
A Study of Data Augmentation for ASR Robustness in Low Bit Rate Contact Center Recordings Including Packet Losses †


Abstract
:1. Introduction
2. Methods
- 1.
- Encode and decode each audio using codecs commonly used in the industry to record calls in call centers (GSM-FR, MP3-8Kbit/s, MP3-16Kbit/s, ...).
- 2.
- After encoding and decoding, remove several packets using different packet loss simulation strategies. Three different strategies have been applied. The first one includes only single packets losses; the second contains only burst packet losses (three contiguous packets losses); and the third one includes individual and bust packet losses comprising two to three contiguous packet losses.
- 3.
- Each speech to text system trained has been evaluated in test data sets which contain each simulated degradation separately to analyze the results obtained in each case and each circumstance, and also to make a decision about which data augmentation techniques could be used to improve the performance obtained.
- 4.
- ITU-T G.711 packet loss concealment standard has been applied in test data sets that contain packet losses and each speech to text system has been evaluated to analyze if it can be a good approach to have a better performance of the system.
- 5.
- The last step has been to evaluate from real call center recording data the best system obtained based on our study on simulated data.
2.1. Automatic Speech Recognition Models
2.2. Data Description
2.3. Degradation Models
2.3.1. Packets Losses
- Individual packet losses: Packets along the audio file are randomly chosen and removed, assuring they are not consecutive packets.
- Burst packet losses: Batches of three consecutive frames are randomly selected and removed (a total of 60 ms) until the packet loss percentage is reached.
- Single and burst packet losses: The two previous modes are merged to have a more realistic simulation, since a real scenario can include both types of losses. Batches of one, two, or three packets are randomly selected and removed (segments of 20, 40 or 60 ms) until the packet loss percentage is reached.
2.3.2. Speech Coding
- MP3 is a lossy audio codec designed originally to compress the audio channel of videos. It is therefore not specifically designed for speech, but it is a very popular standard in Internet audio applications and streaming because it achieves large compression rates, which can even be adjusted to the particular needs of the application. This makes it very convenient for audio transmission and storage. In this paper, MP3 with 16 Kbit/s and 8 Kbit/s bit rates have been applied using the standard FFmpeg tool (https://ffmpeg.org/).
- Full rate GSM 06.10 is a digital speech codec used in digital mobile telephony. The bit rate is 13 Kbit/s with an 8 KHz of sampling rate. The codec works with packets of 160 samples (20 ms). We have applied the full rate GSM coded available in the SoX tool (http://sox.sourceforge.net/).
2.4. Data Augmentation Strategies
- da_model1: The augmented training data set is split into three equal-size parts, each one including a different codec: MP3 8 Kbit/s, MP3 16 Kbit/s, and GSM-FR.
- da_model2, da_model3 and da_model4: First, speech is either kept unaltered or modified by applying one of the three possible codecs used in da_model1. Each of these four possibilities is selected randomly for each recording, with a probability of 1/4. The resulting speech is later distorted again by applying packet losses including only single packet losses (da_model2), only burst packet losses (da_model3) or both individual and burst packet losses (da_model4). The packet loss percentage is randomly selected independently for each recording among 0%, 5%, 10%, 15%, and 20% on a file-by-file basis. The possibility of having 0% packet losses and not applying any codec is discarded, since it will mean no data augmentation.
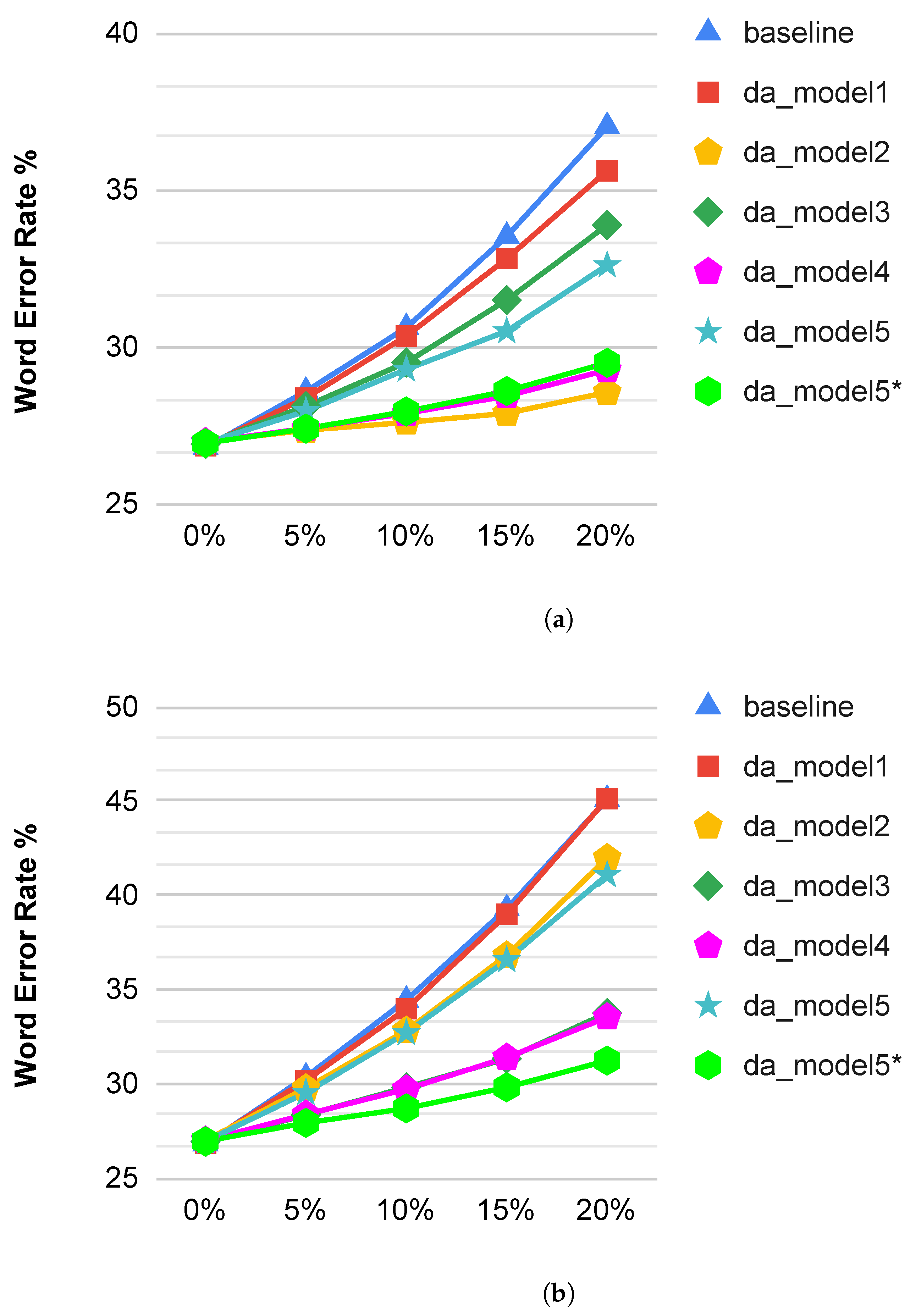
- da_model5: This models follows the same strategy as da_model4, but, after applying the distortions, it also applies the ITU-T G.711 Packet Loss Concealment (PLC) model to try to reconstruct the lost packets. We use this model to generate data augmentation that includes the artifacts introduced by this PLC model, in order to test if applying a PLC model before the use of a robust speech to text system provides increased robustness against packet losses.
2.5. Evaluation Techniques
- Word Error Rate (WER). This is the most common metric used to evaluate the accuracy of speech recognition systems. In the article, we will use it to evaluate the accuracy of each of the systems trained with the different data augmentation strategies. The evaluation will be performed on the development and evaluation sets, distorted with different effects, and also on the real data. All WERs in this article have been computed using the compute_wer tool included as part of the KALDI toolkit [24]. To analyze the statistical significance of WER results, the bootstraping method described in [35] has been used. In particular, the implementation of these methods in the compute_wer_bootci tool included in KALDI have been used to compute 95% confidence intervals of WER estimates, and to estimate the probability of improvement () of one method over another as evaluated for the same test, allowing us to determine if the difference between two results is statistically significant at the 99% level.
- Mean Opinion Score (MOS). This metric is common in the evaluation of speech quality in fields such as speech enhancement and speech coding. In the article, we will use it to evaluate the quality of the data, both original and distorted and both simulated and real. Given that estimating the subjective mean opinion score is costly, we will use the objective estimation of MOS defined by an ITU-T P.563 single ended method for objective speech quality assessment in narrowband telephony applications [36]. In particular, we have used the reference software published along with the ITU-T P.563 standard to estimate the MOS value for each audio file. The software takes as input the audio file and produces the estimated MOS for the file. The MOS scale ranges from 1 to 5, 1 being the worst speech quality and 5 the best.
3. Results and Discussion
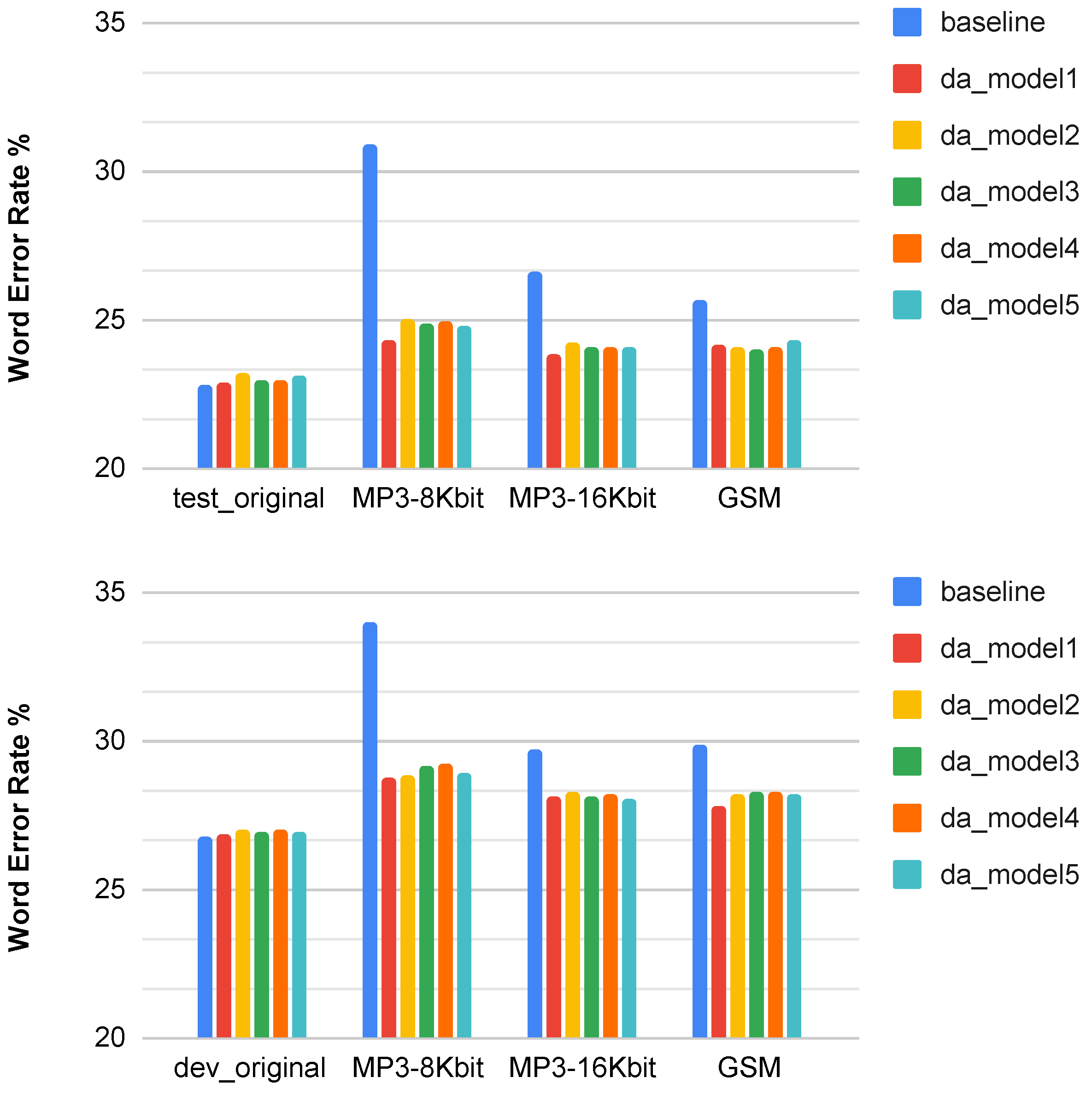
3.1. Speech Recognition Results with Low Bit Rate Coding
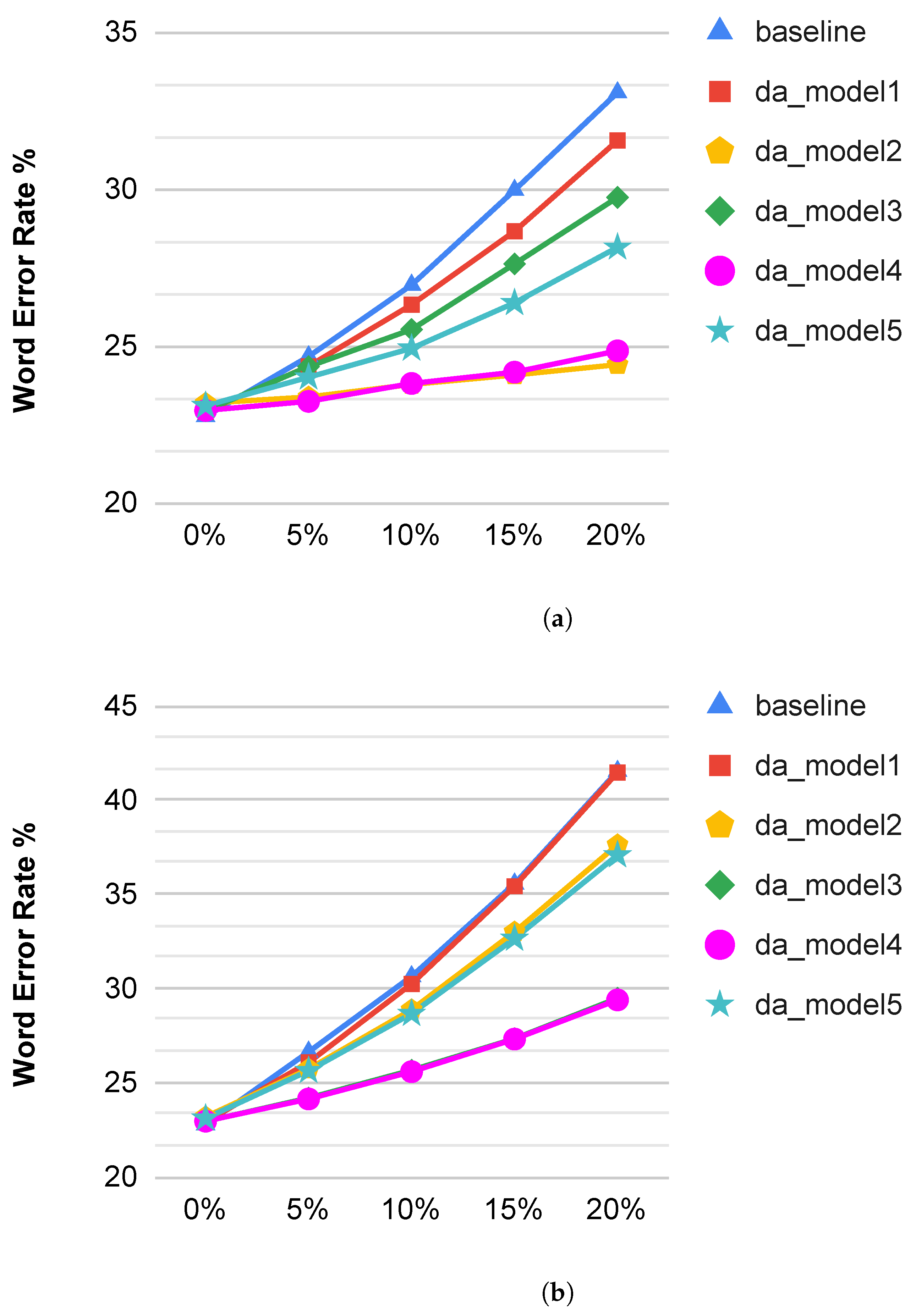
3.2. Speech Recognition Results with Packet Losses
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| VoIP | Voice over IP |
| PLC | Packet Loss Concealment |
| GMM | Gaussian Mixture Models |
| HMM | Hidden Markov Models |
| DNN | Deep Neural Network |
| TDNN | Time Delay Neural Network |
| MFCCs | Mel Frequency Cepstral Coeficients |
| WER | Word Error Rate |
| MOS | Mean Opinion Score |
References
- Takahashi, A.; Yoshino, H.; Kitawaki, N. Perceptual QoS assessment technologies for VoIP. IEEE Trans. Audio Speech Lang. Process. 2004, 42, 28–34. [Google Scholar] [CrossRef]
- Perkins, C.; Hodson, O.; Hardman, V. A survey of packet loss recovery techniques for streaming audio. IEEE Netw. 1998, 12, 40–48. [Google Scholar] [CrossRef]
- Wah, B.W.; Su, X.; Lin, D. A survey of error-concealment schemes for real-time audio and video transmissions over the Internet. In Proceedings of the International Symposium on Multimedia Software Engineering, Taipei, Taiwan, 11–13 December 2000. [Google Scholar] [CrossRef]
- Recommendation G.711 Appendix I (09/99); G.711: A high quality low-complexity algorithm for packet loss concealment with G.711; ITU Telecommunication Standardization Sector: Paris, France, 1999.
- Recommendation G.729 (03/96); Coding of speech at 8 kbits using Conjugate-Structure Algebraic-Code-Excited Linear-Prediction (CS-ACELP); ITU Telecommunication Standardization Sector: Paris, France, 2007.
- Kovesi, B.; Ragot, S. A low complexity packet loss concealment algorithm for ITU-T G. 722. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4769–4772. [Google Scholar]
- Lindblom, J.; Hedelin, P. Packet loss concealment based on sinusoidal modeling. In Proceedings of the 2002 IEEE Speech Coding Workshop: A Paradigm Shift Toward New Coding Functions for the Broadband Age, SCW 2002, Ibaraki, Japan, 9 October 2002. [Google Scholar] [CrossRef]
- Aoki, N. Modification of two-side pitch waveform replication technique for voip packet loss concealment. IEICE Trans. Commun. 2004, 87, 1041–1044. [Google Scholar]
- Nielsen, J.K.; Christensen, M.G.; Cemgil, A.T.; Godsill, S.J.; Jensen, S.H. Bayesian interpolation in a dynamic sinusoidal model with application to packet-loss concealment. In Proceedings of the European Signal Processing Conference, Aalborg, Denmark, 23–27 August 2010. [Google Scholar]
- Lindblom, J.; Samuelsson, J.; Hedelin, P. Model based spectrum prediction. In Proceedings of the 2000 IEEE Workshop on Speech Coding—Proceedings: Meeting the Challenges of the New Millennium, Delavan, WI, USA, 17–20 September 2000. [Google Scholar] [CrossRef]
- Rødbro, C.A.; Murthi, M.N.; Andersen, S.V.; Jensen, S.H. Hidden Markov model-based packet loss concealment for voice over IP. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1609–1623. [Google Scholar] [CrossRef]
- Borgström, B.J.; Borgström, P.H.; Alwan, A. Efficient HMM-based estimation of missing features, with applications to packet loss concealment. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, INTERSPEECH 2010, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Lee, B.K.; Chang, J.H. Packet Loss Concealment Based on Deep Neural Networks for Digital Speech Transmission. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 24, 378–387. [Google Scholar] [CrossRef]
- Lotfidereshgi, R.; Gournay, P. Speech Prediction Using an Adaptive Recurrent Neural Network with Application to Packet Loss Concealment. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar] [CrossRef]
- Mohamed, M.M.; Schuller, B.W. Concealnet: An end-to-end neural network for packet loss concealment in deep speech emotion recognition. arXiv 2020, arXiv:2005.07777. [Google Scholar]
- Kegler, M.; Beckmann, P.; Cernak, M. Deep speech inpainting of time-frequency masks. arXiv 2019, arXiv:1910.09058. [Google Scholar]
- Lin, J.; Wang, Y.; Kalgaonkar, K.; Keren, G.; Zhang, D.; Fuegen, C. A Time-Domain Convolutional Recurrent Network for Packet Loss Concealment. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7148–7152. [Google Scholar] [CrossRef]
- Marafioti, A.; Perraudin, N.; Holighaus, N.; Majdak, P. A context encoder for audio inpainting. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2362–2372. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.L.; Lee, K.Y.; Wu, P.Y.; Lee, H.y.; Hsu, W. Deep long audio inpainting. arXiv 2019, arXiv:1911.06476. [Google Scholar]
- Shi, Y.; Zheng, N.; Kang, Y.; Rong, W. Speech loss compensation by generative adversarial networks. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 347–351. [Google Scholar]
- Zhou, H.; Liu, Z.; Xu, X.; Luo, P.; Wang, X. Vision-infused deep audio inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 283–292. [Google Scholar]
- Marafioti, A.; Majdak, P.; Holighaus, N.; Perraudin, N. GACELA: A Generative Adversarial Context Encoder for Long Audio Inpainting of Music. IEEE J. Sel. Top. Signal Process. 2020, 15, 120–131. [Google Scholar] [CrossRef]
- Pascual, S.; Serrà, J.; Pons, J. Adversarial auto-encoding for packet loss concealment. In Proceedings of the 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 17–20 October 2021; pp. 71–75. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M. The KALDI speech recognition toolkit. In Proceedings of the IEEE 2011 workshop on automatic speech recognition and understanding, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. arXiv 2018, arXiv:1804.00015. [Google Scholar]
- Yu, D.; Seltzer, M.L.; Li, J.; Huang, J.T.; Seide, F. Feature learning in deep neural networks-studies on speech recognition. In Proceedings of the International Conference on Learning Representation, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the INTERSPEECH 2015—16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chung-Cheng Chiu, B.Z.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the INTERSPEECH 2019—The 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar] [CrossRef] [Green Version]
- Hailu, N.; Siegert, I.; Nürnberger, A. Improving Automatic Speech Recognition Utilizing Audio-codecs for Data Augmentation. In Proceedings of the 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 21–24 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Mohamed, M.M.; Schuller, B.W. “I have vxxx bxx connexxxn!”: Facing Packet Loss in Deep Speech Emotion Recognition. arXiv 2020, arXiv:2005.07757. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- ETSI EN 300 961. Digital cellular telecommunications system (Phase 2+) (GSM); Full rate speech; Transcoding (GSM 06.10 version 8.1.1 Release 1999); European Telecommunications Standards Institute: Sophia Antipolis, France, 2000.
- Noll, P. MPEG digital audio coding. IEEE Signal Process. Mag. 1997, 14, 59–81. [Google Scholar] [CrossRef]
- Bisani, M.; Ney, H. Bootstrap estimates for confidence intervals in ASR performance evaluation. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, p. I-409. [Google Scholar]
- Malfait, L.; Berger, J.; Kastner, M.P. 563—The ITU-T standard for single-ended speech quality assessment. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1924–1934. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distortion | Test | Dev |
|---|---|---|
| Original | ||
| MP3 8 Kbit/s | ||
| MP3 16 Kbit/s | ||
| GSM | ||
| 5% Indiv. PL | ||
| 10% Indiv. PL | ||
| 15% Indiv. PL | ||
| 20% Indiv. PL | ||
| 5% Burst PL | ||
| 10% Burst PL | ||
| 15% Burst PL | ||
| 20% Burst PL |
| WER% [95% Conf. Int.] | |||
|---|---|---|---|
| Data Set | Duration (h) | Baseline | da_model4 |
| test_call_center_1 | |||
| test_call_center_2 | 3 | ||
| test_call_center_3 | 2 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-Gallego, M.P.; Toledano, D.T. A Study of Data Augmentation for ASR Robustness in Low Bit Rate Contact Center Recordings Including Packet Losses. Appl. Sci. 2022, 12, 1580. https://doi.org/10.3390/app12031580
Fernández-Gallego MP, Toledano DT. A Study of Data Augmentation for ASR Robustness in Low Bit Rate Contact Center Recordings Including Packet Losses. Applied Sciences. 2022; 12(3):1580. https://doi.org/10.3390/app12031580
Chicago/Turabian StyleFernández-Gallego, María Pilar, and Doroteo T. Toledano. 2022. "A Study of Data Augmentation for ASR Robustness in Low Bit Rate Contact Center Recordings Including Packet Losses" Applied Sciences 12, no. 3: 1580. https://doi.org/10.3390/app12031580
APA StyleFernández-Gallego, M. P., & Toledano, D. T. (2022). A Study of Data Augmentation for ASR Robustness in Low Bit Rate Contact Center Recordings Including Packet Losses. Applied Sciences, 12(3), 1580. https://doi.org/10.3390/app12031580