
Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO

 , , , , and
, , , , and
Abstract
:1. Introduction
- We create a set of samples (Dataset) captured with monocular cameras (cellphone cameras) from the side view of the road. The dataset includes different videos with two cell phones to consider the two operating systems on mobile phones on the market, android and iOs. We configured the cameras of the cellphones with the same properties; nevertheless, the cameras are not calibrated with a reference object.
- We compare five different statistical methods (Linear, Ridge, Lasso, Bayesian Ridge, Elastic Net Regressions) and three machine learning methods (Random Forest, Support Vector Machine Regressions, Artificial Neural Network) to evaluate their precision of estimation of cars’ speeds in real time.
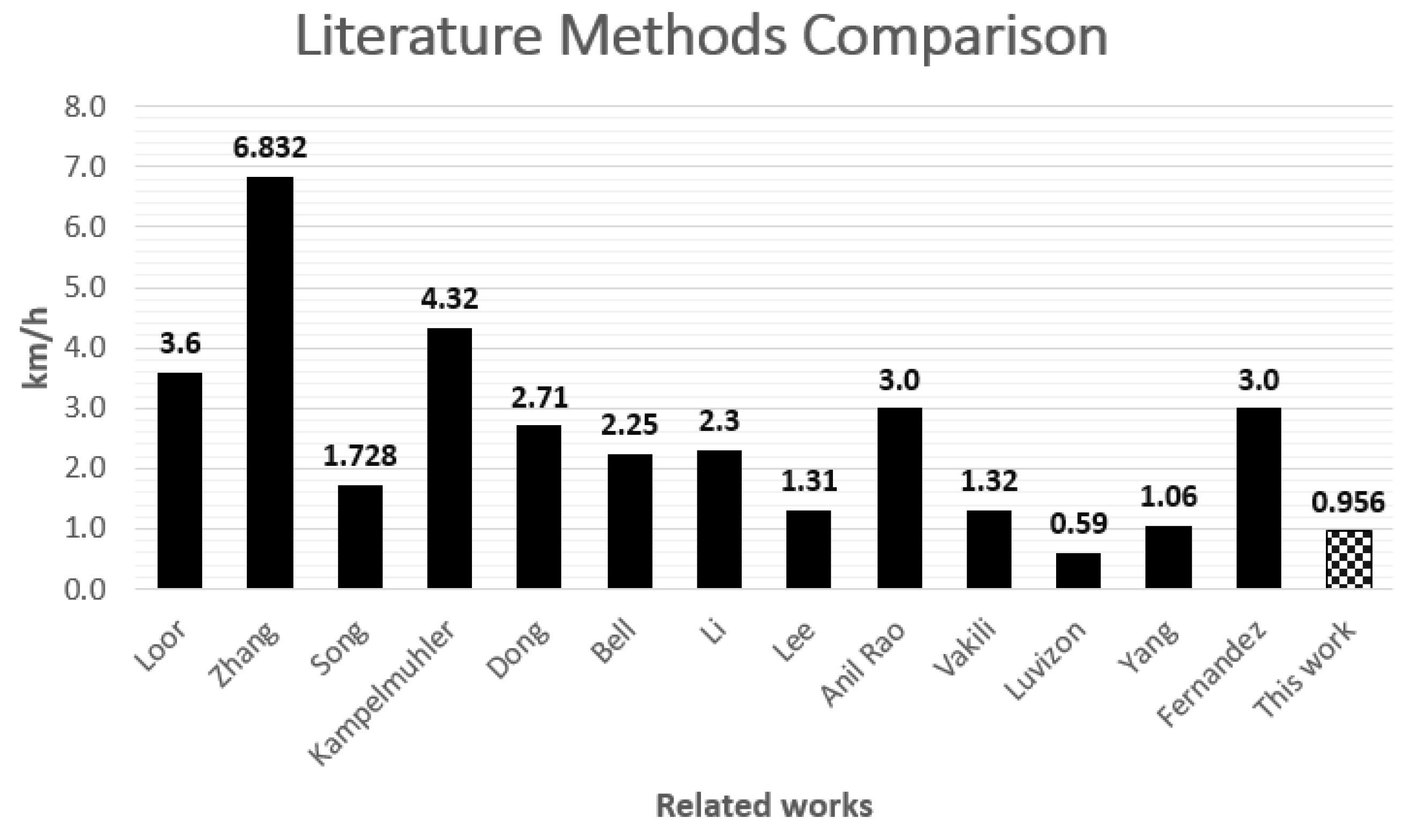
- The Linear Regression Model (LRM) yielded the best results obtaining a Mean Absolute Error (MAE) of 1.694 Km/h for the center lane and 0.956 Km/h for the last lane. The results were compared with several state-of-the-art works, having competitive performance. LRM is fast estimating speed in real time and does not require high computational resources allowing a future hardware implementation. Transport engineers could obtain traffic studies in road zones with limited urban infrastructure by using the LMR model inside cellphones.
2. State of the Art

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Hardware | Method | Precision |
|---|---|---|---|
| Fernández et al. [39] | two Cameras | Physical Formula | <3 km/h |
| Yang et al., 2019 [40] | Stereo Cameras | Physical Formula | −1.6, +1.1 km/h |
| Yang et al., 2020 [41] | Stereo Cameras | Physical Formula | −0.72, +1.17 km/h |
| Yang et al., 2021 [42] | Stereo Cameras | Physical Formula | −0.9, +1.06 km/h |
| Luvizon et al. [43] | Camera | Physical Formula | 0.59 km/h |
| Vakili et al. [23] | Camera | Physical Formula | 1.32 km/h |
| Anil Rao et al. [28] | Camera | Pixels Proportions | 3 km/h |
| Kamoji et al. [21] | Camera | Physical Formula | 98% accuracy |
| Lee et al. [29] | Dron LiDAR | Physical Formula | 1.31 km/h |
| Li et al. [30] | Camera | Physical Formula | 2.3 km/h |
| Kurniawan et al. [31] | Camera | Projective transformation | 97.01% No Shadow 83.86% Shadow |
| Jalalat et al. [32] | Camera | Subpixel Stereo Matching | ±6% |
| Bell et al. [22] * | Camera GNSS IMU | YOLOv2 Faster R-CNN | 2.25 km/h |
| Dong et al. [33] * | Camera | 3D CNN | 2.71 km/h |
| Burnett et al. [34] | GPS LiDAR IMU Camera | SqueezeDet | Only Tracking |
| Kampelmuhler et al. [35] * | Camera | MLP | 4.32 km/h |
| Song et al. [36] * | Camera | PWC-Net | 1.728 km/h |
| Zhang et al. [37] * | Camera | Faster-RCNN CNN AlexNet | 6.832 km/h |
| Loor et al. [38] * | Camera | FlowNet TimeNet SpeedNet CNN | 3.6 km/h |
| Redmon et al. [15] * | Images | CNN | Only Detection |
3. Preliminars
3.1. Statistical Methods
3.1.1. Linear Regression
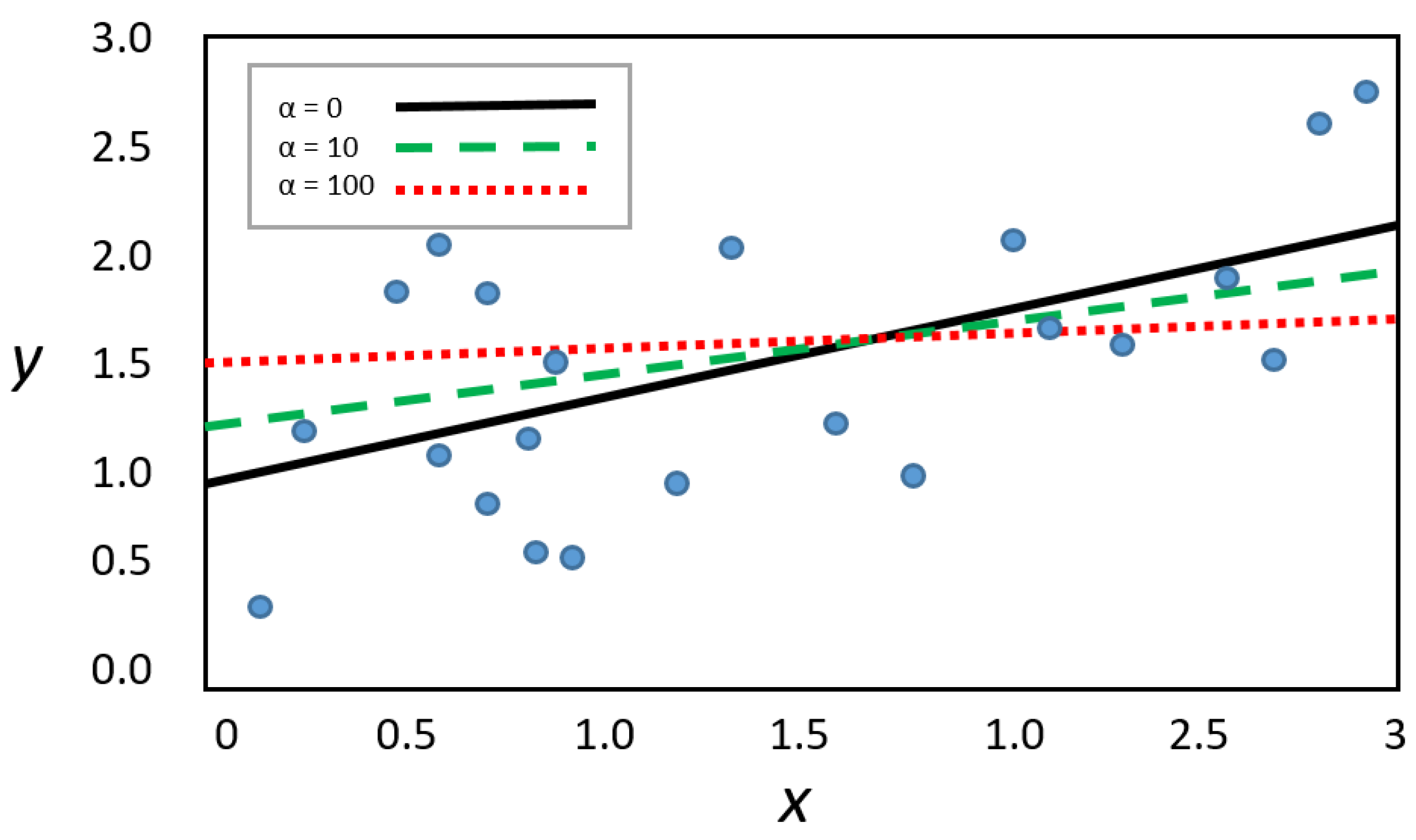
3.1.2. Ridge Regression
3.1.3. Lasso Regression
3.1.4. Elastic Net
3.1.5. Bayesian Ridge Regression
3.1.6. Machine Learning Methods
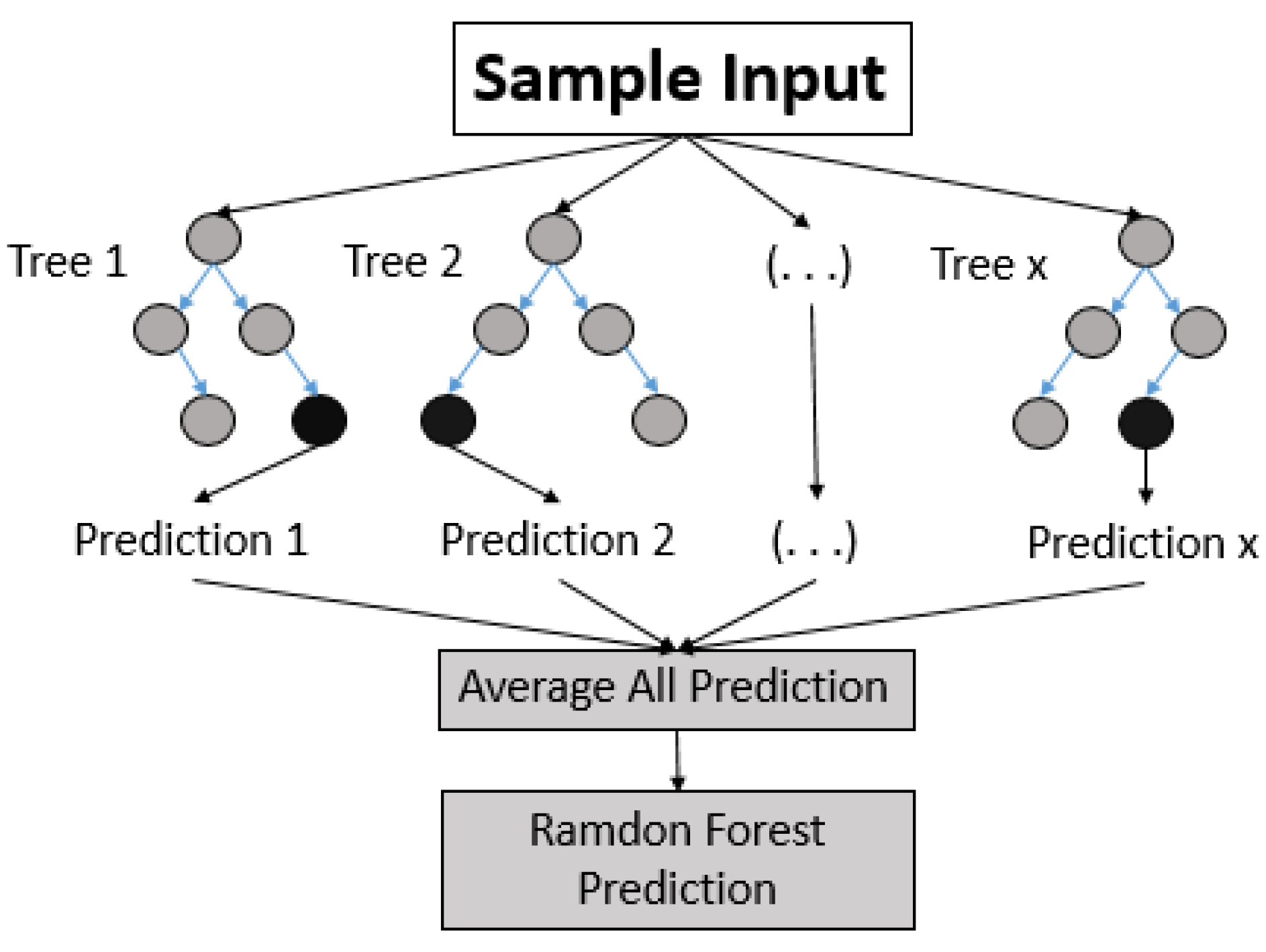
3.1.7. Random Forest Regression
3.1.8. Support Vector Machine Regression (SVMR)
3.1.9. Artificial Neuronal Network (ANN)
4. Materials and Methods
4.1. Materials
4.2. Methods
4.2.1. Data Collection
| Algorithm 1:Data Colletion |
 |
- Sampling: For sampling, two devices were required to extract the dataset that will later be used to train the predictive models. One of the devices is the Bushnell radar. At the same time, the other device is a video camera; both devices are described in the Material Section. The videos are taken at 60 frames per second, but it should be taken into account that having a low resolution may result in a loss of image quality and a smaller area than desired. While having low frames will cause loss of vehicles passing at a higher speed. On the other hand, increasing the resolution and frames per second causes the system to take longer to process the video.There is special care when positioning the camera since we do not want the experiments to be considered 2D speed calculations. Therefore, the camera was placed where vehicular traffic passes with a certain degree of inclination, without pointing the camera directly to the vehicles’ side (Figure 8).Since the camera and the speed radar are devices that are not synchronized, it was necessary to implement a mechanism to associate the radar reading with the video recording.
- Cleaning: The radar device and the tracking system are not linked, so it is essential to combine the speed supplied by the radar with the information received by the tracking system (video camera). For this, a visual inspection of the samples taken is required. The first step is identifying the landmarks to reference vehicle entry and exit points. Using our exit landmark as a reference, we record the second when a vehicle passes through the exit landmark. Figure 8 shows an example of how the landmarks in the images were established as reference points for vehicle entry and exit. Also shown is the inclination of the camera used for sampling.In addition, we identify the lane in which the vehicles pass to separate them in the three street lanes, we represent with zero the first lane, one the central lane, and two the last lane, with this we seek to create three datasets as divided in the work of [35] This information obtained visually we save in a csv (comma-separated values) file, which will have the following three attributes:
- -
- The second that the object passes through the exit point.
- -
- The vehicle’s speed.
- -
- Lane
- Extraction: Specific characteristics of the previously cleaned videos are necessary to perform the speed estimation. These characteristics are the basis to carry out the estimation. The characteristics extracted from the videos are described in Table 2.The execution of the system is simple. We need the CSV file generated earlier with the speeds and limits that we also identified in the previous step. The system is in charge of reading the video using the OpenCV library, and it examines frame by frame the content. Different options were explored in the literature to choose the most appropriate network to detect vehicles, such as the SSD network [51] and its variants, Retina network [52], and its variants (ResNet), YOLO network [17], and its variants. In [17], performance comparisons of these networks were made. The results showed that the YOLOv3 network obtains a significantly lower response time of object detections (between 5 and, in some cases, 12 times lower). With a negligible precision difference, obtaining 55.3 versus 59.1 of mAP-50 (Mean average precision), but with milliseconds of 29 versus 172. We select the neural network YOLOv3 because it is a pretrained (with over 300,000 COCO dataset images) network and response time and accuracy obtained in previous comparative works. By using YOLOv3 [15] we can identify multiple objects in a single prediction; once it has identified all the vehicles, it draws the box corresponding to each one of them. This process allows the detection and identification of the objects of interest inside each frame. It was not necessary to apply data augmentation or similar techniques during feature extraction or model training. However, splitting the video into frames was required during the feature extraction process since the YOLOv3 network uses these frames for vehicle detection.The vehicles are tracked through a Kalman filter [53] to determine their location in the next frame. We choose this filter because it estimates a joint probability distribution over the variables for each timeframe. It has better performance when is used for linear or linearized processes and measurement systems than particle filter, which is more suitable for nonlinear systems. The system is in charge of preserving all the locations of the vehicles over time. Therefore, we can draw each vehicle’s path inside the scenes and calculate the straight line corresponding to each trajectory. Figure 9 shows a detected vehicle in a white box, as well as a pair of lines, one yellow and another red, that correspond to the tracking of the same one and the calculated straight line corresponding to the tracking.
- Validation: The validation of the samples obtained is performed by visual inspection. The validation process starts by identifying the sample in the csv file using the unique identifier assigned to each sample. At the same time, the saved image corresponding to that sample is reviewed, and it is verified that the vehicle in question is entirely within the established delimiter (white box). This delimiter must completely cover the vehicle when passing through the entry and exit landmark. If the cover does not completely cover the vehicle, or the sample is taken moments before or after passing through a landmark, this sample is labeled as invalid. Otherwise, it is considered a valid sample. Figure 10 shows an example of a valid sample, and Figure 11 shows an example of an invalid one.
4.2.2. Predictive Mode
5. Results
5.1. Sampling
5.2. Experimental Configuration
5.3. Speed Estimation
5.4. Methods Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| INEGI | National Institute of Statistics and Geographic Information |
| ADAS | Advanced Driver Assistance Systems |
| ITS | Intelligent Transport Systems |
| YOLO | You Only Look Once |
| LR | Linear Regression |
| CR | Ridge Regression |
| Lasso | Least Absolute Shrinkage and Selection Operator |
| BCR | Bayesian Ridge Regression |
| RRF | Random Forest Regression |
| SVM | Support Vector Machine Regression |
| ANN | Artificial Neuronal Network |
| GPU | Graphic Processing unit |
| RAM | Random access memory |
| CPU | Central Processing Unit |
| HD | High definition |
| FPS | Photoframes Per Second |
| CSV | Comma-Separated Values |
References
- Zaki, P.S.; William, M.M.; Soliman, B.K.; Alexsan, K.G.; Khalil, K.; El-Moursy, M. Traffic signs detection and recognition system using deep learning. arXiv 2020, arXiv:2003.03256. [Google Scholar]
- Velázquez Narváez, Y.; Zamorano González, B.; Ruíz Ramos, L. Siniestralidad vial en la frontera norte de Tamaulipas. Enfoque en los procesos administrativos de control. Estud. Front. 2017, 18, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Carro-Pérez, E.H.; Ampudia-Rueda, A. Conductas de riesgo al conducir un automóvil en zonas urbanas del sur de Tamaulipas y la Ciudad de México. CienciaUAT 2019, 13, 100–112. [Google Scholar] [CrossRef]
- Impedovo, D.; Balducci, F.; Dentamaro, V.; Pirlo, G. Vehicular traffic congestion classification by visual features and deep learning approaches: A comparison. Sensors 2019, 19, 5213. [Google Scholar] [CrossRef] [Green Version]
- Coifman, B.; Neelisetty, S. Improved speed estimation from singleloop detectors with high truck flow. Intell. Transp. Syst. 2014, 18, 138–148. [Google Scholar] [CrossRef]
- Jin, G.; Ye, B.; Wu, Y.; Qu, F. Vehicle Classification Based on Seismic Signatures Using Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 628–632. [Google Scholar] [CrossRef]
- Balid, H.T.W.; Refai, H.H. Intelligent vehicle counting and classification sensor for real-time traffic surveillance. Intell. Transp. Syst. 2017, 19, 1784–1794. [Google Scholar] [CrossRef]
- Bautista, C.M.; Dy, C.A.; Mañalac, M.I.; Orbe, R.A.; Cordel, M. Convolutional neural network for vehicle detection in low resolution traffic videos. In Proceedings of the 2016 IEEE Region 10 Symposium (TENSYMP), Bali, Indonesia, 9–11 May 2016; pp. 277–281. [Google Scholar] [CrossRef]
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar] [CrossRef] [Green Version]
- Taghvaeeyan, S.; Rajamani, R. Portable Roadside Sensors for Vehicle Counting, Classification, and Speed Measurement. IEEE Trans. Intell. Transp. Syst. 2014, 15, 73–83. [Google Scholar] [CrossRef]
- Lee, H.; Coifman, B. Using LIDAR to Validate the Performance of Vehicle Classification Stations. J. Intell. Transp. Syst. 2015, 19, 355–369. [Google Scholar] [CrossRef]
- Won, M.; Zhang, S.; Son, S.H. WiTraffic: Low-Cost and Non-Intrusive Traffic Monitoring System Using WiFi. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Fernández Llorca, D.; Hernández Martínez, A.; García Daza, I. Vision-based vehicle speed estimation: A survey. IET Intell. Transp. Syst. 2021, 15, 8. [Google Scholar] [CrossRef]
- Maduro, C.; Batista, K.; Peixoto, P.; Batista, J. Estimating Vehicle Velocity Using Rectified Images. In Proceedings of the VISAPP (2), Funchal, Portugal, 22–25 January 2008; pp. 551–558. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 1–27. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Kumar, K.K.; Chandrakant, P.; Kumar, S.; Kushal, K. Vehicle Speed Detection Using Corner Detection. In Proceedings of the 2014 Fifth International Conference on Signal and Image Processing, Bangalore, India, 8–10 January 2014; pp. 253–258. [Google Scholar] [CrossRef]
- Kamoji, S.; Koshti, D.; Dmonte, A.; George, S.J.; Sohan Pereira, C. Image Processing based Vehicle Identification and Speed Measurement. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 523–527. [Google Scholar] [CrossRef]
- Bell, D.; Xiao, W.; James, P. Accurate Vehicle Speed Estimation from Monocular Camera Footage. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 419–426. [Google Scholar] [CrossRef]
- Vakili, E.; Shoaran, M.; Sarmadi, M. Single-camera vehicle speed measurement using the geometry of the imaging system. Multimed. Tools Appl. 2020, 79, 19307–19327. [Google Scholar] [CrossRef]
- Dahl, M.; Javadi, S. Analytical modeling for a video-based vehicle speed measurement framework. Sensors 2020, 20, 160. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Huynh, D.Q.; Sun, Y.; Reynolds, M.; Atkinson, S. A Vision-Based Pipeline for Vehicle Counting, Speed Estimation, and Classification. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7547–7560. [Google Scholar] [CrossRef]
- Ho, H.W.; de Croon, G.C.; Chu, Q. Distance and velocity estimation using optical flow from a monocular camera. Int. J. Micro Air Veh. 2017, 9, 198–208. [Google Scholar] [CrossRef]
- Schoepflin, T.; Dailey, D. Dynamic camera calibration of roadside traffic management cameras for vehicle speed estimation. IEEE Trans. Intell. Transp. Syst. 2003, 4, 90–98. [Google Scholar] [CrossRef]
- Anil Rao, Y.; Kumar, N.S.; Amaresh, H.; Chirag, H. Real-time speed estimation of vehicles from uncalibrated view-independent traffic cameras. In Proceedings of the TENCON 2015-2015 IEEE Region 10 Conference, Macao, 1–4 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, K.H. A Study on Distance Measurement Module for Driving Vehicle Velocity Estimation in Multi-Lanes Using Drones. Appl. Sci. 2021, 11, 3884. [Google Scholar] [CrossRef]
- Li, S.; Yu, H.; Zhang, J.; Yang, K.; Bin, R. Video-Based Traffic Data Collection System for Multiple Vehicle Types. IET Intell. Transp. Syst. 2014, 8, 164–174. Available online: https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/iet-its.2012.0099 (accessed on 30 January 2022). [CrossRef] [Green Version]
- Kurniawan, A.; Ramadlan, A.; Yuniarno, E.M. Speed Monitoring for Multiple Vehicle Using Closed Circuit Television (CCTV) Camera. In Proceedings of the 2018 International Conference on Computer Engineering, Network and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 26–27 November 2017; pp. 88–93. [Google Scholar] [CrossRef]
- Jalalat, M.; Nejati, M.; Majidi, A. Vehicle detection and speed estimation using cascade classifier and sub-pixel stereo matching. In Proceedings of the 2016 2nd International Conference of Signal Processing and Intelligent Systems (ICSPIS), Tehran, Iran, 14–15 December 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Dong, H.; Wen, M.; Yang, Z. Vehicle Speed Estimation Based on 3D ConvNets and Non-Local Blocks. Future Internet 2019, 11, 123. [Google Scholar] [CrossRef] [Green Version]
- Burnett, K.; Samavi, S.; Waslander, S.L.; Barfoot, T.D.; Schoellig, A.P. aUToTrack: A Lightweight Object Detection and Tracking System for the SAE AutoDrive Challenge; University of Toronto: Toronto, ON, Canada, 2019; pp. 209–216. [Google Scholar] [CrossRef] [Green Version]
- Moritz Kampelmuhler, M.G.M.; Feichtenhofer, C. Camera-Based Vehicle Velocity Estimation from Monocular Video. In Proceedings of the 23rd Computer Vision Winter Workshop, Cesky Krumlov, Czech Republic, 5–7 February 2018. [Google Scholar]
- Song, Z.; Luand, J.; Zhang, T.; Li, H. End-to-End Learning for Inter-Vehicle Distance and Relative Velocity Estimation in ADAS with a Monocular Camera; Cornell University: Ithaca, NY, USA, 2020. [Google Scholar]
- Yaqi Zhang, B.W.; Liu, W. Vehicle Motion Detection Using CNN; Stanford: Stanford, CA, USA, 2017. [Google Scholar]
- Loor, C. Visual Speedometer: Learning Velocity from Two Images; University of Amsterdam: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Fernández-Llorca, D.; Salinas, C.; Jimenez, M.; Morcillo, A.; Izquierdo, R.; Lorenzo Díaz, J.; Sotelo, M.A. Two-camera based accurate vehicle speed measurement using average speed at a fixed point. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2533–2538. [Google Scholar] [CrossRef]
- Yang, L.; Li, M.; Song, X.; Xiong, Z.; Hou, C.; Qu, B. Vehicle Speed Measurement Based on Binocular Stereovision System. IEEE Access 2019, 7, 106628–106641. [Google Scholar] [CrossRef]
- Yang, L.; Luo, J.; Song, X.; Li, M.; Wen, P.; Xiong, Z. Robust Vehicle Speed Measurement Based on Feature Information Fusion for Vehicle Multi-Characteristic Detection. Entropy 2021, 23, 910. [Google Scholar] [CrossRef]
- Yang, L.; Li, Q.; Song, X.; Cai, W.; Hou, C.; Xiong, Z. An Improved Stereo Matching Algorithm for Vehicle Speed Measurement System Based on Spatial and Temporal Image Fusion. Entropy 2021, 23, 866. [Google Scholar] [CrossRef]
- Luvizon, D.; Nassu, B.; Minetto, R. Vehicle speed estimation by license plate detection and tracking. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 4–9 May 2014. [Google Scholar] [CrossRef]
- Gutiérrez, E.; Vladimirovna, O. Estadística Inferencial 1 para Ingeniería y Ciencias; Grupo Editorial Patria: Ciudad de México, Mexico, 2016; pp. 271–348. [Google Scholar]
- McDonald, G.C. Ridge regression. WIREs Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Hans, C. Bayesian lasso regression. Biometrika 2009, 96, 835–845. [Google Scholar] [CrossRef]
- Zhang, Z.; Lai, Z.; Xu, Y.; Shao, L.; Wu, J.; Xie, G.S. Discriminative Elastic-Net Regularized Linear Regression. IEEE Trans. Image Process. 2017, 26, 1466–1481. [Google Scholar] [CrossRef] [Green Version]
- Minka, T. Bayesian Linear Regression. Technical Report, Citeseer. 2000. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.39.4002&rep=rep1&type=pdf (accessed on 30 January 2022).
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Olabe, X.B. Redes Neuronales Artificiales y sus Aplicaciones; Publicaciones de la Escuela de Ingenieros; Escuela Superior de Ingeniería de Bilbao: Bilbao, Spain, 1998. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter. 1995. Available online: https://perso.crans.org/club-krobot/doc/kalman.pdf (accessed on 30 January 2022).
- Kramer, O. Scikit-Learn; Springer: Berlin/Heidelberg, Germany, 2016; pp. 45–53. [Google Scholar]
- Dillon, J.V.; Langmore, I.; Tran, D.; Brevdo, E.; Vasudevan, S.; Moore, D.; Patton, B.; Alemi, A.; Hoffman, M.; Saurous, R.A. Tensorflow distributions. arXiv 2017, arXiv:1711.10604. [Google Scholar]







| Attribute | Description |
|---|---|
| Output Angle | Angle from the input to the output. |
| Distance Traveled | Distance traveled in pixels from the input to the output. |
| Input Area | Area in pixels at the input. |
| Output Area | Area in pixels at the output. |
| FPS | Frames per seconds. |
| Time | Travel time from the entry to the exit point.. |
| Lane | Street lane where pass the vehicle. |
| Speed | Speed detected by radar. |
| Identifier | Identifier to the created image. |
| Model | Configuration |
|---|---|
| Linear Regresion | copy X = True fit_intercept= True n jobs = None normalize = False positive = False |
| Ridge Regression, Lasso Regression, Bayesian Ridge, Elastic Net, Random Forest, Suppor Vector Machine | alpha = 0.5 copy_X = True fit_intercept = True max_iter = None normalize = False random_state = None solver = auto tol = 0.001 |
| MLP | Input = 2 Hidden = 5 Output = 1 |
| Statistical Models | Machine Learning Models | |||||||
|---|---|---|---|---|---|---|---|---|
| LR | CR | Lasso | BCR | Elastic Net | RFF | SVMR | MLP | |
| SD | 0.143 | 0.142 | 0.143 | 0.143 | 0.143 | 0.0141 | 0.163 | 3.397 |
| MAE | 1.694 | 1.694 | 1.699 | 1.695 | 1.701 | 1.828 | 1.960 | 2.767 |
| Statistical Models | Machine Learning Models | |||||||
|---|---|---|---|---|---|---|---|---|
| LR | CR | Lasso | BCR | Elastic Net | RFF | SVMR | MLP | |
| SD | 0.081 | 0.081 | 0.082 | 0.081 | 0.094 | 0.094 | 0.141 | 1.843 |
| MAE | 0.956 | 0.965 | 0.975 | 0.956 | 0.997 | 1.087 | 1.087 | 3.174 |
| Autor | Dataset | Input Data | Features Extracted | Environment Considerations | Limitations |
|---|---|---|---|---|---|
| Fernandez et al. [13] | Doesn’t Apply | Video images | License plate region | 2 cameras calibration | Calibration of the cameras affect the results. |
| Yang et al. [41] | Does not apply | Video images | Limits of plate, logo and light of vehicle | Compare license plate, light, logo to matching vehicles | Needs two industrial cameras with high resolution. |
| Luvizon et al. [43] | Does not apply | Video images | Characters of license plate | Image rectificaton | If the license plate is not legible or too small it has detection problems. |
| Vakili et al. [23] | 4 dataset | Video images | Coordinates of the license plate corners, number, and type and the color of the vehicle | Camera should have its back to the vehicles and higher height. | If the license plate is not legible or too small it has detection problems. |
| Anil Rao et al. [28] | Doesn’t Apply | Video images | Pixels traveled by the vehicle | Uses homography to perspective transform | Camera calibration parameters must be manually adjusted and monitored. |
| Lee et al. [29] | Doesn’t Apply | Input signal and output signal | Does not extract features | The high of the camera to avoid occlusions | It does not classify vehicles by type, it only makes its detections. |
| Li et al. [30] | Doesn’t Apply | Video images | Distance | Better detections on day | Shadows affect final performance. |
| Bell et al. [22] | COCO dataset | Video images | Vehicle’s coordinates | Distance is obtained by geometric estimation. | Change in size of detections affect velocity estimation. |
| Dong et al. [33] | VehSpeedDataset10 5332 short videos | RGB images and optical flow | Distance | Camera calibration using coordinate system | Lack of quality data. |
| Kampelmuhler et al. [35] | 1074 sequences in freeway traffic | Video images | Vehicle Tracks, Depth and Motion | Does not have considerations | Processing time for feature extraction. |
| Song et al. [36] | KITTI | Video images | Coordinates of vehicle | Does not have considerations | Use a GPU for processing |
| Zhang et al. [37] | KITTI | Video images | Coordinates of vehicle | Does not have considerations | The detection thresholds must be manually calibrated. |
| Loor et al. [38] | KTH data set, KITTI | Video images | Distance on pixels | Does not have considerations | If the image moves, parked vehicles can be detected as moving. |
| This work | COCO dataset and Own dataset | Video images | Distance and time | Does not have considerations | The videos must be analize manually to separate the bad samples. |
| Autor | Vehicles Detection | Speed Estation Algorithm | Performance | ||
|---|---|---|---|---|---|
| Object Segmentation | Object Detection | Object Tracking | |||
| Fernandez et al. [13] | Does not apply | MSER Detector, License plate | Does not use tracking | Uses the detection time of the cameras and the distance between detections. | <3 km/h |
| Yang et al. [41] | Does not apply | SSD (Single-Shot Multibox Detector) YOLOv4, license plate | LNCC+STIF s | Uses combination of logo, badge and light speeds, detects speed of each using distance and time. | 0.9, +1.06 km/h |
| Luvizon et al. [43] | Character filtering | Text detection for license plate detection SNOOPERTEXT | Kanade–Lucas–Tomas (KLT), and Feature Transform (SIFT) | It converts pixels traveled by the vehicle to meters and uses the time it takes to cross the vehicle. | 0.59 km/h |
| Vakili et al. [23] | Does not apply | The license plate | OpenALPR library | Using the geometric information of the system and the distance travelledby vehicles the speed is computed. | 1.32 km/h |
| Anil Rao et al. [28] | Background Subtraction | Vehicle Centroid | Kalman filter, Hungarian Algorithm | Perspective Transform to obtein of distance traveled by the vehicle, then calculate the speed with the distance and time. | 3 km/h |
| Lee et al. [30] | Does not apply | 2 LiDAR sensors | Doesn’t tracking | It uses the distance between 2 points and the time it takes for vehicles to cross those 2 points. | 1.31 km/h |
| Li et al. [30] | Background Subtraction | vehicules | feature point of vehicle head (FPVH) | Use the tracking algorithm to obtain the distance traveled by the vehicle and then use the time. | 2.3 km/h |
| Bell et al. [22] | Does not apply | YOLOv2 vehicles | Simple Online Realtime Tracking (SORT) | Performs pixel-to-distance transformation, and obtains the time the vehicle takes to travel the distance to obtain the speed. | 2.25 km/h |
| Dong et al. [33] | Does not apply | Contours of the vehicle | Detected contours | It uses the calibration of the camera to obtain the distance traveled by the tracked vehicles, and the time to obtain the speed. | 2.71 km/h |
| Kampelmuhler et al. [35] | Does not apply | Vehicles | Median Flow and MIL tracks | Uses a MLP model with the extracted features to obtain the Speed. | 4.32 km/h |
| Song et al. [36] | Does not apply | PWCNet pretrained from FlyingChairs, vehicles | Does not use tracking | Speed estimation with additional geometrical and a temporal optical flow track. | 1.728 km/h |
| Zhang et al. [37] | Does not apply | Region-based CNN (R-CNN), vehicles | Does not use tracking | Uses model of deep learning to obtain speed. | 6.832 km/h |
| Loor et al. [38] | Does not apply | SpeedNet | Does not use tracking | Uses a FlowNet trained to predict speed of Vehicles on a video. | 3.6 km/h |
| This work | Does not apply | YOLO v3 | Kalman Filter | Coordinates are used to measure time and distance vehicles take to cross, then regression models are used to obtain the speed. | 0.956 km/h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Rangel, H.; Morales-Rosales, L.A.; Imperial-Rojo, R.; Roman-Garay, M.A.; Peralta-Peñuñuri, G.E.; Lobato-Báez, M. Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO. Appl. Sci. 2022, 12, 2907. https://doi.org/10.3390/app12062907
Rodríguez-Rangel H, Morales-Rosales LA, Imperial-Rojo R, Roman-Garay MA, Peralta-Peñuñuri GE, Lobato-Báez M. Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO. Applied Sciences. 2022; 12(6):2907. https://doi.org/10.3390/app12062907
Chicago/Turabian StyleRodríguez-Rangel, Héctor, Luis Alberto Morales-Rosales, Rafael Imperial-Rojo, Mario Alberto Roman-Garay, Gloria Ekaterine Peralta-Peñuñuri, and Mariana Lobato-Báez. 2022. "Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO" Applied Sciences 12, no. 6: 2907. https://doi.org/10.3390/app12062907
APA StyleRodríguez-Rangel, H., Morales-Rosales, L. A., Imperial-Rojo, R., Roman-Garay, M. A., Peralta-Peñuñuri, G. E., & Lobato-Báez, M. (2022). Analysis of Statistical and Artificial Intelligence Algorithms for Real-Time Speed Estimation Based on Vehicle Detection with YOLO. Applied Sciences, 12(6), 2907. https://doi.org/10.3390/app12062907