
GANBA: Generative Adversarial Network for Biometric Anti-Spoofing



Abstract
:1. Introduction
- We study the robustness of the complete voice biometric system against adversarial spoofing attacks.
- We also propose a novel generative adversarial network for biometric anti-spoofing (GANBA) which generates adversarial spoofing attacks capable of fooling the PAD system without being detected by the ASV system, i.e., without changing the speaker information of the utterance. Moreover, while our previous work [15] was focused on adversarial attack generation, here we also train the PAD discriminator so that it provides us with a reinforced defense against adversarial and even original spoofing attacks.
- To the best of our knowledge, adversarial spoofing attacks have only been studied on TTS and VC spoofing attacks (LA scenarios). In this paper, replay spoofing attacks (PA scenarios) are also considered.
2. Background
2.1. Automatic Speaker Verification (ASV)
- Probabilistic Linear Discriminant Analysis (PLDA) [22,23]: it is a probabilistic framework which is able to model the inter- and intra-speaker variability. There are three types of PLDA models [24]: simplified [25], standard [22], and two-covariance [26]. In all variants, the expectation-maximization (EM) algorithm [27] is used to train the PLDA model.
- B-vector [28]: it is a DNN-based model which considers ASV as a binary classification problem. Specifically, from the x-vectors and computed for each pair of utterances (enrollment and test utterances), a b-vector representing the relationship between and is computed as follows,where ⊕, ⊖ and ⊗ are the element-wise addition, subtraction and multiplication operations, respectively. Then, the b-vector features are fed to a binary DNN which determines whether the enrollment and test utterances are uttered by the same or different speaker.
2.2. Anti-Spoofing or Presentation Attack Detection (PAD)
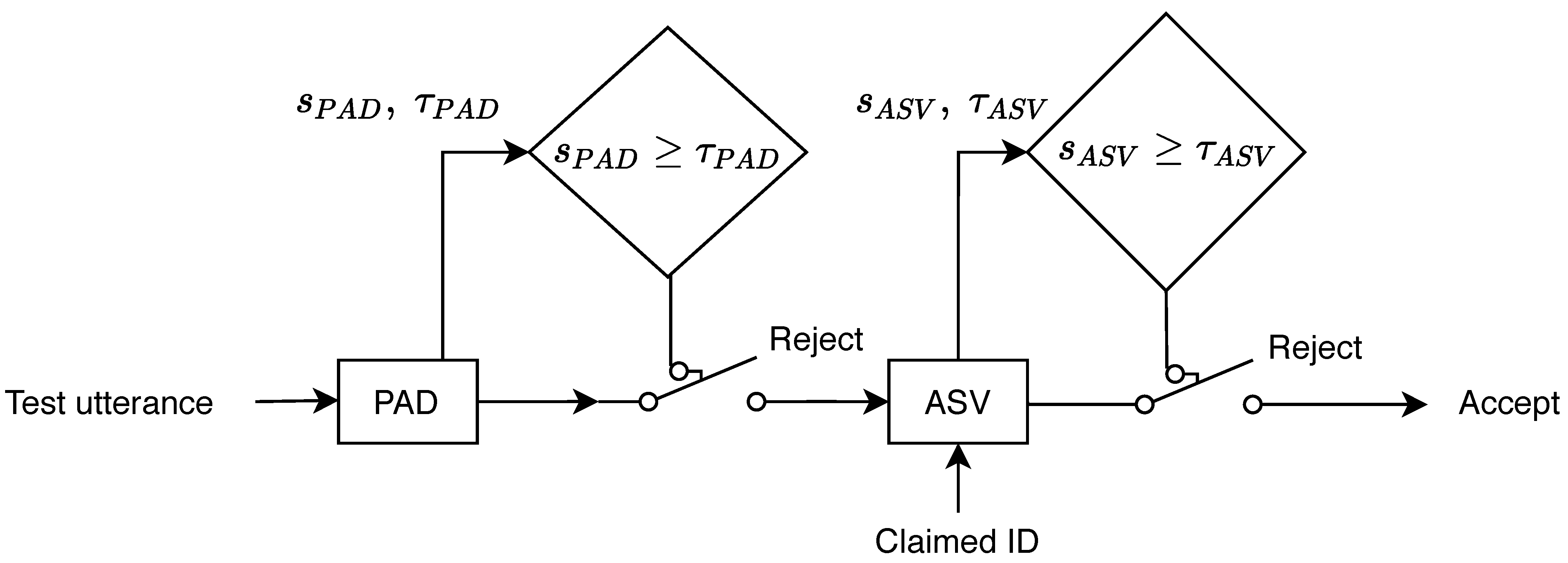
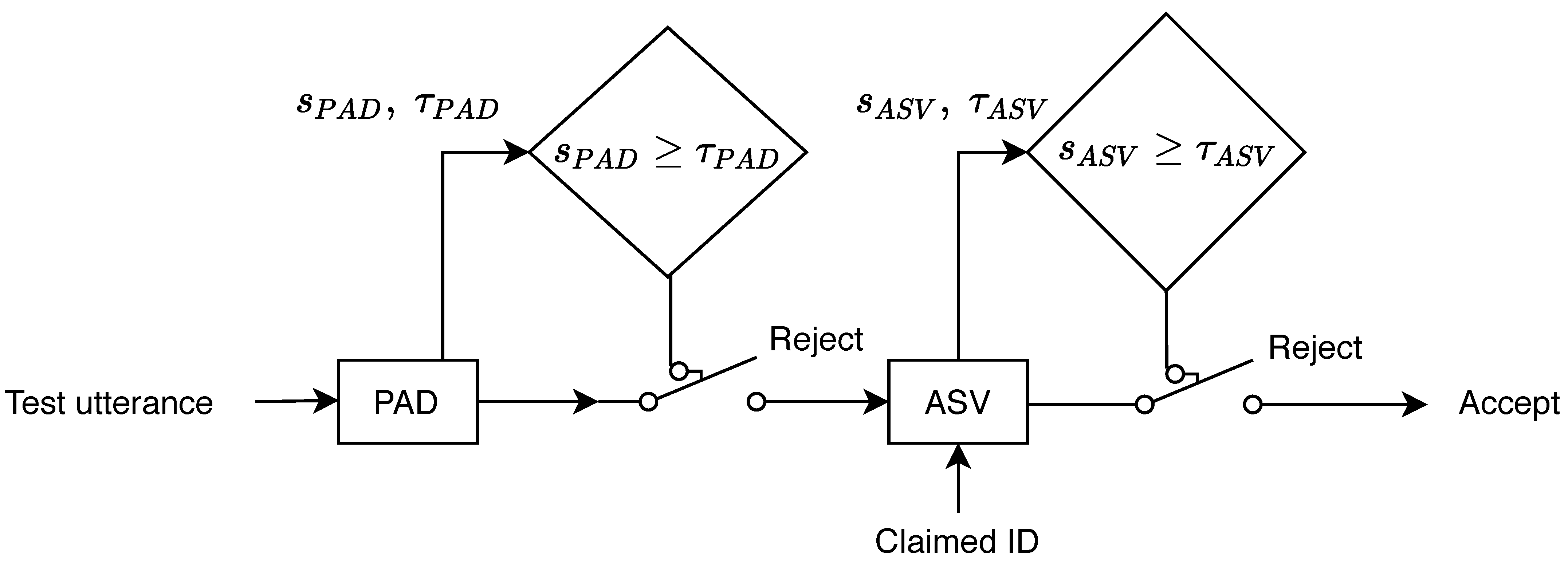
2.3. Voice Integration Systems: Joint ASV and PAD
2.4. Adversarial Spoofing Attacks
3. Proposed Method
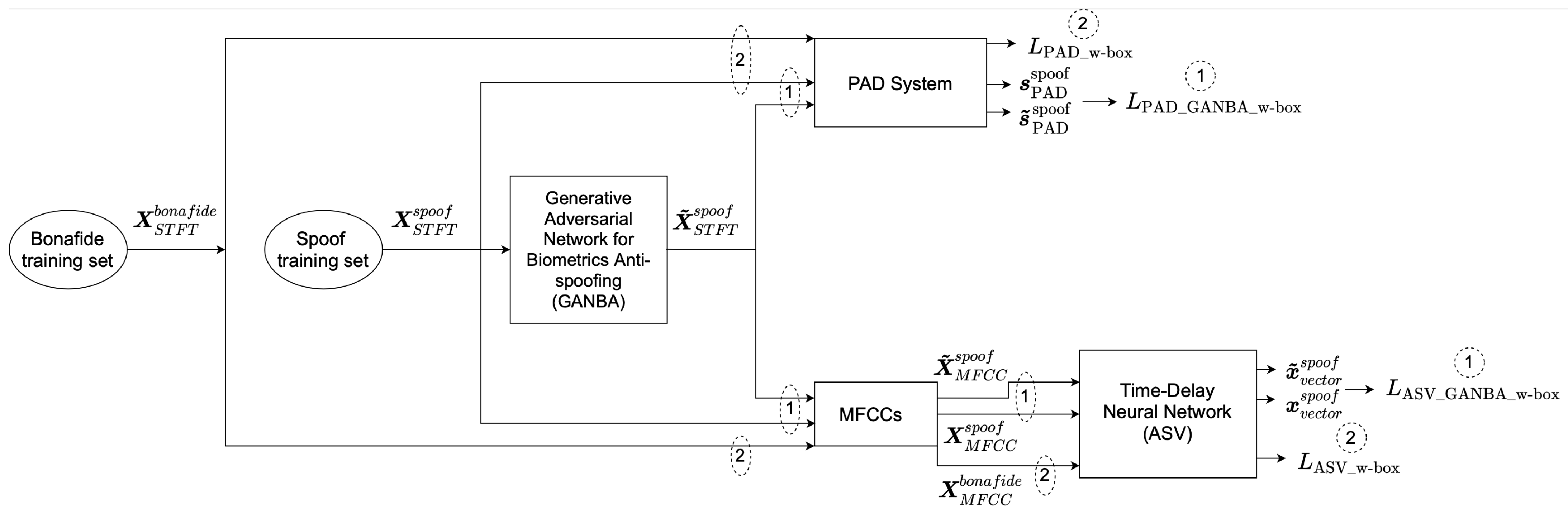
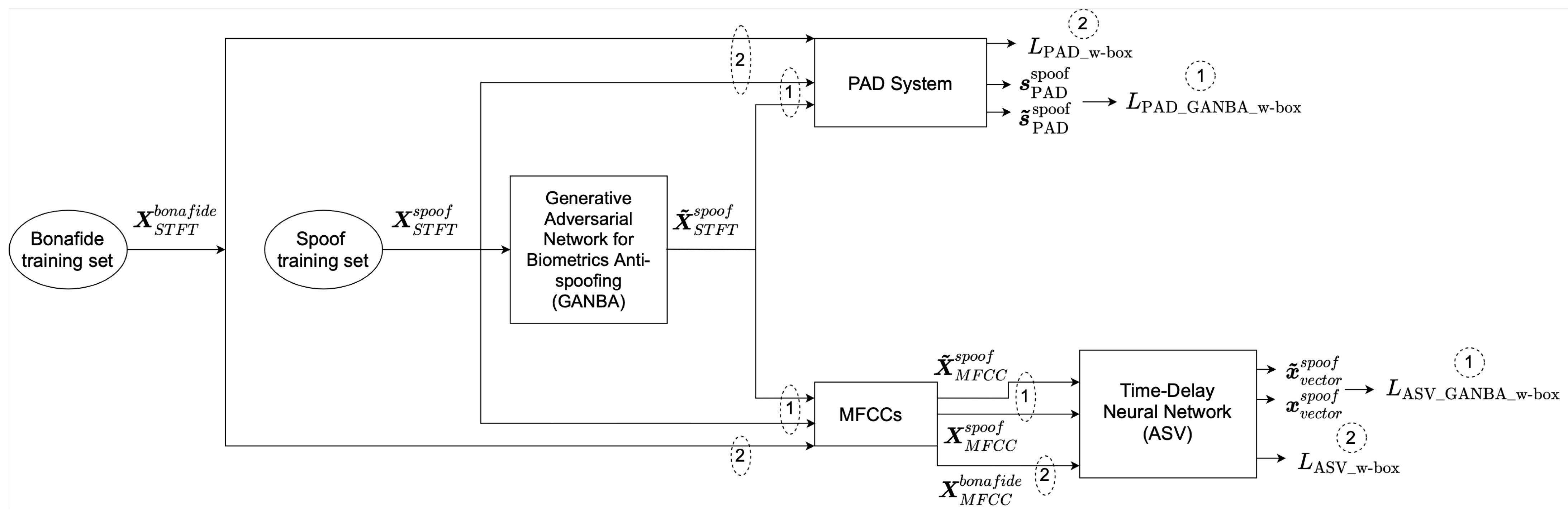
3.1. White-Box GANBA
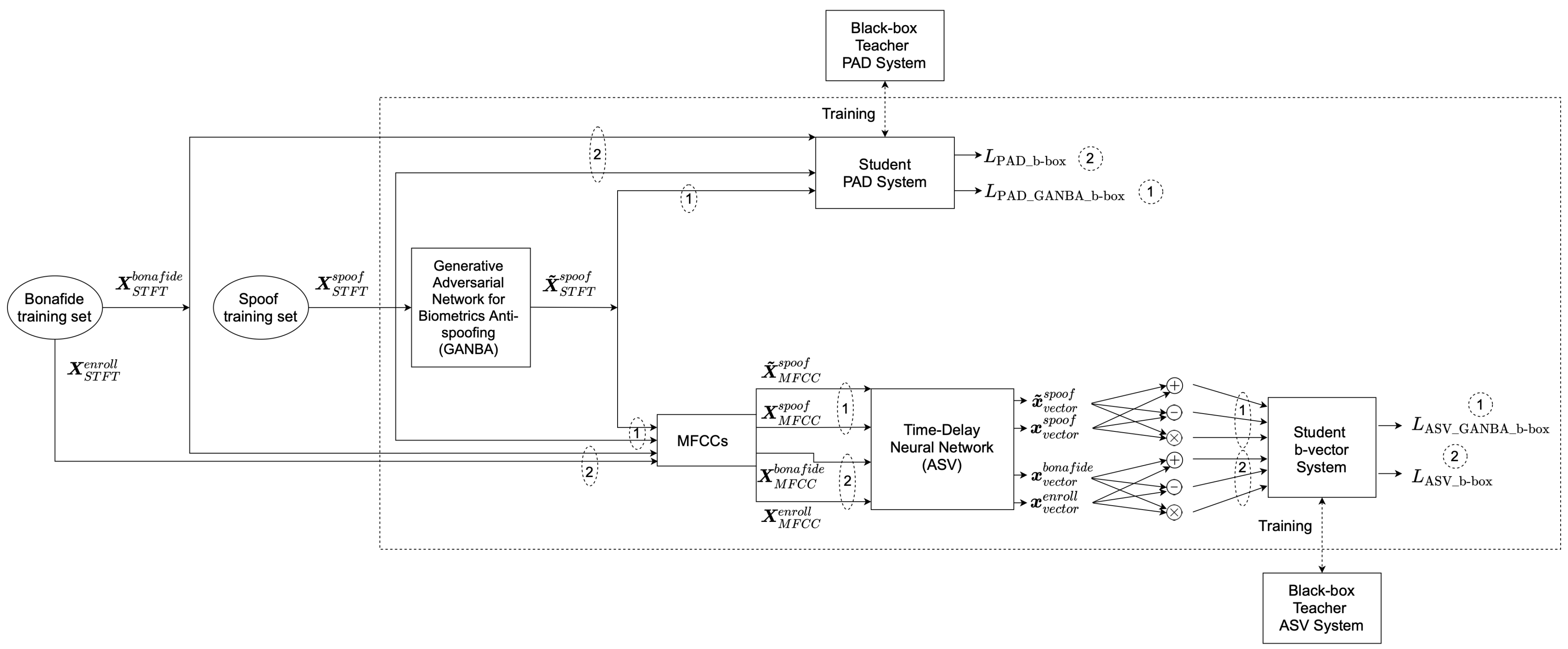
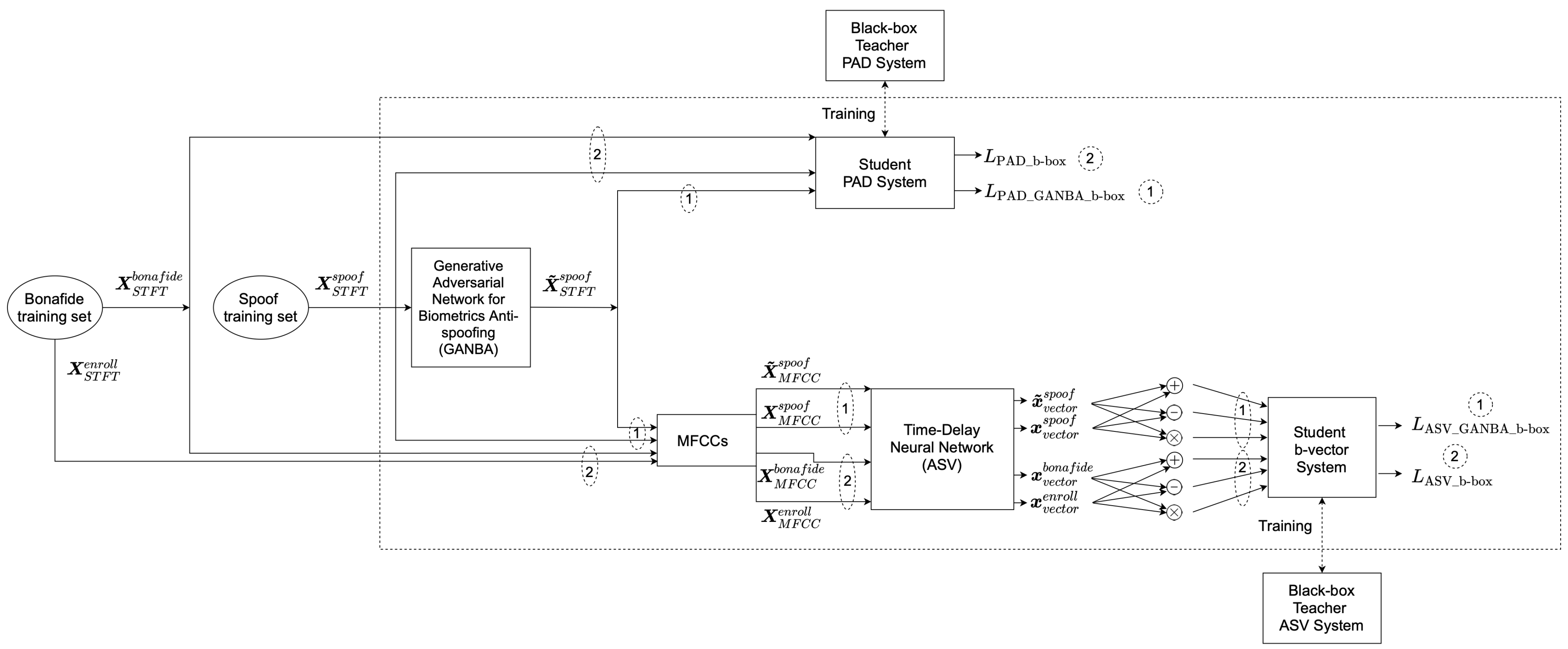
3.2. Black-Box GANBA
4. Experimental Setup
4.1. Speech Datasets
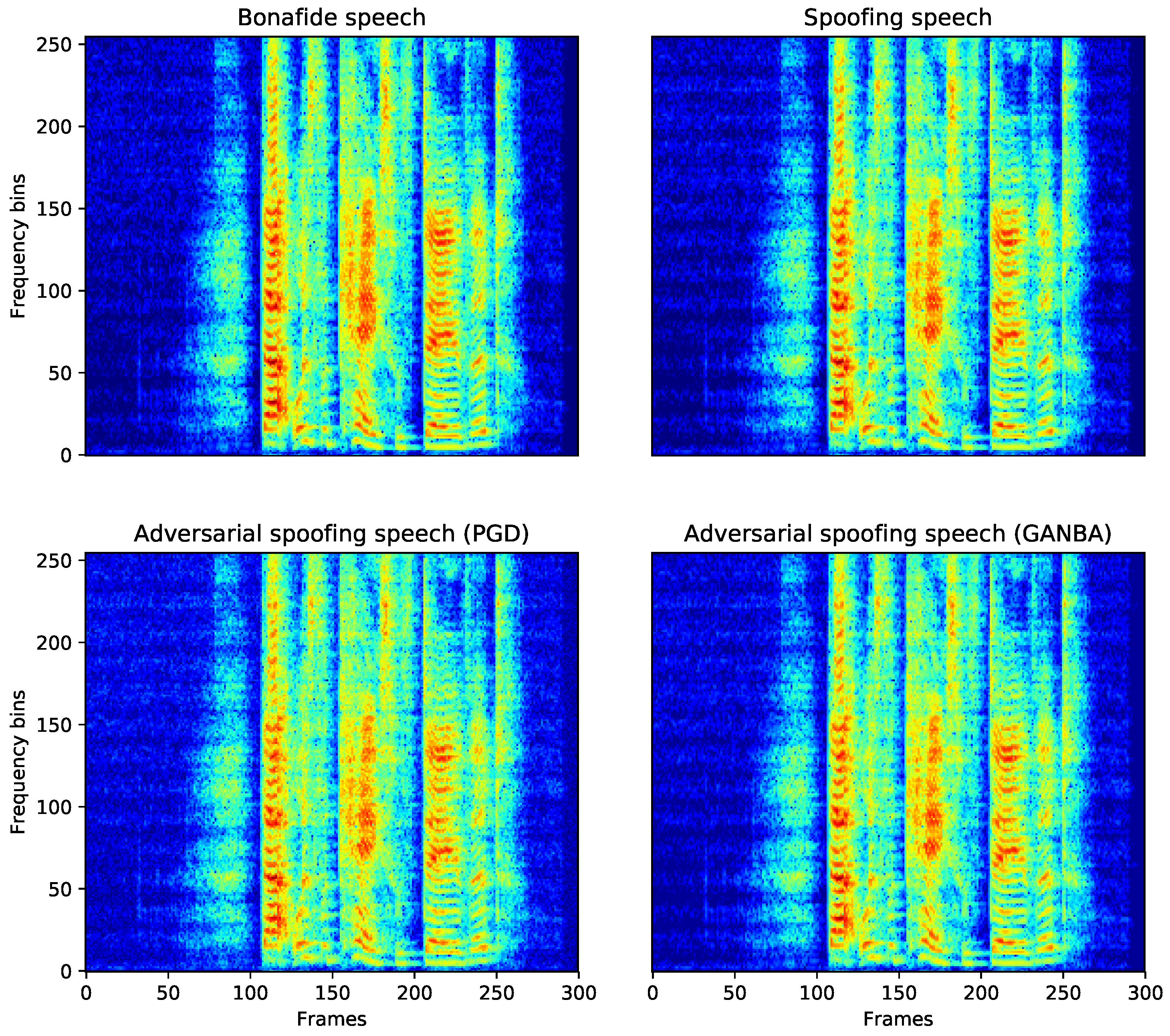
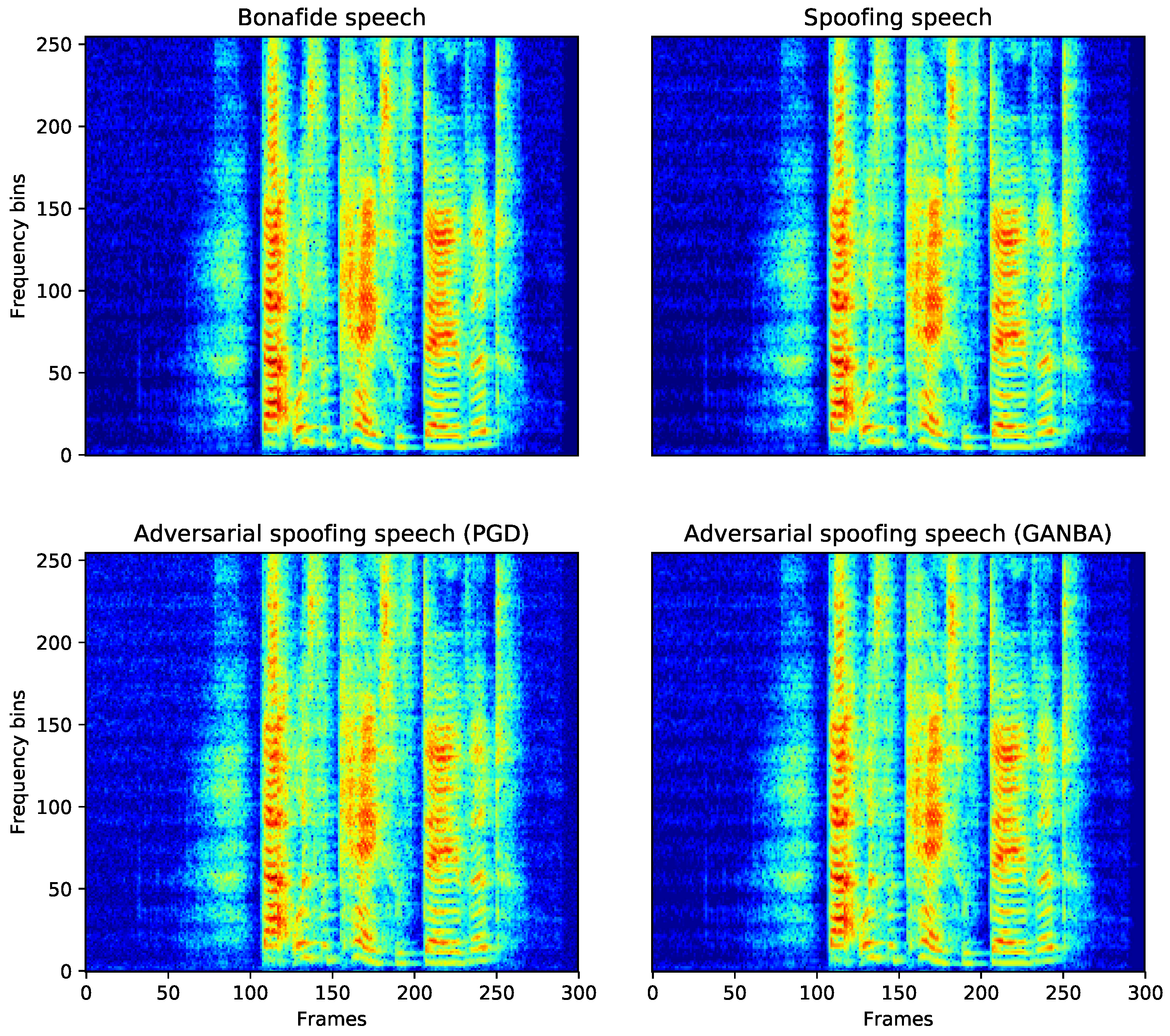
4.2. Spectral Analysis
4.3. Implementation Details
4.4. Evaluation Metrics
5. Results
5.1. Voice Biometric Systems Results
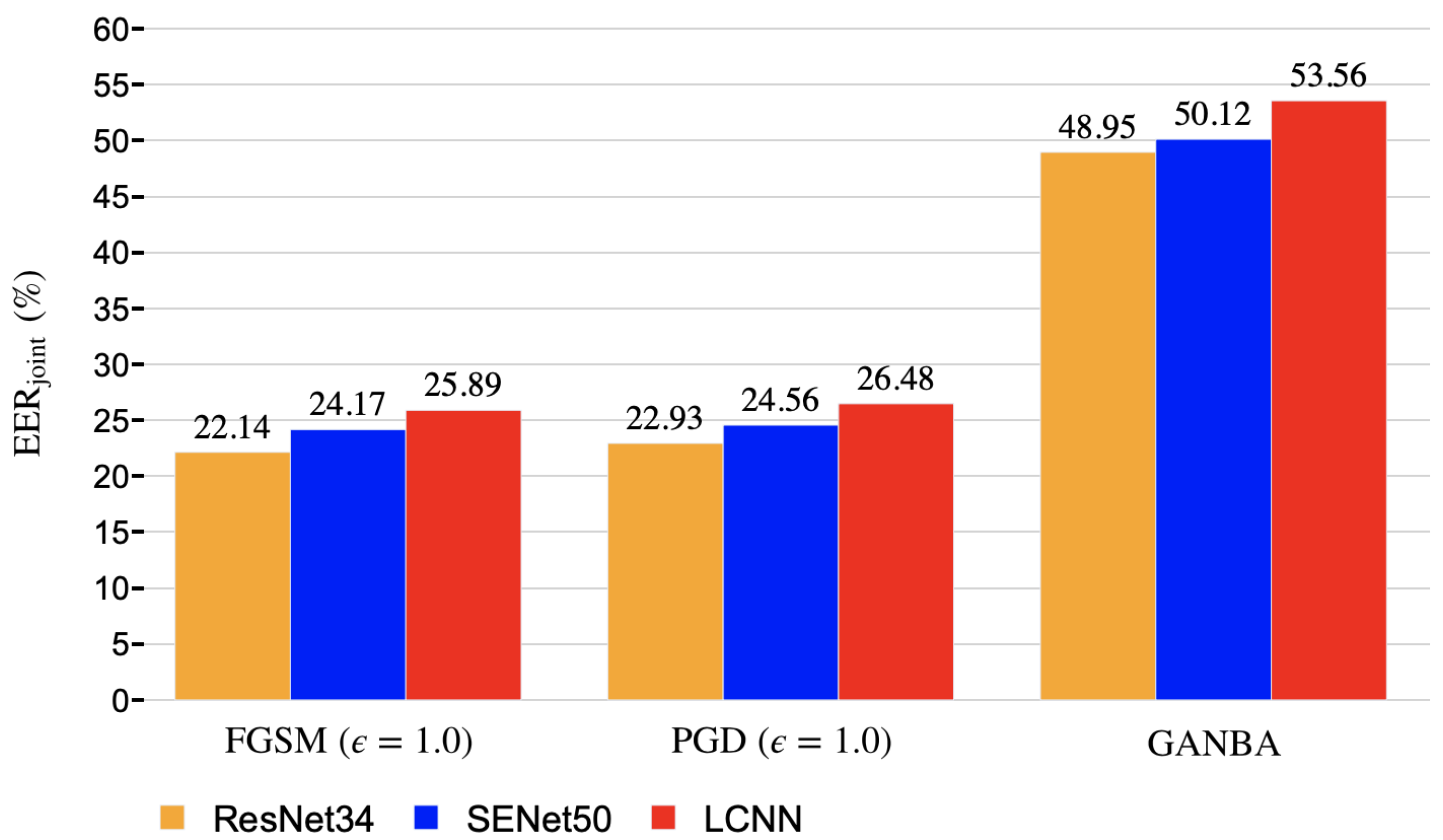
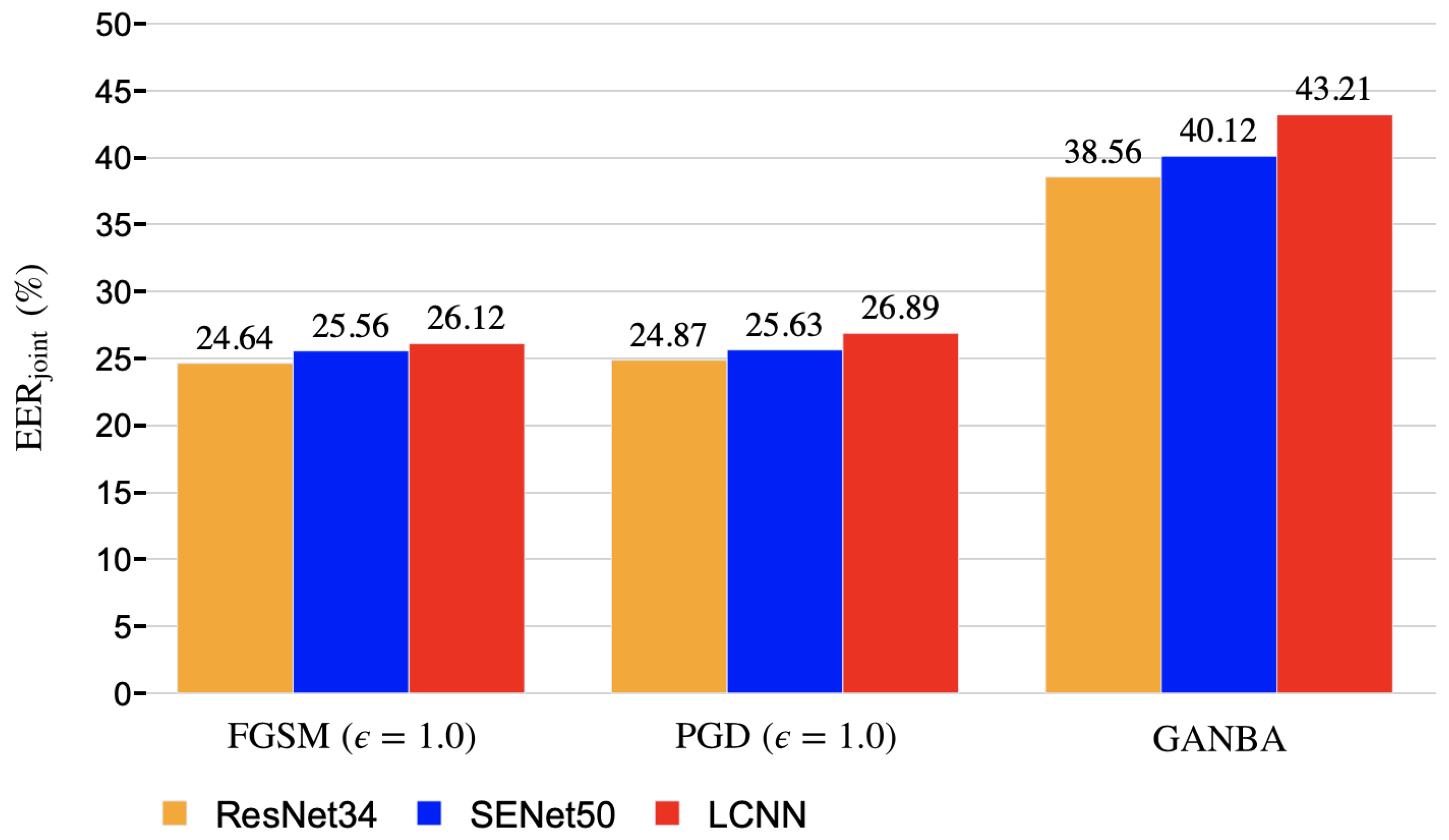
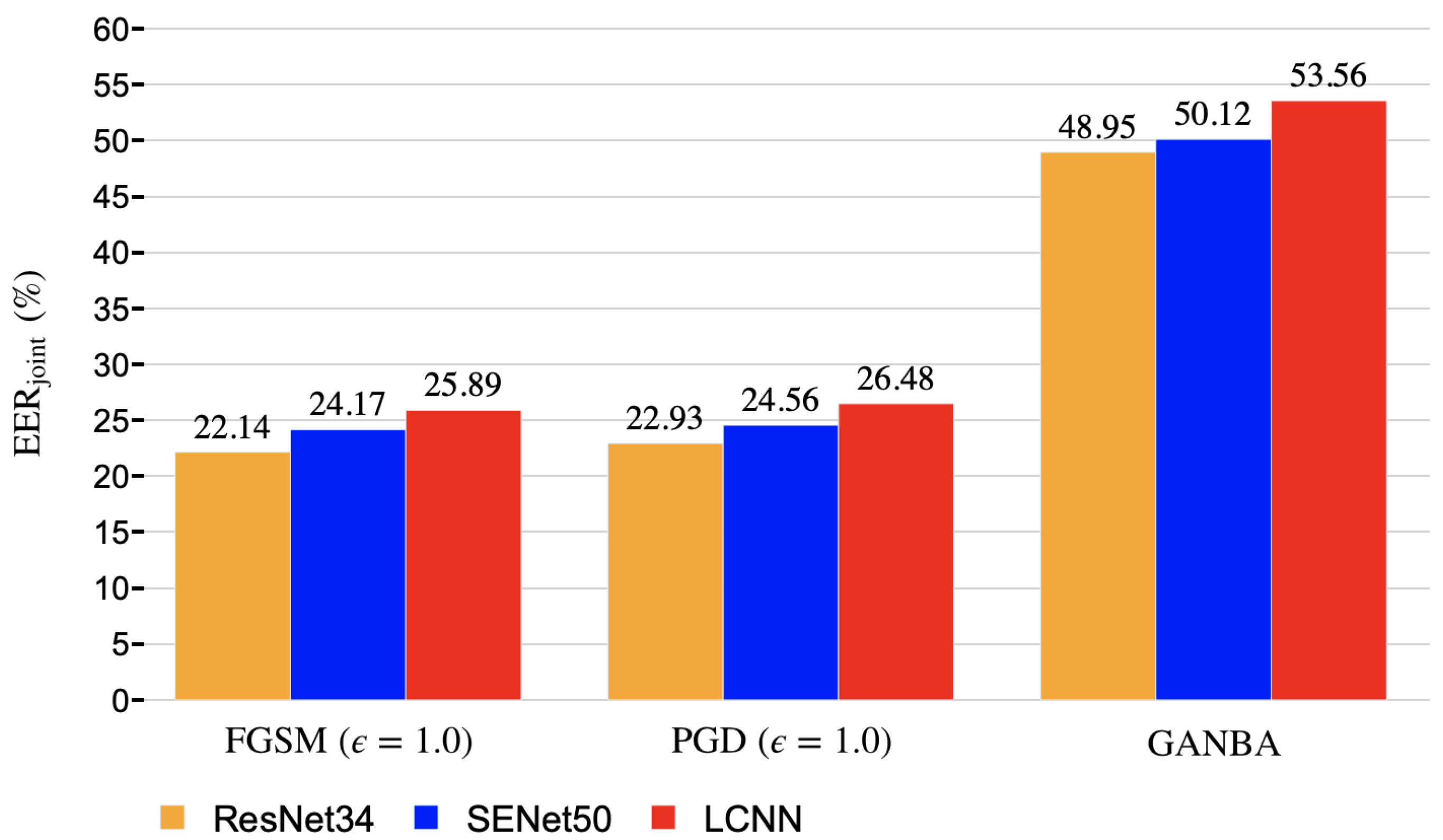
5.2. White-Box Attacks Results
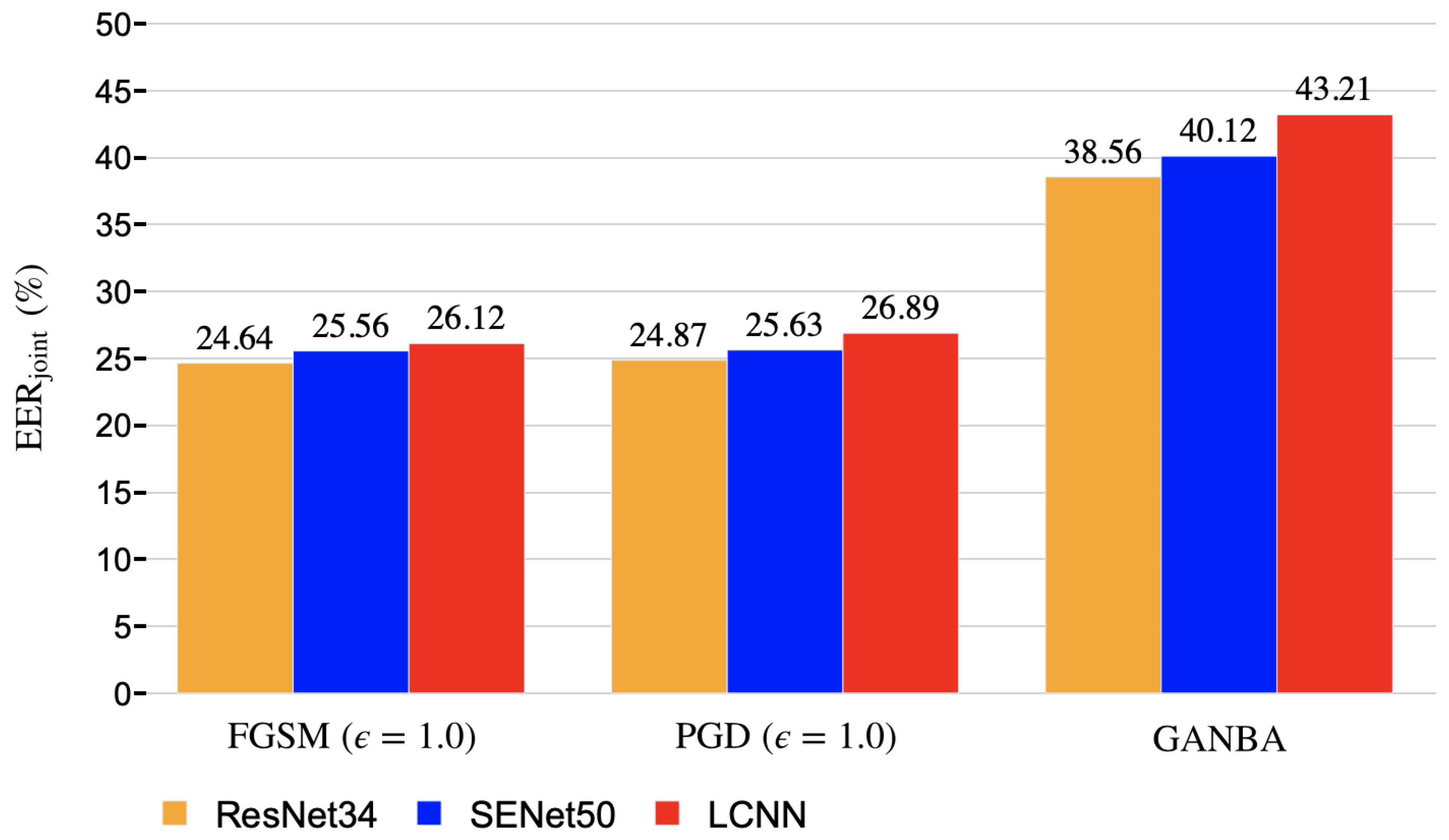
5.3. Black-box Attacks Results
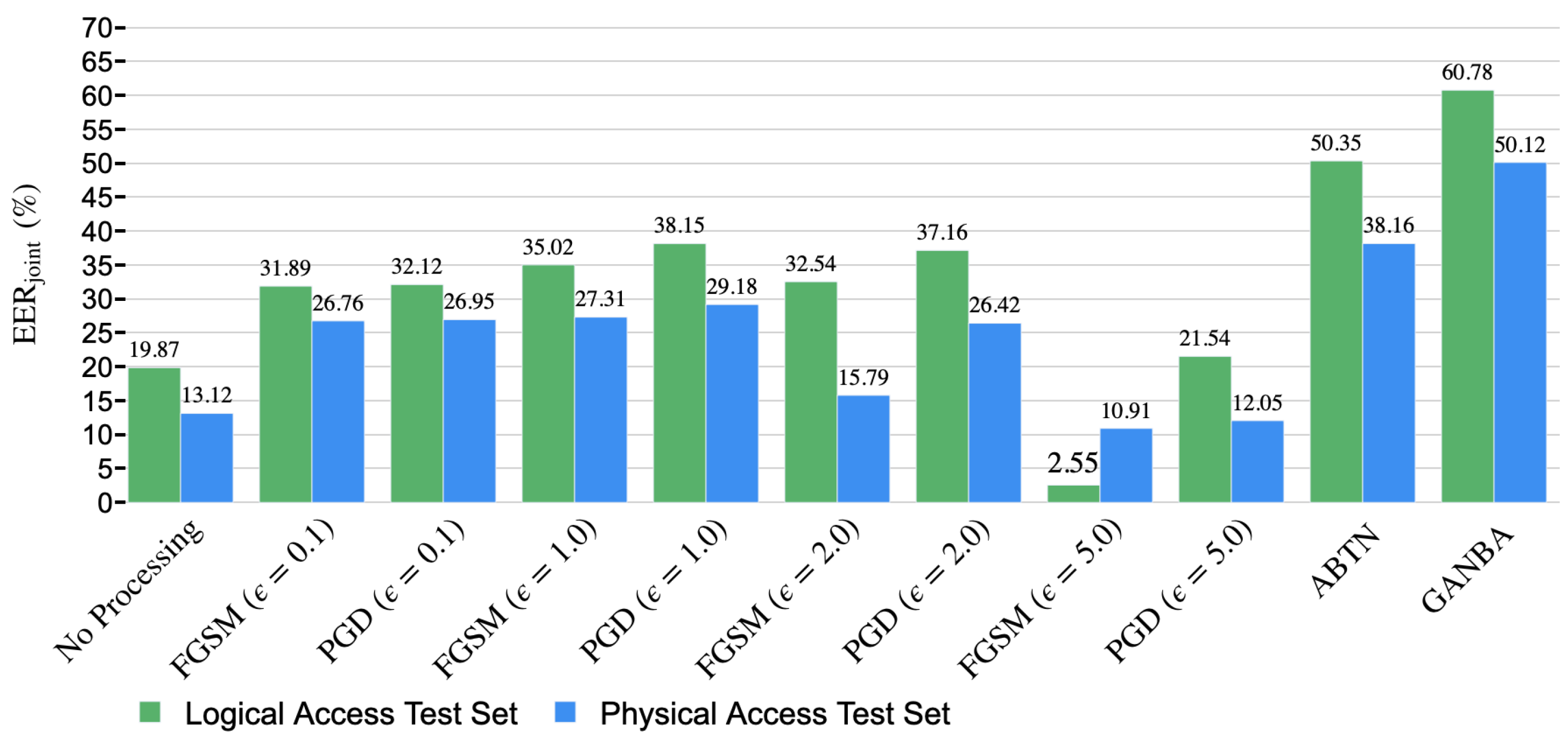
5.4. Defenses against Adversarial Spoofing Attacks
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jain, A.K.; Ross, A.; Pankanti, S. Biometrics: A Tool for Information Security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–143. [Google Scholar] [CrossRef] [Green Version]
- Gomez-Alanis, A.; Gonzalez-Lopez, J.A.; Peinado, A.M. A Kernel Density Estimation Based Loss Function and its Application to ASV-Spoofing Detection. IEEE Access 2020, 8, 108530–108543. [Google Scholar] [CrossRef]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A Gated Recurrent Convolutional Neural Network for Robust Spoofing Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1985–1999. [Google Scholar] [CrossRef]
- Wu, Z.; Leon, P.L.D.; Demiroglu, C.; Khodabakhsh, A.; King, S.; Ling, Z.H.; Saito, D.; Stewart, B.; Toda, T.; Wester, M.; et al. Anti-Spoofing for Text-Independent Speaker Verification: An Initial Database, Comparison of Countermeasures, and Human Performance. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 768–783. [Google Scholar] [CrossRef] [Green Version]
- ISO. Presentation Attack Detection. Available online: https://www.iso.org/standard/67381.html (accessed on 28 December 2021).
- Wu, Z.; Kinnunen, T.; Evans, N.W.D.; Yamagishi, J.; Hanilçi, C.; Sahidullah, M.; Sizov, A. ASVspoof 2015: The First Automatic Speaker Verification Spoofing and Countermeasures Challenge. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 2037–2041. [Google Scholar]
- Korshunov, P.; Marcel, S.; Muckenhirn, H.; Gonçalves, A.R.; Souza Mello, A.G.; Velloso Violato, R.P.; Simoes, F.O.; Neto, M.U.; de Assis Angeloni, M.; Stuchi, J.A.; et al. Overview of BTAS 2016 speaker anti-spoofing competition. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–6. [Google Scholar]
- Kinnunen, T.; Sahidullah, M.; Delgado, H.; Todisco, M.; Evans, N.W.D.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2–6. [Google Scholar]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K. ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1008–1012. [Google Scholar]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online. 16 September 2021; pp. 47–54. [Google Scholar]
- Gomez-Alanis, A.; Gonzalez-Lopez, J.A.; Dubagunta, S.P.; Peinado, A.M.; Magimai-Doss, M. On Joint Optimization of Automatic Speaker Verification and Anti-spoofing in the Embedding Space. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1579–1593. [Google Scholar] [CrossRef]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A Deep Identity Representation for Noise Robust Spoofing Detection. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 676–680. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. Performance evaluation of front- and back-end techniques for ASV spoofing detection systems based on deep features. In Proceedings of the Iberspeech 2018, Barcelona, Spain, 21–23 November 2018; pp. 45–49. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A Light Convolutional GRU-RNN Deep Feature Extractor for ASV Spoofing Detection. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1068–1072. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A. Adversarial Transformation of Spoofing Attacks for Voice Biometrics. In Proceedings of the Iberspeech 2020, Valladolid, Spain, 24-25 March 2021; pp. 255–259. [Google Scholar]
- Liu, S.; Wu, H.; Lee, H.Y.; Meng, H. Adversarial Attacks on Spoofing Countermeasures of Automatic Speaker Verification. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 312–319. [Google Scholar]
- Zhang, Y.; Jiang, Z.; Villalba, J.; Dehak, N. Black-box Attacks on Spoofing Countermeasures Using Transferability of Adversarial Examples. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 September 2020; pp. 4238–4242. [Google Scholar]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Banf, AB, Canada, 14–16 April 2014. [Google Scholar]
- Hansen, J.H.L.; Hasan, T. Speaker Recognition by Machines and Humans: A Tutorial Review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Prince, S.; Elder, J.H. Probabilistic Linear Discriminant Analysis for Inferences About Identity. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Ioffe, S. Probabilistic Linear Discriminant Analysis. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 531–542. [Google Scholar]
- Sizov, A.; Lee, K.A.; Kinnunen, T. Unifying Probabilistic Linear Discriminant Analysis Variants in Biometric Authentication. In Proceedings of the Structural and Syntactic Pattern Recognition, Joensuu, Finland, 20–22 August 2014; pp. 464–475. [Google Scholar]
- Kenny, P. Bayesian Speaker Verification with Heavy-Tailed Priors. In Proceedings of the Odyssey 2010, Brno, Czech Republic, 28 June 28–1 July 2010. [Google Scholar]
- Brümmer, N.; de Villiers, E. The Speaker Partitioning Problem. In Proceedings of the Odyssey 2010, Brno, Czech Republic, 28 June 28–1 July 2010. [Google Scholar]
- Dempster, A.; Laird, N.; Rubin, D. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Lee, H.S.; Tso, Y.; Chang, Y.F.; Wang, H.M.; Jeng, S.K. Speaker Verification using Kernel-based Binary Classifiers with Binary Operation Derived Features. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1660–1664. [Google Scholar]
- Chingovska, I.; Anjos, A.; Marcel, S. Anti-spoofing in Action: Joint Operation with a Verification System. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 98–104. [Google Scholar]
- van Leeuwen, D.A.; Brümmer, N. An Introduction to Application-Independent Evaluation of Speaker Recognition Systems. In Speaker Classification I: Fundamentals and Methods; Springer: Heidelberg, Germany, 2007; pp. 330–353. [Google Scholar]
- Doddington, G.R.; Przybocki, M.A.; Martin, A.F.; Reynolds, D.A. The NIST Speaker Recognition Evaluation—Overview, Methodology, Systems, Results, Perspective. Speech Commun. 2000, 31, 225–254. [Google Scholar] [CrossRef]
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A Comparison of Features for Synthetic Speech Detection. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015; pp. 2087–2091. [Google Scholar]
- Lavrentyeva, G.; Novoselov, S.; Malykh, E.; Kozlov, A.; Kudashev, O.; Shchemelinin, V. Audio Replay Attack Detection with Deep Learning Frameworks. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 82–86. [Google Scholar]
- Todisco, M.; Delgado, H.; Evans, N.W.D. Constant-Q Cepstral Coefficients: A Spoofing Countermeasure for Automatic Speaker Verification. Comput. Speech Lang. 2017, 45, 516–535. [Google Scholar] [CrossRef]
- Muckenhirn, H.; Magimai-Doss, M.; Marcel, S. End-to-End Convolutional Neural Network-Based Voice Presentation Attack Detection. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 335–341. [Google Scholar]
- Kinnunen, T.; Delgado, H.; Evans, N.; Lee, K.A.; Vestman, V.; Nautsch, A.; Todisco, M.; Wang, X.; Sahidullah, M.; Yamagishi, J.; et al. Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification: Fundamentals. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2195–2210. [Google Scholar] [CrossRef]
- Leon, P.L.D.; Pucher, M.; Yamagishi, J.; Hernáez, I.; Saratxaga, I. Evaluation of Speaker Verification Security and Detection of HMM-Based Synthetic Speech. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2280–2290. [Google Scholar] [CrossRef]
- Sizov, A.; Khoury, E.; Kinnunen, T.; Wu, Z.; Marcel, S. Joint Speaker Verification and Antispoofing in the i-Vector Space. IEEE Trans. Inf. Forensics Secur. 2015, 10, 821–832. [Google Scholar] [CrossRef] [Green Version]
- Kinnunen, T.; Lee, K.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah, M.; Yamagishi, J.; Reynolds, D. t-DCF: A Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification. In Proceedings of the Odyssey 2018, Les Sables d’Olonne, France, 26–29 June 2018; pp. 312–319. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, Y.; Karam, L.J. Universal Adversarial Attack Via Enhanced Projected Gradient Descent. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1241–1245. [Google Scholar]
- Pedroni, V.A. Finite State Machines in Hardware: Theory and Design (with VHDL and SystemVerilog); The MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Ling, Z.H.; Becker, M.; Kinnunen, T.; Vestman, V.; et al. ASVspoof 2019: A large-scale public database of synthetized, converted and replayed speech. In Computer Speech and Language; Elsevier: Amsterdam, The Netherlands, 2020; p. 101114. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2616–2620. [Google Scholar]
- Kaldi ASR. SRE16 Xvector Model. Available online: http://kaldi-asr.org/models/m3 (accessed on 28 December 2021).
- Lai, C.I.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-Spoofing with Squeeze-Excitation and Residual Networks. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1013–1017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; Devito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–4. [Google Scholar]
- Uesato, J.; O’Donoghue, B.; Kohli, P.; van den Oord, A. Adversarial Risk and the Dangers of Evaluating Against Weak Attacks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5025–5034. [Google Scholar]
- Korshunov, P.; Marcel, S. Cross-Database Evaluation of Audio-Based Spoofing Detection Systems. In Proceedings of the Interspeech 2017, San Francisco, CA, USA, 8–12 September 2016; pp. 1705–1709. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Biometric Systems | Logical Access Attacks | Physical Access Attacks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| PAD | ASV | (%) | (%) | (%) | min-tDCF | (%) | (%) | (%) | min-tDCF |
| LCNN | TDNN + PLDA | 5.85 | 4.71/30.58 * | 19.87 | 0.1237 | 4.62 | 6.87/18.43 * | 13.12 | 0.1221 |
| LCNN | TDNN + b-vector | 5.85 | 4.89/30.77 * | 20.12 | 0.1256 | 4.62 | 7.13/19.21 * | 13.89 | 0.1274 |
| SENet50 | TDNN + PLDA | 6.29 | 4.71/30.58 * | 21.15 | 0.1307 | 5.17 | 6.87/18.43 * | 14.48 | 0.1328 |
| SENet50 | TDNN + b-vector | 6.29 | 4.89/30.77 * | 21.74 | 0.1332 | 5.17 | 7.13/19.21 * | 14.81 | 0.1356 |
| ResNet34 | TDNN + PLDA | 6.75 | 4.71/30.58 * | 22.68 | 0.1412 | 5.62 | 6.87/18.43 * | 15.75 | 0.1415 |
| ResNet34 | TDNN + b-vector | 6.75 | 4.89/30.77 * | 23.09 | 0.1456 | 5.62 | 7.13/19.21 * | 15.97 | 0.1439 |
| Adv. Attacks/Defenses | Logical Access Attacks | Physical Access Attacks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Adv. Attack | Adv. Defense | (%) | (%) | (%) | min-tDCF | (%) | (%) | (%) | min-tDCF |
| No Processing | No Processing | 5.85 | 30.58 * | 19.87 | 0.1237 | 4.62 | 18.43 * | 13.12 | 0.1221 |
| PGD | Adv. Train FGSM | 8.42 | 30.78 * | 24.68 | 0.1532 | 7.50 | 19.87 * | 16.42 | 0.1434 |
| GANBA | Adv. Train FGSM | 20.34 | 29.18* | 40.12 | 0.3304 | 16.23 | 17.56 * | 35.43 | 0.3012 |
| FGSM | Adv. Train PGD | 7.34 | 31.03 * | 23.75 | 0.1476 | 6.73 | 19.02 * | 15.78 | 0.1389 |
| PGD | Adv. Train PGD | 8.07 | 30.89 * | 23.12 | 0.1502 | 7.82 | 18.07 * | 16.19 | 0.1476 |
| GANBA | Adv. Train PGD | 17.65 | 29.87 * | 38.39 | 0.3009 | 15.03 | 17.10 * | 34.32 | 0.2893 |
| FGSM | Adv. Train GANBA | 5.14 | 30.51 * | 18.95 | 0.1102 | 3.96 | 18.56 * | 12.16 | 0.1084 |
| PGD | Adv. Train GANBA | 5.33 | 30.44 * | 19.22 | 0.1204 | 4.22 | 18.31 * | 12.34 | 0.1121 |
| GANBA | Adv. Train GANBA | 5.45 | 30.66 * | 19.66 | 0.1222 | 4.37 | 18.72 * | 12.48 | 0.1145 |
| FGSM | PAD from GANBA | 4.12 | 30.33 * | 17.74 | 0.1011 | 3.21 | 18.22 * | 11.16 | 0.0976 |
| PGD | PAD from GANBA | 4.46 | 30.74 * | 18.15 | 0.1056 | 3.53 | 18.31 * | 11.24 | 0.0996 |
| GANBA | PAD from GANBA | 4.75 | 30.62 * | 18.53 | 0.1079 | 3.68 | 18.56 * | 11.36 | 0.1015 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomez-Alanis, A.; Gonzalez-Lopez, J.A.; Peinado, A.M. GANBA: Generative Adversarial Network for Biometric Anti-Spoofing. Appl. Sci. 2022, 12, 1454. https://doi.org/10.3390/app12031454
Gomez-Alanis A, Gonzalez-Lopez JA, Peinado AM. GANBA: Generative Adversarial Network for Biometric Anti-Spoofing. Applied Sciences. 2022; 12(3):1454. https://doi.org/10.3390/app12031454
Chicago/Turabian StyleGomez-Alanis, Alejandro, Jose A. Gonzalez-Lopez, and Antonio M. Peinado. 2022. "GANBA: Generative Adversarial Network for Biometric Anti-Spoofing" Applied Sciences 12, no. 3: 1454. https://doi.org/10.3390/app12031454
APA StyleGomez-Alanis, A., Gonzalez-Lopez, J. A., & Peinado, A. M. (2022). GANBA: Generative Adversarial Network for Biometric Anti-Spoofing. Applied Sciences, 12(3), 1454. https://doi.org/10.3390/app12031454