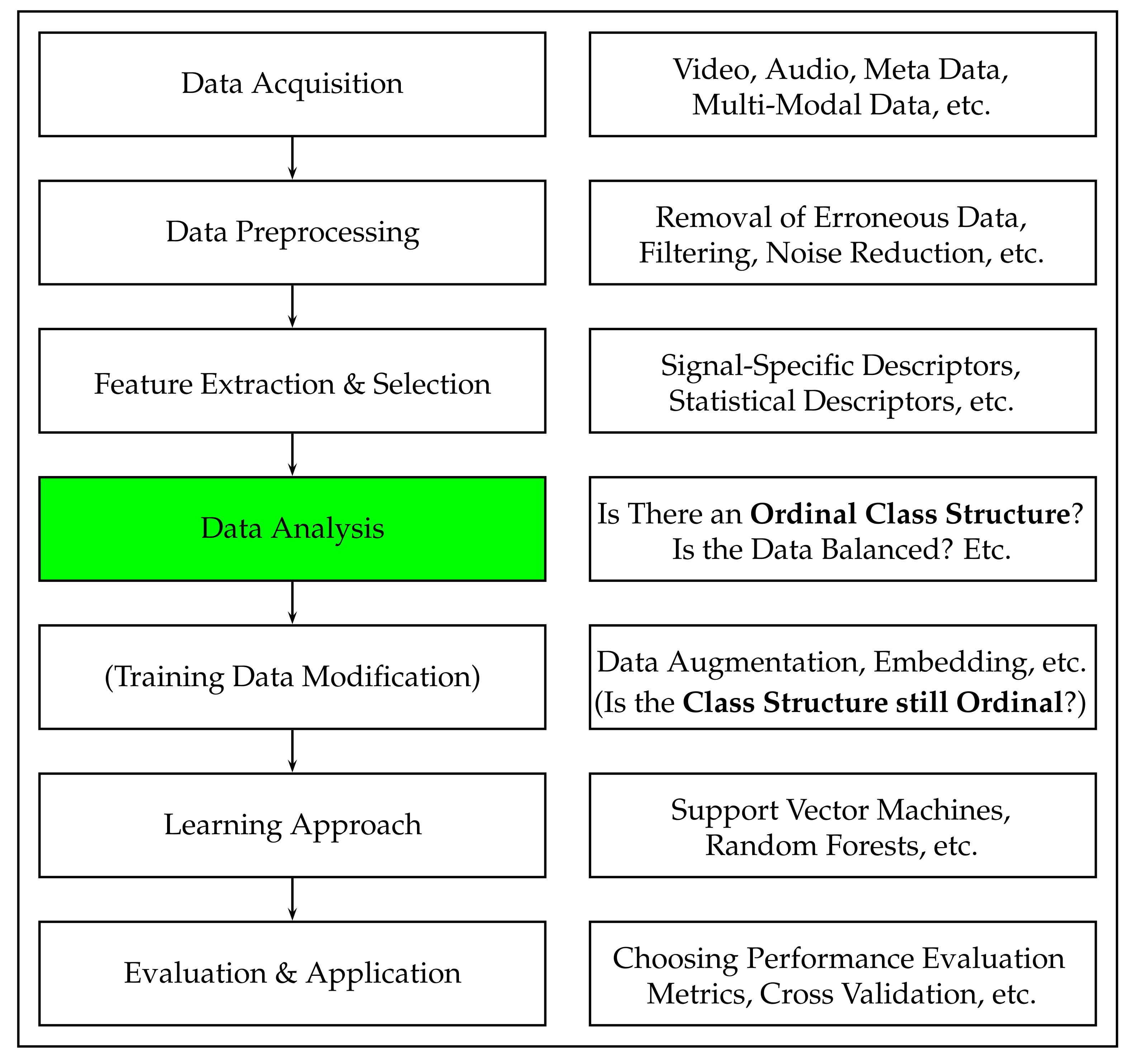
In this section, we will first provide the formalisation for our current work. Subsequently, we will introduce our proposed novel working definition for ordinal classification tasks that is independent from the meaning of the corresponding class labels.
2.1. Formalisation
Let
be a
c-class classification task, which is defined by the
d-dimensional data set
,
, and the corresponding set of class labels
, with
. We denote the resulting index set as
I, i.e.,
. Each element of
is a task-related object, which is a pair consisting of a data sample and its true class label, i.e.,
,
, whereby
denotes the number of elements in the set
. Specifically, it holds,
. Moreover, by
, we denote the binary subtask that is restricted to the classes
and
, i.e., for all
, with
, we define
Therefore, it holds that . For the definition of ordinal classification tasks, in this work, we introduce the term level of separability measures, which we define as follows, in Definition 1.
Definition 1 (Level of Separability Measures).
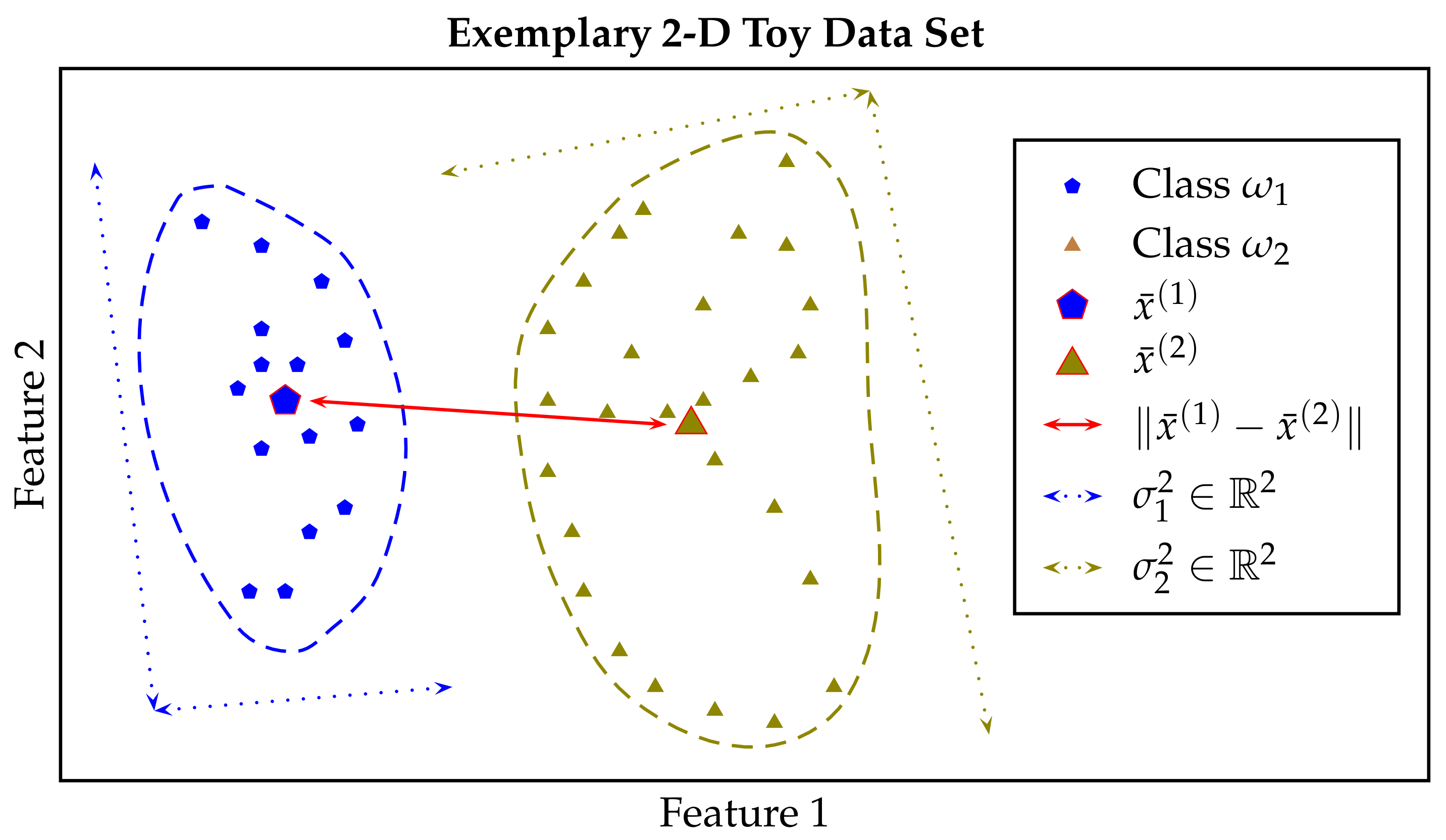
Let , , , and constitute a binary classification task in a d-dimensional feature space. Furthermore, let be the corresponding binary classification task, where we interchange the class labels of all samples from the task , i.e., . Additionally, for each , we define the set as . We denote the non-constant
and non-random
mapping μ as a level of separability measure (LSM)
, if μ fulfils the following properties: Note that a higher value for
implies a higher level of separability. The properties defined in Equation (
2) are further discussed in the following remark, i.e., in Remark 1.
Remark 1 (Properties of LSM mappings).
Let μ be an LSM mapping by Definition 1. Furthermore, let constitute a binary classification task. Property (P1) of Equation (2) implies that if we set , then the value of is equal to the minimum value of μ, across all . Therefore, we say that μ is point-separating
. More precisely, the set is defined as , i.e., . In such a set, each data point is assigned to both of the class labels, leading to the lowest level of separability, in combination with any LSM mapping μ. Property (P2) of Equation (2) simply implies that interchanging the labels of all data points does not change the value of μ, evaluated in combination with the set X. Therefore, we say that μ is label invariant
, or simply symmetric.
By
, we denote the set of all mappings that measure the level of separability of any binary classification task from the
d-dimensional feature space, i.e.,
Note that by Definition 1, each element of the set
, not only fulfils the properties (P0), (P1), and (P2) of Equation (
2), but is also a
non-constant and
non-random mapping. Moreover, note that the set
is non-empty, for all
, as we briefly discuss in the following example, i.e., Example 1.
Example 1 (Existence of LSM mappings).
Note that the set is non-empty, for all . Let CM be a deterministic
classification model, e.g., a support vector machine, which is trained based on the set . Let be the resubstitution error (training error) of classifier CM, i.e., is the fraction of data points in X that are misclassified by classifier CM. Then, fulfils the properties of Equation (2), for each absolute term , and any deterministic classification model CM. Let
be an LSM mapping. For all
, we define
as follows:
which measures the level of separability between the samples from class
and the samples from class
. Therefore, for
, the statement,
, implies that it is
easier to separate the classes
and
from each other, than to separate the classes
and
from each other. Thus, if it holds,
, we simply say that the binary classification task
has a
higher level of separability than the binary classification task
. Note that from Equations (
1) and (
4), it directly follows that
. In addition, note that setting
to zero, for all
, is a logical consequence, as it is not possible to separate two
identical data sets from each other.
Furthermore, let be the set of all permutations of the set I. More precisely, each , is a bijective function. In addition, by , we denote the reversed permutation of . For instance, for the identity permutation, , it holds, .
By
, we denote the
pairwise separability matrix (PSM), consisting of the elements
, i.e.,
. Moreover, by
, we define the PSM whose rows and columns are rearranged specific to permutation
, i.e.,
. For reasons of simplicity, we will denote
simply by
, with
, whereby
denotes the identity permutation. More precisely,
can be depicted as follows:
Note that by definition, matrix
is symmetric for all
. Finally, we summarise all of the required ingredients for our proposed working definition of ordinal classification tasks in
Table 1.
As briefly introduced in
Section 1, in general, an ordinal class structure is denoted by the ≺-sign, e.g.,
. In an OC task, we denote the
first and the
last class of such an ordered class structure as
edge classes, or simply
edges. In that particular example, i.e.,
, the classes
and
would be the corresponding edges. Moreover, in the common understanding of ordinal (class) structures, the reversed order of an ordinal arrangement also constitutes an ordinal structure. More precisely, the relations
and
are equivalent. Therefore, the
uniqueness of an ordinal class structure is defined by
exactly two class orders (or permutations), originating from the two edges. Based on this observation and the definitions introduced above, in the next subsection, we propose a
working definition for OC tasks that is independent from the
meaning of the corresponding class labels.
2.2. Feature Space-Based Working Definition for Ordinal Classification Tasks
As a prior step to our proposed working definition for ordinal classification tasks, we first introduce the term ordinal arrangement, which we present in Definition 2.
Definition 2 (Ordinal Arrangements).
Let be a symmetric matrix with elements , with . Matrix S represents an ordinal arrangement
, if and only if, , it holds that Note that the properties of Equation (
6) can be summarised as follows. Let
,
, constitute an ordinal arrangement by Definition 2. Then, the relations between the elements of
S can be symbolically depicted as
whereby
denotes the transpose of
S. Note that for each symmetric matrix
,
, property
is equivalent to
, and statement
is equivalent to
(which is implied in Equation (
7) by including
). Based on the concept of ordinal arrangements introduced above, we provide the working definition for ordinal classification tasks as follows.
Definition 3 (Working Definition for Ordinal Classification Tasks).
Let , , , constitute a c-class classification task, with . Let be an LSM mapping. Furthermore, let be the set of all permutations of the set and . We denote as feature space-based ordinal (FS-ordinal), with respect to the order
and mapping
μ, if and only if, , for the corresponding PSMs, , it holds that Note that, as defined in
Section 2.1,
denotes the reversed permutation of
, e.g.,
and
.
If the task constitutes an FS-ordinal classification task, with respect to the order and mapping , we simply say that the task is FS-ordinal specific to .
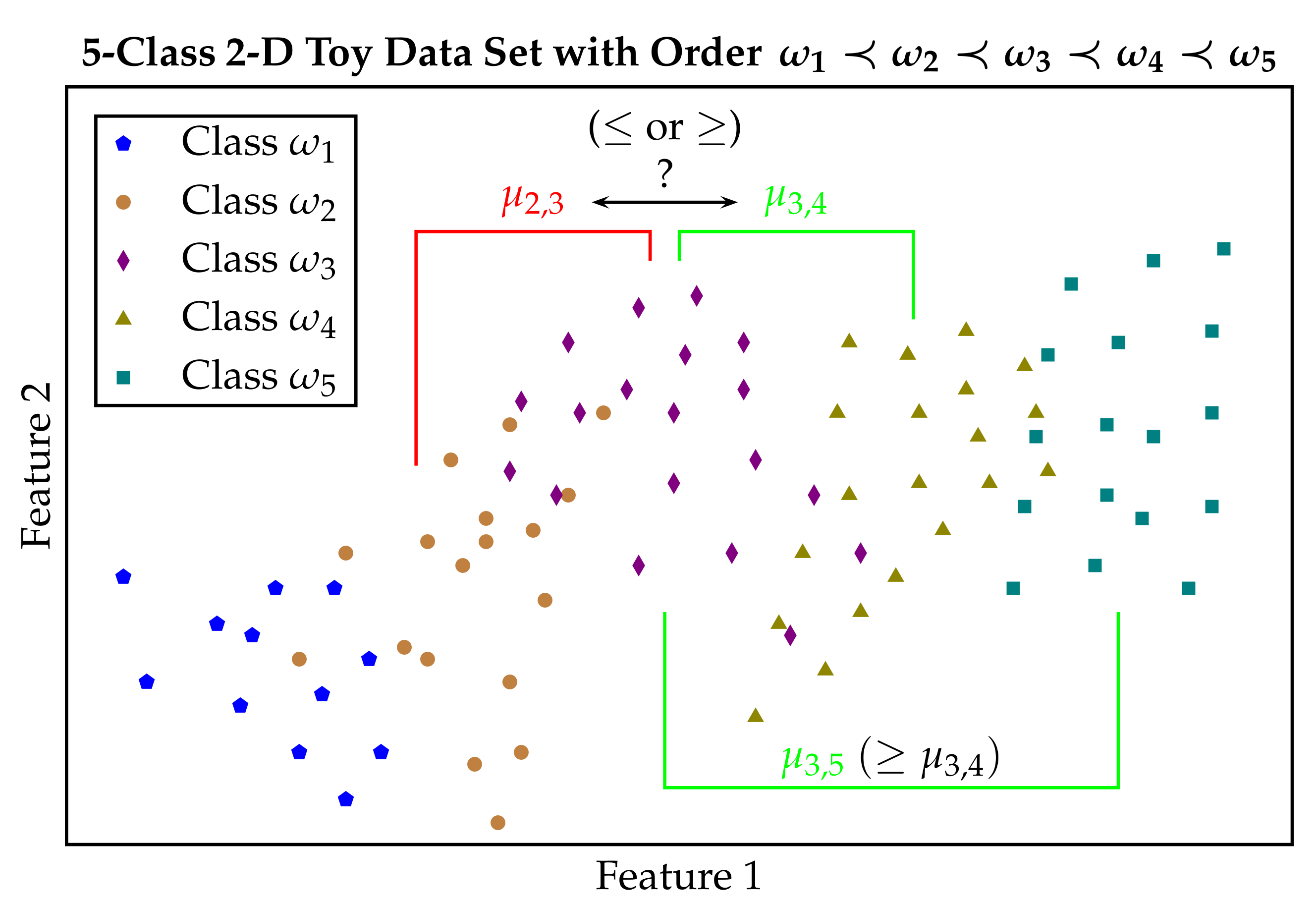
Figure 2 illustrates the properties of an ordinal classification task, based on a two-dimensional 5-class toy data set. Note that the term
closer in the caption of
Figure 2 does not refer to the distances between different class pairs, but to the order of the classes, i.e., the
arrangement of the columns of the corresponding PSM. More precisely, e.g., for the arrangement
, we say that class
is
closer to class
than to class
. However, for instance, the (averaged) Euclidean distance between the samples from the classes
and
could be greater than the (averaged) Euclidean distance between the samples from the classes
and
.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}