
Exploring Language Markers of Mental Health in Psychiatric Stories


Abstract
:1. Introduction
2. Related Work
2.1. Language Markers for Mental Health Disorders
- “Language marker” “mental health” “LIWC”
- “Language marker” “mental health” “language use”
- “Mental health” “deep learning”
- “Dutch” “parser” “NLP”
- “BERT” "mental health” “classification”
- “Alpino” “dependency parser”
- “spaCy” “lemma” “dependency parser”
- “Language” in conjunction with the words below:
- -
- ADHD
- -
- Autism
- -
- Bipolar Disorder
- -
- Borderline personality disorder
- -
- Eating disorder
- -
- Generalised anxiety disorder
- -
- Major depressive disorder
- -
- OCD
- -
- PTSD
- -
- Schizophrenia
2.2. NLP Techniques for Identifying Language Markers
2.2.1. Lexical Processing
2.2.2. Dependency Parsing
2.2.3. Shallow Neural Networks
2.2.4. Deep Neural Networks
2.2.5. Neural Networks for Dutch
3. Methodology
3.1. Dataset and Preprocessing
3.2. Data Analysis
4. Results
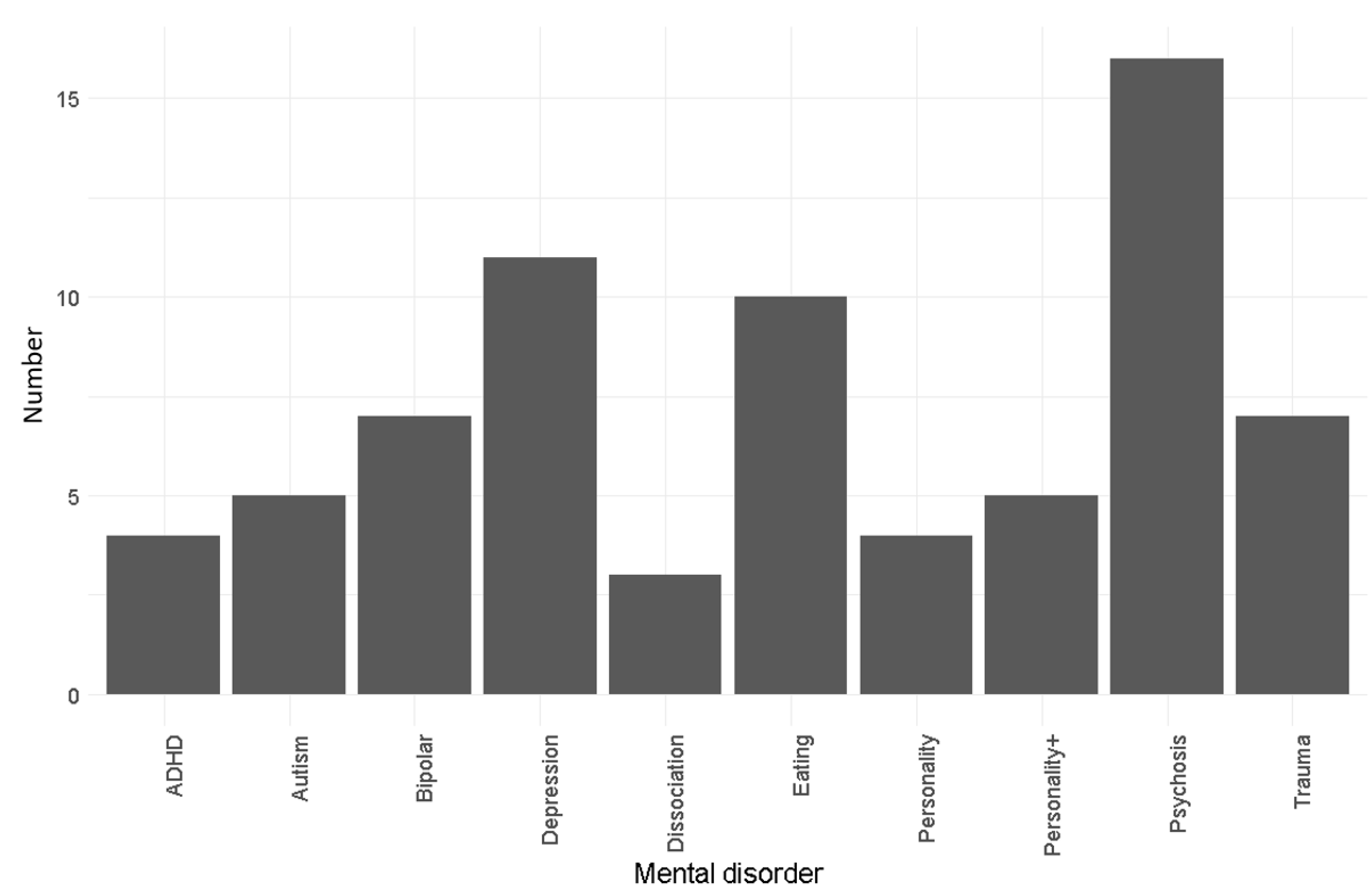
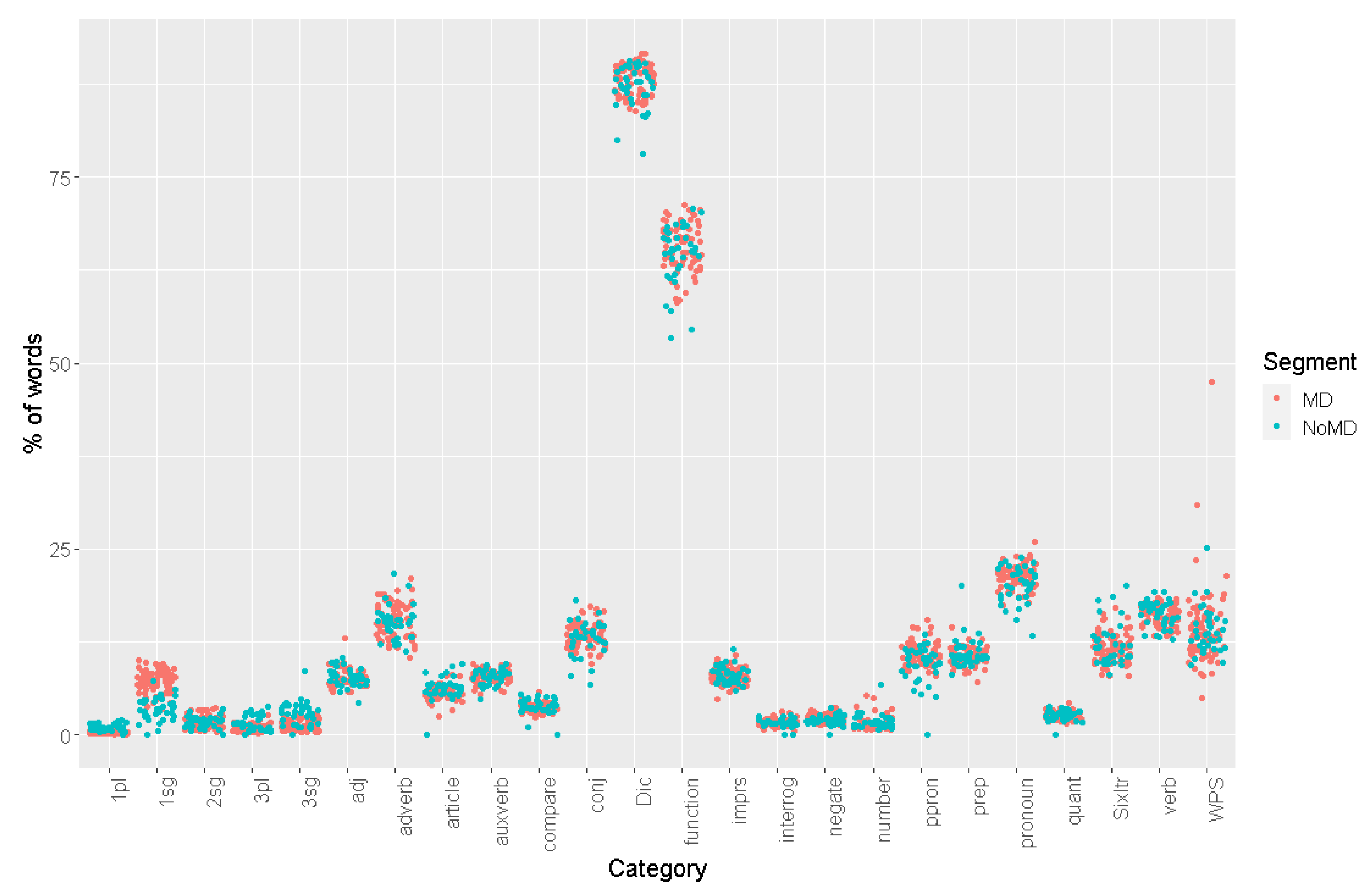
4.1. Descriptive Statistics
4.2. Predictions
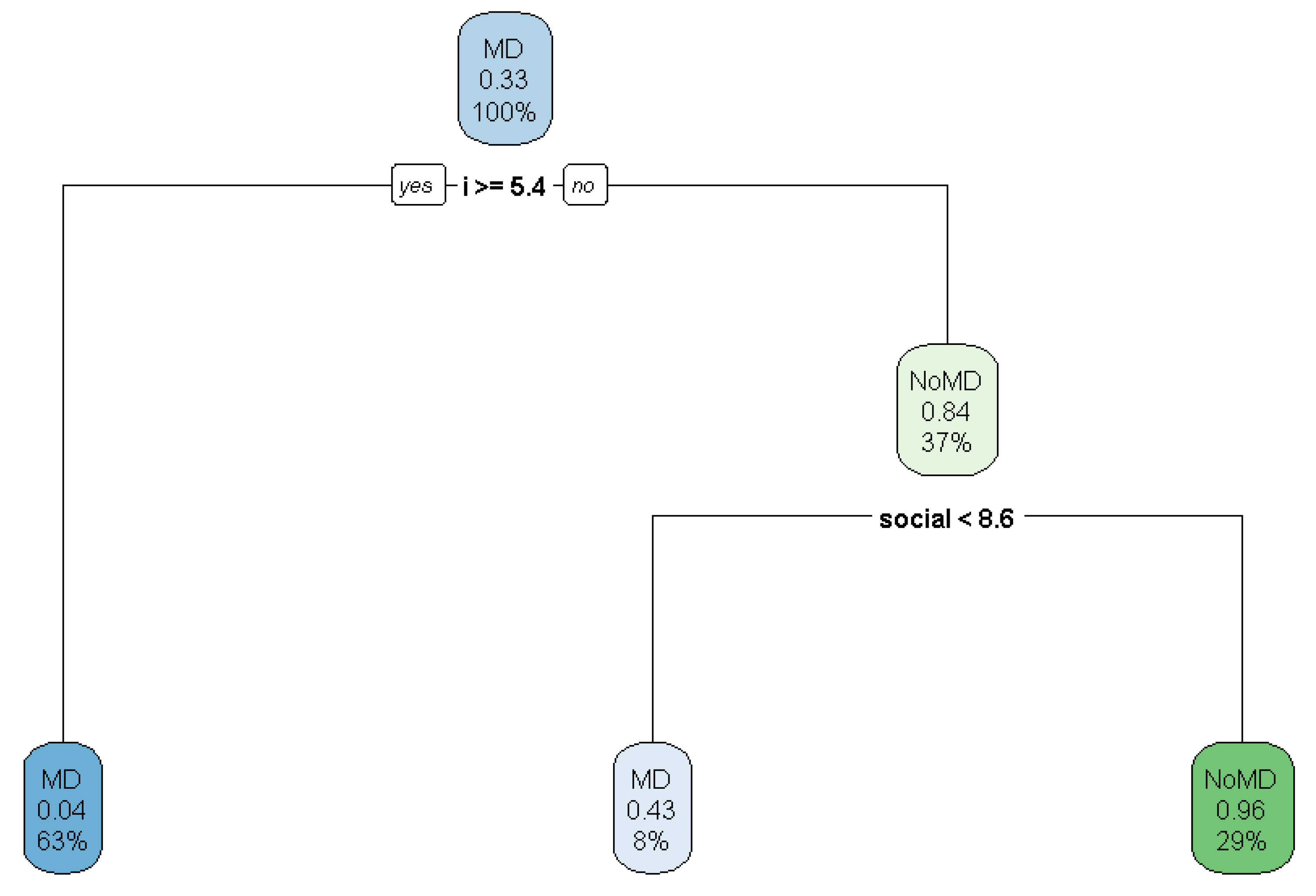
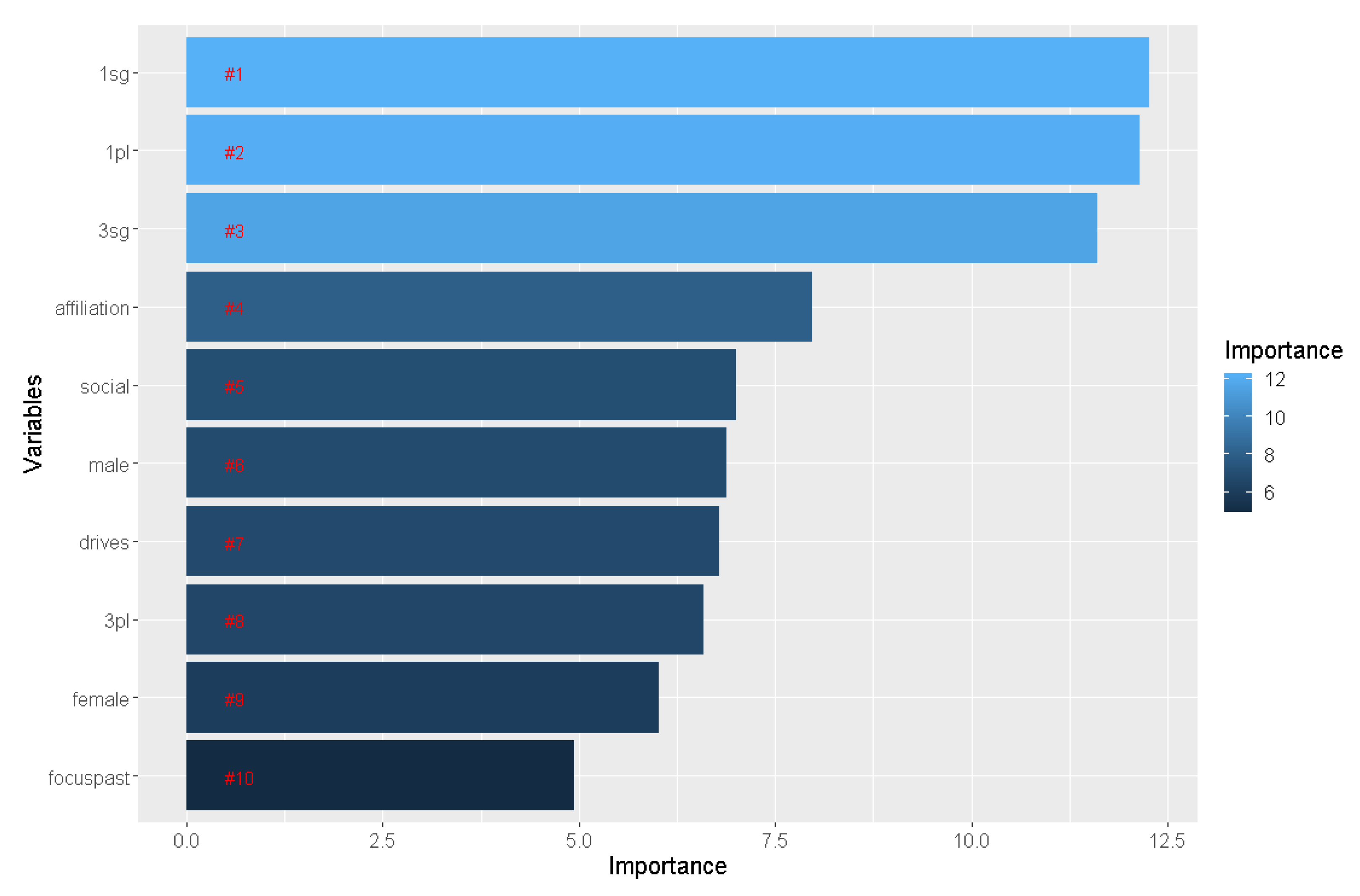
4.3. Interpretation
4.3.1. Lexical Processing with LIWC
4.3.2. Dependency Parsing with SpaCy
4.3.3. Neural Networks with fastText and RobBERT
Quote 1: “I ehm, [silence] the most poignant I will you. Yes, the most poignant what I can tell you is that, I have weekend leave on the weekend and then [name_of_wife] and I lay together in bed. Furthermore, nothing happens there. As I do not need that, haha. However, I cannot even feel that I love her. I know it, that I love her. Furthermore, I know that my wife is and I, and I. However, that is all in here eh, but I do not feel it. Furthermore, that is the biggest measure which you can set⋯ Yes. Furthermore, I talked about it with her.”
Quote 2: “Yes it gives kind of a kick or something to go against it and to see that people you really eh yes I don’t know. That your that your eating disorder is strong and people find that then. Then, you think oh I am good at something. Then, yes I don’t know. Then you want there that you want to be doing something you are good at⋯Eh I am able to walk again since two months. Before I eh stayed in bed and in a wheelchair around half a year, because I eh could not walk myself. Furthermore, I was just to weak to do it. and eh yes I still cannot do quite a lot of things. I am really happy that I can walk again by myself.”
4.4. Summary of Findings: Language Markers
4.5. Focus Group
5. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Whiteford, H.A.; Degenhardt, L.; Rehm, J.; Baxter, A.J.; Ferrari, A.J.; Erskine, H.E.; Charlson, F.J.; Norman, R.E.; Flaxman, A.D.; Johns, N.; et al. Global burden of disease attributable to mental and substance use disorders: Findings from the Global Burden of Disease Study 2010. Lancet 2013, 382, 1575–1586. [Google Scholar] [CrossRef]
- Ritchie, H.; Roser, M. Mental Health. In In Our World in Data; 2020; Available online: https://ourworldindata.org/mental-health (accessed on 20 September 2021).
- McIntosh, A.M.; Stewart, R.; John, A.; Smith, D.J.; Davis, K.; Sudlow, C.; Corvin, A.; Nicodemus, K.K.; Kingdon, D.; Hassan, L.; et al. Data science for mental health: A UK perspective on a global challenge. Lancet Psychiatry 2016, 3, 993–998. [Google Scholar] [CrossRef] [Green Version]
- Russ, T.C.; Woelbert, E.; Davis, K.A.; Hafferty, J.D.; Ibrahim, Z.; Inkster, B.; John, A.; Lee, W.; Maxwell, M.; McIntosh, A.M.; et al. How data science can advance mental health research. Nat. Hum. Behav. 2019, 3, 24–32. [Google Scholar] [CrossRef] [PubMed]
- Lyons, M.; Aksayli, N.D.; Brewer, G. Mental distress and language use: Linguistic analysis of discussion forum posts. Comput. Hum. Behav. 2018, 87, 207–211. [Google Scholar] [CrossRef]
- Calvo, R.A.; Milne, D.N.; Hussain, M.S.; Christensen, H. Natural language processing in mental health applications using non-clinical texts. Nat. Lang. Eng. 2017, 23, 649–685. [Google Scholar] [CrossRef] [Green Version]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Honnibal, M.; Johnson, M. An Improved Non-monotonic Transition System for Dependency Parsing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1373–1378. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Delobelle, P.; Winters, T.; Berendt, B. RobBERT: A dutch RoBERTa-based language model. arXiv 2020, arXiv:2001.06286. [Google Scholar]
- Davcheva, E. Text Mining Mental Health Forums—Learning from User Experiences. In Proceedings of the 26th European Conference on Information Systems: Beyond Digitization—Facets of Socio-Technical Change, ECIS, Portsmouth, UK, 23–28 June 2018; Bednar, P.M., Frank, U., Kautz, K., Eds.; AIS eLibrary: Atlanta, GA, USA, 2018; p. 91. [Google Scholar]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Coppersmith, G.; Dredze, M.; Harman, C.; Hollingshead, K. From ADHD to SAD: Analyzing the language of mental health on Twitter through self-reported diagnoses. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Denver, CO, USA, 5 June 2015; pp. 1–10. [Google Scholar]
- Webster, J.; Watson, R.T. Analyzing the past to prepare for the future: Writing a literature review. MIS Q. 2002, 26, xiii–xxiii. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. IntelligenCe Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Kim, K.; Lee, S.; Lee, C. College students with ADHD traits and their language styles. J. Atten. Disord. 2015, 19, 687–693. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.; Phung, D.; Venkatesh, S. Analysis of psycholinguistic processes and topics in online autism communities. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Forgeard, M. Linguistic styles of eminent writers suffering from unipolar and bipolar mood disorder. Creat. Res. J. 2008, 20, 81–92. [Google Scholar] [CrossRef]
- Remmers, C.; Zander, T. Why you don’t see the forest for the trees when you are anxious: Anxiety impairs intuitive decision making. Clin. Psychol. Sci. 2018, 6, 48–62. [Google Scholar] [CrossRef]
- Trifu, R.N.; Nemeş, B.; Bodea-Hategan, C.; Cozman, D. Linguistic indicators of language in major depressive disorder (MDD). An evidence based research. J. Evid.-Based Psychother. 2017, 17, 105–128. [Google Scholar] [CrossRef]
- Papini, S.; Yoon, P.; Rubin, M.; Lopez-Castro, T.; Hien, D.A. Linguistic characteristics in a non-trauma-related narrative task are associated with PTSD diagnosis and symptom severity. Psychol. Trauma Theory Res. Pract. Policy 2015, 7, 295. [Google Scholar] [CrossRef] [PubMed]
- Corcoran, C.M.; Cecchi, G. Using language processing and speech analysis for the identification of psychosis and other disorders. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2020, 5, 770–779. [Google Scholar] [CrossRef] [PubMed]
- Verkleij, S. Deep and Dutch NLP: Exploring Linguistic Markers for Patient Narratives Analysis. Master’s Thesis, Department of Information and Computing Sciences, Utrecht University, Utrecht, The Netherlands, 2021. [Google Scholar]
- Choi, J.D.; Tetreault, J.; Stent, A. It depends: Dependency parser comparison using a web-based evaluation tool. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 15 July 2015; pp. 387–396. [Google Scholar]
- Hermann, K.M. Distributed representations for compositional semantics. arXiv 2014, arXiv:1411.3146. [Google Scholar]
- Liang, P.; Potts, C. Bringing machine learning and compositional semantics together. Annu. Rev. Linguist. 2015, 1, 355–376. [Google Scholar] [CrossRef] [Green Version]
- Guevara, E.R. A regression model of adjective-noun compositionality in distributional semantics. In Proceedings of the 2010 Workshop on GEometrical Models of Natural Language Semantics, Uppsala, Sweden, 16 July 2010; pp. 33–37. [Google Scholar]
- Gamallo, P. Sense Contextualization in a Dependency-Based Compositional Distributional Model. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; pp. 1–9. [Google Scholar]
- Bohnet, B. Top accuracy and fast dependency parsing is not a contradiction. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010; pp. 89–97. [Google Scholar]
- Lei, T.; Xin, Y.; Zhang, Y.; Barzilay, R.; Jaakkola, T. Low-rank tensors for scoring dependency structures. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 14 June 2014; pp. 1381–1391. [Google Scholar]
- Choi, J.D.; McCallum, A. Transition-based dependency parsing with selectional branching. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 13 August 2013; pp. 1052–1062. [Google Scholar]
- Van den Bosch, A.; Busser, B.; Canisius, S.; Daelemans, W. An efficient memory-based morphosyntactic tagger and parser for Dutch. LOT Occas. Ser. 2007, 7, 191–206. [Google Scholar]
- Van der Beek, L.; Bouma, G.; Malouf, R.; Van Noord, G. The Alpino dependency treebank. In Computational Linguistics in The Netherlands 2001; Brill Rodopi: Amsterdam, The Netherlands, 2002; pp. 8–22. [Google Scholar]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 2, 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Joulin, A.; Grave, E.; Mikolov, P.B.T. Bag of Tricks for Efficient Text Classification. EACL 2017, 2017, 427. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Khattak, F.K.; Jeblee, S.; Pou-Prom, C.; Abdalla, M.; Meaney, C.; Rudzicz, F. A survey of word embeddings for clinical text. J. Biomed. Inform. 2019, 4, 100057. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Briefings Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Yapp, E.K.Y.; Nagasundaram, N.; Yeh, H.Y. Classifying promoters by interpreting the hidden information of DNA sequences via deep learning and combination of continuous fasttext N-grams. Front. Bioeng. Biotechnol. 2019, 7, 305. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- de Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; van Noord, G.; Nissim, M. Bertje: A dutch bert model. arXiv 2019, arXiv:1912.09582. [Google Scholar]
- Sarhan, I.; Spruit, M. Can we survive without labelled data in NLP? Transfer learning for open information extraction. Appl. Sci. 2020, 10, 5758. [Google Scholar] [CrossRef]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disorder | Pron | SC | Word Use | More | N |
|---|---|---|---|---|---|
| ADHD | 3pl | - | - | Relativity, more sentences, less clauses | 4 |
| Autism | 1sg | - | Motion, home, religion and death | - | 5 |
| Bipolar | 1sg | - | Death | - | 7 |
| BPD | 3sg | n | Death | Swearing, less cognitive emotion words | 5 |
| Eating | 1sg | - | Body | Negative emotion words | 10 |
| GAD | imprs | i | Death and health | Tentative words | 4 |
| MDD | 1sg | i | - | Inverse word-order and repetitions | 11 |
| OCD | 1sg | - | Anxiety | More cognitive words | 4 |
| PTSD | sg | - | Death | Less cognitive words | 6 |
| Schizophrenia | 3pl | i | Religion | Hearing voices and sounds | 16 |
| Model | Dutch | Architecture | Input Level | Selected |
|---|---|---|---|---|
| Word2Vec | Yes | CBOW & Skip-gram | Word | No |
| fastText | Yes | RNN | Word | Yes |
| ELMo | Yes | (Bi)LSTM | Sentence | No |
| ULMFit | Yes | Transformer | Sentence | No |
| GPT | No | Transformer | Sentence | No |
| GPT-2 | No | Transformer | Sentence | No |
| GPT-3 | No | Transformer | Sentence | No |
| BERT | Yes | Transformer | Sentence | No |
| RoBERTa/RobBERT | Yes | Transformer | Sentence | Yes |
| ClinicalBERT | No | Transformer | Sentence | No |
| XLnet | No | Transformer-XL | Sentence | No |
| StructBERT | No | Transformer | Sentence | No |
| ALBERT | No | Transformer | Sentence | No |
| T5 | No | Transformer | Sentence | No |
| Comparison | Input | Model | Accuracy | Kappa | Accuracy No Stopwords | Kappa No Stopwords |
|---|---|---|---|---|---|---|
| Mental Disorder vs. No Mental Disorder | LIWC-output | decision tree | 0.857 | 0.667 | 0.857 | 0.674 |
| LIWC-output | random- Forest | 0.952 | 0.889 | 0.952 | 0.877 | |
| LIWC-output | SVM | 0.857 | 0.64 | 0.905 | 0.738 | |
| spaCy | decision tree | 0.810 | 0.391 | 0.444 | −0.309 | |
| spaCy | random- Forest | 0.762 | 0.173 | 0.389 | −0.370 | |
| spaCy | SVM | 0.714 | 0.115 | 0.528 | −0.275 | |
| raw data | fastText | 0.643 | 0.172 | 0.607 | 0.072 | |
| raw data | RobBERT | 0.607 | 0.000 | 0.607 | 0.000 | |
| Mental Disorder multiclass | LIWC-output | decision tree | 0.286 | 0.157 | 0.286 | 0.177 |
| LIWC-output | random- Forest | 0.214 | 0.120 | 0.214 | 0.144 | |
| LIWC-output | SVM | 0.286 | 0.114 | 0.143 | 0.0718 | |
| spaCy | decision tree | 0.143 | −0.0120 | 0.071 | −0.052 | |
| spaCy | random- Forest | 0.429 | 0.304 | 0.214 | 0.078 | |
| spaCy | SVM | 0.357 | 0.067 | 0.143 | 0.091 | |
| raw data | fastText | 0.286 | 0.000 | 0.200 | 0.000 | |
| raw data | RobBERT | 0.200 | 0.000 | 0.267 | 0.120 |
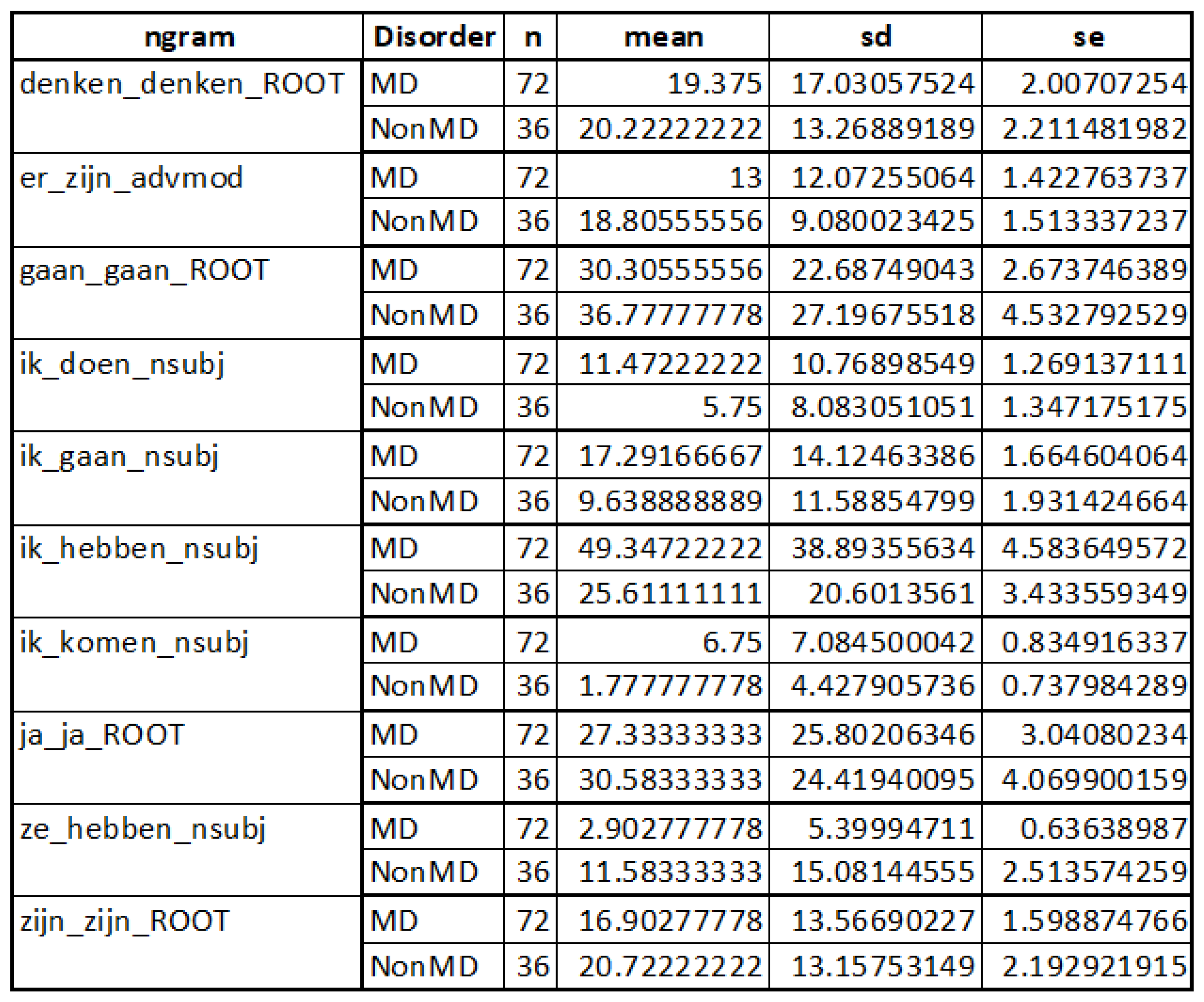
| spaCy Variable | Example Sentence |
|---|---|
| ik_doen_nsubj | Ik doe normaal, haal mijn studie en gebruik geen drugs en ben niet irritant |
| I_do_nsubj | ‘I do normal, get my degree and do not use drugs and am not irritating’ |
| ik_gaan_nsubj | ik ben meer waard dan dit, ik ga voor mezelf opkomen. |
| I_go_nsubj | ‘I am worth more than this, I’m going to stand up for myself’ |
| ik_hebben_nsubj | Ik heb ook behandelingen gehad, of een behandeling gehad |
| I_have_nsubj | ‘I have also gotten treatments, or got a treatment’ |
| ik_komen_nsubj | Ja, ik kwam in de bijstand |
| I_come_nsubj | ‘Yes, I came into welfare’ |
| er_zijn_advmod | Er zijn zo veel vrouwelijke sociotherapeuten in heel [naam][centrum] die opgeroepen kunnen worden |
| there_are_advmod | ‘There are so many female sociotherapists in [name][centre] who can be called’ |
| ze_hebben_nsubj | Al een tijdje maar ze hebben nooit wat aan mij verteld |
| they_have_nsubj | ‘For some time, but they have never told me anything’ |
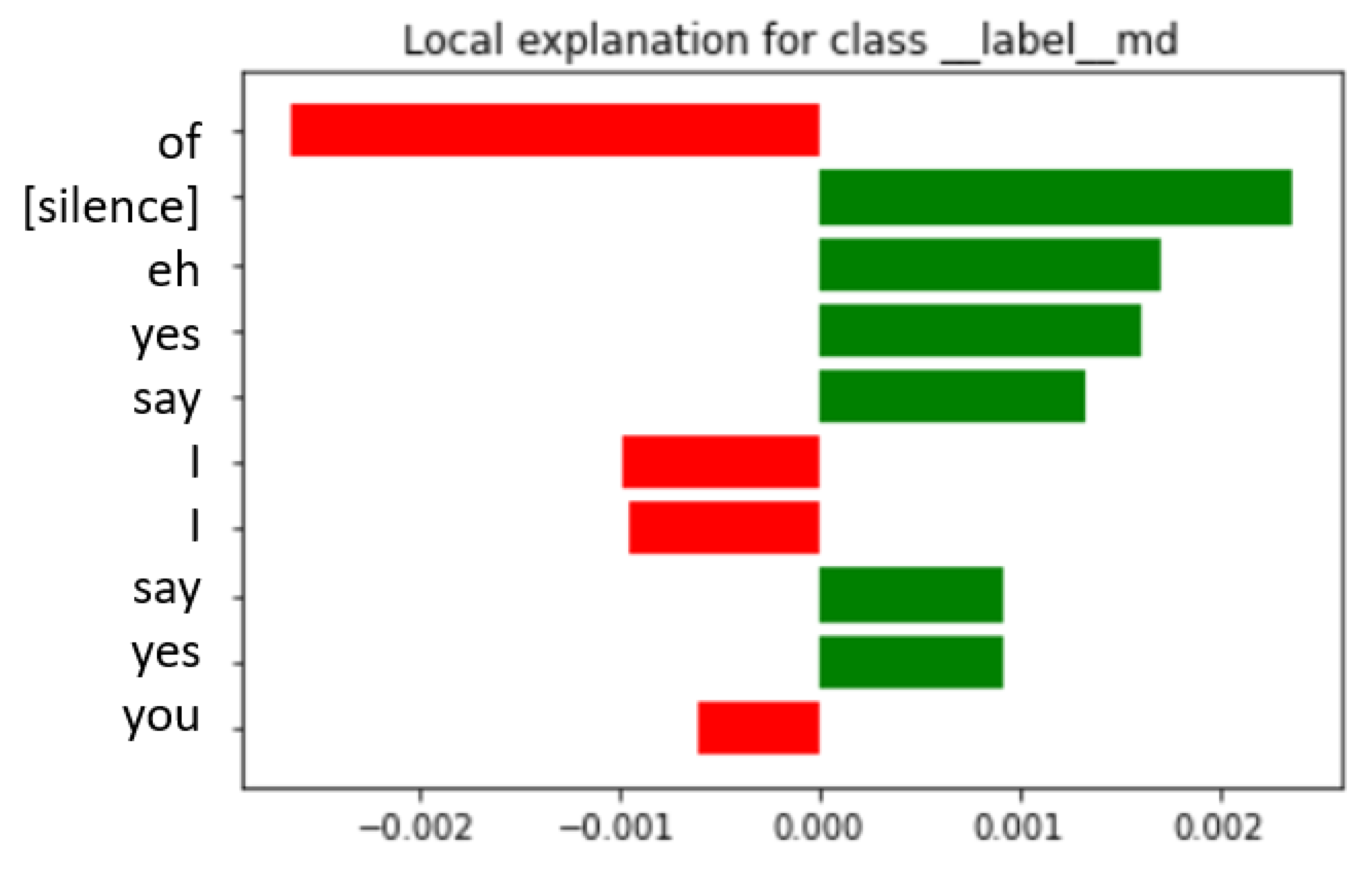
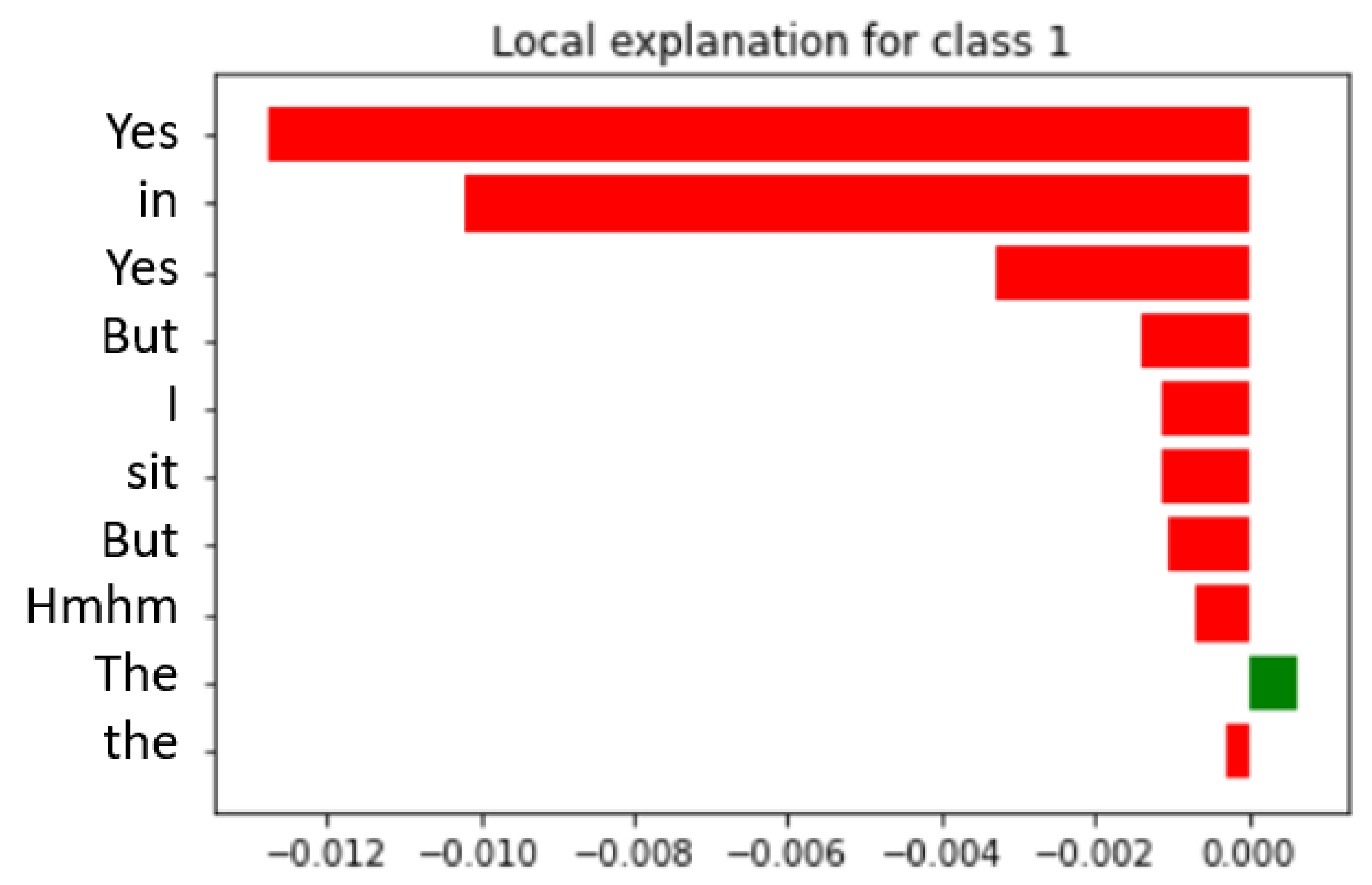
| ID | MD | SW | RobBERT | fastText | Words MD BERT | Words noMD BERT | Words MD fastText | Words noMD fastText |
|---|---|---|---|---|---|---|---|---|
| 1 | Y | Y | 0.68 | 0.77 | everyone, too, because, Yes, For example, too, Yes, I, did | - | yes, with, is, ⋯, common, me | from, common, common, eh |
| 2 | Y | Y | 0.55 | 0.69 | feel, allowed, I, really, eh, angry, they, You | [name], there | together, am, well, well. | am, I, me, my |
| 3 | N | Y | 0.39 | 0.45 | happy, the, looking back, Well, belongs, eh, always, no, well, think | - | say, come, yes, and, causing | not, that, [place name], week, say |
| 4 | N | Y | 0.37 | 0.23 | could, can, Furthermore, That, sat, be, chats, and, whole | walked | protected, to, is, do, bad, have, is, physical, am | walks |
| 5 | Y | N | 0.68 | 0.77 | ehm, one, bill, yes, distraction, recovery | sat, eh, real, goes | yes, well, that, yes, well, rest | if, but, better, care |
| 6 | Y | N | 0.58 | 0.65 | eh | hospital, Furthermore, whole, whole, she, one, also, eh, again | whole, completely, ⋯, further, times | stood, sick, selfish, and, ehm |
| 7 | N | N | 0.41 | 0.46 | eh, nineteen ninety seven, of, notices of objection, say, team | car, ehm, team, through, However, | psychiatrics, performance, one, he | that, en route, exciting, we, go, and |
| 8 | N | N | 0.49 | 0.43 | married, common, a, sit, heaven, times, and, The | ehm, ehm | sewn, healing, and, but, job | huh, hear, term, ready, busy |
| Language Marker | Mental Disorder | W; p < 0.05 | |
|---|---|---|---|
| LIWC | 1sg | Yes | 2487 |
| focuspast | Yes | 1856 | |
| affiliation | No | 380 | |
| drives | No | 568 | |
| female | No | 937 | |
| male | No | 767 | |
| 3sg | No | 454 | |
| social | No | 281 | |
| 3pl | No | 882 | |
| 1pl | No | 217.5 | |
| spaCy | ik_doen_nsubj | Yes | 1700.5 |
| ik_gaan_nsubj | Yes | 1726 | |
| ik_hebben_nsubj | Yes | 1796.5 | |
| ik_komen_nsubj | Yes | 1852.5 | |
| er_zijn_advmod | No | 849 | |
| ze_hebben_nsubj | No | 768.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spruit, M.; Verkleij, S.; de Schepper, K.; Scheepers, F. Exploring Language Markers of Mental Health in Psychiatric Stories. Appl. Sci. 2022, 12, 2179. https://doi.org/10.3390/app12042179
Spruit M, Verkleij S, de Schepper K, Scheepers F. Exploring Language Markers of Mental Health in Psychiatric Stories. Applied Sciences. 2022; 12(4):2179. https://doi.org/10.3390/app12042179
Chicago/Turabian StyleSpruit, Marco, Stephanie Verkleij, Kees de Schepper, and Floortje Scheepers. 2022. "Exploring Language Markers of Mental Health in Psychiatric Stories" Applied Sciences 12, no. 4: 2179. https://doi.org/10.3390/app12042179
APA StyleSpruit, M., Verkleij, S., de Schepper, K., & Scheepers, F. (2022). Exploring Language Markers of Mental Health in Psychiatric Stories. Applied Sciences, 12(4), 2179. https://doi.org/10.3390/app12042179