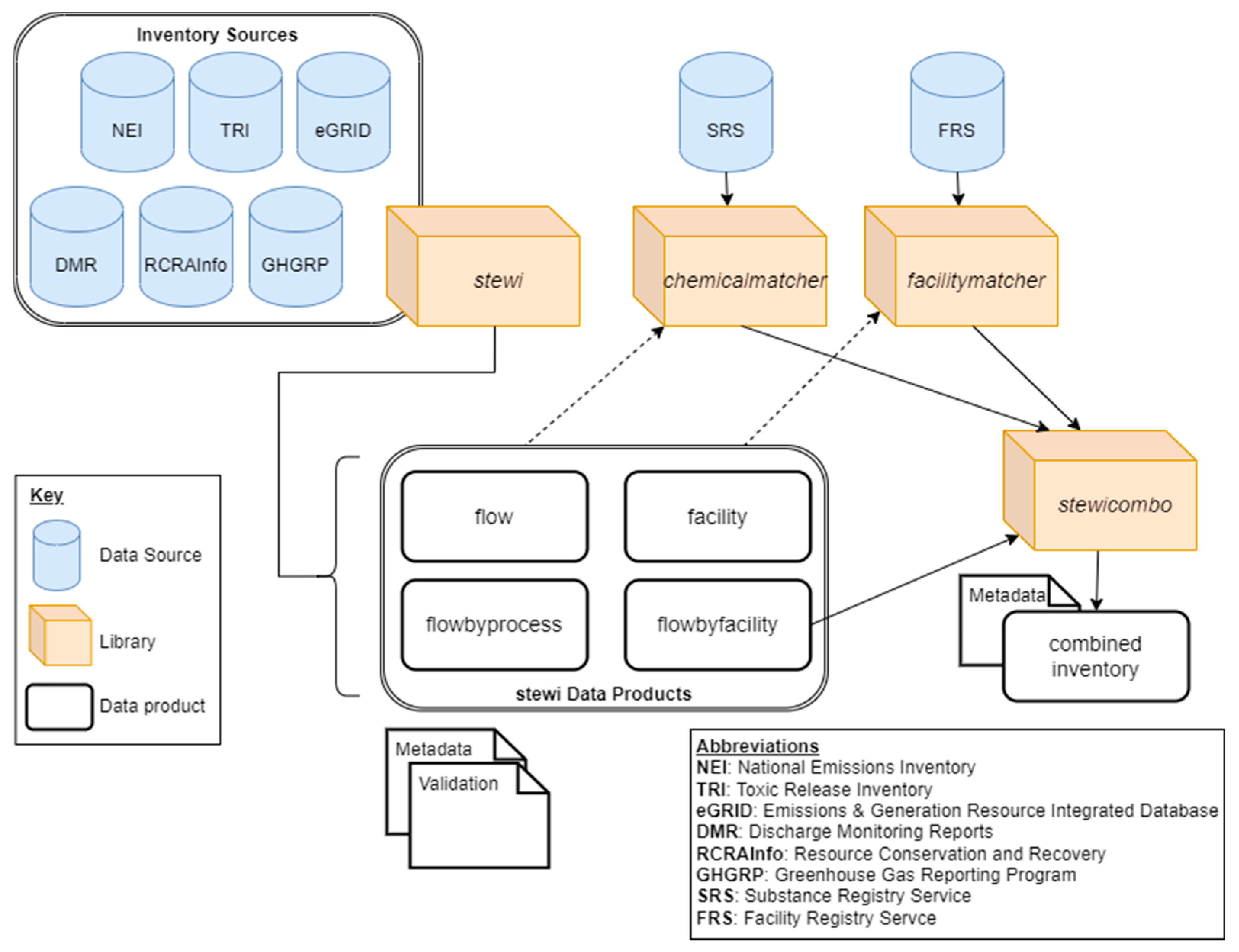
In this section, a general overview of StEWI’s organization is given, followed by an in-depth explanation of the structure and function of each of the constituent libraries.
2.1. Organization and Dependencies
StEWI is designed as a semi-interdependent set of Python libraries (
stewi,
chemicalmatcher,
facilitymatcher, and
stewicombo). Each library performs unique tasks in providing a standardized output or harmonization (
Figure 1). Some libraries have dependencies on other libraries; all have a common structure and analogous Application Programming Interfaces (APIs). Like the other tools in the ecosystem, StEWI draws heavily on the
pandas library [
18] and uses the
pandas dataframe as its basic structure for data storage, import, reshaping, and aggregation.
Pandas is an extremely powerful data manipulation framework that has enabled the rapid rise of the data science field [
19,
20] The
requests library is used generally to pull data from APIs when they are available [
21]. Source data contained in Microsoft Excel files are read using the
openpyxl engine (for .xlsx files) [
22] or the
xlrd engine (for .xls files) [
23]. Outputs are stored in Apache parquet format [
24], which enables efficient processing and retrieval of large datasets via the
pyarrow library. Configurable elements for data retrieval and processing are generally stored in relevant .yaml files. YAML is a simple text-based format that is used to store configuration data across the tool ecosystem [
14]. StEWI relies on the
PyYAML package to parse these files [
25]. Finally, StEWI relies on the USEPA LCA Ecosystem support package
esupy for local file management, metadata processing, and path management.
2.2. Stewi
The
stewi library consists of inventory-specific modules as well as common support modules that select, obtain, clean, and transform raw inventory data into standard output formats. (Note that StEWI is used to refer to the entire collection of libraries described herein, while
stewi describes the individual library that directly accesses the raw inventory data.) Each inventory module includes code used to process original sources into four standard outputs (flowbyfacility, flowbyprocess, facility, and flow) and record metadata. The formats are defined in the GitHub documentation under format specs, while the field names and data types associated with each format are defined in the formats.py module for use by
stewi. Each standard file is processed for each inventory and for each year. URLs, file names, and other identifier information for retrieving inventory data sources are centrally stored as key–value pairs in config.yaml. Core functions in
stewi for processing and retrieving processed data are highlighted in
Table 1.
Data processed in
stewi may include not just pollutant emissions but also inputs of resources and outputs of products or wastes. Therefore, the term ‘flow’ is adopted from the field of life cycle assessment [
26] and is used to describe either a product, emission, or release of waste that is generated by an entity and enters into the environment or will be used or processed (e.g., waste treatment) by a downstream activity or entity. Each flow is assigned to a compartment, which reflects the media to which that flow is released (e.g., air, water, soil). The names and capitalization for flows given in the original inventory data are maintained. Additional metadata on the flows, such as the inventory ID for the flow and CAS number, if applicable, are stored in the unique set of flows for a given inventory and given year in the flow output file. All flow amounts are transformed from standard into metric units, using kilograms (kg) for all mass flows and megaJoules (MJ) for energy flows. Conversation factors and conversion functions are stored in the globals.py module.
Data reliability scores are assigned to each flowbyfacility record using a method previously developed in Edelen et al. [
17]. Meyer et al. [
27] and Cashman et al. [
1] describe the use of this method in the context of facility-level inventories. Upon processing,
stewi assigns a data reliability score based on the method for deriving the flow value in the original inventory, with a flow reliability score of 1 representing a verified measurement, and a score of 5 representing the lowest data quality.
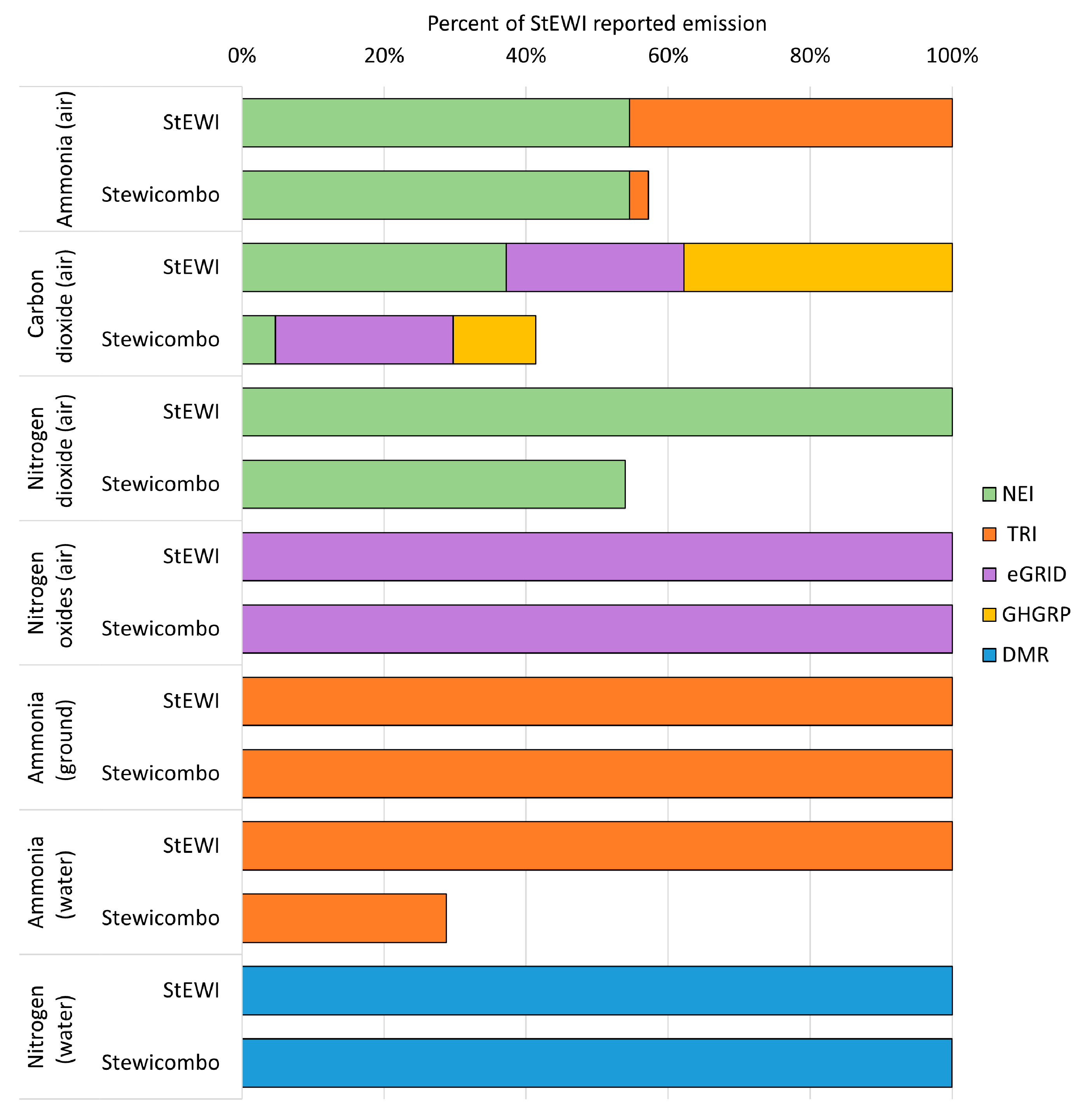
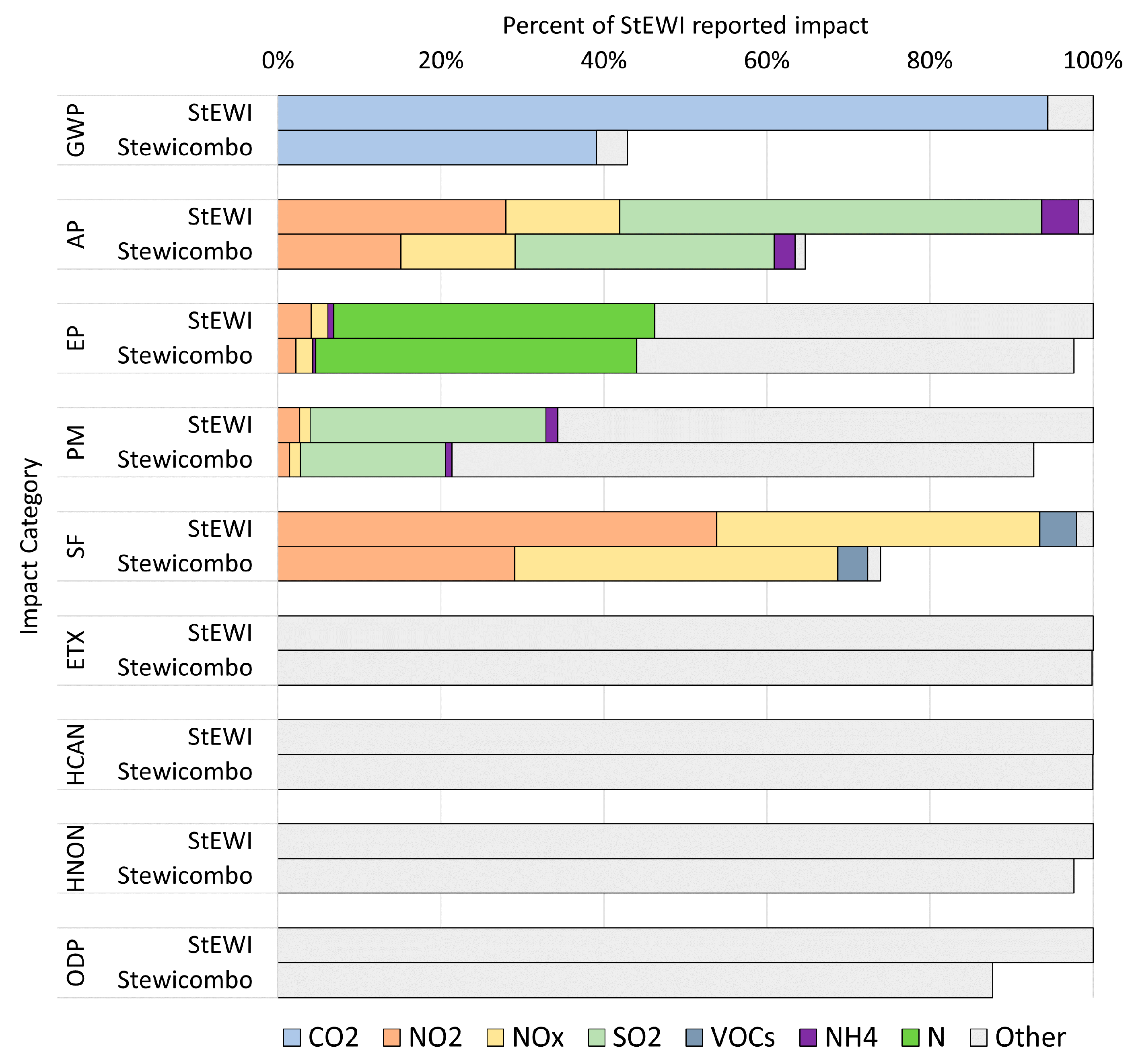
For each inventory processed, the flowbyfacility data totals are validated against reports of flow totals derived independently from the same inventory. The selected reports used as data sources for validation are called validation datasets. Depending on the reports available for each inventory, the flows are aggregated nationally or by state from the flowbyfacility outputs in order to compare these to the validation data. The totals by flows are compared against a calculated percent difference used as a tolerance level, where the default tolerance level is 5%. The result for each flow comparison is reported using the interpretations given in
Table 2 and stored locally in a csv file. Comparisons where a data point is not found in either the processed inventory or the validation dataset are indicated as such. The code for the validation checks is contained in the validation.py module.
stewi captures and records metadata on inventory sources, validation sources, and the output datasets. For inventory and validation source data, stewi records the filename, the URL the data were retrieved from, the date the data were retrieved, the file version, and the version of StEWI used to record the data. For output data, a standard class of source metadata defined in the esupy library is used, including fields for filename, output format (e.g., flowbyfacility), version of StEWI, git hash, and date created. Functions and defaults for metadata records are in the globals.py module.
Output files of type flowbyfacility and flowbyprocess can be filtered to remove records using a set of embedded filters when retrieved with getInventory. Filter names and instructions are stored in
filter.yaml and implemented in functions in the filter.py module.
Table 3 lists the filter, the inventories they apply to, and their functions. Embedded filters were created to generate StEWI output files for specific applications. Additionally, a filter_for_LCI parameter is available in getInventory that, when set to True, applies all the filters given in
Table 3. All available filters can be printed to the console using see available inventory filters.
The following USEPA inventory sources are available for processing in stewi: the NEI (point source data only from the Emission Inventory System), the TRI, the eGRID, the Greenhouse Gas Reporting Program (GHGRP), Discharge Monitoring Reports (DMRs) based on reporting to the National Pollutant Discharge Elimination System, and the Resources Conservation and Recycling Act’s Biennial Report generated from the RCRAInfo system (RCRAInfo). The processing of each of the inventory sources is described further below.
2.2.1. Discharge Monitoring Reports
Facilities report annual and sub-annual discharges to water under the Clean Water Act through the National Pollutant Discharge Elimination System (NPDES). The USEPA’s DMR compiles data submitted by NPDES permit holders. The USEPA updates DMR flow quantities for facilities on an annual basis.
In the DMR.py module,
stewi accesses DMR data via the Water Pollutant Loading Tool [
28], a RESTful web service. Data for facilities are queried by state using the following query parameters:
Flows are aggregated as “parameter groupings” to avoid double counting of flows that represent the same pollutant; this is especially relevant when facilities may be required to report multiple versions of the same release (e.g., different types of Chemical Oxygen Demand);
The default setting for estimation is set to true; this setting estimates pollutant loads when no data are reported for a particular time period; and
Non-detects are set to 50% of the detection limit.
Subsequently, aggregated nutrient quantities for nitrogen and phosphorous are queried by state with the Nutrient Aggregation feature on. With this feature, all nitrogen and phosphorus compounds are converted to N and P, respectively, equivalents based on a hierarchical evaluation in the Loading Tool to avoid double counting of reported nutrients [
28].
Facility emissions are aggregated by state and validated against the State Statistics reported by the USEPA. The State Statistics only report emissions from NPDES Individual Permits and do not consider aggregated nutrients. So, the validation is performed prior to incorporating aggregated nutrients, and emissions captured by stewi from facilities with General Permits are excluded from the validation.
2.2.2. Emissions and Generation Resource Integrated Database
Through the eGRID, the USEPA compiles generation and emissions data for electricity-generating units in the United States [
2]. These data are sourced from USEPA compiled statistics as well as facility-reported information to the Energy Information Administration (EIA). eGRID data are released semi-regularly, often every other year, in the form of Excel files. The specific emissions tracked by the eGRID are carbon dioxide (CO
2), nitrogen oxides (NO
X), sulfur dioxide (SO
2), methane (CH
4), and nitrous oxide (N
2O).
In the egrid.py module, stewi utilizes data from both the unit and plant-level datasets to parse the eGRID inventory. Plant level data tracked by stewi include annual emissions, heat input, and net generation. Where applicable, stewi also tracks the combined heat and power thermal output as steam. The unit level data supply the necessary information to characterize data reliability scores. Plant reliability scores for specific flows reflect the emission-weighted average of all units. While the eGRID reports generation mix by fuel type, the emissions are reported as plant totals. As such, emissions are reported by facility in stewi, but the generation resource mix is maintained as additional facility metadata.
Facility emissions and generation are aggregated across all facilities and validated against national totals reported in the eGRID.
2.2.3. Greenhouse Gas Reporting Program
The GHGRP provides an inventory of greenhouse gases (GHG) at the facility and, in some cases, unit level [
29]. Facilities with GHG emissions from covered sources that exceed 25,000 metric tons of CO
2 equivalent (eq.) per year must report to the GHGRP. Covered sources are listed by GHGRP subpart as documented in the Mandatory Greenhouse Gas Reporting rule in 40 CFR §98, Mandatory Greenhouse Gas Reporting. Example subparts include general stationary fuel combustion sources, electricity generation, ammonia production, aluminum manufacturing, ethanol production, petroleum refineries, and pulp and paper manufacturing. GHGRP reports for covered facilities are prepared on an annual basis.
Within the GHGRP.py module, stewi downloads a series of data tables containing GHGRP emissions data organized by subpart from the USEPA’s Envirofacts API. Data from each subpart table are parsed to ensure a standardized format and concatenated into a master data table. With the GHGRP, emissions from stationary combustion sources (i.e., subpart C) can be estimated using one of four calculation methodologies, referred to as “tiers”, plus one alternative methodology:
The Tier 1 methodology uses default emission factors and high heating values to calculate mass emissions based on company records of fuel consumption;
The Tier 2 methodology uses default emission factors to calculate mass emissions based on measured high heating values and company records of fuel consumption;
The Tier 3 methodology calculates mass emissions based on measured fuel characteristics (e.g., carbon content, molecular weight) and measured fuel consumption;
The Tier 4 methodology relies on a continuous emission monitoring system (CEMS) to calculate mass emissions from the stack gas concentrations and the stack gas flow rates; and
In addition to these four methodologies, a small number of stationary combustion units may rely on 40 CFR §75 calculation methods based on monitoring data already collected under §75 (e.g., heat input, fuel use).
The emissions data from these five estimation methodologies are combined and organized into a standardized table categorized by gas. In some cases, data are reported at the unit level and must be aggregated to the facility level. Certain subparts (including subparts E, BB, CC, LL, L, and O) do not have their own standalone subpart tables and must be extracted from other data tables and parsed separately. After concatenating all subpart data into a master table, data are aggregated into standardized outputs that report GHG emissions by GHG flow (gas) and facility ID. Subpart data are maintained such that GHG data can be accessed in flowbyprocess format, which maintains total emissions by facility from each subpart. Data are validated against national-level data reported by the USEPA.
2.2.4. National Emissions Inventory
The NEI provides facility-level information on CAP and HAP emissions [
4]. The AERR Rule in 40 CFR §51 requires States (via State, local, or tribal (S/L/T) entities) to report CAPs every year for large (Type A) point sources and every three years for other (Type B) point sources (
Table S1). While facility reporting of HAPs is optional, the USEPA will augment facility-reported emissions with estimates based on speciation profiles or from the TRI.
Table S2 provides the share of each method used for facilities reporting HAPs. Facilities report emissions data by source classification code (SCC), which corresponds to a standardized list of specific processes or emissions sources. NEI point sources may include large industrial facilities, electric power plants, and smaller industrial, non-industrial, and commercial facilities.
The NEI point source data are processed within the NEI.py module. stewi imports NEI data exported from the USEPA’s Emissions Inventory System (EIS) Gateway. NEI data files are read into stewi, concatenated into a single data table, and parsed into a standardized format. Data reliability scores are assigned. Data are aggregated into standardized outputs that report emissions by flow and facility ID. Data in the NEI are also compiled in flowbyprocess format, which maintains reported emissions by facility for each unique SCC. Data are validated against national-level data reported by the USEPA.
2.2.5. Resource Conservation and Recovery Act Biennial Report
The Resource Conservation and Recovery Act Information (RCRAInfo) provides the type, disposition, and quantity of hazardous waste generated at the facility level. Facilities that treat, store, or dispose of hazardous waste must submit a Biennial Report [
30] to RCRAInfo every two years.
Biennial Report data are downloaded by stewi from the USEPA’s RCRAInfo Public Extract using the RCRAInfo.py module. Handler waste code descriptions are applied as flow names; where those waste codes are unavailable, form code descriptions are used instead. All facility and flow information is maintained in stewi, including wastes (e.g., imported wastes) and handlers not covered by the National Biennial Report. However, by default these handlers are filtered from the inventory upon accessing it via stewi. Data are validated against flow totals reported by State in the USEPA’s Trends Analysis for the National Biennial Report.
2.2.6. Toxics Release Inventory
The TRI provides an inventory of air, water, and waste flows at the facility level for TRI-reportable chemicals only [
3]. Facilities in the United States are required to report to the TRI if certain conditions are satisfied (e.g., they have 10 or more full-time employees, they are a TRI-covered sector as defined by the NAICS code, and the facility manufactures (defined to include importing), processes, or otherwise uses any EPCRA Section 313 chemical in quantities greater than the established threshold in the course of a calendar year). The TRI releases new inventory reports on an annual basis.
In the TRI.py module,
stewi accesses TRI data through the Basic Plus data files, specifically files ‘1a: Facility, Chemical, Releases, and Other Waste Management Summary Information’ and ‘3a: Details of Off-site Transfers’. Collectively, these files contain the facility and flow information necessary to characterize emissions and releases to air, water, and soil. While the TRI tracks transfers and the storage/management of covered chemicals, currently only exchanges directly with the environment are tracked in
stewi (
Table 4).
Releases are aggregated across all facilities by flow and compartment and validated against national results from the TRI Explorer Release Chemical Report.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}