1. Introduction
Thoracic aortic pathologies, in particular aortic aneurysm and dissection, are among the main cardiovascular causes of morbidity and mortality [
1]. Despite the recent decrease in deaths caused by thoracic aortic pathologies, one review by Abdulameer et al. [
2] highlighted how more than 40% of such deaths occurred in patients who were not considered at high risk for these diseases and thus never examined for aortic abnormalities or overt aortic diseases. Current guidelines recommend imaging surveillance in those patients who present with cardiovascular risk factors such as hypertension or smoking and familiarity with diseases associated with aortic pathologies, such as the Marfan syndrome [
3].
Importantly, along with the aforementioned well-established risk factors, arch anatomy and geometry play a pivotal role in determining the likelihood of aortic disease [
4]. In particular, among aortic arch variants, we take here into consideration the so-called “bovine” arch, a configuration characterized by a common origin of the innominate and left carotid artery (CILCA), including the case of left carotid artery sharing a common orifice and a common trunk with the innominate artery (the latter also known as brachiocephalic trunk or brachiocephalic artery) (CILCA type 1) and the case of the left carotid artery branching off from the innominate artery (CILCA type 2) [
5]. The bovine aortic arch variant has been linked to a higher incidence and relative risk of thoracic aortic diseases such as aneurysms and dissections, particularly type B aortic dissections [
6,
7,
8,
9]. Dumfarth et al. [
6] reported that 556 patients with thoracic aortic diseases (aneurysms, dissections, intramural hematoma, or aortic rupture) showed a significantly higher prevalence of a CILCA variant (24.6%) than that seen among 4617 historical controls (14.0%). Similarly, Moorehead et al. [
7] reported that the prevalence of the CILCA type 2 variant was significantly higher (23.7%) in patients with thoracic aortic aneurysms or dissections compared to controls (15.9%). A recent systematic review and meta-analysis [
8], including 8 studies for a total of 11,381 subjects, showed that the rate of thoracic aortic disease among patients with CILCA was higher than that seen in patients with standard aortic arch configuration (odds ratio 1.4, 95% confidence interval 1.068–1.839). Shalhub et al. [
9] reported a significant general association between aortic arch variants and type B aortic dissections, with patients with CILCA accounting for 33.5% of cases. This increase in the likelihood of thoracic aortic disease has been related to alterations in blood flow caused by the CILCA, generating areas of accelerated flow and heightened wall shear stress [
9], which are linked to endothelial damage and arterial injury [
10]. Furthermore, after dissection, patients with CILCA are more likely to undergo surgical aortic repair and present an increased risk of death [
9,
11]. As a consequence, an early identification of patients with CILCA may be beneficial as it could allow the implementation of tailored surveillance protocols in order to avert unexpected disease diagnoses and potential adverse events.
Computed tomography (CT) scans of the chest that include the supra-aortic vessels in the field of view may allow the detection of CILCA, in particular when contrast media is administered. However, notwithstanding CILCA is estimated with a prevalence varying from 8.0% to 35.2% [
7,
11,
12,
13], this assessment is not part of routine clinical practice of CT, especially for CT scans not performed for cardiovascular indications [
14]. As a consequence, CILCA is only incidentally found and rarely reported in CT diagnostics reports [
9].
During the last years, artificial intelligence (AI) has gained a crucial role in medical image analysis, especially in the field of radiology, where it allows the automation of tasks that would be too cumbersome or not easily feasible in routine practice, thus offering a powerful aid to radiologists and, finally, to clinicians and patients [
15]. In particular, concerning the assessment of aorta by CT thoracic studies, AI applications include, among others, automatic aortic diameter measurements to assess the progression of aortic aneurysms [
16], screening for aortic dissection [
17], and classification of aortic dissection [
18]. Considering the low rate of aortic arch variant described on CT scans in clinical practice (only 5–8% [
9]), suggesting a relevant under-reporting, and the high proportion of CILCA among these variants, the availability of a fully automatic system for CILCA detection on CT thorax studies, not needing any human time-consuming post-processing or segmentation, could help in stratifying the risk of aortic disease and the reporting of incidental findings in patients undergoing chest CT. To the best of our knowledge, no AI application has yet been implemented for the automatic CILCA detection and classification of CT scans acquired for different clinical indications.
Therefore, the purpose of our work was to develop and test the potential of a deep learning segmentation-plus-classification system for the automatic detection, at the single-subject level, of CILCA aortic arch variants on chest CT scans acquired for various clinical indications. The tool design and its performances for training and testing datasets are presented and discussed from the perspective of its future use in a routine clinical context.
2. Materials and Methods
2.1. Study Design
This is a retrospective bicentric study including two Italian centers: IRCCS Policlinico San Donato, San Donato, Milan, Italy (Center 1) and Centro Diagnostico Italiano (CDI), Milan, Italy (Center 2). The local Ethics Committee of Center 1 (Ethics Committees of IRCCS Ospedale San Raffaele, Milan, Italy) approved this retrospective study (protocol code “CardioRetro”, number 122/int/2017; approved on 14 September 2017 and amended on 10 February 2021), and informed consent was waived due to the retrospective nature of the study. The local Ethics Committee of Center 2 (Fondazione IRCCS Ca’ Granda Ospedale Maggiore Policlinico Ethics Committees to which CDI refers) approved this retrospective study (protocol ID “1944” approved on 8 February 2021), and informed consent was waived due to the retrospective nature of the study.
Both Center 1 and Center 2 retrospectively included chest CT datasets, namely, chest CT studies with the aortic arch and supra-aortic vessels belonging to individual patients with type 1 CILCA variant or type 2 CILCA variant (positive class) and CT studies without CILCA, i.e., with an aortic arch with the left internal carotid artery originating directly from the aortic arch (negative class). Classes were assigned supervised by a radiologists’ consensus at visual inspection of the two-dimensional axial and oblique reconstructions of the aortic arch and supra-aortic vessels. A case-control design based on non-consecutive patients was used.
CT examinations were selected aiming for heterogeneity in image acquisition and reconstruction protocols, so that the AI model could be generalizable to a wide range of CT studies [
19]. For this purpose, CT scans with and without intravenous contrast agent administration acquired and reconstructed at different slice thickness and technical parameters, performed for various clinical indications, were included.
2.2. Training and Internal Testing of the Model
The CT images collected at both centers were used to train, tune, and internally test different deep learning classifiers in the binary classification task of interest (CILCA versus non-CILCA).
For these purposes, the TRACE4 research software platform (DeepTrace Technologies, Milan, Italy) [
20] was used. TRACE4 is a stand-alone software, compliant with the European General Data Protection Regulation [
21], which allows: (i) training, cross-validation, and testing ensembles of a variety of convolutional neural networks (CNNs) with different architectures; (ii) processing medical images to easily match specific CNNs’ input constraints (e.g., image size) for the development of machine learning predictive models.
TRACE4 performs data minimization by automatic pseudonymization of medical images (“privacy by design”). Such images are fed into the selected CNNs after an automatic up- or down-sampling procedure applied to images, depending on the different original image size, or an image segmentation procedure, following an automatic up- or down-sampling procedure applied to segmented images, depending on the different segmented image size.
In this study, a model based on a two-step procedure has been developed, including: (A) a semantic segmentation procedure of CT images to extract the aortic arch; and (B) a classification procedure of the extracted aortic arch and supra-aortic vessels into the two classes of interest, cases with CILCA or cases without CILCA (non-CILCA).
2.2.1. Segmentation of Aortic Arch and Supra-Aortic Vessels
Semiautomatic segmentation. The aortic arch was initially segmented from the CT images with a semiautomatic active contour segmentation algorithm. Segmented volume was then manually modified by one expert human to correct segmentation errors. This procedure was adopted for all CT images. Prior to the segmentation procedure, all CT images with slice thicknesses greater than 1.5 mm were resampled to reduce the thickness to 1.5 mm.
Fully automatic segmentation of aortic arch and supra-aortic vessels. A semantic-segmentation algorithm was developed and used for all CT examinations for training (
k-fold cross-validation) and internal testing of the classification model in order to implement a fully automatic process. For this purpose, the 3D Dense U-Net [
22] was trained from scratch in a hold-out fashion using half images of the dataset from Center 1 for training (80%, 40% CILCA and 40% NON-CILCA) and validation phase (20%) and the remaining half for internal testing. This type of network is known to be able to generalize well on relatively small datasets leading to acceptable results [
23,
24]. Due to hardware limitations, the CT scans were not passed entirely as input to the network but were preprocessed and serialized in batches of several slices. In particular, each CT scan and the relative segmentation mask underwent the following preprocessing steps: (i) selection of the slices pertaining only to the aortic arch in both CT scan and segmentation mask generated via semiautomatic segmentation; (ii) thresholding of pixel intensities between −1000 HU and +400 HU in the CT scan where a contrast medium was used, otherwise the threshold range −500 HU +100 HU was used; and (iii) resampling of the CT scans and relative segmentation masks to 128 × 128 × 80 matrices.
The preprocessed CT scans and relative segmentation masks were passed to the network for the training stage in batches of size 1, where each batch was composed of 16 slices. The binary cross-entropy loss and Adam optimizer [
25] were used for training the network, while the Dice coefficient [
26] was monitored as a metric to evaluate the performance on both the training and validation set. The training was stopped if there were no improvements for 20 consecutive epochs on the Dice coefficient evaluated on the validation set. As for the data augmentation techniques used, only the rotations in the range (−15°, +15°) were seen to be effective on the regularization of the training phase. In order to improve the quality of the segmentation results, the model was then fine-tuned, with the same procedure described above, only on the few final slices of the scan where the arteries start to detach from the aortic arch.
In the testing phase, the predicted segmentation masks were resampled to their original shape and then refined in the upper part with the fine-tuned model. As the last step, the predictions were cleaned from spurious findings, keeping only the biggest connected component segmented.
2.2.2. Classification of Segmented Aortic Arch and Supra-Aortic Vessels
The segmented aortic arch and supra-aortic vessels (for both semiautomatic segmentation and fully automatic segmentation) were processed by the following steps: (i) the three-dimensional (3D) segmentation mask was converted into a 3D mesh; (ii) the 3D mesh was rotated on the longitudinal axis in order to maximize the extension of the aortic arch projection on a two-dimensional (2D) plane; (iii) the 2D projection including the maximum extension of the aortic arch was saved in a 2D square image centered on the aortic arch (square image of the aortic arch, SIAA); and (iv) each SIAA was labeled by radiologists as CILCA or non-CILCA and used as a reference standard to train, tune, and internally test the classification model.
Three different CNN architectures were considered for the model: ResNet-50 [
27], SqueezeNet [
28], and DenseNet-201 [
29], three CNNs with deep architecture composed of 50, 18, and 201 layers of neurons, respectively. Each of these CNNs had been previously trained on over a million images from the ImageNet database [
30] to classify images into 1000 object categories. During training, such CNNs were able to learn a rich feature representation of the input image classes. Then they can use these feature representations to classify new images as belonging to one of the input classes’ layers. It must be noted that these three CNNs emerged among the best performing pre-trained architectures in a variety of applications in the medical imaging domain, in particular for images with features similar to those used in our study (e.g., Ahn et al., 2017; Pham et al., 2020; Serte et al., 2020; Sharobeem et al., 2021; Wang et al., 2020; Zhang et al., 2021) [
31,
32,
33,
34,
35,
36].
ResNet-50 preprocesses the input image by one convolutional layer (7 × 7) and one max pooling layer (3 × 3). Then, the preprocessed image is input to four blocks of layers of similar structure, including a different number of 3 × 3 convolutional filters providing different features’ map size. Each block filters the preprocessed image and sends forward the filtered image to the next block of convolutional filters. Moreover, some blocks skip the preprocessed image to the next block. This operation is called “skip connection” and represents one hallmark of ResNet architectures solving the vanishing gradient problem that implies that classifier performance gets saturated rapidly in extremely deep architectures. The last layers of ResNet-50 consist of one average pooling layer and one fully connected layer followed by a support vector machine (SVM) classifier layer.
SqueezeNet preprocesses the input image by one convolutional layer (7 × 7) and one max pooling layer (3 × 3). Then, the preprocessed image is input to nine “Fire modules” blocks of similar structure, composed of one 1 × 1 convolutional filter feeding into an expand layer that has a mix of 1 × 1 and 3 × 3 convolution filters. Each block filters the preprocessed image and sends forward the filtered image to the next block of convolutional filters. The last layers of SqueezeNet consist of one convolutional layer (1 × 1), one average pooling layer, and one classification layer.
DenseNet-201 preprocesses the input image by one convolutional layer (7 × 7) and one max pooling layer (3 × 3). Then, the preprocessed image is input to 112 blocks of layers of similar structure, grouped in 4 larger “dense” blocks (6 blocks in the first dense block, 16 in the second one, 48 in the third one, and 32 in the last one). Each dense block includes a different number of 3 × 3 convolutional filters, but dimensions within each dense block are the same, keeping features’ map size constant inside the single dense block. Moreover, all the blocks of a dense block have direct access to each other. The last layers of DensNet-201 consist of one average pooling layer and one fully connected layer, followed by an SVM classifier layer.
Moreover, we were interested in investigating whether a feature representation learned using a different number of layers (SqueezeNet: 18 layers; ResNet-50: 50 layers; DenseNet-201: 201 layers), which is reflected in a shallower or deeper level of abstraction, respectively, could have an influence on the automatic-classification results. It should be noted that these deep networks include different convolutional filters that are able to learn a rich feature representation of the input image classes during training and to use this learned representation for classifying new images. Basic feature detection filters are learned through the first layers, filters able to detect parts of the target object are learned through the middle layers, while high-representation filters able to detect the entire target are learned through the last layers. These differences can be more emphasized the higher the number of layers.
For each patient considered in this study, the SIAA, obtained from the fully automatic segmentation step, was automatically down-sampled in order to match the ResNet-50 input image size (224 by 224 pixels), the SqueezeNet input image size (227 by 227 pixels), and the DenseNet image size (224 by 224 pixels).
For the training and cross-validation of the deep learning classifiers, we considered the first dataset of CTs, obtained from half of the dataset of Center 1, consisting of 50% of CTs with CILCA and 50% CTs without CILCA, together with 75% of the Center 2 dataset, consisting of 15% of CTs with CILCA and 85% CTs without CILCA. For internally testing the deep learning classifiers, we considered the CTs from both Center 1 and Center 2 datasets consisting of 50% of CTs with CILCA and 50% CTs without CILCA.
In order to increase image diversity among different training phases (epochs), we applied data augmentation and image manipulation techniques to the training image set, as follows: (i) reflections in the top-bottom direction and reflections in the left-right directions applied randomly (50% probability); (ii) planar rotations, with the rotation angle picked randomly from a continuous uniform distribution from −5° to +5°; (iii) horizontal and 100 vertical shears, with shear angle picked randomly from a continuous uniform distribution from −0.05° to +0.05°.
TRACE4 allowed a fine-tuning of the three CNNs architectures to specialize for our binary classification task (CILCA versus non-CILCA), replacing the fifth last layers for SqueezeNet, and the two last layers for ResNet-50 and DenseNet-201. After editing these specific layers, TRACE4 proceeded with the re-training of the CNNs. Specifically, TRACE4 optimized (during training of each CNN) the maximum number of epochs to 300, with an optimal mini-batch size of 8 (the samples of the training set were randomized before each epoch in order to avoid issues related to the choice of samples to include in the mini-batches—e.g., always discarding the same samples). An Adam optimization was used for stochastic gradient computation [
25]. TRACE4 did not optimize the learning rate that was maintained at 1 × 10
−4 constantly throughout the whole training.
A 5-fold cross-validation method was chosen. The division ratio between the training set and the validation set was 4:1 (124:31). For each fold of the cross-validation, each of the three CNNs was trained on the training set and used to classify the validation set. Each of the three CNN was then used to obtain the classification performance on both the training and the validation sets. This resulted in five different CNN-derived classification models and a set of five classification performances (one for each fold). For each of the three CNNs, the final training and validation performance was calculated as the mean of the performances obtained on each of the five CNN-derived classification models.
For each of the three CNNs, internal testing was performed on the second half of the Center 1 dataset and on the second part of the Center 2 dataset, using five classifiers trained and validated as described above in an ensemble strategy. Images of the independent testing set were classified using the five classifiers, thus obtaining five classification outputs and five class-membership probabilities for each image (one for each ensemble classifier). The final classification for each image was calculated by the mean probabilities assigned by the five classifiers. Testing performance was then calculated over the entire independent testing set.
2.3. Statistical Analysis
Data are presented as mean and standard deviation or median and interquartile interval according to the normal or non-normal distribution.
The performance obtained by the three deep learning classifiers for both cross-validation and internal testing were computed in terms of area under the curve (AUC) at receiver operating characteristics analysis, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), positive likelihood ratio (LR+), and negative likelihood ratio (LR-), with their corresponding 95% confidence interval (CI).
Statistical analysis through two-sample t-test was performed to compare the results of automatic segmentation for contrast-enhanced vs. unenhanced scans and for lower-than-1.5 mm vs. higher-than-1.5 mm slice thickness; p-values < 0.05 were considered for statistical significance.
Sub-analysis of true positive versus false negative cases considering CILCA type (1 or 2) as well as technical features (slice thickness reconstruction and administration or non-administration of contrast agent) was performed using the Fisher exact test using Python 3.7.6;
p-values < 0.05 were considered for statistical significance [
37].
3. Results
3.1. Datasets: CT Examinations Included and Technical Parameters
Center 1 retrospectively included 200 chest CT studies including the aortic arch and supra-aortic vessels belonging to 200 individual patients, 100 with CILCA (60 type 1 CILCA and 40 type 2 CILCA) (positive class), and 100 without CILCA (negative class). All CT examinations were acquired on a 64-row CT scanner (Somatom Definition, Siemens Healthineers, Erlangen, Germany) but with different acquisition, reconstruction, and contrast medium conditions. Acquisition collimation ranged from 0.6 to 1.2 mm, slice thickness reconstruction from 1.0 to 5.0 mm, tube voltage between 100 and 140 kVp. Contrast-enhanced scans the protocol included the intravenous injection of iopamidol (Iopamiro, Bracco Imaging S.p.A., Milan, Italy) at 1 mL/kg followed by 30–70 mL of saline solution with a flow rate of 3.0–5.0 mL/s. Among the 200 patients, the median age was 76 years (interquartile range 69–84 years), and 97 were males (49%).
Patients’ demographics and CT technical parameters for the CILCA and non-CILCA groups are reported in
Table 1.
Center 2 retrospectively included 102 chest CT datasets, including the aortic arch and supra-aortic vessels belonging to 102 individual patients, 23 with CILCA (13 type 1 and 10 type 2) (positive class), and 79 without CILCA (negative class). All CT examinations were acquired on a 64-slice scanner (SOMATOM, Siemens, Erlangen, Germania). Collimation ranged from 3 mm, slice thickness reconstruction at 0.6–1.2 mm, tube voltage was set between 100 and 140 kVp. When contrast-enhanced scans were available, the protocol included the intravenous injection of iopamidol (Iopamiro, Bracco Imaging S.p.A., Milan, Italy) ranged from 0.8 to 1.2 mL/kg followed by 30–70 mL of saline solution with a flow rate of 3.0 mL/s.
Among the 102 patients, the median age was 65 years (interquartile range 55–73 years), and 66 were males (65%). Data for the CILCA and non-CILCA groups at Center 2 are reported in
Table 2.
3.2. Training and Testing of the Models
The automatic segmentation process realized by the 3D Dense U-Net tested on CTs from Center 1, when compared with the manual segmentation as the reference standard, showed a mean Dice score of 0.904 (95% CI 0.899–0.909), which improved to 0.916 (95% CI 0.911–0.922) after applying the refinement technique, consisting of focusing only on a portion of the volume to be segmented and zooming in on it. In particular, for the supra-aortic arteries, the Dice score of images from Center 1 improved from 0.604 (95% CI 0.569–0.639) to 0.771 (95% CI 0.757–0.786). For the CTs from Center 2, the Dice score was 0.907 (95% CI 0.903–0.912), which improved to 0.912 (95% CI 0.906–0.917) after refinement. In particular, in the upper arteries, the Dice score from Center 2 improved from 0.714 (95% CI 0.683–0.744) to 0.792 (95% CI 0.778–0.806).
Table 3 deepens the analysis of the results identifying 2 different subgroups: contrast-enhanced CTs vs. non-enhanced CTs and CT slice thickness ≤ 1.5 mm vs. CT slice thickness > 1.5 mm. This analysis was conducted only on Center 1 data since the cardinality of data in these subgroups was not relevant in Center 2 data. The table reports the Dice performances before and after the refinement operation. Statistical comparison (two-sample
t-test) showed significantly better segmentation results for images with contrast media injection and slice thickness lower than 1.5 mm (
p < 0.005 for both gross and refined Dice scores), as expected due to the higher contrast and spatial resolution of images.
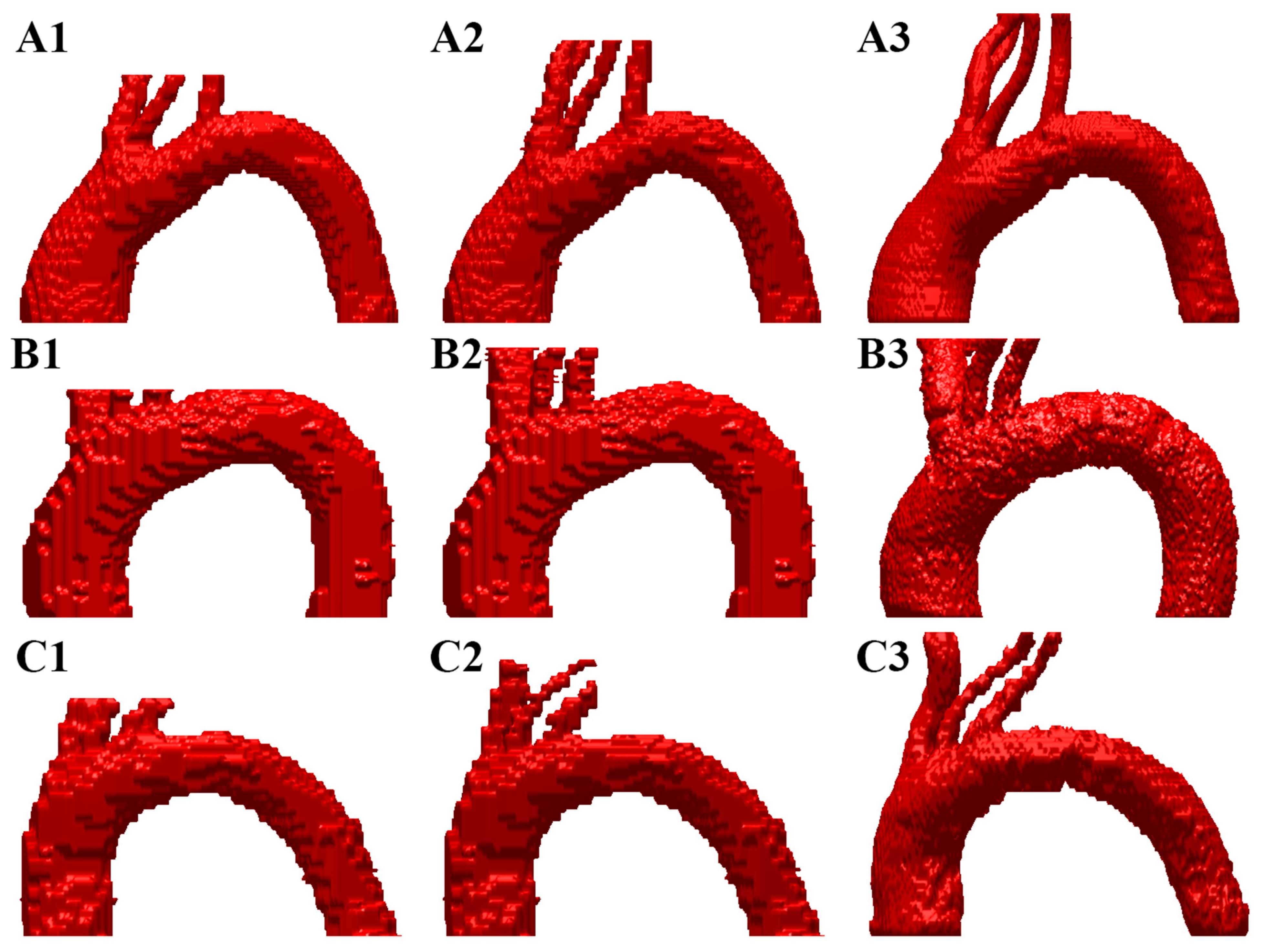
Figure 1 shows 3 representative examples (A, B, and C) of the automatic segmentation process realized by the 3D Dense U-Net when the Dice coefficient was >0.94, >0.91, and >0.90, respectively, both for the first prediction and the refined prediction compared with ground truth.
The procedure of classifying CILCA versus NON-CILCA cases showed different performances for the training (5-fold cross-validation) and the internal independent testing, depending on the choice of the model architecture, as reported in
Table 4. In particular, the best model, i.e., DenseNet201, obtained for the internal independent testing a sensitivity of 66.7% (42/63) associated with a specificity of 90.5% (57/63), a PPV of 87.5% (42/48) and a NPV of 73.1% (57/78).
The initial memory size of each CNN was around 96 MB, 5 MB, and 77 MB for ResNet-50, SqueezeNet, and DenseNet-201, respectively. After structural modifications to each CNN for re-purposing, the memory size of each fold of the trained CNNs dropped to 86 MB, 3 MB, and 68 MB for ResNet-50, SqueezeNet, and DenseNet-201, respectively. The size drop is due to the different number of possible outputs (from 1000 classes to only 2 classes). Even if SqueezeNet memory size was significantly lower, the very low performances in terms of sensitivity prevented this model architecture from being a valuable option compared to the other two.
Subanalysis of the results for the internal independent testing according to the CILCA type revealed that of the 43 CILCA 1, 25 (58.1%) were true positive and 18 (41.9%) were false negative, while of the 20 CILCA 2, 17 (85.9%) were true positive and only 3 (15.0%) were false negative (p = 0.046, Fisher exact test). Considering the whole number of 63 CILCA, of 54 cases with contrast agent administration, 35 (64.8%) were true positive, and 19 (35.2%) were false negative, while of 9 cases without contrast agent administration, 7 (77.8%) were true positive and 2 (22.2%) were false negative (p = 0.705, Fisher exact test). Finally, considering the whole number of 63 CILCA, of the 27 cases with slice reconstruction ≤ 1.5 mm, 18 (66.7%) were true positive and 9 (33.3%) were false negative, while of the 36 cases with slice reconstruction ≥ 3 mm, 24 (66.7%) were true positive and 12 (33.3%) were false negative (p = 1.000, Fisher exact test).
4. Discussion
The main result of this work is the development of an AI tool applied to chest CT scans, enabling the detection of CILCA anatomical variants based on a two-step deep learning procedure. First, a fully automatic semantic segmentation procedure of CT images to extract the aortic arch and the origin of supra-aortic vessels; second, a fully automatic binary classification procedure into the two classes of cases with CILCA or cases without CILCA. In other words, this AI system suggests the presence of a CILCA variant without time-consuming human intervention related to image-specific reconstruction or segmentation.
The clinical value of this approach can be appreciated when considering some epidemiological and clinical implications of the CILCA anatomy variant. As pointed out in the Introduction, the prevalence of CILCA has been reported to vary according to different studies [
7,
11,
12,
13], probably meaning that about 1 out of 5–6 patients might have this anatomical variant. Of note, CILCA is rarely noticed and reported when the CT scan is not a “cardiovascular” examination or specifically aimed at evaluating the aortic arch and supra-aortic vessels. The emergent evidence of CILCA as a risk factor for aortic disease and stroke highlights the potential usefulness of a tool proposing an automatic CILCA detection in a substantial proportion of patients with this anatomical variant by a simple automatic reading of a common CT chest scan.
Several groups of authors reported the association between aortic arch variants and thoracic aortic disease. A systematic review and meta-analysis published in 2020 by Marrocco-Trischitta et al. [
8], including 8 studies enrolling 11,381 subjects, found the rate of thoracic aortic disease among CILCA arch patients to be higher (41.5%, 95% CI 28.1–56.4) than the rate among patients with standard arch configuration (34.0%, 20.1–51.4), with an odds ratio of 1.4 and an overall significant association between CILCA arch and thoracic aortic disease. More recently, Yousef et al. [
38] investigated the prevalence of aortic arch variants in the adult population and their association with thoracic aortic aneurysm disease. On a single-institution large database of 21,336 CT scans, they found 603 (2.8%) described arch anomalies, 354 of them (58.7%) with the bovine arch being the most common diagnosis. Although this low rate of arch anomalies opens the previous discussion about under-reporting, their results are interesting. Patients with arch anomalies were significantly more likely to be female, non-Caucasian, and hypertensive; the prevalence of thoracic aortic aneurysms in the arch anomalies group was 10.8%, significantly higher than 4.1% in the non-variant cohort. Patients with bovine arch showed the second highest prevalence of thoracic aneurysm (13%) after those with right-sided arch combined with aberrant left subclavian configuration (33%) and before those with aberrant right subclavian artery (8.2%). A significantly higher prevalence of bovine arch was also observed by Martens et al. [
39] in male patients undergoing blunt isthmic aortic trauma repair (57.6%) versus controls (34.8%), playing in favor of a role of bovine arch in facilitating trauma effects on the aorta. Finally, children with bovine arch anatomy and coarctation are at a significantly higher risk of re-coarctation following coarctation repair [
40]. The association between aortic arch variants and thoracic aortic diseases depends on differences in hemodynamic flow patterns, and four-dimensional flow magnetic resonance imaging preliminary data corroborate this hypothesis [
9].
While no association between variant aortic arch branching pattern and intracranial aneurysms was found by Salehi et al. [
41], a significant association between CILCA variant and stroke was found by Syperek et al. [
42], who defined the bovine aortic arch as a “biomarker for embolic stroke”. The authors retrospectively evaluated aortic arch branching patterns on contrast-enhanced CT scans of the chest and neck of 474 individuals, 152 of them with and 322 without acute embolic stroke of the anterior cerebral circulation. They observed a significantly higher prevalence of the bovine aortic arch among stroke patients (25.7%) than that among controls (17.1%) (odds ratio 1.67); stroke patients were significantly more likely to have the CILCA 2 (10.5%) than controls (5.0%) (odds ratio 2.25), while the CILCA 1 variant was similarly common in both groups, showing the higher clinical relevance of detecting the CILCA 2 variant. In addition, in a cohort of 615 stroke patients [
43], left laterality of cardioembolic stroke has been shown to be significantly more frequent (51.3%) in patients with the bovine arch variant than in patients with standard arch (43.6%), demonstrating that the arch anatomy influences stroke laterality and fostering further research into the causative hemodynamic factors.
In this work, we have shown that the 3D Dense U-Net applied to chest CT is effective as an automatic segmentation tool on both the Center 1 and Center 2 datasets, with a similarity Dice coefficient of 0.916 and 0.912, respectively. With the refinement technique proposed, we also showed how focusing only on a portion of the volume to be segmented and zooming on it drastically improves the segmentation result on that region. A good segmentation in these final slices is a key factor in determining if a subject pertains to the CILCA category or not.
Moreover, DenseNet-201 resulted in being the best model among three CNNs trained, supervised by a readers’ consensus by visual inspection of the 2D axial and oblique images of the aortic arch. According to the classification performance obtained from an internal testing on 126 patients from the 2 centers, DenseNet-201 achieved ROC-AUC 87.0%, sensitivity 66.7%, specificity 90.5%, PPV 87.5%, NPV 73.1%, LR+ 7.0, and LR− 0.4. False-negative CILCA were found of type 1 in 42% of cases and of type 2 in 15% cases, respectively, proving that the system is less accurate when the geometrical variant is less evident.
The relatively low sensitivity of our tool in the internal testing (66.7%) deserves a double comment.
On the one hand, we should consider the subanalysis of the false-negative cases. The administration or the non-administration of contrast agent and the slice thickness reconstruction did not influence the false-negative rate, thus showing that datasets coming from unenhanced CT scans and obtained with relatively high reconstruction slice thickness are suitable for automatic analysis by our tool. Conversely, the significantly different proportion of false-negative CILCA 1 (42%) and CILCA 2 (15%) highlights that when the CILCA variant is anatomically more different from the non-CILCA pattern (i.e., it is a CILCA 2), the automatic tool reaches an 85% sensitivity, while in the cases of CILCA 1 the tool is more prone to miss the variant (sensitivity 58%). This difference could be related to the fact that the CILCA variants are the results of an embryologic anatomical continuum of the origin of the left carotid artery that moves from distal to proximal portions of the aortic arch, becoming CILCA 1 in the case of common origin with the innominate artery [
40,
44]. So, the difference between a standard arch with a proximal origin from the arch, adjacent to the innominate artery, and a CILCA 1 variant with a very short common vessel may be very subtle and difficult to differentiate.
On the other hand, we should consider that the CILCA variant is rarely reported in clinical practice: a retrospective preliminary analysis performed at Center 1 found a real-world low reporting rate of 2% in a series of unenhanced CT scans of patients without a history of aortic or supra-aortic vessel disease [
45]. Thus, a tool allowing to increase the detection rate to two-thirds of CILCA carriers would be useful for (i) increasing the reporting rate (taking into account an 87.5% PPV, which implies an acceptable rate of false positives to be checked by radiologists); (ii) attracting the attention of radiologists, especially those not dedicated to cardiovascular disease, on variants of the origin of supra-aortic vessels; (iii) allowing the implementation of prospective studies evaluating patients with bovine arch in terms of incidence of cardiovascular events, in particular aortic diseases and stroke.
The main limitation of this study is a relatively small sample size, which implied relatively large 95% CIs for the performance metrics for the internal testing dataset. However, as discussed above, when compared with the heavy current under-reporting of CILCA variants on CT scans, the gain in detection allowed by our tool surely represents a step forward.
The choice of using a deep-learning approach with dimensionality data reduction (from 3D mesh to 2D projection) was led by the specific geometrical nature of the CILCA anomaly, expressed in particular in the upper vessels. Considering that the anomaly can be identified by a human reader very well once looking at the 3D mesh projected on a 2D image, it was supposed that a deep learning-based approach could spot the 2D projected differences with a great improvement in the processing time. Our tool, in a fully-automatic process, takes only 2.5 min per patient for segmenting the aortic arch and upper vessels and classifying the presence or not of the CILCA variant. The possibility to use aortic arch-derived geometrical features to detect the CILCA variant deserves a separate note. Considering the relatively small number of subjects in our study, a traditional machine-learning approach using such features as input for classification could be a good compromise. However, while quite-standard geometric metrics are usually extracted from automatic geometrical models to assess and quantify geometric variants of the aortic arch, no standardized metrics are instead defined from the upper part of the aortic arch, including vessels. These are very important and simple metrics for the visual detection of CILCA. With this work, we wanted to mime the visual detection of radiologists of the CILCA variant, taking advantage of a full computer-vision-based tool in performing this task.
In some studies, e.g., [
34], deep learning has been applied on CT thoracic images for different purposes, including aorta segmentation, aortic disease detection, and risk stratification, demonstrating excellent correlations and adequate agreements compared with manual measurements for most segmented structures. A detailed analysis of these studies is out of the purpose of this work and can be found, for example, in [
16,
17,
18,
46]. To the best of our knowledge, no AI application has yet been implemented for the automatic CILCA detection and classification of CT scans acquired for different clinical indications. A recent study [
47] proposed a deep learning architecture feeding on high-resolution contrast-injected CT thoracic images and providing a comprehensive geometric analysis of the aorta for both standard and CILCA arch configurations, suitable to be used for unbiased quantitative analyses of geometric parameters in population studies for planning thoracic endovascular aortic repair. However, a single subject classifier based on the automatic classification of CILCA variants was not implemented, the above-mentioned method requiring instead the assessment of cut-off values for aortic metrics to define pathological versus normal patients. Moreover, slice thickness > 1.5 mm was excluded from the study, limiting the generalization of the developed geometric-variant detection model to CT scans acquired for different clinical indications than aortic assessment.


 ,
, 


{kind=link}