
PSciLab: An Unified Distributed and Parallel Software Framework for Data Analysis, Simulation and Machine Learning—Design Practice, Software Architecture, and User Experience


Abstract
:1. Introduction
- Strongly coupled, with extensive data dependencies and communication interaction;
- Loosely coupled, with a low degree of inter-function data dependencies and communication.
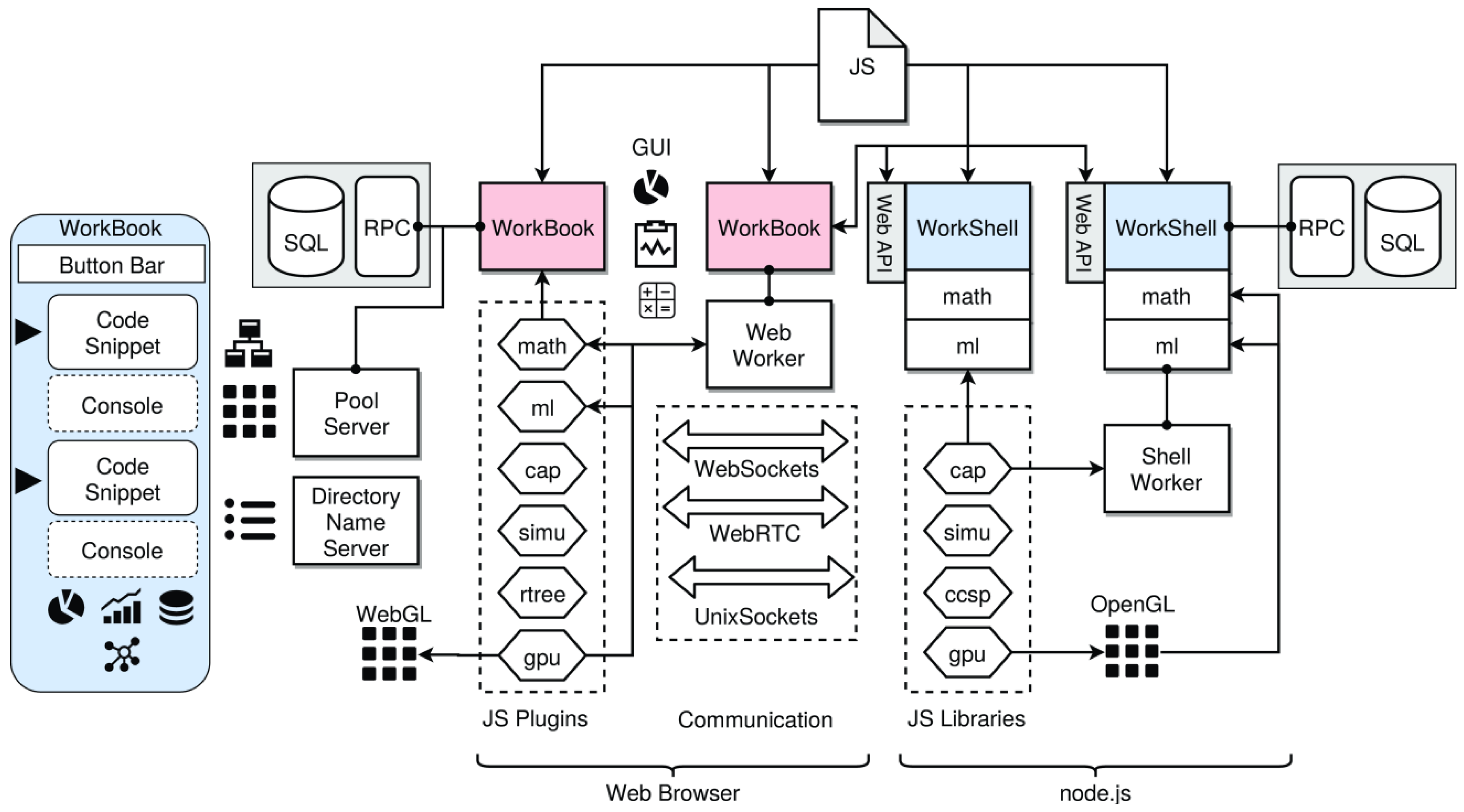
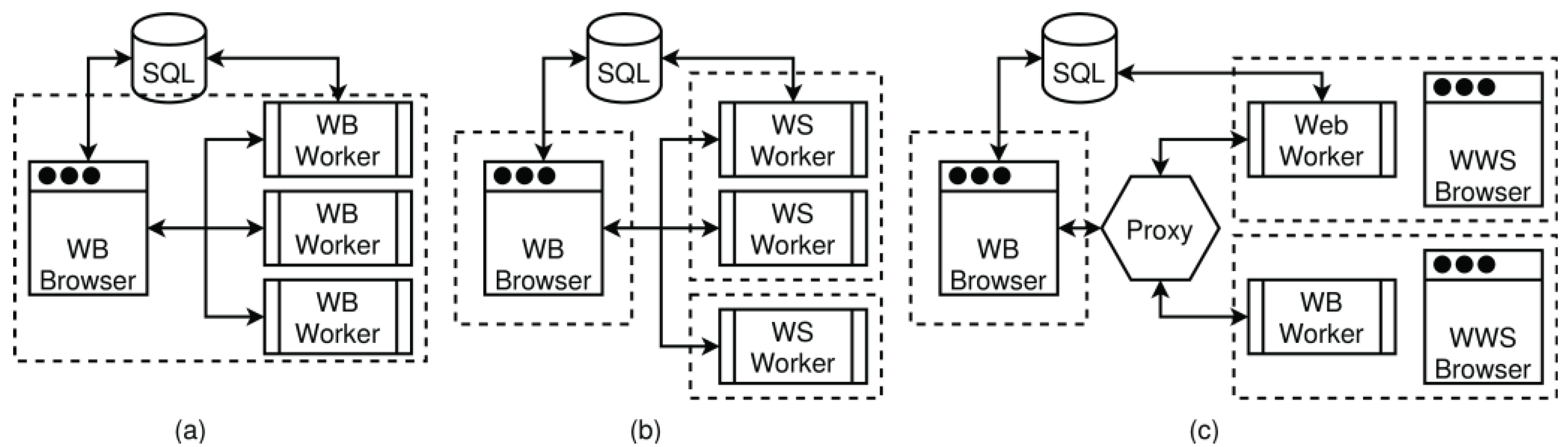
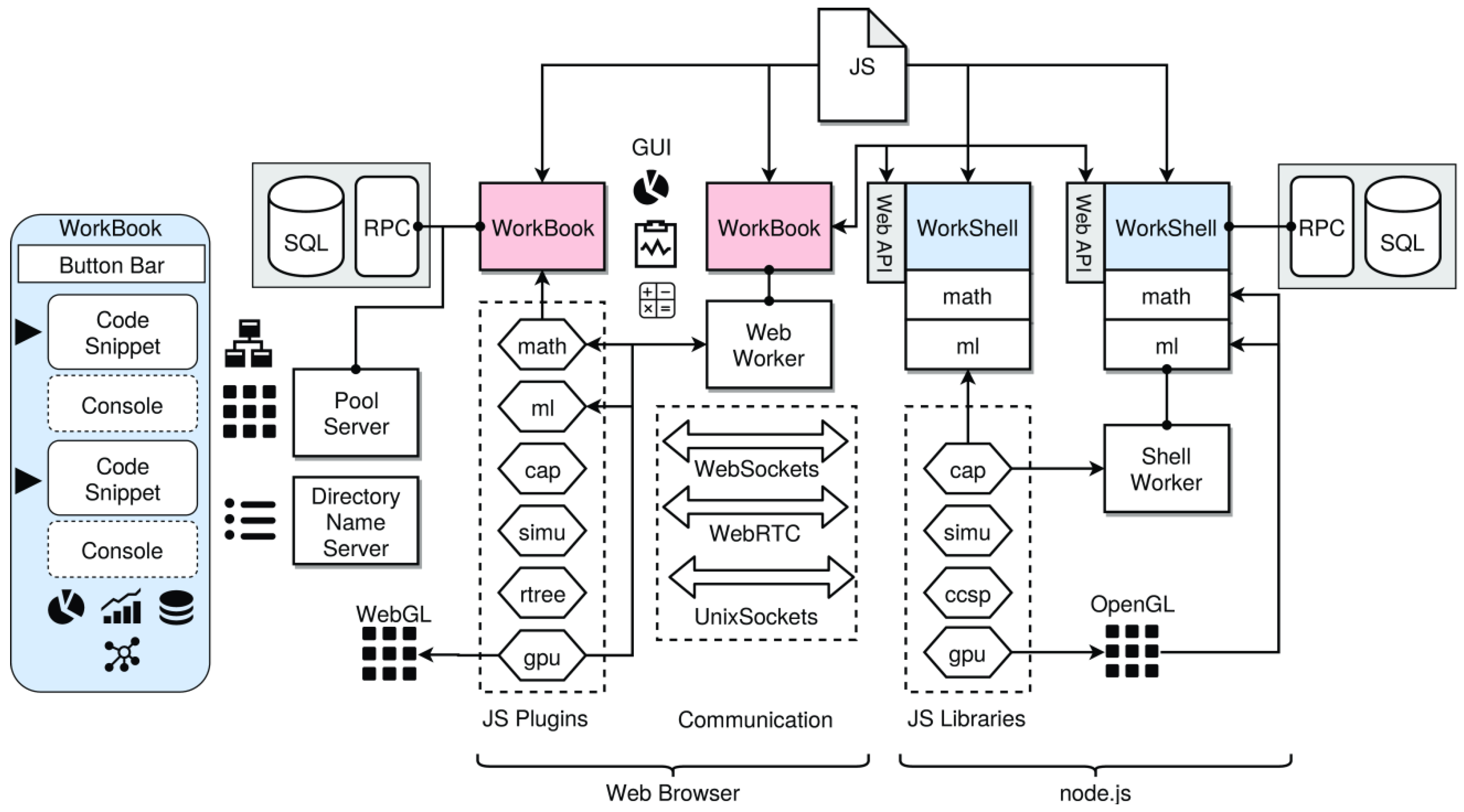
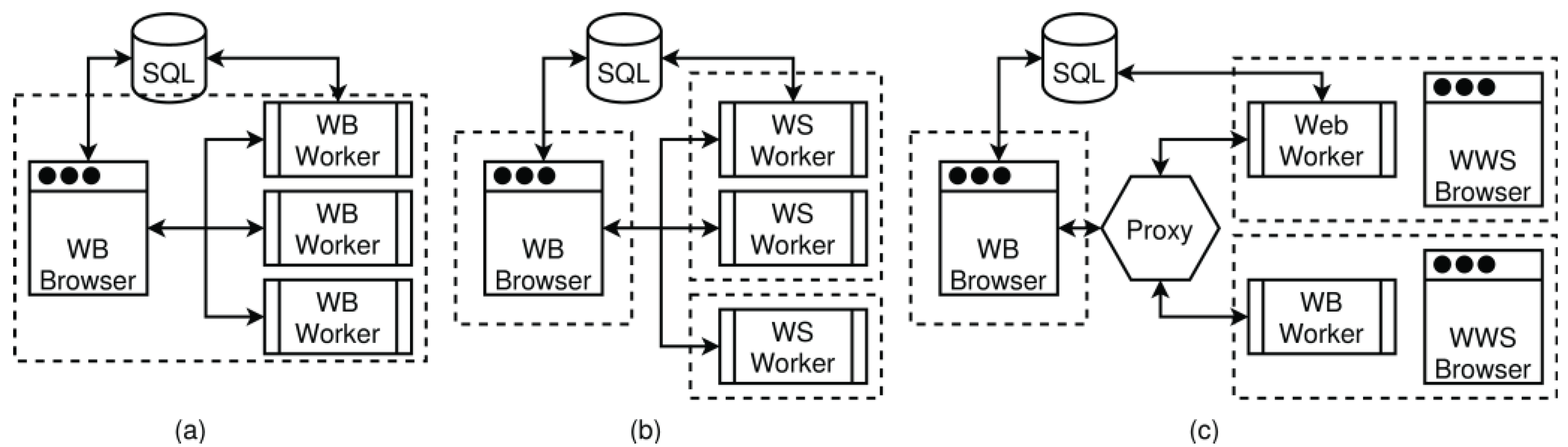
- WorkBook: The first main software component is the WorkBook, processed by a web browser that provides a Graphical User Interface (GUI), including extensive graphical data visualization, like data plotting with code snippet workflows similar to, e.g., MatLab or the Jupiter Notebook. A WorkBook can be used as a standalone or together with WorkShells (or other WorkBooks). A WorkBook can spawn either web workers to perform computational tasks locally in parallel or shell workers for distributed computing. Scripts executed via workers (web and shell) started from a WorkBook can execute visualization operations directly.
- WorkShell: The second main component is a headless and terminal-based WorkShell that is processed by node.js [2] and can be accessed directly by WorkBooks. The WorkShell can be used as a standalone (executing scripts from a command line) or used together with WorkBooks provided by a web service Application Programming Interface (API). A WorkShell can spawn system workers to perform computational tasks in parallel.
- SQLite: The third main component is a set of (distributed) customized SQLite databases, with remote network access services via a JSON-based remote procedure call (RPC) interface used for input, intermediate, and output data exchange.
- Pool/Proxy: An optional worker pool server and Internet proxy for connecting workers (WorkBooks and WorkShells, along with their worker processes) and providing a group service.
2. Related Work
3. Problem Formalization and Taxonomy
- Data classes: vector, matrix, tensor, functional data (cellular automata);
- Algorithm classes: matrix operations in general, data-driven and iterative optimization problems, cellular automata processing, simulation, equation-solving, regression, statistical analysis;
- Data dependency classes: local, global, clustered, static and dynamic content, static and dynamic sizes, and horizontal (time) and vertical dependencies;
- Processing flow classes: data flow ⇔ functional flow, control flow ⇒ synchronization;
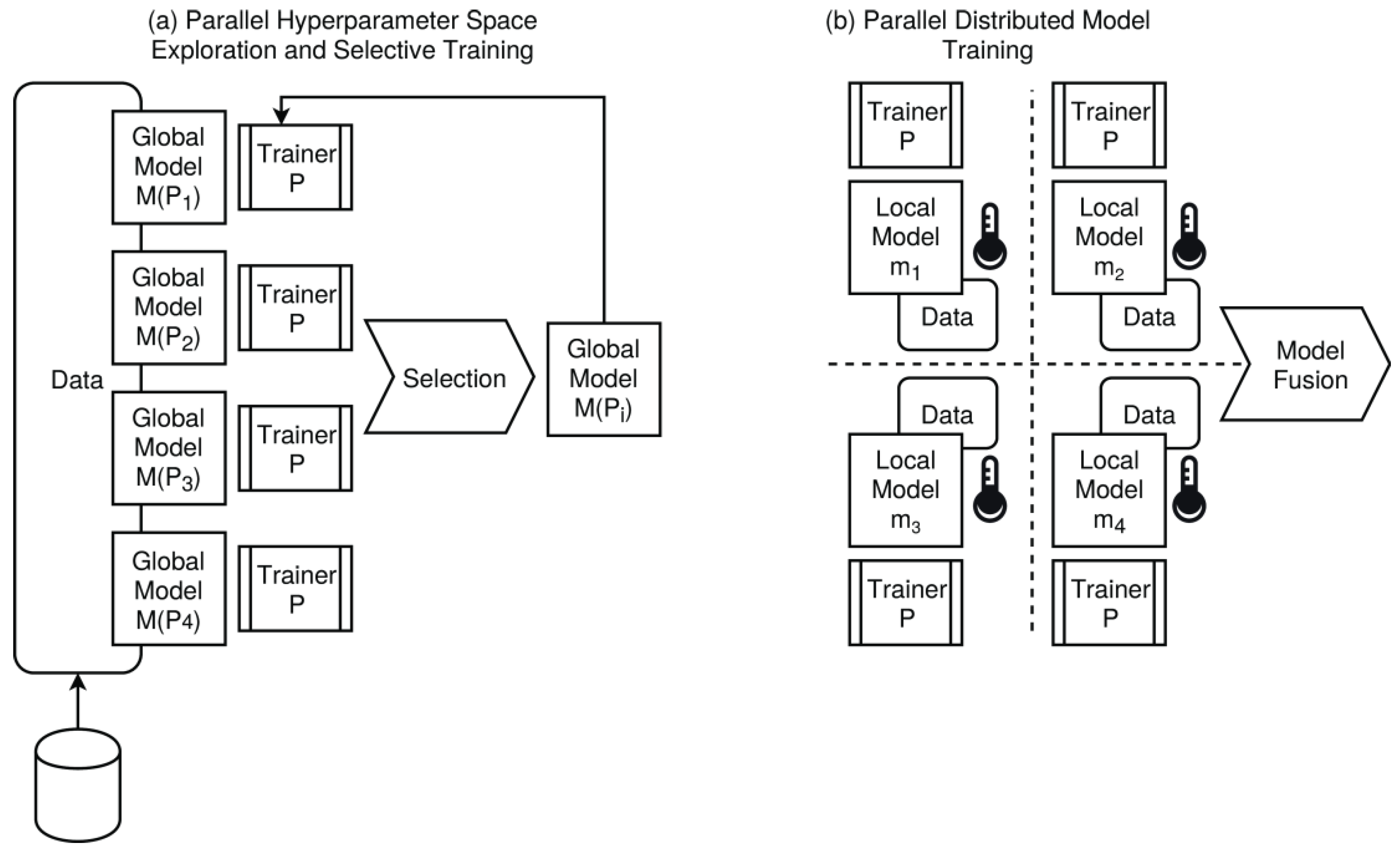
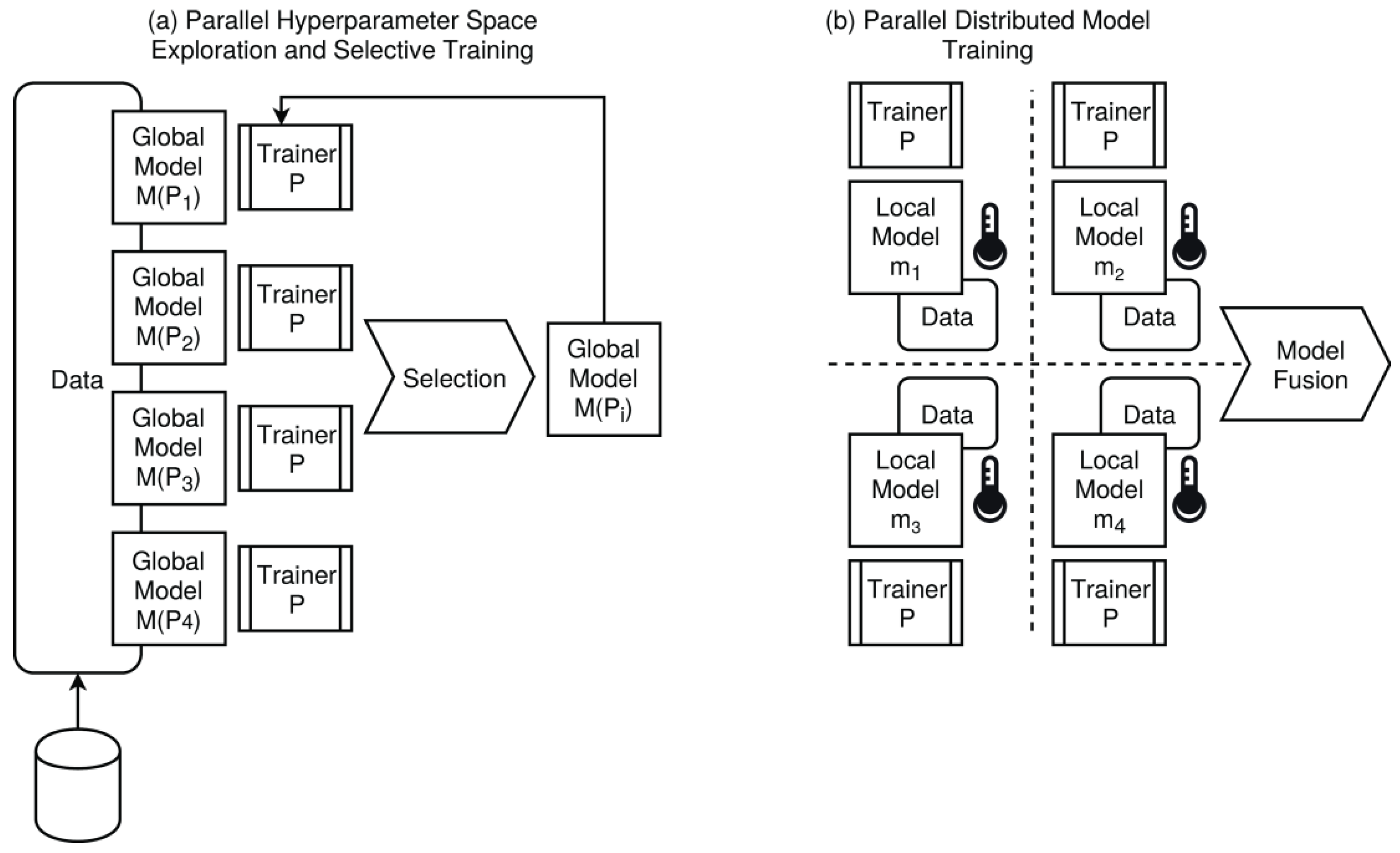
- Partitioning classes: single-data and single-model vs. multi-data and multi-model computation (e.g., ensemble model ML with model fusion, data streams);
- Model classes: data-driven modeling, e.g., using ML methodologies, split into training, test, and validation phases, hypothesis tests and model selection (parallel model space exploration), hyper-parameter space exploration;
- Size classes: static size vs. dynamic size problems.
3.1. Data Classes
- Data Dimension. Matrix (and vector) operations rely on multiply-add and loop instructions that require fine-grained parallelism on a data-path level. If independent matrix segmentation is possible with respect to input and output data, then coarse-grained parallelism on the control path can be partially applied. Cellular automata with a grid world are examples of the deployment of control-path parallelism.
- Data Sets. If there is an unordered data set D~ = {di}i consisting of independent data items, then these data items can be processed independently and in parallel, i.e., d1 → f1 || d2 → f2 || …, where fj are replicated functions derived from a master f.
- Data Streams. If there is an ordered sequential data stream D~ = [*d*<sub>t</sub>]t consisting of independent data items provided in a sequential stream, and there is a functional chain f1 → f2 → … → fn, vertical control-path level parallelism can be exploited efficiently in a functional chain, i.e., dj → fi || dj+1 → fi−1 || dj+2 → fi−2 and so on. Functional pipelines can be used to exploit functional-level parallelism on a horizontal control-path level.
- Model Sets. If there is a non-unique and non-deterministic optimization problem using data sets, e.g., ML, i.e., M~ = {mi}i, then control-path level parallelism (multi-processing) can be used to derive the set of models M~ from the same data set (or any sub-set) but with a different parameter variable set (including random variables), i.e., f1(D,p1) → m1 || f2(D,p2) → m2 || … || fn(D,pn) → mn, where fj are replicated functions derived from a master f.
- Horizontal Fragmentation. There are sub-sets of instances that are stored at different computing nodes N~ = {Ni}i, i.e., D~ = {di}i, d1 → N1, d2 → N2, …, dn → Nn.
- Vertical Fragmentation. There are sub-sets of attributes (variables) of instances that are stored at different sites.
3.2. Problem Classes
- Static. The problem size is static, i.e., |D| = s = const, and does not change with parallelization, i.e., by increasing the number of processing nodes Ni and processes Pj(Ni). Static-sized problems are well suited for partition, as in grid-based simulation (CA), i.e., the full data set is partitioned and processed on multiple nodes (different data on different nodes): D = {di}i, d1 → f1 || d2 → f2 || … || d2 → fk. The aim of parallelization is the reduction of overall computation time, ideally by 1/PN if PN is the number of parallel processes.
- Dynamic. The problem size grows with an increasing number of processing nodes and computational processes. An example is multi-model ML training. Each processing node trains an independent model with different parameter variables from the set V = {vi}i, including random variables (Monte Carlo simulation), either using the same input data D or different input data D1, …, Du, or sub-sets di ∈ D, i.e.: ⟨D,v1⟩ → f1, …, ⟨D,vn⟩ → fn. The aim of parallelization is ideally a constant computational time, with an increasing number of parallel processes (scaling is S = 1), or at least, growth lower than PN = |P|, i.e., 1 < S < PN.
3.3. Algorithmic Classes
3.4. Machine Learning
- Data-path parallelism. This is applied to function evaluation and matrix operations.
- Control-path parallelism. This is applied to the training of multiple models (multi-instance ensemble learning and/or parameter space exploration) or to inferences in multiple data sets and/or multiple model instances.
- STSI. Single-model instance training with single-model instance inference (i.e., 1:1 mapping of input and output data to models); input and output data is not partitioned;
- MTSI. Multi-model instance training with single-model instance inference, either by model and parameter space exploration selecting the best model or by model fusion; input and output data is not partitioned;
- MTMI. Multi-model instance training with multi-model instance inference, i.e., primarily distributed ML; input and output data is partitioned and single model instances operate only on a (local) sub-set of the input data; final global model fusion is optional;
- STMI. Single-model instance training with multi-model instance inference, e.g., pixel-based feature detection being applied to images or replications of the trained model; input data for training is not partitioned, input data for inference data can be partitioned.
3.5. Simulation
3.6. Virtual Machines
4. Multiprocessing: Models and Architectures
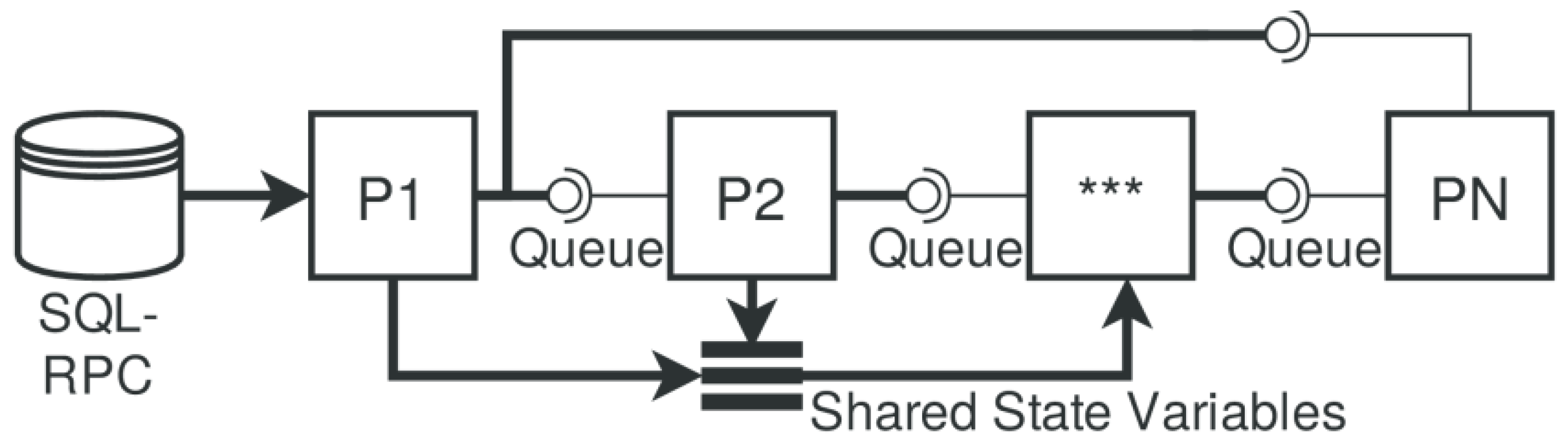
4.1. Processes and Composition
async function sleep(tmo) {
return new Promise(function (resolve) {
setTimeout(resolve,tmo)
})
}
async function serviceloop() {
for(;;) {
// service
await sleep(1000)
}
}
serviceloop()
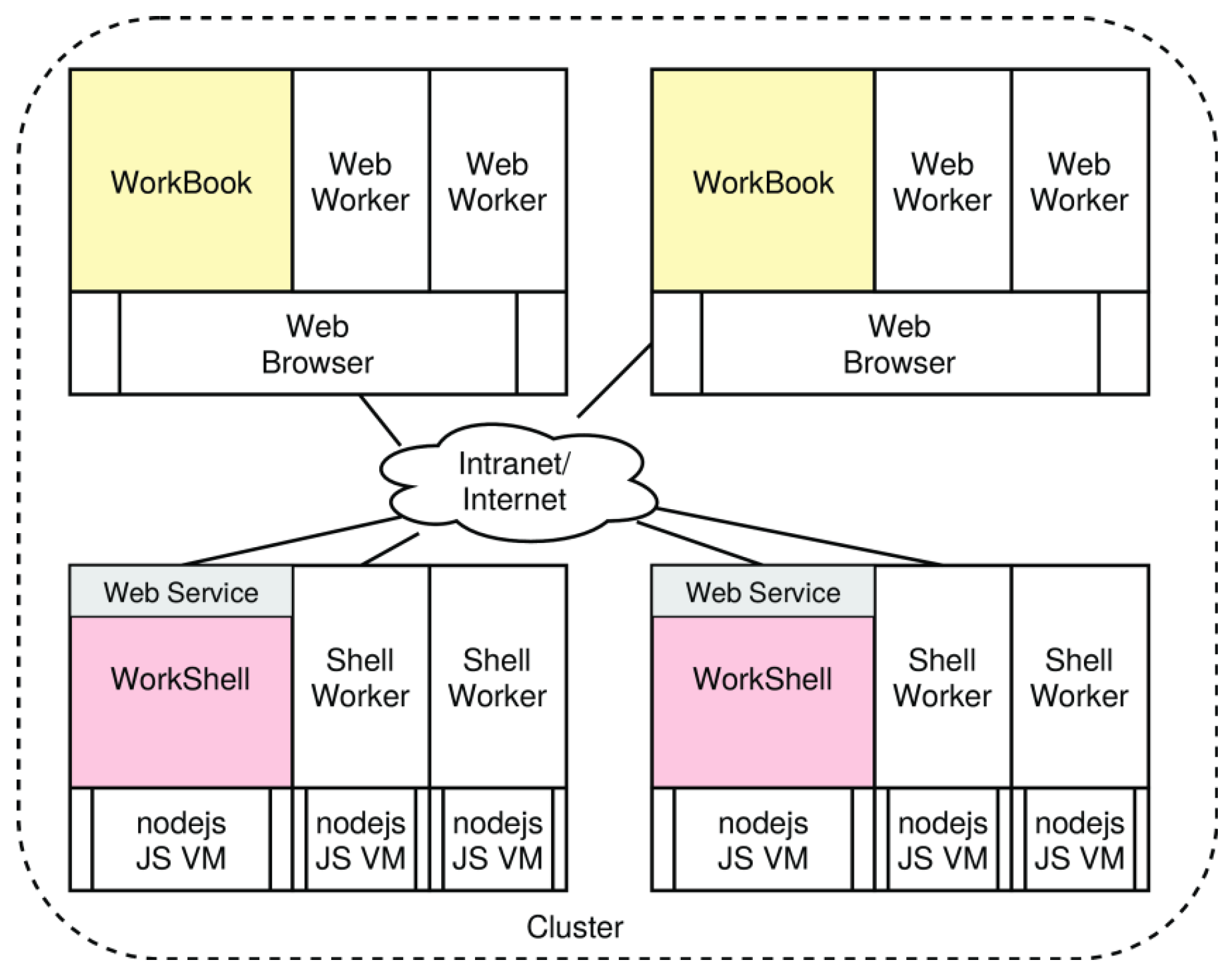
4.2. Hierarchical Processing Architecture
4.3. Process Classes
- Web browser (WorkBook) processing JavaScript via V8 or SpiderMonkey VMs and providing a dynamic Document Object Model (DOM):
- The main process (master execution and control loop);
- Lightweight WebWorker processes (executed by OS threads, controlled by the main process) with a reduced sub-set of the WorkBook (providing control-path parallelism);
- WebGL-based GPGPU kernel processes (providing data-path parallelism).
- Node.js (WorkShell) processing JavaScript by the V8 VM:
- The main process;
- Separate worker processes executed by independent and isolated OS processes, with a full WorkShell code base (providing control-path parallelism);
- OpenGL-based GPGPU kernel processes (providing data-path parallelism).
4.4. Worker
var workers=[] // Creation of local Web or Shell workers // Worker is child process of this parent process var worker = await new Worker(id?,{options}); await worker.ready(); workers.push(worker) // Creation of remote workers // On cpu42 machine start: worksh -p 5104:protkey var workers = [] for(var i=0;i<NUMWORKERS;i++) { var shellworker = await new Worker(’ws://cpu42:5104’,i,{options}); await shellworker.ready(); workers.push(shellworker); }
-
Example 1. Creation of local and remote web and shell workers via the unified “Worker” class. Shell workers can be created remotely via the ShellWorker web API.
// asynchronous execution without reply for(var i=0;i<NUMWORKERS;i++) { workers[i].run( function (i) { var result = compute(i); send(result) }, i); } // join and collect for(var i=0;i<NUMWORKERS;i++) { results.push(await workers[i].receive()) } // synchronous execution waiting for results for(var i=0;i<NUMWORKERS;i++) { var result = await workers[i].eval( function (x) { return 1/(1+Math.exp(-x)) }, Math.random()); }
-
Example 2. Execution of functional code on (web or shell) workers (following Example 1).
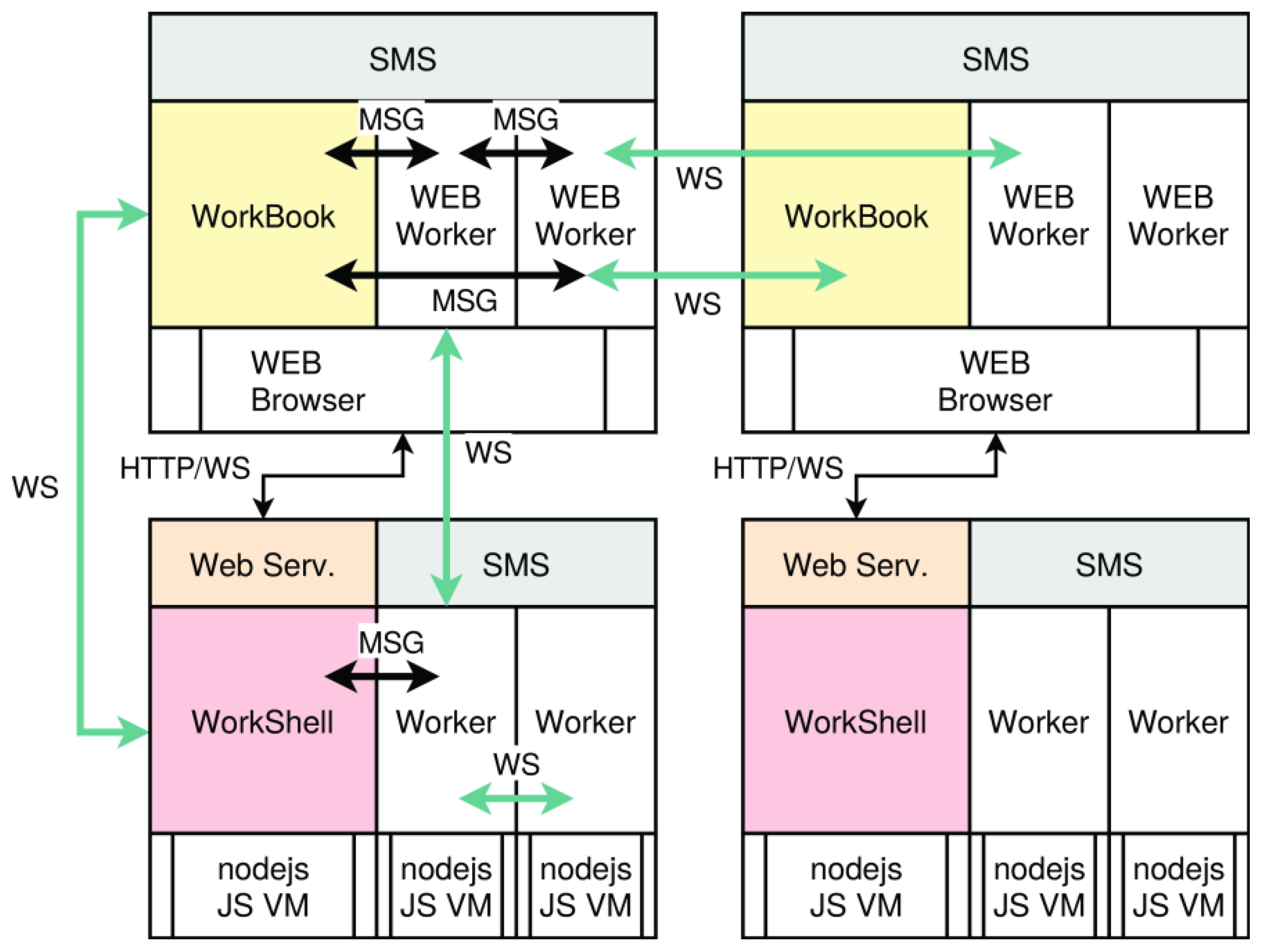
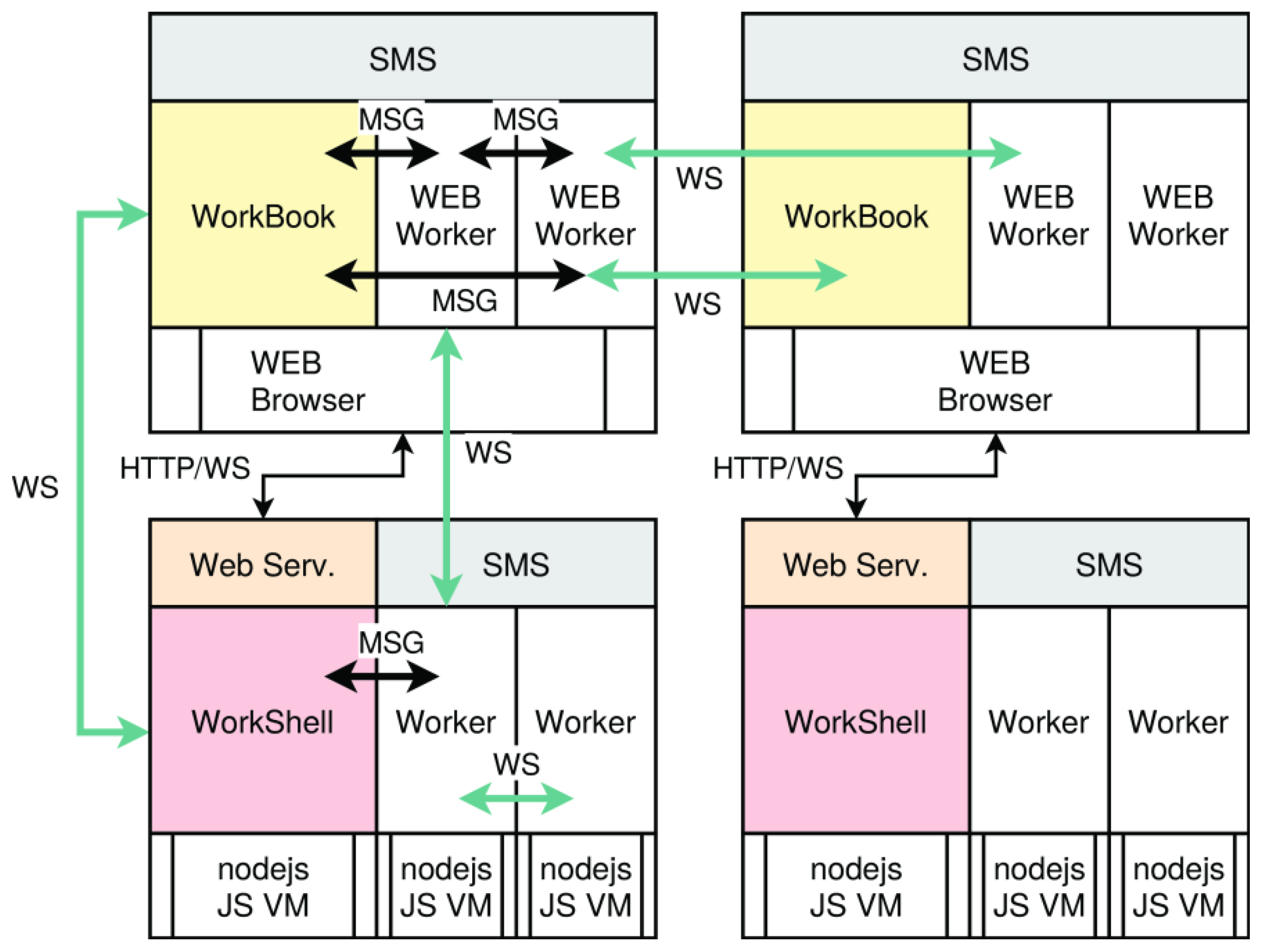
4.5. Communication, Synchronization, and Data Sharing
- Native messages Mnative provided by the browser or by the node.js platform; these can only be used within the same process class and by a parent-worker process group on the same node → synchronization and data transport.
- WebSocket messages Mws can be used between all process classes and different nodes → Synchronization and data transport.
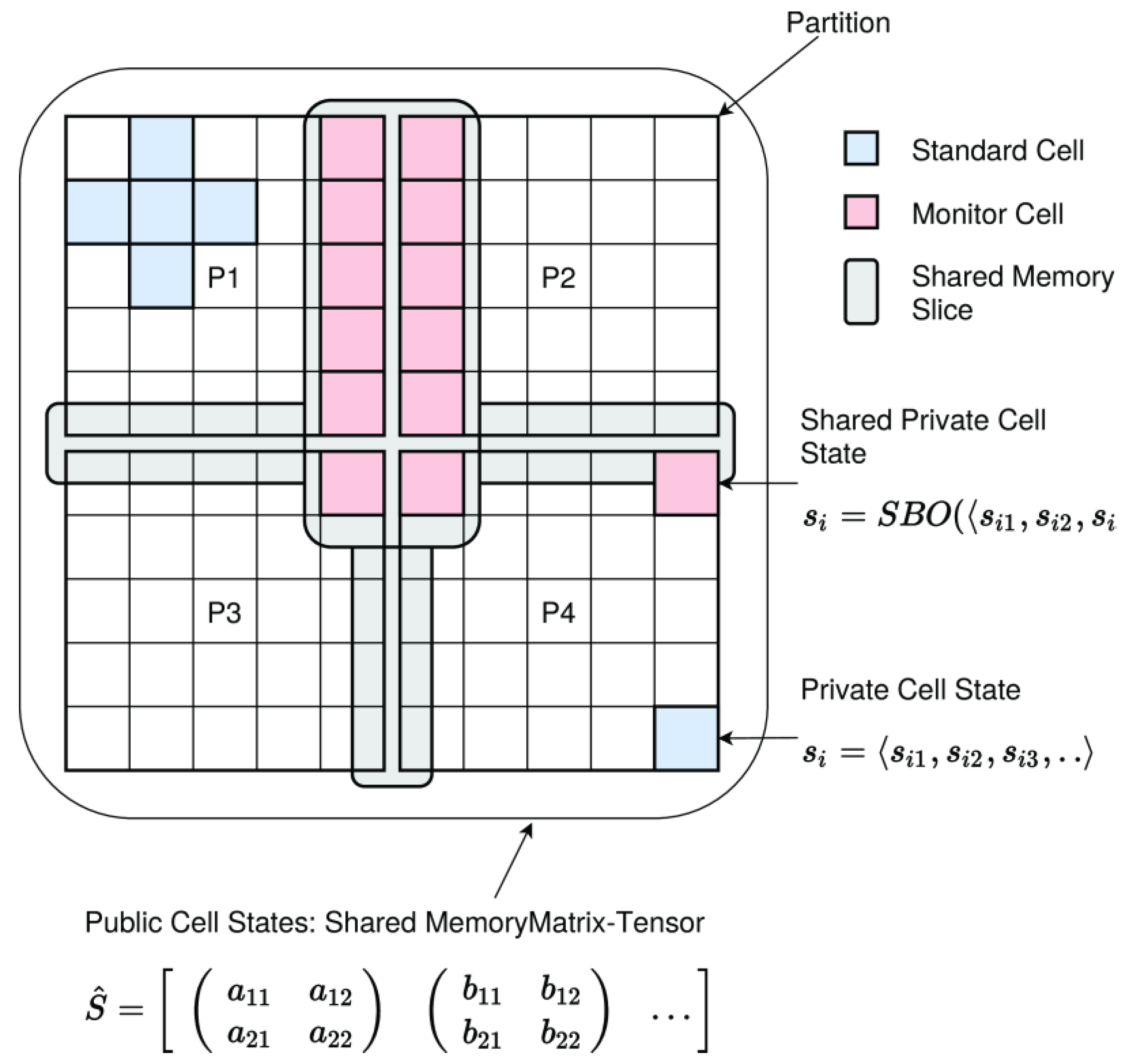
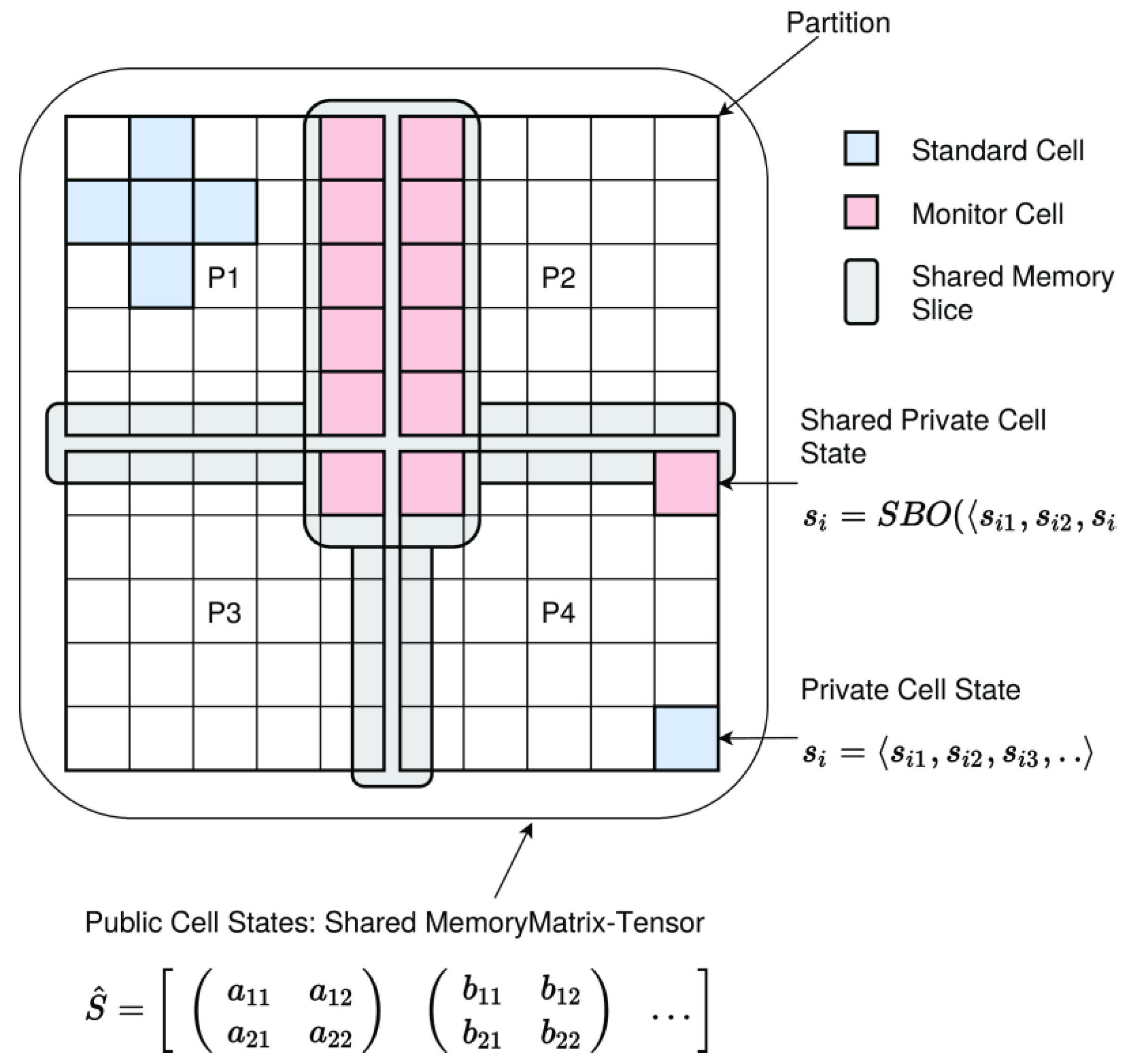
- Shared memory segments Ssms (SMS), implemented either with shared array-buffers in the browser or with native externally mapped shared memory at system-level in node.js; these can only be used within the same process class and on the same node → data sharing without data-driven synchronization.
- Shared buffer objects (BO) Ssmo are implemented in SMS with static typing, supporting atomic core variables, structure variables, and arrays → data sharing without data-driven synchronization.
- A shared matrix Ssma implemented by shared memory and object-wrapper replications; these can only be used within the same process class → data sharing without data-driven synchronization.
- Queued and synchronized data channels Mch built on native streams, Unix or WebSocket messaging, using (1/2), or shared memory (4).
- Remote procedure calls over message channels.
- Mutex;
- Semaphore;
- Barrier;
- Data Queues.
- Using state- and connectionless communication via UDP/WebRTC;
- Workers (or the WorkerShell Web service) can be kind and tolerate temporary connection loss, and wait for a reconnect;
- A persistent snapshot by check-pointing the worker state using secondary storage.
// Create worker with RPC var worker = new Worker({ rpc : { function foo (x) { return x*x } } }) // In worker process var ma = Math.Matrix.Random(10,10), mas = serialize(ma.data); send(mas) var mat = deserialize(await receive()) var result = await rpc.foo(2); // In parent process var data = await worker.receive() var matrix = deserialize(data) matrix.transpose() worker.send(serialize(matrix))
-
Example 3. Master–worker communication using message channels or RPC.
4.6. Security
- A public service port assigning the capability to a specific service, but not a specific host;
- An optional object number of the service (e.g., a specific data base or processor);
- A rights field that specifies the allowed operations of the services (e.g., reading or writing data bases);
- A security port that contains the encrypted rights field by using a private port.
4.7. Pipelines
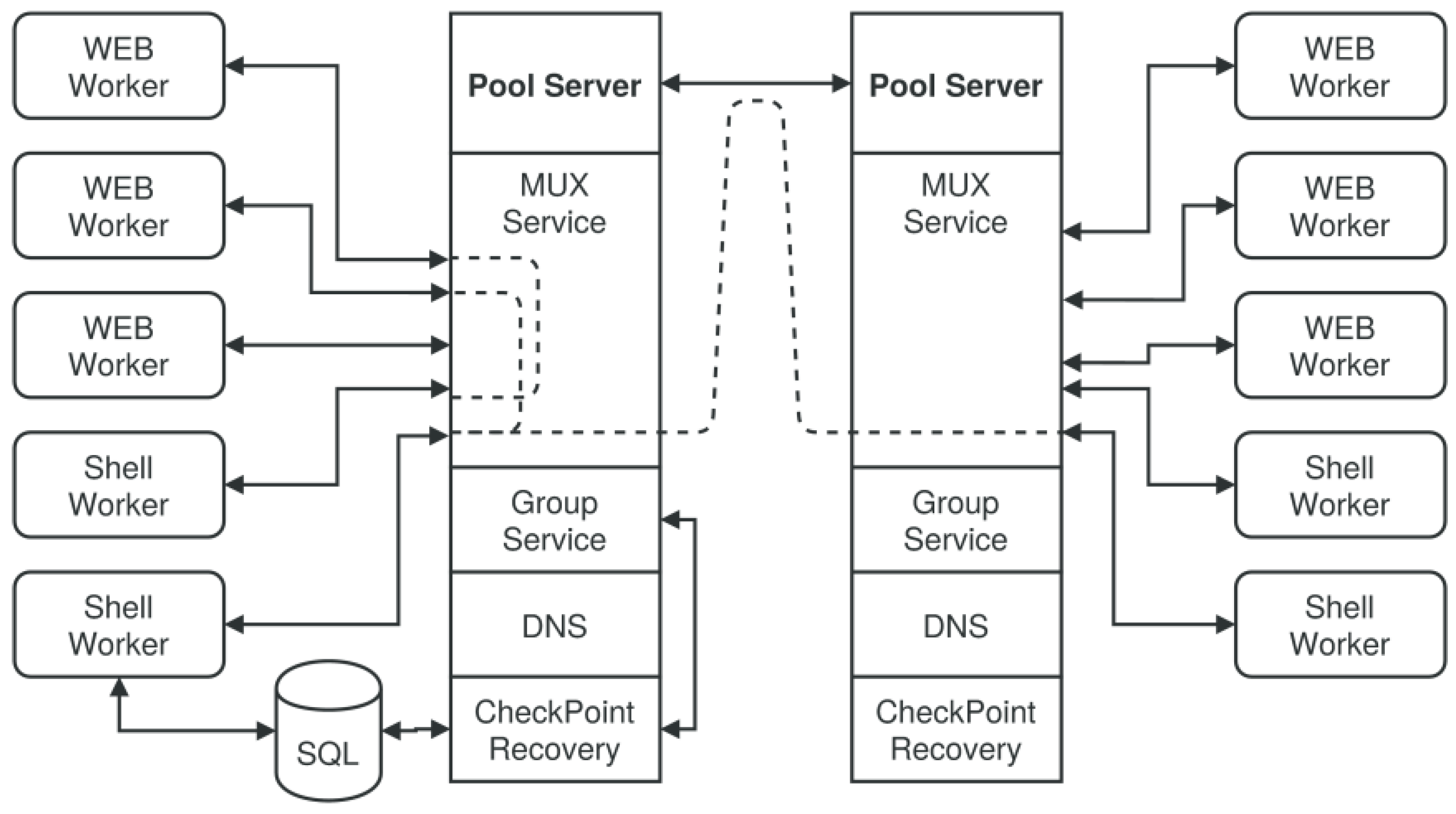
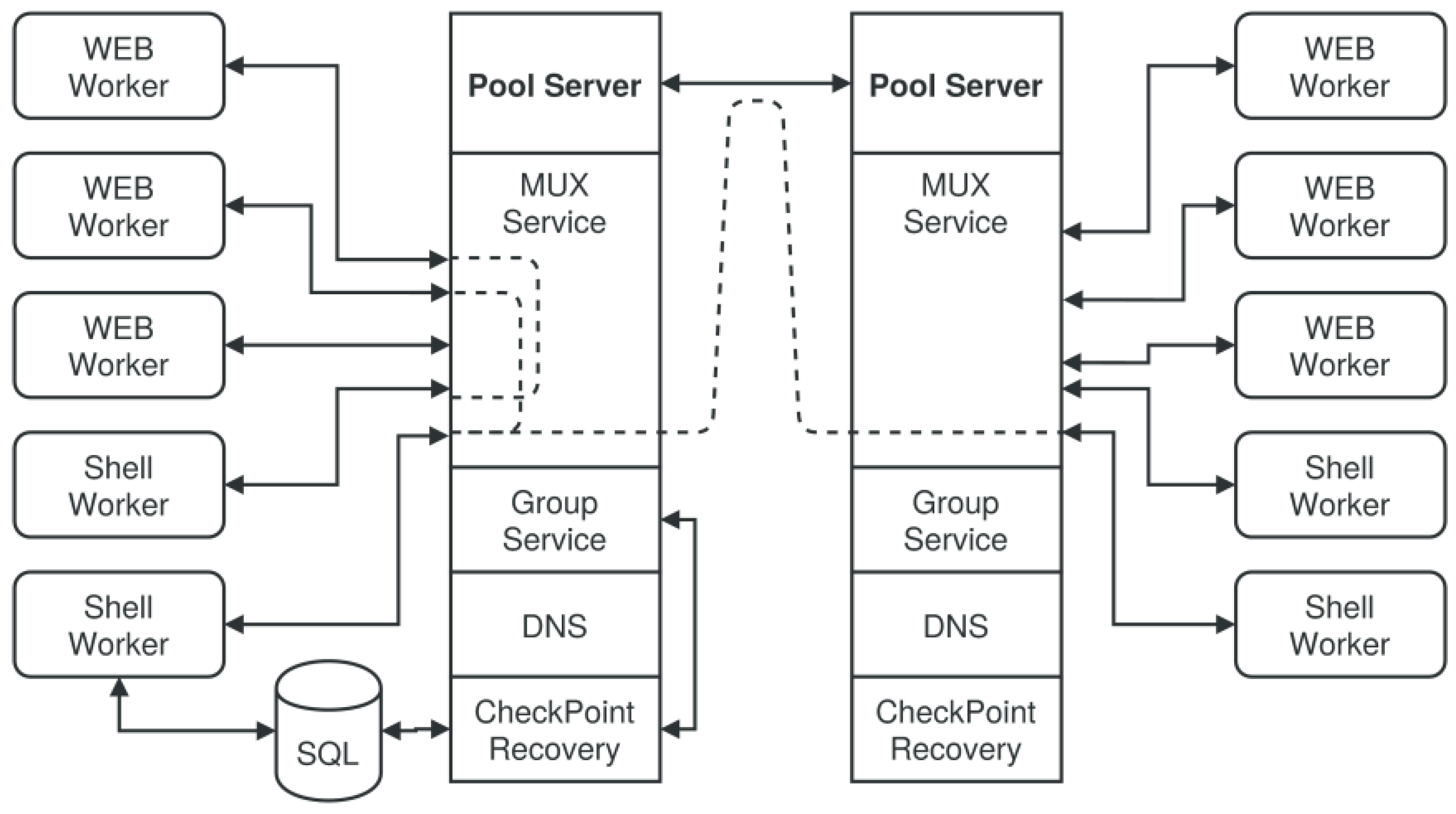
4.8. Pool Server and Working Groups
var gs = group.client(url,{});
var socket = await gs.connect();
gs.create(‘myworkinggroup1’);
... // wait for other members joining the group
var members = await gs.ask(‘myworkinggroup1’)
// connect this peer port with other member ports
for (var i in members ) {
if (members[i]==socket.peerid) continue;
await socket.connect(members[i],true /*bidir*/)
}
socket.write({cmd:‘eval’,f:function (x) { return x*x},
x:Math.random(),from:socket.peerid})
var result = await socket.read();
-
Example 4. Direct worker group programming using the proxy and group service.
4.9. Worker Process Control
// Local Web or Shell Worker
worker = new Worker(id?,options?);
// Remote WorkerShell Service
new Worker(‘shellhost:port:capability’,options?);
// Remote Proxy Service
new Worker(‘proxyhost:port:capability’,options?);
await worker.ready()
await worker.run(‘data={x:1,y:2}; function foo(x) { return x*x }’);
result = await worker.eval(‘return foo(100)’);
result = await worker.evalf(function (x) return foo(x-1) },100);
data = await worker.monitor(‘data’);
print(data.x)
worker.kill();
-
Example 5. Typical snippet for worker creation (internally, with web workers, on a remote WorkShell, and by using the pool/group server proxy service).
5. IO Data Management and Data Sharing
5.1. Distributed SQL Databases with RPC
- A native SQLite3 module for the node.js platform.
- A JavaScript interface module that creates SQLite3 data base instances and provides programmatical access to a data base.
- A JavaScript JSON service API, mapping JSON requests to SQL statements and vice versa.
- A JavaScript RPC service via HTTP/HTTPS or WebSockets, providing JSON-formatted SQL queries and some additional operations. An extended JSON format is used to support functional requests with a function code. The function code consists of state-based micro-operations applied to the SQL data base that are used to compose complex operations. Access can be secured by a capability-based right-key authorization mechanism.
- A file-mapper module that provides virtual SQL tables from data files, e.g., image files can be accessed as raw or converted matrix data, with meta-information organized as rows in SQL tables.
// Create an ANN trainer var sql = DB.sql(‘ws://host:port:key’); // Create a checkpoint tables for data state snapshots var cptable = ‘checkpoint-’+myGroupId+‘-’+myWorkerId if (!options.checkpoint) { sql.create(cptable, { time:‘number’, iter:‘number’, err:‘number’, model : ‘blob’ }) var model = ML.learner(ML.ML.ANN, { options }) } else { var row = sql.query(cptable,‘*’,‘rowid=’+options.checkpoint) var model = ML.deserialize(row[0].model); } while (i < maxIter || err > errThr) { var result = ML.train (model, data, { options }); if (i>0 && (i % 4)==0) sql.insert(cptable, {time : time(), iter:i, err:result.error, model : ML.serialize(model) }); i++; err=result.error; } send (ML.serializes(model)) // delete checkpoint table sql.drop(cptable)
-
Example 6. Worker check-pointing of the data state, enabling recovery.
5.1.1. Replicated Data Bases and Tables
var sql1 = DB.sql(‘ws://hosta:porta:keya’), sql2 = DB,sql(‘ws://hostb:portb:keyb’); sql1.copy(‘tablename’,sql2)
5.1.2. Capability Protection
- Reading tables and table rows.
- Modifying tables and modifying rows.
- Creation and deletion of tables.
- Creation and deletion of data bases.
5.1.3. Application Programming Interface
var sql = await DB.sql(url,options)
var databaseList = await sql.databases()
sql.open(‘mydatabase1’)
var tableList = await sql.tables()
await sql.create(‘mytable’,{$colname:$type})
await sql.insert(‘mytable’,{$colname:$data})
var rows = await sql.select(‘mytable’,colums:string,where:string)
await sql.createDatabase(‘mydatabase2’)
await sql.open(‘mydatabase2’)
await sql.create(‘mytable2’,{$colname:$type})
-
Example 7. Typical RPC-SQL access examples.
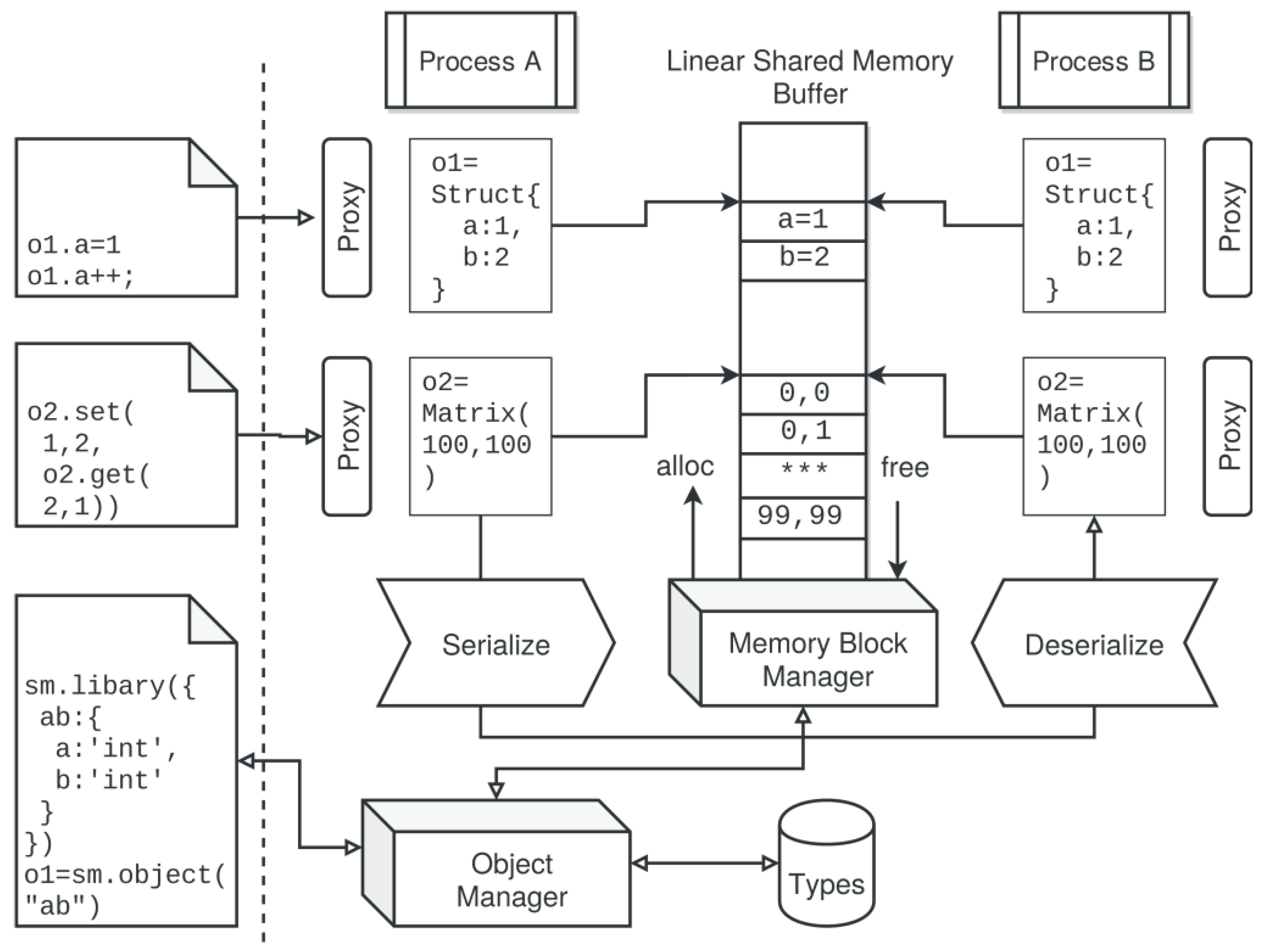
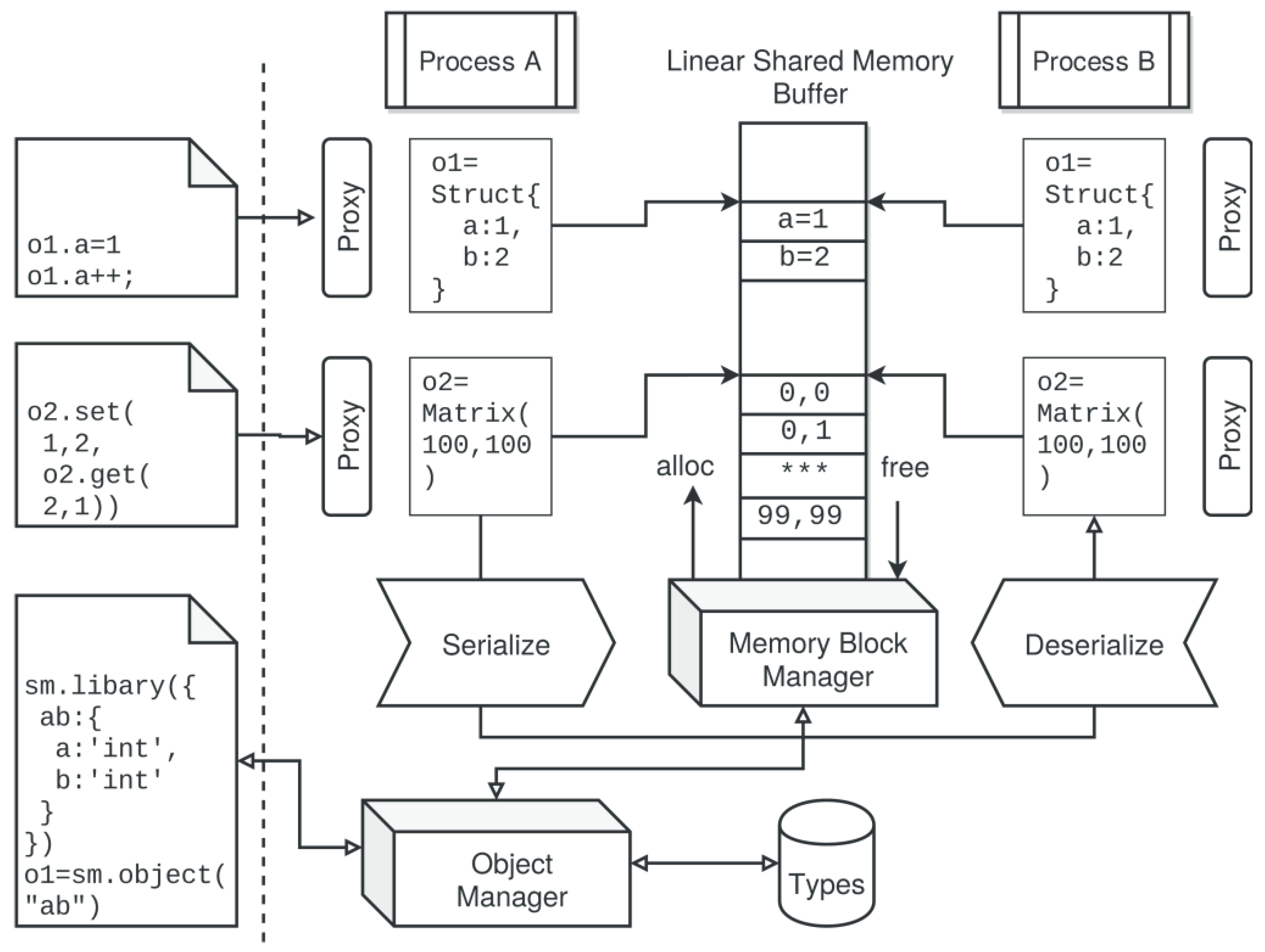
5.2. Shared Memory Segments and Buffer Objects
- Mutex.
- Semaphore.
- Barrier.
- Data queue (synchronization via two semaphores).
// Create type interfaces var typesDef = { xy : { x:‘int’, y:‘int’, z:‘string’ } } // Create a generic shared memory buffer var sharedBuffer = new SharedArrayBuffer(1E5); // Attach shared memory to SBS instance var sm=BufferSegment(sharedBuffer,{key:‘/shm1’}); sm.create(); // add type library sm.library(typesDef); // Create and initialize a shared object objShared = sm.object(‘xy’); objShared.x=0; objShared.y=0; // Create workers var worker = new Worker(...) // Share SMS await worker.share(‘this.sm1’,sm) // Share Buffer Object await worker.share(‘this.objShared’,objShared) // Shared typedarray matrix var matShared = sm.object(‘MatrixTA-Float32’,[1000,1000]); matShared.set(1,1,Math.random()) await worker.share(‘this.matShared’,matShared) // Access shared object in worker await worker.evalf(function (x) { this.objShared.x=x; this.matShared.set(1,2, this.matShared.get(2,1))},1) // That’s all folks!
-
Example 8. Creation and usage of a shared object memory with an initial set of object interfaces and one shared object.
5.3. Distributed Objects
5.4. Object Monitors
// worker A this.data = [1,2,3,4] this.data[5]=5; // main process var data = await workerA.monitor(’this.data’,1,false); var sum = 0; for(var i=0;i<data.length;i++) sum += await data[i];
6. Software Framework
6.1. Parallel WorkBook
6.2. Parallel WorkShell
- Process workers starting a new VM instance in a separate OS-level process, using message-based communication, and interprocessing shared memory segments on OS-level (memory mappings with native code, not controlled by JS VM).
- Thread Workers (available since node.js 10.5) starting a new VM instance in a thread, using message-based communication, and SharedArrayBuffers (memory that is shared by threads but controlled by the JS VMs).
6.3. Plugins and Libraries
6.4. Data Management
6.5. Pool Management
7. Data-Path Parallelism on GPU
7.1. Matrix Operations
const gpu = new GPU.GPU({})
var N = 1024
var multiplyMatrixGPU = gpu.createKernel(function(a, b) {
var sum = 0;
var x = this.thread.x % this.constants.N,
y = Math.floor(this.thread.x / this.constants.N);
for (var i = 0; i < this.constants.N; i++) {
sum += a[y*this.constants.N+i] * b[i*this.constants.N+x];
}
return sum;
}).setConstants({N:N})
.setOutput([N*N]); // using flat array
function multiplyMatrixJS(a, b) {
var c = matrix(N,N);
for(var y=0;y<N;y++) {
for(var x=0;x<N;x++) {
var sum = 0;
for (var i = 0; i < N; i++) {
sum += a[y*N+i] * b[i*N+x];
}
c[y*N+x]=sum
}
}
return c
}
var a = matrix(N,N), b=matix(N,N)
var c1 = multiplyMatrixGPU(a,b) ,
c2 = multiplyMatrixJS(a,b)
-
Example 9. Matrix multiplication a × b, by Vanilla JS and GPU kernel functions (multi-threaded) assuming linear and compact Float32 TypedArray data. Both functions will return a new destination matrix c.
const gpu = new GPU.GPU({})
// Pipe-lined composed GPU kernel
const convMatrix = gpu.createKernel(function(src) {
const kSize = 2*this.constants.kernelRadius+1;
let sum=0;
const tx = this.thread.x,
ty = this.thread.y;
for(let i = -this.constants.kernelRadius; i <= this.constants.kernelRadius; i++) {
const x = tx + i;
if (x < 0 || x >= this.constants.width) continue;
for(let j = -this.constants.kernelRadius;j <= this.constants.kernelRadius;j++) {
const y = ty + j;
if (y < 0 || y >= this.constants.height) continue;
const kernelOffset = (j+this.constants.kernelRadius)*kSize+
i+this.constants.kernelRadius;
const weight = this.constants.kernel[kernelOffset];
const pixel = src[y][x];
sum += (pixel * weight);
}
}
return sum
}).setPipeline(true)
.setOutput([N,N])
.setConstants({width:N, height:N, kernel:kernels.boxBlur,kernelRadius:1});
const layer1 = gpu.createKernel(function(src) {
let sum=0;
for(let i=0;i<this.constants.width;i++) {
for(let j=0;j<this.constants.height;j++) {
sum += (1/this.constants.height*src[j][i]);
}
}
return 1/(1+Math.exp(-sum));
}).setPipeline(true).setOutput([N]).setConstants({width:N, height:N });
const layer2 = gpu.createKernel(function(src) {
let sum=0;
for(let i=0;i<this.constants.height;i++) {
sum += (1/this.constants.height*src[i]);
}
return 1/(1+Math.exp(-sum));
}).setPipeline(true).setOutput([N]).setConstants({height:N });
const cnn = gpu.combineKernels(convMatrix,layer1,layer2,function (a) {
return layer2(layer1(convMatrix(a)))
})
var input = GPU.input(new Floar32Array(..),[N,N]);
var output = cnn(input).toArray();
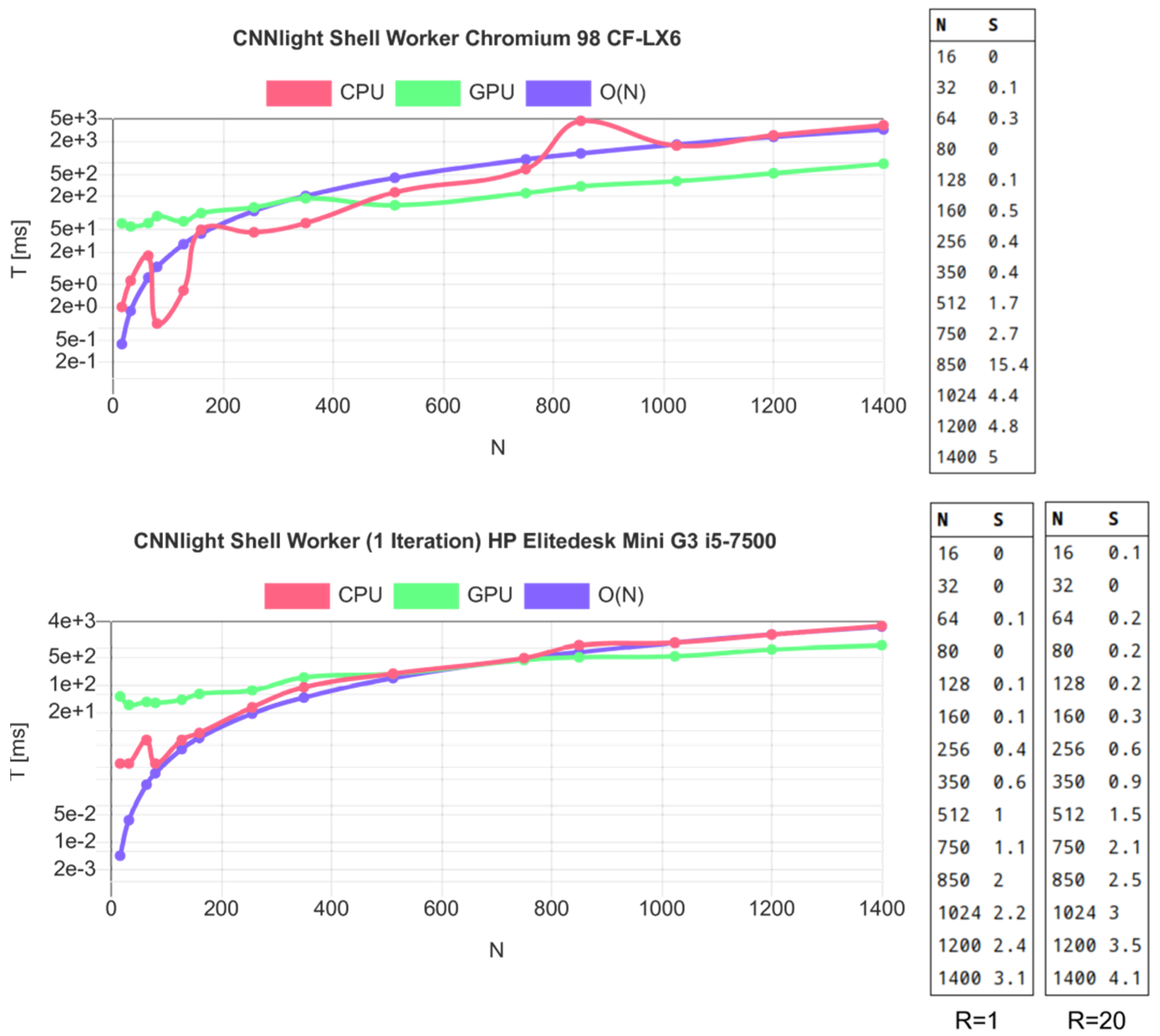
-
Example 10. The source code for the CNN light GPU test with the gpu.js library.
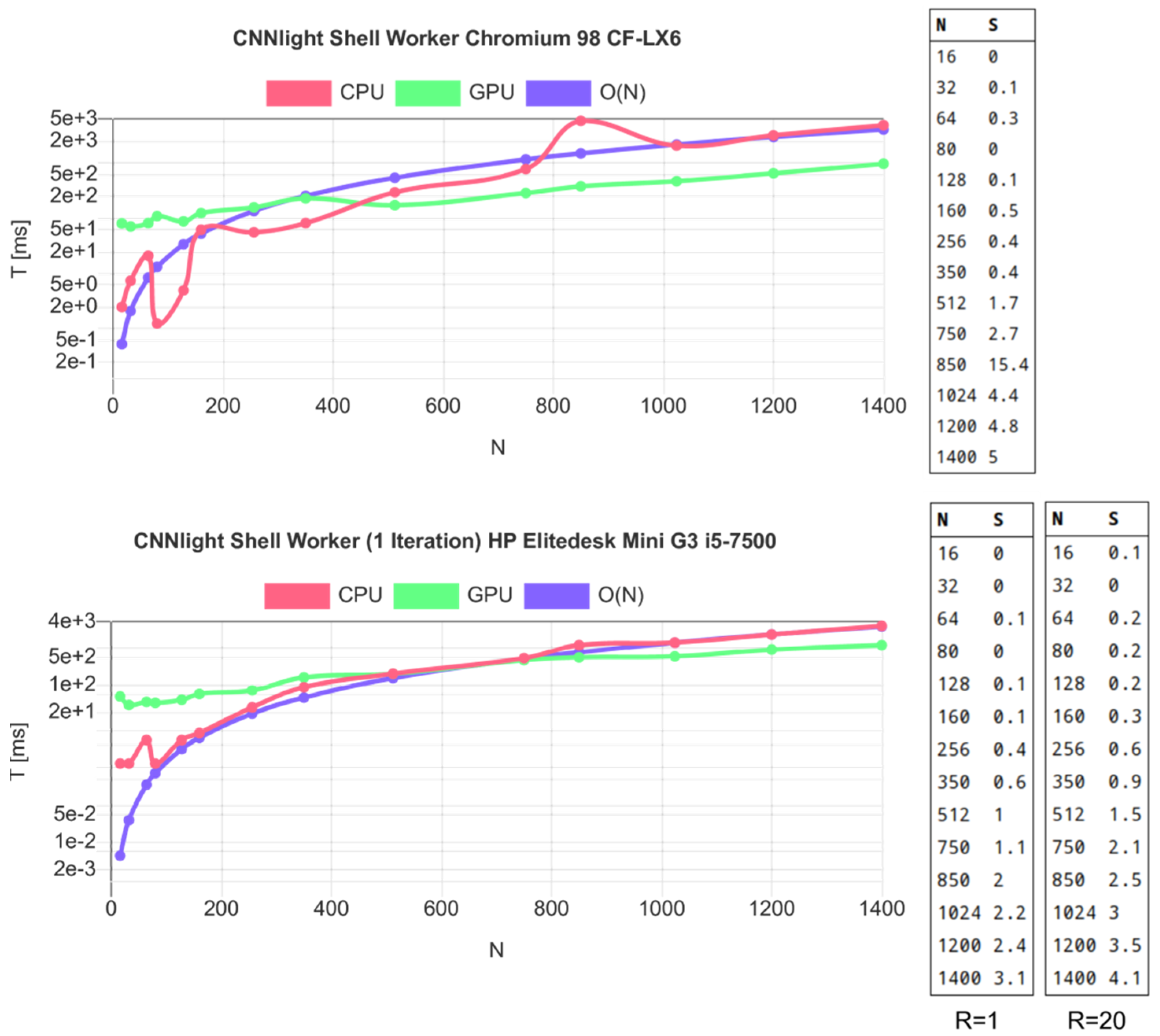
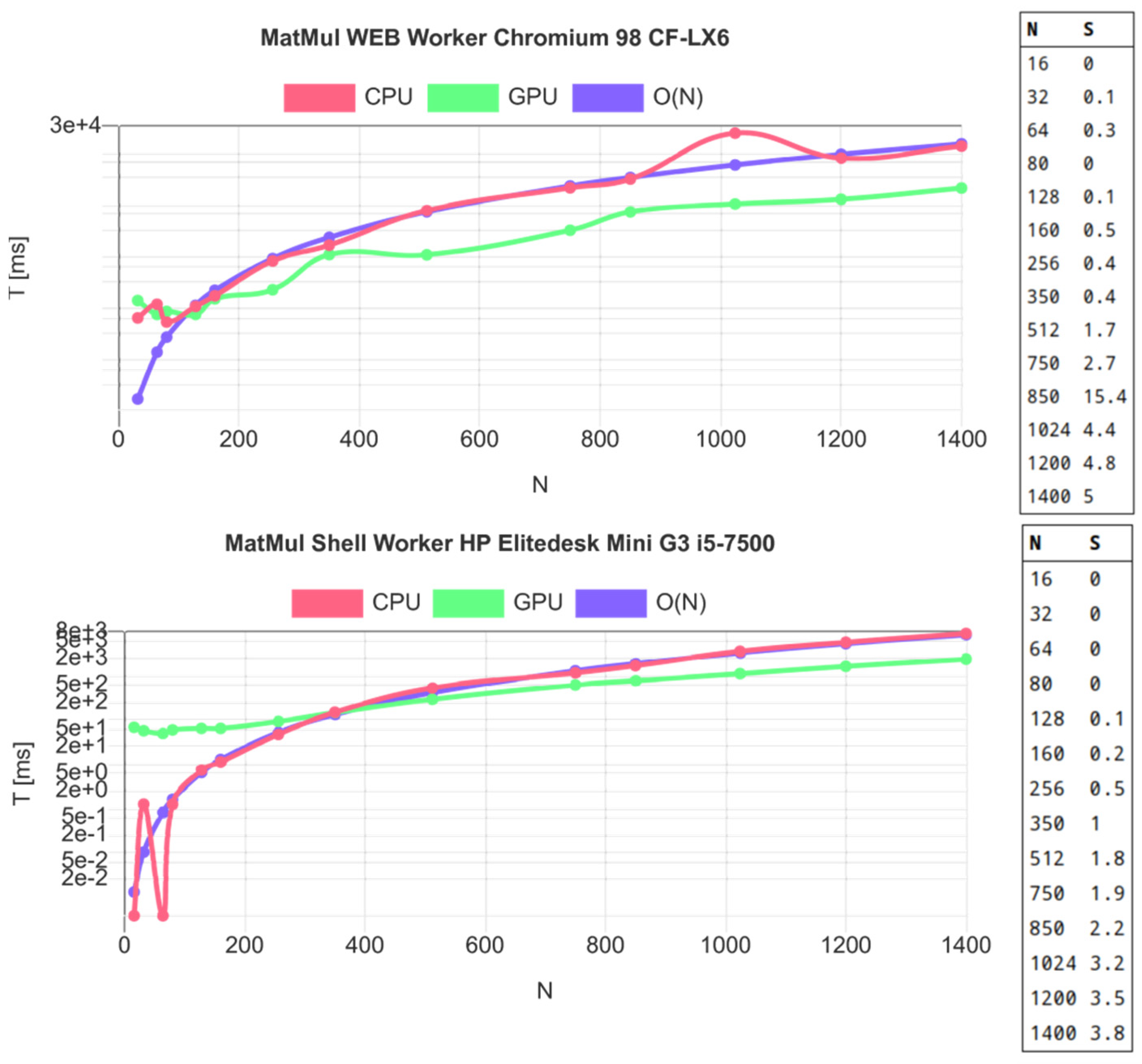
7.2. Evaluation
8. Case Studies
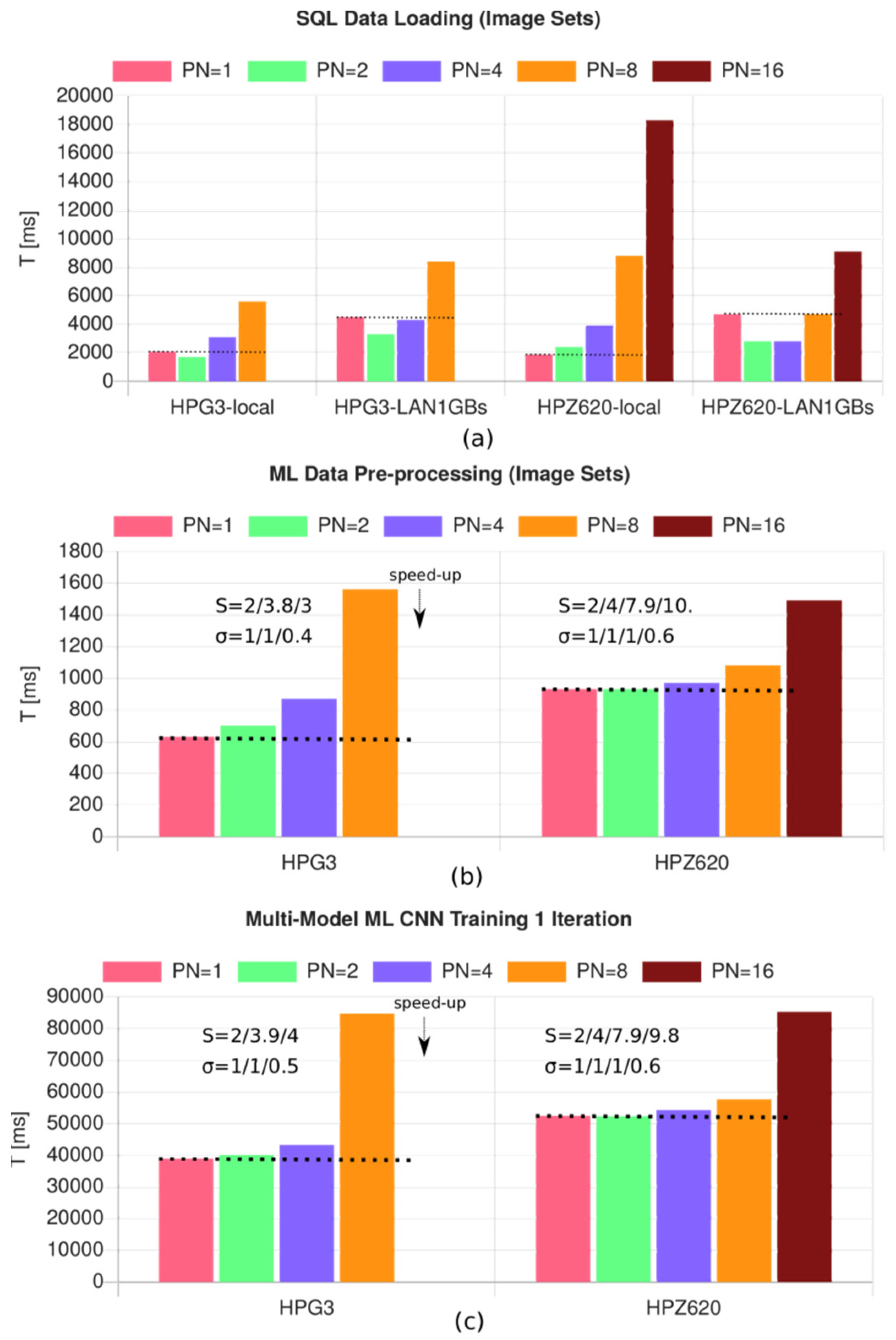
8.1. Test Framework
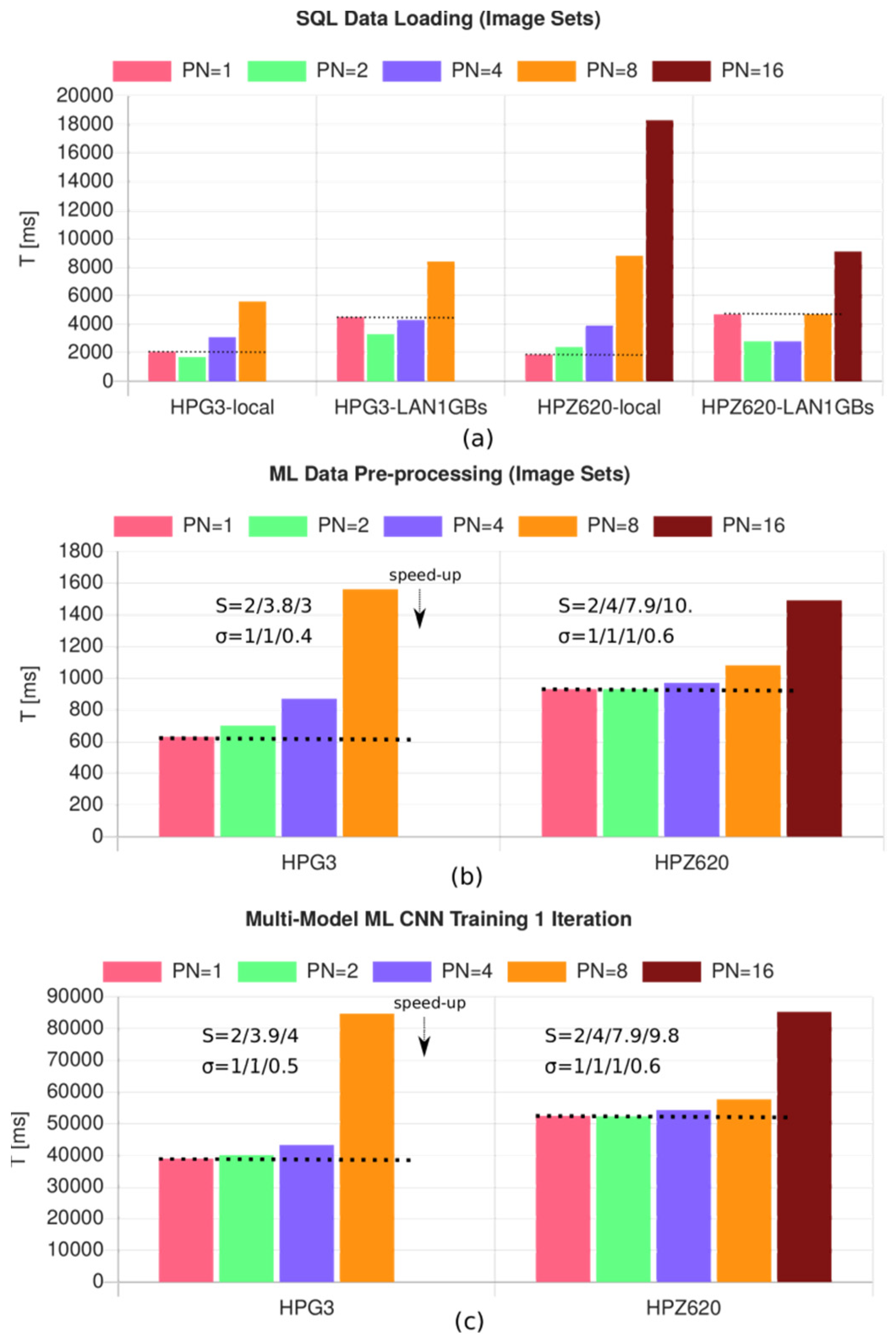
- HPG3-WS: HP G3 Mini, Intel i5-7500 CPU @ 3.40 GHz, 8 GB DRAM, 6 MB L3 Cache, 4 Cores, Debian 10, WorkShell, node.js v8
- HPZ620-WS: HP Z620 Workstation, Intel Xeon CPU E5-2667 0 @ 2.9 GHz, 2 CPU, 6 Cores/CPU, Debian 10, WorkShell, node.js v8 |
- XEON-WS: Intel Xeon Server, Intel Xeon CPU E3-1225 v3 @ 3.2 GHz, 4 Cores, 8 MB L3 cache, 16 GB DRAM, Debian 10, WorkShell, node.js v8 |
- RP3B-WS: Raspberry 3B, ARMv7 Processor rev 4, BCM 2837, 4 Cores @ 1.2 GHz, 1 GB DRAM, 512 kB L2 cache, Debian 10, WorkShell, node.js v10 |
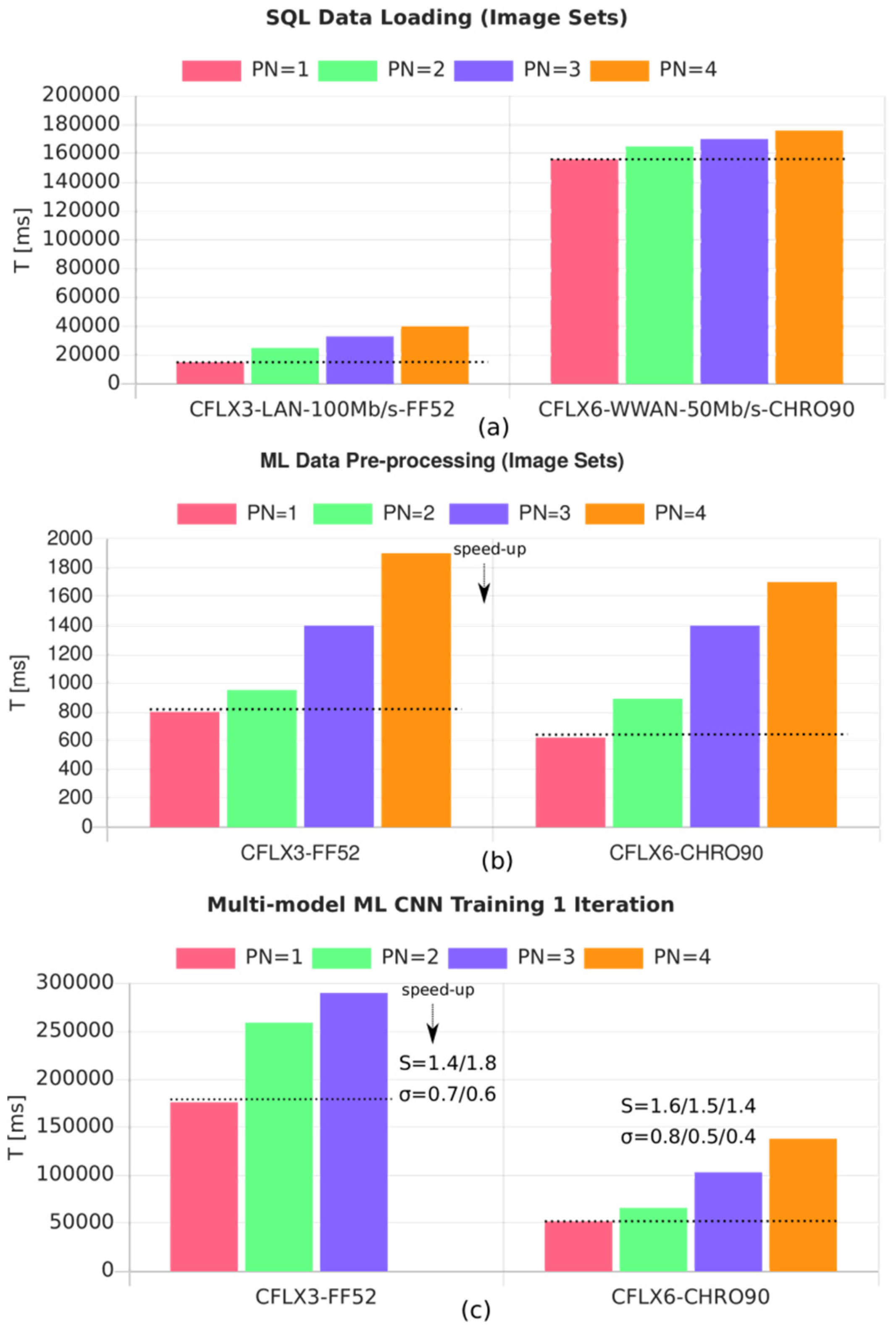
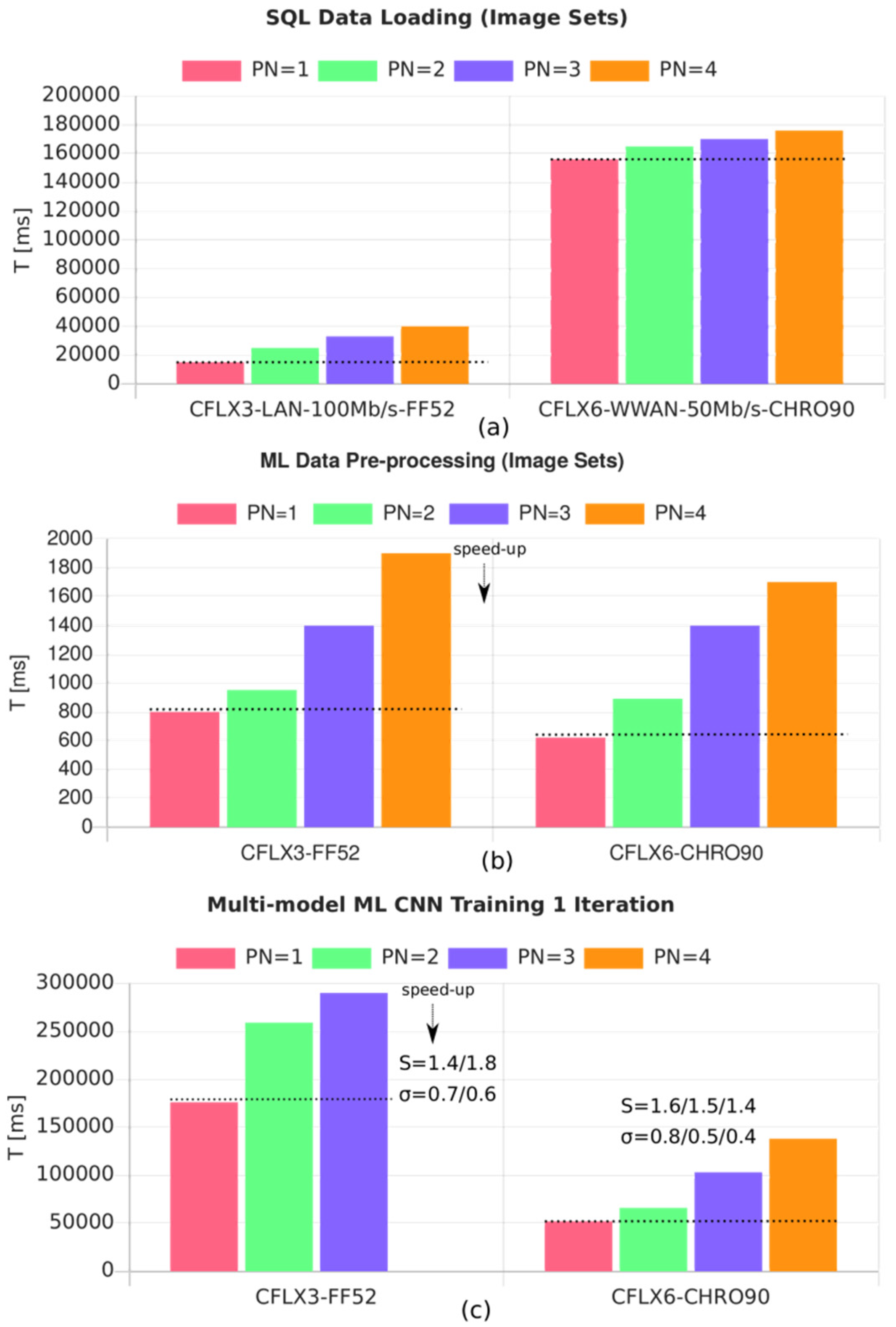
- CFLX3-WB: Panasonic Notebook CF-LX3, Intel i5-4310U @ 3.0 GHz, 8 GB DRAM, 3 MB L3 cache, 2 Cores, SunOS 11.3, WorkBook, Firefox 52
- CFLX6-WB: Panasonic Notebook CF-LX6, Intel i5-7300U @ 3.5 GHz, 8 GB DRAM, 3 MB L3 cache, 2 Cores, Debian 10, WorkBook, Chromium 90
- G3-WB: Motorola Moto G3 smartphone, Qualcomm Snapdragon 410 8916 CPU @ 1.40 GHz, 4 Cores, 1 GB DRAM, Android OS 5.1, WorkBook, Chromium 89
- G7-WB: Motorola Moto G7 smartphone, Qualcomm Snapdragon 632 CPU @ 1.8 GHz, 8 Cores, 2 GB DRAM, Android OS 10, WorkBook, Chromium 89
- XL-WB: Unihertz Atom XL smartphone, Helio P60 CPU @ 2.0 GHz, 4 HP and 4 LP Cores, 2 MB L3 Cache, 6 GB DRAM Android OS 10, WorkBook, Chromium 89
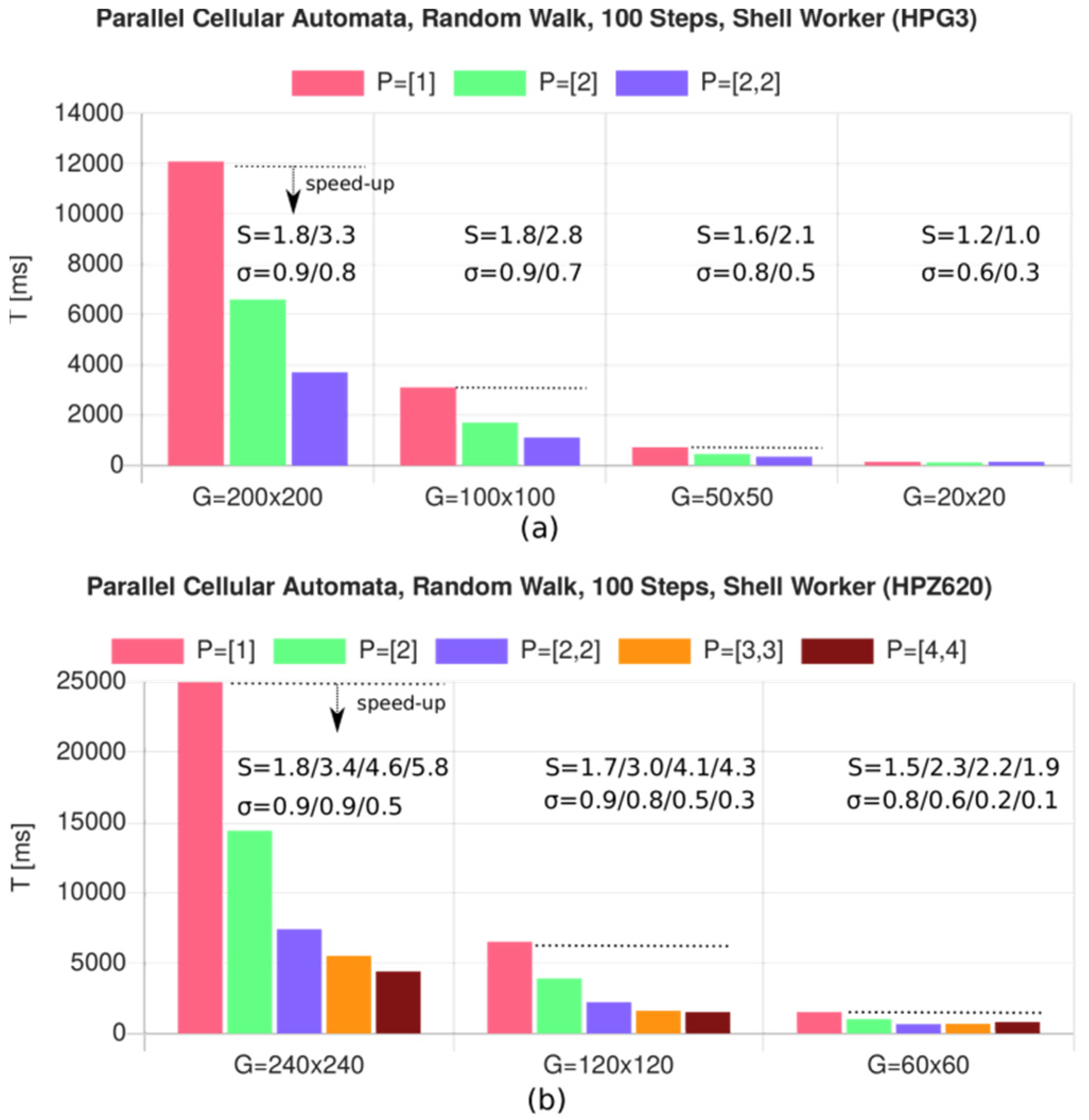
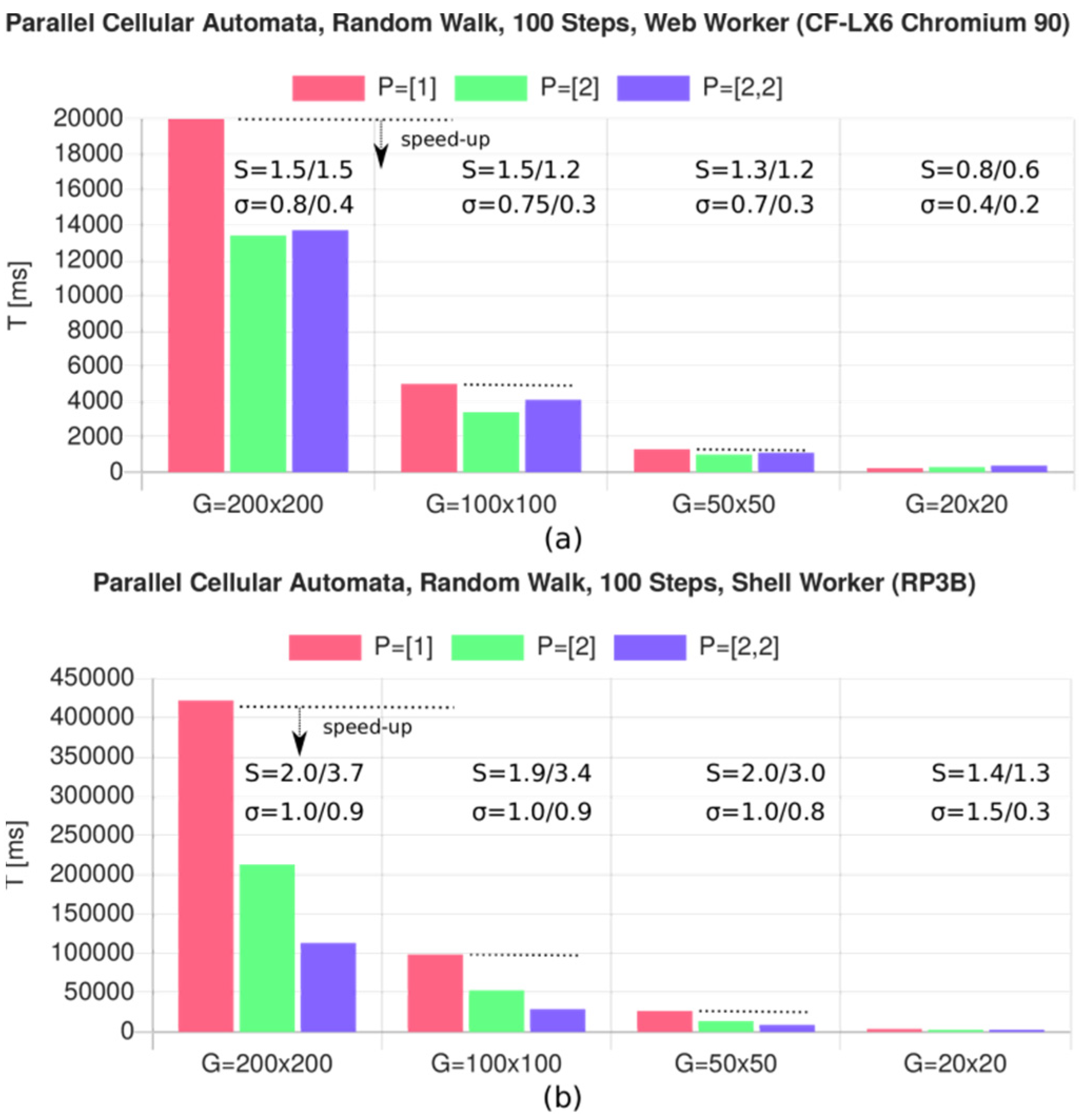
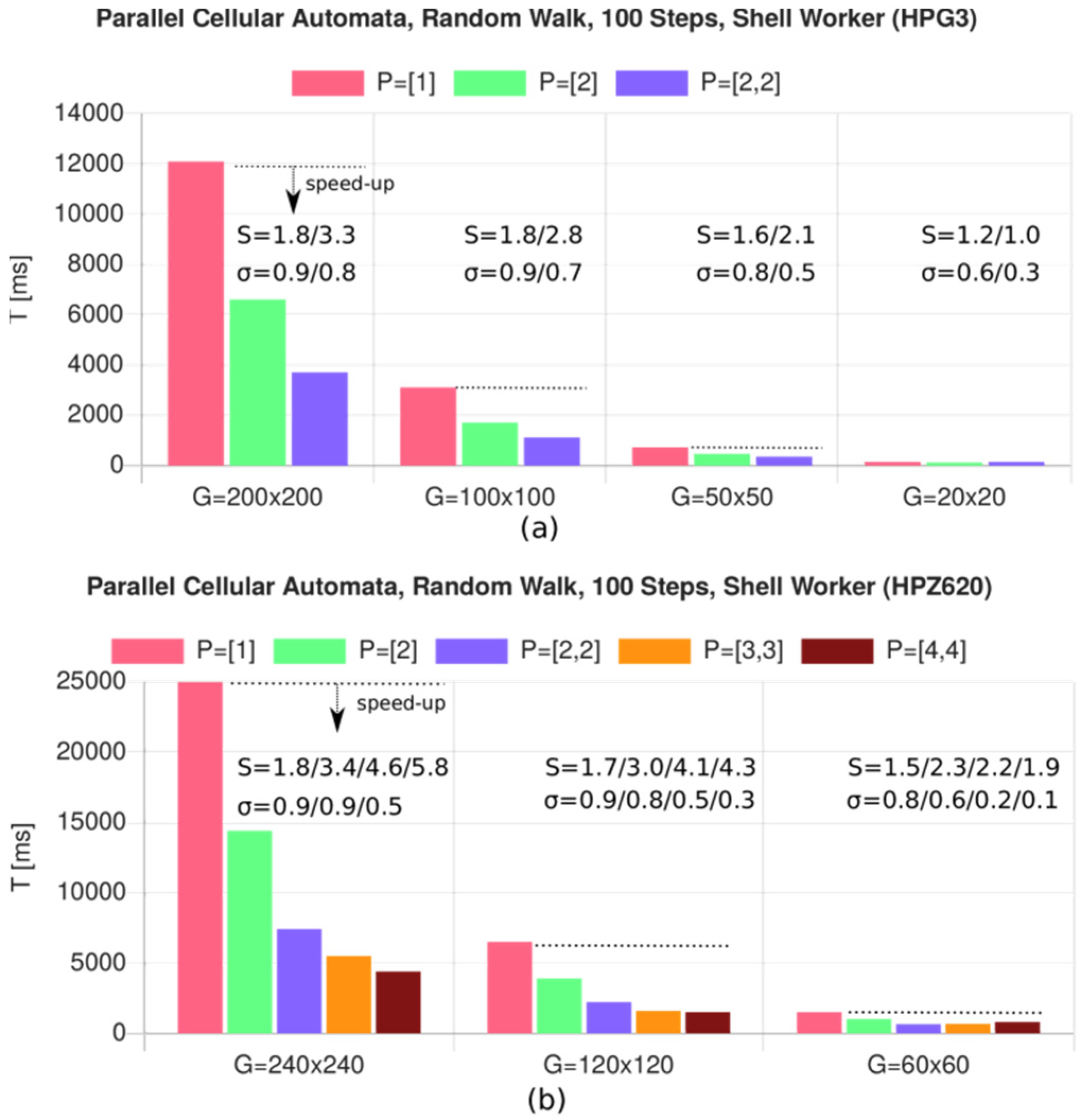
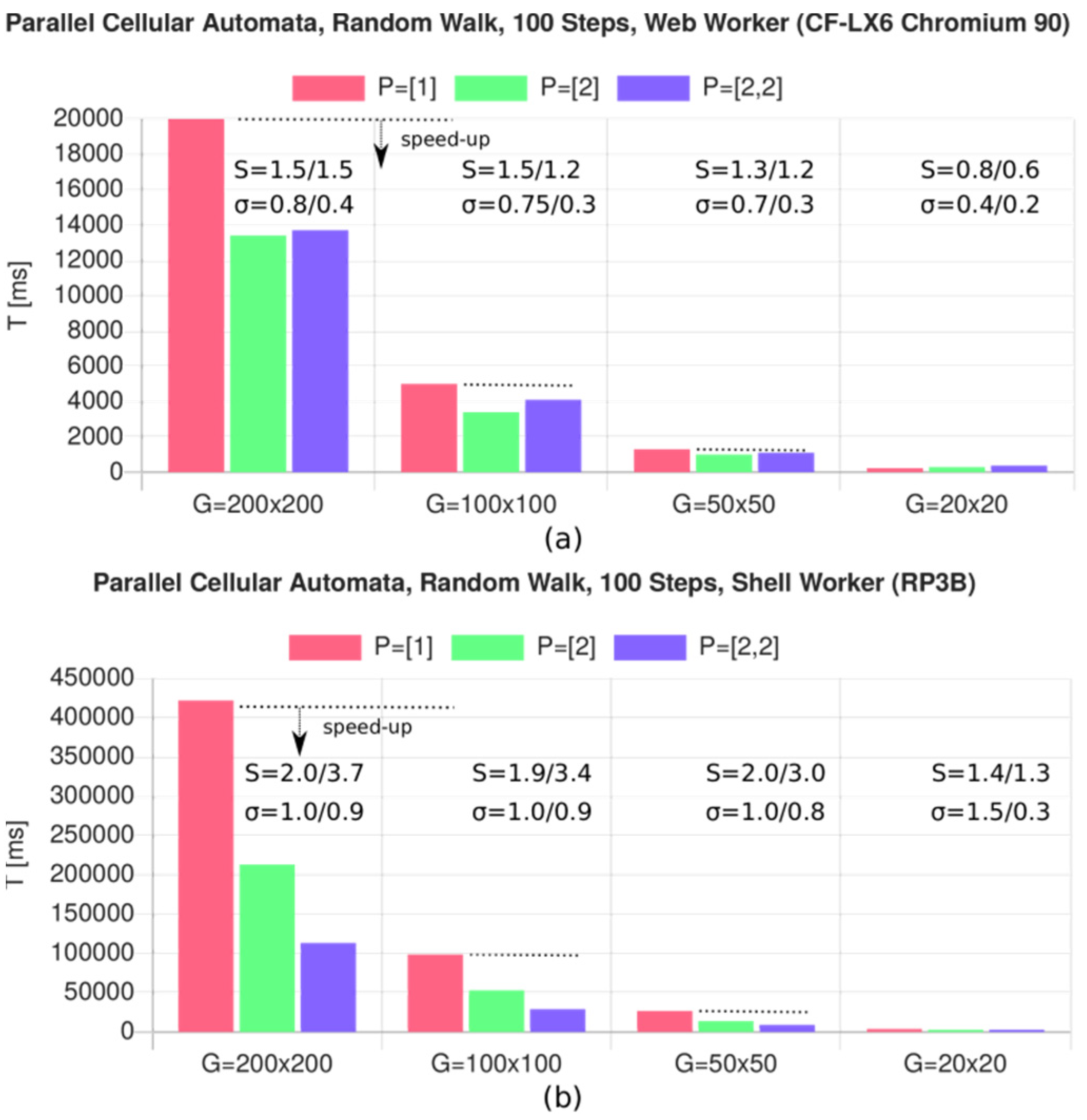
8.2. Simulation with Parallel Cellular Automata
var model = {
rows:20, columns:20, partitions:[2,2],
parameter : { P:0.3 },
radius : 1, neighbors : 8,
cell : {
private : { id:0, next : null },
shared : { place : 0 },
public : { color : 0 },
before : function (x,y) {
if (this.place==0) return;
this.next = this.ask(this.neighbors,‘random’,‘place’,0)
},
activity : function (x,y) {
if (this.place==0) return;
if (this.next) this.next.place=this.id;
},
after : function (x,y) {
if (this.next && this.next.place == this.id) {
this.place=0; // we have won the competition
}
this.next=null;
this.color=this.place==0?0:1
},
init : function (x,y) {
this.id=1+this.model.rows*y+x;
if (Math.random() < this.P) this.place=this.id;
else this.place=0;
this.next=null; this.color=this.place==0?0:1
}
}
}
var simu = CAP.Lib.SimuPar(model,{print:Code.print});
await simu.createWorker()
await simu.init()
await simu.run(100)
-
Example 11. CA random-walk model, used for the parallel simulator (here, with 2 × 2 partitions).
- CFLX6 (Chromium 90): R = 208
- HPG3 (node.js): R = 117
- HPZ620 (node.js): R = 177
- RP3B (node.js) R = 305
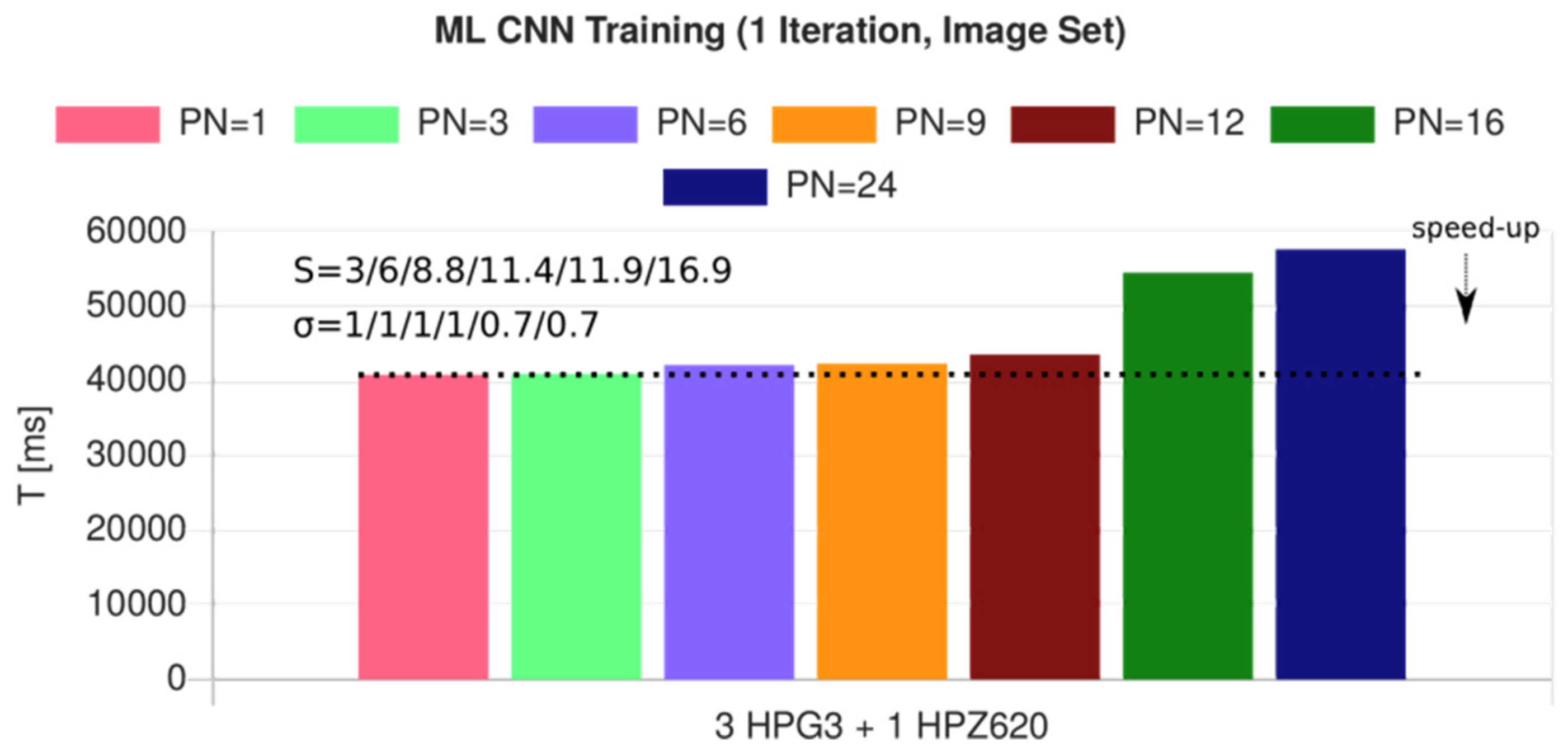
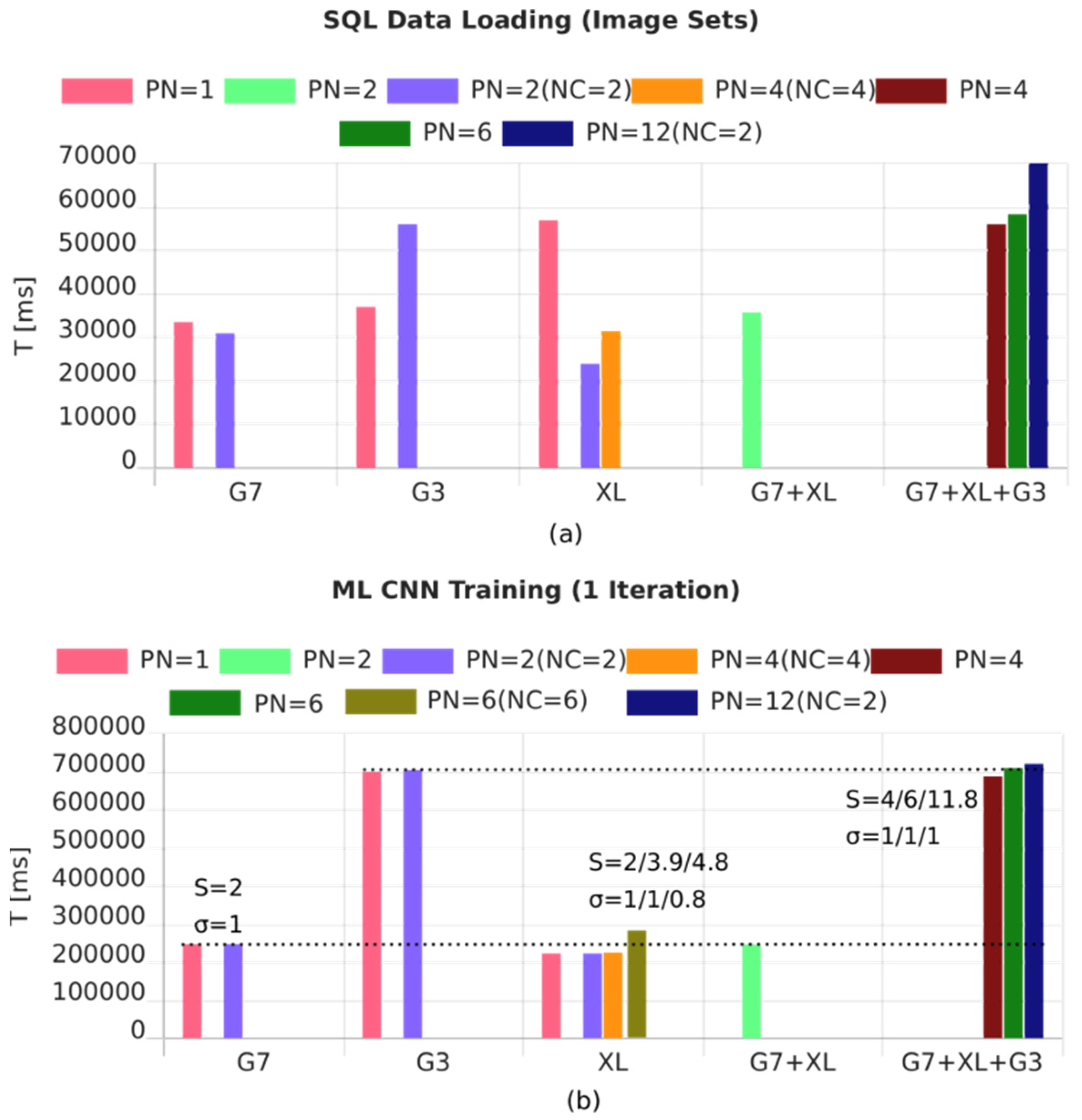
8.3. Multi-Model and Distributed-Parallel Ensemble Machine Learning
for(var i=0;i<P;i++) workers[i]= new Worker(‘ws:shellhost..’,i); Shell worker remotely new Worker(‘ws:proxyhost..’,i); or Pool Proxy new Worker(i); // or Web/Shell worker locally for(var i=0;i<P;i++) await workers[i].ready(); function loadAndProcessData(OPTIONS) { var db = DB.sql(OPTIONS) for (i=1;i<ROWS;i++) data.push(await db.select(INPUTDATATABLE,‘*’,‘rowid=’+i); var data = data.map(function (row) { return SQL2DATA(row) } data = data.map(function (row) { return ML.scale(row,scale) } var parts = ML.split(data,TRAINPART,TESTPART) this.dataTrain = parts[0]; this.dataTest = parts[1]; send({ RESULT }) } function createModel(OPTIONS) { this.model = ML.learner(ML.ML.ANN, { OPTIONS }) send({ RESULT }) } function trainModel(OPTIONS) { ML.train(this.model,this.dataTrain, { OPTIONS }) send({ RESULT }) } function testModel(OPTIONS) { ML.predict(this.model,this.dataTest, { OPTIONS }) send({ RESULT }) } // Four sequential phases for(var i=0;i<P;i++) workers[i].evalf(loadAndProcessData,OPTIONS); // async call for(var i=0;i<P;i++) results[i]=await workers[i].receive(), checkResult(results[i]) for(var i=0;i<P;i++) workers[i].evalf(createModel,OPTIONS); // async call for(var i=0;i<P;i++) results[i]=await workers[i].receive(), checkResult(results[i]) for(var i=0;i<P;i++) workers[i].evalf(trainModel,OPTIONS); // async call for(var i=0;i<P;i++) results[i]=await workers[i].receive(), checkResult(results[i]) for(var i=0;i<P;i++) workers[i].evalf(testModel,OPTIONS); // async call for(var i=0;i<P;i++) results[i]=await workers[i].receive(), checkResult(results[i])
-
Example 12. A typical ML multi-model training program, with hybrid parallel-distributed worker clusters (shortened form).
layers:[
{type:‘input’, out_sx:64, out_sy:64, out_depth:3},
{type:‘conv’, sx:5, filters:8, stride:1, pad:2, activation:‘relu’},
{type:‘pool’, sx:2, stride:2},
{type:‘conv’, sx:5, filters:16, stride:1, pad:2, activation:‘relu’},
{type:‘pool’, sx:3, stride:3},
{type:‘softmax’, num_classes:4}
]
trainer : {method: ‘adadelta’,
l2_decay: 0.002,
batch_size: 10}
- Loading of the input data.
- Pre-processing of the input data (creation of training and test data, data normalization, filtering).
- Model training (here, a CNN), generally the major contribution to the overall computation time.
- Test and verification.
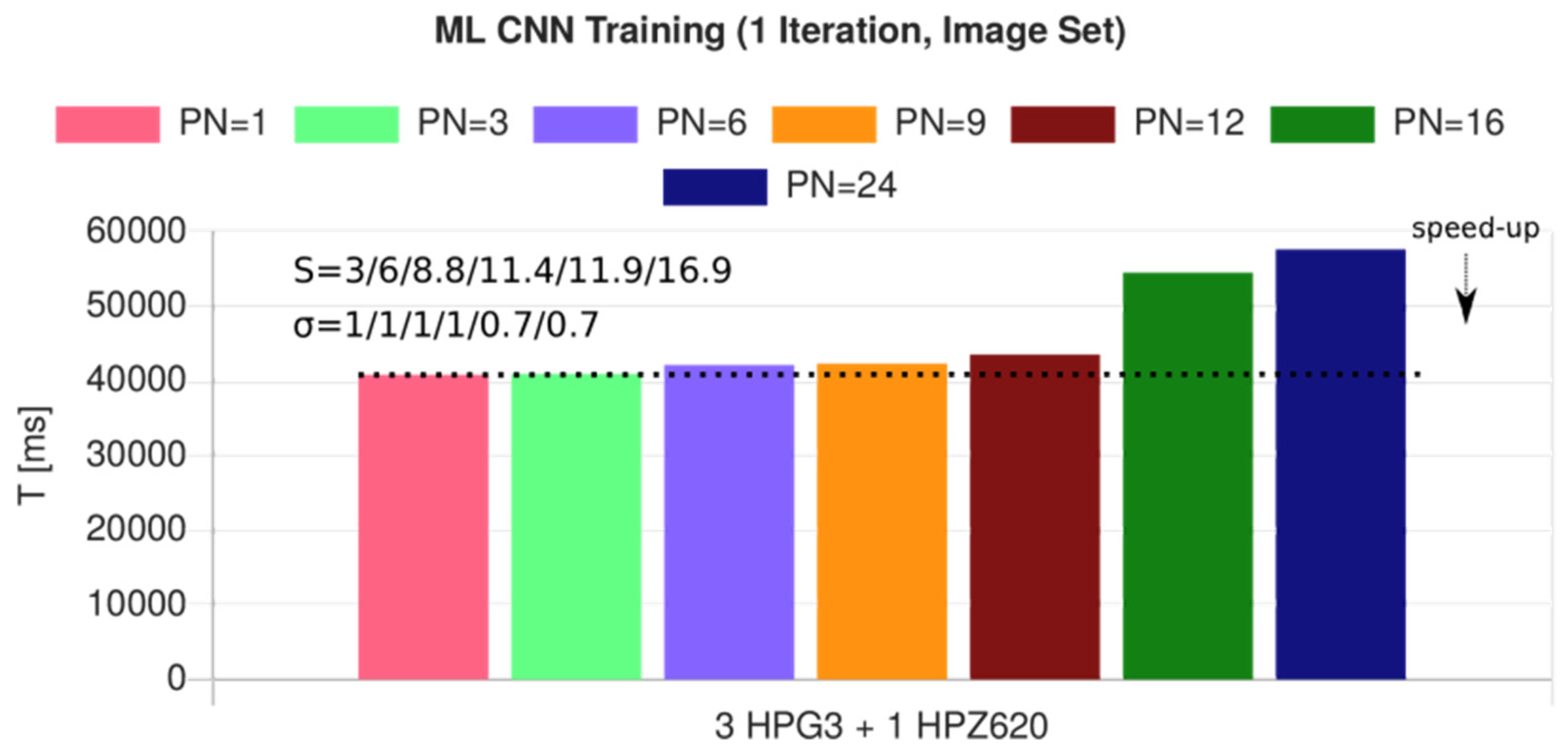
- CFLX3 (Firefox 52): R = 472
- CFLX6 (Chromium 90): R = 540
- HPG3 (node.js): R = 381
- HPZ620 (node.js): R = 372
- RP3B (node.js): R = 498
9. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Source Code Parallel Simulation
load(‘cap.plugin’) // load(‘cap.lib’) for WorkShell load(‘math.plugin’) // only for WorkBook // Simulation model parameters var model = { rows:20, columns:20, partitions:[2,2], palette: ["white","red","blue","green"], parameter : { P:0.3, }, size:4, radius : 1, neighbors : 8, name:‘Random Walk’, // Cell description cell : { private : { next : null, id : 0, }, shared : { place : 0, }, public : { color : 0 }, // before, main, and after cell activities before : function (x,y) { if (this.place==0) return; this.next = this.ask(this.neighbors,‘random’,’place’,0) }, activity : function (x,y) { if (this.place==0) return; if (this.next) { this.next.place=this.id; } }, after : function (x,y) { if (this.next && this.next.place == this.id) { this.place=0; // we have won the competition } this.next=null; this.color=this.place==0?0:1 }, init : function (x,y) { this.id=1+this.model.rows*y+x; if (Math.random() < this.P) this.place=this.id; else this.place=0; this.next=null; this.color=this.place==0?0:1 } } } // Create simulation world and perform the simulation steps async function main() { var simu = CAP.Lib.SimuPar(model,{print:Code.print}); await simu.createWorker() await simu.init() await simu.run(100) } main()
-
Example 13. Complete source code of the program code of the random walk parallel simulation (Section 8.2) using shared memory and worker processes. The number of worker processes is determined by the model.partitions parameter array.
Appendix A.2. Source Code Distributed Multi-Model ML
// Start proxy server: // wproxy -shell webwork.html -host 192.168.0.101 -script worker.js var config = { proxy : ‘http://192.168.0.101:22223’, workgroup : ‘a5908583-31b6-46b1-bc19-1a8826d3409f’, sql : ‘192.168.0.48:9999’, // cpu48 database : ‘MariKI01’, inputData : ‘imagesSeg01’, classes : ["B","P","R","C"], // data partitioning trainP : 0.5, testP : 0.5, // training parameter batchSize : 10, l2decay : 0.002, } var socket,groupControl,channelA,runCodeOnWorker // Initialize the group, connect to proxy async function groupInit() { var url = config.proxy; // Create group/proxy server control channel gs = group.client(url,{}); groupControl = gs; // Connect to proxy, get socket socket = await gs.connect(); // Delete, create, join computing group, ask for members (self only) await gs.delete(config.workgroup) await gs.create(config.workgroup) await gs.join(config.workgroup) await gs.ask(config.workgroup) // Main-Worker IPC channel channelA = Code.channel.create(); // Run code on worker (function(data)) runCodeOnWorker = function (peer,fun,data) { if (data==undefined) data=null; socket.write({ cmd:‘run’, code:‘try { var foo=’+fun.toString()+‘; foo(__data) } ’+ ‘catch (e) { print(e.toString()) }’, from:socket.peerid, data:data, },peer) } // Process messages from worker socket.receiver(function (message) { switch (message.cmd) { case ‘print’: print.apply({},[‘[‘+message.id+’]’].concat(message.data)); break; case ‘send’: channelA.enqueue(message.data); break; case ‘pong’: print(‘Pong from ’+message.id); break; } }); } // Initialize the workers async function initWorkers() { async function loadData(config) { var JO = JSON.parse; var t0 = time() // Create DB API this.db = DB.sqlA(config.sql); // Create or open data base, get all tables await db.createDB(config.database) await db.databases() await db.tables() // #rows of input data table var sampleN = await db.count(config.inputData) if (sampleN.length) sampleN=sampleN[0]; else return "EDBERR"; this.inputData=[]; for (var i = 1;i<=sampleN;i++) { // Read one input data sample (image/matrix) var data = await db.select(config.inputData,"*","rowid="+i); if (data) data=data[0]; // Deserialize data data.dataspace = JO(data.dataspace); this.inputData.push(data); } // Sync. with master process, send message send(this.inputData.length) } // Get all members of the computation group var members = await gs.ask(config.workgroup), waitfor = 0; for (var i in members ) { if (members[i]==socket.peerid) continue; // Run code in group workers runCodeOnWorker(members[i],loadData,{ id:members[i], index:i, sql : config.sql, database : config.database, inputData : config.inputData, }) waitfor++; } // Wait for workers finished their work for (var i=0;i<waitfor;i++) { await channelA.receive() } } async function connectGroup() { var members = await groupControl.ask(config.workgroup) // Connect all workers to this master process (on proxy) for (var i in members ) { if (members[i]==socket.peerid) continue; print(members[i]) await socket.connect(members[i],true /*bidir*/) } } // Pre-process the image data and create tarining and test data tables async function preProcess1(config) { try { var int = function (x) { return x|0 } var t0=time() // 0. Filter out ‘?’ labelled samples var data = this.inputData.filter(function (row) { return row.label!=‘?’ }); // 1. XY transform this.dataXY=data.map(function (row) { return { x: new Float32Array(row.data), y:config.classes.indexOf(row.label) } }) // 2. Scale to [-.5,.5] this.dataXY.forEach(function (row) { row.x=ML.scale(row.x,Math.scale1(0,255,-.5,.5)) }); // 3. Shuffle sample instances randomly this.dataXY=this.dataXY.shuffle(); // 4. Split the sample instances (training/test data) var parts = ML.split(this.dataXY,int(config.trainP*this.dataXY.length)) this.dataTrainXY=parts[0]; this.dataTestXY=parts[1]; this.dataTrainX=this.dataTrainXY.pluck(‘x’); this.dataTrainY=this.dataTrainXY.pluck(‘y’); this.dataTestX=this.dataTestXY.pluck(‘x’); this.dataTestY=this.dataTestXY.pluck(‘y’); this.dataX=this.dataXY.pluck(‘x’); this.dataY=this.dataXY.pluck(‘y’); // Sync. with master process send(this.dataXY.length) } catch (e) { print(e.toString()); send({error:e.toString()}) } } async function preProcess() { var members = await groupControl.ask(config.workgroup), waitfor = 0; for (var i in members ) { if (members[i]==socket.peerid) continue; runCodeOnWorker(members[i],preProcess1,{ id:members[i], index:i, classes : config.classes, trainP : config.trainP, testP : config.testP, }) waitfor++; } for (var i=0;i<waitfor;i++) { await channelA.receive()) } } // Create CNN models on the worker (and the trainer) async function model(config) { this.model = ML.learner({ algorithm:ML.ML.CNN, layers:[ {type:‘input’, out_sx:64, out_sy:64, out_depth:3}, {type:‘conv’, sx:5, filters:8, stride:1, pad:2, activation:’relu’}, {type:‘pool’, sx:2, stride:2}, {type:‘conv’, sx:5, filters:16, stride:1, pad:2, activation:’relu’}, {type:‘pool’, sx:3, stride:3}, {type:‘softmax’, num_classes:config.classes.length} ], trainer : {method: ‘adadelta’, l2_decay: config.l2Deacy, batch_size: config.batchSize} }); send(1) } async function createModels() { var members = await groupControl.ask(config.workgroup), waitfor = 0; for (var i in members ) { if (members[i]==socket.peerid) continue; runCodeOnWorker(members[i],model,{ id:members[i], index:i, classes : config.classes, l2Deacy : config.l2Deacy, batchSize : config.batchSize, }) waitfor++; } for (var i=0;i<waitfor;i++) { await channelA.receive()) } } // Train one model in the worker async function trainOne(config) { var result = ML.train(this.model,{ x:this.dataTrainX, y:this.dataTrainY, width : 64, height : 64, depth : 3, iterations:config.iterations, verbose : 0, async : false, callback : function (result) { print(result.iteration,result.loss,result.time) } }) send(result) } // Parallel Multi-model training async function trainAll () { var members = await groupControl.ask(config.workgroup), waitfor = 0; for (var i in members ) { if (members[i]==socket.peerid) continue; runCodeOnWorker(members[i],trainOne,{ id:members[i], index:i, iterations:1, }) waitfor++; } for (var i=0;i<waitfor;i++) { await channelA.receive()) } } // Main master process function async function main() { await groupInit(); await connectGroup(); await inirWorkers(); await preProcess(); await createModels(); } main()
Appendix A.3
var config = {
PN:4,
proxy : ‘http://192.168.0.101:22223’,
workgroup : ‘a5908583-31b6-46b1-bc19-1a8826d3409f’,
nodeid : Utils.UUIDv4(),
verbose : 1,
}
// Main worker RPC loop waiting for code evalulation requests
async function workerLoop (config) {
print(‘WebWorker started.’,config.workgroup);
// Load plug-ins
load(‘math.plugin.js’)
load(‘ml.plugin.js’)
await sleep(1000);
var url = config.proxy;
// Create group/proxy control channel
var gs = group.client(url,{id:config.workerid});
print(‘ping’,url,inspect(await gs.ping()))
// Connect to proxy server, get a communication socket
var socket = await gs.connect();
// Join computational group, get all members
await gs.join(config.workgroup)
// Returns UUID array
await gs.ask(config.workgroup)
var Env = {
print:function () {
print.apply({},Array.prototype.slice.call(arguments));
socket.write({cmd:‘print’,
id:config.workerid,
data:Array.prototype.slice.call(arguments)});
},
send:function (data) {
socket.write({cmd:‘send’,data:data,from:socket.peerid});
},
sleep:sleep,
schedule:schedule,
time:Date.now,
DB:DB,
JSON:JSON,
ML:ML,
Math:Math,
Utils:Utils,
}
for(;;) {
// Get requests from master
var rpc = await socket.read();
switch (rpc.cmd) {
case ‘run’:
// Run code here!
try { compile(rpc.code,Env,rpc.data) }
catch (e) { print(e.toString()) };
break;
case ‘stop’:
Code.interrupt=true;
case ‘ping’:
socket.write({cmd:‘pong’,id:socket.peerid});
break;
}
}
}
// Start the worker processor code...
async function main() {
var workers=[];
for(var i=0;i<config.PN;i++) {
var worker = Code.worker.create(i);
await Code.worker.ready(worker);
print(‘Worker #’+i+‘ started.’);
workers.push(worker);
}
for(var i=0;i<config.PN;i++) {
Code.worker.evalf(workers[i],workerLoop,{
id:i,
proxy:config.proxy,
workgroup:config.workgroup,
nodeid:config.nodeid,
workerid:config.nodeid+‘-’+i,
verbose:config.verbose,
})
}
print(‘Initialized.’)
}
main()
Appendix A.4
References
- PsiLAB 1/2. Scientific and Numeric Research Software Environment. Available online: http://psilab.sourceforge.net (accessed on 1 January 2022).
- node.js. Available online: https://github.com/nodejs/node (accessed on 1 January 2022).
- Choy, R.; Edelman, A. Parallel MATLAB: Doing It Right. Proc. IEEE 2008, 93, 331–341. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Ounifi, H.A.; Gherbi, A.; Li, W.; Cheriet, M. A hybrid GPU-FPGA based design methodology for enhancing machine learning applications performance. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 2309–2323. [Google Scholar] [CrossRef]
- Romano, J. WebMesh: A Browser-Based Computational Framework for Serverless Applications. Bachelor’s Thesis, Computer Science Department, Brown University, Providence, RI, USA, 2019. [Google Scholar]
- Nicol, D.; Fujimoto, R. Parallel simulation today. Ann. Oper. Res. 1994, 53, 249–285. [Google Scholar] [CrossRef] [Green Version]
- Magee, J.; Dulay, N.; Kramer, J. Structuring parallel and distributed programs. Softw. Eng. J. 1993, 8, 73. [Google Scholar] [CrossRef]
- Bagrodia, R.; Meyer, R.; Takai, M.; Chen, Y.A.; Zeng, X.; Martin, J.; Song, H.Y. Parsec: A parallel simulation environment for complex systems. Computer 1998, 31, 77–85. [Google Scholar] [CrossRef] [Green Version]
- Kao, A.; Krastins, I.; Alexandrakis, M.; Shevchenko, N.; Eckert, S.; Pericleous, K. A parallel cellular automata lattice Boltzmann method for convection-driven solidification. Jom 2019, 71, 48–58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosin, P.L. Training Cellular Automata for Image Processing. IEEE Trans. Image Process. 2002, 15, 2076–2087. [Google Scholar] [CrossRef] [PubMed]
- Giordano, A.; De Rango, A.; Rongo, R.; D’Ambrosio, D.; Spataro, W. Dynamic load balancing in parallel execution of cellular automata. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 470–484. [Google Scholar] [CrossRef]
- Xia, C.; Wang, H.; Zhang, A.; Zhang, W. A high-performance cellular automata model for urban simulation based on vectorization and parallel computing technology. Int. J. Geogr. Inf. Sci. 2018, 32, 399–424. [Google Scholar] [CrossRef]
- Aaby, B.G.; Perumalla, K.S.; Seal, S.K. Efficient Simulation of Agent-Based Models on Multi-GPU and Multi-Core Clusters. In Proceedings of the 3rd International Icst Conference on Simulation Tools and Techniques, Malaga, Spain, 15–19 March 2010. [Google Scholar]
- Xiao, J.; Andelfinger, P.; Eckhoff, D.; Cai, W.; Knoll, A. A Survey on Agent-based Simulation using Hardware Accelerators. ACM Comput. Surv. 2019, 51, 1–35. [Google Scholar] [CrossRef]
- Hughes, D.; Correll, N. Distributed Machine Learning in Materials that Couple Sensing, Actuation, Computation and Communication. arXiv 2016, arXiv:1606.03508. [Google Scholar]
- Ma, Y.; Xiang, D.; Zheng, S.; Tian, D.; Liu, X. Moving Deep Learning into Web Browser: How Far Can We Go? In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Distributed deep neural networks over the cloud, the edge and end devices. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 328–339. [Google Scholar]
- Chahal, K.S.; Grover, M.S.; Dey, K.; Shah, R.R. A hitchhiker’s guide on distributed training of deep neural networks. J. Parallel Distrib. Comput. 2020, 137, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Schlegel, D. Deep Machine Learning on GPUs; University of Heidelber-Ziti: Mannheim, Germany, 2015. [Google Scholar]
- NVIDIA. cuDNN Developer Guide; PG-06702-001_v8.3.2; Available online: https://docs.nvidia.com/deeplearning/cudnn/developer-guide/index.html (accessed on 1 February 2022).
- Kotsifakou, M.; Srivastava, P.; Sinclair, M.D.; Komuravelli, R.; Adve, V.; Adve, S. Hpvm: Heterogeneous parallel virtual machine. In Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Vienna, Austria, 24–28 February 2018; pp. 68–80. [Google Scholar]
- Graham, R.L.; Shipman, G.M.; Barrett, B.W.; Castain, R.H.; Bosilca, G.; Lumsdaine, A. Open MPI: A high-performance, heterogeneous MPI. In Proceedings of the 2006 IEEE International Conference on Cluster Computing, Barcelona, Spain, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2017; pp. 1–9. [Google Scholar]
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa, 26–28 October 2011; IEEE: Piscataway, NJ, USA, 2017; pp. 363–366. [Google Scholar]
- Peteiro-Barral, D.; Guijarro-Berdinas, B. A Survey of methods for distributed machine learning. Prog. Artif. Intell. 2013, 2, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Sarafov, V. Comparison of IoT Data Protocol Overhead. In Proceedings of the Seminars FI/IITM WS 17/18, Network Architectures and Services, Munich, Germany, 1 August 2017–26 February 2018; pp. 7–14. [Google Scholar]
- PSciLab Software Repository. Available online: https://github.com/bsLab/PSciLab (accessed on 21 February 2022).
- gpu.js. Available online: https://github.com/gpujs/gpu.js (accessed on 1 January 2022).
- Bosse, S. Parallel and Distributed Agent-based Simulation of large-scale socio-technical Systems with loosely coupled Virtual Machines. In Proceedings of the SIMULTECH Conference 2021, International Conference on Simulation and Modeling Methodologies, Technologies and Applications, Online, 7–9 July 2021. [Google Scholar]
- ConvNet.js, Deep Learning in the Browser. Available online: https://cs.stanford.edu/people/karpathy/convnetjs/ (accessed on 1 December 2021).
- Bosse, S.; Weiss, D.; Schmidt, D. Supervised Distributed Multi-Instance and Unsupervised Single-Instance Autoencoder Machine Learning for Damage Diagnostics with High-Dimensional Data—A Hybrid Approach and Comparison Study. Computers 2021, 10, 34. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Host | Matrix | Data (Bytes) ×N | RXTX (Bytes) | OF |
|---|---|---|---|---|
| HPG3-WS/CFLX3-WB | 2 × 2 | (30 + 80) × 500,000 | 66,309,928 | 1.21 (1.65) |
| HPG3-WS/CFLX3-WB | 10 × 10 | (30 + 1955) × 20,000 | 42,468,779 | 1.07 (1.09) |
| HPG3-WS/CFLX3-WB | 1000 × 100 | (30 + 1,929,253) × 20 | 40,784,371 | 1.06 (1.06) |
| Host | Matrix | Data (Bytes) | N | τ (ms/msg) | BW (MB/s) |
|---|---|---|---|---|---|
| CFLX3-FF52-WB | 2 × 2 | 81 | 50,000 | 0.37 | 0.21 |
| CFLX3-FF52-WB | 10 × 10 | 1943 | 10,000 | 0.47 | 3.9 |
| CFLX3-FF52-WB | 100 × 100 | 192,880 | 1000 | 8.3 | 22.2 |
| CFLX6-CR90-WB | 2 × 2 | 81 | 50,000 | 0.01 | 7.0 |
| CFLX6-CR90-WB | 10 × 10 | 1945 | 10,000 | 0.02 | 110 |
| CFLX6-CR90-WB | 100 × 100 | 192,929 | 10,000 | 0.42 | 450 |
| CFLX3-WS | 2 × 2 | 80 | 50,000 | 0.018 | 4.2 |
| CFLX3-WS | 10 × 10 | 1950 | 10,000 | 0.08 | 23.5 |
| CFLX3-WS | 100 × 100 | 192,919 | 1000 | 1.44 | 127.8 |
| HPG3-WS | 2 × 2 | 81 | 1,000,000 | 0.005 | 15.4 |
| HPG3-WS | 10 × 10 | 1945 | 1,000,000 | 0.024 | 78.1 |
| HPG3-WS | 100 × 100 | 19,2864 | 10,000 | 1.3 | 141.1 |
| Acronym | Class | NC | Jystones | Tst | TDP | Eff. η |
|---|---|---|---|---|---|---|
| HPG3 | WS | 4 | 9800 k | 200 ms | 65 W | 600 |
| HPZ620 | WS | 2 × 6 | 7100 k | 490 ms | 105/210 W | 405 |
| XEON | WS | 4 | 11,200 k | 300 ms | 84 W | 533 |
| RP3B | WS | 4 | 745 k | 5000 ms | 5 W | 596 |
| CFLX3 | WB | 2 | 6700 k 1 2700 k 2 | 150 ms | 15 W | 890 1 360 2 |
| CFLX6 | WB | 2 | 8200 k 1 10,400 k 4 | 80 ms | 25 W | 656 1 832 2 |
| G3 | WW | 2 | 140 k 3 | - | 5 W | 56 |
| G7 | WW | 4 | 340 k 3 | - | 7 W | 388 |
| XL | WW | 4 + 4 | 360 k 3,5/280 k 3,6 | - | 5 W | 576 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bosse, S. PSciLab: An Unified Distributed and Parallel Software Framework for Data Analysis, Simulation and Machine Learning—Design Practice, Software Architecture, and User Experience. Appl. Sci. 2022, 12, 2887. https://doi.org/10.3390/app12062887
Bosse S. PSciLab: An Unified Distributed and Parallel Software Framework for Data Analysis, Simulation and Machine Learning—Design Practice, Software Architecture, and User Experience. Applied Sciences. 2022; 12(6):2887. https://doi.org/10.3390/app12062887
Chicago/Turabian StyleBosse, Stefan. 2022. "PSciLab: An Unified Distributed and Parallel Software Framework for Data Analysis, Simulation and Machine Learning—Design Practice, Software Architecture, and User Experience" Applied Sciences 12, no. 6: 2887. https://doi.org/10.3390/app12062887
APA StyleBosse, S. (2022). PSciLab: An Unified Distributed and Parallel Software Framework for Data Analysis, Simulation and Machine Learning—Design Practice, Software Architecture, and User Experience. Applied Sciences, 12(6), 2887. https://doi.org/10.3390/app12062887