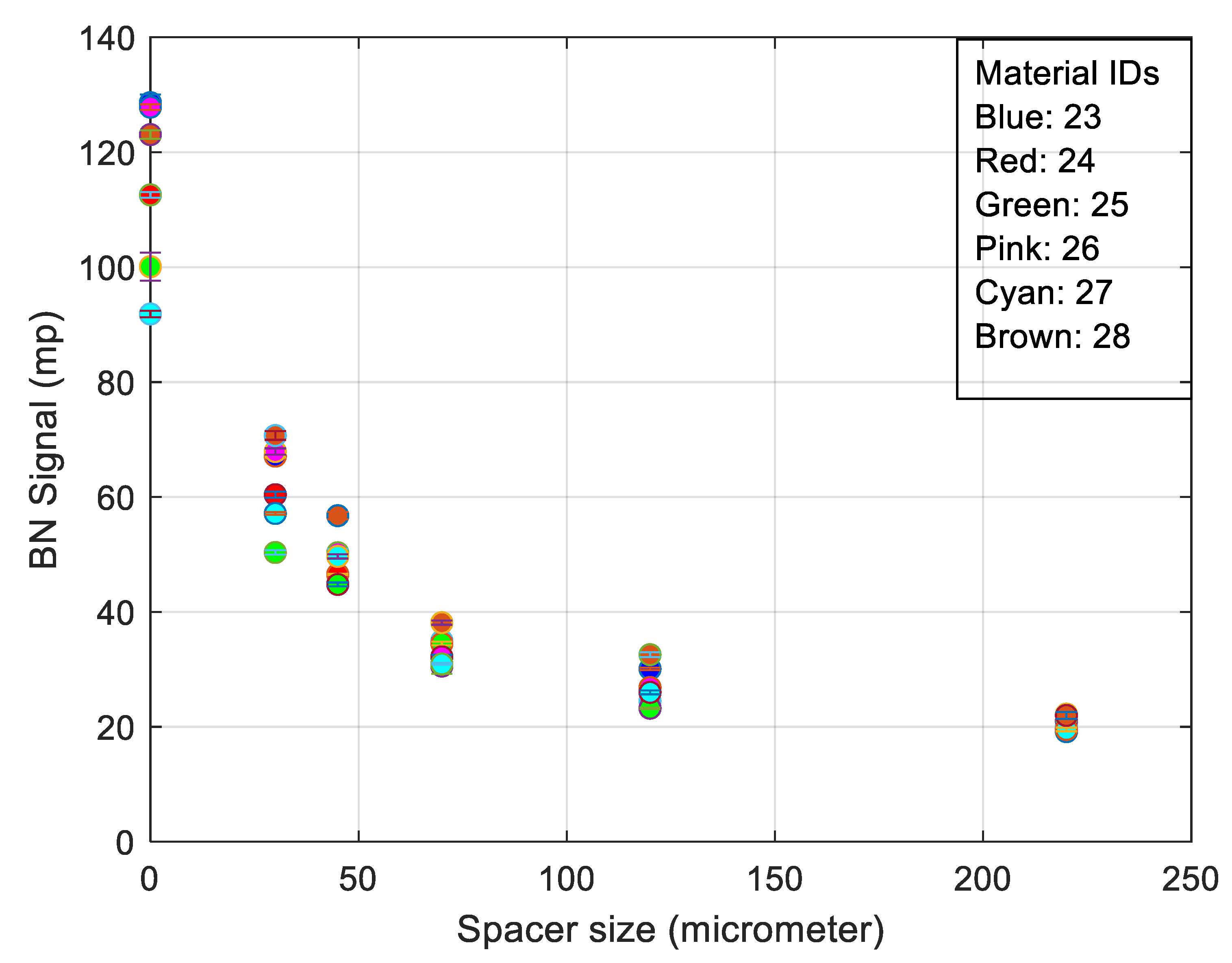
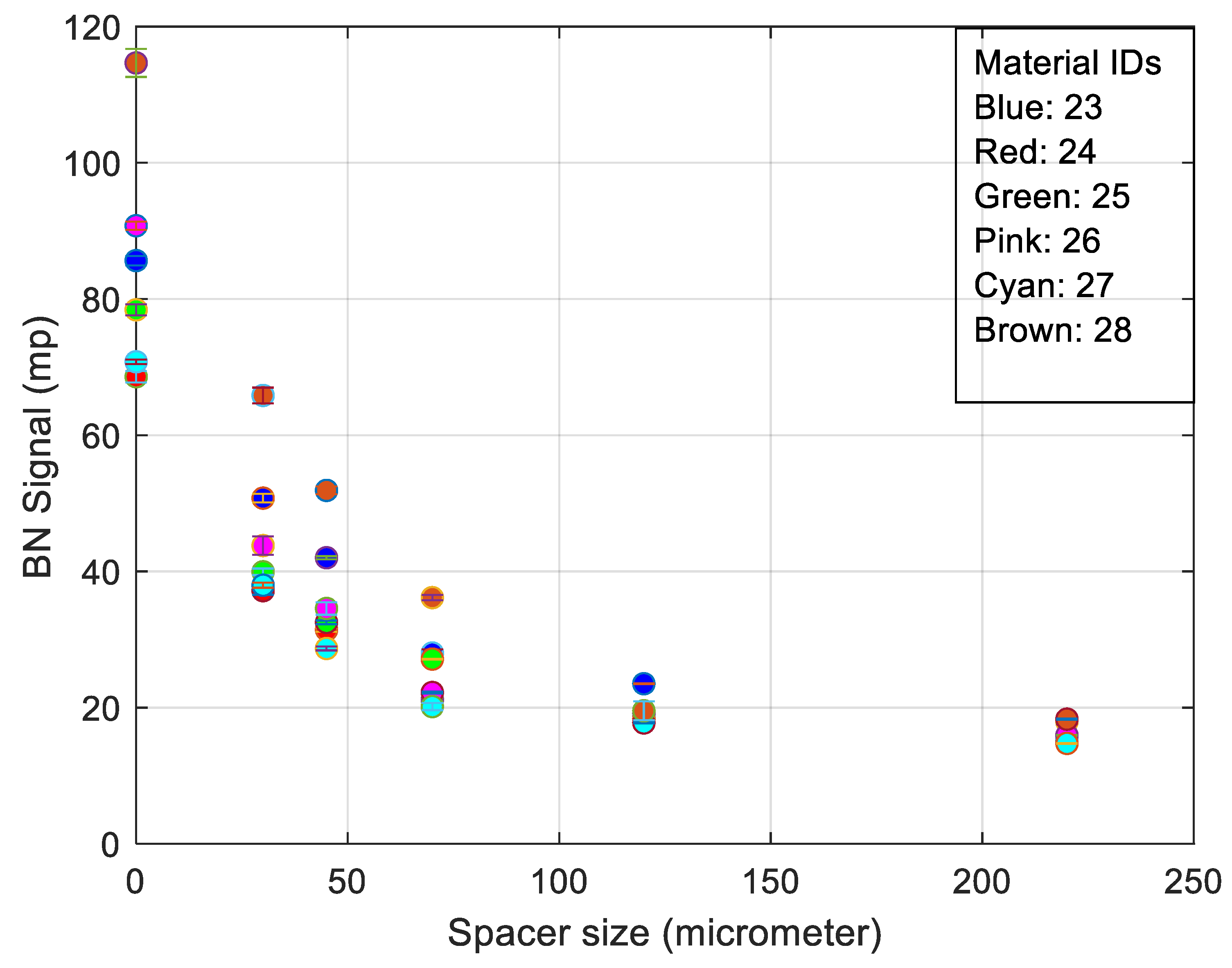
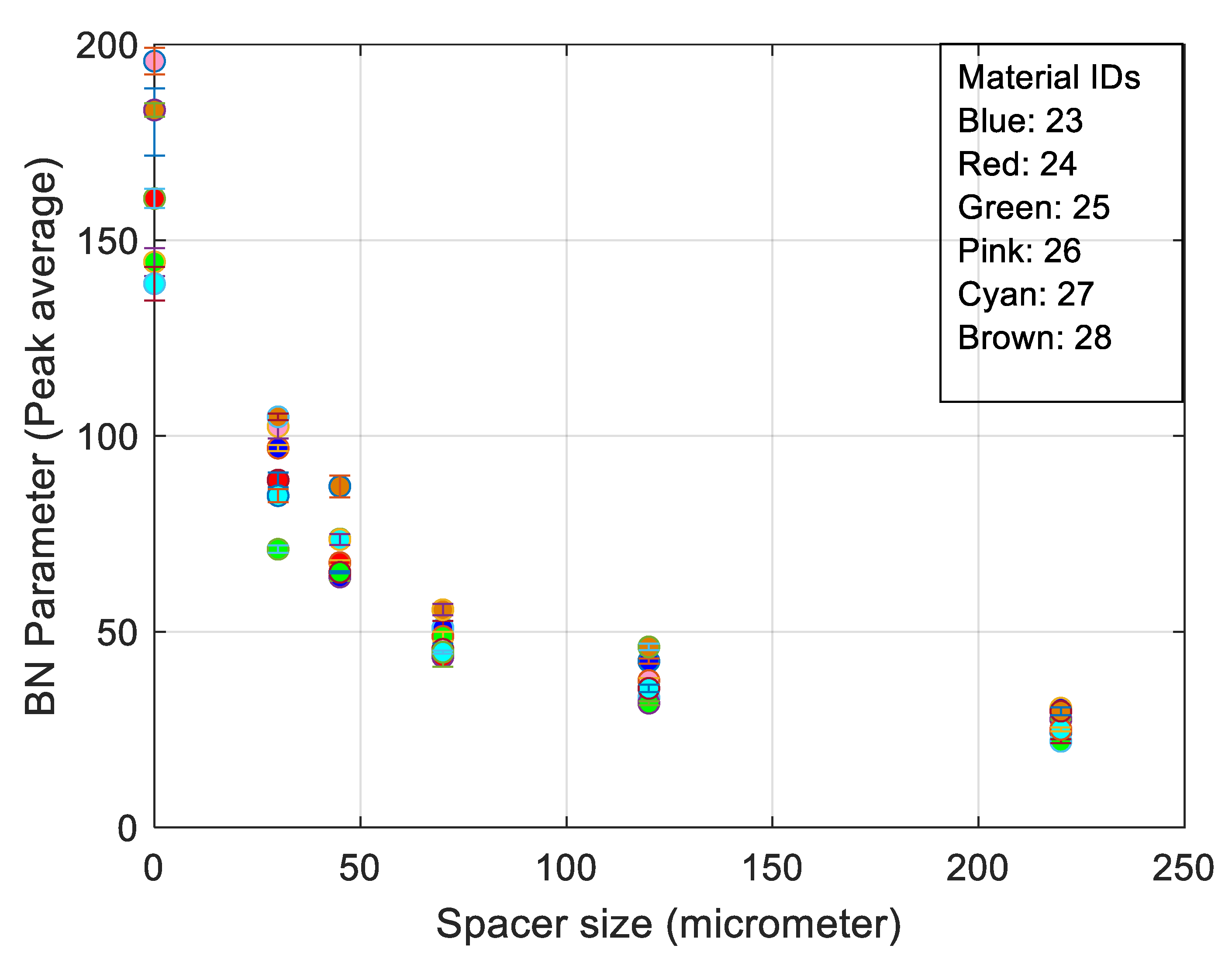
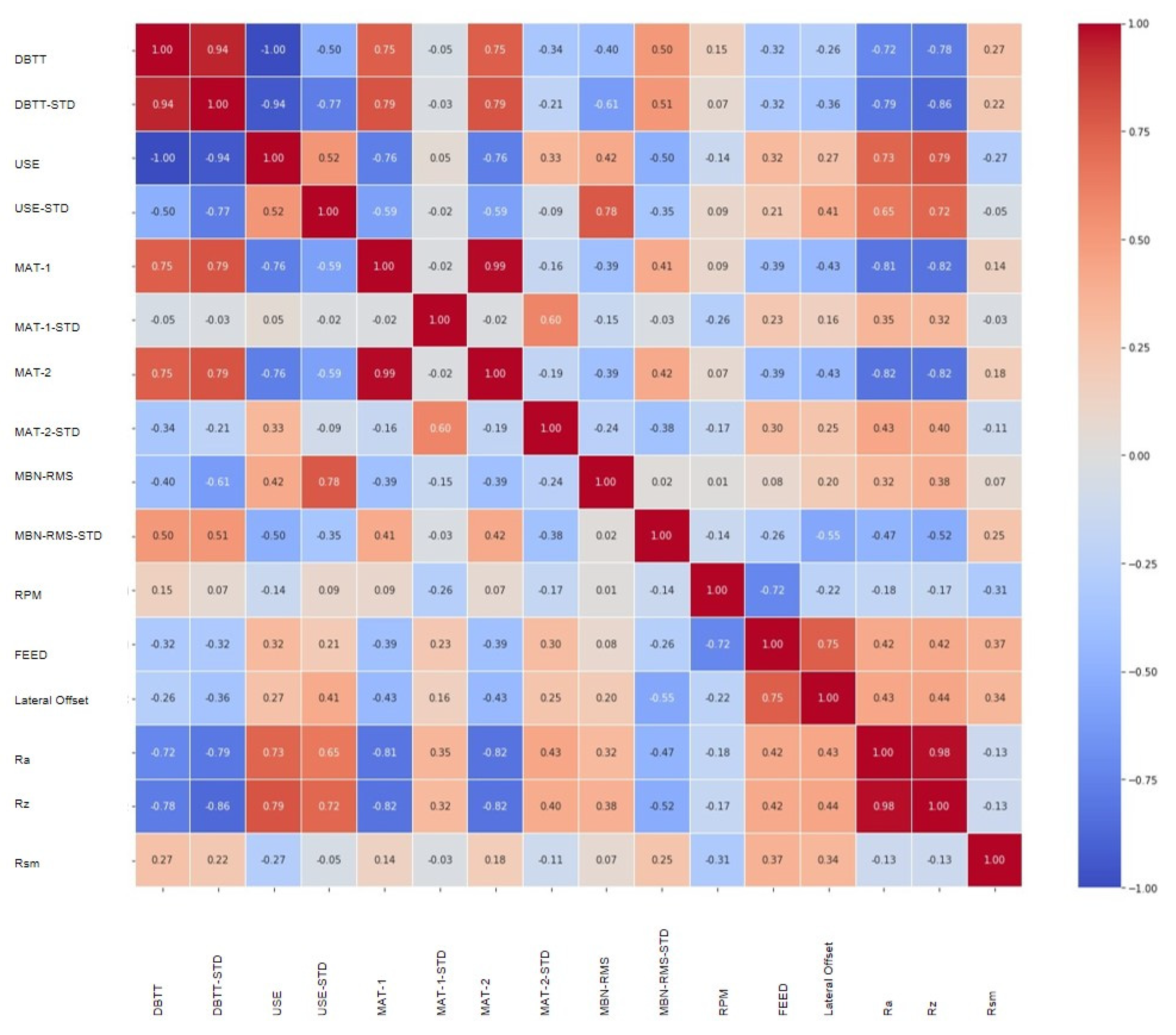
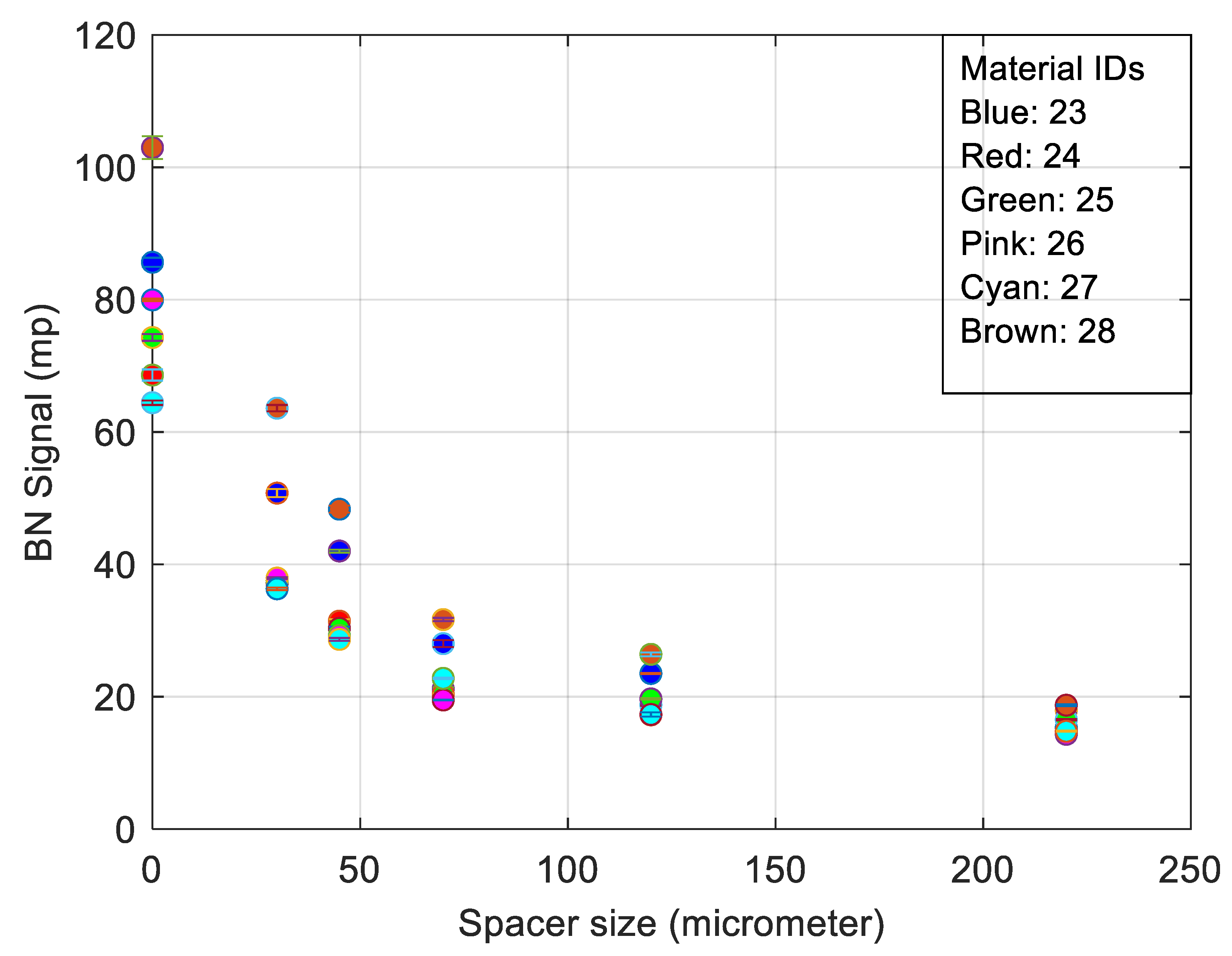
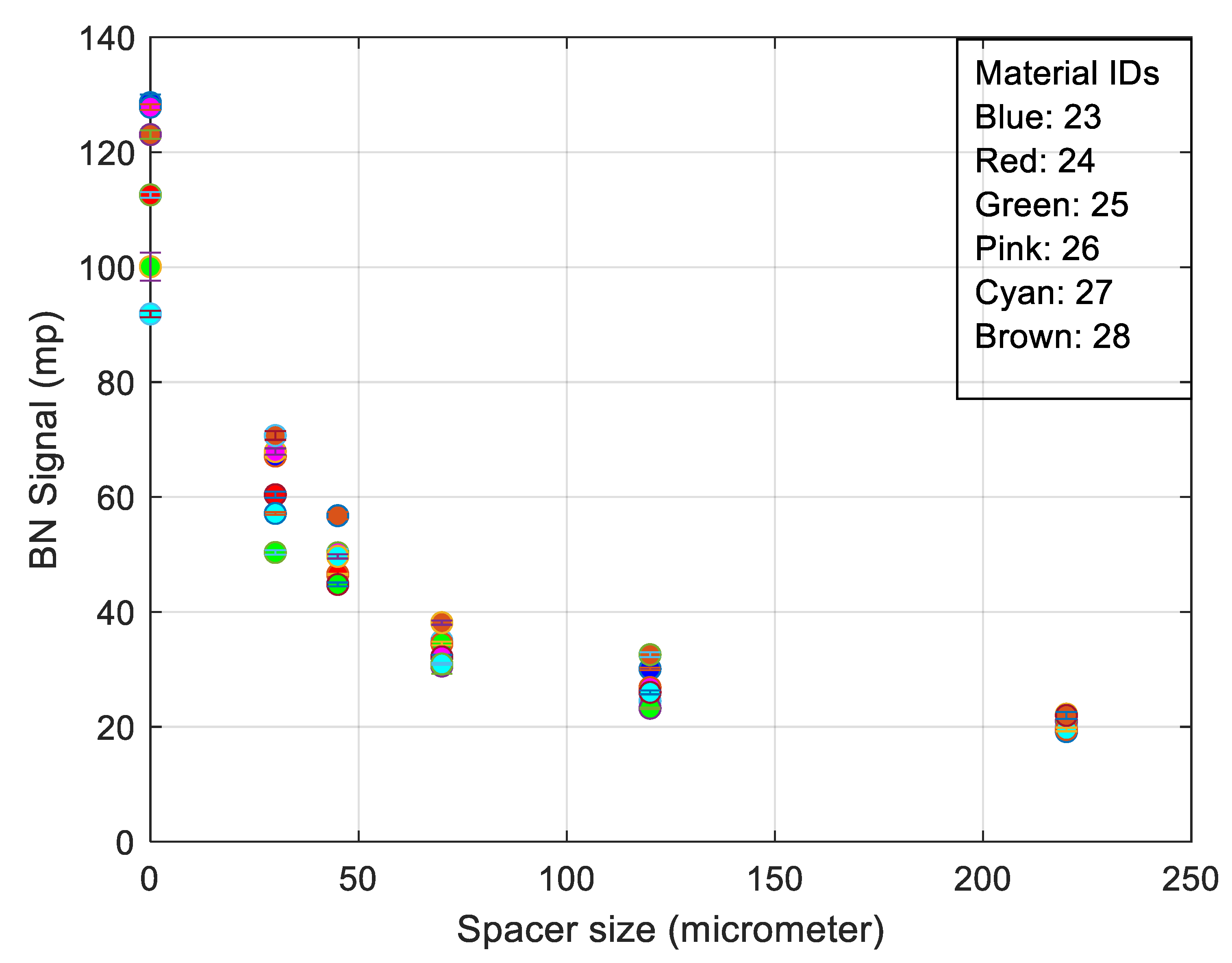
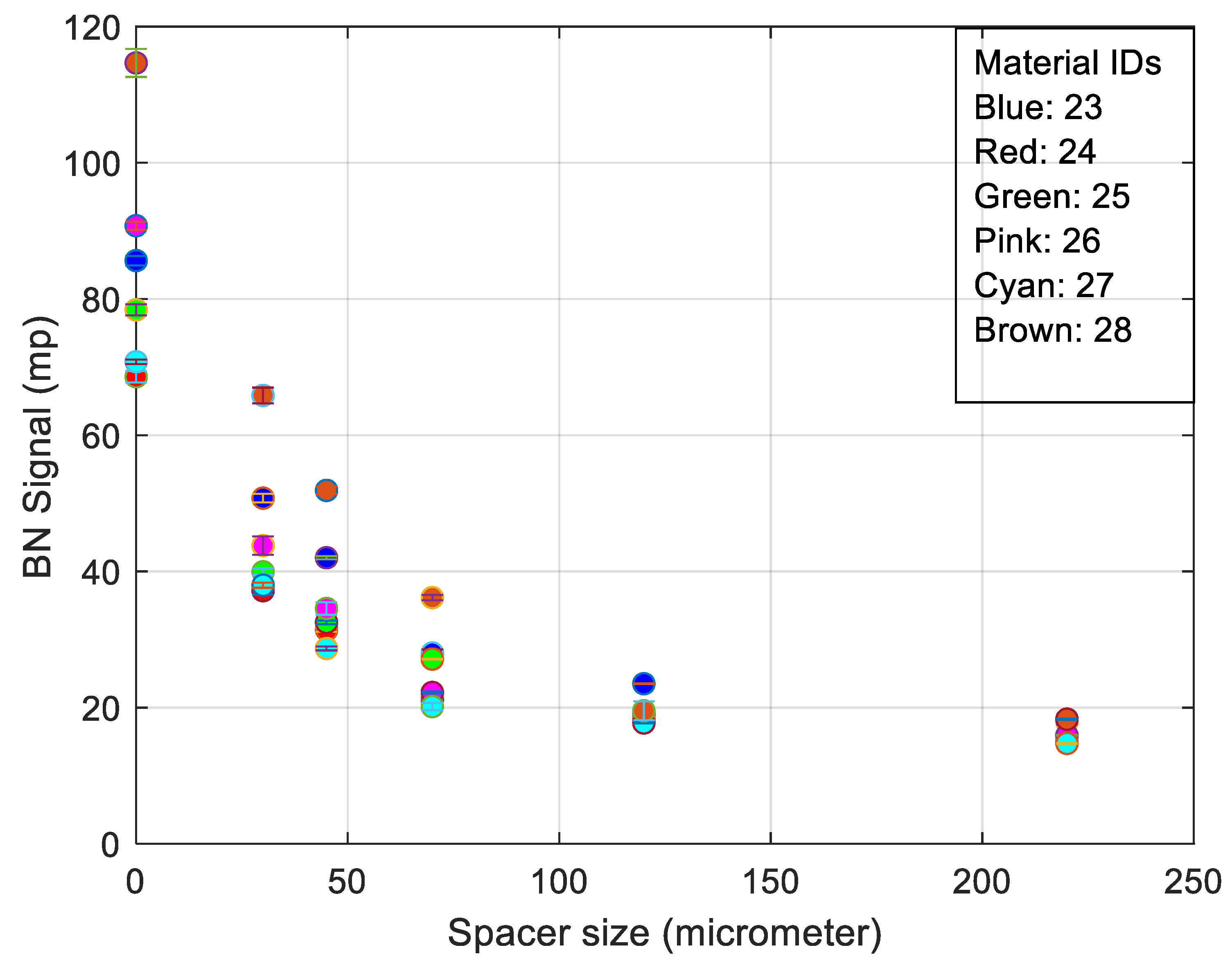
3. RMS Barkhausen Noise and Extended Measured Parameters Applied to Different Spacer Thickness
- Full width half maximum (FWHM) provides a full width at half the max of the filtered burst signal.
- The peak average is the peak of the filtered burst signal over the defined number of bursts, thereby giving a windowed average value.
- The spectrum is calculated from the raw Barkhausen data. The block size is selected so that it is to the power of two and less than the length of the data. The maximum size is currently set as 215. The spectrum calculation is applied for each block so that the blocks overlap by half. First, the Hamming window is seen in Equation (3).
4. Machine Learning Applied to Imputation and Data Augmentation to Increase Classification Accuracy
4.1. Methodology
4.2. Preliminary EDA
Prediction Results
4.3. Machine Learning Applied to Surface Roughness Prediction
4.3.1. Neural Networks, n-Dimensionality and Augmentation
4.3.2. CART, n-Dimensionality and Augmentation
5. Discussion of Results
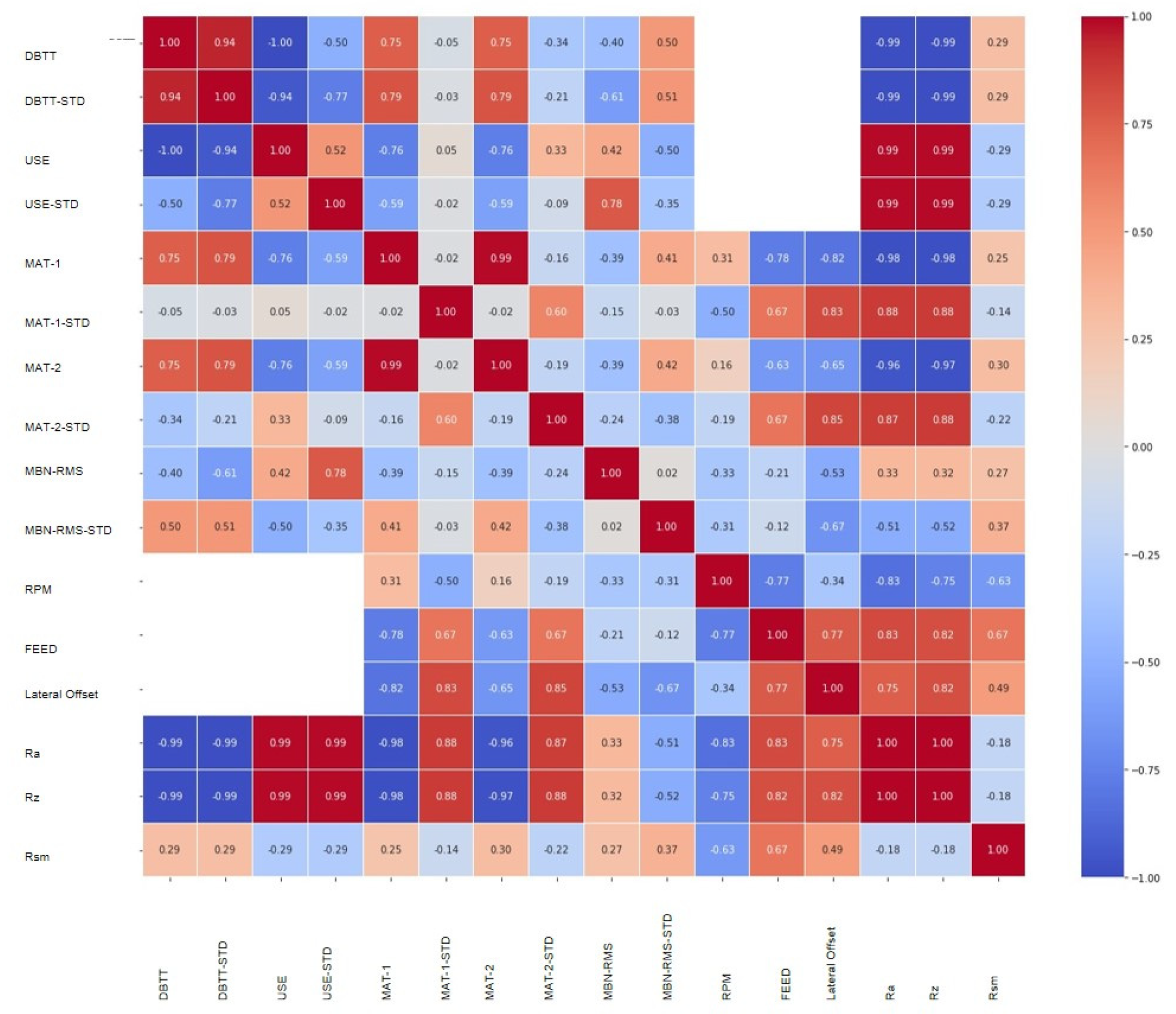
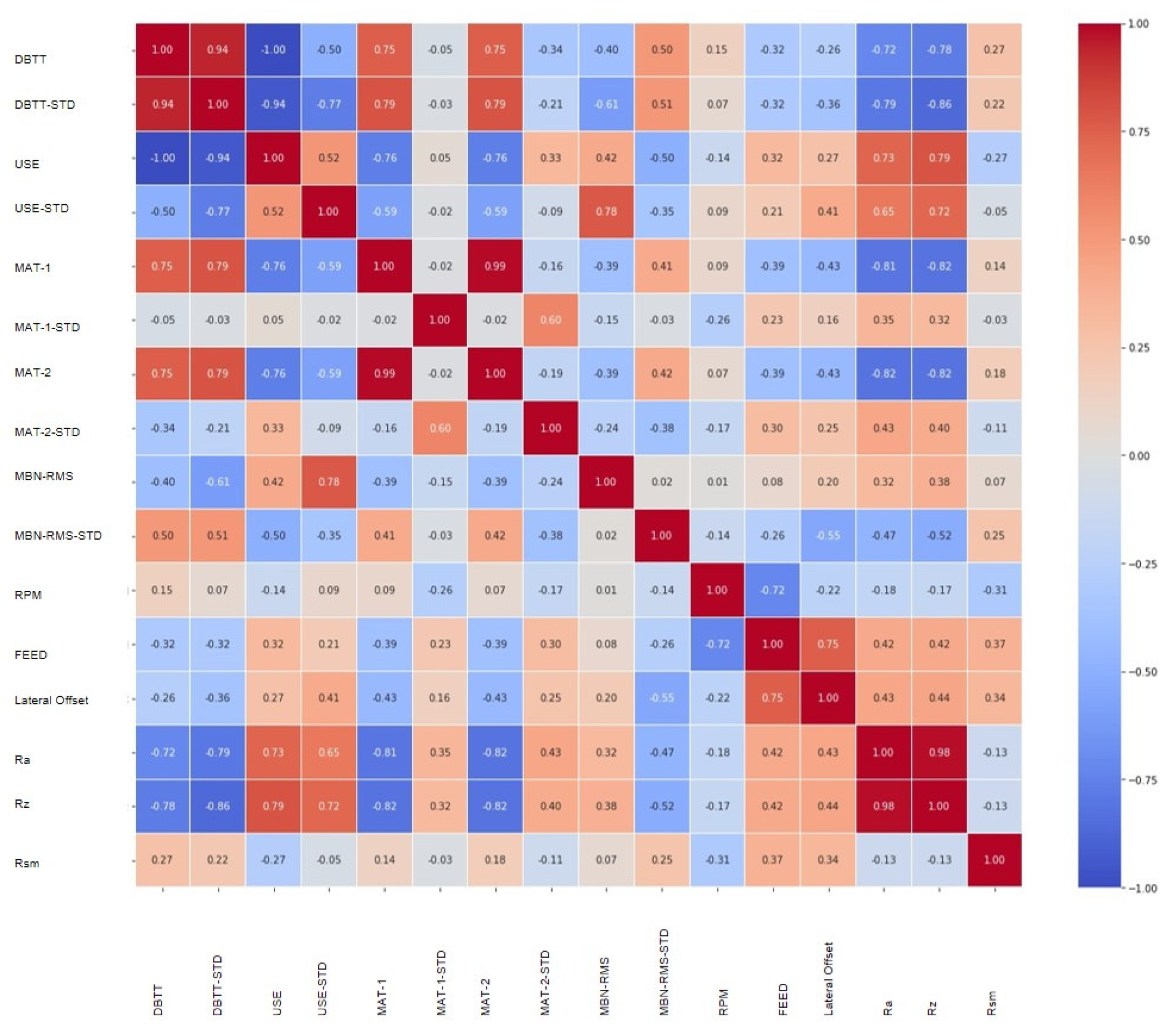
5.1. Barkhausen Noise and Extended Parameters Applied with Surface Roughness Suppression Techniques
5.2. Graphical Techniques for Data Imputation Verification
5.3. Data Augmentation Applied to Machine Learning Techniques to Increase Accuracy When Faced with the ‘Curse of Dimensionality’
6. Conclusions
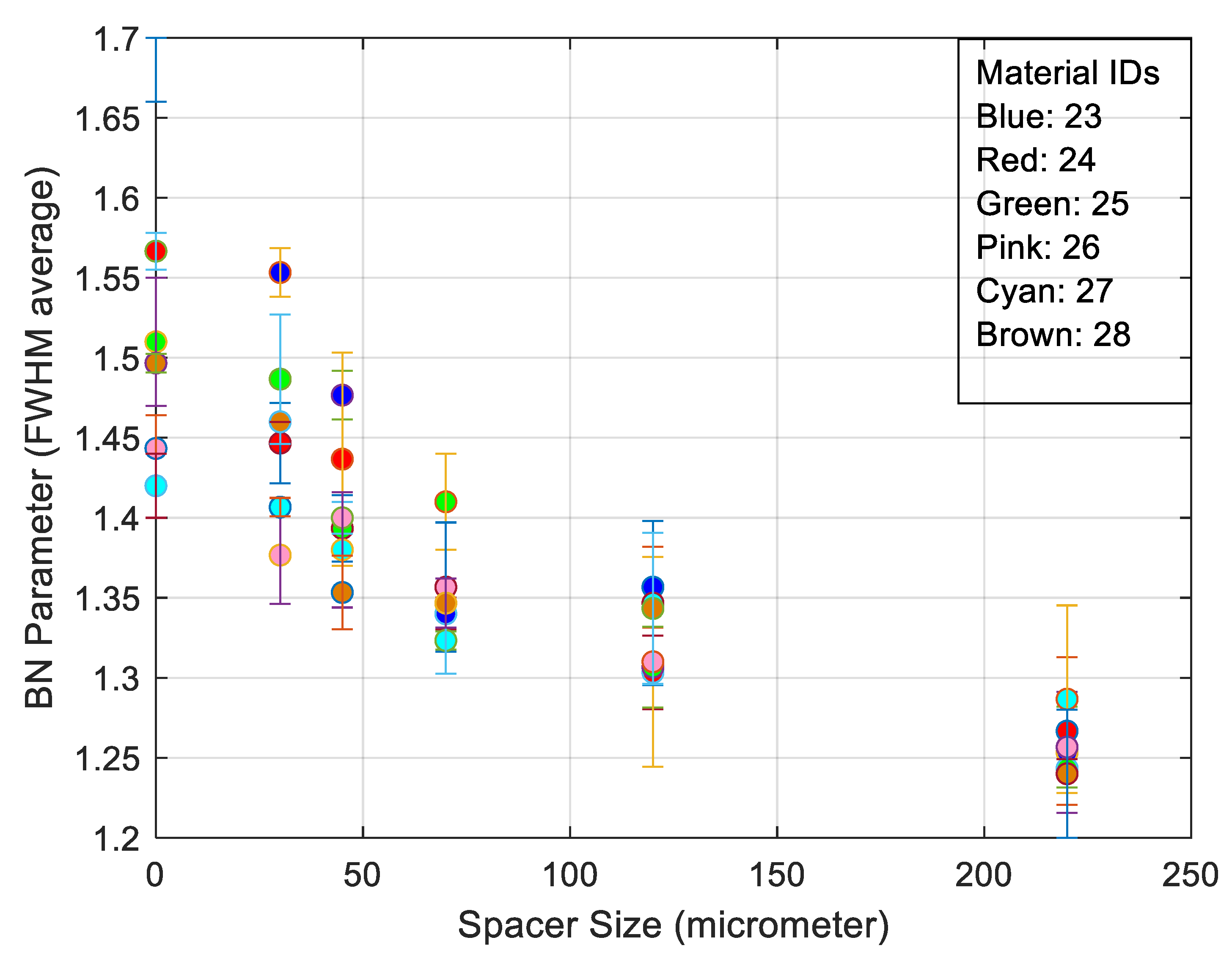
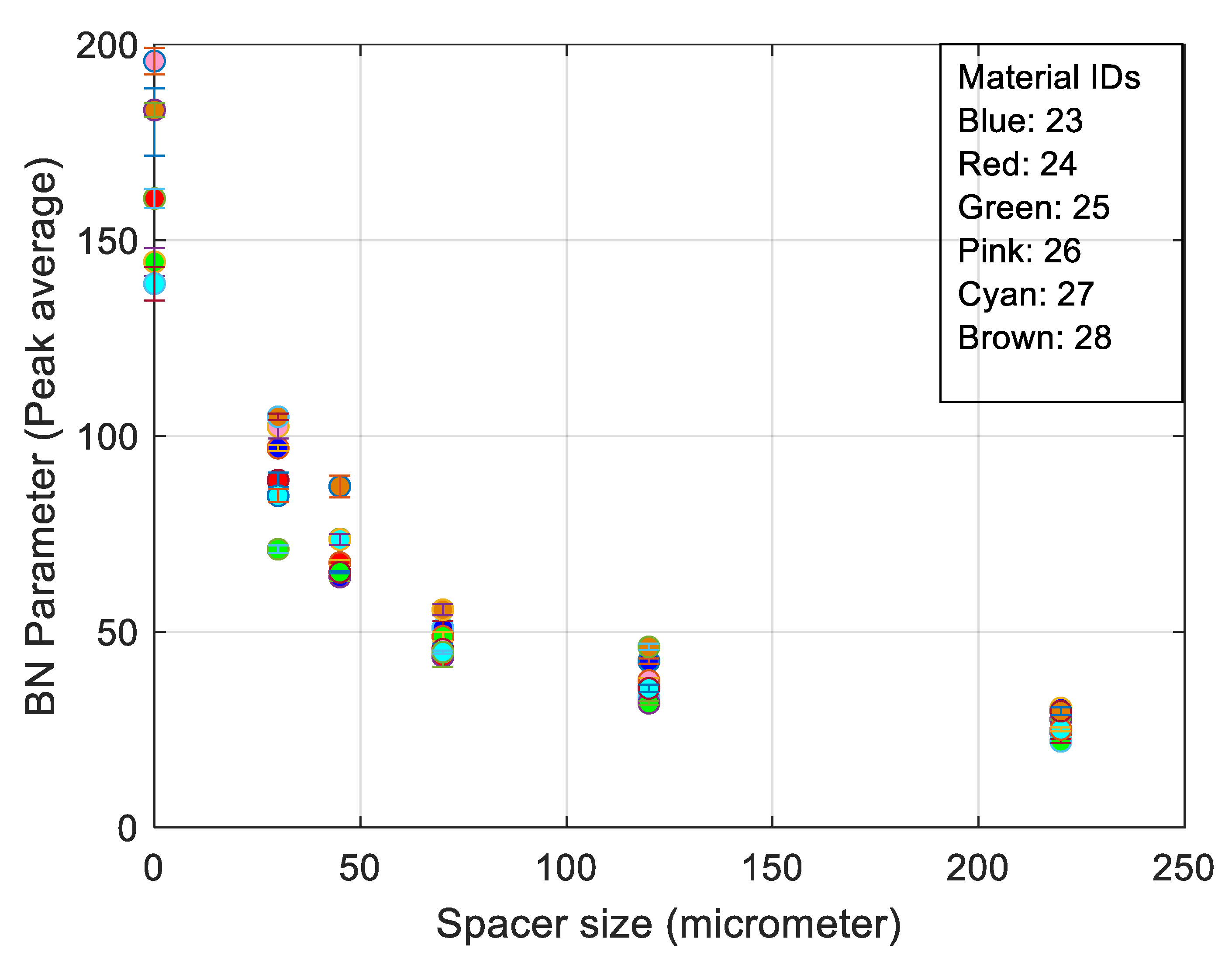
- The best trade-off between electromagnetic response and surface quality was found to be a 30 µm nonmagnetic spacer (Figure 6).
- It is often the case with such measurements that small sets of data exist in terms of describing the different anomaly conditions. For these reasons there was a need to find missing data usually in the form of ‘Not a Number’ or NaNs. By using advanced imputation algorithms, it was possible to impute missing values by intelligent interpolation and the use of other NDT data, such as that provided by Magnetic Adaptive Testing.
- In addition, by using statistical measures it was possible to apply the graphical correlations before making the predictions and imputing the missing data. Such techniques increased the data amounts and were considered to give good coverage and further useable data.
- Further to these findings, it was possible to see the effects on small datasets when n-dimensionality increases due to different parameters given within an NDT measurement, thereby providing more output values. Generally, the increase in dimensionality reduces the capacity for machine learning algorithms to provide generalistic pattern trend fitting capabilities. With the consideration of adding subtle data augmentation amounts (20% augmentation), it was possible to increase trend fitting capabilities. Beyond 20% augmentation, diminishing returns were obtained.
- Furthermore, studies of the data augmentation found that more extreme varying data amounts were better than slight varying data amounts.
- On a final note, classification and regression trees gave the best account when compared with neural networks in coping with the ‘curse of dimensionality’ when n-dimensional data increases.
- Future work will look further into more advanced algorithms to see how increased data can facilitate trend pattern learning as opposed to suppressing it. Also, further investigations into higher levels of data augmentation give reduced accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kronmüller, H.; Fähnle, M. Micromagnetism and the Microstructure of Ferromagnetic Solids; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Jiles, D.C. Magnetic Methods in Nondestructive Testing: Encyclopedia of Materials Science and Technology; Elsevier Press: Oxford, UK, 2001. [Google Scholar]
- Lo, C.C.H.; Jakubovics, J.P.; Scruby, C.B. Non-Destructive Evaluation of Spheroidized Steel Using Magnetoacoustic and Barkhausen Emission. IEEE Trans. Magn. 1997, 33, 4035–4037. [Google Scholar] [CrossRef]
- Kikuchi, H.; Ara, K.; Kamada, Y.; Kobayashi, S. Effect of Microstructure Changes on Barkhausen Noise Properties and Hysteresis Loop in Cold Rolled Low Carbon Steel. IEEE Trans. Magn. 2009, 45, 2744–2747. [Google Scholar] [CrossRef]
- Hartmann, K.; Moses, A.J.; Meydan, T. A System for Measurement of AC Barkhausen Noise in Electrical Steels. J. Magn. Magn. Mater. 2003, 254–255, 318–320. [Google Scholar] [CrossRef]
- Jiles, D.C. Introduction to Magnetism and Magnetic Materials; ASTM-A225; Chapman and Hall: New York, NY, USA, 1991. [Google Scholar]
- Vértesy, G.; Gasparics, A.; Uytdenhouwen, I.; Chaouadi, R. Influence of Surface Roughness on Non-Destructive Magnetic Measurements. Glob. J. Adv. Eng. Technol. Sci. 2019, 6, 25–33. [Google Scholar]
- Tomáš, I.; Kadlecová, J.; Vértesy, G. Measurement of Flat Samples with Rough Surfaces by Magnetic Adaptive Testing. IEEE Trans. Magn. 2012, 48, 1441–1444. [Google Scholar]
- Jakobsen, J.C.; Gluud, C.; Wetterslev, J. When and How Should Multiple Imputation Be Used for Handling Missing Data in Randomised Clinical Trials—A Practical Guide with Flowcharts. BMC Med. Res. Methodol. 2017, 162. [Google Scholar] [CrossRef] [Green Version]
- McNeish, D. Missing Data Methods for Arbitrary Missingness with Small Samples. J. Appl. Stat. 2017, 44, 24–39. [Google Scholar] [CrossRef] [Green Version]
- Taylor, L.; Nitchke, G. Improving Deep Learning Using Generic Data Augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Seltman, J.H. Experimental Design And Analysis; Carnegie Mellon University: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Grolemund, G.; Wickham, H. Exploratory Data Analysis|R For Data Science; O’Reily: Sebastopol, CA, USA, 2020. [Google Scholar]
- Zwan, H. Graphical Analysis|Data Analytics; O’Reilly: Sebastopol, CA, USA, 2019. [Google Scholar]
- PennState. Non-Graphical Exploratory Data Analysis|STAT 504. 2020. Available online: https://online.stat.psu.edu/stat504/lesson/non-graphical-exploratory-data-analysis (accessed on 23 February 2022).
- Sudheer, S. Univariate Data Visualization | Understand Matplotlib And Seaborn Indepth. Available online: https://www.analyticsvidhya.com/blog/2020/07/univariate-analysis-visualization-withillustrations-in-python/ (accessed on 4 May 2020).
- Sarkar, D. Effective Visualization Of Multi-Dimensional Data—A Hands-On Approach. Available online: https://medium.com/swlh/effective-visualization-ofmulti-dimensional-data-a-hands-on-approach-b48f36a56ee8 (accessed on 20 December 2018).
- Yadav, S. Correlation Analysis In Biological Studies. Available online: https://www.j-pcs.org/article.asp?issn=2395-5414;year=2018;volume=4;issue=2;spage=116;epage=121;aulast=Yadav (accessed on 23 February 2022).
- Pandas Pandas. Dataframe.Boxplot—Pandas 1.1.0. Available online: https://pandas.pydata.org/pandas-docs/version/1.1.0/reference/api/pandas.DataFrame.html (accessed on 23 February 2022).
- Pankaj How To Create Pearson Correlation Coefficient Matrix. Available online: http://www.jgyan.com/how-to-create-pearson-correlation-coefficient-matrix/ (accessed on 6 June 2020).
- Haliza, H.; Sanizah, A.; Balkish, O.; Shasiah, S.; Nadirah, O. A Comparison of Model-Based Imputation Methods for Handling Missing Predictor Values in a Linear Regression Model: A Simulation Study. AIP Conf. Proc. 2017. [Google Scholar] [CrossRef]
- Koehrsen, W. An Implementation And Explanation Of The Random Forest In Python. Available online: https://towardsdatascience.com/an-implementation-andexplanation-of-the-random-forest-in-python-77bf308a9b76 (accessed on 3 May 2018).
- Schlagenhauf, T. What Are Decision Trees? 2020. Available online: https://www.researchgate.net/figure/Decision-tree-A-A-typical-decision-tree-A-sequence-of-choices-between-U-left_fig3_221698128 (accessed on 23 February 2022).
- Sage, A.J.; Genschel U and Nettleton, D. Tree Aggregation for Random Forest Class Probability Estimation. Stat. Anal. Data Min. 2020, 13, 134–150. [Google Scholar] [CrossRef]
- Brownlee, J. Iterative Imputation for Missing Values in Machine Learning. Available online: https://machinelearningmastery.com/iterative-imputation-for-missingvalues-in-machine-learning/ (accessed on 20 June 2020).
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Griffin, J.; Chen, X. Real-Time Fuzzy-Clustering and CART Rules Classification of the Characteristics of Emitted Acoustic Emission during Horizontal Single-Grit Scratch Tests. Int. J. Adv. Manuf. Technol. 2014. [Google Scholar] [CrossRef]
- Vértesy, G.; Gasparics, A.; Szenthe, I.; Gillemot, F.; Uytdenhouwen, I. Inspection of Reactor Steel Degradation by Magnetic Adaptive Testing. Materials 2019, 12, 963. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stresstech Group Rollscan 350 Operating Instructions. 2013. Vol. V1.0b. Available online: https://www.stresstech.com/products/barkhausen-noise-equipment/barkhausen-noise-signal-analyzers/rollscan-350/ (accessed on 23 February 2022).
- Stresstech Group Microscan Software—Operating Instructions. 2016. Available online: https://www.stresstech.com/products/barkhausen-noise-equipment/software/microscan/ (accessed on 23 February 2022).
- Gokulnath, K.; Mathew, J.; Griffin, J.; Parfitt, D.; Fitzpatrick, M.E. Magnetic Barkhausen Noise Method for Characterisation of Low Alloy Steel. In Proceedings of the ASME Nondestructive Evaluation, San Antonio, TX, USA, 14–19 July 2019. [Google Scholar]
- Griffin, J.; Chen, X. Real-Time Simulation of Neural Network Classifications from Characteristics Emitted by Acoustic Emission during Horizontal Single Grit Scratch Tests. J. Intell. Manuf. 2014. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample No. | 23 | 24 | 25 | 26 | 27 | 28 | |
|---|---|---|---|---|---|---|---|
| RPM | [t/min] | 1000 | 500 | 600 | 500 | 600 | EDM |
| Feed | [mm/min] | 75 | 1200 | 1700 | 2000 | 2500 | |
| Lateral offset | [mm] | 0.1 | 0.1 | 0.1 | 0.2 | 0.25 | |
| Average surface roughness (Ra) | [μm] | 0.13 | 0.49 | 0.33 | 0.73 | 0.61 | 3.65 |
| Maximum peak to valley height of the profile (Rz) | [μm] | 0.83 | 2.33 | 1.59 | 3.9 | 3.3 | 19.56 |
| Root mean square average of profile height deviations (Rms) | [μm] | 77.6 | 129.1 | 244.3 | 382.2 | 195.3 | 127.3 |
| Data | Data Size (Columns) | SSE | Distance Error | Time to Train | Unseen Test Case Accuracy | Iterations | % Aug * Increase |
|---|---|---|---|---|---|---|---|
| mp (Tx) | 98 (2) | 7.31 × 1016 | −0.02633 | 0:04:48 | 20/20 | 20,000 | 0 |
| mp (TXLx) | 98 (3) | 6.65 × 1015 | −0.02454 | 0:04:46 | 19/20 | 20,000 | 0 |
| mp (TxLx) & Param | 98 (6) | 4.24 × 1014 | −0.77117 | 0:05:11 | 17/20 | 20,000 | 0 |
| mp (TxLx) & Param & Augmented | 108 (6) | 6.09 × 1011 | −0.33589 | 0:10:26 | 18/20 | 20,000 | 10 |
| mp (TxLx) & Param & Augmented | 118 (6) | 1.00 × 1010 | −0.28471 | 0:10:30 | 17/20 | 20,000 | 20 |
| mp (TxLx) & Param & Augmented | 158 (6) | 1.10 × 109 | −2.54116 | 0:12:10 | 13/20 | 20,000 | 60 |
| mp (TxLx) & Param & Augmented | 205 (6) | 6.03 × 109 | −5.31443 | 0:12:46 | 11/20 | 20,000 | 100 |
| mp (TxLx) & Param & Augmented | 158 (6) | 2.80 × 1012 | −2.32811 | 0:11:39 | 17/20 | 20,000 | 60 ** |
| Data | Data Size (Columns) | Distance Error | Unseen Test Cases | % Increase of Augmentation |
|---|---|---|---|---|
| mp (Tx) | 98 (2) | 0 | 20/20 | 0 |
| mp (TxLx) | 98 (3) | 0 | 20/20 | 0 |
| mp (TxLx) & Param | 98 (6) | 0 | 20/20 | 0 |
| mp (TxLx) & Param & Augmented | 108 (6) | 0 | 20/20 | 10 |
| mp (TxLx) & Param & Augmented | 118 (6) | 0 | 20/20 | 20 |
| mp (TxLx) & Param & Augmented | 158 (6) | −2 | 17/20 | 60 |
| mp (TxLx) & Param & Augmented | 205 (6) | −2 | 17/20 | 100 |
| mp (TxLx) & Param & Augmented ** | 158 (6) | −1.2 | 18/20 | 60 (other half) |
| Data | Data Size (Columns) | % Aug * Increase | (NN) Sum Squared Error (SSE) | (NN) R2 | (CART) R2 |
|---|---|---|---|---|---|
| mp (Tx) | 98 (2) | 0 | 7.31 × 1016 | 1 | 1 |
| mp (TXLx) | 98 (3) | 0 | 6.65 × 1015 | 0.9998 | 1 |
| mp (TxLx) & Param | 98 (6) | 0 | 4.24 × 1014 | 0.8338 | 1 |
| mp (TxLx) & Param & Augmented | 108 (6) | 10 | 6.09 × 1011 | 0.9939 | 1 |
| mp (TxLx) & Param & Augmented | 118 (6) | 20 | 1.00 × 1010 | 0.9929 | 1 |
| mp (TxLx) & Param & Augmented | 158 (6) | 60 | 1.10 × 109 | −0.0168 | 0.0882 |
| mp (TxLx) & Param & Augmented | 205 (6) | 100 | 6.03 × 109 | 0.3156 | −1.23 |
| mp (TxLx) & Param & Augmented | 158 (6) | 60 ** | 2.80 × 1012 | 0.3220 | 0.509 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Griffin, J.M.; Mathew, J.; Gasparics, A.; Vértesy, G.; Uytdenhouwen, I.; Chaouadi, R.; Fitzpatrick, M.E. Machine-Learning Approach to Determine Surface Quality on a Reactor Pressure Vessel (RPV) Steel. Appl. Sci. 2022, 12, 3721. https://doi.org/10.3390/app12083721
Griffin JM, Mathew J, Gasparics A, Vértesy G, Uytdenhouwen I, Chaouadi R, Fitzpatrick ME. Machine-Learning Approach to Determine Surface Quality on a Reactor Pressure Vessel (RPV) Steel. Applied Sciences. 2022; 12(8):3721. https://doi.org/10.3390/app12083721
Chicago/Turabian StyleGriffin, James M., Jino Mathew, Antal Gasparics, Gábor Vértesy, Inge Uytdenhouwen, Rachid Chaouadi, and Michael E. Fitzpatrick. 2022. "Machine-Learning Approach to Determine Surface Quality on a Reactor Pressure Vessel (RPV) Steel" Applied Sciences 12, no. 8: 3721. https://doi.org/10.3390/app12083721
APA StyleGriffin, J. M., Mathew, J., Gasparics, A., Vértesy, G., Uytdenhouwen, I., Chaouadi, R., & Fitzpatrick, M. E. (2022). Machine-Learning Approach to Determine Surface Quality on a Reactor Pressure Vessel (RPV) Steel. Applied Sciences, 12(8), 3721. https://doi.org/10.3390/app12083721