
A Pipeline Approach to Context-Aware Handwritten Text Recognition


Abstract
:Featured Application
Abstract
1. Introduction
- -
- A context-aware HTR pipeline made up of a series of carefully chosen pre-processing, text recognition, and context interpretation funnels is presented to deal with a close-to-real-life handwritten text dataset. The pipeline is designed to locate texts on a page and is able to recognize the text types such as handwritten text, printed text, non-text, as well as the text context.
- -
- A ResNet-101T model that has a better ability in handling sequence data compared to RNN variations is proposed for text recognition. The proposed model is compared with the state-of-the-art HTR methods, including CNN-LSTM and Vision Transformer.
- -
- A NER model is proposed to complement the pipeline to recognize the context of the transcribed texts. Transcription of the document can be performed in a fully automatic way.
2. Literature Review
3. Proposed Method
3.1. Data Collection
3.2. The Proposed Context-Aware HTR Pipeline
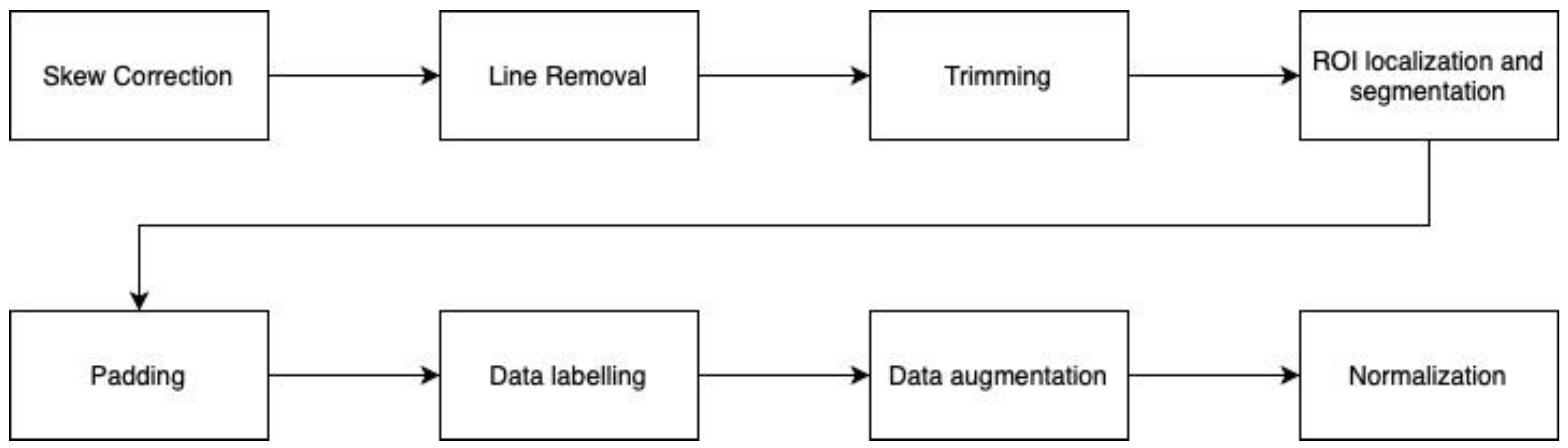
3.2.1. Pre-Processing
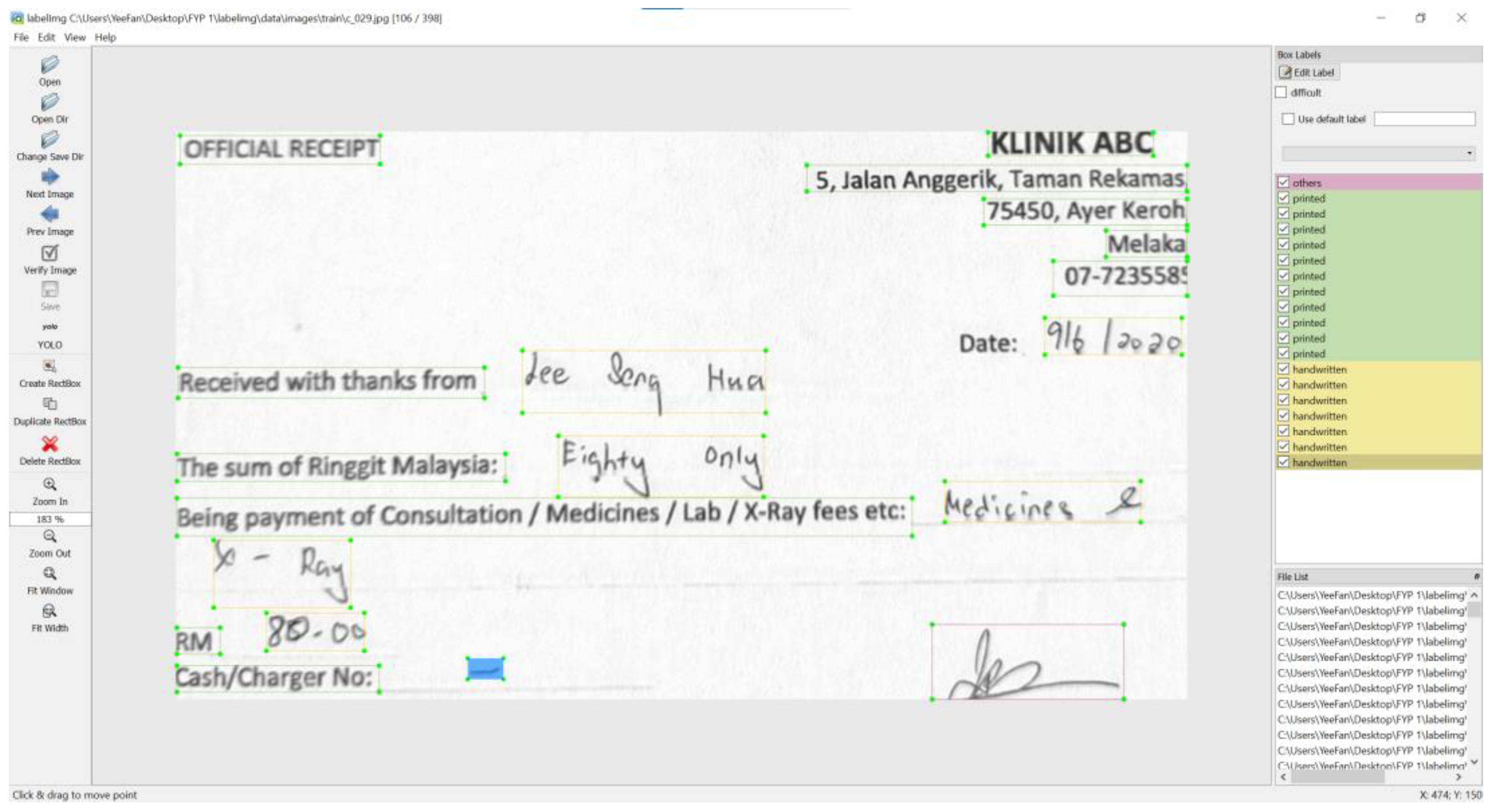
3.2.2. ROI Localization and Categorization
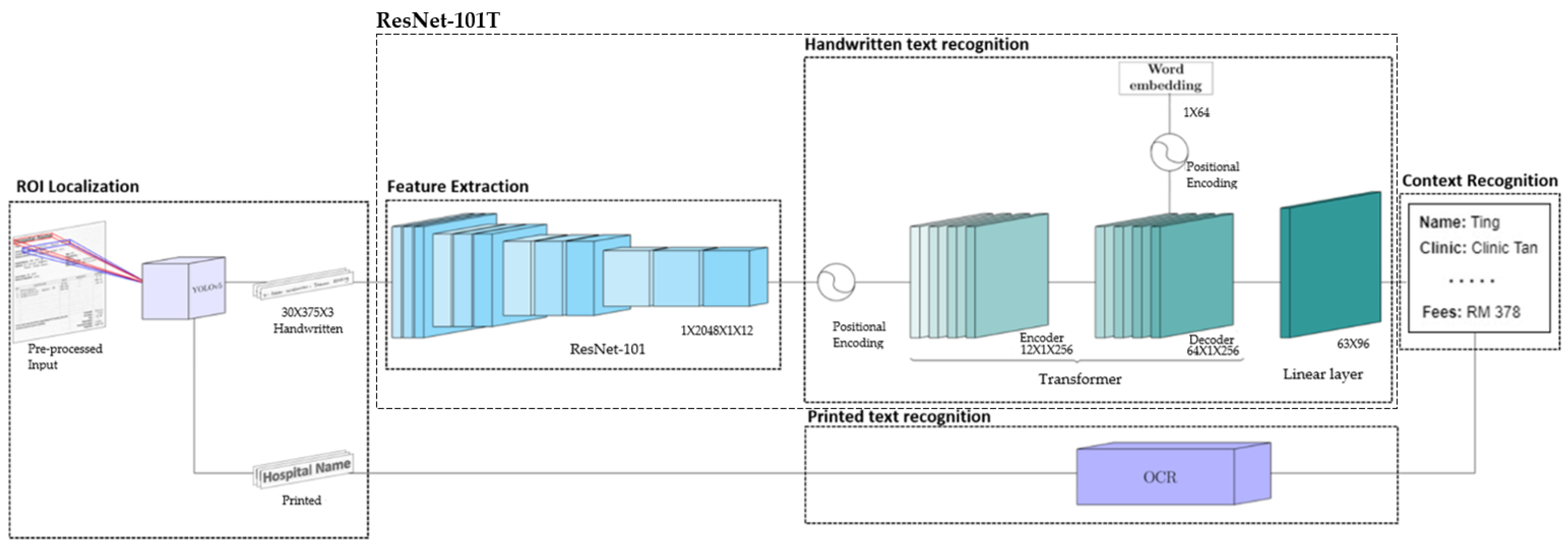
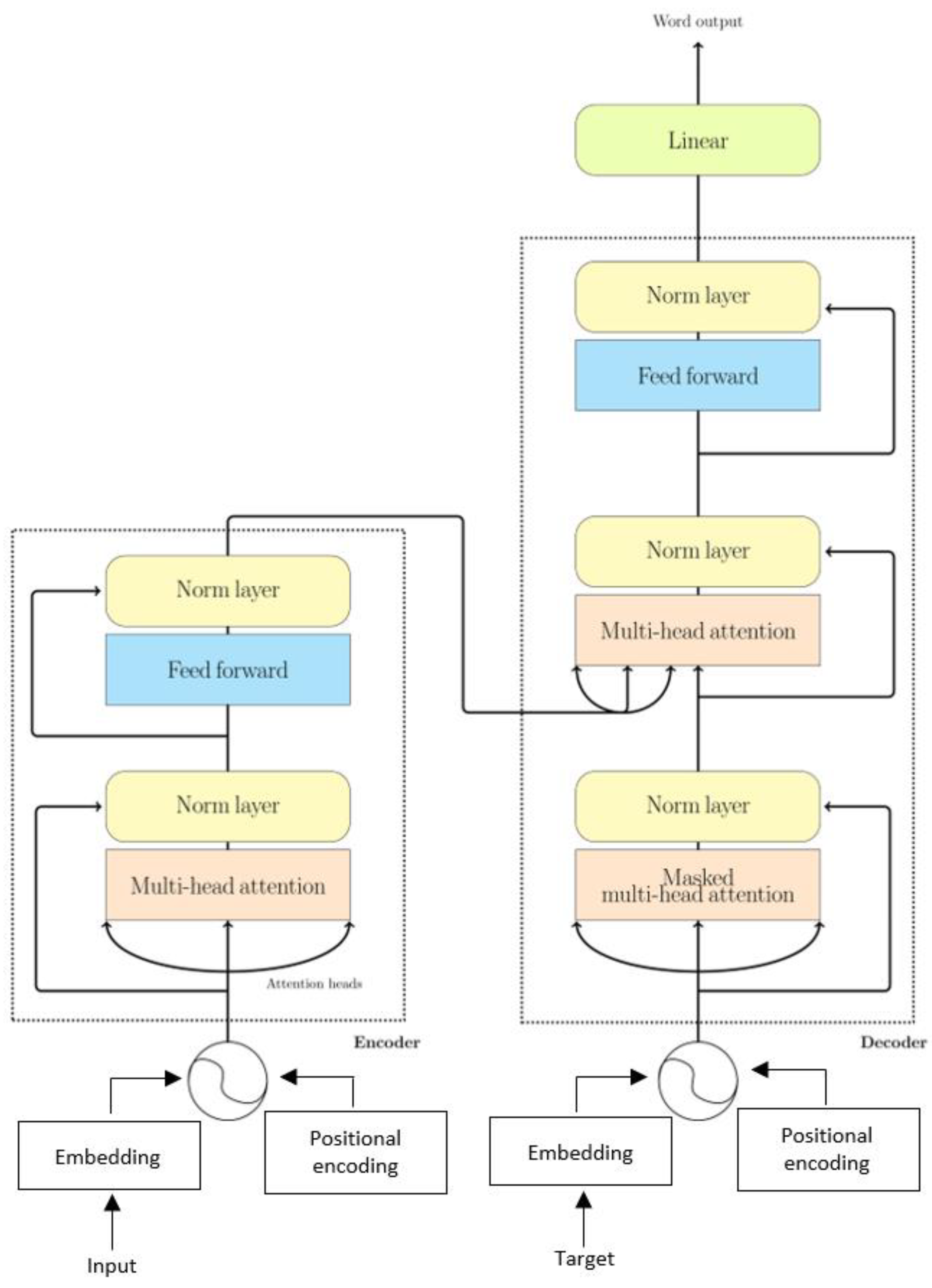
3.2.3. Residual Network with Transformer (ResNet-101T)
3.2.4. Named Entity Recognition (NER)
3.3. Implementation Details
4. Experimental Results
4.1. Experimental Setup
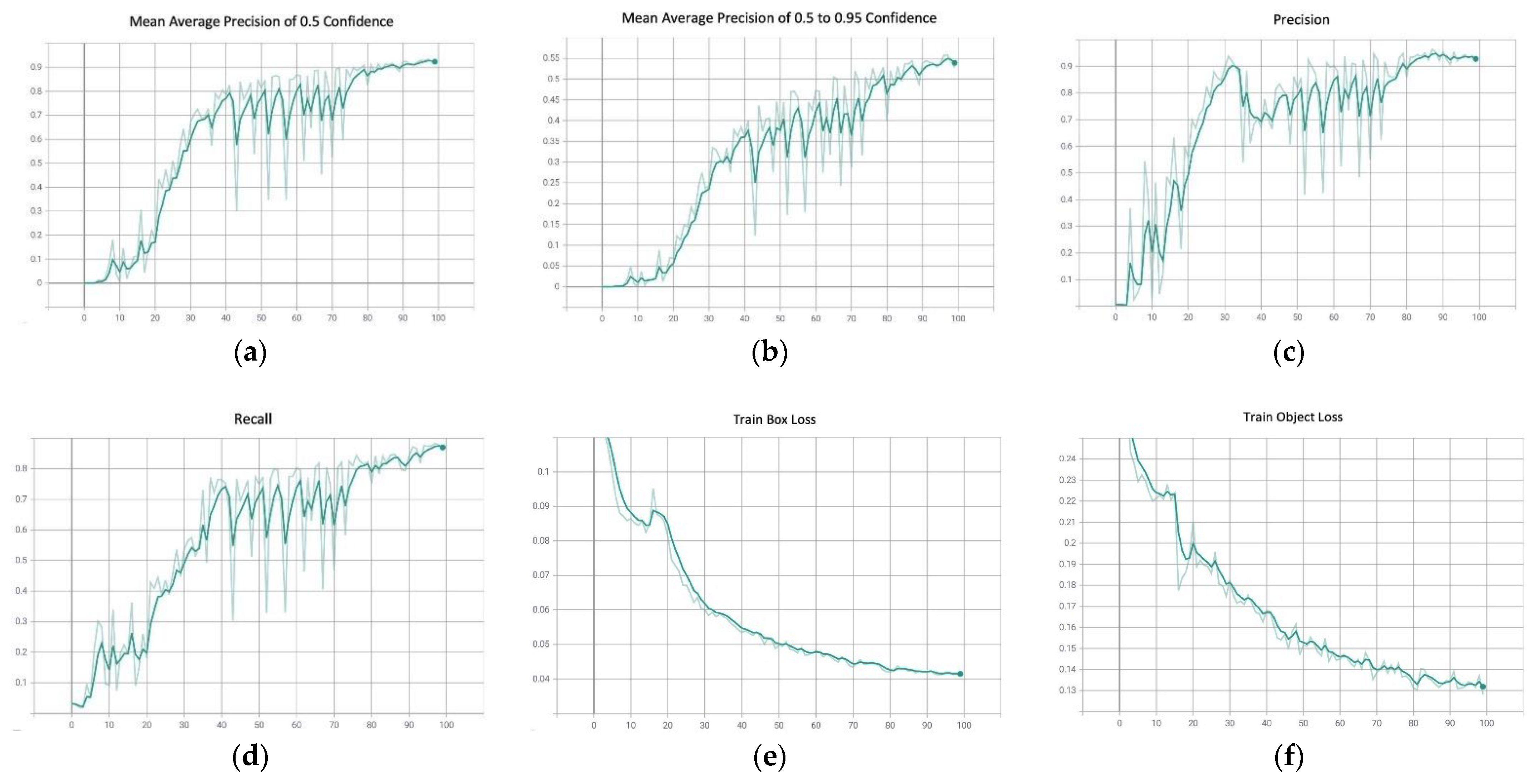
4.2. You Only Look Once v5 (YOLOv5)
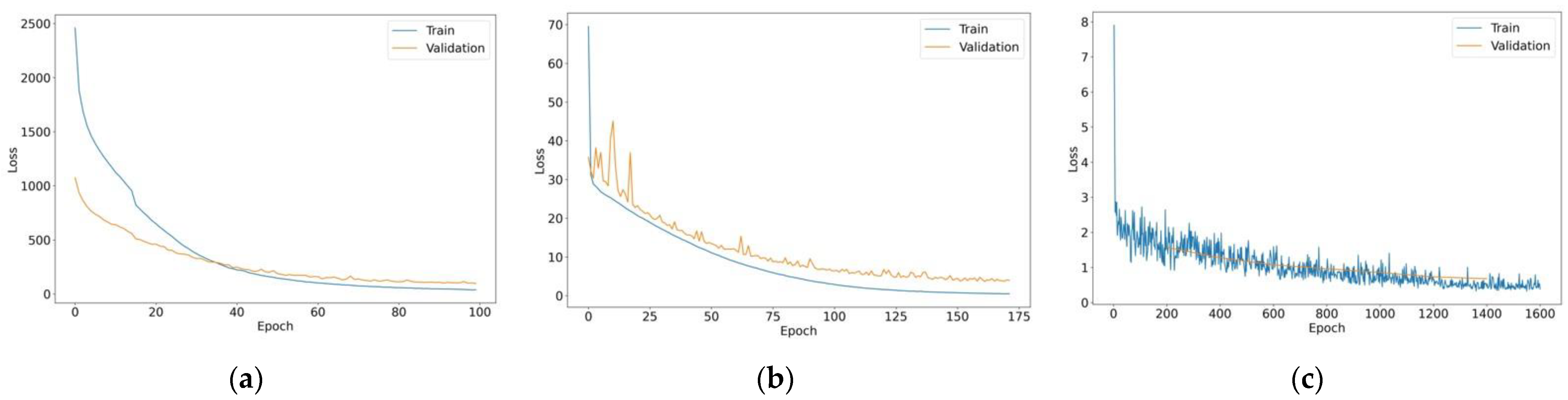
4.3. ResNet-101 with Transformer (ResNet-101T)
4.4. Named Entity Recognition (NER)
4.5. Comparisons with State-of-the-Art Methods
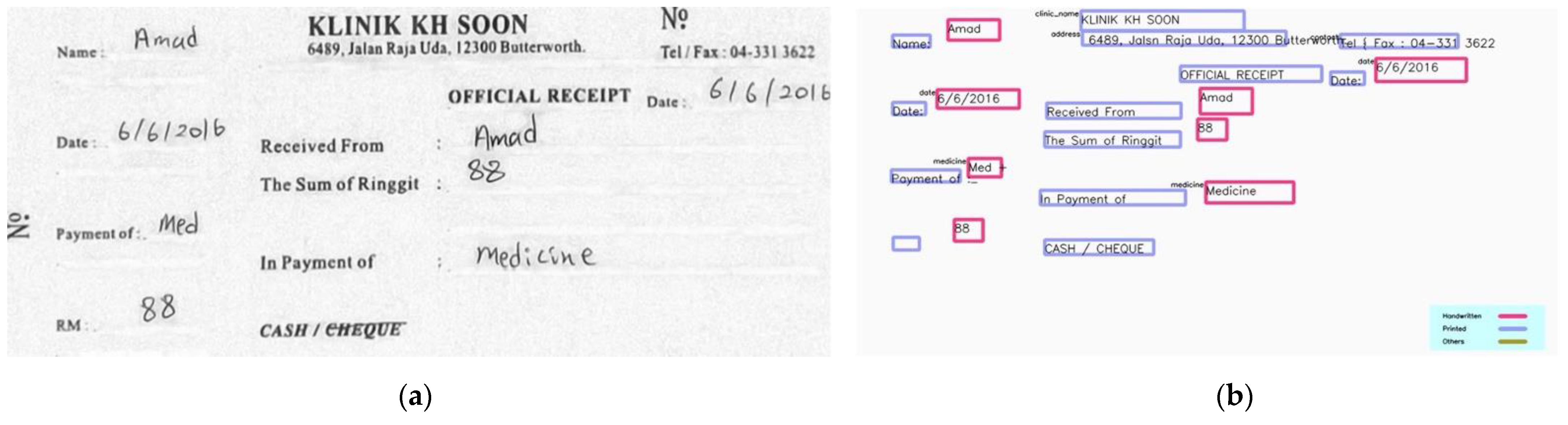
4.6. Demonstration
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chowdhury, A.; Vig, L. An Efficient End-to-End Neural Model for Handwritten Text Recognition. arXiv 2018, arXiv:1807.07965. Available online: http://arxiv.org/abs/1807.07965 (accessed on 22 October 2021).
- Chung, J.; Delteil, T. A Computationally Efficient Pipeline Approach to Full Page Offline Handwritten Text Recognition. arXiv 2020, arXiv:1910.00663. Available online: http://arxiv.org/abs/1910.00663 (accessed on 22 October 2021).
- Ingle, R.R.; Fujii, Y.; Deselaers, T.; Baccash, J.; Popat, A.C. A Scalable Handwritten Text Recognition System. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: New York, NY, 2019; pp. 17–24. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.S.; Karayev, S. Full Page Handwriting Recognition via Image to Sequence Extraction. arXiv 2021, arXiv:2103.06450. Available online: https://arxiv.org/abs/2103.06450 (accessed on 22 October 2021).
- Zhang, X.; Yan, K. An Algorithm of Bidirectional RNN for Offline Handwritten Chinese Text Recognition. In Intelligent Computing Methodologies; Huang, D.-S., Huang, Z.-K., Hussain, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 423–431. [Google Scholar]
- Hassan, S.; Irfan, A.; Mirza, A.; Siddiqi, I. Cursive Handwritten Text Recognition using Bi-Directional LSTMs: A Case Study on Urdu Handwriting. In Proceedings of the 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML), Istanbul, Turkey, 26–28 August 2019; IEEE: New York, NY, USA, 2019; pp. 67–72. [Google Scholar] [CrossRef]
- Nogra, J.A.; Romana, C.L.S.; Maravillas, E. LSTM Neural Networks for Baybáyin Handwriting Recognition. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; IEEE: Singapore, 2019; pp. 62–66. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. Available online: http://arxiv.org/abs/1706.03762 (accessed on 22 October 2021).
- Marti, U.-V.; Bunke, H. The IAM-database: An English sentence database for offline handwriting recognition. Int. J. Doc. Anal. Recognit. IJDAR 2002, 5, 39–46. [Google Scholar] [CrossRef]
- Bluche, T. Joint Line Segmentation and Transcription for End-to-End Handwritten Paragraph Recognition. arXiv 2016, arXiv:1604.08352. [Google Scholar]
- Wigington, C.; Tensmeyer, C.; Davis, B.; Barrett, W.; Price, B.; Cohen, S. Start, Follow, Read: End-to-End Full-Page Handwriting Recognition. In Computer Vision—ECCV 20180; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 372–388. [Google Scholar] [CrossRef]
- Asha, K.; Krishnappa, H. Kannada Handwritten Document Recognition using Convolutional Neural Network. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; IEEE: New York, NY, USA, 2018; pp. 299–301. [Google Scholar] [CrossRef]
- Wu, K.; Fu, H.; Li, W. Handwriting Text-line Detection and Recognition in Answer Sheet Composition with Few Labeled Data. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; IEEE: New York, NY, USA, 2020; pp. 129–132. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Xie, T.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; Abhiram, V.; et al. Ultralytics/Yolov5: v6.0—YOLOv5n “Nano” Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support, Zenodo. 2021. Available online: https://zenodo.org/record/5563715#.YgYOB-pByUk (accessed on 22 October 2021).
- Thakare, S.; Kamble, A.; Thengne, V.; Kamble, U. Document Segmentation and Language Translation Using Tesseract-OCR. In Proceedings of the 2018 IEEE 13th International Conference on Industrial and Information Systems (ICIIS), Rupangar, India, 1–2 December 2018; IEEE: New York, NY, USA, 2018; pp. 148–151. [Google Scholar] [CrossRef]
- Cantoni, V.; Mattia, E. Hough Transform. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 917–918. [Google Scholar] [CrossRef]
- Galamhos, C.; Matas, J.; Kittler, J. Progressive probabilistic Hough transform for line detection. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 1, pp. 554–560. [Google Scholar] [CrossRef] [Green Version]
- Bradski, G. The openCV library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 9 November 2021).
- Tzutalin, LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 22 October 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. Available online: http://arxiv.org/abs/2005.12872 (accessed on 1 December 2021).
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python, (2020). Available online: https://zenodo.org/record/5764736#.YgYOaupByUk (accessed on 1 December 2021).
- Tarcar, A.K.; Tiwari, A.; Dhaimodker, V.N.; Rebelo, P.; Desai, R.; Rao, D. NER Models Using Pre-Training and Transfer Learning for Healthcare. arXiv 2019, arXiv:1910.11241. Available online: http://arxiv.org/abs/1910.11241 (accessed on 22 October 2021).
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. arXiv 2016, arXiv:1603.01360. Available online: http://arxiv.org/abs/1603.01360 (accessed on 23 October 2021).
- Wigington, C.; Stewart, S.; Davis, B.; Barrett, B.; Price, B.; Cohen, S. Data Augmentation for Recognition of Handwritten Words and Lines Using a CNN-LSTM Network. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 639–645. [Google Scholar] [CrossRef]
- Li, M.; Lv, T.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv 2021, arXiv:2109.10282. Available online: http://arxiv.org/abs/2109.10282 (accessed on 6 December 2021).
- Zhou, X.; Jin, K.; Shang, Y.; Guo, G. Visually Interpretable Representation Learning for Depression Recognition from Facial Images. IEEE Trans. Affect. Comput. 2018, 11, 542–552. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Subject of Study | Proposed Solution | Dataset | Experimental Results |
|---|---|---|---|---|
| Bluche (2016) [11] | Joint line segmentation and transcription | MDLSTM-RNN | RIMES and IAM database | CER of 4.9 and 2.5 on IAM and RIMES data, respectively |
| Wigington et al. (2018) [12] | Historical document processing | SFT | ICDAR 2017 competition dataset, IAM, RIMES | BLEU score of 72.3 on ICDAR dataset. CER and WER of 2.1 and 9.3, 6.4 and 23.2 on both IAM and RIMES datasets, respectively |
| Asha and Krishnappa (2018) [13] | Kannada Handwritten Document Recognition | CNN | Chars74K dataset | 99% of accuracy |
| Ingle et al. (2019) [3] | Line-level text style classification and recognition | GRCL | IAM online and offline database, self-collected handwritten online samples | CER and WER of 4.0 and 10.8 |
| Wu et al. (2020) [14] | Recognition of handwritten text and text-line | CTPN to detect text lines, MLC-CRNN for text recognition | 3883 training images and 297 testing images | Accuracy of 91.4% |
| Sign and Karayev (2021) [4] | Full-page handwritten document recognition | Transformer | IAM, WIKITEXT, FREE FORM ANSWERS, ANSWERS2 | CER of 7.6% |
| Layer (Type) | Input Shape | Parameter |
|---|---|---|
| ResNet | [1, 3, 30, 375] | 9408 |
| Embedding layer | [1, 63] | 25,344 |
| Positional Encoding | [1, 63, 256] | 0 |
| Transformer Encoder | [12, 1, 256] | 5,260,800 |
| Transformer Decoder | [12, 1, 256], [63, 1, 256] | 6,315,520 |
| Linear | [1, 63, 256] | 25,443 |
| Total parameter: 12,151,651 Trainable parameter: 12,151,651 Non-trainable parameters: 0 | ||
| Number of Encoders, Decoders, Attention Heads | Unit Dimension | ||
|---|---|---|---|
| 256 | 512 | 1024 | |
| 4, 4, 4 | |||
| CER | 7.77 | 8.66 | 20.93 |
| WER | 10.77 | 11.81 | 29.02 |
| Times (Second) | 350,864 | 392,254 | 592,497 |
| 6, 6, 4 | |||
| CER | 9.15 | 11.87 | 86.76 |
| WER | 13.08 | 16.93 | 87.39 |
| Times (Second) | 388,399 | 487,445 | 73,817 (Stopped at 11) |
| 8, 8, 8 | |||
| CER | 12.96 | 13.35 | 1.0 |
| WER | 17.15 | 19.25 | 1.0 |
| Times (Second) | 429,401 | 539,650 | 87,148 (Stopped at 11) |
| Entities | Precision | Recall | F1-Score |
|---|---|---|---|
| Medicine | 1 | 1 | 1 |
| Payment | 0.9967 | 1 | 0.9983 |
| Clinic Name | 1 | 1 | 1 |
| Address | 1 | 1 | 1 |
| Contact | 1 | 1 | 1 |
| Website | 1 | 1 | 1 |
| Receipt Number | 1 | 1 | 1 |
| Name | 1 | 1 | 1 |
| 1 | 1 | 1 | |
| Service | 1 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Y.F.; Connie, T.; Goh, M.K.O.; Teoh, A.B.J. A Pipeline Approach to Context-Aware Handwritten Text Recognition. Appl. Sci. 2022, 12, 1870. https://doi.org/10.3390/app12041870
Tan YF, Connie T, Goh MKO, Teoh ABJ. A Pipeline Approach to Context-Aware Handwritten Text Recognition. Applied Sciences. 2022; 12(4):1870. https://doi.org/10.3390/app12041870
Chicago/Turabian StyleTan, Yee Fan, Tee Connie, Michael Kah Ong Goh, and Andrew Beng Jin Teoh. 2022. "A Pipeline Approach to Context-Aware Handwritten Text Recognition" Applied Sciences 12, no. 4: 1870. https://doi.org/10.3390/app12041870