
Automated Graffiti Detection: A Novel Approach to Maintaining Historical Architecture in Communities

 ,
,  ,
,  and
and
Abstract
:1. Introduction
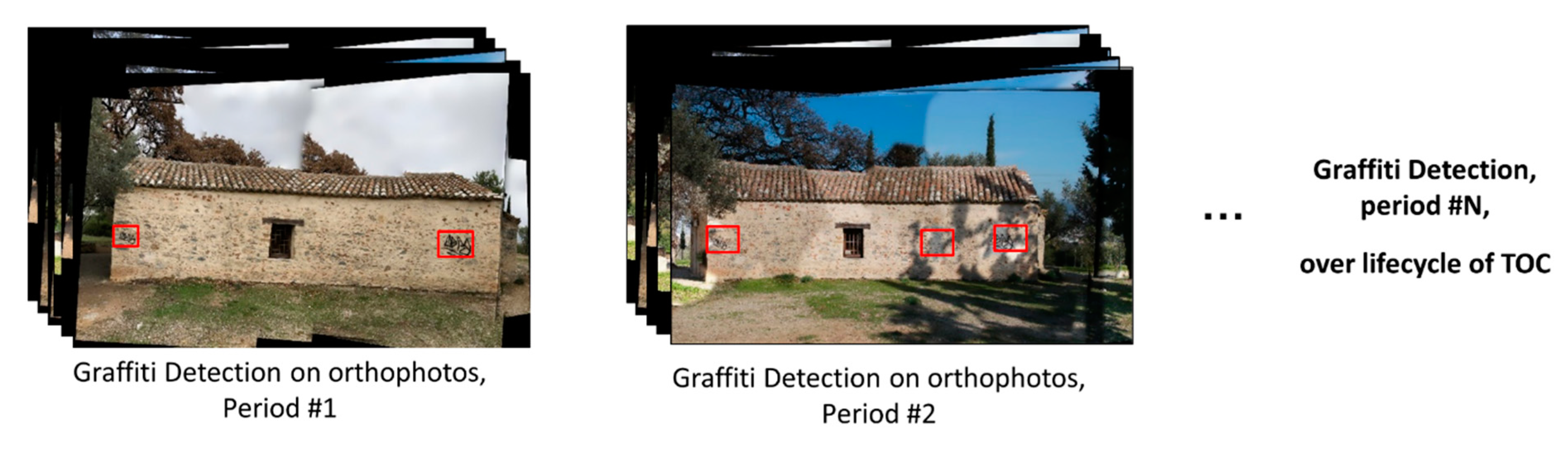
2. Materials and Methods
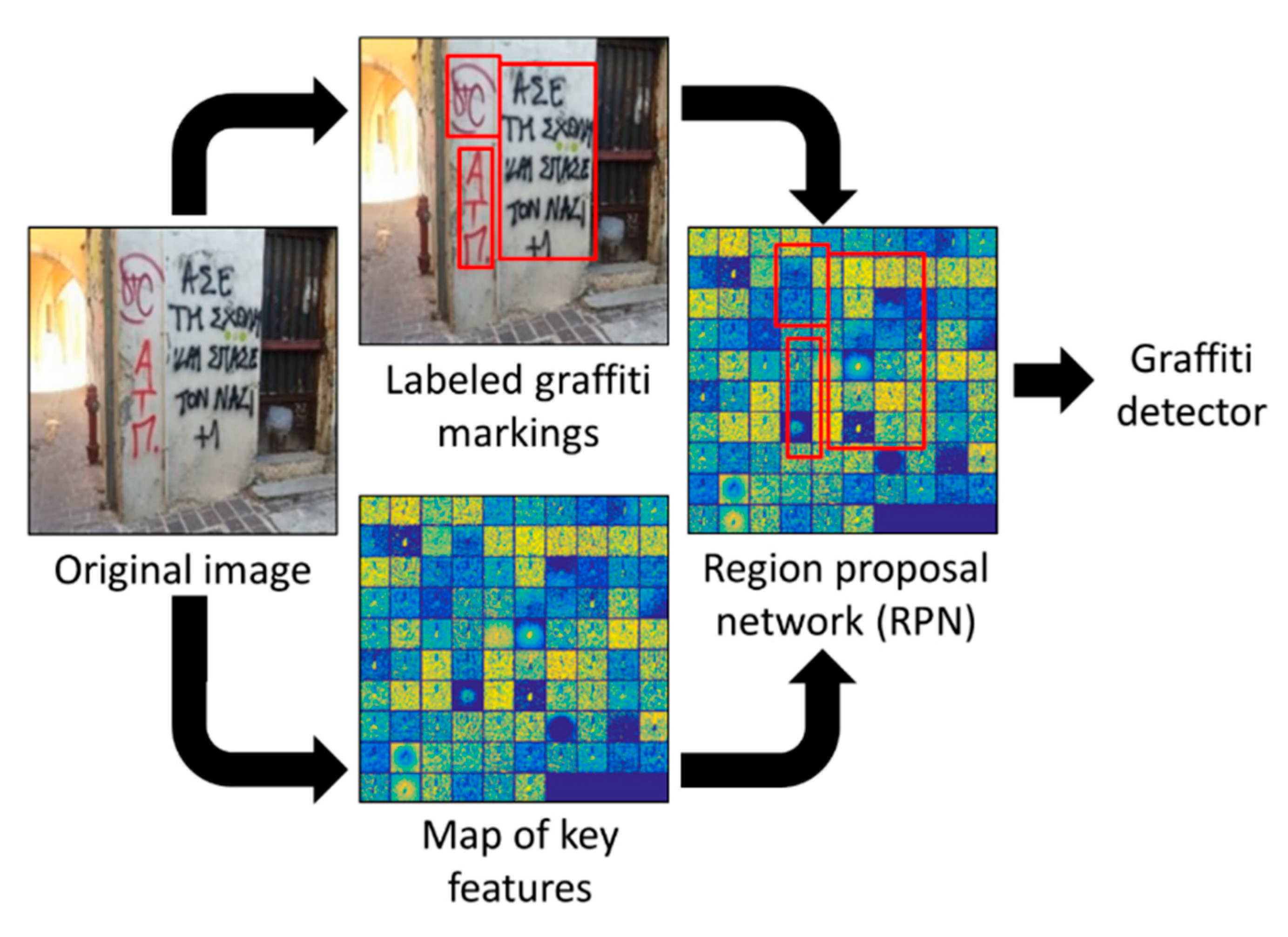
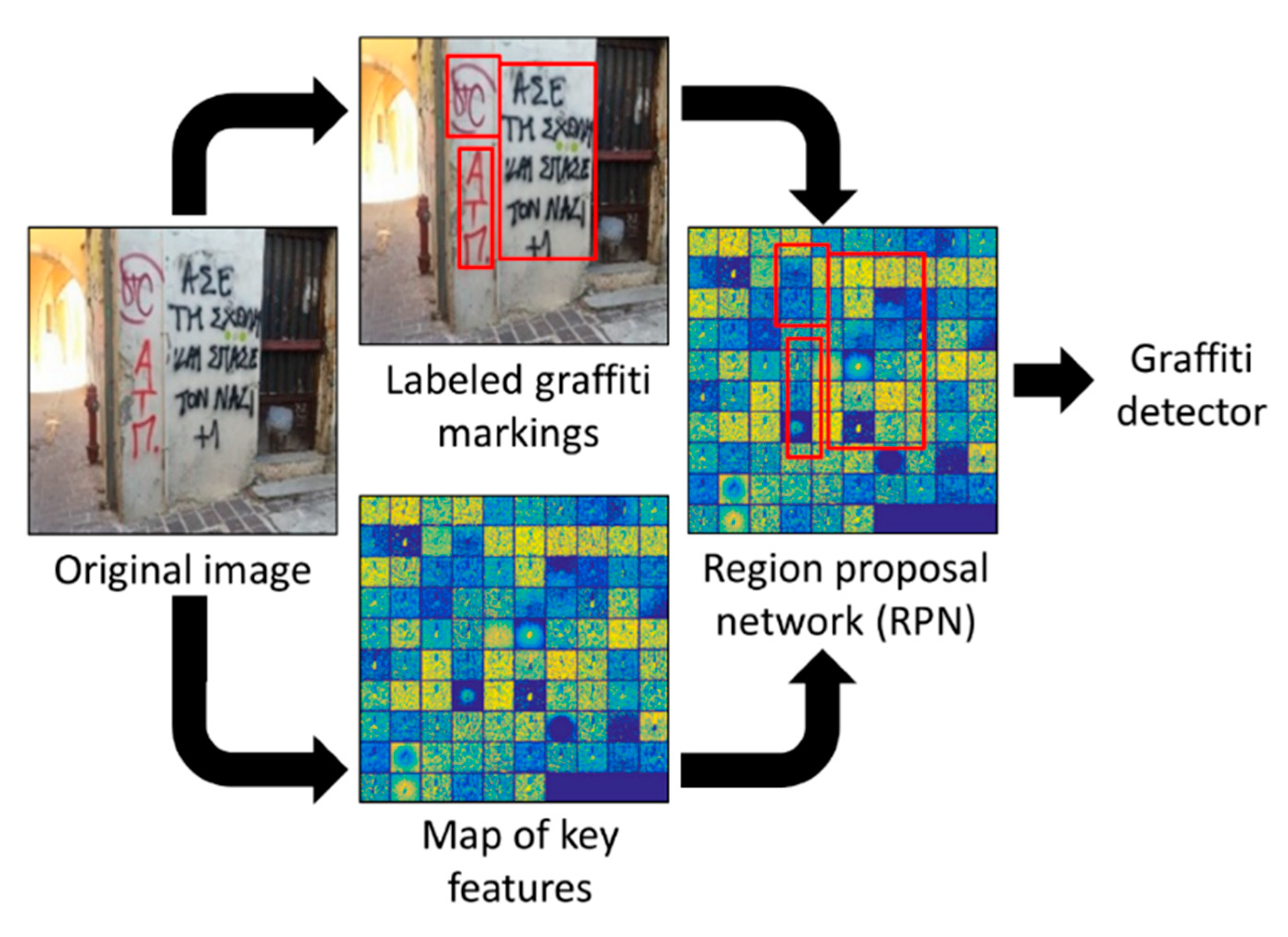
2.1. Preliminary Step: Graffiti Detector
2.2. Step 1: Community Data Collection
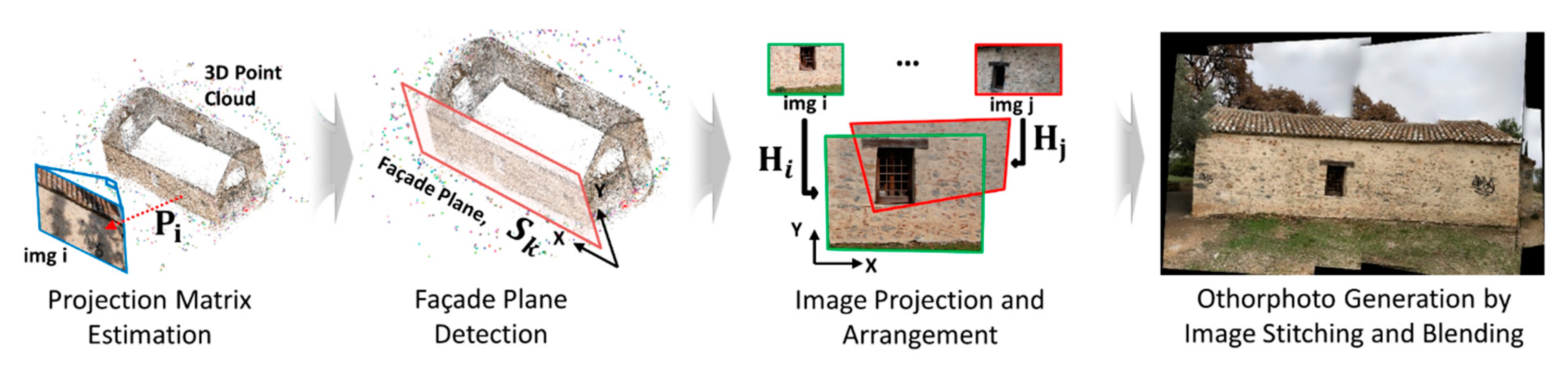
2.3. Step 2: Façade Image (Orthophoto) Generation
2.4. Step 3: Graffiti Detection on Orthophotos
3. Experimental Verification
3.1. Graffiti Detector
3.2. Description of the Target Object in a Community (TOC): Historical Structure in Kantza, Greece
3.3. Façade Image (Orthophoto) Generation
3.4. Graffiti Detection on Orthophotos
4. Conclusions
5. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Home. Oxford English Dictionary. Available online: https://www.oed.com/ (accessed on 25 February 2022).
- Holocaust Monument in Central Athens Vandalized with Graffiti. Naftemporiki.gr. 2017. Available online: https://www.naftemporiki.gr/story/1300966/holocaust-monument-in-central-athens-vandalized-with-graffiti (accessed on 25 February 2022).
- Armstrong, J.S. The Graffiti Problem. University Library of Munich, Germany, 0412035. 2004. Available online: https://ideas.repec.org/p/wpa/wuwpgt/0412035.html (accessed on 25 February 2022).
- Sanmartín, P.; Cappitelli, F.; Mitchell, R. Current methods of graffiti removal: A review. Const. Build. Mater. 2014, 30, 363–374. [Google Scholar] [CrossRef]
- White, R. Graffiti, Crime Prevention & Cultural Space. Curr. Issues Crim. Justice 2001, 12, 253–268. [Google Scholar] [CrossRef]
- Halsey, M.; Young, A. The Meanings of Graffiti and Municipal Administration. Aust. New Zeeland J. Criminol. 2002, 35, 165–186. [Google Scholar] [CrossRef]
- Macdonald, N. The Graffiti Subculture: Youth, Masculinity, and Identity in London and New York; Palgrave: New York, NY, USA, 2001. [Google Scholar]
- Ferrell, J. Crimes of Style: Urban Graffiti and the Politics of Criminality; Garland: New York, NY, USA, 1993. [Google Scholar]
- Ley, D.; Cybriwsky, R. Urban Graffiti as Territorial Markers. Ann. Assoc. Am. Geogr. 1974, 64, 491–505. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F.; Padgett, C.W.; Sukhatme, G.S. An innovative methodology for detection and quantification of cracks through incorporation of depth perception. Mach. Vis. Appl. 2013, 24, 227–241. [Google Scholar] [CrossRef]
- Ham, Y.; Han, K.K.; Lin, J.J.; Golparvar-Fard, M. Visual monitoring of civil infrastructure systems via camera-equipped Unmanned Aerial Vehicles (UAVs): A review of related works. Vis. Eng. 2016, 4, 118–261. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Dyke, S.J.; Yeum, C.M.; Bilionis, I.; Lenjani, A.; Choi, J. Automated Indoor Image Localization to Support a Post-Event Building Assessment. Sensors 2020, 20, 1610. [Google Scholar] [CrossRef] [Green Version]
- Narazaki, Y.; Hoskere, V.; Eick, B.A.; Smith, M.D.; Spencer, B.F. Vision-based dense displacement and strain estimation of miter gates with the performance evaluation using physics-based graphics models. Smart Struct. Syst. 2019, 24, 709–721. [Google Scholar] [CrossRef]
- Kong, X.; Li, J. Vision-Based Fatigue Crack Detection of Steel Structures Using Video Feature Tracking. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 783–799. [Google Scholar] [CrossRef]
- Gong, J.; Azambuja, M. Visualizing Construction Supply Chains with Google Cloud Computing Tools. In Proceedings of the International Conference on Sustainable Design, Engineering, and Construction, ICSDEC, Fort Worth, TX, USA, 7–9 November 2012; pp. 671–678. [Google Scholar] [CrossRef]
- Choi, J.; Park, J.A.; Dyke, S.J.; Yeum, C.M.; Liu, X.; Lenjani, A.; Bilionis, I. Autonomous image localization for visual inspection of civil infrastructure. Smart Mater. Struct. 2017, 26, 035051. [Google Scholar] [CrossRef]
- JChoi, J.; Park, J.A.; Dyke, S.J.; Yeum, C.M.; Liu, X.; Lenjani, A.; Bilionis, I. Similarity learning to enable building searches in post-event image data. Comput. Aided Civ. Inf. 2022, 37, 261–275. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Yeum, C.M.; Choi, J.; Dyke, S.J. Automated region-of-interest localization and classification for vision-based visual assessment of civil infrastructure. Struct. Health Monit. 2019, 18, 675–689. [Google Scholar] [CrossRef]
- Lenjani, A.; Dyke, S.J.; Bilionis, I.; Yeum, C.M.; Kamiya, K.; Choi, J.; Liu, X.; Chowdhury, A.G. Towards fully automated post-event data collection and analysis: Pre-event and post-event information fusion. Eng. Struct. 2020, 208, 109884. [Google Scholar] [CrossRef] [Green Version]
- Wu, R.; Singla, A.; Jahanshahi, M.R.; Bertino, E.; Ko, B.J.; Verma, D. Pruning deep convolutional neural networks for efficient edge computing in condition assessment of infrastructures. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 774–789. [Google Scholar] [CrossRef]
- Koch, C.; Paal, S.; Rashidi, A.; Zhu, Z.; König, M.; Brilakis, I. Achievements and challenges in machine vision-based inspection of large concrete structures. Adv. Struct. Eng. 2014, 17, 303–318. [Google Scholar] [CrossRef]
- Mondal, T.G.; Jahanshahi, M.R.; Wu, R.; Wu, Z.Y. Deep learning-based multi-class damage detection for autonomous post-disaster reconnaissance. Struct. Control Health Monit. 2020, 27, e2507. [Google Scholar] [CrossRef]
- Kraus, K. Photogrammetry: Geometry from Images and Laser Scans; Walter de Gruyter: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Modeling the World from Internet Photo Collections. Int. J. Comput. Vis. 2008, 80, 189–210. [Google Scholar] [CrossRef] [Green Version]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. Structure-from-Motion’ photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Allene, C.; Pons, J.-P.; Keriven, R. Seamless Image-Based Texture Atlases Using Multi-Band Blending. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- ΒΥΖAΝΤΙΝA ΜΝHΜΕΙA AΤΤΙΚHΣ. Available online: http://byzantineattica.eie.gr/byzantineattica/ (accessed on 25 February 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: La Jolla, CA, USA, 2015; pp. 91–99. Available online: http://papers.nips.cc/paper/5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks.pdf (accessed on 25 February 2022).
- Patrikakis, C.; Kasnesis, P.; Toumanidis, L.; Tzitamidis, A. zenodo.org; STORM Graffiti/Tagging Detection Dataset; CERN: Meyrin, Switzerland, 2019. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. 2015. Available online: http://openaccess.thecvf.com/content_iccv_2015/html/Girshick_Fast_R-CNN_ICCV_2015_paper.html (accessed on 25 February 2022).
- Gkioxari, G.; Johnson, J.; Malik, J. Mesh r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9785–9795. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Replicated Softmax: An Undirected Topic Model. In Advances in Neural Information Processing Systems 22; Bengio, Y., Schuurmans, D., Lafferty, J.D., Williams, C.K.I., Culotta, A., Eds.; Curran Associates, Inc.: Nice, France, 2009; pp. 1607–1614. Available online: http://papers.nips.cc/paper/3856-replicated-softmax-an-undirected-topic-model.pdf (accessed on 25 February 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Cham, Switzerland, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. 2017. Available online: http://openaccess.thecvf.com/content_cvpr_2017/html/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.html (accessed on 25 February 2022).
- Saxton, G.D.; Oh, O.; Kishore, R. Rules of Crowdsourcing: Models, Issues, and Systems of Control. Inf. Syst. Manag. 2013, 30, 2–20. [Google Scholar] [CrossRef]
- Follett, R.; Strezov, V. An Analysis of Citizen Science Based Research: Usage and Publication Patterns. PLoS ONE 2015, 10, e0143687. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Dyke, S.J. CrowdLIM: Crowdsourcing to enable lifecycle infrastructure management. Comput. Ind. 2020, 115, 103185. [Google Scholar] [CrossRef]
- Agisoft Metashape. Available online: https://www.agisoft.com/ (accessed on 25 February 2022).
- Wu, C. Critical Configurations for Radial Distortion Self-Calibration. 2014, p. 25. Available online: http://openaccess.thecvf.com/content_cvpr_2014/html/Wu_Critical_Configurations_For_2014_CVPR_paper.html (accessed on 25 February 2022).
- Choi, J.; Yeum, C.M.; Dyke, S.J.; Jahanshahi, M.R. Computer-Aided Approach for Rapid Post-Event Visual Evaluation of a Building Façade. Sensors 2018, 18, 3017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torr, P.H.S.; Zisserman, A. MLESAC: A New Robust Estimator with Application to Estimating Image Geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- TensorFlow. Available online: https://www.tensorflow.org/?hl=ko (accessed on 25 February 2022).
- Chen, X.; Gupta, A. An Implementation of Faster RCNN with Study for Region Sampling. arXiv 2017, arXiv:170202138 Cs. Available online: http://arxiv.org/abs/1702.02138 (accessed on 25 February 2022).
- Toumanidis, L.; Bocaj, E.; Kasnesis, P.; Patrikakis, C.Z. Supporting Cultural Heritage Preservation Through Game-Based Crowdsourcing. In Strategic Innovative Marketing and Tourism; Springer: Cham, Switzerland, 2019; pp. 989–997. [Google Scholar] [CrossRef]
- Kasnesis, P.; Kogias, D.G.; Toumanidis, L.; Xevgenis, M.G.; Patrikakis, C.Z.; Giunta, G.; Calsi, G.L. An IoE Architecture for the Preservation of the Cultural Heritage: The STORM Use Case. Harnessing the Internet of Everything (IoE) for Accelerated Innovation Opportunities. 2019. Available online: www.igi-global.com/chapter/an-ioe-architecture-for-the-preservation-of-the-cultural-heritage/221288 (accessed on 25 February 2022).
- VisualSFM: A Visual Structure from Motion System. Available online: http://ccwu.me/vsfm/ (accessed on 25 February 2022).
- MATLAB—MathWorks—MATLAB & Simulink. Available online: https://www.mathworks.com/products/matlab.html (accessed on 25 February 2022).
- Kuzmin, Y.P.; Korytnik, S.A.; Long, O. Polygon-based true orthophoto generation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 35, 529–531. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | Positive | 482 | 83 |
| Negative | 61 | 574 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Toumanidis, L.; Yeum, C.M.; Charalampos, P.; Lenjani, A.; Liu, X.; Kasnesis, P.; Ortiz, R.; Jiang, N.-J.; Dyke, S.J. Automated Graffiti Detection: A Novel Approach to Maintaining Historical Architecture in Communities. Appl. Sci. 2022, 12, 2983. https://doi.org/10.3390/app12062983
Choi J, Toumanidis L, Yeum CM, Charalampos P, Lenjani A, Liu X, Kasnesis P, Ortiz R, Jiang N-J, Dyke SJ. Automated Graffiti Detection: A Novel Approach to Maintaining Historical Architecture in Communities. Applied Sciences. 2022; 12(6):2983. https://doi.org/10.3390/app12062983
Chicago/Turabian StyleChoi, Jongseong, Lazaros Toumanidis, Chul Min Yeum, Patrikakis Charalampos, Ali Lenjani, Xiaoyu Liu, Panagiotis Kasnesis, Ricardo Ortiz, Ning-Jun Jiang, and Shirley J. Dyke. 2022. "Automated Graffiti Detection: A Novel Approach to Maintaining Historical Architecture in Communities" Applied Sciences 12, no. 6: 2983. https://doi.org/10.3390/app12062983
APA StyleChoi, J., Toumanidis, L., Yeum, C. M., Charalampos, P., Lenjani, A., Liu, X., Kasnesis, P., Ortiz, R., Jiang, N.-J., & Dyke, S. J. (2022). Automated Graffiti Detection: A Novel Approach to Maintaining Historical Architecture in Communities. Applied Sciences, 12(6), 2983. https://doi.org/10.3390/app12062983