
Multimodal Biometric Template Protection Based on a Cancelable SoftmaxOut Fusion Network




Abstract
:1. Introduction
- -
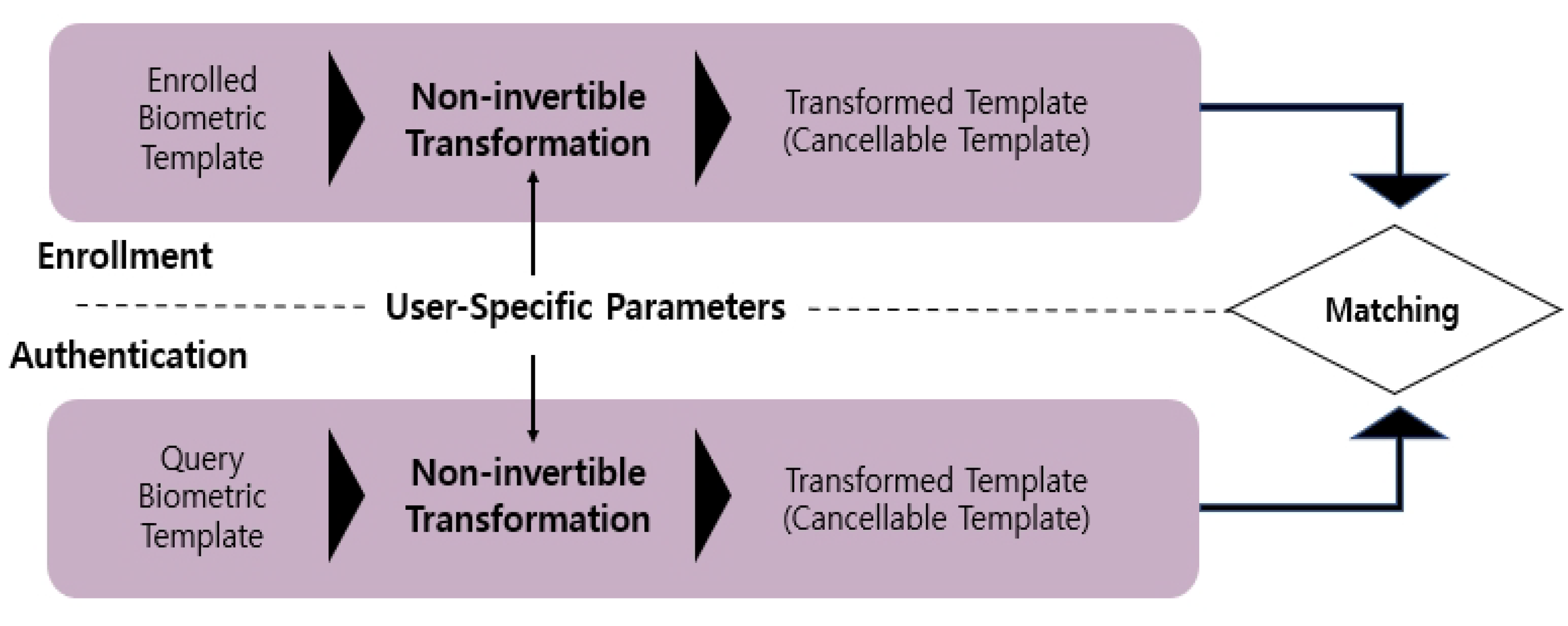
- Non-invertibility: It must be extremely difficult to restore the original biometric template from the CB template.
- -
- Revocability: If a CB template is exposed, a new template should be generated immediately from the original biometric data. This implies that there should be no limit on the number of CB templates generated from one biometric template.
- -
- Unlinkability: Two or more CB templates generated by the same user should not be distinguishable, in order to reduce the risk of a cross-matching attack.
- -
- Performance: The accuracy performance of a CB-based system should not be poorer than its original counterpart.
1.1. Related Work
1.1.1. Multimodal Biometrics with Deep Learning
1.1.2. Cancelable Multimodal Biometrics with Deep Learning
1.2. Motivations and Contributions
- A deep-learning-based CB scheme for multimodal biometrics is proposed. Although the face and periocular biometrics form the focus of this paper, our proposed method can also be applied to other biometrics modalities, provided the input is a raw image.
- A deep network, CSMoFN is composed of three modules: a feature extraction and fusion module, a PSMoT module, and an MDC module is proposed to realize the above proposal. The first module is responsible for performing feature extraction and fusion and the latter two are cancelable transformation functions, which are devised with respect to the four CB design criteria.
- The three modules are trained in an end-to-end manner with a combination of classification loss and representation learning, namely ArcFace loss and PA loss.
- We evaluate the proposed network on six face–periocular multimodal datasets in terms of verification performance, unlinkability, revocability, and non-invertibility.
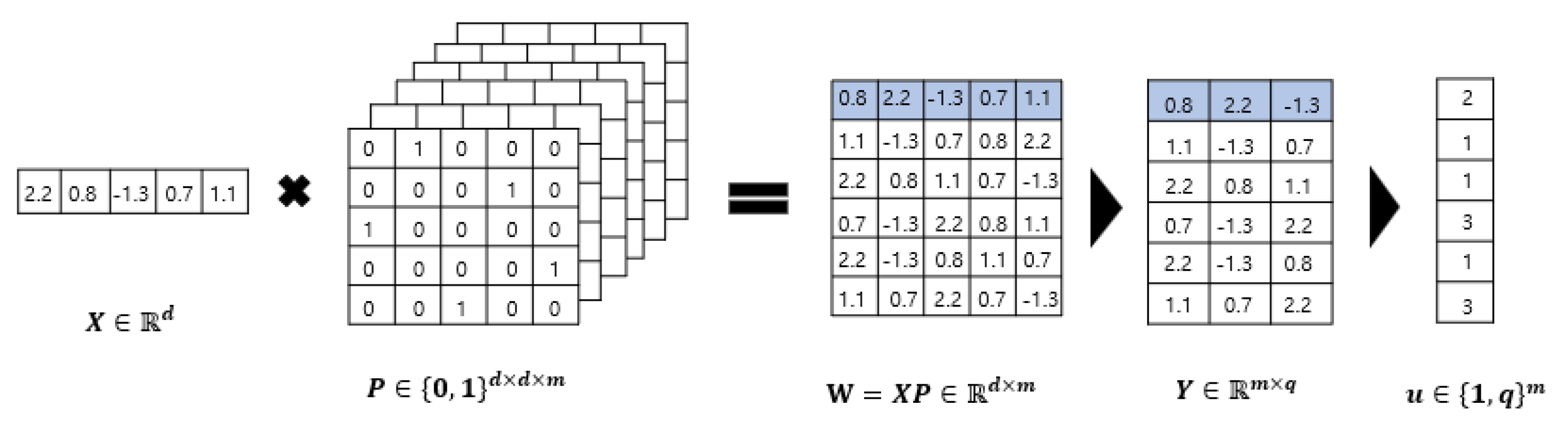
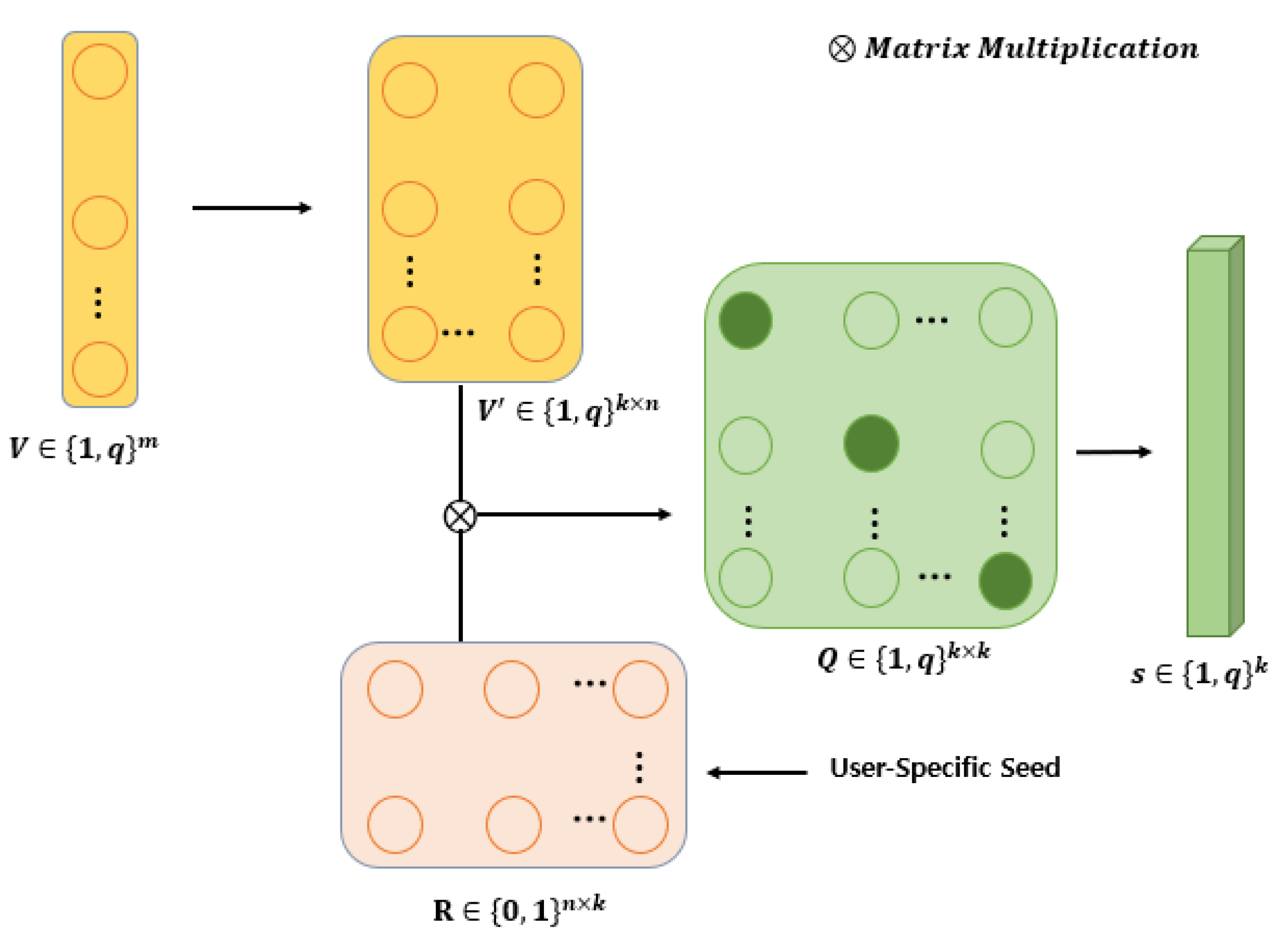
2. Preliminaries: Random Permutation Maxout Transform
- 1.
- A user-specific permutation matrix is first created. Suppose the size of the biometric feature vector is and permutation matrix is . There are permutation matrices that are generated and stacked to form .
- 2.
- and are multiplied to yield a matrix with size .
- 3.
- The first column vectors of are used and the rest are discarded, yielding a matrix with size .
- 4.
- Finally, the position of the feature with the largest value in each row of is recorded as the index value. When all rows have been processed, the RPMoT hash vector with size is obtained. Note that is an integer-value vector ranging from 1 to .
3. Proposed Method
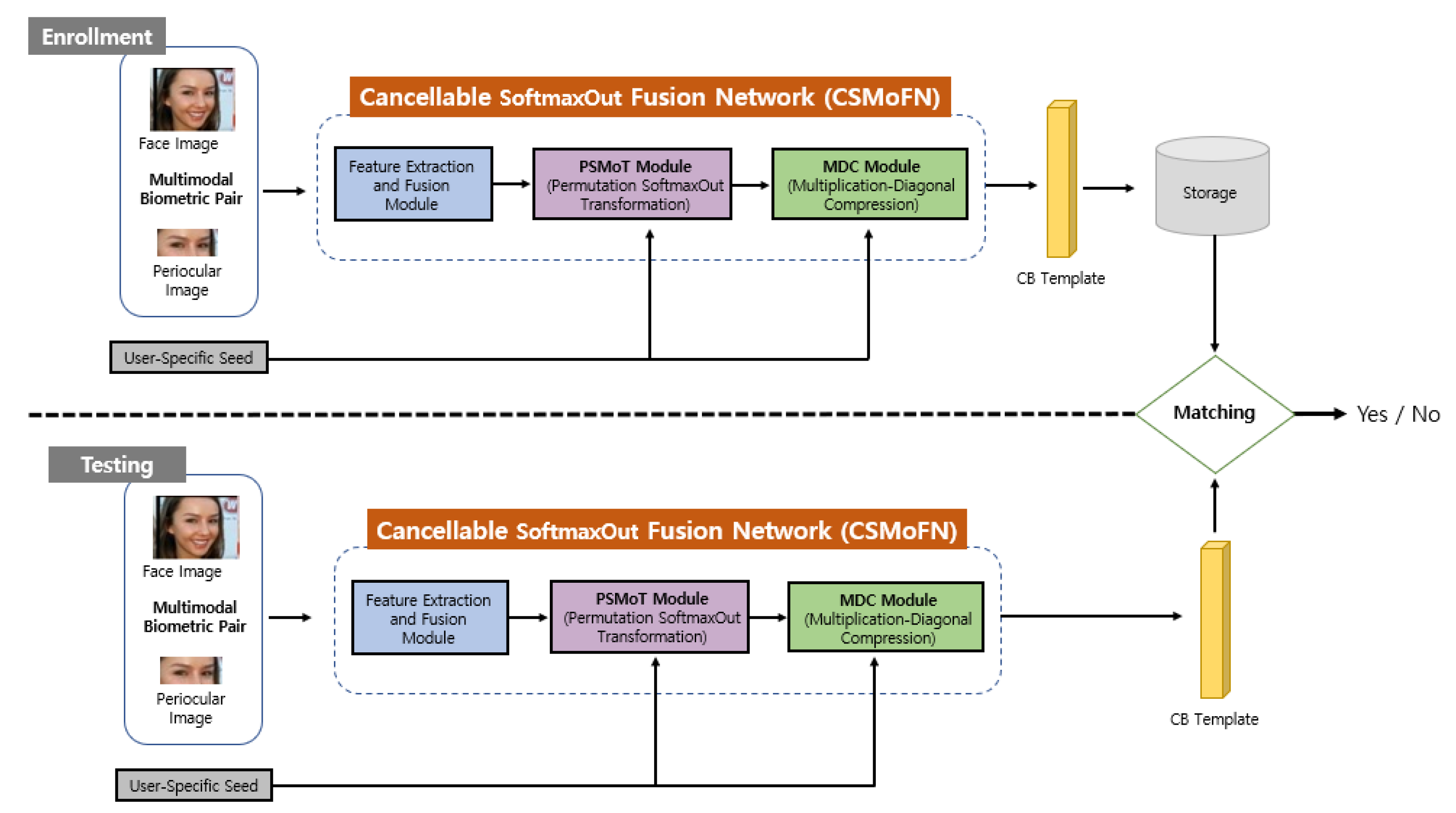
3.1. Overview
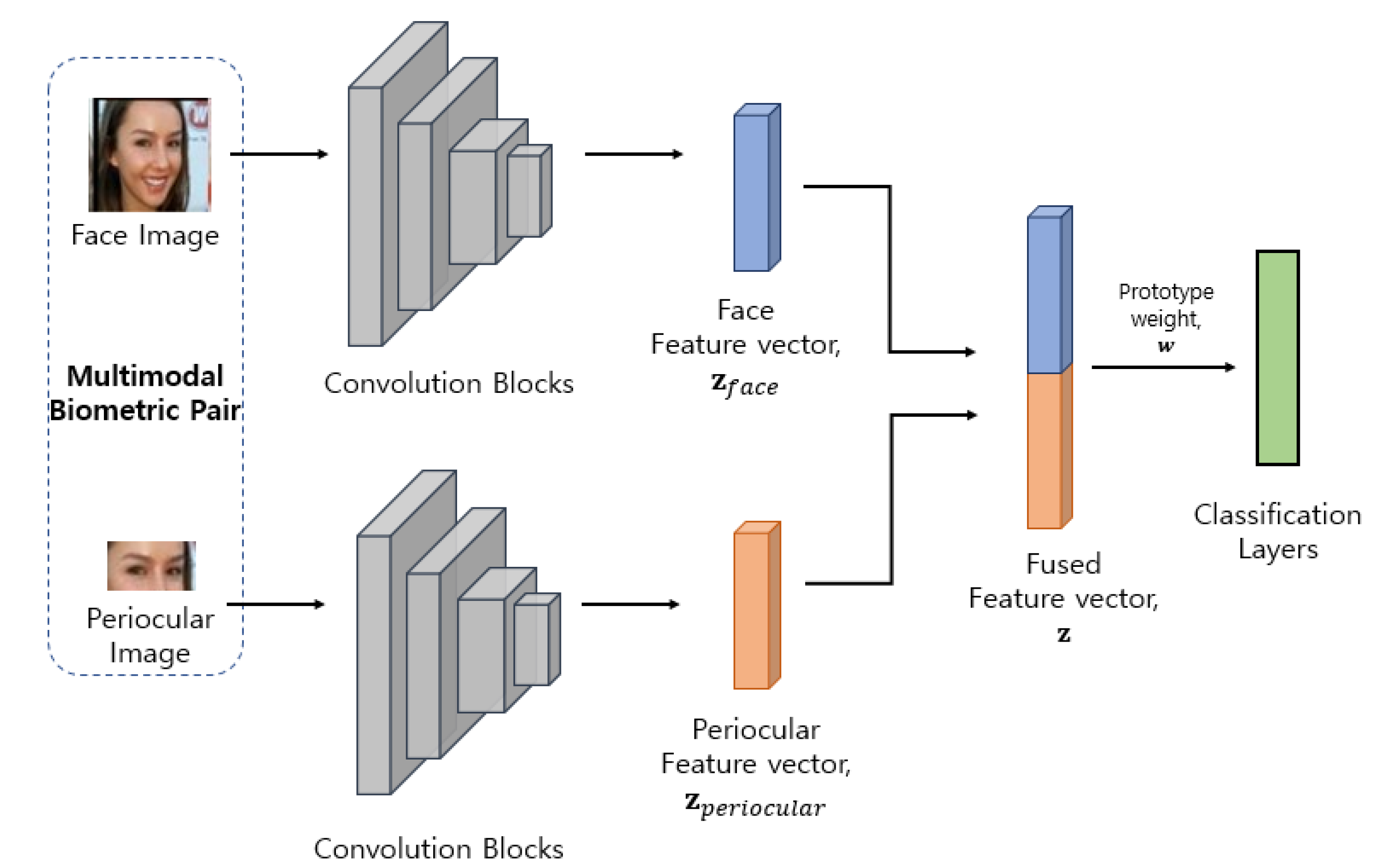
3.2. Feature Extraction and Fusion Module
3.3. Permutation SoftmaxOut Transform (PSMoT) Module
3.4. Multiplication-Diagonal Compression (MDC) Module
3.5. Loss Function
- ArcFace Loss
- Pairwise Angular Loss
- Total Loss
4. Experiments
4.1. Datasets
- AR was generated by the Computer Vision Center (CVC) at Universitat Autonoma de Barcelona and consists of over 4000 frontal view color images of 126 subjects. It was constructed under strictly controlled conditions, and each image shows a different facial expression, with different illumination conditions and occlusions.
- Ethnic is a large collection dataset composed of subjects of different ethnicities. All periocular images were obtained under various uncontrolled conditions as found in a wild environment (i.e., with variations in camera distance, pose, and location). It consists of 85,394 images of 1034 subjects.
- Facescrub is a large face dataset composed of 530 celebrity face images. It consists of about 200 images per person, with a total of 106,863 images. Images were retrieved from the Internet and shot in a real-world environment, i.e., under uncontrolled conditions.
- IMDB Wiki is a large dataset of celebrities, including their birthdays, names, genders, and related images. A dataset was constructed by obtaining meta-information from Wikipedia as well as the IMDB website. It consists of a total of 523,051 face images of 20,284 celebrities, of which 460,723 images were drawn from IMDB and 62,328 from Wikipedia.
- Pubfig (Public Figures Face) consists of 58,797 images of 200 people obtained from the Internet. Images were taken in completely uncontrolled situations and with non-cooperative subjects. It therefore has large variations in the characteristics of the environment, such as pose, lighting, expression, and camera.
- YTF (YouTube Face) dataset consists of 1595 subjects and 3425 videos. All videos were downloaded from YouTube, with an average of 2.15 videos per subject, and each video ranged from 48 to 6070 frames.
4.2. Experimental Setup
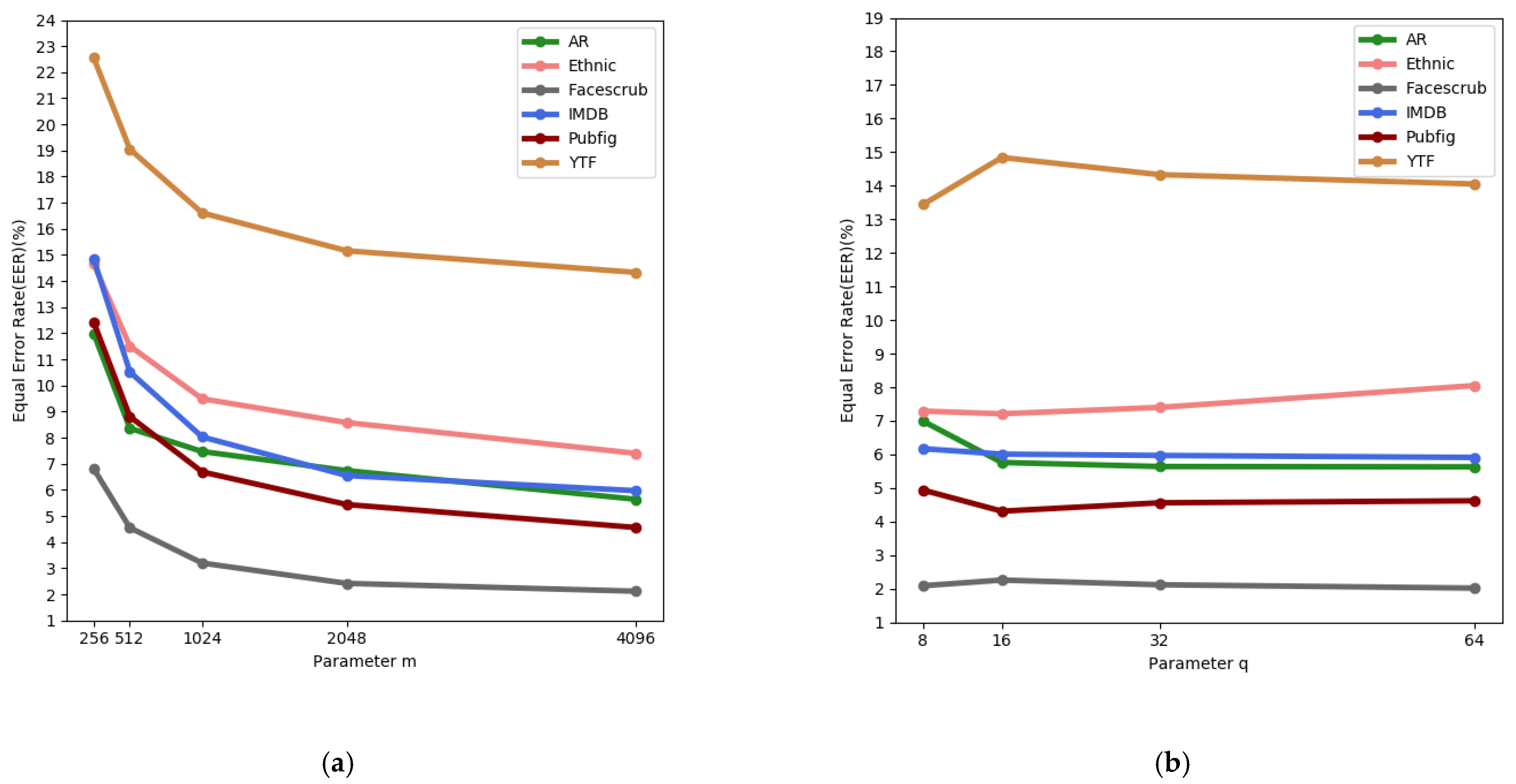
4.3. Hyperparameter Analysis
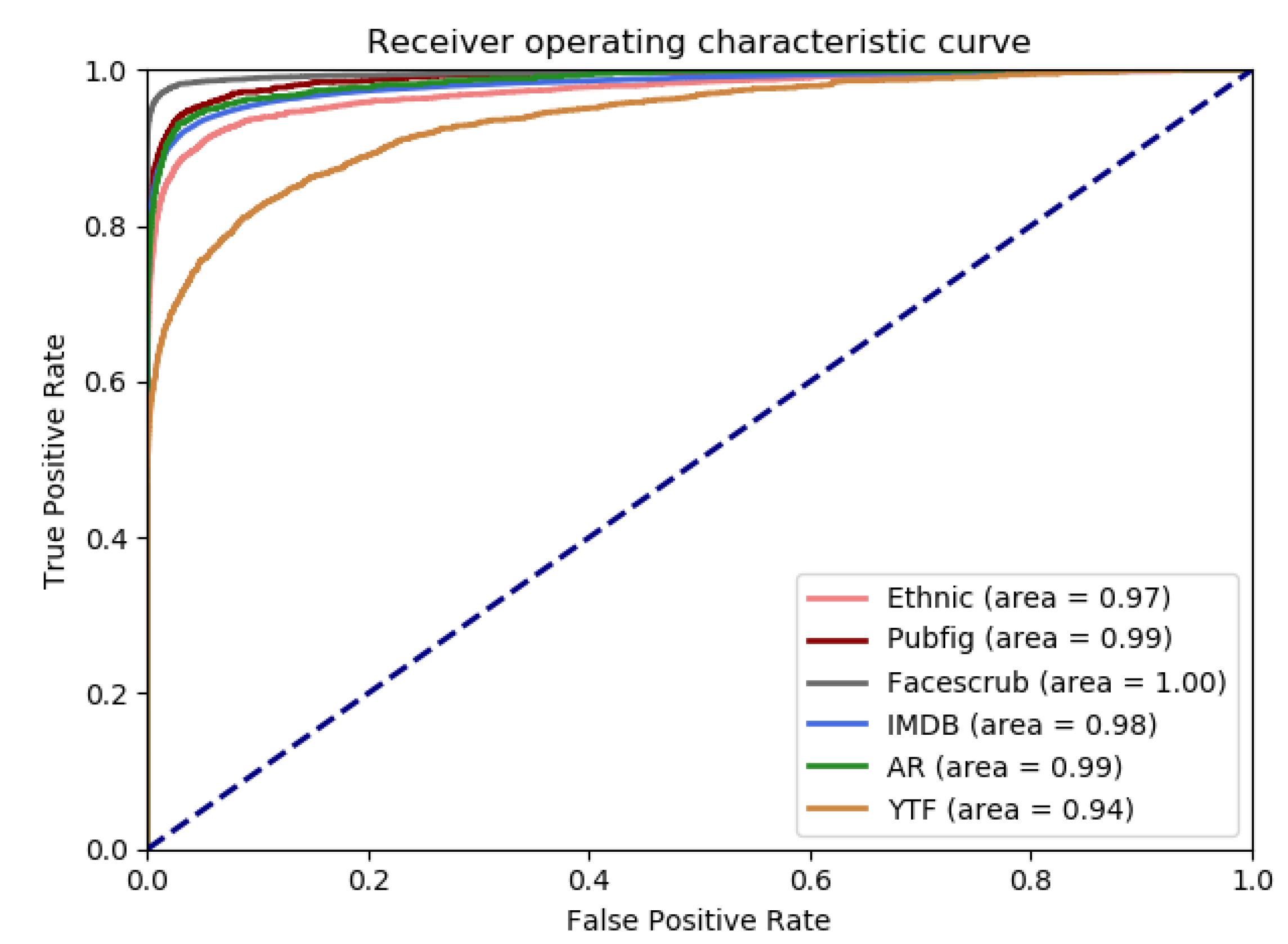
4.4. Performance Comparison with Unimodal CB Systems
4.5. Ablation Studies
4.6. Remarks on Deep-Learning-Based Multimodal Cancelable Biometrics Schemes
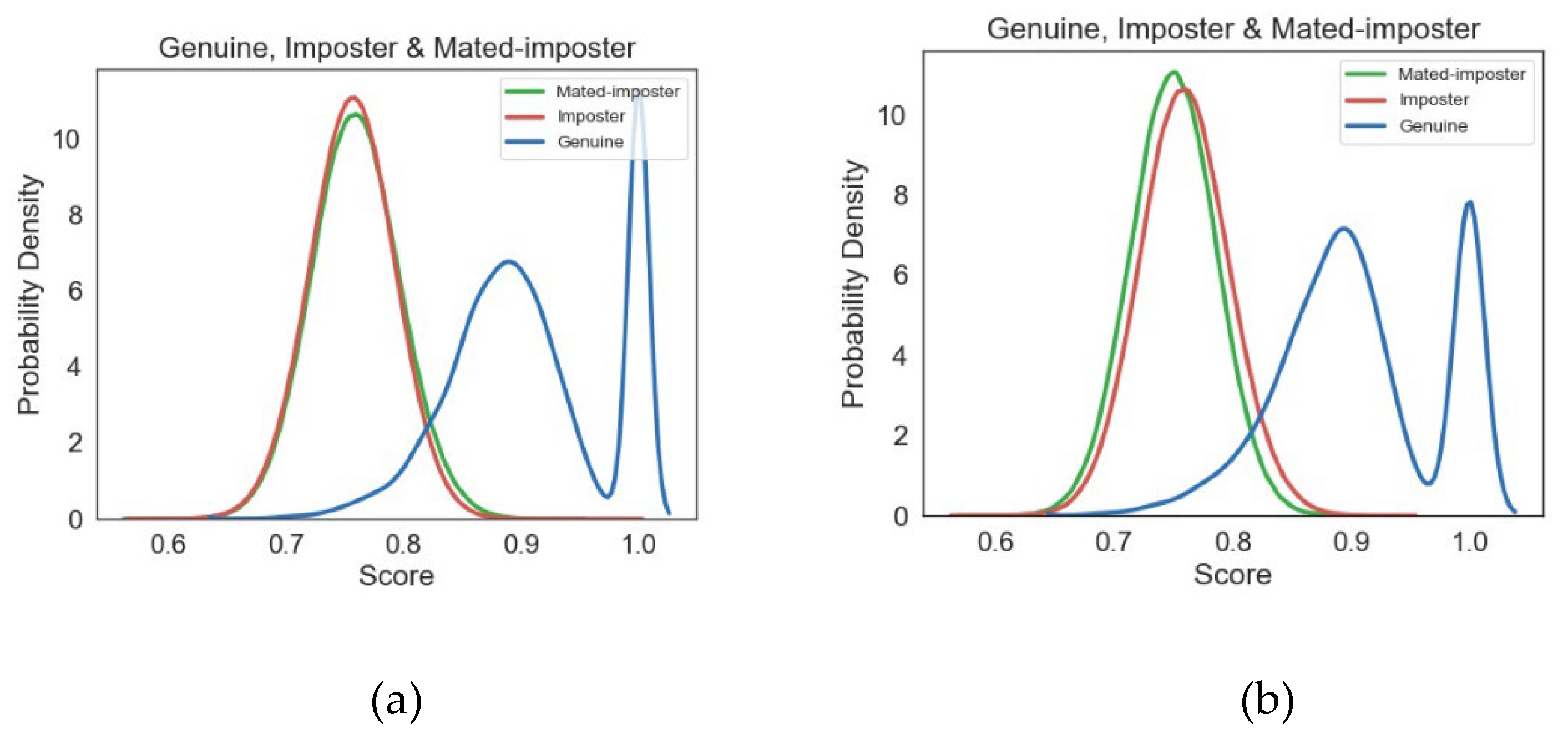
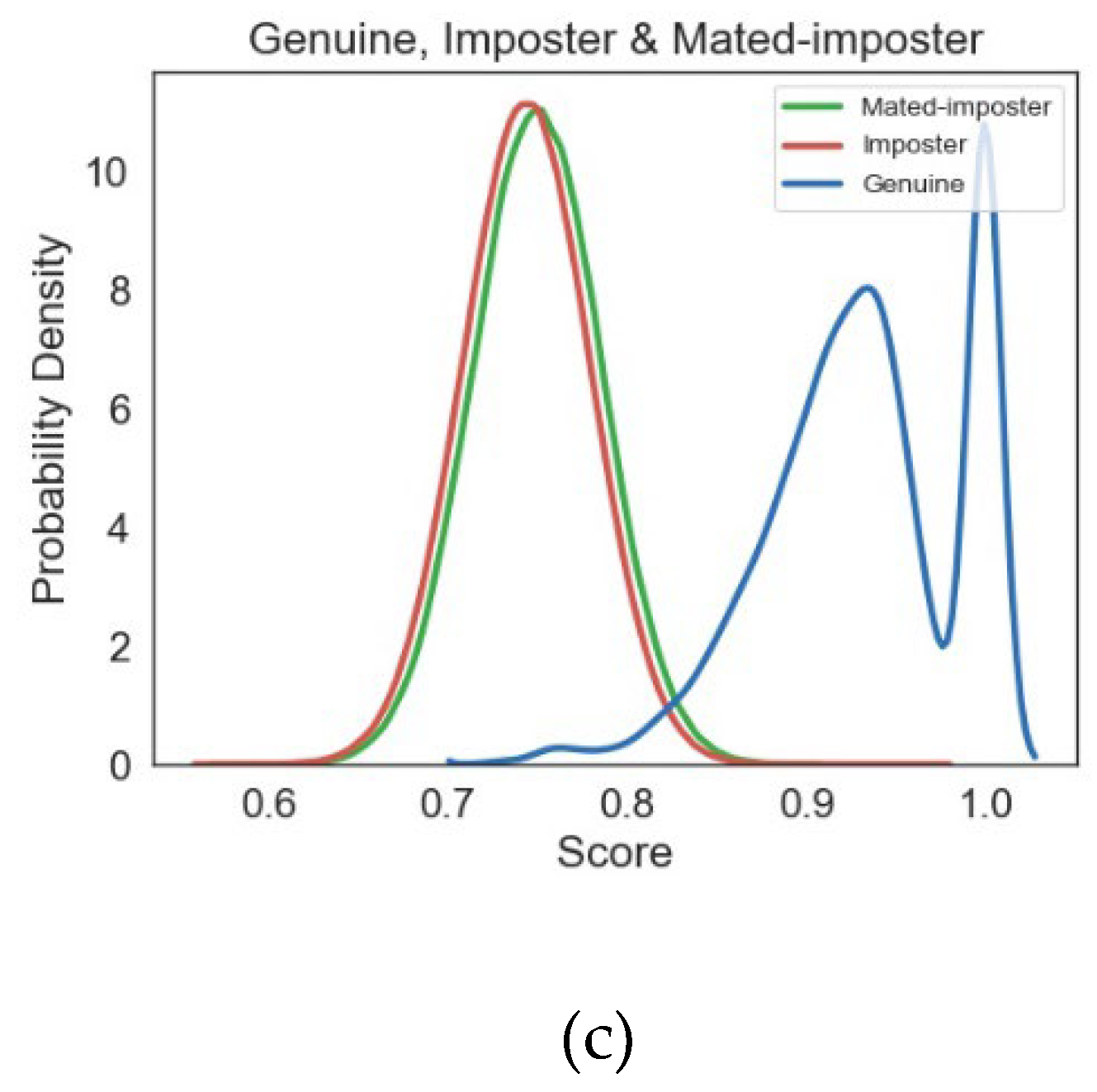
5. Unlinkability and Revocability Analysis
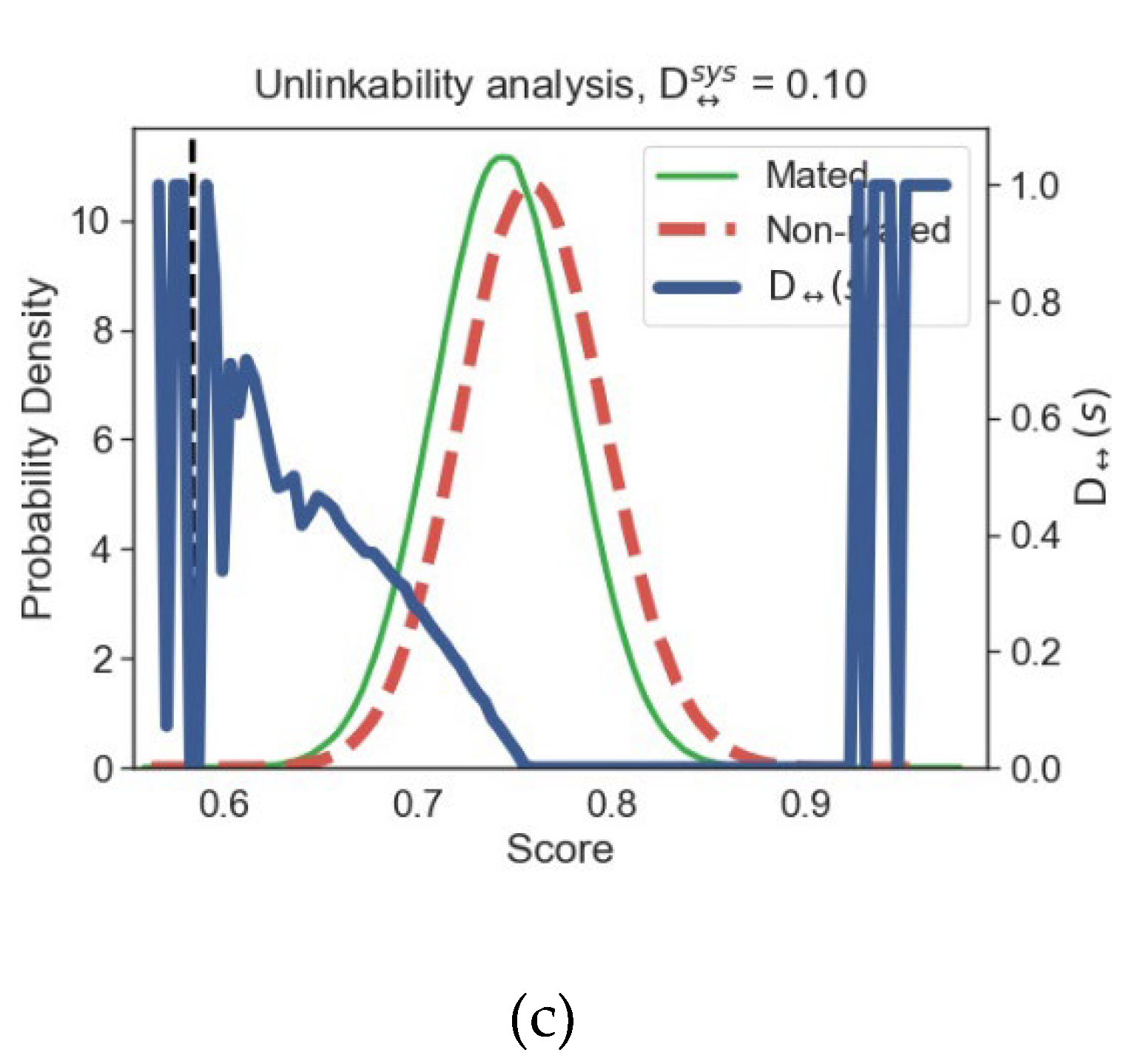
5.1. Unlinkability Analysis
5.2. Revocability Analysis
6. Non-Invertibility Analysis
6.1. Brute-Force Attack
6.2. False Acceptance Attack
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jain, A.K.; Nandakumar, K.; Nagar, A. Biometric Template Security. EURASIP J. Adv. Signal Process. 2008, 2008, 1–17. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.; Prabhakar, S. An Introduction to Biometric Recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef] [Green Version]
- Ratha, N.K.; Chikkerur, S.; Connell, J.H.; Bolle, R.M. Generating Cancelable Fingerprint Templates. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 561–572. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Ross, A.A.; Nandakumar, K. Introduction to Biometrics; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar]
- Lahat, D.; Adali, T.; Jutten, C. Multimodal Data Fusion: An Overview of Methods, Challenges, and Prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef] [Green Version]
- Oloyede, M.O.; Hancke, G.P. Unimodal and Multimodal Biometric Sensing Systems: A Review. IEEE Access 2016, 4, 7532–7555. [Google Scholar] [CrossRef]
- Canuto, A.M.P.; Pintro, F.; Xavier-Junior, J.C. Investigating Fusion Approaches in Multi-Biometric Cancellable Recognition. Expert Syst. Appl. 2013, 40, 1971–1980. [Google Scholar] [CrossRef]
- Pinto, J.R.; Cardoso, J.S.; Correia, M.V. Secure Triplet Loss for End-to-End Deep Biometrics. In Proceedings of the 2020 8th International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; pp. 1–6. [Google Scholar]
- Ding, C.; Tao, D. Robust Face Recognition Via Multimodal Deep Face Representation. IEEE Trans. Multimed. 2015, 17, 2049–2058. [Google Scholar] [CrossRef]
- Al-Waisy, A.S.; Qahwaji, R.; Ipson, S.; Al-Fahdawi, S.; Nagem, T.A. A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal. Appl. 2018, 21, 783–802. [Google Scholar] [CrossRef] [Green Version]
- Alay, N.; Al-Baity, H.H. Deep Learning Approach for Multimodal Biometric Recognition System Based on Fusion of Iris, Face, and Finger Vein Traits. Sensors 2020, 20, 5523. [Google Scholar] [CrossRef]
- Gunasekaran, K.; Raja, J.; Pitchai, R. Deep Multimodal Biometric Recognition Using Contourlet Derivative Weighted Rank Fusion with Human Face, Fingerprint and Iris Images. Autom. J. Control. Meas. Electron. Comput. Commun. 2019, 60, 253–265. [Google Scholar] [CrossRef] [Green Version]
- Tiong, L.C.O.; Kim, S.T.; Ro, Y.M. Implementation of Multimodal Biometric Recognition Via Multi-Feature Deep Learning Networks and Feature Fusion. Multimed. Tools Appl. 2019, 78, 22743–22772. [Google Scholar] [CrossRef]
- Algashaam, F.; Nguyen, K.; Banks, J.; Chandran, V.; Do, T.-A.; Alkanhal, M. Hierarchical Fusion Network for Periocular and Iris by Neural Network Approximation and Sparse Autoencoder. Mach. Vis. Appl. 2020, 32, 15. [Google Scholar] [CrossRef]
- Luo, Z.; Li, J.; Zhu, Y. A Deep Feature Fusion Network Based on Multiple Attention Mechanisms for Joint Iris-Periocular Biometric Recognition. IEEE Signal Process. Lett. 2021, 28, 1060–1064. [Google Scholar] [CrossRef]
- Jung, Y.G.; Low, C.Y.; Park, J.; Teoh, A.B.J. Periocular Recognition in the Wild With Generalized Label Smoothing Regularization. IEEE Signal Process. Lett. 2020, 27, 1455–1459. [Google Scholar] [CrossRef]
- Soleymani, S.; Torfi, A.; Dawson, J.; Nasrabadi, N.M. Generalized Bilinear Deep Convolutional Neural Networks for Multimodal Biometric Identification. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 763–767. [Google Scholar]
- Gomez-Barrero, M.; Rathgeb, C.; Li, G.; Ramachandra, R.; Galbally, J.; Busch, C. Multi-Biometric Template Protection Based on Bloom Filters. Inf. Fusion 2018, 42, 37–50. [Google Scholar] [CrossRef]
- Jeng, R.-H.; Chen, W.-S. Two Feature-Level Fusion Methods with Feature Scaling and Hashing For Multimodal Biometrics. IETE Tech. Rev. 2017, 34, 91–101. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Hu, J.; Zheng, G.; Valli, C. A Fingerprint and Finger-Vein Based Cancelable Multi-Biometric System. Pattern Recognit. 2018, 78, 242–251. [Google Scholar] [CrossRef]
- Lee, M.J.; Teoh, A.B.J.; Uhl, A.; Liang, S.N.; Jin, Z. A Tokenless Cancellable Scheme for Multimodal Biometric Systems. Comput. Secur. 2021, 108, 102350. [Google Scholar] [CrossRef]
- Gupta, K.; Walia, G.S.; Sharma, K. Novel Approach for Multimodal Feature Fusion to Generate Cancelable Biometric. Vis. Comput. 2021, 37, 1401–1413. [Google Scholar] [CrossRef]
- Abdellatef, E.; Ismail, N.A.; Abd Elrahman, S.E.S.E.; Ismail, K.N.; Rihan, M.; Abd El-Samie, F.E. Cancelable Multi-Biometric Recognition System Based on Deep Learning. Vis. Comput. 2020, 36, 1097–1109. [Google Scholar] [CrossRef]
- Talreja, V.; Valenti, M.C.; Nasrabadi, N.M. Deep Hashing for Secure Multimodal Biometrics. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1306–1321. [Google Scholar] [CrossRef]
- Sudhakar, T.; Gavrilova, M. Deep Learning for Multi-Instance Biometric Privacy. ACM Trans. Manag. Inf. Syst. (TMIS) 2020, 12, 1–23. [Google Scholar] [CrossRef]
- El-Rahiem, B.A.; Amin, M.; Sedik, A.; Samie, F.E.; Iliyasu, A.M. An efficient multi-biometric cancellable biometric scheme based on deep fusion and deep dream. J. Ambient. Intell. Humaniz. Comput. 2021, in press. [CrossRef] [PubMed]
- Teoh, A.B.J.; Cho, S.; Kim, J. Random Permutation Maxout Transform for Cancellable Facial Template Protection. Multimed. Tools Appl. 2018, 77, 27733–27759. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, T.; Song, J.; Sebe, N.; Shen, H.T. A Survey on Learning to Hash. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 769–790. [Google Scholar] [CrossRef]
- Du, H.; Shi, H.; Zeng, D.; Mei, T. The Elements of End-to-End Deep Face Recognition: A Survey of Recent Advances. arXiv 2009, arXiv:2009.13290. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A Dataset and Benchmark for Large-Scale Face Recognition. In Proceedings of the European Conference on Computer Vision, Amstedrdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Eds.; Max Welling Springer: Cham, Switzerland; pp. 87–102. [Google Scholar]
- Lee, H.; Low, C.Y.; Teoh, A.B.J. SoftmaxOut Transformation-Permutation Network for Facial Template Protection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Li, W.; Zhang, S. Binary Random Projections with Controllable Sparsity Patterns. arXiv 2020, arXiv:2006.16180 [cs, stat]. [Google Scholar]
- Jin, A.T.B. Cancellable biometrics and multispace random projections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 164. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4690–4699. [Google Scholar]
- Martinez, A.; Benavente, R. The AR Face Database: CVC Technical Report, 24; Centre de Visioper Computador Universitat Aut onoma de Barcelona: Barcelona, Spain, 1998. [Google Scholar]
- Tiong, L.C.O.; Teoh, A.B.J.; Lee, Y. Periocular Recognition in the Wild with Orthogonal Combination of Local Binary Coded Pattern in Dual-Stream Convolutional Neural Network. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019. [Google Scholar]
- Ng, H.-W.; Winkler, S. A Data-Driven Approach to Cleaning Large Face Datasets. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Rothe, R.; Timofte, R.; Van Gool, L. Dex: Deep Expectation of Apparent Age from a Single Image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 10–15. [Google Scholar]
- Kumar, N.; Berg, A.C.; Belhumeur, P.N.; Nayar, S.K. Attribute and simile classifiers for face verification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 365–372. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face Recognition in Unconstrained Videos with Matched Background Similarity. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Gomez-Barrero, M.; Galbally, J.; Rathgeb, C.; Busch, C. General Framework to Evaluate Unlinkability in Biometric Template Protection Systems. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1406–1420. [Google Scholar] [CrossRef]
- Jin, Z.; Hwang, J.Y.; Lai, Y.-L.; Kim, S.; Teoh, A.B.J. Ranking-Based Locality Sensitive Hashing-Enabled Cancelable Biometrics: Index-of-Max Hashing. IEEE Trans. Inf. Forensics Secur. 2017, 13, 393–407. [Google Scholar] [CrossRef] [Green Version]
- Tams, B.; Mihăilescu, P.; Munk, A. Security Considerations in Minutiae-Based Fuzzy Vaults. IEEE Trans. Inf. Forensics Secur. 2015, 10, 985–998. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Testing Set | ||||||
|---|---|---|---|---|---|---|---|
| AR | Ethnic | Facescrub | IMDB Wiki | Pubfig | YTF | ||
| No. of subjects | 1054 | 126 | 325 | 530 | 2129 | 200 | 1595 |
| No. of images | 166,737 | 700 | 1645 | 31,066 | 40,241 | 9220 | 150,259 |
| Equal Error Rate (EER) (%) | |||||
|---|---|---|---|---|---|
| = 32 | |||||
| 256 | 512 | 1024 | 2048 | 4096 | |
| AR | 11.99 | 8.36 | 7.47 | 6.74 | 5.64 |
| Ethnic | 14.66 | 11.51 | 9.49 | 8.58 | 7.40 |
| Facescrub | 6.81 | 4.55 | 3.20 | 2.42 | 2.12 |
| IMDB Wiki | 14.84 | 10.52 | 8.03 | 6.55 | 5.97 |
| Pubfig | 12.43 | 8.81 | 6.69 | 5.44 | 4.56 |
| YTF | 22.55 | 19.05 | 16.61 | 15.16 | 14.33 |
| Average | 13.88 | 10.47 | 8.58 | 7.48 | 6.67 |
| Equal Error Rate (EER) (%) | ||||
|---|---|---|---|---|
| 8 | 16 | 32 | 64 | |
| AR | 6.99 | 5.76 | 5.64 | 5.63 |
| Ethnic | 7.29 | 7.21 | 7.40 | 8.05 |
| Facescrub | 2.09 | 2.26 | 2.12 | 2.02 |
| IMDB Wiki | 6.17 | 6.01 | 5.97 | 5.91 |
| Pubfig | 4.94 | 4.31 | 4.56 | 4.62 |
| YTF | 14.44 | 14.84 | 14.33 | 14.05 |
| Average | 6.99 | 6.73 | 6.67 | 6.71 |
| Equal Error Rate (EER) (%) | |||
|---|---|---|---|
| Without Reshaping | (128, 16) | (256, 8) | |
| AR | 6.74 | 7.12 | 6.74 |
| Ethnic | 8.58 | 8.88 | 8.58 |
| Facescrub | 2.42 | 3.11 | 2.42 |
| IMDB Wiki | 6.55 | 7.83 | 6.55 |
| Pubfig | 5.44 | 6.19 | 5.44 |
| YTF | 15.16 | 16.33 | 15.16 |
| Average | 7.48 | 8.24 | 7.48 |
| Equal Error Rate (EER) (%) | |||||
|---|---|---|---|---|---|
| Face | |||||
| 256(32) | 512(64) | 1024(128) | 2048(256) | 4096(512) | |
| 8 | 15.68 | 14.82 | 13.83 | 12.87 | 12.56 |
| 16 | 18.06 | 15.27 | 14.30 | 13.66 | 13.01 |
| 32 | 17.65 | 15.85 | 14.14 | 13.62 | 13.16 |
| 64 | 17.83 | 15.87 | 14.90 | 13.70 | 13.31 |
| Periocular | |||||
| 256(32) | 512(64) | 1024(128) | 2048(256) | 4096(512) | |
| 8 | 16.35 | 15.43 | 15.61 | 15.00 | 15.20 |
| 16 | 18.35 | 17.96 | 16.04 | 15.57 | 15.02 |
| 32 | 19.44 | 17.75 | 16.74 | 15.94 | 15.33 |
| 64 | 19.70 | 18.34 | 17.27 | 15.91 | 15.29 |
| Fused | |||||
| 256(32) | 512(64) | 1024(128) | 2048(256) | 4096(512) | |
| 8 | 13.63 | 10.73 | 8.53 | 7.35 | 6.99 |
| 16 | 14.33 | 10.69 | 8.53 | 7.43 | 6.73 |
| 32 | 13.88 | 10.47 | 8.58 | 7.48 | 6.67 |
| 64 | 13.64 | 10.53 | 8.44 | 7.49 | 6.71 |
| Equal Error Rate (EER) (%) | |||||||
|---|---|---|---|---|---|---|---|
| Baseline (Feature Extraction without Hashing) | |||||||
| AR | Ethnic | Facescrub | IMDB Wiki | Pubfig | YTF | Average | |
| Face | 4.23 | 4.06 | 1.58 | 4.79 | 3.50 | 11.84 | 5.00 |
| Periocular | 6.77 | 5.61 | 3.13 | 6.53 | 5.48 | 15.16 | 7.11 |
| Fused | 4.67 | 5.29 | 1.75 | 5.12 | 4.07 | 13.56 | 5.74 |
| ) | |||||||
| AR | Ethnic | Facescrub | IMDB Wiki | Pubfig | YTF | Average | |
| Face | 10.71 | 15.98 | 5.89 | 16.92 | 14.93 | 22.66 | 14.51 |
| Periocular | 15.36 | 16.85 | 10.40 | 18.69 | 16.31 | 22.73 | 16.72 |
| Fused | 5.90 | 7.48 | 2.16 | 5.97 | 4.68 | 14.55 | 6.79 |
| CSMoFN (PSMoT + MDC) | |||||||
| AR | Ethnic | Facescrub | IMDB Wiki | Pubfig | YTF | Average | |
| Face | 9.62 | 15.34 | 5.07 | 15.64 | 12.68 | 20.61 | 13.16 |
| Periocular | 11.75 | 16.56 | 9.43 | 17.40 | 15.43 | 21.38 | 15.32 |
| Fused | 5.64 | 7.40 | 2.12 | 5.97 | 4.56 | 14.33 | 6.67 |
| Ref. | Modalities | Fusion | Remarks |
|---|---|---|---|
| Our proposed method | Face, periocular region | Feature-level | Methods: End-to-end deep-learning-based cancelable biometrics scheme with three modules (feature extraction and fusion module, permutation SoftmaxOut transformation module, multiplication-diagonal compression module). Revocability: ✔ Unlinkability: ✔ Non-invertibility: ✔ Accuracy performance: EER = 2.12% (Facescrub dataset), EER = 6.67% (average over six datasets) |
| Abdellatef et al. [23] | Face, eye region, nose region, mouthregion | Feature-Level | Methods: Feature extraction is performed with multiple CNNs. After fusion of multiple deep features, BTP transformation is performed with bioconvolving encryption. Revocability: ✘ Unlinkability: ✘ Non-invertibility: ✘ Accuracy performance: Accuracy = 93.4% (PaSC dataset) |
| Talreja et al. [24] | Face, iris | Feature-level | Methods: Deep feature extraction and binarization using CNN from multimodal modalities. A random component is selected from the generated features and used as a transformation key. The transformed templates are converted to a secure sketch via an FEC decoder and cryptographic hashing. Revocability:✘ Unlinkability: ✘ Non-invertibility: ✘ Accuracy performance: Accuracy = 99.16% (stolen key scenario) |
| Sudhakar et al. [25] | Finger vein, right and left irises | Feature-level | Methods: Feature extraction is performed through a CNN and SVM is used for verification. The template is protected with a random projection-based approach. Revocability: ✔ Unlinkability:✔ Non-invertibility: ✔ Accuracy performance: EER = 0.05% (FV-USM dataset) |
| El-Rahiem et al. [26] | Fingerprint, finger vein, Iris | Feature-level | Methods: After feature extraction with a CNN, fusion is performed through the fusion layer. A cancelable template is generated through the reconstruction process by applying the DeepDream algorithm consisting of many Convnets. Revocability:✘ Unlinkability: ✘ Non-invertibility:✘ Accuracy performance: EER = 0.0032% |
| Datasets | Total Attack Complexity | GAR | ||||||
|---|---|---|---|---|---|---|---|---|
| AR | 512 | 0.783 | 0.821 | 0.038 | 85% | |||
| Ethnic | 0.771 | 0.805 | 0.034 | |||||
| Facescrub | 0.789 | 0.824 | 0.035 | |||||
| IMDB Wiki | 0.792 | 0.817 | 0.025 | |||||
| Pubfig | 0.784 | 0.811 | 0.027 | |||||
| YTF | 0.785 | 0.818 | 0.033 | |||||
| AR | 512 | 0.783 | 0.807 | 0.024 | 90% | |||
| Ethnic | 0.771 | 0.790 | 0.019 | |||||
| Facescrub | 0.789 | 0.811 | 0.022 | |||||
| IMDB Wiki | 0.792 | 0.805 | 0.013 | |||||
| Pubfig | 0.784 | 0.798 | 0.014 | |||||
| YTF | 0.785 | 0.802 | 0.017 | |||||
| AR | 512 | 0.783 | 0.794 | 0.011 | 95% | |||
| Ethnic | 0.771 | 0.785 | 0.014 | |||||
| Facescrub | 0.789 | 0.803 | 0.014 | |||||
| IMDB Wiki | 0.792 | 0.787 | −0.005 | |||||
| Pubfig | 0.784 | 0.786 | 0.002 | |||||
| YTF | 0.785 | 0.791 | 0.006 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
KIM, J.; Jung, Y.G.; Teoh, A.B.J. Multimodal Biometric Template Protection Based on a Cancelable SoftmaxOut Fusion Network. Appl. Sci. 2022, 12, 2023. https://doi.org/10.3390/app12042023
KIM J, Jung YG, Teoh ABJ. Multimodal Biometric Template Protection Based on a Cancelable SoftmaxOut Fusion Network. Applied Sciences. 2022; 12(4):2023. https://doi.org/10.3390/app12042023
Chicago/Turabian StyleKIM, Jihyeon, Yoon Gyo Jung, and Andrew Beng Jin Teoh. 2022. "Multimodal Biometric Template Protection Based on a Cancelable SoftmaxOut Fusion Network" Applied Sciences 12, no. 4: 2023. https://doi.org/10.3390/app12042023
APA StyleKIM, J., Jung, Y. G., & Teoh, A. B. J. (2022). Multimodal Biometric Template Protection Based on a Cancelable SoftmaxOut Fusion Network. Applied Sciences, 12(4), 2023. https://doi.org/10.3390/app12042023