
Double Branch Attention Block for Discriminative Representation of Siamese Trackers



Abstract
:1. Introduction
2. Related Work
2.1. Siamese Trackers
2.2. Attention Mechanism
3. Proposed Method
3.1. Overall Overview
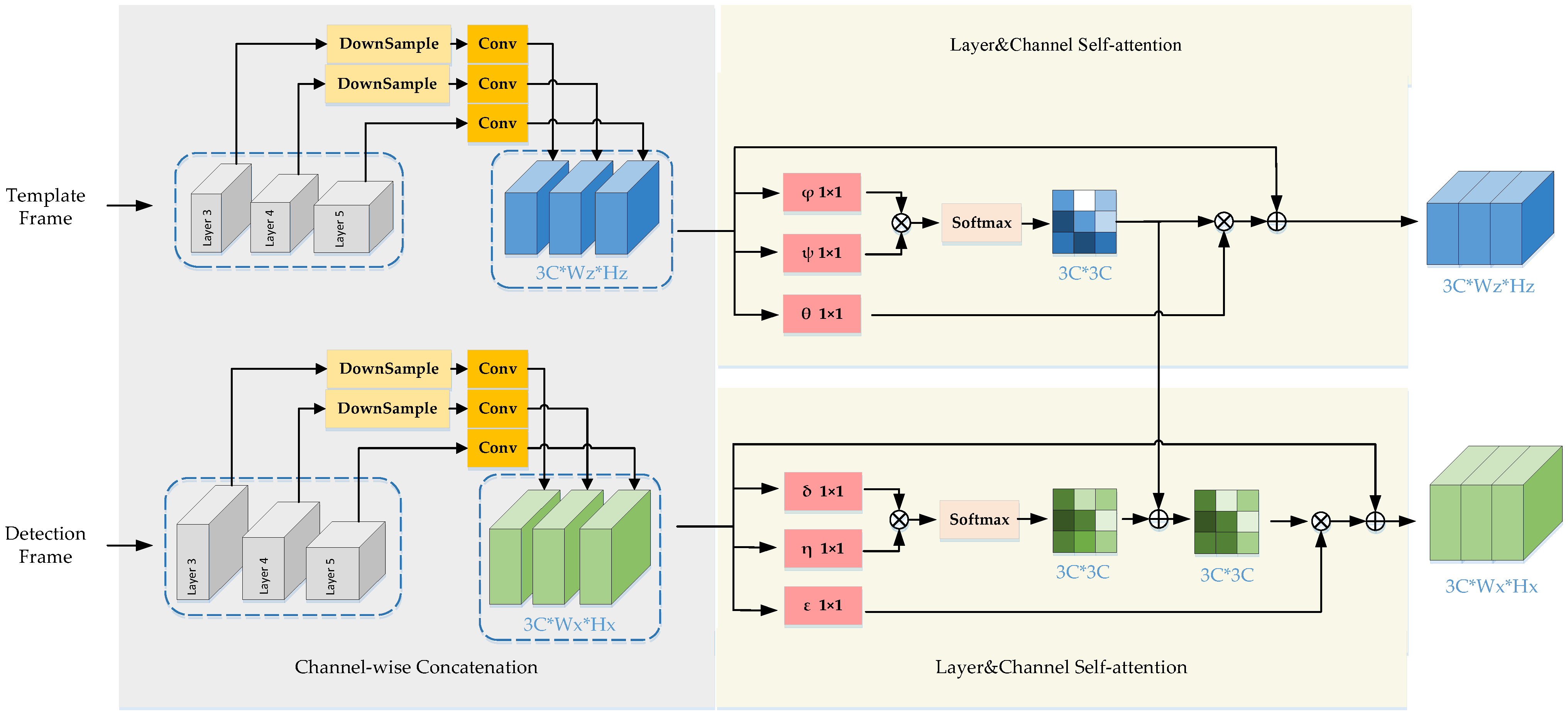
3.2. DBA Block
3.2.1. Channel-Wise Concatenation
3.2.2. Channel Self-Attention
3.2.3. Information Compensation
4. Results
4.1. Experimental Details
4.2. Algorithm Comparison
4.2.1. UAV123 Benchmark
4.2.2. VOT Benchmark
4.3. Ablation Experiment
4.3.1. Data Experiments
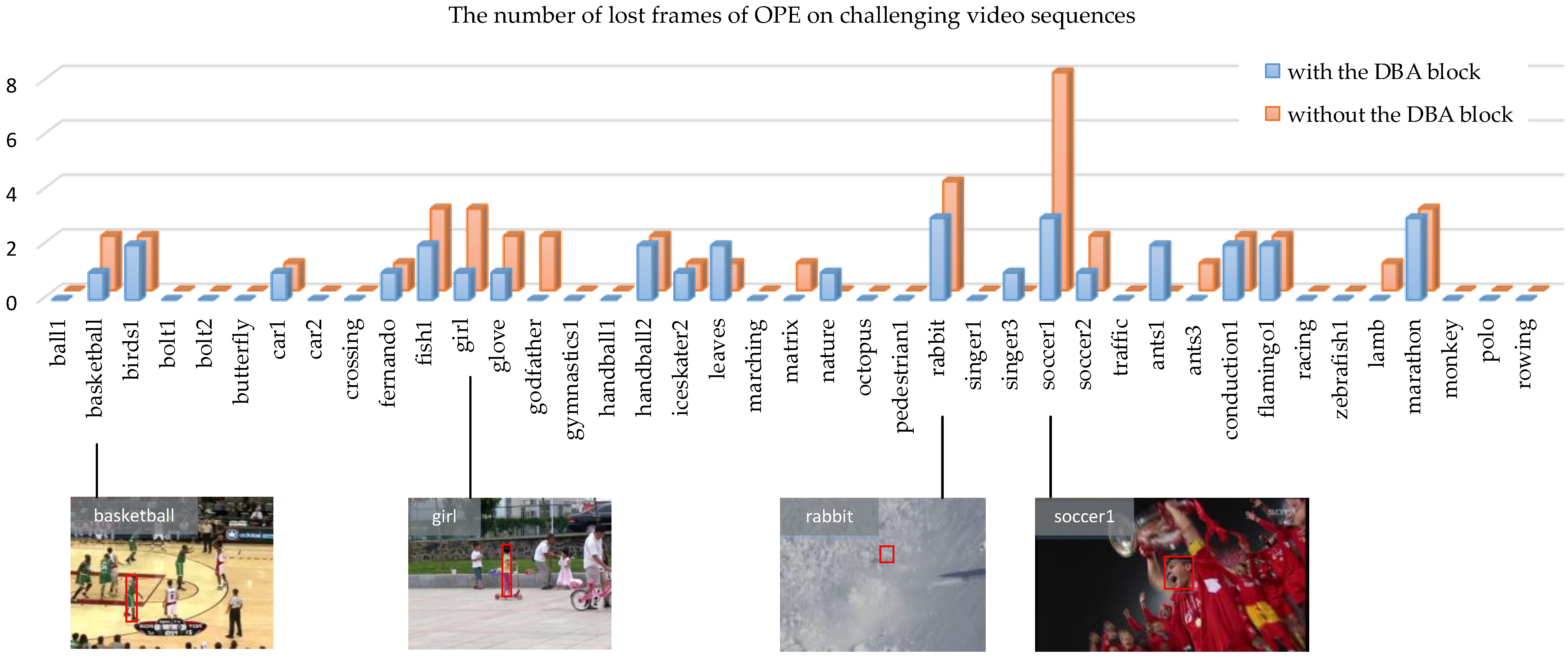
4.3.2. Visualization Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, K.-H.; Hwang, J.-N. On-Road Pedestrian Tracking across Multiple Driving Recorders. IEEE Trans. Multimed. 2015, 17, 1429–1438. [Google Scholar] [CrossRef]
- Li-Tian, Z.; Meng-Yin, F.; Yi, Y.; Mei-Ling, W. A framework of traffic lights detection, tracking and recognition based on motion models. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 2298–2303. [Google Scholar] [CrossRef]
- Jia, T.; Taylor, Z.A.; Chen, X. Computerized Medical Imaging and Graphics Long term and robust 6DoF motion tracking for highly dynamic stereo endoscopy videos. Comput. Med. Imaging Graph. 2021, 94, 101995. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Xing, J.; Ai, H.; Ruan, X. Hand Posture Recognition Using Finger Geometric Feature. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 565–568. [Google Scholar]
- Chang, C.-Y.; Lie, H.W. Real-Time Visual Tracking and Measurement to Control Fast Dynamics of Overhead Cranes. IEEE Trans. Ind. Electron. 2011, 59, 1640–1649. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. STCT: Sequentially Training Convolutional Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1373–1381. [Google Scholar] [CrossRef]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning Dynamic Siamese Network for Visual Object Tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1781–1789. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4586–4595. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Jiang, Z.; Gu, Y.; Wu, Y.; Wang, Y.; Tai, Y.; Wang, C.; Lin, W. SiamRCR: Reciprocal Classification and Regression for Visual Object Tracking. arXiv 2021, arXiv:2105.11237. [Google Scholar] [CrossRef]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A Twofold Siamese Network for Real-Time Object Tracking. arXiv 2018, arXiv:1802.08817. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Luo, C.; Xiong, Z.; Zeng, W. SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3638–3647. [Google Scholar] [CrossRef] [Green Version]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Kristan, M.; Fern, G.; Gupta, A.; Petrosino, A. The Visual Object Tracking VOT2017 challenge results. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2016; ISBN 9783319488813. [Google Scholar]
- Kristan, M.; Fern, G. The Seventh Visual Object Tracking VOT2019 Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 2206–2241. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.html (accessed on 24 December 2021).
- Yang, T.; Chan, A.B. Learning Dynamic Memory Networks for Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 153–169. [Google Scholar] [CrossRef] [Green Version]
- Abdelpakey, M.H.; Shehata, M.S.; Mohamed, M.M. DensSiam: End-to-End Densely-Siamese Network with Self-Attention Model for Object Tracking. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 19–21 November 2018; Springer: Cham, Switzerland, 2018; pp. 463–473. [Google Scholar] [CrossRef] [Green Version]
- Ni, Z.-L.; Bian, G.-B.; Xie, X.-L.; Hou, Z.-G.; Zhou, X.-H.; Zhou, Y.-J. RASNet: Segmentation for Tracking Surgical Instruments in Surgical Videos Using Refined Attention Segmentation Network. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5735–5738. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6667–6676. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Jan, C.V.; Krause, J.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Xu, N.; Yang, L.; Fan, Y.; Yang, J.; Yue, D.; Sep, C.V. YouTube-VOS: Sequence-to-Sequence Video Object Segmentation. In European Conference on Computer Vision, Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 603–619. [Google Scholar]
- Huang, Z.; Fu, C.; Li, Y.; Lin, F.; Lu, P. Learning Aberrance Repressed Correlation Filters for Real-Time UAV Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2891–2900. [Google Scholar] [CrossRef] [Green Version]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.-H. Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Danelljan, M.; Robinson, A.; Shahbaz Khan, F.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 472–488. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar] [CrossRef] [Green Version]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary Learners for Real-Time Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar] [CrossRef] [Green Version]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Wu, W.; Zou, W.; Yan, J. End-to-End Flow Correlation Tracking with Spatial-Temporal Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 548–557. [Google Scholar] [CrossRef] [Green Version]
- Yao, S.; Zhang, H.; Ren, W.; Ma, C.; Han, X.; Cao, X. Robust Online Tracking via Contrastive Spatio-Temporal Aware Network. IEEE Trans. Image Process. 2021, 30, 1989–2002. [Google Scholar] [CrossRef]
- Li, X.; Ma, C.; Wu, B.; He, Z.; Yang, M.-H. Target-Aware Deep Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, 18–20 June 2019; pp. 1369–1378. [Google Scholar] [CrossRef] [Green Version]
- Kristan, M. The Sixth Visual Object Tracking VOT2018 Challenge Results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshop, Munich, Germany, 8–14 September 2018; ISBN 9783030110093. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy ↑ | Precision ↑ | |
|---|---|---|
| SiamFC [9] | 0.447 | 0.681 |
| ARCF [31] | 0.470 | 0.670 |
| STAPLE_CA [32] | 0.425 | 0.597 |
| STRCF [33] | 0.457 | 0.627 |
| CCOT [34] | 0.409 | 0.659 |
| CFNet [35] | 0.428 | 0.680 |
| SiamRPN [12] | 0.527 | 0.748 |
| ECO [36] | 0.525 | 0.741 |
| ECOhc [36] | 0.472 | 0.660 |
| DaSiamRPN [11] | 0.586 | 0.796 |
| Ours | 0.604 | 0.792 |
| VOT2016 | VOT2019 | |||||
|---|---|---|---|---|---|---|
| A ↑ | R ↓ | EAO ↑ | A ↑ | R ↓ | EAO ↑ | |
| Staple [37] | 0.544 | 0.378 | 0.295 | |||
| DeepSRDCF [38] | 0.528 | 0.326 | 0.276 | |||
| SiamFC [9] | 0.532 | 0.461 | 0.235 | 0.477 | 0.687 | 0.204 |
| SiamRPN [12] | 0.560 | 0.260 | 0.344 | 0.517 | 0.552 | 0.224 |
| DaSiamRPN [11] | 0.610 | 0.220 | 0.411 | |||
| ECOhc [36] | 0.540 | 1.190 | 0.322 | |||
| CCOT [34] | 0.539 | 0.238 | 0.331 | 0.495 | 0.507 | 0.234 |
| FlowTrack [39] | 0.578 | 0.241 | 0.334 | |||
| MemTrack [24] | 0.530 | 1.440 | 0.273 | |||
| SA-SIAM [15] | 0.540 | 1.080 | 0.291 | 0.559 | 0.492 | 0.253 |
| S_SiamFC | 0.487 | 0.261 | 0.328 | 0.459 | 0.577 | 0.207 |
| CSTNet [40] | 0.571 | 0.219 | 0.349 | |||
| TADT [41] | 0.516 | 0.677 | 0.207 | |||
| Gasiamrpn [42] | 0.548 | 0.522 | 0.247 | |||
| CSRDCF [19] | 0.496 | 0.632 | 0.201 | |||
| Gasiamrpn [19] | 0.548 | 0.522 | 0.247 | |||
| SiamMsST [19] | 0.575 | 0.552 | 0.252 | |||
| Ours | 0.634 | 0.242 | 0.415 | 0.587 | 0.602 | 0.261 |
| DBA Block | VOT2016-EAO ↑ | VOT2019-EAO ↑ | UAV123-Accuracy ↑ | UAV123-Precision ↑ | Speed FPS ↑ |
|---|---|---|---|---|---|
| 0.344 | 0.260 | 0.582 | 0.772 | 31.6 | |
| √ | 0.415 | 0.261 | 0.604 | 0.792 | 30.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, J.; Yang, J.; Chen, X.; Wang, Y.; Cai, H. Double Branch Attention Block for Discriminative Representation of Siamese Trackers. Appl. Sci. 2022, 12, 2897. https://doi.org/10.3390/app12062897
Xi J, Yang J, Chen X, Wang Y, Cai H. Double Branch Attention Block for Discriminative Representation of Siamese Trackers. Applied Sciences. 2022; 12(6):2897. https://doi.org/10.3390/app12062897
Chicago/Turabian StyleXi, Jiaqi, Jin Yang, Xiaodong Chen, Yi Wang, and Huaiyu Cai. 2022. "Double Branch Attention Block for Discriminative Representation of Siamese Trackers" Applied Sciences 12, no. 6: 2897. https://doi.org/10.3390/app12062897
APA StyleXi, J., Yang, J., Chen, X., Wang, Y., & Cai, H. (2022). Double Branch Attention Block for Discriminative Representation of Siamese Trackers. Applied Sciences, 12(6), 2897. https://doi.org/10.3390/app12062897