
PrimeNet: Adaptive Multi-Layer Deep Neural Structure for Enhanced Feature Selection in Early Convolution Stage


Abstract
:1. Introduction
- A backward-locking free novel dynamic MLP structure ‘PrimeNet’ is proposed to encourage the most vital distinctive attributes within highly correlated multiscale activations.
- PrimeNet builds a localized learning strategy to train the weight layers with locally generated errors.
- To avoid extreme compression of the information passing through PrimeNet and to avoid correlated regions concentrating in local regions, a summarized local translation-invariant features projection is utilized in this research.
2. Relevant Work
2.1. Conditional Computation
2.2. Network Pruning and Distillation
2.3. Knowledge Distillation
2.4. Discussion
3. Method
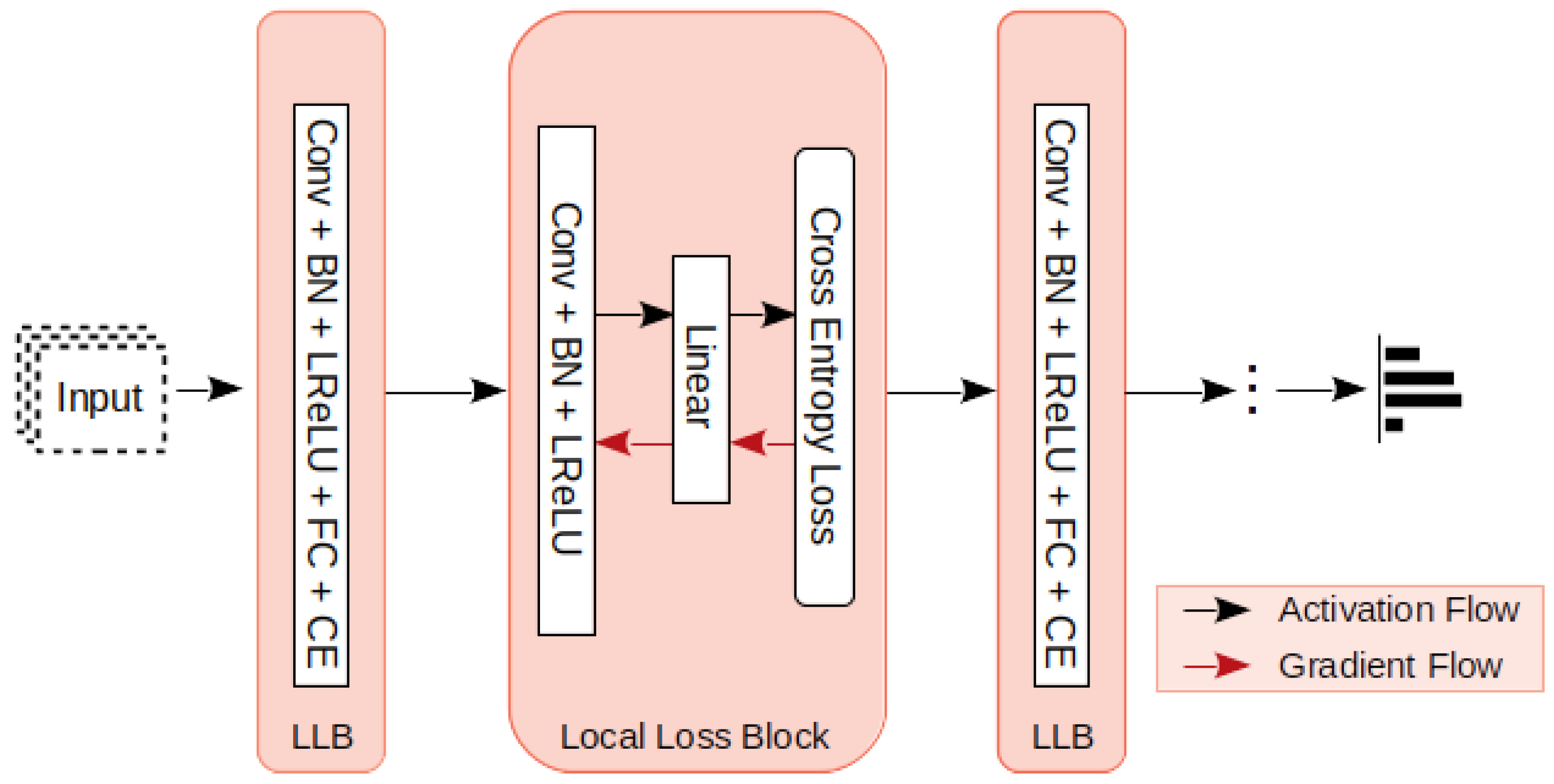
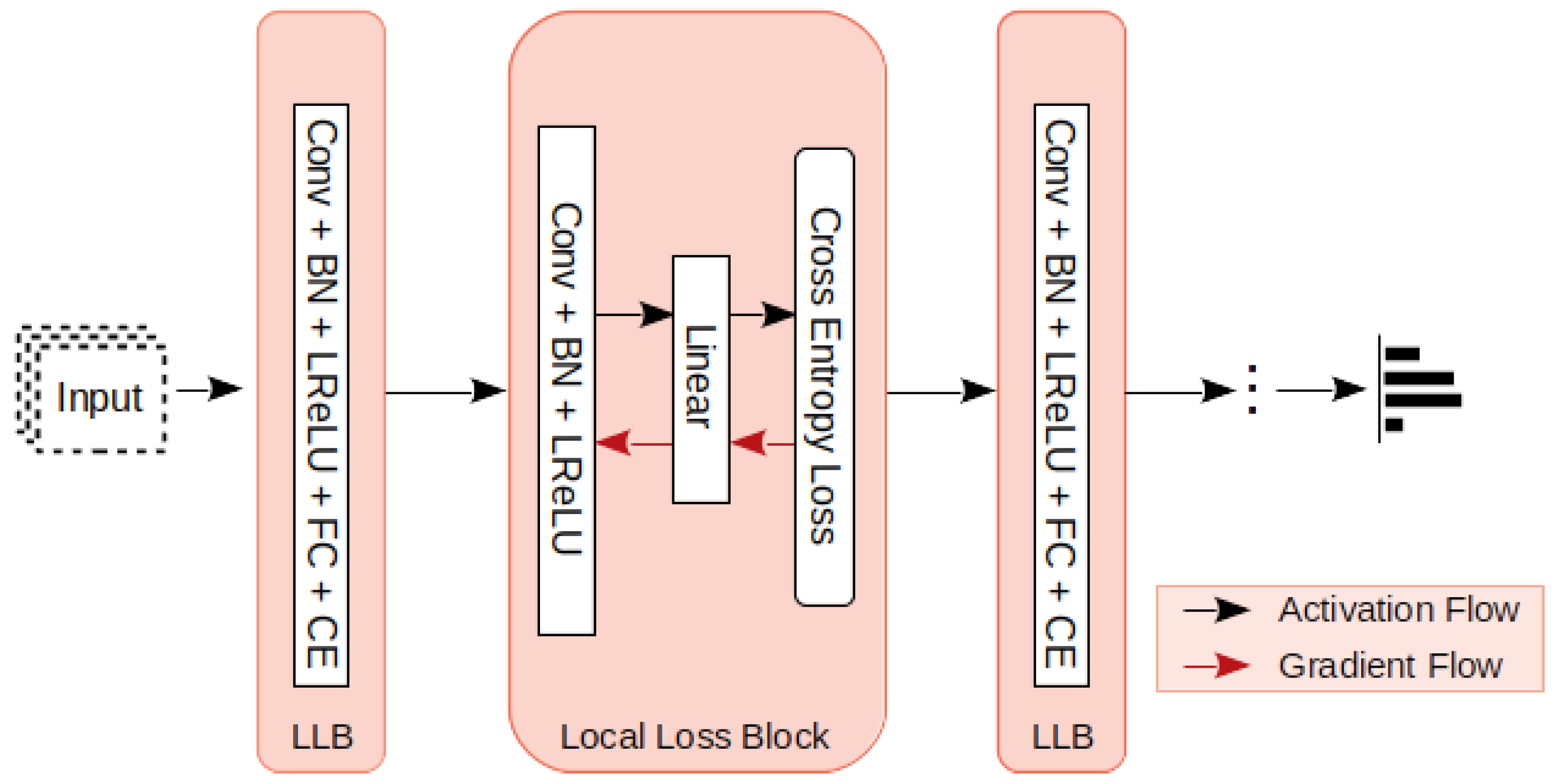
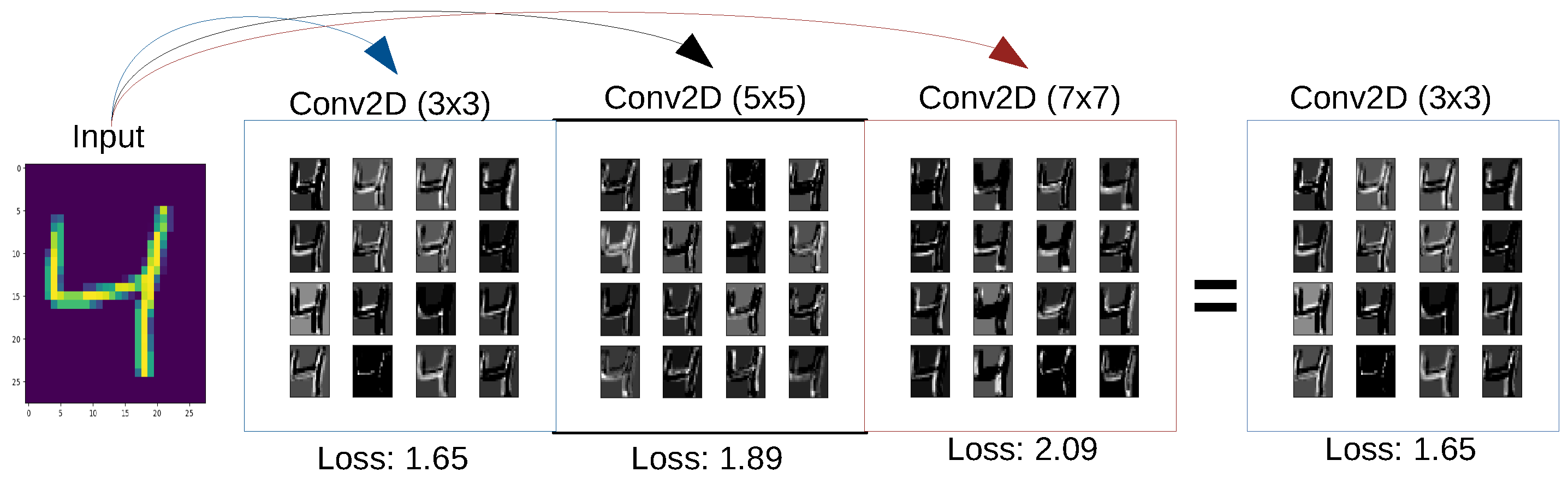
3.1. Local Loss Computation
3.2. Convolution with Local Loss
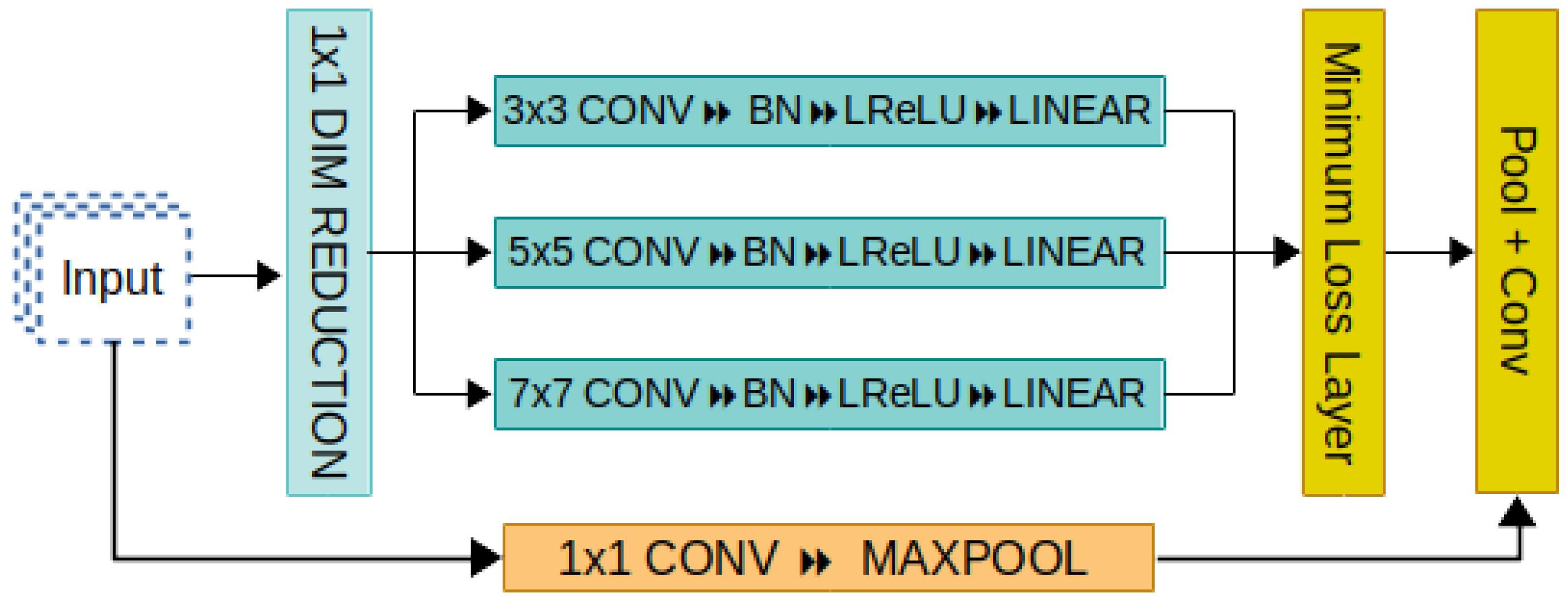
3.3. PrimeNet
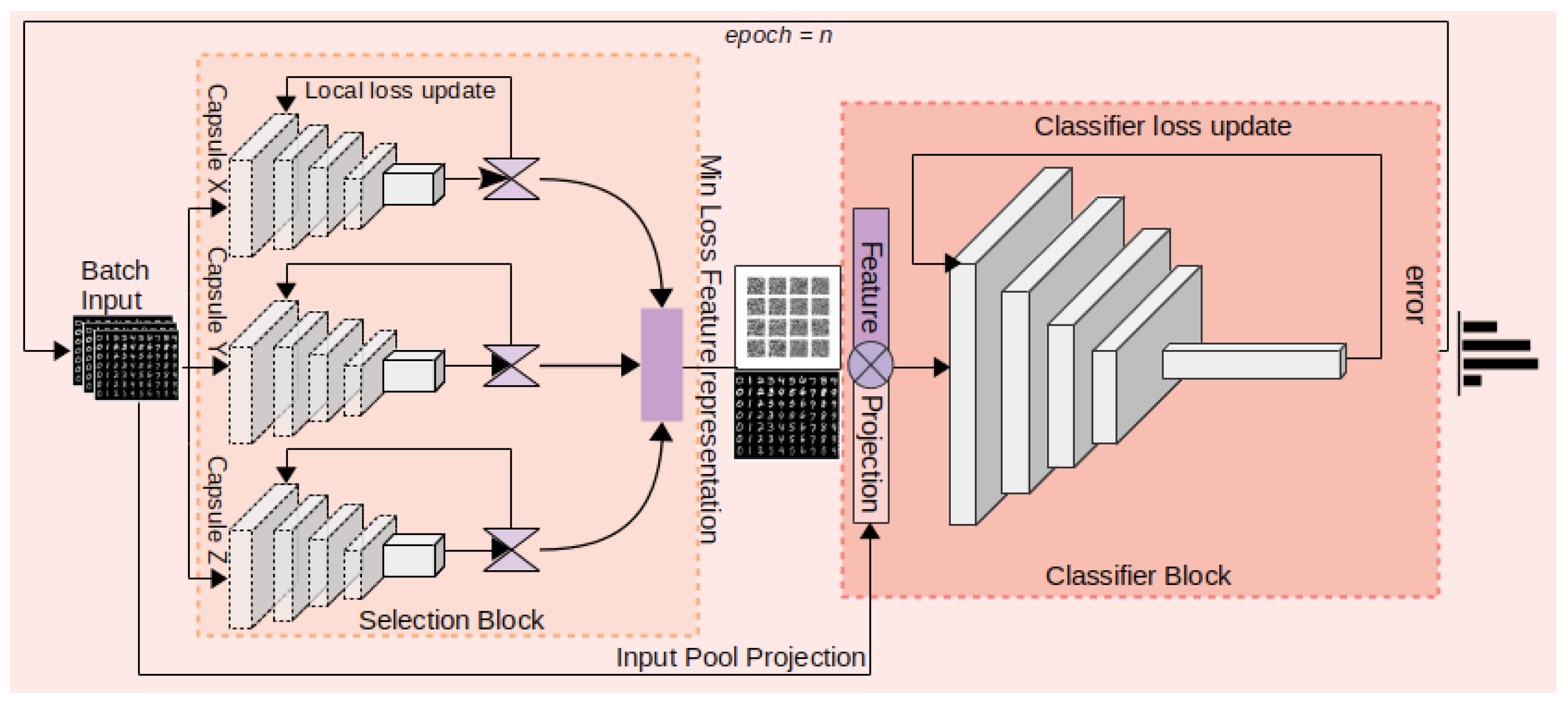
3.4. Feature Representation with Minimum Loss Local Structure Transferring
3.5. Learning Algorithm
| Algorithm 1 Training algorithm for classifier model. | |
| Input: Batch Images | |
| Output: Prediction | |
| 1: procedure TRAIN( ) | |
| 2: capsuleX=Capsule() | ▷ Shallow network instance for x scale. |
| 3: capsuleY=Capsule() | ▷ Shallow network instance for y scale. |
| 4: capsuleZ=Capsule() | ▷ Shallow network instance for z scale. |
| 5: classi f ier=PrimeNet() | ▷ Classifier Network Instance. |
| 6: procedure FEATURE_TRAIN(images) | ▷ Individual capsule training for feature generarion |
| 7: featuresX = capsule(images) | ▷ Features X from Capsule X. |
| 8: lossX = loss( featuresX) | ▷ loss from feature X. |
| 9: featuresY = capsule(images) | ▷ Features Y from Capsule Y. |
| 10: lossY = loss( featuresY) | ▷ loss from feature Y. |
| 11: featuresZ = capsule(images) | ▷ Features Z from Capsule Z. |
| 12: lossZ = loss( featuresZ) | ▷ loss from feature Z. |
| 13: if (lossX < lossY)&(lossX < lossZ) then | |
| 14: min_loss_ features=featureX | |
| 15: else if (lossY > lossX)&(lossY > lossZ) then | |
| 16: min_loss_ features=featureY | |
| 17: else | |
| 18: min_loss_ features=featureZ | |
| 19: end if | |
| 20: gradient_update(capsuleX, capsuleY, capsuleZ) | ▷ local gradient update |
| 21: end procedure | |
| 22: for epoch in range(epochs) do | |
| 23: classifier_loss = 0 | |
| 24: total_classifier_loss = 0 | |
| 25: for batch_images in train_dataset do | |
| 26: MinLossFeature=feature_train(batch_images) | |
| 27: features=MinLossFeature + input_projection | ▷ Input feature projection is concatenated. |
| 28: classifier_output = classifier( features) | |
| 29: classifier_loss = loss(classifier_output) | |
| 30: total_classifier_loss += classifier_loss | ▷ Combined classifier loss |
| 31: update_weights=gradient_update(classifier) | |
| 32: end for | |
| 33: end for | |
| 34: end procedure | |
4. Experiments and Results
4.1. Implementation Details
4.2. Experimental Setup
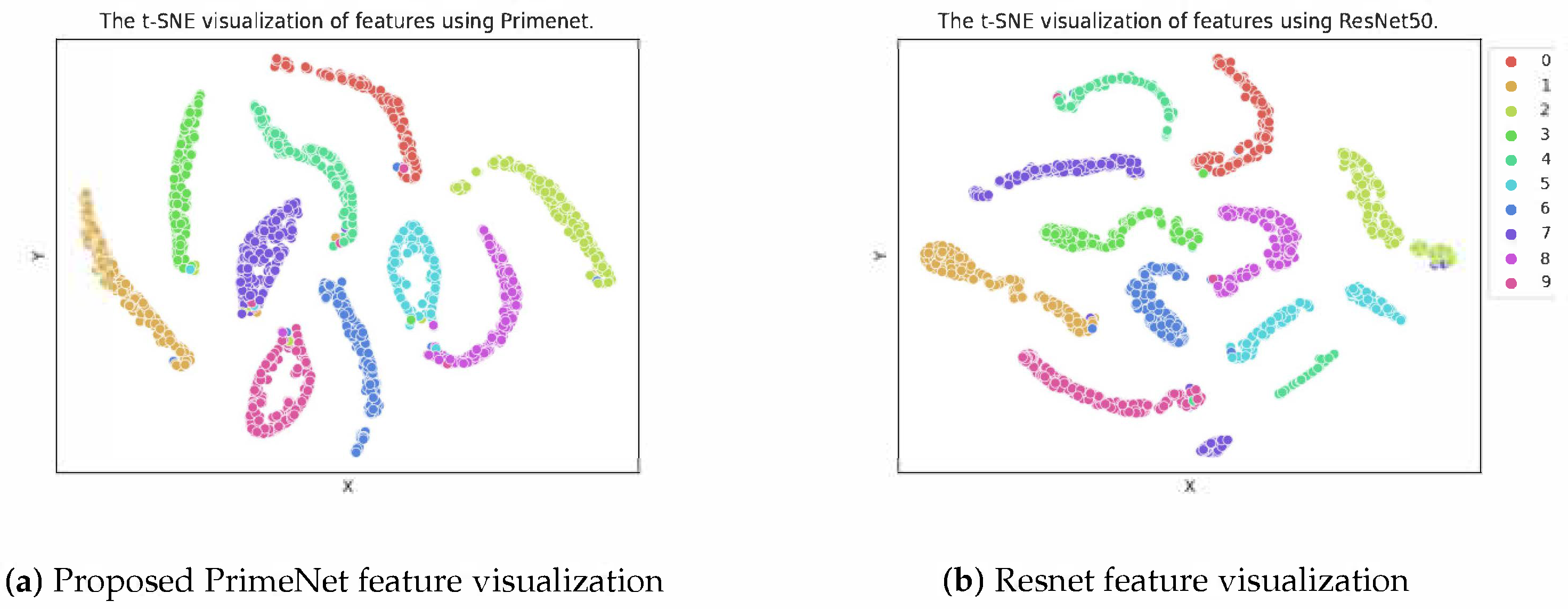
4.3. Results
4.4. Computational Analysis
5. Ablation Study
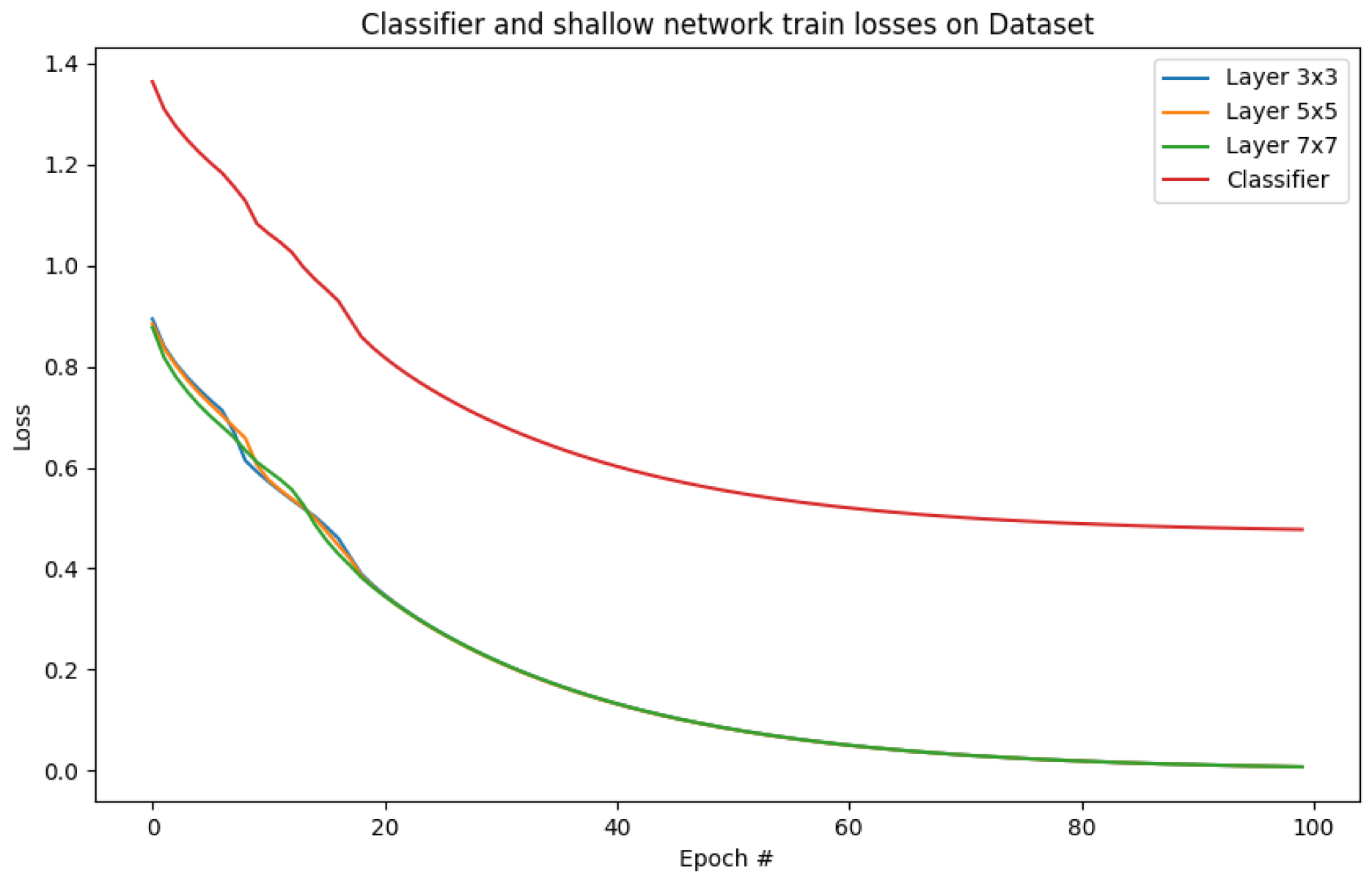
5.1. Local Gradient Update
5.2. Adaptive Cost-Conscious Local Structure Transfer
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Rosenblatt, F. Principles of Neurodynamics. Perceptrons and the Theory of Brain Mechanisms; Technical Report; Cornell Aeronautical Lab. Inc.: Buffalo, NY, USA, 1961. [Google Scholar]
- Nøkland, A.; Eidnes, L.H. Training neural networks with local error signals. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4839–4850. [Google Scholar]
- Bolukbasi, T.; Wang, J.; Dekel, O.; Saligrama, V. Adaptive neural networks for fast test-time prediction. arXiv 2017, arXiv:1702.07811. [Google Scholar]
- Huang, G.; Chen, D.; Li, T.; Wu, F.; van der Maaten, L.; Weinberger, K.Q. Multi-scale dense networks for resource efficient image classification. arXiv 2017, arXiv:1703.09844. [Google Scholar]
- Lin, J.; Rao, Y.; Lu, J.; Zhou, J. Runtime neural pruning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2178–2188. [Google Scholar]
- Wang, X.; Yu, F.; Dou, Z.Y.; Darrell, T.; Gonzalez, J.E. Skipnet: Learning dynamic routing in convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 409–424. [Google Scholar]
- Veit, A.; Belongie, S. Convolutional networks with adaptive inference graphs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Figurnov, M.; Collins, M.D.; Zhu, Y.; Zhang, L.; Huang, J.; Vetrov, D.; Salakhutdinov, R. Spatially adaptive computation time for residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1039–1048. [Google Scholar]
- Kong, S.; Fowlkes, C. Pixel-wise attentional gating for parsimonious pixel labeling. arXiv 2018, arXiv:1805.01556. [Google Scholar]
- Li, Z.; Yang, Y.; Liu, X.; Zhou, F.; Wen, S.; Xu, W. Dynamic computational time for visual attention. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1199–1209. [Google Scholar]
- Ying, C.; Fragkiadaki, K. Depth-adaptive computational policies for efficient visual tracking. In International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2017; pp. 109–122. [Google Scholar]
- Wu, Z.; Nagarajan, T.; Kumar, A.; Rennie, S.; Davis, L.S.; Grauman, K.; Feris, R. Blockdrop: Dynamic inference paths in residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8817–8826. [Google Scholar]
- McIntosh, L.; Maheswaranathan, N.; Sussillo, D.; Shlens, J. Recurrent segmentation for variable computational budgets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1648–1657. [Google Scholar]
- Kang, D.; Dhar, D.; Chan, A.B. Incorporating Side Information by Adaptive Convolution. Int. J. Comput. Vis. 2020, 128, 2897–2918. [Google Scholar] [CrossRef]
- Li, H.; Zhang, H.; Qi, X.; Yang, R.; Huang, G. Improved techniques for training adaptive deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1891–1900. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2752–2761. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Khan, F.U.; Aziz, I.B.; Akhir, E.A.P. Pluggable Micronetwork for Layer Configuration Relay in a Dynamic Deep Neural Surface. IEEE Access 2021, 9, 124831–124846. [Google Scholar] [CrossRef]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. Play and prune: Adaptive filter pruning for deep model compression. arXiv 2019, arXiv:1905.04446. [Google Scholar]
- Lin, M.; Ji, R.; Zhang, Y.; Zhang, B.; Wu, Y.; Tian, Y. Channel pruning via automatic structure search. arXiv 2020, arXiv:2001.08565. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring Sparsity in Image Super-Resolution for Efficient Inference. arXiv 2021, arXiv:2006.09603. [Google Scholar]
- Kim, J.; Chang, S.; Yun, S.; Kwak, N. Prototype-based Personalized Pruning. arXiv 2021, arXiv:2103.15564. [Google Scholar]
- Luo, C.; Zhan, J.; Hao, T.; Wang, L.; Gao, W. Shift-and-Balance Attention. arXiv 2021, arXiv:2103.13080. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S. Knowledge distillation by on-the-fly native ensemble. arXiv 2018, arXiv:1806.04606. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2015, arXiv:1412.6806. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Panchal, G.; Ganatra, A.; Shah, P.; Panchal, D. Determination of over-learning and over-fitting problem in back propagation neural network. Int. J. Soft Comput. 2011, 2, 40–51. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Capsule (Shallow Network) | PrimeNet (Classifer) | ||
|---|---|---|---|
| Layer | Parameter | Layer | Parameter |
| Conv2D | 1 × 1, 32 | MaxPool | 3 × 3 |
| Conv2D | 3 × 3, 5 × 5, 7 × 7, 64 | Conv2D | 1 × 1, 64 |
| BN | NA | BN | NA |
| LReLU | NA | MaxPool | 2 × 2 |
| Flatten | NA | Conv2D | 3 × 3, 128 |
| Dense | 28 × 28 × 1, 32 × 32 × 3 | GAP | NA |
| Flatten | NA | ||
| Dense | 10 | ||
| Dataset | Input Size | No. of Classes | Train Size | Test Size |
|---|---|---|---|---|
| MNIST | 28 × 28 × 1 | 10 | 60,000 | 10,000 |
| CIFAR-10 | 32 × 32 × 3 | 10 | 50,000 | 10,000 |
| SVHN | 32 × 32 × 3 | 10 | 73,257 | 26,032 |
| Dataset | PrimeNet Test Error (%) | Model | Baseline Error (%) | Baseline Method | ||
|---|---|---|---|---|---|---|
| Top-1 | Top-5 () | |||||
| MNIST | 0.59 | 0.706 | 0.14 | DT-RAM [12] | 1.46, 1.12 | Conditional Computation |
| Condensenet [18] | 3.46, 3.76 | Conditional Computation | ||||
| ITADN [17] | 5.9 | Conditional Computation | ||||
| CIFAR-10 | 6.21 | 7.34 | 3.67 | RNP [7] | 15.05 | Network Pruning |
| SFP [21] | 7.74, 6.32 | Network Pruning | ||||
| ITADN [17] | 3.13, 5.99 | Knowledge Distillation | ||||
| SVHN | 1.71 | 2.2 | 0.42 | ONE [27] | 1.63 | Knowledge Distillation |
| Model | Dataset | Params (Millions) | FLOPs (Millions) | Epochs |
|---|---|---|---|---|
| ResNet [34] | All Three | 23.6 | 409 | 50 |
| PrimeNet (Ours) | All Three | 0.41 | 2.7 | 100 + 50 |
| Condensenetlight [18] | CIFAR-10 | 0.33 | 122 | 300 |
| Condensenet86 [18] | CIFAR-10 | 0.52 | 65 | 300 |
| ONE [27] | SVHN | 0.5 | 2.28 | 300, 40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, F.U.; Aziz, I. PrimeNet: Adaptive Multi-Layer Deep Neural Structure for Enhanced Feature Selection in Early Convolution Stage. Appl. Sci. 2022, 12, 1842. https://doi.org/10.3390/app12041842
Khan FU, Aziz I. PrimeNet: Adaptive Multi-Layer Deep Neural Structure for Enhanced Feature Selection in Early Convolution Stage. Applied Sciences. 2022; 12(4):1842. https://doi.org/10.3390/app12041842
Chicago/Turabian StyleKhan, Farhat Ullah, and Izzatdin Aziz. 2022. "PrimeNet: Adaptive Multi-Layer Deep Neural Structure for Enhanced Feature Selection in Early Convolution Stage" Applied Sciences 12, no. 4: 1842. https://doi.org/10.3390/app12041842
APA StyleKhan, F. U., & Aziz, I. (2022). PrimeNet: Adaptive Multi-Layer Deep Neural Structure for Enhanced Feature Selection in Early Convolution Stage. Applied Sciences, 12(4), 1842. https://doi.org/10.3390/app12041842