
Improved MSRN-Based Attention Block for Mask Alignment Mark Detection in Photolithography



Abstract
:1. Introduction
- A Multi-Scale Residual Attention Block was constructed by applying an Attention Mechanism based on the Multi-Scale Residual Network. We proposed a High-Resolution (HR) model in which the resolution of Low-Resolution (LR) images is improved and the extracted features are improved by reconstructing the model structure of a multiscale network.
- We proved that object detection is improved by increasing the image resolution of the proposed model. When detecting an object through a vision machine, the detection performance is improved by improving the resolution.
- The data collected through the equipment is pre-processed and learned, and it is reliable in practical application through the analysis of the results, images, and detection obtained by conducting various experiments.
2. Related Work
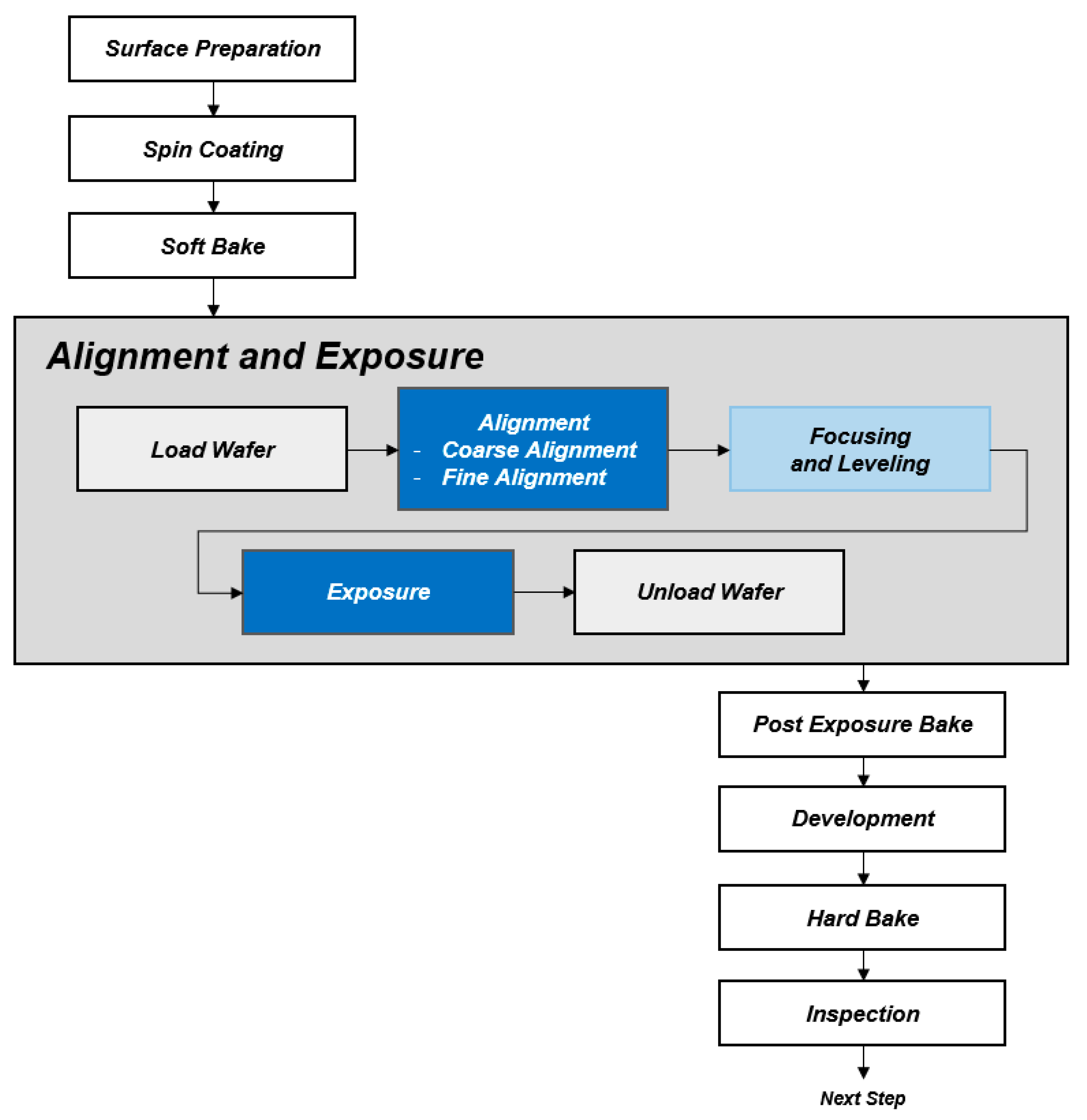
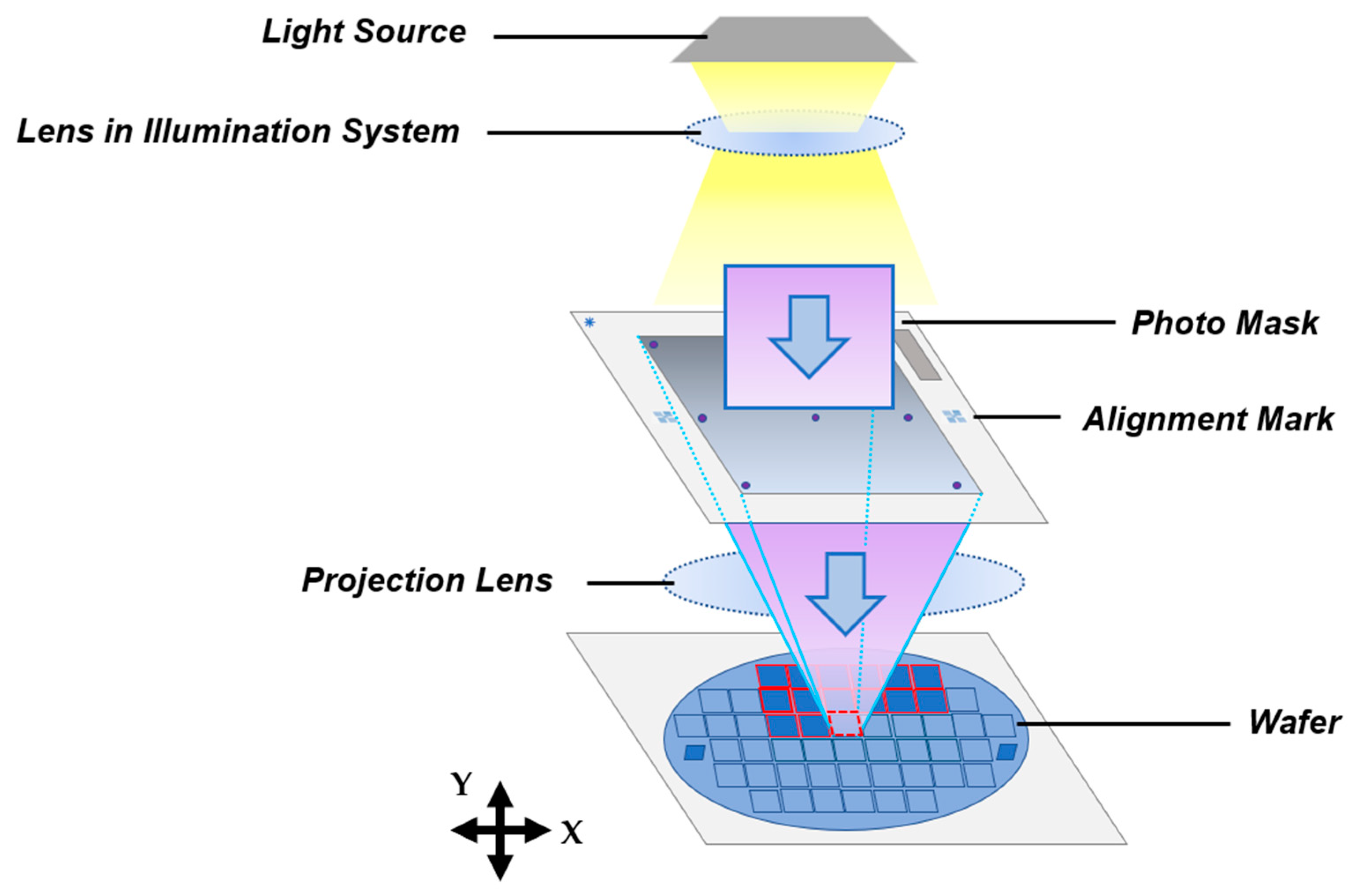
2.1. Semiconductor Mask Aligner
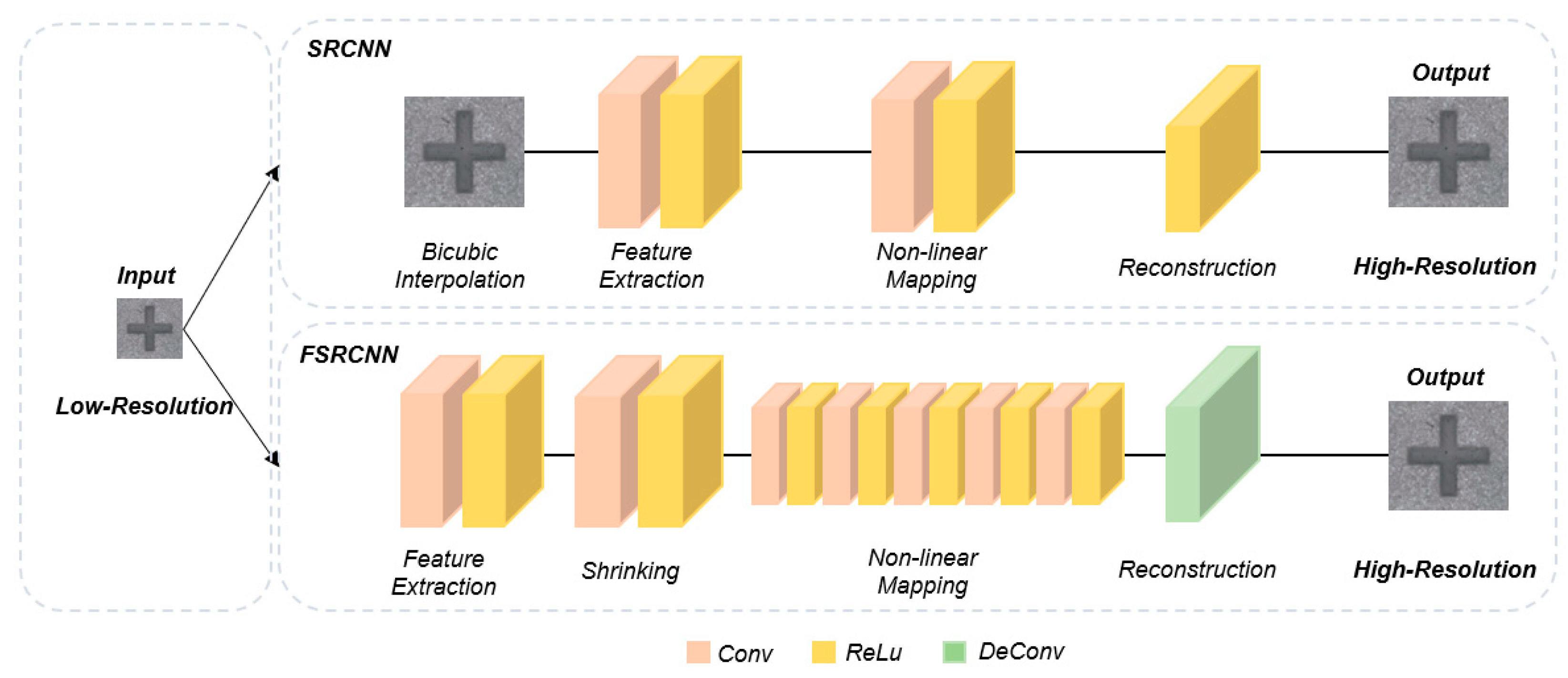
2.2. Deep Learning for Super-Resolution
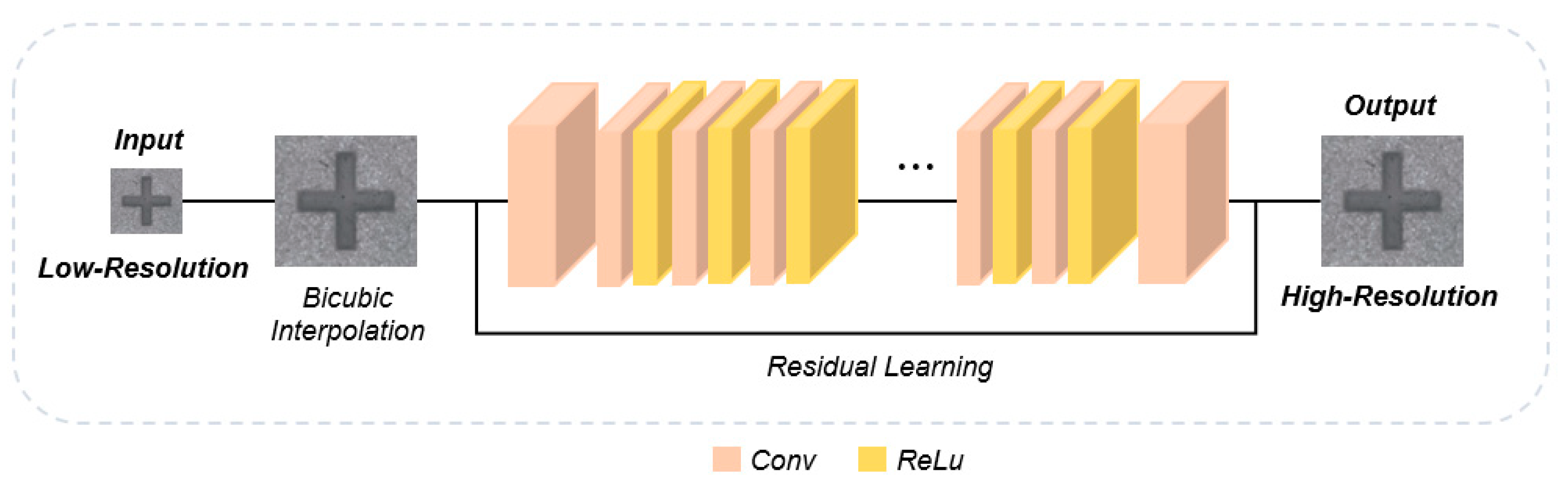
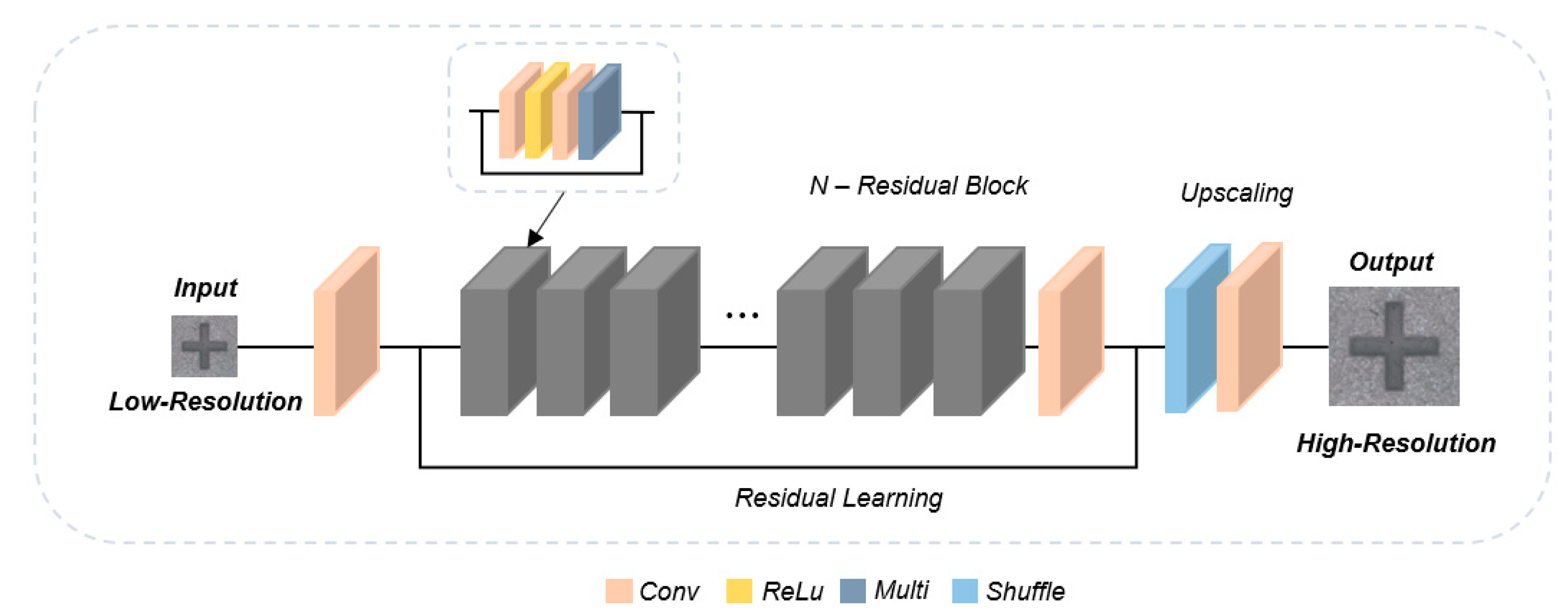
2.3. MSRB
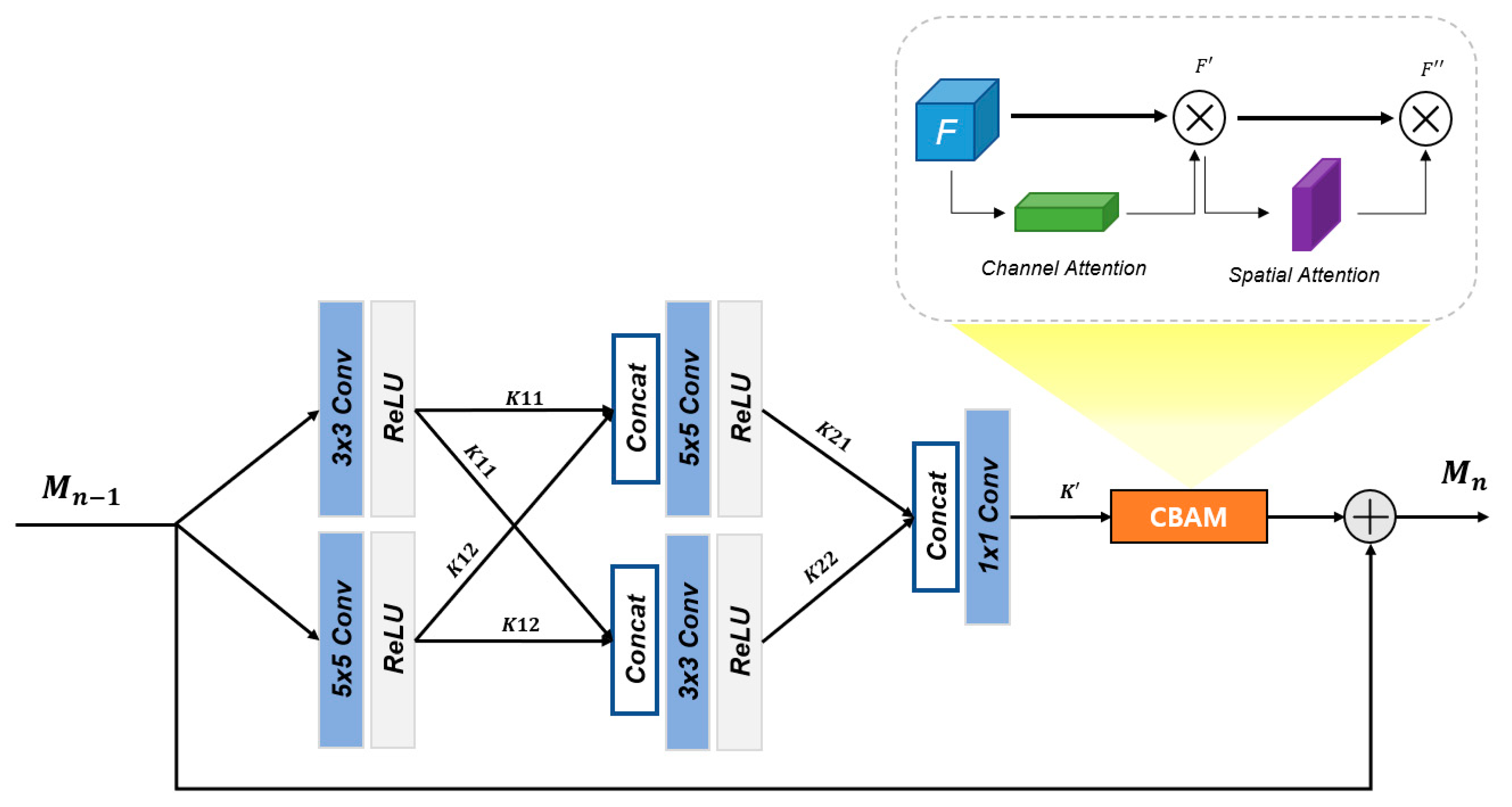
2.4. Attention Mechanism
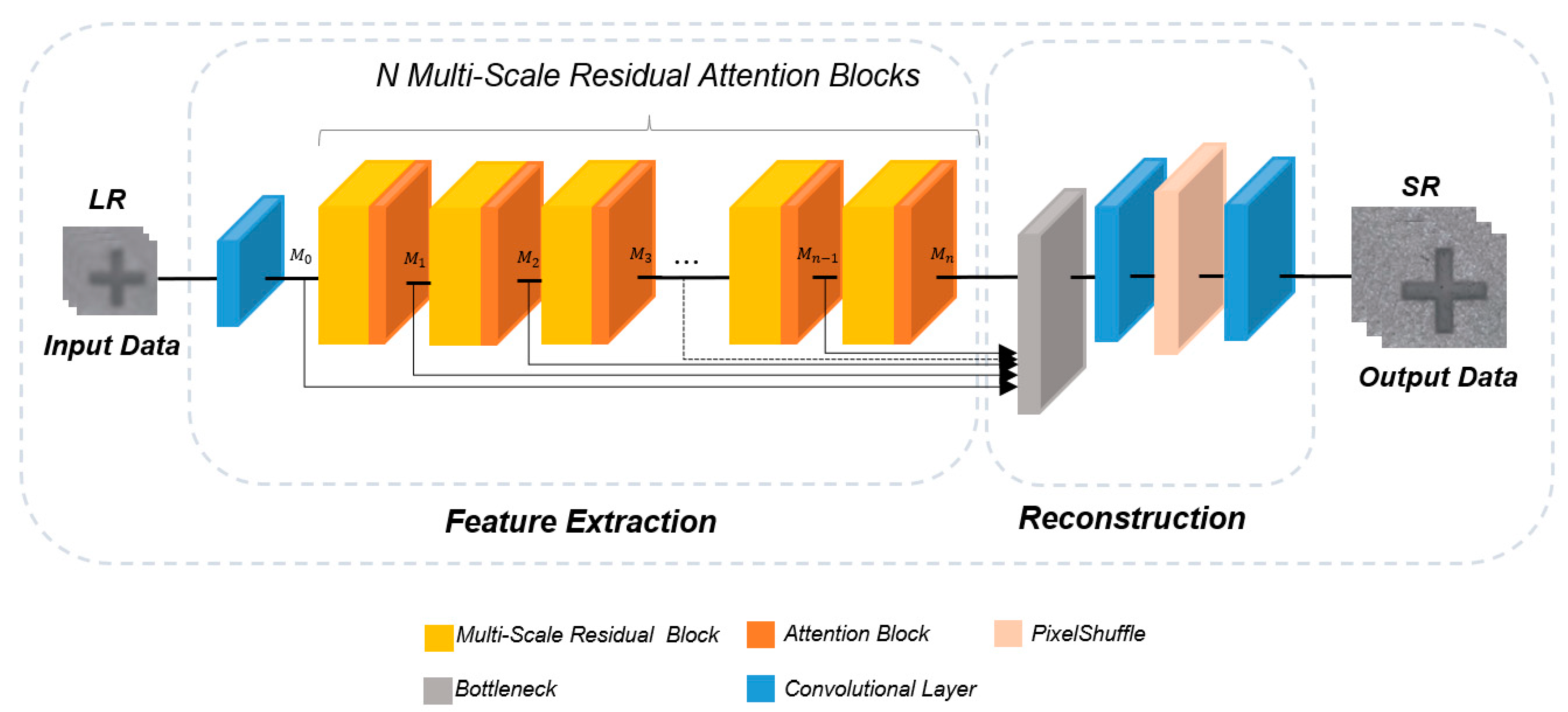
3. Improved MSRN-Based Attention Block
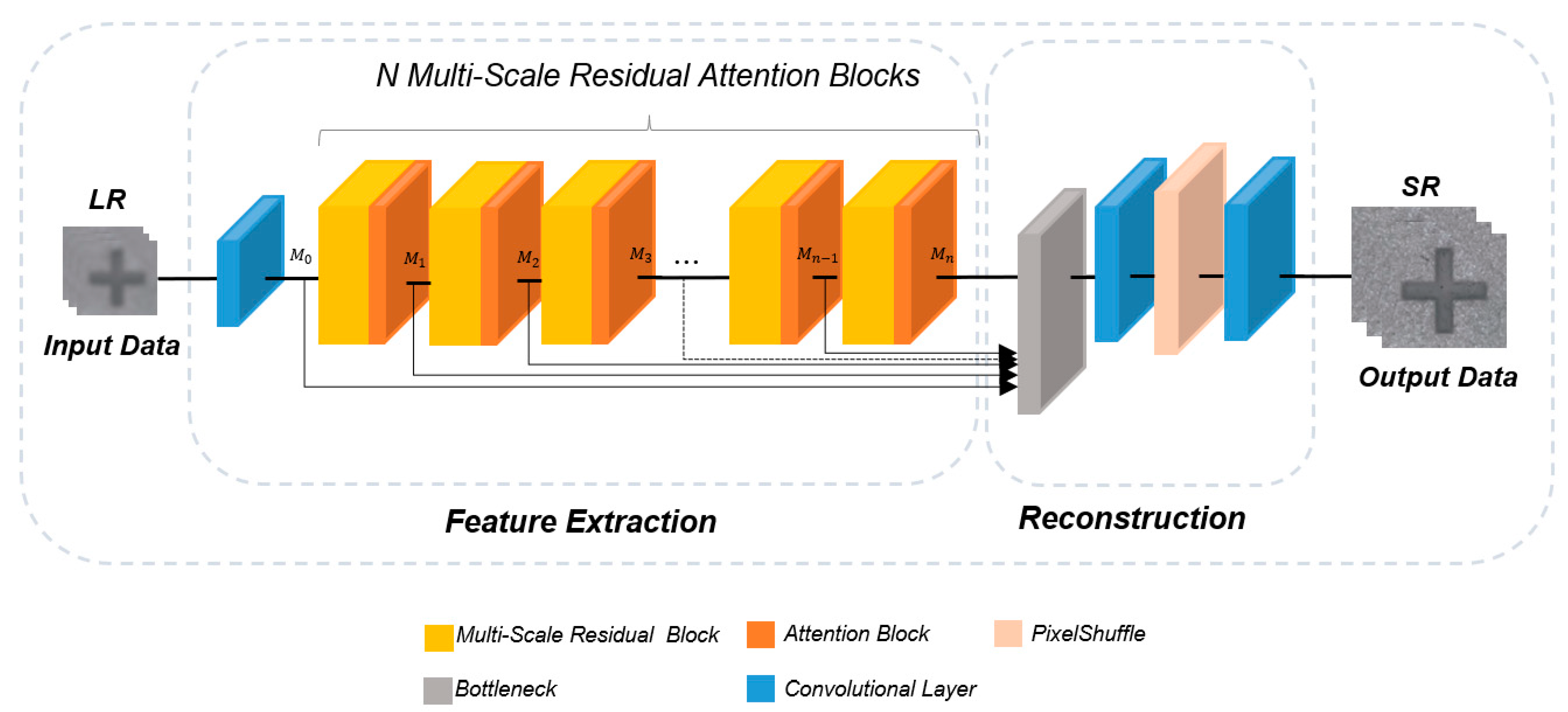
3.1. System Architecture
3.2. MSRAB
4. Experiment and Results
4.1. Experimental Environments
4.2. Data Acquisition
4.3. Evaluation Metrics
4.4. Results
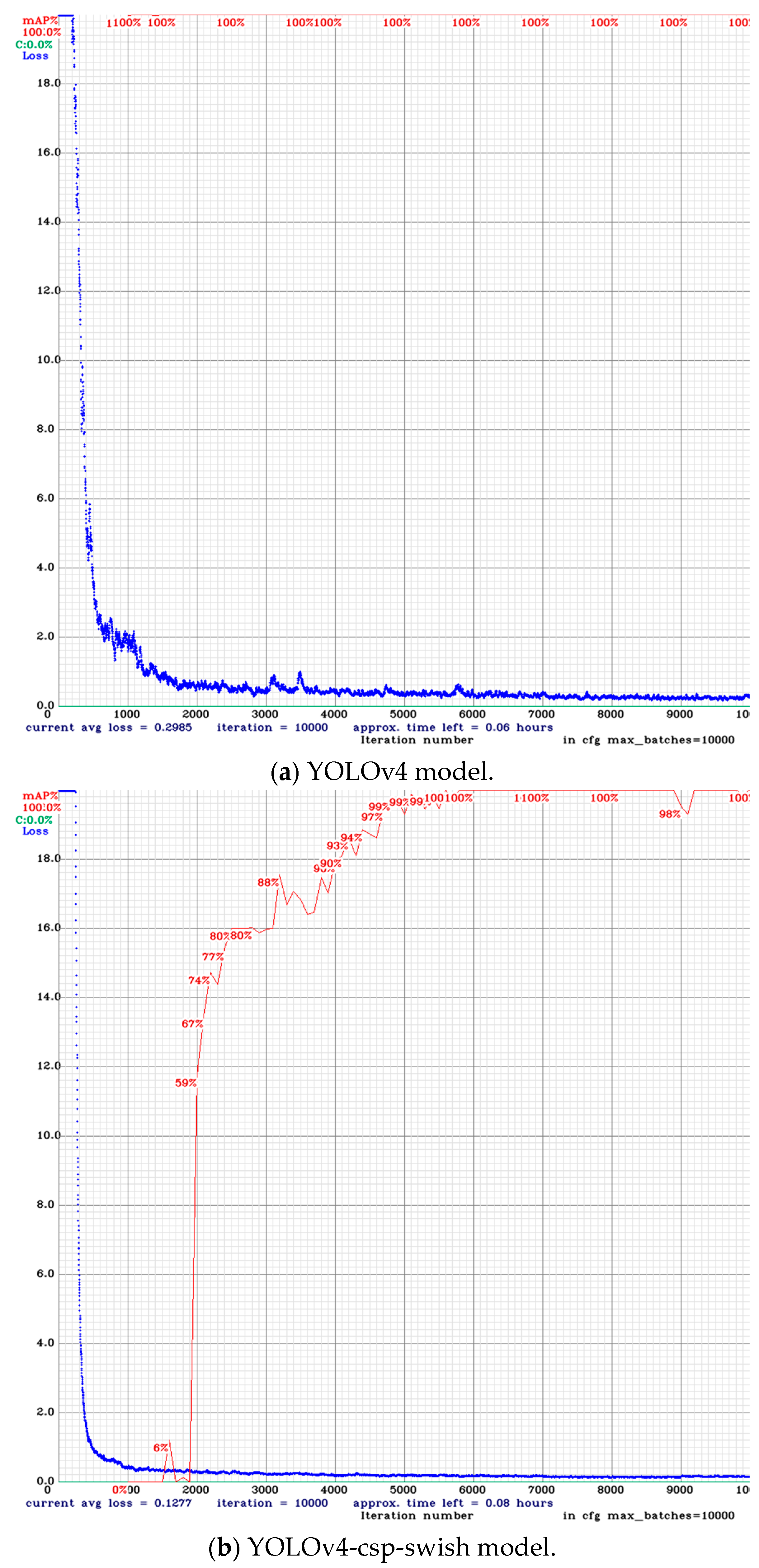
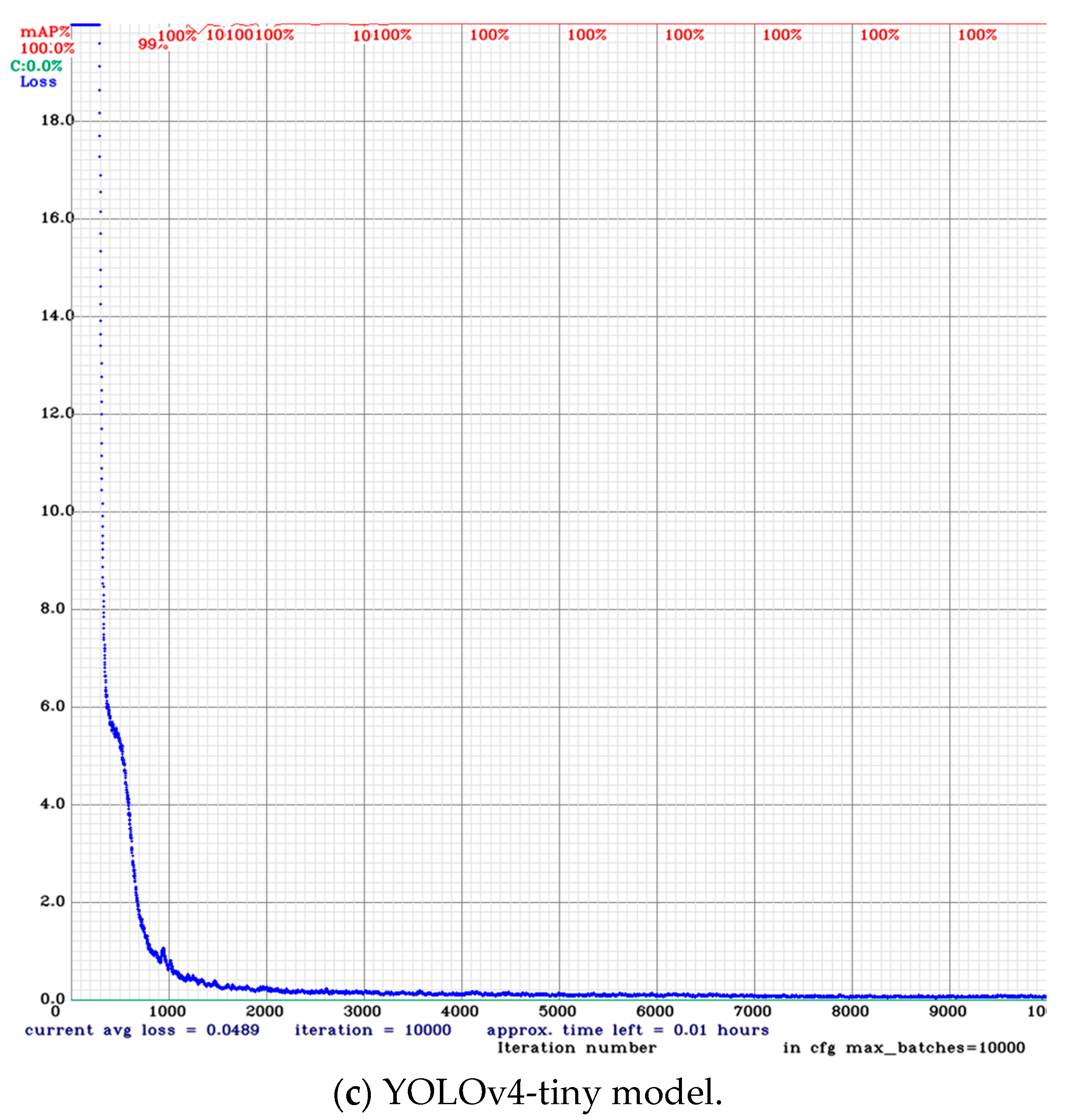
4.4.1. Training Model
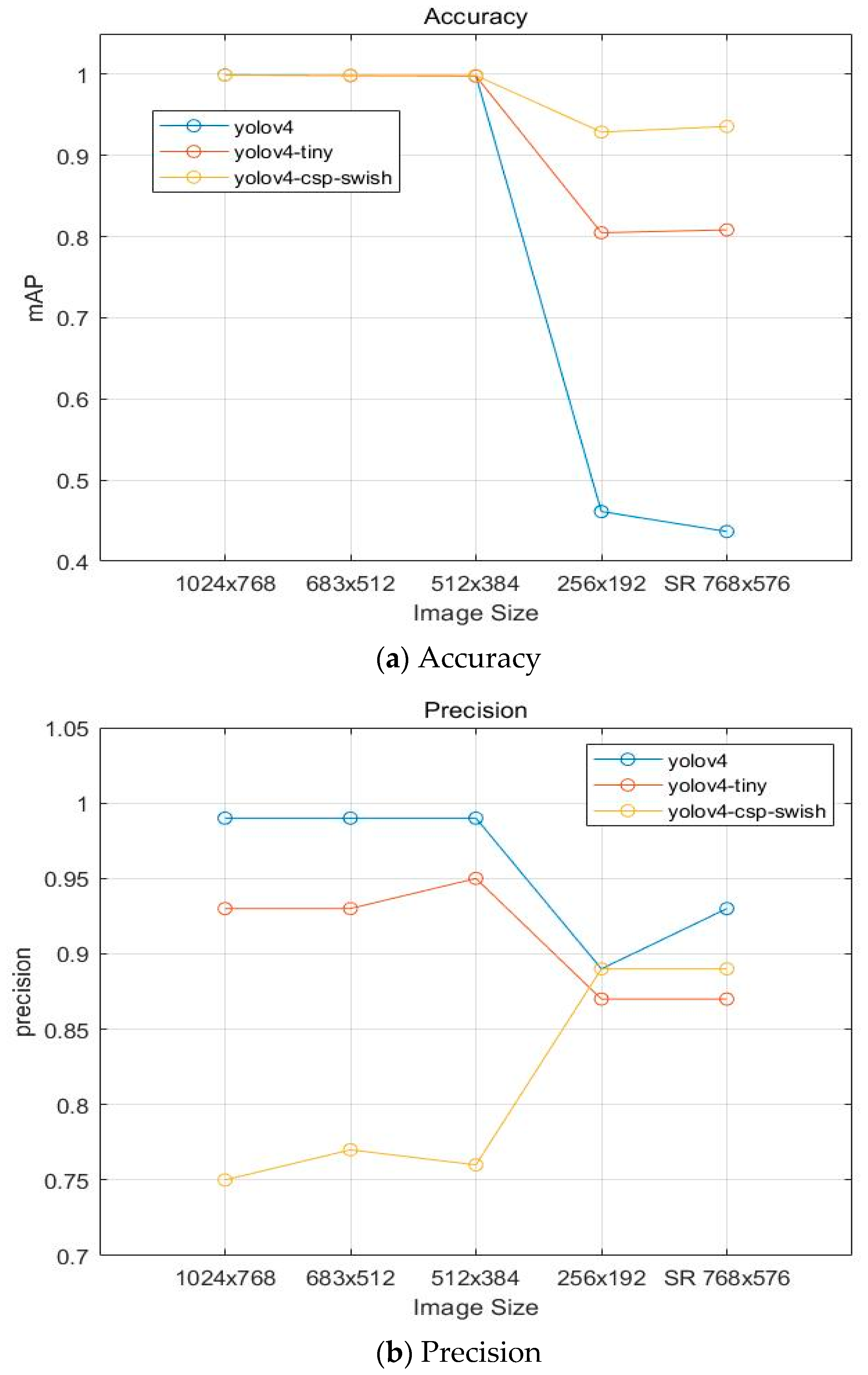
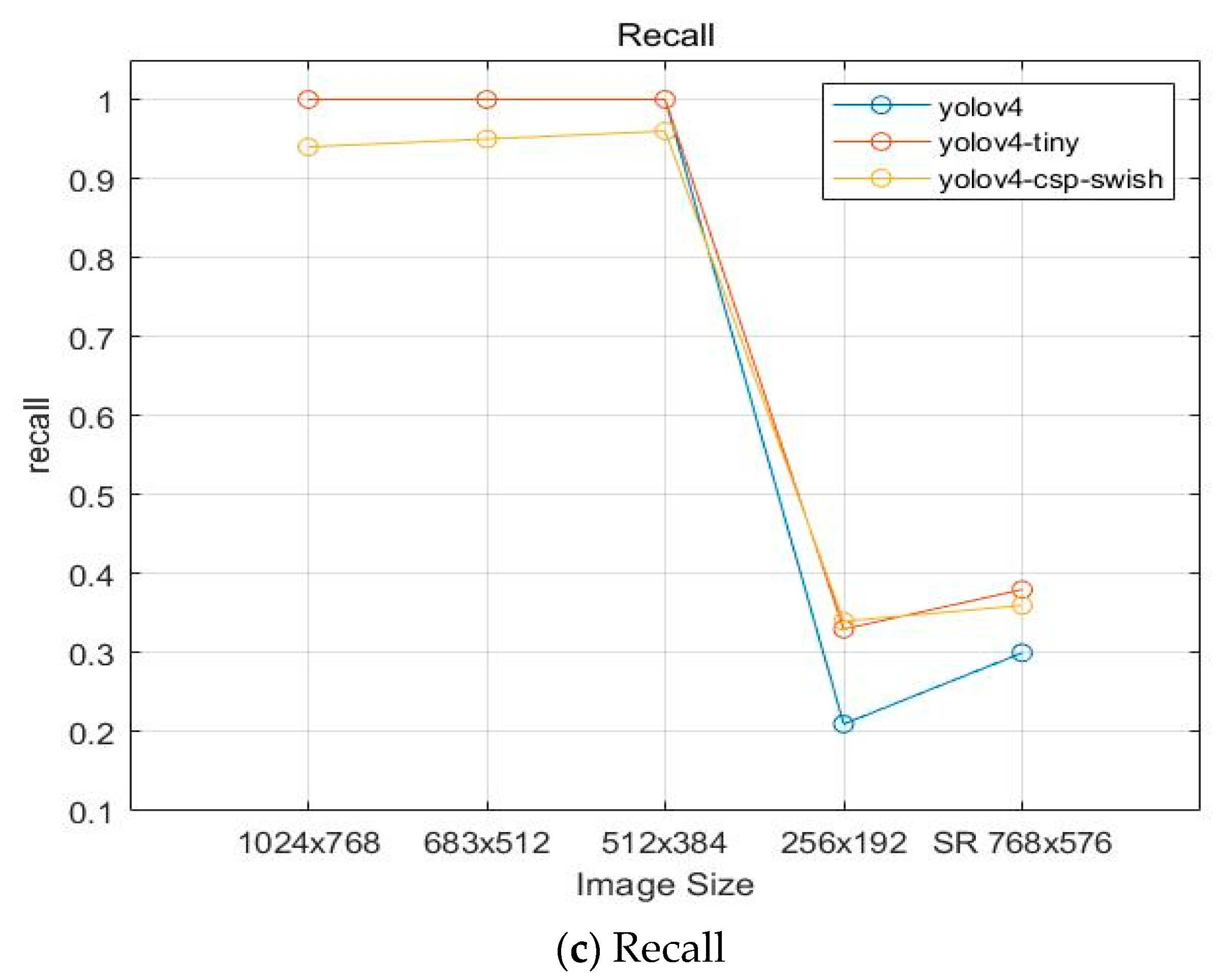
4.4.2. Alignment Mark Detection
4.4.3. Super Resolution
4.4.4. Alignment Mark Detection for Our Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, D.; Yang, J.; Lee, C.; Kim, K. A data-driven approach to selection of critical process steps in the semiconductor manufacturing process considering missing and imbalanced data. J. Manuf. Syst. 2019, 52, 146–156. [Google Scholar] [CrossRef]
- Yang, Y. A Deep Learning Model for Identification of Defect Patterns in Semiconductor Wafer Map. In Proceedings of the 2019 30th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), New York, NY, USA, 6–9 May 2019; pp. 1–6. [Google Scholar]
- Yu, J. Enhanced Stacked Denoising Autoencoder-Based Feature Learning for Recognition of Wafer Map Defects. IEEE Trans. Semicond. Manuf. 2019, 32, 613–624. [Google Scholar] [CrossRef]
- Chien, J.-C.; Wu, M.-T.; Lee, J.-D. Inspection and Classification of Semiconductor Wafer Surface Defects Using CNN Deep Learning Networks. Appl. Sci. 2020, 10, 5340. [Google Scholar] [CrossRef]
- Chien, C.-F.; Chen, Y.-H.; Lo, M.-F. Advanced Quality Control (AQC) of Silicon Wafer Specifications for Yield Enhancement for Smart Manufacturing. IEEE Trans. Semicond. Manuf. 2020, 33, 569–577. [Google Scholar] [CrossRef]
- Zhang, H.; Feng, T.; Djurdjanovic, D. Dynamic Down-Selection of Measurement Markers for Optimized Robust Control of Overlay Errors in Photolithography Processes. IEEE Trans. Semicond. Manuf. 2022, 1. [Google Scholar] [CrossRef]
- Miyamoto, A.; Kawahara, T. Automatic extraction technique of CD-SEM evaluation points to measure semiconductor overlay error. IEEE Trans. Electron. Inf. Syst. 2019, 138, 1278–1286. [Google Scholar] [CrossRef]
- Goswami, S.; Hall, S.; Wyko, W.; Elson, J.T.; Galea, J.; Kretchmer, J. In-line Photoresist Defect Reduction through Failure Mode and Root-Cause Analysis:Topics/categories: EO (Equipment Optimization)/DR (Defect Reduction). In Proceedings of the 2020 31st Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), New York, NY, USA, 24–26 August 2020; pp. 1–5. [Google Scholar]
- Frustaci, F.; Perri, S.; Cocorullo, G.; Corsonello, P. An embedded machine vision system for an in-line quality check of assembly processes. Procedia Manuf. 2020, 42, 211–218. [Google Scholar] [CrossRef]
- Mennel, L.; Symonowicz, J.; Wachter, S.; Polyushkin, D.K.; Molina-Mendoza, A.J.; Mueller, T. Ultrafast machine vision with 2D material neural network image sensors. Nature 2020, 579, 62–66. [Google Scholar] [CrossRef]
- Penumuru, D.P.; Muthuswamy, S.; Karumbu, P. Identification and classification of materials using machine vision and machine learning in the context of industry 4.0. J. Intell. Manuf. 2020, 31, 1229–1241. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Borui, J.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Liang, G.; Pan, S.; Zheng, L. A Fast Medical Image Super Resolution Method Based on Deep Learning Network. IEEE Access 2019, 7, 12319–12327. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Alganci, U.; Mehmet, S.; Elif, S. Comparative Research on Deep Learning Approaches for Airplane Detection from Very High-Resolution Satellite Images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Ma, X.; Zhang, F.; Huang, H. Telecentricity measurement for exposure system of photolithography tools. Opt. Eng. 2020, 59, 034109. [Google Scholar] [CrossRef]
- Adel, M.; Ghinovker, M.; Golovanevsky, B.; Izikson, P.; Kassel, E.; Yaffe, D.; Bruckstein, A.M.; Goldenberg, R.; Rubner, Y.; Rudzsky, M. Optimized overlay metrology marks: Theory and experiment. IEEE Trans. Semicond. Manuf. 2004, 17, 166–179. [Google Scholar] [CrossRef]
- Fung, R.; Hanna, A.M.; Vendrell, O.; Ramakrishna, S.; Seideman, T.; Santra, R.; Ourmazd, A. Dynamics from noisy data with extreme timing uncertainty. Nature 2016, 532, 471–475. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.; Barry, R.M. Digital Image Processing. 2008. Available online: https://www.imageprocessingplace.com/ (accessed on 29 January 2022).
- Qi, C.; Sivakumar, A.I.; Gershwin, S.B. Impact of Production Control and System Factors in Semiconductor. Wafer Fabrication. IEEE Trans. Semicond. Manuf. 2008, 21, 376–389. [Google Scholar]
- KIM, J. New Wafer Alignment Process Using Multiple Vision Method for Industrial Manufacturing. Electronics 2018, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Emil, S.-W.; Kaustuve, B. Pairing wafer leveling metrology from a lithographic apparatus with deep learning to enable cost effective dense wafer alignment metrology. SPIE Adv. Lithogr. 2019, 10961, 35–40. [Google Scholar]
- Jeong, I.; Kim, H.; Kong, Y.; Song, J.; Ju, J.; Kim, Y.; Lambregts, C.; Yu, M.; Rahman, R.; Karssemeijer, L.; et al. Improved wafer alignment model algorithm for better on-product overlay. Proc. SPIE 2019, 10961, 41–50. [Google Scholar]
- Lee, K.; Kim, C. Marker layout for optimizing the overlay alignment in a photolithography process. IEEE Trans. Semicond. Manuf. 2019, 32, 212–219. [Google Scholar] [CrossRef]
- Kim, H.; Song, C.; Yang, H. Algorithm for automatic alignment in 2D space by object transformation. Microelectron. Reliab. 2006, 46, 100–108. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 1920–1927. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Qin, J.; Huang, Y.; Wen, W. Multi-scale feature fusion residual network for Single Image Super-Resolution. Neurocomputing 2020, 379, 334–342. [Google Scholar] [CrossRef]
- Li, G.; Li, L.; Zhu, H.; Liu, X.; Jiao, L. Adaptive multiscale deep fusion residual network for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8506–8521. [Google Scholar] [CrossRef]
- Dai, Y.; Zhuang, P. Compressed sensing MRI via a multi-scale dilated residual convolution network. Magn. Reson. Imaging 2019, 63, 93–104. [Google Scholar] [CrossRef] [Green Version]
- Esmaeilzehi, A.; Ahmad, M.O.; Swamy, M.N.S. PHMNet: A Deep Super Resolution Network using Parallel and Hierarchical Multi-scale Residual Blocks. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Zhang, B.; Xiong, D.; Su, J. Neural machine translation with deep attention. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 154–163. [Google Scholar] [CrossRef]
- Liu, T.; Wang, K.; Sha, L.; Chang, B.; Sui, Z. Table-to-text generation by structure-aware seq2seq learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wu, X.; Huang, S.; Li, M.; Deng, Y. Vector Magnetic Anomaly Detection via an Attention Mechanism Deep-Learning Model. Appl. Sci. 2021, 11, 11533. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Sentence Representation Method Based on Multi-Layer Semantic Network. Appl. Sci. 2021, 11, 1316. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3186–3195. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Environment | Software Environment |
|---|---|
| CPU: Intel Core i7-8700k, 3.7 Ghz, | Window PyTorch framework |
| Six-core twelve threads 16 GB GPU: GeForce GTX 1080Ti | Python 3.6 Darknet C++ Interface |
| Contents | Specifications |
|---|---|
| Overview | UV broadband (250–450 nm), I-line (365 nm), and G-line (436 nm) wavelength available |
| Exposure methods | Flood, proximity, soft and hard contacts, low vacuum andvacuum contacts |
| Mask size | |
| Wafer size for top-side alignment | up to 6” in diameter (small samples, 2”, 3”, 4”, and 6”) |
| Wafer size for bottom-side alignment | 3″ and 4″ chucksore |
| Maximum wafer thickness | 3 mm |
| Other | The machine is exclusively intended for use as an alignment and/or exposure device for substrates used in semiconductor and microsystems technology |
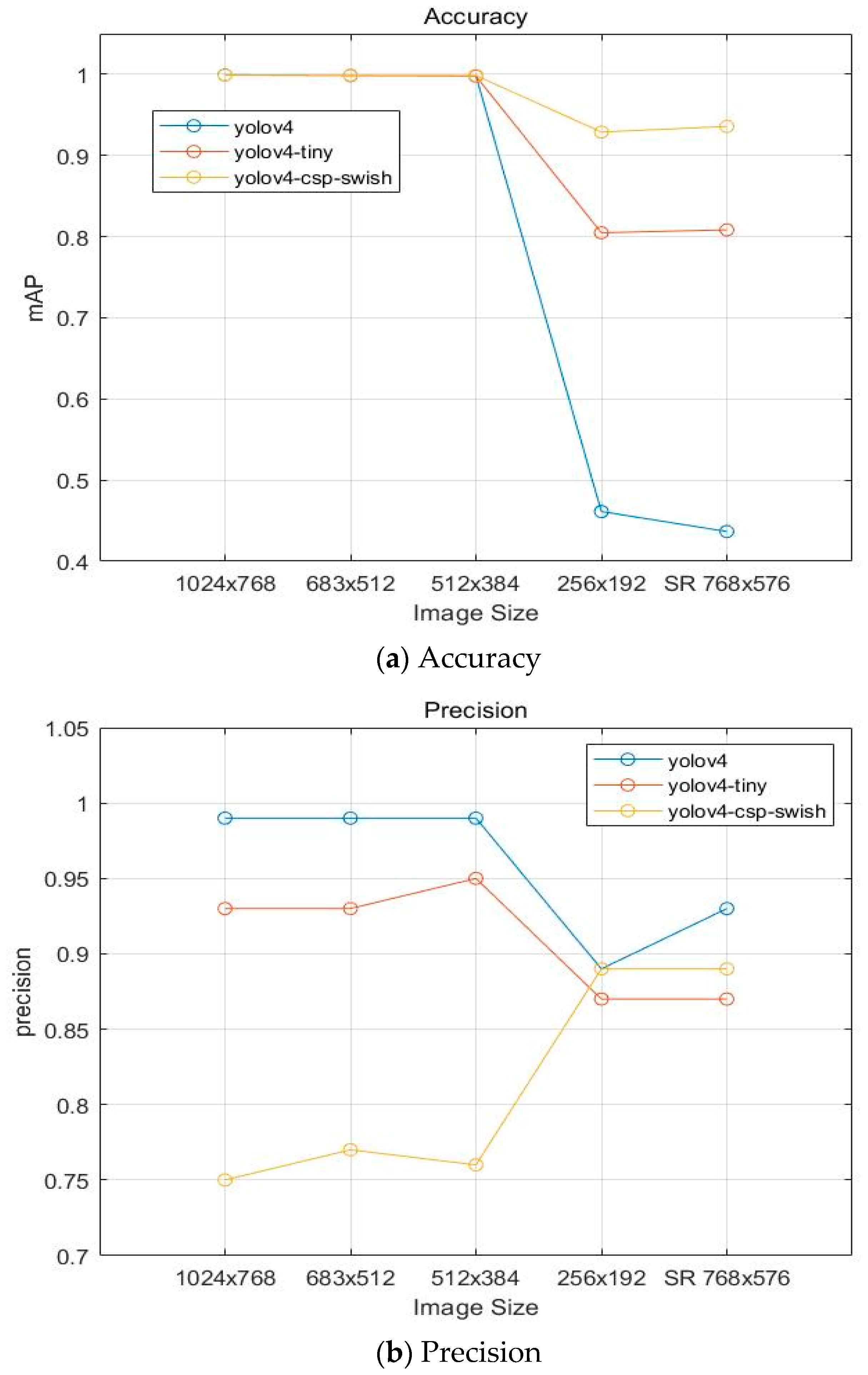
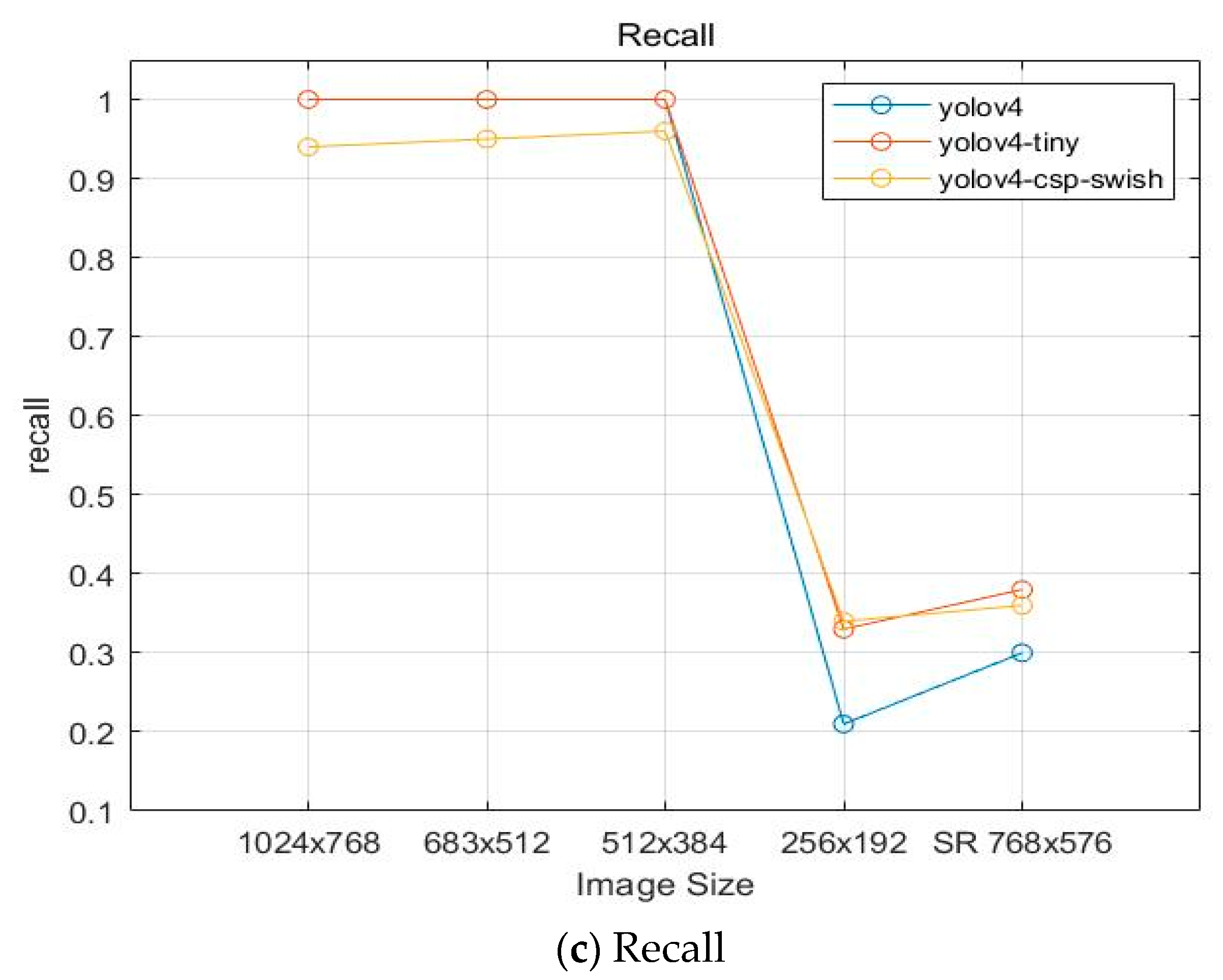
| Model | Image Size | mAP@50 | Precision | Recall | F1-Score | IOU |
|---|---|---|---|---|---|---|
| YOLOv4 | 99.93 | 0.99 | 1 | 1 | 92.39 | |
| 98.89 | 0.99 | 1 | 0.99 | 91.2 | ||
| 99.82 | 0.99 | 1 | 0.99 | 89.88 | ||
| 46.13 | 0.89 | 0.21 | 0.34 | 73.89 | ||
| YOLOv4-csp-swish | 99.90 | 0.75 | 0.94 | 0.83 | 69.78 | |
| 99.89 | 0.77 | 0.95 | 0.85 | 71.22 | ||
| 92.86 | 0.76 | 0.96 | 0.85 | 69.62 | ||
| 92.89 | 0.89 | 0.34 | 0.49 | 74.34 | ||
| YOLOv4-tiny | 99.91 | 0.95 | 1 | 0.96 | 84.13 | |
| 99.84 | 0.93 | 1 | 0.97 | 84.01 | ||
| 99.72 | 0.93 | 1 | 0.97 | 84.2 | ||
| 80.48 | 0.87 | 0.33 | 0.48 | 66.25 |
| Method | Scale | PSNR | SSIM |
|---|---|---|---|
| Bicubic | 2 | 30.56 | 0.871 |
| A+ [27] | 32.29 | 0.895 | |
| SRCNN [29] | 32.45 | 0.903 | |
| ESPCN [33] | 32.91 | 0.911 | |
| MSRN [32] | 33.26 | 0.914 | |
| Ours | 33.52 | 0.917 | |
| Bicubic | 3 | 27.73 | 0.783 |
| A+ [27] | 28.97 | 0.807 | |
| SRCNN [29] | 29.28 | 0.820 | |
| ESPCN [33] | 29.51 | 0.825 | |
| MSRN [32] | 29.64 | 0.831 | |
| Ours | 29.87 | 0.839 |
| Model | Image Size | mAP@50 | Precision | Recall | F1-Score | IOU |
|---|---|---|---|---|---|---|
| YOLOv4 | 46.13 | 0.89 | 0.21 | 0.34 | 73.89 | |
| (SR) | 46.67 | 0.93 | 0.30 | 0.46 | 78.29 | |
| YOLOv4-csp-swish | 92.89 | 0.89 | 0.34 | 0.49 | 74.34 | |
| (SR) | 93.58 | 0.89 | 0.36 | 0.51 | 74.46 | |
| YOLOv4-tiny | 80.48 | 0.87 | 0.33 | 0.48 | 66.25 | |
| (SR) | 80.85 | 0.87 | 0.38 | 0.53 | 67.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Jeong, J. Improved MSRN-Based Attention Block for Mask Alignment Mark Detection in Photolithography. Appl. Sci. 2022, 12, 2721. https://doi.org/10.3390/app12052721
Park J, Jeong J. Improved MSRN-Based Attention Block for Mask Alignment Mark Detection in Photolithography. Applied Sciences. 2022; 12(5):2721. https://doi.org/10.3390/app12052721
Chicago/Turabian StylePark, Juyong, and Jongpil Jeong. 2022. "Improved MSRN-Based Attention Block for Mask Alignment Mark Detection in Photolithography" Applied Sciences 12, no. 5: 2721. https://doi.org/10.3390/app12052721
APA StylePark, J., & Jeong, J. (2022). Improved MSRN-Based Attention Block for Mask Alignment Mark Detection in Photolithography. Applied Sciences, 12(5), 2721. https://doi.org/10.3390/app12052721