
Mask R-CNN with New Data Augmentation Features for Smart Detection of Retail Products



Abstract
:1. Introduction
2. Proposed Methods
2.1. A. Preprocessing
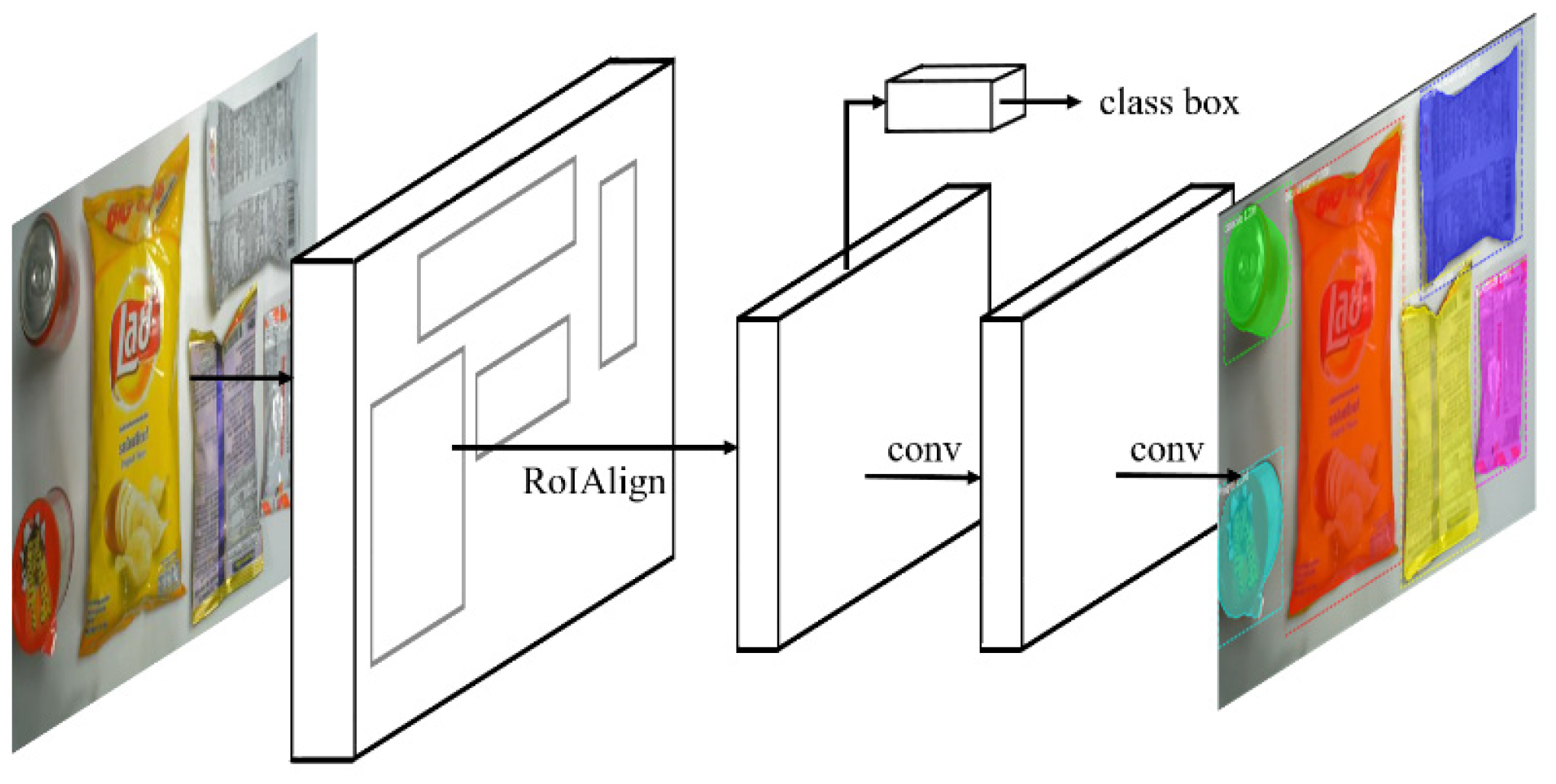
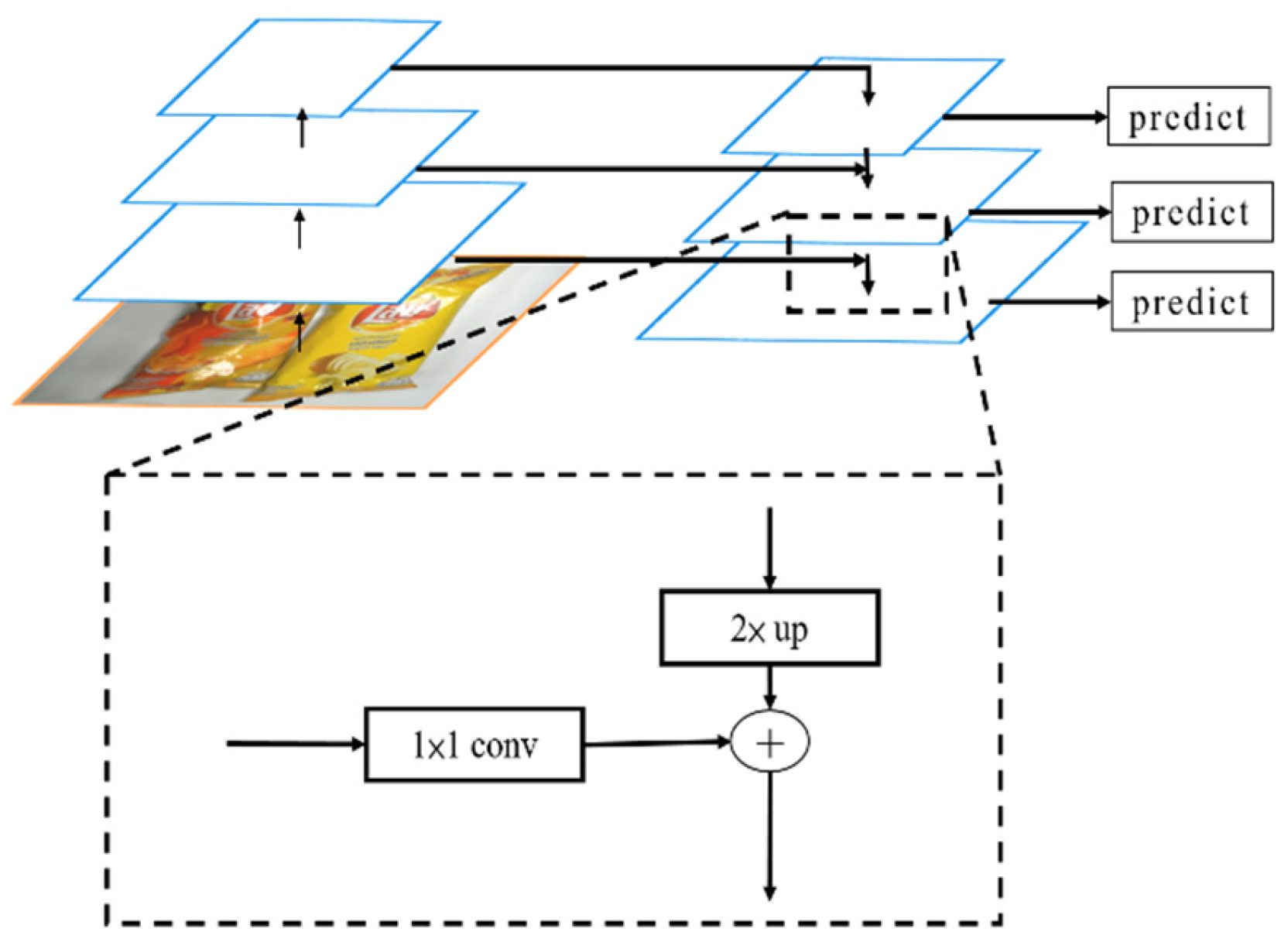
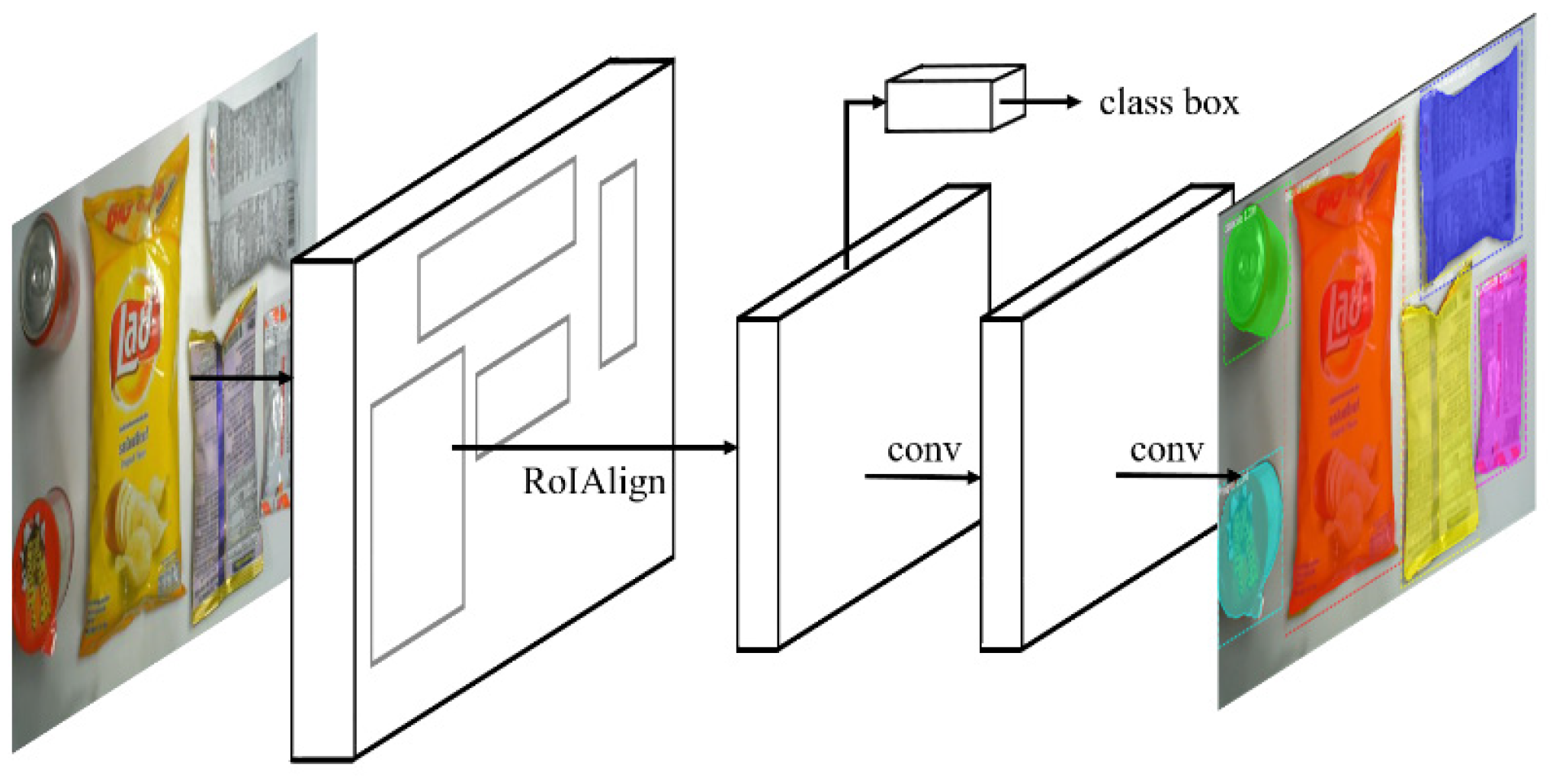
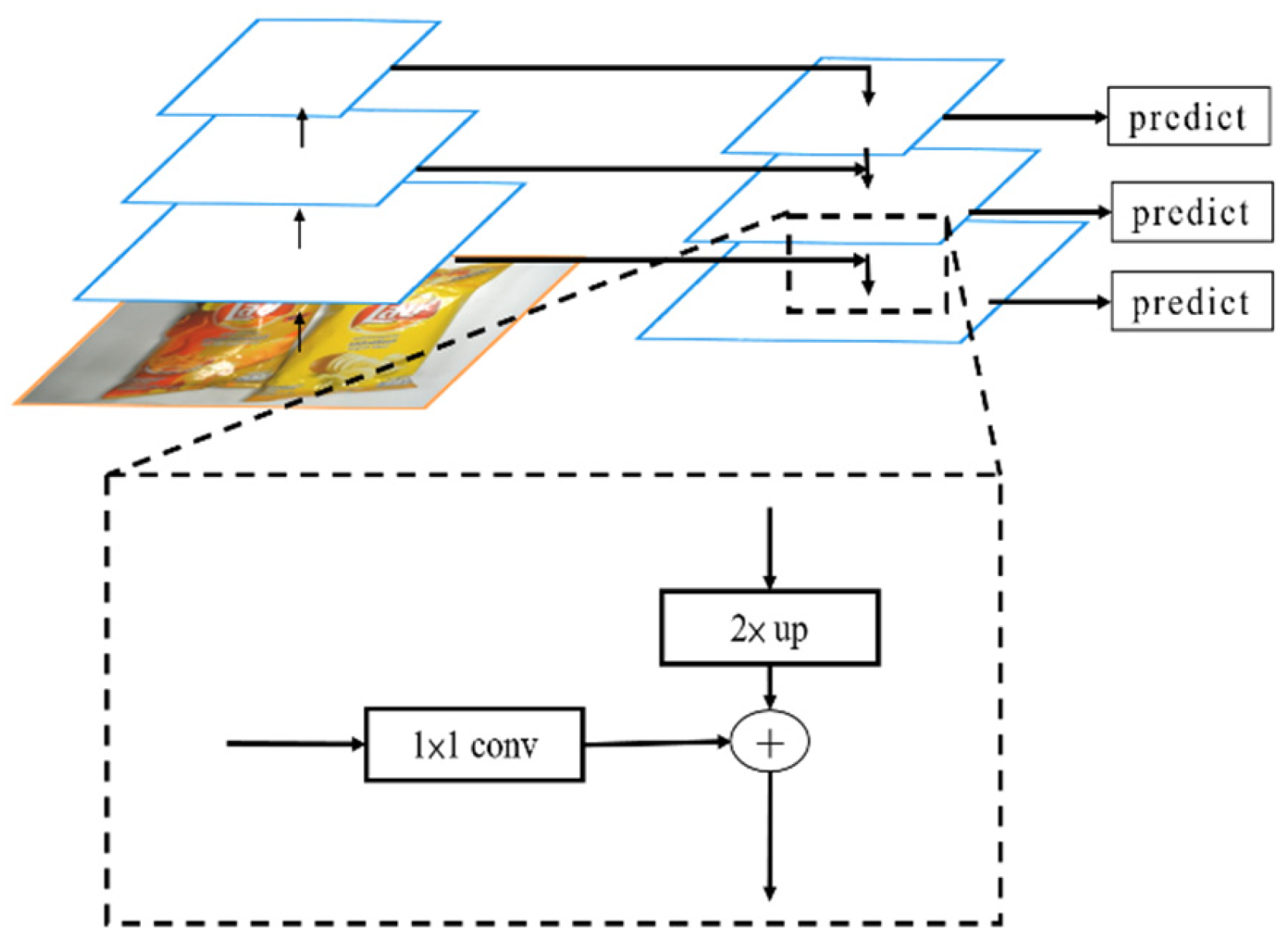
2.2. B. Mask R-CNN
3. Experimental Results
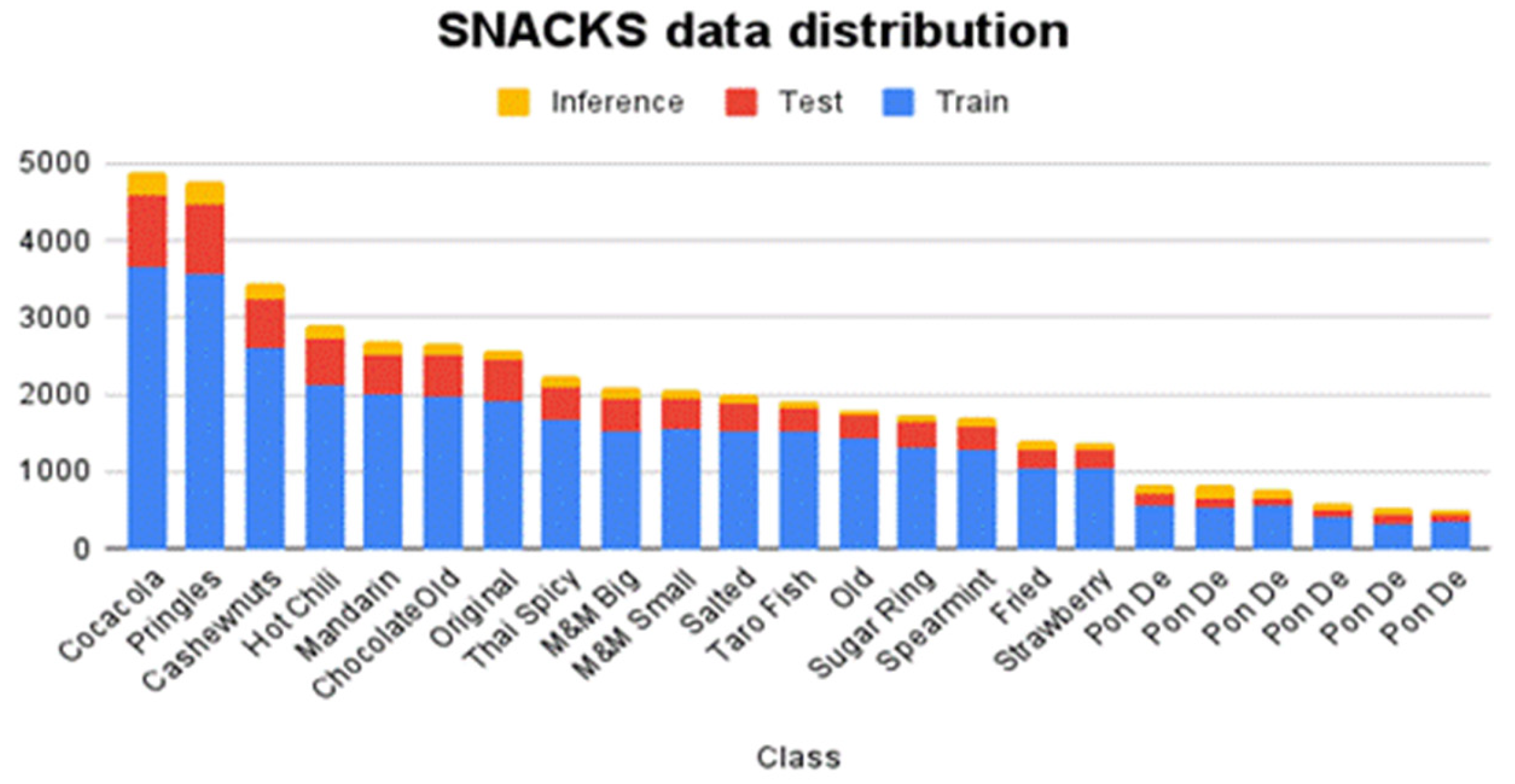
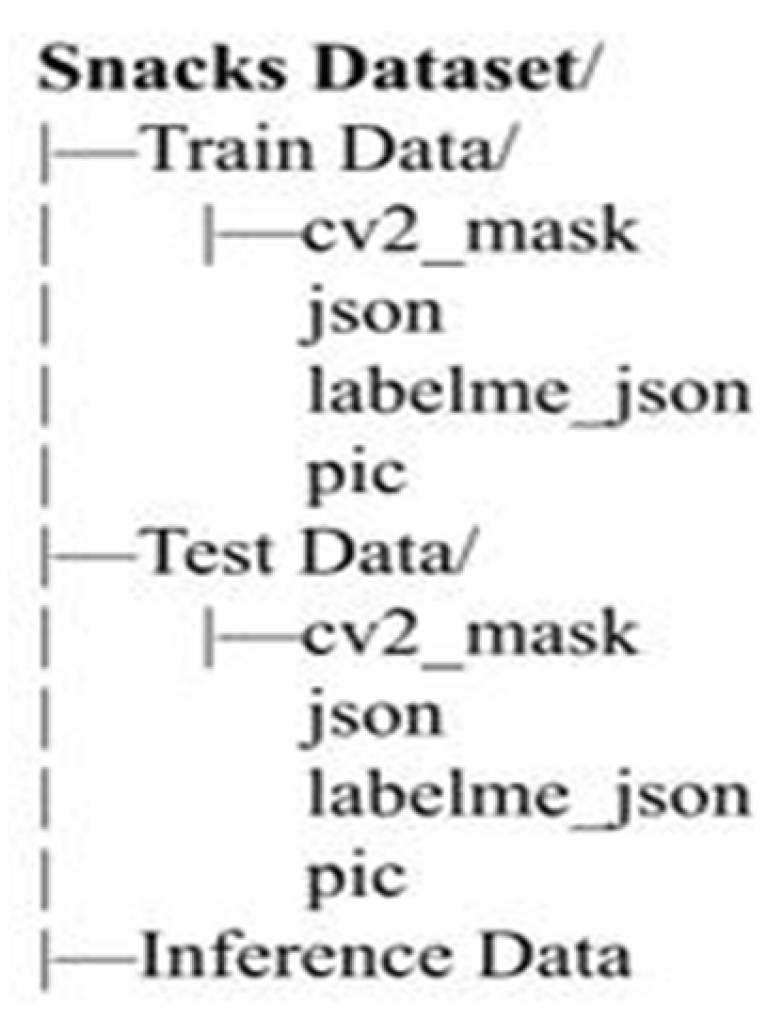
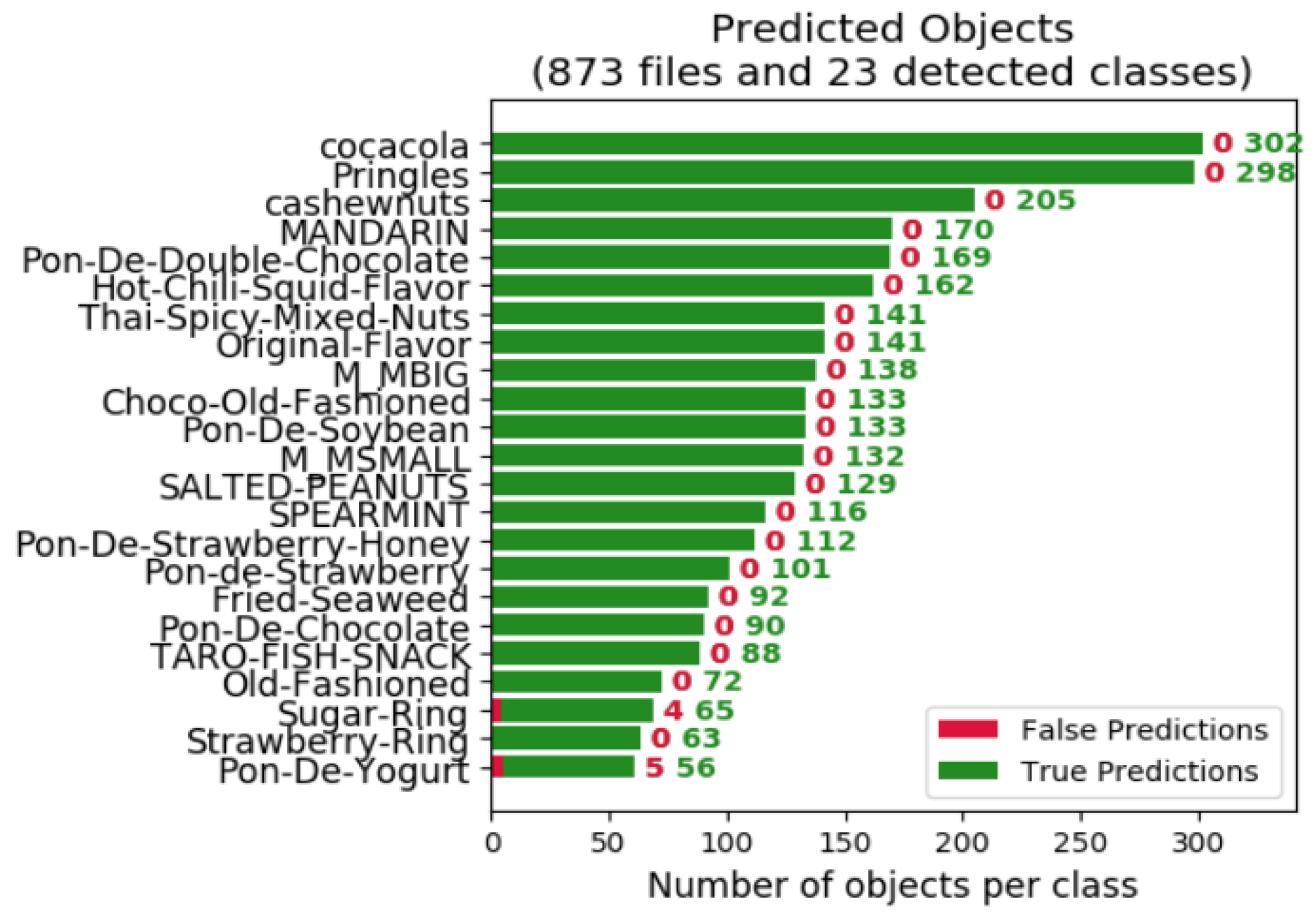
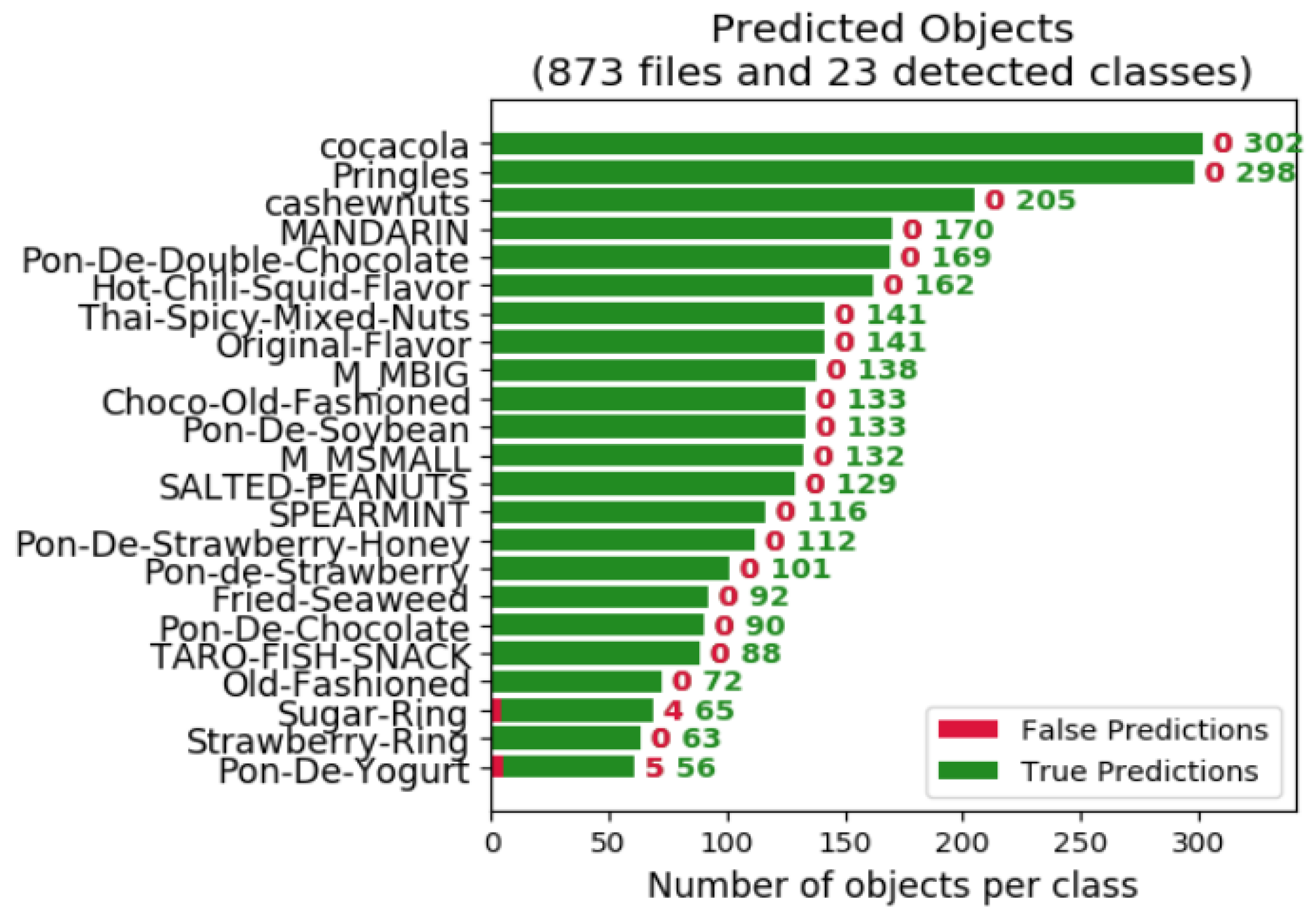
3.1. A. Database
3.2. B. Analysis Criteria
3.3. C. Experimental Tools
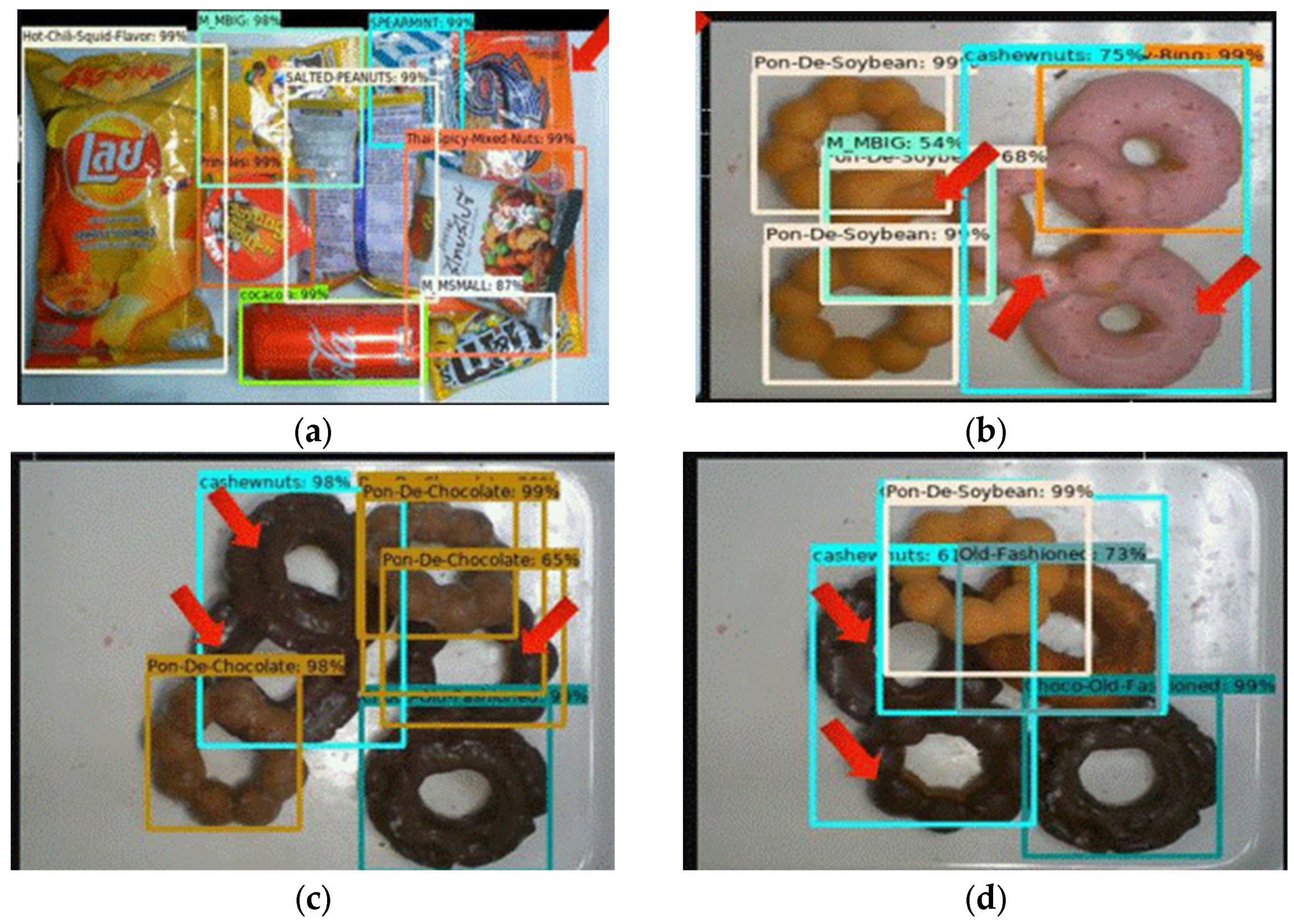
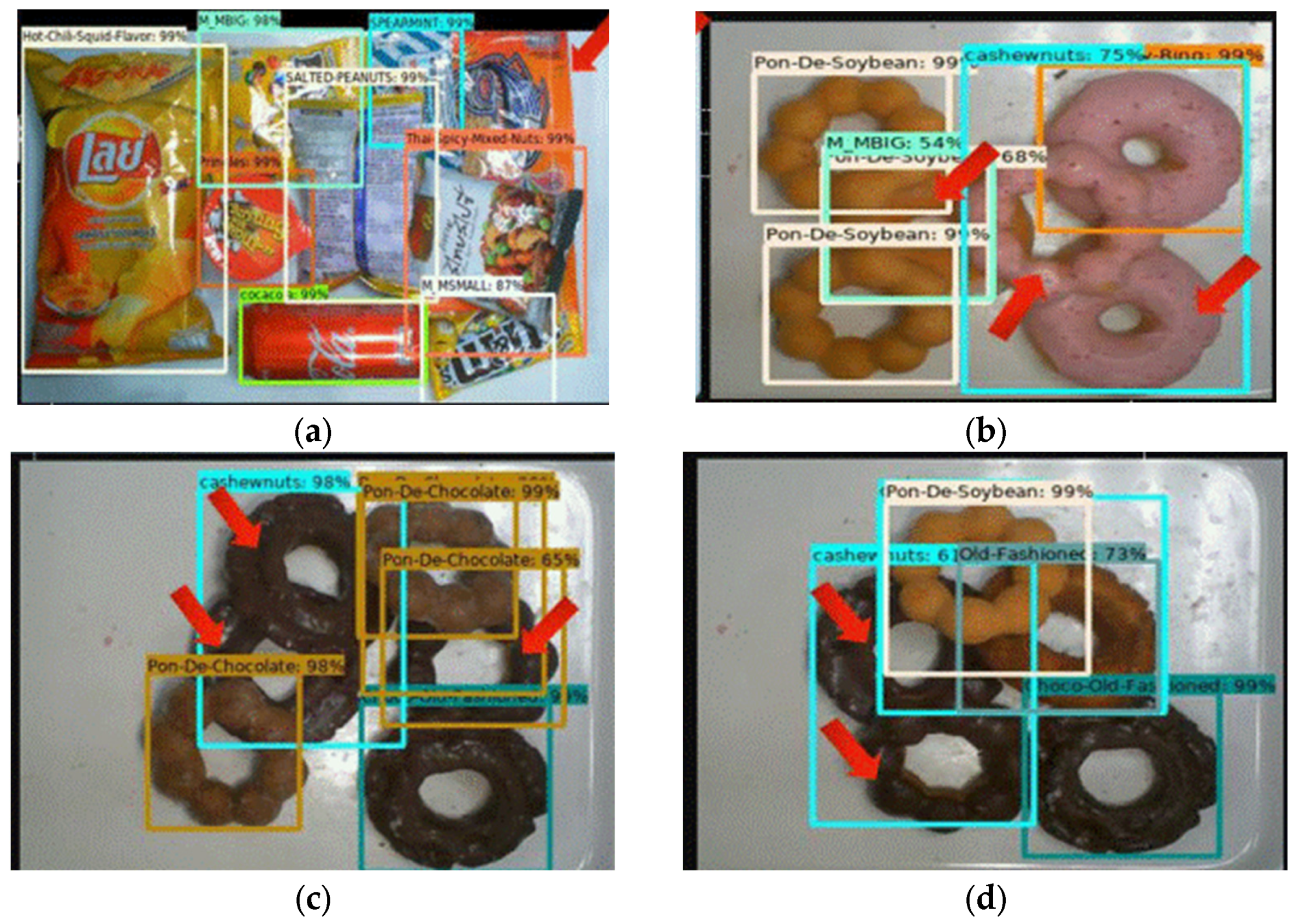
3.4. D. Results and Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bridges, T.; Jacobs, K.; Rietra, M.; Cherian, S. Smart Stores—Rebooting the Retail Store through in-Store Automation; Capgemini Research Institute: Paris, France, 2019. [Google Scholar]
- Hsia, C.-H.; Chang, T.-H.W.; Chiang, C.-Y.; Chan, H.-T. Real-time retail product detection with new augmentation features. In Proceedings of the IEEE International Conference on Electronic Communications, Internet of Things and Big Data, Yilan County, Taiwan, 10–12 December 2021. [Google Scholar]
- Sagues-Tanco, R.; Benages-Pardo, L.; López-Nicolás, G.; Llorente, S. Fast synthetic dataset for kitchen object segmentation in deep learning. IEEE Access 2020, 8, 220496–220506. [Google Scholar] [CrossRef]
- Ren, H.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-ime object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Grishick, R. Mask R-CNN. In Proceedings of the IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, Venice, Italy, 22–29 October 2017; pp. 386–397. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid network for object detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 936–944. [Google Scholar]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Ruan, C.; Sun, Y. Cucumber fruits detection in greenhouses based on instance segmentation. IEEE Access 2019, 7, 139635–139642. [Google Scholar] [CrossRef]
- Sizkouhi, A.M.M.; Aghaei, M.; Esmailifar, S.M.; Mohammadi, M.R.; Grimaccia, F. Automatic boundary extraction of large-scale photovoltaic plants using a fully convolutional network on aerial imagery. IEEE J. Photovolt. 2020, 10, 1061–1067. [Google Scholar] [CrossRef]
- Zhang, Q.; Chang, X.; Bian, S.B. Vehicle-damage-detection segmentation algorithm based on improved mask RCNN. IEEE Access 2020, 8, 6997–7004. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolution neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Song, F.; Wu, L.; Zheng, G.; He, X.; Wu, G.; Zhong, Y. Multisize plate detection algorithm based on improved Mask RCNN. In Proceedings of the IEEE International Conference on Smart Internet of Things, Beijing, China, 14–16 August 2020; pp. 277–281. [Google Scholar]
- Hsia, C.-H.; Chiang, J.-S.; Guo, J.-M. Memory-Efficient hardware architecture of 2-D dual-Mode lifting-Based discrete wavelet transform. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 671–683. [Google Scholar] [CrossRef]
- Hsia, C.-H.; Guo, J.-M.; Chiang, J.-S. Improved low-Complexity algorithm for 2-D integer lifting-Based discrete wavelet transform using symmetric mask-based scheme. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 1201–1208. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | APkp | APkp50 | APkp75 | APkpM | APkpL |
|---|---|---|---|---|---|
| ROI pool | 59.8 | 86.2 | 66.7 | 55.1 | 67.4 |
| ROI align | 64.2 | 86.6 | 69.7 | 58.7 | 73.0 |
| +4.4 | +0.4 | +3.0 | +3.6 | +5.6 |
 |  |  |  |
| CocaCola | Cashewnuts | M & M large | M & M small |
 |  |  |  |
| Hot chili squid flavor | Original flavor | Thai spicy mixed nuts | Pringles |
 |  |  |  |
| Taro fish snack | Salted peanuts | Mandarin | Spearmint |
 |  |  |  |
| Fried seaweed | Pon de strawberry honey | Pon de strawberry | Pon de double chocolate |
 |  |  |  |
| Pon de chocolate | Pon de soybean | Pon de yogurt | Chocolate old fashioned |
 |  |  | |
| Old fashioned | Strawberry ring | Sugar ring |
| Models | Top-1 Err. | Top-5 Err. |
|---|---|---|
| VGG-16 | 28.07 | 9.33 |
| GoogLeNet | - | 9.15 |
| PReLU-net | 24.27 | 7.38 |
| ResNet-34A | 25.03 | 7.76 |
| ResNet-34B | 24.52 | 7.46 |
| ResNet-34C | 24.19 | 7.40 |
| ResNet-50 | 22.85 | 6.71 |
| ResNet-101 | 21.75 | 6.05 |
| ResNet-152 | 21.43 | 5.71 |
| Faster R-CNN | AP | APs | APm | APt |
|---|---|---|---|---|
| Baseline on conv4 | 31.9 | 13.9 | 36.5 | 45.5 |
| Baseline on conv5 | 28.8 | 11.9 | 32.4 | 43.4 |
| FPN | 33.9 | 17.8 | 37.7 | 45.8 |
| Stage | 5Layer | Epochs | LR |
|---|---|---|---|
| 1 | RPN, mask heads | 100 | 0.001 |
| 2 | ResNet stage 4 and up | 200 | 0.001 |
| 3 | All | 300 | 0.0001 |
| Architectures | ACT (ms) | mAP (%) |
|---|---|---|
| SSD [17] | 581 | 83.91 |
| YOLO v3 | <100 | 92.89 |
| Faster R-CNN [4] | 1900 | 95.71 |
| Mask R-CNN [8] | 194.099 | 97.09 |
| Mask R-CNN + Aug. | 192.285 | 98.26 |
| Mask R-CNN + Aug.+ DWT (LL) | 220.072 | 98.95 |
| Mask R-CNN + Aug.+ DWT (HH + LL) | 194.470 | 99.27 |
| Items | YOLO v3 | Faster R-CNN [4] | Mask R-CNN [8] | Mask R-CNN + Aug. | Mask R-CNN + Aug. + DWT (LL) | Mask R-CNN + Aug. + DWT (LL + HH) |
|---|---|---|---|---|---|---|
| CocoCola | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 |
| Cashewnuts | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| M&M large | 0.94 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| M&M small | 0.97 | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 |
| Hot chili squid flavor | 0.97 | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 |
| Original flavor | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Thai spicy mixed nuts | 0.94 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 |
| Pringles | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 |
| Taro fish snack | 0.82 | 0.89 | 0.94 | 0.91 | 0.95 | 0.95 |
| Salted peanuts | 0.94 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Mandarin | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 |
| Spearmint | 0.93 | 0.88 | 0.94 | 0.97 | 0.96 | 0.98 |
| Fried seaweed | 1.00 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 |
| Pon de strawberry honey | 0.96 | 1.00 | 1.00 | 0.96 | 1.00 | 1.00 |
| Pon de strawberry | 0.96 | 0.95 | 0.95 | 1.00 | 1.00 | 1.00 |
| Pon de double chocolate | 0.90 | 0.91 | 1.00 | 1.00 | 1.00 | 1.00 |
| Pon de chocolate | 0.80 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 |
| Pon de soybean | 0.77 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Pon de yogurt | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Chocolate old fashioned | 0.80 | 0.74 | 0.85 | 0.92 | 0.96 | 1.00 |
| Old fashioned | 0.81 | 0.92 | 1.00 | 1.00 | 1.00 | 1.00 |
| Strawberry ring | 1.00 | 0.92 | 0.84 | 1.00 | 1.00 | 1.00 |
| Sugar ring | 0.87 | 0.93 | 0.86 | 0.86 | 0.92 | 0.92 |
| ACT (ms) | <100 | 1900 | 194.10 | 192.29 | 220.07 | 194.47 |
| mAP (%) | 92.89 | 95.71 | 97.09 | 98.26 | 98.95 | 99.27 |
| Faster R-CNN | Set | This Work |
|---|---|---|
 | 1 |  |
 | 2 |  |
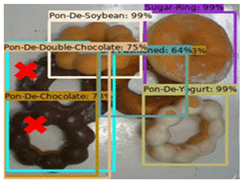 | 3 |  |
 | 4 |  |
 | 5 |  |
 | 6 |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsia, C.-H.; Chang, T.-H.W.; Chiang, C.-Y.; Chan, H.-T. Mask R-CNN with New Data Augmentation Features for Smart Detection of Retail Products. Appl. Sci. 2022, 12, 2902. https://doi.org/10.3390/app12062902
Hsia C-H, Chang T-HW, Chiang C-Y, Chan H-T. Mask R-CNN with New Data Augmentation Features for Smart Detection of Retail Products. Applied Sciences. 2022; 12(6):2902. https://doi.org/10.3390/app12062902
Chicago/Turabian StyleHsia, Chih-Hsien, Tsung-Hsien William Chang, Chun-Yen Chiang, and Hung-Tse Chan. 2022. "Mask R-CNN with New Data Augmentation Features for Smart Detection of Retail Products" Applied Sciences 12, no. 6: 2902. https://doi.org/10.3390/app12062902
APA StyleHsia, C.-H., Chang, T.-H. W., Chiang, C.-Y., & Chan, H.-T. (2022). Mask R-CNN with New Data Augmentation Features for Smart Detection of Retail Products. Applied Sciences, 12(6), 2902. https://doi.org/10.3390/app12062902