
A Rapid and Affordable Screening Tool for Early-Stage Ovarian Cancer Detection Based on MALDI-ToF MS of Blood Serum

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Samples and Patients
2.2. Low Versus High Mass Spectral Pattern Analysis
2.2.1. Low Mass (2000 to 20,000 m/z) Spectra Range Data Generation
2.2.2. High Mass (20,000 to 200,000 m/z) Spectra Range Data Generation
2.3. Data Processing
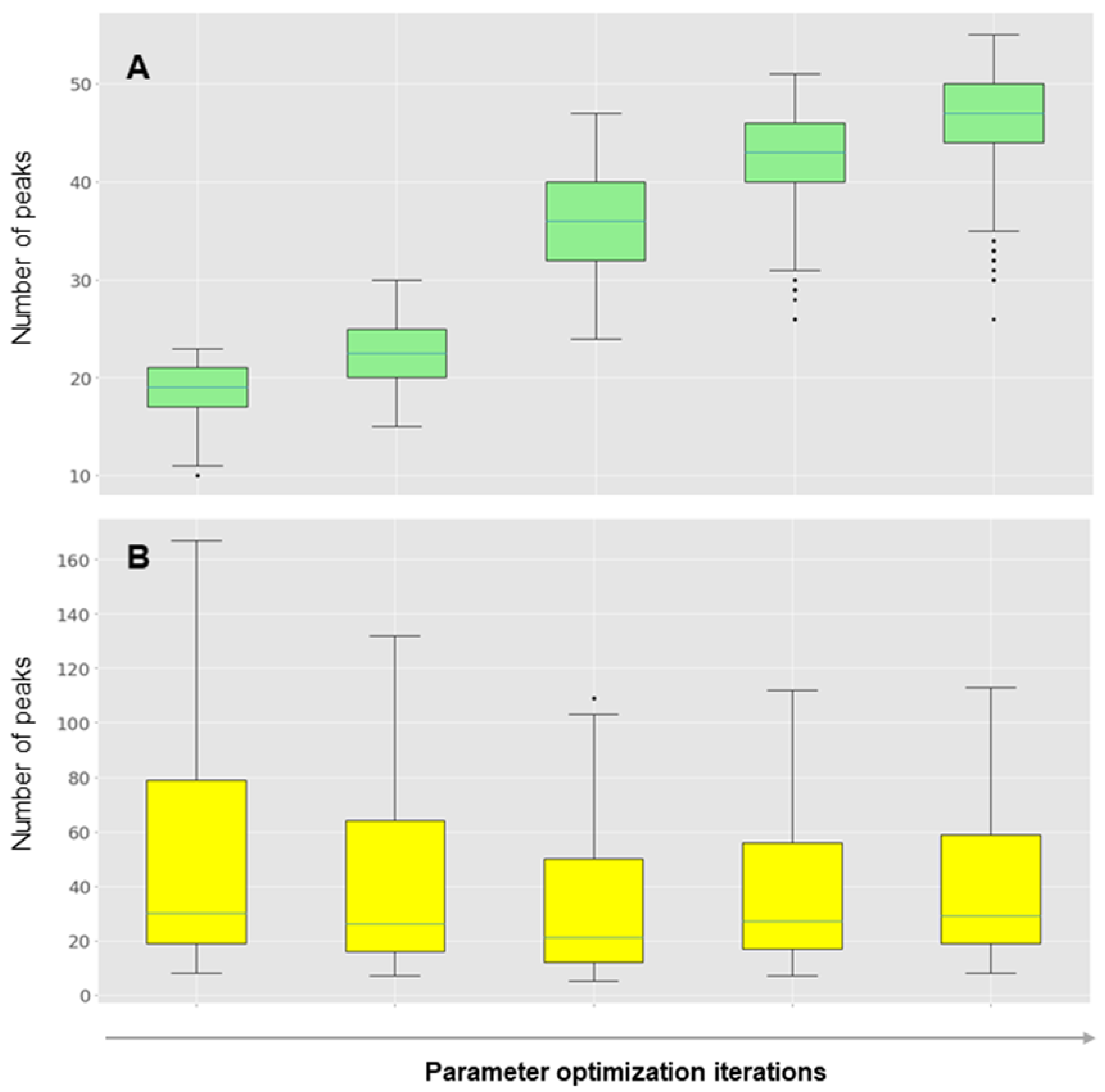
2.3.1. Comparative Analysis and Scoring
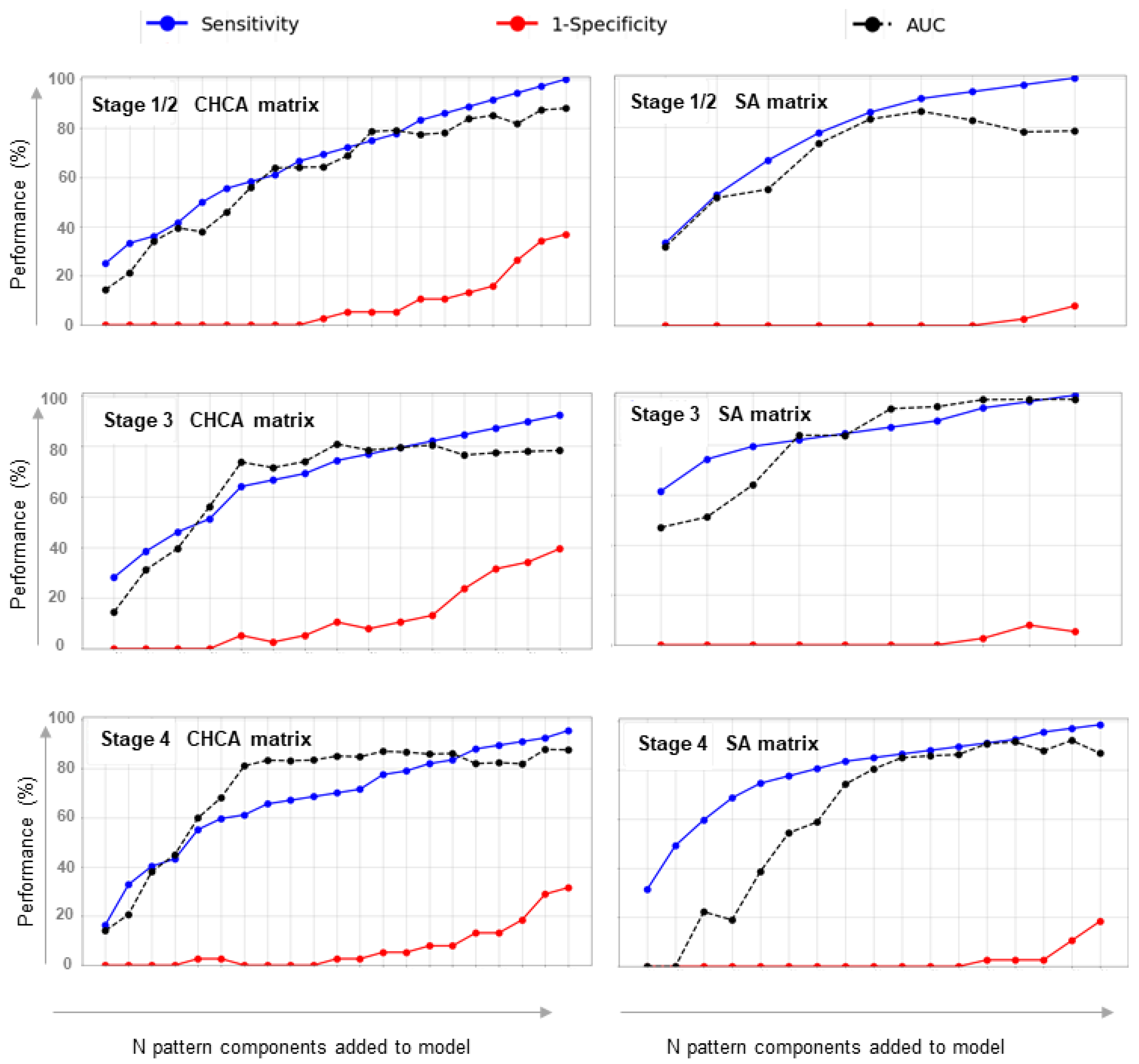
2.3.2. Classification Model Extraction
2.3.3. Bioinformatics Pipelines
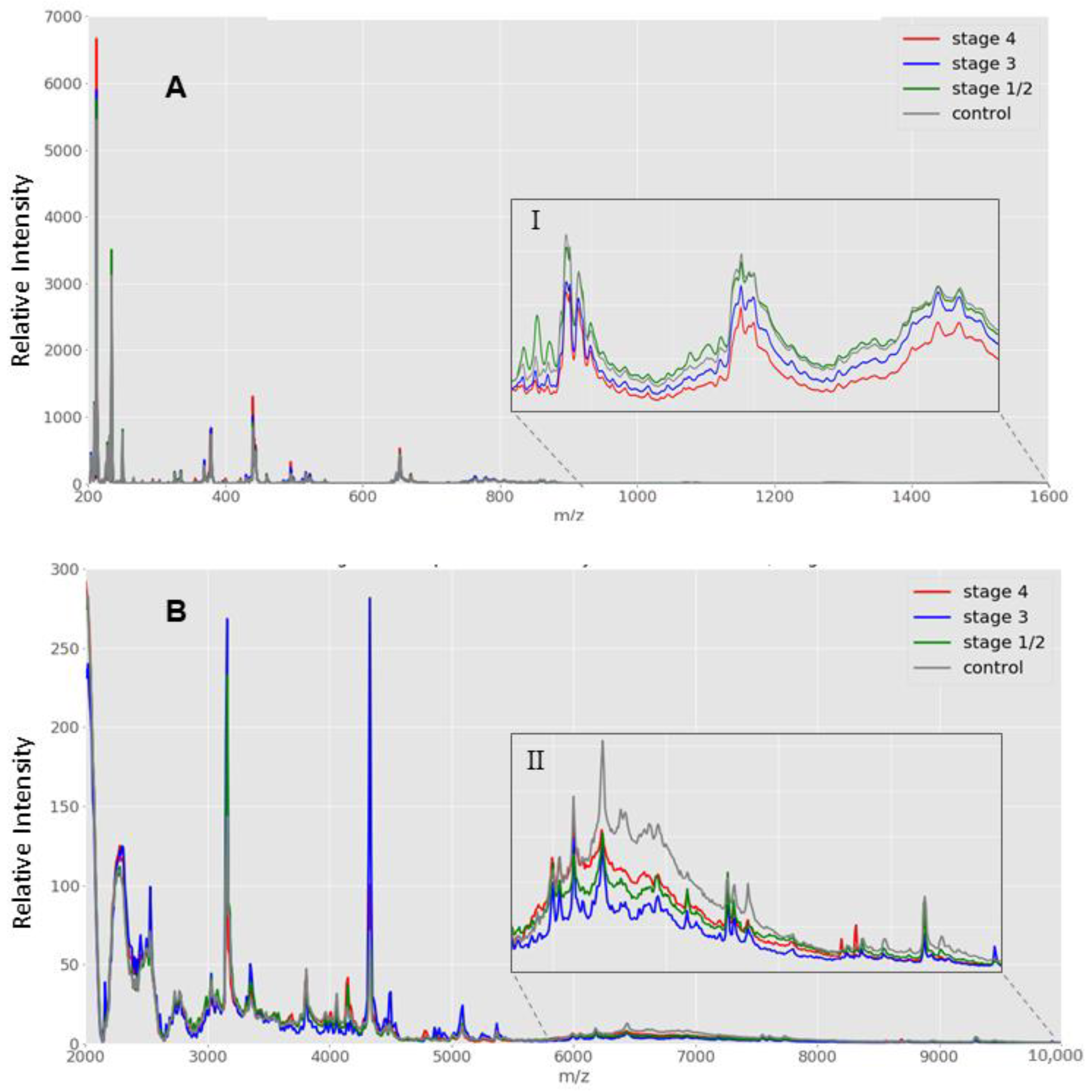
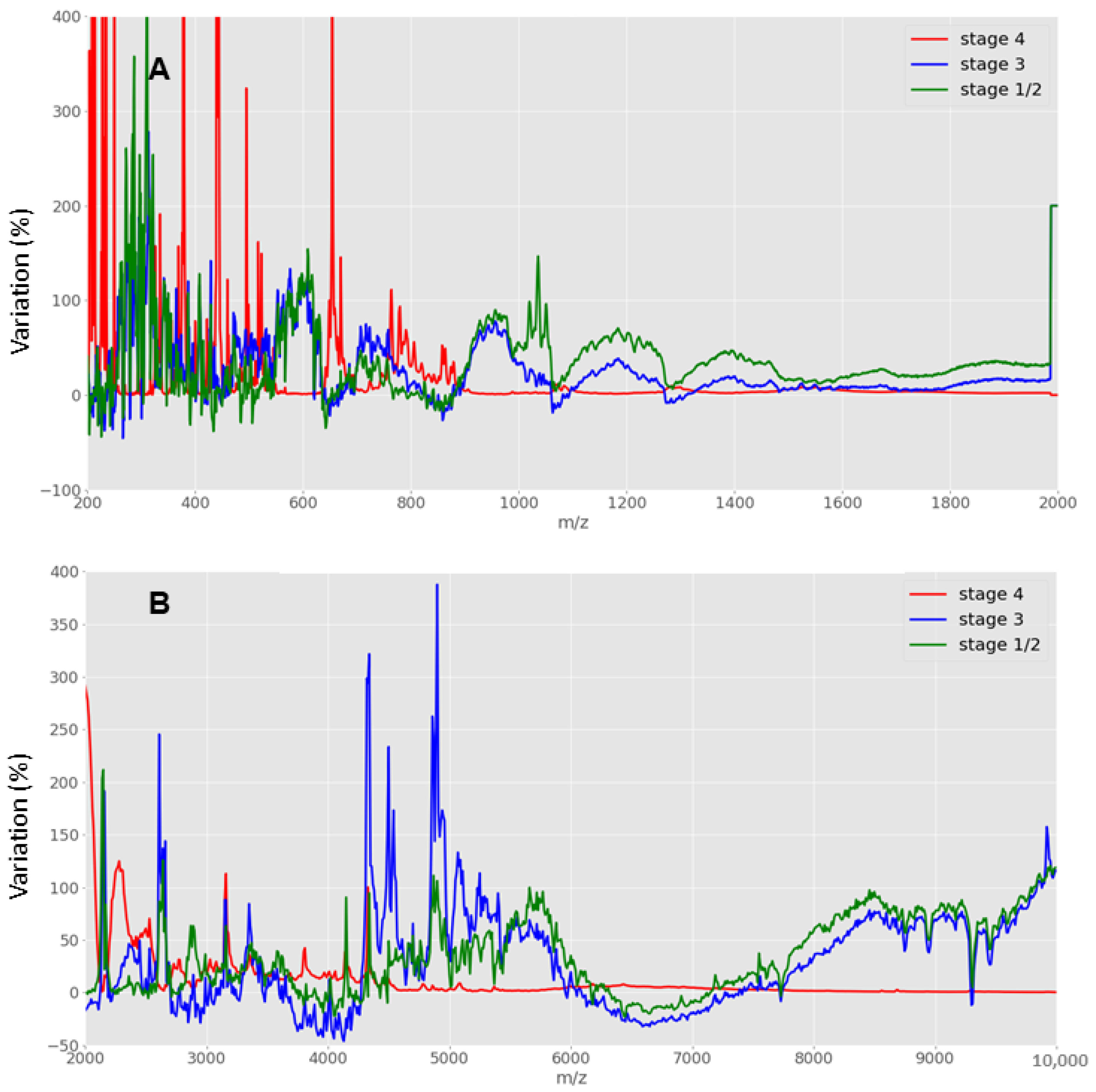
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2019. CA Cancer J. Clin. 2019, 69, 7–34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aust, S.; Seebacher-Shariat, V. Screening for ovarian cancer: Is there still hope? Mag. Eur. Med. Oncol. 2020, 13, 189–192. [Google Scholar] [CrossRef] [Green Version]
- Rauh-Hain, J.A.; Krivak, T.C.; del Carmen, M.G.; Olawaiye, A.B. Ovarian cancer screening and early detection in the general population. Rev. Obstet. Gynecol. 2011, 4, 15–21. [Google Scholar] [CrossRef] [PubMed]
- Patni, R. Screening for ovarian cancer: An update. J. Midlife. Health 2019, 10, 3–5. [Google Scholar] [CrossRef]
- Menon, U.; Griffin, M.; Gentry-Maharaj, A. Ovarian cancer screening—Current status, future directions. Gynecol. Oncol. 2014, 132, 490–495. [Google Scholar] [CrossRef] [Green Version]
- Kong, A.A.; Gupta, C.; Ferrari, M.; Agostini, M.; Bedin, C.; Bouamrani, A.; Tasciotti, E.; Azencott, R. Biomarker Signature Discovery from Mass Spectrometry Data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2014, 11, 766–772. [Google Scholar] [CrossRef]
- Gorski, J.W.; Quattrone, M.; van Nagell, J.R.; Pavlik, E.J. Assessing the Costs of Screening for Ovarian Cancer in the United States: An Evolving Analysis. Diagnostics 2020, 10, 67. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Zhu, Y.; Zhang, W.; Lang, J.; Ning, L. Utility Of Plasma circBNC2 as a Diagnostic Biomarker In Epithelial Ovarian Cancer. Onco. Targets. Ther. 2019, 12, 9715–9723. [Google Scholar] [CrossRef] [Green Version]
- Whitwell, H.J.; Worthington, J.; Blyuss, O.; Gentry-Maharaj, A.; Ryan, A.; Gunu, R.; Kalsi, J.; Menon, U.; Jacobs, I.; Zaikin, A.; et al. Improved early detection of ovarian cancer using longitudinal multimarker models. Br. J. Cancer 2020, 122, 847–856. [Google Scholar] [CrossRef] [Green Version]
- Angeletti, S. Matrix assisted laser desorption time of flight mass spectrometry (MALDI-TOF MS) in clinical microbiology. J. Microbiol. Methods 2017, 138, 20–29. [Google Scholar] [CrossRef]
- Gaillot, O.; Blondiaux, N.; Loïez, C.; Wallet, F.; Lemaître, N.; Herwegh, S.; Courcol, R.J. Cost-effectiveness of switch to matrix-assisted laser desorption ionization-time of flight mass spectrometry for routine bacterial identification. J. Clin. Microbiol. 2011, 49, 4412. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, K.E.; Ellis, B.C.; Lee, R.; Stamper, P.D.; Zhang, S.X.; Carroll, K.C. Prospective evaluation of a matrix-assisted laser desorption ionization-time of flight mass spectrometry system in a hospital clinical microbiology laboratory for identification of bacteria and yeasts: A bench-by-bench study for assessing the impact on ti. J. Clin. Microbiol. 2012, 50, 3301–3308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duncan, M.W.; Nedelkov, D.; Walsh, R.; Hattan, S.J. Applications of MALDI Mass Spectrometry in Clinical Chemistry. Clin. Chem. 2015, 62, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iles, R.; Naase, M. Future Laboratory Medicine: Rapid, Efficient and Affordable Screening for Haemoglobinopathies by MALDI-ToF Mass Spectrometry. Adv. Biochem. Biotechnol. 2018, 2018, 1–5. [Google Scholar]
- Haslam, C.; Hellicar, J.; Dunn, A.; Fuetterer, A.; Hardy, N.; Marshall, P.; Paape, R.; Pemberton, M.; Resemannand, A.; Leveridge, M. The Evolution of MALDI-TOF Mass Spectrometry toward Ultra-High-Throughput Screening: 1536-Well Format and Beyond. J. Biomol. Screen. 2016, 21, 176–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swiatly, A.; Horala, A.; Hajduk, J.; Matysiak, J.; Nowak-Markwitz, E.; Kokot, Z.J. MALDI-TOF-MS analysis in discovery and identification of serum proteomic patterns of ovarian cancer. BMC Cancer 2017, 17, 1–9. [Google Scholar] [CrossRef]
- Pais, R.J.; Iles, R.K.; Zmuidinaite, R. MALDI-ToF Mass Spectra Phenomic Analysis for Human Disease Diagnosis Enabled by Cutting-Edge Data Processing Pipelines and Bioinformatics Tools. Curr. Med. Chem. 2020, 28, 6532–6547. [Google Scholar] [CrossRef]
- Pais, R.J.; Zmuidinaite, R.; Butler, S.A.; Iles, R.K. An automated workflow for MALDI-ToF mass spectra pattern identification on large data sets: An application to detect aneuploidies from pregnancy urine. Inform. Med. Unlocked 2019, 16, 100194. [Google Scholar] [CrossRef]
- Pais, R.J.; Jardine, C.; Zmuidinaite, R.; Lacey, J.; Butler, S. Rapid, Affordable and Efficient Screening of Multiple Blood Abnormalities Made Possible Using an Automated Tool for MALDI-ToF Spectrometry Analysis. Appl. Sci. 2019, 9, 4999. [Google Scholar] [CrossRef] [Green Version]
- Pais, R.J.; Sharara, F.; Zmuidinaite, R.; Butler, S.; Keshavarz, S.; Iles, R. Bioinformatic identification of euploid and aneuploid embryo secretome signatures in IVF culture media based on MALDI-ToF mass spectrometry. J. Assist. Reprod. Genet. 2020, 37, 2189–2198. [Google Scholar] [CrossRef]
- Iles, R.K.; Nicolaides, K.; Pais, R.; Zmuidinaite, R.; Keshavarz, S.; Poon, L.; Butler, S. The importance of gestational age in first trimester, maternal urine MALDI-Tof MS screening tests for Down Syndrome. Ann. Proteomics Bioinform. 2019, 3, 010–017. [Google Scholar] [CrossRef] [Green Version]
- Sharara, F.; Butler, S.A.; Pais, R.J.; Zmuidinaite, R.; Keshavarz, S.; Iles, R.K. BESST, a Non-Invasive Computational Tool for Embryo Selection Using Mass Spectral Profiling of Embryo Culture Media. EMJ Reprod. Health 2019, 5, 59–60. [Google Scholar]
- Dai, Y.; Whittal, R.M.; Li, L. Two-layer sample preparation: A method for MALDI-MS analysis of complex peptide and protein mixtures. Anal. Chem. 1999, 71, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Galleani, L.; Cohen, L.; Nelson, D. Local signal to noise ratio. In Advanced Signal Processing Algorithms, Architectures, and Implementations XVI; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; Volume 6313, p. 63130Q. [Google Scholar] [CrossRef]
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [Green Version]
- Dankers, F.J.W.M.; Traverso, A.; Wee, L.; van Kuijk, S.M.J. Prediction Modeling Methodology. In Fundamentals of Clinical Data Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 101–120. [Google Scholar]
- Baggerly, K.A.; Baggerly, K.A.; Coombes, K.R.; Morris, J.S. Bias, Randomization, and Ovarian Proteomic Data: A Reply to “Producers and Consumers”. Cancer Inform. 2005, 1, 9–14. [Google Scholar]
- Li, K.; Pei, Y.; Wu, Y.; Guo, Y.; Cui, W. Performance of matrix-assisted laser desorption/ionization time-of-flight mass spectrometry (MALDI-TOF-MS) in diagnosis of ovarian cancer: A systematic review and meta-analysis. J. Ovarian Res. 2020, 13, 1–9. [Google Scholar] [CrossRef]
- Alexandrov, T. MALDI imaging mass spectrometry: Statistical data analysis and current computational challenges. BMC Bioinform. 2012, 13, S11. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.; Zhang, H.; Rush, J.; Eng, J.; Zhang, N.; Patterson, D.; Comb, M.J.; Aebersold, R. High Throughput Proteome Screening for Biomarker Detection. Mol. Cell. Proteomics 2005, 4, 182–190. [Google Scholar] [CrossRef] [Green Version]
- de Ridder, D.; de Ridder, J.; Reinders, M.J.T. Pattern recognition in bioinformatics. Brief. Bioinform. 2013, 14, 633–647. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swan, A.L.; Mobasheri, A.; Allaway, D.; Liddell, S.; Bacardit, J. Application of Machine Learning to Proteomics Data: Classification and Biomarker Identification in Postgenomics Biology. Omics A J. Integr. Biol. 2013, 17, 595–610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Menon, U.; McGuire, A.J.; Raikou, M.; Ryan, A.; Davies, S.K.; Burnell, M.; Gentry-Maharaj, A.; Kalsi, J.K.; Singh, N.; Amso, N.N.; et al. The cost-effectiveness of screening for ovarian cancer: Results from the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS). Br. J. Cancer 2017, 117, 619–627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jacobs, I.J.; Menon, U.; Ryan, A.; Gentry-Maharaj, A.; Burnell, M.; Kalsi, J.K.; Amso, N.N.; Apostolidou, S.; Benjamin, E.; Cruickshank, D.; et al. Ovarian cancer screening and mortality in the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS): A randomised controlled trial. Lancet 2016, 387, 945–956. [Google Scholar] [CrossRef] [Green Version]
- Iles, R.K.; Shahpari, M.E.; Cuckle, H.; Butler, S.A. Direct and rapid mass spectral fingerprinting of maternal urine for the detection of Down syndrome pregnancy. Clin. Proteomics 2015, 12, 9. [Google Scholar] [CrossRef] [Green Version]
- Albrethsen, J. Reproducibility in protein profiling by MALDI-TOF mass spectrometry. Clin. Chem. 2007, 53, 852–858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antoniadis, A.; Bigot, J.; Lambert-Lacroix, S. Peaks detection and alignment for mass spectrometry data. J. Société Française Stat. 2010, 151, 17–37. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pais, R.J.; Zmuidinaite, R.; Lacey, J.C.; Jardine, C.S.; Iles, R.K. A Rapid and Affordable Screening Tool for Early-Stage Ovarian Cancer Detection Based on MALDI-ToF MS of Blood Serum. Appl. Sci. 2022, 12, 3030. https://doi.org/10.3390/app12063030
Pais RJ, Zmuidinaite R, Lacey JC, Jardine CS, Iles RK. A Rapid and Affordable Screening Tool for Early-Stage Ovarian Cancer Detection Based on MALDI-ToF MS of Blood Serum. Applied Sciences. 2022; 12(6):3030. https://doi.org/10.3390/app12063030
Chicago/Turabian StylePais, Ricardo J., Raminta Zmuidinaite, Jonathan C. Lacey, Christian S. Jardine, and Ray K. Iles. 2022. "A Rapid and Affordable Screening Tool for Early-Stage Ovarian Cancer Detection Based on MALDI-ToF MS of Blood Serum" Applied Sciences 12, no. 6: 3030. https://doi.org/10.3390/app12063030
APA StylePais, R. J., Zmuidinaite, R., Lacey, J. C., Jardine, C. S., & Iles, R. K. (2022). A Rapid and Affordable Screening Tool for Early-Stage Ovarian Cancer Detection Based on MALDI-ToF MS of Blood Serum. Applied Sciences, 12(6), 3030. https://doi.org/10.3390/app12063030