
Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure


Abstract
:1. Introduction
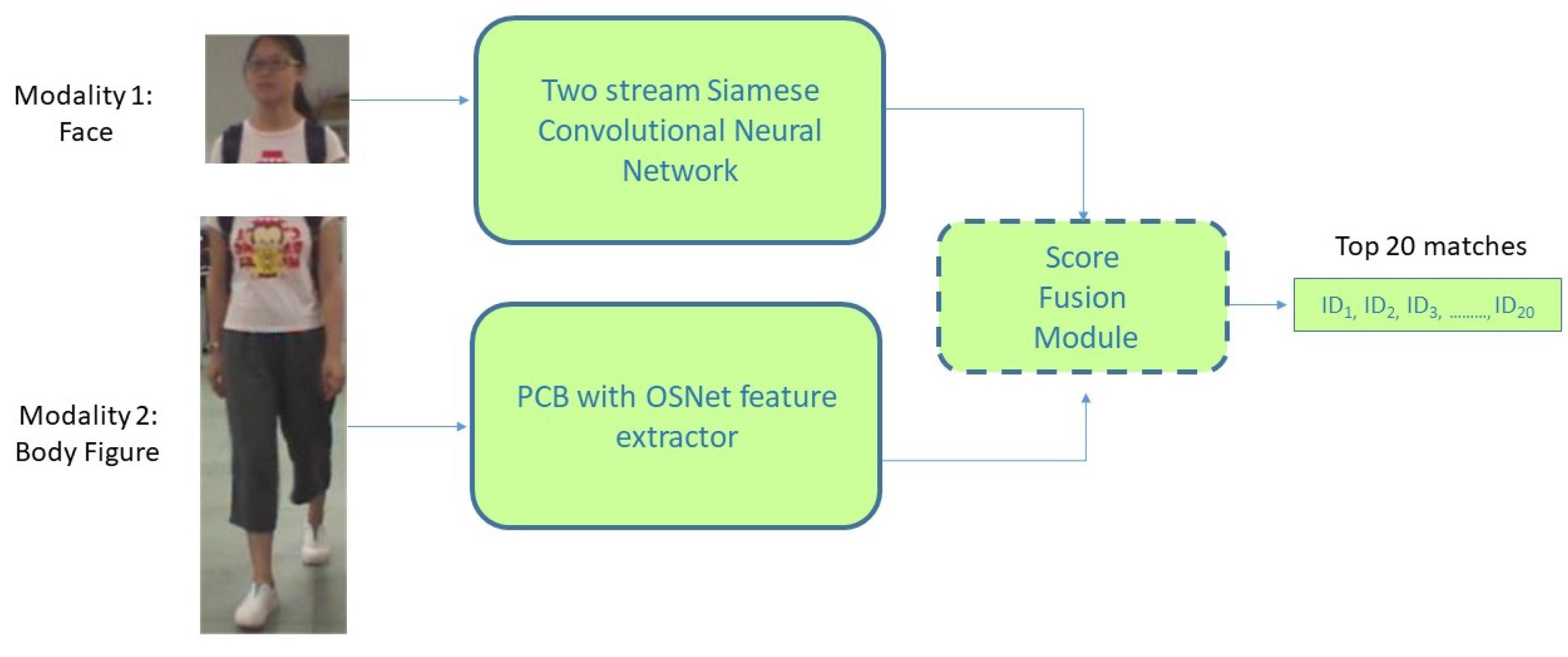
- A novel approach is presented to address the problem of person re-identification under cloth-changing conditions by combining different modalities to achieve the task. The first modality is the facial region and the second modality is the remaining body part. A separate neural network was built for each modality to extract appropriate features, the resulting features from both modalities were combined to produce an informative decision using score-level fusion module.
- The proposed methodology was tested on a challenging dataset, PRCC dataset is one of the few public datasets that incorporate cloth-changing.
- The approach is compared against recent state-of-the-art models. Also to our knowledge, this is the first result of the MLFN model on the PRCC dataset.
2. Related Work
2.1. CNN-Based Multi-Modal Deep Learning for Person Re-Identification
2.2. Multi-Scale Deep Learning Architectures for Person Re-Identification
- Tied Convolution for pre-processing the input
- Multi-scale stream layers: Analyses the data stream with several receptive field sizes.
- Saliency-based learning fusion layer: To fuse the output streams from the previous layers.
- Sub-nets for person re-identification: Used for verification so the problem can be transformed into a binary classification one, stating whether a pair of images represent the same person or not.
2.3. Part-Based Deep Learning for Person Re-Identification
2.4. Face Detection Models
2.5. Discussion
3. Methodology
3.1. Dataset
3.2. Data Pre-Processing
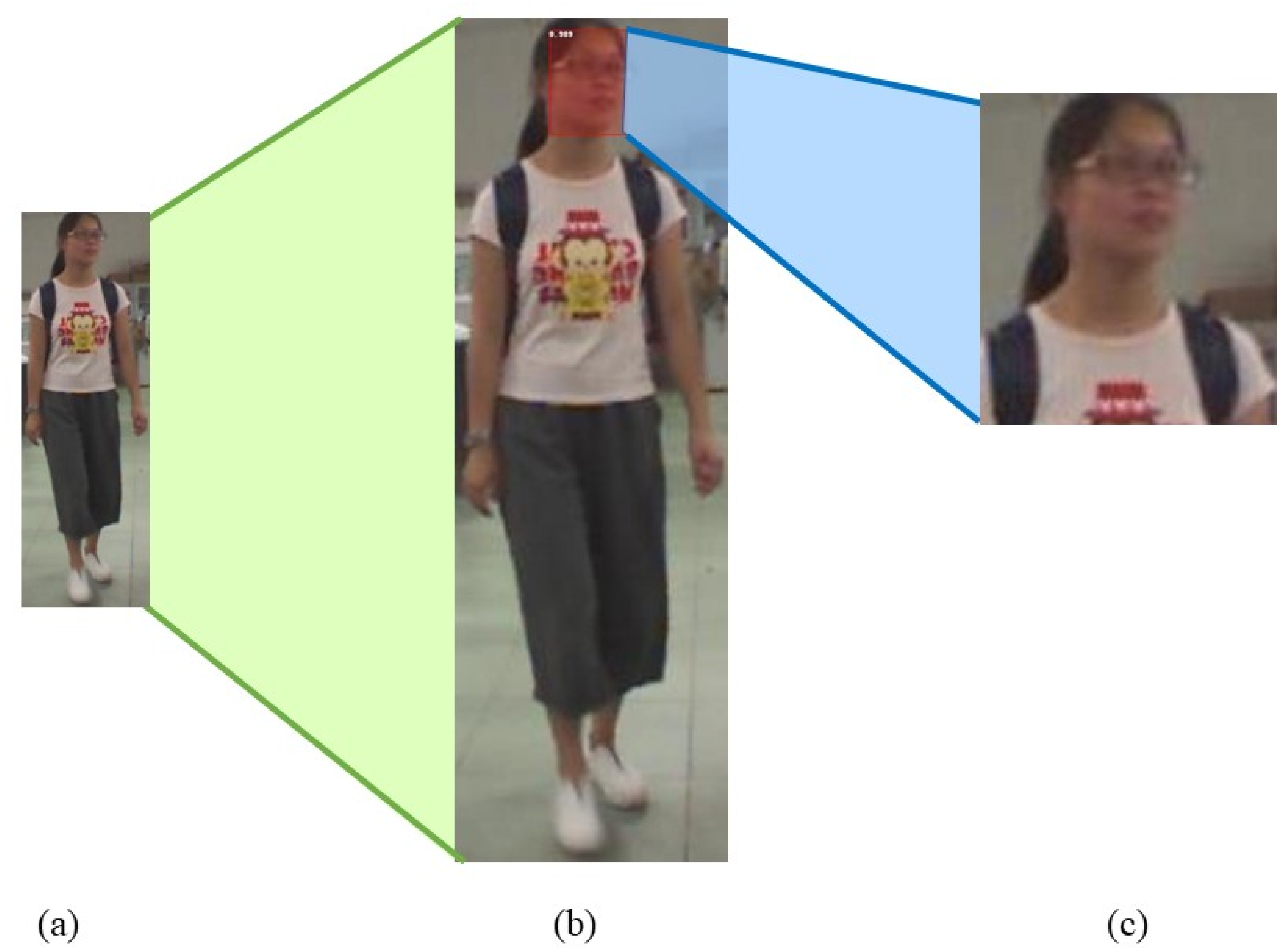
3.3. Face Detection
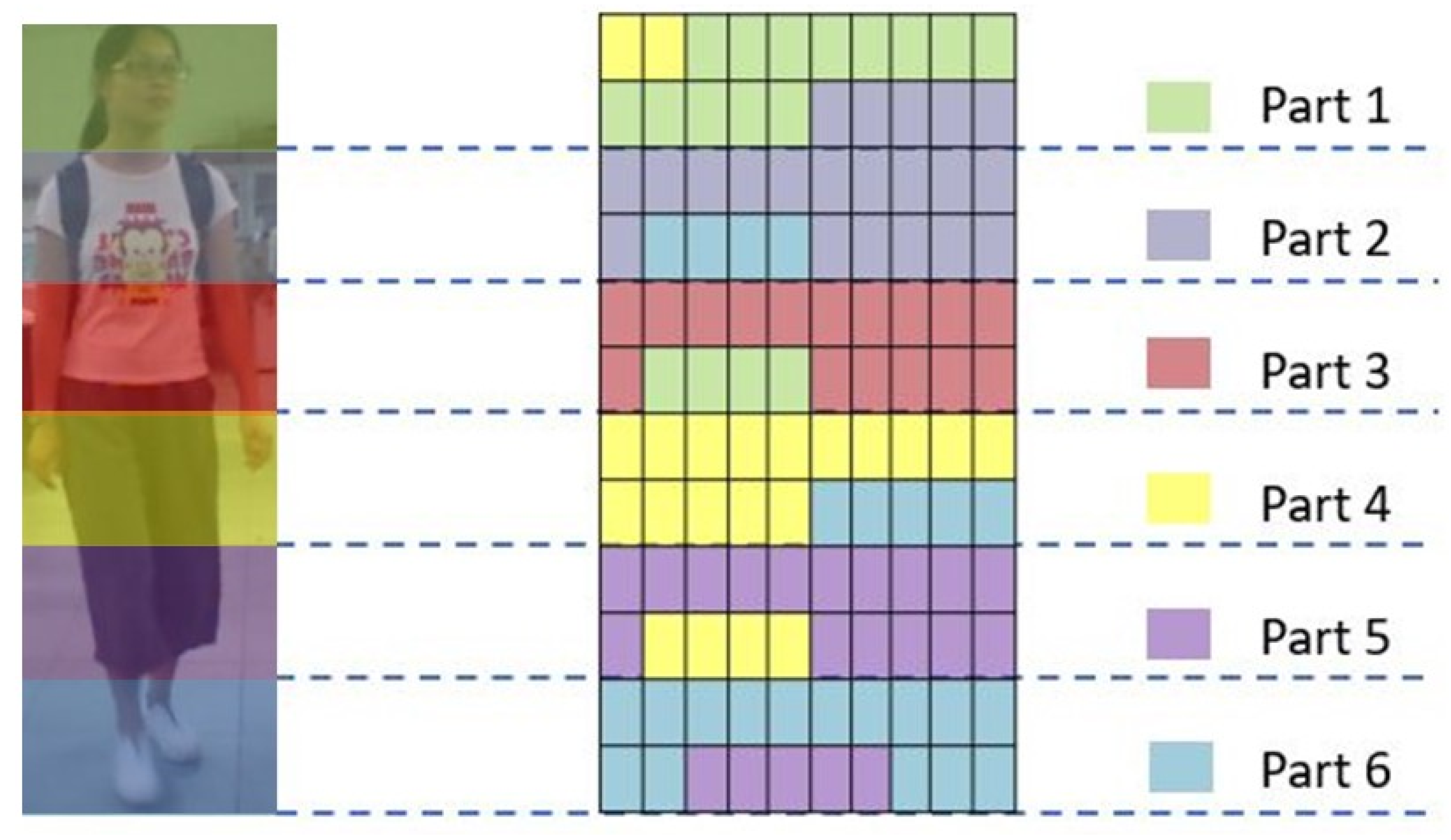
3.4. Extending Features
- Head;
- From the bottom of the head to the middle of the chest;
- From the middle of the chest to the navel;
- From the navel to the upper edge of the pubis;
- From the upper edge of the pubis to the middle height of the thigh;
- From the middle height of thigh to the middle height of the calf;
- From the middle height of calf to the point below the ankles;
- From the point below the ankles to the feet.
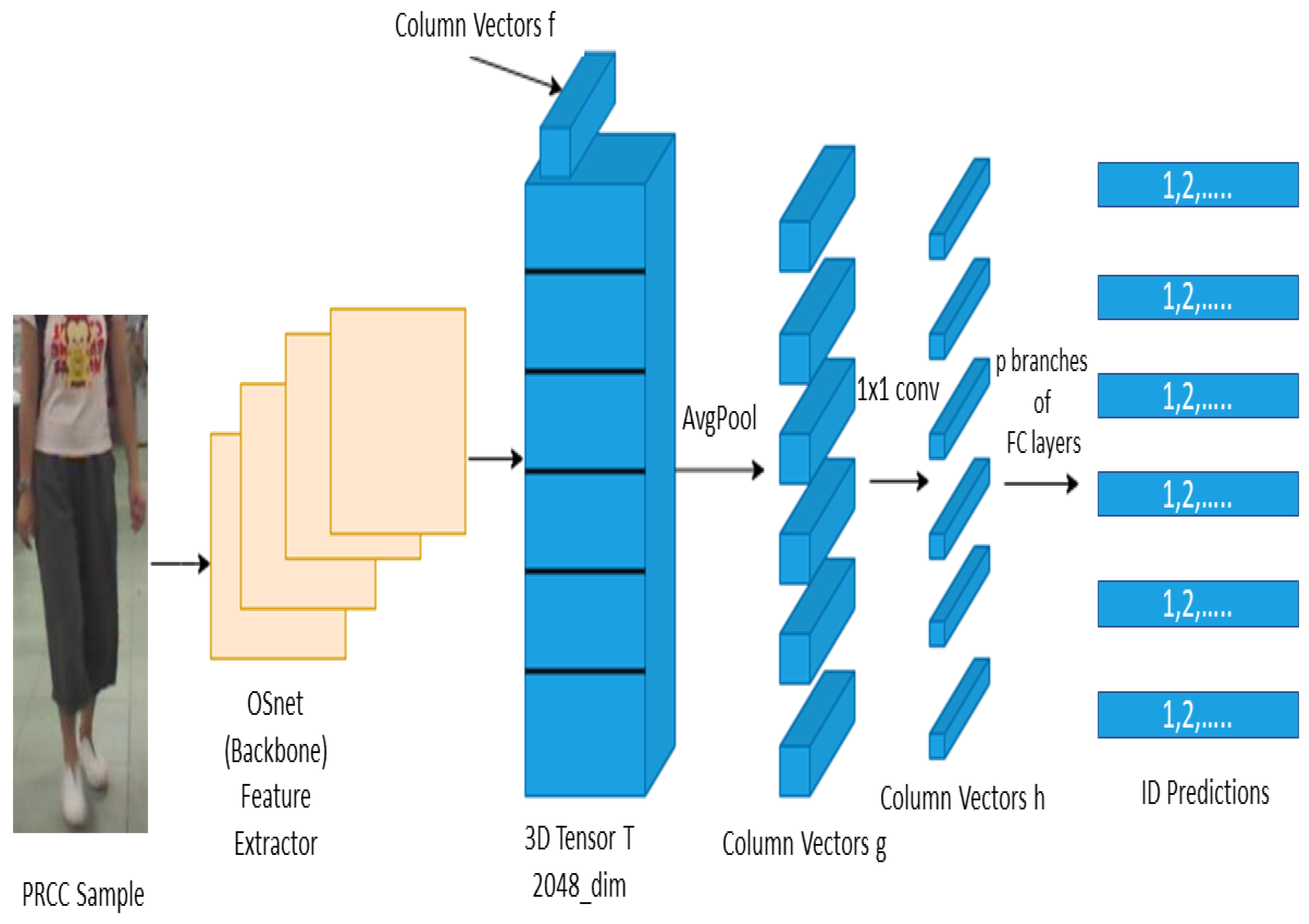
3.5. Proposed Architecture
4. Experimental Results and Analysis
4.1. Experiment Setup
4.2. Evaluation Protocol
- Cumulated Matching Characteristics (CMC): shows the probability that a query identity matches the candidate lists retrieved by the model, thus this evaluation metric is valid only for supervised learning algorithms since it relies on comparing the model’s prediction with the ground truth [21]. As an example, consider a simple single-gallery-shot setting in which each gallery identity is only present once. Using the ground truth of the dataset the algorithm will rank all the gallery samples based on their distances compared to the query from small to large, and the CMC top-k accuracy is which is a shifted step function as shown in Equation (5). The final CMC curve is computed by averaging the shifted step functions over all the queries.
- Mean Average Precision (mAp): evaluates the overall performance of the model. The average precision calculates the area under the precision-recall curve for each query, mAp calculates the mean of all queries. CMC curve combined with mAp can give a clear representation of the model’s performance. Figure 6 shows the top five ranks of two different models on the same query image. Both models were able to retrieve two correct matches in the first five ranks, but model b was able to achieve them earlier. The mean average precision shows this difference. Table 2 shows the calculation of precision on ranks 1 through 5 for modela a and b, respectively, using the precision Equation (6) as well as the mean average precision using Equation (7)
4.3. Experiments
- HACNN.
- MLFN.
- SCRNet.
- MuDeep
- ResNet50.
- PCB with a backbone network ResNet50: The Part-based Convolutional Baseline (PCB) network was utilized to conduct this experiment. The key idea behind PCB is to partition the produced column vector of an image to p equal partitions. Empirically PCB was always used with . As mentioned the idealized human figure approximately eight heads tall. The first modality represents two heads which makes the remaining column vector contain around six equal partitions. The presented model utilizes . As mentioned earlier PCB network needs the backbone to act as a feature extractor. This experiment employs ResNet50 because of its outstanding performance and its relatively compressed architecture. The ResNet50 model used was the pre-trained one which exploits the pre-trained parameters on ImageNet.
- PCB with ResNet50 as a backbone network augmented with RPP module: As mentioned one of the main contributions represented in [18] is augmenting the PCB network with a refined part-pooling (RPP) module. The RPP module is an attempt to relocate outliers. Outliers are part of the feature mAp inevitably located in the wrong partitions. RPP will measure the similarity between parts to assign each part to its correct partition, as shown in Figure 7.
- OSNet.
- PCB with OSNet as a backbone network: Since OSNet proved to be a strong feature extractor in the person re-identification task. In this experiment, we proposed augmenting the PCB network with OSNet as the feature extractor to improve the performance. OSNet is a lightweight network compared to ResNet50. In addition to improving the model’s overall performance, the training time is also reduced.
- The proposed architecture utilized two separate neural networks for each modality. For the first modality (faces), the FaceNet Siamese model was trained on the extracted facial features from the PRCC dataset using the Faceboxes detector. For the second modality (body), the second model that fuses OSNet and PCB was trained on the PRCC dataset after removing the soft bio-metrics region extracted for the first modality.
4.4. Validation of Proposed Model
4.5. Results
- ResNet-50 model performed relatively better than MuDeep (from Table 3 MuDeep Rank-1 accuracy: 58.5%, ResNet50 Rank-1 accuracy: 62.9%) which is why it was used as a backbone network to the PCB achieving 59.2%.
- To improve the performance of ResNet50 with PCB, the model was augmented with the RPP module, but it seemed to harm the model’s performance decreasing the accuracy from 59.2 % to 51.2% accuracy on Rank-1.
- The outstanding performance of OSNet producing an accuracy of 63.6% on Rank-1 was the inspiration to replace the ResNet-50 used as a feature extraction for PCB with OSNet. This combination improved the accuracy on Rank-1 to 73.5%.
- The proposed architecture produced an accuracy of 81.4% on Rank-1. Our model was able to outperform some of the recent state-of-the-art approaches such as HACNN, MLFN and SCRNet in terms of accuracy and mAP.
- Our model does not consume an enormous amount of training time due to its lightweight architecture and exploiting pre-trained models.
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kanigel, R. Eyes on the Street: The Life of Jane Jacobs, New York; Vintage: New York, NY, USA, 2017. [Google Scholar]
- Vezzani, R.; Baltieri, D.; Cucchiara, R. People reidentification in surveillance and forensics: A survey. ACM Comput. Surv. 2013, 46, 1–37. [Google Scholar] [CrossRef]
- Qian, X.; Fu, Y.; Jiang, Y.G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5399–5408. [Google Scholar]
- Sanchez-Reyes, L.M.; Rodriguez-Resendiz, J.; Salazar-Colores, S.; Avecilla-Ramírez, G.N.; Pérez-Soto, G.I. A High-accuracy mathematical morphology and multilayer perceptron-based approach for melanoma detection. Appl. Sci. 2020, 10, 1098. [Google Scholar] [CrossRef] [Green Version]
- Gallegos-Duarte, M.; Mendiola-Santiba nez, J.D.; Ibrahimi, D.; Paredes-Orta, C.; Rodríguez-Reséndiz, J.; González-Gutiérrez, C.A. A novel method for measuring subtle alterations in pupil size in children with congenital strabismus. IEEE Access 2020, 8, 125331–125344. [Google Scholar] [CrossRef]
- Salazar-Colores, S.; Ramos-Arreguín, J.M.; Pedraza-Ortega, J.C.; Rodríguez-Reséndiz, J. Efficient single image dehazing by modifying the dark channel prior. EURASIP J. Image Video Process. 2019, 2019, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ortiz-Echeverri, C.J.; Salazar-Colores, S.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A new approach for motor imagery classification based on sorted blind source separation, continuous wavelet transform, and convolutional neural network. Sensors 2019, 19, 4541. [Google Scholar] [CrossRef] [Green Version]
- Koo, J.H.; Cho, S.W.; Baek, N.R.; Kim, M.C.; Park, K.R. CNN-based multimodal human recognition in surveillance environments. Sensors 2018, 18, 3040. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qawaqneh, Z.; Mallouh, A.A.; Barkana, B.D. Deep convolutional neural network for age estimation based on VGG-face model. arXiv 2017, arXiv:1709.01664. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2109–2118. [Google Scholar]
- Chen, H.; Lagadec, B.; Bremond, F. Learning discriminative and generalizable representations by spatial-channel partition for person re-identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2483–2492. [Google Scholar]
- Sharma, N.; Jain, V.; Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The importance of skip connections in biomedical image segmentation. In Deep Learning and Data Labeling for Medical Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 179–187. [Google Scholar]
- Dong, X.; Shen, J. Triplet loss in siamese network for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3702–3712. [Google Scholar]
- Yoo, H.J. Deep convolution neural networks in computer vision: A review. IEIE Trans. Smart Process. Comput. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Labelled Faces in the Wild (LFW). Available online: http://vis-www.cs.umass.edu/lfw/ (accessed on 21 July 2021).
- Qian, X.; Wang, W.; Zhang, L.; Zhu, F.; Fu, Y.; Xiang, T.; Jiang, Y.G.; Xue, X. Long-term cloth-changing person re-identification. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Chen, Y.; Duffner, S.; Stoian, A.; Dufour, J.Y.; Baskurt, A. Person re-identification with a body orientation-specific convolutional neural network. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Auckland, New Zealand, 10–14 February 2018; pp. 26–37. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Gray, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance (PETS), Rio de Janeiro, Brazil, 14 October 2007; Volume 3, pp. 1–7. [Google Scholar]
- Munaro, M.; Fossati, A.; Basso, A.; Menegatti, E.; Van Gool, L. One-shot person re-identification with a consumer depth camera. In Person Re-Identification; Springer: Berlin/Heidelberg, Germany, 2014; pp. 161–181. [Google Scholar]
- Yang, Q.; Wu, A.; Zheng, W.S. Person re-identification by contour sketch under moderate clothing change. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 2029–2046. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. Faceboxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Piva, S.; Comes, L.; Asadi, M.; Regazzoni, C.S. Grouped-People Splitting Based on Face Detection and Body Proportion Constraints. In Proceedings of the 2006 IEEE International Conference on Video and Signal Based Surveillance, Sydney, NSW, Australia, 22–24 November 2006; p. 24. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Learning generalisable omni-scale representations for person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2021; Early Access. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Zhu, Z.; Jiang, X.; Zheng, F.; Guo, X.; Huang, F.; Sun, X.; Zheng, W. Aware loss with angular regularization for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13114–13121. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Dokmanic, I.; Parhizkar, R.; Ranieri, J.; Vetterli, M. Euclidean distance matrices: Essential theory, algorithms, and applications. IEEE Signal Process. Mag. 2015, 32, 12–30. [Google Scholar] [CrossRef] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Gamal, A.; Shoukry, N.; Salem, M.A. Long-Term Person Re-identification Model with a Strong Feature Extractor. In Proceedings of the Tenth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2021. [Google Scholar]
- Google Colaboratory. Available online: https://colab.research.google.com/notebooks/intro.ipynb (accessed on 15 July 2021).
- Zhou, K.; Xiang, T. Torchreid: A library for deep learning person re-identification in pytorch. arXiv 2019, arXiv:1910.10093. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset | IDs | Images | Cameras |
|---|---|---|---|
| Train | 150 | 22,898 | 3 |
| Gallery | 71 | 10,374 | 3 |
| Query | 71 | 426 | 3 |
| Model | Rank-1 | Rank-2 | Rank-3 | Rank-4 | Rank-5 | mAP |
|---|---|---|---|---|---|---|
| Model A | 1/1 | 1/2 | 1/3 | 1/4 | 1/5 | 0.496 |
| Model B | 1/1 | 2/2 | 2/3 | 2/4 | 2/5 | 0.712 |
| Method | Rank-1 | Rank-5 | Rank-10 | Rank-20 | mAP | Training Time |
|---|---|---|---|---|---|---|
| HACNN | 64.1 | 68.1 | 70.2 | 72.1 | 41.5 | 2:48:49 |
| MLFN | 50.2 | 56.1 | 59.4 | 62.7 | 29.6 | 2:54:21 |
| MuDeep | 58.5 | 64.6 | 67.6 | 71.6 | 34.1 | 3:46:54 |
| SCRNet | 78.1 | 79.5 | 81.7 | 83.2 | 58.2 | 1:57:32 |
| ResNet50 | 62.9 | 67.1 | 68.3 | 70.7 | 35.5 | 1:49:11 |
| PCB + ResNet50 | 59.2 | 66.4 | 69.7 | 71.4 | 31.8 | 2:14:49 |
| PCB + ResNet50 (RPP) | 51.2 | 52.3 | 52.5 | 53.4 | 28.0 | 2:47:12 |
| OSNet | 63.6 | 67.6 | 70.4 | 73.2 | 33.7 | 1:12:08 |
| PCB + OSNet | 73.5 | 75.1 | 75.8 | 76.8 | 48.6 | 2:10:01 |
| Our model | 81.4 | 82.3 | 83.1 | 83.7 | 60.2 | 2:35:42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shoukry, N.; Abd El Ghany, M.A.; Salem, M.A.-M. Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure. Appl. Sci. 2022, 12, 2835. https://doi.org/10.3390/app12062835
Shoukry N, Abd El Ghany MA, Salem MA-M. Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure. Applied Sciences. 2022; 12(6):2835. https://doi.org/10.3390/app12062835
Chicago/Turabian StyleShoukry, Nadeen, Mohamed A. Abd El Ghany, and Mohammed A.-M. Salem. 2022. "Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure" Applied Sciences 12, no. 6: 2835. https://doi.org/10.3390/app12062835
APA StyleShoukry, N., Abd El Ghany, M. A., & Salem, M. A.-M. (2022). Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure. Applied Sciences, 12(6), 2835. https://doi.org/10.3390/app12062835