
Multi-Attribute Decision Making Method for Node Importance Metric in Complex Network

Abstract
:1. Introduction
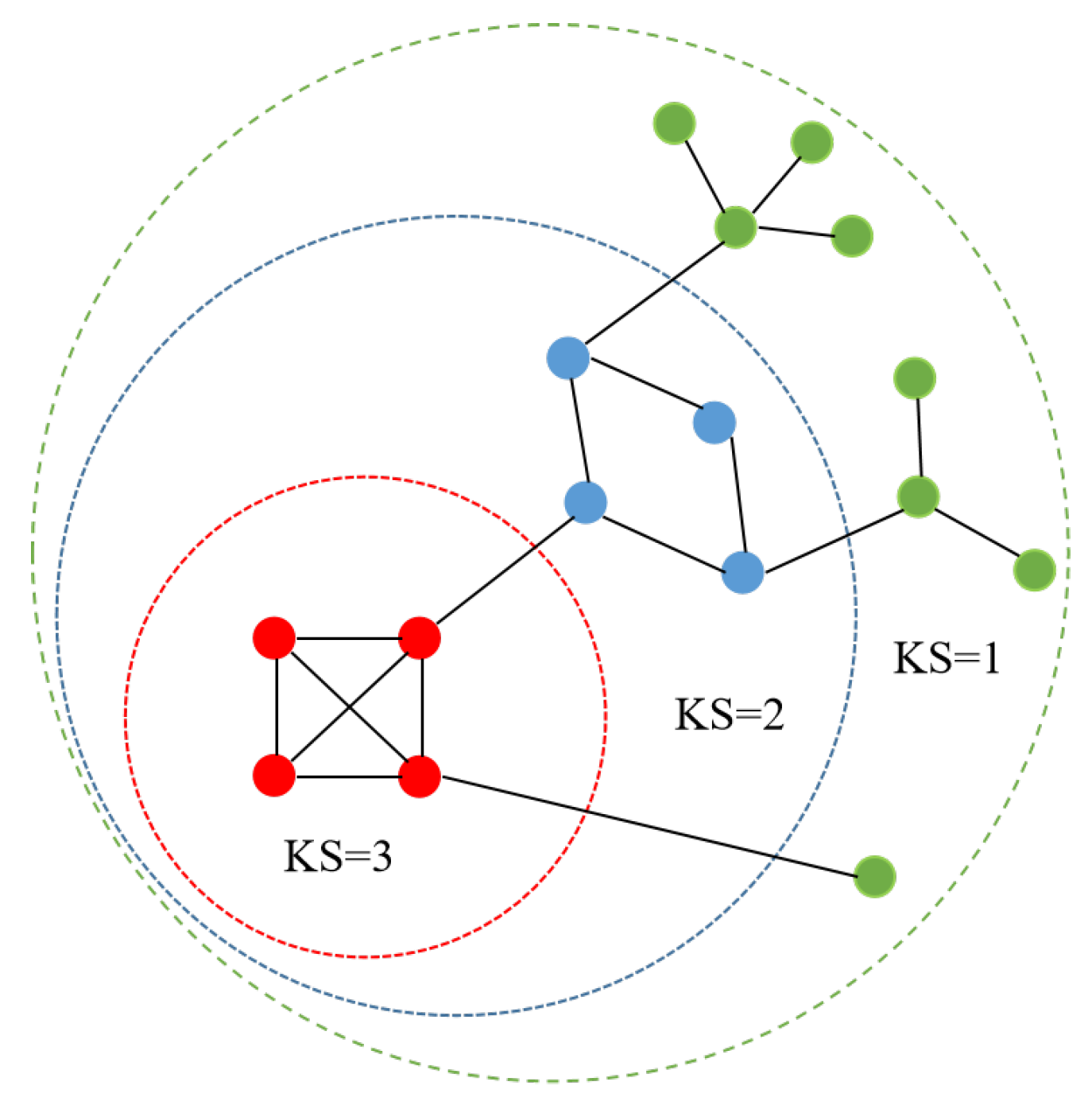
2. Related Theoretical Foundations
3. Multi-Attribute Composite Measure of Node Importance
4. Experimental Results and Analysis
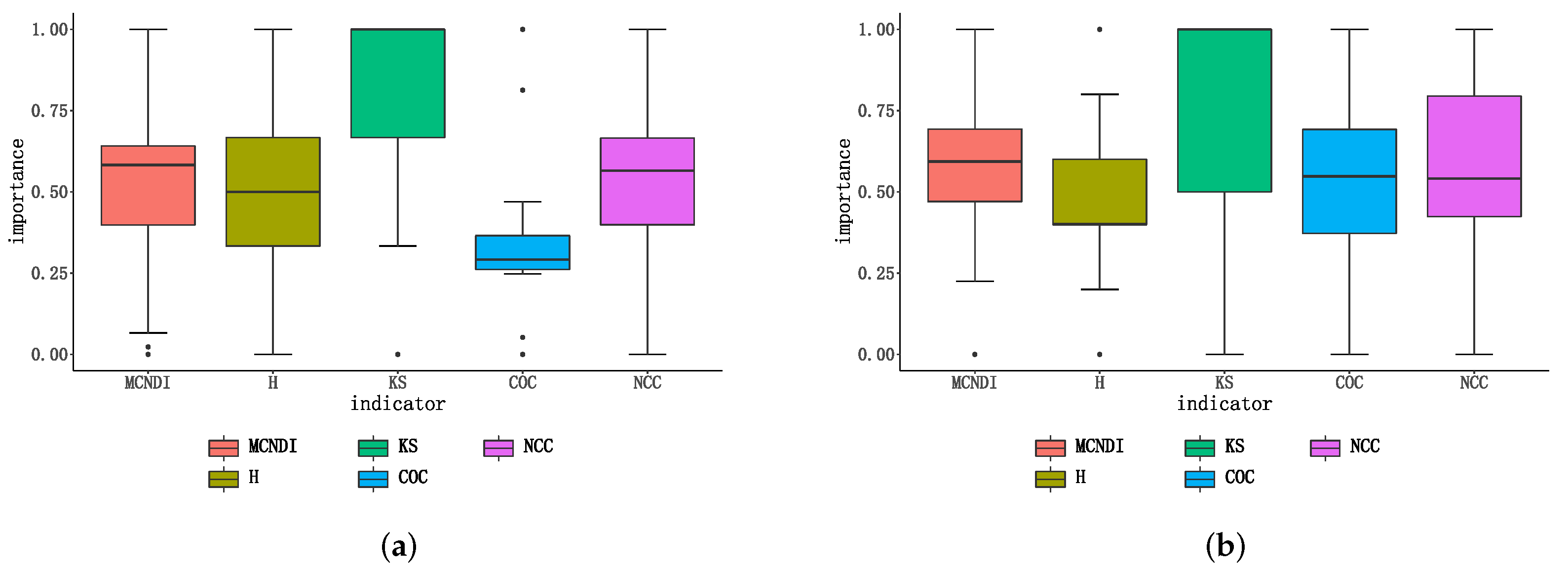
4.1. Network Metrics Experiment
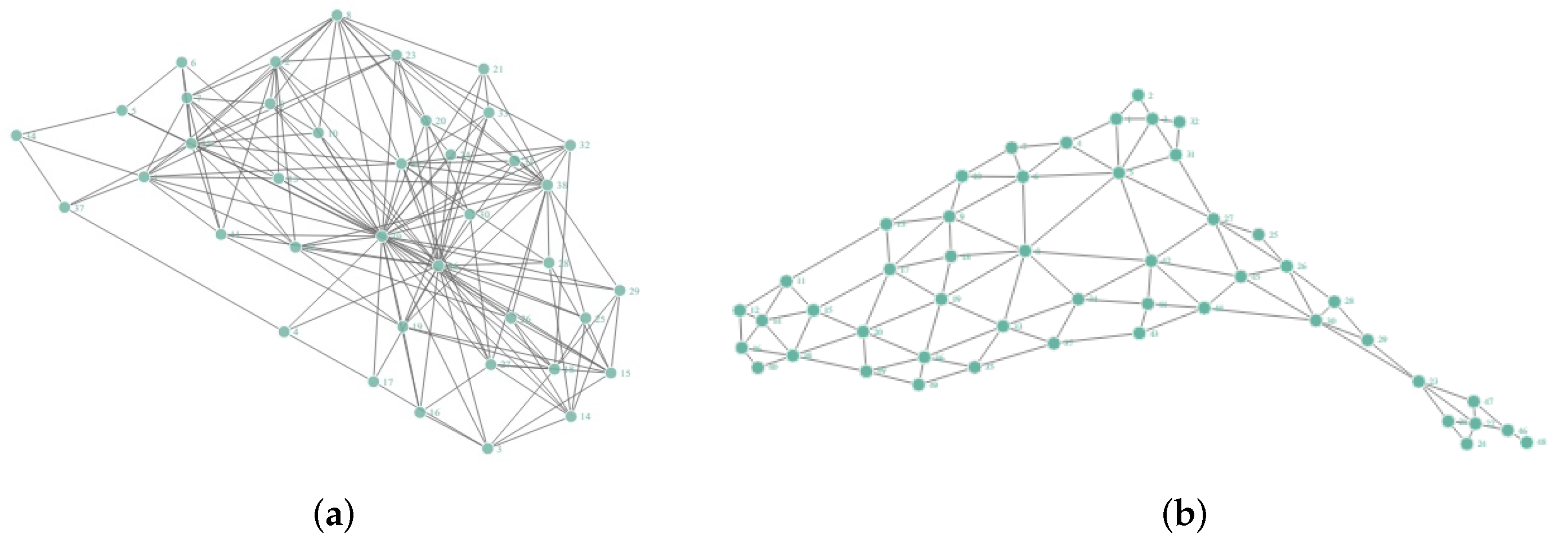
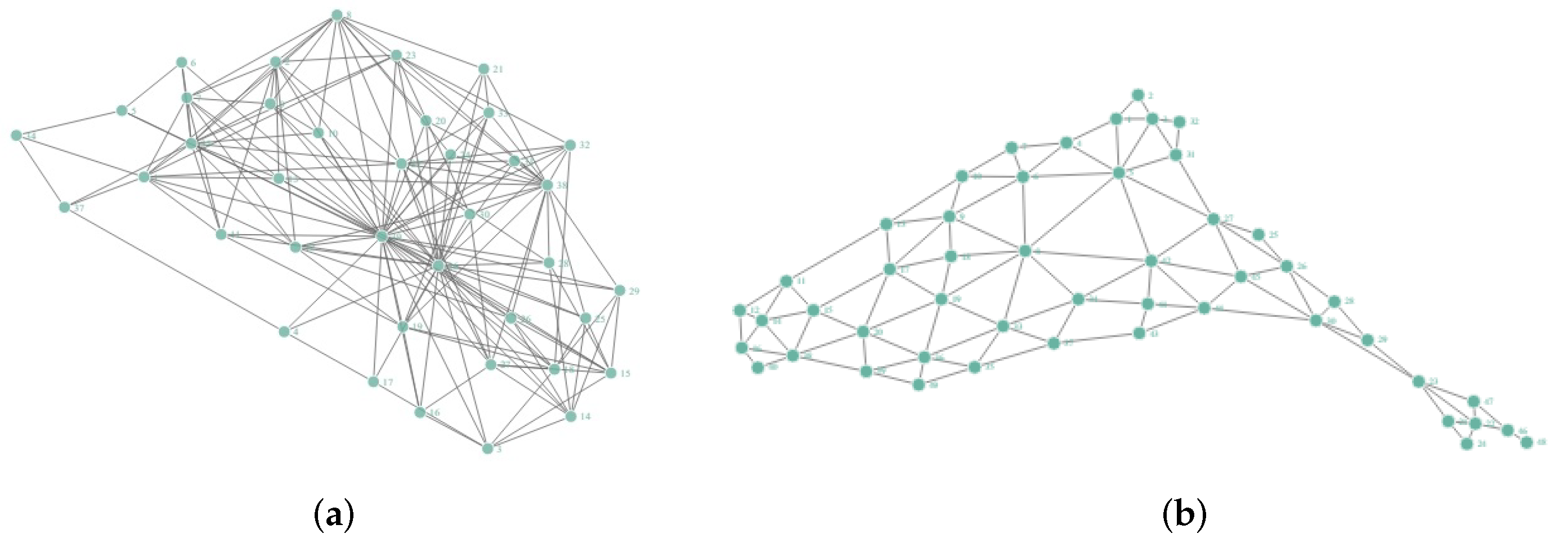
4.1.1. Chesapeake Bay Network Experiment
4.1.2. Contiguous USA Network Experiment
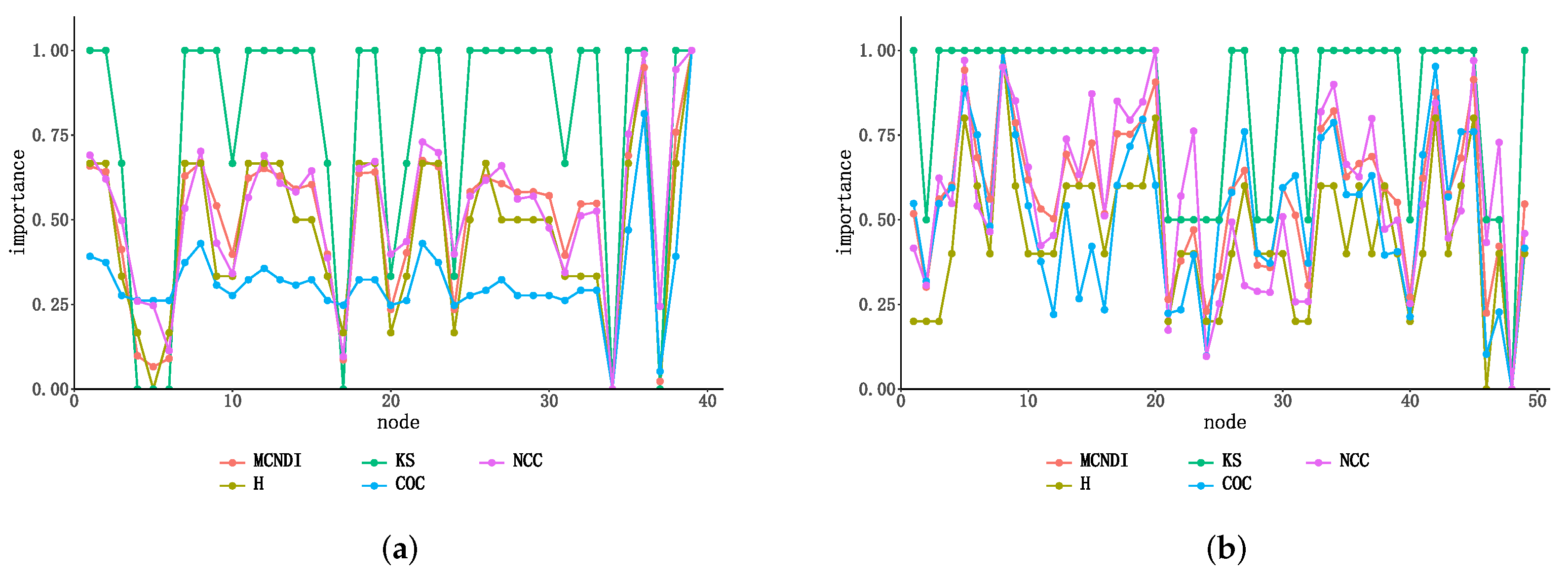
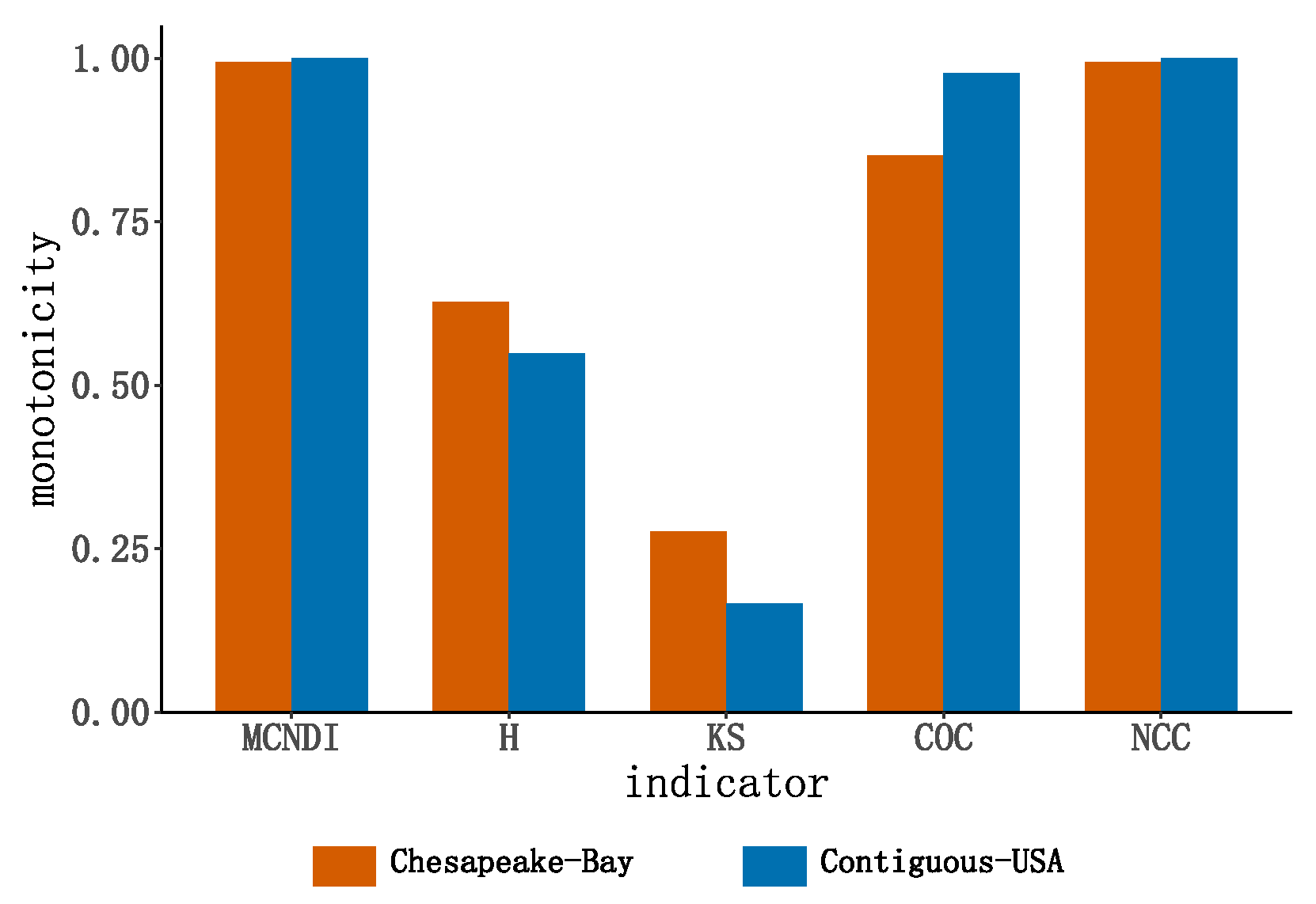
4.1.3. Node Ranking Monotonicity Analysis
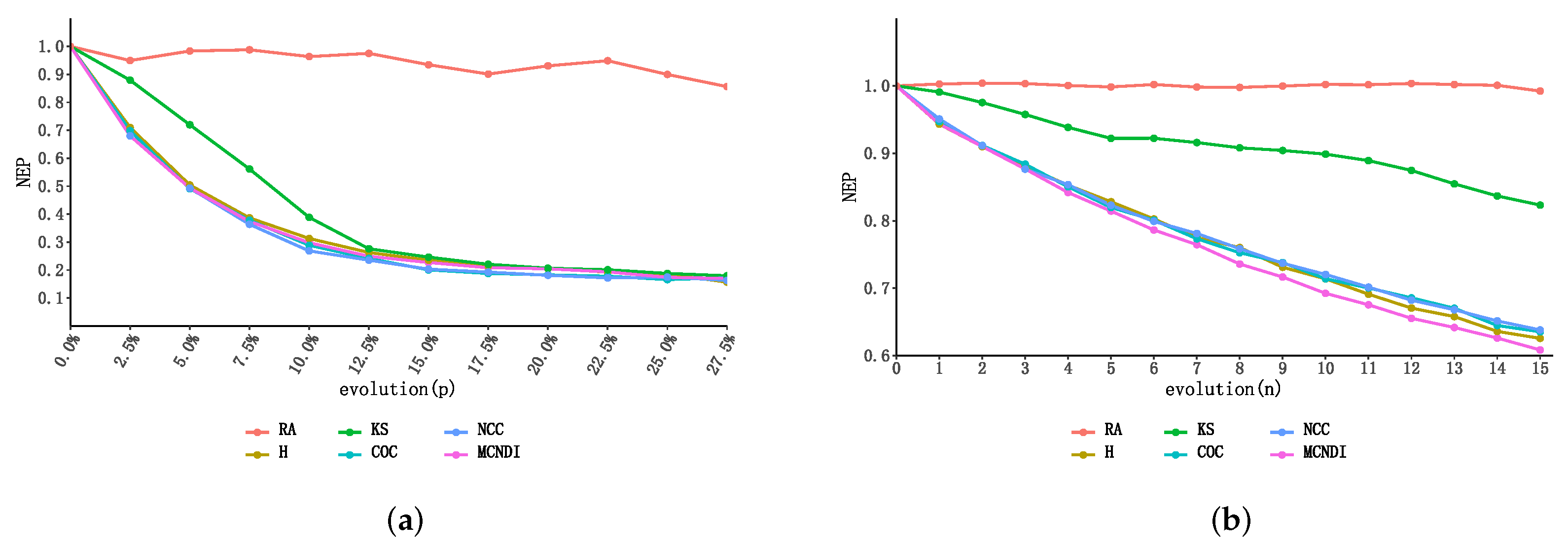
4.2. Network Attack Simulation Experiment
4.2.1. Attack Simulation to the USAir97 Network
4.2.2. Attack Simulation to the Technology Routes Network
4.2.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Newman, M.E. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, A.; Hu, Q.; Liu, J.; Pan, Y. Resistance and Security Index of Networks: Structural Information Perspective of Network Security. Sci. Rep. 2016, 6, 26810. [Google Scholar] [CrossRef] [Green Version]
- Garcia, J.O.; Ashourvan, A.; Muldoon, S.; Vettel, J.M.; Bassett, D.S. Applications of community detection techniques to brain graphs: Algorithmic considerations and implications for neural function. Proc. IEEE 2018, 106, 846–867. [Google Scholar] [CrossRef]
- Khosrosereshki, F.; Moaveni, B. Traffic modeling and validation for intersecting metro lines by considering the effect of transfer stations. IEEE Access 2022, 10, 1946–1955. [Google Scholar] [CrossRef]
- Kiedanski, D.; Rodríguez-Bocca, P. Instability of clustering metrics in overlapping community detection algorithms. In Proceedings of the 2021 XLVII Latin American Computing Conference (CLEI), Cartago, Costa Rica, 25–29 October 2021; pp. 1–11. [Google Scholar]
- Yin, T.; Zha, L.; Liu, J.; Wang, Y.; Yang, M.; Suo, W. Adaptive event-triggered controller design for cyber-physical systems with complex cyber-attacks. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 4202–4207. [Google Scholar]
- Tu, J.J.; Ou-Yang, L.; Hu, X.; Zhang, X.F. Inferring gene network rewiring by combining gene expression and gene mutation data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1042–1048. [Google Scholar] [CrossRef]
- Shao, J.; Yang, W.; Jiang, H. Evaluation of airline alliance route network efficiency based on complex network. In Proceedings of the2019 4th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Guilin, China, 26–28 April 2019; pp. 307–311. [Google Scholar]
- Xie, T.; Wu, C.; Zheng, K. A forwarding prediction model of social network based on heterogeneous network. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; Volume 5, pp. 960–964. [Google Scholar]
- Jia, H.; Han, Y.; Wu, X.; Zhu, S. Node importance evaluation algorithm for complex network based on time series and topsis. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 786–790. [Google Scholar]
- Tan, Y.J.; Jun, W.U.; Deng, H.Z. Evaluation method for node importance based on node contraction in complex networks. Syst. Eng.-Theory Pract. 2006, 11, 79–83. [Google Scholar]
- Peng, W.; Wang, H.; Yu, L. Determination of the hub nodes in the emergencies’ information dissemination supernetwork. Manag. Rev. 2013, 25, 104–111. [Google Scholar] [CrossRef]
- Goh, K.-I.; Oh, E.; Kahng, B.; Kim, D. Betweenness centrality correlation in social networks. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2003, 67, 017101. [Google Scholar] [CrossRef] [Green Version]
- Chalancon, G.; Kai, K.; Babu, M.M. Clustering Coefficient; Springer: New York, NY, USA, 2013. [Google Scholar]
- Lü, L.; Zhou, T.; Zhang, Q.M.; Stanley, H.E. The H-index of a network node and its relation to degree and coreness. Nat. Commun. 2016, 7, 10168. [Google Scholar] [CrossRef] [Green Version]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Bandar, Z.A.; Mclean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–882. [Google Scholar]
- Motter, A.E.; Lai, Y.C. Cascade-based attacks on complex networks. Phys. Rev. E 2002, 66, 065102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Cai, W.; Duan, Q.; Li, H. On survivable network topology optimization under the restraint of tenacity. J. Northwest. Polytech. Univ. 2009, 27, 443–448. [Google Scholar]
- Chen, B.; Wang, Z.; Luo, C. Integrated evaluation approach for node importance of complex networks based on relative entropy. J. Syst. Eng. Electron. 2016, 27, 1219–1226. [Google Scholar] [CrossRef]
- Zhang, X.J.; Wang, X.F. Evaluation Formula for Communication Network Node Impor tance. J. Northeast. Univ. 2014, 35, 663–666. [Google Scholar]
- Jiang, Z.P.; Zhang, D.L.; Jing, M.A.; Xu-Guang, W.U. Research on Evaluation Method for Node Importance Based on Weight-evolving Network Model. J. Air Force Eng. Univ. 2015, 16, 19–23. [Google Scholar]
- Hui, Y.; Liu, Z.; Li, Y. Using Local Improved Structural Holes Method to Identify Key Nodes in Complex Networks. In Proceedings of the 2013 Fifth International Conference on Measuring Technology and Mechatronics Automation, Hong Kong, China, 16–17 January 2013. [Google Scholar]
- Yu, H.; Liu, Z.; Li, Y.J. Key nodes in complex networks identified by multi-attribute decision-making method. Wuli Xuebao/Acta Phys. Sin. 2013, 62, 1–9. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, J. Multi-attribute integrated measurement of node importance in complex networks. Chaos 2015, 25, 113105. [Google Scholar] [CrossRef]
- Diakoulaki, D.; Mavrotas, G.; Papayannakis, L. Determining objective weights in multiple criteria problems: The critic method. Comput. Oper. Res. 1995, 22, 763–770. [Google Scholar] [CrossRef]
- Batagelj, V.; Zaveršnik, M. Fast algorithms for determining (generalized) core groups in social networks. Adv. Data Anal. Classif. 2011, 5, 129–145. [Google Scholar] [CrossRef]
- Burt, R.S. Structural holes and good ideas. Am. J. Sociol. 2004, 110, 349–399. [Google Scholar] [CrossRef]
- Baird, D.; Ulanowicz, R.E. The Seasonal Dynamics of the Chesapeake Bay Ecosystem. Ecol. Monogr. 1989, 59, 329–364. [Google Scholar] [CrossRef]
- Knuth, D.E. The Art of Computer Programming, Volume 4, Fascicle 0: Introduction to Combinatorial and Boolean Functions; Addison-Wesley: Boston, MA, USA, 2008. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Bae, J.; Kim, S. Identifying and ranking influential spreaders in complex networks by neighborhood coreness. Phys. A Stat. Mech. Appl. 2014, 395, 549–559. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Y. Node similarity measure in directed weighted complex network based on node nearest neighbor local network relative weighted entropy. IEEE Access 2020, 8, 32432–32441. [Google Scholar] [CrossRef]
- Aleta, A.; Moreno, Y. Multilayer Networks in a Nutshell. Annu. Rev. Condens. Matter Phys. 2019, 10, 45–62. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.H.; Eun, D.Y. Exploiting Heterogeneity for Improving Forwarding Performance in Mobile Opportunistic Networks: An Analytic Approach. IEEE Trans. Mob. Comput. 2016, 15, 150–162. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | H | COC | KS | NCC | MCNDI |
|---|---|---|---|---|---|
| 1 | 118 | 118 | 118 | 118 | 118 |
| 2 | 112 | 261 | 112 | 261 | 261 |
| 3 | 255 | 67 | 67 | 182 | 255 |
| 4 | 261 | 255 | 179 | 255 | 182 |
| 5 | 67 | 201 | 255 | 152 | 67 |
| 6 | 109 | 182 | 232 | 201 | 152 |
| 7 | 147 | 47 | 248 | 67 | 166 |
| 8 | 152 | 166 | 258 | 166 | 201 |
| 9 | 166 | 248 | 261 | 230 | 230 |
| 10 | 176 | 112 | 172 | 47 | 112 |
| 0.53 | 0.98 | 0.00 | 1.00 | 1.00 |
| Rank | H | COC | KS | NCC | MCNDI |
|---|---|---|---|---|---|
| 1 | 343 | 698 | 224 | 619 | 619 |
| 2 | 1808 | 619 | 1074 | 155 | 1808 |
| 3 | 619 | 343 | 343 | 1808 | 464 |
| 4 | 50 | 1808 | 50 | 614 | 50 |
| 5 | 464 | 464 | 1376 | 1404 | 155 |
| 6 | 277 | 1890 | 1605 | 464 | 1404 |
| 7 | 698 | 1301 | 2026 | 605 | 605 |
| 8 | 1196 | 1378 | 865 | 1850 | 698 |
| 9 | 1301 | 614 | 1034 | 80 | 614 |
| 10 | 708 | 306 | 1136 | 50 | 343 |
| 0.84 | 1.00 | 0.00 | 1.00 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lu, Y.; Yang, G.; Hang, Z. Multi-Attribute Decision Making Method for Node Importance Metric in Complex Network. Appl. Sci. 2022, 12, 1944. https://doi.org/10.3390/app12041944
Zhang Y, Lu Y, Yang G, Hang Z. Multi-Attribute Decision Making Method for Node Importance Metric in Complex Network. Applied Sciences. 2022; 12(4):1944. https://doi.org/10.3390/app12041944
Chicago/Turabian StyleZhang, Yongheng, Yuliang Lu, Guozheng Yang, and Zijun Hang. 2022. "Multi-Attribute Decision Making Method for Node Importance Metric in Complex Network" Applied Sciences 12, no. 4: 1944. https://doi.org/10.3390/app12041944
APA StyleZhang, Y., Lu, Y., Yang, G., & Hang, Z. (2022). Multi-Attribute Decision Making Method for Node Importance Metric in Complex Network. Applied Sciences, 12(4), 1944. https://doi.org/10.3390/app12041944