
Chainlet-Based Ear Recognition Using Image Multi-Banding and Support Vector Machine




Abstract
:1. Introduction
2. Proposed CERMB-SVM Technique
2.1. Image Pre-Processing
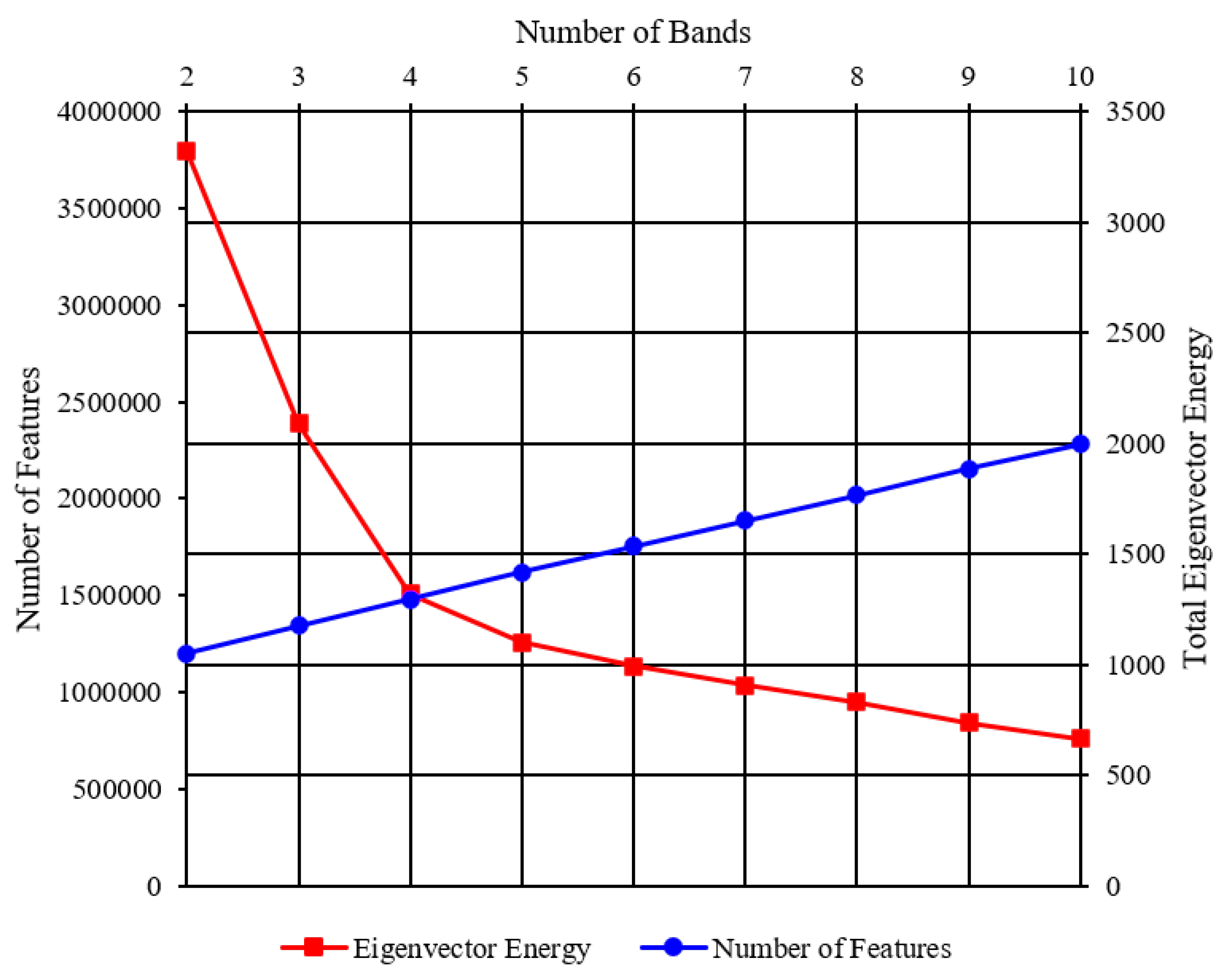
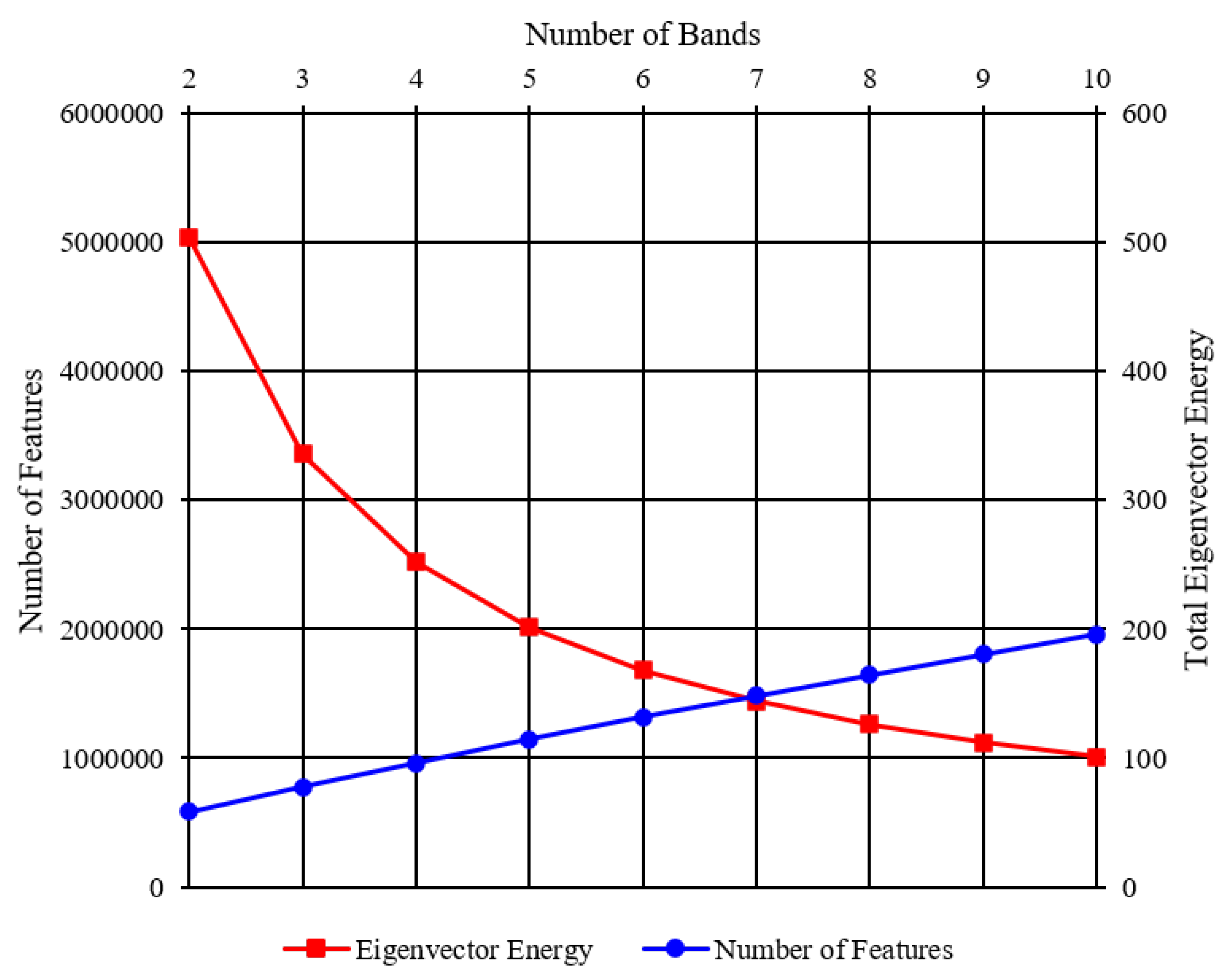
2.2. Multi-Band Image Generation
2.3. Edge Selection
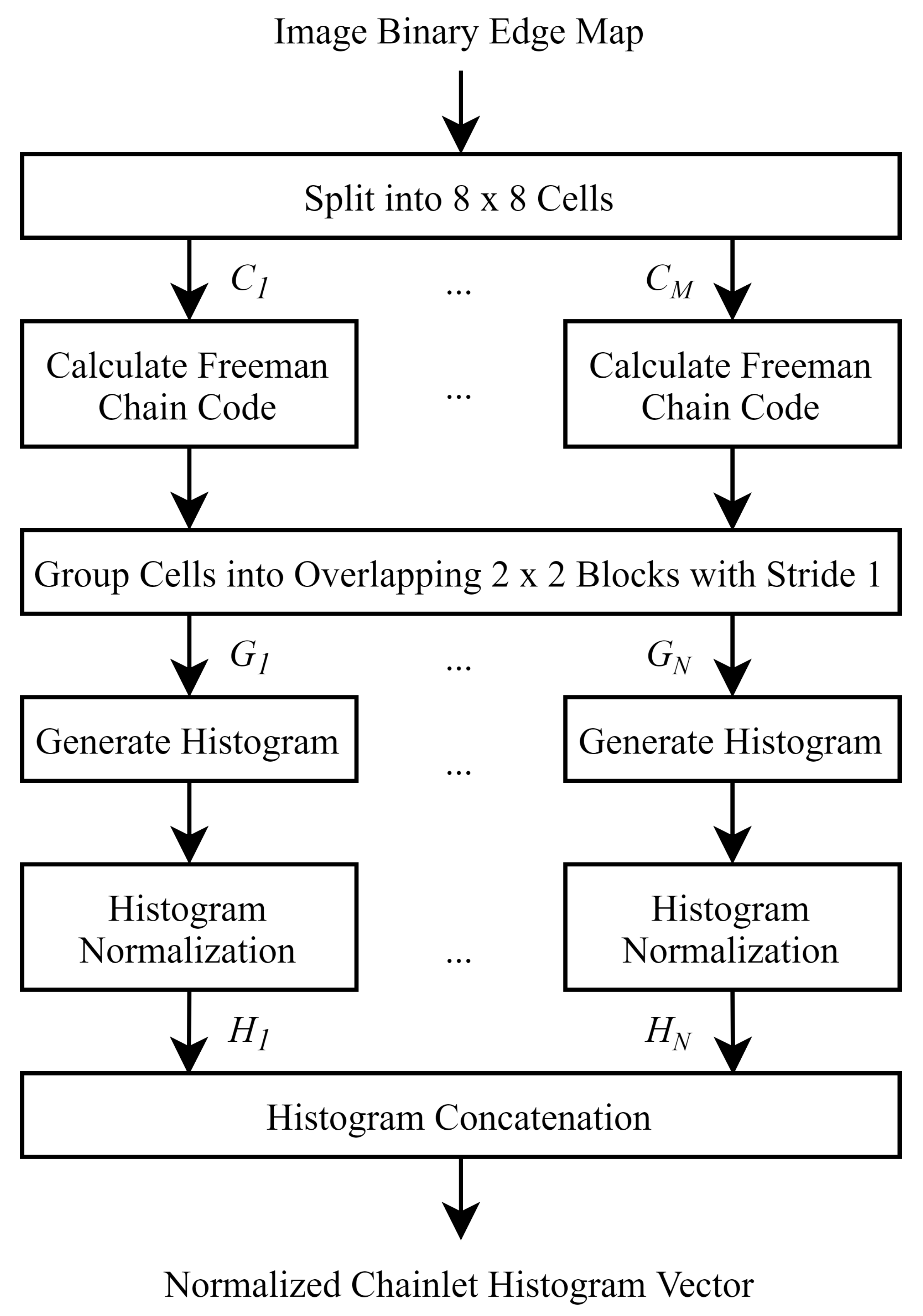
2.4. Chainlet Calculation
3. Pairwise Support Vector Machine
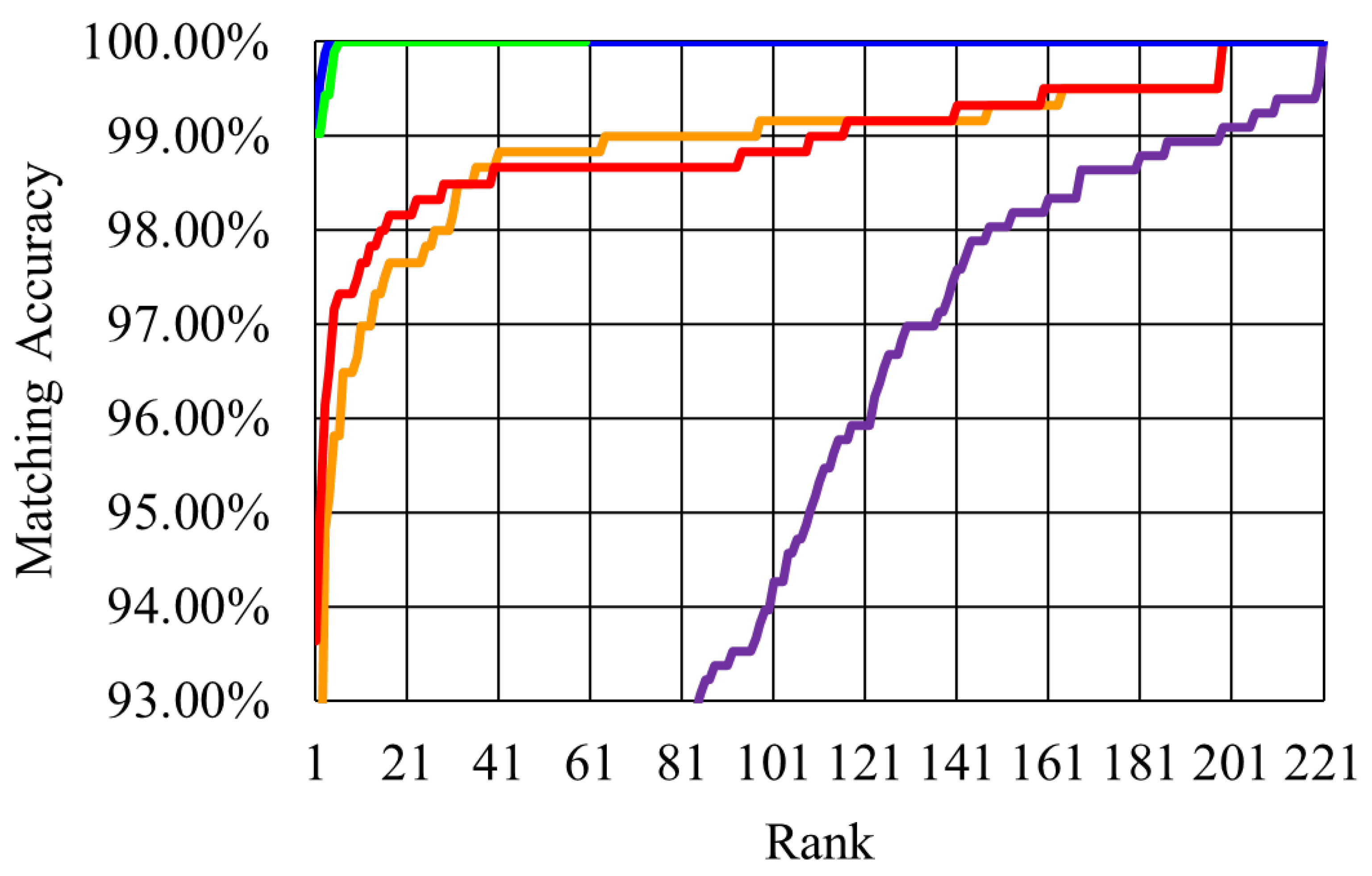
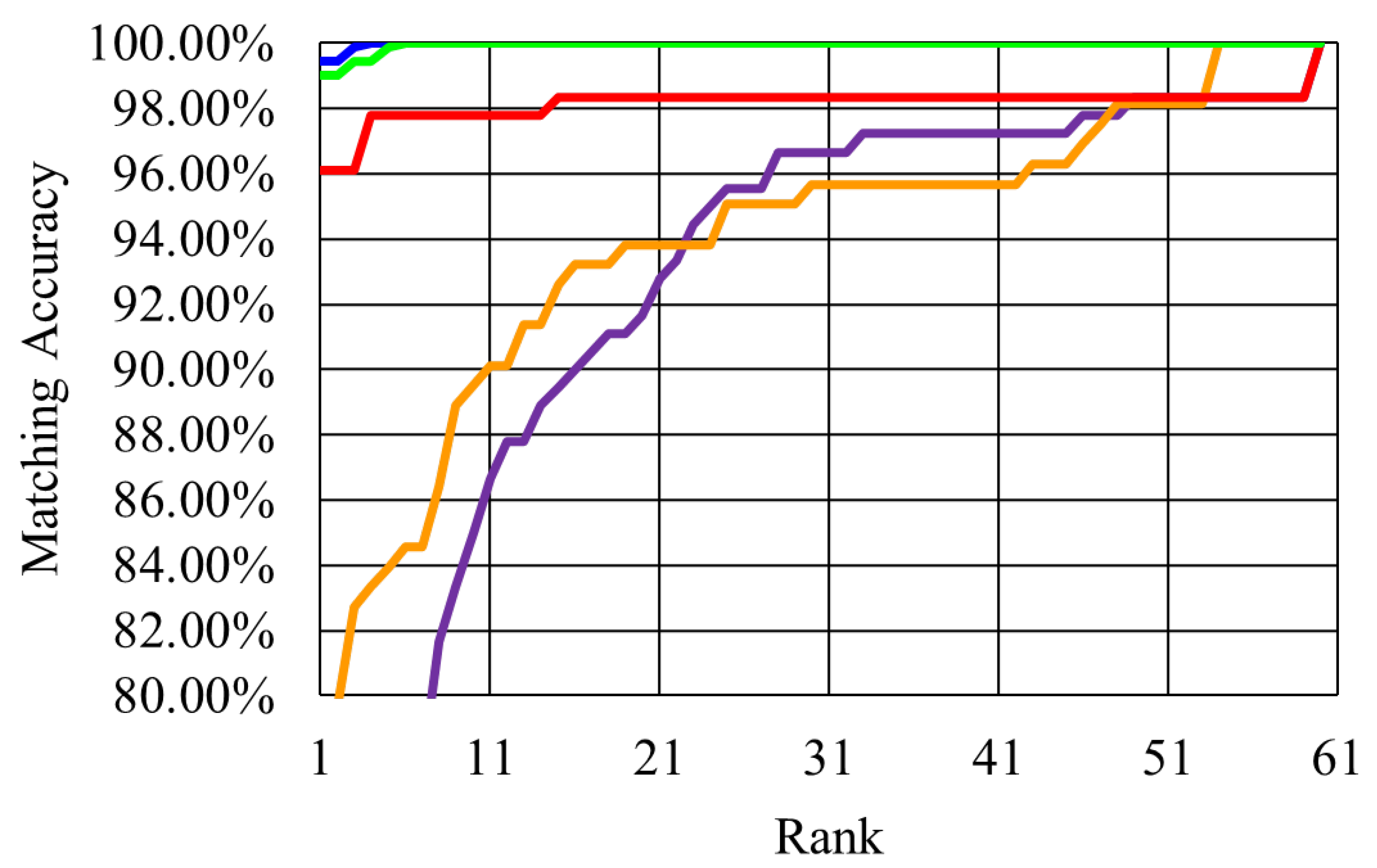
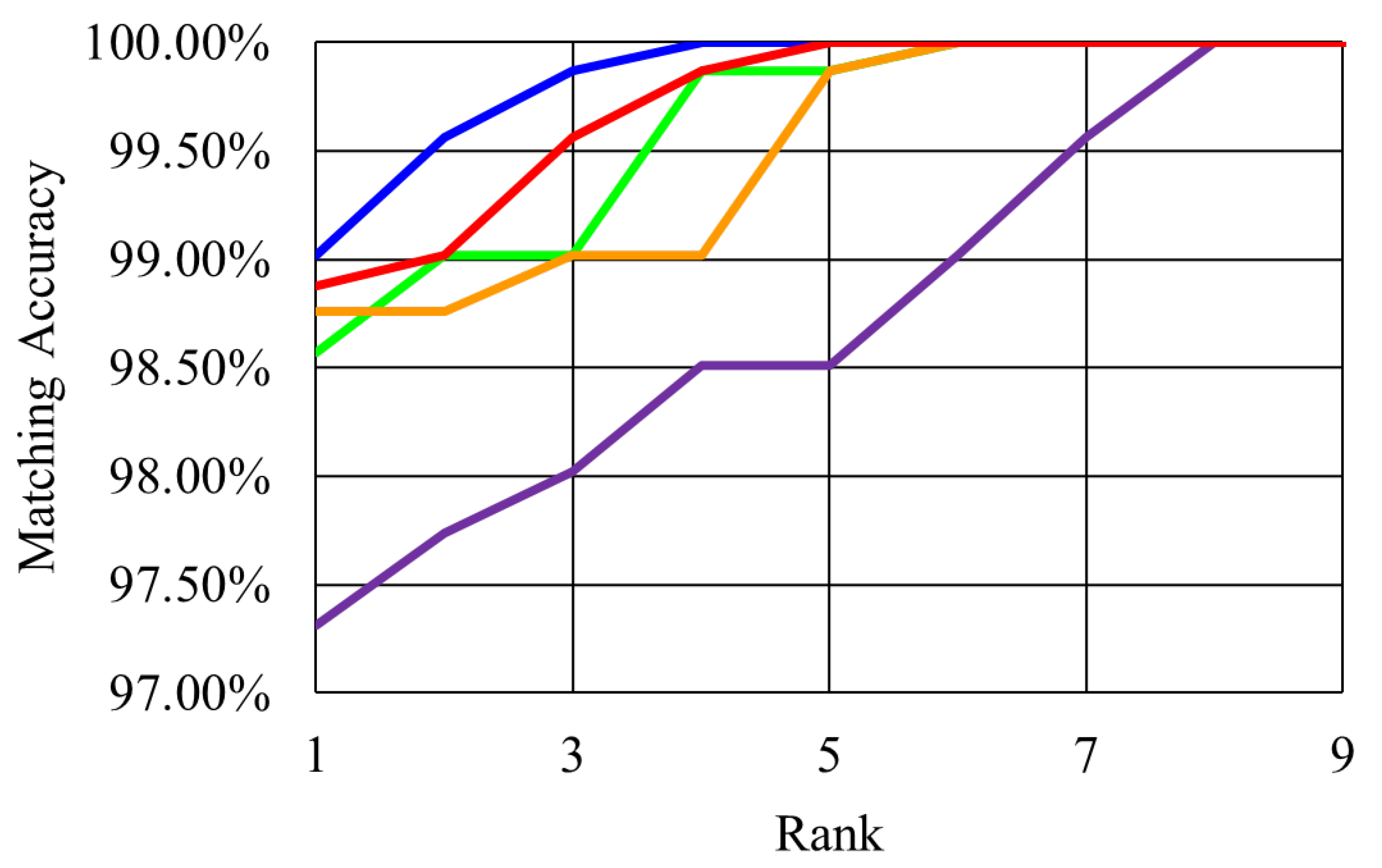
4. Experimental Results
4.1. Justification of the Achieved Performance
4.2. Execution Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nejati, H.; Zhang, L.; Sim, T.; Martinez-Marroquin, E.; Dong, G. Wonder ears: Identification of identical twins from ear images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1201–1204. [Google Scholar]
- Emeršič, V.; Štruc, V.; Peer, P. Ear recognition: More than a survey. Neurocomputing 2017, 255, 26–39. [Google Scholar] [CrossRef] [Green Version]
- Victor, B.; Bowyer, K.; Sarkar, S. An evaluation of face and ear biometrics. Object Recognit. Support. User Interact. Serv. Robot. 2002, 1, 429–432. [Google Scholar] [CrossRef]
- Chang, K.; Bowyer, K.W.; Sarkar, S.; Victor, B. Comparison and combination of ear and face images in appearance-based biometrics. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1160–1165. [Google Scholar] [CrossRef]
- Querencias-Uceta, D.; Ríos-Sánchez, B.; Sánchez-Ávila, C. Principal component analysis for ear-based biometric verification. In Proceedings of the 2017 International Carnahan Conference on Security Technology (ICCST), Madrid, Spain, 23–26 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Turk, M.A.; Pentland, A.P. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Proceedings, Maui, HI, USA, 3–6 June 1991; pp. 586–591. [Google Scholar] [CrossRef]
- Basit, A.; Shoaib, M. A human ear recognition method using nonlinear curvelet feature subspace. Int. J. Comput. Math. 2014, 91, 616–624. [Google Scholar] [CrossRef]
- Nosrati, M.S.; Faez, K.; Faradji, F. Using 2D wavelet and principal component analysis for personal identification based on 2D ear structure. In Proceedings of the 2007 International Conference on Intelligent and Advanced Systems, Kuala Lumpur, Malaysia, 25–28 November 2007; pp. 616–620. [Google Scholar] [CrossRef]
- Hassaballah, M.; Alshazly, H.A.; Ali, A.A. Robust local oriented patterns for ear recognition. Multimed. Tools Appl. 2020, 79, 31183–31204. [Google Scholar] [CrossRef]
- Galdámez, P.L.; Arrieta, A.G.; Ramón, M.R. Ear recognition using a hybrid approach based on neural networks. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–6. [Google Scholar]
- Eyiokur, F.I.; Yaman, D.; Ekenel, H.K. Domain adaptation for ear recognition using deep convolutional neural networks. IET Biom. 2018, 7, 199–206. [Google Scholar] [CrossRef] [Green Version]
- Dodge, S.; Mounsef, J.; Karam, L. Unconstrained ear recognition using deep neural networks. IET Biom. 2018, 7, 207–214. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Deep Convolutional Neural Networks for Unconstrained Ear Recognition. IEEE Access 2020, 8, 170295–170310. [Google Scholar] [CrossRef]
- Omara, I.; Wu, X.; Zhang, H.; Du, Y.; Zuo, W. Learning pairwise SVM on deep features for ear recognition. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 341–346. [Google Scholar] [CrossRef]
- Benzaoui, A.; Hezil, N.; Boukrouche, A. Identity recognition based on the external shape of the human ear. In Proceedings of the 2015 International Conference on Applied Research in Computer Science and Engineering (ICAR), Beirut, Lebanon, 8–9 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Ahmad, A.; Lemmond, D.; Boult, T.E. Chainlets: A New Descriptor for Detection and Recognition. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1897–1906. [Google Scholar] [CrossRef]
- Zarachoff, M.; Sheikh-Akbari, A.; Monekosso, D. 2D Multi-Band PCA and its Application for Ear Recognition. In Proceedings of the 2018 IEEE International Conference on Imaging Systems and Techniques (IST), Krakow, Poland, 16–18 October 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Zarachoff, M.M.; Sheikh-Akbari, A.; Monekosso, D. Non-Decimated Wavelet Based Multi-Band Ear Recognition Using Principal Component Analysis. IEEE Access 2022, 10, 3949–3961. [Google Scholar] [CrossRef]
- IIT Delhi Ear Database. Available online: https://bit.ly/3rAPbWE. (accessed on 13 March 2018).
- Ear Recoginition Laboratory at USTB. Available online: http://www1.ustb.edu.cn/resb/en/index.htm (accessed on 25 June 2018).
- Brunner, C.; Fischer, A.; Luig, K.; Thies, T. Pairwise Support Vector Machines and their Application to Large Scale Problems. J. Mach. Learn. Res. 2012, 13, 2279–2292. [Google Scholar]
- Benzaoui, A.; Boukrouche, A. Ear recognition using local color texture descriptors from one sample image per person. In Proceedings of the 2017 4th International Conference on Control, Decision and Information Technologies (CoDIT), Barcelona, Spain, 5–7 April 2017; pp. 0827–0832. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Ensembles of Deep Learning Models and Transfer Learning for Ear Recognition. Sensors 2019, 19, 4139. [Google Scholar] [CrossRef] [PubMed] [Green Version]

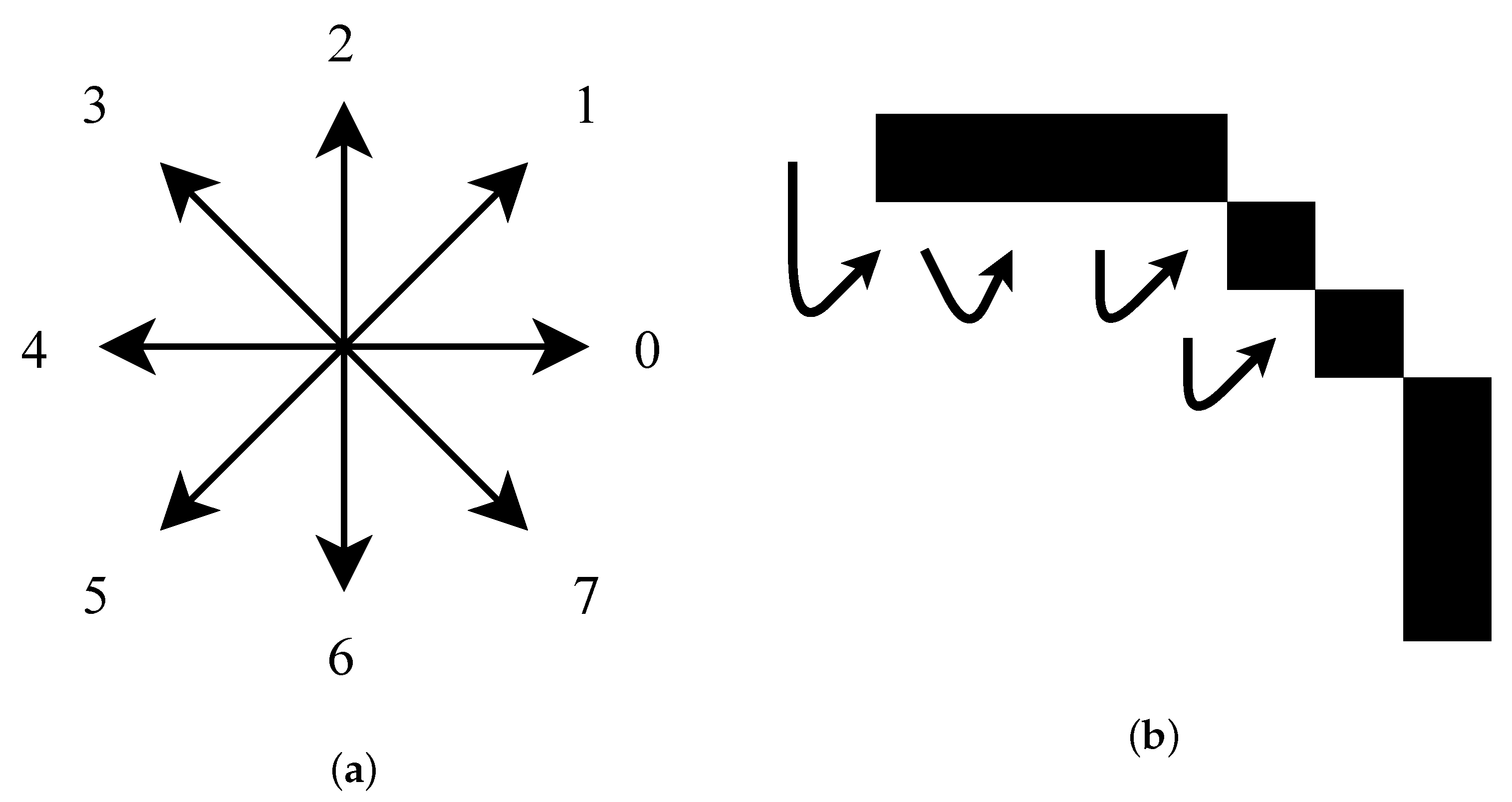



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Bands | Rank-1 | Rank-5 |
|---|---|---|
| 2 | 97.79 | 99.85 |
| 3 | 98.44 | 100.00 |
| 4 | 99.02 | 100.00 |
| 5 | 98.25 | 100.00 |
| 6 | 96.94 | 99.63 |
| Number of Bands | Rank-1 | Rank-5 |
|---|---|---|
| 5 | 99.17 | 100.00 |
| 6 | 99.17 | 100.00 |
| 7 | 99.44 | 100.00 |
| 8 | 99.44 | 100.00 |
| 9 | 98.89 | 100.00 |
| Algorithm | Dataset | |
|---|---|---|
| IITD II | USTB I | |
| Statistical based Techniques | ||
| Single Image PCA | 36.35 | 45.00 |
| Eigenfaces [4] | 89.78 | 75.93 |
| 2D-MBPCA [17] | 91.12 | 85.19 |
| Chainlets [16] | 98.54 | 99.02 |
| Learning based Techniques | ||
| BSIF and SVM [15] | 97.31 | - |
| GoogLeNet [11] | 98.57 | 99.36 |
| ResNet18 and SVM [12] | 98.76 | 99.44 |
| VGG-based Ensembles [23] | 98.88 | 99.24 |
| Neural Network and SVM [14] | - | 98.30 |
| Proposed CERMB-SVM Technique | 99.02 | 99.44 |
| Algorithm | Dataset | |
|---|---|---|
| IITD II | USTB I | |
| PCA-based Techniques | ||
| Single Image PCA | 13.55 | 12.16 |
| Eigenfaces [4] | 3.10 | 1.82 |
| 2D-MBPCA [17] | 13.64 | 13.07 |
| Learning based Techniques | ||
| BSIF and SVM [15] | 23.57 | - |
| GoogLeNet [11] | 22.88 | 21.59 |
| ResNet18 and SVM [12] | 24.24 | 23.88 |
| VGG-based Ensembles [23] | 23.51 | 22.79 |
| Neural Network and SVM [14] | - | 22.78 |
| Proposed CERMB-SVM Technique | 22.21 | 21.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zarachoff, M.M.; Sheikh-Akbari, A.; Monekosso, D. Chainlet-Based Ear Recognition Using Image Multi-Banding and Support Vector Machine. Appl. Sci. 2022, 12, 2033. https://doi.org/10.3390/app12042033
Zarachoff MM, Sheikh-Akbari A, Monekosso D. Chainlet-Based Ear Recognition Using Image Multi-Banding and Support Vector Machine. Applied Sciences. 2022; 12(4):2033. https://doi.org/10.3390/app12042033
Chicago/Turabian StyleZarachoff, Matthew Martin, Akbar Sheikh-Akbari, and Dorothy Monekosso. 2022. "Chainlet-Based Ear Recognition Using Image Multi-Banding and Support Vector Machine" Applied Sciences 12, no. 4: 2033. https://doi.org/10.3390/app12042033
APA StyleZarachoff, M. M., Sheikh-Akbari, A., & Monekosso, D. (2022). Chainlet-Based Ear Recognition Using Image Multi-Banding and Support Vector Machine. Applied Sciences, 12(4), 2033. https://doi.org/10.3390/app12042033