1. Introduction
The constant technological evolution, which, thanks to the ubiquity of the Internet and the services offered by cloud computing, allows a large part of human activities to be developed in an online and digital way, through the widespread use of electronic devices and computers. The design of new solutions offered as scalable and on-demand systems has connected society in fields such as education, health, privacy and security, culture, personal development, and, to a large extent, e-commerce. This has served to transform technical information, previously understood only by experts, into easy-to-understand ontologies for the average end-user, to operate their technology needs. As a result, there is a big demand for access to this new era of easy digitization of payments, benefiting monetary transactions that are now better comprised and can be carried out instantaneously, overcoming currency or regional barriers [
1,
2].
The new era of digital finance has been gradually replacing the physical form of money provision with an electronic one, which, in turn, involves a better level of independence, but has consequences for the privacy and confidentiality of payments.
Indeed, the security and anonymity offered by VPNs, together with sophisticated authentication mechanisms and multi-factor add-ons [
3] have gained the trust of the common user, but undoubtedly one of the forms of electronic money that have been adopted in a considerable way are cryptocurrencies, which touch on the advantages mentioned before and also the freedom of banking intermediaries: digital cash that is handled on a peer-to-peer (P2P) basis. The appeal of cryptocurrencies is that they offer a distributed transactional model, using cryptographic techniques and a puzzle-solving stage to address the risks of counterfeiting and double-spending, also known as anti-tampering resistance. Although a degree of confidentiality and integrity is implied, cryptocurrencies are not backed by a trusted third party; however, this has not limited their commercial use, which has increased since their creation in 2009, becoming a newly popular method for online payment transactions and investment [
4]. In fact, the interest in cryptocurrencies has spread to such an extent, that it is a matter of selecting the desired cryptocurrency house, reading the documentation provided, using a recommended application and then start monitoring trends, mining blocks, or simply making the desired monetary transactions [
5]. The cryptocurrency boom has been presented as a consumer commodity, even used as part of marketing campaigns. One of the most convincing cases is the one explained in [
6], in which airlines suggested the adoption of the advertising of large cryptocurrency houses as a promotional medium on the Internet and the generation of more popularity ratings, within them.
Many cryptocurrencies are decentralized networks based on blockchain technologies, i.e., distributed operations enforced by a network of computers, involving an arduous computational process to cryptomine new blocks towards the blockchain network. This procedure, namely, the proof-of-Work (PoW), is a pool of consensus, aimed to solve a puzzle that avoids cheating the system by solving expensive and difficult cryptographic calculations, to eventually gain the binding of a new block, restricted to a hashing rate. The latter is performed thanks to the distributive capabilities of various device networks, where different participants provide, in an individual manner, processing capacity in terms of specialized hardware, GPUs, FPGAs, or ASICs, which can efficiently protect the transaction, given the algorithmic power, and the resistance to fault attacks [
7]. Finally, if the block is successfully constructed, users are rewarded with a certain amount of the cryptocurrency, which is undoubtedly a lucrative business for digital money enthusiasts.
The growing phenomenon of investing in crypto-processing has led developers to implement more flexible ways for solving PoWs. For example, Monero, the once-popular cryptocurrency brokerage company, designed an algorithm called CryptoNight, which offered new opportunities to process calculations over standard CPU-oriented systems. With this in mind, several POW systems opted to take advantage of the large-scale communication capabilities of the Internet, thus giving birth to web-based cryptomining, which has as its main advantage, the distributed use of computational resources. With the consent of a large number of users, the scripts are executed from the carrier site, through the browser, which binds the puzzle fraction to be solved to the CPU, adding it as another node in the transactional network [
8].
In the same way, the market demand has increased the commercial value of cryptocurrencies, with Bitcoin, Ethereium, Litecoin, Dogecoin, and Riple as main exchanges, all of which offer attractive ways to join the PoW network, via system software, shareware, or web scripting [
9]. An interesting example is what happened during the early days of the COVID-19 pandemic, which according to [
10], special attention was paid to cryptocurrency investment as an alternative means of profit, with Bitcoin being the dominant currency in the market. Given this ease of joining the network of crypto-processing competitors, malicious actors have also been attracted to make money illicitly, leveraging classic attack vectors such as malware, botnets, or by simply taking advantage from already discovered security breaches, to embed malicious mining code over IT infrastructure, targeting numberless third-party computing services; therefore, the rise of illegal mining has alarmed governments and security providers, assessing illegitimate cryptocurrency as a significant threat over the Internet, affecting numerous visitors who fall prey to the lure of infected sites. Based on a CTA (Cyber Threat Alliance) white paper, the growth of counterfeited cryptocurrency mining has intensified since the last months of 2017 and shows a rapid development with no signs of slowing down [
11].
Although infections by cryptocurrency-related malware can be found on malicious links in email messages and attachments, applications with masqueraded activity and hijacked browser extensions, the last, remains as the main and most lucrative way of web-based-mining scripting, namely, web-based cryptojacking; which according to [
12] contains stealthy attack vectors to make use of several computational resources without any restriction. This is a great advantage on the attacker’s side as it only requires the visitor to stay long enough on the website to proceed with the execution of the malicious code. In a point of fact, this implies a critical security point, since this form of cryptojacking does not require the download of executables, binaries, or adware, but as a primary tool, a common web browser, which is a native component of numerous operating systems from everyday devices: personal computers, workstations, smart-phones, and IoT gadgets.
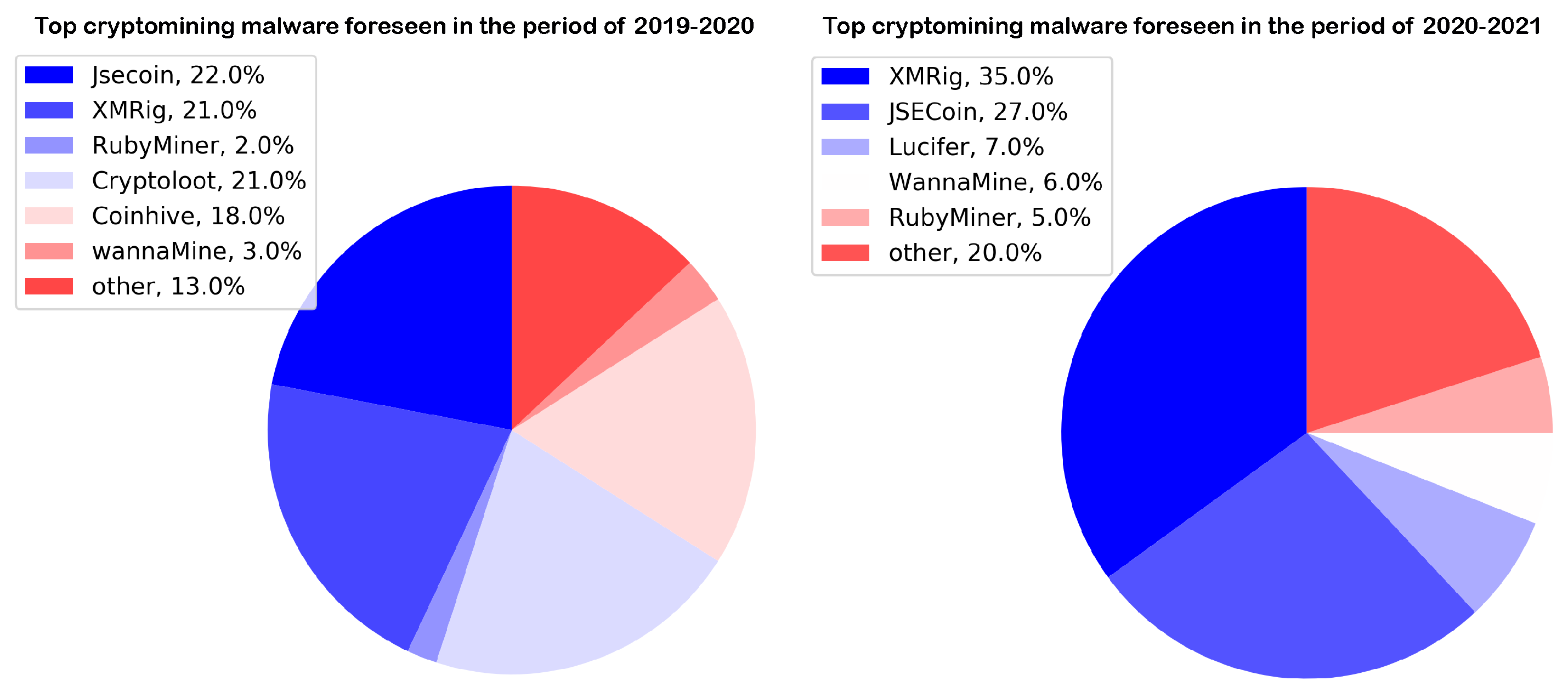
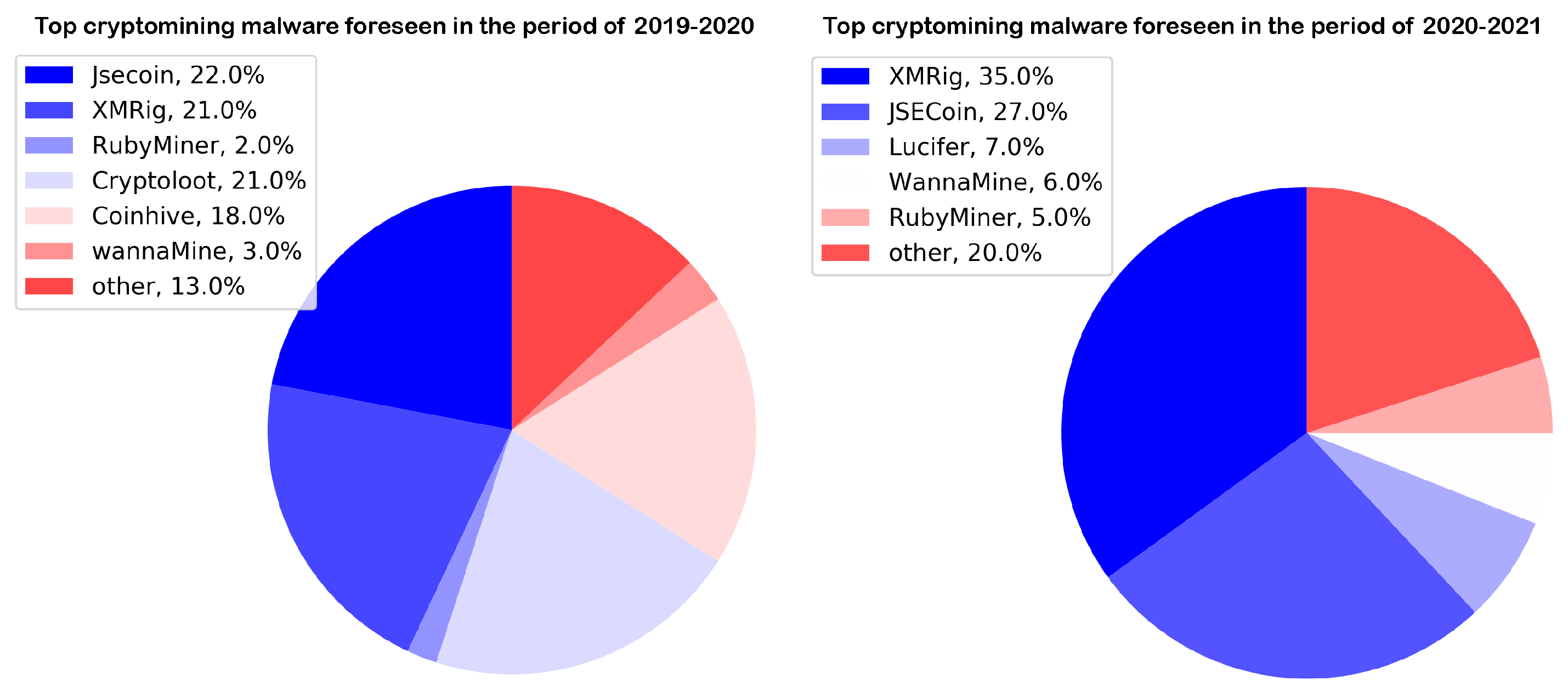
As an example of malware persistence, between the years 2017 and 2018, Coinhive, one of the most expanded malicious platforms for the development of cryptojacking-oriented scripts, quickly defaced a significant number of websites, via server-side content injection, where more than 45,000,000 illicit transactions were recorded in that period [
13].
Figure 1 describes different platforms, which are used as cryptocurrency malware or web-based cryptojacking.
Web-based cryptojacking is a threat that seems difficult to fade, according to a report by the European Union Agency For Cybersecurity (ENISA), between January 2019 and April 2020 were detected million sites with some kind of unlawful cryptocurrency activities, with novel and more sophisticated attack vectors. In addition, the ENISA confirmed that 65% of cryptocurrency transactions are subject to weak or leaky know-your-customer-processes, leaving a loophole in the illegal exploitation of IT resources for cryptomining purposes. This was increased severely during the first months of 2021, where a significant increase in the illicit cryptomining market was reported, and although the trend is against infected files, web-based propagation is still striking. An example of this was zero-day attacks on unpatched Microsoft Exchange Servers, where the first payloads had traces of web-based cryptomining code, with new tactics of concealment.
Even though the shutdown of several classic web-based cryptocurrency sites is well known, the attention of malicious actors has shifted to cloud infrastructures, exploiting APIs and containers (e.g., Docker and Kubernetes) to install illegal cryptocurrency images. In any case, the strength of cryptojacking strains is coupled with the handiness of coding, thanks to the incorporation of technologies such as WebSAssembly, WebWorkers, and Websockets, which simplify the execution of high-performance multi-platform scripts, intensifying the number of potential victims [
16].
Being a threat that encompasses a high proportion of risk, due to its high level of profitability, it is therefore necessary to understand the current landscape, in order to gather the necessary elements for timely detection. Classical reverse engineering scopes and those based on anomaly modeling have not been sufficient to project the threat. Beforehand it can be considered that the user’s activities are the primary task in information security events, the same that allow to trace failures, intrusions, bad functionality, and in general any point that is considered surface and vector of attack, where it interacts [
17]. An important point in this type of research related to a malicious agent that spreads on different surfaces is to understand the taxonomy of the anomaly, therefore, in [
18] it is proposed that it is necessary for security systems to reason the change in the normal activity flows and to be able to discriminate similar/non-similar objects.
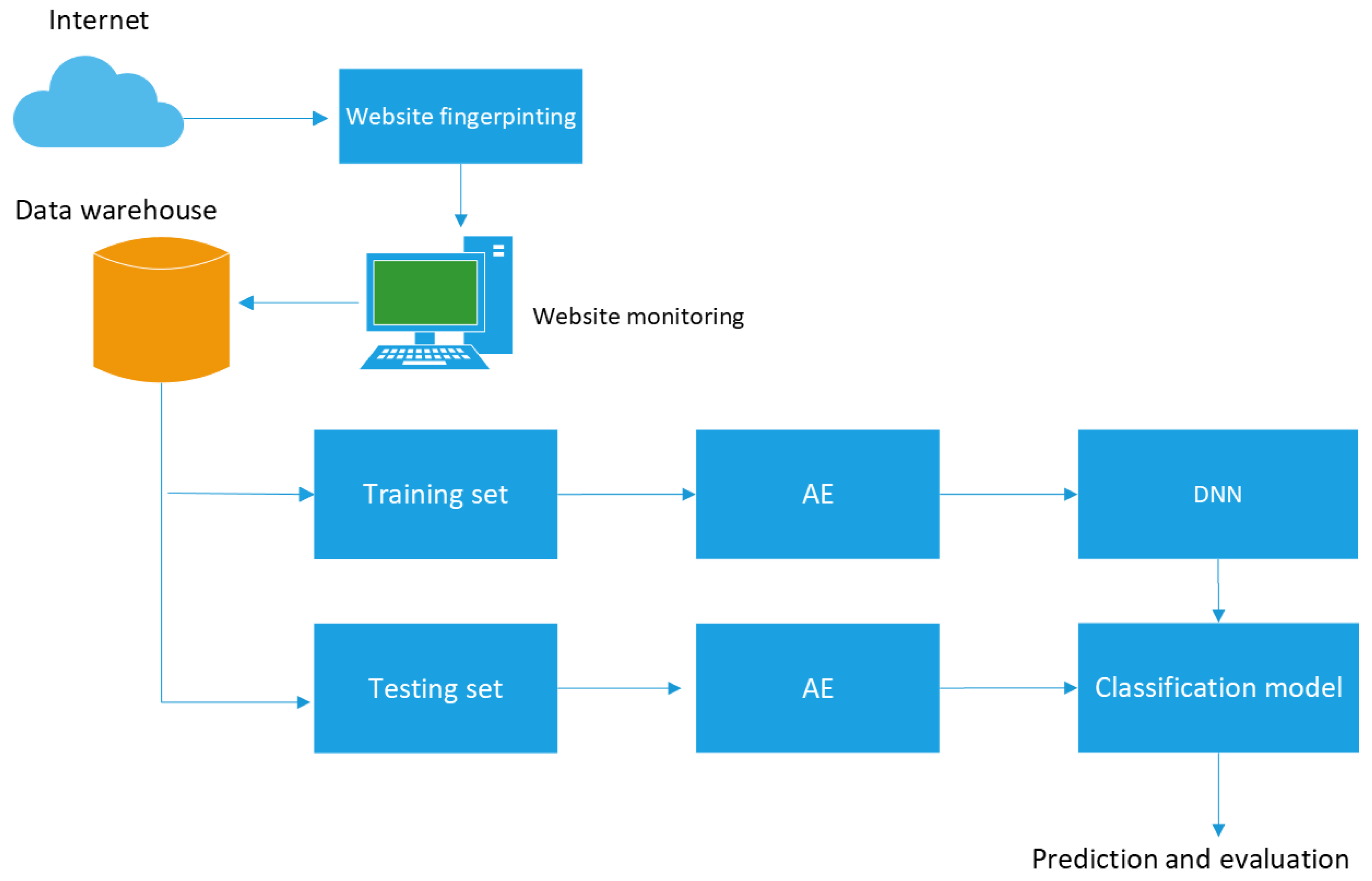
This manuscript takes the above references as a key starting point and is intended to contribute to solve the problem of web-based cryptojacking with a novel form of latent representation of malicious traces, which are trained by a deep learning algorithm that maximizes the capabilities of sensing, from different flanks, specifically network, and host characteristics. The results discussed later in
Section 6 show that by means of the strategy proposed in this paper it is possible to achieve a Precision of 99.41%, a Recall with a score of 99.11%, and an F1 Score of 99.26%, with a time no longer than a minute and a half for the generation of the final model. Thus, this methodology can be quickly adapted to different threat properties and attack the problem of web-based cryptojacking.
The remainder of the manuscript is organized as follows.
Section 2 explains the motivation and background that gave rise to this research.
Section 3 describes the phenomenon of cryptomining, the threats of web-based cryptojacking, and its prevalence.
Section 4 discusses the most employed detection methods, the scope of the algorithms, and the related work through the incorporation of ML techniques. In
Section 5, the AE and DDNN framework is extensively described.
Section 6 describes the results obtained, their discussion, and improvements presented against other state-of-the-art works. Finally,
Section 7 concludes this work.
2. Background and Motivation
Like any other security threat, cryptojacking has been subjected to different solutions for its mitigation and eradication. As a malware where the cryptographic element is present, there is a relationship between new strands, such as crypto-ransomware, where symmetric cipher blocks can be distinguished during the exploitation stage and heuristic flagging from different antivirus vendors [
19].
Beyond detecting such malware merely by cryptographic elements, the first scans presented in the state-of-the-art have distinguished the inherent properties of the executable as a starting point for examinations by means of the well-known static (SA) and dynamic (DA) analyses. The last-mentioned can provide preliminary results that can be used for triaging and exploratory data analysis, which can reveal important points in end-to-end network traffic forensics, source code auditing, CPU stress operations, and functional monitoring of infected sites, within user interactions [
16]. It is well known that SA and DA are the first and primordial stage for discovering and tracing a malicious agent in a chain of custody, however, these practices, lack of automation properties, and therefore any kind of knowledge-base to further learn from significant patterns, beyond what can be humanly configured, interpreted, and managed using a wide repertoire of security tools. Therefore, the outputs of SA and DA cannot be used to construct simple detection signatures, nor to be released to work as a single security mechanism, instead, the resulting data can be properly characterized and tuned to serve as input for machine learning ML algorithms, capable of discovering important underlying information [
20].
The literature for detection, classification, and clustering of samples for timely detection of web-based cryptomining threats, especially for observations of different varieties of cryptojacking, comprises a broad spectrum of supervised learning (SL) [
21], unsupervised learning (UL) [
22], and deep learning (DL) algorithms [
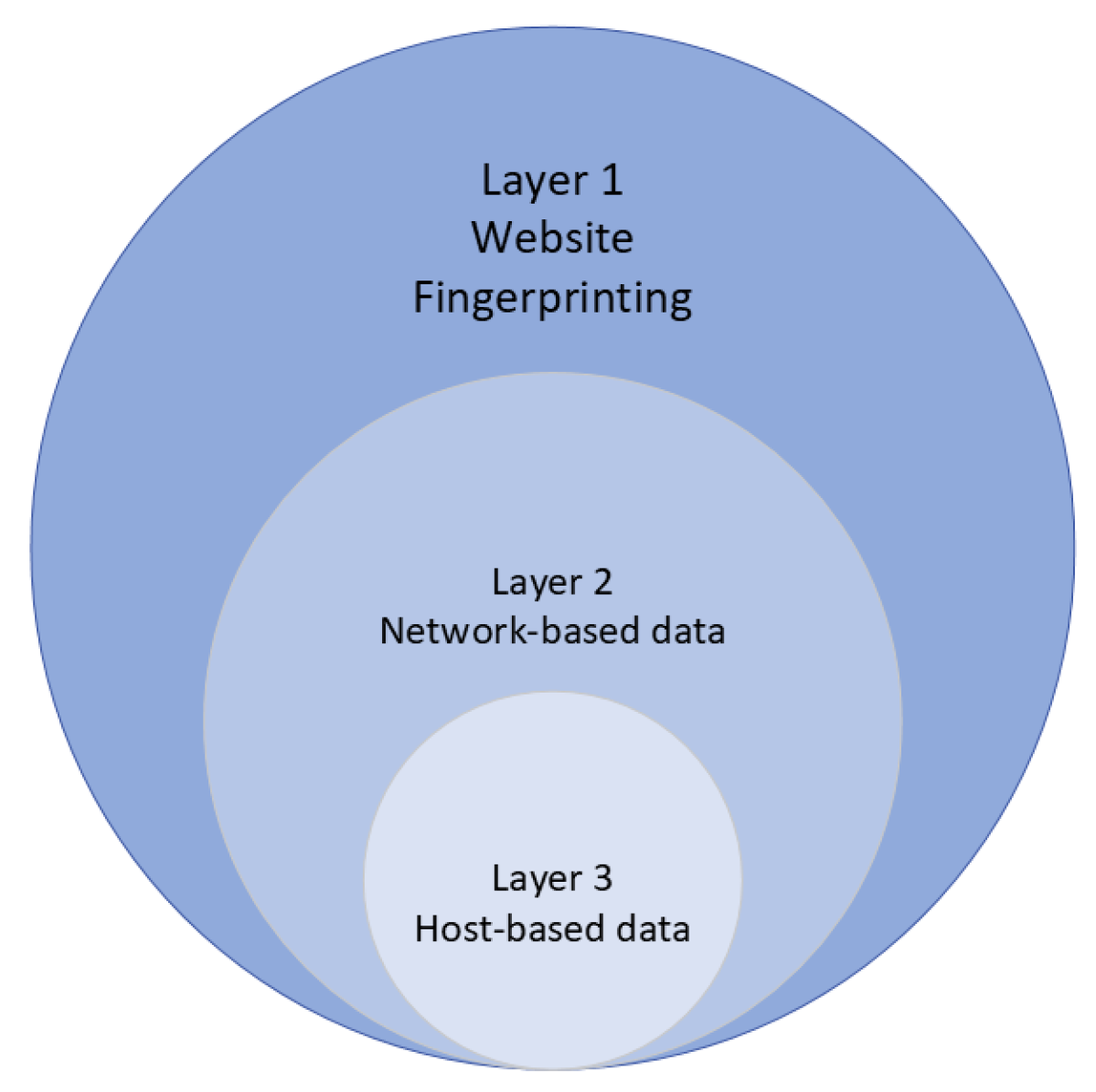
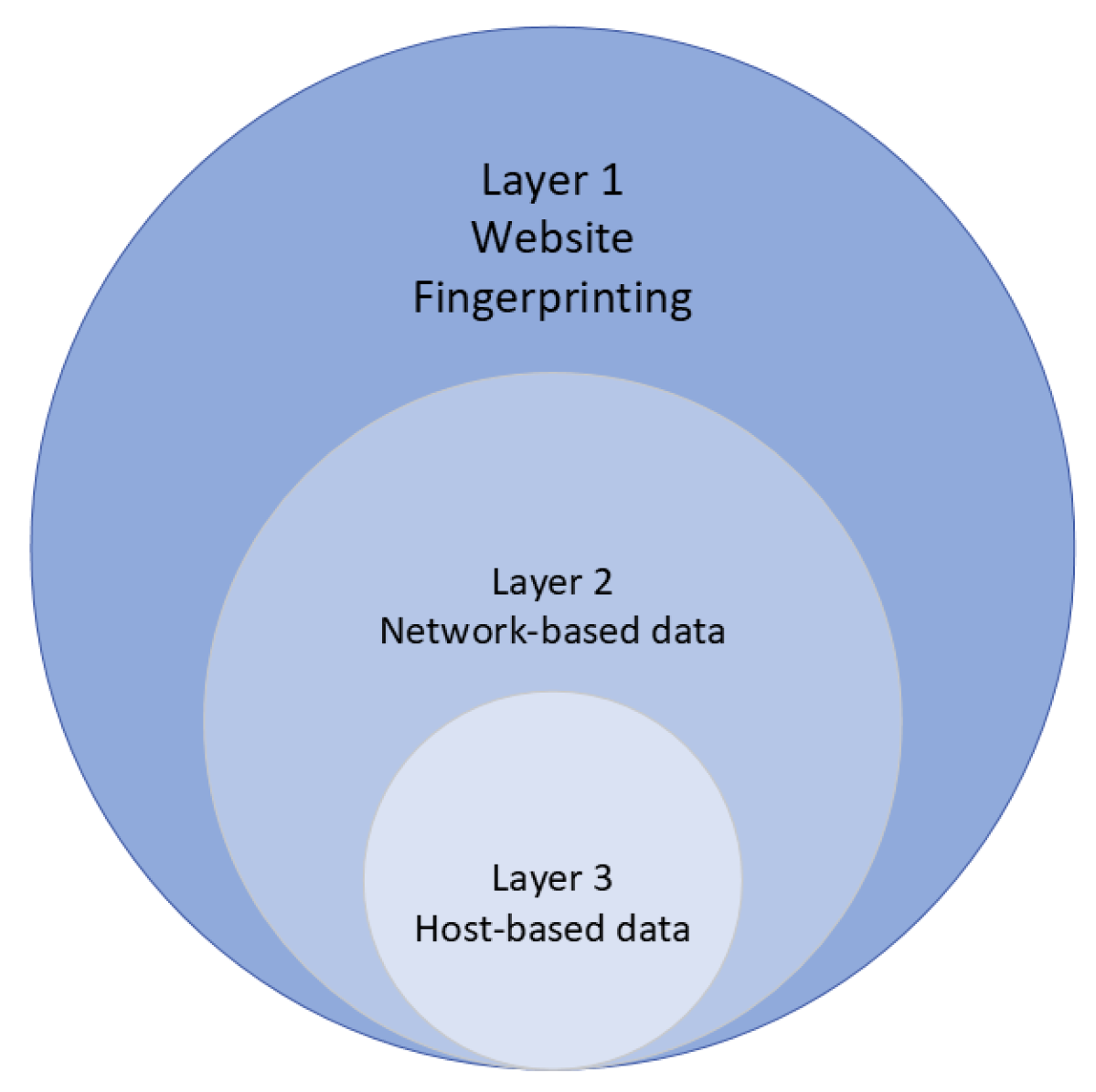
23], where an emphasis is placed on the true positive (TP) radius enhancement. It is worth mentioning, that the above-named fields presented interesting findings with more than 90% of accuracy for cryptojacking classification. Despite their theoretical effectiveness, there is no consensus on what set of features can represent the threat as a whole, given the attack surfaces where it unfolds. The first surface resides on the LAN and WAN (Internet) networks since it is the point where traffic connections are made between the attacker’s PoW and the victim executing the malicious script. The second surface involves the events that occur on the client (host) side when the malicious script is running. In this part, it is possible to log the activities from the operating system related to the consumption of resources from the browser during the time it is hijacked. The purpose of outlining the above is simple: by adding features from the network and host side, the generalization of the cryptojacking problem can be increased, thus expanding the likelihood of successful feature extraction, selection, and learning process.
In agreement with [
24], when incorporating ML solutions in the cybersecurity domain, it is important to take into account a holistic view of the event occurring on the network and host fronts; therefore, the algorithm proposal is not enough, we also require the acquisition, processing, and proper characterization of the observed and fused data. Cryptojacking does not operate in a traditional way compared to other types of malware, its nature is a pivot attack, where the browser concentrates the payloads and acts as an intermediary between the remote site and the user, without a direct infection. So then, it is important to meet the criteria for an optimal representation of the observed samples, from various edges. A great challenge can be encountered when capturing a pivoted threat: samples from different but interlinked origins can lead to a large occurrence of outliers due to dissimilar measurements, sizes, and types of data, incrementing the chances of high dispersion, as some records could only be observed under the presence of well-configured sandboxed cryptojacking instance.
As described in
Section 3, there are two important gaps in the state-of-the-art regarding cryptojacking detection: 1. In the first instance, it has already been proven that traditional scopes are outdated and not sufficient, therefore SA and DA techniques can serve only as a basis for congregating sample-features 2. The source and selection of the features, either at the network or host level, may be merged to achieve a desired level of detection, but not to be considered separately. This raises an important research question:
Research question: How to optimize web-based cryptojacking detection by a procedure that takes the best of network and host features and merges them?
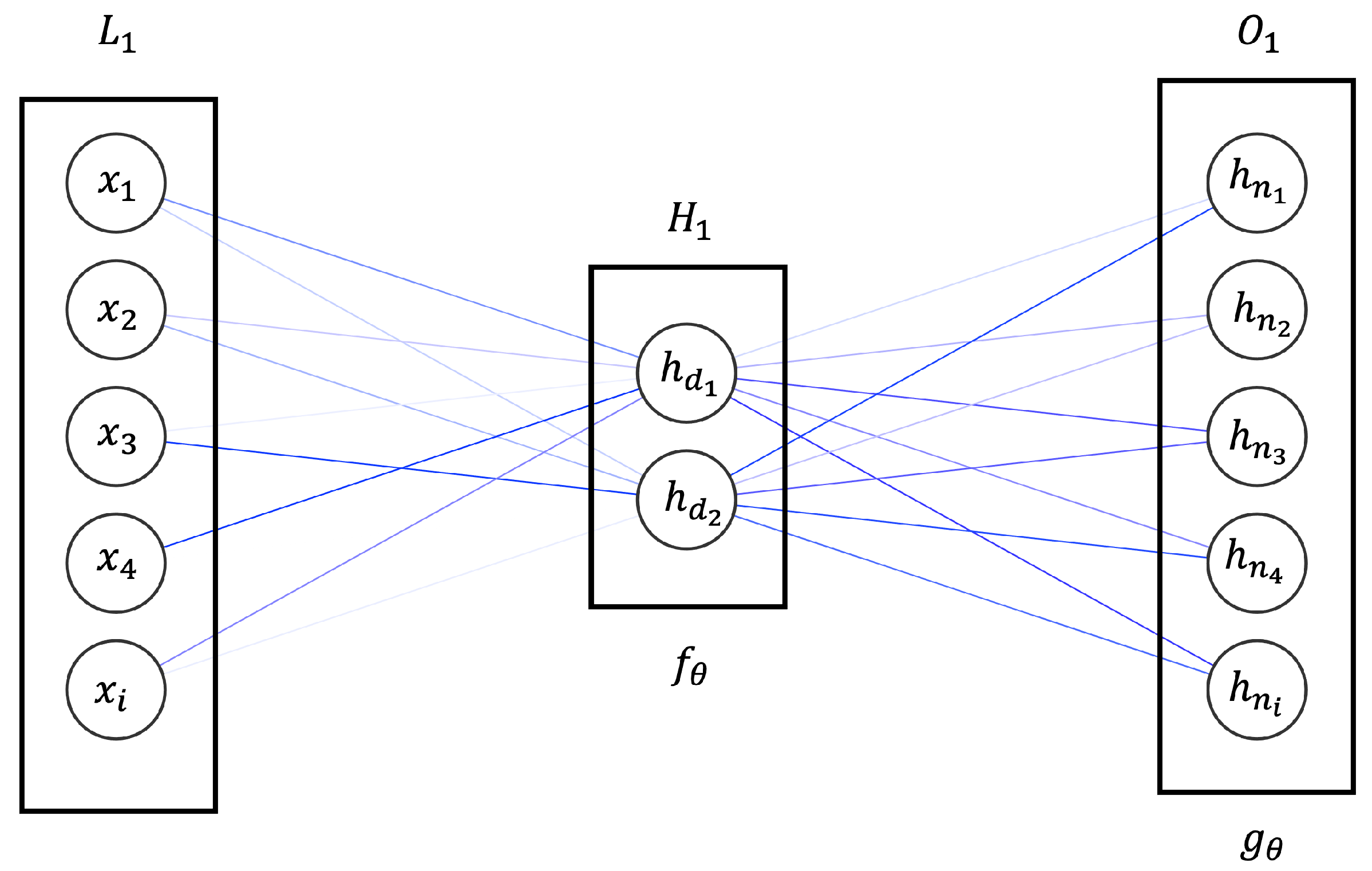
This work concentrates on a new form of cryptojacking feature representation technique, recently adopted for ML-oriented cybersecurity scenarios, called autencoding (AE) [
25], which is a specific structure of neural network (NN) focused on compressively capturing the latent information from unstructured data, in virtue of dissimulating the effects of noise, high dimensionality, and non-linearity. Then, the outputs are subjected to a deep dense neural network (DDNN) [
26], a type of deep neural network, which has demonstrated nice effectiveness in the treatment of a vast number of malware-related scenarios. As a sign of a successful performance, the resulting model is compared with different methodologies presented in the state-of-the-art for cryptojacking detection.
3. Cryptomining, Cryptojacking, and Web-Based Mining Threats
As mentioned in
Section 1, legal cryptomining is an attractive activity in order to earn a profit by mining new blocks to the blockchain-based currency network, where the puzzle-solving process is the most lucrative component, within a network of competitors. At its most fundamental level, cryptocurrency mining is simply the use or reuse of any system resource to increase the performance of complex mathematical calculations over a PoW, usually involving a hashing-type solution. These calculations maintain and validate the transaction history of the distributed ledger, generally known as the blockchain-net. As the cryptocurrency network grows, the calculations become more difficult, making individual machines less likely to solve equations with their limited processing power. Hence, it is common for specialized hardware components, better known as ASICs, to be used in conjunction with other workstations to serve as cryptomining farms. Consequently, alternatives have been sought when sufficient processing capacity is not available, where collaborative works (P2P nodes) are a way to pool the distributed power of single devices and solve more expensive computations [
27]. The latter is known as pool mining, a technique aimed to help parallelized mining procedures and successfully create new blocks to obtain an expected reward.
The phenomenon of distributed lending of resources has led to a fierce career within the mining chain since the final dividend is proportional to the hashing power, i.e., the performance of each individual miner, which depends directly on the speed to verify the data through hashing algorithms: the faster the performance, the more cryptocurrency the miner will receive [
28]. The arduous struggle to complete mining tasks, especially those implemented by Bitcoin, proved that the exponential volume for power consumption and the difficulty of the PoW challenges, require extensive configurations found in ASICs such as FPGAs or GPUs, and therefore, an unattractive high-cost investment in the face of the growing demand for faster hashing operations. In consequence, other cryptocurrencies such as Monero decided to turn the well-known P2P collaborative network into software alternatives, specifically, scripts that can be run inside a web browser, proficient in exploiting average CPU architectures [
29].
This fashioned form of rapid access to cryptomining has generated a significant enrichment within the stakeholders, incorporating a new kind of informal economy, since miners do not need to have deep knowledge of IT, only the ability to build and operate a command base with sufficient computational power, to rapidly construct emerging blocks [
30]. These attractive financial movements have engaged the attention of malicious actors, who take advantage of the distribution of resources, thus abusing personal devices and ultimately, profiting without funding or adequate infrastructure. Illegal cryptomining is a stealthy cybercrime, the victim usually is not aware of being hijacked, leaving few indicators of compromise, in such a way to be difficult to detect at a first glance [
31]. This class of threats, attacks, and electronic crimes are included as cryptojacking, since they share the same goal: an unauthorized way of cryptomining, which is carried out by stealing resources of one or several victims, to exfiltrate specialized hashes towards the PoW endpoints.
Because of the diverse range of attack vectors, cryptojacking can be set up on mobile devices, software, binaries, network appliances, compromised third-party libraries, botnets, IoT instruments, and server-side applications [
13,
32]. With those residing on the web being the most prevalent, given the simplicity of inserting a few lines of code into a website and thus forcing the execution of the malicious payload [
33] against the visitor’s CPU. For its part, the now-defunct Monero, was one of the pioneers in developing web-based cryptomining with ASIC resistance, allowing the incorporation of scripts compatible with common desktop processors and a wide range of operating systems.
The sudden use of Monero API intermediary programs and the extensibility/reusability of the code allowed the accelerated expansion of sites with embedded mining scripts, which in most cases did not require user consent, as well as an authorization note to warn that the site contains cryptomining code. According to [
34], due to a large number of visits in a short time, streaming sites, online games, pornographic sites, download shortener redirection sites, and e-commerce platforms remain the main target for attackers to compromise the dynamics of the web page by inserting arbitrary code; however, the constant search for more feasible and integrated (all-in-one) means to disseminate the Monero code led to the development of frameworks such as Coinhive, capable of capturing 30% of new block transactions on the black market, and designed with anonymity options such as no traceability and no perceptibility at a browser level. Although Monero started with a benign purpose, it gradually grew as a hazardous strain that quickly spread over vulnerable websites, being almost 81% of the adware threats formally detected in [
35].
Despite the fact that Monero closed its operations in 2019, cyberattacks related to browser-based cryptomining are still present and with regular intervals of an uprising. An example of which are recent malicious scripts such as Cryptoloot, JSECoin, Miner, XMROmine, and deepMinerAnonymous, that according to statistics presented in [
36], as of 2020 were found within 66,000 domains with
million active URLs.
To conclude this section, it is important to mention that the speculative price of cryptocurrencies, as it is a flourishing phenomenon, will continue to attract cybercriminals to attempt the disruption of web applications, at the expense of innumerable vulnerabilities, poor source code auditing, lax security configurations, and intrusion detection/prevention systems or antivirus with inadequate signatures.
4. Detecting Browser-Based Cryptojacking and Related Works
As many other viruses, malware, and suspicious objects, the first line of defense against cryptojacking is through antiviruses and web browser extensions, anti-malware software, firewalls, intrusion detection (IDS), or intrusion prevention systems (IPS), which depending on their structure, share as a common point: an up-to-date detection signature capable of performing a match and flag procedure [
37]. Nevertheless, it is important to note that such solutions must differentiate between those contexts where the user expressly agrees to the execution of cryptomining scripts and those who do not, making this, a difficult task to accomplish, since a signature-based appliance works by mapping sequences of bits towards a targeted object and presents the result in terms of similarity, which is, therefore, not an expert system, but an effective one for detecting already observed samples. On the other hand, cryptojacking detection can also be categorized into host-based defenses, including primarily, the so-called resource consumption analysis (RCA) [
31], which use the threads generated by the web browser to detect if the use of computational resources on the client side is being abused by comparing with previously established thresholds.
In addition, with SA, a well-known technique for evaluating syntactically and semantically patterns in source code, bytecodes, opcodes, and configurations of an executable or binary, malicious cryptomining scripts [
38] can be partially identified and blocked from execution. An example of SA, is the proposed NoCoin blacklisting of the Opera browser, which is used as an extension, to block requests from malicious net ranges [
39]. In [
29], a hybrid scope of SA and DA over time series is presented, where malware feeds and OSINT (Open Source Intelligence) techniques are merged to differentiate between different classes of executable binaries: illegal and benign cryptomining. To accomplish the workflow, data from URLs and public domains were scraped to monitor wallets and mining pools and determine the number of records generated per block. With this, the hashing ratio can be computed to provide sufficient values to conclude if the binary is considered a cryptojacking attack scenario as part of a botnet or produced by a single attacker.
Further on, in [
40] a detection scenario is presented by identifying PoWs signatures and a profile detector, based on the calculation of workloads from several websites appended on Alexa’s Top Domain list [
41]. It is concluded that by means of a considerable number of heavy hash rates, measured by a stack structure-based profiler (SSBP), it is possible to verify if a signature corresponds to an abnormal cumulative processing time, compared to regular loads of benign sites. In the same sense, in [
8] a reconnaissance system was developed to find different types of cryptomining scripts distributed in popular search categories such as: technology and communications, games, dynamic sites, business, pornography, and digital marketing. The system works by determining the origin of a malicious transaction and mapping the link between the PoW and the Merkle tree used to mine the block. With this, it is possible to discern between an indirect command execution, the size of the mining network and the destination of the forged request.
In the last SA scope, in [
42], a system titled MANiC: Multi-step Assessment for Crypto-miners was implemented with the ability to parse different sites with possible illegal mining or cryptojacking, using a web crawling method composed with several regular expressions related to already flagged code syntax. The authors demonstrate that MANiC is able to recognize more than fourteen crypto-malware families.
Among the works using DA, in [
43] a controlled sandbox environment is fed with samples of different malicious scripts, then, monitoring techniques are used to classify the irregular behavior of crypto-malware compared to benign software, in terms of sequences from the processing opcode flows and win32 api functions. In the same vein, the authors in [
44] proposed to identify connections between the web browser and dynamic executions of programs running in JavaSript and WebAssembly (WASM). It is argued that due to the sophistication of obfuscation methods in the script code, detection by SA or DA may be difficult. Instead, if semantic signatures are defined, the detection will be more accurate as it pinpoints on portions of crafted WASM code that cannot be hidden.
Although advances in cryptojacking detection are important at different layers and levels via SA, DA, or both, it is mentioned in [
45] that most of the physical and logical devices that offer solutions based on pre-built signatures have proven not to be as effective due to a high false positive rate, which is a major disadvantage for unveiling unfamiliar samples.
Even so, in [
46] it is discussed that SA and DA processes executed individually are not entirely useful for building an effective detection system, but rather, they serve as initial steps for building datasets that will lead to the design of intelligent sensors that can figure deeper patterns. This has gradually led to more robust detection systems, which as a nucleus use artificial intelligence (AI) algorithms to assemble and enhance the capabilities of traditional solutions.
One of the first works to employ ML for cryptojacking detection is [
31], where a complex feature analysis based on SA and web content, specifically JavaScript source code, is applied. On the content side, it is shown that web-based cryptocurrency mining is a widespread threat that can be quickly camouflaged within other scripts and tags, mostly due to security holes in request filtering, allowing arbitrary injection of malicious objects. The authors inferred that a large part of the samples found belonged to Coinhive, where an extensive demand for counterfeited calculations around Monero’s PoW points was revealed, being the main source of cryptojacking-related traffic. The authors estimated that through the application of algorithms called cyclomatic complexity (CC) and cyclomatic complexity density (CCD), it is possible to formally screen script execution flows, which are assessed by a non-supervised learning (NSL) process, aimed to differentiate groups of benign and malignant sites.
On the other hand, in [
47], BMDetector was presented as a framework that locates some peculiarities in the execution of client-side codes programmed in JavaScript: first, the heap snapshot is monitored as a process tree between the document object model (DOM) nodes and the malicious script triggers, in order to cover samples that could be obfuscated. Then, a representative set of memory stack-related features is presented and evaluated by tracking low-level memory calls through JavaScript APIs, since some scripts could be encrypted or encoded. The former process is sequenced within a recurrent neural network (RNR) connection with long short-term memory (LSTM) units. As a result, a global precision of
% was obtained. Likewise, in [
12] Crypto-Aegis was built, which couples two aspects in a multi-adversary scope: insiders and outsiders. The first flank operates as a LAN network examiner, i.e., on the client side it can monitor the entire blockchain transaction pipeline, across the host’s local network; the second one observes the outgoing load flows from the client to the remote PoW command and control center. In conjunction, adversarial observations are characterized as host-based and network-based traffic, conforming a dataset that is trained in its last stage by an ensemble algorithm (EA). It is shown that by profiling various network features of a web-based cryptojacking attack, in alignment with the distributive power of EA learning, it is possible to achieve an average F1 score of
%.
Otherwise, in the work carried out in [
48] it is assumed that by characterizing different CPU metrics: kernel-level usage, the start of processes and threads, interrupt and end time, and disk operations it is possible to fine-tune the detection of sites that send large amounts of batch processing from the browser to the operating system. Significantly, a portfolio of SL algorithms was used to evaluate the characterized CPU samples, on the basis of the following two-level classification algorithms: multiple-instance support vector machine (MISVM), random-subspace (RS) + decision trees (DT), and sequential minimal optimization (SMO) + SVM. On an overall average, a favorable result was obtained for the RS + DT algorithm by obtaining results in excess of
% of accuracy. In view of WASM as the main indicator of cryptojacking traces, the authors in [
16] developed a methodology known as MINOS, which dumps the sections of benign and malicious executable binaries, represented as gray-scale images. Then, a convolutional neural network (CNN) can learn from anomalous patterns, sensing them as malicious or benign. It is argued then, that it is possible to implement the methodology as a blocking extension in browsers such as Chrome, as the process is computationally lightweight and supported with an overall performance metrics above
%.
To conclude with the related works that occupy ML as the main focus of their contribution, in [
49], a method for characterizing Botnets with some cryptojacking patterns in physical IoT devices was developed by combining an adaptive filter with an AE and a scatter graph to identify the P2P nodes that congregate the commands from a control and command center, that pushes the requests as a distributed denial of service (DDoS) attack. It is shown that by identifying the root of a botmaster using network features and client resources, logistic regression (RL) and support vector machine (SVM) algorithms can achieve accuracy rates of up to
%. Aggregating the above information,
Table 1 describes most of the relevant work that has been developed to mitigate web-based cryptojacking. It is organized by including the type of scope, its algorithm/technique, the analyzed threat, and the type of defense employed.
Of the widely identified works tabulated in
Table 1, refs. [
8,
29,
37,
39,
40,
42] contain some type of static or dynamic defense, particularly on the client side (host-based) [
8,
29,
40,
42], which is a great advantage for a first kick-off and triaging of raw cryptojacking observations, but in any case, it is possible to fail in the process of rapid assimilation of numerous samples that may interact with higher incidence, because its strength lies entirely in manually generated efforts to unveil the results. The two remaining hybrid works [
37,
39] employ SA and DA jointly, but continue to follow the so-called mechanism of comparison based on bit distances or similarity, leaving aside important aspects that can be better implemented through anomaly detection processes. In contrast, there are eight recommendations that make use of some type of intelligent mechanism or are ML-driven, of which four are host-based solutions [
16,
43,
44,
48], two network-based [
12,
38], and three hybrids [
31,
47,
49].
The great advantage of AI or ML applications is an improvement for quickly portraying emergent cryptojacking scenarios, in addition to tools that can be integrated in an enhanced manner; however, there is still a question mark derived from the type of characteristics to be analyzed, firstly, some authors agree in giving more steadiness to the client side, since the computation of blocks resides in the operating system of the infected device; but, on the other hand, it is stated that there are important details that emerge in the communications network, since it is the entry point of the threat. Of the hybrid solutions using ML, the former [
31] delegates more importance to client-side activity, concentrating its logs on outgoing network packets and subsequently on the effects of malware responses on the CPU, specifically on prolonged power consumption. In turn, the second one [
47], is more oriented to handle several elements belonging to the content of the infected sites, which could be a great advantage when trying to categorize the type of cryptojacking families, as it is often performed for phishing menaces in accordance with natural language processing (NLP) methods. Conversely, this would not help in the construction of the dataset, by considering web content in co-occurrence with network and host features, since as a consequence, the dimension of the data could increase, magnifying the risk of misgeneralization and leading to a possibly slower analysis. The third and last one [
49] is the only manuscript that applies a similar AE technique, but the pre-processing steps first lie in the operation of a botnet, assuming that cryptojacking attacks are derived from it, and in the course of the tests, the authors refer to shallow algorithms as the machinery for detection. From this perspective, authors [
50] who evaluated a similar threat, but within IoT spoofed nodes, emphasize that the content of the threat, e.g., printable characters, payloads, or encoding, is important for the initial recognition tasks, but not sufficient to assume that a malicious object is identifiable through these factors, since for experienced malicious actors, these are only the vehicle of the attack, and the activity occurs mostly at the client level, at the network layer and the incidents that converge in both.
After presenting the list of advances that have been made historically in terms of cryptojacking detection on the web, it can be summarized that there is currently no consensus on the type of features to evaluate in order to generalize the picture. Similarly, there is no clear context to address which pre-processing steps may be the most ideal to employ to improve data quality, and finally it has been shown that although shallow algorithms can quickly generalize the sample set, by their nature, they tend to work only on well-structured data, losing learning power if the proportion of information contains variable multidata [
51].
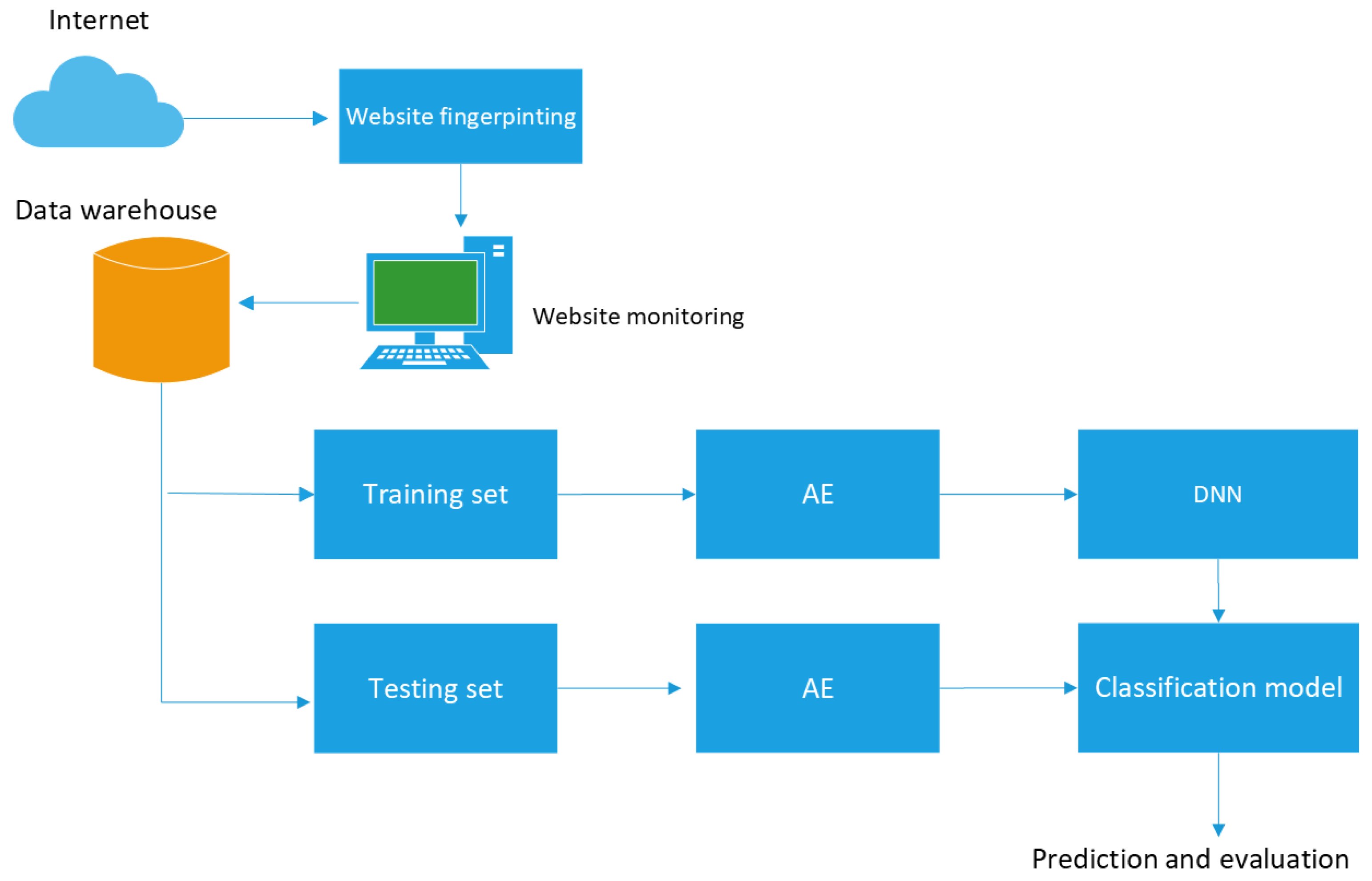
For this reason, a multi-layered viewpoint (host-based and network-based) is proposed in this project, with a new scope in the characterization of the cryptojacking samples, as a fundamental element in a proper detection. Thus, it can be said that the following hypothesis arises:
Research hypothesis: by addressing the two feature selection flanks on which the cryptojacking attack vector extends, the host and the network, and by representing their best latent information employing algorithms that maximizes them, such as an AE and a deep dense neural network (DNN), the detection radius can increase significantly.
6. Results and Discussion
This section describes the classification results of the SAE + DDNN, to demonstrate the viability of the algorithms presented in this project. For the experimental tests, it was decided to first train an unnormalised set
X directly towards the DDNN algorithm, with raw samples and then by transforming each one, via SAE characterization. Furthermore, using the normalized set
, by feeding raw normalized samples towards the DDNN inputs, and subsequently, by applying the SAE encoder. Both scopes engage training sets
and
with 80% of random samples without replacement, from which validation subsets
and
with 20% samples to obtain preliminary metrics in terms of accuracy, during each epoch. In due course, the test subsets are divided
, with 20% of observations for the final DDNN model evaluation. The metrics used to display the performance values are Precision, Recall, and F1 score, as described in
Table 6.
Table 7 shows the results obtained through the above-mentioned data set configurations.
Table 7 shows an improvement in pressure for raw
and normalized samples
with the SAE + DDNN configuration, with an average score of
% and
%, respectively; however, for raw samples
, a lower Recall rate, with a value of
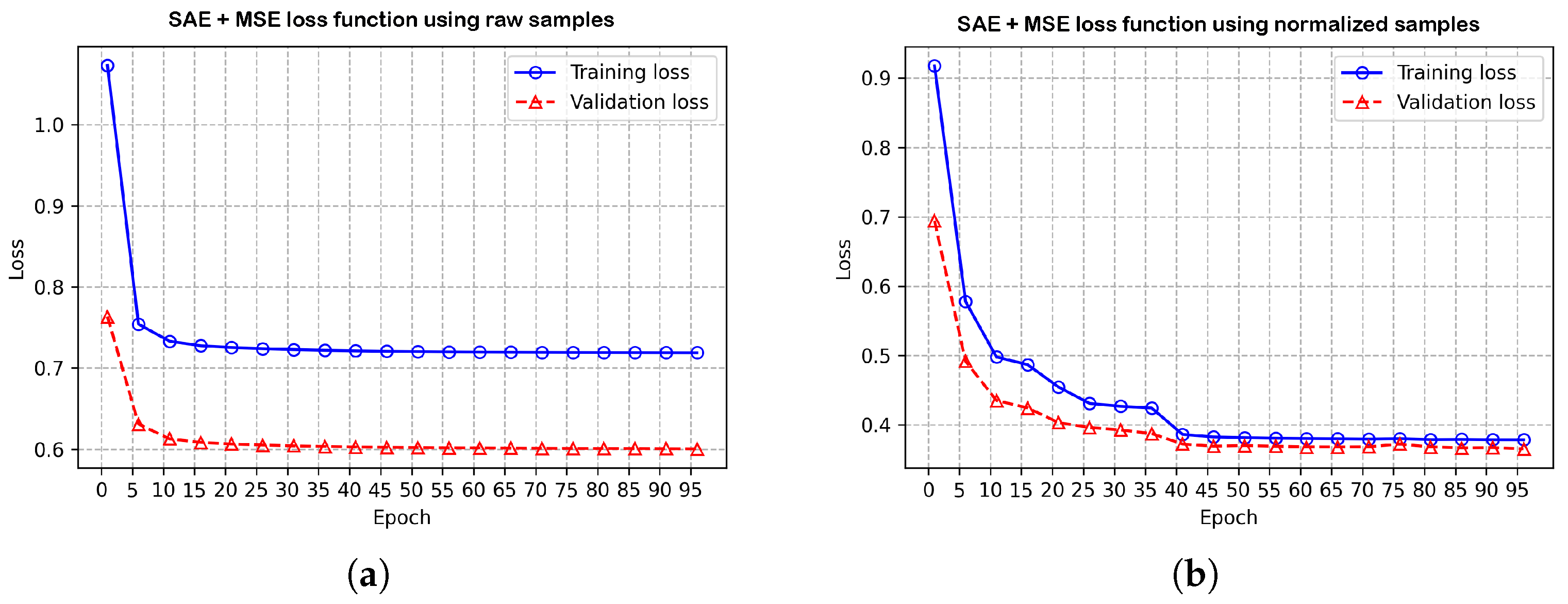
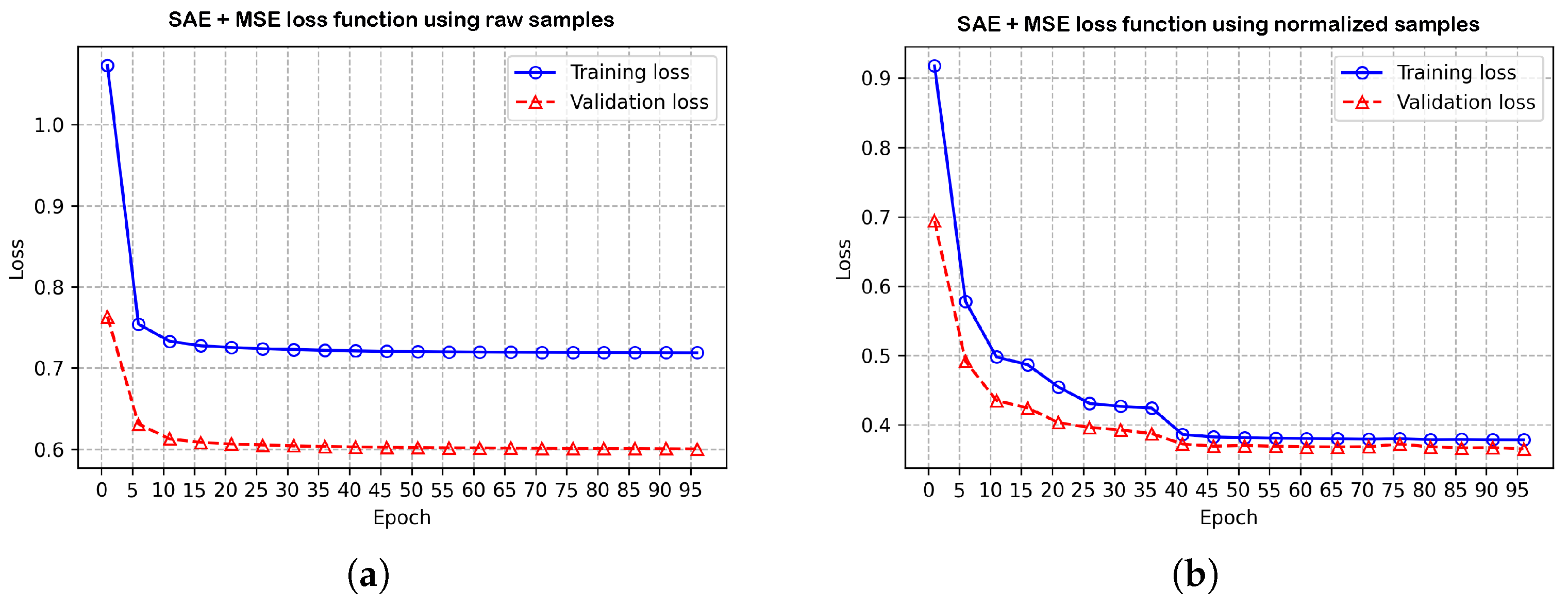
% was presented. This is an effect explained in [
64], as the reconstruction of the output is facilitated with normalization processes, as it is well known that high variability ensembles are prone to fail when copying the information in the bottleneck layer, that is called as, reconstruction error effect. This problem can be commonly observed by plotting the MSE cost function of the SAE in terms of training data losses versus model validation losses. Two events occur during this representation, when the training set is not sufficiently representative or the validation set presents problems to generalize each sample–characteristic relationship. Both conditions generate a gap in the convergence of the reconstruction of the SAE inputs, causing a decay in the output layer, finally leading to underfitting, as portrayed in
Figure 8a. In turn,
Figure 8b shows the stability of the losses during training and validation in regard to
and
from epoch 80 onwards, where the two are coupled in a constant decrease.
At this point, the proposed SAE+DDNN architecture is initially compared with shallow state-of-the-art algorithms, as described in
Section 4. To run the comparative tests, a grid-search cross-validation [
45] approach is considered, which is a method of hyper-parameter tuning that seeks to maximize the performance of supervised algorithms by setting a series of values prior to training. The grid combines a cross-validation with
k iterations, to calculate the average ability of the algorithms under test, towards a persistent accuracy. To find the optimal subset, it was formulated the approach described in Equation (
8).
thus then,
L denotes the loss function,
F is the objective function,
A is the algorithm to be submitted,
is the normalized training set, where each sample
is a fixed vector
, and
the hyper-parameters to be evaluated, resulting in a subset
of optimal parameters.
Table 8 lists the authors, algorithms, and hyper-parameters to be compared. Likewise, from the works that present applications of DL algorithms, a base architecture was arranged, to resemble as close as possible the authors scopes. The configurations used for training and comparison are tabulated in
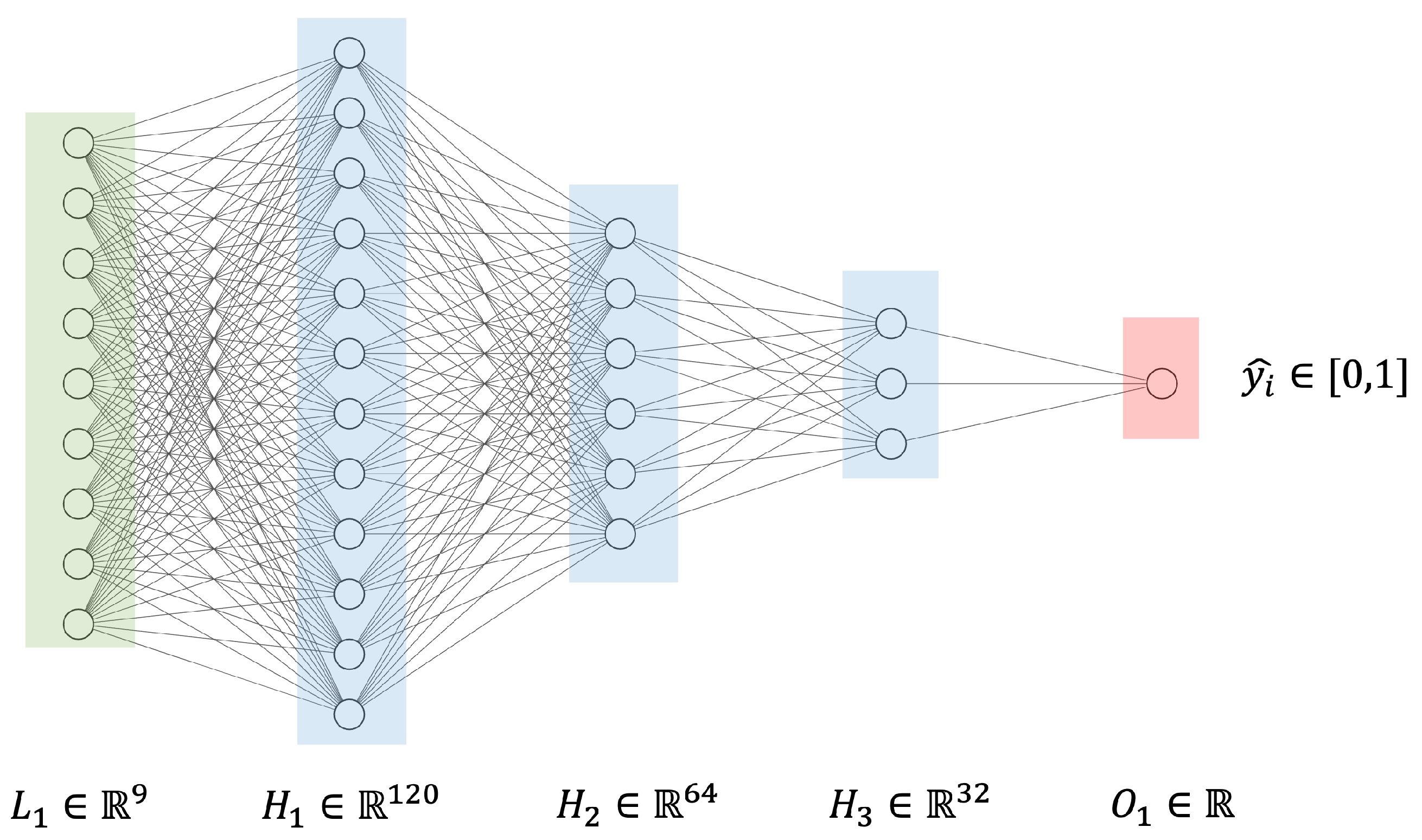
Table 9. It should be mentioned that the classification strategy for the LSTM network employs a many-to-one design, since this work does not consider a sequential network, in this sense, for the CNN a fixed vector was used as with the shallow algorithms, since the samples can hardly be coupled to the dimensions of an image with 2D spatial layers for the convolution of graphs.
From
Table 9, a general configuration was proposed comprising: the loss function via binary cross-entropy, ADAM optimization, and Accuracy as validation metrics. The overall results, with the aforementioned performance metrics, can be observed in
Table 10.
As shown in
Table 10, after brute-forcing different hyper-parameters around the grid search technique, the algorithms that are closer to neural behavior, MLP [
38], and RL [
49], perform better on the F1 score ratio and reduced the training time. Although the LSTM network [
47] also falls within this concept, its recurrent engineering could be better exploited by considering a scenario more focused entirely on content-based detection, but, as described in
Section 5, an NLP-based fingerprinting process is more feasible, since it saves time in the initial recognition, without increasing the number of features in the dataset. The CNN [
16,
49] architecture achieves considerable results, but the transformation of samples to images and then to fixed vectors may degrade the ability to be spatially invariant to one-dimensional data such as those collected in this project. The maximum margin algorithms, SVM [
38,
44], and SMO + SVM [
48], behaved with average performance, a major disadvantage is that the training stage requires considerable time and the search for suitable values for the penalty values
C, increases the desired complexity. Of these, it is noted that the MISVM algorithm [
48] adds more processing time, since the samples must be grouped and fixed in length in labeled bags, if the dataset is not large enough, the algorithm will end up misinterpreting the classification judgment for each bag, leading to major underfitting problems. The ensemble algorithms, RF [
12,
38,
43], and RS + DT [
48], on the other hand, obtained a timely performance in terms of F1 score rates, in addition to a fast training utilization, which is undoubtedly a clear example of why the authors decided to select them as their base classification engine, since both algorithms share in common the selection of random features subsets, resulting in multiple learners of low correlation, even in high dimensional ensembles. The fuzzy C-means [
16] algorithm has an effective learning time, but its complexity increases, as with the maximum margin algorithms, when the fuzzifier
m obtains small number ranges, leading to a large number of iterations for seeking the a priori number of specified clusters: benign sites and cryptojacking. It is demonstrated then, that with the development of SAE + DDNN it is possible to improve the performance of several works mentioned above and with a training speed similar to MLP. This is expected, since the algorithm can also be considered as deep, due to the number of neurons implemented in the hidden layer, and it could even be said that DDNN is an extension of MLP.
7. Conclusions
Cryptojacking is a stealthy threat that constantly affects users, who without realizing it, fall under the traps of malicious actors, who wait to consume the victim’s resources without warning, in order to mine illicit operations towards a PoW. This paper proposes an ML-based solution that employs a holistic view of cryptojacking, concentrating its effort on two major attack surfaces: the network, which is the entry point of the threat, and the host, which is where the malware payload is executed and disseminated. Considering the sophistication of several new strains, it is possible to characterize cryptojacking appropriately utilizing host and network features. To achieve this goal, it was first proposed a traversal web crawl towards possibly infected websites to perform the well-known fingerprinting process, using statistical comparison techniques. This reduces the dimensional size of the dataset and helps to follow a line of recognition similar to pentesting tests. This made it possible to analyze important sites and rule out several false positives or URLs with inaccessibility codes. Each site was subjected to a controlled environment that demonstrated that it is possible to capture evidence of cryptojacking by presenting activity on the network and within the victim’s operating system once the attack is triggered. To represent the most important information, a novel feature extraction and selection technique called SAE was employed, which reduces dimensionality while retaining the best latent data for variant inputs such as those in the proposed dataset. The compressed and normalized outputs fed a DDNN, which, thanks to its deep design, allowed higher performance rates, compared to other state-of-the-art works, with a shorter training time. The values included are, for Precision 99.41%, for Recall 99.10%, and for F1 score 99.25%, with an approximate training time of one minute and twenty seconds. With the detailed metrics, one could recommend the development of detection tools at the browser level or as an addition to antivirus systems or industrial devices such as IPS and IDS, however, it must also be considered that there are limitations to carry them out, which are addressed in two key points of improvement. Firstly, it will be necessary to compile the model in such a way that a baseline detection with a sensing agent can recognize and classify the samples, to produce an alert or trigger a mitigation/remediation policy over minimal or restricted environments. The second, is to consider the detection of cryptojacking binaries and executables; here the procedure would be similar to the one developed in the present project, but at a lower level of abstraction. It should be considered the addition of a bilateral LSTM communication network, where the operating system API calls would extend the dataset and can be merged as a single row of network, host and operating system process activities, and calls.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}