
Multicriteria Route Planning for In-Operation Mass Transit under Urban Data


Abstract
1. Introduction
- We formulate the nonmonotonic multicriteria constrained route planning problem that arranges new routes in an existing mass-transit system, which includes the nonmonotonic characteristic originated from the heterogeneous urban feature and heuristics developed from the neural-network-based inference module;
- We propose BiasSpan for the targeted constraint planning problem considering optimization criteria: (1) Maximizing PF of route (refers to social welfare and revenue of fixed fares), (2) Minimizing length of route (refers to the cost for sustainability concerns);
- Evaluation using two existing public transportation systems with different urban characteristics and structures shows the adaptability of the proposed method, which performs well in comparison with peer methods from the literature.
2. Related Work
3. Preliminary
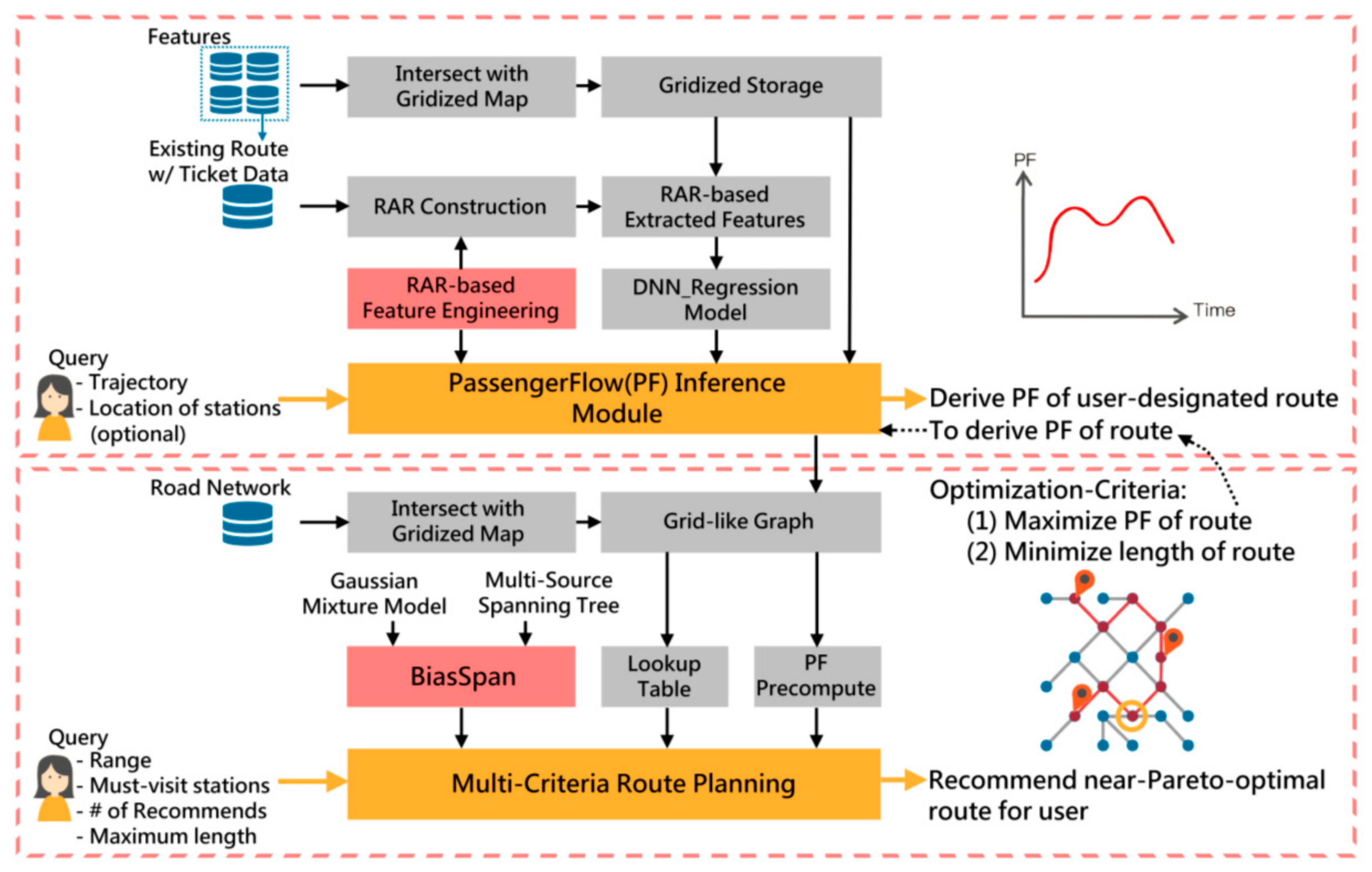
3.1. PF Inference Module
3.2. Variable Desrcription
4. Multicriteria Route Planning for Mass Transit
4.1. Problem Formulation
4.2. The Strategy in BiasSpan
4.2.1. Grid-like Graph Construction
4.2.2. PF Precomputation with Lookup Table Construction
4.2.3. Multisource Bidirectional Spanning
4.2.4. Gaussian Mixture Model for Modelling Spatial Influence
4.3. The Algorithm
| Algorithm 1: Grid-Preprocessing for BiasSpan |
| input: grids and must_visit_grids (stations) in map area Proposed PF inference model pf( ) output: Table gd( ) and tgd( ) |
| foreach grid in area do /*assign grid PF based on proposed inference model*/ let pf(grid) be the PF of grid if grid is in must_visit_grids then /*assign weights to nodes based on Gaussian-Distributed PF*/ foreach g in area do let G(g, grid) be Gaussian function in 2 dimension gd(g, grid) ← G(g, grid) × pf(grid) tgd(g) ← tgd(g) + gd(g, grid) |
| Algorithm 2: Station-Recommending for BiasSpan |
| input: grids and must_visit_grids (stations) in map area Gaussian-Distributed PF gd( ) and accumulated GD-PF tgd( ) Proposed PF inference model pf( ) Given number_of_recommendedation output: Set recommended_grids |
| foreach j from 0 to number_of_recommendation do max(j) ← 0 choice ← null /*search maximum grid PF with accumulated GD-PF feedback*/ foreach g in area do if g is not in (must_visit_grids + recommended_grids) then if pf(g) − tgd(g) > max(j) then max(j) ← pf(g) − tgd(g) choice ← g add choice to recommended_grids /*assign weights to nodes based on Gaussian-Distributed PF*/ foreach g in area do let G(g, choice) be Gaussian function in 2 dimension gd(g, choice) ← G(g, choice) × pf(choice) tgd(g) ← tgd(g) + gd(g, choice) |
| Algorithm 3: Trajectory-Routing for BiasSpan |
| input: grids and must_visit_grids (stations) in map area road network (grid-like graph) Gaussian-Distributed PF gd( ) and accumulated GD-PF tgd( ) Set of recommended_grids output: route with starter as stations |
| starter ← must_visit_grids + recommended_grids /*initial the root, set and counter for each selected station*/ foreach grid in area do sid(grid) ← −1 if grid is in starter then root[starter_id] ← grid set[starter_id, 0].add(root[starter_id]) sid(grid) ← starter_id count(starter_id) ← 0 /*renew accumulated GD-PF based on negative feedback*/ foreach g in area do tgd[starter_id,0](g) ← tgd(g) − 2 × gd(g, grid) route ← null /*iterates until route is formed, restriction relaxes if fail*/ foreach i from 0 to infinite do /*each starter marches only one step in each iteration*/ foreach s in starter do /*there are multiple spanning trees for each starter*/ foreach st in set[s, i] do /*one starter meets at most 2 other starters*/ if count(s) ≥ 2 then break nst ← st/*deep copy*/ pt(nst, s) ← 0 max(st) ← 0 choice ← null /*search best direction among reachable & legal grids*/ foreach g in nearby_grid do if reachable in road network and sid(g) = s then renew relative parameters if current path is better if reachable in road network and sid(g) ≠ s then if tgd[s, i](g) > max(st) then max(st) ← tgd[s, i](g) choice ← g if choice ≠ null then nst.visit(choice) /*add to route if meets segment from other starter*/ if sid(g) ≠ −1 and count(sid(g)) < 2 then route.addseg(nst, obj(g)) count(s) ← count(s) + 1 count(sid(g)) ← count(sid(g)) + 1 if success to form a route with all starters then break /*accumulated GD-PF on negative feedback*/ foreach g in area do tgd[s,i](g)←tgd[s,i](g) − 2 × gd(g,root[sid(g)]) if count(sid(g)) = 2/*same for count(s) = 2*/then foreach st in starter do foreach g in area do tgd[st,i](g)←tgd[st,i](g) − 2 × gd(g,root[sid(g)]) else set[s, i + 1].add(nst) sid(g) ← s obj(g) ← nst pt(st, s) ← pt(st, s) + 1 /*each spanning tree tries at most 2 directions*/ if pt(st, s) > 1 then set[s, i].delete(st) set[s, i + 1].add(set[s, i]) tgd[s, i + 1] ← tgd[s, i] if success to form a route with all starters then break return route and starter |
4.4. Summary of the Properties of BiasSpan
- BiasSpan employs GMM to deal with nonmonotonic gain function;
- The size of problem space for the algorithm is reduced based on the grid-like graph;
- BiasSpan prunes the searching space with a bidirectional goal-prioritized technique;
- The herding effect (crowding-out effect) in station recommendation is neutralized by the adopted GMM with negative feedback.
4.5. Time Complexity
5. Evaluation
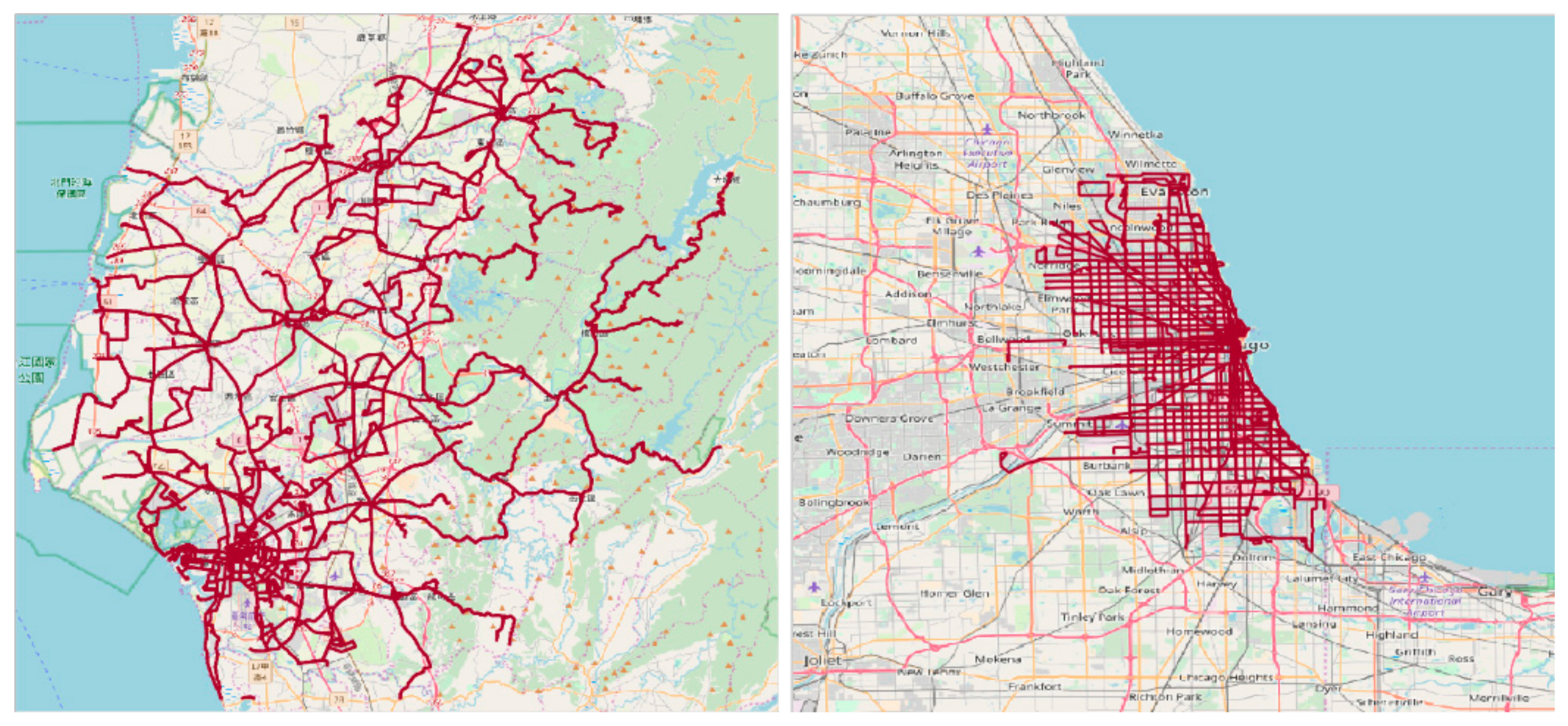
5.1. Dataset and Preprocessing
5.2. Evaluation Setting
- Dijkstra’s Algorithm (Dijkstra’s) [94]—Dijkstra’s algorithm is performed to search from one must-visit station towards other stations, either a must-visit one or recommended one. The destination then turns out to be the origin of a searching process in the next round for the Dijkstra’s algorithm to look for another stations. As an iterative process, it terminates until a route that connects all stations exactly once is formed.
- Breadth-First Search (BFS)—BFS is applied to take turns beginning the searching process from each of the must-visit stations. During the searching process, BFS will iteratively explore the adjacent candidate until there is no candidate that can be reached. Accordingly, the route planning is terminated until BFS successfully visits all the stations at least once, where a linear route is constructed.
- Iterative Deepening Depth-First Search (IDDFS) [95]—IDDFS acts as a depth-limited version of deep-first search (DFS). Towards the route planning problem, IDDFS is adopted to search for stations iteratively and employed with an increasing value in the setting of depth limit. Precisely, the searching process terminates once IDDFS can reach the stopping criteria where a route with all stations connected is formed under any setting of depth limit.
- Best-First Search (Best-First)—similar to the concept of BFS towards the routing process, Best-First explores the adjacent candidate with the highest PF iteratively. As a somewhat greedy algorithm focusing on the local optimal, the searching process terminates until a legal route is suggested.
- Distance-Based A* (Distance-A*)—the A* algorithm [25] is adopted with a heuristic emphasizing the distance between the candidate grid and the destination.
- Passenger-Flow-Based A* (PF-A*)—similar to Distance-A*, the A* algorithm here is adopted with a heuristic that predicts the PF between the candidate grid and the destination based on the pre-trained PF inference module introduced in Section 3.1.
- Brute-Force (BF)—acting as a baseline method, BF systematically enumerates all possible combinations in the problem space, and then the solution that retains the Pareto optimal among all enumerated candidate solutions is retrieved.
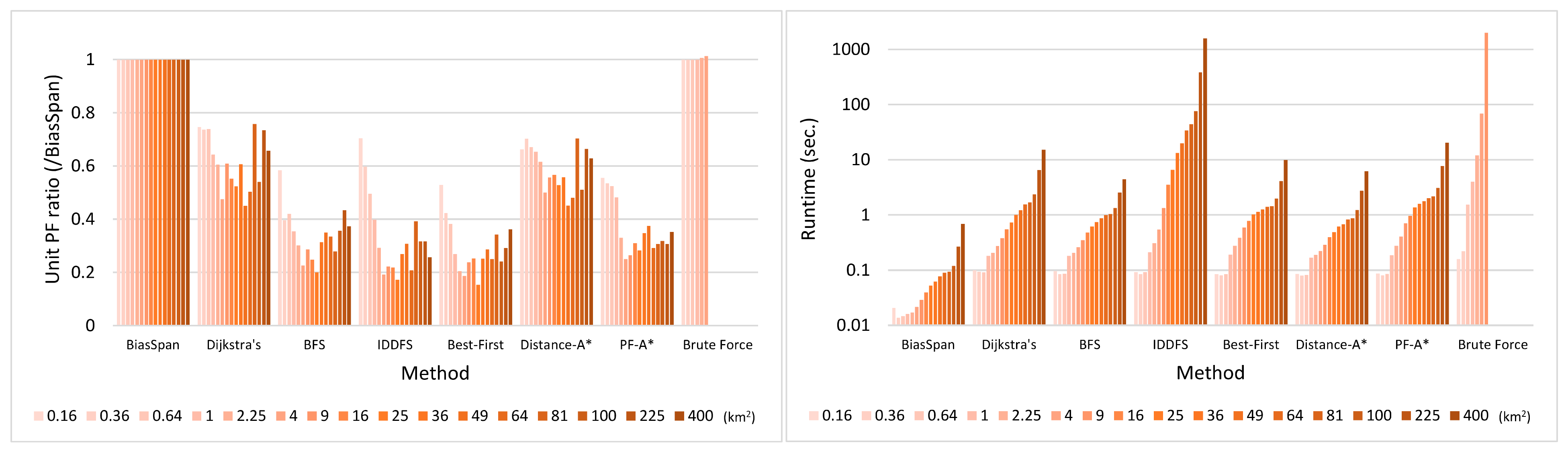
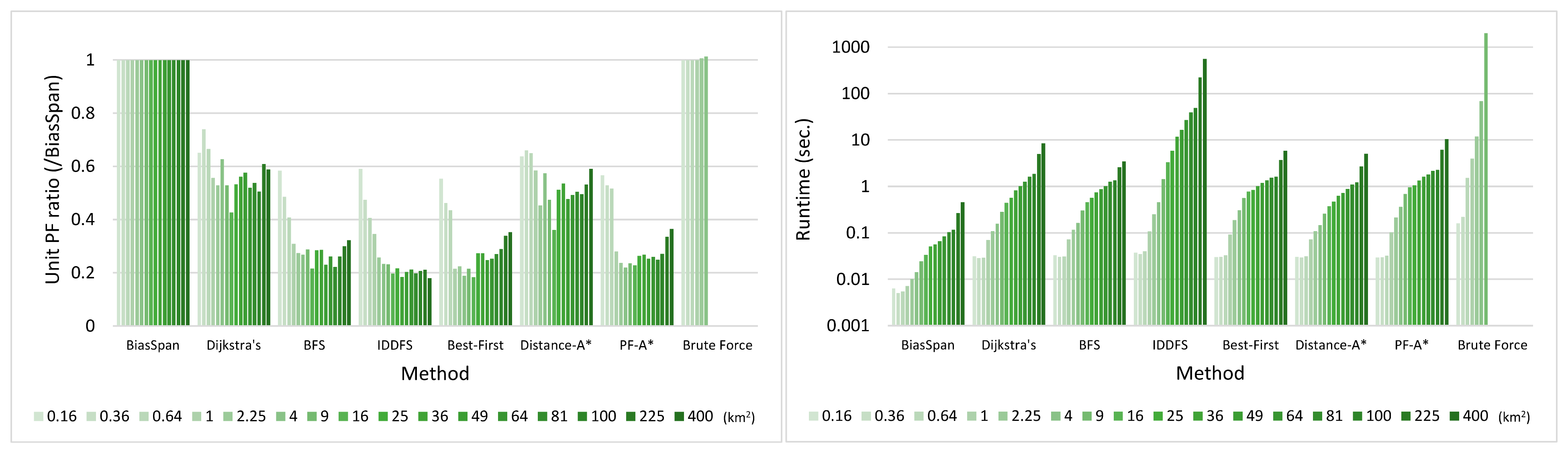
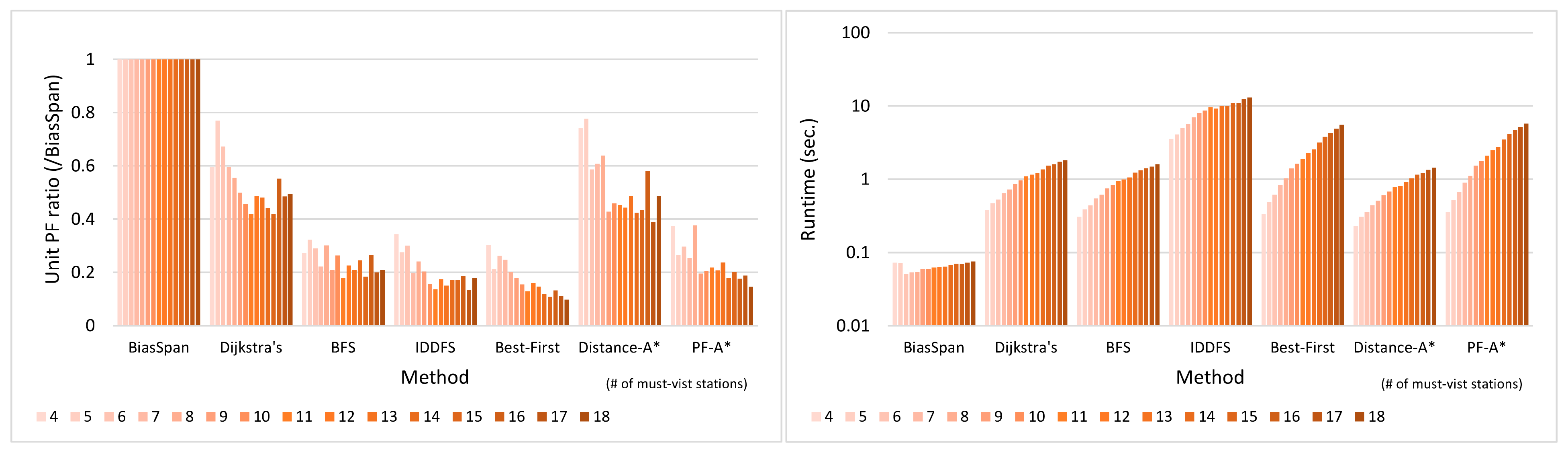
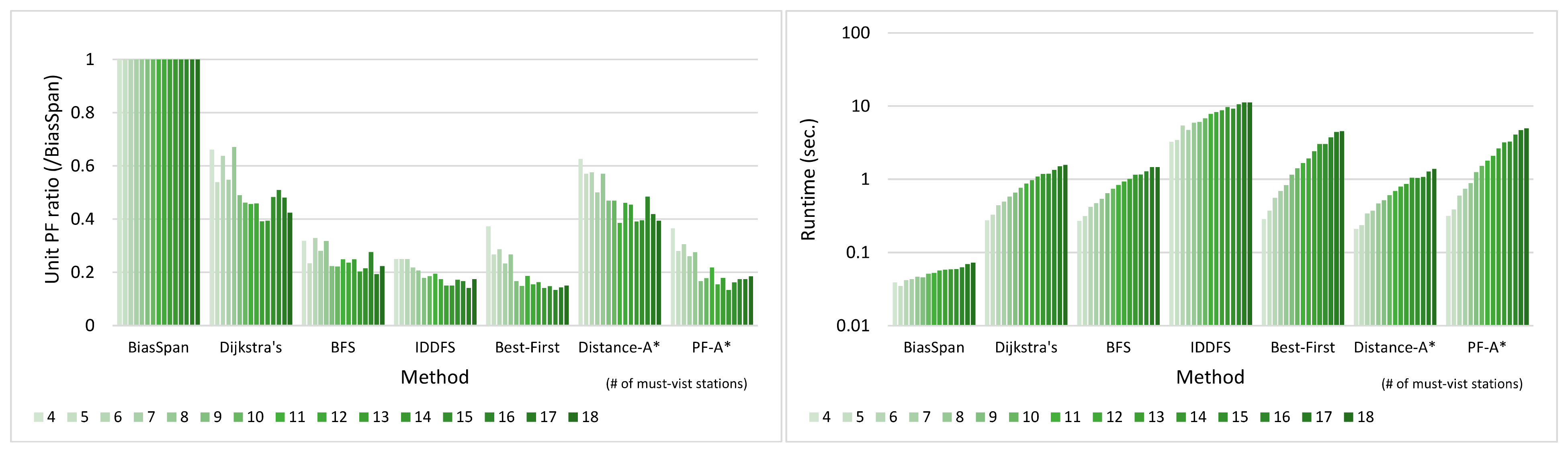
5.3. Evaluation of BiasSpan against Comparative Methods
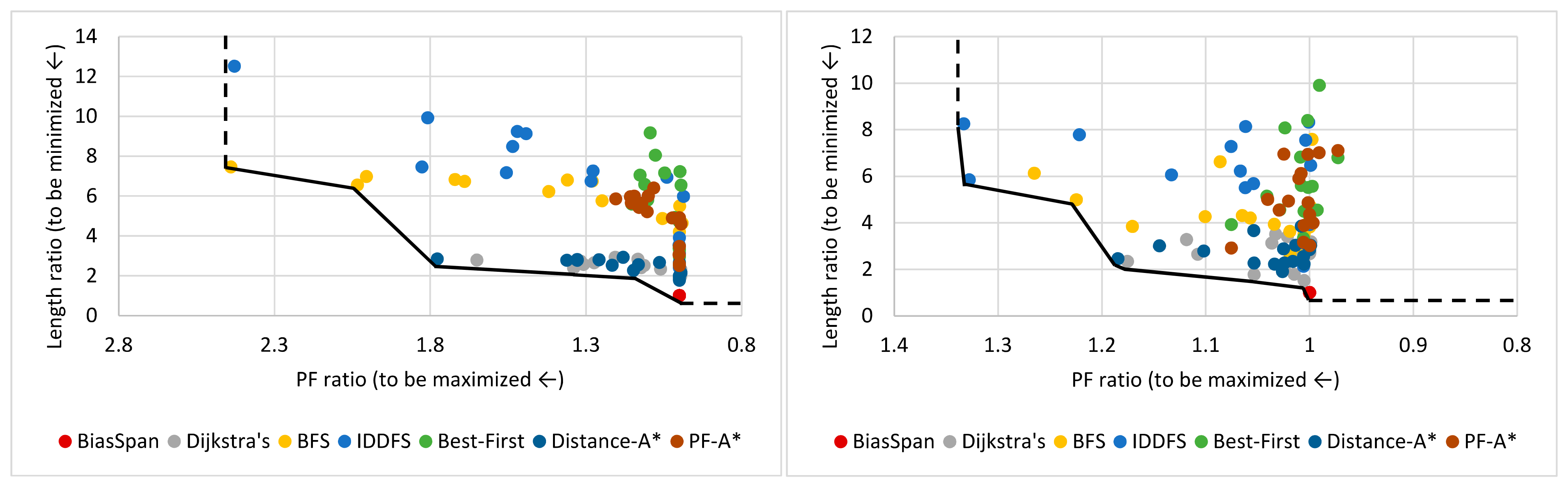
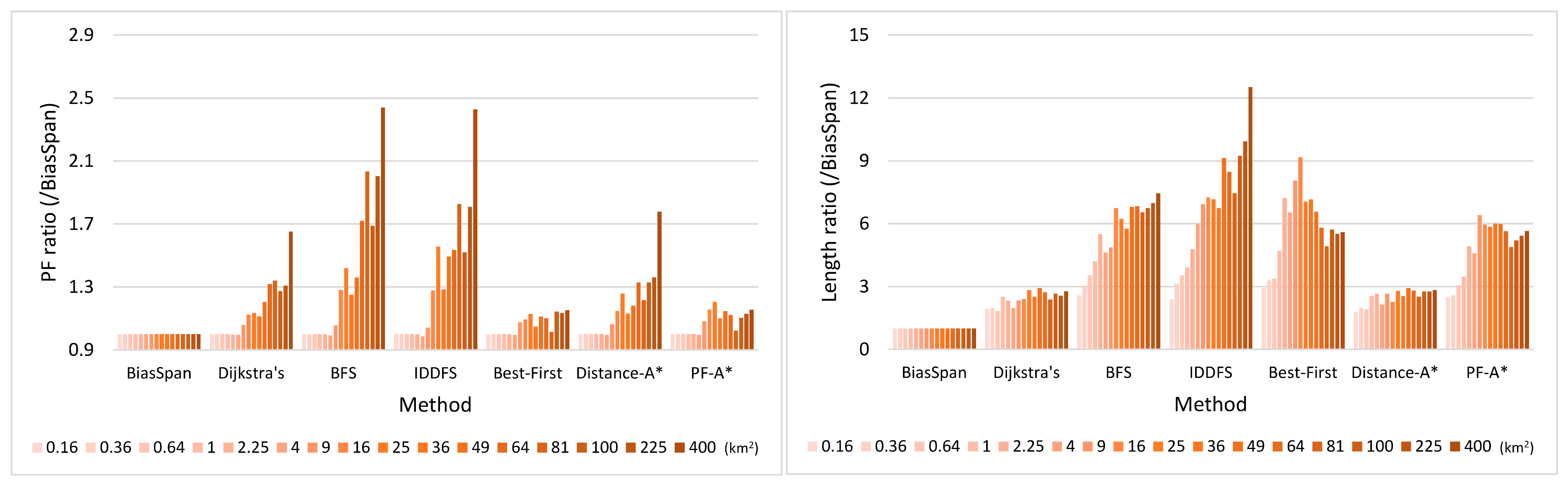
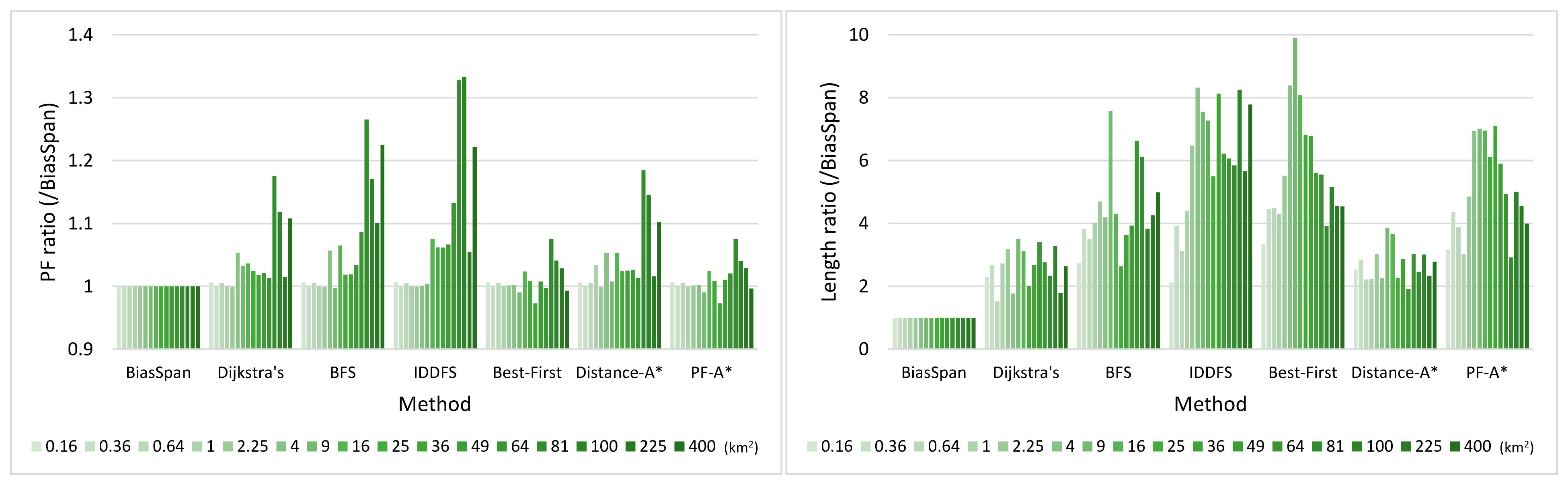
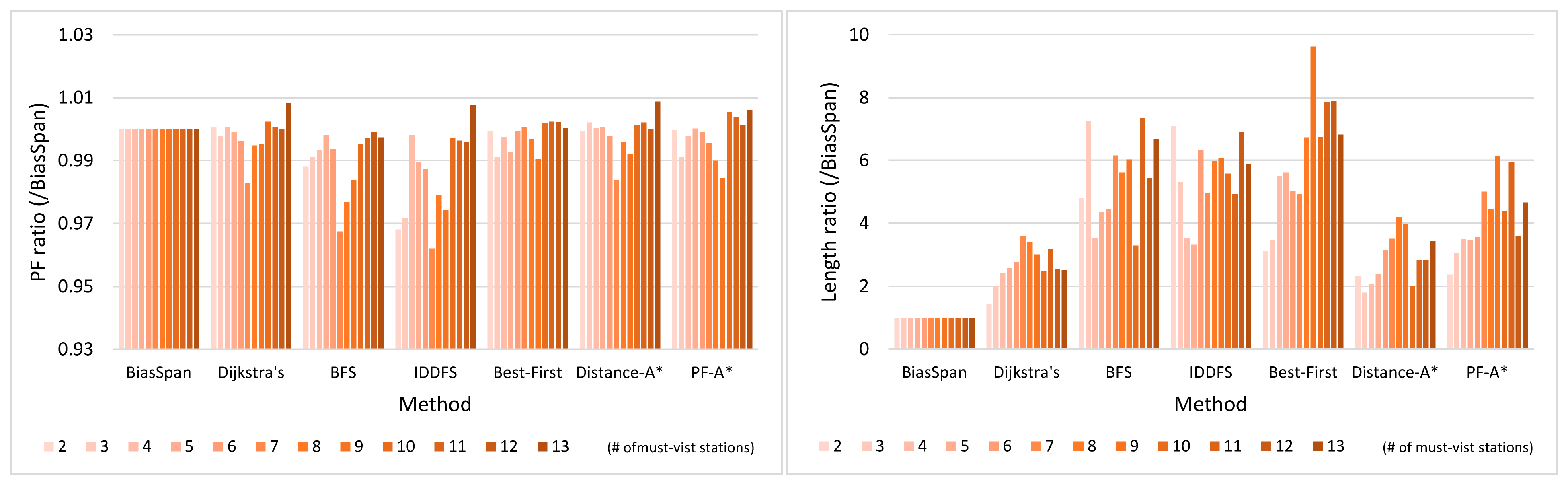
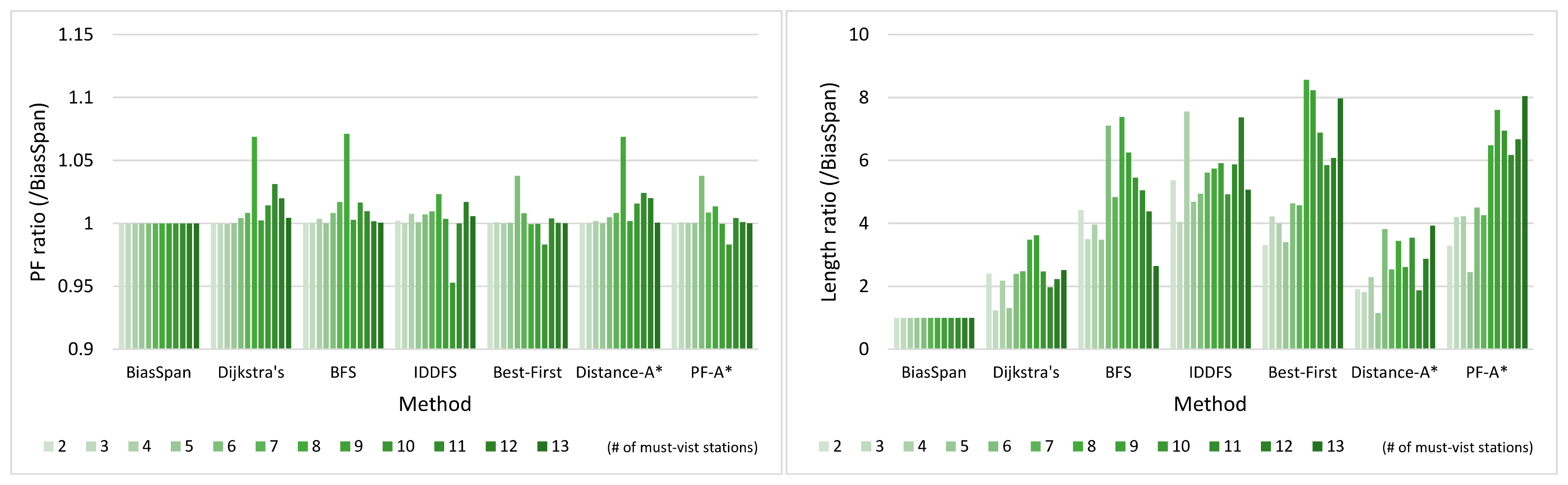
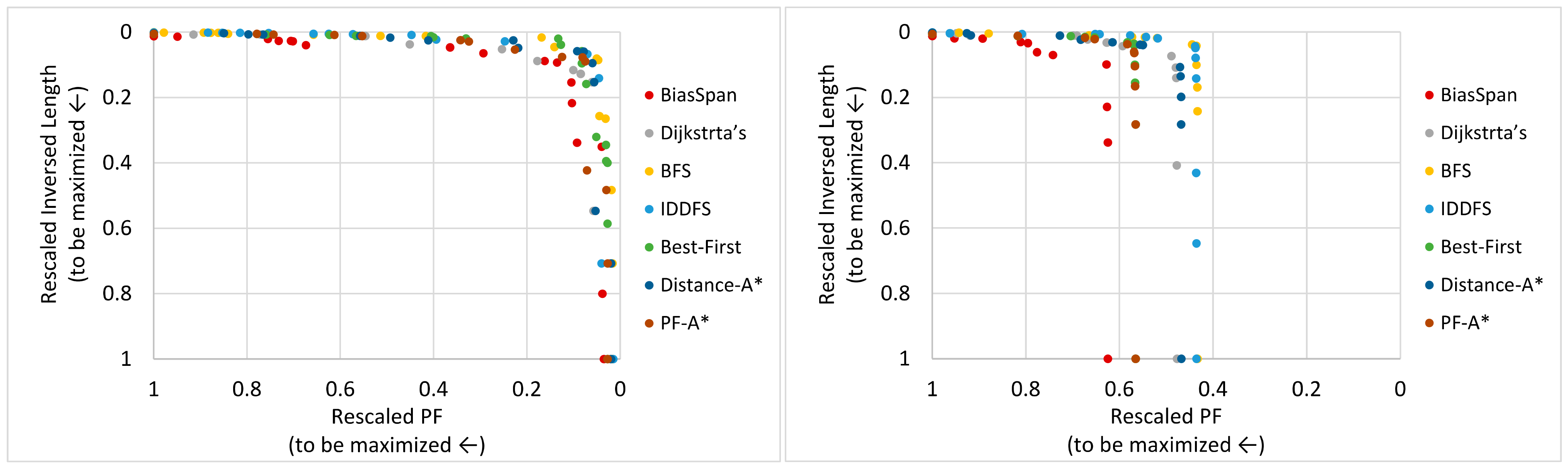
5.3.1. Pareto-Optimal between Profit and Cost
5.3.2. Runtime
5.3.3. Trade-Off between Profit and Cost
5.3.4. Statistical Analysis for BiasSpan
5.3.5. Summary
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jacek, M. GIS-based multicriteria decision analysis: A survey of the literature. Int. J. Geogr. Inf. Sci. 2006, 20, 703–726. [Google Scholar] [CrossRef]
- Keng, N.; Yun, Y.Y.D. A planning/scheduling methodology for the constrained resource problem. In Proceedings of the 11th International Joint Conference on Artificial Intelligence, Detroit, MI, USA, 20–25 August 1989; Volume 2, pp. 998–1003. [Google Scholar] [CrossRef]
- Bueno-Delgado, M.-V.; Romero-Gázquez, J.-L.; Jiménez, P.; Pavón-Mariño, P. Optimal Path Planning for Selective Waste Collection in Smart Cities. Sensors 2019, 19, 1973. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Fery, P.; Xue, L.; Wang, Y. Seeking the Pareto front for multiobjective spatial optimization problems. Int. J. Geogr. Inf. Sci. 2008, 22, 507–526. [Google Scholar] [CrossRef]
- Jakimavičius, M.; Palevičius, V.; Antuchevičiene, J.; Karpavičius, T. Internet GIS-Based Multimodal Public Transport Trip Planning Information System for Travelers in Lithuania. ISPRS Int. J. Geo-Inf. 2019, 8, 319. [Google Scholar] [CrossRef]
- Li, R.; Leung, Y.; Huang, B.; Lin, H. A genetic algorithm for multiobjective dangerous goods route planning. Int. J. Geogr. Inf. Sci. 2013, 27, 1073–1089. [Google Scholar] [CrossRef]
- Nisyak, A.K.; Ramdani, F.; Suprapto. Web-GIS development and analysis of land suitability for rice plant using GIS-MCDA method in Batu city. In Proceedings of the International Symposium on Geoinformatics (ISyG), Malang, Indonesia, 24–25 November 2017. [Google Scholar] [CrossRef]
- Qian, Z.; Hu, C. Optimal Path Selection for Fault Repair Based on Grid GIS Platform and Improved Fireworks Algorithm. In Proceedings of the 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 2452–2456. [Google Scholar] [CrossRef]
- Lin, F.; Hsieh, H.-P. An intelligent and interactive route planning maker for deploying new transportation services. In Proceedings of the 26th ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 6–9 November 2018; pp. 620–621. [Google Scholar] [CrossRef]
- Bast, H. Car or public transport–two worlds. In Efficient Algorithms; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5760, pp. 355–367. [Google Scholar] [CrossRef]
- Delling, D.; Sanders, P.; Schultes, D.; Wagner, D. Engineering route planning algorithms. In Algorithmics of Large and Complex Networks; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5515, pp. 117–139. [Google Scholar] [CrossRef]
- Abraham, I.; Delling, D.; Goldberg, A.; Werneck, R. A Hub-Based Labeling Algorithm for Shortest Paths in Road Networks. In Proceedings of the 10th International Symposium on Experimental Algorithms, Crete, Greece, 5–7 May 2011; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6630, pp. 230–241. [Google Scholar] [CrossRef]
- Goldberg, A.V. A Practical Shortest Path Algorithm with Linear Expected Time. SIAM J. Comput. 2008, 37, 1637–1655. [Google Scholar] [CrossRef][Green Version]
- Julian, D.; Thomas, P.; Dorothea, W. User-Constrained Multi-Modal Route Planning. J. Exp. Algorithmics 2015, 19, 1–19. [Google Scholar] [CrossRef]
- Goldberg, A.V.; Harrelson, C. Computing the shortest path: A* search meets graph theory. In Proceedings of the 16th Annual ACM–SIAM Symposium on Discrete Algorithms, Philadelphia, PA, USA, 23–25 January 2005; pp. 156–165. [Google Scholar] [CrossRef]
- Yoshizumi, T.; Miura, T.; Ishida, T. A* with Partial Expansion for Large Branching Factor Problems. In Proceedings of the 17th National Conference on Artificial Intelligence, Austin, TX, USA, 31 July–2 August 2000; pp. 923–929. [Google Scholar]
- Wagner, D.; Willhalm, T.; Zaroliagis, C. Geometric containers for efficient shortest-path computation. J. Exp. Algorithmics 2005, 10, 1–30. [Google Scholar] [CrossRef]
- Delling, D.; Goldberg, A.V.; Pajor, T.; Werneck, R.F. Customizable route planning. In Proceedings of the 10th International Symposium on Experimental Algorithms, Crete, Greece, 5–7 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6630, pp. 376–387. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A Reinforcement Learning approach to the traveling salesman problem. In Proceedings of the Twelfth International Conference on Machine Learning (ICML), Tahoe City, CA, USA, 9–12 July 1995; pp. 252–260. [Google Scholar] [CrossRef]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement Learning for Combinatorial Optimization: A Survey. arXiv 2020, arXiv:2003.03600v3. [Google Scholar] [CrossRef]
- Bast, H.; Carlsson, E.; Eigenwillig, A.; Geisberger, R.; Harrelson, C.; Raychev, V.; Viger, F. Fast Routing in Very Large Public Transportation Networks Using Transfer Patterns. In Proceedings of the 18th Annual European Symposium on Algorithms, Liverpool, UK, 6–8 September 2010; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2010; Volume 6346, pp. 290–301. [Google Scholar] [CrossRef]
- Dieudonné, T.; Éric, S.; Christophe, C. A bidirectional path-finding algorithm and data structure for maritime routing. Int. J. Geogr. Inf. Sci. 2014, 28, 1355–1377. [Google Scholar] [CrossRef]
- Ehrgott, M.; Klamroth, K. Connectedness of efficient solutions in multiple criteria combinatorial optimization. Eur. J. Oper. Res. 1997, 97, 159–166. [Google Scholar] [CrossRef]
- Zhang, R.; Kabadi, S.N.; Punnen, A.P. The minimum spanning tree problem with conflict constraints and its variations. Discret. Optim. 2011, 8, 191–205. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Etherington, D.W.; Kraus, S.; Perlis, D. Nonmonotonicity and the scope of reasoning. Artif. Intell. 1991, 52, 221–261. [Google Scholar] [CrossRef]
- Ikeda, T.; Hsu, M.-Y.; Imai, H.; Nishimura, S.; Shimoura, H.; Hashimoto, T.; Tenmoku, K.; Mitoh, K. A fast algorithm for finding better routes by AI search techniques. In Proceedings of the VNIS’94-1994 Vehicle Navigation and Information Systems Conference (VNIS), Yokohama, Japan, 31 August–2 September 1994; pp. 291–296. [Google Scholar] [CrossRef]
- Rice, M.N.; Tsotras, V. Bidirectional A* search with additive approximation bounds. In Proceedings of the 5th Annual Symposium on Combinatorial Search (SoCS), Guangzhou, China, 26–30 July 2012; pp. 80–87. [Google Scholar]
- Ziebart, B.D.; Dey, A.D.; Bagnell, J.A. Fast Planning for Dynamic Preferences. In Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), Berkeley, CA, USA, 11–15 July 2008; pp. 412–419. [Google Scholar] [CrossRef]
- Brandes, U.; Schulz, F.; Wagner, D.; Willhalm, T. Travel Planning with Self-Made Maps. In Proceedings of the Algorithm Engineering and Experimentation (ALENEX), Alexandria, VA, USA, 9–10 January 2001; Volume 2153, pp. 132–144. [Google Scholar] [CrossRef]
- Schulz, F.; Wagner, D.; Zaroliagis, C.D. Using Multi-level Graphs for Timetable Information in Railway Systems. In Proceedings of the 4th International Workshop on Algorithm Engineering and Experiments (ALENEX), San Francisco, CA, USA, 4–5 January 2002; pp. 43–59. [Google Scholar] [CrossRef]
- Schulz, F.; Wagner, D.; Weihe, K. Dijkstra’s algorithm on-line: An empirical case study from public railroad transport. ACM J. Exp. Algorithm 2000, 5, 12-es. [Google Scholar] [CrossRef]
- Thorup, M. Compact Oracles for Reachability and Approximate Distances in Planar Digraphs. J. ACM 2004, 51, 993–1024. [Google Scholar] [CrossRef]
- Muller, L.F.; Zachariasen, M. Fast and Compact Oracles for Approximate Distances in Planar Graphs. In Proceedings of the 15th Annual European Conference on Algorithms (ESA), Eilat, Israel, 8–10 October 2007; pp. 657–668. [Google Scholar] [CrossRef]
- Falek, A.M.; Pelsser, C.; Julien, S.; Theoleyre, F. Muse: Multimodal separators for efficient route planning in transportation networks. Transp. Sci. 2022. ahead of print. [Google Scholar] [CrossRef]
- Giannakopoulou, K.; Paraskevopoulos, A.; Zaroliagis, C. Multimodal Dynamic Journey-Planning. Algorithms 2019, 12, 213. [Google Scholar] [CrossRef]
- Sauer, J.; Wagner, D.; Zündorf, T. Faster Multi-Modal Route Planning With Bike Sharing Using ULTRA. In Proceedings of the 18th International Symposium on Experimental Algorithms (SEA), Catania, Italy, 16–18 June 2020; Volume 16, pp. 1–14. [Google Scholar] [CrossRef]
- Bast, H.; Funke, S.; Matijevic, D.; Demetrescu, C.; Goldberg, A.V.; Johnson, D.S. TRANSIT: Ultrafast Shortest-Path Queries with Linear-Time Preprocessing. In The Shortest Path Problem: Ninth DIMACS Implementation Challenge; Center for Discrete Mathematics & Theoretical Computer Science: Piscataway, NJ, USA, 2006; pp. 175–192. [Google Scholar]
- Efentakis, A.; Pfoser, D.; Voisard, A. Efficient data management in support of shortest-path computation. In Proceedings of the 4th ACM SIGSPATIAL International Workshop on Computational Transportation Science, New York, NY, USA, 31 October–3 November 2011; pp. 28–33. [Google Scholar] [CrossRef]
- Geisberger, R.; Sanders, P.; Schultes, D.; Vetter, C. Exact Routing in Large Road Networks Using Contraction Hierarchies. Transp. Sci. 2012, 46, 388–404. [Google Scholar] [CrossRef]
- Cohen, E.; Halperin, E.; Kaplan, H.; Zwick, U. Reachability and distance queries via 2-hop labels. In Proceedings of the thirteenth annual ACM-SIAM symposium on Discrete algorithms (SODA), Philadelphia, PA, USA, 6–8 January 2002; pp. 937–946. [Google Scholar] [CrossRef]
- Gavoille, C.; Peleg, D.; Pérennes, S.; Raz, R. Distance labeling in graphs. J. Algorithms 2004, 53, 85–112. [Google Scholar] [CrossRef]
- Lin, F.; Fang, J.-Y.; Hsieh, H.-P. A Gaussian-Prioritized Approach for Deploying Additional Route on Existing Mass Transportation with Neural-Network-Based Passenger Flow Inference. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Fang, J.-Y.; Lin, F.; Hsieh, H.-P. A Multi-criteria System for Recommending Taxi Routes with an Advance Reservation. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Bilbao, Spain, 13–17 September 2020; pp. 308–322. [Google Scholar] [CrossRef]
- Lin, F.; Hsieh, H.-P. Conntrans: A Two-Stage Concentric Annealing Approach for Multi-Criteria Distributed Competitive Stationary Resource Searching. In Proceedings of the 29th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 2–5 November 2021; pp. 163–174. [Google Scholar] [CrossRef]
- Shao, W.; Salim, F.D.; Gu, T.; Dinh, N.-T.; Chan, J. Traveling Officer Problem: Managing Car Parking Violations Efficiently Using Sensor Data. IEEE Internet Things J. 2017, 5, 802–810. [Google Scholar] [CrossRef]
- Abdallah, M.; Adghim, M.; Maraqa, M.; Aldahab, E. Simulation and optimization of dynamic waste collection routes. Waste Manag. Res. J. A Sustain. Circ. Econ. 2019, 37, 793–802. [Google Scholar] [CrossRef]
- Musolino, G.; Polimeni, A.; Rindone, C.; Vitetta, A. Travel Time Forecasting and Dynamic Routes Design for Emergency Vehicles. Procedia Soc. Behav. Sci. 2013, 87, 193–2020. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, Y.; Duan, X. Dynamic Path Planning of Emergency Vehicles Based on Travel Time Prediction. J. Adv. Transp. 2017, 11–12, 1–14. [Google Scholar] [CrossRef]
- Borutta, F.; Schmoll, S.; Friedl, S. Optimizing the Spatio-Temporal Resource Search Problem with Reinforcement Learning (GIS Cup). In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 5–8 November 2019; pp. 628–631. [Google Scholar] [CrossRef]
- Kim, J.-S.; Pfoser, D.; Züfle, A. Distance-Aware Competitive Spatiotemporal Searching Using Spatiotemporal Resource Matrix Factorization (GIS Cup). In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 5–8 November 2019; pp. 624–627. [Google Scholar] [CrossRef]
- Buchin, K.; Kostitsyna, I.; Custers, B.; Struijs, M. A Sampling-based Strategy for Distributing Taxis in a Road Network for Occupancy Maximization (GIS Cup). In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 5–8 November 2019; pp. 616–619. [Google Scholar] [CrossRef]
- Ming, L.; Hu, Q.; Dong, M.; Zheng, B. An Effective Fleet Management Strategy for Collaborative Spatio-Temporal Searching: GIS Cup. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 3–6 November 2020; pp. 651–654. [Google Scholar] [CrossRef]
- Ayala, D.; Wolfson, O.; Xu, B.; Dasgupta, B.; Lin, J. Parking slot assignment games. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (GIS), New York, NY, USA, 1–4 November 2011; pp. 299–308. [Google Scholar] [CrossRef]
- Jossé, G.; Schubert, M.; Kriegel, H.-P. Probabilistic parking queries using aging functions. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL), New York, NY, USA, 5–8 November 2013; pp. 452–455. [Google Scholar] [CrossRef]
- Ayala, D.; Wolfson, O.; Xu, B.; DasGupta, B.; Lin, J. Parking in Competitive Settings: A Gravitational Approach. In Proceedings of the IEEE 13th International Conference on Mobile Data Management (MDM), Bengaluru, India, 23–26 July 2012; pp. 27–32. [Google Scholar] [CrossRef]
- Ayala, D.; Wolfson, O.; Dasgupta, B.; Lin, J.; Xu, B. Spatio-Temporal Matching for Urban Transportation Applications. ACM Trans. Spat. Algorithms Syst. 2018, 3, 1–39. [Google Scholar] [CrossRef]
- Delling, D.; Dibbelt, J.; Pajor, T. Fast and Exact Public Transit Routing with Restricted Pareto Sets. In Proceedings of the Twenty-First Workshop on Algorithm Engineering and Experiments (ALENEX), San Diego, CA, USA, 7–8 January 2019; pp. 54–65. [Google Scholar] [CrossRef]
- Delling, D.; Pajor, T.; Werneck, R.F. Round-Based Public Transit Routing. Transp. Sci. 2015, 49, 591–604. [Google Scholar] [CrossRef]
- Ahmed, F.; Deb, K. Multi-objective optimal path planning using elitist non-dominated sorting genetic algorithms. Soft Comput. 2013, 17, 1283–1299. [Google Scholar] [CrossRef]
- Masoumi, Z.; Genderen, J.V.; Niaraki, A.S. An improved ant colony optimization-based algorithm for user-centric multi-objective path planning for ubiquitous environments. Geocarto Int. 2021, 36, 137–154. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.-W.; Zhang, J.-H. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013, 103, 172–185. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 246–252. [Google Scholar] [CrossRef]
- Feo, T.A.; Resende, M.G.C. Greedy randomized adaptive search procedures. J. Glob. Optim. 1995, 6, 109–133. [Google Scholar] [CrossRef]
- Mestria, M.; Ochi, L.S.; Martins, S.L. GRASP with path relinking for the symmetric Euclidean clustered traveling salesman problem. Comput. Oper. Res. 2013, 40, 3218–3229. [Google Scholar] [CrossRef]
- Bruni, M.E.; Beraldi, P.; Khodaparasti, S. A hybrid reactive GRASP heuristic for the risk-averse k-traveling repairman problem with profits. Comput. Oper. Res. 2020, 115, 104854. [Google Scholar] [CrossRef]
- Ferdi, I.; Layeb, A. A GRASP algorithm based new heuristic for the capacitated location routing problem. J. Exp. Theor. Artif. Intell. 2018, 30, 369–387. [Google Scholar] [CrossRef]
- Ferone, D.; Gruler, A.; Festa, P.; Juan, A.A. Enhancing and extending the classical GRASP framework with biased randomisation and simulation. J. Oper. Res. Soc. 2019, 70, 1362–1375. [Google Scholar] [CrossRef]
- Murata, T.; Ishibuchi, H. MOGA: Multi-objective genetic algorithms. In Proceedings of the 1995 IEEE International Conference on Evolutionary Computation (CEC), Indianapolis, IN, USA, 13–16 April 1995; pp. 289–294. [Google Scholar]
- Borhani, M.; Akbari, K.; Matkan, A.A.; Tanasan, M. A Multicriteria Optimization for Flight Route Networks in Large-Scale Airlines Using Intelligent Spatial Information. Int. J. Interact. Multimed. Artif. Intell. 2020, 6, 123–131. [Google Scholar] [CrossRef]
- Damos, M.A.; Zhu, J.; Li, W.; Hassan, A.; Khalifa, E. A Novel Urban Tourism Path Planning Approach Based on a Multiobjective Genetic Algorithm. ISPRS Int. J. Geo-Inf. 2021, 10, 530. [Google Scholar] [CrossRef]
- Tiausas, F.; Talusan, J.P.; Ishimaki, Y.; Yamana, H.; Yamaguchi, H.; Bhattacharjee, S.; Dubey, A.; Yasumoto, K.; Das, S.K. User-centric Distributed Route Planning in Smart Cities based on Multi-objective Optimization. In Proceedings of the IEEE International Conference on Smart Computing (SMARTCOMP), Irvine, CA, USA, 23–27 August 2021; pp. 77–82. [Google Scholar] [CrossRef]
- Yip, P.P.C.; Pao, Y.-H. Combinatorial optimization with use of guided evolutionary simulated annealing. IEEE Trans. Neural Netw. 1995, 6, 290–295. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Y.; Deng, Z.; Xiang, Y.; Joy, C.P. A Group-based Approach to Improve Multifactorial Evolutionary Algorithm. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 3870–3876. [Google Scholar]
- Nayyar, A.; Garg, S.; Gupta, D.; Khanna, A. Evolutionary computation: Theory and algorithms. In Advances in Swarm Intelligence for Optimizing Problems in Computer Science; Chapman and Hall/CRC: London, UK, 2018; pp. 1–26. [Google Scholar]
- Potvin, J.Y. Genetic algorithms for the traveling salesman problem. Ann. Oper. Res. 1996, 63, 337–370. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Xue, Y. Mobile Robot Path Planning with a Non-Dominated Sorting Genetic Algorithm. Appl. Sci. 2018, 8, 2253. [Google Scholar] [CrossRef]
- Ghambari, S.; Golabi, M.; Lepagnot, J.; Brévilliers, M.; Jourdan, L.; Idoumghar, L. An Enhanced NSGA-II for Multiobjective UAV Path Planning in Urban Environments. In Proceedings of the IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 106–111. [Google Scholar] [CrossRef]
- Liazos, A.; Iliopoulou, C.; Kepaptsoglou, K.; Bakogiannis, E. Geofence planning for electric scooters. Transp. Res. Part D Transp. Environ. 2022, 102, 103149. [Google Scholar] [CrossRef]
- Mokhtarimousavi, S.; Talebi, D.; Asgari, H. A Non-Dominated Sorting Genetic Algorithm Approach for Optimization of Multi-Objective Airport Gate Assignment Problem. Transp. Res. Rec. 2018, 2672, 59–70. [Google Scholar] [CrossRef]
- Owais, M.; Osman, M.K. Complete hierarchical multi-objective genetic algorithm for transit network design problem. Expert Syst. Appl. 2018, 114, 143–154. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; Computer Engineering and Networks Laboratory (TIK); ETH Zurich: Zurich, Switzerland, 2001; TIK Report; Volume 103. [Google Scholar] [CrossRef]
- Silman, L.A.; Barzily, Z.; Passy, U. Planning the route system for urban buses. Comput. Oper. Res. 1974, 1, 201–211. [Google Scholar] [CrossRef]
- Lin, F.; Hsieh, H.-P.; Fang, J.-Y. A Route-Affecting Region Based Approach for Feature Extraction in Transportation Route Planning. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Ghent, Belgium, 14–18 September 2020; pp. 275–290. [Google Scholar] [CrossRef]
- Su, H.-M.; Kuan, C.-C. Planning and Design Guidelines. Design Manual for Urban Sidewalks. 2003, pp. 1–4. Available online: Necis.nhu.edu.tw/Object/download.aspx?File_System_ID=7ec06f0d-22e1-423d-bf21-d4d2f02acc04 (accessed on 23 February 2022).
- Peterson, A. The Origin–Destination Matrix Estimation Problem—Analysis and Computations. Ph.D. Thesis, Department of Science and Technology, Linköping University, Linkoping, Sweden, 2007. Available online: Urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-8859 (accessed on 23 February 2022).
- Yang, H.; Zhou, J. Optimal traffic counting locations for origin–destination matrix estimation. Transp. Res. Part B Methodol. 1998, 32, 109–126. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Entropy, relative entropy and mutual information. In Elements of Information Theory; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1991; pp. 12–13. [Google Scholar]
- Bast, H.; Delling, D.; Goldberg, A.; Müller-Hannemann, M.; Pajor, T.; Sanders, P.; Wagner, D.; Werneck, R. Route Planning in Transportation Networks. In Algorithm Engineering; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9220. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S.; Stockmeyer, L. Some simplified NP-complete graph problems. Theor. Comput. Sci. 1976, 1, 237–267. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman and Company: New York, NY, USA, 1979; Appendix B. [Google Scholar]
- Garey, M.R.; Johnson, D.S.; Tarjan, R.E. The Planar Hamiltonian Circuit Problem is NP-Complete. SIAM J. Comput. 1976, 5, 704–714. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Korf, R.E. Depth-first iterative-deepening: An optimal admissible tree search. Artif. Intell. 1985, 27, 97–109. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Imada, R.; Setoguchi, Y.; Nojima, Y. How to Specify a Reference Point in Hypervolume Calculation for Fair Performance Comparison. Evol. Comput. 2018, 26, 411–440. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Variable | Description |
|---|---|---|---|
| A | A range for planning. | F( ) | The cost matrix associated with the edge. |
| G | A weighted, directed grid-like graph. | PF( ) | The PF (profit) matrix associated with the route. |
| E | A set of edges (trajectories). | S | The set of stations. |
| EA | The set of edges located in area A. | SM | The set of must-visit stations. |
| eij | The edge-connecting node i and node j. | SMi | The must-visit station numbered i. |
| V | A set of nodes (grids). | SR | The set of recommended stations. |
| VA | The set of nodes located in area A. | SRi | The recommended station numbered i. |
| vi | The node i. | R | The number of recommended stations. |
| V’ | A set of nodes (grids) as station candidates. | L | The maximum length for the route. |
| R | A route composed of stations and edges. |
| Instance\Dataset | Tainan | Chicago | |
|---|---|---|---|
| Bus data | Existing routes | 104 | 139 |
| Existing stations | 6575 | 11,592 | |
| Ticket records | 14,336,226 | 231,196,847 | |
| Period | 1 January 2017–31 December 2017 | 1 November 2017–30 October 2018 | |
| Gridization | Grids (0.1 km × 0.1 km) | 505,296 | 330,335 |
| Features | POI | 8734 | 21,889 |
| Bike trips (for human mobility) | 139,478 | N/A | |
| Taxi trips (for human mobility) | N/A | 68,461,612 | |
| Road nodes | 237,866 | 390,509 | |
| Road edges | 414,409 | 560,810 | |
| Census blocks (for population) | 14,730 | 46,293 | |
| City | Tainan | Chicago | ||
|---|---|---|---|---|
| Projection | EPSG:3857 | EPSG:4326 | EPSG:3857 | EPSG:4326 |
| Upper bound | 2,685,908.464 | 23.4448777 | 5,173,573.713 | 42.08402107 |
| Lower bound | 2,616,308.464 | 22.8700296 | 5,106,973.713 | 41.63844856 |
| Right bound | 13,433,041.310 | 120.6710632 | 9,742,334.669 | 87.51688136 |
| Left bound | 13,360,441.310 | 120.0188863 | 9,791,934.669 | 87.96244574 |
| Instance\Method | BiasSpan | Dijkstrta’s | BFS | IDDFS | Best-First | Distance-A* | PF-A* | ||
|---|---|---|---|---|---|---|---|---|---|
| City | Area | Indicator | |||||||
| Chicago | Overall | Unit PF | 0.25 ± 0.31 | 0.16 ± 0.24 | 0.09 ± 0.17 | 0.09 ± 0.18 | 0.08 ± 0.15 | 0.15 ± 0.23 | 0.10 ± 0.18 |
| PF | 2.12 ± 3.36 | 2.67 ± 5.19 | 3.48 ± 7.61 | 3.38 ± 7.30 | 2.32 ± 4.05 | 2.74 ± 5.43 | 2.34 ± 4.11 | ||
| Length | 15.10 ± 12.72 | 39.21 ± 44.55 | 98.37 ± 113.16 | 132.64 ± 183.12 | 92.09 ± 107.54 | 40.59 ± 45.98 | 82.48 ± 104.16 | ||
| Runtime | 10.78 ± 30.46 | 198.06 ± 387.53 | 93.92 ± 120.88 | 9792.84 ± 3.0 × 104 | 158.74 ± 269.83 | 94.17 ± 155.97 | 271.98 ± 558.73 | ||
| Small | Unit PF | 0.56 ± 0.39 | 0.36 ± 0.33 | 0.24 ± 0.26 | 0.26 ± 0.28 | 0.22 ± 0.23 | 0.36 ± 0.32 | 0.26 ± 0.27 | |
| PF | 0.91 ± 0.35 | 0.91 ± 0.35 | 0.91 ± 0.35 | 0.91 ± 0.35 | 0.91 ± 0.35 | 0.91 ± 0.35 | 0.91 ± 0.35 | ||
| Length | 2.33 ± 1.44 | 5.14 ± 5.19 | 8.53 ± 7.88 | 8.18 ± 7.96 | 9.23 ± 9.52 | 5.17 ± 5.15 | 7.26 ± 7.13 | ||
| Runtime | 1.50 ± 0.26 | 10.60 ± 3.74 | 10.09 ± 3.51 | 11.75 ± 5.06 | 11.02 ± 4.50 | 10.43 ± 3.77 | 10.91 ± 4.47 | ||
| Middle | Unit PF | 0.16 ± 0.19 | 0.09 ± 0.14 | 0.04 ± 0.08 | 0.04 ± 0.06 | 0.03 ± 0.06 | 0.08 ± 0.12 | 0.04 ± 0.08 | |
| PF | 1.94 ± 2.60 | 2.28 ± 3.78 | 2.77 ± 5.36 | 2.74 ± 5.33 | 2.08 ± 3.09 | 2.29 ± 3.72 | 2.15 ± 3.32 | ||
| Length | 14.22 ± 6.72 | 36.38 ± 28.14 | 88.56 ± 69.11 | 106.35 ± 87.45 | 94.72 ± 66.09 | 37.44 ± 28.44 | 80.01 ± 54.41 | ||
| Runtime | 5.55 ± 3.45 | 88.34 ± 71.11 | 66.71 ± 40.85 | 1390.57 ± 2.1 × 103 | 101.87 ± 63.18 | 55.44 ± 36.19 | 141.23 ± 109.75 | ||
| Large | Unit PF | 0.14 ± 0.21 | 0.09 ± 0.15 | 0.05 ± 0.08 | 0.04 ± 0.08 | 0.04 ± 0.06 | 0.08 ± 0.12 | 0.04 ± 0.06 | |
| PF | 4.28 ± 5.76 | 6.18 ± 9.15 | 9.05 ± 13.45 | 8.57 ± 12.74 | 4.89 ± 6.99 | 6.54 ± 9.81 | 4.85 ± 6.92 | ||
| Length | 34.78 ± 10.84 | 93.14 ± 60.75 | 247.59 ± 143.38 | 377.47 ± 270.44 | 194.69 ± 169.58 | 97.24 ± 62.46 | 190.19 ± 168.51 | ||
| Runtime | 38.85 ± 62.68 | 777.19 ± 606.13 | 287.31 ± 154.63 | 4.8 × 104 ± 5.6 × 104 | 526.29 ± 449.92 | 321.99 ± 245.04 | 1012.30 ± 968.80 | ||
| Tainan | Overall | Unit PF | 0.08 ± 0.15 | 0.05 ± 0.10 | 0.04 ± 0.09 | 0.03 ± 0.08 | 0.03 ± 0.09 | 0.04 ± 0.10 | 0.04 ± 0.09 |
| PF | 0.25 ± 0.04 | 0.26 ± 0.06 | 0.26 ± 0.07 | 0.27 ± 0.08 | 0.25 ± 0.04 | 0.26 ± 0.06 | 0.25 ± 0.04 | ||
| Length | 18.40 ± 18.95 | 47.03 ± 51.53 | 85.68 ± 96.02 | 122.39 ± 160.31 | 100.40 ± 114.80 | 49.01 ± 53.38 | 91.84 ± 107.23 | ||
| Runtime | 7.57 ± 11.57 | 103.87 ± 172.85 | 74.98 ± 91.16 | 3625.33 ± 8.3 × 103 | 151.76 ± 233.04 | 77.46 ± 123.33 | 106.24 ± 137.43 | ||
| Small | Unit PF | 0.24 ± 0.19 | 0.14 ± 0.14 | 0.12 ± 0.15 | 0.11 ± 0.12 | 0.10 ± 0.14 | 0.13 ± 0.14 | 0.11 ± 0.14 | |
| PF | 0.22 ± 2.8 × 10−3 | 0.22 ± 6.1 × 10−4 | 0.22 ± 6.1 × 10−4 | 0.22 ± 6.1 × 10−4 | 0.22 ± 6.1 × 10−4 | 0.23 ± 7.7 × 10−3 | 0.22 ± 6.1 × 10−4 | ||
| Length | 1.92 ± 1.54 | 4.56 ± 4.90 | 7.11 ± 7.50 | 7.13 ± 8.55 | 8.14 ± 7.53 | 4.52 ± 3.92 | 6.60 ± 5.53 | ||
| Runtime | 0.94 ± 0.51 | 4.68 ± 2.19 | 4.79 ± 2.71 | 7.44 ± 3.54 | 5.43 ± 3.23 | 4.96 ± 2.70 | 5.68 ± 3.41 | ||
| Middle | Unit PF | 0.02 ± 0.01 | 0.01 ± 0.01 | 5.2 × 10−3 ± 3.7 × 10−3 | 3.6 × 10−3 ± 2.6 × 10−3 | 3.9 × 10−3 ± 3.2 × 10−3 | 8.0 × 10−3 ± 4.8 × 10−3 | 4.4 × 10−3 ± 3.8 × 10−3 | |
| PF | 0.25 ± 0.04 | 0.26 ± 0.05 | 0.27 ± 0.06 | 0.28 ± 0.07 | 0.26 ± 0.04 | 0.26 ± 0.05 | 0.26 ± 0.04 | ||
| Length | 17.70 ± 8.25 | 48.64 ± 37.37 | 87.04 ± 71.63 | 117.40 ± 74.56 | 110.66 ± 70.85 | 48.27 ± 33.19 | 98.83 ± 66.85 | ||
| Runtime | 4.95 ± 3.23 | 72.36 ± 57.11 | 62.19 ± 41.38 | 1294.13 ± 1.9 × 103 | 115.71 ± 64.87 | 50.62 ± 34.34 | 87.36 ± 46.36 | ||
| Large | Unit PF | 7.1 × 10−3 ± 3.3 × 10−3 | 3.6 × 10−3 ± 2.3 × 10−3 | 2.1 × 10−3 ± 1.5 × 10−3 | 2.0 × 10−3 ± 1.8 × 10−3 | 2.4 × 10−3 ± 2.1 × 10−3 | 3.2 × 10−3 ± 2.1 × 10−3 | 2.4 × 10−3 ± 2.1 × 10−3 | |
| PF | 0.27 ± 0.05 | 0.29 ± 0.08 | 0.32 ± 0.10 | 0.33 ± 0.10 | 0.28 ± 0.06 | 0.30 ± 0.08 | 0.28 ± 0.06 | ||
| Length | 47.95 ± 22.34 | 113.02 ± 58.71 | 212.53 ± 101.88 | 329.43 ± 252.49 | 223.36 ± 172.93 | 125.35 ± 60.73 | 212.93 ± 157.40 | ||
| Runtime | 26.48 ± 16.60 | 363.74 ± 269.45 | 230.32 ± 95.46 | 1.7×104 ± 1.3×104 | 503.83 ± 362.70 | 278.79 ± 176.58 | 330.48 ± 179.88 | ||
| Instance\Method | BiasSpan | Dijkstrta’s | BFS | IDDFS | Best-First | Distance-A* | PF-A* | |
|---|---|---|---|---|---|---|---|---|
| City | Area | |||||||
| Chicago | Overall | 0.107014 | 0.088183 | 0.045771 | 0.067346 | 0.057848 | 0.066998 | 0.076158 |
| Small | 0.436986 | 0.549837 | 0.404202 | 0.675657 | 0.367308 | 0.541177 | 0.452289 | |
| Middle | 0.624969 | 0.408880 | 0.302886 | 0.383707 | 0.343325 | 0.289418 | 0.475395 | |
| Large | 0.926956 | 0.663704 | 0.835865 | 0.636061 | 0.614135 | 0.464512 | 0.613291 | |
| Tainan | Overall | 0.646061 | 0.493045 | 0.442171 | 0.443477 | 0.573544 | 0.485285 | 0.575067 |
| Small | 0.997011 | 0.996559 | 0.995518 | 0.995249 | 0.995512 | 0.867559 | 0.995548 | |
| Middle | 0.866878 | 0.753219 | 0.672815 | 0.733803 | 0.785875 | 0.875773 | 0.782592 | |
| Large | 0.972058 | 0.819815 | 0.967445 | 0.863522 | 0.985707 | 0.895531 | 0.985480 | |
| Instance\Comparative | Dijkstrta’s | BFS | IDDFS | Best-First | Distance-A* | PF-A* | |
|---|---|---|---|---|---|---|---|
| Chicago | Unit PF | 76.25% | 98.91% | 97.66% | 99.69% | 78.59% | 98.75% |
| PF | 57.19% | 59.22% | 60.16% | 61.41% | 56.56% | 63.91% | |
| Length | 77.03% | 99.38% | 98.28% | 99.84% | 79.53% | 98.91% | |
| Tainan | Unit PF | 89.11% | 100.00% | 99.01% | 100.00% | 94.06% | 100.00% |
| PF | 39.60% | 36.63% | 37.62% | 51.49% | 40.59% | 47.52% | |
| Length | 89.33% | 100.00% | 99.21% | 100.00% | 94.12% | 100.00% | |
| City | Source | DF | SS | MS | F-Value | p-Value |
|---|---|---|---|---|---|---|
| Chicago | Method | 6 | 0.361537984 | 0.060256331 | 33.77470726 | 4.77 × 10−21 |
| Area | 15 | 2.021735304 | 0.134782354 | 75.54782186 | 3.09 × 10−44 | |
| Error | 90 | 0.160566003 | 0.001784067 | |||
| Total | 111 | 2.543839291 | ||||
| Method | 6 | 0.240735177 | 0.040122529 | 23.67341257 | 1.00 × 10−14 | |
| Station | 11 | 0.318606133 | 0.028964194 | 17.08968306 | 2.44 × 10−15 | |
| Error | 66 | 0.111859114 | 0.001694835 | |||
| Total | 83 | 0.671200423 | ||||
| Tainan | Method | 6 | 0.016672738 | 0.002778790 | 5.828486175 | 3.64 × 10−5 |
| Area | 15 | 0.411747878 | 0.027449859 | 57.57582978 | 1.96 × 10−39 | |
| Error | 90 | 0.042908409 | 0.000476760 | |||
| Total | 111 | 0.471329025 | ||||
| Method | 6 | 0.006929104 | 0.001154851 | 58.45235695 | 1.66 × 10−24 | |
| Station | 11 | 0.003567283 | 0.000324298 | 16.41425121 | 6.22 × 10−15 | |
| Error | 66 | 0.001303970 | 1.98 × 10−5 | |||
| Total | 83 | 0.011800358 |
| City | Source | DF | Unit PF | PF | Length |
|---|---|---|---|---|---|
| Chicago | Method | 6 | 4.77 × 10−21 | 3.27 × 10−5 | 2.10 × 10−10 |
| Area | 15 | 3.09 × 10−44 | 1.11 × 10−35 | 1.10 × 10−17 | |
| Method | 6 | 1.00 × 10−14 | 1.48 × 10−7 | 2.46 × 10−17 | |
| Station | 11 | 2.44 × 10−15 | 7.34 × 10−80 | 5.45 × 10−13 | |
| Tainan | Method | 6 | 3.64 × 10−5 | 1.56 × 10−6 | 1.43 × 10−12 |
| Area | 15 | 1.96 × 10−39 | 6.48 × 10−43 | 2.13 × 10−23 | |
| Method | 6 | 1.66 × 10−24 | 0.07 × 10−2 | 3.50 × 10−16 | |
| Station | 11 | 6.22 × 10−15 | 1.11 × 10−34 | 3.34 × 10−10 |
| City | Source | DF | SS | MS | F-Value | p-Value |
|---|---|---|---|---|---|---|
| Chicago | Method | 6 | 1.203675884 | 0.200612647 | 21.56892294 | 4.55 × 10−22 |
| Error | 413 | 3.841314821 | 0.009301004 | |||
| Total | 419 | 5.044990705 | ||||
| Tainan | Method | 6 | 0.034645522 | 0.005774254 | 32.96143117 | 1.88 × 10−32 |
| Error | 413 | 0.072350218 | 0.000175182 | |||
| Total | 419 | 0.106995740 |
| City | LSD | Indicator | BiasSpan | Dijkstrta’s | BFS | IDDFS | Best-First | Distance-A* | PF-A* |
|---|---|---|---|---|---|---|---|---|---|
| Chicago | 0.03461 | Mean | 0.25280 | 0.15798 | 0.09373 | 0.09114 | 0.08128 | 0.15277 | 0.09747 |
| Std. | 0.31434 | 0.23687 | 0.16829 | 0.17891 | 0.14793 | 0.22618 | 0.17577 | ||
| Grouping | A | B | C | C | C | B | C | ||
| Tainan | 0.00475 | Mean | 0.08129 | 0.04597 | 0.03702 | 0.03378 | 0.03255 | 0.04262 | 0.03597 |
| Std. | 0.14666 | 0.09651 | 0.09355 | 0.07890 | 0.08870 | 0.09504 | 0.09162 | ||
| Grouping | A | B | C | D | D | B | C |
| City | Objective | Indicator | Dijkstra | BFS | IDDFS | Best-First | Distance-A* | PF-A* |
|---|---|---|---|---|---|---|---|---|
| Chicago | Unit PF | p-value | 6.07 × 10−6 | 8.67 × 10−19 | 8.67 × 10−19 | 8.67 × 10−19 | 2.60 × 10−9 | 8.67 × 10−19 |
| Positive ranks | 47 | 60 | 60 | 60 | 52 | 60 | ||
| Negative ranks | 13 | 0 | 0 | 0 | 8 | 0 | ||
| PF | p-value | 0.1225 | 0.0031 | 0.0067 | 0.0259 | 0.1831 | 0.0462 | |
| Positive ranks | 35 | 41 | 40 | 38 | 34 | 37 | ||
| Negative ranks | 24 | 19 | 20 | 22 | 25 | 23 | ||
| Length | p-value | 6.07 × 10−6 | 8.67 × 10−19 | 8.67 × 10−19 | 8.67 × 10−19 | 2.60 × 10−9 | 8.67 × 10−19 | |
| Positive ranks | 13 | 0 | 0 | 0 | 8 | 0 | ||
| Negative ranks | 47 | 60 | 60 | 60 | 52 | 60 | ||
| Tainan | Unit PF | p-value | 0.0031 | 8.67 × 10−19 | 8.67 × 10−19 | 8.67 × 10−19 | 8.08 × 10−8 | 8.67 × 10−19 |
| Positive ranks | 41 | 60 | 60 | 60 | 50 | 60 | ||
| Negative ranks | 18 | 0 | 0 | 0 | 10 | 0 | ||
| PF | p-value | 0.2595 | 0.0005 | 0.0259 | 0.0259 | 0.0775 | 0.0031 | |
| Positive ranks | 27 | 17 | 22 | 22 | 24 | 19 | ||
| Negative ranks | 29 | 41 | 36 | 36 | 33 | 39 | ||
| Length | p-value | 0.0031 | 8.67 × 10−19 | 8.67 × 10−19 | 8.67 × 10−19 | 8.08 × 10−8 | 8.67 × 10−19 | |
| Positive ranks | 18 | 0 | 0 | 0 | 10 | 0 | ||
| Negative ranks | 41 | 60 | 60 | 60 | 50 | 60 |
| City | Method | Comparative Method | ||||||
|---|---|---|---|---|---|---|---|---|
| BiasSpan | Dijkstra | BFS | IDDFS | Best-First | Distance-A* | PF-A* | ||
| Chicago | BiasSpan | N.A. | 6.07× 10−6 | 8.67× 10−19 | 8.67× 10−19 | 8.67× 10−19 | 2.60× 10−9 | 8.67× 10−19 |
| Dijkstra | D.A. | N.A. | 4.86 × 10−11 | 1.54 × 10−8 | 1.54 × 10−8 | 1.59 × 10−6 | 6.73 × 10−5 | |
| BFS | D.A. | D.A. | N.A. | 0.5513 | 0.4487 | D.A. | D.A. | |
| IDDFS | D.A. | D.A. | D.A. | N.A. | 0.0775 | D.A. | D.A. | |
| BestFirst | D.A. | D.A. | D.A. | D.A. | N.A. | D.A. | D.A. | |
| Distance-A* | D.A. | D.A. | 3.84 × 10−10 | 1.54 × 10−8 | 6.07 × 10−6 | N.A. | 0.0002 | |
| PF-A* | D.A. | D.A. | 0.0067 | 0.0259 | 0.0002 | D.A. | N.A. | |
| Tainan | BiasSpan | N.A. | 0.0031 | 8.67× 10−19 | 8.67× 10−19 | 8.67× 10−19 | 8.08× 10−8 | 8.67× 10−19 |
| Dijkstra | D.A. | N.A. | 5.19 × 10−12 | 4.54 × 10−13 | 5.19 × 10−12 | 0.0005 | 2.60 × 10−9 | |
| BFS | D.A. | D.A. | N.A. | 0.0259 | 0.3494 | D.A. | 0.1225 | |
| IDDFS | D.A. | D.A. | D.A. | N.A. | D.A. | D.A. | D.A. | |
| BestFirst | D.A. | D.A. | D.A. | 0.0462 | N.A. | D.A. | D.A. | |
| Distance-A* | D.A. | D.A. | 1.54 × 10−8 | 1.59 × 10−6 | 8.08 × 10−8 | N.A. | 8.08 × 10−8 | |
| PF-A* | D.A. | D.A. | D.A. | 0.1225 | 0.0031 | D.A. | N.A. | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, F.; Hsieh, H.-P. Multicriteria Route Planning for In-Operation Mass Transit under Urban Data. Appl. Sci. 2022, 12, 3127. https://doi.org/10.3390/app12063127
Lin F, Hsieh H-P. Multicriteria Route Planning for In-Operation Mass Transit under Urban Data. Applied Sciences. 2022; 12(6):3127. https://doi.org/10.3390/app12063127
Chicago/Turabian StyleLin, Fandel, and Hsun-Ping Hsieh. 2022. "Multicriteria Route Planning for In-Operation Mass Transit under Urban Data" Applied Sciences 12, no. 6: 3127. https://doi.org/10.3390/app12063127
APA StyleLin, F., & Hsieh, H.-P. (2022). Multicriteria Route Planning for In-Operation Mass Transit under Urban Data. Applied Sciences, 12(6), 3127. https://doi.org/10.3390/app12063127